An Autoencoder-Based Deep Learning Classifier for Efficient Diagnosis of Autism


Abstract
:1. Introduction
2. Literature Review
2.1. Image-Based Classification
2.2. Questionnaire-Based Classification Methods
2.3. Behavioural-Based Classification Methods
3. Machine Learning and Deep Learning Classifiers
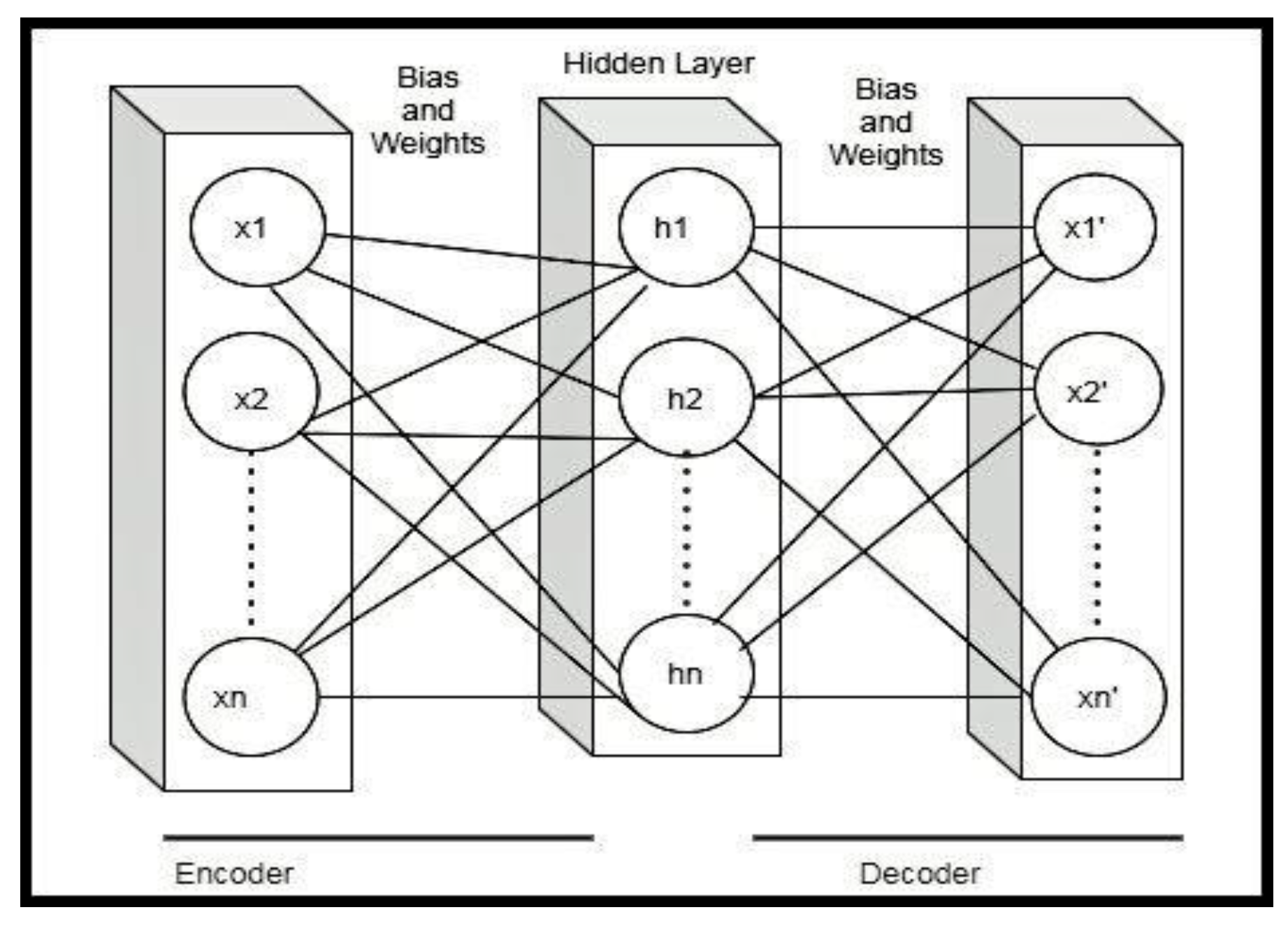
3.1. Autoencoder
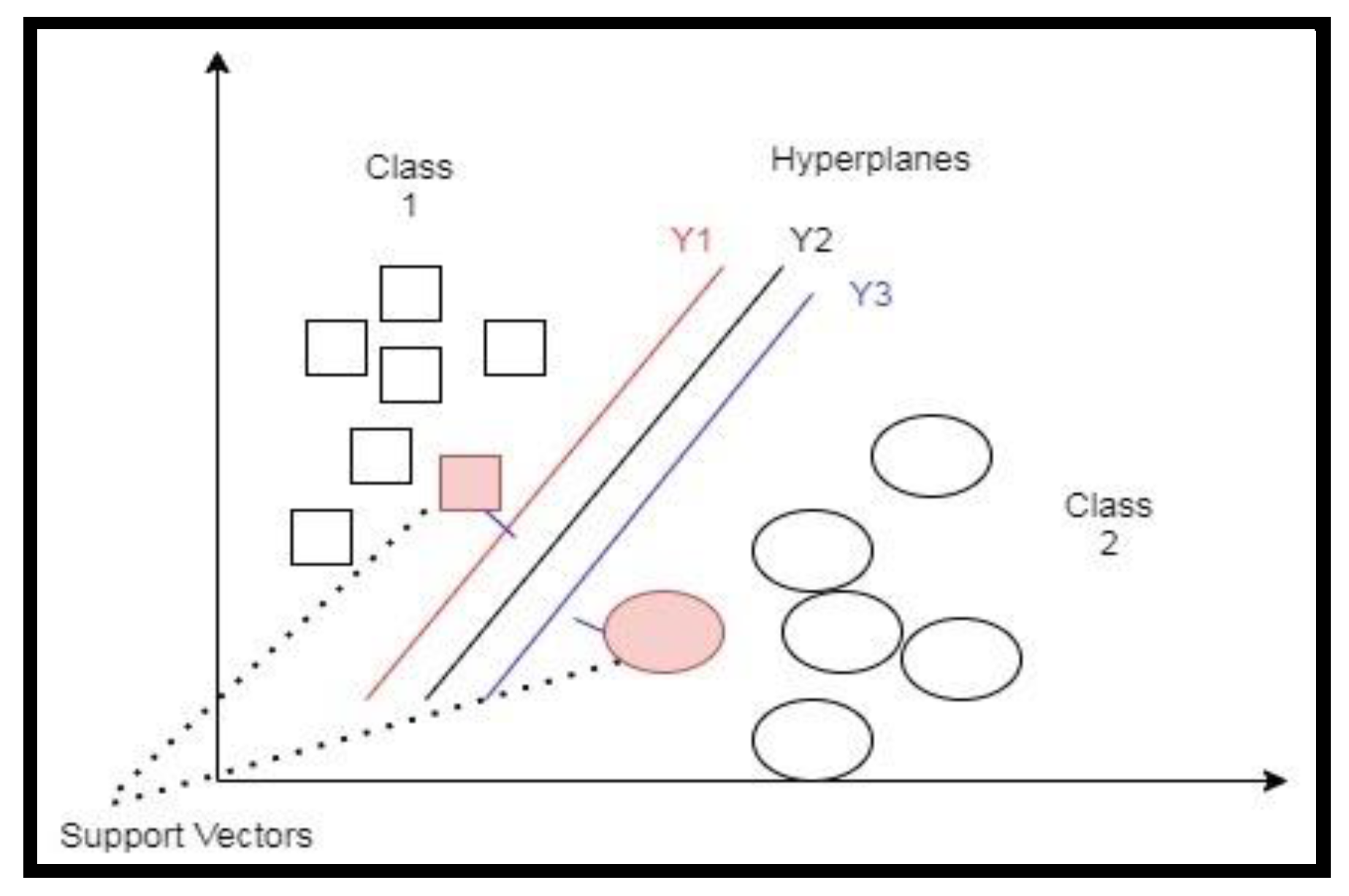
3.2. Support Vector Machines (SVMs)
- Linear: This form of kernel function is very simple, straightforward. It is given by the inner product of (x,y) plus an optional constant bias, as shown in Equation (3):
- Sigmoid: The sigmoid kernel is also called hyperbolic tangent kernel and as a multilayer perceptron kernel. The sigmoid kernel is obtained from the neural network field, where the bipolar sigmoid function is used as an activation function for the neurons.
- Radial basis function (RBF): is used when we have no prior knowledge of data.
