6.2. Results and Analysis
Inter-rater agreement was computed according to Fleiss’ kappa (
) and Krippendorff’s alpha (
) (cf.
Table 4). Pairwise percentage agreement and Cohen’s kappa (cf.
Table 5) between each rater was also calculated.
There is widespread disagreement within the research community regarding the interpretation of the Fleiss’ kappa scores partly because an “acceptable” level of inter-rater agreement largely depends on the specific field of study. Among the several interpretations of kappa (
) values, the one proposed by Landis and Koch [
43] seems to have been cited most by researchers. As such, according to this scheme, our raters had a slight agreement among themselves, as a 0.17 (cf.
Table 4) kappa score falls in the range 0.01–0.20, which is the range for such a category of agreement. With such a low agreement score among our raters, the correlation results calculated subsequently (between the raters and the system scores) was bound to lie within a spectrum of high and low values i.e., some raters scores would have high correlation with the evaluation metrics while others, not so much. The same fact is further corroborated by the alpha value obtained. From the pairwise inter-rater agreement figures given below, it is clear that several pairs of raters agreed more, than they did with the rest.
The cells marked in ‘green’ (in the upper triangle) indicate pairwise inter-rater percentage agreement while those marked in blue (in the lower triangle) indicate pairwise Cohen’s kappa agreement.
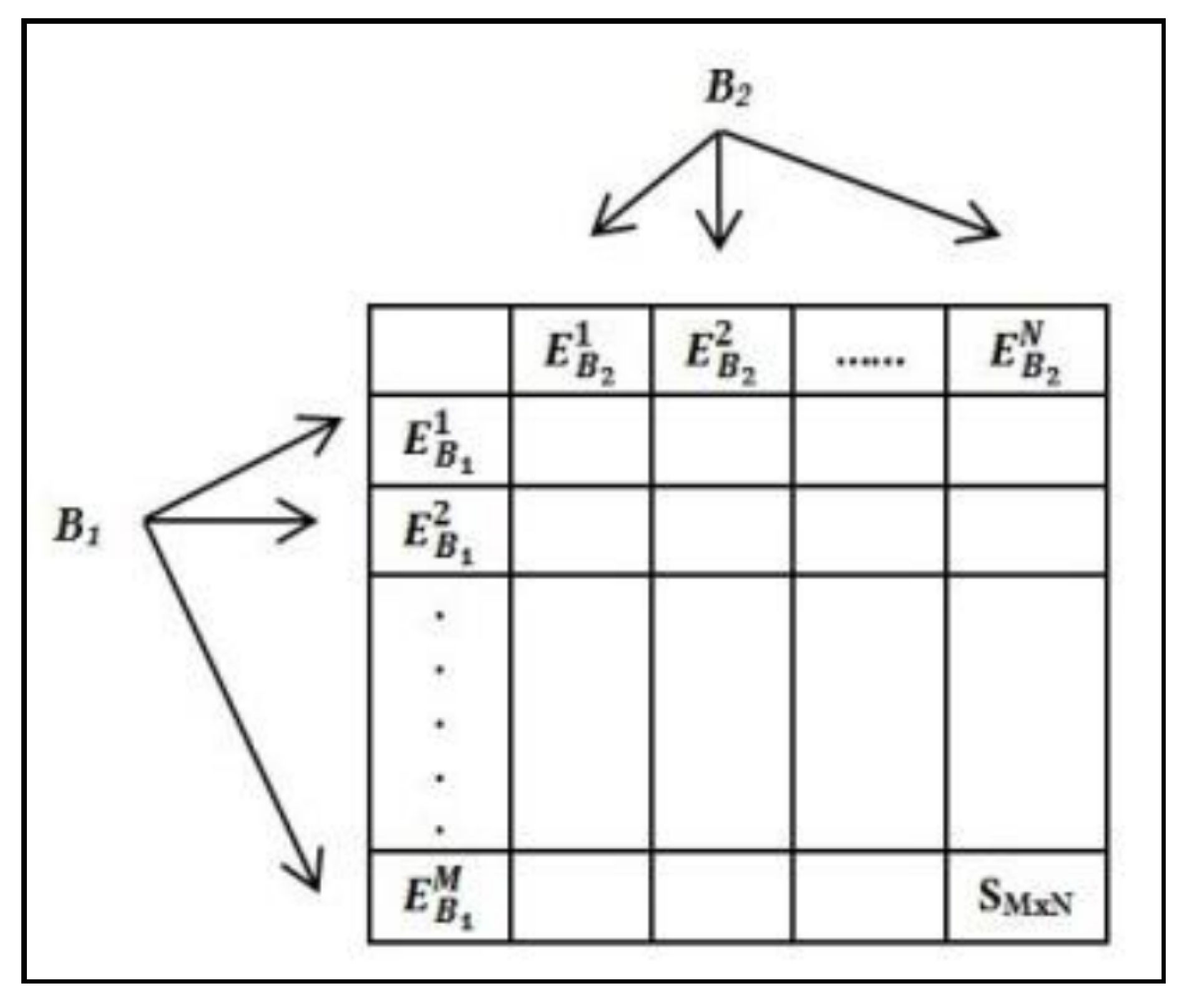
We compute similarity between each word pair using the four different similarity metrics and compare the metric scores with the gold standard similarity scores as defined by human annotators to evaluate the similarity metrics.
