
Surface Enhanced Raman Spectroscopy Pb2+ Ion Detection Based on a Gradient Boosting Decision Tree Algorithm

Abstract
:1. Introduction
2. Materials and Methods
2.1. Material
2.2. Raman Spectrum Pretreatment
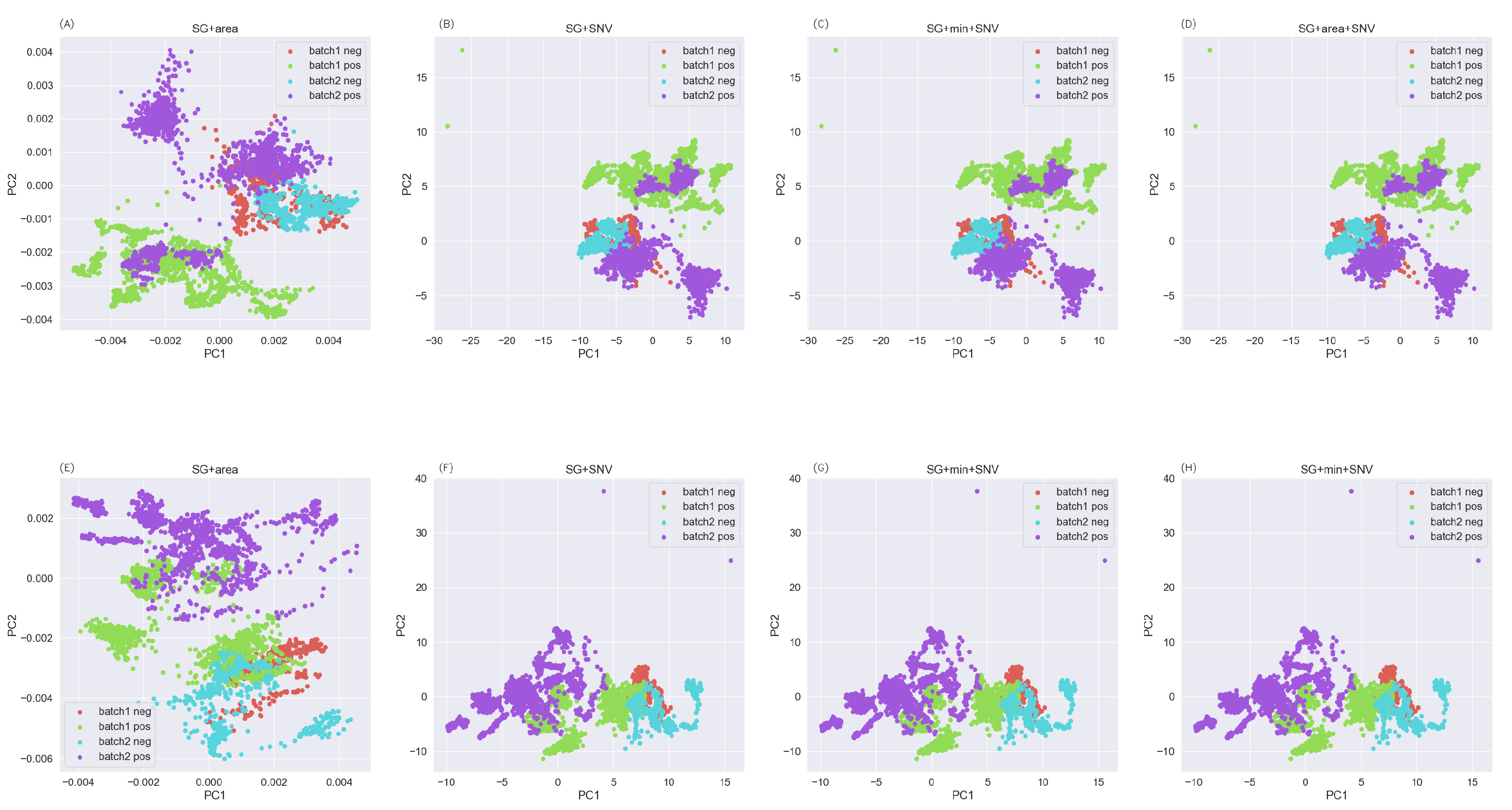
2.3. Feature Extraction
2.4. Model Optimization, Training/Testing, and Model Evaluation
3. Results
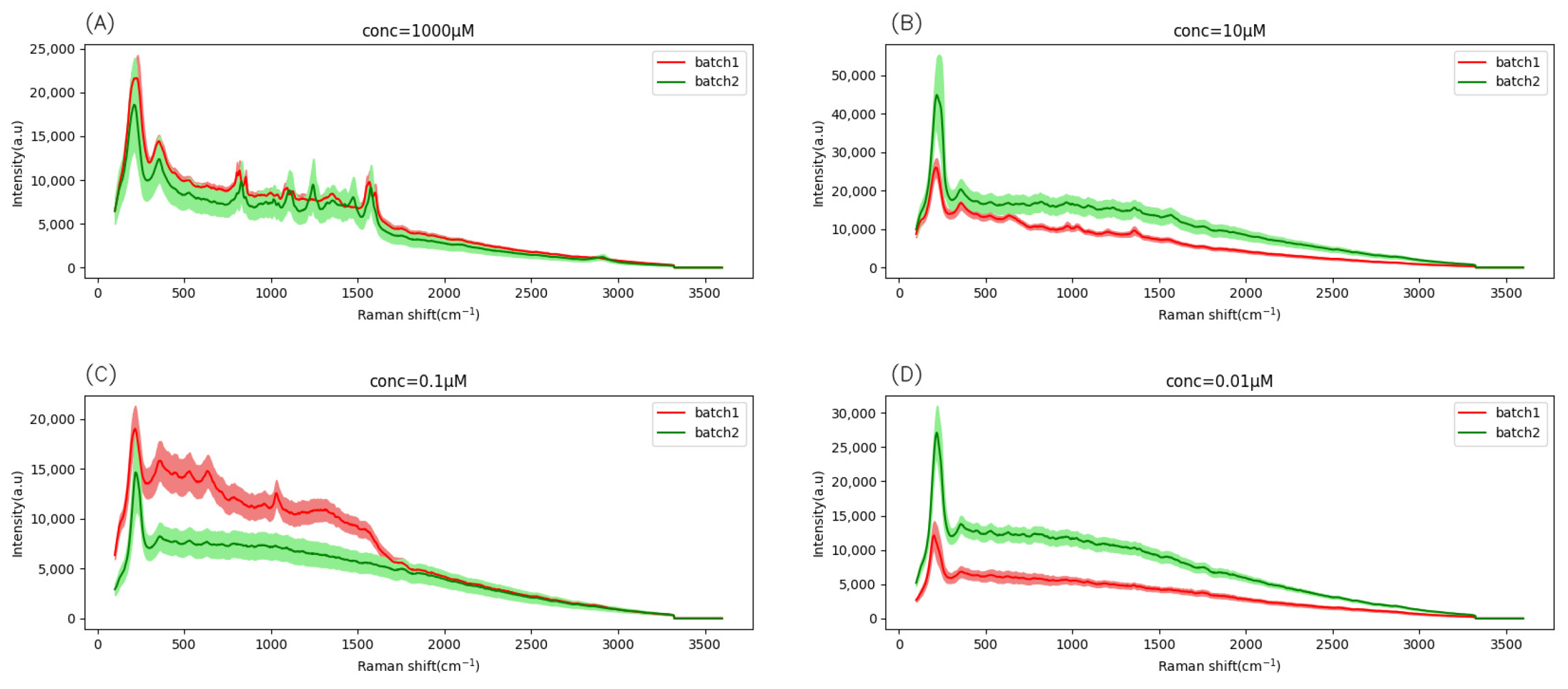
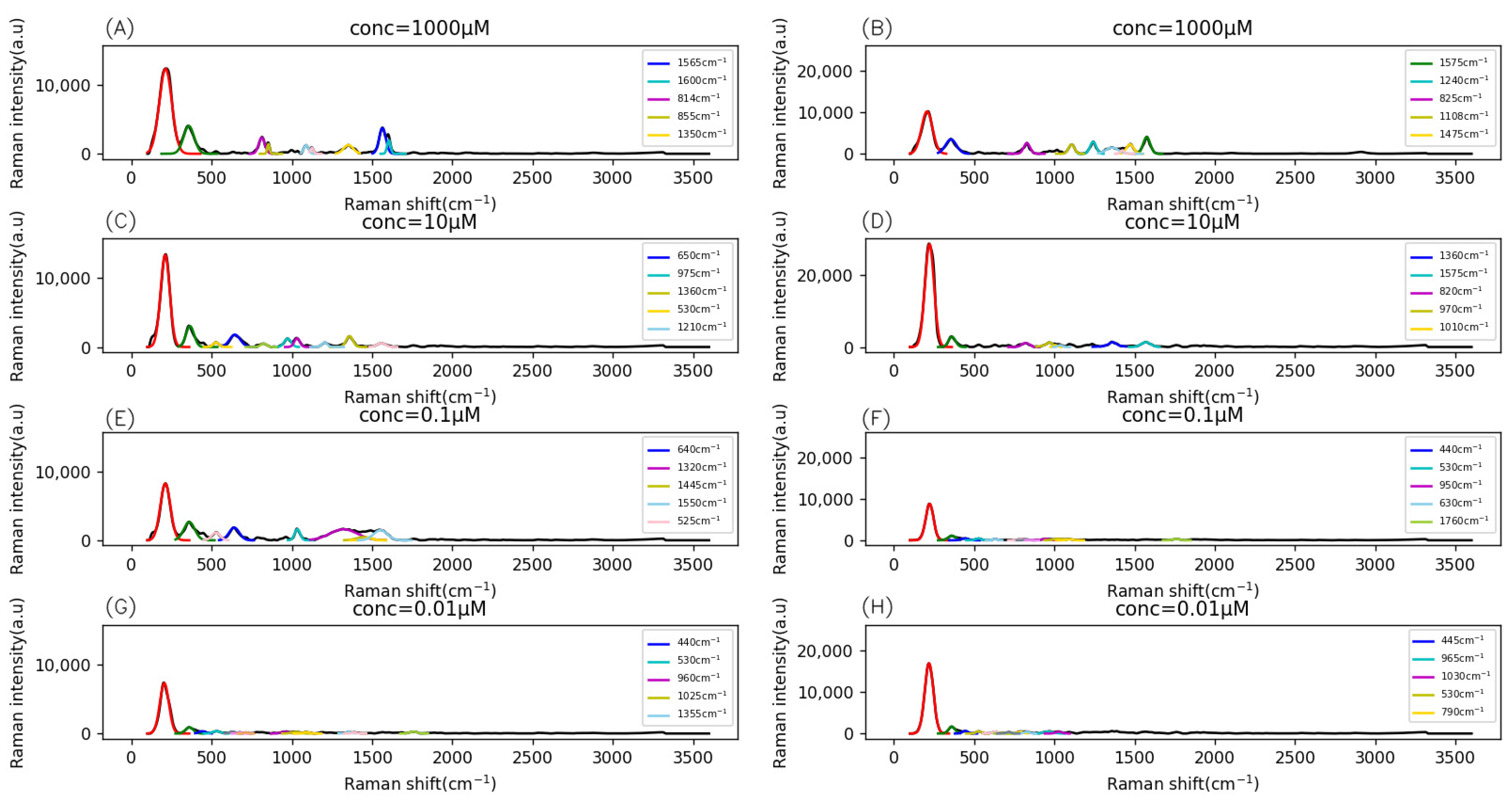
3.1. Fingerprint Range Analysis Results
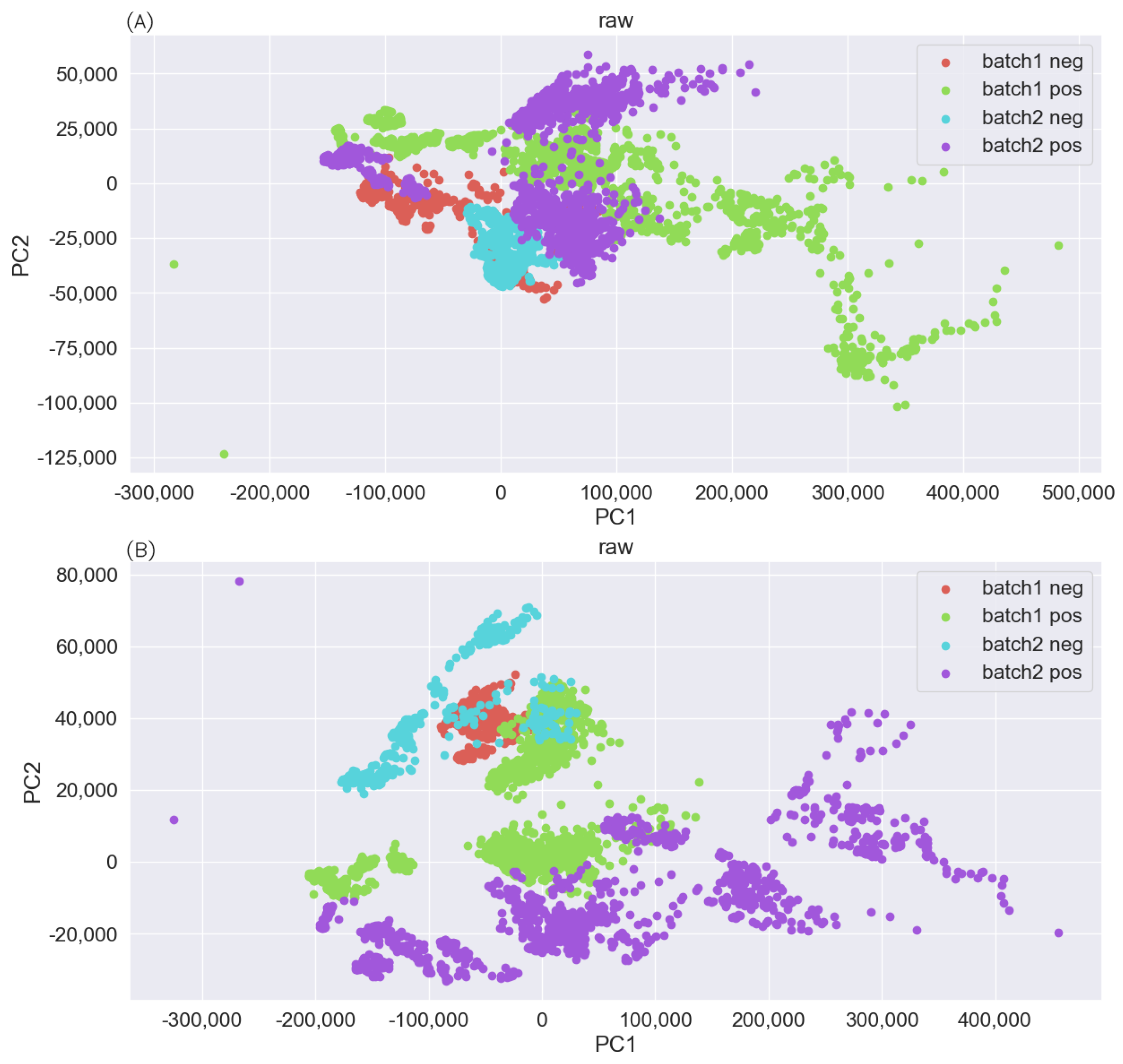
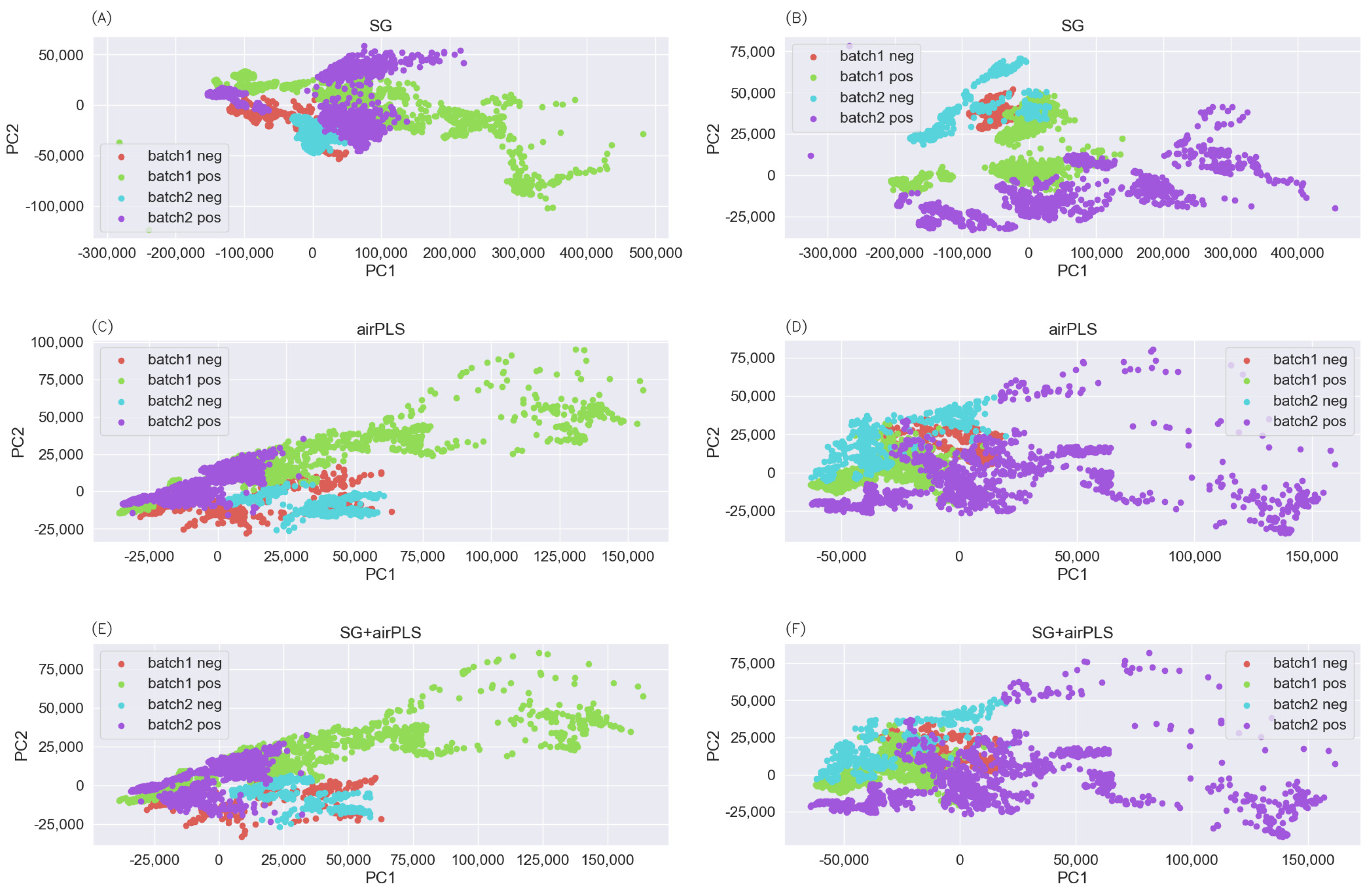
3.2. Exploratory Analysis of Data Sets
3.3. Models Built with Advanced GBDT Algorithms
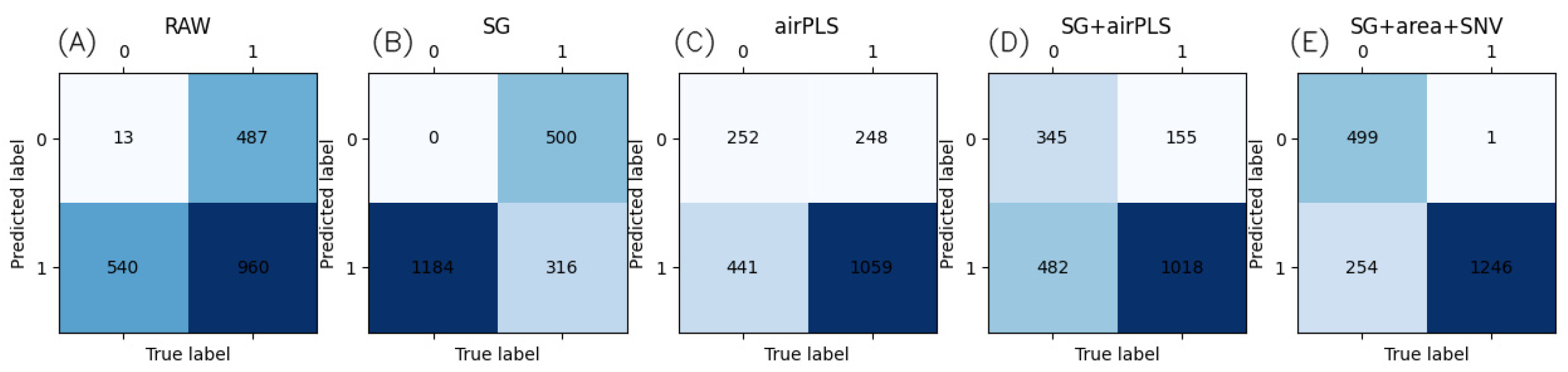
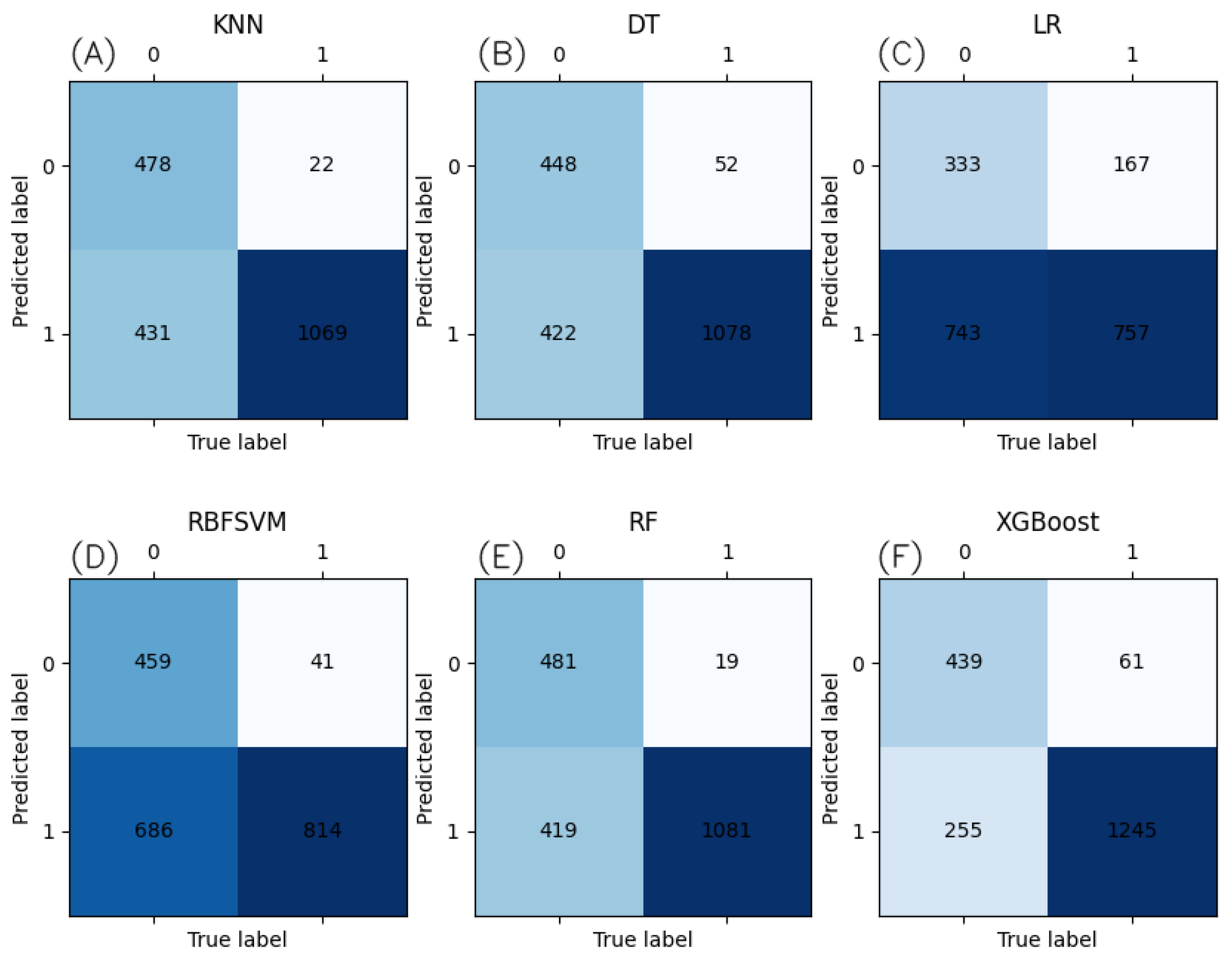
3.4. Comparison and Analysis with Traditional Machine Learning Algorithms