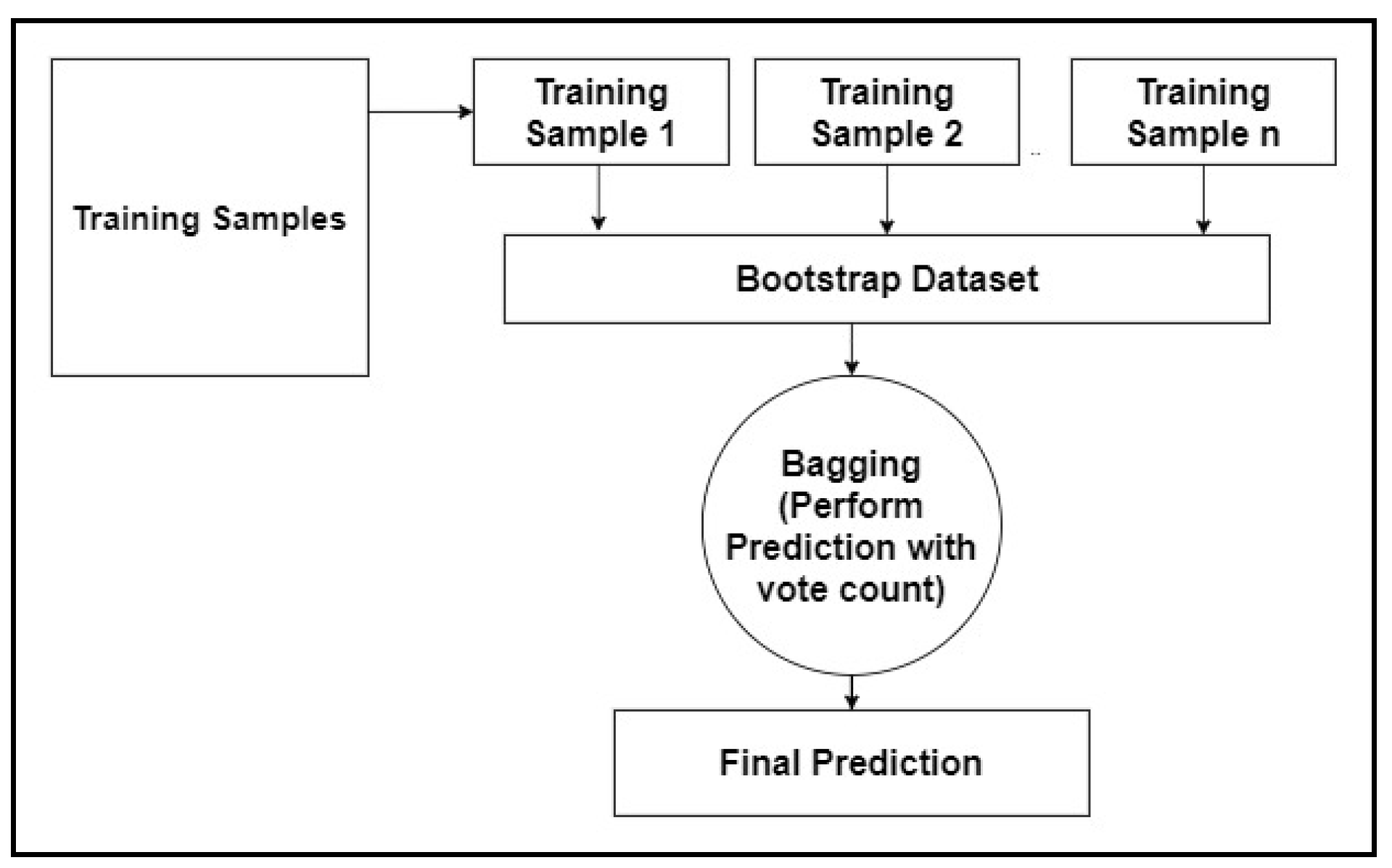
3.3. Random Forest
- Step 1: Building decision trees using a bootstrap dataset.
- Step 2: Consider a random subset of variables at each step.
- Step 3: Perform a vote for a new dataset by sending it to all the trees.
- Step 4: Select the prediction result with the highest votes as the final prediction.
3.4. K-Nearest Neighbours
3.5. Convolutional Neural Network (CNN)
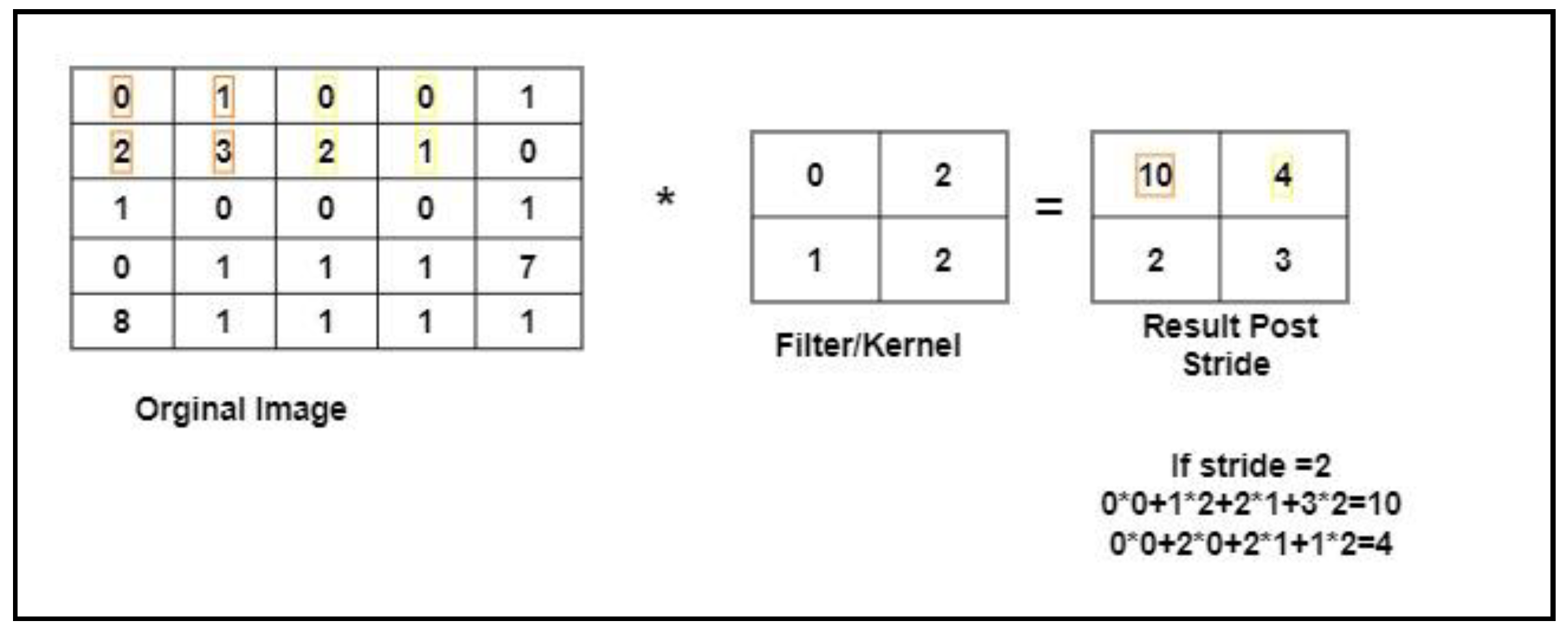
3.5.1. Stride
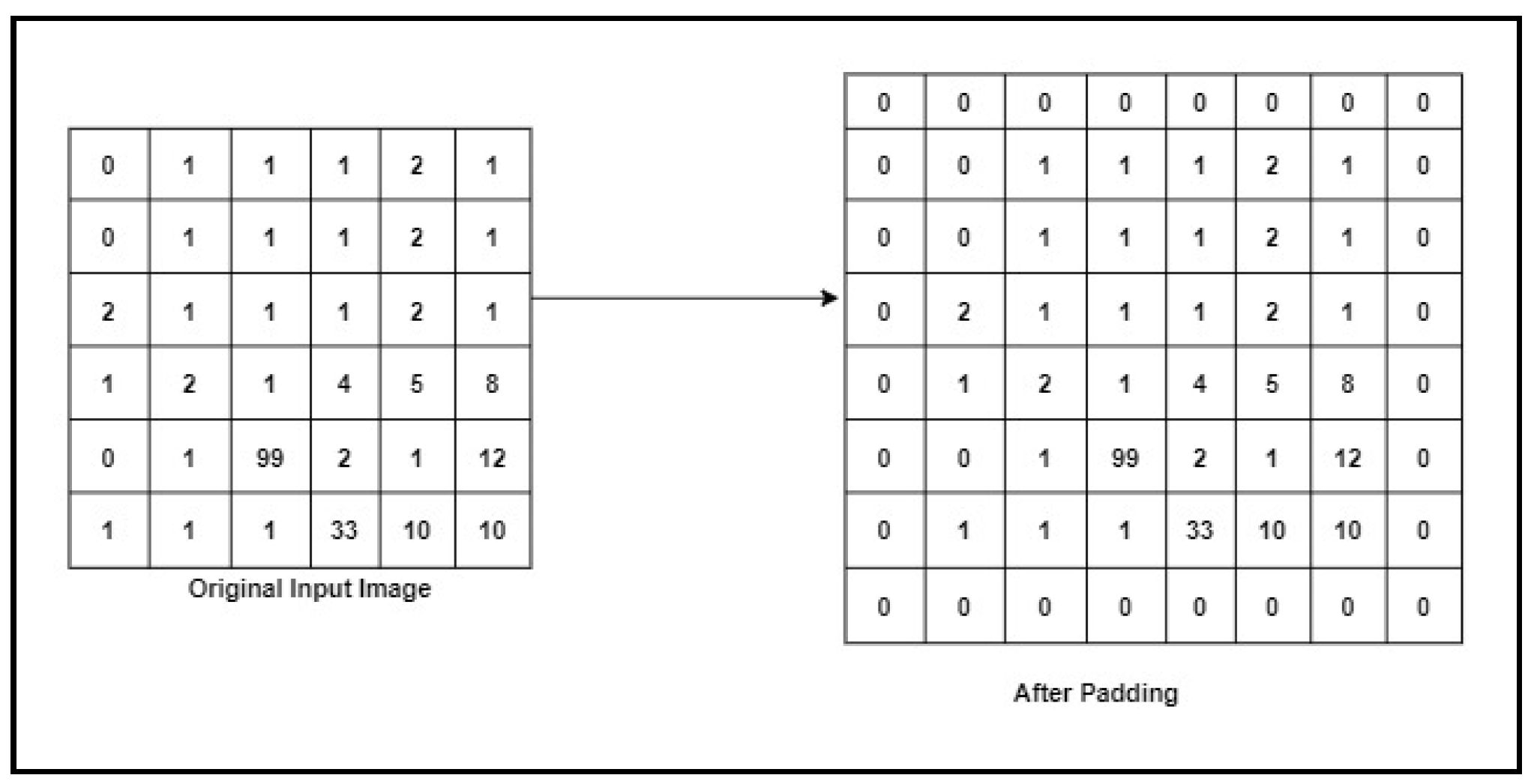
3.5.2. Padding
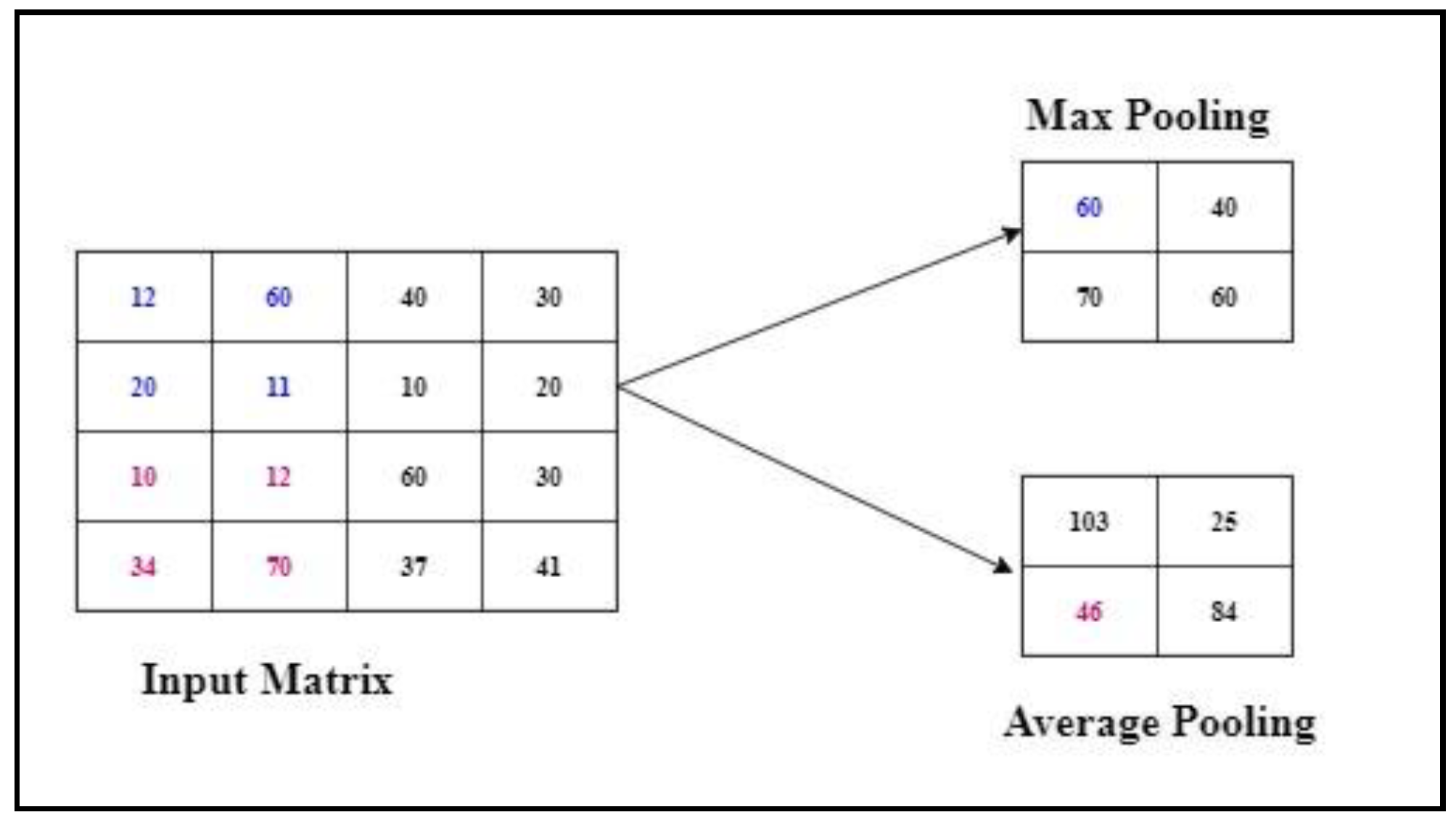
3.5.3. Max Pooling
3.5.4. Activation Function
- Sigmoid function: The sigmoid function exists between 0 and 1, and its shape looks like an S shape. Sigmoid is the correct choice when we have to predict the likelihood of a model. Equation (7) illustrates the sigmoid function. Since the sigmoid function is differentiable, the sigmoid function’s derivative is shown in Equation (8) to calculate the slope of the sigmoid curve.
