Web-Scale Multidimensional Visualization of Big Spatial Data to Support Earth Sciences—A Case Study with Visualizing Climate Simulation Data



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Literature Review
2.1. Popular Visualization Platforms for Climate Research
2.2. Key Techniques in Multidimensional Visualization of Spatial Data
3. Methodology
3.1. Three-Dimensional Data Volume Rendering
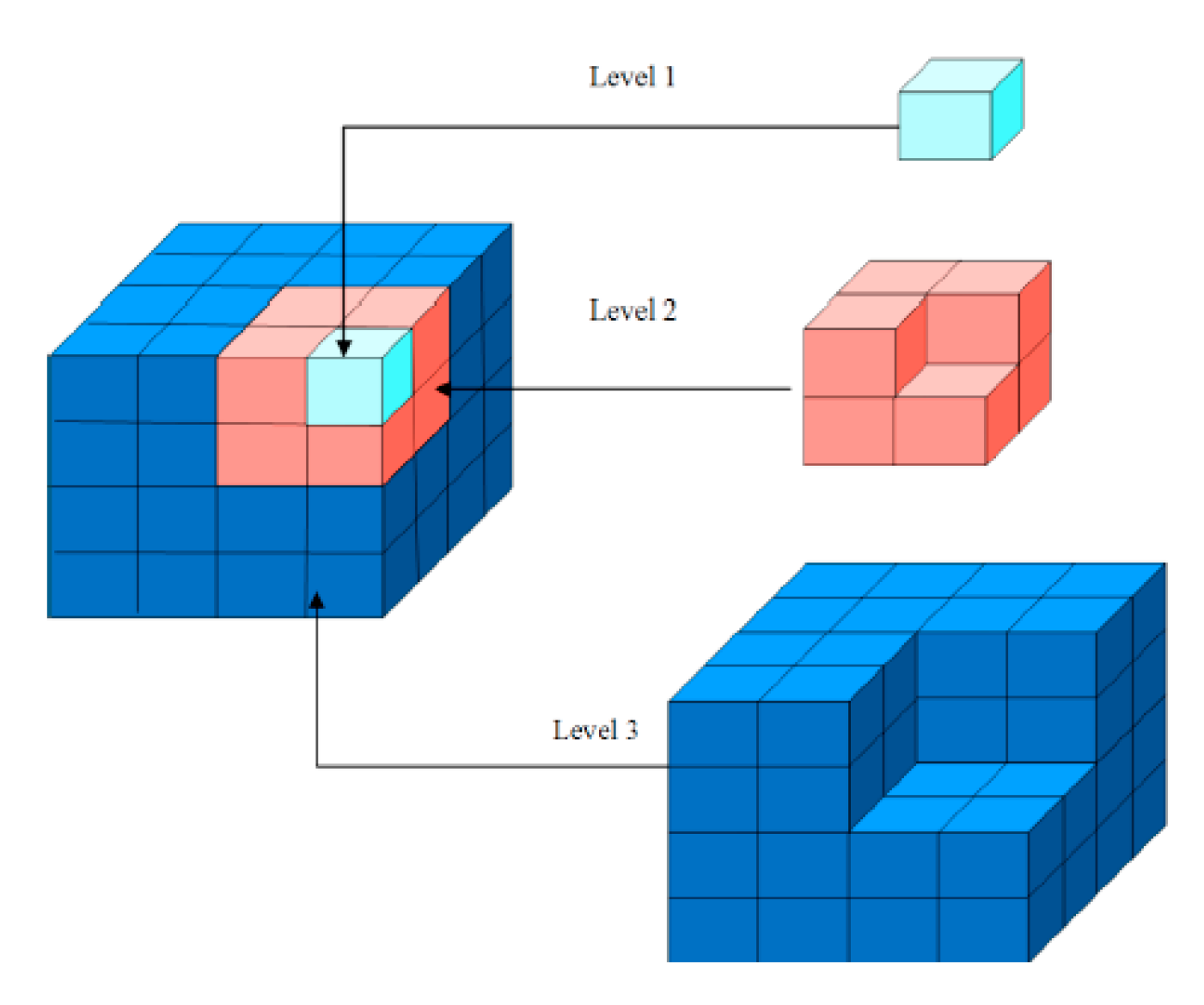
3.1.1. Data Preparation at the Server Side
3.1.2. Data Rendering on the Client Side
3.2. Data Filtering
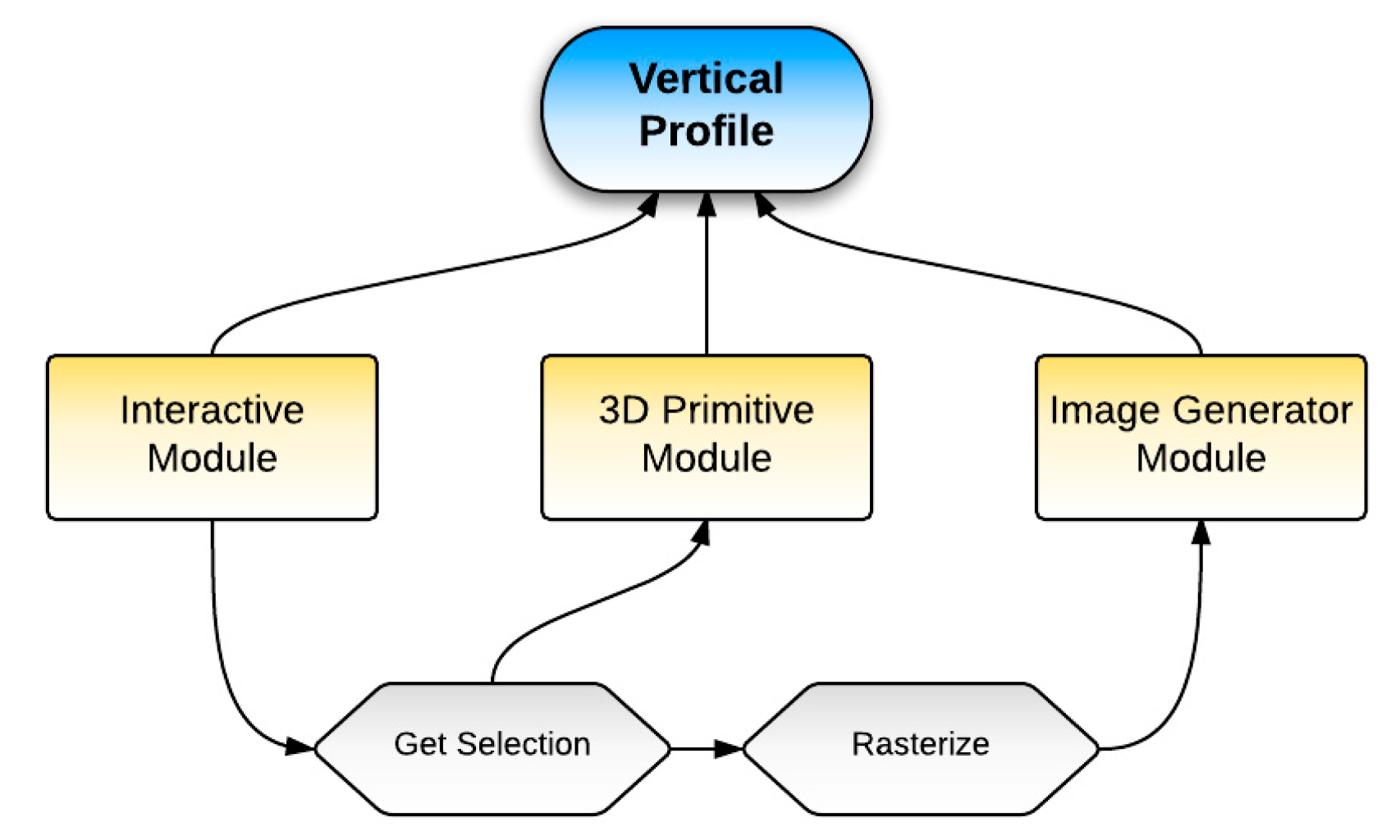
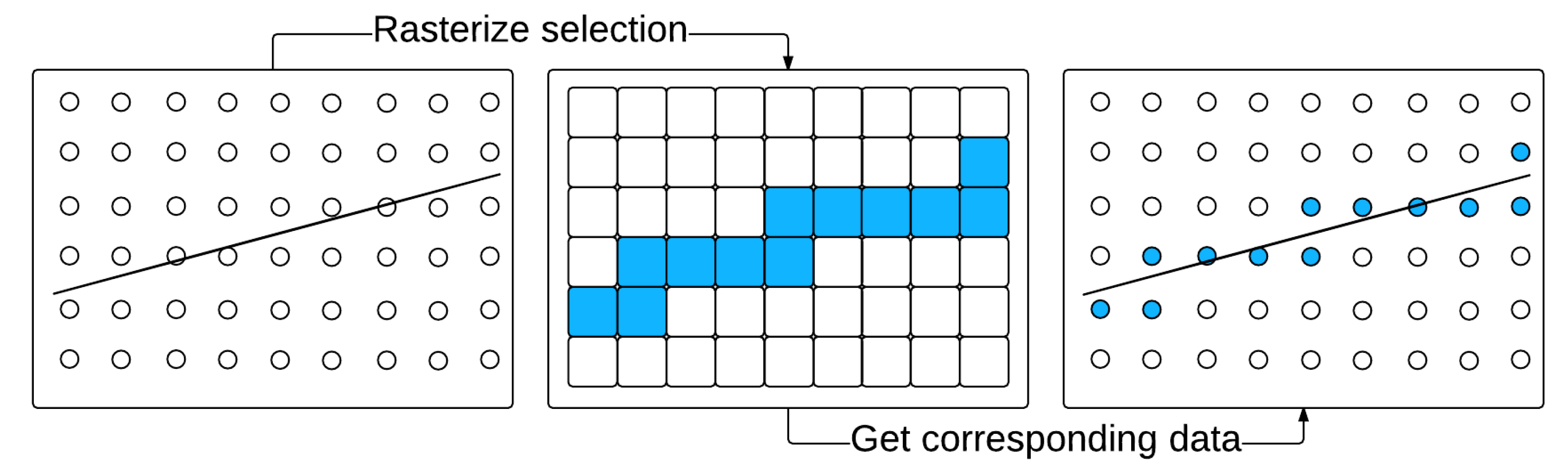
3.3. Vertical Profile Visualization
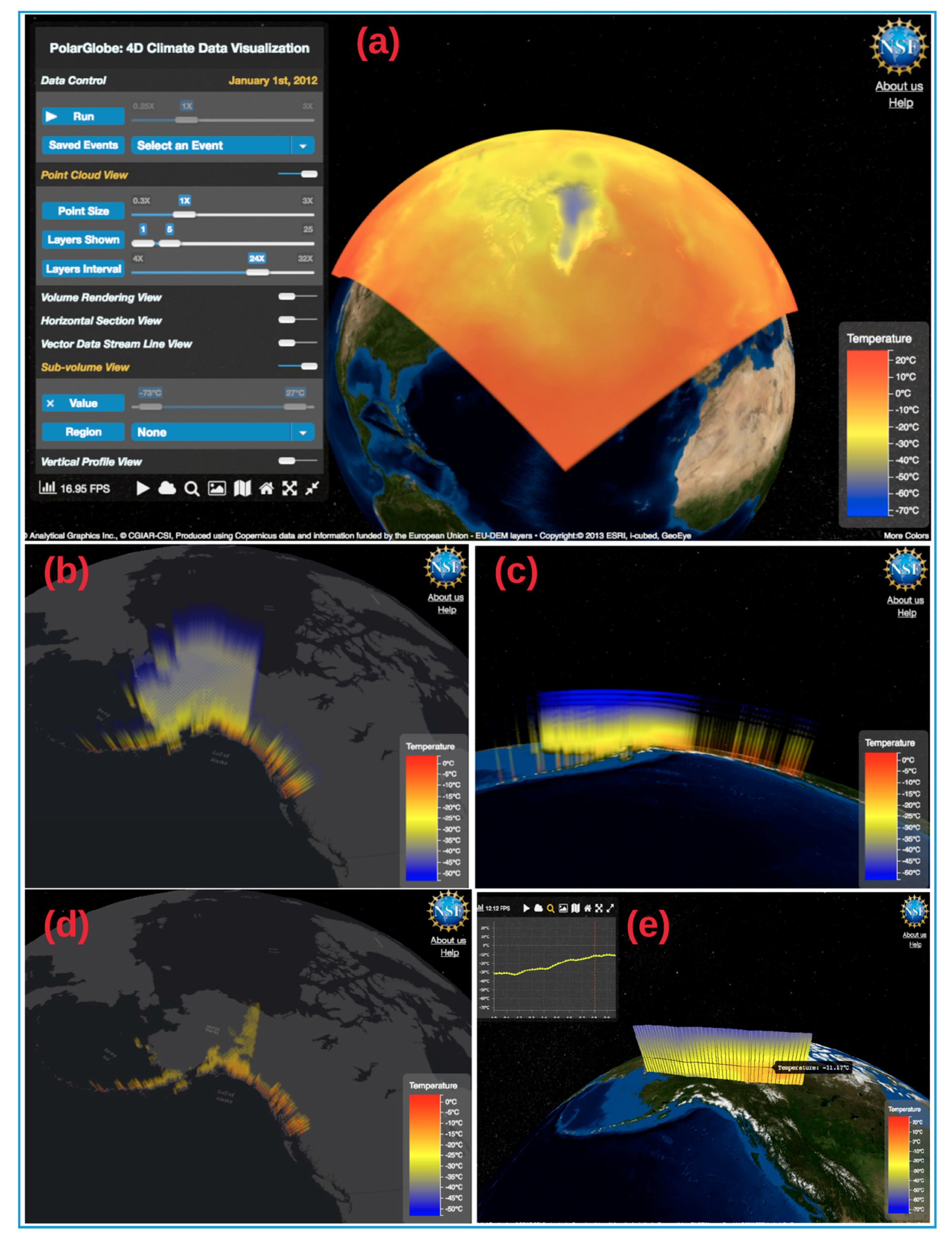
4. Graphic User Interface
5. Experiments and Results
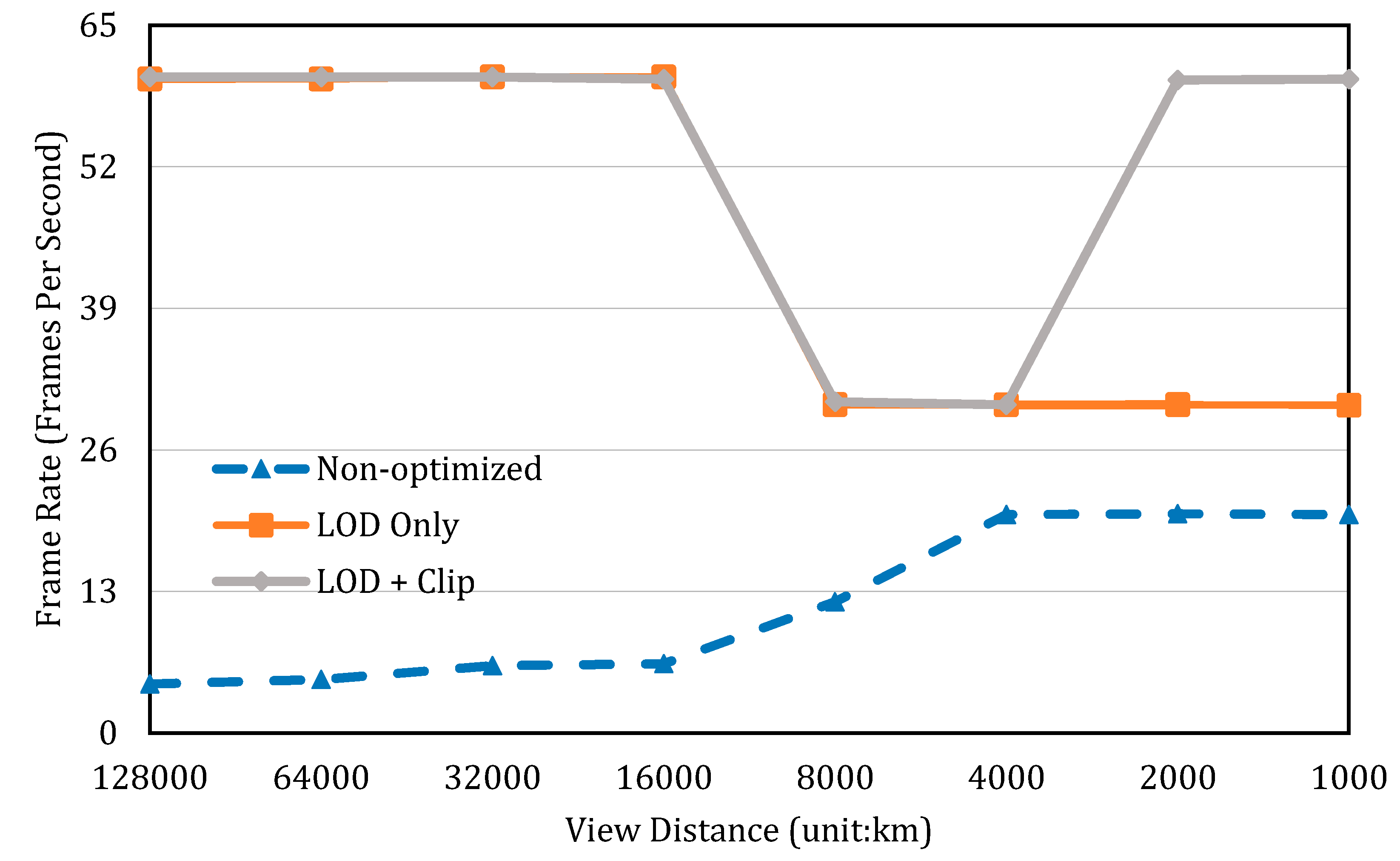
5.1. Performance on Data Loading and Rendering
5.2. Experiment on Accuracy vs. Efficiency in Spatial Filtering and Generalization
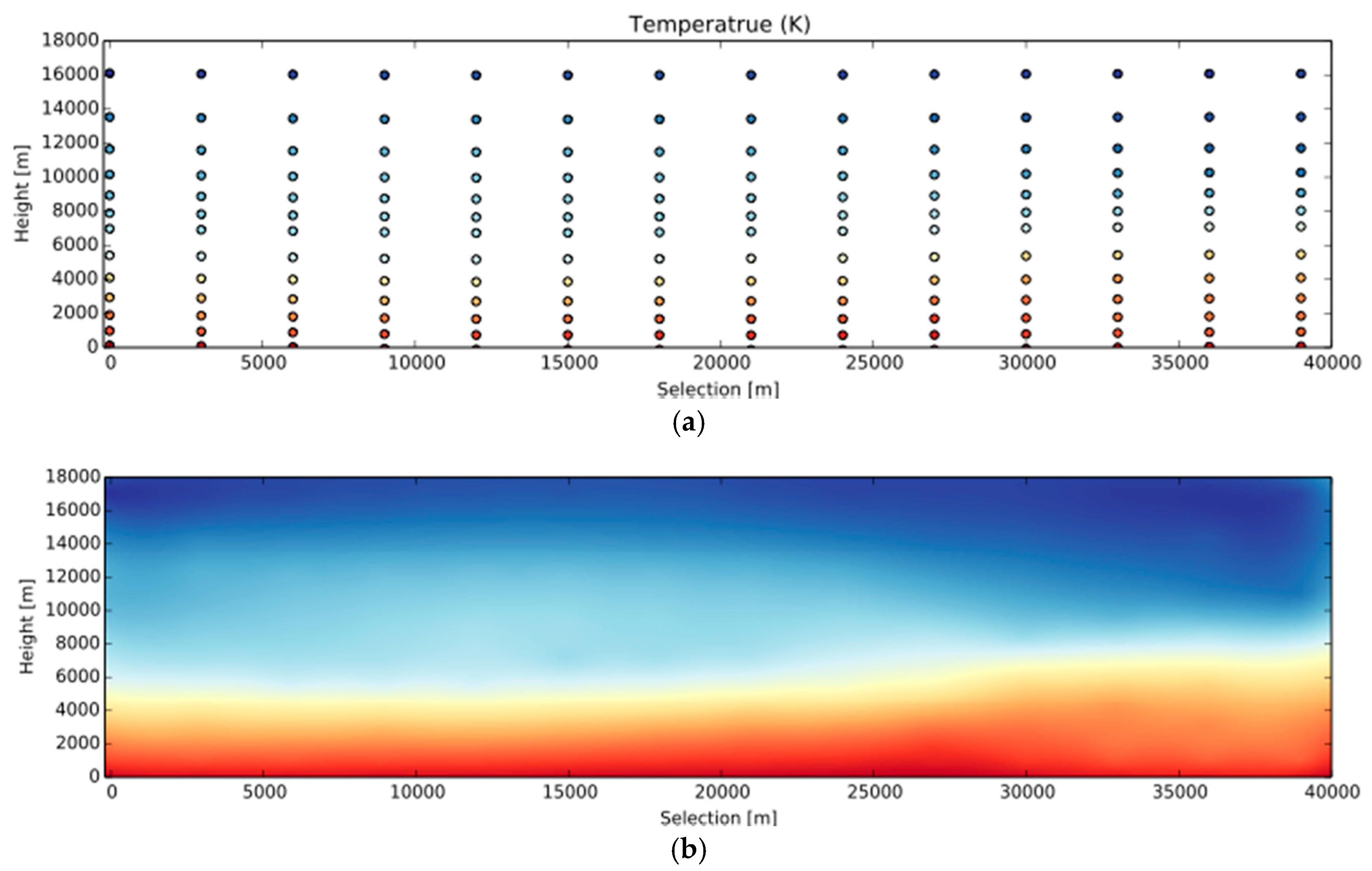
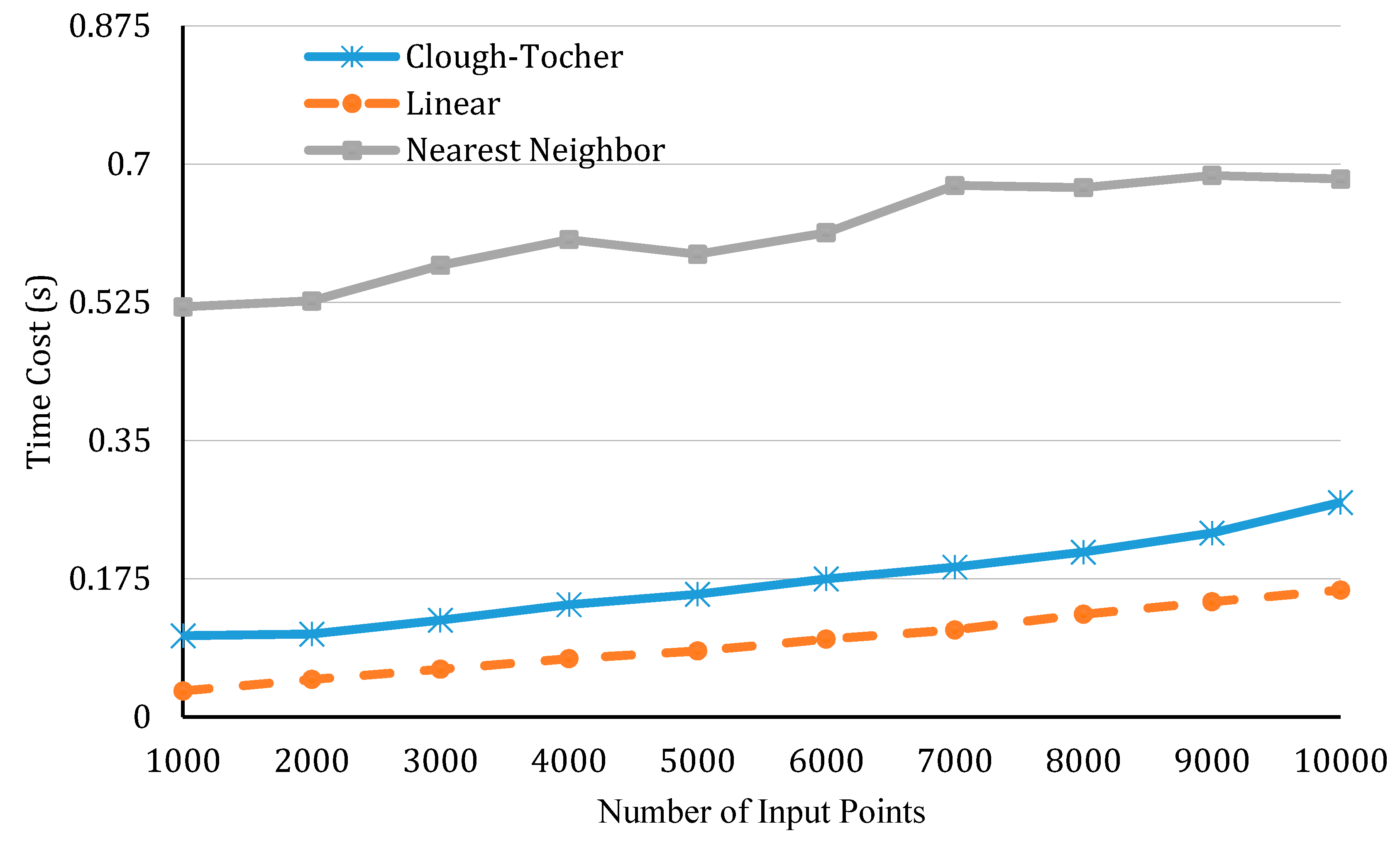
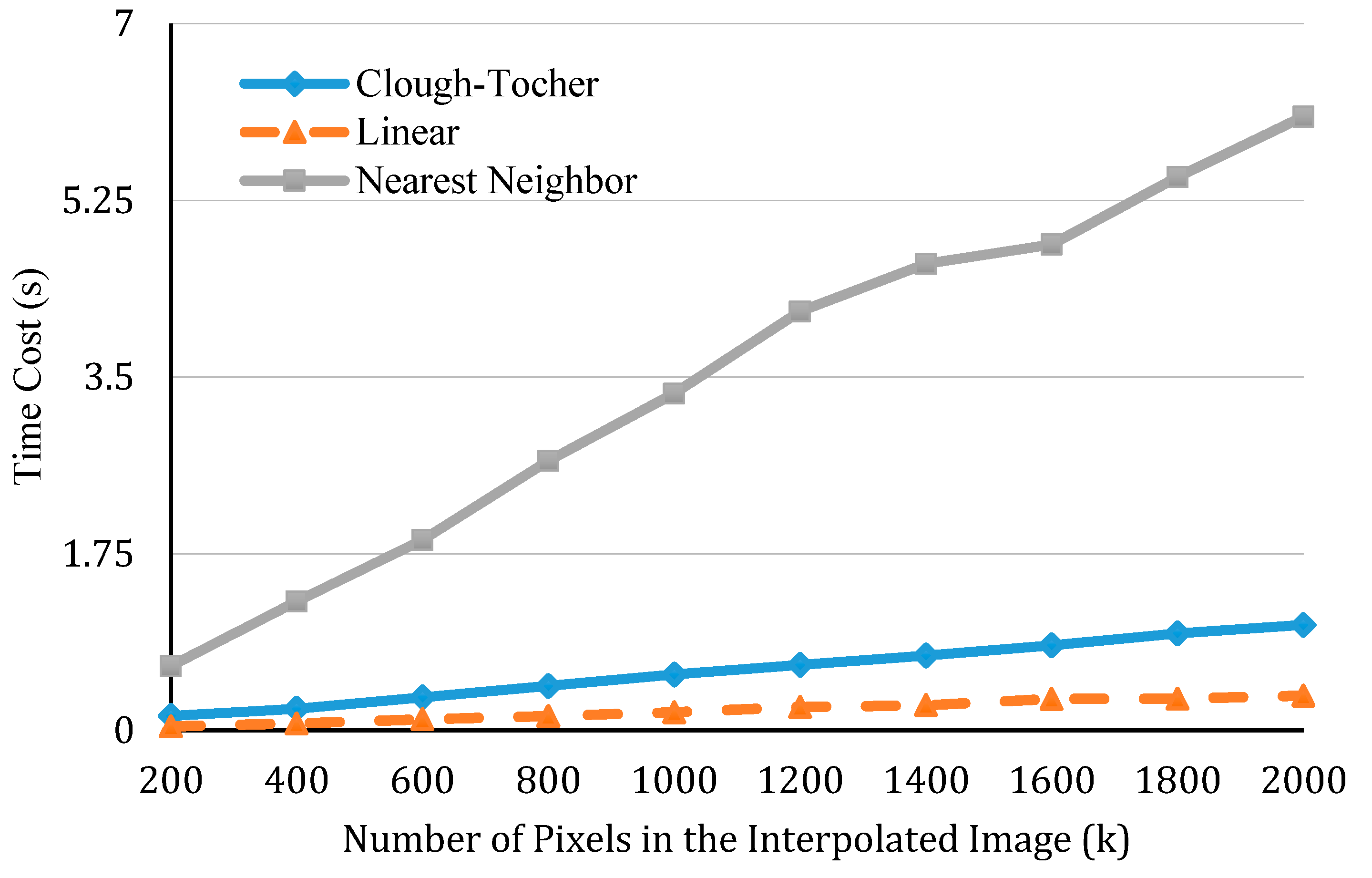
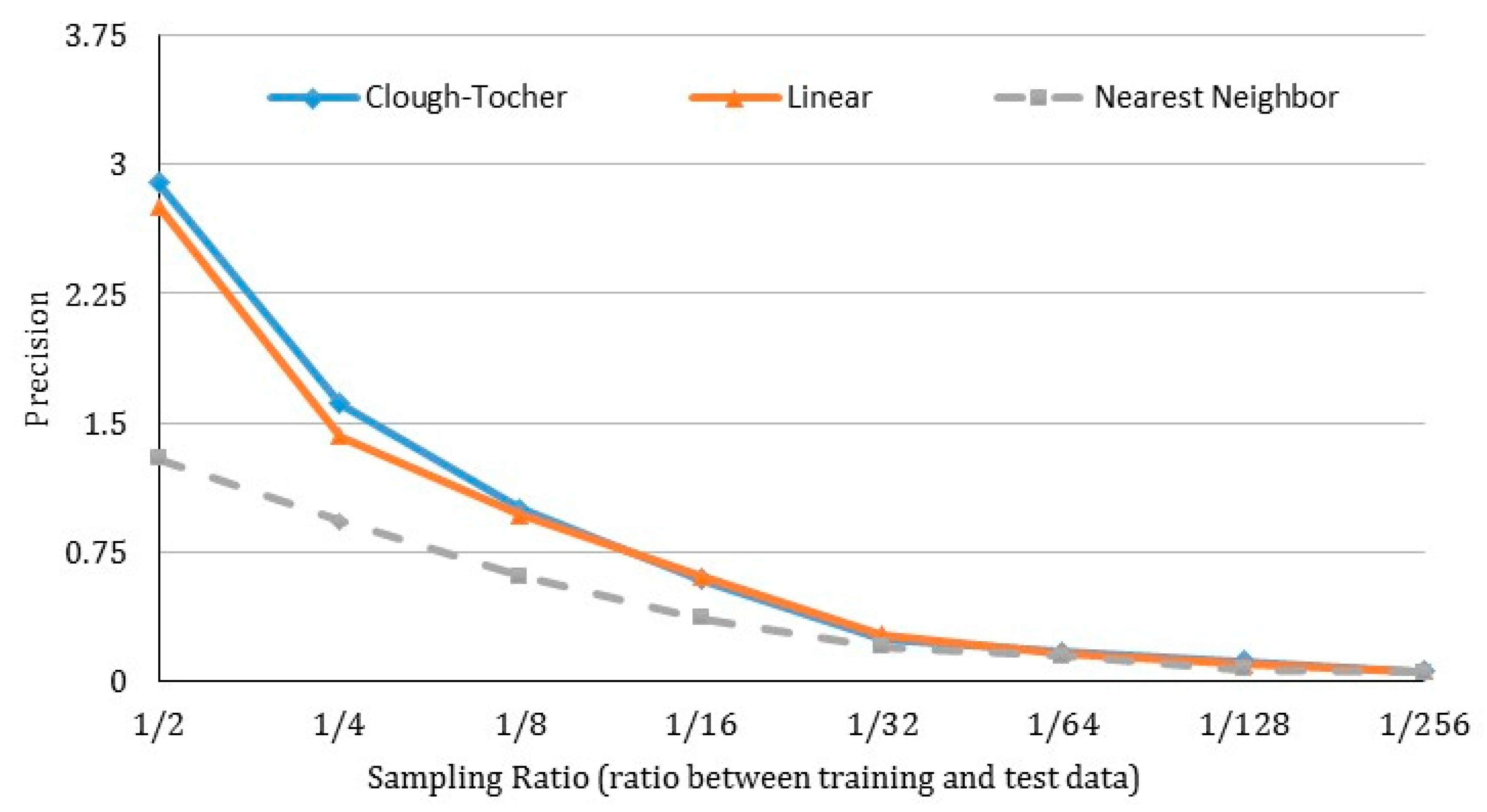
5.3. Impact of Interpolation on the Efficiency of Vertical Profile Generation and Visualization
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Dasgupta, S.; Mody, A.; Roy, S.; Wheeler, D. Environmental regulation and development: A cross-country empirical analysis. Oxf. Dev. Stud. 2001, 29, 173–187. [Google Scholar] [CrossRef]
