
Reinforcement Learning for Predictive Analytics in Smart Cities

Abstract
:1. Introduction
1.1. Smart Governance and Smart Cities
1.2. Motivation and Research Challenges
1.3. Contribution, Research Outcome & Organization
- we propose two learners responsible to deliver the assignment of queries to a set of s. The first comes from reinforcement learning and the second from clustering;
- we involve in the learning process a set of parameters related to the behaviour of s (e.g., response time, load, ) to be fully aligned with their performance;
- we propose a multiple Q-tables scheme as the knowledge base of the (in the RL case) and a technique for deriving the compactness of the generated clusters (in the clustering case) adopted to deliver the best for each assignment;
- we build on top of an incremental clustering scheme for updating the available clusters;
- we provide a comprehensive performance evaluation of the proposed learning schemes and a comparative assessment with a baseline solution;
- we setup the basis for our next research step where we will rely on a pool of learners and deliver and intelligent scheme for their combination.
2. Related Work
3. Rationale and Preliminary
4. The Query Assignment Learning Schemes
4.1. Reinforcement Learning
- the time required for deriving the final result (response time - ) as realized by historical values. We can adopt a simple (e.g., average performance values) or a more complex process over these values. It should be noted that could be depicted by the physical time e.g., in milliseconds;
- the retrieved by the also based on historical values. This parameter is affected by the and the . We can adopt any desired algorithm for the realization of the ;
- the minimum number of steps (in the discrete time) required for the selection of the appropriate . As we focus on a query streaming scenario, the serves a huge number of queries and, thus, the assignment process should be concluded in the minimum time;
- the lowest load L in order to minimize the load of the selected s.
4.2. The Training Phase
- the response time (). We actually get the result of a function applied in the historical values;