- Rectilinear function: The Rectilinear function, also called ReLU. It has values between 0 and infinity, and it provides better performance than the sigmoid function. Equation (9) shows the derivative of the ReLU function.
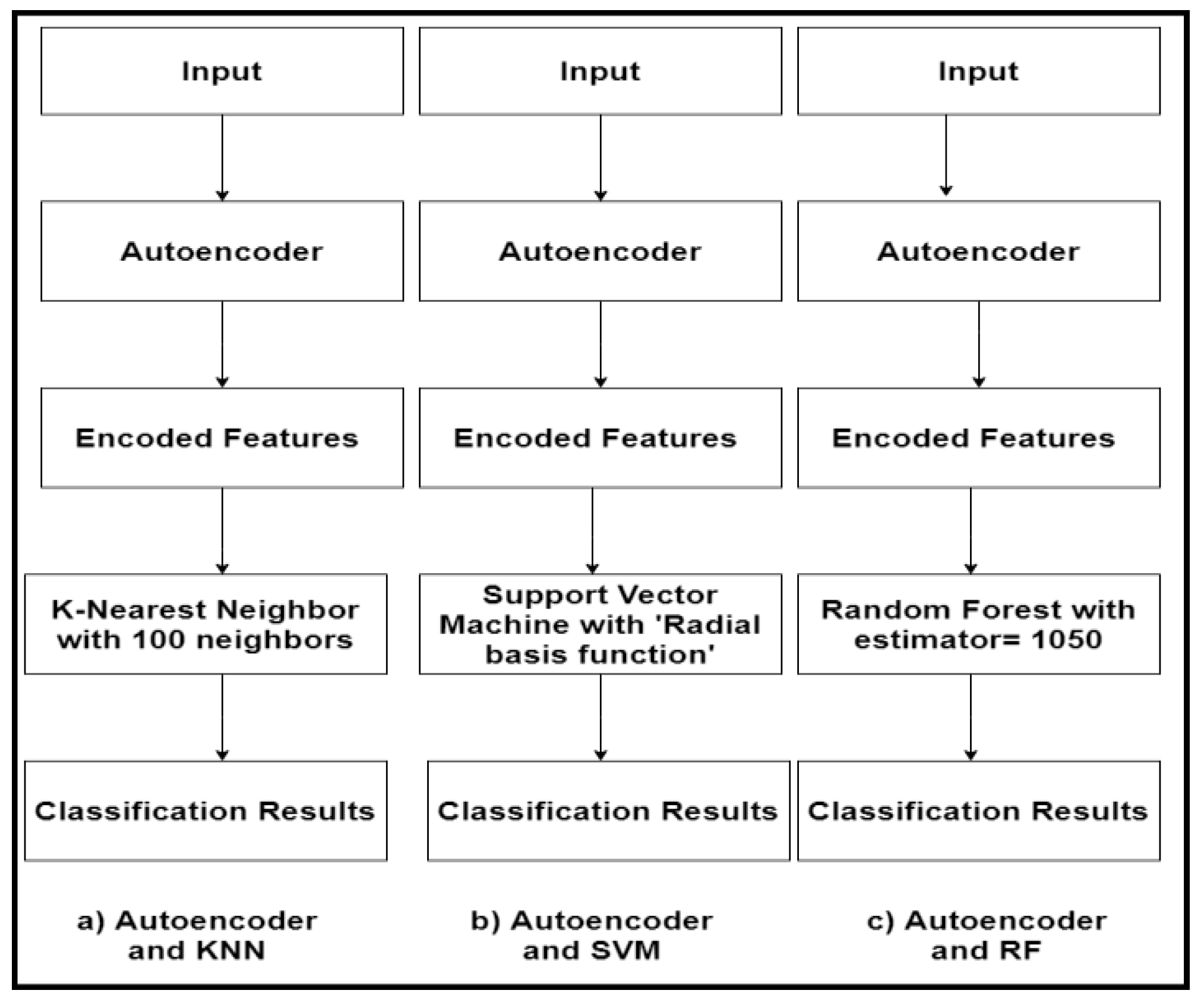
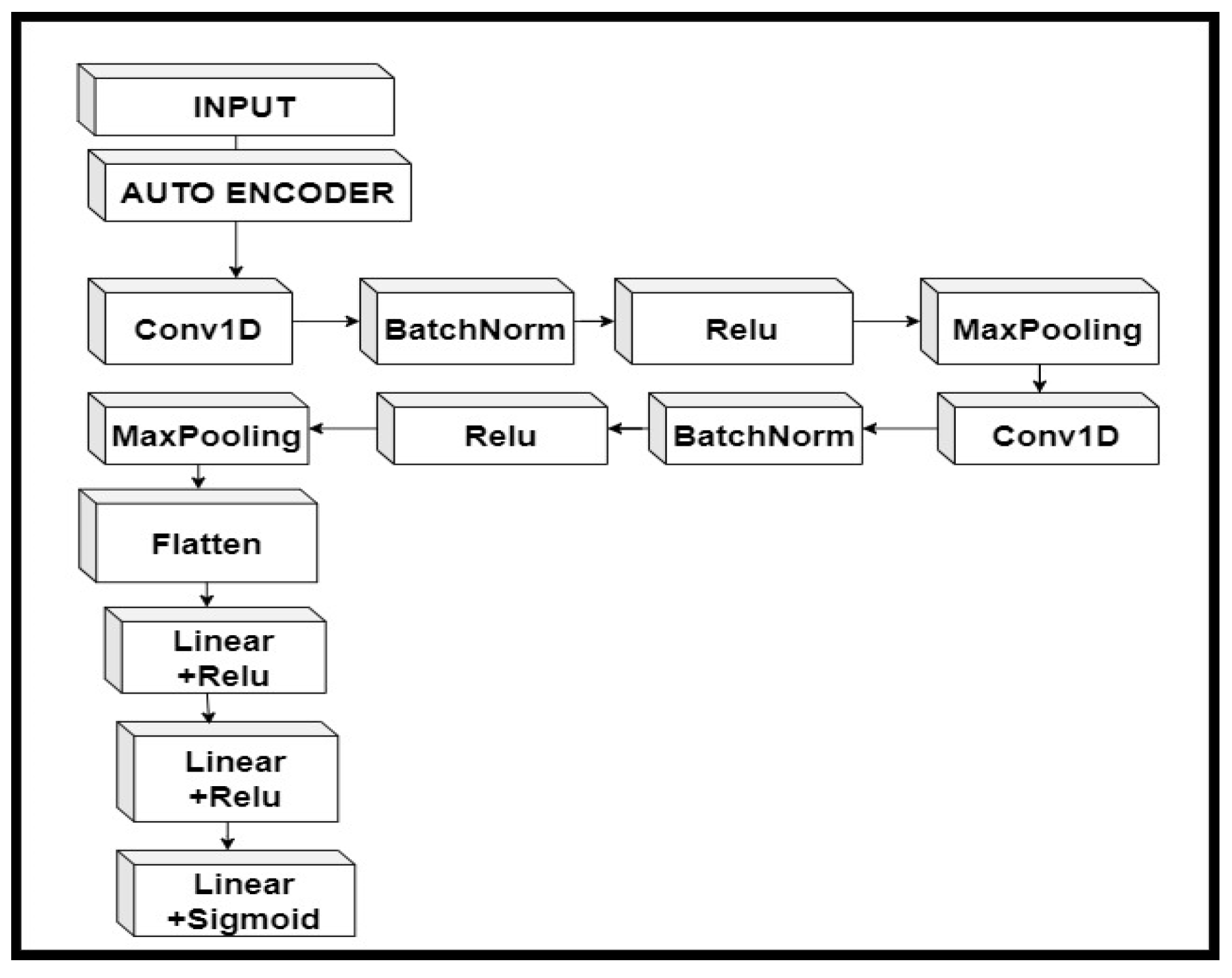
4. The Proposed Hybrid Autoencoder-Based Classifier
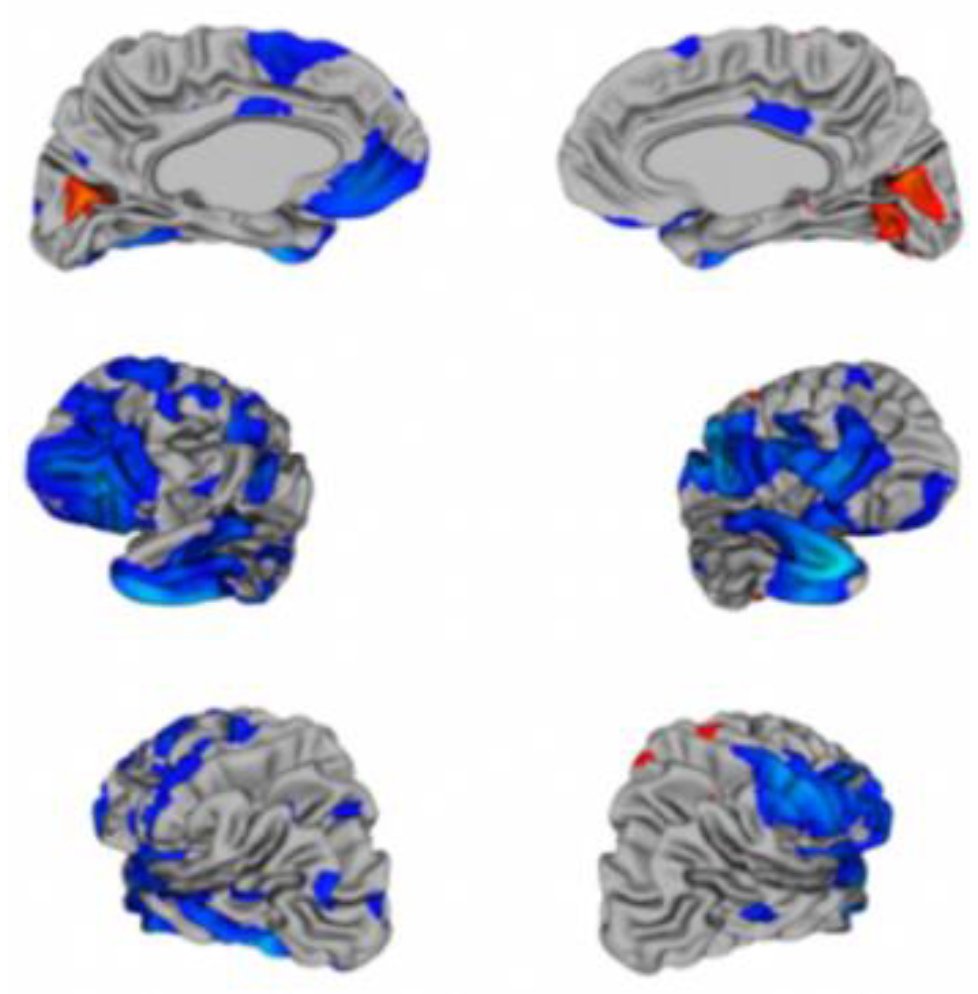
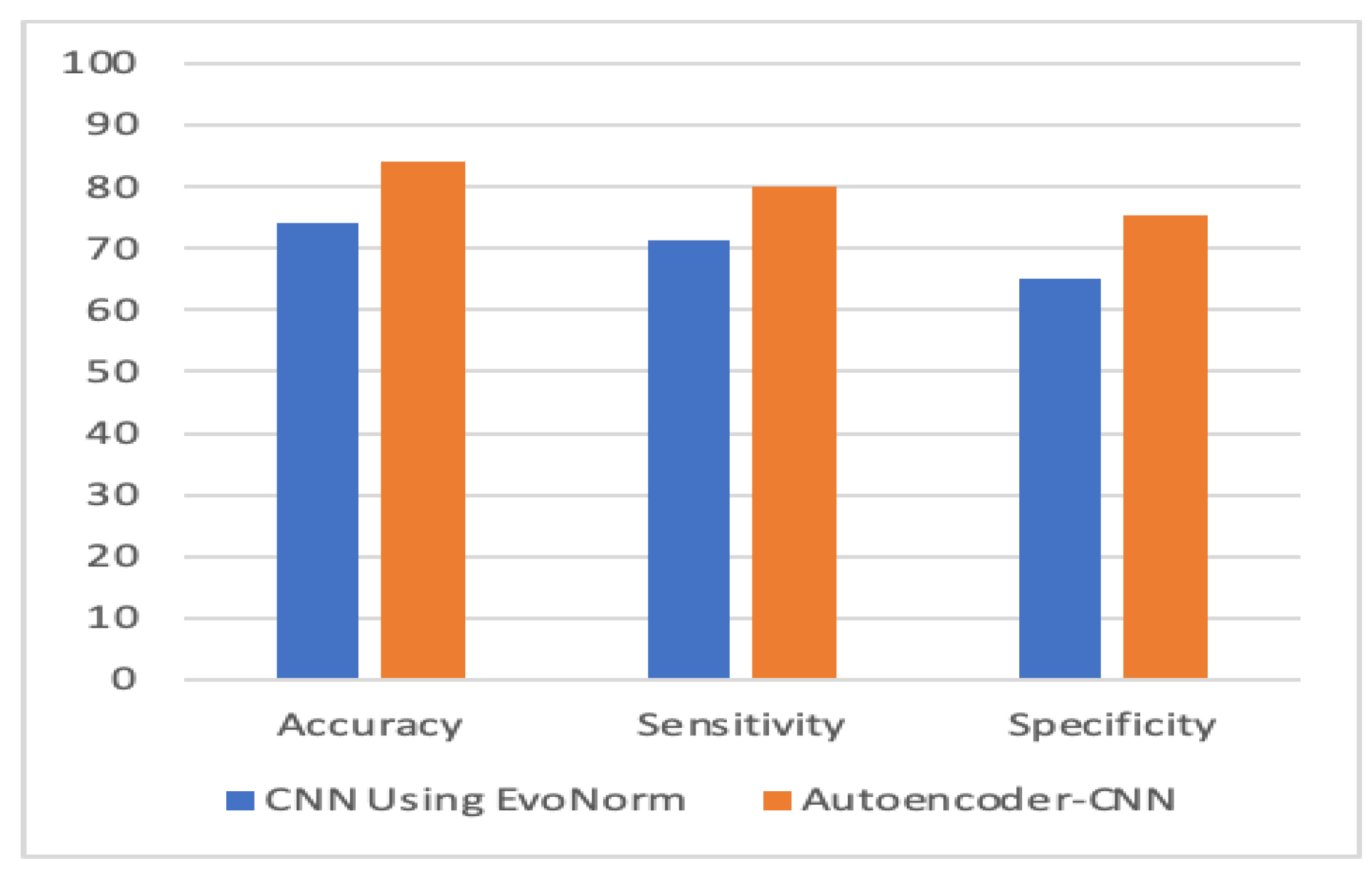
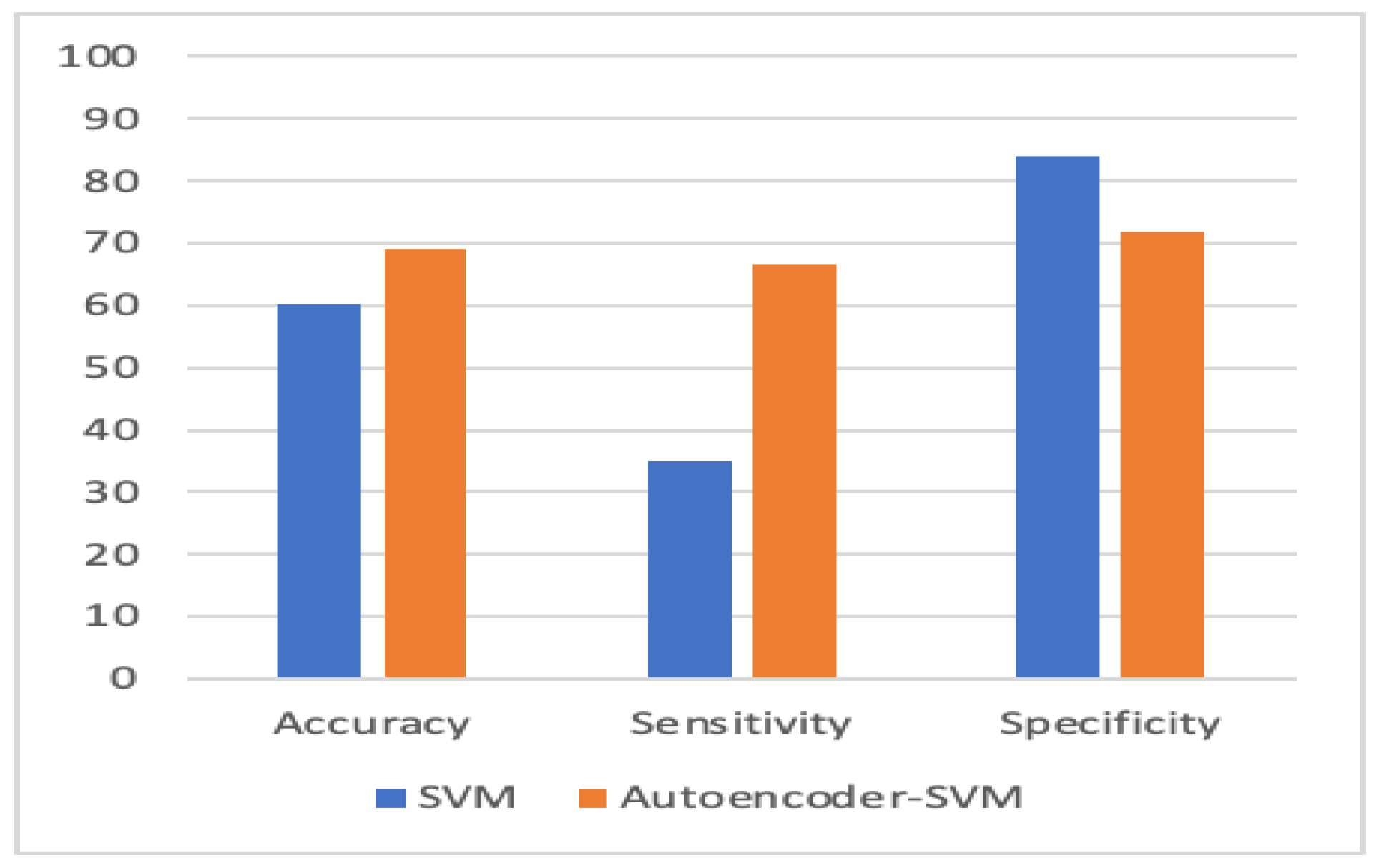
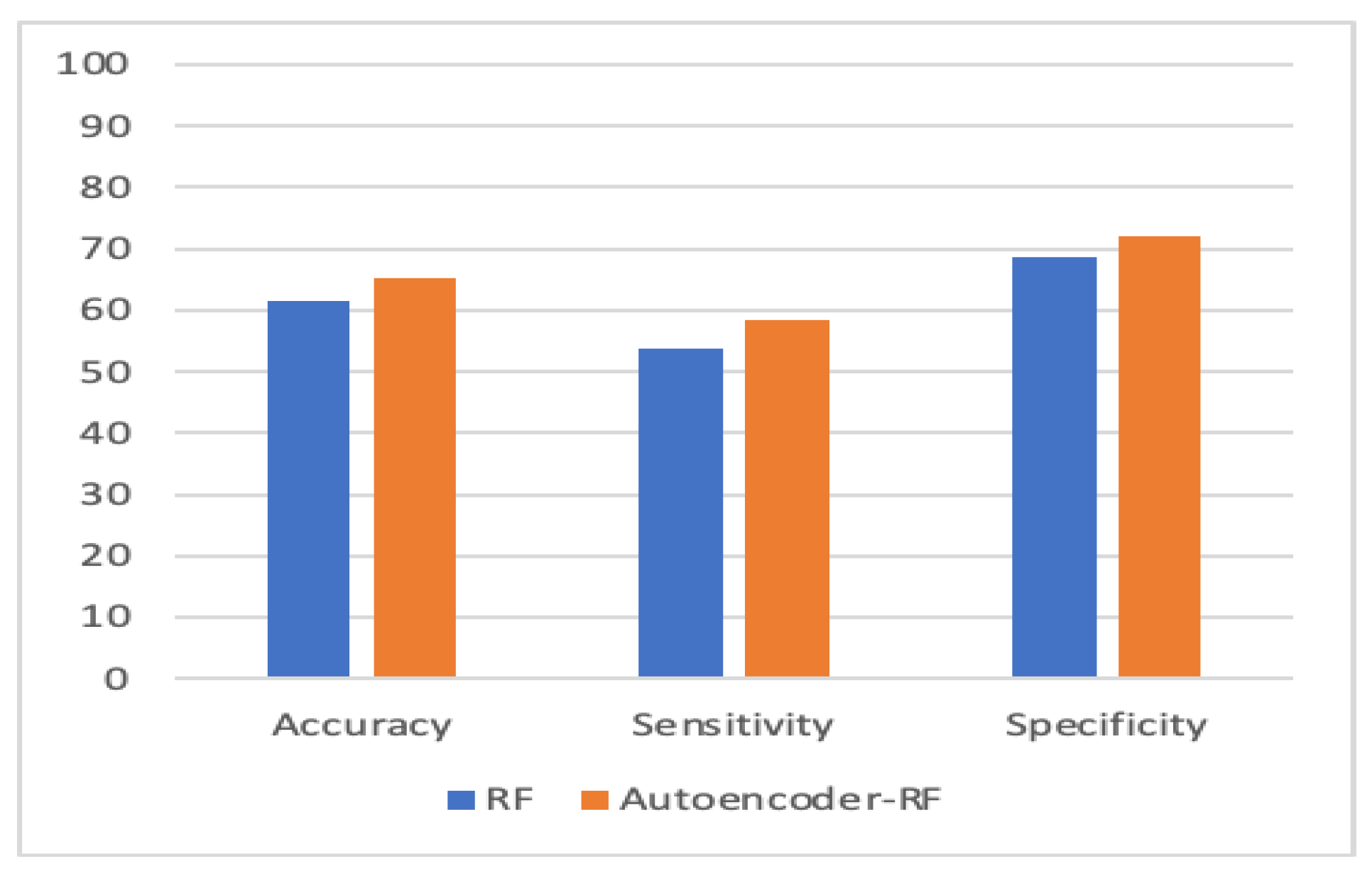
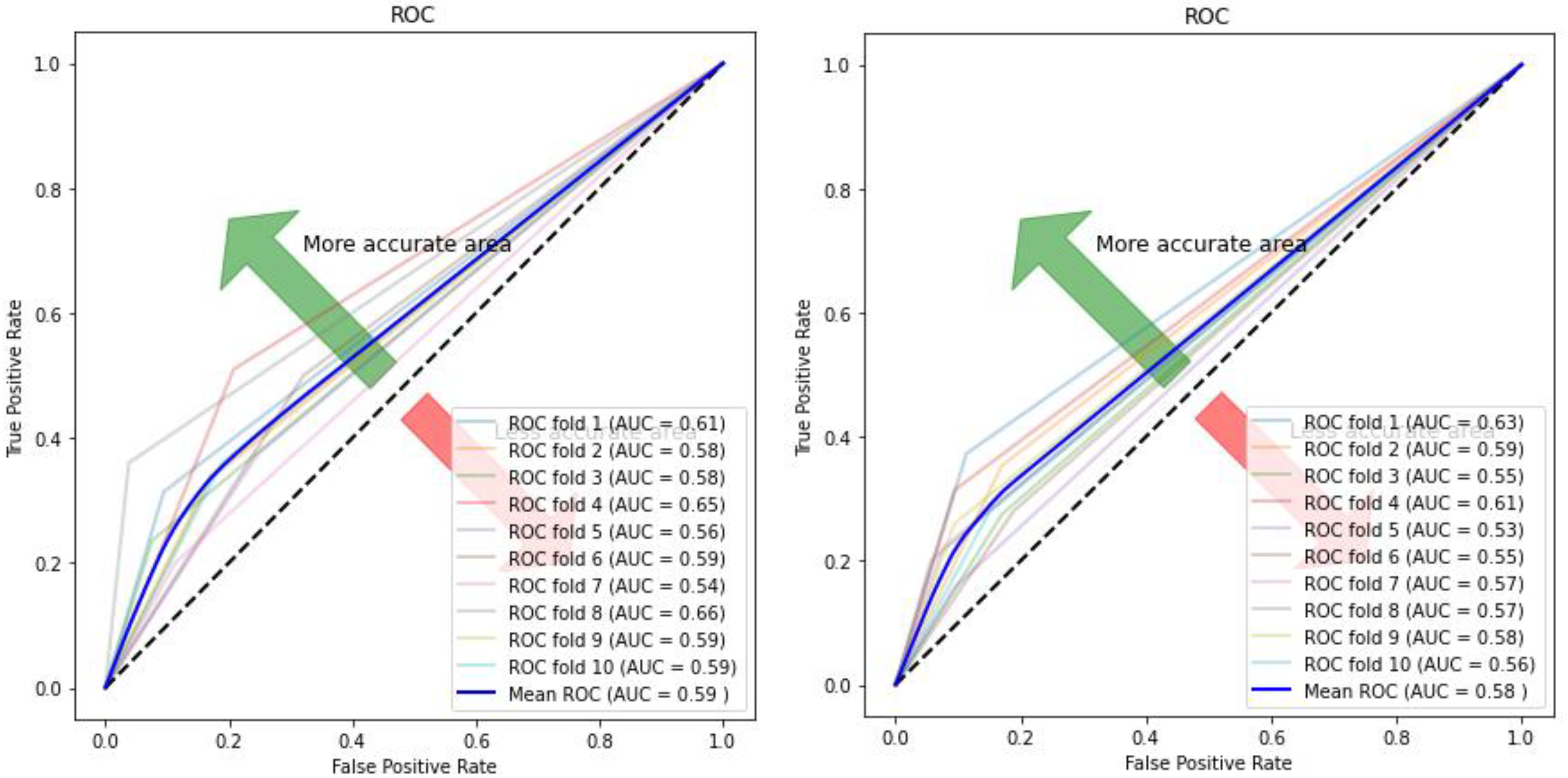
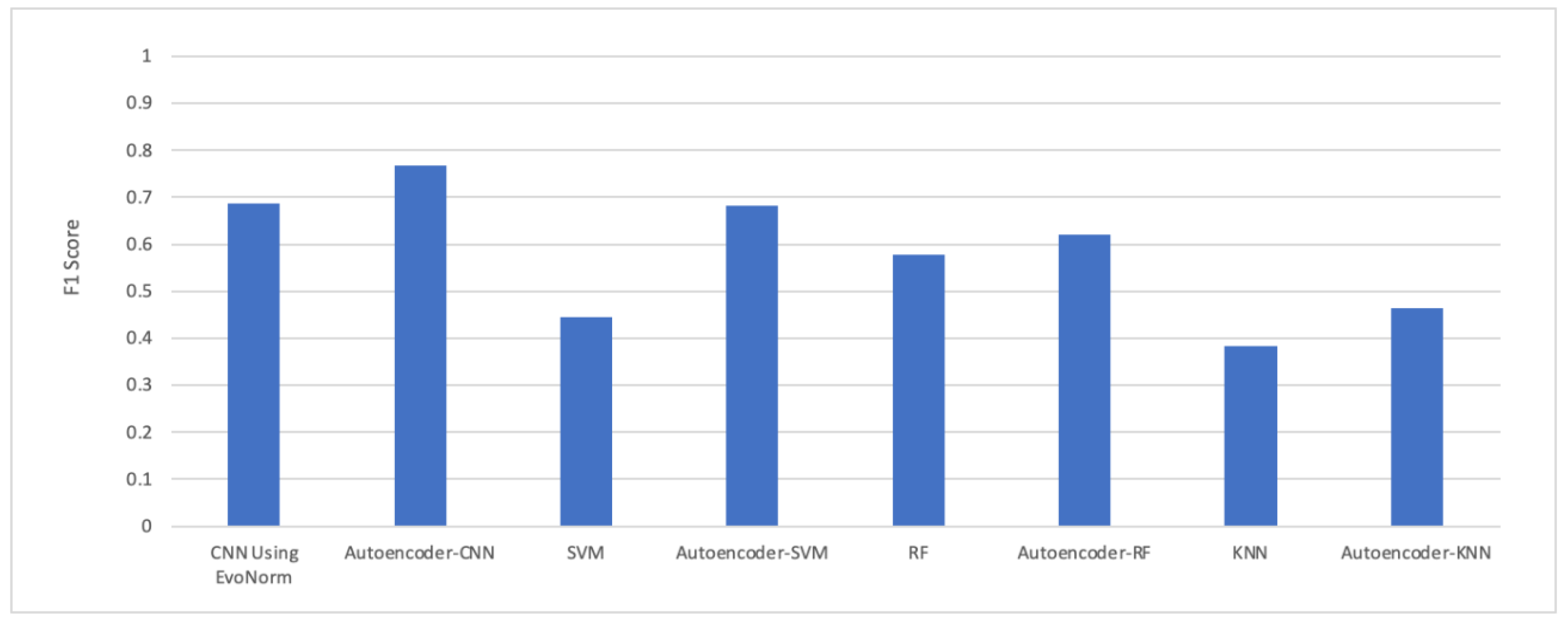
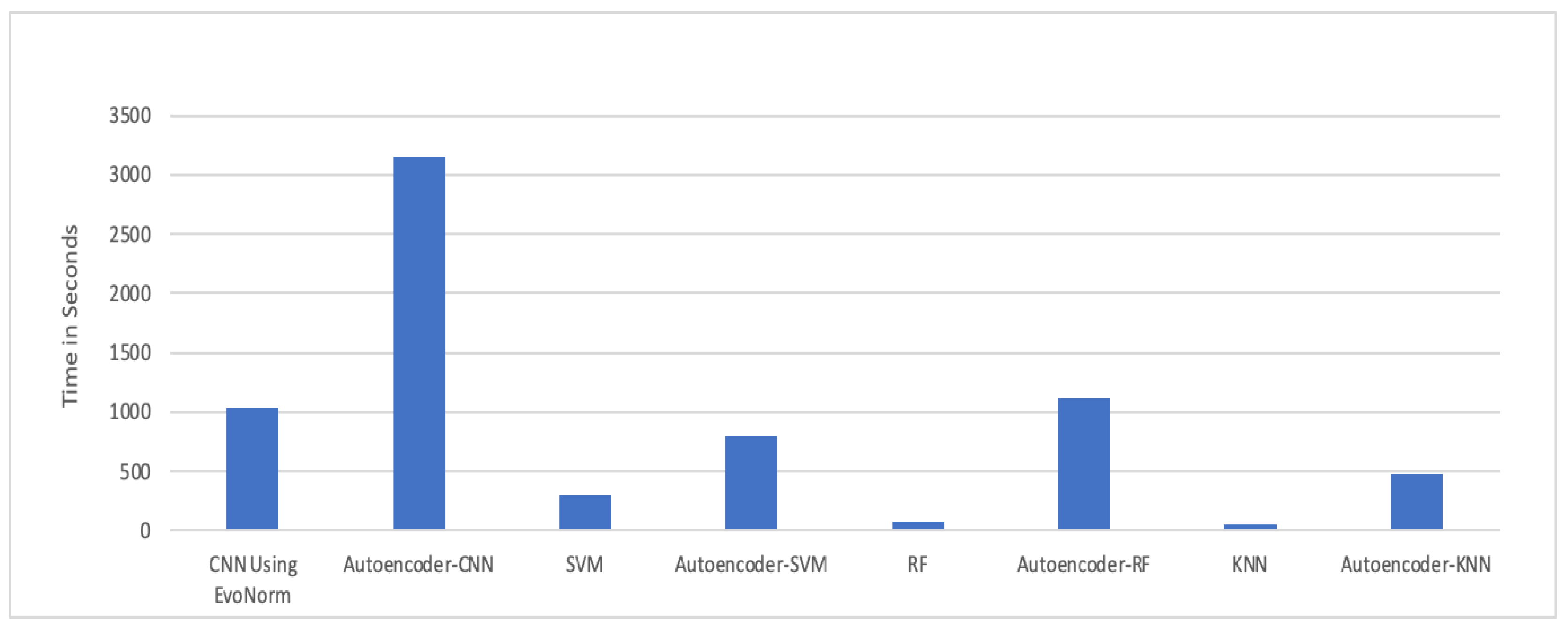
5. Experiment Results
Experimental Analysis
6. Conclusions and Future Direction
Author Contributions
Funding
Conflicts of Interest
References
- World Health Organization (WHO). Autism Spectrum Disorders. Available online: https://www.who.int/news-room/fact-sheets/detail/autism-spectrum-disorders (accessed on 3 June 2020).
- Autism Spectrum Disorder among Children and Youth in Canada 2018. Available online: https://www.canada.ca/en/public-health/services/publications/diseases-conditions/autism-spectrum-disorder-children-youth-canada-2018.html (accessed on 22 May 2020).
- Autism Spectrum Disorder. Available online: https://www.nimh.nih.gov/health/topics/autism-spectrum-disorders-asd/index.shtml (accessed on 22 May 2020).
