1. Introduction
The distribution of lifetime random variable,
X, is named as the two-parameter Lomax distribution, Lomax
, if its probability density function (PDF) and cumulative distribution function (CDF) are respectively defined as
and
where
and
. The Lomax
was originally derived by Lomax [
1] for the model of business failure and is also called Pareto type-II distribution. Recently, Lomax
has been proved to be useful in engineering, industry and medical science. For example, Hassan and Al-Ghamdi [
2] utilized Lomax
in the reliability inference, Al-Zahrani and Al-Sobhi [
3] applied Lomax
for the stress-strength analysis and Burkhalter and Lio [
4] developed Bootstrap control charts for Lomax
to maintain the quality of lifetime quantiles. The reliability,
, and hazard rate,
, of Lomax
are respectively presented as
and
where
illustrates the chance of an item surviving at least a specified time
x and
illustrates the likelihood of an item surviving at time
x given its survival time over time
x.
Since the advanced manufacturing procedure has prolonged product lifetimes, collecting life times of all items placed on life test takes longer time. Among numerous censoring schemes developed to overcome this obstacle, type-I and type-II censoring schemes have been extensively applied to the industry life test as well as medical survival analysis because of easy implementation. Given positive integers
m and
n with
and
, place
n items on the failure test at the same initial time, labeled by
, and let
be the lifetime of the
ith failure, where
. The type-I censoring scheme is executed till
units of time reached; while the type-II censoring scheme is performed until the
mth failure observed at
. The type-I censoring scheme is called time censoring scheme and could result with less number of failure times and type-II censoring ensures a pre fixed number,
m, of failure times received; however, it could be a time-consuming process. To improve the drawbacks of both schemes, Epstein [
5] introduced the type-I hybrid censoring scheme that must expire at time
= min{
}; while Childs et al. [
6] studied the type-II hybrid censoring scheme, which must terminate at
= max{
}. The aforementioned censoring schemes do not allow items be removed at any other time before the terminal time. In order to allow the items removed at other time points before the terminal time to save time and cost, the progressive censoring schemes have been applied to the life test. Let
be non-negative integers such that
. The progressive type-II censoring scheme performs with
n items on failure test at the same time,
, and
items are randomly removed from remaining survival items at the
ith failure,
, for
. Balakrishnan and Aggarwala [
7] and Balakrishnan and Cramer [
8] provided more information about censoring schemes and life tests. Merging the progressive type-II and hybrid censoring schemes, the type-I progressive hybrid censoring scheme that was studied by Kundu and Joarder [
9] conducts the progressive type-II scheme until time
= min{
} and the type-II progressive hybrid censoring scheme, which was discussed by Childs et al. [
10], implements the progressive type-II scheme up to time
= max{
}. All survival items will be removed at the respective terminated random time when the progressive hybrid censoring schemes are implemented.
Two new adaptive hybrid censoring schemes (HCSs), named as adaptive type-I progressive (AT-IP) HCS and adaptive type-II progressive (AT-IIP) HCS, have been developed recently. The AT-IIP HCS, discussed by Ng et al. [
11] and Balakrishnan and Kundu [
12], implements progressive type-II scheme until
and has no survival items removed after the life test experiment passes
. The AT-IP HCS, which was shown to have a higher efficiency in estimations by Lin and Huang [
13], implements progressive type-II scheme and must terminate at time
. Let
D be the number of failed items just right afore
. If the failure time
is obtained before
, the life time experiment will continue to observe failures without withdrawing survival items until
. Hence, at time
, all survival items
will be removed, where
when
; otherwise, the AT-IP HCS uses the progressive censoring scheme
.
