
Variable Selection Algorithm for a Mixture of Poisson Regression for Handling Overdispersion in Claims Frequency Modeling Using Telematics Car Driving Data



{kind=link}
Abstract
:1. Introduction
2. Literature Survey
2.1. A General Review
2.2. A Review of Mixture Poisson Regression Models and Subset Covariate Selection
3. An Algorithm for Subset Covariate Selection
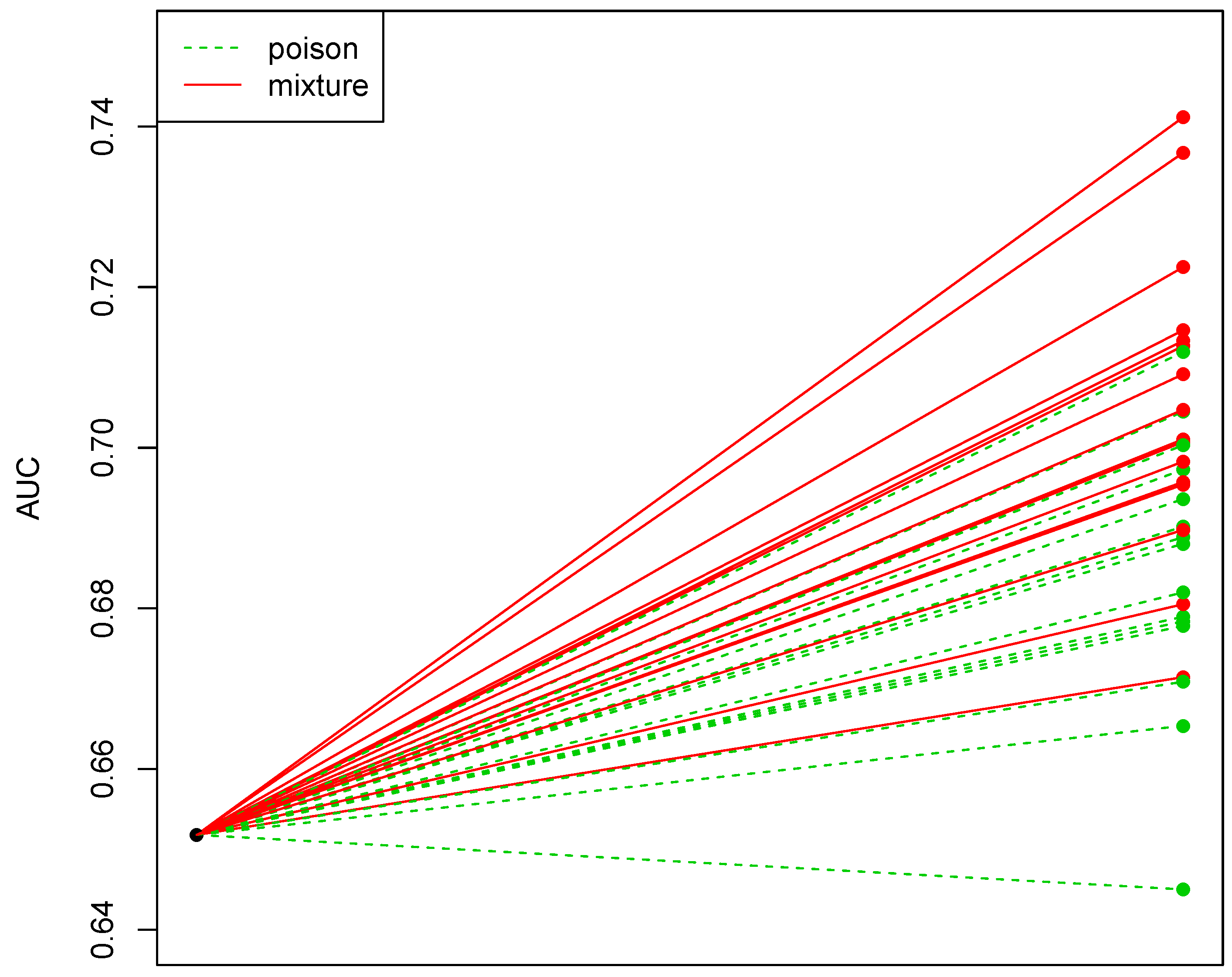
4. Discussion of Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ayuso, Mercedes, Montserrat Guillen, and Jens Perch Nielsen. 2019. Improving automobile insurance ratemaking using telematics: Incorporating mileage and driver behaviour data. Transportation 46: 735–52. [Google Scholar] [CrossRef] [Green Version]
- Barrio, Irantzu, Inmaculada Arostegui, María-Xose Rodríguez-Álvarez, and Jose-María Quintana. 2017. A new approach to categorising continuous variables in prediction models: Proposal and validation. Statistical Methods in Medical Research 26: 2586–602. [Google Scholar] [CrossRef] [PubMed]
- Bekkar, Mohamed, Hassiba K. Djemaa, and Taklit A. Alitouche. 2013. Evaluation measures for models assessment over imbalanced data sets. Journal of Information Engineering and Applications 3: 27–38. [Google Scholar]
- Bermúdez, Lluis, Dimitris Karlis, and Isabel Morillo. 2020. Modeling Unobserved Heterogeneity in Claim Counts Using Finite Mixture Models. Risks 8: 10. [Google Scholar] [CrossRef] [Green Version]
- Brown, Garfield O., Steve Brooks, and Winston Buckley. 2015. Experience rating with Poisson mixtures. Annals of Actuarial Science 9: 304–21. [Google Scholar] [CrossRef] [Green Version]
- Boucher, Jean-Philippe, Michel Denuit, Montserrat Guillén, and Philip Morrison. 2007. Risk classification for claim counts: A comparative analysis of various zeroinflated mixed Poisson and hurdle models. North American Actuarial Journal 11: 110–31. [Google Scholar] [CrossRef] [Green Version]
- Cameron, A. Colin, and Pravin K. Trivedi. 2013. Regression Analysis of Count Data. Cambridge: Cambridge University Press, vol. 53. [Google Scholar]
- Dai, Lin, Junhui Yin, Zhengfen Xie, and Liucang Wu. 2019. Robust variable selection in finite mixture of regression models using the t distribution. Communications in Statistics-Theory and Methods 48: 5370–86. [Google Scholar] [CrossRef]