- Heinsfeld, A.S.; Franco, A.R.; Craddock, R.C.; Buchweitz, A.; Meneguzzi, F. Identification of autism spectrum disorder using deep learning and the ABIDE dataset. NeuroImage: Clin. 2018, 17, 16–23. [Google Scholar] [CrossRef] [PubMed]
- Eslami, T.; Mirjalili, V.; Fong, A.; Laird, A.R.; Saeed, F. ASD-DiagNet: A Hybrid Learning Approach for Detection of Autism Spectrum Disorder Using fMRI Data. Front. Aging Neurosci. 2019, 13, 70. [Google Scholar] [CrossRef] [PubMed]
- Iidaka, T. Resting state functional magnetic resonance imaging and neural network classified autism and control. Cortex 2015, 63, 55–67. [Google Scholar] [CrossRef] [PubMed]
- Khosla, M.; Jamison, K.; Kuceyeski, A.; Sabuncu, M.R. 3D Convolutional Neural Networks for Classification of Functional Connectomes. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Quebec City, QC, Canada, 2018; pp. 137–145. [Google Scholar]
- Craddock, R.C.; Yassine, B.; Carlton, C.; Francois, C.; Alan, E.; András, J.; Budhachandra, K.; John, L.; Qingyang, L.; Michael, M.; et al. The Neuro Bureau Preprocessing Initiative: Open sharing of preprocessed neuroimaging data and derivatives. Front. Aging Neurosci. 2013, 7. [Google Scholar] [CrossRef]
- Sen, B.; Borle, N.C.; Greiner, R.; Brown, M.R.G. A general prediction model for the detection of ADHD and Autism using structural and functional MRI. PLoS ONE 2018, 13, e0194856. [Google Scholar] [CrossRef] [PubMed]
- Parikh, M.N.; Li, H.; He, L. Enhancing Diagnosis of Autism with Optimized Machine Learning Models and Personal Characteristic Data. Front. Comput. Neurosci. 2019, 13. [Google Scholar] [CrossRef] [PubMed]
