
Incorporating Biotic Information in Species Distribution Models: A Coregionalized Approach

 ,
,  ,
,  , , and
, , and
Abstract
:1. Introduction
2. Coregionalized Models for Multivariate SDMs
2.1. The Hierarchical Bayesian Coregionalisation Model
2.2. Inference and Prediction within INLA
3. Simulation Study
3.1. Generation of the Simulated Dataset
3.2. Fitting Univariate and Coregionalized Models
3.3. Results
4. Describing the Prey-Predator Interaction between European Anchovy and Hake
4.1. Data Collection
4.2. Coregionalized Model
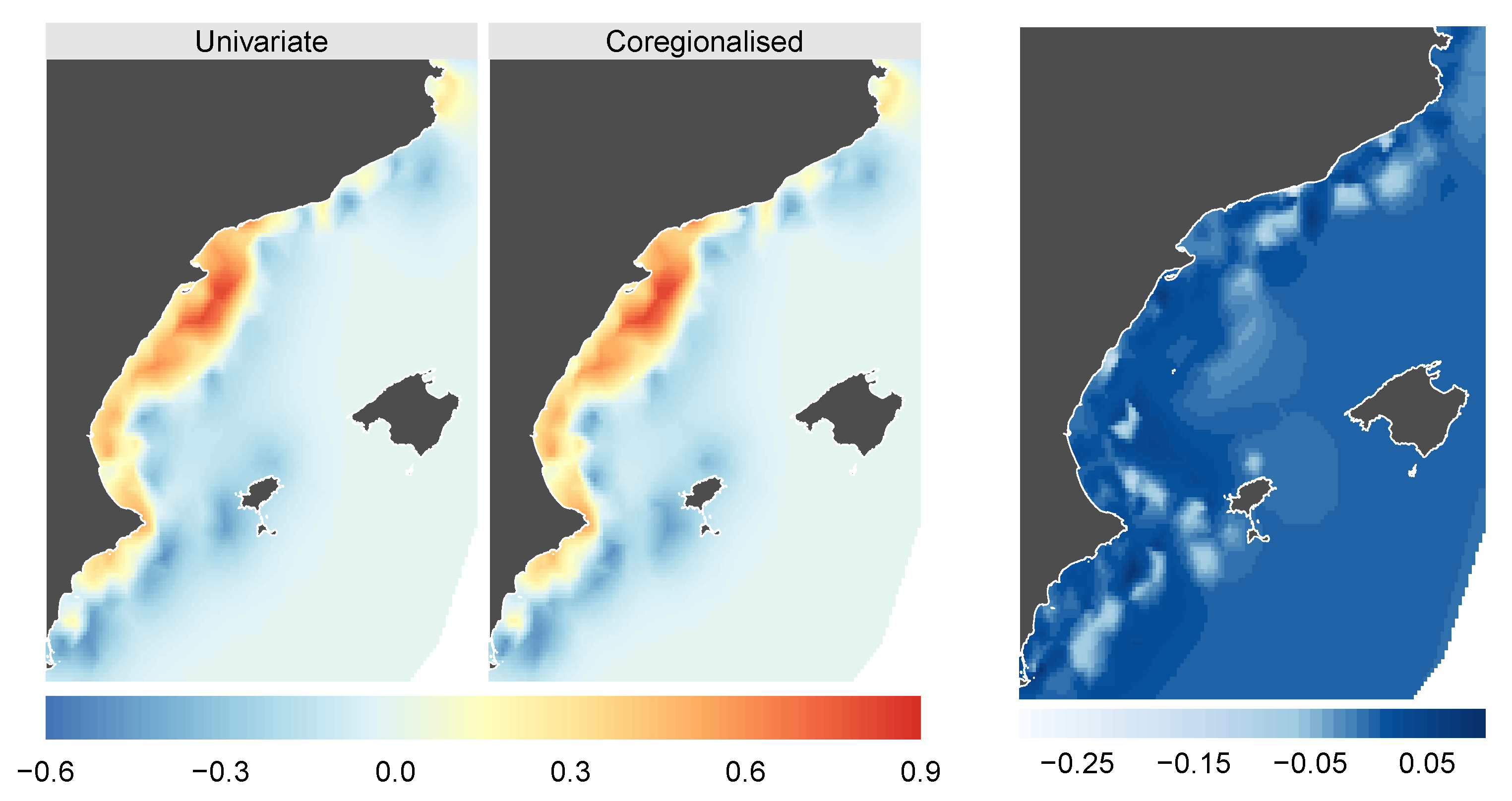
4.3. Results
5. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Guisan, A.; Thuiller, W. Predicting species distribution: Offering more than simple habitat models. Ecol. Lett. 2005, 8, 993–1009. [Google Scholar] [CrossRef]
- Elith, J.; Leathwick, J.R. Species distribution models: Ecological explanation and prediction across space and time. Annu. Rev. Ecol. Evol. Syst. 2009, 40, 677–697. [Google Scholar] [CrossRef]
- Fois, M.; Cuena-Lombraña, A.; Fenu, G.; Bacchetta, G. Using species distribution models at local scale to guide the search of poorly known species: Review, methodological issues and future directions. Ecol. Model. 2018, 385, 124–132. [Google Scholar] [CrossRef] [Green Version]
- Martínez-Minaya, J.; Cameletti, M.; Conesa, D.; Pennino, M.G. Species distribution modeling: A statistical review with focus in spatio-temporal issues. Stoch. Environ. Res. Risk Assess. 2018, 32, 3227–3244. [Google Scholar] [CrossRef]
- Coll, M.; Pennino, M.G.; Steenbeek, J.; Solé, J.; Bellido, J.M. Predicting marine species distributions: Complementarity of food-web and Bayesian hierarchical modelling approaches. Ecol. Model. 2019, 405, 86–101. [Google Scholar] [CrossRef]
- Pearson, R.G.; Dawson, T. Predicting the impacts of climate change on the distribution of species: Are bioclimate envelope models useful? Glob. Ecol. Biogeogr. 2003, 12, 361–371. [Google Scholar] [CrossRef] [Green Version]
- Wisz, M.S.; Pottier, J.; Kissling, W.D.; Pellissier, L.; Lenoir, J.; Damgaard, C.F.; Dormann, C.F.; Forchhammer, M.C.; Grytnes, J.A.; Guisan, A.; et al. The role of biotic interactions in shaping distributions and realised assemblages of species: Implications for species distribution modelling. Biol. Rev. 2013, 88, 15–30. [Google Scholar] [CrossRef] [Green Version]
