_Bryant.png)
Federated Secure Computing


Abstract
:1. Introduction
2. Materials and Methods
2.1. Pain Points and Design Goals
2.2. Resulting Architecture
2.3. Overall Concept of Federated Secure Computing
2.4. Client–Server Topologies
2.4.1. Example 1: Clients Act as Data and Researcher Nodes and Servers Act as Compute nodes
2.4.2. Example 2: Servers Act as Data and Compute Nodes, and a Single Client Acts as Researcher Node
2.4.3. Example 3: Servers Run Middleware Only, and Additional Compute Nodes Are in the Backend
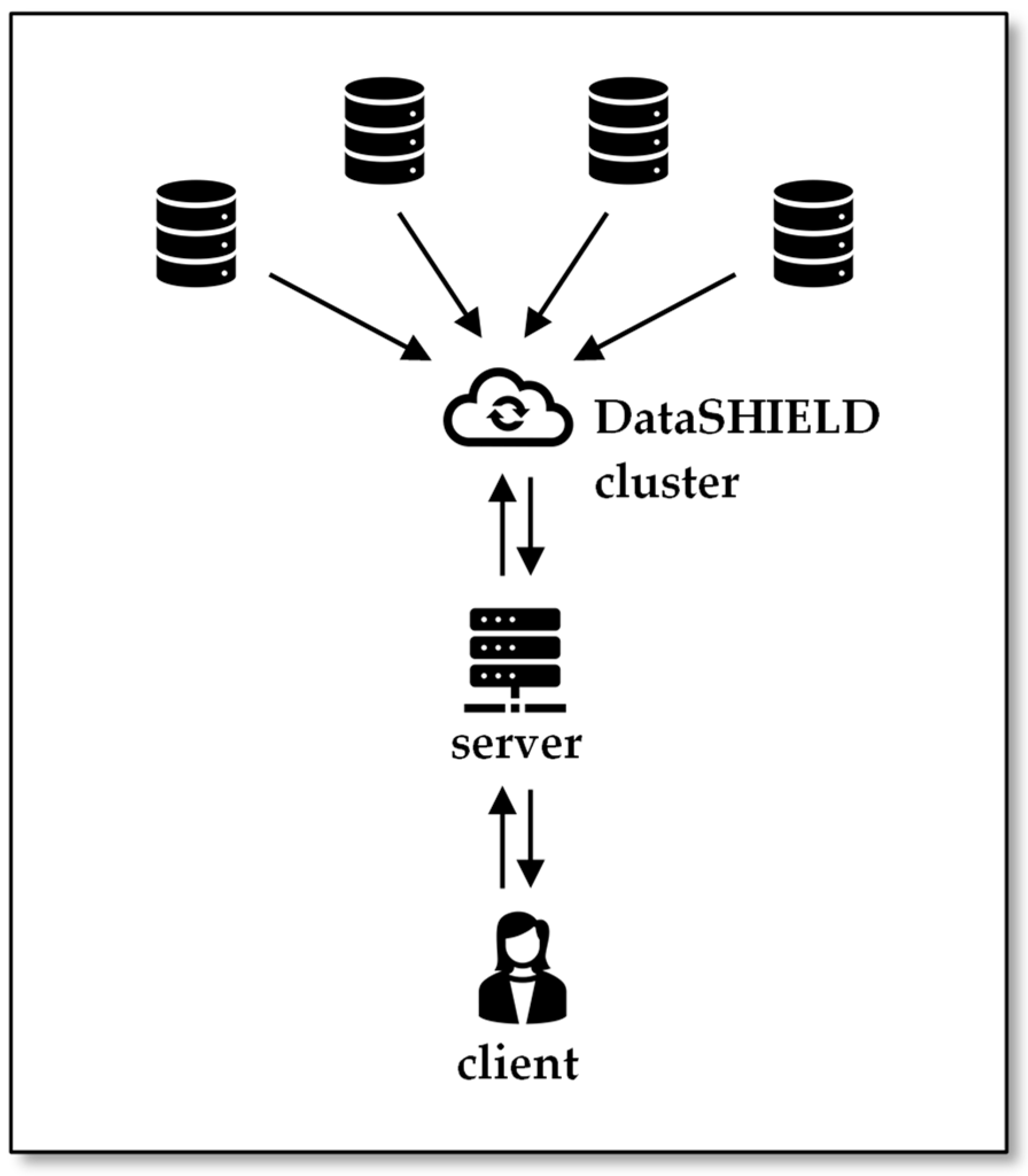
2.4.4. Example 4: DataSHIELD
2.4.5. Heterogeneous Networks
2.5. Client-Side Stack
2.5.1. Representation of Server-Side Objects
| Listing 1. Example of how client-side code should interact with server-side objects. |
| import federatedsecure.client # connect to the server, return API handle api = federatedsecure.client.connect(“https://my.server”) # find a microservice that matches some requirements microservice = api.create(functionality = “can do some stuff”}) # connect to some specific server-side database database = api.create(connector = “myconnector”, version = “1.2.3”) # fetch input data data = database.get_handle().query(row = 2, column = 5) # do some server-side computation result = microservice.compute(data) # download and output the result print(api.download(result)) |
| Listing 2. Representation class (simplified). |
| Class Representation: def __init__(self, api, uuid): self.api = api self.uuid = uuid def __getattr__(self, member_name): return self.api.attribute(self.uuid, member_name) def __call__(self, *args, **kwargs): return self.api.call(self.uuid, *args, **kwargs) |
| Listing 3. In some languages, client code will be more verbose than in Python. |
| source (“…/federatedsecure/client.r”) # connect to the server, return API handle api <- Api(“https://my.server”) # find a microservice that matches some requirements microservice <- api$create(kwargs = list( functionality = “can do some stuff”)) # connect to some specific server-side database database <- api$create(kwargs = list( connector = “myconnector”, version = “1.2.3”)) # fetch input data func_handle <- database$attribute(“get_handle”) handle <- func_handle$call() func_query <- handle$attribute(“query”) data <- func_query$call(list(row = 2, column = 5)) # do some server-side computation func_compute <- microservice$attribute(“compute”) result <- func_compute$call(list(data = data)) # download and output the result print(api$download(result)) |