- Sherkatghanad, Z.; Akhondzadeh, M.; Salari, S.; Zomorodi-Moghadam, M.; Abdar, M.; Acharya, U.R.; Khosrowabadi, R.; Salari, V. Automated Detection of Autism Spectrum Disorder Using a Convolutional Neural Network. Front. Neurosci. 2020, 13, 1325. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Duda, M.; Haber, N.; Daniels, J.; Wall, D.P. Crowdsourced validation of a machine-learning classification system for autism and ADHD. Transl. Psychiatry 2017, 7, e1133. [Google Scholar] [CrossRef] [PubMed]
- Support Vector Machines. Available online: https://scikit-learn.org/stable/modules/svm.html# (accessed on 17 May 2020).
- Linear Discriminant Analysis in Python. Available online: https://towardsdatascience.com/linear-discriminant-analysis-in-python-76b8b17817c2 (accessed on 3 June 2020).
- Abbas, H.; Garberson, F.; Glover, E.; Wall, D.P. Machine learning approach for early detection of autism by combining questionnaire and home video screening. J. Am. Med Informatics Assoc. 2018, 25, 1000–1007. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Erkan, U.; Thanh, D.N.H. Autism Spectrum Disorder Detection with Machine Learning Methods. Curr. Psychiatry Res. Rev. 2020, 15, 297–308. [Google Scholar] [CrossRef]
- Raj, S.; Masood, S. Analysis and Detection of Autism Spectrum Disorder Using Machine Learning Techniques. Procedia Comput. Sci. 2020, 167, 994–1004. [Google Scholar] [CrossRef]
- University of California Irvine (UCI). Available online: http://archive.ics.uci.edu/ml/index.php (accessed on 11 May 2020).