- Denuit, Michel, Xavier Maréchal, Sandra Pitrebois, and Jean-Francois F. Walhin. 2007. Actuarial Modeling of Claim Counts: Risk Classification, Credibility and Bonus-Malus Systems. Hoboken: John Wiley & Sons. [Google Scholar]
- Devijver, Emilie. 2015. Finite mixture regression: A sparse variable selection by model selection for clustering. Electronic Journal of Statistics 9: 2642–74. [Google Scholar] [CrossRef]
- Dionne, Georges, and Charles Vanasse. 1992. Automobile insurance ratemaking in the presence of asymmetrical information. Journal of Applied Econometrics 7: 149–65. [Google Scholar] [CrossRef]
- Duan, Zhenmin, Yonglian Chang, Qi Wang, Tianyao Chen, and Qing Zhao. 2018. A logistic regression based auto insurance rate-making model designed for the insurance rate reform. International Journal of Financial Studies 6: 18. [Google Scholar] [CrossRef] [Green Version]
- de Figueiredo, Miguel, Christophe B. Y. Cordella, Delphine J. R. Bouveresse, Xavier Archer, Jean-Marc Bégué, and Douglas N. Rutledge. 2018. A variable selection method for multiclass classification problems using two-class ROC analysis. Chemometrics and Intelligent Laboratory Systems 177: 35–46. [Google Scholar] [CrossRef] [Green Version]
- Everitt, Brian S., and David J. Hand. 1981. Finite Mixture Distributions. London: Chapman and Hall. [Google Scholar]
- Flynn, Mathew. 2009. More Flexible GLMs Zero-Inflated Models and Hybrid Models. Casualty Actuarial Society E-Forum, 148–224. Available online: https://www.casact.org/pubs/forum/09wforum/flynn_francis.pdf (accessed on 20 March 2021).
- Fruhwirth-Schnatter, Sylvia, Gilles Celeux, and Christian P. Robert. 2019. Handbook of Mixture Analysis. London: Chapman and Hall/CRC. [Google Scholar]
- Gruen, Bettina, Friedrich Leisch, Deepayan Sarkar, Frederic Mortier, Nicolas Picard, and Maintainer Bettina Gruen. 2019. Package ‘Flexmix’. Available online: https://mran.microsoft.com/snapshot/2016-06-0/web/packages/flexmix/index.html (accessed on 22 June 2016).
- Grun, Bettina, and Friedrich Leisch. 2007. FlexMix: An R Package for Finite Mixture Modeling. Available online: https://cran.r-project.org/web/packages/flexmix/vignettes/flexmix-intro.pdf (accessed on 22 March 2021).
