Visible and Near Infrared Image Fusion Using Base Tone Compression and Detail Transform Fusion


Abstract
:1. Introduction
2. Related Works
2.1. Image Fusion with Visible and NIR Images
2.2. Contourlet Transform
2.3. Image Align Adjustment
3. Proposed Method
3.1. Dual Sensor-Capturing System
3.2. Visible and NIR Image Fusion Algorithm
3.2.1. Base Layer—Tone Compression
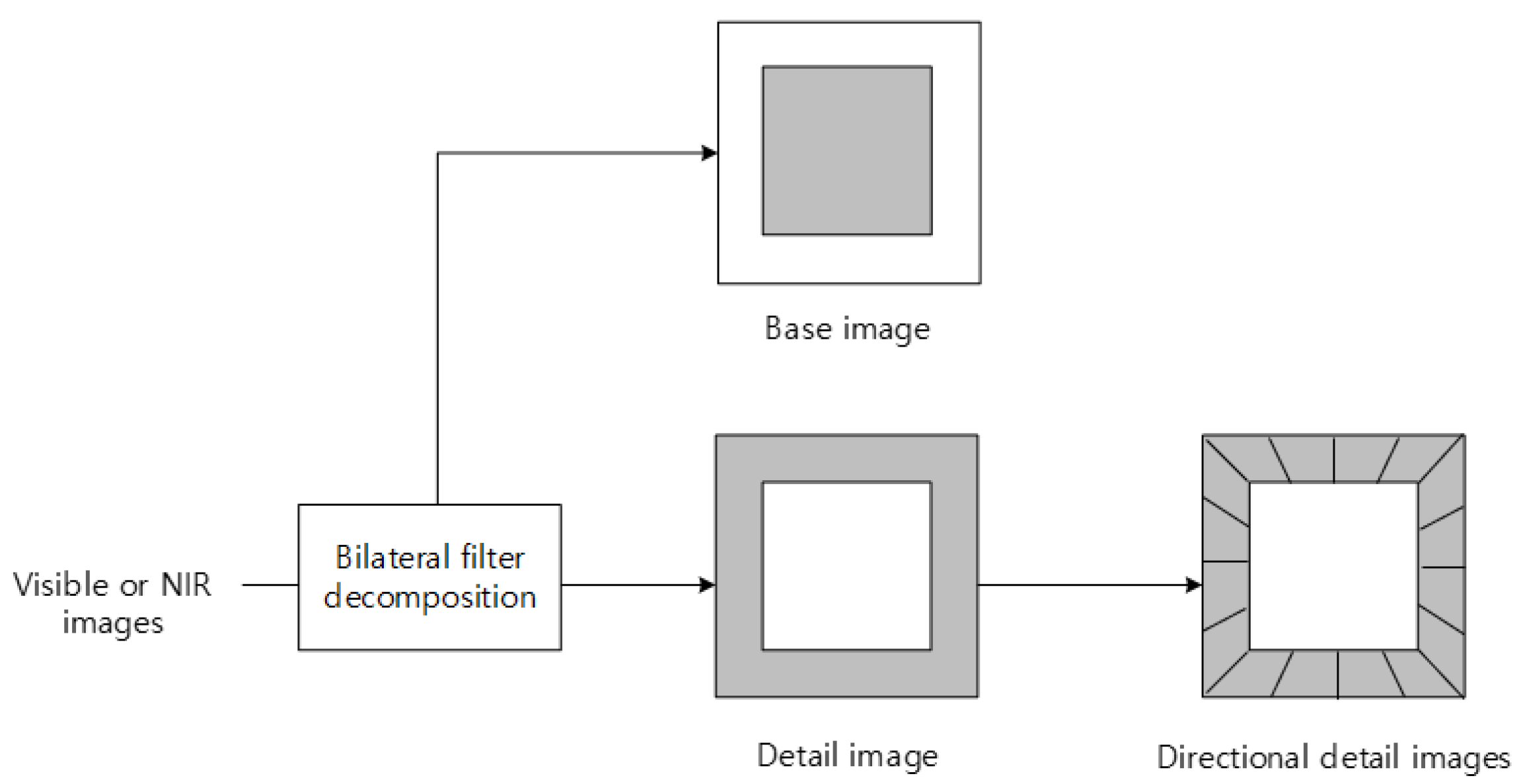
3.2.2. Detail Layer—Transform Fusion
3.2.3. Color Compensation and Adjustment
4. Simulation Results
4.1. Computer and Software Specification
4.2. Visible and NIR Image Fusion Simulation Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, X.; Zhai, G.; Wang, J.; Hu, C.; Chen, Y. Color Guided Thermal Image Super Resolution. In Proceedings of the VCIP 2016—30th Anniversary of Visual Communication and Image Processing, Chengdu, China, 27–30 November 2016. [Google Scholar] [CrossRef]
- Kil, T.; Cho, N.I. Image Fusion using RGB and Near Infrared Image. J. Broadcast Eng. 2016, 21, 515–524. [Google Scholar] [CrossRef]
- Sukthankar, R.; Stockton, R.G.; Mullin, M.D. Smarter Presentations: Exploiting Homography in Camera-Projector Systems. In Proceedings of the IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; Volume 1, pp. 247–253. [Google Scholar] [CrossRef]
- Vanmali, A.V.; Gadre, V.M. Visible and NIR Image Fusion Using Weight-Map-Guided Laplacian–Gaussian Pyramid for Improving Scene Visibility. Sadhana-Acad. Proc. Eng. Sci. 2017, 42, 1063–1082. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Wu, X.-J. Infrared and Visible Image Fusion Using Latent Low-Rank Representation. arXiv 2018, arXiv:1804.08992. [Google Scholar]
- Li, H.; Wu, X.J. DenseFuse: A Fusion Approach to Infrared and Visible Images. IEEE Trans. Image Process. 2019, 28, 2614–2623. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Son, D.; Kwon, H.; Lee, S. Visible and Near-Infrared Image Synthesis Using PCA Fusion of Multiscale Layers. Appl. Sci. 2020, 10, 8702. [Google Scholar] [CrossRef]
- Do, M.N.; Vetterli, M. The Contourlet Transform: An Efficient Directional Multiresolution Image Representation. IEEE Trans. Image Process. 2005, 14, 2091–2106. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Desale, R.P.; Verma, S.V. Study and Analysis of PCA, DCT & DWT Based Image Fusion Techniques. In Proceedings of the International Conference on Signal Processing, Image Processing and Pattern Recognition 2013, ICSIPR 2013, Coimbatore, India, 7–8 February 2013; Volume 1, pp. 66–69. [Google Scholar] [CrossRef]