- Duda, M.; Ma, R.; Haber, N.; Wall, D.P. Use of machine learning for behavioral distinction of autism and ADHD. Transl. Psychiatry 2016, 6, e732. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, H.; Brock, A.; Simonyan, K.; Le, Q.V. Evolving Normalization-Activation Layers. arXiv 2020, arXiv:2004.02967v5. [Google Scholar]
- Pinaya, W.H.L.; Vieira, S.; Garcia-Dias, R.; Mechelli, A. Autoencoders. In Machine Learning; Academic Press: Cambridge, MA, USA, 2020; pp. 193–208. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, H.; Zhao, S. Auto-encoder based dimensionality reduction. Neurocomputing 2016, 184, 232–242. [Google Scholar] [CrossRef]
- Karen, S.; Andrew, Z. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Traore, B.B.; Kamsu-Foguem, B.; Tangara, F. Deep convolution neural network for image recognition. Ecol. Inform. 2018, 48, 257–268. [Google Scholar] [CrossRef] [Green Version]
- Activation Functions Neural Networks. Available online: https://towardsdatascience.com/activation-functions-neural-networks-1cbd9f8d91d6 (accessed on 22 May 2020).
- Kernel Functions for Machine Learning Applications. Available online: http://crsouza.com/2010/03/17/kernel-functions-for-machine-learning-applications/ (accessed on 22 May 2020).
- Ridge Regression and Classification. Available online: https://scikit-learn.org/stable/modules/linear_model.html#ridge-regression-and-classification (accessed on 22 May 2020).
