1. Introduction
Suppose that we have an autonomous dynamical system
that is accessible only through snapshots from a sequence of trajectories with different (possibly unknown) initial conditions. More precisely,
is the flow associated with (
1). In a real application,
t is a fixed time step, and it is possible that the time resolution precludes any approach based on estimating the derivatives; the dataset could also be scarce, sparsely collected from several trajectories/short bursts of the dynamics under study. The task is to identify
and express it analytically, using a suitably chosen class of functions. This is the essence of data-driven system identification, which is a powerful modeling technique in applied sciences and engineering—for a review see e.g., [
1]. Approaches like that of SINDy [
2] rely on numerical differentiation, which is a formidable task in cases of scarce and/or noisy data, and it requires special techniques such as e.g., total-variation regularization [
3] or e.g., weak formulation [
4]. With an appropriate ansatz (e.g., physics-informed) on the structure of the right hand side in (
1), the identification process is computationally executed as sparse regression, see e.g., [
2,
5,
6]. An alternative approach is machine learning techniques such as physics-informed neural networks, which proved a powerful tool for learning nonlinear partial differential equations [
7].
Recently, Mauroy and Goncalves [
8] proposed an elegant method for learning
from the data, based on the semigroup
of Koopman operators acting on a space of suitably chosen scalar observables
. In the case of the main method proposed in [
8],
is the space
, where
is compact, forward invariant, and big enough to contain all data snapshots. The method has two main steps. First, a compression of
onto a suitable finite dimensional but rich enough subspace
of
is computed. On a convenient basis
of
, having only a limited number of snapshots (
2), this compression is executed in the algebraic (discrete) least squares framework, yielding the matrix representation
of
.
It can be shown that
is an approximation of the matrix exponential
, or equivalently
, where
is a finite dimensional compression of the infinitesimal generator
defined by
Note that the infinitesimal generator is well-defined (on its domain
) since the Koopman semigroup of operators is strongly continuous in
(i.e.,
, where
denotes the
norm on
X). We refer to [
9] for more details on semigroups of operators and their properties, and to [
10] for the theory and applications of the Koopman operator.
In the second step, the vector field is recovered by using the fact that
can also be expressed as (see e.g., [
11])
If
, then the action of
to the basis’s vectors
can be computed, using (
4), by straightforward calculus, and its matrix representation will, by comparison with
, reveal the coefficients
. Of course, in real applications, the quality of the computed approximations will heavily depend on the information content in the supplied data snapshots. Finer sampling (smaller time resolution) and more trajectories with different initial data are certainly desirable. If
, then a modification, called a dual method, is based on the logarithm of a
matrix
. Mauroy and Goncalves [
8] proved the convergence (with probability one as
,
,
) and illustrated the performances of the method (including the dual formulation) on a series of numerical examples.
In this paper, we consider numerical aspects of the method and study its potential as a robust software tool. Our main thesis is that a seemingly simple implementation based on the off-the-shelf software components has certain limitations. For instance, with the increased dimension that guarantees theoretically better approximation and ultimate convergence, the numerical implementation, due to severe ill-conditioning, may become unstable and eventually it may break down. In other words, it can happen that with more data the potentially better approximation does not materialize in the computation. This is an undesirable chasm between analytical properties and numerical finite precision realization of the method. Hence, more numerical analysis work is needed before the method becomes mature enough to be implemented as a robust and reliable software tool.
Contributions and Organisation of the Paper
We identify, analyze and resolve the two main sources of numerical instability of the original method [
8]. First, for a given time lag
t, numerical computation of the matrix representation
of a compression of the Koopman operator
on a (finite)
N-dimensional subspace may not be computed accurately enough. Secondly, even if computed accurately, the matrix
may be so ill-conditioned as to preclude stable computation of the logarithm. Both issues are analyzed in detail, and we propose a new numerical algorithm that implements the method.
This material can be considered a numerical supplement to [
8], and as an instructive case study for numerical software development. Moreover, the techniques developed here are used in the computational part of the recently developed framework [
12]. The infinitesimal generator approach has also been successfully used for learning stochastic models from aggregated trajectory data [
13,
14], as well as for inverse modelling of Markov jump processes [
15]. The stochastic framework is not considered in this paper, but its results apply to systems defined by stochastic differential equations as described in [
8]. The stochastic setting contains many challenging problems and requires sophisticated tools, based e.g., on the Kolmogorov backward equation [
8], the forward and adjoint Fokker–Planck equations [
16,
17,
18], or the Koopman operator fitting [
19].
The rest of paper is organized as follows. In
Section 2 we set the stage and setup a numerical linear algebra framework for the analysis of subtle details related to numerical implementation of the method. This is standard, well known material and it is included for the reader’s convenience and to introduce necessary notation. In particular, we give detailed description of a finite dimensional compression (in a discrete least squares sense) of the Koopman operator (
Section 2.1), and we review the basic properties of the matrix logarithm (
Section 2.3). Then, in
Section 3, we review the details of the Mauroy–Goncalves method, including a particular choice of the monomial basis
and in
Section 3.2 the details on the corresponding matrix representation of the generator (
4). A case study example that illustrates the problem of numerical ill-conditioning is provided in
Section 4. In
Section 5, we propose a preconditioning step that allows for a more accurate computation of the logarithm
in the case
. In
Section 6 we consider the dual method for the case
, and formulate it as a compression of
onto a particular
K dimensional subspace of
. This formulation is then generalized in
Section 7, where we introduce a new algorithm that (out of a given
N) selects a prescribed number of (at most
K) basis functions that are most linearly independent, as seen on the discrete set of data snapshots. The proposed algorithm, designated as
basis pruning, can be used in both the dual and the main method, and it can be combined with the preconditioning introduced in
Section 5.
2. Preliminaries: Finite Dimensional Compression of and Its Logarithm
To set up the stage, in
Section 2.1 we first describe matrix representation
of the Koopman operator compressed to a finite dimensional subspace
. Some details of the numerical computation of
are discussed in
Section 2.2. In
Section 2.3, we briefly review the matrix logarithm from the numerical linear algebra perspective.
2.1. Compression of and the Anatomy of Its Matrix Representation
Given and an N-dimensional subspace , we want to compress to and to work with a finite dimensional approximation , where is an appropriate projection. The subspace contains functions that are simple for computation, but it is rich enough to provide good approximations for the functions in ; it will be materialized through an ordered basis . If an is expressed as , then the coordinates of f in the basis are written as . The ambient space is equipped with the Hilbert space structure.
2.1.1. Discrete Least Squares Projection
Since in a data-driven setting the function is known only at the points
, an operator compression will be defined using discrete least squares projection. For
, the projection
of
g is defined so that the
’s solve the problem
where
is a weight attached to each sample
, and
is the Euclidean norm. This is a
residual with respect to the empirical measure
defined as the sum of the Dirac measures concentrated at the
’s,
. The weighting will be important in the case of noisy data; it can also be used in connection with a quadrature formula so that (
5) mimics a continuous norm (defined by an integral) approximation in
. In the unweighted case
for all
k. The objective function (
5) can be written as
where
,
. More generally,
W can be a suitable positive definite (e.g., inverse of the noise covariance) matrix. In a numerical computation the positive definite square root
is replaced, equivalently, with the Cholesky factor: if
is the Cholesky factorization with the unique lower triangular factor
L, then
must be orthogonal and when we replace
with
, we can omit
because the norm in the above objective function is invariant under orthogonal transformations.
At this point we assume that the
matrix
is of full column rank
N; this requires
. (The rank deficient case will be discussed later.) This full column rank assumption yields the unique least squares solution
which defines the projection
. If
, then
. In the unweighted case,
, we have
.