2.5.2. API Wrapper
| Listing 4. Api class (simplified). |
| class Api: def __init__(self, url): self.http = HttpInterface(url) def list(self): return self.http.GET('representations') def create(self, *args, **kwargs): response = self.http.POST('representations', body = {'args': args, 'kwargs': kwargs}) return Representation(self, response['uuid']) def upload(self, *args, **kwargs): response = self.http.PUT('representations', body = {'args': args, 'kwargs': kwargs}) return Representation(self, response['uuid']) def call(self, uuid, *args, **kwargs): response = self.http.PATCH('representation', uuid, body = {'args': args, 'kwargs': kwargs}) return Representation(self, response['uuid']) def attribute(self, uuid, attr): response = self.http.GET('representation', uuid, attr) return Representation(self, response['uuid']) def download(self, representation): response = self.http.GET('representation', representation.uuid) return response['object'] def release(self, uuid): self.http.DELETE('representation', uuid) return None |
2.5.3. Client Design Considerations
2.6. Server-Side Stack
2.6.1. Registry, Discovery, and Bus
2.6.2. OpenAPI 3.0
| Listing 5. Open API 3.0 definition (excerpt). |
| /representation/{representation_uuid}: patch: summary: call a server-side object description: call a server-side object such as a static function, a member function, or in case of a class, its constructor operationId: call_representation parameters: - in: path name: representation_uuid required: true schema: type: string format: uuid requestBody: $ref: '#/components/requestBodies/ArgsKwargs' responses: '200': $ref: '#/components/responses/ResponseOk' 'default': $ref: '#/components/responses/ResponseError' |
2.6.3. Representation of Server-Side Objects
| Listing 6. Server-side implementation of calls to server-side objects (simplified). |
| def call_representation(self, representation_uuid, body): args, kwargs = self.get_arguments(body) pointer = self.lut_uuid_to_repr[representation_uuid] result = pointer(*args, **kwargs) if result is None: return None uuid = str(uuid.uuid4()) self.lut_uuid_to_repr[uuid] = result return uuid |
- Security consideration: The client should not be able to access any data on the server. This can be solved by restricting the download functionality to certain objects labeled as output. Proper object-level authorization is thus required in production settings.