- the as defined by function applied on the historical values. historical values are recorded by the after concluding past transactions with each ;
- the number of transitions (T). T shows how many transitions the needs to conclude a decision (selection of a );
- the predicted load (L). L is defined as the result of a predictive scheme that indicates the future load for each .
4.3. The Assignment Process
| Algorithm 1 The assignment process |
|
4.4. The Predictive Phase
4.5. The Clustering Scheme
4.6. The Incremental Clusters Update Process
| Algorithm 2 The incremental clustering update |
|
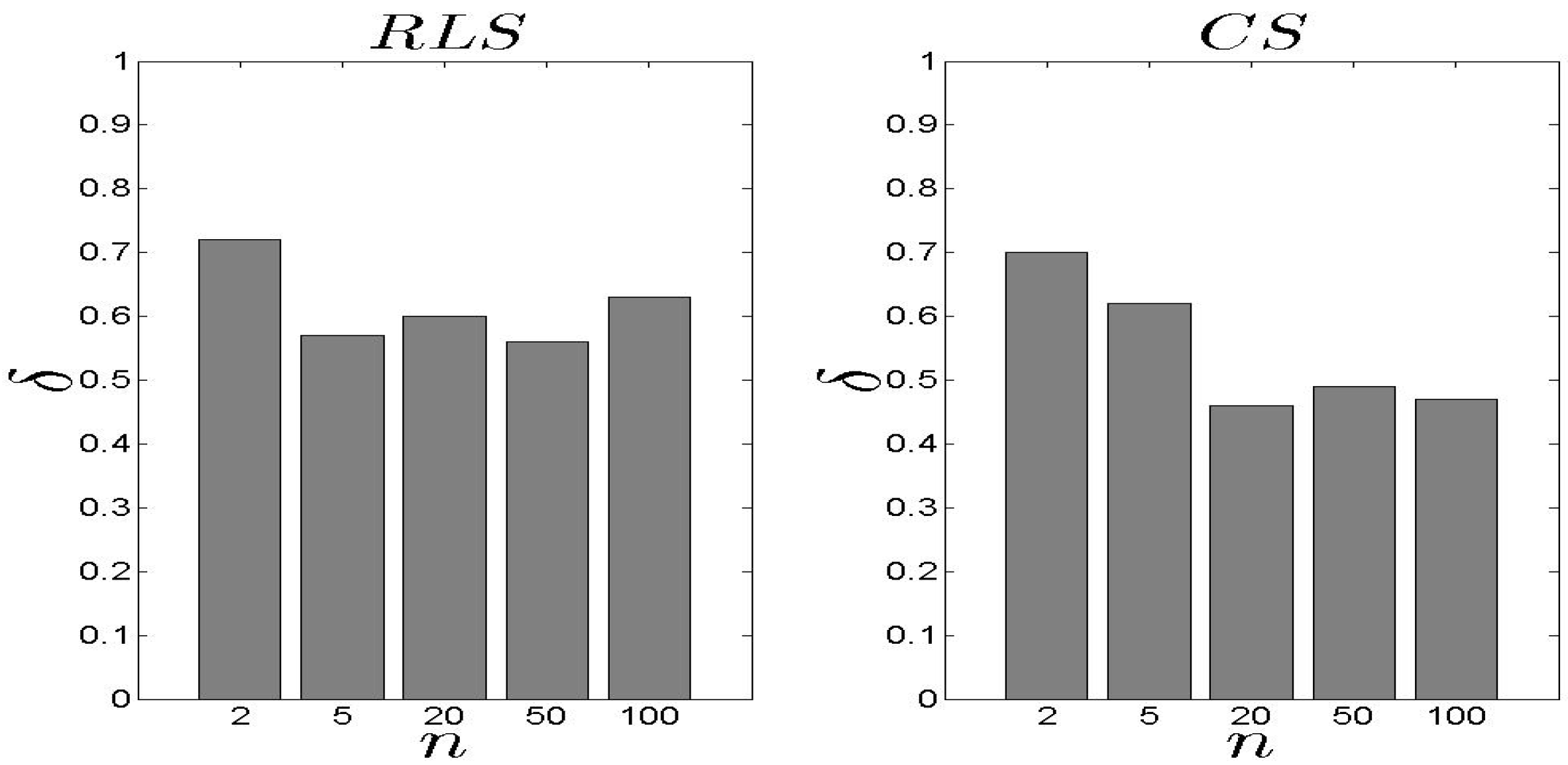
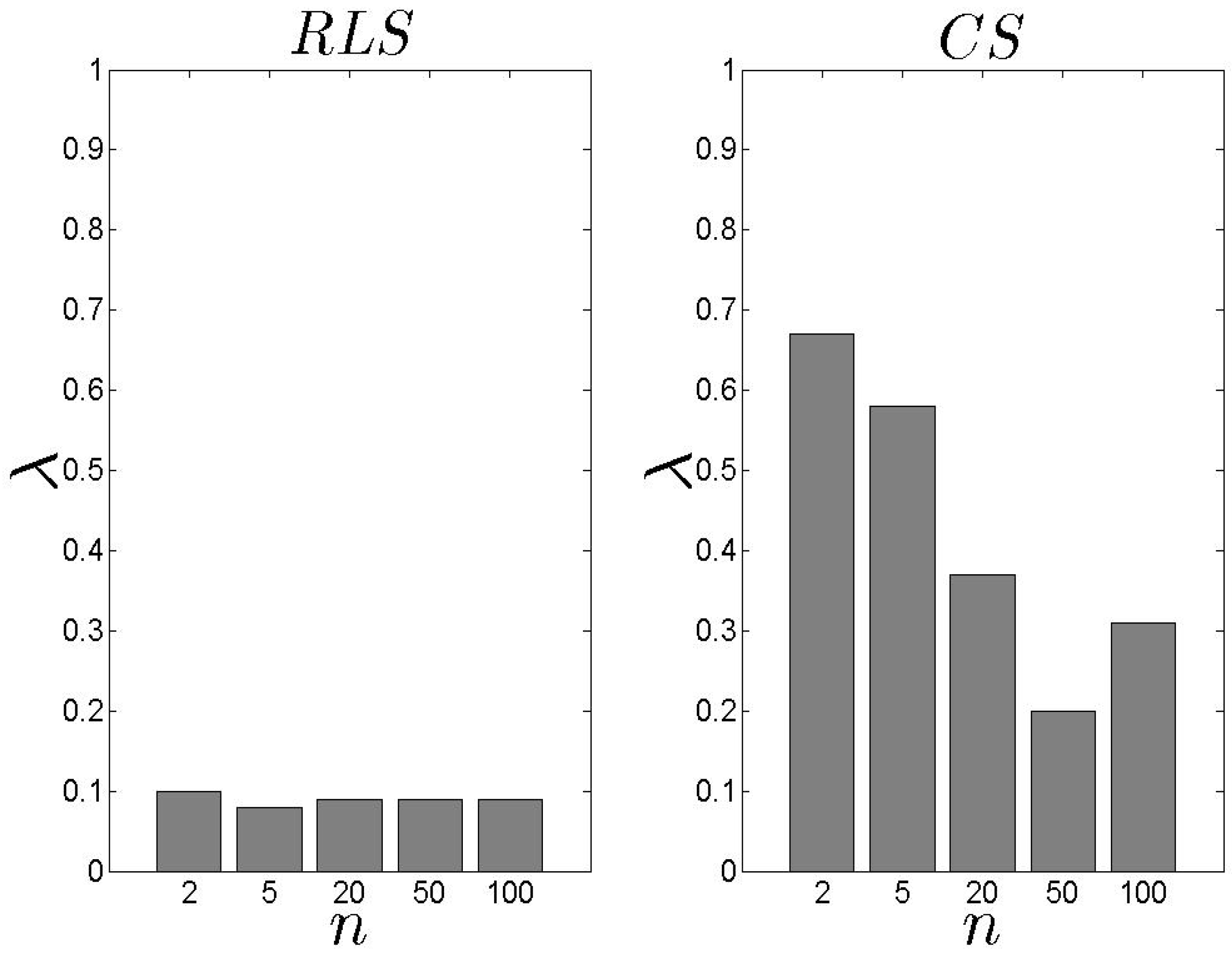
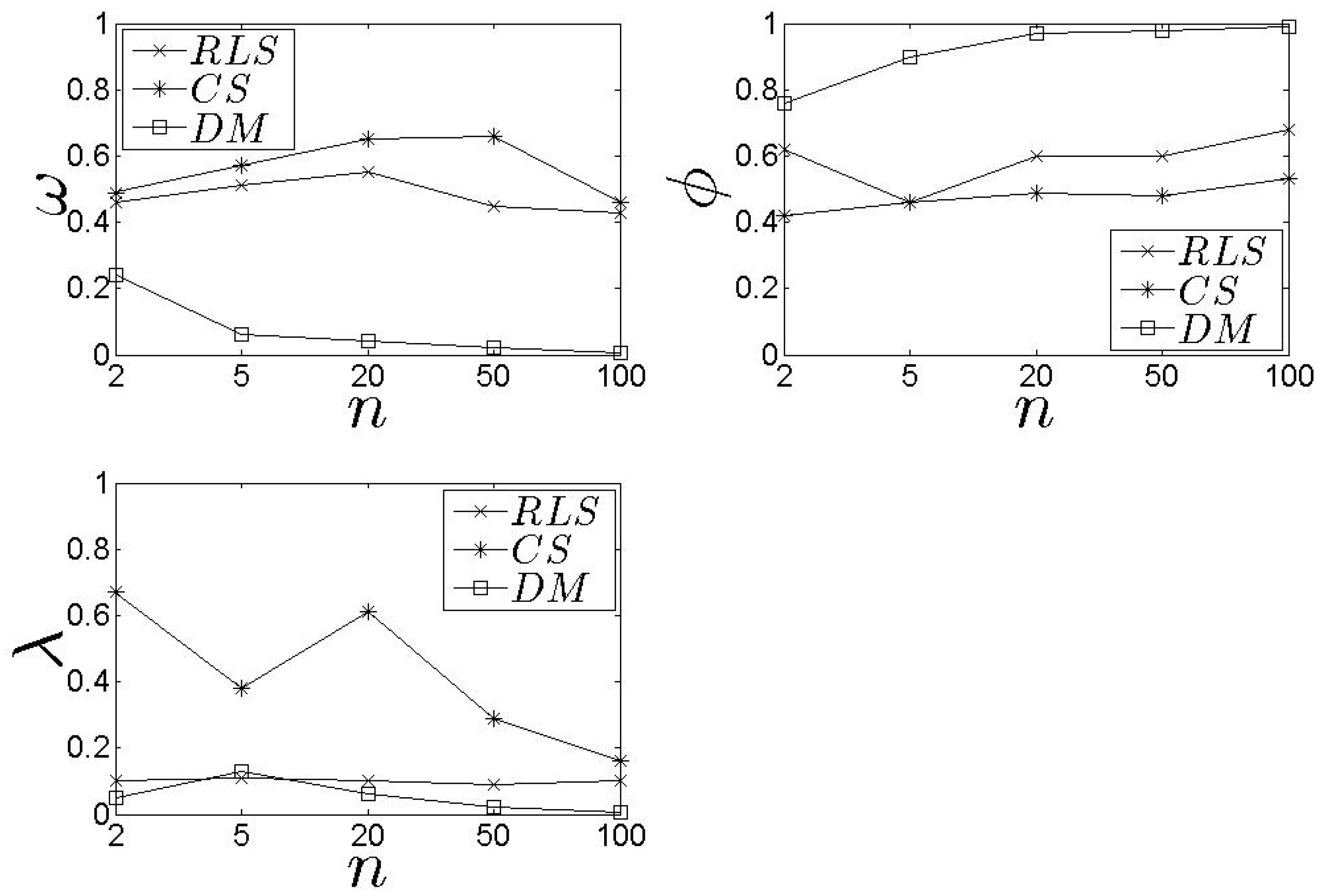
5. Experimental Evaluation
5.1. Performance Metrics & Simulation Set-up
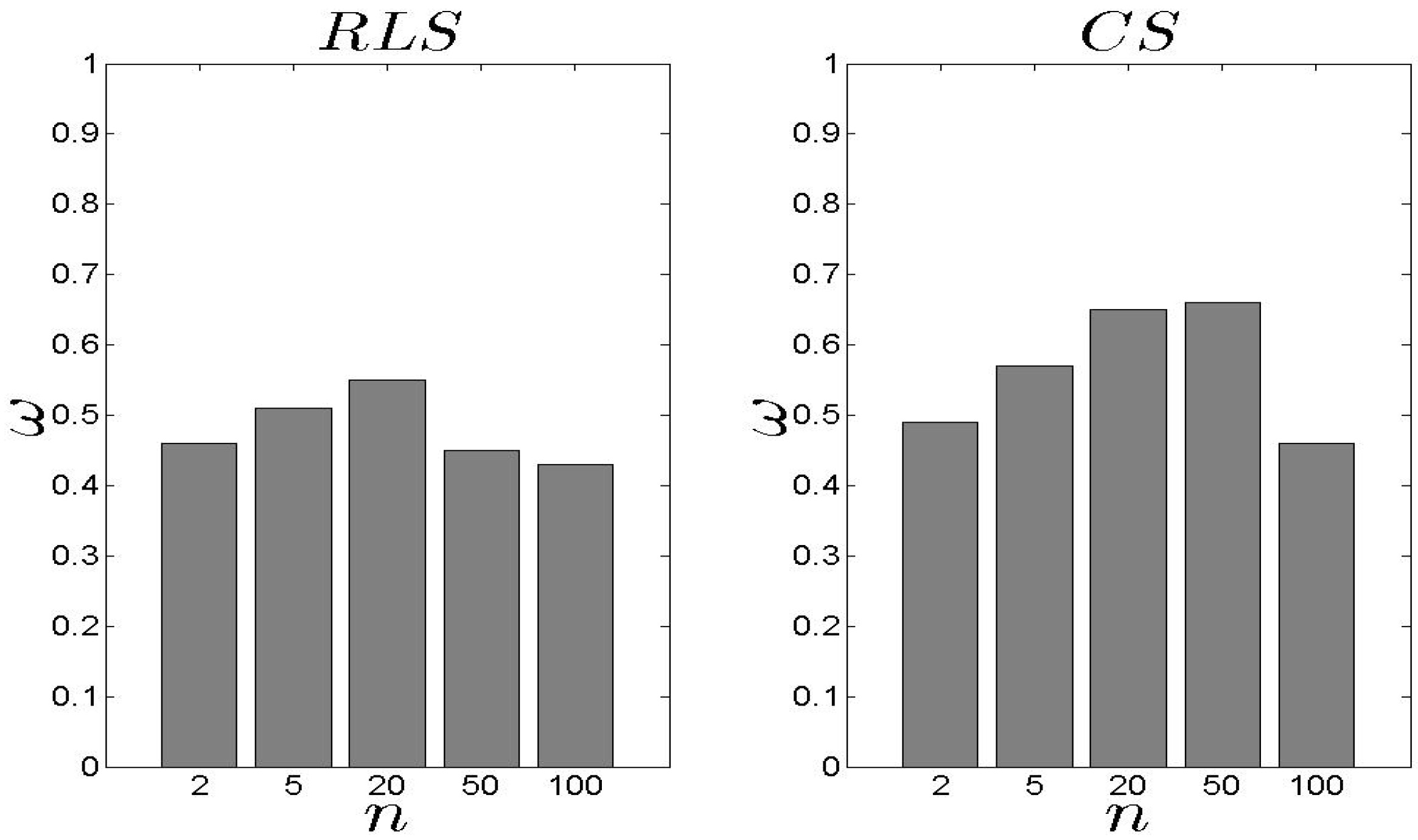
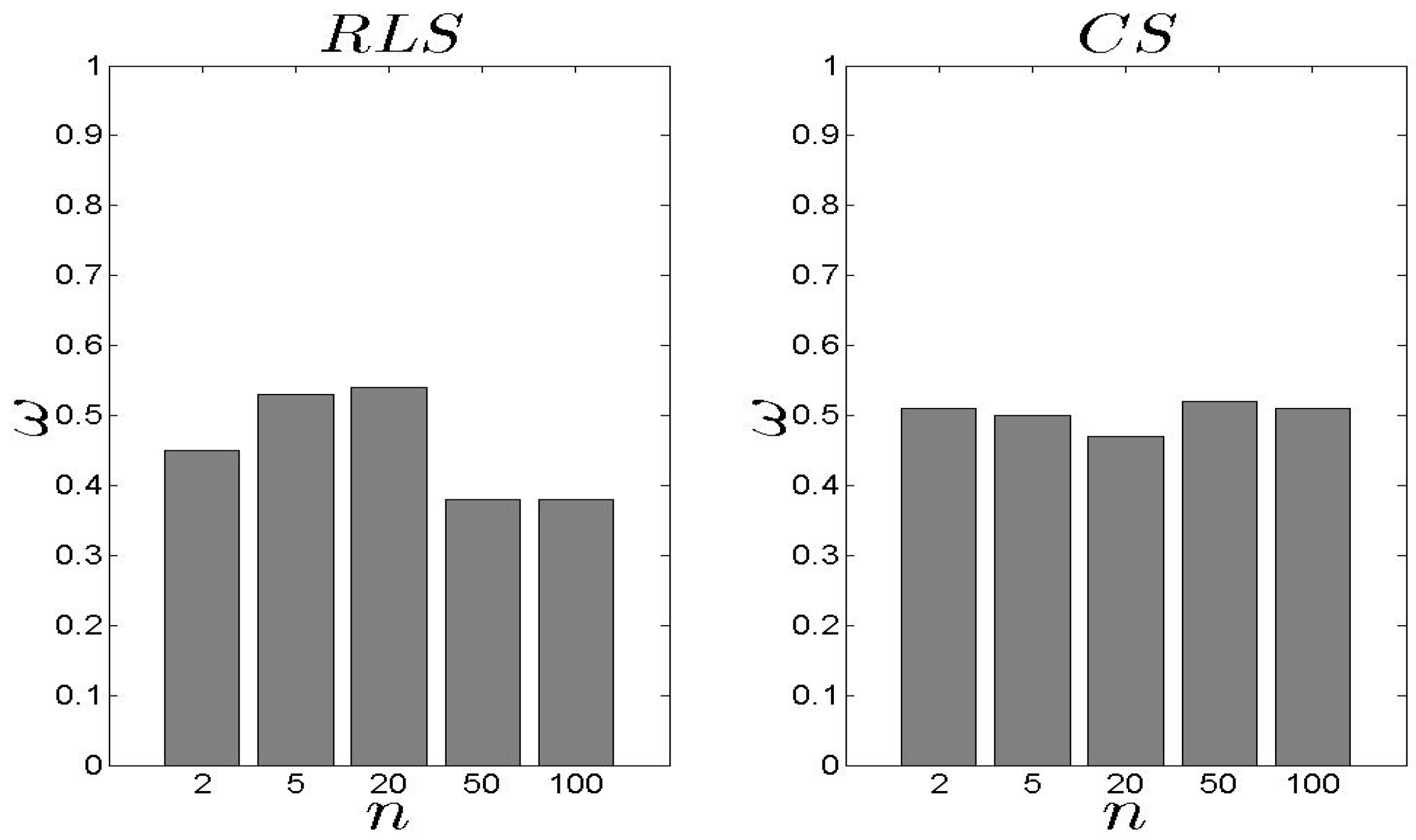
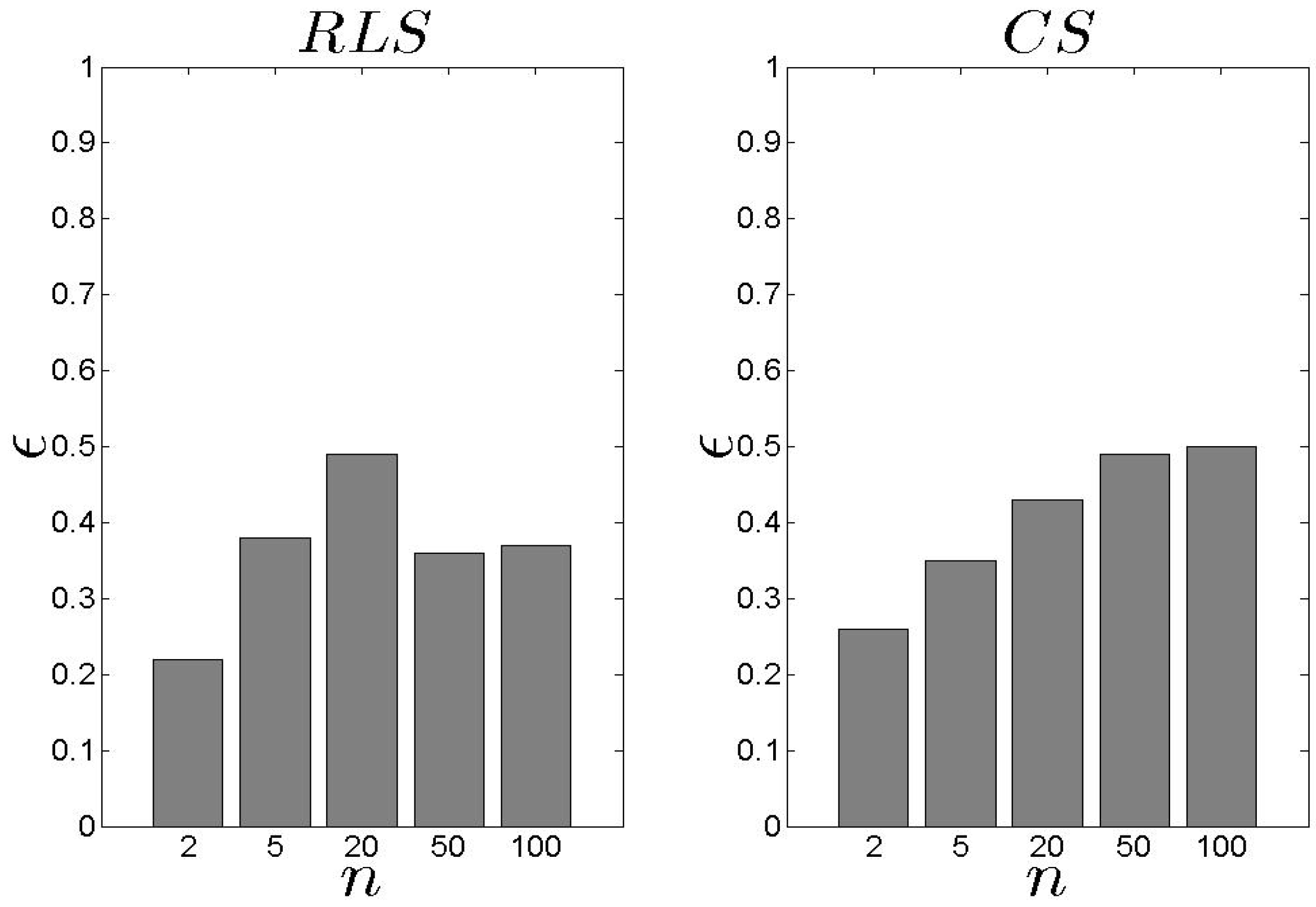
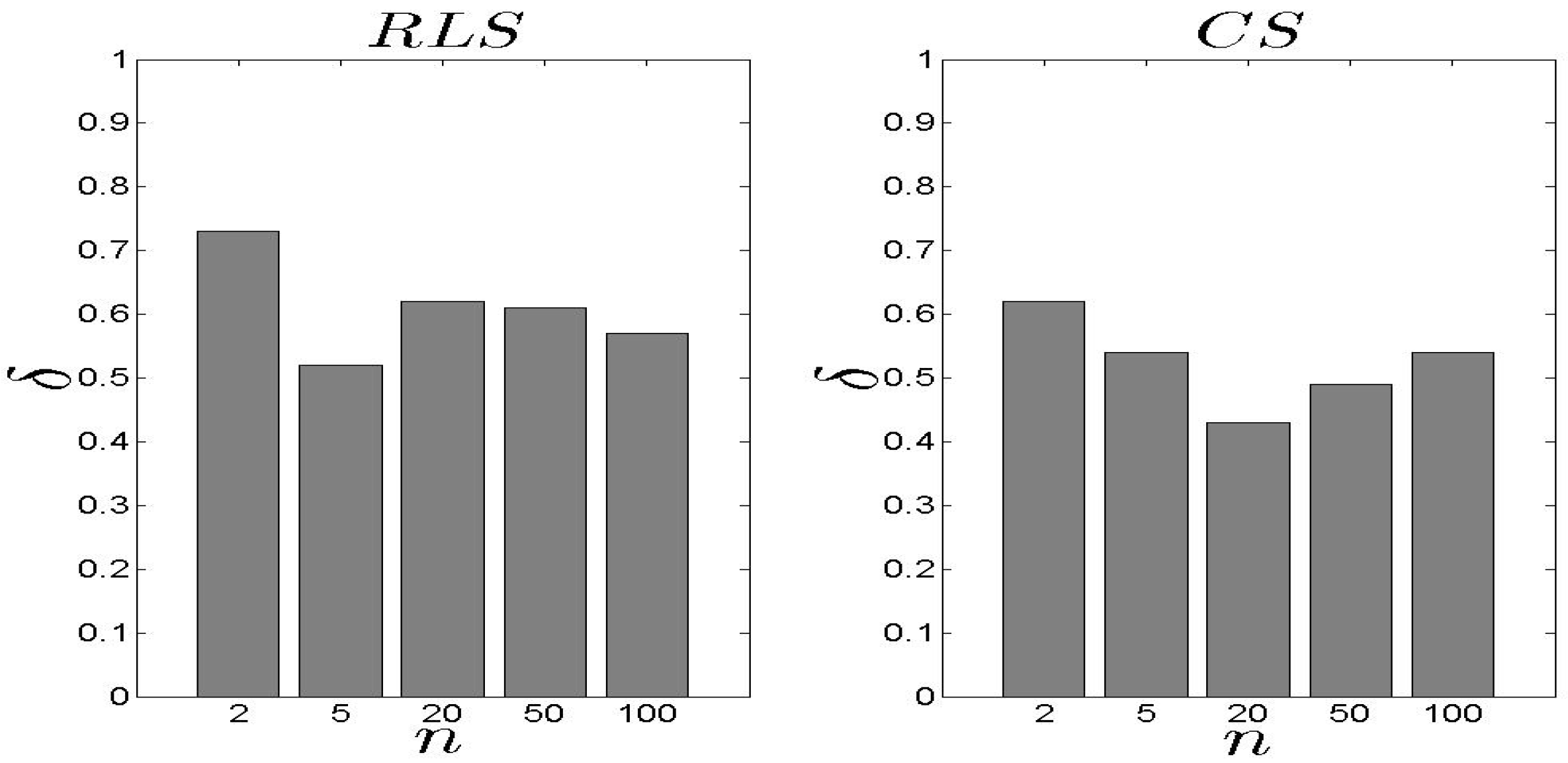
5.2. Performance Assessment
6. Conclusions and Future Work
Author Contributions
Conflicts of Interest
References