- Grimm, N.B.; Faeth, S.H.; Golubiewski, N.E.; Redman, C.L.; Wu, J.; Bai, X.; Briggs, J.M. Global change and the ecology of cities. Science 2008, 319, 756–760. [Google Scholar] [CrossRef] [PubMed]
- Tacoli, C. Crisis or adaptation? Migration and climate change in a context of high mobility. Environ. Urban. 2009, 21, 513–525. [Google Scholar] [CrossRef]
- Li, Y.; Li, Y.; Zhou, Y.; Shi, Y.; Zhu, X. Investigation of a coupling model of coordination between urbanization and the environment. J. Environ. Manag. 2012, 98, 127–133. [Google Scholar] [CrossRef] [PubMed]
- Emanuel, K. Increasing destructiveness of tropical cyclones over the past 30 years. Nature 2005, 436, 686–688. [Google Scholar] [CrossRef] [PubMed]
- Goudie, A.S. Dust storms: Recent developments. J. Environ. Manag. 2009, 90, 89–94. [Google Scholar] [CrossRef] [PubMed]
- Meehl, G.A.; Zwiers, F.; Evans, J.; Knutson, T. Trends in extreme weather and climate events: Issues related to modeling extremes in projections of future climate change. Bull. Am. Meteorol. Soc. 2000, 81, 427–436. [Google Scholar] [CrossRef]
- Mitrovica, J.X.; Tamisiea, M.E.; Davis, J.L.; Milne, G.A. Recent mass balance of polar ice sheets inferred from patterns of global sea-level change. Nature 2001, 409, 1026–1029. [Google Scholar] [CrossRef] [PubMed]
