2.1. Linear Associator
The linear associator requires a dataset
that consists of ordered pairs of patterns (also called associations) whose components are real numbers. The first element of each association is an input column pattern, while the second element is the corresponding output column pattern [
5,
6]. By convention, the three positive integers
facilitate symbolic manipulation. The symbol
represents the number of associations, such that
In addition,
and
represent the dimensions of the input and output patterns, respectively, so that the
th input pattern and the
th output pattern are expressed as follows:
The linear associator algorithm consists of two phases: the training (or learning) phase and the recalling phase. To carry out these two phases, the dataset is partitioned into two disjoint subsets: a training or learning set and a test set .
For each training couple of patterns
, the matrix that represents its association is calculated with the outer product:
If
is the cardinality of
, then
, and
matrices will be generated, which will be added to obtain the matrix
that represents the linear associator.:
The previous expression shows the trained memory, where the
ijth component of
M is expressed as follows:
Once the memory is trained, the recalling phase takes place. For this, the product of the trained memory with a test pattern
xω is performed:
Ideally, Equation (6) should return the output pattern . In the specialized literature, it is not possible to find theoretical results that establish sufficient conditions to recover, in all cases, the output pattern from the input pattern .
However, it is possible to use the well-known resubstitution error mechanism in order to establish the recovery conditions for the patterns in the learning set; that is, the memory will be tested with the patterns of the learning set. The following theorem establishes the necessary and sufficient conditions for this to occur.
Theorem 1.
Let M be a linear associator which was built from the learning set by applying Equation (4), and let be an association in . Then, the output pattern is correctly retrieved from the input pattern if and only if all input patterns are orthonormal.
Proof. Given that in the set
there are
associations, by applying Equation (4), we obtain
:
We will try to retrieve the output pattern and, by applying Equation (6), we find
Therefore, the right term will be
if and only if two conditions are met:
In other words, and .
These conditions are met if and only if the input vectors are orthonormal. □
In order to illustrate the operation of both phases of the linear associator, it is pertinent to follow each of the algorithmic steps through a simple example. In order for the example to satisfy the hypothesis of Theorem 1, it is assumed that the training or learning phase is performed with the complete dataset and that the trained memory is tested with each and every one of the dataset patterns; that is,
. In the specialized literature, this method is known as the resubstitution error calculation [
16].
The example consists of three pairs of patterns, where the input patterns are of dimension 3, and the output patterns are of dimension 5; namely,
:
By applying Equation (3) to the associations in Equation (7), it is possible to get the three outer products as in Equation (8):
According to Equation (4), the three matrices obtained are added to generate the linear associator
M:
With the linear associator trained in Equation (9), it is now possible to try to recover the output patterns. For this, the matrix
M is operated with the input patterns as in Equation (10):
As shown in Equation (10), the recalling of the three output patterns from the three corresponding input patterns was carried out correctly. This convenient result was obtained thanks to the fact that the input patterns complied with Theorem 1; in other words, the three input patterns were orthonormal [
17].
Interesting questions arise here. What about real-life datasets? Is it possible to find datasets of medical, financial, educational, or commercial applications whose patterns are orthonormal? The answers to the previous questions are daunting for the use of this classic associative model, as it is almost impossible to find real-life datasets that comply with this severe restriction imposed by the linear associator.
What will happen if an input pattern that is not orthonormal to the others is added to the set in Equation (7)? In order to illustrate how this fact affects the linear associator, the set in Equation (7) is incremented with the association (
x4,
y4):
The outer product of the pair in Equation (11) is presented in Equation (12):
According to Equation (4), the matrix
M must then be updated:
With the memory updated in Equation (13), we proceed to try to recover the four output patterns from the corresponding four input patterns:
By performing a quick analysis and a comparison between the results obtained in Equation (10) and those obtained in Equation (14), we can observe the devastating effects that non-orthonormality has on the performance of the linear associator.