- Sánchez-Cordero, V.; Martínez-Meyer, E. Museum specimen data predict crop damage by tropical rodents. Proc. Natl. Acad. Sci. USA 2000, 97, 7074–7077. [Google Scholar] [CrossRef] [PubMed]
- Hebblewhite, M.; Merrill, E.; McDonald, T. Spatial decomposition of predation risk using resource selection functions: An example in a wolf-elk predator-prey system. Oikos 2005, 111, 101–111. [Google Scholar] [CrossRef]
- Trainor, A.M.; Schmitz, O.J.; Ivan, J.S.; Shenk, T.M. Enhancing species distribution modeling by characterizing predator–prey interactions. Ecol. Appl. 2014, 24, 204–216. [Google Scholar] [CrossRef]
- Peterson, A.; Sánchez-Cordero, V.; Beard, C.; Ramsey, J. Ecologic niche modeling and potential reservoirs for Chagas disease, Mexico. Emerg. Infect. Dis. 2002, 8, 662–667. [Google Scholar] [CrossRef]
- Giannini, T.C.; Chapman, D.S.; Saraiva, A.M.; Alves-dos Santos, I.; Biesmeijer, J.C. Improving species distribution models using biotic interactions: A case study of parasites, pollinators and plants. Ecography 2013, 36, 649–656. [Google Scholar] [CrossRef] [Green Version]
- Gutiérrez, D.; Fernández, P.; Seymour, A.; Jordano, D. Habitat distribution models: Are mutualist distributions good predictors of their associates? Ecol. Appl. 2005, 15, 3–18. [Google Scholar] [CrossRef]
- Vasconcelos, T.S.; Antonelli, C.P.; Napoli, M.F. Mutualism influences species distribution predictions for a bromeliad-breeding anuran under climate change. Austral Ecol. 2017, 42, 869–877. [Google Scholar] [CrossRef]
- Aarts, G.; Jones, E.; Brasseur, S.; Rindorf, A.; Smout, S.; Dickey-Collas, M.; Wright, P.; Russell, D.; McConnell, B.; Kirkwood, R.; et al. Prey habitat model outperforms prey data in explaining grey seal distribution. In Proceedings of the Annual Conferenec of the European Cetacean Society, La Rochelle, France, 5–9 April 2014. [Google Scholar]
- Pennino, M.G.; Guijarro-García, E.; Vilela, R.; del Río, J.L.; Bellido, J.M. Modeling the distribution of thorny skate (Amblyraja radiata) in the southern Grand Banks (Newfoundland, Canada). Can. J. Fish. Aquat. Sci. 2019, 76, 2121–2130. [Google Scholar] [CrossRef]
- Chiles, J.; Delfiner, P. Geoestatistics: Modeling Spatial Uncertainty; Wiley: New York, NY, USA, 1999. [Google Scholar]
- Wackernagel, H. Multivariate Geostatistics: An Introduction with Applications, 3rd ed.; Springer: New York, NY, USA, 2003. [Google Scholar]