2.1.2. Matrix Representation of
To describe the action of
in
, we first consider how it changes the basis vectors:
can be split as a sum of a component belonging to
, and a residual,
Given the limited information (only the snapshot pairs
), the coefficients
are determined so that the residual
is small over the data
. Since
, we have
and we can select the
’s to minimize
The solution is the projection (see e.g., ([
20], §2.1.3, §2.7.4))
Then, for any
, we have
Hence,
is on the basis
represented by the matrix
where we use
for the sake of technical simplicity, and
is the Moore–Penrose generalized inverse. If
, then
.
2.1.3. When Is Nonsingular?
If both and are of full column rank N, then the rank of depends on the canonical angles between the ranges of and . Indeed, if , are the thin QR factorizations, then , where the singular values of can be written in terms of the canonical angles as . Hence, in the case of full column rank of and , nonsingularity of is equivalent to . To visualize this condition, will be nonsigular if none of the ranges of and contain a direction that is orthogonal to the other one. If the basis function and the flow map are well behaved and the sampling time is reasonable, it is reasonable to expect .
2.1.4. Relations with the DMD
In the DMD framework,
are the scalar components of a
vector valued observable evaluated at the sequence of snapshots
, and it is customary to arrange them in a
matrix, i.e.,
. Similarly, the values of the observables at the
’s are in the matrix
. The Exact DMD matrix is then
. For more details on this connection we refer to [
21,
22].
2.2. On the Numerical Solution of
In general, the least squares projection is uniquely determined, but, unless is of full column rank N, the solution of the problem is not unique—each of its columns is from a linear manifold determined by the null-space of and we can vary them independently by adding to them arbitrary vectors from the null space of . Furthermore, even when is of rank N but ill-conditioned, a typical numerical least squares solver will detect the ill-conditioning by revealing that the matrix is close to singular matrices and it will treat it as numerically rank deficient. Then, the computed solution becomes non-unique, the concrete result depends on the least squares solution algorithm, and it may be rank deficient. This calls for caution when computing and numerically.
We discuss this in
Section 2.2.1, and illustrate the problems in practice using a case study example in
Section 4.
2.2.1. Least Squares Solution in Case of Numerical Rank Deficiency
If
is not of full column rank
N, then
is one of infinitely many solutions to the least squares problem for the matrix
that is used to represent the operator compression. Furthermore, since it is necessarily singular, its logarithm does not exist and identifying a matrix approximation of the infinitesimal generator is not feasible. This is certainly the case when
(recall that in this case a dual form of the method is used; see
Section 6), and in the case
, considered here, the matrix
can be numerically rank deficient and the software solution will return a solution that depends on a particular algorithm for solving the least squares problem.
Let be the SVD of and let r be the rank of such that . Let , where are the nonzero singular values. Partition the singular vector matrices as , , where and have r columns, so that , . Recall that the columns of the matrix are an orthonormal basis for the null space of .
In the rank deficient case, the solution set for the least squares problem
is a linear manifold—in this case of the form
Clearly
.
The particular choice
, as (
8), is distinguished by being of minimal Frobenius norm, because
The minimality of the Euclidean norm is one criterion to pinpoint the unique solution and uniquely define the pseudo-inverse. Such minimal norm solution, which is of rank at most
r, may indeed be desirable in some applications, but here it is useless if
, because we cannot proceed with computing
.
It remains an interesting question whether in the rank deficient cases we can explore the solution set (
10) and with some additional constraints define a meaningful matrix representation. In general, a matrix representation should as much as possible reproduce the behaviour of the operator in that subspace. For example, if
is of full column rank
N (i.e., we have sufficiently large
K and well selected observables) and the first basis function is constant,
, then the first columns of
and
are
and simple argument implies that in (
8) the first column of
is the first canonical vector
and
which corresponds to
. If
(so that
has a nontrivial null space), then we do not expect
, but we can show that
contains a matrix
such that
.
Proposition 1. If , then we can choose an such that .
Proof. To satisfy
,
must be such that
. Note that
is in the null-space of
:
Hence,
, and
can be set e.g., to zero to obtain
of minimal Frobenius norm. Here also
is an interesting choice, but we omit the details because, in this paper, following [
8], we treat the rank deficiency by a form of dual method as described in
Section 6 and
Section 7. □
Remark 1. The global non-uniqueness in form of the additive term is non-essential when instead of we use its compression in a certain subspace. For instance, if the Rayleigh quotient of with respect to the range of remains unchanged, see Section 6. In practice, the least squares solution using the SVD and the formula for the pseudo-inverse are often replaced by a more efficient method based on the column pivoted (rank revealing) QR factorization. For instance, the factorization [
23] uses a greedy matrix volume maximizing scheme to determine a permutation
such that in the QR factorization
the triangular factor
R has a strong diagonal dominance of the form
If
is of rank
, then
is nonsingular and
, and the least squares solution of
is computed as
In a nearly rank deficient (i.e., ill-conditioned) case, the index
r is determined so that setting
to zero introduces error below a tolerance that is of order of machine precision. This is the solution returned by the backslash operator in Matlab. Hence, in the numerical rank deficient cases, the solution will have at least
zero components, and it will be in general different from the solution obtained using the pseudo-inverse. Here too, some additional constraints can be satisfied under some conditions, as shown in the following:
Proposition 2. Let be the column pivoted QR factorization in the first step of the backslash operator when solving the least squares problem , where and . If the first column of is selected among the leading k pivotal columns in the permutation matrix Π, then .
2.3. Computing the Logarithm
The key element of the Mauroy–Goncalves method is that
, where
is a matrix representation of a compression of the infinitesimal generator (
3), that is computed as
. Hence, to use the matrix
as an ingredient of the identification method, it is necessary that
is nonsingular; otherwise
does not exist. Furthermore, to achieve the primary value of the logarithm (as a primary matrix function, i.e., the same branch of the logarithm used in all Jordan blocks), the matrix must not have any real negative eigenvalues. Only under those conditions we can obtain a real (assuming real
) logarithm as the primary function.
For the reader’s convenience, we summarize the key properties of the matrix logarithm and refer to [
24] for proofs and more details.
Theorem 1. Let A be real nonsingular matrix. Then A has real logarithm if and only if A has an even number of Jordan blocks of each size for every negative eigenvalue.
Theorem 2. Let A be real nonsingular matrix. Then A has a unique real logarithm if and only if all eigenvalues of A are positive real and no eigenvalue has more than one Jordan block in the Jordan normal form of A.
Theorem 3. Suppose that the complex A has no eigenvalue on . Then a unique logarithm of A can be defined with eigenvalues in the strip . It is called the principal logarithm and denoted by . If A is real, then its principal logarithm is real as well.
In an application, the matrix
may be difficult to compute accurately and it may be so severely ill-conditioned that in the finite precision computations it could appear numerically rank deficient (recall the discussion in
Section 2.2). Thus, from the numerical point of view, the most critical part of the method is computing
and its logarithm. For a detailed analysis of numerical methods for computing the matrix logarithm we refer the reader to ([
25], Chapter 11).
3. Identification Method
To introduce the new numerical implementation, we need more detailed description of the method [
8] and its concrete realization. In
Section 3.1, we select the subspace
as the span of the monomials in
n variables. The key idea of the method, to explore the connection
in the framework of finite dimensional compressions of
and
, is reviewed in detail in
Section 3.2. This is a rather challenging step, both in terms of theoretical justification of the approximation (including convergence when
,
) and the numerical realization. As an interesting detail, we point out in
Section 3.3.1 that a structure aware reconstruction/identification can be naturally formulated for e.g., the important class of quadratic systems. This generates an interesting structured least squares problem.
