1. Introduction
Numerous studies have used questionnaires to conduct satisfaction surveys and identified service items that need to be improved by means of performance evaluation matrices. Improvements have been made to enhance customer satisfaction [
1,
2,
3]. The purpose of a shop improving customer satisfaction is to raise the percentage of customers’ purchases in the shops so as to increase its total revenue. On the whole, the amount of customer arrival at a shop belongs to an attribute Poisson process [
4,
5]. A user-friendly evaluation index for the Poisson process of the attribute characteristic can assist a shop in assessing its business performance. An excellent and practical evaluation method for service performance can be of help for the improvement of the shop’s service quality as well as its image. Then, the shop can be profitable and competitive.
As noted by some study, the number of customers arriving at a shop gives a good answer for the performance measurement of a company since it immediately influences profitability and operating costs [
6,
7]. In early related research, Yang and Chen [
8] proposed a performance index approach for controlling service quality based on the Poisson process. Some research pointed out that the number of customers arriving at a shop is a Poisson process [
9,
10,
11]. Furthermore, Chen [
5,
12] used an operating performance index for the Poisson process and an exponential distribution to develop a fuzzy testing model based on confidence intervals. According to many scholars’ viewpoints, an index is a simple and unitless management tool, which is very convenient for management and communication [
13,
14,
15]. Therefore, no matter whether it is the process quality index of the manufacturing industry or the service performance index of the service industry, it is a unitless and easy-to-use communication and management tool [
16,
17,
18,
19,
20].
Based on the above-mentioned, this paper sets rules with an easy-to-use principle. Furthermore, this paper refers to the performance index proposed by Yang and Chen [
8] to define an attribute service performance index based on the Poisson process. Since the index has unknown parameters, this paper then finds the uniformly minimum variance unbiased estimator (UMVUE) of the service performance index based on random samples. Additionally, the UMVUE is regarded as the test statistic to measure whether the shop’s operating performance reaches the required performance level.
Additionally, some studies have pointed out that various business data measurement and collection technologies are frequently rectified to generate massive production data, as internet of things (IoT) is growing more or more popular [
21,
22]. Efficient data analysis and application can help companies make smart and efficient decisions in a short period of time [
23,
24]. Based on some studies, data collection for the Poisson process is slow [
4,
5]. Furthermore, given enterprises’ needs for quick responses and cost considerations, the sample size
n of the random samples is usually not too large in practice, so the accuracy of statistical inference will be affected [
25,
26]. In order to solve this problem, the fuzzy testing method proposed by this paper is built on traditional statistical laws as well as designed to incorporate the past production information or expert experience. Therefore, when the samples are small, it is hoped that the testing accuracy can be remained unchanged or improved. Additionally, another advantage of the fuzzy testing method based on the confidence interval is that the existing measurement of simple random sampling can be maintained during data collection, which is easier than the data collection of various fuzzy numbers; also, the calculation of the data is relatively easy [
1,
19]. It can be said that it takes into account the accuracy of the assessment and meets the needs of enterprises for quick responses. Obviously, the evaluation model of this article contains more evaluation information (e.g., the past production information or expert experience) than the traditional statistical test. Therefore, it is more effective and practical than the traditional statistical test in the case of a small sample size.
Furthermore, the evaluation model presented by this paper can grasp the timeliness. Therefore, when the evaluation result is that the service operation performance is poor, the opportunity for improvement can be immediately grasped. Since this fuzzy testing method is constructed by deriving the confidence interval of the index, it can not only reduce the risk of misjudgment due to sampling error, but also can be finally applied to a case provided by this paper to explain its use for the application of the industry.
The other sections of this paper are organized as follows. In
Section 2, we propose an attribute service performance index based on the Poisson process and discuss its characteristics. Next, we discover the uniformly minimum variance unbiased estimator of the service performance index. In
Section 3, we use the central limit theorem to derive the confidence interval of the service efficiency index, and a confidence-interval-based fuzzy testing method is proposed to assess the performance of the shop as well as determine whether the process needs to improve. In
Section 4, we present an application example illustrating the applicability of the proposed approach. In
Section 5, we make conclusions.
2. An Attribute Service Performance Index
As noted above, Yang and Chen [
8] proposed a performance index approach for managing service quality. Based on Chen and Yang [
4], the spirit of index setting is simple and easy to use. Owing to this concept, this paper proposes an attribute service performance index based on the Poisson process as follows:
where
is the process mean, and
is the minimally required amount of customers entering into the shop in a unit of time. Obviously, the process mean
is bigger than the minimally required number of customers
, and then the value of attribute service performance index
is bigger than 1. When process mean
is bigger, then the value of the attribute service performance index is bigger as well.
