
A Method to Automate the Prediction of Student Academic Performance from Early Stages of the Course


Abstract
:1. Introduction
- (i)
- to capture descriptive information of the interactions,
- (ii)
- to categorize and characterize the information collected and
- (iii)
- to intervene in the improvement of the collaborative activity.
- (i)
- information to be processed by the students (analysis indicators to be displayed, advice to be shown, new exercise to be solved, etc.),
- (ii)
- a trigger moment or situation that puts the intervention in action,
- (iii)
- learners who receive each intervention.
1.1. Related Work
1.2. Our Research Contribution
2. Materials and Methods
- 1.
- Is it possible to predict successfully the average grade over the N tasks based on the two first tasks performed by the students?
- 2.
- Is it possible to predict successfully the average grade over the N tasks based on the three first tasks performed by the students?
- 3.
- Is it possible to predict successfully the average grade over the N tasks based on the four first tasks performed by the students?
- 4.
- Is it possible to predict successfully the average grade over the N tasks based on the five first tasks performed by the students?
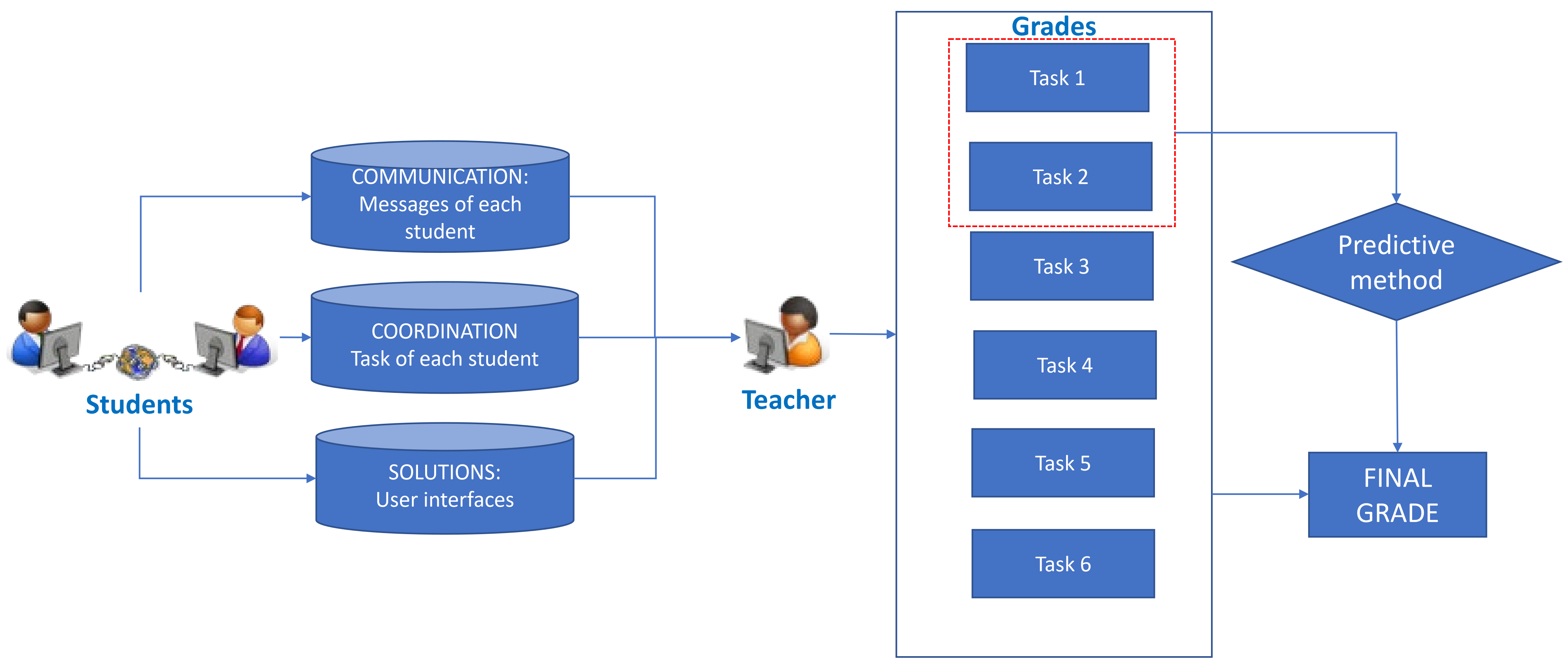
- Communication between classmates: These data measure the fluency in exchanging ideas on how to solve the activities (e.g.: contributions from each student, perception of the quality of the proposals of others, etc.).