- Kuang, J.; Johnson, G.M.; Fairchild, M.D. ICAM06: A Refined Image Appearance Model for HDR Image Rendering. J. Vis. Commun. Image Represent. 2007, 18, 406–414. [Google Scholar] [CrossRef]
- Nayar, S.K.; Narasimhan, S.G. Vision in Bad Weather. In Proceedings of the IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 820–827. [Google Scholar]
- Schechner, Y.Y.; Narasimhan, S.G.; Nayar, S.K. Instant Dehazing of Images Using Polarization. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; Volume 1. [Google Scholar]
- Fattal, R. Single Image Dehazing. ACM Trans. Graph. 2008, 27, 1–9. [Google Scholar] [CrossRef]
- Kaur, R.; Kaur, S. An Approach for Image Fusion Using PCA and Genetic Algorithm. Int. J. Comput. Appl. 2016, 145, 54–59. [Google Scholar] [CrossRef]
- Katsigiannis, S.; Keramidas, E.G.; Maroulis, D. A contourlet transform feature extraction scheme for ultrasound thyroid texture classification. Eng. Intell. Syst. 2010, 18, 167–177. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Kwon, H.J.; Lee, S.H. CAM-Based HDR Image Reproduction Using CA–TC Decoupled JCh Decomposition. Signal Process. Image Commun. 2019, 70, 1–13. [Google Scholar] [CrossRef]
- Paris, S.; Durand, F. A Fast Approximation of the Bilateral Filter Using a Signal Processing Approach. Int. J. Comput. Vis. 2009, 81, 24–52. [Google Scholar] [CrossRef] [Green Version]
- Mantiuk, R.; Mantiuk, R.; Tomaszewska, A.; Heidrich, W. Color Correction for Tone Mapping. Comput. Graph. Forum 2009, 28, 193–202. [Google Scholar] [CrossRef]
- Fairchild, M.D. Chromatic Adaptation. JOSA 2013, 46, 500–513. [Google Scholar]
- Ma, J.; Ma, Y.; Li, C. Infrared and visible image fusion methods and applications: A survey. Inf. Fusion 2019, 45, 153–178. [Google Scholar] [CrossRef]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-Reference Image Quality Assessment in the Spatial Domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef] [PubMed]
- Han, Y.; Cai, Y.; Cao, Y.; Xu, X. A new image fusion performance metric based on visual information fidelity. Inf. Fusion 2013, 14, 127–135. [Google Scholar] [CrossRef]
- Van Aardt, J. Assessment of image fusion procedures using entropy, image quality, and multispectral classification. J. Appl. Remote Sens. 2008, 2, 023522. [Google Scholar] [CrossRef]
- Bulanon, D.M.; Burks, T.F.; Alchanatis, V. Image fusion of visible and thermal images for fruit detection. Biosyst. Eng. 2009, 103, 12–22. [Google Scholar] [CrossRef]