3.1. The Choice of the Basis —Monomials
For a concrete application, the choice of a suitable basis depends on the assumption on the structure of
. The monomial basis is convenient if
is a polynomial field, or if it can be well approximated by polynomials. We assume that
where
are monomials written in multi-index notation and have a total degree of at most
. In that case,
is chosen as the space of polynomials up to some total degree
m,
i.e.,
, where
To facilitate automatic and relatively simple matrix representation of linear operators acting on
, we choose graded lexicographic ordering (
grlex) of
, which is one of the standard procedures in the multivariate polynomial framework.
Grlex orders the basis so that it first divides the monomials in groups with same total degree; the groups are listed with increasing total degree and inside each group the monomials are ordered so that their exponents
are lexicographically ordered. For example, if
,
, we have the order as follows (read the tables in (
16) column-wise; each column corresponds to the monomials of the same total degree, ordered lexicographically):
If we want to emphasize that
is at the
kth position in this ordering, we write
, and the corresponding monomial is written as
. An advantage of
grlex in our setting is that it allows simple extraction of the operator compression to a subspace spanned by monomials of lower total degree.
It should be noted that the dimension N grows extremely fast with increased n and m, which is the source of many computational difficulties, in particular when combined with the requirement which is a necessary condition for the non-singularity of . (This difficulty is alleviated by the dual method.)
Even though polynomial basis is not always the best choice, it serves well for the purposes of this paper because, with increased total degree, it generates highly ill-conditioned numerical examples that are good stress test cases for development, testing and analysis of numerical implementation.
3.2. Compression of in the Monomial Basis
Consider now the action of
to the vectors of the monomial basis
. It is a straightforward and technically tedious task to identify the columns of the corresponding matrix
, whose approximation can also be computed as
. Since we are interested only in the coefficients
in (
14), it is enough to compute only some selected columns of
.
Let
ℓ be the index of
in the
grlex ordering, i.e.,
;
(see the scheme (
16)). Then the application of (
4) to
reads
If
, then also
(because of the assumption (
14)
). Hence, in the basis
we have
In other words, the coordinates of
are encoded in
. Finally the entries of
can be obtained with the compression
computed from data. Indeed, it is shown in [
8] that
Hence, provided that
contains independent basis functions, we have
and it follows that, for
t small enough,
For each
, its coefficients in the expansion (
14) are simply read off from the corresponding column of
. Alternatively, we can identify additional columns and determine the coefficients by solving a least squares problem. For more details we refer to [
8].
3.3. Imposing the Structure in the Reconstruction of F
Using (
17), the values of
at the
’s can be approximated using the values
These can be used for expressing
using another suitable dictionary of functions
(e.g., rational) by decoupled least squares fitting for the functions
: with an ansatz
, the coefficients
are determined to minimize
where
is an appropriate (possibly weighted) norm.
Remark 2. Note that (20) is slightly more general than in [8]—we can use separate dictionaries for each coordinate function , which allows fitting variables of different (physical, thus mathematical) nature separately, with most appropriate classes of basis functions. In [
8], it is recommended to solve the regression problem (
20) with a sparsity promoting method, thus revealing the underlying structure. In many cases, the sparsity is known to be specially structured, and we can exploit that information. We illustrate our proposed approach using the quadratic systems.
3.3.1. Quadratic Systems
Suppose we know that the system under study is quadratic, i.e.,
. Quadratic systems are important class of dynamical systems, with many applications and interesting theoretical properties, see e.g., [
26].
With the approximate field values
, we can seek
and
to achieve
If we set
,
, then the identification of the coefficient matrices
and
reduces to solve the matrix least squares problem
where
is the Khatri–Rao product. Here too, one can add a sparsity promoting regularization, with the implicitly defined underlying quadratic structure.
4. Numerical Implementation—A Case Study Analysis