- Coordination to distribute tasks: These data allow us to quantify how the efforts are distributed between the members of the group (e.g.: hours of work of each member of the group, perception of the effort of the classmates, etc.).
- Collaboration for building quality solutions: These data quantify whether the collective process allowed the student to improve solutions (e.g.: grades in collaborative activities, perception of how solutions are improved by the classmates, etc.).
- 1.
- The individual work of the students. Examples of these indicators are the number of proposal of each learner and the amount of individual interaction with the solution.
- 2.
- The degree of collaboration. Examples of these indicators are the number of proposals commented by other learners and the degree in which the task distribution was equitable.
- 3.
- The solutions generated. Examples are the degree to which the solution is well-formed according to the syntax rules of the programming language and the assessment of whether the solution solves the task goals.
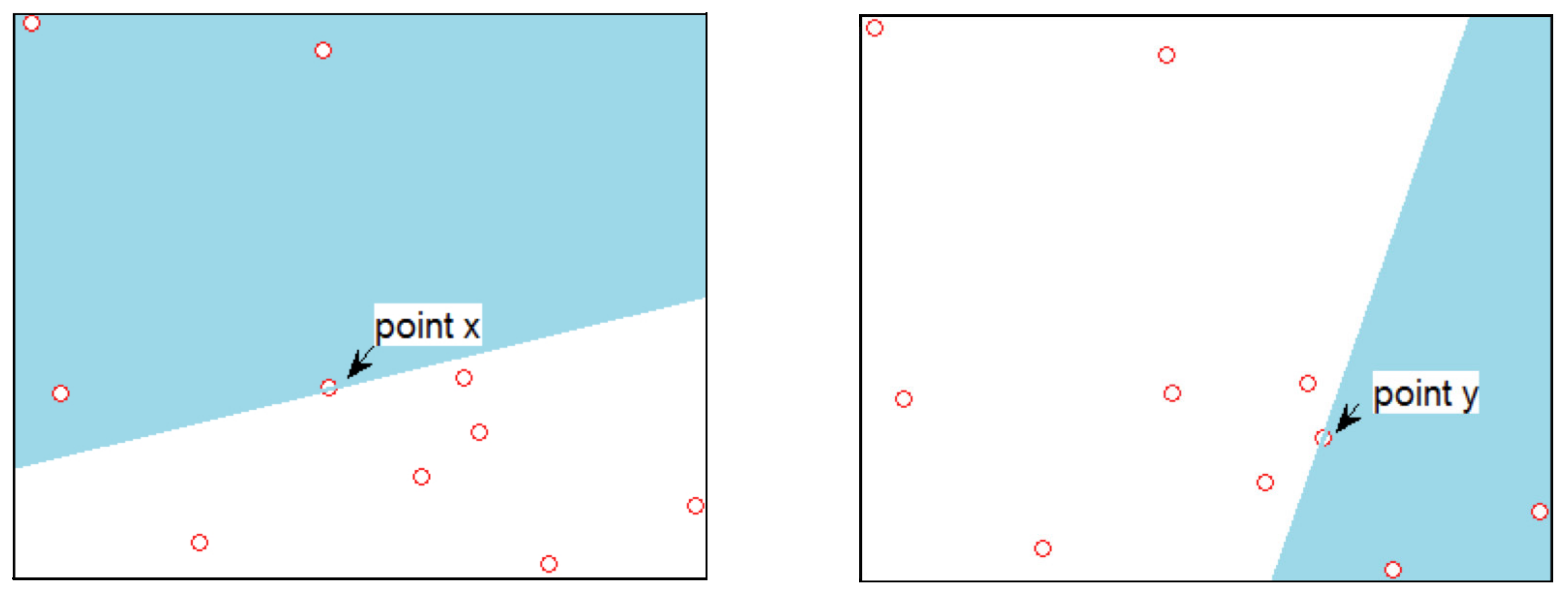
2.1. Statistical Data Depth
2.2. Methodology in Practice
- A letter in the set with the highest possible grade and U the lowest. This is a common grading system in the United Kingdom.
- A number in the set with 1 the highest possible grade and 5 the lowest. This is the system used in Germany.