- Guillen, Montserrat, Jens Perch Nielsen, Mercedes Ayuso, and Ana M. Pérez-Marín. 2019. The use of telematics devices to improve automobile insurance rates. Risk Analysis 39: 662–72. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Shuang, Guanghua Xiao, Andrew Y. Koh, Jiwoong Kim, Qiwei Li, and Xiaowei Zhan. 2021. A Bayesian zero-inflated negative binomial regression model for the integrative analysis of microbiome data. Biostatistics 22: 522–40. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Karlis, Dimitris. 2019. Mixture modeling of Discrete Data. In Handbook of Mixture Analysis. London: Chapman and Hall/CRC, pp. 193–218. [Google Scholar]
- Khalili, Abbas, and Jiahua Chen. 2007. Variable selection in finite mixture of regression models. Journal of the American Statistical Association 102: 1025–38. [Google Scholar] [CrossRef] [Green Version]
- Khalili, Abbas, Jiahua Chen, and Shili Lin. 2011. Feature selection in finite mixture of sparse normal linear models in high-dimensional feature space. Biostatistics 12: 156–72. [Google Scholar] [CrossRef] [Green Version]
- Krzanowski, Wojtek J., and David J. Hand. 2009. ROC Curves for Continuous Data. Boca Raton: CRC Press. [Google Scholar]
- Lambert, Diane. 1992. Zero-inflated Poisson regression, with an application to defects in manufacturing. Technometrics 34: 1–14. [Google Scholar] [CrossRef]
- Leisch, Friedrich. 2004. Flexmix: A General Framework for Finite Mixture Models and Latent Glass Regression in R. Available online: https://ro.uow.edu.au/cgi/viewcontent.cgi?article=1489&context=buspapers (accessed on 18 October 2004).
- McLachlan, Geoffrey J., and David Peel. 2004. Finite Mixture Models. Hoboken: John Wiley & Sons. [Google Scholar]
- McLachlan, Geoffrey J., Sharon X. Lee, and Suren I. Rathnayake. 2019. Finite mixture models. Annual Review of Statistics and Its Application 6: 355–78. [Google Scholar] [CrossRef]
- Miller, Alan. 2002. Subset Selection in Regression. London: Chapman and Hall/CRC. [Google Scholar]
- Muoka, Alexander Kasyoki, Oscar Owino Ngesa, and Anthony Gichuhi Waititu. 2016. Statistical models for count data. Science Journal of Applied Mathematics and Statistics 4: 256–62. [Google Scholar] [CrossRef] [Green Version]
- Ormoz, Ehsan, and Farzad Eskandari. 2016. Variable selection in finite mixture of semi-parametric regression models. Communications in Statistics-Theory and Methods 45: 695–711. [Google Scholar] [CrossRef]
- Park, Byung-Jung, and Dominique Lord. 2009. Application of finite mixture models for vehicle crash data analysis. Accident Analysis and Prevention 41: 683–91. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Park, Byung-Jung, Dominique Lord, and Chungwon Lee. 2014. Finite mixture modeling for vehicle crash data with application to hotspot identification. Accident Analysis & Prevention 71: 319–26. [Google Scholar]
- Park, Byung-Jung, Dominique Lord, and Lingtao Wu. 2016. Finite mixture modeling approach for developing crash modification factors in highway safety analysis. Accident Analysis & Prevention 97: 274–87. [Google Scholar]
- Ren, Xu, and Pei-Fen Kuan. 2020. Negative binomial additive model for RNA-Seq data analysis. BMC Bioinformatics 21: 171. [Google Scholar] [CrossRef] [PubMed]
- Sarul, Latife Sinem, and Serap Sahin. 2015. An application of claim frequency data using zero inflated and hurdle models in general insurance. Journal of Business Economics and Finance 4: 732–43. [Google Scholar] [CrossRef] [Green Version]
- Serrano, Antonio J., Emilio Soria Olivas, Jose D. Martín-Guerrero, Rafael Magdalena, and Juan Gomez-Sanchis. 2010. Feature selection using roc curves on classification problems. Paper presented at IEEE 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, July 18–23; pp. 1–6. [Google Scholar]
- Siami, Mohammad, Mohsen Naderpour, and Jie Lu. 2020. A Mobile Telematics Pattern Recognition Framework for Driving Behavior Extraction. IEEE Transactions on Intelligent Transportation Systems 22: 1459–72. [Google Scholar] [CrossRef]
- Steinmetz, Holger. 2015. Problems with the Flexmix-Package in R for Using Mixture Regression Models. Available online: https://www.researchgate.net/post/Problems_with_the_flexmix-package_in_R_for_using_mixture_regression_models (accessed on 7 May 2015).