Table 6 shows the evaluation results. Each cell in this table indicates the Pearson correlation value between the scores provided by a rater and the corresponding similarity metric scores. The column titled ‘majority’ denotes the correlation scores obtained when the majority score from among the five annotators is considered. In case of a tie, we selected a score randomly from among the scores that tied. The column titled ‘overall’ represents the correlation values for a particular metric with respect to all the raters.
The path-based similarity metric based on Bangla WordNet produces correlation scores in between 0.16 and 0.20. However, it is to be noted that out of a total 162 test cases, it returned a score of zero in 55 (33.95%) cases. A detailed analysis of these 55 cases revealed the following.
In 21(12.96%) cases, one of the words (cases) was absent in the Bangla WordNet. There were no cases where both words in a test word pair were absent in the Bangla WordNet.
Ineight8 (4.94%) cases, one of the words, in spite of being present in the WordNet, did not have any hypernym relations. Similarly, in three (1.85%) cases, neither word in the test word pair possessed any hypernym.
For 18 (11.11%) cases, the words in the test word pairs did not share a common ancestor and thus obtaining zero score.
From the statistics above, it can be noticed that the numbers do not add up to the number of cases (55) producing zero score. This is owing to the fact that there were several cases among the 55, in which a word in a test pair was repeated in another test pair producing zero score for both test pairs. As such, we wanted the analysis of the cases to reflect only the unique test pairs. These discrepancies reveal the weaknesses of the Bangla WordNet and in turn the path-based similarity metric built on it.
The main motive behind using cross-lingual approaches to semantic similarity was to take advantage of the well-developed resources in English. The path-based similarity model with translation and English WordNet
shows significant improvements over the monolingual counterpart as can be observed from the results in
Table 6. It improved the correlation scores across all the annotators; the improvements being very high (more than double) with respect to
R2,
R4 and
R5 and moderate for
R1 and
R3. The correlation for
with respect to majority voting annotation scores was also found to be more than double than that for
, thus marking significant improvements from the monolingual path-based setting.
is really put into perspective when we consider only those cases (106, 65.43% of the test set) for which both the path-based approaches produced non-zero similarity scores. Such a setup is needed in order to truly appreciate the improvements obtained in light of the English WordNet. This is because several pairs obtained zero scores for the
approach thus lowering the correlation for the
method. As such, observing those zero scores along with the other non-zero scores for other pairs would not lead to comparable results. Therefore, we recomputed the correlation scores considering only those scores for which both path-based metrics produced non-zero scores which would help in truly identifying how much improvement the English WordNet results in. The results for this setup are presented in
Table 7.
Correlation values improved for
with respect to each annotator as well as majority voting and overall scoring when compared to
. As a consequence of removing the zero similarity scored pairs from both path-based metrics, we find several changes in the correlation values for the setup in comparison to when all the test cases were included (cf.
Table 6). It can be seen that
correlation scores increased for annotators
R2,
R4 and
R5 with a good improvement with respect to the majority and overall scores as well. This was quite expected owing to the fact that 55 zero scores were removed from the analysis and only the non-zero scores were used for measuring correlation. However, scores declined for raters
R1 and
R3. On the other hand,
was found to produce lower correlation scores (except for
R3 and overall) in comparison to the ones obtained with the metric when all the pairs were considered. Intuitively, it can be understood that eliminating the zero scored pairs for
from the dataset also removed good scores obtained with
which in turn caused the reduction in correlation values. However, the overall
correlation score remains the same. It is evident from
Table 7 that, although the correlations improve substantially for
for this subset,
still outclasses
even on this dataset.
