1. Introduction
Recent developments for the analysis and control of nonlinear systems focus on the properties of linear transformations of these systems [
1], such as the Koopman operator [
2]. Although this latter transformation is infinite dimensional, there are approximation methods that allow for capturing the point spectrum of the operator based on datasets that were collected from the nonlinear system. The prevalent technique to perform this finite dimensional approximation is the dynamic mode decomposition (DMD) [
3], and its generalization, the extended dynamic mode decomposition (EDMD) [
4,
5], which can make use of a variety of dictionaries of observable functions spanning subspaces over which the Koopman operator can be approximated. The main advantage of these techniques is the ability to analyze the spectral decomposition of the regression matrix or Koopman matrix [
6,
7,
8,
9,
10,
11,
12,
13]. An additional advantage is the possibility to include the forcing signals of the system into the transformation in view of its control [
14,
15,
16,
17]. These latter developments make use of model predictive control (MPC), but the availability of the Koopman matrix and its spectral decomposition should allow the extension of classical linear control techniques to the linear evolution of observables.
A key aspect is the selection of the observables to capture complex dynamics and avoid excessive data requirement. For example, the sparse identification on the non-linear dynamics (SINDY) algorithm [
18] starts with a dictionary of observables and performs a sparse regression by regularized least squares on the original state variables of the system to identify the ones that best describe the dynamics. An alternative is the EDMD algorithm with dictionary learning [
19] (EDMD-DL), where, instead of starting with a predefined set of observables, the algorithm iterates between learning a dictionary via an artificial neural network, and the approximation of the Koopman matrix via traditional EDMD. These techniques have the advantage of reducing the dimension of the set of observables, and possibly the requirement for data to approximate the dynamics. In addition to these techniques, a common practice is to use norm-based expansions, radial-basis functions, kernel-based [
20], orthogonal polynomials, and their variations [
16]. Conversely, these methods have some numerical stability problems when dealing with the set of observables. All of these must deal with the problem of recovering the state, and, for this purpose, a common practice is to include the state in the set of observables, at the cost of the possibility of not having a basis that spans the function space that is necessary for an accurate approximation. When the inclusion of the state is not the case, the solution is to solve a second optimization problem that finds the best projection matrix of the state onto the set of observables. The problem of this approach is the addition of an additional algebraic step that relies on the accuracy of a pseudo inverse, again, at the cost of the possibility of this matrix not spanning the state space.
In a previous work of the authors [
12], an improvement of the EDMD algorithm is proposed through the use of orthogonal polynomials and a p-q-quasi norm reduction method, coupled with a selection procedure for the best p-q values. This algorithm allows for a set of observables that is a basis and, therefore, solves the drawbacks of traditional methods and does not require the solution of a second optimization problem to recover the state. The basis reduction and the preservation of the spectrum can be achieved based on a small dataset. Even though the technique achieves good performance for systems that have a polynomial structure in the underlying dynamics, or systems with periodic behavior, where the evolution of states has trigonometric components, the polynomial methods offer room for improvement.
The main contribution of this study is to embed trigonometric functions [
21], or any particular functions, into the orthogonal polynomial basis in order to better represent systems with cyclic behavior, respectively, any particular behavior. These embeddings improve the accuracy of the algorithm, while preserving the advantage of the reduction method previously introduced in [
12]. The performance of the approach is demonstrated in simulation and real-life experiments with an inverted pendulum on a cart.
This paper is organized, as follows. The next section introduces the EDMD algorithm along with some recent improvements that allow the use of reduced orthogonal basis for its computation.
Section 3 describes the concept of embedding trigonometric functions, or any kind of function into the state space of the system to exploit the a priori knowledge of a variable behavior.
Section 4 illustrates how these embeddings perform by modeling a pendulum on a cart. Finally,
Section 5 gives some analysis and conclusions.
Notation denotes the field of complex numbers. and denote the field of real and nonnegative real numbers, respectively. For any matrix , denotes transpose, denotes its pseudoinverse, and represents the Euclidean norm. For a complex number , represents its absolute value. For any set A, denotes the closure of A. The vector exponentiation is defined term by term. A level set of an arbitrary function for any constant c is .
2. Preliminaries
The extended dynamic mode decomposition (EDMD) algorithm [
5] is a numerical procedure closely related to modern data-driven and machine learning techniques, where the information comes either from the numerical integration of a nonlinear differential equation system or from the measurements of real system variables. This has to be contrasted with traditional system identification techniques that rely upon both the explicit knowledge of the differential equation model [
22,
23,
24] and gathered experimental data. Because EDMD is the backbone of the linear predictors developed in this study, this section presents a description of the algorithm along with its improvements and shows via simulations of the pendulum on a cart its advantages over the current alternative methods.
Consider the non-autonomous nonlinear system
in discrete time, with state variables
, where
is the nonempty compact state space, forcing signals
, where
is the nonempty compact input space,
is the discrete time, and
is the differentiable vector-valued evolution map, i.e.,
where a trajectory, or an orbit of the system is the sequence of states
that come from the solution of (1), which is the successive application of the non-linear mapping
T from an initial condition
at
and a specific sequence of forcing signals
.