- Narvekar, N.D.; Karam, L.J. A No-Reference Image Blur Metric Based on the Cumulative Probability of Blur Detection (CPBD). IEEE Trans. Image Process. 2011, 20, 2678–2683. [Google Scholar] [CrossRef] [PubMed]
- Vu, C.T.; Chandler, D.M. S3: A Spectral and Spatial Sharpness Measure. In Proceedings of the 2009 1st International Conference on Advances in Multimedia, MMEDIA, Colmar, France, 20–25 July 2009; pp. 37–43. [Google Scholar]
- Eskicioglu, A.M.; Fisher, P.S. Image Quality Measures and Their Performance. IEEE Trans. Commun. 1995, 43, 2959–2965. [Google Scholar] [CrossRef] [Green Version]
- Cui, G.; Feng, H.; Xu, Z.; Li, Q.; Chen, Y. Detail preserved fusion of visible and infrared images using regional saliency extraction and multi-scale image decomposition. Opt. Commun. 2015, 341, 199–209. [Google Scholar] [CrossRef]
- Balakrishnan, R.; Rajalingam, B.; Priya, R. Hybrid Multimodality Medical Image Fusion Technique for Feature Enhancement in Medical Diagnosis. Int. J. Eng. Sci. Invent. 2018, 2, 52–60. [Google Scholar]
- Brown, M.; Süsstrunk, S. Multi-spectral SIFT for scene category recognition. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 177–184. [Google Scholar] [CrossRef] [Green Version]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device | Wavelength |
|---|---|
| OmniVision OV5640 CMOS camera | 400–1000 nm |
| Visible cut filter (blocking wavelength) | 450–625 nm |
| IR cut filter (cut-off wavelength) | 750 nm |
| Average Probability of Success | Wavelength | |
|---|---|---|
| Transmitted visible light | 425–675 nm | |
| Reflected infrared light | 750–1125 nm |
| LP Fusion | LP_PCA Fusion | Low_Rank Fusion | Dense Fusion | Luminance Fusion (Prop.) | XYZ Fusion (Prop.) | |
|---|---|---|---|---|---|---|
| 1 | 33.615 | 39.622 | 38.707 | 41.127 | 18.644 | 31.957 |
| 2 | 23.424 | 21.638 | 20.699 | 22.219 | 17.292 | 20.087 |
| 3 | 15.174 | 17.538 | 17.905 | 19.576 | 14.088 | 9.681 |
| 4 | 12.181 | 21.319 | 27.108 | 16.451 | 22.319 | 20.253 |
| 5 | 26.063 | 10.656 | 8.623 | 6.321 | 18.693 | 18.343 |
| 6 | 23.892 | 19.987 | 18.093 | 23.106 | 10.529 | 15.697 |
| 7 | 15.158 | 16.933 | 13.476 | 10.627 | 7.037 | 7.037 |
| 8 | 22.185 | 29.324 | 37.309 | 39.427 | 8.224 | 20.089 |
| 9 | 6.017 | 24.910 | 21.209 | 23.474 | 4.152 | 4.366 |
| 10 | 17.642 | 21.278 | 5.511 | 23.815 | 6.985 | 6.697 |
| 11 | 1.550 | 28.352 | 23.192 | 33.216 | 11.045 | 18.427 |