- A number in the interval [0, 10] with 0 the lowest possible grade and 10 the highest. This system is the one established in Spain.
- the training sample consists of the pairs for ,
- the test sample is given by the pairs forwhere, for each , provides the membership to the intervals inof Note that these intervals are of larger length, to emulate confidence bands.
2.3. The Dataset
- 43 of them took the subject during the academic period 2017/18,
- 41 during 2018/19,
- 63 during 2019/20 and
- 61 during 2020/21.
- 1.
- Prototype a mockup of a user interface for smartphones.
- 2.
- Build user interfaces using the Android platform.
- 3.
- Design and build user interfaces for desktop computers using a WIMP (windows icons menus and pointers) style.
- 4.
- Design and build user interfaces for desktop computers using a WYSIWYG (What You See Is What You Get) style.
- 5.
- Design and build the user interfaces of a website.
- 6.
- Perform a usability test process.
- 14 of them for the academic period 2017/18,
- 15 for 2018/19,
- 21 for 2019/20 and
- 29 for 2020/21.
- (i)
- the quality of the user interfaces,
- (ii)
- the extent to which group members distribute the workload equitably, and
- (iii)
- the contributions and proposals that arise to establish a real collaboration.
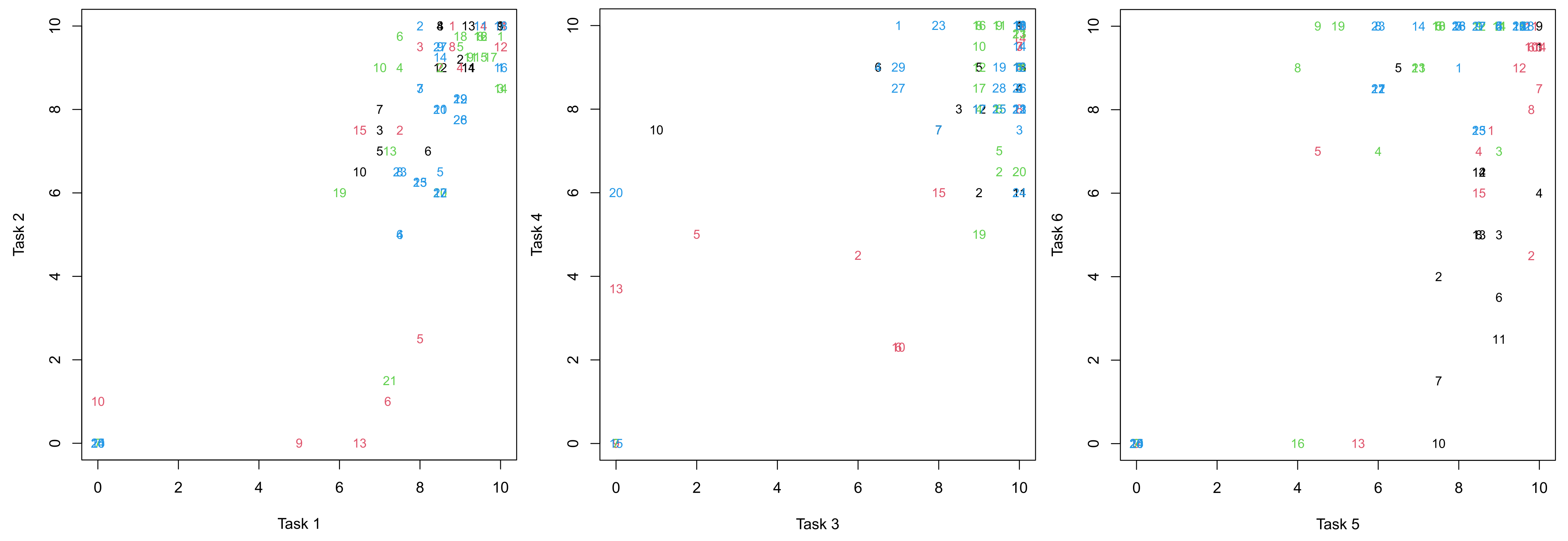
- Group 3 of the academic period 2017/18 had grades in the interval [6,8) in Tasks 1 and 2 that improved to the range [8,10) for Tasks 3, 4 and 5 and decreased to the range [4,6) for Task 6.
- Group 5 of the academic period 2018/19 had grades in the range [8,10) in Task 1 that worsened to the range [2,4) for Tasks 2 and 3 and slighted improved to the interval [4,6) for Tasks 4 an 5 and again improved to the interval [6,8) for Task 6.