We assume that
are independent, identically distributed random variables with a Poisson distribution process, denoted as
~
. Then, the unbiased estimator of attribute service performance index
is expressed as follows:
where
. The characteristic function of
is
then
, and
is distributed as a Poisson distribution, denoted as
~
. Obviously, the distribution of
is a one-parameter exponential type p. d. f. of
, and can be rewritten as
where
is the observed value of random variable
and
,
,
, and
are independent of
,
j =1, 2, …, n. Then, the exponential family is
where
and
are complete and sufficient statistics for
. In fact,
is the function of
only,
and
Therefore, . Based on the Lehmann–Scheffé theorem, is the uniformly minimum variance unbiased estimators (UMVUE) of .
3. Fuzzy Hypothesis Testing Based on Service Performance Index
Suppose that
R is the requirement performance value of the index
. Then, we consider the problem of the hypothesis test as follows:
at a desired level of significance level
. Let
where
is the expected value of
and
is the standard deviation of
. Then, by the central limits theorem (CLT),
approximates the standard normal distribution when the sample size is large. Thus, the critical region is
, where critical value
is determined by
Therefore, the critical value
can be displayed as follows:
Let
be the observed value of
. Then, the observed value of
is
where
is the observed value of
. Then, the statistical test decision rules are:
- (1)
Reject if , then the service performance needs to improve.
- (2)
Do not reject if , then the service performance has no need to improve.
In practice,
of
is usually replaced by
. Then,
approximates the standard normal distribution when the sample size is large. Therefore, we have
Then, the
confidence intervals (
) of
is
The observed value of
is shown as follows:
where
is the upper
quintiles of
. Based on Yu et al. [
26], the
of triangular shaped fuzzy number
is
where
and
Therefore, the triangular shaped fuzzy number is
=
, where
and
Consequently, the membership function of
is:
Similar to
, the
of triangular shaped fuzzy number
is
where
and
Therefore, the triangular shaped fuzzy number is
=
, where
and
Consequently, the membership function of
is:
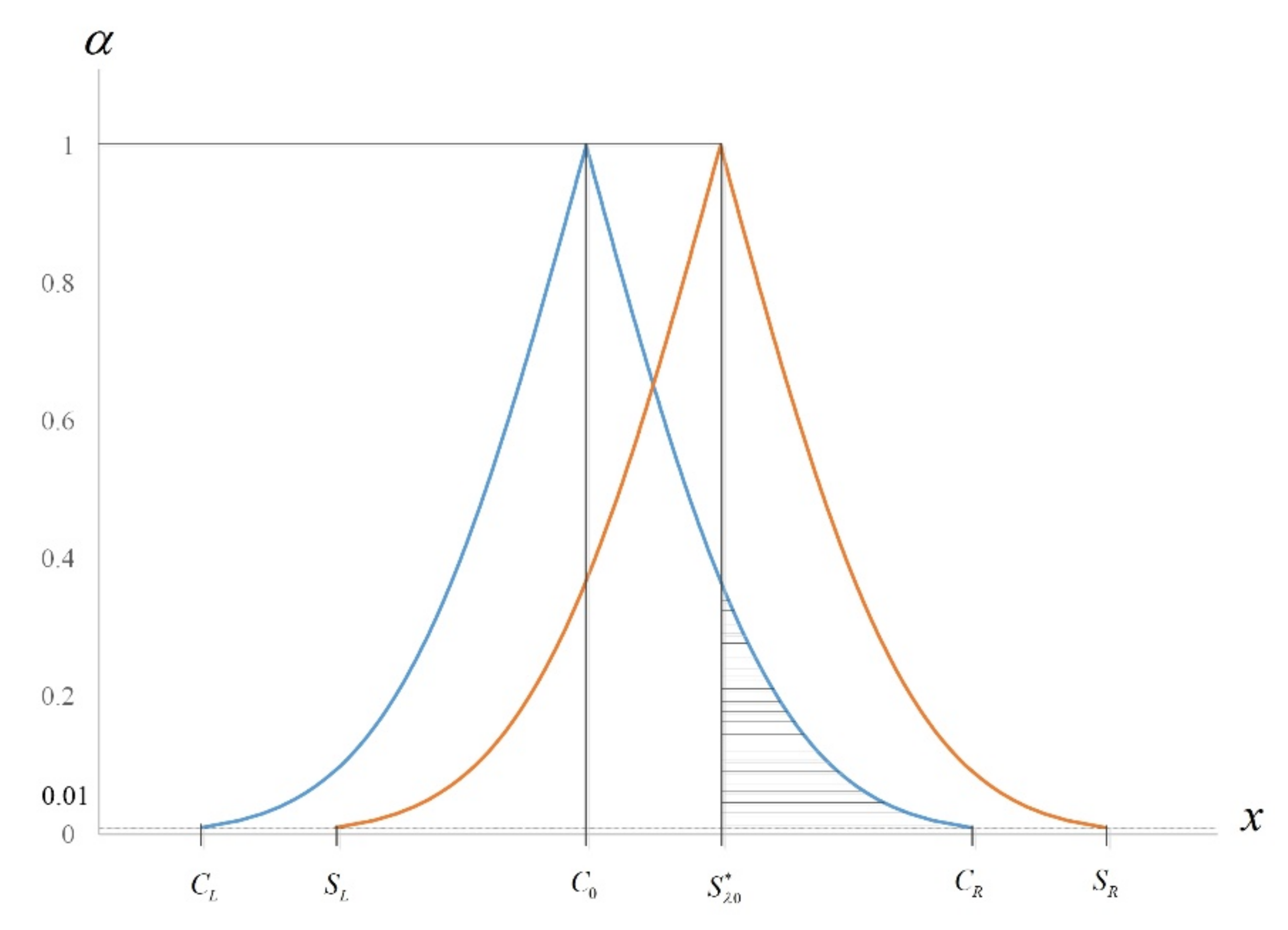
