
DSTnet: Deformable Spatio-Temporal Convolutional Residual Network for Video Super-Resolution



Abstract
:1. Introduction
2. Related Work
2.1. Single Image Super-Resolution (SSIR)
2.2. Video Super-Resolution (VSR)
2.3. Deformable Convolution-Based Methods
2.4. 3D Convolution-Based Methods
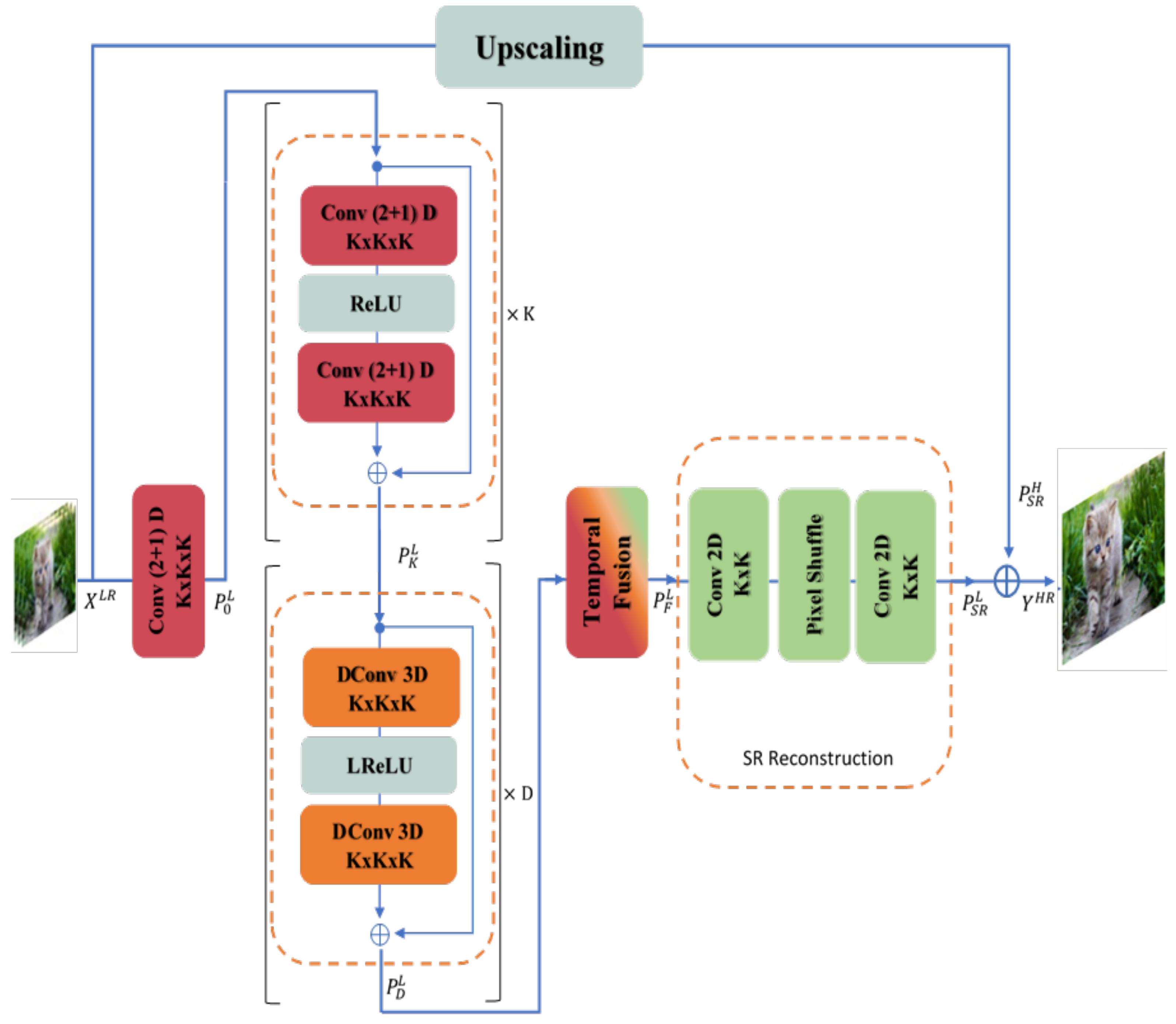
3. Methodology
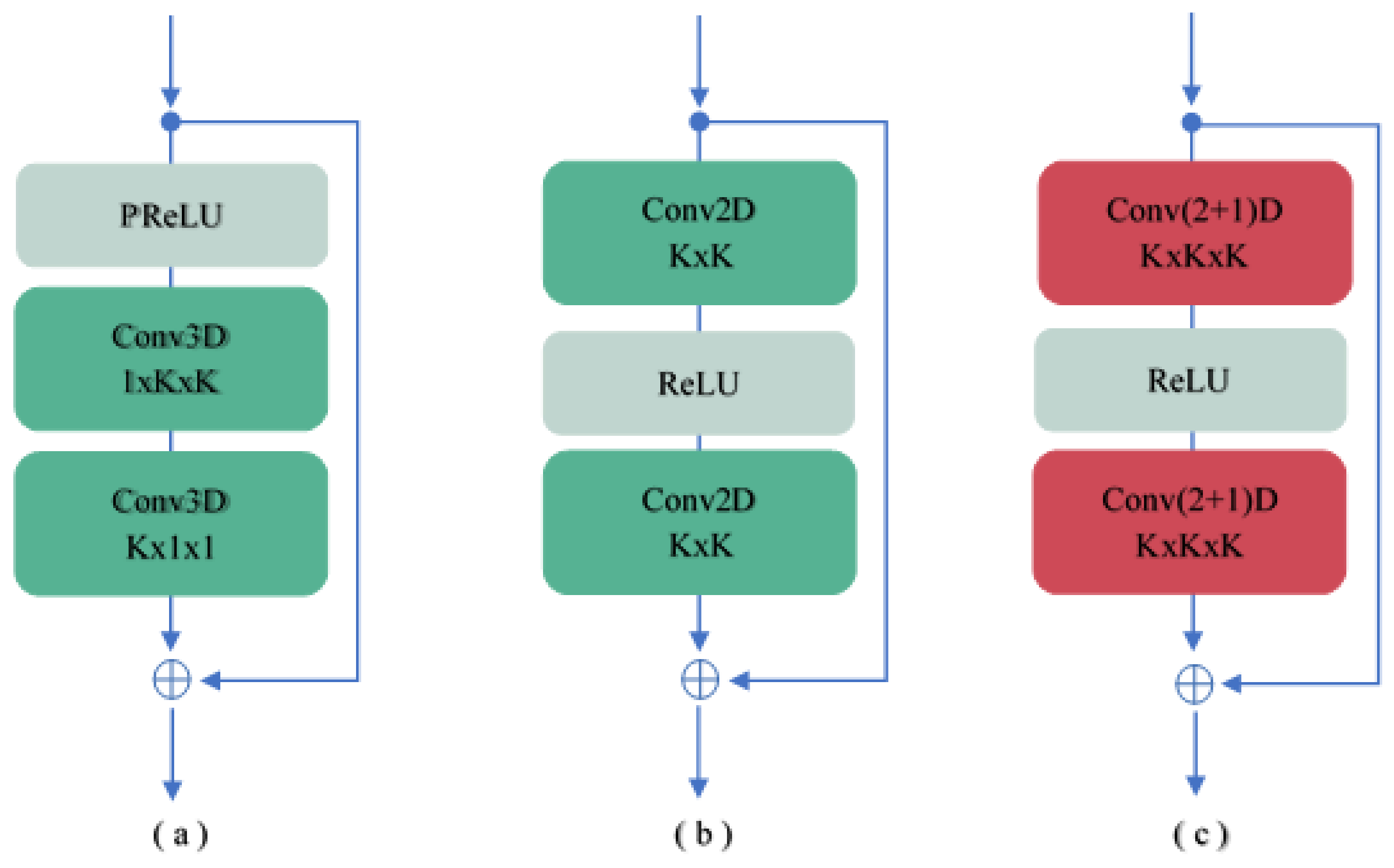
3.1. Spatio-Temporal Convolutional Residual Blocks
3.2. Deformable Spatio-Temporal Convolutional Residual Block
3.3. Temporal Fusion
3.4. SR Reconstruction
4. Experimentation and Results
4.1. Dataset
4.2. Experiment Details
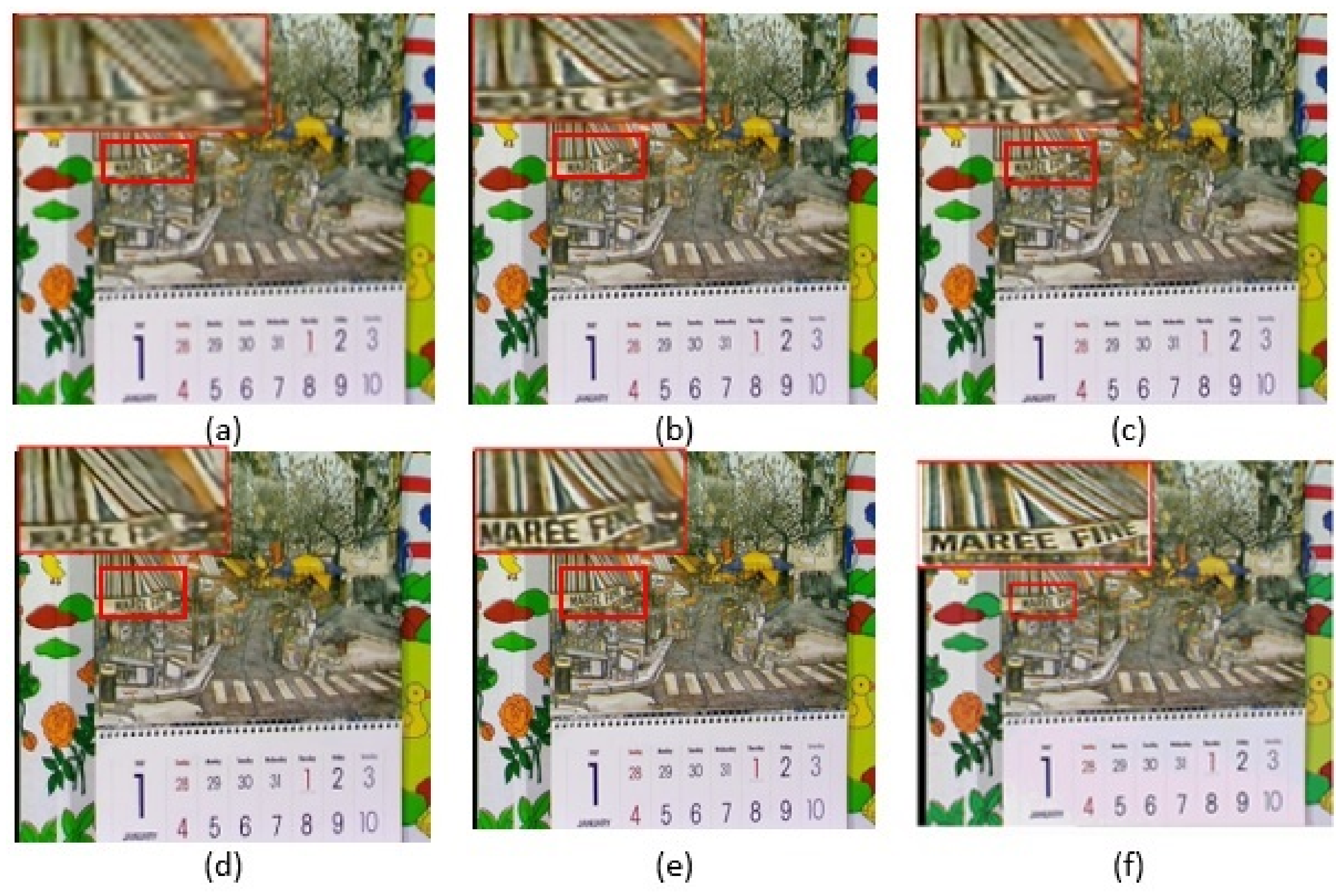
4.3. Results
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rasti, P.; Uiboupin, T.; Escalera, S.; Anbarjafari, G. Convolutional neural network super resolution for face recognition in surveillance monitoring. In Proceedings of the International Conference on Articulated Motion and Deformable Objects, Palma de Mallorca, Spain, 13–15 July 2016; Springer: Cham, Switzerland, 2016; pp. 175–184. [Google Scholar]
- Cao, L.; Ji, R.; Wang, C.; Li, J. Towards domain adaptive vehicle detection in satellite image by supervised super-resolution transfer. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Gunturk, B.K.; Altunbasak, Y.; Mersereau, R.M. Multiframe resolution-enhancement methods for compressed video. IEEE Signal Process. Lett. 2002, 9, 170–174. [Google Scholar] [CrossRef]
- Liu, H.; Ruan, Z.; Zhao, P.; Dong, C.; Shang, F.; Liu, Y.; Yang, L. Video Super Resolution Based on Deep Learning: A comprehensive survey. arXiv 2020, arXiv:2007.12928. [Google Scholar]
- Liao, R.; Tao, X.; Li, R.; Ma, Z.; Jia, J. Video super-resolution via deep draft-ensemble learning. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 531–539. [Google Scholar]
- Xue, T.; Chen, B.; Wu, J.; Wei, D.; Freeman, W.T. Video enhancement with task-oriented flow. Int. J. Comput. Vis. 2019, 127, 1106–1125. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Chan, K.C.; Yu, K.; Dong, C.; Change Loy, C. Edvr: Video restoration with enhanced deformable convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–19 June 2019. [Google Scholar]