- Scholl, H.; Scholl, M. Smart Governance: A Roadmap for Research and Practice. In Proceedings of the iConference Summary, Berlin, Germany, 4–7 March 2014; pp. 163–176. [Google Scholar]
- Meijer, A.; Bolivar, M. Governing the Smart City: Scaling-Up the Search for Socio-Techno Synergy. In Proceedings of the 2013 EGPA Conference, Scotland, UK, 11–13 September 2013. [Google Scholar]
- Bolivar, M.P.R. Smart Cities: Big Cities, Complex Governance? In Transforming City Governments for Successful Smart Cities; Public Administration and Information Technology 8; Springer International Publishing: Berlin, Germany, 2015. [Google Scholar]
- Kresin, C. Design Rules for Smarter Cities. In ‘Smart Citizens’ Future Everything; Hemmet, D., Townsend, A., Eds.; Future Everything Publications: Manchester, UK, 2013; pp. 51–54. [Google Scholar]
- Silva, B.N.; Khan, M.; Han, K. Big Data Analytics Embedded Smart City Architecture for Performance Enhancement through Real-Time Data Processing and Decision-Making. Wirel. Commun. Mobile Comput. 2017, 2017, 9429676. [Google Scholar]
- Abadi, D.J.; Carney, D.; Cetintemel, U.; Cherniack, M.; Convey, C.; Lee, S.; Stonebraker, M.; Tatbul, N.; Zdonik, S.B. Aurora: A New Model and Architecture for Data Stream Management. VLDB J. 2003, 12, 120–139. [Google Scholar] [CrossRef]
- Arasu, A.; Babcock, B.; Babu, S.; Cieslewicz, J.; Datar, M.; Ito, K.; Motwani, R.; Srivastava, U.; Widom, J. STREAM: The Stanford Data Stream Management System; Part of the series Data-Centric Systems and Applications; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Chandrasekaran, S.; Franklin, M.J.P. Soup: A system for streaming queries over streaming data. VLDB J. 2003, 12, 140–156. [Google Scholar] [CrossRef]
- Cranor, C.; Johnson, T.; Spataschek, O.; Shkapenyuk, V. Gigascope: A Stream Database for Network Applications. In Proceedings of the International Conference on Management of Data and Symposium on Principles Database and Systems (SIGMOD), San Diego, CA, USA, 9–12 June 2003. [Google Scholar]
- Hammad, M.A.; Ghanem, T.M.; Aref, W.G.; Elmagarmid, A.K.; Mokbel, M.F. Efficient Pipelined Execution of Sliding-Window Queries Over Data Streams; Technical Report; Department of Computer Science, Purdue University: West Lafayette, IN, USA, 2003. [Google Scholar]
- Motwani, R.; Widom, J.; Arasu, A.; Babcock, B.; Babu, S.; Datar, M.; Manku, G.S.; Olston, C.; Rosenstein, J.; Varma, R. Query Processing, Approximation, and Resource Management in a Data Stream Management System. In Proceedings of the First Biennial Conference on Innovative Data Systems Research (CIDR), Asilomar, CA, USA, 5–8 January 2003. [Google Scholar]
- Yao, Y.; Gehrke, J. The Cougar Approach to In-Network Query Processing in Sensor Networks. SIGMOD Rec. 2002, 31, 9–18. [Google Scholar] [CrossRef]
- Mokbel, M.; Xiong, X.; Hammad, M.; Aref, W. Continuous Query Processing of Spatio-Temporal Data Streams in PLACE. Geoinformatics 2005, 9, 4. [Google Scholar] [CrossRef]
- Funellblack, Supporting Multiple Query Processors. Available online: https://docs.funnelback.com/more/extra/supporting_multiple_query_processors.html (accessed on 20 March 2017).
- Oracle Parallel Server Concepts and Administration. Available online: https://docs.oracle.com/cd/A58617_01/server.804/a58238/ch1_unde.htm (accessed on 20 March 2017).