- Stroiński, Krzysztof J., and Iain D. Currie. 1989. Selection of variables for automobile insurance rating. Insurance: Mathematics and Economics 8: 35–46. [Google Scholar] [CrossRef]
- Tang, Qingguo, and Rohana J. Karunamuni. 2018. Robust variable selection for finite mixture regression models. Annals of the Institute of Statistical Mathematics 70: 489–521. [Google Scholar] [CrossRef]
- Titterington, D. Michael, Adrian F. M. Smith, and Udi E. Makov. 1985. Statistical Analysis of Finite Mixture Distributions. Chichester: John Wiley & Sons Ltd. [Google Scholar]
- Tselentis, Dimitrios I., George Yannis, and Eleni I. Vlahogianni. 2017. Innovative motor insurance schemes: A review of current practices and emerging challenges. Accident Analysis & Prevention 98: 139–48. [Google Scholar]
- Van Dijk, B. 2009. Essays on Finite Mixture Models (No. 458). Tinbergen Institute Research Series; Amsterdam: Tinbergen Institute. [Google Scholar]
- Verbelen, Roel, Katrien Antonio, and Gerda Claeskens. 2018. Unravelling the predictive power of telematics data in car insurance pricing. Journal of the Royal Statistical Society: Series C (Applied Statistics) 67: 1275–304. [Google Scholar] [CrossRef] [Green Version]
- Vuong, Quang H. 1989. Likelihood ratio tests for model selection and non-nested hypotheses. Econometrica: Journal of the Econometric Society 57: 307–33. [Google Scholar] [CrossRef] [Green Version]
- Wagh, Yogita S., and Kirtee K. Kamalja. 2018. Zero-inflated models and estimation in zero-inflated Poisson distribution. Communications in Statistics-Simulation and Computation 47: 2248–65. [Google Scholar] [CrossRef]
- Winkelmann, Rainer. 2008. Econometric Analysis of Count Data, 5th ed. Berlin: Springer. [Google Scholar]
- Wixted, John T., Laura Mickes, Stacy A. Wetmore, Scott D. Gronlund, and Jeffrey S. Neuschatz. 2017. ROC analysis in theory and practice. Journal of Applied Research in Memory and Cognition 6: 343–51. [Google Scholar] [CrossRef]
- Xu, Jian-Wu, and Kenji Suzuki. 2013. Max-AUC feature selection in computer-aided detection of polyps in CT colonography. IEEE Journal of Biomedical and Health Informatics 18: 585–93. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yin, Junhui, Liucang Wu, and Lin Dai. 2020. Variable selection in finite mixture of regression models using the skew-normal distribution. Journal of Applied Statistics 47: 2941–60. [Google Scholar] [CrossRef]
- Yip, Karen C. H., and Kelvin K. W. Yau. 2005. On modeling claim frequency data in general insurance with extra zeros. Insurance: Mathematics and Economics 36: 153–63. [Google Scholar] [CrossRef]
- Zahi, Jamal. 2021. Non-life insurance ratemaking techniques. International Journal of Accounting. Finance, Auditing, Management and Economics 2: 344–61. [Google Scholar]
- Zamzuri, Zamira Hasanah, Mohd Syafiq Sapuan, and Kamarulzaman Ibrahim. 2018. The Extra Zeros in Traffic Accident Data: A Study on the Mixture of Discrete Distributions. Sains Malaysiana 47: 1931–40. [Google Scholar] [CrossRef]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chan, J.S.K.; Choy, S.T.B.; Makov, U.; Shamir, A.; Shapovalov, V. Variable Selection Algorithm for a Mixture of Poisson Regression for Handling Overdispersion in Claims Frequency Modeling Using Telematics Car Driving Data. Risks 2022, 10, 83. https://doi.org/10.3390/risks10040083
Chan JSK, Choy STB, Makov U, Shamir A, Shapovalov V. Variable Selection Algorithm for a Mixture of Poisson Regression for Handling Overdispersion in Claims Frequency Modeling Using Telematics Car Driving Data. Risks. 2022; 10(4):83. https://doi.org/10.3390/risks10040083
Chicago/Turabian StyleChan, Jennifer S. K., S. T. Boris Choy, Udi Makov, Ariel Shamir, and Vered Shapovalov. 2022. "Variable Selection Algorithm for a Mixture of Poisson Regression for Handling Overdispersion in Claims Frequency Modeling Using Telematics Car Driving Data" Risks 10, no. 4: 83. https://doi.org/10.3390/risks10040083
APA StyleChan, J. S. K., Choy, S. T. B., Makov, U., Shamir, A., & Shapovalov, V. (2022). Variable Selection Algorithm for a Mixture of Poisson Regression for Handling Overdispersion in Claims Frequency Modeling Using Telematics Car Driving Data. Risks, 10(4), 83. https://doi.org/10.3390/risks10040083