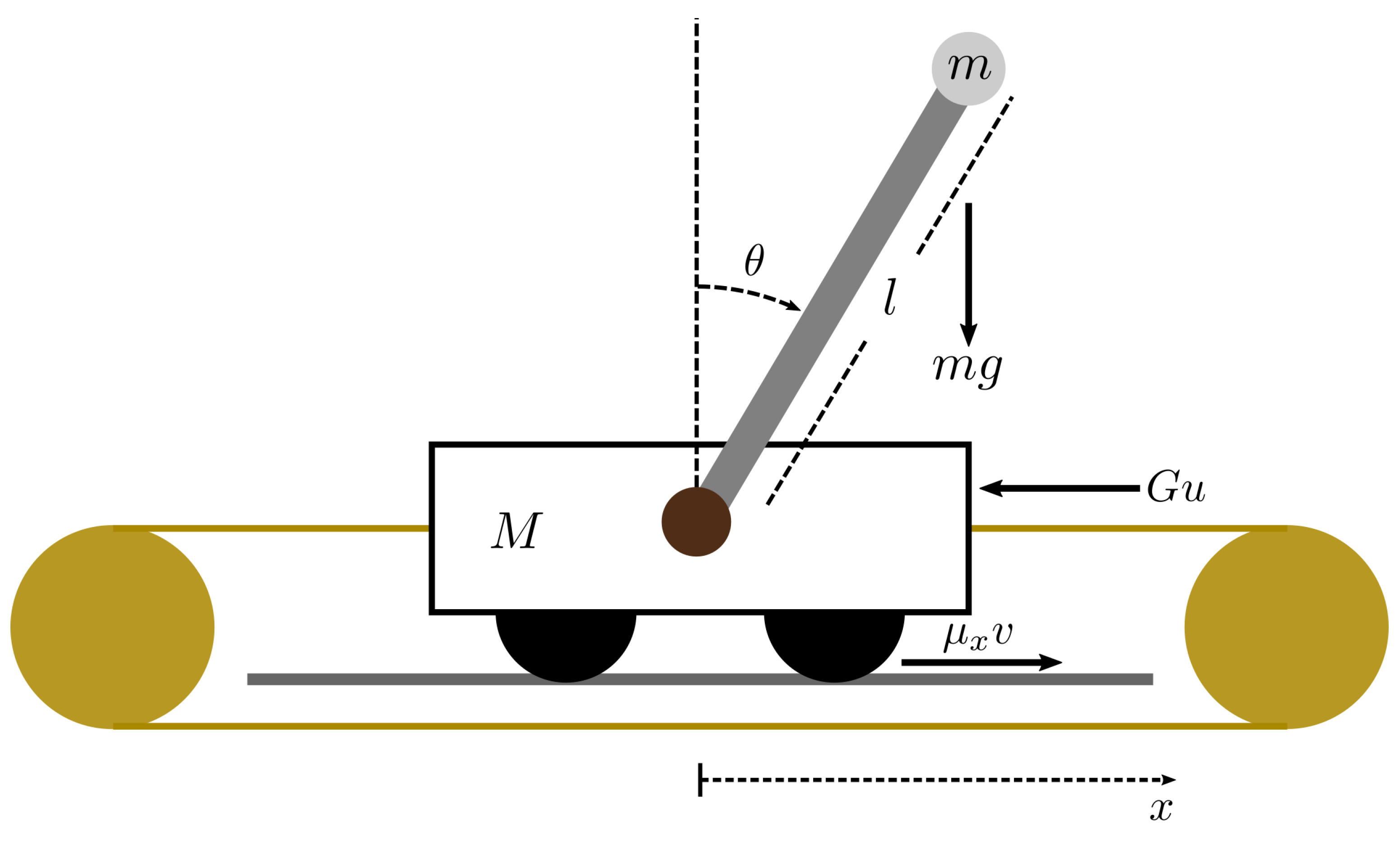
For example, consider the experimental set-up that will be used later on in this study for the validation of the trigonometric embeddings. The system consists of a pendulum and a moving cart attached by a swivel that allows the pendulum to rotate freely. The cart wheels rotate on a rail and a DC motor drives the whole system. The available information from two encoders are the displacement of the cart and angular rotation of the pendulum.
Figure 1 depicts the experimental set-up, where
x is the horizontal displacement of the cart and
is the angle of the pendulum with respect to the vertical axis. Mass and energy balances give a set of ordinary differential equations that describe the dynamics of the system.
The system equations, which depend on the masses of the cart and pendulum, the length of the pendulum rod, the linear damping of the cart wheels with the rails, and the gravitational constant, are given by
where the states are the cart displacement
x, the cart velocity
v, the rod angle
, and the angular velocity
. The model also considers a gain
G between the voltage of the motor
u and the resulting force on the cart. The parameter of the model come either from the available data from the manufacturer (Feedback Instruments Ltd. Crowborough, UK) or from an identification of the parameter from a set of data collected in preliminary experiments with the system.
Table 1 lists the value of these parameters.
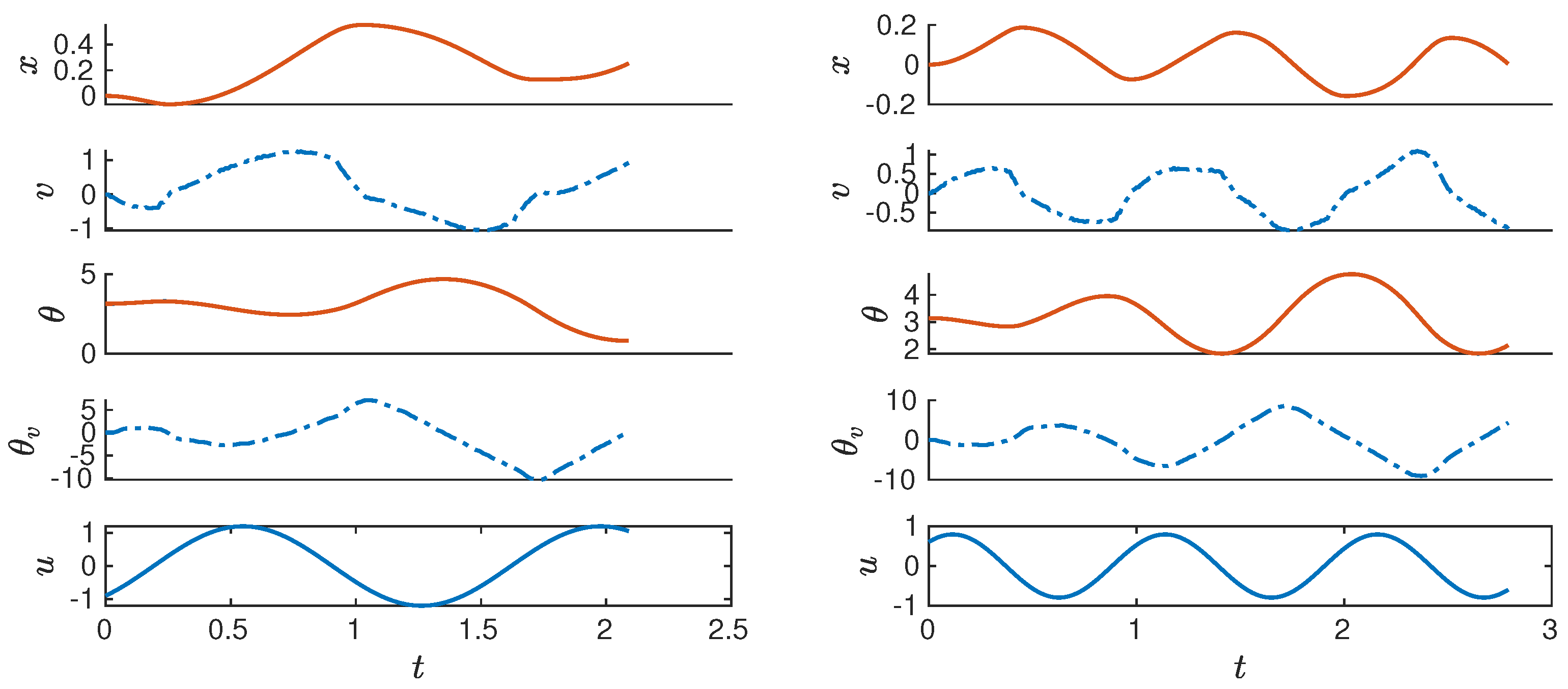
Let us now consider a set of seven orbits or trajectories that were obtained by the numerical integration of (2) with the assumption that all of the state variables of the system are available. For the accuracy of the algorithm, it is necessary that the trajectory samples are collected at a constant rate, which is chosen equal to 0.01 s, in both the numerical simulation and experimental study. This set of orbits sampled at a constant correspond to the solution of the non-linear discrete-time mapping (1).