- Cook, A.J.; Fox, A.J.; Vaughan, D.G.; Ferrigno, J.G. Retreating glacier fronts on the Antarctic Peninsula over the past half-century. Science 2005, 308, 541–544. [Google Scholar] [CrossRef] [PubMed]
- Sheppard, S.R. Visualizing Climate Change: A Guide to Visual Communication of Climate Change and Developing Local Solutions; Routledge: Florence, KY, USA, 2012; p. 511. [Google Scholar]
- Giorgi, F.; Mearns, L.O. Approaches to the simulation of regional climate change: A review. Rev. Geophys. 1991, 29, 191–216. [Google Scholar] [CrossRef]
- Chervenak, A.; Deelman, E.; Kesselman, C.; Allcock, B.; Foster, I.; Nefedova, V.; Lee, J.; Sim, A.; Shoshani, A.; Drach, B. High-performance remote access to climate simulation data: A challenge problem for data grid technologies. Parallel Comput. 2003, 29, 1335–1356. [Google Scholar] [CrossRef]
- Overpeck, J.T.; Meehl, G.A.; Bony, S.; Easterling, D.R. Climate data challenges in the 21st century. Science 2011, 331, 700–702. [Google Scholar] [CrossRef] [PubMed]
- Gordin, D.N.; Polman, J.L.; Pea, R.D. The Climate Visualizer: Sense-making through scientific visualization. J. Sci. Educ. Technol. 1994, 3, 203–226. [Google Scholar] [CrossRef]
- Van Wijk, J.J. The value of visualization. In Proceedings of the IEEE Visualization VIS 05, Minneapolis, MN, USA, 23–28 October 2005; pp. 79–86. [Google Scholar]