- Group 19 of the academic period 2019/20 had grades in the range [6,8) in Tasks 1 and 2 that improved to the range [8,10) for Tasks 3, decreased to the range [4,6) for Tasks 4 and 5 and then highly increased to a 10 for Task 6.
3. Results
4. Discussion
- 1.
- The random Tukey depth is computationally effective in reducing the dimension to one even if the original data dimension is high, as it happens with high dimensional or functional data [40].
- 2.
- The random Tukey depth behaves adequately [35] as it generally inherits the good properties of the Tukey depth, which is the most well-known in the literature but for it expensive computational time.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| CSCL | Computer-Supported Cooperative Learning |
| HCI | Human-computer interaction |
| HTML | HyperText Markup Language |
| i.i.d. | independent and identically distributed |
| PBL | Project-Based Learning |
| WIMP | Windows Icon Menu Pointer |
References
- Duque, R.; Bollen, L.; Anjewierden, A.; Bravo, C. Automating the Analysis of Problem-solving Activities in Learning Environments: The Co-Lab Case Study. J. Univ. Comput. Sci. 2012, 18, 1279–1307. [Google Scholar]
- Kutlu, B.; Aggul, Y.G.; Atasu, I.; Kaymaz, Z. A Meta-Analysis of Studies on Groupware for Collaborative Work Environments. Proceedings 2021, 74, 9. [Google Scholar] [CrossRef]
- Dennis, A.R.; Carte, T.A.; Kelly, G.G. Breaking the rules: Success and failure in groupware-supported business process reengineering. Decis. Support Syst. 2003, 36, 31–47. [Google Scholar] [CrossRef] [Green Version]
- Duque, R.; Gómez-Pérez, D.; Nieto-Reyes, A.; Bravo, C. Analyzing collaboration and interaction in learning environments to form learner groups. Comput. Hum. Behav. 2015, 47, 42–49. [Google Scholar] [CrossRef] [Green Version]
- Bravo, C.; Redondo, M.A.; Verdejo, M.F.; Ortega, M. A framework for process–solution analysis in collaborative learning environments. Int. J. Hum. Comput. Stud. 2008, 66, 812–832. [Google Scholar] [CrossRef] [Green Version]
- Anderson, J.R.; Boyle, C.; Corbett, A.T.; Lewis, M.W. Cognitive modeling and intelligent tutoring. Artif. Intell. 1990, 42, 7–49. [Google Scholar] [CrossRef]
- Selker, T. COACH: A Teaching Agent That Learns. Commun. ACM 1994, 37, 92–99. [Google Scholar] [CrossRef]
- Paolucci, M.; Suthers, D.; Weiner, A. Automated advice-giving strategies for scientific inquiry. In Intelligent Tutoring Systems; Frasson, C., Gauthier, G., Lesgold, A., Eds.; Springer: Berlin/Heidelberg, Germany, 1996; pp. 372–381. [Google Scholar]
- Mørch, A.; Jondahl, S.; Dolonen, J. Supporting Conceptual Awareness with Pedagogical Agents. Inf. Syst. Front. 2005, 7, 39–53. [Google Scholar] [CrossRef] [Green Version]
- Du Boulay, B. Artificial Intelligence as an Effective Classroom Assistant. IEEE Intell. Syst. 2016, 31, 76–81. [Google Scholar] [CrossRef]
- Goel, A.K.; Polepeddi, L. Jill Watson: A Virtual Teaching Assistant for Online Education. In Learning Engineering for Online Education: Theoretical Contexts and Design-Based Examples; Routledge: New York, NY, USA, 2018. [Google Scholar]
- Uskola Ibarluzea, A.; Madariaga Orbea, J.M.; Arribillaga Iriarte, A.; Maguregi González, G.; Fernández Alonso, L. Categorisation of the Interventions of Faciliting Tutors on PBL and Their Relationship with Students’ Response. Profr.: Rev. Curric. Form. Profr. 2018, 22, 153–170. [Google Scholar] [CrossRef]
- Splichal, J.M.; Oshima, J.; Oshima, R. Regulation of collaboration in project-based learning mediated by CSCL scripting reflection. Comput. Educ. 2018, 125, 132–145. [Google Scholar] [CrossRef]
- Chen, L.; Chen, P.; Lin, Z. Artificial Intelligence in Education: A Review. IEEE Access 2020, 8, 75264–75278. [Google Scholar] [CrossRef]