- Ciaccia, P.; Patella, M. Approximate Similarity Queries: A Survey; University of Bolognia: Bologna, Italy, 2001. [Google Scholar]
- Ramakrishnan, G.; Uma Maheswari, S. Novel Approach for Predicting Difficult Keyword Queries over Databases using Effective Ranking. Int. J. Eng. Res. Technol. 2015, 4. [Google Scholar] [CrossRef]
- Zhang, W.; Li, J. Processing Probabilistic Range Query over Imprecise Data Based on Quality of Result. In APWeb Workshops; LNCS; Springer: Berlin/Heidelberg, Germany, 2006; pp. 441–449. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Bishop, C. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Alpaydin, E. Introduction to Machine Learning, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Kolomvatsos, K.; Hadjiefthymiades, S. Learning the Engagement of Query Processors for Intelligent Analytics. Springer Appl. Intell. J. 2016, 1–17. [Google Scholar] [CrossRef]
- Singh, S.; Singh, N. Big Data Analytics. In Proceedings of the International Conference on Communication, Information, Computing Technology, Mumbai, India, 19–20 October 2012. [Google Scholar]
- Herodotou, H.; Lim, H.; Luo, G.; Borisov, N.; Dong, L.; Cetin, F.B.; Babu, S. Starfish: A Self-tuning System for Big Data Analytics. In Proceedings of the Biennial Conference on Innovative Data Systems Research (CIDR), Asilomar, CA, USA, 9–12 January 2011. [Google Scholar]
- Agarwal, S.; Milner, H.; Kleiner, A.; Talwalkar, A.; Jordan, M.; Madden, S.; Mozafari, B.; Stoica, I. Knowing When You’re Wrong: Building Fast and Reliable Approximate Query Processing Systems. In Proceedings of the ACM SIGMOD Conference, Snowbird, UT, USA, 22–27 June 2014. [Google Scholar]
- Chaudhuri, S.; Das, G.; Srivastava, U. Effective use of block-level sampling in statistics estimation. In Proceedings of the 2004 ACM SIGMOD international conference on Management of data, Paris, France, 13–18 June 2004. [Google Scholar]
- Hellerstein, J.M.; Avnur, R. Informix under control: Online query Processing. Data Min. Knowl. Discov. J. 2000, 4, 281–314. [Google Scholar] [CrossRef]
- Pansare, N.; Borkar, V.R.; Jermaine, C.; Condie, T. Online aggregation for large MapReduce jobs. In Proceedings of the 37th International Conference on Very Large Data Bases (VLDB), Seattle, WA, USA, 29 August–3 September 2011. [Google Scholar]
- Doucet, A.; Briers, M.; Senecal, S. Efficient block sampling strategies for sequential Monte Carlo methods. J. Comput. Graphical Stat. 2006. [Google Scholar] [CrossRef]
- Raman, V.; Raman, B.; Hellerstein, J.M. Online dynamic reordering for interactive data processing. In Proceedings of the 25th International Conference on Very Large Data Bases (VLDB), Scotland, UK, 7–10 September 1999. [Google Scholar]
- Chandramouli, B.; Goldstein, J.; Quamar, A. Scalable Progressive Analytics on Big Data in the Cloud. Proc. VLDB Endow. 2013, 6, 1726–1737. [Google Scholar] [CrossRef]
- Condie, T.; Conway, N.; Alvaro, P.; Hellerstein, J.M.; Elmeleegy, K.; Sears, R. MapReduce online. In Proceedings of the 7th Conference on Networked Systems Design and Implementation, San Jose, CA, USA, 28–30 April 2010. [Google Scholar]
- Logothetis, D.; Yocum, K. Ad-hoc Data Processing in the Cloud. Proc. VLDB Endow. 2008, 1, 1472–1475. [Google Scholar] [CrossRef]
- Jermaine, C.; Arumugam, S.; Pol, A.; Dobra, A. Scalable approximate query processing with the DBO engine. In Proceedings of the ’07 International Conference on Management of Data (SIGMOD), Beijing, China, 11–14 June 2007. [Google Scholar]
- Bakhtiar, A.; Joan, L. Sketch of Big Data Real-Time Analytics Model. In Proceedings of the The Fifth International Conference on Advances in Information Mining and Management, Brussels, Belgium, 21–26 June 2015. [Google Scholar]
- Vennila, V.; Kannan, A.R. Symmetric Matrix-based Predictive Classifier for Big Data computation and information sharing in Cloud. Comput. Electr. Eng. 2016, 56, 831–841. [Google Scholar] [CrossRef]
- Hassani, M.; Spaus, P.; Cuzzocrea, A.; Seidi, T. I-HASTREAM: Density-Based Hierarchical Clustering of Big Data Streams and Its Application to Big Graph Analytics Tools. In Proceedings of the 16th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, Cartagena, Colombia, 16–19 May 2016. [Google Scholar]
- Ma, S.; Liang, Z. Design and Implementation of Smart City Big Data Processing Platform Based on Distributed Architecture. In Proceedings of the 10th International Conference on Intelligent Systems and Knowledge Engineering (ISKE), Taipei, Taiwan, 24–27 November 2015. [Google Scholar]
- Arasteh, H.; Hosseinnezhad, V.; Loia, V.; Tommasetti, A.; Troisi, O.; Shafie-khah, M.; Siano, P. IoT-based Smart Cities: A Survey. In Proceedings of the IEEE 16th International Conference on Environment and Electrical Engineering (EEEIC), Florence, Italy, 6–8 June 2016. [Google Scholar]
- Eiman, A.N.; Hind, A.N.; Nader, M.; Jameela, A.J. Applications of big data to smart cities. J. Internet Ser. Appl. 2015, 6, 25. [Google Scholar]
- Kumar, S.; Prakash, A. Role of Big Data and Analytics in Smart Cities. Int. J. Sci. Res. 2016, 5, 12–23. [Google Scholar]
- Sun, Y.; Song, H.; Jara, A.; Bie, R. Internet of Things and Big data Analytics for Smart Cities and Connected Communities. IEEE Access 2016, 4, 766–773. [Google Scholar] [CrossRef]
- Spatti, D.H.; Bartocci Lobini, L.H. Computational Tools for Data Processing in Smart Cities. In Smart Cities Technologies; InTech: Rijeka, Croatia, 2016. [Google Scholar]