Compared to 55 (33.95%) cases of 0 scores for
,
resulted in 0 scores for only 2 (1.23%) cases; a significant (96.36%) improvement as is visible from both
Table 6 and
Table 7. In both these two cases, a proper translation of Bangla words was not obtained using our resources; the cases being রোদ্দুর (sunlight) and ধারে (nearby). Thus, this method becomes reliant on the translation resources, considering the errors creeping in by the translation process. All in all, improvement can be attributed due to the wide coverage of the English WordNet.
However, this method did show weaknesses in certain cases, e.g., in case of computing similarity between বন্যা (flood) and পর্বত (mountain). The translations produced by the translation tools for these two words are as follows.
Tr (বন্যা) = {‘cataclysm’, ‘diluvium’, ‘feral’, ‘flood’, ‘inundation’, ‘spate’}
Tr (পর্বত) = {‘fell’, ‘hill’, ‘mountain’, ‘rock’}.
The path-based similarity between ‘spate’ and ‘mountain’ turned out to be 1 since spate#n#1 and mountain#n#2 belong to the same synset (“a large number or amount or extent”) in English WordNet. Although, according to the English WordNet this approach results in such a high similarity score between বন্যা and পর্বত, native speakers seldom think of this similarity in the metaphoric (and rare) usage of these two words. This example is perhaps an indication that when considering similarity between word pairs, we should not consider their very rare usages.
The Bangla Word2Vec model produced really poor correlation scores compared to the path-based models with the correlation scores ranging from 0.08 to 0.16. However, an interesting finding is that it correlated better than the model with respect to the majority score. The based correlation score with respect to the majority score was also found to be higher than the -based correlation scores with respect to individual rater scores. It is interesting to note that whenever we obtain a zero similarity score for a test word pair for either of the path-based methods, it can be due to a variety of factors as discussed before. However, when we obtain a zero score from a distributional approach, it simply implies that either (or both) of the words is absent from the corpus on which the model was trained and as such their vectors could not be generated.
The cross-lingual Word2Vec models
produced much better correlation scores than the
model; the correlation scores being much higher than for the
model with respect to each annotator. Predictably, among the two English Word2Vec models, the model (pre)trained on the Gigaword corpus performed better than the one trained on the BNC corpus with a sharp increase in correlation score with respect to majority voting; however the scores either declined or stayed same for raters
R3 and
R5. The comparative study (cf.
Table 6) of the results obtained with
and
is an indicator of the fact that using a richer and more diverse corpus results in better word vectors and in turn better similarity scores.
When contrasted with , the distributional model trained on the Gigaword corpus showed as much as 125% increase in correlation scores with respect to rater R1 while it showed a maximum of 87.5% increase over the model trained on the British National corpus for the same rater. Correlation scores improved for annotators R1, R2 and R4 increasing to almost double whereas the improvement was slightly less evident for R3 and R5 when contrasting with . Similar to , the correlation score with respect to majority score for the Word2Vec model trained on the Gigaword corpus was higher than the correlation scores with respect to all annotators.
It is to be noted that performs better than despite the size of the English BNC corpus being smaller than the Bangla TDIL training data. This result is quite surprising. One could perhaps conjecture that Bangla is a morphologically richer language and therefore for corpora of comparable size, the Bangla corpus would have a much larger vocabulary size than English corpus. However, that is not the case here; in fact, the English corpus despite being smaller than the Bangla corpus has a larger vocabulary than the Bangla corpus. Linguistically speaking there are other reasons behind this phenomenon, which however is not elaborated in this paper.
The models could not beat the performance of the model with respect to raters R1, R2 and R3 and overall, however they correlate better than the model with respect to R4, R5 and majority score. These observations were quite consistent with our expectations and could be justified as such owing to the robust nature of the cross-lingual distributional model on account of the vast vocabulary size of the English corpora leading to the generation of high quality word vectors.
It was presupposed that when detecting similarity between Bangla words using the distributional models, the monolingual Word2Vec approach would offer near competitive human correlated scores with respect to the cross-lingual approach. This is because the language in which we are trying to discover similarity is Bangla and as such, the Bangla corpora should have been able to provide more insightful and varied contexts and in turn better word embeddings suitable for measuring semantic similarity in Bangla. However, as can be seen from
Table 6, this is not the case.