- Li, Z.; Hoiem, D. Learning without Forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2935–2947. [Google Scholar] [CrossRef] [Green Version]
- Aljundi, R.; Chakravarty, P.; Tuytelaars, T. Expert Gate: Lifelong Learning with a Network of Experts. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7120–7129. [Google Scholar] [CrossRef] [Green Version]
- Phielix, C.; Prins, F.J.; Kirschner, P.A. The Design of Peer Feedback and Reflection Tools in a CSCL Environment. In Proceedings of the 9th International Conference on Computer Supported Collaborative Learning, Rhodes, Greece, 8–13 June 2009; Volume 1, pp. 626–635. [Google Scholar]
- Zuo, Y.; Serfling, R. General notions of statistical depth function. Ann. Statist. 2000, 28, 461–482. [Google Scholar] [CrossRef]
- Härdle, W. Applied Nonparametric Regression; Econometric Society Monographs, Cambridge University Press: Cambridge, UK, 1990. [Google Scholar] [CrossRef]
- Gerosa, M.A.; Pimentel, M.; Fuks, H.; de Lucena, C.J.P. Development of Groupware Based on the 3C Collaboration Model and Component Technology. In Groupware: Design, Implementation, and Use; Dimitriadis, Y.A., Zigurs, I., Gómez-Sánchez, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 302–309. [Google Scholar]
- Duque, R.; Bravo, C.; Ortega, M. A model-based framework to automate the analysis of users’ activity in collaborative systems. J. Netw. Comput. Appl. 2011, 34, 1200–1209. [Google Scholar] [CrossRef]
- Cuesta-Albertos, J.A.; Nieto-Reyes, A. The random Tukey depth. Comput. Statist. Data Anal. 2008, 52, 4979–4988. [Google Scholar] [CrossRef]
- Zuo, Y. On General Notions of Depth for Regression. Stat. Sci. 2021, 36, 142–157. [Google Scholar] [CrossRef]
- Nieto-Reyes, A.; Battey, H. A Topologically Valid Definition of Depth for Functional Data. Stat. Sci. 2016, 31, 61–79. [Google Scholar] [CrossRef]
- Nieto-Reyes, A.; Battey, H. A topologically valid construction of depth for functional data. J. Multivar. Anal. 2021, 184, 104738. [Google Scholar] [CrossRef]
- Nieto-Reyes, A.; Battey, H.; Francisci, G. Functional Symmetry and Statistical Depth for the Analysis of Movement Patterns in Alzheimer’s Patients. Mathematics 2021, 9, 820. [Google Scholar] [CrossRef]
- Saraceno, G.; Agostinelli, C. Robust multivariate estimation based on statistical depth filters. TEST 2021, 1–25. [Google Scholar] [CrossRef]
- Pandolfo, G.; Iorio, C.; Staiano, M.; Aria, M.; Siciliano, R. Multivariate process control charts based on the Lp depth. Appl. Stoch. Model. Bus. Ind. 2007, 37, 229–250. [Google Scholar] [CrossRef]
- Liu, R.Y. On a notion of data depth based on random simplices. Ann. Statist. 1990, 18, 405–414. [Google Scholar] [CrossRef]
- Serfling, R. A depth function and a scale curve based on spatial quantiles. In Statistical Data Analysis Based on the L1-norm and Related Methods (Neuchâtel, 2002); Stat. Ind. Technol.: Basel, Switzerland, 2002; pp. 25–38. [Google Scholar]
- Liu, R.Y.; Serfling, R.; Souvaine, D.L. (Eds.) Data Depth: Robust Multivariate Analysis, Computational Geometry and Applications; DIMACS Series in Discrete Mathematics and Theoretical Computer Science, 72; American Mathematical Society: Providence, RI, USA, 2006; p. xiv+246. [Google Scholar]
- Liu, Z.; Modarres, R. Lens data depth and median. J. Nonparametric Stat. 2011, 23, 1063–1074. [Google Scholar] [CrossRef]
- Tukey, J.W. Mathematics and the picturing of data. In Proceedings of the International Congress of Mathematicians (Vancouver, B. C., 1974), Vancouver, Canada, 21–29 August 1974; Canadian Mathematical Congress. 1975; Volume 2, pp. 523–531. Available online: https://www.mathunion.org/fileadmin/ICM/Proceedings/ICM1974.2/ICM1974.2.ocr.pdf (accessed on 20 October 2021).