To deal with the selection of hyper-parameters in the Bayesian inference, Han [
14,
15] investigated and compared the hierarchical Bayesian and E-Bayesian methods by utilizing the quadratic loss function with three different hyper-parameters’ priors. For the E-Bayeisan estimation procedures under type-II censoring, Jaheen and Okasha [
16] provided the estimates of the Burr type XII outer power parameter and reliability by means of squared error loss (SEL) and LINEX loss functions; Okasha [
17] worked on the estimates of the rate parameter, parallel and series systems reliabilities and failure rate of WEI
; and Okasha [
18] investigated the estimates of Lomax distribution power parameter and reliability by means of the balanced SEL function, which was used by Ahmadi et al. [
19]. Recently, Okasha and Mustafa [
20] investigated E-Bayesian estimate utilizing competing risks sample from Weibull distributions under AT-IP HCS and Okasha et al. [
21] extended the work by Okasha [
17] to progressive type-II censoring. The common remarks of the works mentioned above indicate that the E-Bayesian estimation method outperforms over the Bayesian one. The empirical Bayesian estimation method is an alternative procedure for the hyper-parameters’ determination. Chiang et al. [
22] proposed an empirical Bayesian strategy for sampling plans under Burr XII distribution. Mohammed [
23] introduced an empirical E-Bayesian estimate of the Poisson distribution parameter based on random sample. Jaheen [
24] studied an empirical Bayesian estimate for the exponential parameter by using Linex and quadratic loss functions based on record statistics.
Current research is an extension work by Okasha [
18] for E-Bayesian estimation methods under type-II censoring. Okasha [
18] did not successfully finish the mathematical proof of the comparison among the E-Bayesian estimates of Reliability under the balanced SEL function even if he obtained similar integral presentations for the difference between two E-Bayesian estimates of reliability as we did under SEL function. In our study, the SEL function as well as two asymmetric loss functions, which contain the general entropy (GE) from Calabria and Pulcini [
25] and LINEX from Pandey et al. [
26], will be utilized to investigate Bayesian, E-Bayesian and empirical Bayesian estimates for any function of the Lomax
shape parameter based on the adaptive type-I progressively hybrid censored sample.
The rest of this paper is organized as follows. In
Section 2, the likelihood model and maximum likelihood estimates based on a given adaptive type-I progressively hybrid censored sample will be presented.
Section 3 will discuss and formulate the Bayesian estimates of the Lomax shape functions and
Section 4 will provide detail derivation of the E-Bayesian estimates.
Section 5 addresses empirical Bayesian estimation procedure. The mathematical properties of all the E-Bayesian estimates are developed in
Section 6. In
Section 7, an extensive Monte Carlo simulation will be performed to investigate the performance of all estimates considered. Following that, one simulated data set and two practical data sets will be utilized for the illustrative purpose. Some notes will be addressed at the end.
6. Properties of E-Bayesian Estimates
In order to derive the properties for E-Bayesian estimates of , more conditions or structures on are needed. However, the general conditions are not available. Therefore, the aforementioned functions will be focused. Some relationships among all E-Bayesian estimates mentioned above will be established in this section.
6.1. Properties of E-Bayesian Estimates under SEL
Some relationships among , and () are given by Propositions 1–3.
Relationships among ()
Proposition 1. Let , , and () be presented by (29), (30) and (31). Then - (i)
.
- (ii)
.
Proof. When ,
Let
. Since
and
,
According to (68) and (69), we have
that is
(ii) From (68) and (69), we get
That is . Thus, the proof is completed. □
Relationships among ()
Proposition 2. Let , , and () be addressed by (32)–(34). Then - (i)
.
- (ii)
.
Proof. - (i)
It can be shown that for
and
,
and
Hence, and [i] is proven.
- (ii)
Given
,
,
,
and
is a continuous and bounded function over
and
. It can be seen that
Therefore,
is uniformly integrable over
. Moreover,
Following the same proof procedure of Vitali Convergence Theorem for Integral, we have
That is . Thus, the proof is completed. □
Relationships among ()
Proposition 3. Let , , , and () be addressed by (35)–(37). Then - (i)
.
- (ii)
.