- Bonino, D.; Rizzo, F.; Pastrone, C.; Soto, J.A.C.; Ahlsen, M.; Axling, M. Block-based realtime big-data processing for smart cities. In Proceedings of the IEEE International Smart Cities Conference (ISC2), Trento, Italy, 12–15 September 2016. [Google Scholar]
- Lei, C.; Zhuang, Z.; Rundensteiner, E.A.; Eltabakh, M. Redoop Infrastructure for Recurring Big Data Queries. In Proceedings of the 40th International Conference on very Large Data Bases (VLDB), Hangzhou, China, 1–5 September 2014. [Google Scholar]
- Bu, Y.; Howe, B.; Balazinska, M.; Ernst, M.D. The HaLoop approach to large-scale iterative data analysis. VLDB J. 2012, 21, 169–190. [Google Scholar] [CrossRef]
- Ekanayake, J.; Li, H.; Zhang, B.; Gunarathne, T.; Bae, S.-H.; Qiu, J.; Fox, G. Twister: A runtime for iterative mapreduce. In Proceedings of the 19th ACM International Symposium on High Performance Distributed Computing, Chicago, IL, USA, 21–25 June 2010; pp. 810–818. [Google Scholar]
- Olston, C.; Chiou, G.; Chitnis, L.; Liu, F.; Han, Y.; Larsson, M.; Neumann, A.; Rao, V.B.N.; Karasubramanian, V.; Seth, S.; et al. Nova: continuous pig/hadoop workflows. In Proceedings of the SIGMOD Conference, Athens, Greece, 12–16 June 2011; pp. 1081–1090. [Google Scholar]
- Al-Jarrah, O.Y.; Yoo, P.D.; Muhaidat, S.; Karagiannidis, G.K.; Taha, K. Efficient Machine Learning for Big Data: A Review. Big Data Res. 2015, 2, 87–93. [Google Scholar] [CrossRef]
- Zhou, L.; Pan, S.; Wang, J.; Vasilakos, A.V. Machine learning on big data: Opportunities and challenges. Neurocomputing 2017, 237, 350–361. [Google Scholar] [CrossRef]
- Jang, J.-S.R.; Sun, C.T.; Mizutani, E. Neuro-Fuzzy and Soft Computing—A Computational Approach to Learning and Machine Intelligence; Prentice Hall: Upper Saddle River, NJ, USA, 1997. [Google Scholar]
- Boulougaris, G.; Kolomvatsos, K.; Hadjiefthymiades, S. Building the Knowledge Base of a Buyer Agent Using Reinforcement Learning Techniques. In Proceedings of the 2010 IEEE World Congress on Computational Intelligence (WCCI 2010), IJCNN, Barcelona, Spain, 18–23 July 2010; pp. 1166–1173. [Google Scholar]
- Manyika, J.; Durrant-Whyte, H. Data Fusion and Sensor Management: A Decentralized Information-Theoretic Approach; Ellis Horwood: New York, NY, USA; London, UK, 1994. [Google Scholar]
- Charikar, M.; Chekuri, C.; Feder, T.; Motwani, R. Incremental clustering and dynamic infomation retrieval. In Proceedings of the ACM 29th Annual Symposium on Theory of Computing, El Paso, TX, USA, 4–6 May 1997. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predictor | Attributes | Short Description |
|---|---|---|
| Cycle | Window size | It returns the same data in a specific window |
| Single Exponential | Smoothing factor | It consists of a weighted average of past values |
| Double Exponential | Smoothing factor | It uses a simple linear regression equation |
| Seasonal Naive | Seasonal period | Each forecast is equal to the last observed value from the same season in the past |
| Drift | Time window | Time window |
| Extrapolation | - | It estimates the value of a variable on the basis of its relation with another variable |
| Additive Holt Winters | Level, Slope, Season | It deals with time series containing both trend and seasonal variations |
| Multiplicative Holt Winters | Level, Slope, Season | It deals with time series containing both trend and seasonal variations |
| Geometric Moving Average | Window size | It smooths past data by geometrically averaging over a specified period and projects forward in time |
| Moving Average | Window size | It smooths past data by arithmetically averaging over a specified period and projects forward in time |
| Parabolic Moving Average | Trend value | It is a weighted moving average with weights that form a parabolic shape |
| Triangular Moving Average | Window size | It is a weighted moving average with weights that form a triangular shape |
| Neural Network | Network nodes | It uses a neural network for estimating future values |
| Linear | Coefficients | It uses the Levinson-Durbin algorithm for linear prediction |
| Linear Regression | Coefficients | It fits the time series to a straight line and projects forward in time |
| Polynomial | Coefficients | It fits a polynomial equation to the data and projects forward in time |
| Rounded Average | Window size | It returns the rounded average of past values defined in a specific window |
| n | ||
|---|---|---|
| 2 | 0.54 | 1.19 |
| 5 | 0.57 | 1.87 |
| 20 | 0.54 | 5.69 |
| 50 | 0.50 | 13.12 |
| 100 | 0.49 | 25.52 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kolomvatsos, K.; Anagnostopoulos, C. Reinforcement Learning for Predictive Analytics in Smart Cities. Informatics 2017, 4, 16. https://doi.org/10.3390/informatics4030016
Kolomvatsos K, Anagnostopoulos C. Reinforcement Learning for Predictive Analytics in Smart Cities. Informatics. 2017; 4(3):16. https://doi.org/10.3390/informatics4030016
Chicago/Turabian StyleKolomvatsos, Kostas, and Christos Anagnostopoulos. 2017. "Reinforcement Learning for Predictive Analytics in Smart Cities" Informatics 4, no. 3: 16. https://doi.org/10.3390/informatics4030016
APA StyleKolomvatsos, K., & Anagnostopoulos, C. (2017). Reinforcement Learning for Predictive Analytics in Smart Cities. Informatics, 4(3), 16. https://doi.org/10.3390/informatics4030016