- Dyckerhoff, R.; Mozharovskyi, P. Exact computation of the halfspace depth. Comput. Stat. Data Anal. 2016, 98, 19–30. [Google Scholar] [CrossRef] [Green Version]
- Cuesta-Albertos, J.; Nieto-Reyes, A. The Tukey and the random Tukey depths characterize discrete distributions. J. Multivar. Anal. 2008, 99, 2304–2311. [Google Scholar] [CrossRef] [Green Version]
- Ferraty, F.; Vieu, P. Nonparametric Functional Data Analysis: Theory and Practice (Springer Series in Statistics); Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Ferraty, F.; Vieu, P. Curves discrimination: A nonparametric functional approach. Comput. Stat. Data Anal. 2003, 44, 161–173. [Google Scholar] [CrossRef]
- Nadaraya, E.A. On estimating regression. Theory Probab. Appl. 1964, 9, 141–142. [Google Scholar] [CrossRef]
- Watson, G.S. Smooth regression analysis. Sankhyā Ser. 1964, 26, 359–372. [Google Scholar]
- Cuesta-Albertos, J.A.; Nieto-Reyes, A. Functional Classification and the Random Tukey Depth. Practical Issues. In Combining Soft Computing and Statistical Methods in Data Analysis; Borgelt, C., González-Rodríguez, G., Trutschnig, W., Lubiano, M.A., Gil, M.Á., Grzegorzewski, P., Hryniewicz, O., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 123–130. [Google Scholar]
- Zheng, L. Optimize CSCL Activities Based on a Data-Driven Approach. In Data-Driven Design for Computer-Supported Collaborative Learning: Design Matters; Springer: Singapore, 2021; pp. 147–162. [Google Scholar] [CrossRef]
- Omae, Y.; Furuya, T.; Mizukoshi, K.; Oshima, T.; Sakakibara, N.; Mizuochi, Y.; Yatsushiro, K.; Takahashi, H. Machine learning-based collaborative learning optimizer toward intelligent CSCL system. In Proceedings of the 2017 IEEE/SICE International Symposium on System Integration (SII), Taipei, Taiwan, 11–14 December 2017; pp. 577–582. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TEST SAMPLE | ||||||
|---|---|---|---|---|---|---|
| Tasks 1–2 (research problem 1) | ||||||