Proof. According to (69) and (71), we obtain
(ii) By using (70) and (71),
That is and the proof is completed. □
Remark 1. Section 6.1 provides the comparison among E-Bayesian estimations , and for , respectively. presents the data information that includes the number of observed failure times and time schedule τ. Actually, is equivalent to under a given time schedule . Therefore, for are asymptotically equivalent if within a finite time schedule . The asymptotic equivalence property is also true for as well as , for . 6.2. Properties of E-Bayesian Estimates under LINEX Loss
Some relationships among , and () will be addressed by Propositions 4–6.
Relationships among ()
Proposition 4. Let and , , , and () be given by (38)–(40). Then - (i)
.
- (ii)
Proof. - (i)
Let
It can be shown that for
Therefore, .
- (ii)
It is noted that
,
and
. By using the series expansion,
for
to represent
,
and
in their respective series. Then it can be shown the following result,
where
Based on the result above, it is difficult to compare the values among
and
. However, it can be shown that for any given
,
, we have
That is . Thus, the proof is completed. □
Relationships among ()
Proposition 5. Let , , , , and of (41) for . Then - (i)
.
- (ii)
Proof. From (
41),
where
was given by (
22).
- (i)
Therefore, we have
where
and
and
are density functions of random variables
and
, respectively, and the likelihood ratio is given as follows,
which is an increasing function over
for any given
. The increasing likelihood ratio implies
. That means
is stochastically larger than
. When
,
is a decreasing function over
. Hence,
When
,
is an increasing function over
. Hence,
Using (78) and (79), we have
Therefore, and .
- (ii)
Since is a continuous and bounded function with respect to c and k over and , is uniformly integrable.
Following the similar proof procedure of Bounded Convergence Theorem for Integral, we have
That is . Thus, the proof is completed. □
Relationships among ()
Proposition 6. Let , , , , and () be (42)–(44). Then - (i)
.
- (ii)
.
Proof. - (i)
Following the same argument of the proof for
of Proposition 4, we can prove
Hence, is proved.
- (ii)
Because
and
, by using series expansion we have
Following the same argument of the proof for
of Proposition 4, it can be shown that
,
,
and
imply
That is, . Thus, the proof is completed. □
Remark 2. Section 6.2 provides the comparison among E-Bayesian estimates , and for under LINEX loss function, respectively. Section 6.2 also shows that for , for and are asymptotically equivalent as D is getting to infinity for a given finite time schedule, τ. 6.3. Properties of E-Bayesian Estimates under GE Loss
Some relationships among , and () will be addressed as follows.
Relationships among ()
Proposition 7. Let , , , , and () be given by (45)–(47). Then
- (i)
.
- (ii)
.
Proof. (i) From (45)–(47),
where
Following the same procedure shown in (69) and
we have
that is
(ii) From (69) and (83), we get
That is . Thus, the proof is completed. □
Relationships among ()
Proposition 8. Let , , , and () be described by (49)–(51). Then
- (i)
- (ii)
.
Proof. - (i)
Similar to the proof of Proposition 2, we can prove
Hence,
- (ii)
Given
,
,
,
,
,
is a continuous and bounded function over
and
. Moreover,
By Bounded Convergence Theorem for Integral, we have
Thus, the proof is completed. □
Relationships among ()
Proposition 9. Let , , , and () be defined by (52)–(54). Then
- (i)
.
- (ii)
.
Proof. According to (69) and (86), we obtain
that is
(ii) From (69) and (86), we get
That is and the proof is completed. □
Remark 3. Section 6.3 provides the comparison among E-Bayesian estimations , and for , respectively. Section 6.3 also provides the asymptotically equivalent properties among , and for , respectively, if D approaches to infinity and τ is given a finite. 7. Simulation Study and Comparisons
The estimation accuracy of any estimate is usually measured by mean square error (MSE) and bias. Because the explicit forms of MSE and bias for all Bayesian estimates are not available, an extensive Monte Carlo simulation is performed to evaluate the MSEs of all estimates for , , , respectively, for comparisons under three different progressive type-II censoring schemes (Sch I, Sch II and Sch III), which are given as follows,
Sch I: ,
Sch II: ,
Sch III: .
The simulation parameter inputs include the Lomax parameters, , the number of test items, , life test time schedule , the LINEX loss function parameter, , the GE loss function parameter, , for Bayesian estimation method, and , for E-Bayesian estimation method.