Figure 2 depicts the discrete-time evolution of some of these trajectories with their respective forcing signals. These trajectories serve as the available data to approximate the non-linear dynamics via the EDMD algorithm.
Because EDMD is a data-driven approach, the set of trajectories is divided into training and testing sets for the approximation and validation of the algorithm. In our case study, the selection is five orbits for training the linear predictor, and two for testing (
Figure 2). Finally, the snapshot data are defined as a set of tuples
, where
. From these tuples, the snapshot matrices are given by:
according to the traditional EDMD algorithm [
5] and the extension for including the inputs of the system [
17]. The rationale behind the approach is to obtain linear predictors of the state evaluated on a vector-valued function of observables
where
d is the dimension of the set of observables that must satisfy the condition
is the residual term that has to be minimized in order to find matrices
and
. This leads to the least squares problem
which as a closed-form solution
Because the purpose of these predictors is the synthesis of controllers, it is necessary to recover the state from the observable functions. Thus, an additional least squares problem for the best projection matrix of
x onto the span of
has to be solved. The projection must satisfy the condition
where
is the residual term to be minimized to find
, which accepts a pseudo-inverse based least squares solution
Instead of solving (8) to recover the state, a common practice is to include the state in the set of observables, so that matrix after reordering the observables, such that the state vector forms the first n elements.
The EDMD formulation (6) and (8) can be used with a basis of Jacobi type monomials for the approximation of the pendulum dynamics (2), i.e., a sequence of orthogonal polynomials
where
is a univariate polynomial (i.e., a polynomial in only one of the state variables
,
) of degree
up to order
p. This sequence is defined over a range
, where some inner product between distinct elements is zero, i.e.,
for
, and it satisfies a particular ordinary differential equation. Each element of the observable basis is the tensor product of
n univariate polynomials,
For the approximation of the pendulum dynamics, the order
can be chosen, giving a set of observables of dimension
(16 for the state and 1 for the input) with maximum order 4, i.e., the last observable of the state is the product of all the univariate monomials
for parameters
and
of a Jacobi type monomial of order one in the variable
x,
. When considering the pendulum states,
Table 2 shows the set of indices
for each of the observables of the state.
Note that
Table 2 shows a base
counting solution with
n significant figures, so that the base 10 digits from zero up to
in a
base is given by
This set of indices has a simple computational solution using Matlab, not only for generating it, but also as an input for the subsequent reductions. Along with the set of indices, and the method for generating the basis as a tensor product of the univariate polynomials from (9), the orthogonal basis is
![Mathematics 09 01119 i001]()
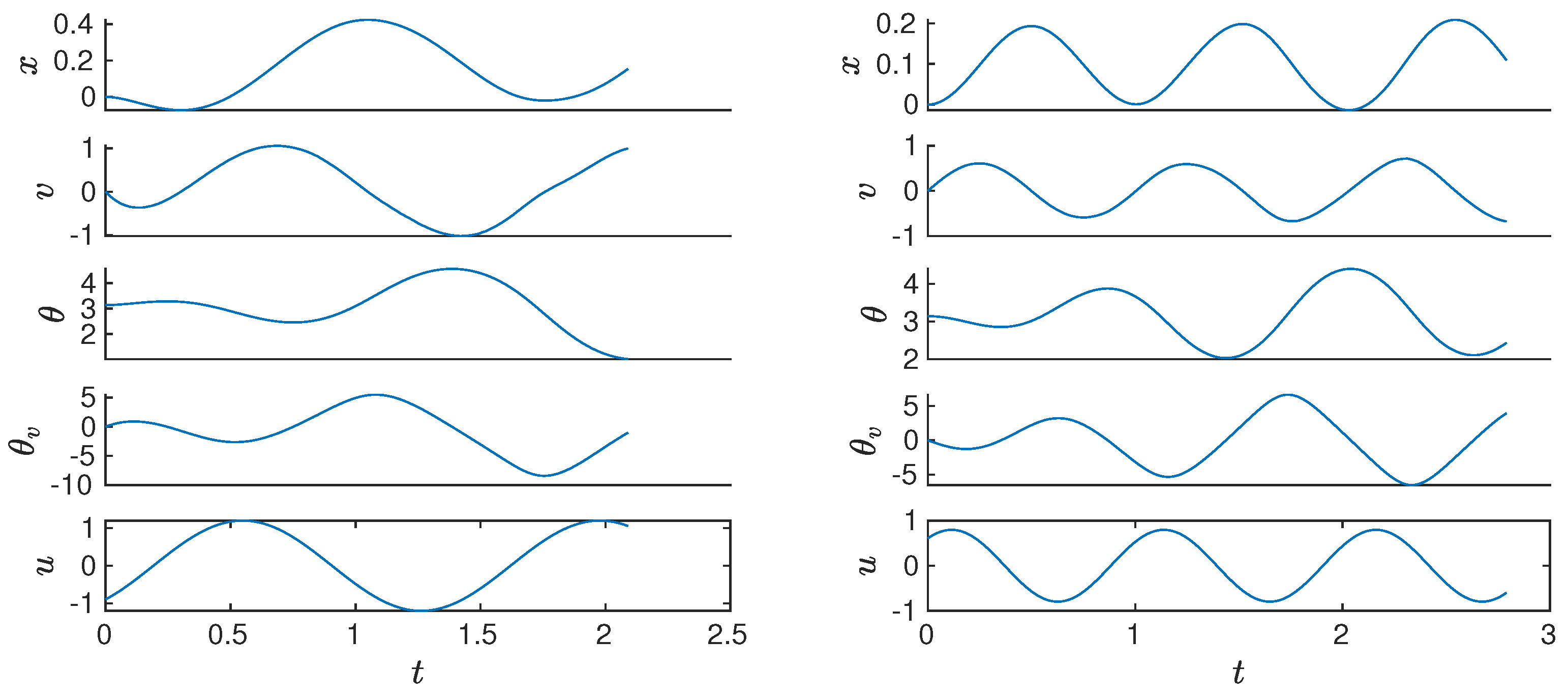
When considering five trajectories of the training set that sum 1110 data points, two trajectories of the testing set that sum 490 data points, and a Jacobi type set of polynomials, the solution of the EDMD algorithm gives a linear predictor of the extended state.
