In this experiment, we used a cloud-based service, Google Colaboratory. This supports Intel Xeon CPU (13 GB RAM), Nvidia GPU (12 GB RAM), and Ubuntu 18.04.5 LTS. Python 3.6.9, TensorFlow 2.4.1, and Keras 2.4.0 were utilized for the programming environment.
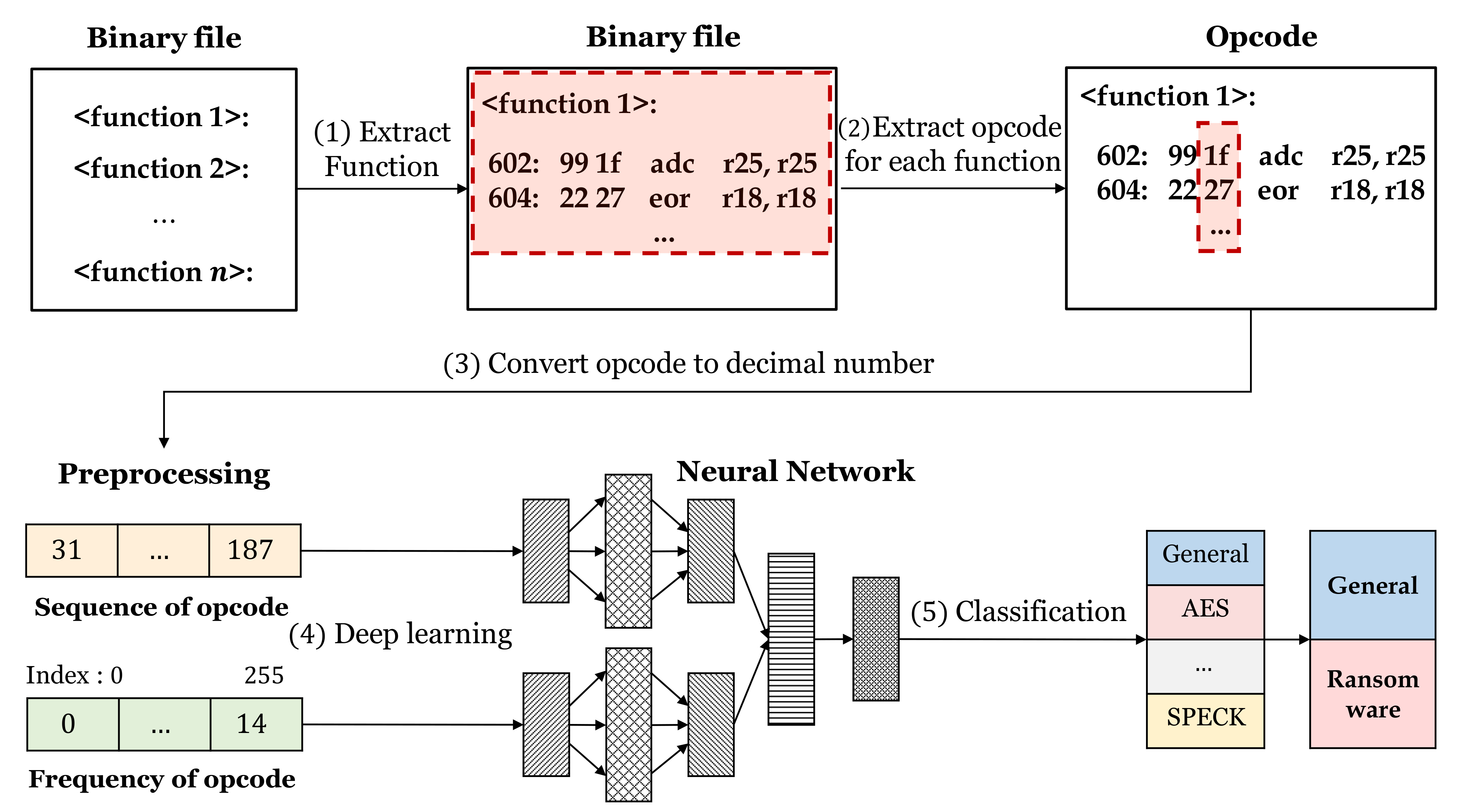
Since the encryption is performed unlike benign firmware when the crypto ransomware runs, the encryption process is set as a characteristic of ransomware.