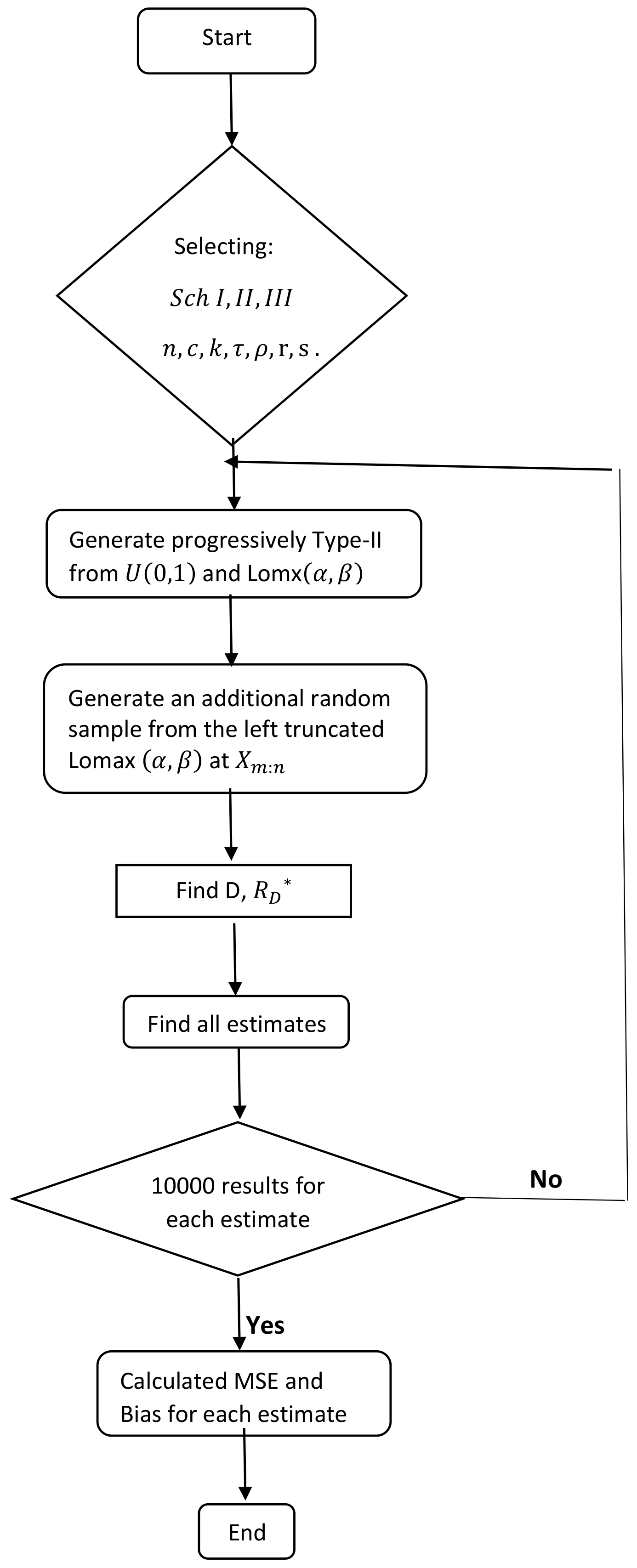
Given one of aforementioned progressive type-II censoring schemes with a combination of parameters addressed above, the simulation study was conducted according to the following steps:
Generate a conventional progressively type-II censored sample from Lomax(
) via the transformation,
, where
are a conventional progressively type-II censored sample from uniform over
interval by using the technique of Balakrishnan and Sandhu [
32].
Generate an additional random sample of size from the left truncated Lomax at by using the transformation , where u is the uniform over random variable.
Determine the values of D and , where D is the number of failures just right before time .
MLEs, and are computed simultaneously through Equations (57) and (58) for the empirical Bayesian estimations.
MLEs,
,
and
, are computed through Equation (
8) and plug-in method, respectively.