Figure 3 shows the trajectories that were produced by the EDMD, where the mean absolute error
is 1.31, and the max absolute error
is 11.79. While it is possible to perform the approximation with higher
p values, the results do not necessarily improve. For
, as the maximum order of the univariate polynomials, the basis has dimension
with a maximum order of eight, which shows that these two numbers grow exponentially with the maximum univariate order
p. Moreover, in this particular case the mean absolute error increases to 1.77, which is also a sign of numerical issues due to the maximum order, even though the maximum absolute error decreases to 8.43.
Indeed, there are some inherent numerical instabilities with the method. First, the EDMD algorithm is a linear map on the function space that the set of observables span, and the accuracy of the solution depends on the characteristics of this set. Choosing an orthogonal basis with an observable that corresponds to a constant generally improves the performance of the approximation. In contrast, adding the state to the set of observables is prone to breaking the orthogonality of the observables, depending on their actual choice. As a consequence, the square matrix in (6) becomes singular or close to singular and, while replacing the inverse by a Moore–Penrose pseudo inverse can partly alleviate this issue, the result can still be inaccurate. Second, preserving an orthogonal basis, without explicitly including the states as observables poses a similar matrix inversion problem, when there is no solution to the projection of the state space onto the set of observables.
The way out of this dilemma is the selection of order-one, univariate, injective, polynomial elements for the recovery of the state [
13], which implies that there is no need for breaking the orthogonality of the set while still being able to recover the state as a linear function of the observables, completely avoiding the burden of a matrix inversion.
Besides, the exponential growth of the maximum order and dimension of the set of observables based on orthogonal polynomial has a solution via p-q-quasi norms and polynomial accuracy methods.
The reduction by p-q-quasi norms (the quantity
is not a norm because it does not satisfy the triangle inequality) [
25] is the truncation of higher order elements from the basis by defining the q-quasi norm
and by defining a maximum degree
and a quasi norm
to obtain a set of indexes
, which defines the order of each of the univariate polynomial elements whose products form the elements of the observables. With this truncated set of indices, every element of the vector valued function of observables is the tensor product of
n univariate polynomials, as in (9). When considering the previous Matlab code example, the necessary modification consists in the addition of one line of code that performs the truncation before calculating the univariate polynomials.
![Mathematics 09 01119 i002]()
The result of the truncation has as a consequence that different values of q for a particular value of p give the same basis of polynomials. As the current method to determine the best p-q combination is a sweep over the parameters, it is necessary to determine the equivalent sets of parameters before calculating the different EDMD algorithms in order to avoid the computational burden of calculating the same EDMD for an equal basis. Moreover, the sweep over the parameters is a process that achieves a sub-optimal solution because an optimal selection based on the dynamics of the system or the analysis of the data samples is still an open question. The only limitation on the selection of the sweep is in terms of the computational burden from the exponential growth of the dimension of the basis according to the p-q parameters. when considering this limitation, the full set of indices without truncation has the potential of becoming too big for the computers memory In this case, it is possible to revert the matrix-based calculation of the truncated indices to an element-wise process, adding at least two orders of magnitude to the required time to complete the process. Along with this limitation, the dimension of the polynomial basis is also computationally taxing on the inverse or pseudo inverse in (6).
The vector valued function of observables can be further reduced by considering the polynomial accuracy
where
is the
l-th row of the EDMD matrix.
Because the
n injective order-one univariate elements have to remain in the basis, so as to be able to recover the state later on, the threshold
for the elimination of elements is the maximum of the errors with an alpha index equal to one
and the multivariate polynomial elements that stay in the reduced vector-valued function of observables
are
Above this threshold, the corresponding observables are discarded. Consequently, a reduction of the mean absolute error is expected.
In our case study of the inverted pendulum, we can consider the same orthogonal basis of Jacobi polynomials with a sweep of p-q parameters corresponding to:
and
. Although there are 18 possible combinations, some p-q parametrizations produce equal basis. There are only 12 distinct sets of observables, ranging from six elements of maximum order 2 to 173 elements of maximum order 5. The result of the reduction gives a sub-optimal basis of 33 elements of maximum order 3 that achieves a mean absolute error of 0.62 and a maximum absolute error of 4.85, as compared to 1.31 and 11.79 for the traditional EDMD. Note that the reduction provides the possibility to test higher-order polynomial basis than in the traditional form, where a basis of maximum order 5 would count 625 elements. In addition to the versatile selection of higher order polynomial basis, the p-q-EDMD also reduces the necessary amount of data for producing accurate linear predictors (in our case study, the algorithm needs 1110 data points for the training set). This reduction allows the implementation of the algorithm in real systems, where it is expensive and time consuming to acquire big data-sets.