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Seongyong, P.; Jaeseok, L.; Shujaat, K.; Abdul, W.; Minseok, K. Machine Learning-Based Heavy Metal Ion Detection Using Surface-Enhanced Raman Spectroscopy. Sensors 2022, 22, 596. [Google Scholar]
- Lu, Y.; Yin, W.; Huang, L.; Zhang, G.; Zhao, Y. Assessment of bioaccessibility and exposure risk of arsenic and lead in urban soils of Guangzhou City, China. Environ. Geochem. Health 2011, 33, 93–102. [Google Scholar] [CrossRef] [PubMed]
- Zong, C.; Xu, M.; Xu, L.J.; Wei, T.; Ma, X.; Zheng, X.S.; Hu, R.; Ren, B. Surface-enhanced Raman spectroscopy for bioanalysis: Reliability and challenges. Chem. Rev. 2018, 118, 4946–4980. [Google Scholar] [CrossRef] [PubMed]
- Landrigan, P.J.; Fuller, R.; Acosta, N.J.R.; Adeyi, O.; Arnold, R.; Basu, N.N.; Baldé, A.B.; Bertollini, R.; Bose-O’Reilly, S.; Boufford, J.I.; et al. The Lancet Commission on pollution and health. Lancet 2018, 391, 462–512. [Google Scholar] [CrossRef]