By manually analyzing the distributional similarity scores on the evaluation dataset, we found that typically provided higher similarity scores than model (107 cases, 66.05%). It was also observed that for 62 (38.27%) cases, both models provided higher similarity scores than the model, and for 61 (37.65%) cases similarity scores were higher than the corresponding similarity scores. However, higher similarity scores do not necessarily indicate better similarity scores unless it correlates well with human evaluation. For example, considering the word pair গ্রাম (village) and জীবন (life), the distributional semantic similarity scores are as shown below.
generated a score of 0.12.
generated a score of 0.84.
generated a score of 0.53.
Here four out of the five annotators gave a score of 1 to this word pair indicating least similarity. Thus, provides the best similarity score among the distributional-based metrics for this word pair. Furthermore, it goes without saying that the model does not always produce scores highly correlating with human assignments for all the test pairs in our dataset.
However, as can be seen from
Table 8, which reports the correlation scores for cases when both
models provide greater similarity than the
with respect to the majority-voting scheme, the correlation was stronger for the cross-lingual Word2Vec models. The improvement was much more pronounced for the British National corpus than for the Gigaword corpus.
Almost all the word pairs in our dataset followed the general trend that their semantic similarity scores according to the cross-lingual approach outshined their monolingual counterparts. Nevertheless, examples such as those described previously revealed a few weaknesses with the cross-lingual approaches. Thus, it cannot be said definitively that using English resources would always guarantee better results.
generated poor similarity and correlation scores. This was quite expected owing to the limited coverage of the Bangla WordNet. Several words in the dataset are missing from the WordNet such as অসুখ (illness) and বাতাস (wind); words like প্রথমে (initially) have no hypernym structure and as such, their similarity scores could not be generated using the path-based method. Thus, it can be out rightly stated that the Bangla WordNet needs further improvement in terms of both structure and scope based on the examples provided and the statistics reported.
was used as the baseline method in our work over which we needed ways to improve. This is where the translation came into the picture.
involved projecting the Bangla words into their corresponding English counterparts (i.e., translations). This approach showed a marked improvement by as much as 156% increase in correlation score with respect to annotator