- Gelfand, A.; Diggle, P.; Guttorp, P.; Fuentes, M. Handbook of Spatial Statistics; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Banerjee, S.; Carlin, B.; Gelfand, A. Hierarchical Modeling and Analysis for Spatial Data, 2nd ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2014. [Google Scholar]
- Gelfand, A.E.; Banerjee, S. Bayesian Modeling and Analysis of Geostatistical Data. Annu. Rev. Stat. Appl. 2017, 4, 245–266. [Google Scholar] [CrossRef] [Green Version]
- Schmidt, A.M.; Gelfand, A.E. A Bayesian coregionalization approach for multivariate pollutant data. J. Geophys. Res. Atmos. 2003, 108, 8783. [Google Scholar] [CrossRef]
- Jones-Todd, C.M.; Swallow, B.; Illian, J.B.; Toms, M. A spatiotemporal multispecies model of a semicontinuous response. J. R. Stat. Soc. Ser. C Appl. Stat. 2018, 67, 705–722. [Google Scholar] [CrossRef]
- Barber, X.; Conesa, D.; López-Quílez, A.; Morales, J. Multivariate Bioclimatic Indices Modelling: A Coregionalised Approach. J. Agric. Biol. Environ. Stat. 2019, 24, 225–244. [Google Scholar] [CrossRef]
- Rue, H.; Martino, S.; Chopin, N. Approximate Bayesian inference for latent Gaussian models by using integrated nested Laplace approximations. J. R. Stat. Soc. Ser. B Stat. Methodol. 2009, 71, 319–392. [Google Scholar] [CrossRef]
- Gilks, W.; Richardson, S.; Spiegelhalter, D. Markov Chain Monte Carlo in Practice; Chapman and Hall/CRC: Boca Raton, FL, USA, 1996. [Google Scholar]
- Barber, X.; Conesa, D.; López-Quílez, A.; Mayoral, A.; Morales, J.; Barber, A. Bayesian hierarchical models for analysing the spatial distribution of bioclimatic indices. SORT-Stat. Oper. Res. Trans. 2017, 1, 277–296. [Google Scholar]
- Genton, M.G.; Kleiber, W. Cross-covariance functions for multivariate geostatistics. Stat. Sci. 2015, 30, 147–163. [Google Scholar] [CrossRef]
- Cressie, N.; Zammit-Mangion, A. Multivariate spatial covariance models: A conditional approach. Biometrika 2016, 103, 915–935. [Google Scholar] [CrossRef]
- Gelfand, A. Hierarchical modeling for spatial data problems. Spat. Stat. 2012, 1, 30–39. [Google Scholar] [CrossRef] [Green Version]
- Matérn, B. Spatial Variation, 2nd ed.; Springer: Berlin, Germany, 1986. [Google Scholar]
- Abramowitz, M.; Stegun, I. Handbook of Mathematical Functions: With Formulas, Graphs, and Mathematical Tables; National Bureau of Standards: Washington, DC, USA, 1964. [Google Scholar]