- Aaron, R.; Avshalom, C.; Belsky, D.W.; Jonathan, B.; Honalee, H.; Karen, S.; Renate, M.H.; Sandhya, R.; Richie, P.; Terrie, E.M. Association of Childhood Blood Lead Levels with Cognitive Function and Socioeconomic Status at Age 38 Years and With IQ Change and Socioeconomic Mobility Between Childhood and Adulthood. JAMA 2017, 317, 1244. [Google Scholar]
- Zhao, Q.; Wang, Y.; Cao, Y.; Chen, A.; Ren, M.; Ge, Y.; Yu, Z.; Wan, S.; Hu, A.; Bo, Q.; et al. Potential health risks of heavy metals in cultivated topsoil and grain, including correlations with human primary liver, lung and gastric cancer, in Anhui province, Eastern China. Sci. Total Environ. 2014, 470–471, 340–347. [Google Scholar] [CrossRef] [PubMed]
- Wang, E.E.; Mahajan, N.; Wills, B.; Leikin, J. Successful Treatment of Potentially Fatal Heavy Metal Poisonings. J. Emerg. Med. 2007, 32, 289–294. [Google Scholar] [CrossRef]
- Zhao, Y.; Xu, M.; Liu, Q.; Wang, Z.; Zhao, L.; Chen, Y. Study of heavy metal pollution, ecological risk and source apportionment in the surface water and sediments of the Jiangsu coastal region, China: A case study of the Sheyang Estuary. Mar. Pollut. Bull. 2018, 137, 601–609. [Google Scholar] [CrossRef]
- Halder, D.; Saha, J.K.; Biswas, A. Accumulation of Essential and Non-essential Trace Elements in Rice Grain: Possible Health Impacts on Rice Consumers in West Bengal, India. Sci. Total Environ. 2020, 706, 135944. [Google Scholar] [CrossRef]
- Eskandari, E.; Kosari, M.; Farahani, M.H.; Khiavi, N.D.; Saeedikhani, M.; Katal, R.; Zarinejad, M. A Review on Polyaniline-based Materials Applications in Heavy Metals Removal and Catalytic Processes. Sep. Purif. Technol. 2020, 231, 27. [Google Scholar] [CrossRef]
- Hou, D.; Qi, S.; Zhao, B.; Rigby, M.; O’Connor, D. Incorporating Life Cycle Assessment with Health Risk Assessment to Select the ‘Greenest’ Cleanup Level for Pb Contaminated Soil. J. Clean. Prod. 2017, 162, 1157–1168. [Google Scholar] [CrossRef]
- Rai, P.K.; Lee, S.S.; Zhang, M.; Tsang, Y.F.; Kim, K.H. Heavy metals in food crops: Health risks, fate, mechanisms, and management. Environ. Int. 2019, 125, 365–385. [Google Scholar] [CrossRef] [PubMed]
- Smithsonian Magazine. Available online: https://www.smithsonianmag.com/smart-news/worldwide-use-leaded-gasoline-vehicles-nowcompletely-phased-out-180978549/ (accessed on 8 December 2021).