- Tian, Y.; Zhang, Y.; Fu, Y.; Xu, C. Tdan: Temporally-deformable alignment network for video super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3360–3369. [Google Scholar]
- Kappeler, A.; Yoo, S.; Dai, Q.; Katsaggelos, A.K. Super-resolution of compressed videos using convolutional neural networks. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 1150–1154. [Google Scholar]
- Hayat, K. Multimedia super-resolution via deep learning: A survey. Digit. Signal Process. 2018, 81, 198–217. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; He, F.; Du, B.; Zhang, L.; Xu, Y.; Tao, D. Fast spatio-temporal residual network for video super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10522–10531. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Freedman, G.; Fattal, R. Image and video upscaling from local self-examples. ACM Trans. Graph. (TOG) 2011, 30, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Lin, Z.; Cohen, S. Fast image super-resolution based on in-place example regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1059–1066. [Google Scholar]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Timofte, R.; Agustsson, E.; Van Gool, L.; Yang, M.H.; Zhang, L. Ntire 2017 challenge on single image super-resolution: Methods and results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 114–125. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2472–2481. [Google Scholar]
- Kappeler, A.; Yoo, S.; Dai, Q.; Katsaggelos, A.K. Video super-resolution with convolutional neural networks. IEEE Trans. Comput. Imaging 2016, 2, 109–122. [Google Scholar] [CrossRef]
- Wang, L.; Guo, Y.; Lin, Z.; Deng, X.; An, W. Learning for video super-resolution through HR optical flow estimation. In Proceedings of the Asian Conference on Computer Vision, Perth, WA, Australia, 2–6 December 2018; Springer: Cham, Switzerland, 2018; pp. 514–529. [Google Scholar]