R1 as can be seen from
Table 7. The difference in the results yielded by
clearly demonstrates the edge of the English WordNet over the Bangla WordNet in terms of coverage and design.
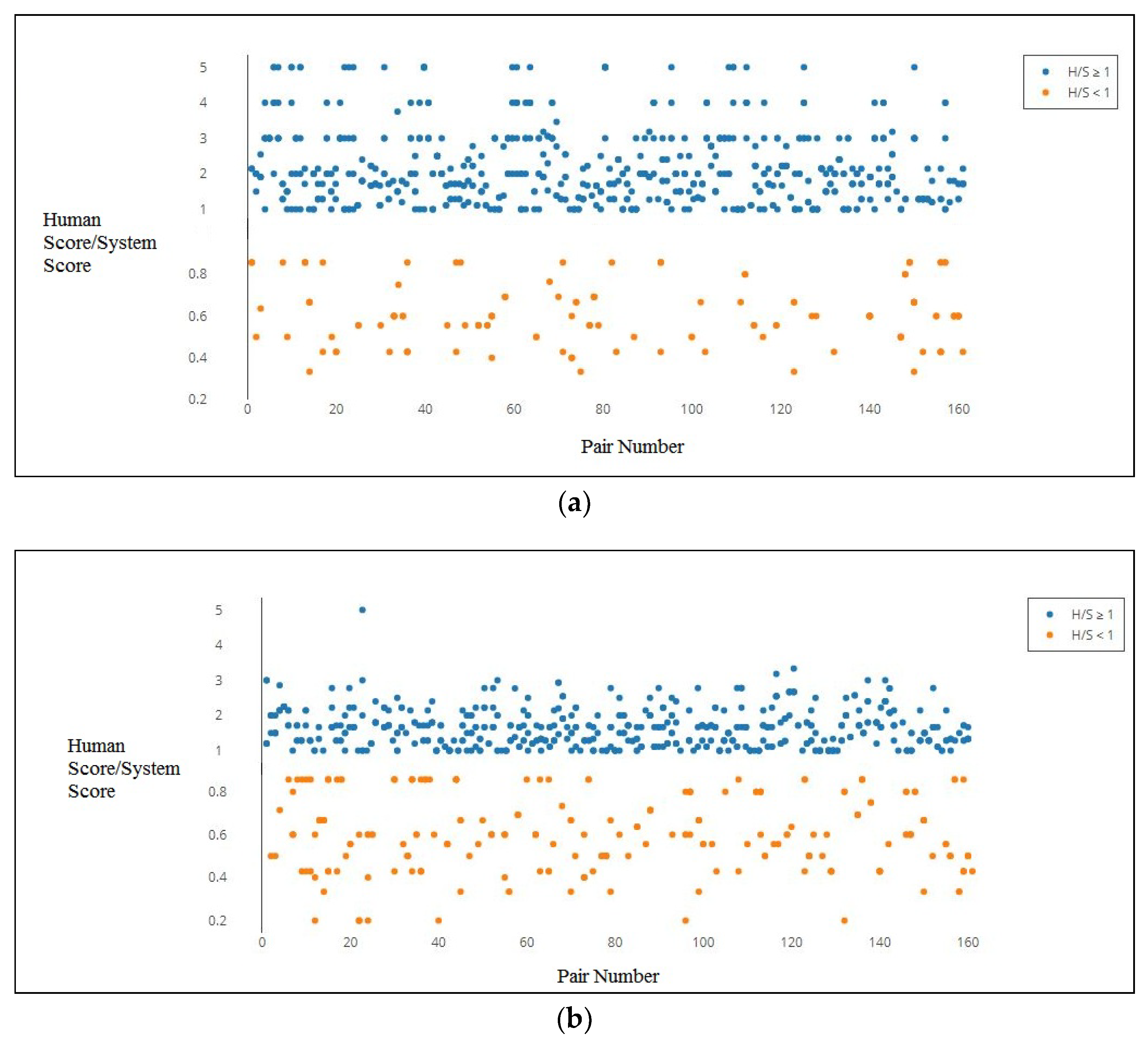
In order to further investigate and visualize how human scores relate to the similarity metric scores, we plotted graphs (for all the metrics) where the
x-axis denotes the test pair (i.e., word pair) ids and
y-axis represents the
. These graphs were created first by up scaling the system scores, which originally lie in the [0, 1] range, to the annotator scoring range [1, 5] so as to avoid division by zero errors, and then by plotting the
s. The reason for choosing such a plotting scheme is to examine the proximity of the plotted points to the y = 1 line in the graphs. If a similarity metric perfectly correlates (i.e., r = 1) with a human annotation, then the corresponding points will fall on the y = 1 line. More the number of points that lie on or near this line, stronger will be the correlation between the metric considered and the human annotation scores. Since both the human score and the up-scaled system scores lie in the [1, 5] range, the
lies in the [0.2, 5] range. Since the score pairs (2, 1) and (1, 2) results in
of 2.0 and 0.5 respectively and the both the ratios are equally divergent from y = 1, we make the lines y = 2 and y = 0.5 equally distant from the y = 1 line in the graphs. Similarly (3, 0.333), (4, 0.25), (5, 0.2) line pairs are also shown equally distant from the y = 1 line in the graphs. The graphs for the five metrics are shown in
Figure 3.
Table 9 shows some statistics of the results presented in
Figure 3. Finding the number of points lying in the vicinity of the y = 1 line in these graphs gives a strong indication about the correlation. We observed that both
and
produced highest number of points (92) aligned on the y = 1 line, followed by
(61),
(43) and
(19).
From the obtained scatter plots in
Figure 3 and the statistics in
Table 9, a phenomenon becomes visible. The distributional models very frequently produce higher scores resulting in
less than one, forming several dense regions prominently visible below the y = 1 line in the plots for
,
and
models. On the other hand, the path-based metrics typically provided lower similarity scores yielding
greater than one which is visible from the majority of the plotted points above the y = 1 line in
Figure 3a,b. Most of the points in the
graph (cf.
Figure 3b) being close to the y = 1 line is reasoned out to be providing the most accurate similarity scores, a fact which is further corroborated by the correlation results (cf.
Table 6). Furthermore, a sharp drop in the spread of the data points between the graphs of
(cf.