- Thakur, S.; Singh, L.; Wahid, Z.A.; Siddiqui, M.F.; Atnaw, S.M.; Din, M.F. Plant-driven removal of heavy metals from soil: Uptake, translocation, tolerance mechanism, challenges, and future perspectives. Environ. Monit. Assess. 2016, 188, 206–216. [Google Scholar] [CrossRef] [PubMed]
- Shi, R.; Liu, X.; Ying, Y. Facing Challenges in Real-Life Application of Surface-Enhanced Raman Scattering: Design and Nanofabrication of Surface-Enhanced Raman Scattering Substrates for Rapid Field Test of Food Contaminants. J. Agric. Food Chem. 2018, 66, 6525–6543. [Google Scholar] [CrossRef] [PubMed]
- Plácido, J.; Bustamante-López, S.; Meissner, K.; Kelly, D.; Kelly, S. Microalgae biochar-derived carbon dots and their application in heavy metal sensing in aqueous systems. Sci. Total Environ. 2019, 656, 531–539. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.N.; Ren, W.X.; Kim, J.S.; Yoon, J. Fluorescent and colorimetric sensors for detection of lead, cadmium, and mercury ions. Chem. Soc. Rev. 2012, 41, 3210–3244. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Yu, K.; Zhang, H.; Zhang, X.; Zhang, H.; Zhang, J.; Gao, J.; Li, N.; Jiang, J. A Portable Electromagnetic Heating-microplasma Atomic Emission Spectrometry for Direct Determination of Heavy Metals in Soil. Talanta 2020, 219, 121348. [Google Scholar] [CrossRef]
- Wang, L.; Peng, X.; Fu, H.; Huang, C.; Li, Y.; Liu, Z. Recent advances in the development of electrochemical aptasensors for detection of heavy metals in food. Biosens. Bioelectron. 2020, 147, 111777. [Google Scholar] [CrossRef]
- Wang, S.; Chen, H.; Sun, B. Recent progress in food flavor analysis using gas chromatography–ion mobility spectrometry (GC–IMS). Food Chem. 2020, 315, 126158. [Google Scholar] [CrossRef]
- Tatineni, B.; Sherif, A.E.; Hideyuki, M.; Takaaki, H.; Fujio, M. Optical Sensors Based on Nanostructured Cage Materials for the Detection of Toxic Metal Ions. Angew. Chem. 2006, 118, 7360–7366. [Google Scholar]
- Knecht, M.R.; Sethi, M. Bio-inspired colorimetric detection of Hg2+ and Pb2+ heavy metal ions using Au nanoparticles. Anal. Bioanal. Chem. 2009, 394, 33–46. [Google Scholar] [CrossRef]
- Qvarnström, J.; Lambertsson, L.; Havarinasab, S.; Hultman, P.; Frech, W. Determination of Methylmercury, Ethylmercury, and Inorganic Mercury in Mouse Tissues, Following Administration of Thimerosal, by Species-Specific Isotope Dilution GC-Inductively Coupled Plasma-MS. Anal. Chem. 2003, 75, 4120–4124. [Google Scholar] [CrossRef] [PubMed]
- Ichinoki, S.; Kitahata, N.; Fujii, Y. Selective Determination of Mercury(II) Ion in Water by Solvent Extraction Followed by Reversed-Phase HPLC. J. Liq. Chromatogr. Relat. Technol. 2004, 27, 1785–1798. [Google Scholar] [CrossRef]
- Lin, Q.; Lin, H.; Zhang, Y.; Rong, M.; Ke, H.; Tang, X.; Chen, X. Simultaneous determination of trace Pb(II), Cd(II), and Zn(II) using an integrated three-electrode modiffed with bismuth fflm. Microchem. J. 2021, 168, 106390. [Google Scholar]
- Ma, H.; An, R.; Chen, L.; Fu, Y.; Ma, C.; Dong, X.; Zhang, X. A study of the photodeposition over Ti/TiO2 electrode for electrochemical detection of heavy metal ions. Electrochem. Commun. 2015, 57, 18–21. [Google Scholar] [CrossRef]
- Veselkov, K.A.; Vingara, L.K.; Masson, P.; Robinette, S.L.; Want, E.; Li, J.V.; Barton, R.H.; Boursier-Neyret, C.; Walther, B.; Ebbels, T.M.; et al. Optimized Preprocessing of Ultra-Performance Liquid Chromatography/Mass Spectrometry Urinary Metabolic Profiles for Improved Information Recovery. Anal. Chem 2011, 83, 5864–5872. [Google Scholar] [CrossRef] [PubMed]
- Orlando, A.; Franceschini, F.; Muscas, C.; Pidkova, S.; Bartoli, M.; Rovere, M.; Tagliaferro, A. A Comprehensive Review on Raman Spectroscopy Applications. Chemosensors 2021, 9, 262. [Google Scholar] [CrossRef]
- Yu, B.; Ge, M.; Li, P.; Xie, Q.; Yang, L. Development of surface-enhanced Raman spectroscopy application for determination of illicit drugs: Towards a practical sensor. Talanta 2019, 191, 1–10. [Google Scholar] [CrossRef]