- Best practice: The client should send appropriate delete requests to the server whenever client-side representations are discarded or going out of scope. This prevents a buildup of obsolete representations on the bus and memory leakage on the server. As the server cannot control the graceful termination of client-side scripts, additional garbage collection mechanisms may be a good idea. For example, automatic removal of unused representations after a certain grace period.
- Best practice: The server may keep look-up-tables for the representation of commonly used objects instead of issuing new UUIDs every time.
- Best practice: Implementation of microservices needs to balance the overhead of creating representations with microservice design. Few objects with many properties/methods each require fewer representations. Deeply nested object hierarchies, on the other hand, would lead to more intermediate handles being generated. Similarly, structures instead of many small arguments save representations: somemicroservice.somefunction(someargument) creates 3 representations while somemicroservice.somemodule.somesubmodule.somefunction(argument1, argument2, argument3) creates 7 representations. In particular, loops over function calls may create potentially very many representations, while calling a single function with a table or array would not.
2.6.4. Microservices
- (Required): One or more PPC protocols. These microservices will, at the minimum, provide functionality to build peer-to-peer networks with other servers, accept input data and generate cryptographic shares, and execute the PPC protocol. They may interact with their peers through the bus and the API or through their own third-party networks;
- (Probably required): Some basic microservices for synchronization, e.g., to broadcast public parameters of calculations to other nodes or to control the joint flow of computation through semaphores and other signals;