While in Equation (10), where all input patterns are orthonormal, 100% of the patterns were recalled correctly, the results of Equation (14) indicate that it was enough that one of the patterns was not orthonormal to the others, leading the performance to decrease in a very noticeable way. There were 75% errors. As can be seen, adding a pattern that is not orthonormal to the training set is detrimental to the linear associator model. The phenomenon it generates is known as cross-talk [
5].
In an attempt to improve the results, some researchers tried preprocessing the input patterns. In some cases, orthogonalization methods were applied to the input patterns of the linear associator [
10,
11,
12,
13]. The results were not successful, and this line of investigation was abandoned.
The key to understanding the reasons these attempts failed is found in elementary linear algebra [
17]. It is well known that given a vector in a Euclidean space of dimension
, the maximum number of orthonormal patterns is precisely
. For this reason, even if orthogonalization methods such as Gram–Scmidt are applied, in a space of dimension
, there cannot be more than
orthonormal vectors.
In specifying these ideas in Equation (7), the results of elementary linear algebra tell us that it is not possible to find a fourth vector of three components that is orthonormal to the vectors , , and . Additionally, if the vectors have four components, the maximum number of orthonormal vectors will be five. In general, for a set of input vectors of the linear associator of compents, in a set of n + 1 vectors or greater, it will no longer be possible to make all vectors orthonormal.
2.2. The Linear Associator as a Pattern Classifier
The key to converting an associative memory into a pattern classifier is found in the encoding of the output patterns. If class labels can be represented as output patterns in a dataset designed for classification, it is possible to carry out the classification task through an associative memory. For instance, the linear associator (whose natural task is recalling) can be converted into a classifier of patterns that represent the absence or presence of some disease. To achieve this, each label is represented by a positive integer. By choosing this representation of the labels as patterns, the patterns of dimension in Equation (1) are converted to positive integers, so in Equation (2), the value of is 1.
During the training phase of the linear associator, each outer product in Equation (3) will be a matrix of dimension , and the same happens with the matrix in Equation (4), whose dimension is . Consequently, and as expected, during the recalling phase of the linear associator, the product will have dimension 1, because the test pattern is a column vector of dimension ; that is, a real number is recalled, which will have a direct relationship with a class label in the dataset.
An example will illustrate this process of converting the linear associator (which is an associative memory) into a pattern classifier. For this, one of the most famous and long-lived datsets that has been used for many years in machine learning, pattern recognition, and related areas will be used. It is the Iris Dataset, which consists of 150 patterns of dimension 4. Each pattern consists of four real numerical values that represent measurements on three different kinds of iris flowers. It is a balanced dataset with 3 classes of 50 patterns each: Iris setosa, Iris versicolor, and Iris virginica. These three classes are assigned the three labels—1, 2, and 3—so that the class Iris setosa corresponds to label 1, the class Iris versicolor corresponds to label 2, and finally, label 3 is for the class Iris virginica.
In the file distributed by the UCI Machine Learning Repository [
18], the patterns are ordered by class. The file contains the 50 patterns of class 1 first, the patterns from 51 to 100 are those of class 2, and finally, the patterns from l101 to 150 are found, which belong to class 3.
According to Equation (2), the first two patterns of the Iris Dataset are
As these first two patterns belong to the class
Iris setosa, they are labeled 1; namely
Additionally, the remaining patterns of the class
Iris setosa are labeled 1:
It is at this moment that we should mention a very relevant note in relation to the patterns that feed the linear associator. Typically, in datasets distributed by repositories, patterns appear as rows in a matrix.