- Ding, X.; Kong, L.; Wang, J.; Fang, F.; Li, D.; Liu, J. Highly Sensitive SERS Detection of Hg2+ Ions in Aqueous Media Using Gold Nanoparticles/Graphene Heterojunctions. ACS Appl. Mater. Interfaces 2013, 5, 7072–7078. [Google Scholar] [CrossRef]
- Li, H.; Chen, Q.; Hassan, M.M.; Ouyang, Q.; Jiao, T.; Xu, Y.; Chen, M. AuNS@Ag core-shell nanocubes grafted with rhodamine for concurrent metalenhanced fluorescence and surfaced enhanced Raman determination of mercury ions. Anal. Chim. Acta 2018, 1018, 94–103. [Google Scholar] [CrossRef]
- Bao, H.; Fu, H.; Zhou, L.; Cai, W.; Zhang, H. Rapid and Ultrasensitive Surface-Enhanced Raman Spectroscopy Detection of Mercury Ions with Gold Film Supported Organometallic Nanobelts. Nanotechnology 2020, 31, 155501. [Google Scholar] [CrossRef]
- Zuo, Q.; Chen, Y.; Chen, Z.P.; Yu, R.Q. Quantification of Cadmium in Rice by Surface-Enhanced Raman Spectroscopy Based on a Ratiometric Indicator and Conical Holed Enhancing Substrates. Anal. Sci. 2018, 34, 1405–1410. [Google Scholar] [CrossRef]
- Xu, Y.; Zhong, P.; Jiang, A.; Shen, X.; Li, X.; Xu, Z.; Shen, Y.; Sun, Y.; Lei, H. Raman spectroscopy coupled with chemometrics for food authentication: A review. Trends Anal. Chem. 2020, 131, 116017. [Google Scholar] [CrossRef]
- Bai, S.; Xueli, R.; Kotaro, O.; Yoshihiro, I.; Koji, S. Label-free trace detection of bio-molecules by liquid-interface assisted surface-enhanced Raman scattering using a microfluidic chip. Opto-Electron. Adv. 2022, 5, 210121. [Google Scholar] [CrossRef]
- Luca, G.; Ramon, A. Alvarez-Puebla. Surface-Enhanced Raman Scattering Sensing of Transition Metal Ions in Waters. ACS Omega 2021, 6, 1054–1063. [Google Scholar]
- Moram, S.; Satya, B.; Venugopal Rao, S. Flexible SERS substrates for hazardous materials detection: Recent advances. Opto-Electron. Adv. 2021, 4, 210048. [Google Scholar]
- Guo, Z.; Chen, P.; Yosri, N.; Chen, Q.; Elseedi, H.R.; Zou, X.; Yang, H. Detection of Heavy Metals in Food and Agricultural Products by Surface-enhanced Raman Spectroscopy. Food Rev. Int. 2023, 39, 1440. [Google Scholar] [CrossRef]
- Ji, W.; Li, L.; Zhang, Y.; Wang, X.; Ozaki, Y. Recent advances in surface-enhanced Raman scattering-based sensors for the detection of inorganic ions: Sensing mechanism and beyond. J. Raman Spectrosc. 2020, 52, 14. [Google Scholar] [CrossRef]
- Wang, Y.; Irudayaraj, J. A SERS DNAzyme biosensor for lead ion detection. Chem. Commun. 2011, 15, 4394–4396. [Google Scholar] [CrossRef]
- Guangda, X.; Peng, S.; Lixin, X. Examples in the detection of heavy metal ions based on surface-enhanced Raman scattering spectroscopy. Nanophotonics 2021, 10, 4419–4445. [Google Scholar]
- Frost, M.S.; Dempsey, M.J.; Whitehead, D.E. Highly sensitive SERS detection of Pb2+ ions in aqueous media usingcitrate functionalised gold nanoparticles. Sens. Actuators 2015, 221, 1003–1008. [Google Scholar] [CrossRef]
- Zhang, L.; Li, C.; Peng, D.; Yi, X.; He, S.; Liu, F.; Zheng, X.; Huang, W.E.; Zhao, L.; Huang, X. Raman spectroscopy and machine learning for the classification of breast cancers. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 264, 120300. [Google Scholar] [CrossRef] [PubMed]
- Gao, W.; Zhou, L.; Liu, S.; Guan, Y.; Gao, H.; Hui, B. Machine learning prediction of lignin content in poplar with Raman spectroscopy. Bioresour. Technol. 2022, 348, 126812. [Google Scholar] [CrossRef] [PubMed]
- Fengye, C.; Chen, S.; Zengqi, Y.; Yuqing, Z.; Weijie, X.; Sahar, S.; Long, Z. Screening ovarian cancers with Raman spectroscopy of blood plasma coupled with machine learning data processing. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 265, 120355. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 3149–3157. [Google Scholar]
- Larkin, P. Correlations: Characteristic Group Frequencies. In IR and Raman Spectra-Structure, 1st ed.; Elsevier: Amsterdam, The Netherlands, 2011; pp. 73–115. [Google Scholar]