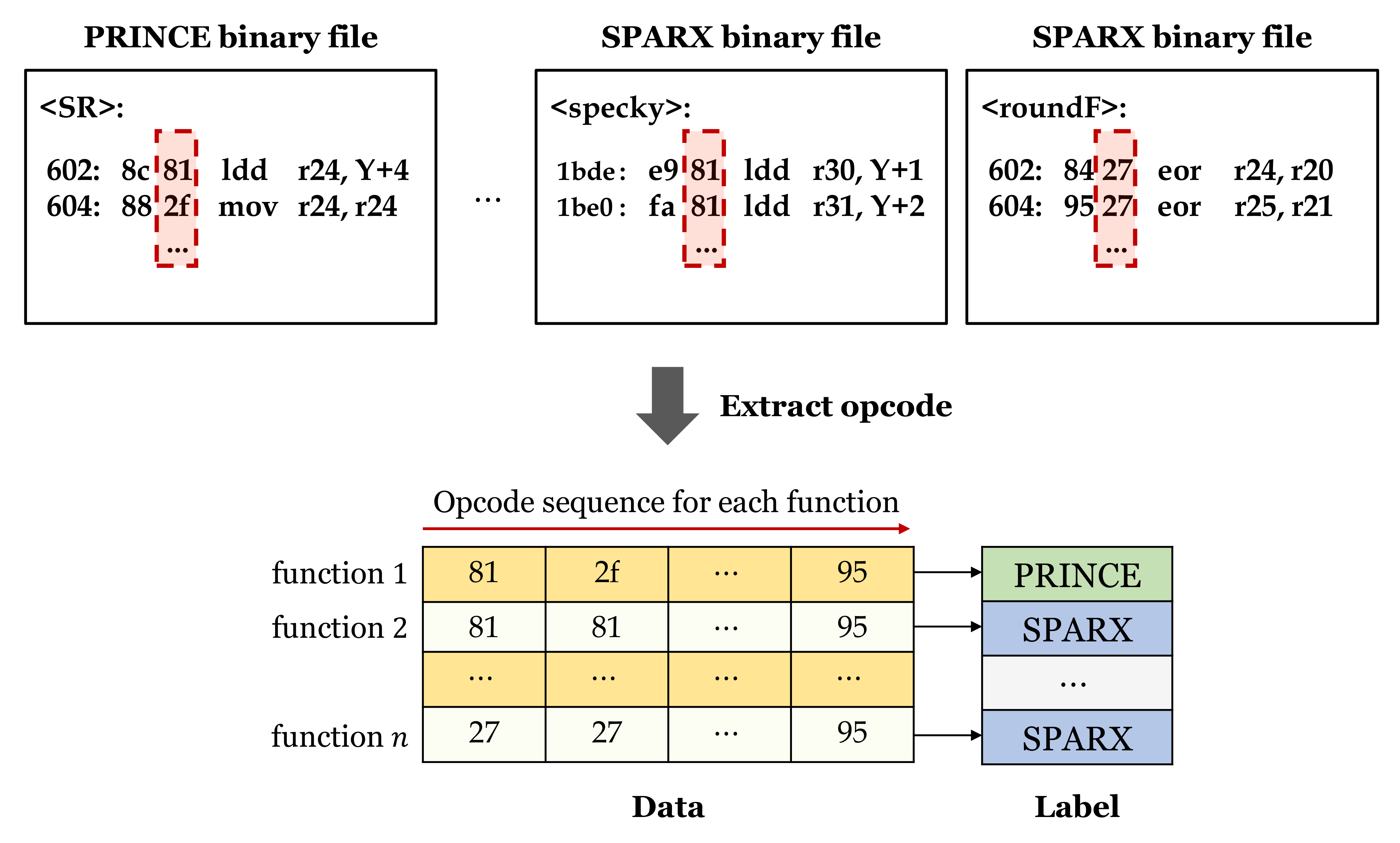
Table 3 shows the detailed dataset of general firmware and symmetric key cryptography (e.g., substitution-permutation-network and addition-rotation-exclusive-or architectures) in IoT environments. Among the FELICS implementations, we used cryptographic modules written in the C language. General programs, including Radio-Frequency Identification (RFID), WiFi, xBee, and Bluetooth, are used as general firmware. In addition, values in parentheses are the number of data, and the training set, validation set, and test set are divided into approximately 7:2:1. In the detection phase, only binary files of block ciphers belonging to the test set are used. However, they are not divided by function, and their entire binary files are used.
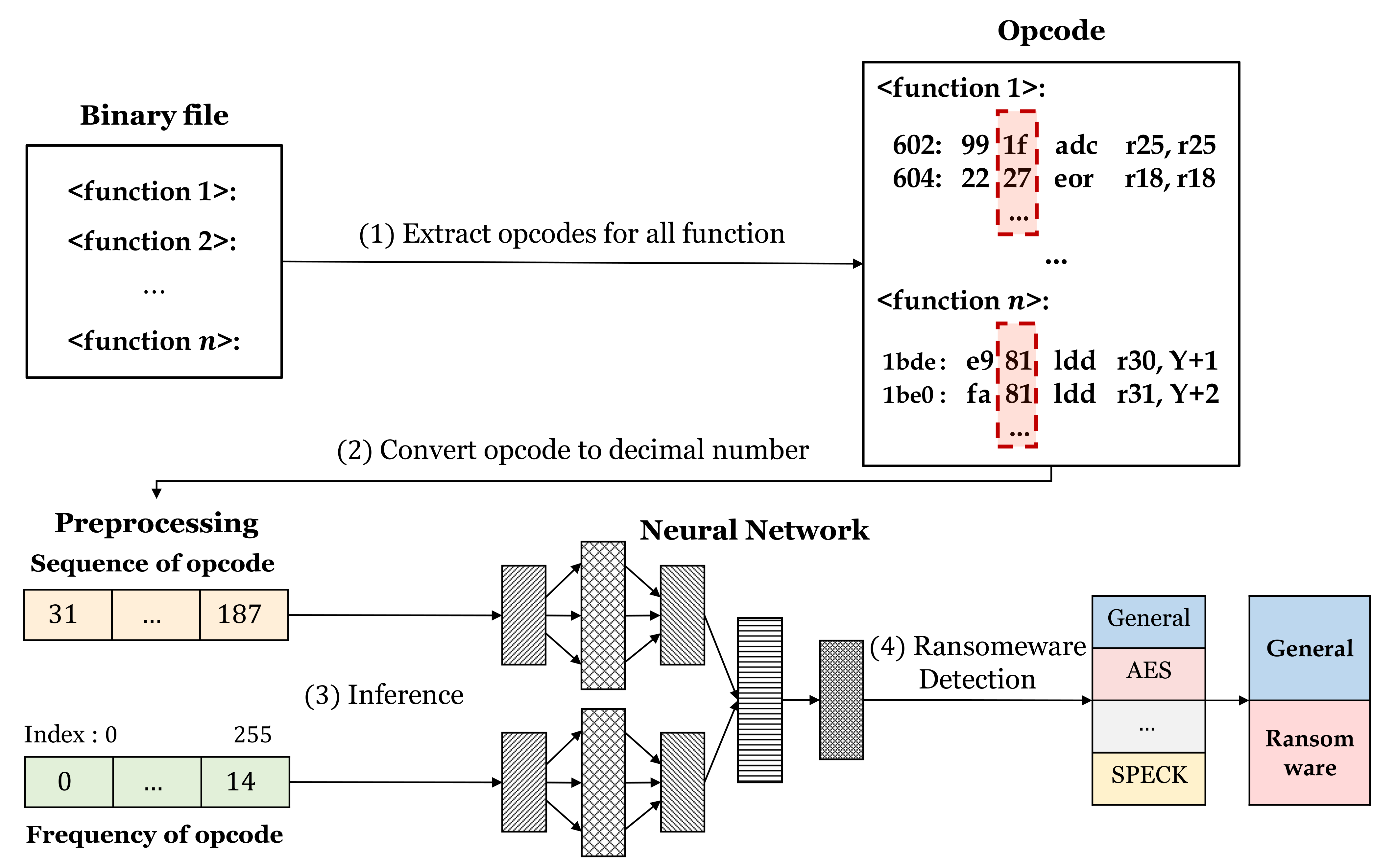
The experiment is conducted in three ways. The first experiment is conducted about opcodes. This way will construct a dataset with the proposed system and then detect the ransomware. The second experiment is carried out in the same way. However, the dataset consists of instructions containing operand, and opcode, not opcode. The third experiment is done only with opcode sequences, without considering the frequency