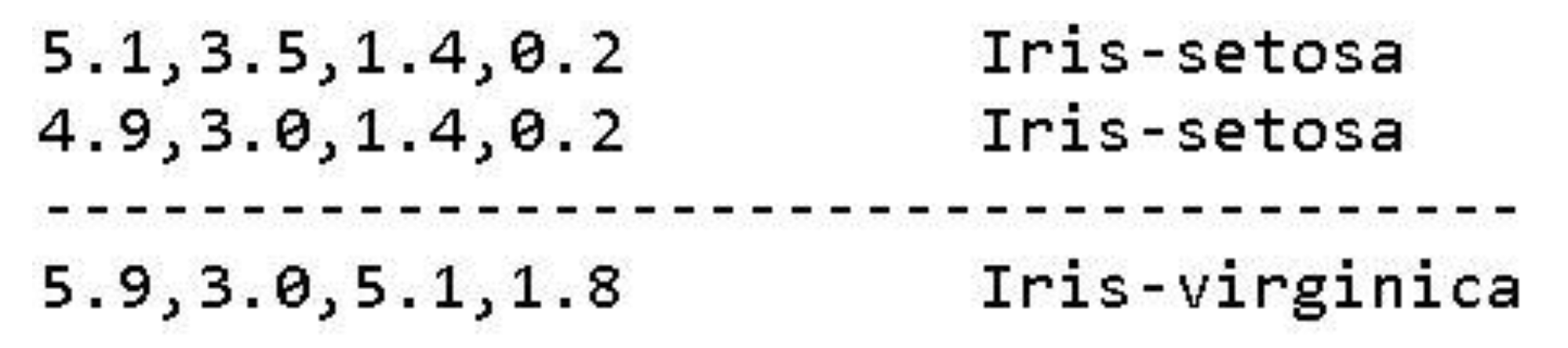
Figure 1 illustrates the first two patterns (
Iris setosa) and the last pattern (
Iris virginica) from the iris.data file, which was downloaded from the UCI Machine Learning Repository [
18]. Regardless of class labels, this is a
matrix (i.e., there are 150
row patterns of 4 real numbers each).
However, the algorithmic steps of the linear associator require column patterns, both for the input and output. Therefore, when implementing the algorithm, each of the row patterns is simply taken and converted into a column pattern as in Equation (15), thus avoiding unnecessary excess notation.
Below is an example of an
Iris versicolor class pattern and the corresponding class labels for patterns 51 through 100:
Similarly, the class pattern is as follows for the class
Iris virginica:
As in any pattern classification experiment, the first thing to do is choose a validation method. For this example, leave-one-out [
16] has been selected. Therefore, the first pattern of class 1,
, is chosen as the test pattern, while all the remaining 149 patterns constitute the training set.
The training phase of the linear associator is started by applying Equation (3) to the first pattern of the training set, which is
, and whose class label is
:
The same process is carried out with the following association, which is
:
This continues until concluding with the 49 pattern associations of class 1. Then, the same process is applied to the first association of class 2, which is
:
This continues until concluding with the 50 pattern associations of class 2. Then, the same process is applied to the first association of class 3, which is
:
This process continues until the last association is reached, which is
. At the end, there are 149 matrices of dimensions
, which are added according to Equation (4) to finally obtain the linear associator. The matrix M representing the linear associator is also of dimensions
:
The symbol (1) as a superscript in indicates that the pattern , being the test pattern, has not participated in the learning phase.
Now that the linear associator
has been trained, it is time to move on to the classification phase. For this, Equation (6) is applied to linear associator
in Equation (26) and to the test pattern
in Equation (15):
The returned value in Equation (27), 14,281, is a long way from the expected value, which is the class label . This is because the 149 patterns the linear associator trains with are far from orthonormal, as is required by the original linear associator model for pattern recalling to be correct (Theorem 1).
This is where one of the original contributions of this paper comes into play. By applying this idea, it is possible to solve the problem of obtaining a number that is very far from the class label. By applying a scaling and a rounding, it is possible to bring the result closer to the class label of the test pattern
:
The class label for test pattern was successfully recalled. It was a hit of the classifier, but what will happen to the other patterns in the dataset?
To find out, let us go to the second iteration of the leave-one-out validation method, where the pattern
will now become a test pattern, while the training set will be formed with the 149 remaining patterns from the dataset, which are
When executing steps similar to those of iteration 1 based on Equations (3) and (4), the linear associator is obtained:
Again, the symbol (2) as a superscript in
indicates that the pattern
, being the test pattern, has not participated in the learning phase. Now that the linear associator
has been trained, it is time to move on to the classification phase. For this, Equation (6) is applied to linear associator
in Equation (30) and to the test pattern
in Equation (15):
Again, by applying a scaling and a rounding, it is possible to bring the result closer to the class label of the test pattern
:
Something similar happens when executing iterations 3, 4 and 5, where the class labels of the test patterns
, and
are correctly recalled. However, it is interesting to observe what happens in iteration 6, where the test pattern is now
:
This is a classifier error, because the result should be label 1, while the linear associator assigns label 2 to the test pattern . However, this is not the only mistake. The total number of patterns in class 1 (Iris setosa) that are mislabeled is 12.