- (Optional): Helper microservices facilitation server-side integration into the non-cryptographic infrastructure. This includes interfaces to database prompts or interfaces to IoT data acquisition.
2.6.5. Webserver and API
- Security consideration: In a production setting, all the usual best practices of securing a webserver and API should be followed. In particular, user authentication and proper object-level authorization.
2.6.6. Programming Language
3. Results
3.1. Implementation
3.1.1. Namespaces
3.1.2. Packages
3.1.3. Repository Structure
3.1.4. Correspondence
3.1.5. Code Availability and Licensing
3.2. Installation
3.2.1. Server-Side Installation
| git clone https://github.com/federatedsecure/webserver-connexion cd webserver-connexion pip install -r requirements.txt |
| pip install federatedsecure-server pip install federatedsecure-simon |
| python ./src/__main__.py --port = 55500 |
| curl http://localhost:55500/representations |
3.2.2. Client-Side Installation
| pip install federatedsecure-client |
| import pip pip.main([‘install’, ‘federatedsecure-client’]) |
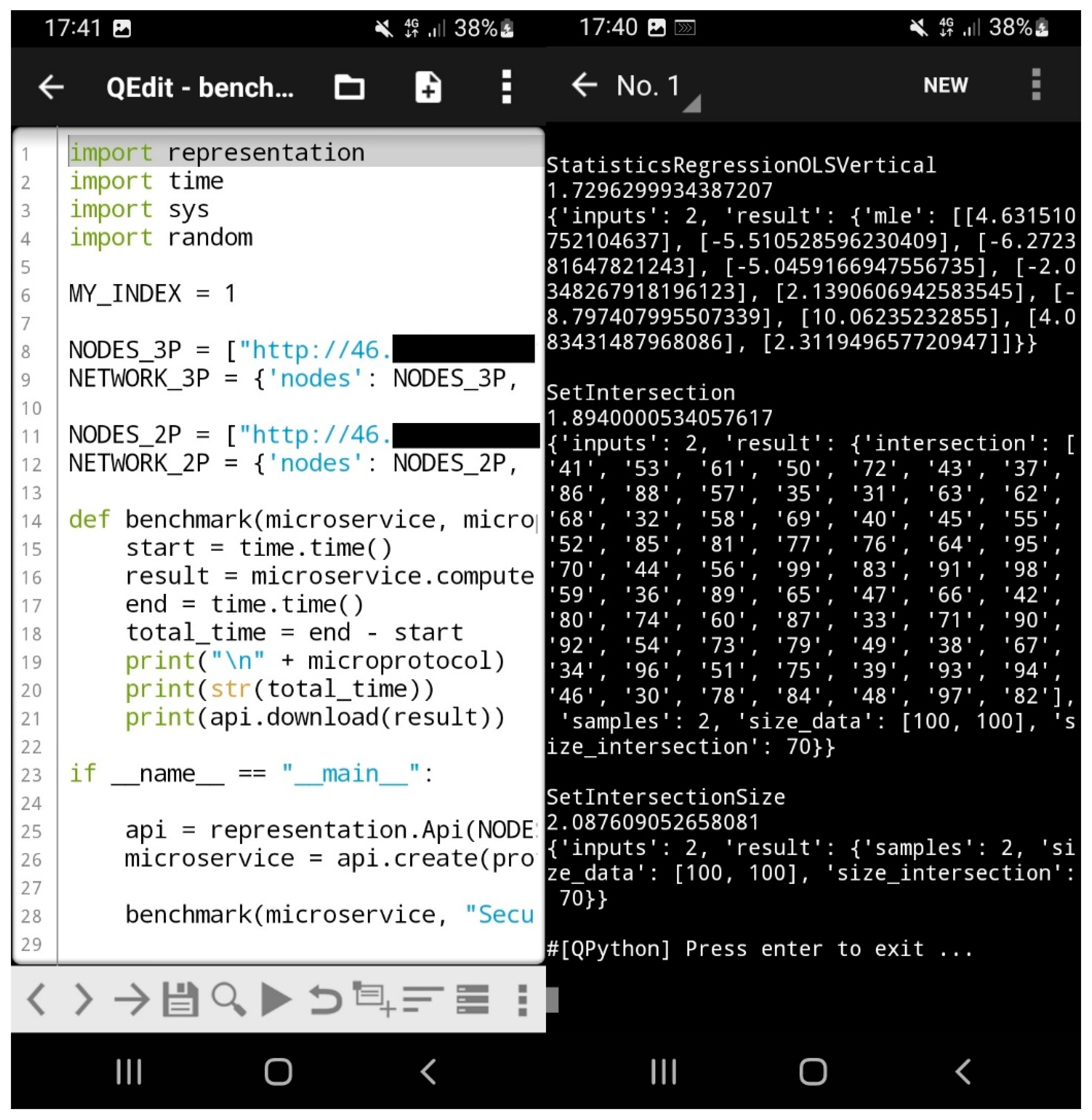
3.3. Benchmarks
3.3.1. Impact of Server Hardware
3.3.2. Impact of Server–Server Connectivity
3.3.3. Impact of Client–Server Connectivity
3.3.4. Code Size Benchmarks
3.3.5. Setup in IoT Environments
| import pip pip.main([‘install’, ‘federatedsecure-client’]) |
3.4. Other Computing Frameworks
3.4.1. Homomorphic Encryption with Amazon Web Services
3.4.2. Differential Privacy with DataSHIELD as Backend
3.4.3. Secure Multiparty Computation with Sharemind
4. Discussion
4.1. Project Background and Ownership
4.2. Project Status
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Deloitte. The Analytics Advantage; Deloitte: London, UK, 2013. [Google Scholar]
- AIG. The Data Sharing Economy: Quantifying Tradeoffs That Power New Business Models; AIG: New York, NY, USA, 2016. [Google Scholar]
- European Commission. Study on Data Sharing between Companies in Europe. 2018. Available online: https://op.europa.eu/s/y2R4 (accessed on 23 August 2023).