characteristics. The last one is an experiment on the pruned model. Because an unbalanced dataset is used in this experiment, we use an F-measure. It is the harmonic mean of precision and recall rather than accuracy. There are micro and macro averaged F-measures. The micro approach takes into account the data belonging to each class. The macro approach takes into account the all classes with the same weight. The dataset used for these experiments has a different number of data for each class. Therefore, we evaluated through micro F-measure for each experiment. In addition, all results are the average value of 10 experiments. In addition, the result table consists of validation F-measure, test F-measure, and detection F-measure. Since validation and test results are about the training phase, these are results performed with each function in the binary file. Since the detection is about the detection phase, the detection is done with the entire binary file, not a function.
4.1. Instruction-Based vs. Opcode-Based
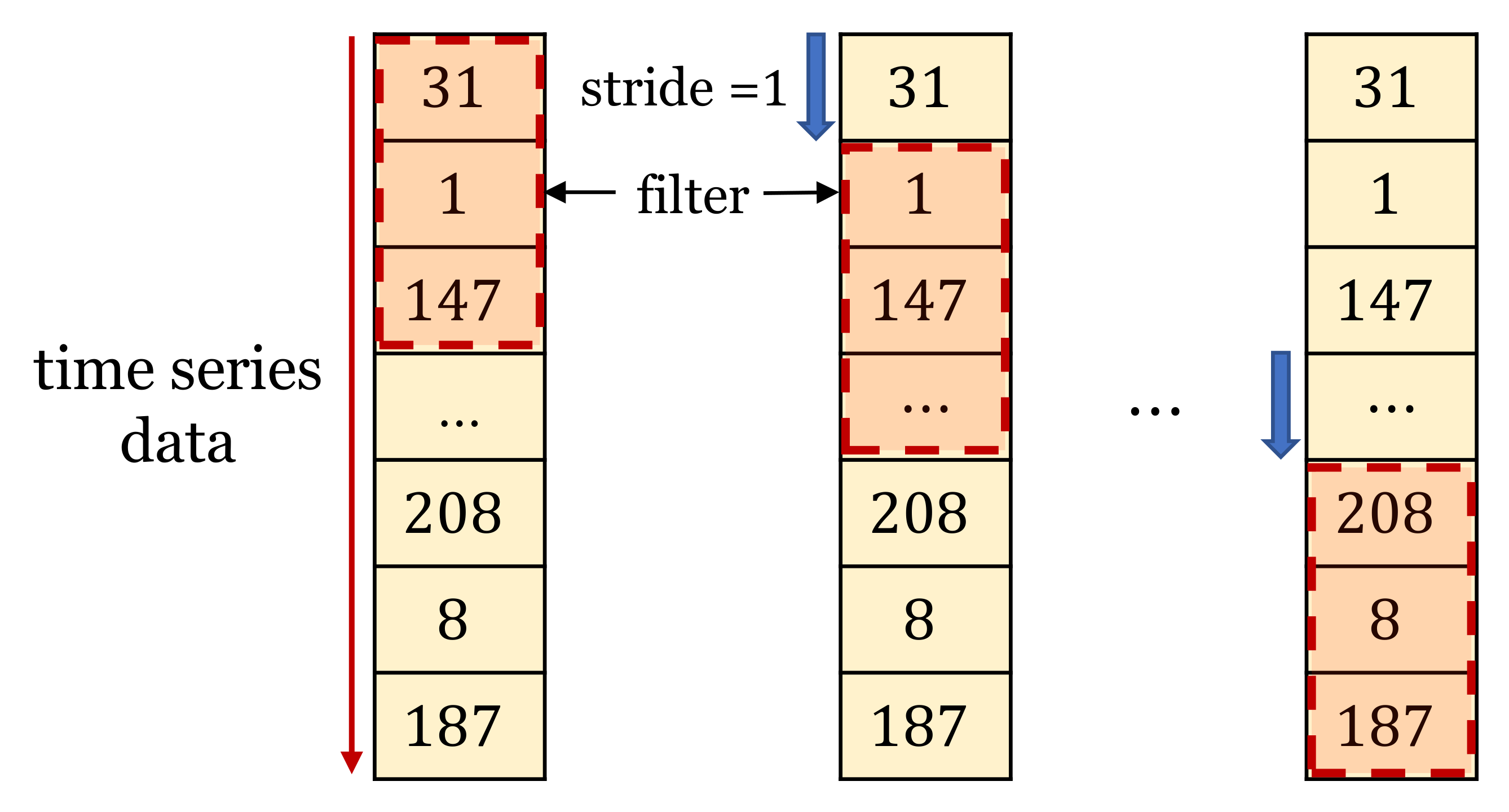