- Random Forests Classifier Python. Available online: https://www.datacamp.com/community/tutorials/random-forests-classifier-python (accessed on 17 May 2020).
- Random Forest Classifier. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html (accessed on 3 June 2020).
- KNeighbors Classifier. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html (accessed on 22 May 2020).
- Mitchell, T. Machine Learning; MIT Press: Cambridge, MA, USA; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Nwankpa, C.; Ijomah, W.; Gachagan, A.; Marshall, S. Activation Functions: Comparison of trends in Practice and Research for Deep Learning. arXiv 2018, arXiv:1811. [Google Scholar]
- Large set Brain Scans. Available online: https://www.spectrumnews.org/news/large-set-brain-scans-reveals-no-telltale-signs-autism/ (accessed on 13 May 2020).
- Deep Learning. Available online: https://www.deeplearningbook.org/ (accessed on 3 June 2020).
- Model Evaluation. Available online: https://scikit-learn.org/stable/modules/model_evaluation.html (accessed on 11 July 2020).
- Kashef, R.; Kamel, M. Distributed cooperative hard-fuzzy document clustering. In Proceedings of the Annual Scientific Conference of the LORNET Research Network, Montreal, QC, Canada, November 2006; Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.612.3974&rep=rep1&type=pdf (accessed on 11 July 2020).
- Ibrahim, A.; Rayside, D.; Kashef, R. Cooperative based software clustering on dependency graphs. In Proceedings of the 2014 IEEE 27th Canadian Conference on Electrical and Computer Engineering (CCECE), Toronto, ON, Canada, 4–7 May 2014. [Google Scholar]
- Abu-Zeid, N.; Kashif, R.; Badawy, O.M. Immune based clustering for medical diagnostic systems. In Proceedings of the 2012 International Conference on Advanced Computer Science Applications and Technologies (ACSAT), Kuala Lumpur, Malaysia, 26–28 November 2012. [Google Scholar]
- F1-Score. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html (accessed on 11 July 2020).
- Kashef, R.; Kamel, M.S. Towards better outliers detection for gene expression datasets. In Proceedings of the 2008 International Conference on Biocomputation, Bioinformatics, and Biomedical Technologies, Bucharest, Romania, 29 June–5 July 2008. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy % | Sensitivity % | Specificity % |