| 12 | 6.946 | 22.106 | 23.368 | 21.731 | 0.966 | 0.755 |
| 13 | 34.044 | 39.707 | 43.329 | 42.452 | 35.200 | 32.130 |
| 14 | 38.073 | 39.859 | 44.786 | 48.686 | 36.111 | 36.033 |
| 15 | 35.868 | 37.992 | 43.015 | 45.783 | 36.450 | 37.066 |
| 16 | 39.741 | 44.610 | 45.893 | 54.164 | 46.784 | 47.427 |
| 17 | 19.369 | 21.168 | 22.021 | 22.062 | 25.765 | 28.515 |
| 18 | 19.091 | 16.077 | 24.095 | 22.961 | 27.337 | 26.598 |
| 19 | 26.026 | 16.866 | 24.863 | 25.986 | 29.448 | 28.307 |
| 20 | 29.952 | 25.508 | 22.201 | 36.070 | 31.533 | 30.644 |
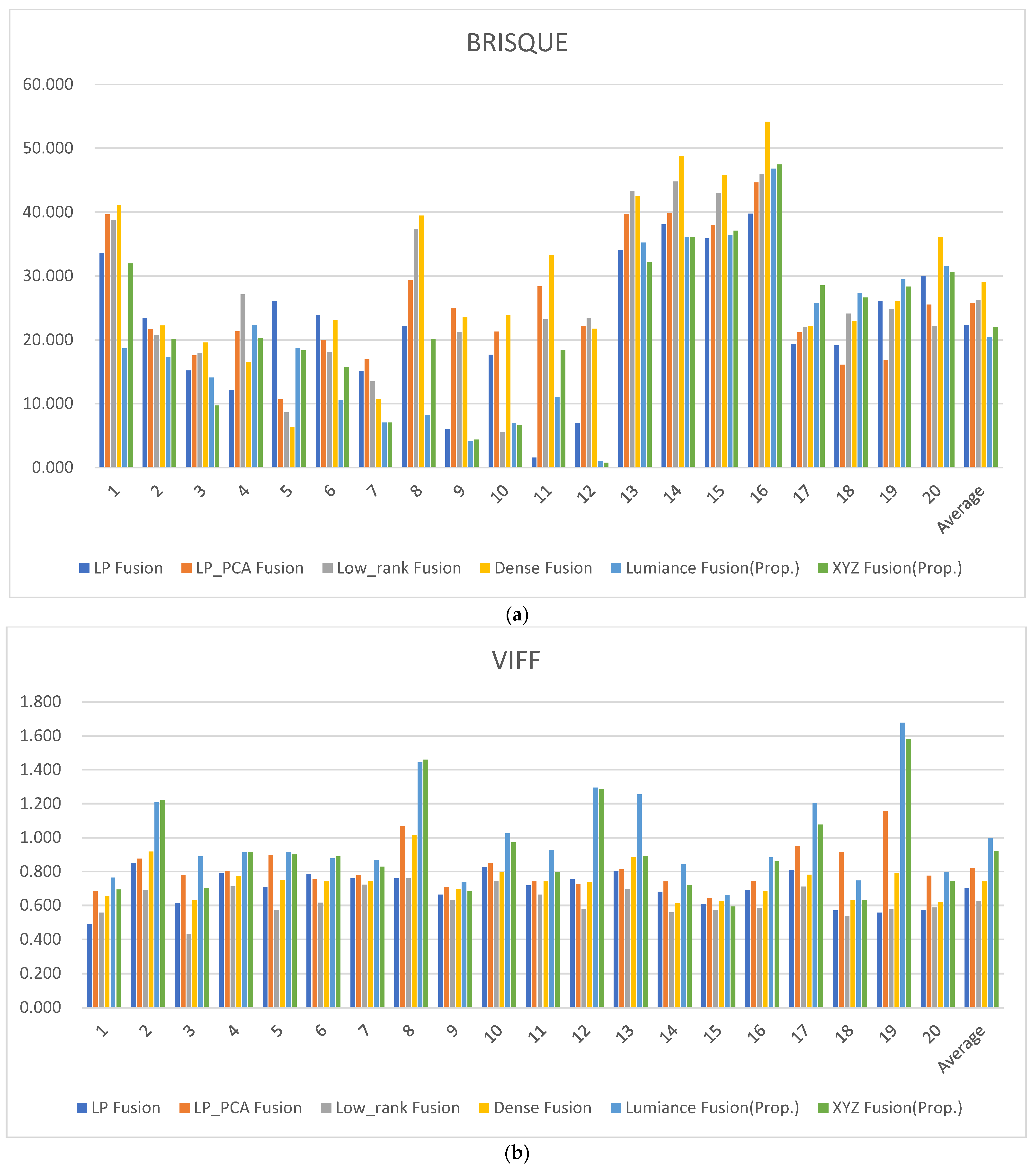
| Average | 22.301 | 25.772 | 26.270 | 28.963 | 20.430 | 22.006 |
| LP Fusion | LP_PCA Fusion | Low_Rank Fusion | Dense Fusion | Luminance Fusion (Prop.) | XYZ Fusion (Prop.) | |
|---|---|---|---|---|---|---|
| 1 | 0.489 | 0.683 | 0.557 | 0.656 | 0.763 | 0.693 |
| 2 | 0.851 | 0.875 | 0.692 | 0.917 | 1.207 | 1.221 |
| 3 | 0.614 | 0.778 | 0.431 | 0.629 | 0.889 | 0.702 |
| 4 | 0.787 | 0.800 | 0.712 | 0.773 | 0.912 | 0.915 |
| 5 | 0.709 | 0.896 | 0.571 | 0.751 | 0.916 | 0.900 |
| 6 | 0.784 | 0.754 | 0.616 | 0.741 | 0.877 | 0.889 |
| 7 | 0.759 | 0.778 | 0.722 | 0.745 | 0.866 | 0.828 |
| 8 | 0.760 | 1.066 | 0.759 | 1.012 | 1.443 | 1.458 |
| 9 | 0.664 | 0.709 | 0.633 | 0.696 | 0.738 | 0.682 |
| 10 | 0.826 | 0.849 | 0.744 | 0.798 | 1.024 | 0.972 |
| 11 | 0.718 | 0.740 | 0.663 | 0.741 | 0.927 | 0.797 |
| 12 | 0.754 | 0.725 | 0.577 | 0.739 | 1.294 | 1.287 |
| 13 | 0.801 | 0.812 | 0.698 | 0.883 | 1.253 | 0.890 |
| 14 | 0.680 | 0.741 | 0.558 | 0.611 | 0.840 | 0.719 |
| 15 | 0.608 | 0.644 | 0.572 | 0.626 | 0.662 | 0.593 |
| 16 | 0.688 | 0.742 | 0.585 | 0.685 | 0.883 | 0.859 |
| 17 | 0.809 | 0.952 | 0.711 | 0.781 | 1.203 | 1.076 |
| 18 | 0.570 | 0.914 | 0.539 | 0.628 | 0.746 | 0.632 |
| 19 | 0.558 | 1.157 | 0.576 | 0.788 | 1.676 | 1.580 |
| 20 | 0.571 | 0.776 | 0.588 | 0.619 | 0.798 | 0.744 |
| Average | 0.700 | 0.819 | 0.625 | 0.741 | 0.996 | 0.922 |
| LP Fusion | LP_PCA Fusion | Low_Rank Fusion | Dense Fusion | Luminance Fusion (Prop.) | XYZ Fusion (Prop.) | |
|---|---|---|---|---|---|---|
| 1 | 7.051 | 7.337 | 7.057 | 7.201 | 7.320 | 7.305 |
| 2 | 7.080 | 6.901 | 6.870 | 7.092 | 7.370 | 7.365 |
| 3 | 6.871 | 7.500 | 6.756 | 6.772 | 7.309 | 7.192 |
| 4 | 6.777 | 6.743 | 6.620 | 6.860 | 7.239 | 7.228 |
| 5 | 7.313 | 7.437 | 7.049 | 7.292 | 7.546 | 7.444 |
| 6 | 7.367 | 7.336 | 7.280 | 7.340 | 7.301 | 7.280 |
| 7 | 7.253 | 7.370 | 7.123 | 7.284 | 7.614 | 7.495 |