Under the SEL function, the Bayesian estimates, E-Bayesian estimates and empirical Bayesian estimates are computed by using Equations developed from
Section 3,
Section 4 and
Section 5.
Under the LINEX loss function, the Bayesian estimates, E-Bayesian estimates and empirical Bayesian estimates are computed by using Equations developed from
Section 3,
Section 4 and
Section 5.
Under the GE loss function, the Bayesian estimates, E-Bayesian estimates and empirical Bayesian estimates are computed by using Equations developed from
Section 3,
Section 4 and
Section 5.
Repeat Steps 1–8 10,000 times to obtain 10,000 MLEs as well as Bayesian, empirical Bayesian and E-Bayesian estimates. Then MSEs and biases are respectively calculated based on these 10,000 values for all estimates, respectively.
The entire simulation procedure has been shown in
Figure 1.
All computations were performed using Mathcad program and the computational results are displayed in
Table 1 and
Table 2 that display the following:
- (1)
The bias and MSE of each estimate decrease as n increases.
- (2)
The bias and MSE of each estimate in case of LINEX (Bayesian, empirical Bayesian and E-Bayesian) except for MSEs of the and failure rate, h, functions decrease as b increases.
- (3)
The bias and MSE of each estimate in case of GE loss function (Bayesian, empirical Bayesian and E-Bayesian) except for MSEs of the and failure rate, h, functions decrease as P decrease.
- (4)
The Bayesian estimates of , R and h have the smallest MSE comparing among MLE, Bayesian and Emirical Bayesian estimtes.
- (5)
The E-Bayesian estimates of and failure rate, h, perform better than MLE in terms of MSE.
- (6)
The E-Bayesian estimates of and h under LINEX loss (with ) perform better than the E-Bayesian estimates of and h under LINEX loss with ().
- (7)
The E-Bayesian estimates for and h are always underestimated (with negetive bias). The E-Bayesian estimates for R are always overestimated (with positive bias). And simulation study results are consistent with mathematical propositions for comparisons.
- (8)
The E-Bayesian estimates of the square error in case first prior except for MSEs of the and failure rate, h, functions perform better than the E-Bayesian estimates of the another square error (in case two and third priors).
- (9)
The E-Bayesian estimates of GE Loss Function (p decrease) in case first prior except for MSEs of the and failure rate, h, functions perform better than the E-Bayesian estimates of the another GE Loss Function (in case two and third priors).
- (10)
The E-Bayesian estimates of and h under GE Loss have the smallest bias comparing with all other estimates.
Overall, the Bayesian and E-Bayesian procedures with SEL, LINEX loss or GE loss can provide reliable estimates of the parameter , R and h using the adaptive type-I progressively hybrid censored sample from Lomax(). Therefore, it is suggested to use Bayesian or E-Bayesian estimates for Lomax() under AT-IP HCS. We do not suggest use MLE and empirical Bayesian because the results from MLE have higher MLE generally. Additionally, MLE and empirical Bayesian estimation methods are sensitive to the censoring rate and cannot always produce stable results because they are dependent upon the iterative process using quasi-Newton methods with box constraints to find MLE.
8. Applications
In this section, one simulated data set and two real data sets will be used for the illustration of Lomax
modeling and the applications of all estimation methods developed. For easy reference, all three complete data sets are reported in
Appendix A. The first data set, which is random sample generated from Lomax
, is displayed in
Table A1. The second data set, which was originally used by Lawless [
33], consists of 60 failures is shown in
Table A3. The third one comprises the 128 remission times (in months) of bladder cancer patients that was initially published by Lee and Wang [
34] and is displayed in
Table A5. The third data set was also used by Okasha et al. [
21] for Weibull distribution modeling. However, they also mentioned that the pattern of hazard rate function revealed from data set could not be decreasing. Hence, through the intuitive guess, this data set may also be goodness-of-fitted with the Lomax distribution.