- Galton, F. Meteographics, or, Methods of Mapping the Weather, Macmillan, London; British Library: London, UK, 1863. [Google Scholar]
- Nocke, T.; Heyder, U.; Petri, S.; Vohland, K.; Wrobel, M.; Lucht, W. Visualization of Biosphere Changes in the Context of Climate Change. In Proceedings of the Conference on Information Technology and Climate Change, Berlin, Germany, 25–26 September 2008. [Google Scholar]
- Santos, E.; Poco, J.; Wei, Y.; Liu, S.; Cook, B.; Williams, D.N.; Silva, C.T. UV-CDAT: Analyzing Climate Datasets from a User’s Perspective. Comput. Sci. Eng. 2013, 15, 94–103. [Google Scholar] [CrossRef]
- Williams, D. The ultra-scale visualization climate data analysis tools (UV-CDAT): Data analysis and visualization for geoscience data. IEEE Comp. 2013, 46, 68–76. [Google Scholar] [CrossRef]
- Li, W.; Wu, S.; Song, M.; Zhou, X. A scalable cyberinfrastructure solution to support big data management and multivariate visualization of time-series sensor observation data. Earth Sci. Inform. 2016, 9, 449–464. [Google Scholar] [CrossRef]
- Gore, A. The Digital Earth: Understanding our planet in the 21st century. Aust. Surv. 1998, 43, 89–91. [Google Scholar] [CrossRef]
- Sheppard, S.R.; Cizek, P. The ethics of Google Earth: Crossing thresholds from spatial data to landscape visualisation. J. Environ. Manag. 2009, 90, 2102–2117. [Google Scholar] [CrossRef] [PubMed]