Now, it is the turn of iteration 51, which corresponds to the first test pattern of class 2 (
Iris versicolor). When executing steps similar to those of iteration 1, based on Equations (3) and (4), the linear associator is obtained:
This is a hit of the classifier, because the linear associator correctly assigns label 2 to the test pattern . The same happens with all 50 patterns of class 2. There are zero errors in this class.
Now, it is the turn of iteration 101, which corresponds to the first test pattern of class 3 (
Iris virginica). When executing steps similar to those of iteration 1, based on Equations (3) and (4), the linear associator is obtained:
This is a classifier error, because test pattern belongs to class 3. There are 43 errors in this class, and only 7 of the 50 patterns in class 3 (Iris virginica) are correctly classified by the linear associator.
The sum of all the errors of the linear associator in the Iris Dataset is 55. That is, the Linear Associator acting as a pattern classifier on the Iris Dataset obtains 95 total hits. Since the Iris Dataset is balanced, it is possible to use accuracy as a good performance measure [
16]:
How good or bad is this performance? A good way to find out is to compare the accuracy obtained by the linear associator with the performances exhibited by the classifiers of the state of the art.
For this, seven of the most important classifiers of the state of the art have been selected, which will be detailed in
Section 4.2: a Bayesian classifier (Naïve Bayes [
19]), two algorithms of the nearest neighbors family (1-NN and 3-NN [
20]), a decision tree (C4.5 [
21]), a support vector machine (SVM [
22]), a neural network (MLP [
23]), and an ensemble of classifiers (random forest [
24]).
In all cases, the same validation method has been used: leave-one-out.
Table 1 contains the accuracy values (best in bold), where LA stands for linear associator.
The accuracy obtained by the linear associator is more than thirty percentage points below the performance exhibited by the seven most important classifiers of the state of the art for different approaches.
This means that if the linear associator is to be converted into a competitive classifier, at least in the Iris Dataset, it is necessary to improve performance by thirty or more percentage points when accuracy is used as a performance measure.
That is not easy at all.
In
Section 2.1, it was pointed out that, based on the known results of elementary linear algebra, it happens to be that, in general, for a set of input vectors of the linear associator of
compents, in a set of
vectors or greater, it will no longer be possible to make all vectors orthonormal. This means, among other things, that it is not possible to orthonormalize the 150 patterns of 4 attributes of the Iris Dataset.
The central and most relevant proposal of this paper is to improve the performance of the linear associator through a transformation of the patterns. That transformation is achieved through a powerful mathematical tool called singular value decomposition.
2.3. Singular Value Decomposition (SVD)
Given a matrix
where
are positive integral numbers, it is possible to represent that matrix using the singular value decomposition (SVD) [
14] as in Equation (43):
where
and
are orthonormal matrices with respect to the columns. In addition,
is a non-negative matrix diagonal containing the square roots of the eigenvalues (which are called singular values) from
or
in descending order and the zeros off the diagonal.
If , it is possible to establish the equality .