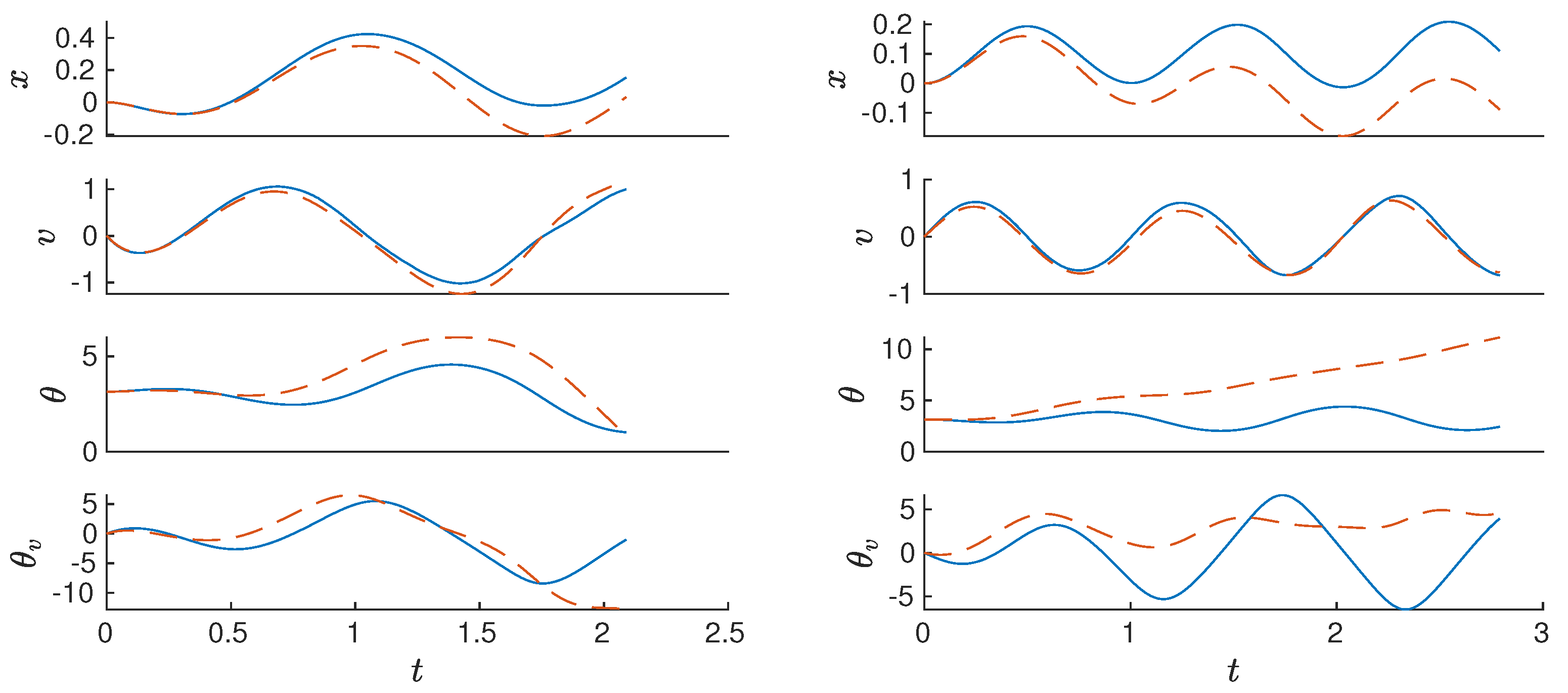
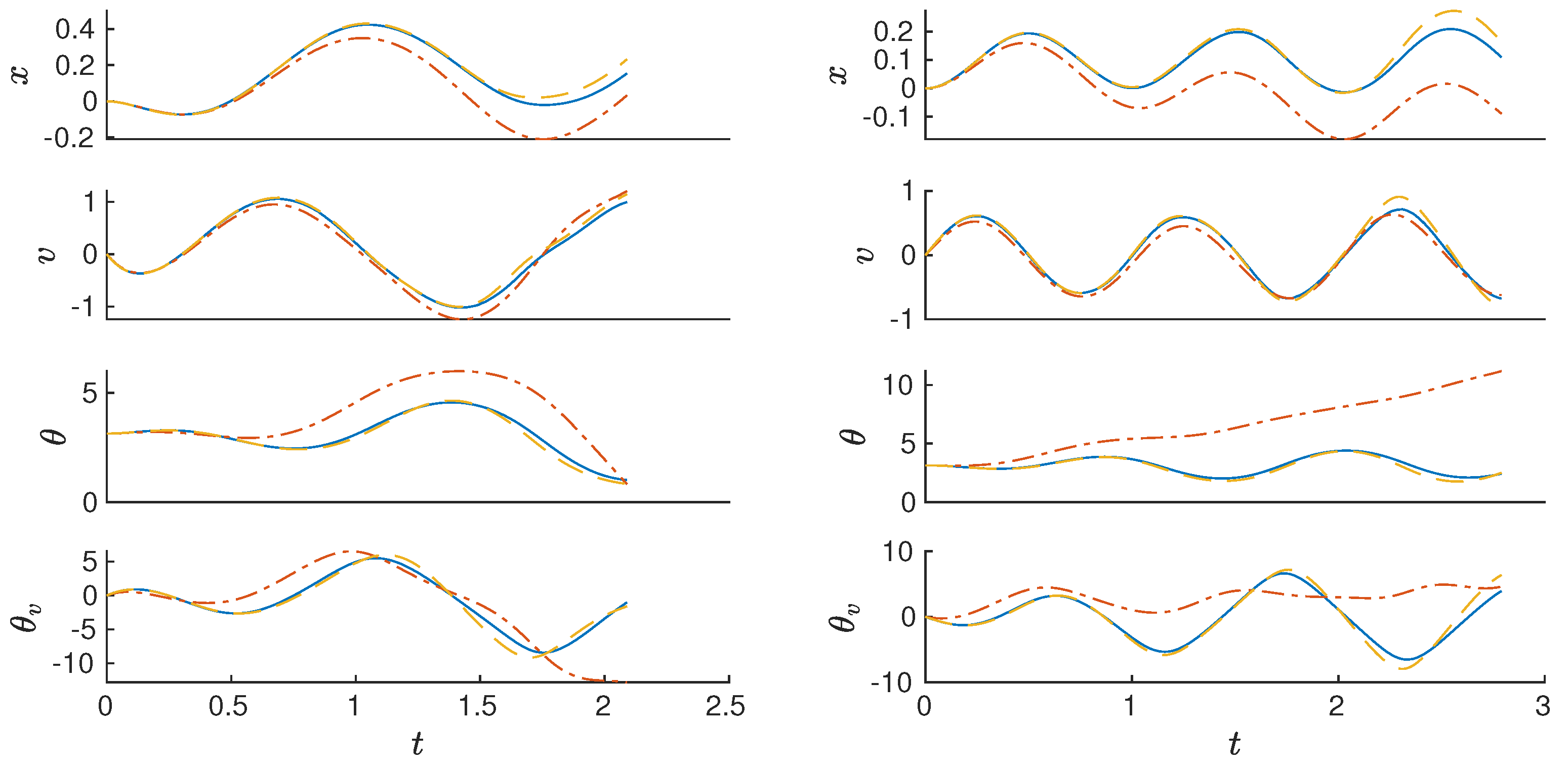
Figure 4 shows the performance of the sub-optimal basis of the p-q-EDMD in comparison to the traditional EDMD.