- Boschetti, L.; Roy, D.P.; Justice, C.O. Using NASA’s World Wind virtual globe for interactive internet visualization of the global MODIS burned area product. Int. J. Remote Sens. 2008, 29, 3067–3072. [Google Scholar] [CrossRef]
- Boulos, M.N. Web GIS in practice III: Creating a simple interactive map of England’s strategic Health Authorities using Google Maps API, Google Earth KML, and MSN Virtual Earth Map Control. Int. J. Health Geogr. 2005, 4, 22. [Google Scholar] [CrossRef] [PubMed]
- Sun, X.; Shen, S.; Leptoukh, G.G.; Wang, P.; Di, L.; Lu, M. Development of a Web-based visualization platform for climate research using Google Earth. Comput. Geosci. 2012, 47, 160–168. [Google Scholar] [CrossRef]
- Varun, C.; Vatsavai, R.; Bhaduri, B. iGlobe: An interactive visualization and analysis framework for geospatial data. In Proceedings of the 2nd International Conference on Computing for Geospatial Research & Applications, Washington, DC, USA, 23–25 May 2011; p. 21. [Google Scholar]
- Helbig, C.; Bauer, H.S.; Rink, K.; Wulfmeyer, V.; Frank, M.; Kolditz, O. Concept and workflow for 3D visualization of atmospheric data in a virtual reality environment for analytical approaches. Environ. Earth Sci. 2014, 72, 3767–3780. [Google Scholar] [CrossRef]