- Liu, D.; Wang, Z.; Fan, Y.; Liu, X.; Wang, Z.; Chang, S.; Huang, T. Robust video super-resolution with learned temporal dynamics. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2507–2515. [Google Scholar]
- Caballero, J.; Ledig, C.; Aitken, A.; Acosta, A.; Totz, J.; Wang, Z.; Shi, W. Real-time video super-resolution with spatio-temporal networks and motion compensation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4778–4787. [Google Scholar]
- Tao, X.; Gao, H.; Liao, R.; Wang, J.; Jia, J. Detail-revealing deep video super-resolution. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4472–4480. [Google Scholar]
- Huang, Y.; Wang, W.; Wang, L. Bidirectional recurrent convolutional networks for multi-frame super-resolution. Adv. Neural Inf. Process. Syst. 2015, 28, 235–243. [Google Scholar]
- Sajjadi, M.S.; Vemulapalli, R.; Brown, M. Frame-recurrent video super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6626–6634. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1664–1673. [Google Scholar]
- Lucas, A.; Lopez-Tapia, S.; Molina, R.; Katsaggelos, A.K. Generative adversarial networks and perceptual losses for video super-resolution. IEEE Trans. Image Process. 2019, 28, 3312–3327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Z.; Sze, V. FAST: A framework to accelerate super-resolution processing on compressed videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 19–28. [Google Scholar]
- Jo, Y.; Oh, S.W.; Kang, J.; Kim, S.J. Deep video super-resolution network using dynamic upsampling filters without explicit motion compensation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3224–3232. [Google Scholar]
- Bao, W.; Lai, W.S.; Zhang, X.; Gao, Z.; Yang, M.H. MEMC-Net: Motion Estimation and Motion Compensation Driven Neural Network for Video Interpolation and Enhancement. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 933–948. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Bertasius, G.; Torresani, L.; Shi, J. Object detection in video with spatiotemporal sampling networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 331–346. [Google Scholar]