First, the Kolmogorov-Smirnov (K-S) test and scaled total time on test (TTT) plot discussed in Aarset [
35] are utilized to exam the three data sets for modeling investigation. Since K-S test has been well-known and can be conducted through current existing software, we only briefly address the scaled TTT transform in this section. The scaled TTT transform is defined by
with
and
. Given the order statistic,
, of random sample,
, the empirical scaled TTT transform is derived via
with
and
. Then the empirical scaled TTT plot is defined as
. Aarset [
35] declared if the hazard increases (decreases) then the scaled TTT transform is concave (convex); moreover if the scaled TTT transform has both convex and concave joint together then the shape of hazard function is either bathtub or unimodal. The simulated data set used for Example 1 and all adaptive type-I progressively hybrid censored samples used for all examples were generated by using R that is available from author on request.
8.1. Example 1
The complete data set from
Table A1 is used to fit with Lomax
and the MLE of the unknown
and
are obtained as
and
based on the complete data set. The K-S test produces test statistic value 0.077293 with
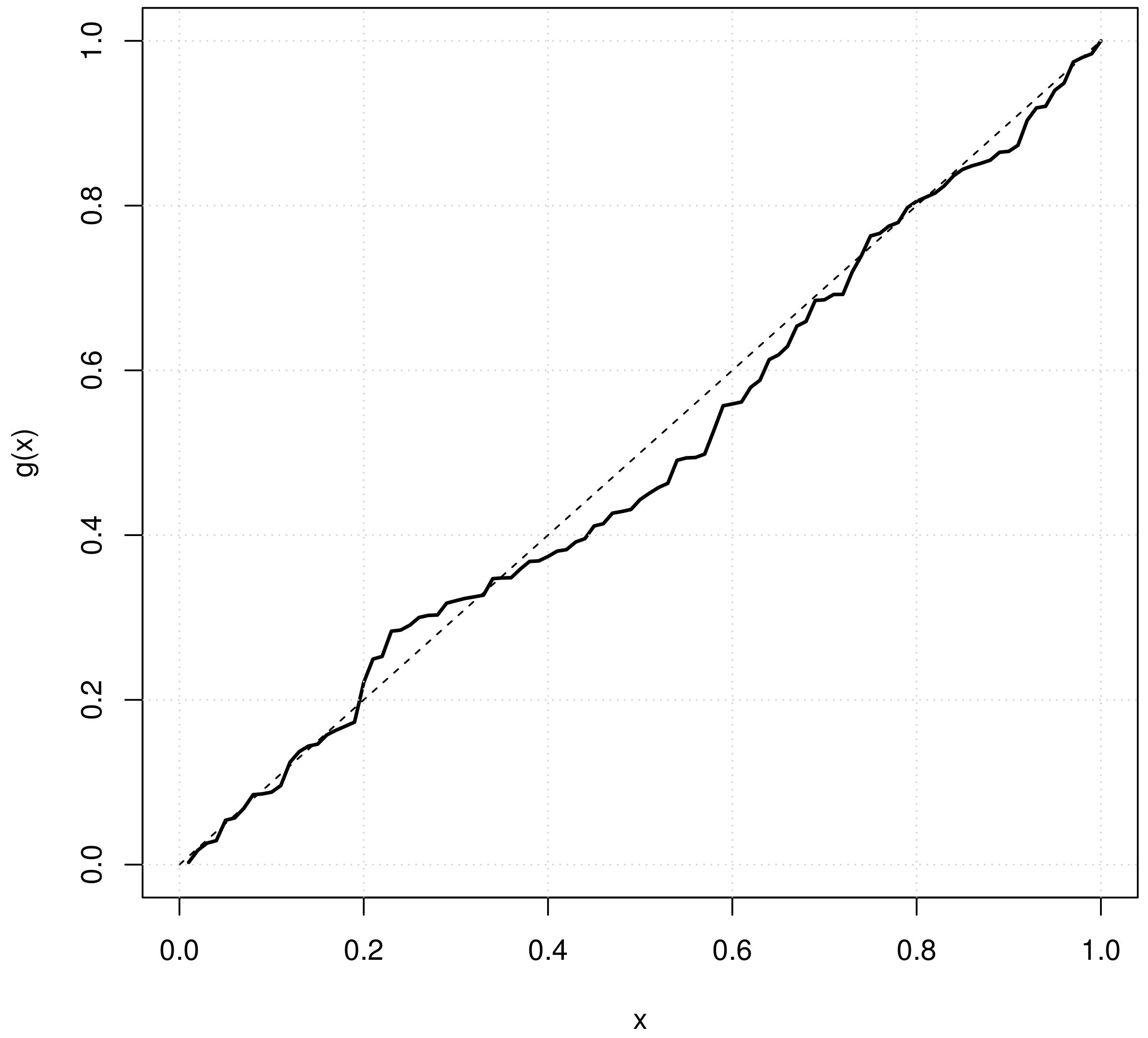
p-value = 0.5887. The empirical scaled TTT plot of the complete data from
Table A1 is displayed in
Figure 2 that reveals slightly convex in the small middle region of data set, concave over the small region just to the left side of the middle region and no significant pattern on both the left lower corner and the right upper corner. The pattern of TTT plot seems consistent with the pattern of hazard function that shows slightly decreasing because