- Berberich, M.; Amburn, P.; Dyer, J.; Moorhead, R.; Brill, M. HurricaneVis: Real Time Volume Visualization of Hurricane Data. In Proceedings of the Eurographics/IEEE Symposium on Visualization, Berlin, Germany, 10–12 June 2009. [Google Scholar]
- Wang, F.; Li, W.; Wang, S. Polar Cyclone Identification from 4D Climate Data in a Knowledge-Driven Visualization System. Climate 2016, 4, 43. [Google Scholar] [CrossRef]
- Li, Z.; Yang, C.; Sun, M.; Li, J.; Xu, C.; Huang, Q.; Liu, K. A high performance web-based system for analyzing and visualizing spatiotemporal data for climate studies. In Proceedings of the International Symposium on Web and Wireless Geographical Information Systems, Banff, AB, Canada, 4–5 April 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 190–198. [Google Scholar]
- Alder, J.R.; Hostetler, S.W. Web based visualization of large climate data sets. Environ. Model. Softw. 2015, 68, 175–180. [Google Scholar] [CrossRef]
- Liu, Z.; Ostrenga, D.; Teng, W.; Kempler, S. Developing online visualization and analysis services for NASA satellite-derived global precipitation products during the Big Geospatial Data era. In Big Data: Techniques and Technologies in Geoinformatics; CRC Press: Boca Raton, FL, USA, 2014; pp. 91–116. [Google Scholar]