| estimated | ||||||
| [0,4] | [5,7] | [6,8] | [7,9] | [8,10] | ||
| [0,4) | 3 | |||||
| real | [7,8) | 4 | ||||
| [8,9) | 3 | 10 | ||||
| [9,10) | 1 | 1 | 7 | |||
| Tasks 1–3 (research problem 2) | ||||||
| estimated | ||||||
| [0,4] | [5,7] | [6,8] | [7,9] | [8,10] | ||
| [0,4) | 2 | 1 | ||||
| real | [7,8) | 1 | 3 | |||
| [8,9) | 13 | |||||
| [9,10) | 2 | 7 | ||||
| Tasks 1–4 (research problem 3) | ||||||
| estimated | ||||||
| [0,4] | [5,7] | [6,8] | [7,9] | [8,10] | ||
| [0,4) | 1 | 2 | ||||
| real | [7,8) | 4 | ||||
| [8,9) | 13 | |||||
| [9,10) | 9 | |||||
| Tasks 1–5 (research problem 4) | ||||||
| estimated | ||||||
| [0,4] | [5,7] | [6,8] | [7,9] | [8,10] | ||
| [0,4) | 1 | 2 | ||||
| real | [7,8) | 4 | ||||
| [8,9) | 13 | |||||
| [9,10) | 9 | |||||
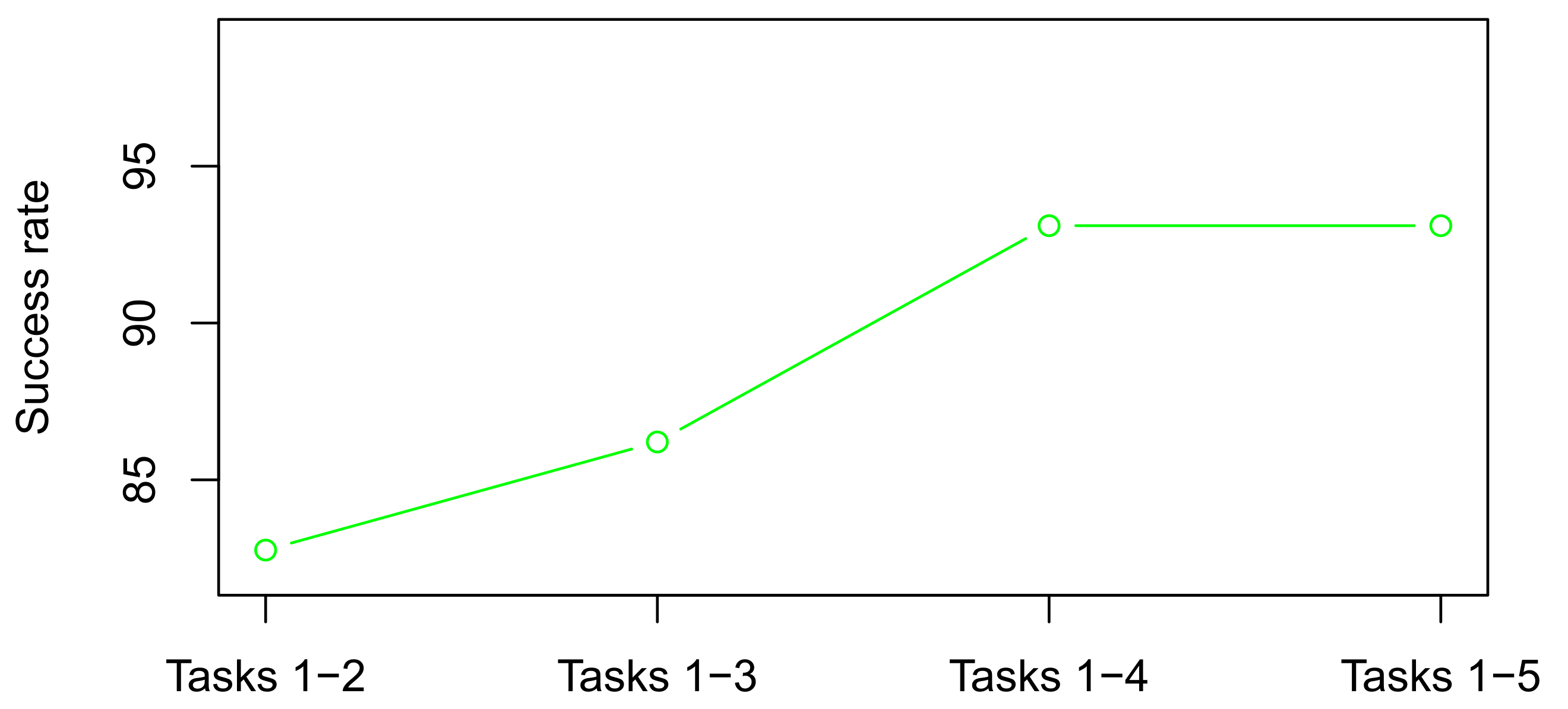
| Tasks 1–2 (Research Problem 1) | Tasks 1–3 (Research Problem 2) | Tasks 1–4 (Research Problem 3) | Tasks 1–5 (Research Problem 4) | |
|---|---|---|---|---|
| Test | 82.76% | 86.21% | 93.10% | 93.10% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nieto-Reyes, A.; Duque, R.; Francisci, G. A Method to Automate the Prediction of Student Academic Performance from Early Stages of the Course. Mathematics 2021, 9, 2677. https://doi.org/10.3390/math9212677
Nieto-Reyes A, Duque R, Francisci G. A Method to Automate the Prediction of Student Academic Performance from Early Stages of the Course. Mathematics. 2021; 9(21):2677. https://doi.org/10.3390/math9212677
Chicago/Turabian StyleNieto-Reyes, Alicia, Rafael Duque, and Giacomo Francisci. 2021. "A Method to Automate the Prediction of Student Academic Performance from Early Stages of the Course" Mathematics 9, no. 21: 2677. https://doi.org/10.3390/math9212677
APA StyleNieto-Reyes, A., Duque, R., & Francisci, G. (2021). A Method to Automate the Prediction of Student Academic Performance from Early Stages of the Course. Mathematics, 9(21), 2677. https://doi.org/10.3390/math9212677