| 8 | 7.424 | 7.631 | 7.353 | 7.597 | 7.226 | 7.382 |
| 9 | 7.310 | 7.423 | 7.065 | 7.195 | 7.465 | 7.377 |
| 10 | 7.243 | 7.216 | 7.062 | 7.173 | 7.553 | 7.450 |
| 11 | 7.300 | 7.248 | 7.111 | 7.252 | 7.596 | 7.464 |
| 12 | 6.157 | 6.106 | 6.012 | 6.143 | 6.430 | 6.454 |
| 13 | 7.175 | 7.217 | 7.208 | 7.226 | 7.567 | 7.291 |
| 14 | 7.499 | 7.434 | 7.392 | 7.568 | 7.623 | 7.443 |
| 15 | 7.590 | 7.677 | 7.563 | 7.671 | 7.828 | 7.677 |
| 16 | 7.671 | 7.654 | 7.625 | 7.718 | 7.654 | 7.616 |
| 17 | 7.419 | 7.459 | 7.280 | 7.470 | 7.573 | 7.483 |
| 18 | 7.561 | 7.568 | 7.349 | 7.551 | 7.687 | 7.583 |
| 19 | 7.049 | 7.340 | 7.102 | 7.424 | 7.595 | 7.509 |
| 20 | 6.925 | 6.914 | 6.866 | 7.028 | 6.445 | 6.480 |
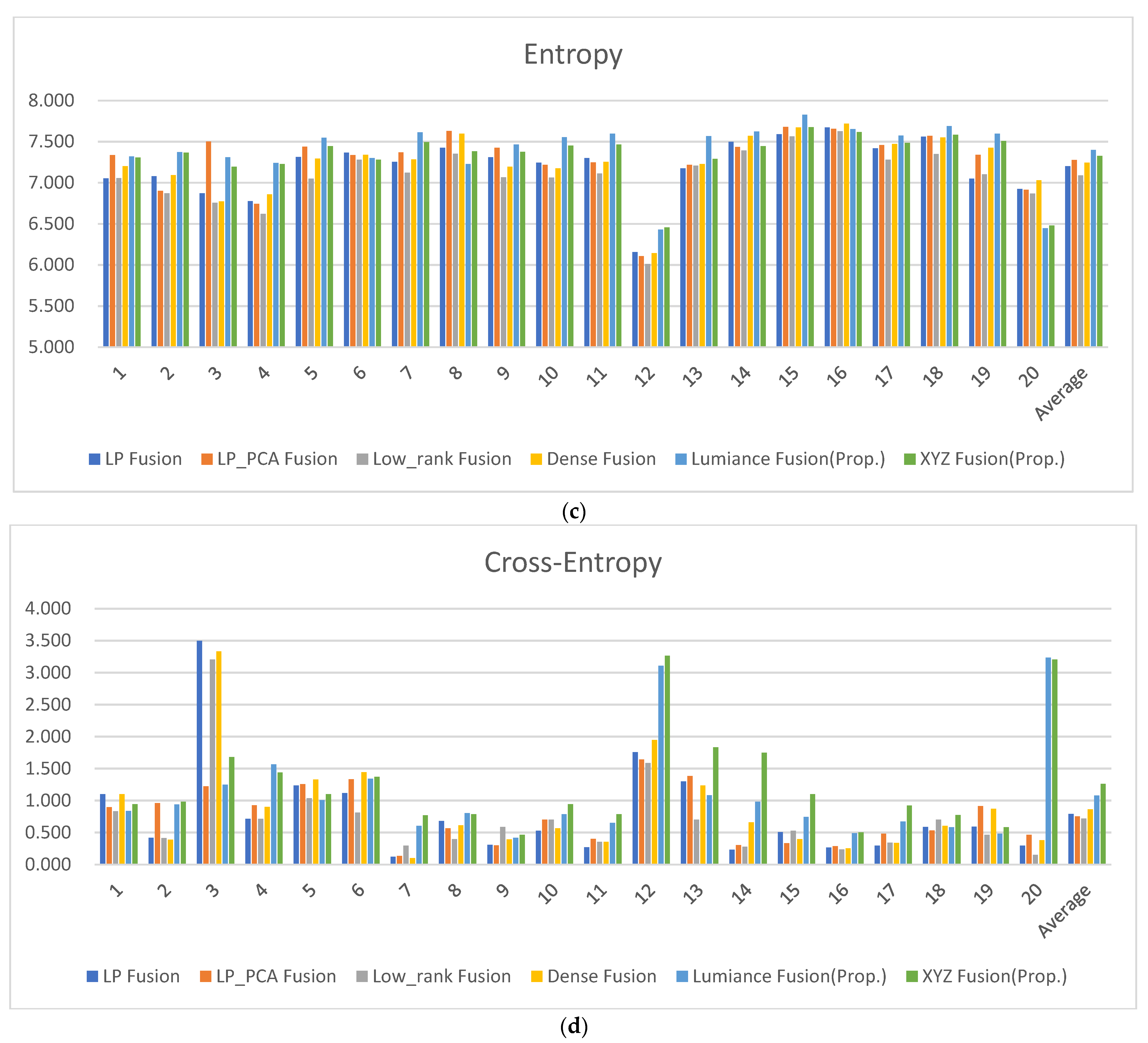
| Average | 7.202 | 7.276 | 7.087 | 7.243 | 7.397 | 7.326 |
| LP Fusion | LP_PCA Fusion | Low_Rank Fusion | Dense Fusion | Luminance Fusion (Prop.) | XYZ Fusion (Prop.) | |
|---|---|---|---|---|---|---|
| 1 | 1.098 | 0.896 | 0.834 | 1.100 | 0.839 | 0.942 |
| 2 | 0.415 | 0.960 | 0.414 | 0.387 | 0.938 | 0.982 |
| 3 | 3.497 | 1.224 | 3.204 | 3.333 | 1.246 | 1.681 |
| 4 | 0.715 | 0.924 | 0.713 | 0.902 | 1.565 | 1.437 |
| 5 | 1.234 | 1.256 | 1.036 | 1.330 | 1.007 | 1.100 |
| 6 | 1.116 | 1.331 | 0.813 | 1.443 | 1.343 | 1.372 |
| 7 | 0.121 | 0.133 | 0.293 | 0.101 | 0.606 | 0.770 |
| 8 | 0.680 | 0.564 | 0.395 | 0.612 | 0.804 | 0.788 |
| 9 | 0.308 | 0.298 | 0.585 | 0.393 | 0.417 | 0.465 |
| 10 | 0.529 | 0.700 | 0.702 | 0.566 | 0.787 | 0.941 |
| 11 | 0.269 | 0.400 | 0.356 | 0.352 | 0.648 | 0.785 |
| 12 | 1.757 | 1.641 | 1.586 | 1.947 | 3.109 | 3.265 |
| 13 | 1.300 | 1.385 | 0.701 | 1.236 | 1.082 | 1.834 |
| 14 | 0.230 | 0.303 | 0.278 | 0.659 | 0.981 | 1.746 |
| 15 | 0.505 | 0.333 | 0.527 | 0.397 | 0.745 | 1.097 |
| 16 | 0.266 | 0.287 | 0.235 | 0.253 | 0.491 | 0.501 |
| 17 | 0.294 | 0.482 | 0.339 | 0.338 | 0.673 | 0.922 |
| 18 | 0.587 | 0.532 | 0.703 | 0.605 | 0.583 | 0.775 |
| 19 | 0.591 | 0.913 | 0.462 | 0.870 | 0.480 | 0.583 |
| 20 | 0.294 | 0.462 | 0.152 | 0.379 | 3.234 | 3.204 |
| Average | 0.790 | 0.751 | 0.716 | 0.860 | 1.079 | 1.260 |
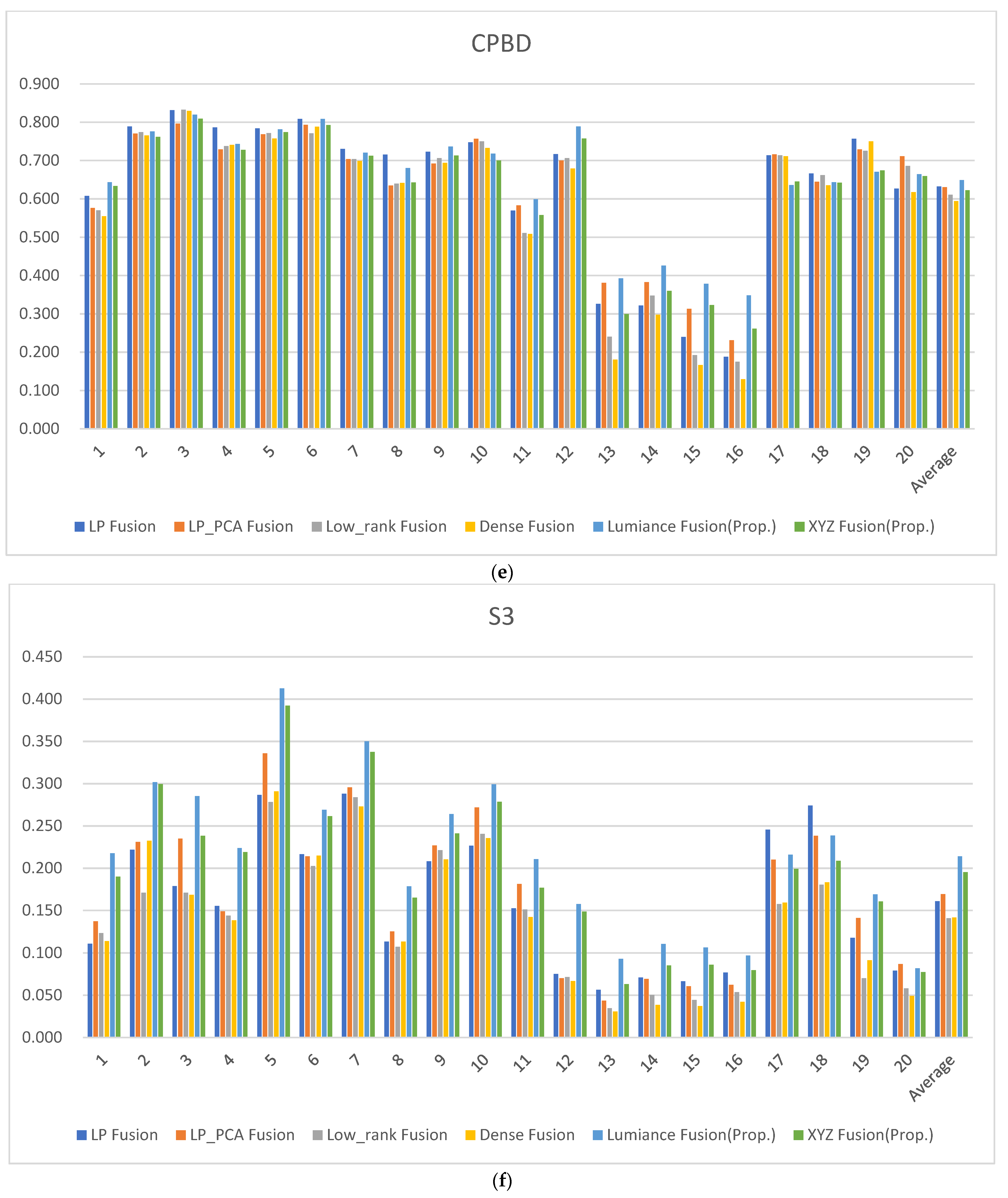
| LP Fusion | LP_PCA Fusion | Low_Rank Fusion | Dense Fusion | Luminance Fusion (Prop.) | XYZ Fusion (Prop.) | |
|---|---|---|---|---|---|---|
| 1 | 0.607 | 0.576 | 0.570 | 0.555 | 0.643 | 0.634 |
| 2 | 0.789 | 0.770 | 0.774 | 0.765 | 0.776 | 0.762 |
| 3 | 0.831 | 0.796 | 0.833 | 0.829 | 0.820 | 0.809 |