is small, (for example, below 0.5). Based on
p-value, the Lomax(10.69, 0.0347) is accepted to be a goodness-of-fit model.
By utilizing progressive censoring scheme II with
and
that was defined in
Section 7, two adaptive type-I progressively hybrid censored samples with
and with
are, respectively, generated from
Table A1 and displayed in
Table A2. The first adaptive type-I progressively hybrid censored sample has
,
under
for
and
for
. The second adaptive type-I progressively hybrid censored sample has
,
under
for
and
for
. To derive the estimates of
,
and
, we assumed
. All estimation results for
,
and
are calculated and displaced in
Table 3 and
Table 4, where Bayesian estimates were evaluated by utilizing
, since there are no other information available.
8.2. Example 2
The complete data set from
Table A3 is used to fit with Lomax
and the MLE of the unknown
and
are obtained as
and
based on the complete data set. The K-S test generates the test statistic 0.087169 with
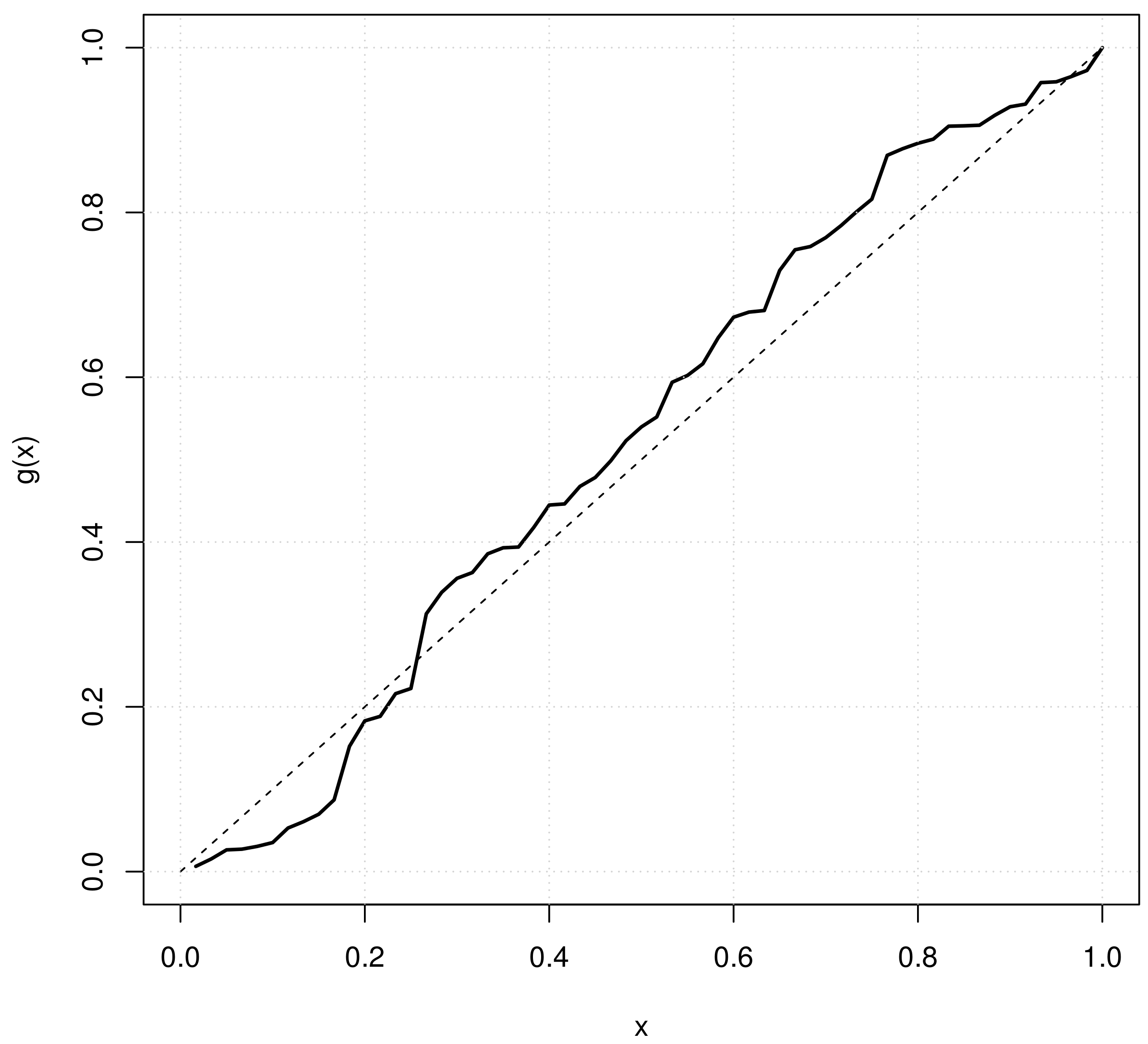
p-value = 0.719. The empirical scaled TTT plot by using the complete data from
Table A3 is shown in
Figure 3, which reveals slightly convex in the most left lower small corner and slightly concave with no significant pattern climbing up to the most right upper corner. The pattern of TTT plot seems consistent with the pattern of hazard function that shows slightly decreasing because
is small (for example, below 0.5). Based on
p-value, the Lomax(11.61, 0.0418) is accepted to be a goodness-of-fit model.
From
Table A3, two adaptive type-I progressively hybrid censored samples with