- Zhang, Y.; Shi, L.; Wu, Y.; Cheng, K.; Cheng, J.; Lu, H. Gesture recognition based on deep deformable 3D convolutional neural networks. Pattern Recognit. 2020, 107, 107416. [Google Scholar] [CrossRef]
- Xiang, X.; Tian, Y.; Zhang, Y.; Fu, Y.; Allebach, J.P.; Xu, C. Zooming slow-mo: Fast and accurate one-stage space-time video super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3370–3379. [Google Scholar]
- Wang, H.; Su, D.; Liu, C.; Jin, L.; Sun, X.; Peng, X. Deformable non-local network for video super-resolution. IEEE Access 2019, 7, 177734–177744. [Google Scholar] [CrossRef]
- López-Tapia, S.; Lucas, A.; Molina, R.; Katsaggelos, A.K. Gated Recurrent Networks for Video Super Resolution. In Proceedings of the 2020 28th European Signal Processing Conference (EUSIPCO), Amsterdam, The Netherlands, 24–28 August 2020; pp. 700–704. [Google Scholar]
- Huang, Y.; Wang, W.; Wang, L. Video super-resolution via bidirectional recurrent convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1015–1028. [Google Scholar] [CrossRef] [PubMed]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar]
- Liu, C.; Sun, D. On Bayesian adaptive video super resolution. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 346–360. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the NIPS-W, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; Volume 30, p. 3. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Output Shape | Layer’s Detail |
|---|---|---|
| Feature Extraction | 64, 7, 64, 112 | |
| resST blocks | 64, 7, 64, 112 | |
| Deformable resST blocks | 64, 7, 64, 112 | |
| Temporal Fusion | 64, 64, 112 | 1 × 1, 64, |
| SR Reconstruction | 1, 256, 448 |
| Method | Year | City | Walk | Calendar | Foliage | Average |
|---|---|---|---|---|---|---|
| Proposed | 2021 | 27.08 | 29.56 | 23.14 | 25.77 | 26.39 |
| TDAN [8] | 2020 | 26.99 | 29.50 | 22.98 | 25.51 | 26.24 |