When it comes to turning a numerical algorithm into software, it is often straightforward to write a few lines in Matlab, Python, Octave or some other software package and have a running implementation of a sophisticated procedure obtained by composition of building blocks (subroutines). However, one should keep in mind that the final numerical computation is in finite precision (machine) arithmetic, and that in some cases development of robust numerical software requires a more careful approach. In this section, we use a case study example that reveals difficulties from the numerical software point of view, and that motivates modifications to alleviate them.
4.1. An Example: Lorenz System
A good way to test robustness of a numerical algorithm is to push it to its limits. In this case, we choose a difficult test case and let the dimensions of the data matrices grow by increasing the total degree m of the polynomial basis (and thus the dimension N) and matching that with increased K so that . The main goal is to provide a case study example.
Example 1. Consider the Lorenz systemThe exact coefficients, ordered to match the grlex
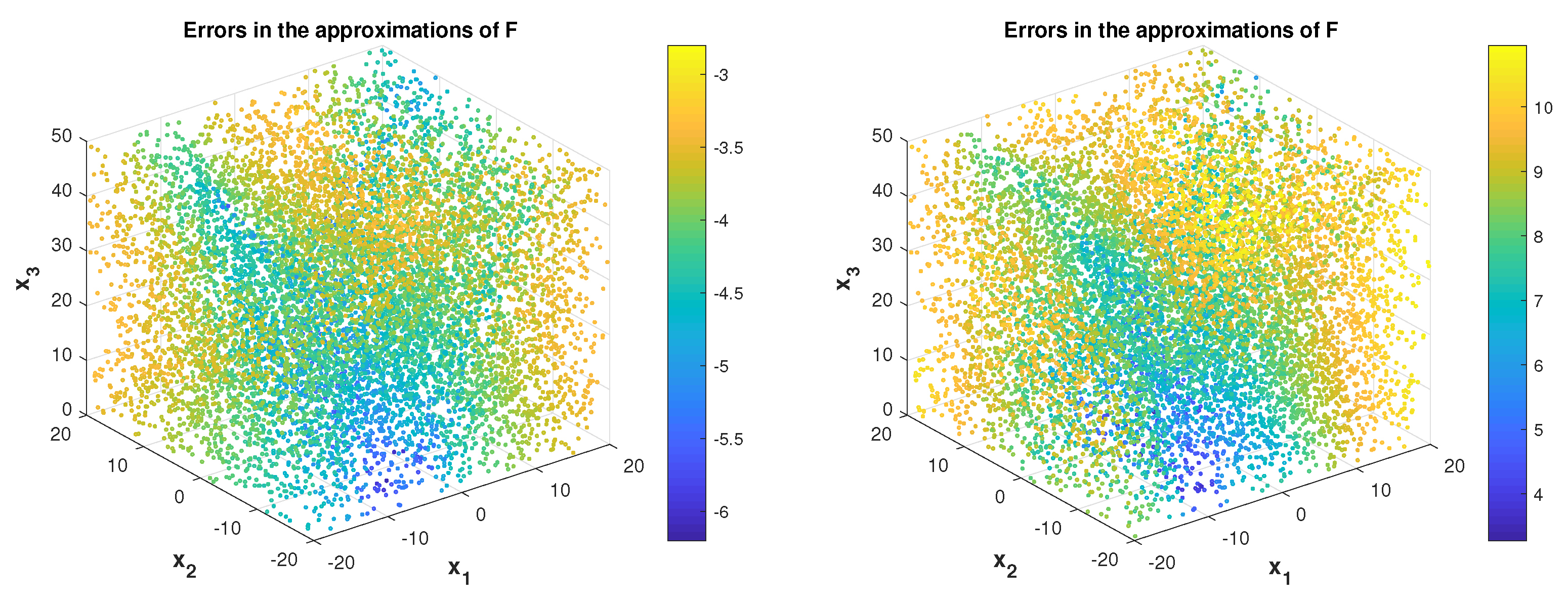
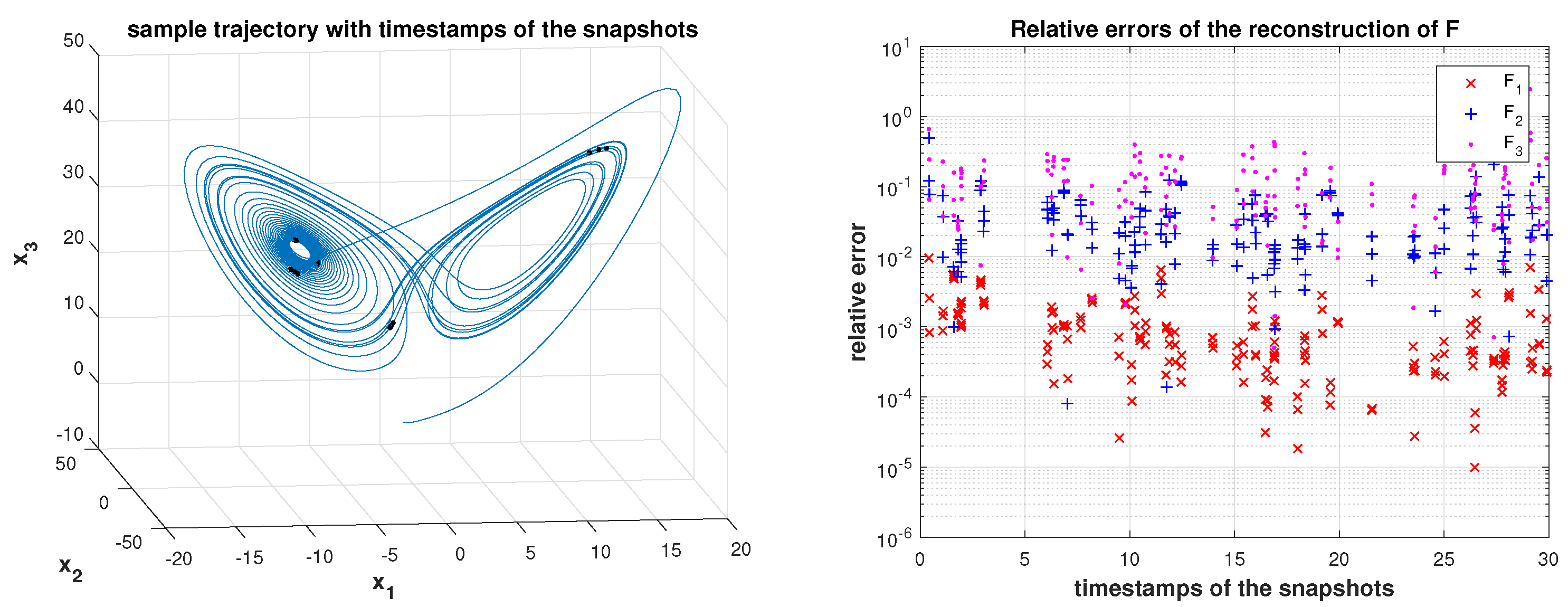
ordering of the monomial basis areTo collect data, we ran simulations with 55 random initial conditions and from each trajectory we randomly (independently) selected 55 points, giving a total of pairs . The simulations were performed in Matlab, using the ode45() solver in the time interval with the time step . In the key Formula (18), we computed the logarithm in Matlab in two ways, as logm (pinv ) and as logm and obtained nearly the same matrix. Of course, using the pseudoinverse explicitly is not recommended. We will use it in this section for illustrative purposes; recall the discussion in Section 2.2. The computed approximations of the coefficients of (23), with , and , areThe nonzero coefficients are matched to five digits of accuracy, and the remaining coefficients are below . Nearly the same result is obtained if the samples from all trajectories have the same time stamps. Given the difficulty of the Lorenz example and the fact that the results are obtained by a low dimensional approximation of a nontrivial (numerically simulated) dynamics, the results are good. Analytical properties of the method indicate that increasing dimensions provides increased accuracy, ultimately yielding convergence. Example 2. Next, we illustrate the reconstruction of the function . We simulated the system in the interval with , and used the monomials with the total degree up to . In the discrete time grid, we randomly selected 9 positions at which we took three consecutive values from each trajectory; in the second experiment 27 randomly selected values of are taken from each trajectory. The total number of trajectories (with random initial conditions) was set to 150.
is approximated using (19). For each , we compute the approximation error asThe sampling points and the values of are shown in Figure 1. Example 3. Now we use the data snapshots from Example 1, and increase the total degree to , thus increasing N from to . Recall that . Surprisingly, the computed coefficients are all complex, and are completely off; their absolute values are (the euclidean norms of the real and the imaginary parts of the vector of the computed coefficients are .The approximation of is also bad, see Figure 2. Increasing the number of trajectories and samples per trajectory to obtain 24,025 did not bring any improvement. Although increasing N, with correspondingly large K, should be the step toward better approximation, the numerical implementation breaks down. In situation like this one, it is important to find out and understand the sources of the problem.
4.2. What Went Wrong
It is clear that in this computation the most sensitive part is computation of the matrix logarithm, and that this is the most likely source of problems. Indeed, in the last run in Example 3 a warning was issued by the logm() function:
A closer inspection of the eigenvalues of
, shown in
Figure 3 confirms that
indeed has problematic (real negative) eigenvalues.
Although
Figure 3 and
Figure 4 show numerically computed eigenvalues, by a backward stability analysis argument one can argue that
is certainly close to matrices with eigenvalues that preclude computing the logarithm in finite precision arithmetic. Hence, computation of the logarithm must be ill-conditioned as the ill-conditioning is essentially measured as the inverse distance to singularity [
27].
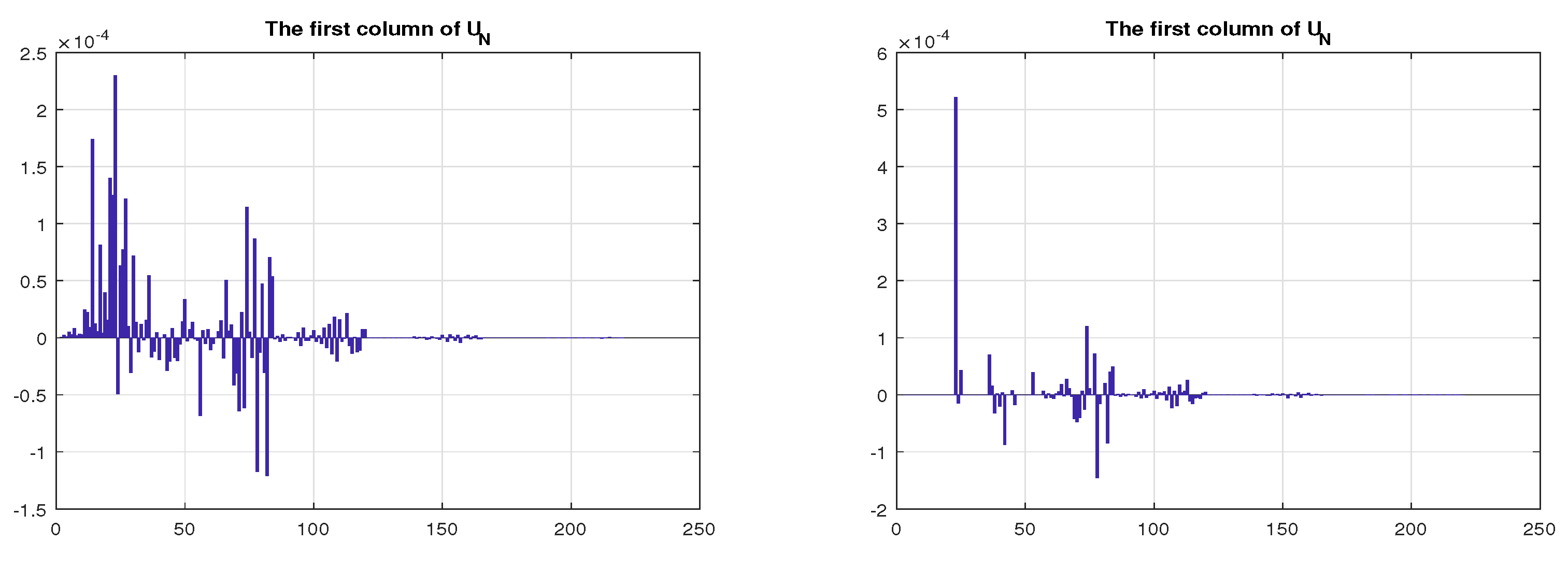
Another look at
reveals that its first column is not what it should be. In this example we use monomials and the first basis vector is the constant. Since
, we expect
, which clearly follows from the solution of the least squares problem (
7), if the coefficient matrix is of full column rank. On the other hand, the first column of
is computed as shown in
Figure 5.