and with
were, respectively, generated through progressive censoring scheme II with
and
that was defined in
Section 7 and displayed in
Table A4. The first adaptive type-I progressively hybrid censored sample has
,
under
for
and
for
. The second adaptive type-I progressively hybrid censored sample has
,
under
for
and
for
. The estimates of
,
and
are derived assuming the true rate parameter
. All estimation results for
,
and
are calculated and displaced in
Table 3 and
Table 4, where Bayesian estimates were evaluated by using
, since there are no other information available.
8.3. Example 3
The complete data set from
Table A5 is used to fit with Lomax
and the MLE of unknown
and
are obtained as
and
based on the complete data set. The K-S test has test statistic value 0.096605 with
p-value = 0.1833. The TTT plot of this data set had been discussed by Okasha et al. [
21]. Based on
p-value, there is no significant different from Lomax (13.9384, 0.00826) model fitting.
In this example, two adaptive type-I progressively hybrid censored samples with
and with
were respectively generated via progressive censoring scheme II with
and
that was defined in
Section 7 and displayed in
Table A6. The first adaptive type-I progressively hybrid censored sample has
,
under
for
and
for
. The second adaptive type-I progressively hybrid censored sample has
,
under
for
and
for
. The estimates of
,
and
are derived by utilizing
. All estimation results for
,
and
are calculated and displaced in
Table 3 and
Table 4, where Bayesian estimates were computed with
, since there are no other information available.




{kind=link}
{kind=link}
{kind=link}