This experiment is to compare the performance of the proposed method (opcode-based) and instruction-based (opcode and operand). In case of instruction-based, the pre-process method is same, but operand and opcode are inputted into the neural network as feature values for one time series data. The sequence data of opcode-based method has 1 feature (i.e., opcode). However, the sequence data of instruction-based method has 2 features (operand and opcode).That is, if the proposed method has one column for n time-series data, the instruction-based method has two columns for n time series data. If the same operation is performed, it has same opcodes. However, operands are different in high possibility.
The experiment results of training and detecting on opcode-based and instruction-based methods are in
Table 4 and
Table 5. These values mean the success rate. In case of classifying 11 cryptographic algorithms and benign firmware into 12 labels, the opcode-based method achieved 4%, 10%, and 10% higher detection performance in validation, testing, and detection, respectively, than the instruction-based method. For this reason, we proposed the opcode-based method.
In the opcode-based method, most of the misclassifications were for (SPECK and LEA) and (SPECK and SPARX) in experiment for each algorithm. In the instruction-based method, most of the misclassifications were for (SIMON and SPECK), (SPARX and SPECK), and (LEA and SPECK) in the same experiment.
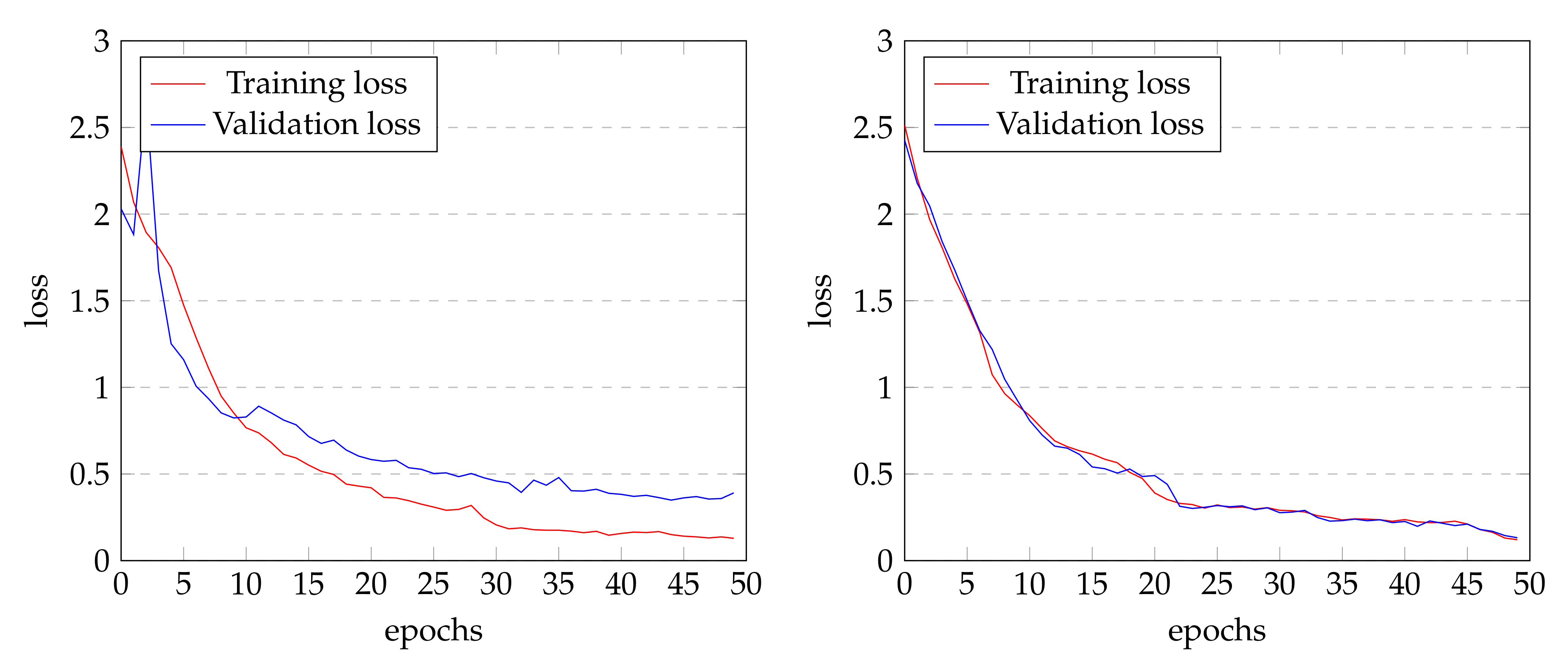
In SPN versus ARX versus General firmware, the opcode-based method misclassified SPECK and general firmware in validation and test. In addition, in detection, the general firmware was incorrectly detected as SPARX. That is, there were no cases of misclassifying SPN and ARX structures. However, the instruction-based method misclassified between RECTANGLE, PRIDE, HIGHT, and general firmware in validation and test. In addition, in the detection, there were misclassification between RECTANGLE, SPARX, SPECK, and generic firmware. SPN and ARX structures are sometimes misclassified. However, both opcode-based and instruction-based methods show the same performance for the ransomware detection. Results of detecting ransomware is the same percentage. However, as shown in
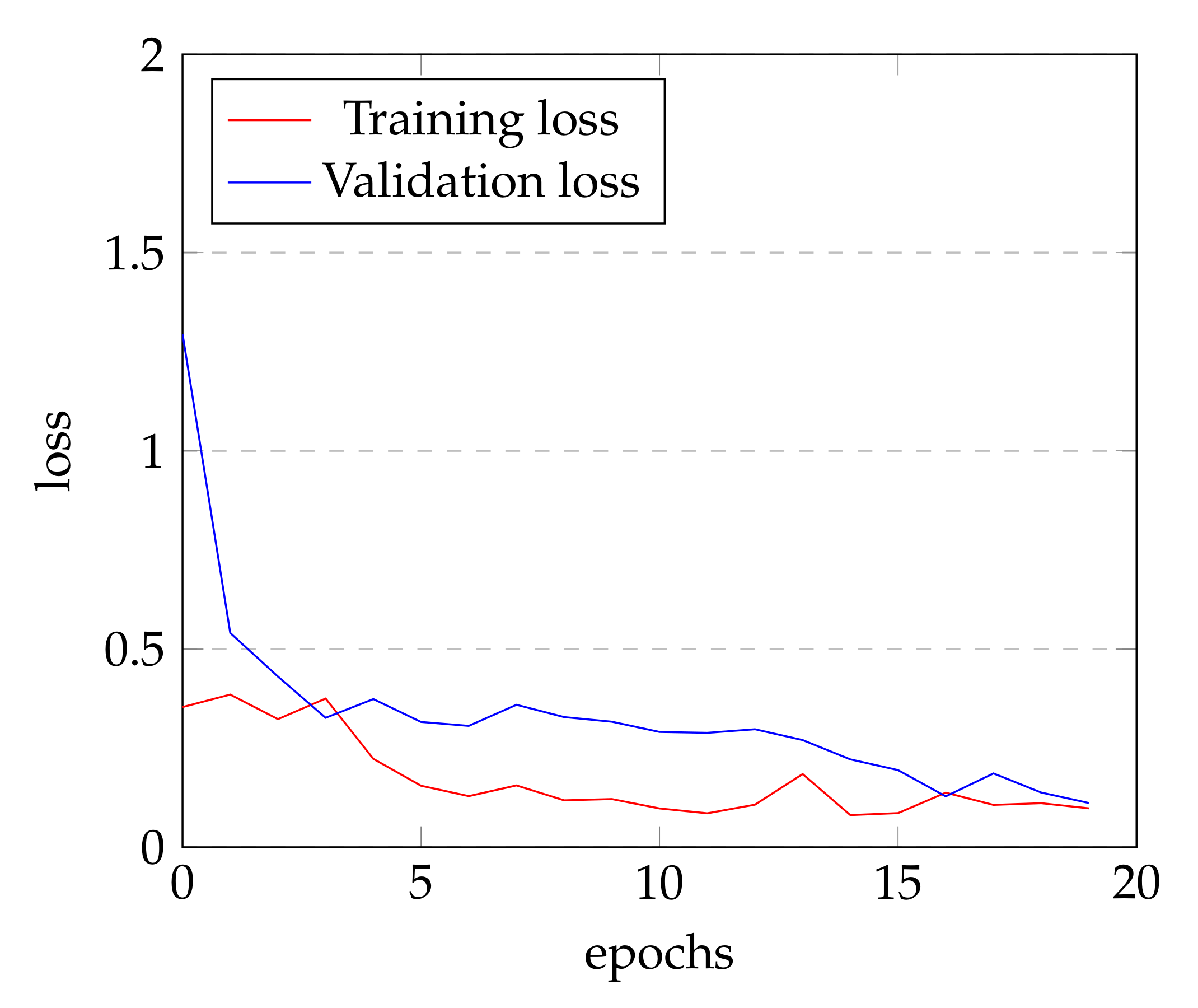
Figure 7, the instruction-based method has about 2 times higher loss value than the opcode-based method. Due to the nature of the training process that trains to minimize the loss, a model with a smaller loss value can classify in the accurate manner. Therefore, the opcode-based method is a better way to detect ransomware.