- TrustArc. TRUSTe/National Cyber Security Alliance U.S. Consumer Privacy Index; TrustArc: San Francisco, CA, USA, 2016. [Google Scholar]
- Yao, A.C. Protocols for secure computations. In Proceedings of the 2013 IEEE 54th Annual Symposium on Foundations of Computer Science, Chicago, IL, USA, 3–5 November 1982; pp. 160–164. [Google Scholar]
- Damgard, I.; Pastro, V.; Smart, N.; Zakarias, S. Multiparty Computation from Somewhat Homomorphic Encryption. In Proceedings of the 32nd Annual International Cryptology Conference (CRYPTO), University of California Santa Barbara, Santa Barbara, CA, USA, 19–23 August 2012; pp. 643–662. [Google Scholar]
- Gentry, C. Fully Homomorphic Encryption Using Ideal Lattices. In Proceedings of the 41st Annual ACM Symposium on Theory of Computing, Bethesda, MD, USA, 31 May–2 June 2009; pp. 169–178. [Google Scholar]
- Paillier, P. Public-key cryptosystems based on composite degree residuosity classes. In Advances in Cryptology—Eurocrypt'99; Stern, J., Ed.; Lecture Notes in Computer Science; Springer: Berlin, Germany, 1999; Volume 1592, pp. 223–238. [Google Scholar]
- Dwork, C. Differential privacy. In Automata, Languages and Programming, Pt 2; Bugliesi, M., Prennel, B., Sassone, V., Wegener, I., Eds.; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2006; Volume 4052, pp. 1–12. [Google Scholar]
- Dwork, C.; Roth, A. The Algorithmic Foundations of Differential Privacy. Found. Trends Theor. Comput. Sci. 2013, 9, 211–406. [Google Scholar] [CrossRef]
- Craddock, M.; Archer, D.W.; Bogdanov, D.; Gascon, A.; de Balle Pigem, B.; Laine, K.; Trask, A.; Raykova, M.; Jug, M.; McLellan, R.; et al. UN Handbook on Privacy-Preserving Computation Techniques. 2019. Available online: https://unstats.un.org/bigdata/task-teams/privacy/UN%20Handbook%20for%20Privacy-Preserving%20Techniques.pdf (accessed on 23 August 2023).
- Kolesnikov, V.; Schneider, T. Improved garbled circuit: Free XOR gates and applications. In Proceedings of the 35th International Colloquium on Automata, Languages and Programming, Reykjavik, Iceland, 7–11 July 2008; pp. 486–498. [Google Scholar]
- Shpilka, A.; Yehudayoff, A. Arithmetic Circuits: A Survey of Recent Results and Open Questions. Found. Trends Theor. Comput. Sci. 2009, 5, 207–388. [Google Scholar] [CrossRef]
- Bernstein, D.J. Curve25519: New Diffie-Hellman speed records. In Public Key Cryptography—Pkc 2006, Proceedings; Yung, M., Dodis, Y., Kiayias, A., Malkin, T., Eds.; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2006; Volume 3958, pp. 207–228. [Google Scholar]
- Diffie, W.; Hellman, M.E. New directions in cryptography. IEEE Trans. Inf. Theory 1976, 22, 644–654. [Google Scholar] [CrossRef]
- Rabin, M.O. How to Exchange Secrets with Oblivious Transfer; Aiken Computation Laboratory, Harvard University: Cambridge, MA, USA, 1981. [Google Scholar]
- Bogdanov, D.; Laur, S.; Willemson, J. Sharemind: A Framework for Fast Privacy-Preserving Computations. In Proceedings of the 13th European Symposium on Research in Computer Security, Malaga, Spain, 6–8 October 2008; pp. 192–206. [Google Scholar]
- Wirth, F.N.; Kussel, T.; Muller, A.; Hamacher, K.; Prasser, F. EasySMPC: A simple but powerful no-code tool for practical secure multiparty computation. BMC Bioinform. 2022, 23, 531. [Google Scholar] [CrossRef]
- Gay, W. Raspberry Pi Hardware Reference; Apress: Berkeley, CA, USA, 2014. [Google Scholar]
- Gaye, A.; Marcon, Y.; Isaeva, J.; LaFlamme, P.; Turner, A.; Jones, E.M.; Minion, J.; Boyd, A.W.; Newby, C.J.; Nuotio, M.L.; et al. DataSHIELD: Taking the analysis to the data, not the data to the analysis. Int. J. Epidemiol. 2014, 43, 1929–1944. [Google Scholar] [CrossRef] [PubMed]
- Wolfson, M.; Wallace, S.E.; Masca, N.; Rowe, G.; Sheehan, N.A.; Ferretti, V.; LaFlamme, P.; Tobin, M.D.; Macleod, J.; Little, J.; et al. DataSHIELD: Resolving a conflict in contemporary bioscience-performing a pooled analysis of individual-level data without sharing the data. Int. J. Epidemiol. 2010, 39, 1372–1382. [Google Scholar] [CrossRef] [PubMed]
- The Linux Foundation. New Collaborative Project to Extend Swagger Specification for Building Connected Applications and Services. 2015. Available online: https://www.linuxfoundation.org/press/press-release/new-collaborative-project-to-extend-swagger-specification-for-building-connected-applications-and-services (accessed on 23 August 2023).