| 4 | 0.786 | 0.729 | 0.737 | 0.741 | 0.743 | 0.728 |
| 5 | 0.784 | 0.768 | 0.772 | 0.758 | 0.781 | 0.774 |
| 6 | 0.809 | 0.793 | 0.771 | 0.788 | 0.808 | 0.793 |
| 7 | 0.730 | 0.704 | 0.704 | 0.699 | 0.720 | 0.712 |
| 8 | 0.716 | 0.635 | 0.639 | 0.641 | 0.680 | 0.643 |
| 9 | 0.723 | 0.692 | 0.706 | 0.694 | 0.736 | 0.713 |
| 10 | 0.748 | 0.757 | 0.750 | 0.733 | 0.718 | 0.700 |
| 11 | 0.569 | 0.583 | 0.511 | 0.509 | 0.599 | 0.558 |
| 12 | 0.717 | 0.700 | 0.706 | 0.679 | 0.789 | 0.757 |
| 13 | 0.326 | 0.381 | 0.240 | 0.180 | 0.393 | 0.299 |
| 14 | 0.322 | 0.383 | 0.347 | 0.298 | 0.426 | 0.360 |
| 15 | 0.240 | 0.313 | 0.192 | 0.166 | 0.379 | 0.323 |
| 16 | 0.188 | 0.231 | 0.175 | 0.129 | 0.348 | 0.261 |
| 17 | 0.713 | 0.716 | 0.713 | 0.711 | 0.636 | 0.645 |
| 18 | 0.666 | 0.644 | 0.662 | 0.635 | 0.643 | 0.642 |
| 19 | 0.756 | 0.729 | 0.725 | 0.750 | 0.670 | 0.674 |
| 20 | 0.627 | 0.711 | 0.686 | 0.618 | 0.664 | 0.659 |
| Average | 0.632 | 0.630 | 0.611 | 0.594 | 0.649 | 0.622 |
| LP Fusion | LP_PCA Fusion | Low_Rank Fusion | Dense Fusion | Luminance Fusion (Prop.) | XYZ Fusion (Prop.) | |
|---|---|---|---|---|---|---|
| 1 | 0.111 | 0.137 | 0.123 | 0.114 | 0.218 | 0.190 |
| 2 | 0.222 | 0.231 | 0.171 | 0.232 | 0.302 | 0.300 |
| 3 | 0.179 | 0.235 | 0.171 | 0.169 | 0.285 | 0.238 |
| 4 | 0.155 | 0.149 | 0.144 | 0.138 | 0.224 | 0.219 |
| 5 | 0.287 | 0.336 | 0.278 | 0.291 | 0.413 | 0.392 |
| 6 | 0.216 | 0.214 | 0.203 | 0.215 | 0.269 | 0.261 |
| 7 | 0.288 | 0.296 | 0.284 | 0.273 | 0.350 | 0.338 |
| 8 | 0.113 | 0.125 | 0.107 | 0.113 | 0.178 | 0.165 |
| 9 | 0.208 | 0.227 | 0.221 | 0.210 | 0.264 | 0.241 |
| 10 | 0.227 | 0.272 | 0.241 | 0.235 | 0.299 | 0.279 |
| 11 | 0.152 | 0.181 | 0.151 | 0.142 | 0.211 | 0.177 |
| 12 | 0.075 | 0.070 | 0.072 | 0.067 | 0.157 | 0.149 |
| 13 | 0.056 | 0.044 | 0.035 | 0.031 | 0.093 | 0.063 |
| 14 | 0.071 | 0.069 | 0.050 | 0.039 | 0.111 | 0.085 |
| 15 | 0.067 | 0.061 | 0.044 | 0.037 | 0.107 | 0.086 |
| 16 | 0.077 | 0.062 | 0.054 | 0.042 | 0.097 | 0.080 |
| 17 | 0.246 | 0.210 | 0.157 | 0.159 | 0.216 | 0.199 |
| 18 | 0.274 | 0.238 | 0.180 | 0.183 | 0.238 | 0.209 |
| 19 | 0.118 | 0.141 | 0.070 | 0.091 | 0.169 | 0.161 |
| 20 | 0.079 | 0.087 | 0.058 | 0.049 | 0.082 | 0.077 |
| Average | 0.161 | 0.169 | 0.141 | 0.142 | 0.214 | 0.195 |
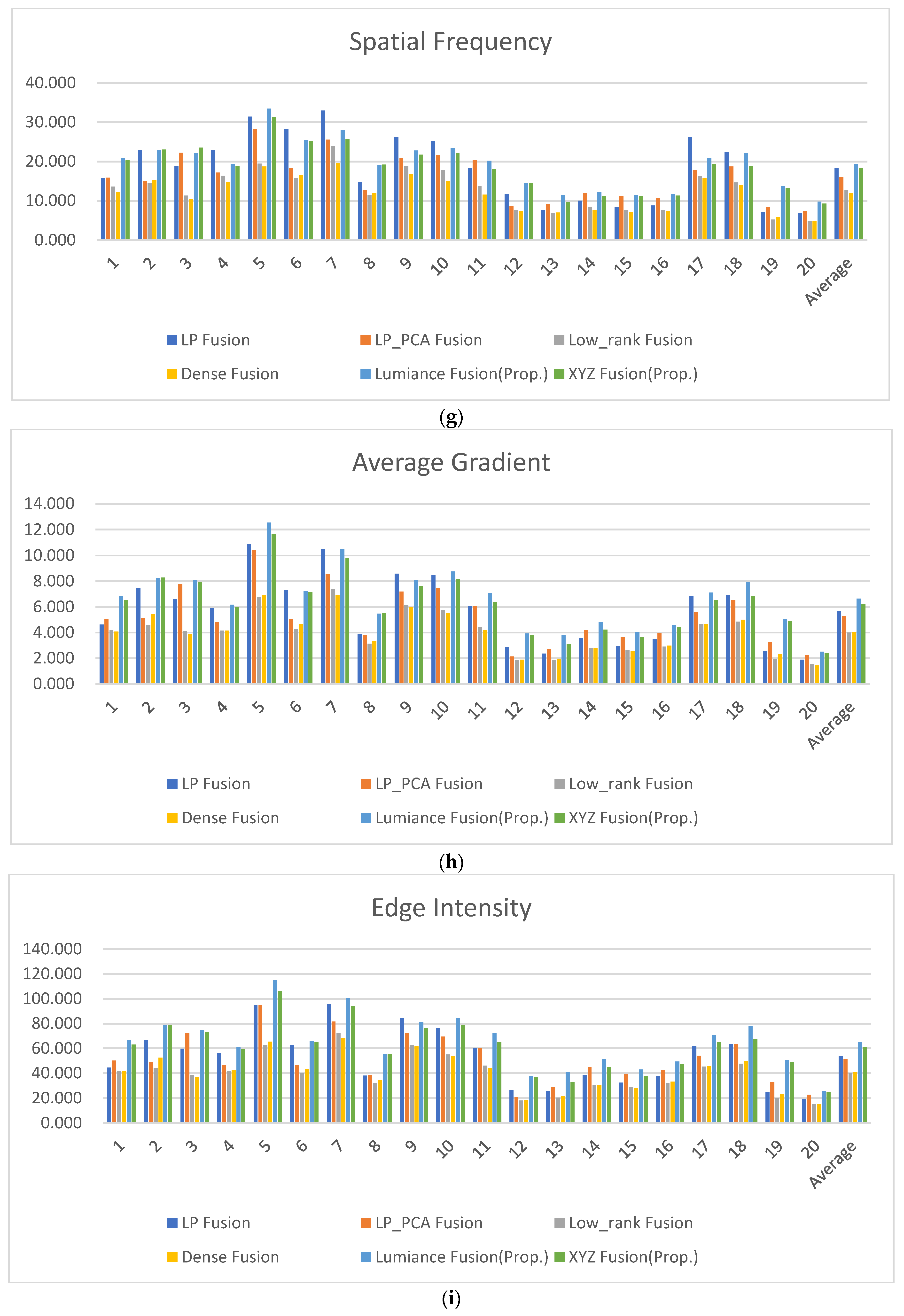
| LP Fusion | LP_PCA Fusion | Low_Rank Fusion | Dense Fusion | Luminance Fusion (Prop.) | XYZ Fusion (Prop.) | |