|---|---|---|---|
| Autoencoder–CNN | 84.05 | 80 | 75.3 |
| Evo Norm CNN | 74 | 71.33 | 65.2 |
| SVM | 60.2 | 35.1 | 84.1 |
| Autoencoder–SVM | 69.1 | 66.5 | 71.69 |
| Random Forest (RF) | 61.5 | 53.8 | 68.8 |
| Autoencoder–RF | 65.3 | 58.3 | 72.1 |
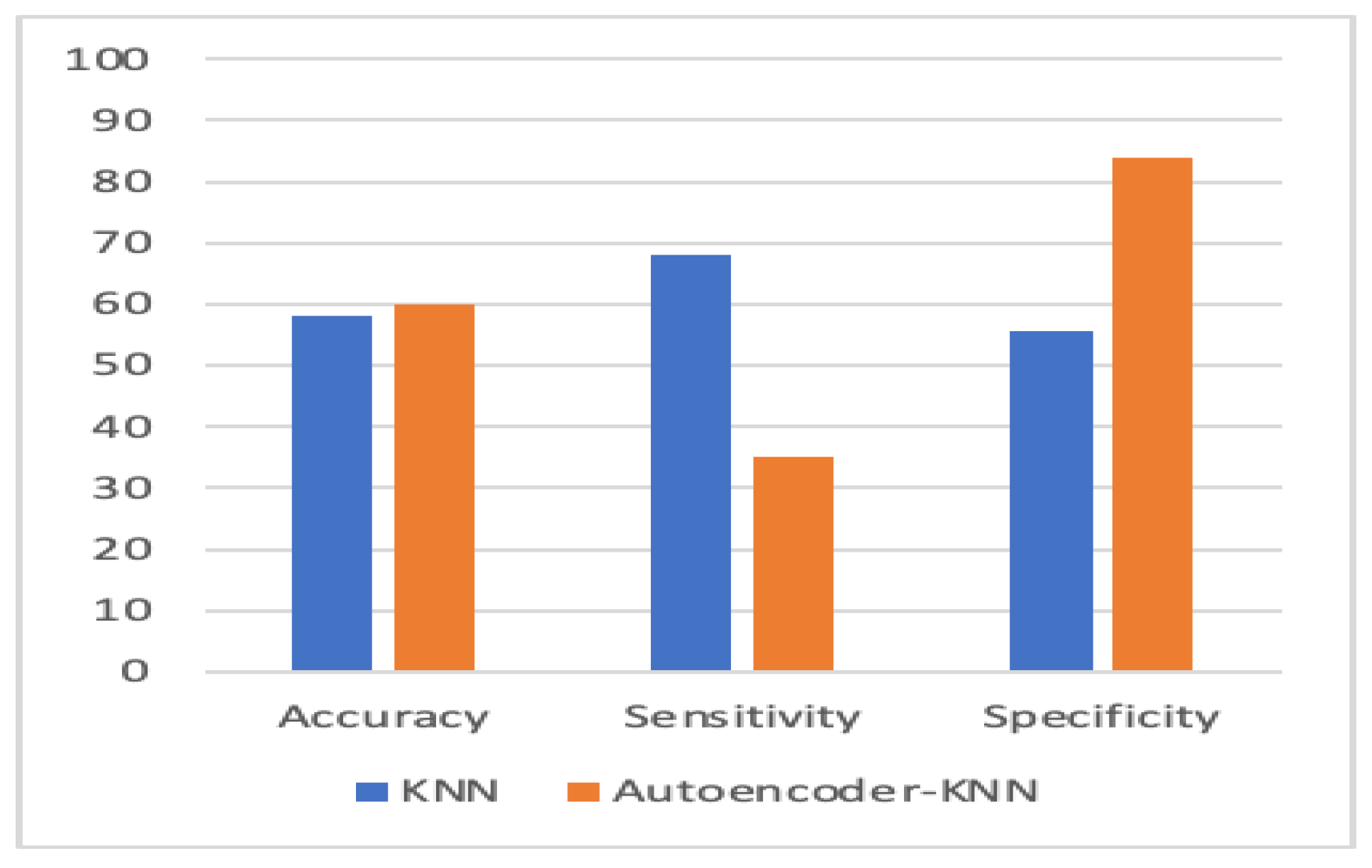
| KNN | 58.1 | 68.2 | 55.5 |
| Autoencoder–KNN | 60.1 | 35 | 84 |
| Model | Accuracy % | Sensitivity % | Specificity % |
|---|---|---|---|
| Autoencoder–CNN | 10.05% | 8.67% | 10.1% |
| Autoencoder–SVM | 8.9% | 31.4% | −12.41% |
| Autoencoder–RF | 3.8% | −0.5% | 3.3% |
| Autoencoder–KNN | 2% | −33.2% | 28.5% |
| Model | Accuracy % | Sensitivity % | Specificity % | AUC |
|---|---|---|---|---|
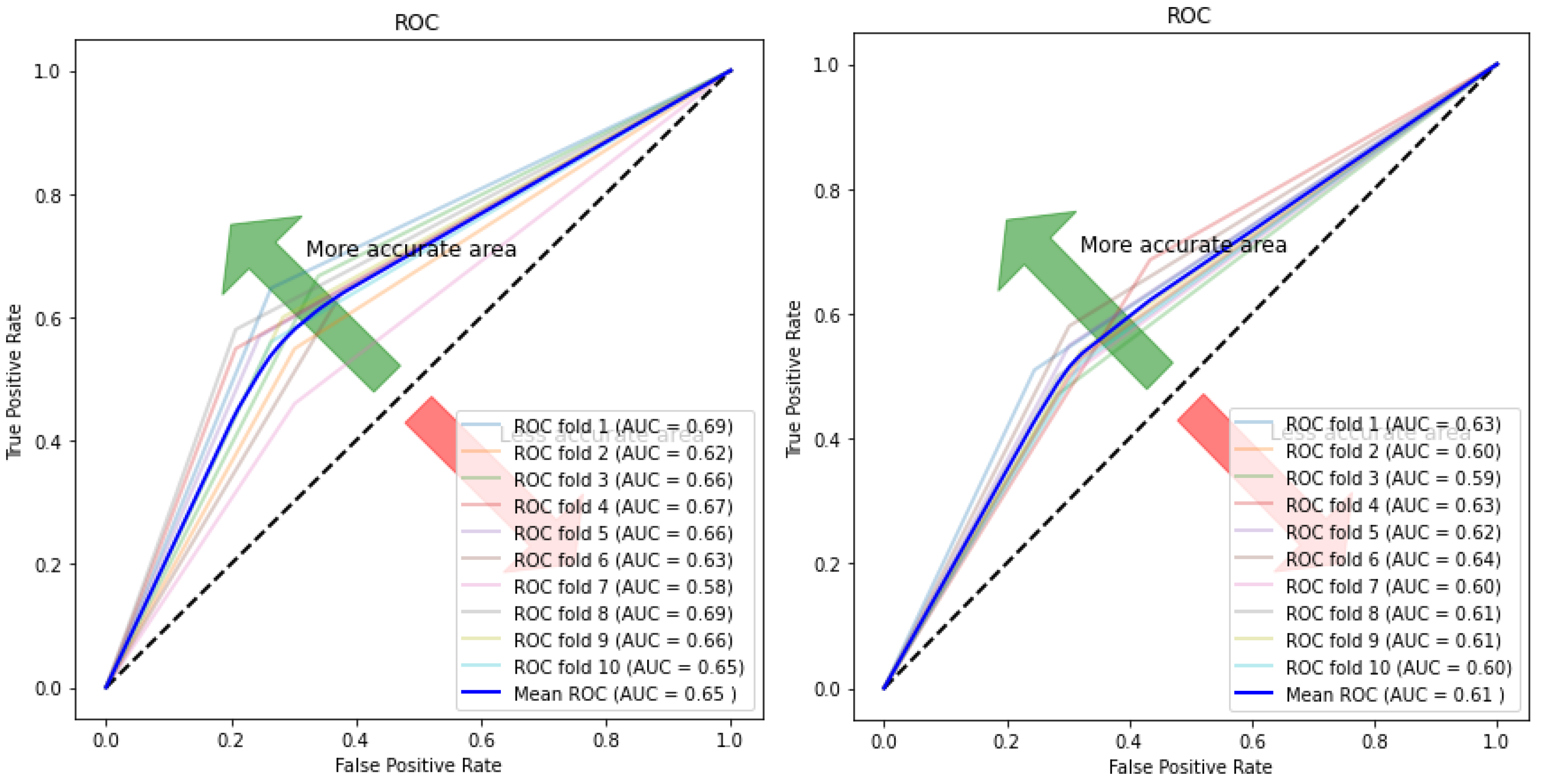
| KNN | 0.582 (+/−) 0.02 | 0.682 (+/−) 0.07 | 0.555 (+/−) 0.02 | 0.58 (+/−) 0.02 |
| Autoencoder–KNN | 0.601 (+/−) 0.035 | 0.35 (+/−) 0.09 | 0.84 (+/−) 0.08 | 0.595 (+/−) 0.03 |
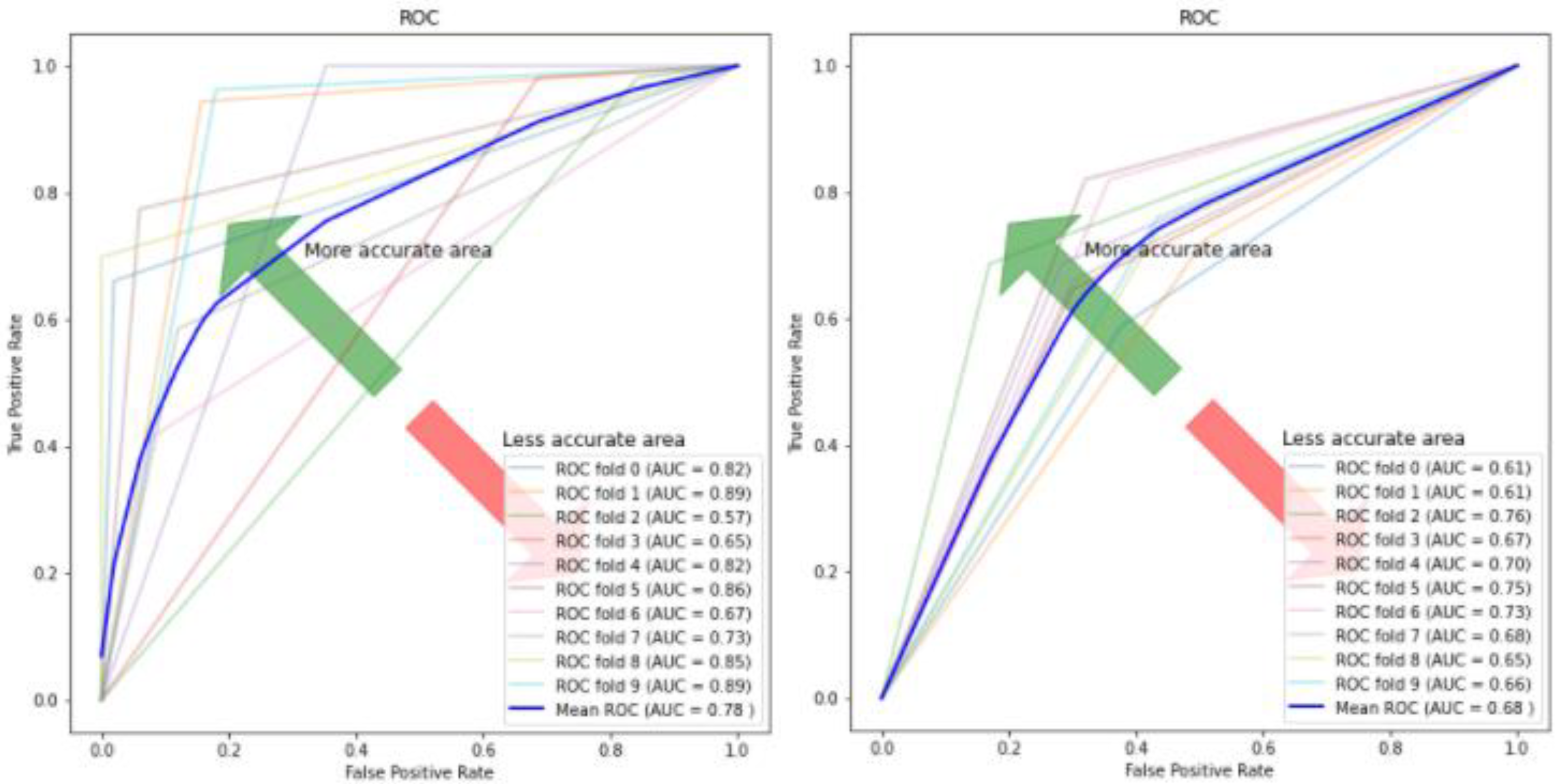
| Evo Norm CNN | 0.743 (+/−) 0.05 | 0.713 (+/−) 0.07 | 0.652 (+/−) 0.09 | 0.68 (+/−) 0.05 |
| Autoencoder–CNN | 0.84 (+/−) 0.07 | 0.8 (+/−) 0.19 | 0.753 (+/−) 0.22 | 0.78 (+/−) 0.11 |
| RF | 0.615 (+/−) 0.01 | 0.583 (+/−) 0.06 | 0.688 (+/−) 0.04 | 0.612 (+/−) 0.01 |
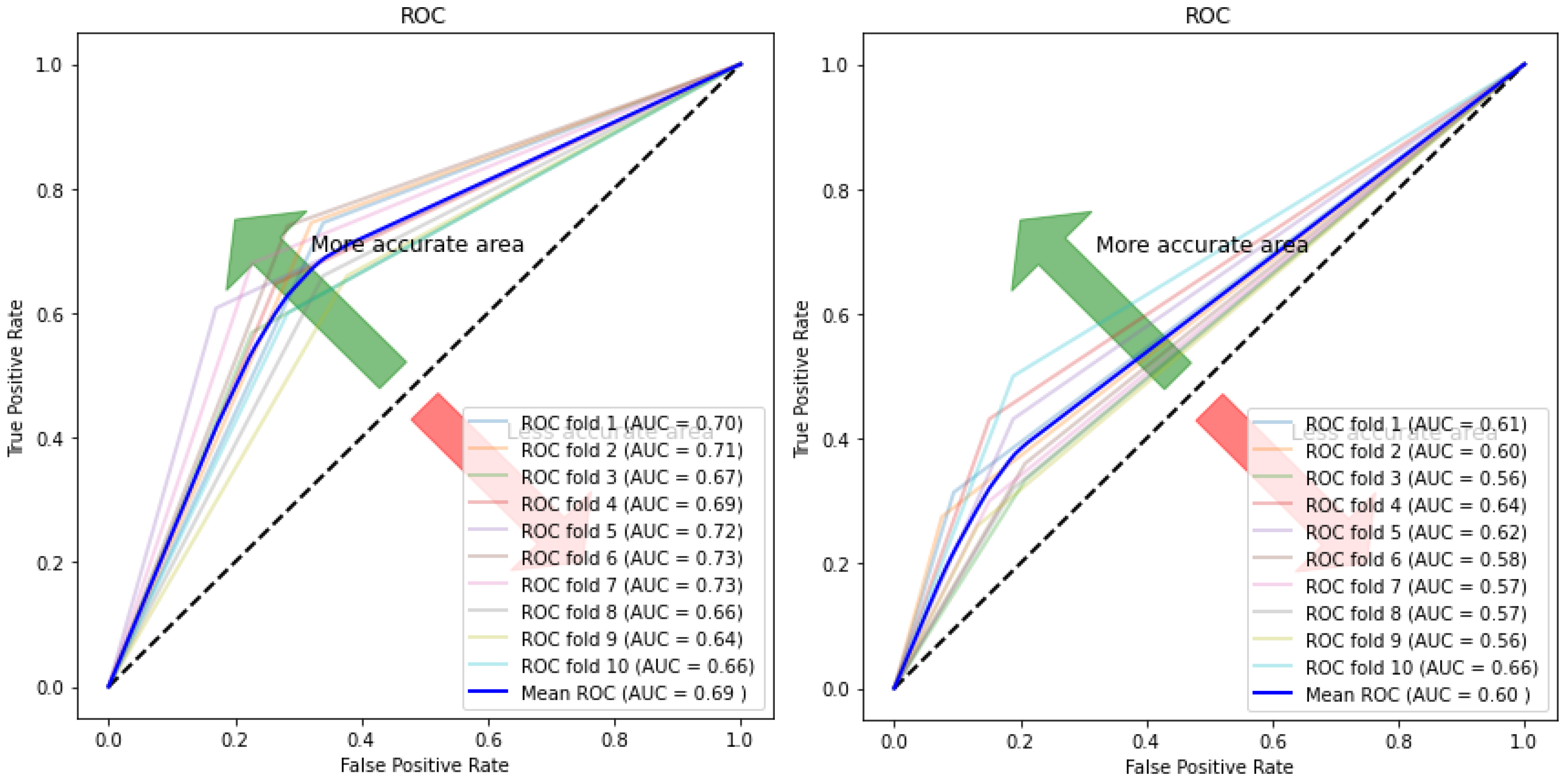
| Autoencoder–RF | 0.653 (+/−) 0.02 | 0.583 (+/−) 0.06 | 0.721 (+/−) 0.05 | 0.651 (+/−) 0.03 |
| SVM | 0.603 (+/−) 0.03 | 0.351 (+/−) 0.07 | 0.841 (+/−) 0.04 | 0.6 (+/−) 0.03 |
| Autoencoder–SVM | 0.691 (+/−) 0.03 | 0.665 (+/−) 0.06 | 0.716 (+/−) 0.06 | 0.69 (+/−) 0.03 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sewani, H.; Kashef, R. An Autoencoder-Based Deep Learning Classifier for Efficient Diagnosis of Autism. Children 2020, 7, 182. https://doi.org/10.3390/children7100182
Sewani H, Kashef R. An Autoencoder-Based Deep Learning Classifier for Efficient Diagnosis of Autism. Children. 2020; 7(10):182. https://doi.org/10.3390/children7100182
Chicago/Turabian StyleSewani, Harshini, and Rasha Kashef. 2020. "An Autoencoder-Based Deep Learning Classifier for Efficient Diagnosis of Autism" Children 7, no. 10: 182. https://doi.org/10.3390/children7100182
APA StyleSewani, H., & Kashef, R. (2020). An Autoencoder-Based Deep Learning Classifier for Efficient Diagnosis of Autism. Children, 7(10), 182. https://doi.org/10.3390/children7100182