Two conclusions are immediate. First,
is considered (by the software) numerically rank deficient. Secondly, two different software solutions of the same problem return two different solutions. For the data shown in
Figure 3 and
Figure 4, we computed
as
. This is in general not a good idea for solving least squares problems; nevertheless, it can be often seen in the literature and software implementations as a textbook-style numerical method for least squares problems, albeit a wrong one. We included it here for instructive purposes. If we repeat the experiment with the backslash operator,
, the results are, unfortunately, not better. One conspicuous difference is that, instead of the cluster of absolutely small eigenvalues of
(see
Figure 4),
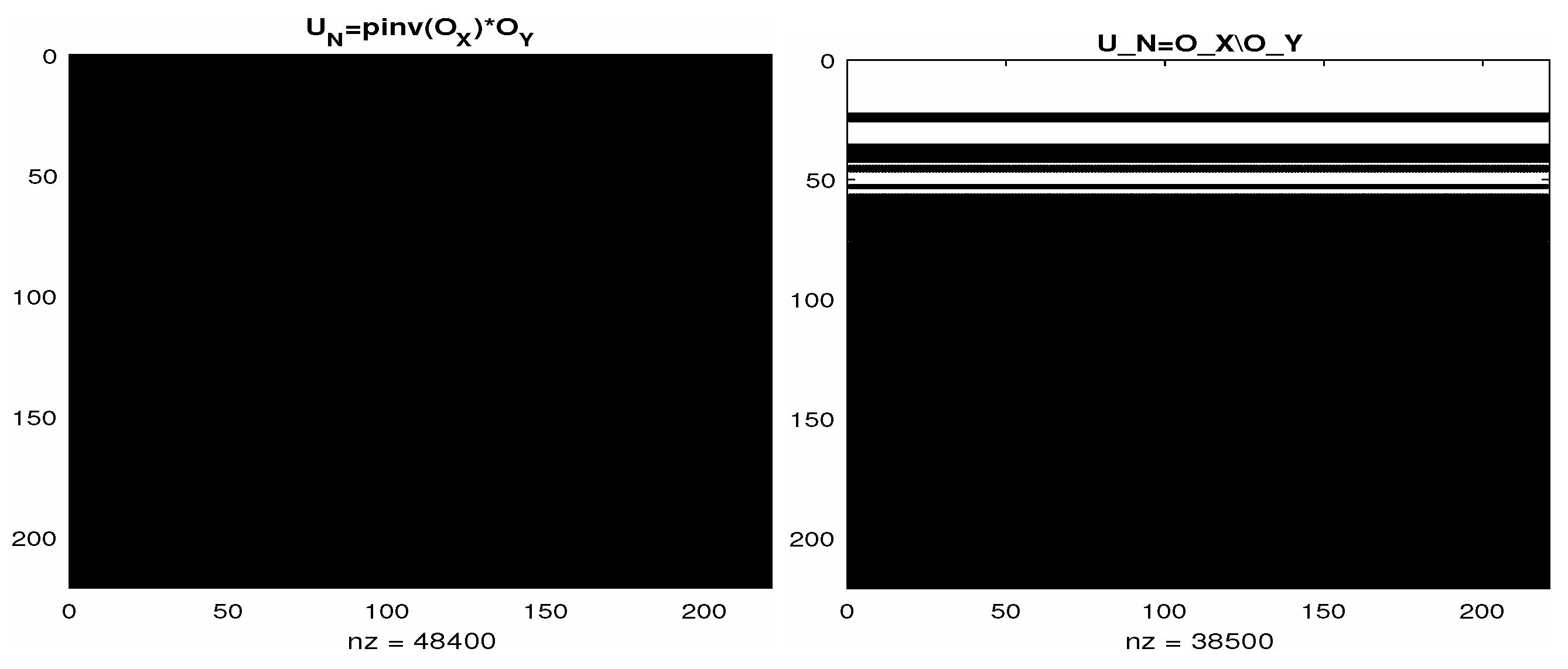
has a zero eigenvalue of multiplicity 45. This multiple zero eigenvalue is a consequence of the sparsity structure of
, see
Figure 6.
In the course of solving the least squares problem, in both methods (explicit use of the pseudoinverse or the backslash operator), the coefficient matrix is truncated (small singular values are set to zero if is used; the upper triangular factor is truncated in the case of backslash, which uses a rank revealing QR factorization) and the computed , due to rounding errors, is small a perturbation of a rank-deficient matrix with a number of eigenvalues in the vicinity of zero. As a result, the matrix logarithm function fails.
The data shown in
Figure 7 are instructive. The condition number of
and the distribution of its singular values are nicely revealed by the column norms of
. The LS solver automatically truncates small singular values that originate from small columns (small basis function values over the snapshots
) and not necessarily from collinearity in the sense of small angles between basis functions.
Look at the singular values in the right panel, in particular the gap . The numerical rank of is determined as 176 because is the smallest singular value that is above the threshold . The index 176 originates in the numerical rank of which is determined in Matlab ( returns 176) by the default tolerance. Note that there is no such visible gap (cliff) in the ordered singular values of .
Remark 3. It should be also mentioned here that the cosines of the canonical angles between the ranges of and are between 0.988 and one (cf. Section 2.1.3), and that we expect the spectrum of not to be too far away from the unit circle. The intuition is that (in the process of computation of ) the truncated part of did not (could not) cancel the corresponding part in , which resulted in the problematic cluster of eigenvalues near zero. (In Figure 3, the number of eigenvalues in the cluster around zero is 44, which is the numerical rank deficiency, because the numerical rank is determined (from the singular values) as 176.) Remark 4. In the computations pinv and , the truncation is conducted based on the SVD and the rank revealing QR factorization, respectively, of , independent of . It is more appropriate to solve each LS problem (7) separately (for the corresponding column of ), and use the truncation strategy following Rust [28]. Note that this is a more general issue because the matrix is often used in the Koopman/DMD setting. (See [29] for a detailed numerical analysis of the DMD and its variations.) Furthermore, the problem can become even more difficult if we have weighting matrix W with scaling factors that spread over several orders of magnitude. (In this paper, we work with for the sake of brevity.) Remark 5. In the case of noisy data, it might be advantageous to replace the least squares fit with the total least squares ([20], §2.7.6). This is an important issue and we leave it for our future work. 5. Computing with Preconditioning
Numerical examples in
Section 4 show that implementation of the method in state of the art packages such as Matlab which is straightforward and effortless: the key computation is coded as
or as
. However, the results are not always satisfactory, and the problems are both in the computation of
(solving the least squares problem) and in computing the matrix logarithm. In this section, we use the structure of the least squares problem solver (reviewed in
Section 2.2.1) to introduce a simple modification and then to construct preconditioned computations of
. These techniques can be combined with the dual method that is analyzed in detail in
Section 6 and
Section 7.