Figure 8 is the visualization of opcodes sequence for each function. First, functions that perform the same operation show almost similar patterns, and different functions have different patterns. We can see that rotation functions of SIMON and SPARX have a very similar sequence. In addition, the same pattern is repeated in the function.
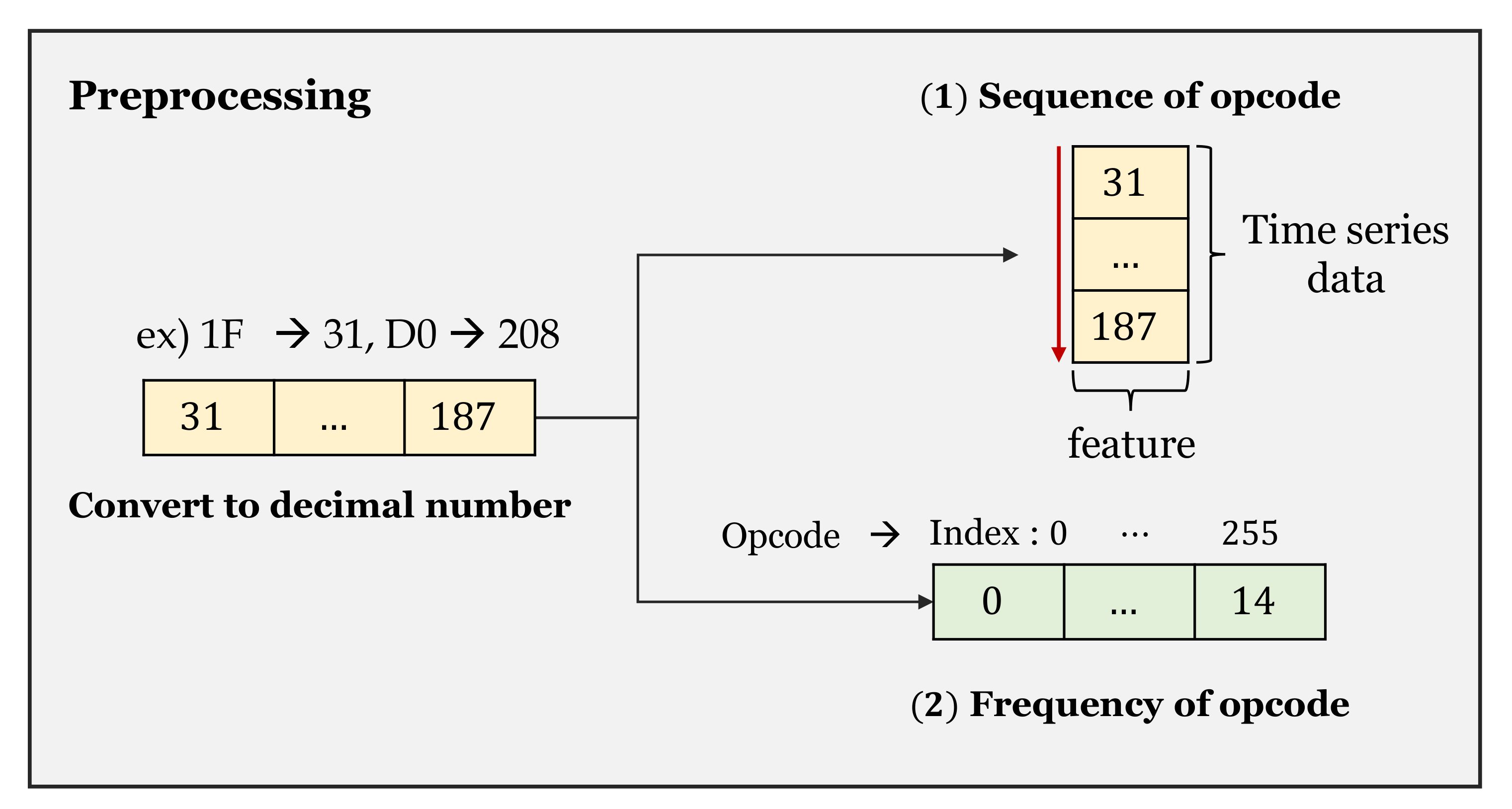
Figure 9 shows the frequency of opcodes for each algorithm. These images can be represented in an array with 256 columns. Therefore, each index represents an opcode, and elements of this array represent the number of times the opcode is used. The opcode used is represented by the vertical line in these Figures. Therefore, it is visually revealed that the distribution of opcodes is different for each structure through the location and contrast of the lines. In the gray scale, 0 means black, and 255 means white. The frequency was normalized to be within the range. The line of color closer to white is the more used opcode. The comparison is made between
Figure 9 and
Table 6. The most commonly used operations, such as
LD, ST, and
MOVW, are 129, 131, and 1, respectively. The middle of the images is expressed close to white, and there is a common line in the leftmost part. The cryptographic algorithms which have ARX (Addition-Rotation-Xor) structure frequently performed arithmetic and logical operations, such as
ADIW, XOR, SBCI, and
ADC. The third most frequently used
ADIW is 150.