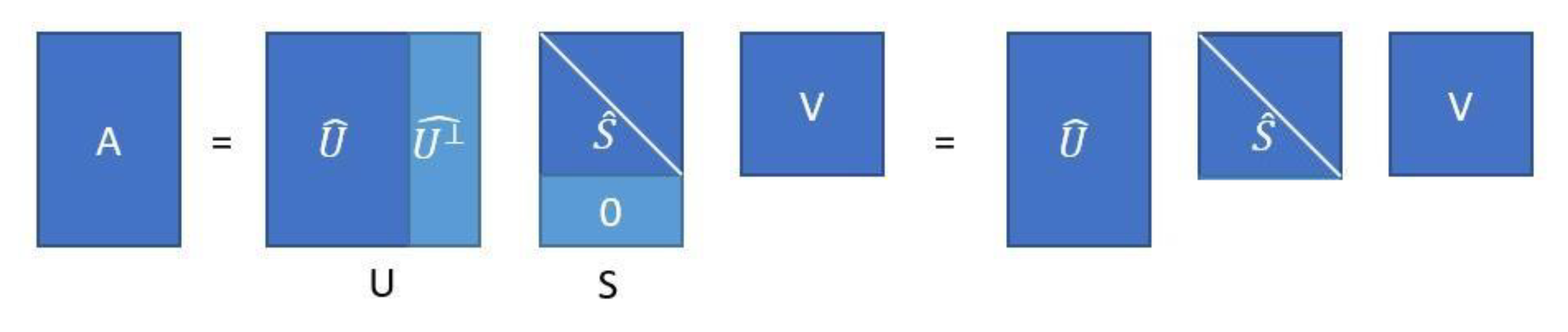
Therefore, matrix A in Equation (43) can be represented by the “economy SVD” [
15]:
where
contains the columns that make up a complementary vector space orthogonal to
. Note that matrix
has the same dimensions as matrix
. In
Figure 2, the economy SVD is schematized.
The process followed to obtain the SVD from matrix
in Equation (45) is exemplified below:
The first step is to find
in Equation (46) and then calculate
in Equation (47):
Next, we need to find the eigenvectors of
and their corresponding eigenvalues. Therefore, we will use Equation (48), which defines the eigenvectors of the matrix
:
From Equation (48), we obtain the system of equations shown in Equation (49):
Solving for
by the method of minors in Equation (50) yields
Therefore, the eigenvalues of
are
To obtain the eigenvector of
, the system in Equation (49) is used:
Consequently, the eigenvector for the eigenvalue
is
The corresponding expressions to find the eigenvectors of the remaining eigenvalues
and
are
When ordering the eigenvectors
,
, and
with Equations (52)–(54) as columns of a matrix, we obtain
By normalization of Equation (55), the matrix
is obtained [
17]:
The calculation of
is similar, but this time, it will be based on the matrix
, which is calculated in Equation (57), from the matrices
in Equation (46) and
in Equation (45):
After executing the algorithmic steps corresponding to those performed in Equations (48)–(54), this matrix is obtained:
By normalization of Equation (58), the matrix
is obtained [
17]:
The matrix is built from a matrix full of zeros of dimensions . Then, the zeros of the diagonal are replaced with the singular values (which are the square roots of the eigenvalues) of matrix in descending order.
In our example, the singular values of the matrix
are obtained with the square root of the first two eigenvalues in Equation (51):
Therefore, according to Equation (43), the SVD of matrix A is expressed as in Equation (61):
Now, from Equation (60), it is possible to obtain the matrix
:
Finally, according to Equation (44), the economy SVD of matrix
A is expressed as in Equation (63):
The matrices
and
in Equations (44) and (63) have something in common. For both matrices, the inverse matrix is defined, and its calculation is extremely simple [
15]. The importance of this property for this paper will be evident in
Section 3, where the proposed methodology is described.
The inverse matrix of
V is calculated as follows:
On the other hand, let
be of dimensions
, whose elements on its diagonal are
. Then, the inverse matrix of
is calculated as follows:
It can be easily verified that Equations (64) and (65) are fulfilled in the matrices of Equation (63).
An interesting application of Equations (64) and (65) is that it is possible to express the matrix
in Equation (44) as a function of
and
:
It is possible to interpret Equation (66) in an unorthodox way. This novel interpretation gives rise to one of the original contributions of this paper.
If the matrices , , and are known, it is possible to interpret Equation (66) as the generation of the matrix by transforming the data in through the modulation of these data by the product.
However, there is something else of great relevance for the original proposal of this paper, which will be explained in
Section 3. It is possible to set a vector as
so that
will be a vector transformed in the same way as matrix
in Equation (66).


 ,
, 




{kind=link}
{kind=link}