5.1. A Simple Modification
The first attempt to avoid some of the problems illustrated in
Section 4 is to prevent truncation when computing
. So we simply run the procedure used in the backslash solver (see
Section 2.2.1), but without truncation. More precisely, using the column pivoted QR factorization
,
is computed as
.
With
and same setting as in Example 1, the computation of the logarithm of
was successful. (Matlab function
logm() computed a real valued logarithm, without an error/warning message) and the coefficients of (
23) are recovered to four digits of accuracy, which is satisfactory. The remaining coefficients are below
and are discarded in the Formula (
19) for reconstructing
. The first column of
was
up to an error of the order of the roundoff.
The results shown in
Figure 8 are encouraging, because they show that the data contain information that can be turned into more accurate output, provided that the algorithm successfully curbs the ill-conditioning. Furthermore, test with
(
) showed nearly the same four digit accuracy; with
(
) the accuracy dropped to two digits (but the logarithm was successfully computed); with
(
) the logarithm is still computed as real matrix, but the accuracy of the computed coefficients drops to
and the reconstruction of
fails. However, if we increase
K to 24,025 (by sampling more points from more trajectories) the accuracy rebounds to at least for digits both in the coefficients and the reconstruction of
. At
(
and
24,025, or
) the accuracy is lost. The condition number of
is greater than
.
Our adversarial testing is used to expose potential weaknesses of the computational steps in a software implementation of the algorithm. Of course, all these outcomes may vary, depending on the number of trajectories, initial conditions, sampling resolution; in some examples it is possible that the computation of the matrix logarithm breaks down even for smaller values of m. ( Moreover, numerical accuracy, i.e., the conditioning of the problem, heavily depends on the underlying dynamics). In any case, at this point we have to conclude that using the is a source of nontrivial numerical difficulties that preclude efficient and robust deployment of the Mauroy–Goncalves method. The theoretical convergence (as , ) is not matched by numerical convergence of a straightforward implementation of the method in finite precision computation.
5.2. Preconditioning the Logarithm of
The discussion in
Section 4.2 and
Section 5.1 is only one step toward more robust computation—it merely identifies the problem and shows how small changes in an implementation substantially change the final result. Clearly, sufficiently accurate computation of
is among the necessary conditions for successful computation of the matrix algorithms. However, this is not sufficient; even if we compute
accurately, computation of the logarithm may fail if the matrix is ill-conditioned.
We now introduce a new scheme that uses functional calculus-based preconditioning. If
S is any nonsingular matrix, then
Note that replacing
with the similar matrix
corresponds to changing the basis for matrix representation of the compressed Koopman operator. With the experience from
Section 4.2, it is clear that the key is to compute the preconditioned matrix
without first computing
. (Once we compute
explicitly in floating point arithmetic and store it in the machine memory, it may be then too late even for exact computation.)
The conditions on S are:
- (i)
Tt should facilitate more accurate computation of the argument for the matrix logarithm;
- (ii)
It should have preconditioning effect for computing the logarithm of ;
- (iii)
The application of S and should be efficient and numerically stable.
Example 4. To test the concept, we use the same data as in Example 1 with
, and for the matrix
S we take
and compute
Contrary to the failure of the formula
, (
26) computes the real logarithm of the explicitly computed
, and recovers the coefficients with an
relative error. That is, we scale
and
by
, and then proceed by solving the least squares problem with the thus scaled matrices. To understand the positive result, we first note that the condition number of
is
, so the least squares solution is computed without truncation. The condition number of
was
. (The condition number of
is
so that the matrix is considered numerically rank deficient.) With
we had
and
; the coefficients are recovered to three accurate digits and approximation of
is with error slightly larger than the one in the right panel of
Figure 8.
However, as m increases, the diagonal scaling cannot cope with the increased condition number; already at , a complex non-principal value of the logarithm is computed, with some eigenvalues whose imaginary parts are equal . The computed has a cluster of eigenvalues around zero. For the record, , . Surprisingly, the approximate coefficients, although complex, have small imaginary parts (of the order of the roundoff) and their real parts still provide reasonably good approximations of the true coefficients.
5.2.1. Scaled QR Factorization Based Preconditioner
To develop a stronger preconditioner, we start with the following observation: No matter how ill-conditioned and may be (in the sense of badly scaled columns), the distance between the ranges of and , as measured by the canonical angles between the subspaces, should not be too big. (Intuitively, contains the observables evaluated at the states downstream in time from the ’s used in . Recall Remark 3.)
Hence, if we compute the QR factorization of
, the inverse of its triangular factor will have a preconditioning effect on
by postmultiplication. This leads to Algorithm 1.
| Algorithm 1
|
- Input:
, , - 1:
- 2:
{QR factorization} - 3:
{ is similar to .} - 4:
- 5:
- Output:
. {}
|
Example 5. To test this algorithm, we use the data from Example 1, take and increase the number of snapshots to K = 24,025. The matrix is well conditioned, , and computing the matrix logarithm is successful. The coefficients are recovered to four digits of accuracy, and the reconstruction of is slightly better than the one shown in the right panel in Figure 8. This example, as a test of the proposed approach, is encouraging. Our next task is to further develop the method along the lines of Algorithm 1, and to provide a robust method with accompanying numerical analysis, and finally to implement it as a reliable software toolbox.
5.2.2. Pivoted QR Factorization Based Preconditioner
Since in this approach the matrix logarithm is the most critical and numerically most difficult computational task, the preprocessing/preconditioning aims to ensure successful completion of that particular step in the method. The back application of the similarity is also an important step. In Algorithm 1, the main preconditioning is performed by an upper triangular factor from the QR factorization, and by its inverse. For a numerically robust computation, it is important that the QR factorization is computed accurately even in the case of wildly scaled data, and, moreover, that the resulting triangular factor is rank revealing and well structured. These goals can be accomplished by pivoting. In this subsection we outline the main principles along which the idea of QR factorization-based preconditioned computation of the matrix (matrix representation of a compression of the infinitesimal generator) can be further pursued.
The column pivoting has the rank revealing property and the triangular factor is diagonally dominant in a very strong sense, see e.g., [
23,
30] and (
13).
In the case of Businger–Golub pivoting, we know that
, where
and
is well conditioned. Hence,
, and after Line 3 in Algorithm 2 one can insert another preconditioning with
. We omit the details for the sake of brevity. Instead, we conclude this theme with few remarks that should be useful for further study and implementation.
| Algorithm 2
|
- Input:
, , - 1:
Reorder the snapshots by simultaneous row permutation of and ; see Remark 6. - 2:
{Rank revealing QR factorization with column pivoting} - 3:
{ is similar to .} - 4:
- 5:
- Output:
. {}
|
Remark 6. For the numerical accuracy of the QR factorization, an additional row pivoting may be needed to obtain that the rows are ordered so that their norms are decreasing, see [31,32]. If Ψ is a permutation matrix that encodes the row pivoting, then , so that . This means that using the additional row pivoting in the QR factorization in Algorithm 2 is equivalent to a particular ordering of the data snapshots. The column pivoting corresponds to reordering the basis’ functions. Both reorders of the data are allowed operations and can thus be used to enhance numerical robustness of the computation. Remark 7. If then it pays off to change the coordinates by computing the QR factorizationand use the corresponding columns of instead of and . This follows the idea of the QR-compressed DMD [29]. Remark 8. The key assumption in the above described method is that , i.e., that both and are tall matrices; their columns are in a high dimensional space and with suitable transformation S in the column spaces (, ) we can improve the condition numbers. By the (variational) monotonicity principle, supplying more snapshots (increasing K) moves the singular values of and to the right, thus improving the condition numbers of both matrices. Since, by the underlying continuity, the canonical angles between the ranges of and are expected to be away from , and is going to be nonsingular. Moreover, the overall condition number of the computation can be controlled using our proposed modifications that are designed to ensure stable computation of the matrix logarithm.