XOR and
ADC are 30 and 40, respectively. There are lines close to the white color in the left part, which represent those operations. The cryptographic algorithms of SPN structure have operations to access the memory in the part of S-box operation. It is common and frequently performed. Similar operation to ARX was used, but the part corresponding to
XOR or
ADC was expressed in gray compared to ARX. In the general firmware, there are many branch instructions, and instructions that access I/O registers, which are rarely found in cryptographic code, such as
RJMP,
BRNE, and
OUT. The operation like
NOP is not used in cryptographic algorithms. Since operations of the collected general firmware are different, it is difficult to have a common pattern like encryption algorithms. There are no particular emphasized parts. Compared to this, cryptographic algorithms with the same architecture tend to share similar operation patterns. In addition, certain patterns are repeated because block cipher algorithms repeat rounds.
4.2. Frequency and Opcode Sequence Versus Sequence-Only
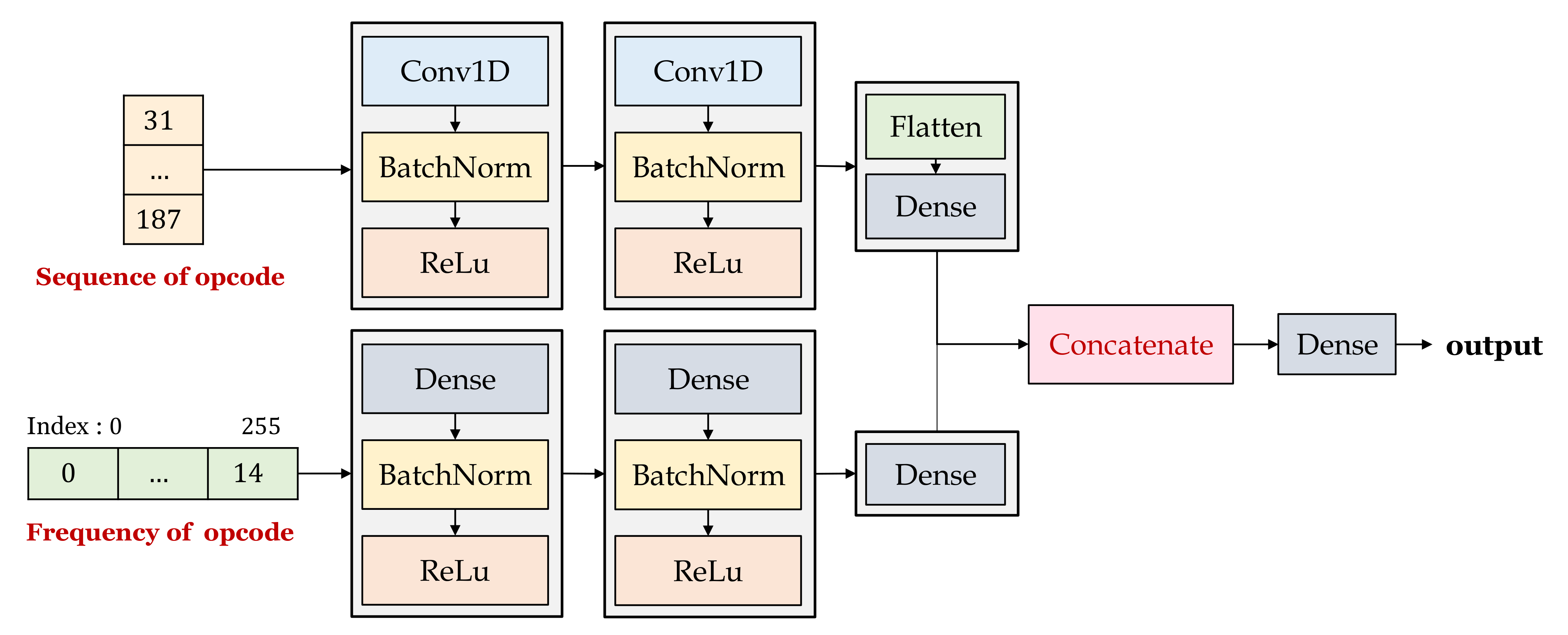
In this experiment, we evaluated the model reflecting frequency and opcode (proposed model) and the model reflecting only the sequence. We applied the late fusion in proposed model. As mentioned in
Section 3.2, the late fusion model can cope with a problem that the one of inputs is wrong, and it has independent error propagation. The post-concatenation process focuses on learned strengths (features) for each input. Therefore, better performance is achieved in general.