|---|---|---|---|---|---|---|
| 1 | 15.799 | 15.899 | 13.597 | 12.201 | 20.891 | 20.415 |
| 2 | 22.981 | 15.023 | 14.438 | 15.244 | 22.988 | 23.043 |
| 3 | 18.788 | 22.257 | 11.336 | 10.529 | 22.090 | 23.544 |
| 4 | 22.867 | 17.196 | 16.349 | 14.700 | 19.402 | 18.904 |
| 5 | 31.402 | 28.178 | 19.458 | 18.746 | 33.474 | 31.220 |
| 6 | 28.161 | 18.374 | 15.673 | 16.407 | 25.412 | 25.274 |
| 7 | 32.951 | 25.579 | 23.863 | 19.595 | 27.987 | 25.774 |
| 8 | 14.849 | 12.799 | 11.514 | 11.856 | 19.010 | 19.216 |
| 9 | 26.216 | 20.920 | 18.851 | 16.789 | 22.757 | 21.759 |
| 10 | 25.254 | 21.634 | 17.759 | 15.097 | 23.455 | 22.103 |
| 11 | 18.222 | 20.316 | 13.634 | 11.553 | 20.194 | 18.065 |
| 12 | 11.642 | 8.606 | 7.561 | 7.445 | 14.380 | 14.407 |
| 13 | 7.622 | 9.096 | 6.829 | 7.025 | 11.414 | 9.671 |
| 14 | 10.036 | 11.959 | 8.453 | 7.691 | 12.211 | 11.281 |
| 15 | 8.429 | 11.187 | 7.573 | 7.046 | 11.519 | 11.183 |
| 16 | 8.808 | 10.583 | 7.638 | 7.352 | 11.616 | 11.341 |
| 17 | 26.204 | 17.828 | 16.259 | 15.800 | 20.962 | 19.286 |
| 18 | 22.354 | 18.740 | 14.655 | 13.959 | 22.169 | 18.836 |
| 19 | 7.163 | 8.321 | 5.203 | 5.847 | 13.754 | 13.264 |
| 20 | 6.952 | 7.403 | 4.857 | 4.750 | 9.770 | 9.269 |
| Average | 18.335 | 16.095 | 12.775 | 11.982 | 19.273 | 18.393 |
| LP Fusion | LP_PCA Fusion | Low_Rank Fusion | Dense Fusion | Luminance Fusion (Prop.) | XYZ Fusion (Prop.) | |
|---|---|---|---|---|---|---|
| 1 | 4.624 | 5.015 | 4.175 | 4.075 | 6.807 | 6.513 |
| 2 | 7.440 | 5.129 | 4.603 | 5.443 | 8.248 | 8.271 |
| 3 | 6.619 | 7.760 | 4.108 | 3.867 | 8.045 | 7.941 |
| 4 | 5.893 | 4.805 | 4.148 | 4.155 | 6.160 | 5.987 |
| 5 | 10.881 | 10.434 | 6.727 | 6.939 | 12.535 | 11.604 |
| 6 | 7.269 | 5.072 | 4.289 | 4.642 | 7.221 | 7.133 |
| 7 | 10.507 | 8.567 | 7.396 | 6.919 | 10.523 | 9.780 |
| 8 | 3.873 | 3.796 | 3.139 | 3.326 | 5.469 | 5.483 |
| 9 | 8.582 | 7.181 | 6.122 | 5.999 | 8.076 | 7.612 |
| 10 | 8.477 | 7.474 | 5.748 | 5.533 | 8.746 | 8.169 |
| 11 | 6.069 | 6.034 | 4.442 | 4.191 | 7.086 | 6.357 |
| 12 | 2.839 | 2.135 | 1.875 | 1.893 | 3.919 | 3.791 |
| 13 | 2.361 | 2.742 | 1.857 | 1.961 | 3.793 | 3.080 |
| 14 | 3.571 | 4.206 | 2.779 | 2.774 | 4.806 | 4.220 |
| 15 | 2.959 | 3.622 | 2.594 | 2.523 | 4.055 | 3.629 |
| 16 | 3.477 | 3.939 | 2.896 | 2.988 | 4.573 | 4.393 |
| 17 | 6.823 | 5.609 | 4.650 | 4.677 | 7.099 | 6.549 |
| 18 | 6.940 | 6.510 | 4.837 | 4.988 | 7.898 | 6.819 |
| 19 | 2.522 | 3.260 | 1.940 | 2.304 | 5.023 | 4.872 |