- Lindgren, F.; Rue, H.; Lindström, J. An explicit link between Gaussian fields 670 and Gaussian Markov random fields: The SPDE approach (with discussion). J. R. Stat. Soc. Ser. B 2011, 73, 423–498. [Google Scholar] [CrossRef] [Green Version]
- Krainski, E.; Gómez-Rubio, V.; Bakka, H.; Lenzi, A.; Castro-Camilo, D.; Simpson, D.; Lindgren, F.; Rue, H. Advanced Spatial Modeling with Stochastic Partial Differential Equations Using R and INLA; Chapman and Hall/CRC: Boca Raton, FL, USA, 2019. [Google Scholar]
- Rue, H.; Riebler, A.; Sørbye, S.; Illian, J.; Simpson, D.; Lindgren, F. Bayesian computing with INLA: A review. Annu. Rev. Stat. Appl. 2017, 4, 395–421. [Google Scholar] [CrossRef] [Green Version]
- Blangiardo, M.; Cameletti, M. Spatial and Spatio-Temporal Bayesian Models with R-INLA; John Wiley & Sons: New York, NY, USA, 2015. [Google Scholar]
- Fuglstad, G.A.; Simpson, D.; Lindgren, F.; Rue, H. Constructing priors that penalize the complexity of Gaussian random fields. J. Am. Stat. Assoc. 2019, 114, 445–452. [Google Scholar] [CrossRef] [Green Version]
- Simpson, D.; Rue, H.; Riebler, A.; Martins, T.G.; Sørbye, S.H. Penalising model component complexity: A principled, practical approach to constructing priors. Stat. Sci. 2017, 32, 1–28. [Google Scholar] [CrossRef]
- Schlather, M.; Malinowski, A.; Menck, P.J.; Oesting, M.; Strokorb, K. Analysis, simulation and prediction of multivariate random fields with package RandomFields. J. Stat. Softw. 2015, 63, 1–25. [Google Scholar] [CrossRef] [Green Version]
- Bertrand, J.A.; de Sola, L.G.; Papaconstantinou, C.; Relini, G.; Souplet, A. The general specifications of the MEDITS surveys. Sci. Mar. 2002, 66, 9–17. [Google Scholar] [CrossRef] [Green Version]
- Fahrmeir, L.; Lang, S. Bayesian semiparametric regression analysis of multicategorical time-space data. Ann. Inst. Stat. Math. 2001, 53, 11–30. [Google Scholar] [CrossRef]
- Watanabe, S. Asymptotic equivalence of Bayes cross validation and widely applicable information criterion in singular learning theory. J. Mach. Learn. Res. 2010, 11, 3571–3594. [Google Scholar]
- Zurell, D.; Pollock, L.; Thuiller, W. GDo joint species distribution models reliably detect interspecific interactions from co-occurrence data in homogenous environments? Ecogr. Model. 2018, 41, 1812–1819. [Google Scholar] [CrossRef] [Green Version]