Subsequently, according to Equations (21) and (28), the diagram of
and
is presented below (see
Figure 1).
Let set
be the area in the graph of
, such that
As noted by Yu et al. [
26], since the calculation of
is complicated, this study uses
to replace
, where
is the length of the bottom of
, then
is as follows:
On the other hand, let set
be the area in the graph of
but to the right of the vertical line
, then
where
such that
. Therefore,
is as follows:
Thus, the value of
can be calculated as follows:
Note that we let 0
,
0.5, where the value of
and
can be determined based on the past accumulated production data or expert experience [
1]. Therefore, we let
. As noted by Huang et al. [
27] and Buckley [
28], we may obtain the following fuzzy testing rules:
- (1)
If , then do not reject and assume that .
- (2)
If , then do not make any decision on whether to reject or not.
- (3)
If 0.5, then reject and assume that .
4. A Practical Application
As mentioned earlier, the number of customers arriving at a shop provides a good solution for the performance measurement of a company and is distributed as a Poisson process. A shop sets the minimally required number of customers who enter into the shop as
10 in a unit of time. The required performance value of the index is bigger than or equal to 1 (
1), and the significance level is
0.05. Therefore, the problem of the hypothesis test is listed as follows:
To proceed the above statistical test, the simple random samples are surveyed in the shop of case study. The observed values of random samples with sample size
n 25 are shown as follows:
then
and
Based on the statistical test decision rule, do not reject
, and the service performance needs to improve. In fact, the value of
is equal to 0.9 or smaller than 1. However, the conclusion is
because the sample size is relatively small, which leads to a longer confidence interval, that is to say, it is caused by the sampling error. According to the study of Chen [
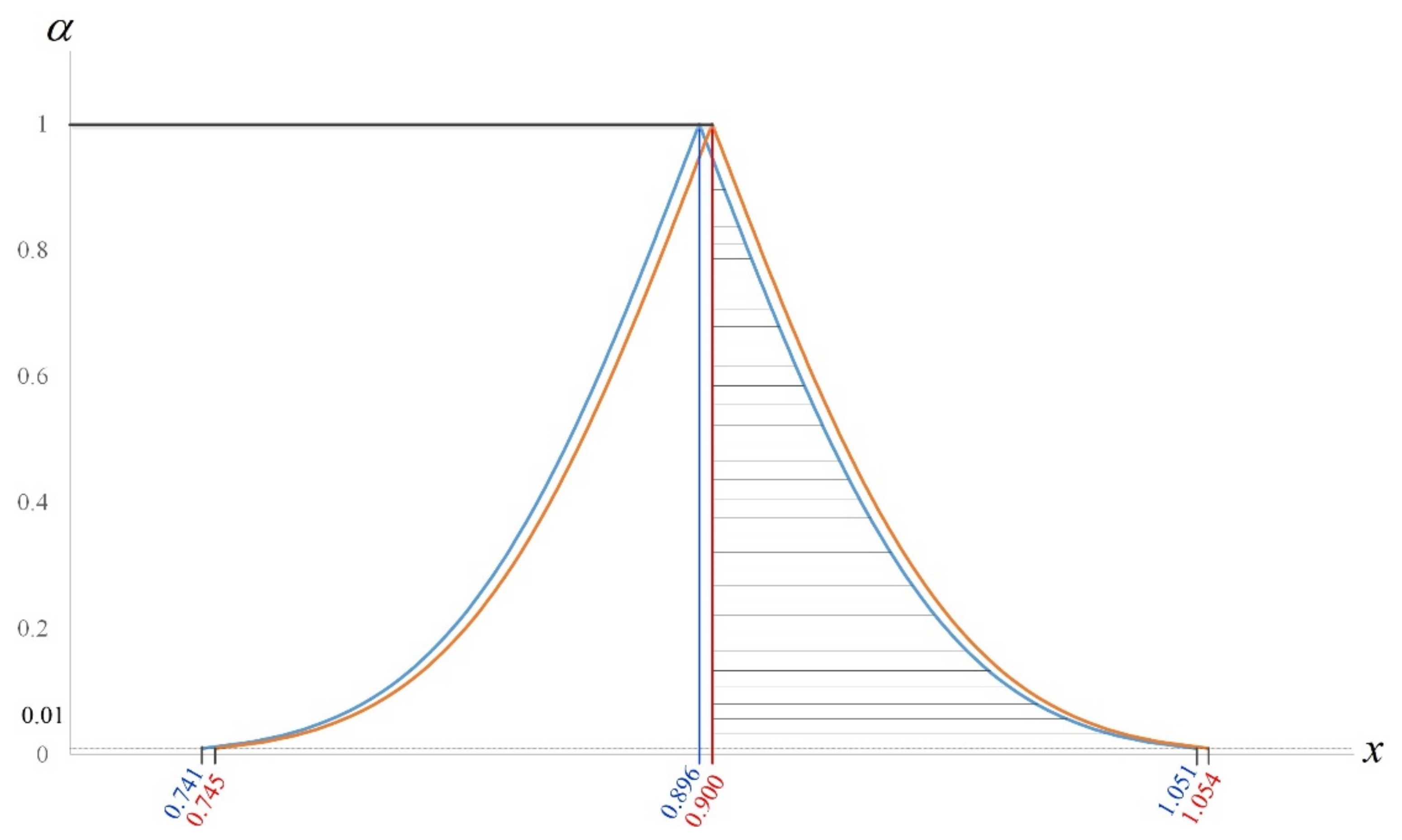
12], the probability of misjudgment is relatively high. Then, the fuzzy hypothesis testing method proposed in this study can be used to evaluate the service performance. Based on Equations (25)–(27), we have
and
Therefore, the membership function of
with