- Krüger-Brand, H.E. Innovatives IT-Verfahren soll sensible Daten in der Krebsforschung schützen. Ärzteblatt. 2019. Available online: https://www.aerzteblatt.de/nachrichten/103090/Innovatives-IT-Verfahren-soll-sensible-Daten-in-der-Krebsforschung-schuetzen (accessed on 23 August 2023).
- Ballhausen, H.; von Maltitz, M.; Niyazi, M.; Kaul, D.; Belka, C.; Carle, G. Secure Multiparty Computation in Clinical Research and Digital Health. In Proceedings of the E-Science-Tage 2019, Heidelberg, Germany, 27–29 March 2019. [Google Scholar]
- von Maltitz, M.; Ballhausen, H.; Kaul, D.; Fleischmann, D.F.; Niyazi, M.; Belka, C.; Carle, G. A Privacy-Preserving Log-Rank Test for the Kaplan-Meier Estimator With Secure Multiparty Computation: Algorithm Development and Validation. JMIR Med. Inform. 2021, 9, e22158. [Google Scholar] [CrossRef] [PubMed]
- Keller, M. MP-SPDZ: A Versatile Framework for Multi-Party Computation. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security (ACM CCS), Virtual Event, 9–13 November 2020; pp. 1575–1590. [Google Scholar]
- Keller, M.; Pastro, V.; Rotaru, D. Overdrive: Making SPDZ Great Again. In Proceedings of the 37th Annual International Conference on the Theory and Applications of Cryptographic Techniques (EUROCRYPT), Tel Aviv, Israel, 29 April–3 May 2018; pp. 158–189. [Google Scholar]
- Keller, M.; Scholl, P. Efficient, Oblivious Data Structures for MPC. In Proceedings of the 20th Annual International Conference on the Theory and Application of Cryptology and Information Security (Asiacrypt), Kaoshiung, Taiwan, 7–11 December 2014; pp. 506–525. [Google Scholar]
- Niebuhr, C. Daten tauschen und schützen—Das muss kein Widerspruch sein. MERTON. 2021. Available online: https://merton-magazin.de/daten-tauschen-und-schuetzen-das-muss-kein-widerspruch-sein (accessed on 23 August 2023).
- LMU-Forschende mit Ideen zu Innovation und Bildung Erfolgreich. Available online: https://www.lmu.de/de/newsroom/newsuebersicht/news/lmu-forschende-mit-ideen-zu-innovation-und-bildung-erfolgreich.html (accessed on 22 September 2021).
- Federated Secure Computing. Available online: https://www.stifterverband.org/wirkunghoch100/3projekte/computing (accessed on 16 August 2023).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pain Points | Design Goals |
|---|---|
| related to capabilities (C) | |
| front-end and business logic developers rarely have any expert knowledge of PPC | provide high-level computing routines that hide low-level cryptography protocols (C1) |
| PPC is inaccessible to marginal groups lacking computing and personal resources | build a minimalistic solution that can be run by a single developer on a Raspberry Pi [19] (C2) |
| PPC is difficult to teach and experience in the limited time frame of a typical lesson | provide a propaedeutic solution that works in a school or university teaching setting (C3) |
| related to development (D) | |
| PPC often appears as the core functionality, so far as to even require to be a main routine | PPC should be a network-level concern, separated from high-level concerns (D1) |
| introducing PPC functionality to a business logic often requires a complete rework | enable piecewise introduction of PPC into an existing legacy business logic codebase (D2) |