Although the use of reduced orthogonal polynomials for the p-q-EDMD provides a method for improving the accuracy of the algorithm while avoiding computationally heavy high-order and dimensional solutions, the accuracy of the algorithm for systems that have trigonometric components or an arbitrary behavior, like exponentials or logarithms, is not enough. Therefore, the next section introduces the concept of trigonometric embeddings.
3. Trigonometric Embeddings
In this section, we consider the problem of representing dynamic systems with oscillatory behavior by polynomial expansions and the possibility to increase the parsimony of the approximation by the inclusion of trigonometric functions as elementary units of the polynomial expansion. Similar embeddings could be used for any particular behavior, using associated functions. Similar to the idea that took the dynamic mode decomposition algorithm to the extended version, where, instead of performing a regression on the states, the extended method considers a set of functions of the state (the so-called observables), the trigonometric embeddings, or more generally function embeddings, provide specific functions of the state conveying particular information.
Consider the discrete-time dynamical system (1) and assume that a subset
m of the state
has trigonometric components in the difference equation
. For each of these state variables, an extension of the state vector is achieved with 2 additional variables, leading to
where
and
belongs to some extended space, i.e.,
where
. In this extended space, a set of observables
is defined, where each element comes from (9), with the same p-q-quasi norm reduction (10) of the p-q-EDMD algorithm. Therefore, preserving the advantages of working with a reduced orthogonal basis.
Consider, for example, an arbitrary discrete-time dynamical system
, where
,
and
, i.e., the system has two state variables where the second one has a trigonometric component and two inputs within the non-linear mapping
. Moreover, a Hermite basis of orthogonal polynomials of univariate elements up to order 2, i.e.,
, is used. For illustration purposes, assume an arbitrary p-q parametrization
and
. The resulting polynomial basis of the extended space is
To bring the set of observables from the extended space into the original state space of the system, the following transformation has to be applied,
for
. In our case study, the set of observables of the state becomes
Note that the embeddings are not restricted to trigonometric functions, but could, for instance, include logarithmic, exponential, or hyperbolic functions, if the non-linear mapping has state variables with such a behavior. However, the functional embeddings and, particularly the trigonometric embeddings, which add two more variables for each trigonometric state, exponentially increases the dimension of the set of observables and it is necessary to resort to the previous p-q-quasi norm reduction.