0.896 is:
Similarly, based on Equations (18)–(20), we have
and
Consequently, the membership function of
with
0.90 is:
Therefore, the membership functions diagram of
with
0.896 and
with
0.90 is presented below (see
Figure 2):
Thus, the value of
can be calculated as follows:
Based on the past accumulated production data and expert experience, we take 0.2 and 0.4. Then, according to the fuzzy testing rules, since 0.4870.5, we reject and conclude that . Based on the statistical test decision rule, do not reject , and the service performance has no need to improve. In fact, the value of is equal to 0.9 but smaller than 1. However, the conclusion is ; this is because the sample size is so small that the confidence interval becomes longer. That is to say, the probability of misjudgment is relatively high because of the relatively large sampling error. Therefore, through the fuzzy testing model proposed by this study, it seems that the traditional statistical test is more reasonable from a practical point of view.
5. Conclusions
According to the principle of arranging an easy-to-use index, this paper proposed an attribute service performance index built on a Poisson process. Because the service performance index contained untraced parameters, this paper discussed the nature of the index in
Section 2 and found its best estimator from the random samples so that it could be used as a test statistic. To satisfy enterprises’ needs for rapid responses and cost considerations, in practice, the sample size
n of random samples is usually not too large. Therefore, it will affect the accuracy of the statistical test. In order to solve this problem, this paper proposed a confidence-interval-based fuzzy testing model for a service performance index. Since this method can be integrated into the past accumulated data experience, it can maintain the accuracy of the evaluation when the sample size
n is not large. Moreover, because this method is built on the confidence interval, it can diminish the risk of misjudgment caused by sampling errors. From the practical cases mentioned in this paper, it is clearly seen that the fuzzy testing model proposed by this paper seems to be more reasonable than the traditional statistical test method.



{kind=link}
{kind=link}