| PPC frameworks require a specific tech stack and introduce a lot of dependencies | client side and the core of the server side should be free of any dependencies (D3) |
| coding for any particular PPC framework locks the developer to a specific language | let client-side developers freely choose their language or keep the legacy one (D4) |
| related to security concerns (S) | |
| some PPC frameworks are developed by non-experts in cryptography and are unsafe | do not reinvent the wheel; make use of existing and proven PPC frameworks (S1) |
| PPC involves sensitive data that should not be visible to the front end or the outside | enable topologies with data flow confined to trusted machines on the backend (S2) |
| many PPC use cases involve a third-party researcher who must be able to run analyses | enable topologies with control flow coming from an external researcher (S3) |
| every PPC calculation requires a complete re-evaluation by data security officers | separate topology, protocol, and function so they can be assessed independently (S4) |
| related to deployment and operation (O) | |
| PPC often requires all parties to agree on the exact same tech stack and IT environment | enable joint computation between parties using different hardware or software (O1) |
| without a lot of experience, it is often unclear which PPC framework is best suited for a task | frameworks should be replaceable without the need to rewrite business logic (O2) |
| universal PPC solutions often have enormous overhead in terms of space and processing | provide “small and fast” solutions that cater to the most often encountered tasks (O3) |
| Design Decision | Rationale and Addressed Design Goals |
|---|---|
| client–server architecture |
|
| one dedicated server per client |
|
| solution should be a middleware |
|
| provide microservices |
|
| provide RESTful API |
|
| represent server-side objects 1:1 client-side |
|
| implement server middleware in Python (optional) |
|
| Verb | Endpoint | Server-Side Effect and Response |
|---|---|---|
| GET | /representations |
|
| POST | /representations |
|
| PUT | /representations |
|
| PATCH | /representation/{uuid} |
|
| GET | /representation/{uuid}/{attr} |
|
| GET | /representation/{uuid} |
|
| DELETE | /representation/{uuid} |
|
| Language | Namespace Structure |
|---|---|
| Python |
|
| Java |
|
| Repository | Packages |
|---|---|
| PyPI |
|
| Repository | Contents |
|---|---|
| github |
|
| api |
|
| client-<language> |
|
| server |
|
| service-<name> |
|
| utility-<category>-<name> |
|
| webserver-<name> |
|
| whitepaper |
|
| Python Namespace | PyPI Package | GitHub Repository |
|---|---|---|
| federatedsecure.client | federatedsecure-client | client-python |
| federatedsecure.server | federatedsecure-server | server |
| federatedsecure.services. <name> | federatedsecure- <name> | service-<name> |
| federatedsecure.services. <category>.<name> | federatedsecure- <category>-<name> | utility-<category>-<name> |
| Task | Workstation 1 | Laptop 2 | Raspberry Zero 3 |
|---|---|---|---|
| horizontally partitioned data (without record linkage) | |||
| floating point additions 4 | 0.10 ± 0.01 | 0.26 ± 0.01 | 6.8 ± 1.3 |
| matrix multiplications 6 | 0.26 ± 0.02 | 0.64 ± 0.24 | 7.7 ± 0.2 |
| histograms 5 | 0.25 ± 0.04 | 0.59 ± 0.10 | 16.4 ± 0.3 |
| contingency tables 5 | 0.38 ± 0.07 | 1.00 ± 0.12 | 27.8 ± 0.6 |