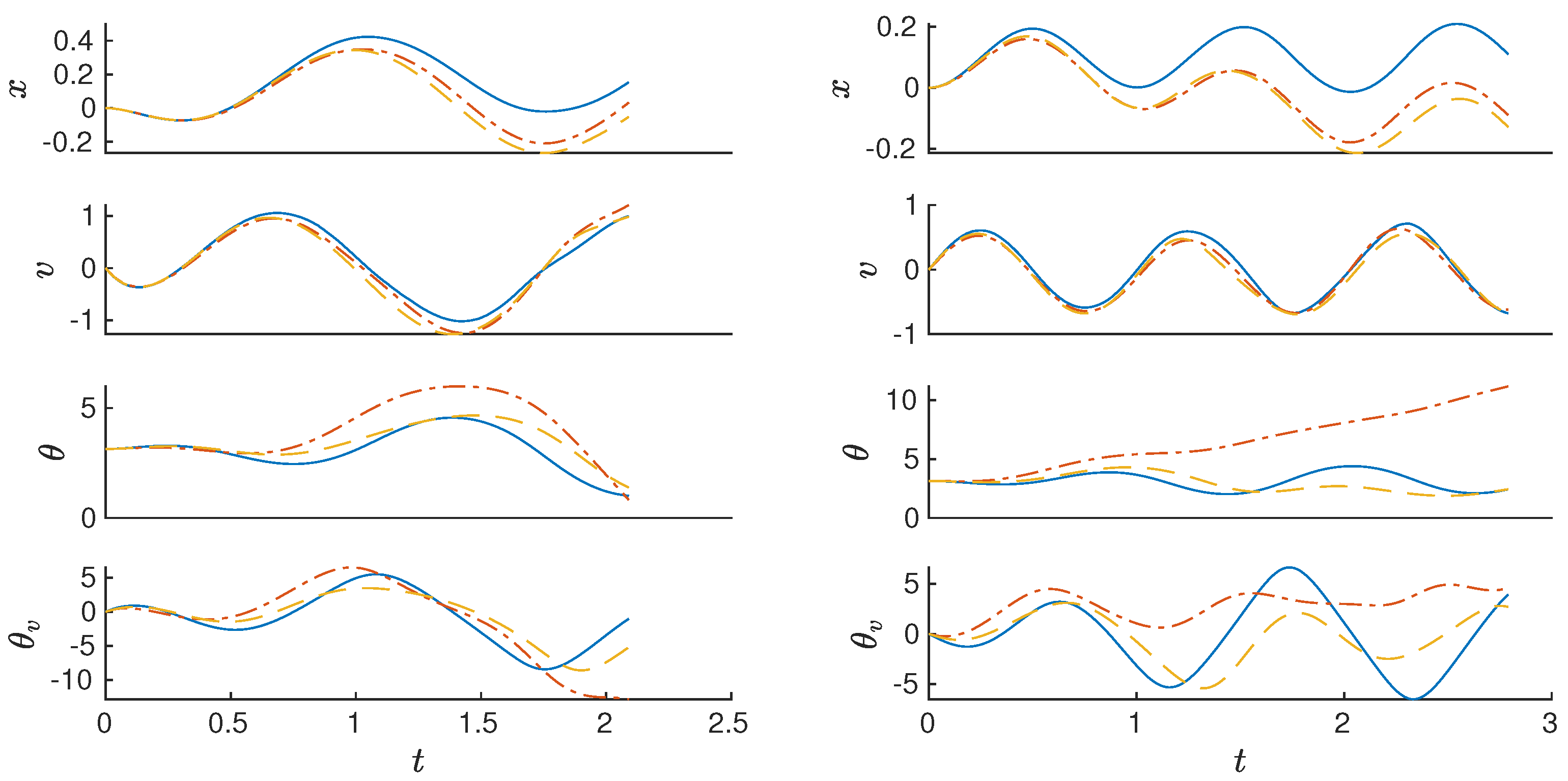
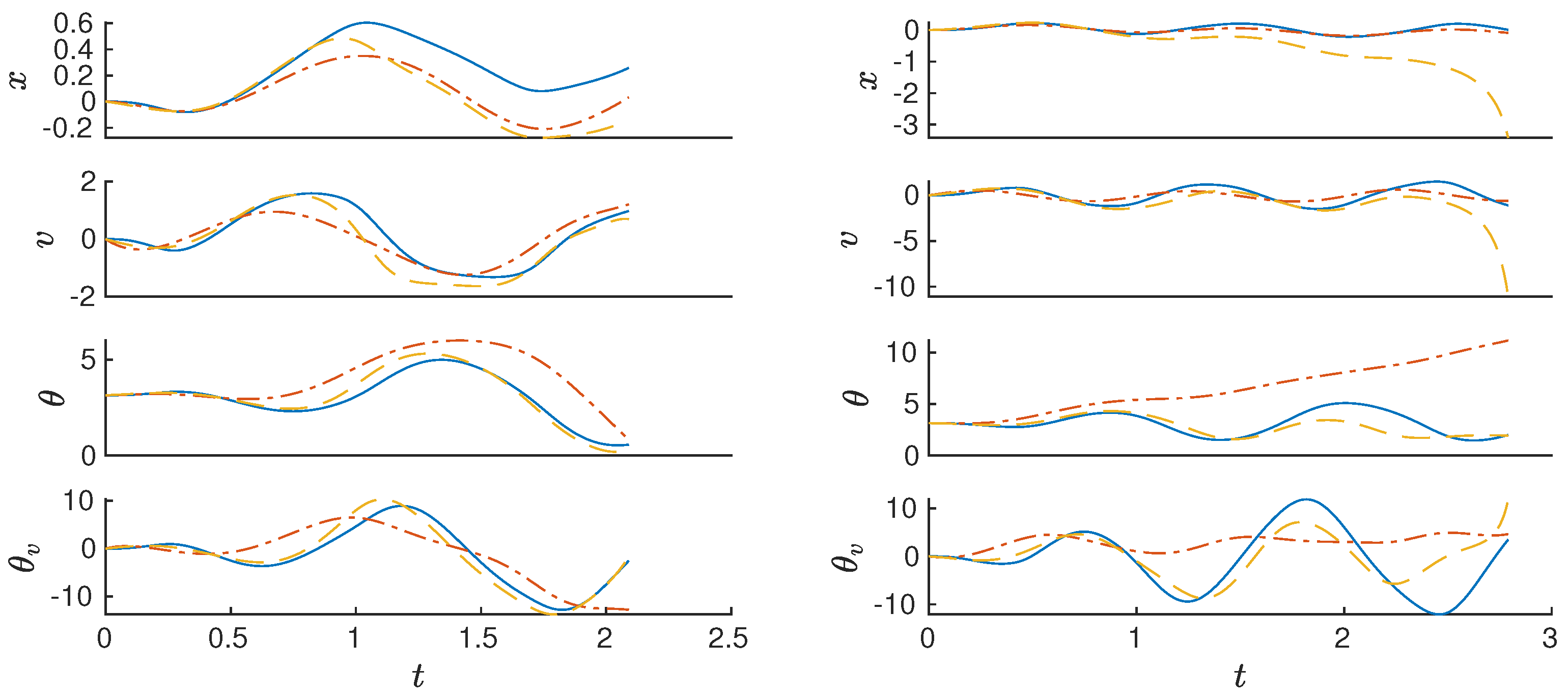
The application of trigonometric embeddings to the orbits of the pendulum problem, when considering that only the angle
has trigonometric components, reduces both error metrics, the mean absolute error of the approximation, from the aforementioned value of 0.62 (provided by p-q-EDMD) to 0.17 and the maximum absolute error from 4.85 to 2.46. To achieve these results, we consider a p-q sweep where
,
and the available orthogonal polynomials in Matlab.
Table 3 shows the mean absolute errors and the maximum absolute errors for the best sub-optimal solution for each polynomial basis. The sub-optimal solution is a Laguerre polynomial basis with parameters
and
. Although the approximation error in the test set is reduced, the inclusion of the two extra trigonometric variables and the increased
p value produce a basis of 65 elements.
Figure 5 depicts the result of the algorithm in comparison with the benchmark EDMD.
4. Inverted Pendulum: Experimental Results
For illustration purposes, and to compare numerically various expansions, we consider the real-life application that was provided by a Feedback Digital Pendulum 33-005-PCI (
Figure 6).
This pendulum is the same as that described in
Section 2. A DC motor drives the cart along the rail to which a pendulum is attached. The available experimental set-up provides, through two encoders, the noisy measurements of the cart position, and the pendulum angle every 0.01 [s]. Therefore, the output equation is given by:
where
.
However, the knowledge of the cart velocity and the angular velocity are necessary for computing an approximation through the EDMD algorithm. A simple differentiation of the displacements gives an amplification of the noise, impeding the possibility of obtaining accurate approximations of the dynamics. This can be alleviated by the design of two Kalman filters based on simple kinematic expressions. The Kalman filter [
26] is a model-based technique that allows recovering on-line estimations by blending the prediction of a mathematical model with the available on-line measurements. Here, the idea is to avoid using a full differential equation model, such as (2), as this would be contradictory with the objective of developing a data-driven EDMD model. Hence, the method relies on basic kinematic relations
where the acceleration is assumed constant. The basic model prediction is completed by a correction (or state update) in the form
where
is the estimate of the corresponding variable,
is the measurement of the cart position or pendulum angle, and
is the Kalman gain that is based on the solution of a Ricatti equation for the estimation covariance matrix [
26]. Furthermore, each of the position–velocity pairs has an independent filter with their corresponding parametrization.