| TOFlow [6] | 2019 | 26.78 | 29.05 | 22.47 | 25.27 | 25.89 |
| VSRResNet [32] | 2019 | – | – | – | – | 25.51 |
| SOF-VSR [25] | 2018 | – | – | – | – | 26.02 |
| RCAN [22] | 2018 | 26.06 | 28.64 | 22.33 | 24.77 | 25.45 |
| DBPN [31] | 2018 | 25.80 | 28.64 | 22.29 | 24.73 | 25.37 |
| VESPCN [27] | 2017 | 26.17 | 28.31 | 21.98 | 24.91 | 25.34 |
| VSRnet [24] | 2016 | 25.62 | 27.54 | 21.34 | 24.41 | 24.73 |
| BRCN [29] | 2015 | – | – | – | – | 24.43 |
| Method | Year | City | Walk | Calender | Foliage | Aaverage |
|---|---|---|---|---|---|---|
| Proposed | 2021 | 0.779 | 0.899 | 0.769 | 0.733 | 0.795 |
| TDAN [8] | 2020 | 0.757 | 0.890 | 0.756 | 0.717 | 0.780 |
| TOFlow [6] | 2019 | 0.740 | 0.879 | 0.732 | 0.709 | 0.765 |
| VSRResNet [32] | 2019 | – | – | – | – | 0.753 |
| SOF-VSR [25] | 2018 | – | – | – | – | 0.771 |
| RCAN [22] | 2018 | 0.694 | 0.873 | 0.723 | 0.664 | 0.738 |
| DBPN [31] | 2018 | 0.682 | 0.872 | 0.715 | 0.661 | 0.732 |
| VESPCN [27] | 2017 | 0.696 | 0.861 | 0.691 | 0.673 | 0.730 |
| VSRnet [24] | 2016 | 0.654 | 0.844 | 0.644 | 0.645 | 0.697 |
| BRCN [29] | 2015 | – | – | – | – | 0.633 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, A.; Sargano, A.B.; Habib, Z. DSTnet: Deformable Spatio-Temporal Convolutional Residual Network for Video Super-Resolution. Mathematics 2021, 9, 2873. https://doi.org/10.3390/math9222873
Khan A, Sargano AB, Habib Z. DSTnet: Deformable Spatio-Temporal Convolutional Residual Network for Video Super-Resolution. Mathematics. 2021; 9(22):2873. https://doi.org/10.3390/math9222873
Chicago/Turabian StyleKhan, Anusha, Allah Bux Sargano, and Zulfiqar Habib. 2021. "DSTnet: Deformable Spatio-Temporal Convolutional Residual Network for Video Super-Resolution" Mathematics 9, no. 22: 2873. https://doi.org/10.3390/math9222873
APA StyleKhan, A., Sargano, A. B., & Habib, Z. (2021). DSTnet: Deformable Spatio-Temporal Convolutional Residual Network for Video Super-Resolution. Mathematics, 9(22), 2873. https://doi.org/10.3390/math9222873