- Pan, S.; Zheng, Z.; Guo, Z.; Luo, H. An optimized XGBoost method for predicting reservoir porosity using petrophysical logs. J. Pet. Sci. Eng. 2022, 208, 109520. [Google Scholar] [CrossRef]
- Anghel, A.; Papandreou, N.; Parnell, T.; De Palma, A.; Pozidis, H. Benchmarking and Optimization of Gradient Boosted Decision Tree Algorithms. arxiv 2018, arXiv:1809.04559. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | Train | Test | BACC | AUROC | F1 | MCC | Youden’s Index |
|---|---|---|---|---|---|---|---|
| Raw | Batch 1 | Batch 2 | 0.345 | 0.336 | 0.652 | −0.298 | −0.311 |
| Batch 2 | Batch 1 | 0.3213 | 0.363 | 0.650 | −0.349 | −0.357 | |
| Average | 0.333 | 0.349 | 0.651 | −0.324 | −0.334 | ||
| SG | Batch 1 | Batch 2 | 0.295 | 0.367 | 0.613 | −0.385 | −0.410 |
| Batch 2 | Batch 1 | 0.337 | 0.414 | 0.668 | −0.319 | −0.326 | |
| Average | 0.316 | 0.390 | 0.641 | −0.352 | −0.368 | ||
| airPLS | Batch 1 | Batch 2 | 0.524 | 0.709 | 0.652 | 0.038 | 0.048 |
| Batch 2 | Batch 1 | 0.686 | 0.753 | 0.816 | 0.469 | 0.372 | |
| Average | 0.605 | 0.731 | 0.734 | 0.254 | 0.210 | ||
| SG+airPLS | Batch 1 | Batch 2 | 0.708 | 0.852 | 0.588 | 0.389 | 0.417 |
| Batch 2 | Batch 1 | 0.661 | 0.598 | 0.871 | 0.461 | 0.321 | |
| Average | 0.685 | 0.725 | 0.730 | 0.425 | 0.369 | ||
| SG+area+SNV | Batch 1 | Batch 2 | 0.833 | 0.865 | 0.799 | 0.576 | 0.665 |
| Batch 2 | Batch 1 | 0.996 | 0.997 | 0.998 | 0.992 | 0.993 | |
| Average | 0.915 | 0.931 | 0.898 | 0.784 | 0.829 | ||
| Data Set | Train | Test | Accuracy | Recall | Precision | Specificity |
|---|---|---|---|---|---|---|
| Raw | Batch 1 | Batch 2 | 0.491 | 0.637 | 0.668 | 0.052 |
| Batch 2 | Batch 1 | 0.482 | 0.643 | 0.657 | 0 | |
| Average | 0.486 | 0.640 | 0.662 | 0.026 | ||
| SG | Batch 1 | Batch 2 | 0.442 | 0.590 | 0.638 | 0 |
| Batch 2 | Batch 1 | 0.506 | 0.674 | 0.662 | 0 | |
| Average | 0.474 | 0.632 | 0.650 | 0 | ||
| airPLS | Batch 1 | Batch 2 | 0.551 | 0.578 | 0.748 | 0.469 |
| Batch 2 | Batch 1 | 0.760 | 0.834 | 0.799 | 0.538 | |
| Average | 0.656 | 0.706 | 0.764 | 0.504 | ||
| SG+airPLS | Batch 1 | Batch 2 | 0.563 | 0.417 | 0.997 | 1 |
| Batch 2 | Batch 1 | 0.801 | 0.941 | 0.811 | 0.380 | |
| Average | 0.682 | 0.679 | 0.789 | 0.690 | ||
| SG+area+SNV | Batch 1 | Batch 2 | 0.749 | 0.665 | 1 | 1 |
| Batch 2 | Batch 1 | 0.997 | 0.998 | 0.998 | 0.995 | |
| Average | 0.873 | 0.831 | 0.977 | 0.998 | ||
| Model | BACC | AUROC | F1 | MCC | Youden’s Index |
|---|---|---|---|---|---|
| KNN | 0.8352 | 0.842 | 0.795 | 0.652 | 0.670 |
| DT | 0.807 | 0.807 | 0.787 | 0.617 | 0.615 |
| LR | 0.586 | 0.677 | 0.607 | 0.171 | 0.172 |
| RBFSVM | 0.731 | 0.799 | 0.666 | 0.431 | 0.462 |
| RF | 0.842 | 0.864 | 0.801 | 0.672 | 0.683 |
| XGBoost | 0.834 | 0.904 | 0.879 | 0.695 | 0.707 |
| LightGBM | 0.915 | 0.931 | 0.898 | 0.784 | 0.829 |
| Model | Accuracy | Recall | Precision | Specificity |
|---|---|---|---|---|
| KNN | 0.774 | 0.713 | 0.898 | 0.957 |
| DT | 0.763 | 0.719 | 0.869 | 0.896 |
| LR | 0.546 | 0.505 | 0.761 | 0.667 |
| RBFSVM | 0.637 | 0.543 | 0.861 | 0.919 |
| RF | 0.781 | 0.721 | 0.901 | 0.962 |
| XGBoost | 0.842 | 0.830 | 0.934 | 0.878 |
| LightGBM | 0.873 | 0.831 | 0.977 | 0.998 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, M.; Zhang, J. Surface Enhanced Raman Spectroscopy Pb2+ Ion Detection Based on a Gradient Boosting Decision Tree Algorithm. Chemosensors 2023, 11, 509. https://doi.org/10.3390/chemosensors11090509
Wang M, Zhang J. Surface Enhanced Raman Spectroscopy Pb2+ Ion Detection Based on a Gradient Boosting Decision Tree Algorithm. Chemosensors. 2023; 11(9):509. https://doi.org/10.3390/chemosensors11090509
Chicago/Turabian StyleWang, Minghao, and Jing Zhang. 2023. "Surface Enhanced Raman Spectroscopy Pb2+ Ion Detection Based on a Gradient Boosting Decision Tree Algorithm" Chemosensors 11, no. 9: 509. https://doi.org/10.3390/chemosensors11090509
APA StyleWang, M., & Zhang, J. (2023). Surface Enhanced Raman Spectroscopy Pb2+ Ion Detection Based on a Gradient Boosting Decision Tree Algorithm. Chemosensors, 11(9), 509. https://doi.org/10.3390/chemosensors11090509