For generating the experimental data, the pendulum starts at the stable point
and it is exited with a sinusoidal signal at various frequencies and amplitudes, i.e.,
where the ranges of the different parameters of the forcing signal are:
,
,
. The selection of these parameters ensures that the cart movement does not exceed the track limits.
Figure 7 depicts the result of gathering and filtering the experimental data.
The application of the p-q trigonometric EDMD on the experimental data is a linear predictor suitable for controller synthesis. To this end, we consider a sweep where , , a trigonometric embedding over the third state . Additionally, and for the consistency of the results, the training and testing sets correspond with the ones that are used in the simulation results.
The chosen solution for the experimental case is a Chebyshev polynomial of the first type with parameters
,
and 18 observables that give a mean absolute error of 0.85 and a max absolute error of 11.79. For the experimental case, the max absolute error is independent of the type of polynomial, i.e., all of the available orthogonal polynomial basis in Matlab show the same error. Even though the maximum absolute error does not give a suboptimal solution for the basis selection, it does give a better classification in terms of p-q-quasi norm in contrast to the best approximation according to the mean absolute error, where
,
, has a set of 85 observables, and
.
Figure 8 shows the results of the approximation in the test set.
The EDMD algorithm gives a linear predictor equivalent to a discrete-time dynamical system. This predictor is suitable for the synthesis of controllers that drive the system to a desired state. The reliability of such a controller depends on the ability of the predictor to give accurate approximation of the dynamics for arbitrarily long time intervals. Therefore, for testing the strength of the algorithm, an additional test trajectory is considered where the simulation or experimental times are three times longer than the training and testing sets used for the computation and validation of the method. The result of evaluating the p-q-Trigonometric EDMD linear predictors on these additional long-term sets is depicted in
Figure 9, where the mean absolute error for the approximation of the numerical simulation of the pendulum is 0.75 and the maximum absolute error is 6.05. For the experimental trajectories, the mean absolute error is 0.72 and the maximum absolute error is 7.31. These results show that, for these particular cases, the method is reliable enough for the prediction of the long term dynamics of the system.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
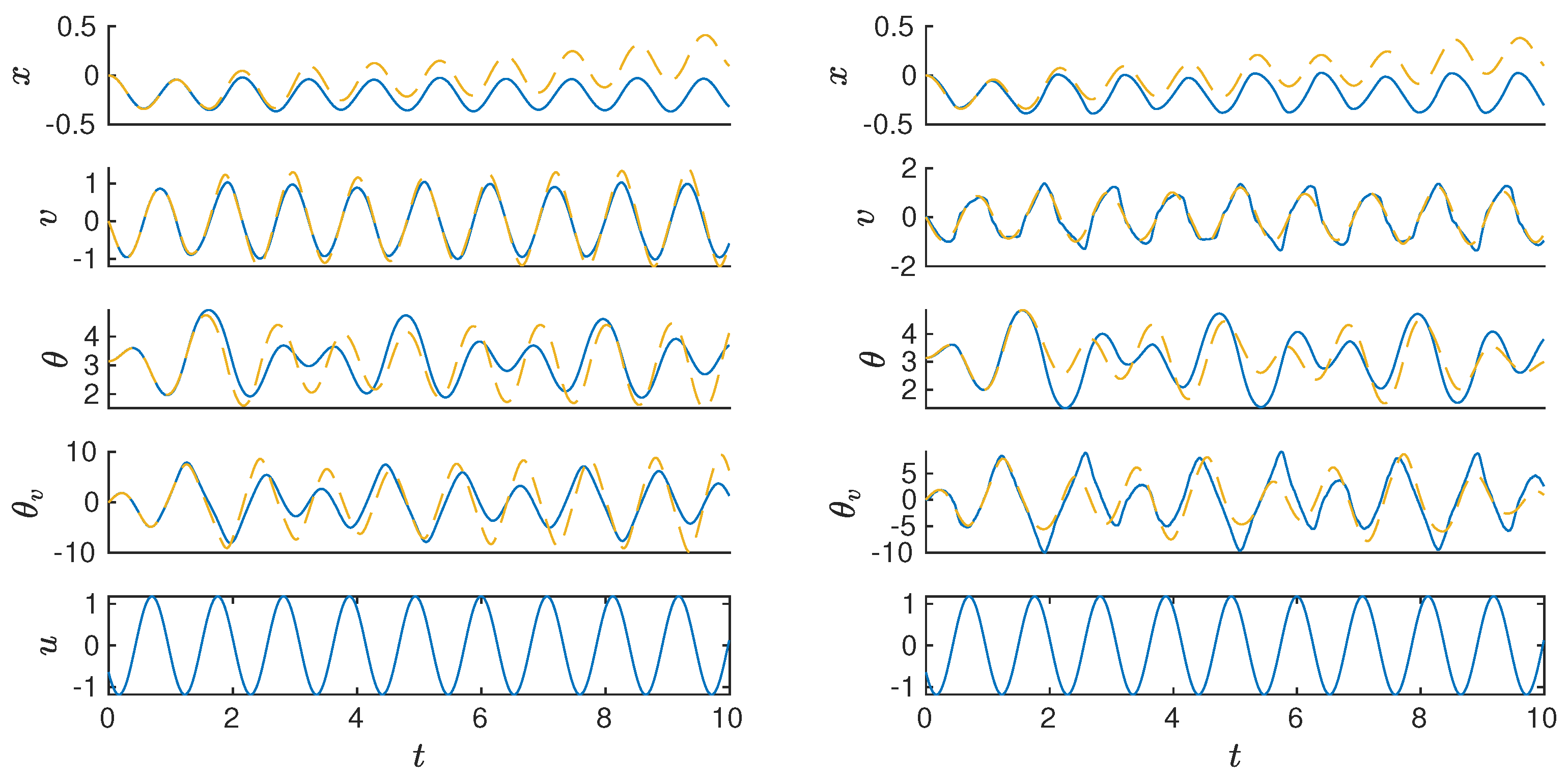{kind=link}