| univariate statistics 5 | 0.64 ± 0.05 | 1.71 ± 0.18 | 52.4 ± 0.5 |
| bivariate statistics 5 | 1.93 ± 0.05 | 5.70 ± 0.11 | 155.7 ± 1.7 |
| set intersections 5 | 0.57 ± 0.06 | 1.30 ± 0.07 | 35.7 ± 0.5 |
| set intersection size 5 | 0.48 ± 0.08 | 1.18 ± 0.10 | 35.9 ± 0.7 |
| vertically partitioned data (with record linkage) | |||
| contingency tables 5 | 1.33 ± 0.16 | 3.29 ± 0.35 | 84.3 ± 2.1 |
| OLS regression 6 | 0.86 ± 0.01 | 0.24 ± 0.01 | 5.8 ± 0.2 |
| Task | Localhost 1 (<1 ms ping) | LAN/WLAN 2 (2 ms ping) | Internet 3 (28 ms ping) |
|---|---|---|---|
| horizontally partitioned data (without record linkage) | |||
| floating point additions 4 | n/a | 0.50 ± 0.02 | 2.5 ± 0.7 |
| matrix multiplications 5 | 0.26 ± 0.02 | 0.81 ± 0.22 | 2.7 ± 0.8 |
| histograms 4 | 0.25 ± 0.04 | 1.72 ± 0.05 | 9.4 ± 2.0 |
| contingency tables 4 | 0.38 ± 0.07 | 3.12 ± 0.13 | 16.1 ± 4.2 |
| univariate statistics 4 | 0.64 ± 0.05 | 4.10 ± 0.74 | 22.3 ± 4.5 |
| bivariate statistics 4 | 1.93 ± 0.05 | 11.14 ± 0.54 | 59.2 ± 5.3 |
| set intersections 4 | 0.57 ± 0.06 | 1.50 ± 0.27 | 4.0 ± 0.6 |
| set intersection size 4 | 0.48 ± 0.08 | 1.30 ± 0.06 | 3.1 ± 0.5 |
| vertically partitioned data (with record linkage) | |||
| contingency tables 4 | 1.33 ± 0.16 | 4.78 ± 0.25 | 14.9 ± 1.9 |
| OLS regression 5 | 0.86 ± 0.01 | 0.52 ± 0.07 | 2.3 ± 0.4 |
| Task | Localhost 1 | LAN/WLAN 2 | Mobile Network 3 |
|---|---|---|---|
| horizontally partitioned data (without record linkage) | |||
| floating point additions 4 | 0.10 ± 0.01 | 0.26 ± 0.01 | 6.8 ± 1.3 |
| matrix multiplications 6 | 0.26 ± 0.02 | 0.64 ± 0.24 | 7.7 ± 0.2 |
| histograms 5 | 0.25 ± 0.04 | 0.59 ± 0.10 | 16.4 ± 0.3 |
| contingency tables 5 | 0.38 ± 0.07 | 1.00 ± 0.12 | 27.8 ± 0.6 |
| univariate statistics 5 | 0.64 ± 0.05 | 1.71 ± 0.18 | 52.4 ± 0.5 |
| bivariate statistics 5 | 1.93 ± 0.05 | 5.70 ± 0.11 | 155.7 ± 1.7 |
| set intersections 5 | 0.57 ± 0.06 | 1.30 ± 0.07 | 35.7 ± 0.5 |
| set intersection size 5 | 0.48 ± 0.08 | 0.51 ± 0.14 | 1.62 ± 0.20 |
| vertically partitioned data (with record linkage) | |||
| contingency tables 5 | 1.33 ± 0.16 | 3.29 ± 0.35 | 84.3 ± 2.1 |
| OLS regression 6 | 0.86 ± 0.01 | 0.24 ± 0.01 | 5.8 ± 0.2 |
| Language | Without HTTP Interface | With HTTP Interface |
|---|---|---|
| Python | 2.8 kilobyte | 7.4 kilobyte |
| R | 2.1 kilobyte | 6.6 kilobyte |
| Javascript | 2.1 kilobyte | 3.4 kilobyte |
| Language | Without Webserver | With Webserver |
|---|---|---|
| Python | 12.4 kilobyte | 31.6 kilobyte |
| Earlier Work [12,13,14,15,16,17,18,20,21,22,23,24,25] | Federated Secure Computing | |
|---|---|---|
| data |
|
|
| routing |
|
|
| protocol |
|
|
| software |
|
|
| hardware |
|
|
| implementation effort |
|
|
| achieved precision |
|
|
| runtime |
|
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ballhausen, H.; Hinske, L.C. Federated Secure Computing. Informatics 2023, 10, 83. https://doi.org/10.3390/informatics10040083
Ballhausen H, Hinske LC. Federated Secure Computing. Informatics. 2023; 10(4):83. https://doi.org/10.3390/informatics10040083
Chicago/Turabian StyleBallhausen, Hendrik, and Ludwig Christian Hinske. 2023. "Federated Secure Computing" Informatics 10, no. 4: 83. https://doi.org/10.3390/informatics10040083
APA StyleBallhausen, H., & Hinske, L. C. (2023). Federated Secure Computing. Informatics, 10(4), 83. https://doi.org/10.3390/informatics10040083