| 20 | 1.890 | 2.258 | 1.520 | 1.431 | 2.509 | 2.409 |
| Average | 5.681 | 5.277 | 3.992 | 4.031 | 6.630 | 6.231 |
| LP Fusion | LP_PCA Fusion | Low_Rank Fusion | Dense Fusion | Luminance Fusion (Prop.) | XYZ Fusion (Prop.) | |
|---|---|---|---|---|---|---|
| 1 | 44.375 | 50.055 | 41.895 | 41.568 | 66.308 | 62.923 |
| 2 | 66.760 | 48.948 | 44.124 | 52.473 | 78.536 | 78.791 |
| 3 | 59.643 | 72.194 | 38.662 | 36.850 | 74.705 | 73.197 |
| 4 | 56.052 | 46.668 | 41.572 | 42.060 | 60.719 | 59.214 |
| 5 | 94.790 | 94.975 | 62.605 | 65.308 | 114.770 | 106.058 |
| 6 | 62.547 | 46.466 | 39.726 | 43.260 | 65.672 | 64.884 |
| 7 | 95.865 | 81.542 | 71.994 | 68.164 | 100.647 | 93.973 |
| 8 | 38.059 | 38.608 | 32.003 | 34.487 | 55.291 | 55.357 |
| 9 | 84.024 | 72.322 | 62.470 | 61.656 | 81.379 | 76.368 |
| 10 | 76.361 | 69.437 | 54.963 | 53.532 | 84.405 | 78.788 |
| 11 | 60.472 | 60.208 | 45.969 | 44.020 | 72.322 | 65.005 |
| 12 | 26.262 | 20.560 | 18.049 | 18.679 | 37.882 | 36.827 |
| 13 | 25.482 | 28.848 | 20.346 | 21.629 | 40.502 | 32.566 |
| 14 | 38.686 | 45.105 | 30.416 | 30.512 | 51.235 | 44.599 |
| 15 | 32.313 | 38.959 | 28.636 | 28.005 | 42.814 | 37.680 |
| 16 | 37.871 | 42.775 | 31.869 | 33.088 | 49.259 | 47.356 |
| 17 | 61.738 | 54.011 | 45.294 | 45.718 | 70.678 | 65.108 |
| 18 | 63.374 | 63.255 | 47.642 | 49.658 | 77.877 | 67.538 |
| 19 | 24.789 | 32.570 | 19.989 | 23.636 | 50.319 | 49.015 |
| 20 | 18.983 | 22.809 | 15.444 | 15.023 | 25.606 | 24.645 |
| Average | 53.422 | 51.516 | 39.683 | 40.466 | 65.046 | 60.994 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Son, D.-M.; Kwon, H.-J.; Lee, S.-H. Visible and Near Infrared Image Fusion Using Base Tone Compression and Detail Transform Fusion. Chemosensors 2022, 10, 124. https://doi.org/10.3390/chemosensors10040124
Son D-M, Kwon H-J, Lee S-H. Visible and Near Infrared Image Fusion Using Base Tone Compression and Detail Transform Fusion. Chemosensors. 2022; 10(4):124. https://doi.org/10.3390/chemosensors10040124
Chicago/Turabian StyleSon, Dong-Min, Hyuk-Ju Kwon, and Sung-Hak Lee. 2022. "Visible and Near Infrared Image Fusion Using Base Tone Compression and Detail Transform Fusion" Chemosensors 10, no. 4: 124. https://doi.org/10.3390/chemosensors10040124
APA StyleSon, D. -M., Kwon, H. -J., & Lee, S. -H. (2022). Visible and Near Infrared Image Fusion Using Base Tone Compression and Detail Transform Fusion. Chemosensors, 10(4), 124. https://doi.org/10.3390/chemosensors10040124