6. Dual Method
It is clear that the values of N linearly independent functions over the discrete set of snapshots (that is, with only the tabulated values in the matrices , ) contain redundancy. On the other hand, increasing the space dimension N is a way to lift the data to higher dimensional space; more observables improve both the DMD and KMD analyses. Note that, in the case , both the compression and the EDMD matrix () are rank deficient; unfortunately, the infinitesimal generator identification framework cannot work in that setting because the matrix logarithm is not defined. It should be stressed here that, e.g., in the DMD setting, the action of the operator given by the data is restricted to an at most K-dimensional subspace in the N dimensional space, and that the approximations of the Koopman modes are obtained by a Rayleigh–Ritz extraction. Hence, any operator (matrix) function of only makes sense and has a practical usability in the context of an approximation from the subspace defined by the data.
In [
8], a dual method is proposed, which instead of
works with the logarithm of
. In this section we first provide, in
Section 6.1, a detailed linear algebra description of the dual method that will facilitate a more general formulation that allows for modifications which may lead to better numerical algorithms. In fact, we show in
Section 7 that the dual method of [
8] is but a special case of subspace projection methods, and we show how to exploit this for design of numerically better schemes.
6.1. A Rayleigh Quotient Formulation
In the dual formulation, the transition from to can be formulated as another compression of onto a particular K-dimensional subspace of .
Proposition 3. If we define , then (assuming is of full row rank K), is a basis of the K dimensional subspace , and is the matrix representation of the Rayleigh quotient in which is the least squares projection as in Section 2.1.1. The matrix is the matrix Rayleigh quotient of with respect to the range of , i.e., and . Furthermore, the Rayleigh quotient with respect to is the same for all matrices from the set (see (10)): Proof. First, note that the basis functions
evaluated at
can be tabulated as the matrix
and that for a
, its representation in the basis
is
; see (
6), where we take
for the sake of simplicity. Similarly,
evaluated at
yields the matrix
. Now, as in
Section 2.1.2,
. Relation (
27) is easily checked. □
If is nonsingular then the identification scheme should be recast in terms of . In the basis we have then the following representations of the Rayleigh quotient and its logarithm.
Corollary 1. The matrix representations of the compressed and its logarithm (if defined) are as follows: For any , Next, we consider function evaluation at , .
Proposition 4. Let . ThenIf , then the second term on the right hand side in (28) is zero if and only if the ’s are of the form with arbitrary ’s. Furthermore, if , then and Proof. For (
28), it suffices to write
For the first relation in (
29), note that
evaluated at
reads
□
Hence, using the last relation and
in
(evaluated at the snapshots
), we have
If we choose
,
, respectively, (where
) then
and we obtain approximate filed values
defined as
Note however that (
30), (
31) require that
. Furthermore, the approximations of
are given only at the sequence
.
Global Identification of
After identifying the values
, the idea is to use the ansatz
where
are chosen from a dictionary of functions, possibly different from the basis used to lift the data and identify the compression of the infinitesimal generator. Then we obtain the sequence of least squares problems
that can also be equipped with a regularization factor that promotes sparse solution.
6.2. A Numerical Example
As in
Section 4, a simple but difficult example can be used to explore the numerical feasibility of the derived scheme. It has been shown in [
8] that the method works well for the Lorenz system on small time intervals. In the following example, we increase the time domain and test the accuracy of the reconstruction of
. An ill-conditioned problem is obtained by taking the total degree of the polynomials to be 12. Although this may seem artificial, it is useful because it provides numerically difficult cases that expose the weaknesses of the computational scheme and excellent case studies for better understanding and further development.
Example 6. In this example we run simulation of the Lorenz system with time resolution on the intervals , and . The basis functions are the monomials with total degree up to . We generate 12 trajectories with random initial conditions, and from each trajectory we sample three consecutive snapshots at ten randomly selected positions; the matrices , are thus . In the reconstruction Formula (31), the matrix logarithm is computed in Matlab as logm(OY/OX); in all three runs, logm() issued a warning that a non-principal value of the algorithm was computed. The reconstruction error is measured component-wise and snapshot-wise asIn addition, we measure the total error of the tabulated values in the Frobenius norm asIn Figure 9, we show the errors for the intervals and ; in the case of the time interval , the method broke down and the reconstructed values were computed as NaN’s. The results depend on the initial conditions used to generate sample trajectories. In the above experiments, each initial condition is taken as a normally distributed vector generated in Matlab using randn. If we generate the initial conditions as uniformly distributed inside the sphere of radius , centered at the origin, then for all three test intervals the error τ was . With such initialization, the same level of accuracy is then maintained for larger time intervals, up to ; for the error increased to and for the result was NaN.
This example shows that numerical (software) implementation of the dual method requires additional analysis and modifications, similar to the main method. In the next section we explore numerical linear algebra techniques that could facilitate a more robust implementation.
7. Subspace Selection
The approximation (
31) is based on a particular
K-dimensional subspace of
, where (in the case of monomial basis) the choice of the new basis functions precludes direct coefficient comparisons with (
17), (
19). Instead, the identification procedure follows the lines of (
30)–(
33).
We can set up a more general framework: independent of the ratio (and independent of the formulation—original or dual) we can seek other suitable subspaces of , and not necessarily of dimension K. The selection criterion is numerical: both the subspace and its dimension should be determined with respect to the numerical conditioning of the matrix representations at the finite sequence . A basis of such a -dimensional subspace of is written as , where is selection operator, i.e., matrix, of rank . The tabulated values of at are easily computed as . Similarly, the tabulated values of are .
Certainly, . If e.g., , we aim at , but we will have option that a numerical algorithm decides whether that choice is feasible, depending on the level of ill-conditioning.
The subspace selection operator
should ensure that, if needed, the constructed basis of
contains
a priori selected functions
(recall the identification procedure outlined in
Section 3.2) and that
is well conditioned. This implicitly restricts
ℓ to be at most
K, and in practice
. Furthermore, the remaining
basis functions should be selected among the
’s. In other words, we seek
as a selection of
columns of the identity
. This is achieved by the following two step procedure:
(Optional) Define as the permutation matrix that moves the selected functions to the leading positions, i.e., such that .
Add to these ℓ functions a selection of functions that are most linearly independent in the orthogonal complement of as seen on the discrete points .
The second step, which can be designated as basis pruning, is based on the numerical rank revealing techniques.
7.1. Pruning the Basis
Removing the basis functions
that carry numerically redundant information on the set
can be automated using the rank revealing QR factorization [
23] as follows. First, compute the QR factorization of the selected functions, with an optional column pivoting
and then apply
to the remaining
columns to obtain
(The structure of the computed matrices is illustrated in (
36), (
37) for
,
,
.) Now, the columns of
are the coordinates of the projection of the trailing
columns of
onto the
dimensional orthogonal complement of the span of the leading
ℓ columns (of
, at this moment assumed linearly independent). A well conditioned selection of
columns can be computed by another column pivoted (rank revealing) QR factorization
Altogether, we have the factorization
and the leading
columns of
are the desired selection. Note that in this formula we have not used the permutation
of the first
ℓ columns (here assumed independent so that
is nonsingular), to respect the requested ordering
encoded in
7.2. Well Conditioned Selection by Basis Pruning—General Case
In
Section 7.1 we assumed that it was indeed possible to select
linearly independent columns from
. This may not be the case; moreover, the mere linear independence in finite precision numerical computation is not enough. We need well-conditioned selection of the columns of
, i.e., well conditioned matrix
, but also well conditioned
. The rank revealing pivoting (materialized in the permutation matrices
,
) will provide relevant information.