- Van Meersbergen, M.; Drost, N.; Blower, J.; Griffiths, G.; Hut, R.; van de Giesen, N. Remote web-based 3D visualization of hydrological forecasting datasets. In Proceedings of the EGU General Assembly Conference, Vienna, Austria, 12–17 April 2015; Volume 17, p. 4865. [Google Scholar]
- Hunter, J.; Brooking, C.; Reading, L.; Vink, S. A Web-based system enabling the integration, analysis, and 3D sub-surface visualization of groundwater monitoring data and geological models. Int. J. Digit. Earth 2016, 9, 197–214. [Google Scholar] [CrossRef]
- Moroni, D.F.; Armstrong, E.; Tsontos, V.; Hausman, J.; Jiang, Y. Managing and servicing physical oceanographic data at a NASA Distributed Active Archive Center. In Proceedings of the OCEANS 2016 MTS/IEEE Monterey, Monterey, CA, USA, 19–23 September 2016; pp. 1–6. [Google Scholar]
- AGI. Cesium-WebGL Virtual Globe and Map Engine. Available online: https://cesiumjs.org/ (accessed on 17 January 2015).
- Brovelli, M.A.; Hogan, P.; Prestifilippo, G.; Zamboni, G. NASA Webworldwind: Multidimensional Virtual Globe for Geo Big Data Visualization. In Proceedings of the ISPRS-International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences 2016, Prague, Czech Republic, 12–19 July 2016; pp. 563–566. [Google Scholar]
- Voumard, Y.; Sacramento, P.; Marchetti, P.G.; Hogan, P. WebWorldWind, Achievements and Future of the ESA-NASA Partnership (No. e2134v1). Available online: https://peerj.com/preprints/2134.pdf (accessed on 18 April 2017).