- Pennino, M.G.; Paradinas, I.; Illian, J.B.; Muñoz, F.; Bellido, J.M.; López-Quílez, A.; Conesa, D. Accounting for preferential sampling in species distribution models. Ecol. Evol. 2019, 9, 653–663. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mean | sd | |||||
|---|---|---|---|---|---|---|
| Hake | ||||||
| 6.5634 | 0.2711 | 6.0059 | 6.5727 | 7.0698 | ||
| −0.0039 | 0.0007 | −0.0053 | −0.0039 | −0.0025 | ||
| 0.154 | 0.027 | 0.107 | 0.152 | 0.214 | ||
| 2.147 | 0.154 | 1.863 | 2.141 | 2.466 | ||
| Anchovies | ||||||
| 4.4756 | 0.4160 | 3.58831 | 4.4972 | 5.2391 | ||
| −0.0025 | 0.0007 | −0.0039 | −0.0025 | −0.0010 | ||
| 0.614 | 0.166 | 0.371 | 0.585 | 1.015 | ||
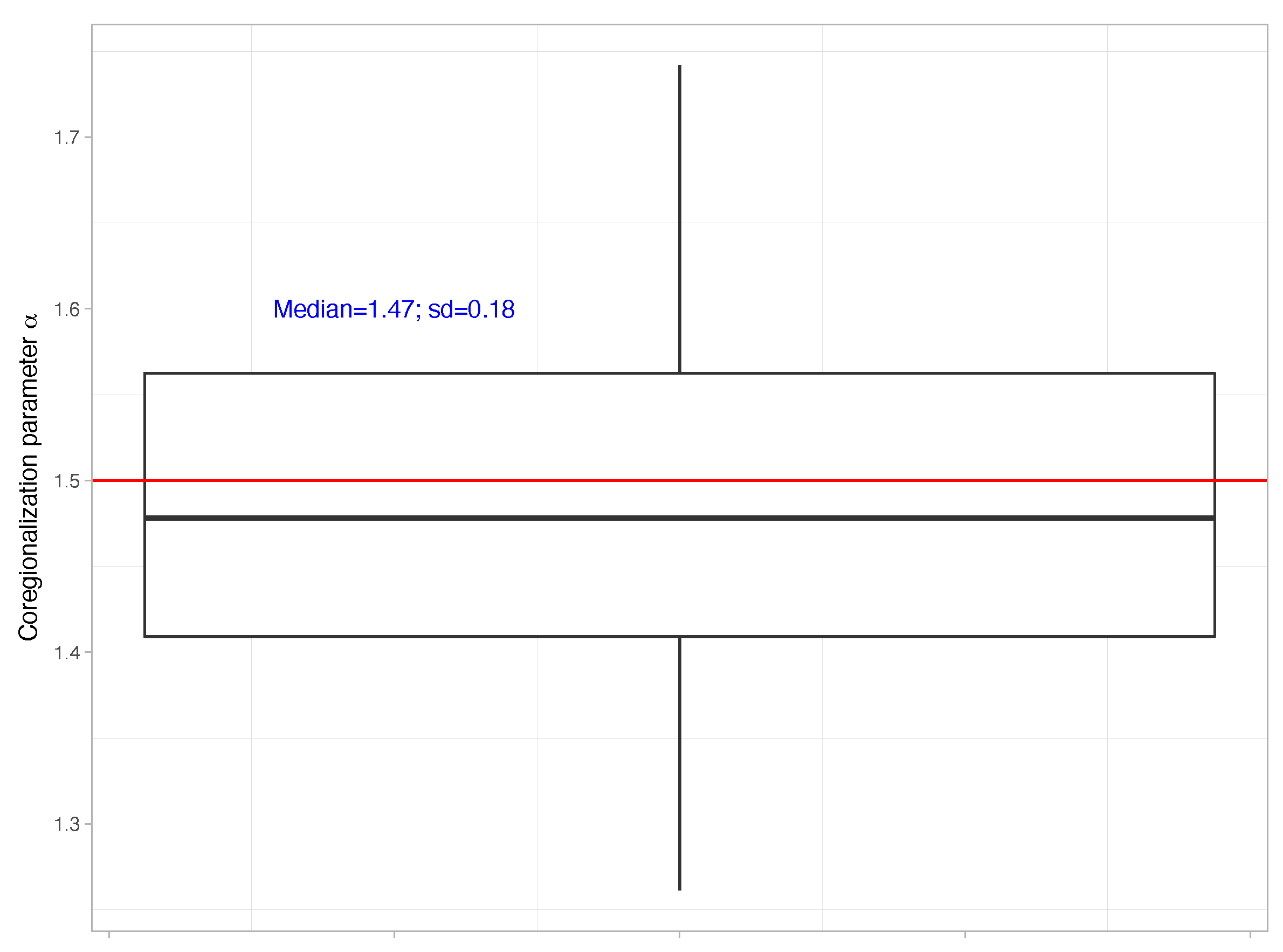
| 1.623 | 0.220 | 1.251 | 1.602 | 2.113 |
| Mean | sd | ||||
|---|---|---|---|---|---|
| 6.5258 | 0.2759 | 5.9600 | 6.5343 | 7.0434 | |
| 4.4426 | 0.3934 | 3.6091 | 4.4609 | 5.1692 | |
| −0.0038 | 0.0007 | −0.0052 | −0.0038 | −0.0024 | |
| −0.0021 | 0.0008 | −0.0036 | −0.0021 | −0.0006 | |
| 0.161 | 0.028 | 0.113 | 0.158 | 0.223 | |
| 2.148 | 0.152 | 1.864 | 2.143 | 2.463 | |
| 0.575 | 0.154 | 0.350 | 0.548 | 0.948 | |
| 1.544 | 0.194 | 1.212 | 1.527 | 1.971 | |
| 0.143 | 0.073 | −0.003 | 0.144 | 0.285 |
| Model | Measure | Value |
|---|---|---|
| Univariate | MAE | 4212.35 |
| Coregionalisation | MAE | 3842.35 |
| Univariate | RMSE | 8422.54 |
| Coregionalisation | RMSE | 7697.88 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barber, X.; Conesa, D.; López-Quílez , A.; Martínez-Minaya , J.; Paradinas, I.; Pennino, M.G. Incorporating Biotic Information in Species Distribution Models: A Coregionalized Approach. Mathematics 2021, 9, 417. https://doi.org/10.3390/math9040417
Barber X, Conesa D, López-Quílez A, Martínez-Minaya J, Paradinas I, Pennino MG. Incorporating Biotic Information in Species Distribution Models: A Coregionalized Approach. Mathematics. 2021; 9(4):417. https://doi.org/10.3390/math9040417
Chicago/Turabian StyleBarber, Xavier, David Conesa, Antonio López-Quílez , Joaquín Martínez-Minaya , Iosu Paradinas, and Maria Grazia Pennino. 2021. "Incorporating Biotic Information in Species Distribution Models: A Coregionalized Approach" Mathematics 9, no. 4: 417. https://doi.org/10.3390/math9040417
APA StyleBarber, X., Conesa, D., López-Quílez , A., Martínez-Minaya , J., Paradinas, I., & Pennino, M. G. (2021). Incorporating Biotic Information in Species Distribution Models: A Coregionalized Approach. Mathematics, 9(4), 417. https://doi.org/10.3390/math9040417