If the initially selected
ℓ functions are nearly linearly dependent on the supplied snapshots, but
of them can be considered well conditioned, then on the diagonal of
we will see that
. In that case, we set
, and the submatrix
is now defined as the subarray at the positions
. Since its first column is now zero, the pivoting
will eliminate it from further selections (unless the entire
is zero). To illustrate, assume that in (
37) the
position carries a value
that is smaller than a prescribed threshold. Then, we have
Altogether, this discussion can be summarized in Algorithm 3.
| Algorithm 3
|
- Input:
, , , - 1:
(Optional) Reorder the snapshots by simultaneous row permutation of and ; see Remark 6. - 2:
Bring the selected functions forward to the leading ℓ positions: . Implement as a sequence of swaps to avoid excess data movement (in the case of large dimensions). - 3:
{ Rank revealing QR factorization with column pivoting. Overwrite over the leading ℓ columns of . See (36).} - 4:
Determine the numerical rank of and in the case set . - 5:
. - 6:
. {Rank revealing QR factorization with column pivoting. overwrites } - 7:
Determine the numerical rank of . Set . - 8:
; - Output:
.
|
7.3. Implementation Details
Remark 9. Note that the case triggers an exception if the selected ℓ functions are essential in the overall computation, as for example in (17), (19), (30), (31). In the examples used in this paper , so that no additional action is needed. Remark 10. The columns of can be severely ill-conditioned and the rank revealing QR factorization should be carefully implemented [33]. The thresholding strategy can vary from soft, mild, to hard, depending on the the concrete example, see [34]. Algorithm 3 can be used to determine the numerical rank but also to ensure that the condition number of the selected columns of is the below specified value. This can be efficiently implemented using incremental condition estimators tailored for triangular matrices. Remark 11. If the column dimension of and is at most K, then we can also apply the original approach from Section 2. Furthermore, the pruning scheme can be also directly applied to the original method. Remark 12. Suppose that and that K is moderate or also big. Then computational complexity is an issue and the algorithm can be modified as follows:
In Line 3, ℓ is expected to be small or moderate compared to K, so that this step can be efficiently implemented using LAPACK (the functions xGEQRF and xGEQP3) or ScaLAPACK using PxGEQPF (but using the most recent implementation [35]). In the second part of the algorithm, we need a well-conditioned submatrix of a submatrix of . To do that, we do not need to compute the whole matrix. We can apply the scheme from [36] and sample the columns of until we form a well-conditioned . 7.4. Numerical Experiments with the Dictionary Pruning Algorithm
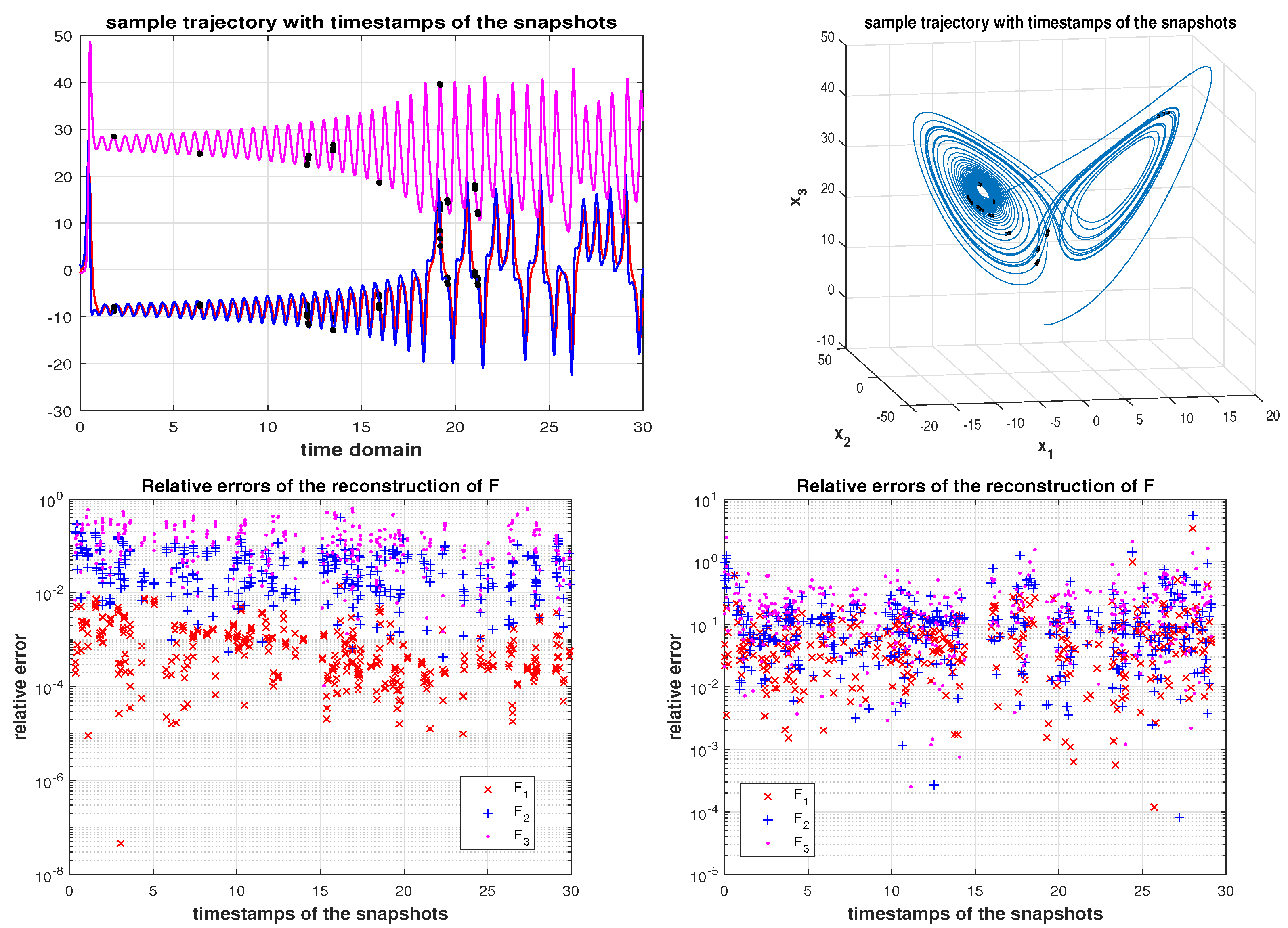
Example 7. (Continuation of Example 6) We use the same data as in Example 6, but instead of and we use K-column submatrices , , selected by Algorithm 3 with the requirement that must be kept in the subspace . More precisely, we set , and the numerical rank is determined with , so that . The results shown in Figure 10 show a significant improvement. Example 8. The purpose of this example is to illustrate the robustness of the proposed algorithm: we take the sampling interval as big as or with the resolution of the numerical simulation and , and the samples are taken, as before, at randomly selected time instances. For illustration, the time stamps of the snapshots are marked on the first generated trajectory (with ) and shown in the first row in Figure 11. The accuracy is satisfactory, given the length of the interval (), the discretization step of the simulation (, ) and the number of samples. Next, we increase the interval to ; the results are in Figure 12. Now, we reduce the number of samples—from each trajectory we sample at five positions (instead of ten), giving the total of 180 instead of 360 snapshots . The results are summarized in Figure 13. In all examples, the rank revealing was conducted with a hard threshold, with no attempt in the direction of strong rank revealing, which could further improve the numerical accuracy. The details are omitted for the sake of brevity and will be available in our future work.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