Table 7 shows the result of experiment with the model reflecting only the sequence. Compared to
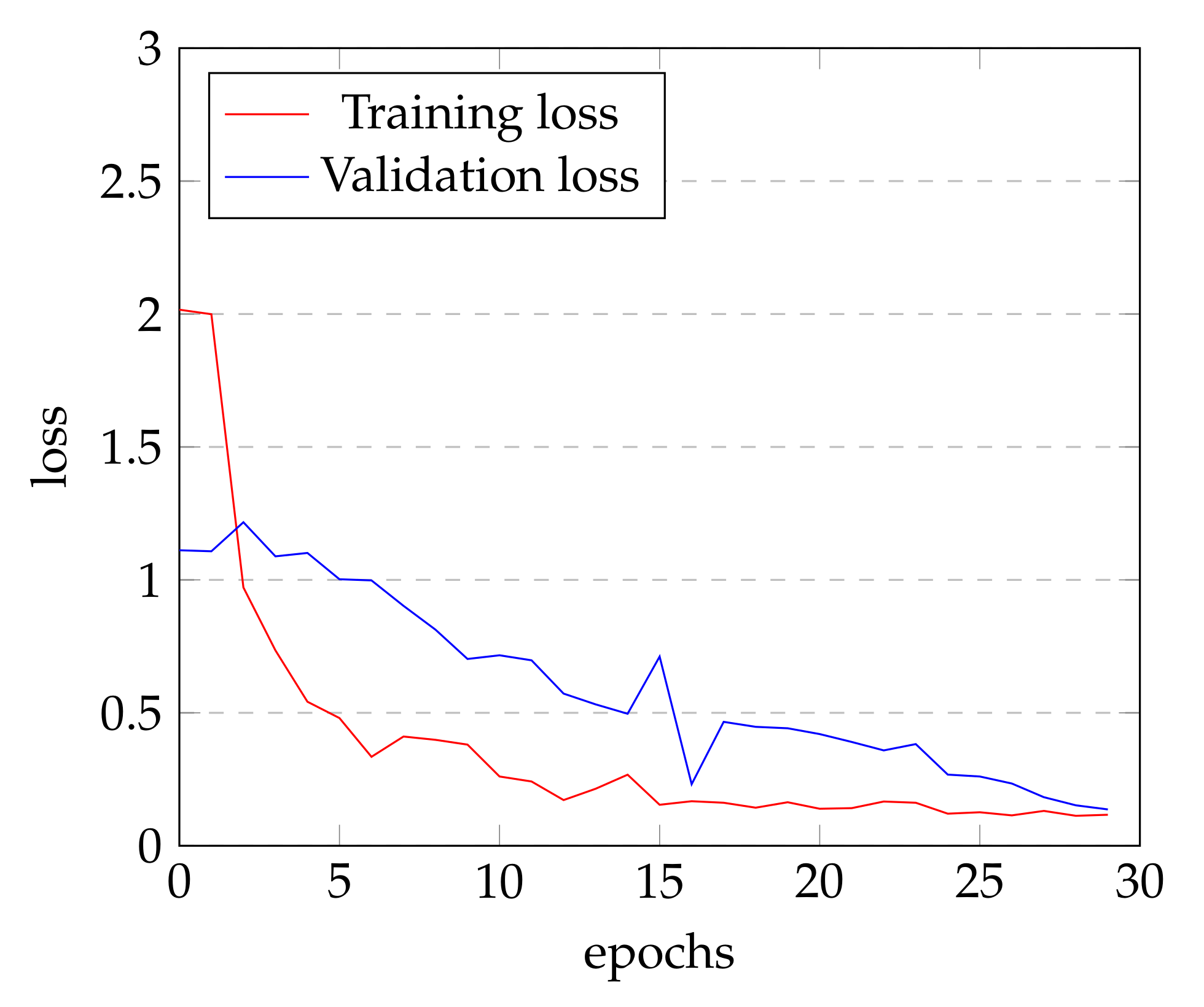
Table 4, in ransomware versus general firmware, the classification success rate decreased by 5% and 4% for the test data and data for ransomware detection, respectively. For validation and test data, there is no misclassification between SPN and ARX. In the detection phase, the classification success rate decreased by 10% between two cryptographic algorithms. Besides, in the case of classification by each algorithm, the performance was significantly degraded. The loss of the sequence-only model is shown in
Figure 10. The loss value is sufficiently decreased, but there is slight gap between training loss and validation loss. In the case of this model, the detection success rate tends to be decreased for the full binary file in the detection.
4.4. Comparison with Other Methods
Table 10 shows the comparison with other methods. There are implementations of cryptographic algorithms, such as the OpenSSL and Cryptopp library. Since this work is an AVR environment, the implementation written in C in
FELICS was used. Crypto-ransomware mainly consists of AES and RSA algorithms. Therefore, these two algorithms should be detected. In Reference [
7], there are three approaches: chains, mnemonic-const, and verifier. Among them, the verifier identification method checks the existence and parameters of the symmetric encryption process, and it has the best performance. The verifier method achieved a detection success rate of 0.946 in AES. However, it was not possible to detect Message-Digest (MD5) algorithm and RSA, and if the chains method is used, both AES and RSA can be detected. In Reference [
19], another factor that enables identification of the existence of the encryption process, the key scheduling process, can also be detected. It can detect AES, Data Encryption Standard (DES), RC4, MD5, and RSA with simple mechanisms. Proposed methods can cover a wider range of cryptographic algorithms. It is possible to detect lightweight block ciphers for low-power embedded processor environments. Therefore, it can be used to detect the ransomware for IoT environments.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}