- Li, W.; Wang, S. PolarGlobe: A web-wide virtual globe system for visualizing multidimensional, time-varying, big climate data. Int. J. Geogr. Inf. Sci. 2017, 31, 1562–1582. [Google Scholar] [CrossRef]
- Cox, M.; Ellsworth, D. Managing Big Data for Scientific Visualization; ACM Siggraph: Los Angeles, CA, USA, 1997; Volume 97, pp. 146–162. [Google Scholar]
- Demchenko, Y.; Grosso, P.; De Laat, C.; Membrey, P. Addressing big data issues in scientific data infrastructure. In Proceedings of the IEEE 2013 International Conference on Collaboration Technologies and Systems (CTS), San Diego, CA, USA, 20–24 May 2013; pp. 48–55. [Google Scholar]
- Baccarelli, E.; Cordeschi, N.; Mei, A.; Panella, M.; Shojafar, M.; Stefa, J. Energy-efficient dynamic traffic offloading and reconfiguration of networked data centers for big data stream mobile computing: Review, challenges, and a case study. IEEE Netw. 2016, 30, 54–61. [Google Scholar] [CrossRef]
- Cordeschi, N.; Shojafar, M.; Amendola, D.; Baccarelli, E. Energy-efficient adaptive networked datacenters for the QoS support of real-time applications. J. Supercomput. 2015, 71, 448–478. [Google Scholar] [CrossRef]
- Wong, P.C.; Shen, H.W.; Leung, R.; Hagos, S.; Lee, T.Y.; Tong, X.; Lu, K. Visual analytics of large-scale climate model data. In Proceedings of the 2014 IEEE 4th Symposium on Large Data Analysis and Visualization (LDAV), Paris, France, 9–10 November 2014; pp. 85–92. [Google Scholar]
- Li, J.; Wu, H.; Yang, C.; Wong, D.W.; Xie, J. Visualizing dynamic geosciences phenomena using an octree-based view-dependent LOD strategy within virtual globes. Comput. Geosci. 2011, 37, 1295–1302. [Google Scholar] [CrossRef]
- Liang, J.; Gong, J.; Li, W.; Ibrahim, A.N. Visualizing 3D atmospheric data with spherical volume texture on virtual globes. Comput. Geosci. 2014, 68, 81–91. [Google Scholar] [CrossRef]
- Kruger, J.; Westermann, R. Acceleration techniques for GPU-based volume rendering. In Proceedings of the 14th IEEE Visualization 2003 (VIS’03), Seattle, WA, USA, 13–24 October 2003; p. 38. [Google Scholar]
- Wang, F.; Wang, G.; Pan, D.; Liu, Y.; Yang, Y.; Wang, H. A parallel algorithm for viewshed analysis in three-dimensional Digital Earth. Comput. Geosci. 2015, 75, 57–65. [Google Scholar]
- Drebin, R.A.; Carpenter, L.; Hanrahan, P. Volume rendering. Comput. Graph. 1988, 22, 65–74. [Google Scholar] [CrossRef]
- National Center for Atmospheric Research Staff. The Climate Data Guide: Arctic System Reanalysis (ASR). Available online: https://climatedataguide.ucar.edu/climate-data/arctic-system-reanalysis-asr (accessed on 22 June 2017).
- Luebke, D.P. Level of Detail for 3D Graphics; Morgan Kaufmann: San Francisco, CA, USA, 2003. [Google Scholar]
- Weiskopf, D.; Engel, K.; Ertl, T. Interactive clipping techniques for texture-based volume visualization and volume shading. IEEE Trans. Vis. Comput. Graph. 2003, 9, 298–312. [Google Scholar] [CrossRef]
- Douglas, D.H.; Peucker, T.K. Algorithms for the reduction of the number of points required to represent a digitized line or its caricature. Cartogr. Int. J. Geogr. Inf. Geovis. 1973, 10, 112–122. [Google Scholar] [CrossRef]
- Menon, S.; Hansen, J.; Nazarenko, L.; Luo, Y. Climate effects of black carbon aerosols in China and India. Science 2002, 297, 2250–2253. [Google Scholar] [CrossRef] [PubMed]
- Malys, S. The WGS84 Reference Frame. National Imagery and Mapping Agency. 1996. Available online: http://earth-info.nga.mil/GandG/publications/tr8350.2/wgs84fin.pdf (accessed on 10 March 2017).
- Hinks, A.R. A retro-azimuthal equidistant projection of the whole sphere. Geogr. J. 1929, 73, 245–247. [Google Scholar] [CrossRef]
- Parker, J.A.; Kenyon, R.V.; Troxel, D.E. Comparison of interpolating methods for image resampling. IEEE Trans. Med. Imaging 1983, 2, 31–39. [Google Scholar] [CrossRef] [PubMed]
- De Boor, C.; De Boor, C.; Mathématicien, E.U.; De Boor, C.; De Boor, C. A Practical Guide to Splines; Springer: New York, NY, USA, 1978; Volume 27, p. 325. [Google Scholar]
- Mann, S. Cubic precision Clough-Tocher interpolation. Comput. Aided Geom. Des. 1999, 16, 85–88. [Google Scholar] [CrossRef]











© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Li, W.; Wang, F. Web-Scale Multidimensional Visualization of Big Spatial Data to Support Earth Sciences—A Case Study with Visualizing Climate Simulation Data. Informatics 2017, 4, 17. https://doi.org/10.3390/informatics4030017
Wang S, Li W, Wang F. Web-Scale Multidimensional Visualization of Big Spatial Data to Support Earth Sciences—A Case Study with Visualizing Climate Simulation Data. Informatics. 2017; 4(3):17. https://doi.org/10.3390/informatics4030017
Chicago/Turabian StyleWang, Sizhe, Wenwen Li, and Feng Wang. 2017. "Web-Scale Multidimensional Visualization of Big Spatial Data to Support Earth Sciences—A Case Study with Visualizing Climate Simulation Data" Informatics 4, no. 3: 17. https://doi.org/10.3390/informatics4030017
APA StyleWang, S., Li, W., & Wang, F. (2017). Web-Scale Multidimensional Visualization of Big Spatial Data to Support Earth Sciences—A Case Study with Visualizing Climate Simulation Data. Informatics, 4(3), 17. https://doi.org/10.3390/informatics4030017