Figure 3a) and
can also be observed indicating that
produces more correlated similarity scores than
which shows divergent scores all across its plot. This fact goes on to show what a marked improvement translation brings to semantic similarity.
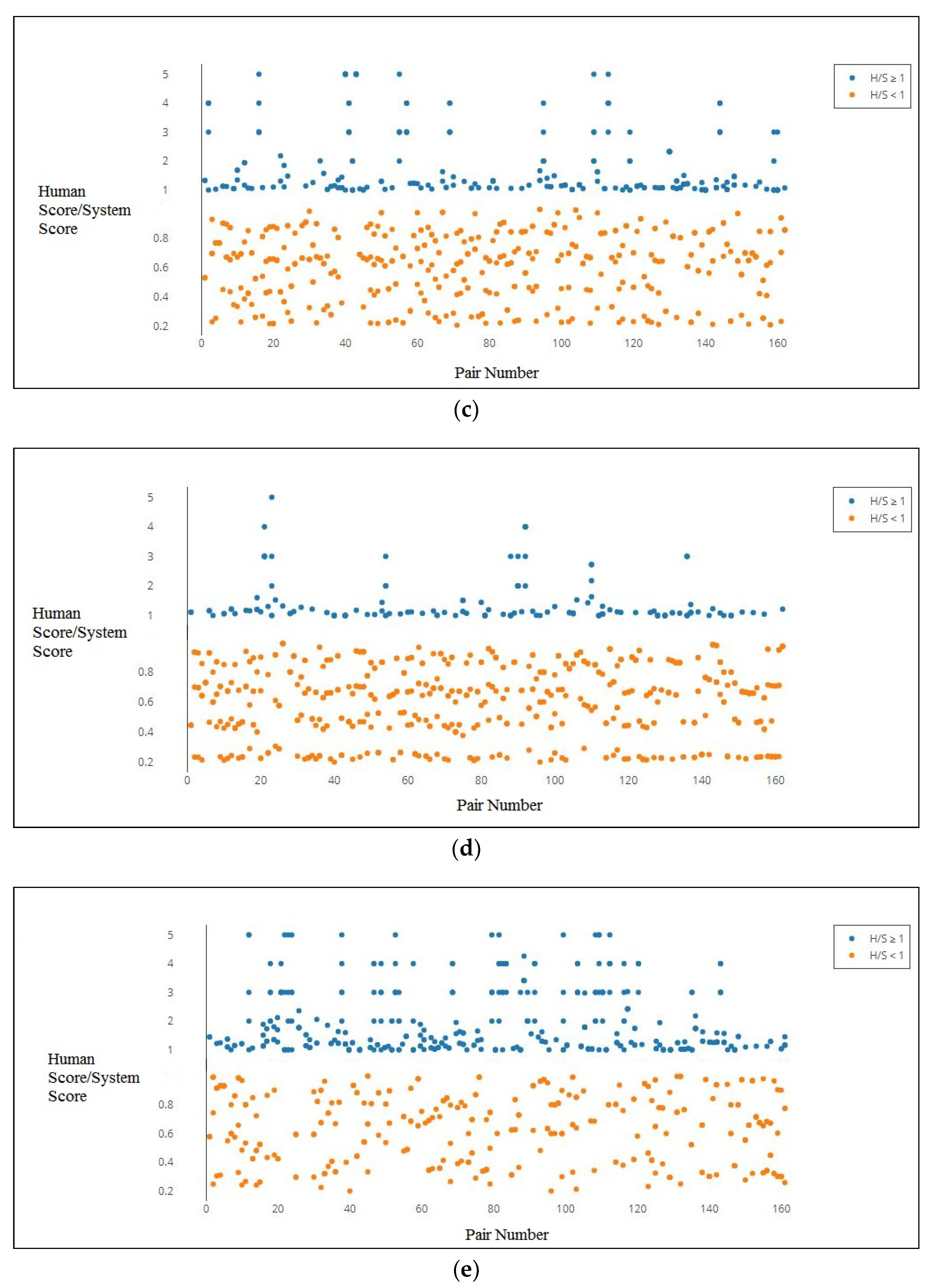
Among the graphs for
and
, the graph of the latter showed less dispersion from the y = 1 line meaning that the scores produced from the method were better correlated with the human judgments; a fact which can also be verified from
Table 6.
Figure 3e shows the graph for the
metric. When it is examined in light of the other two distributional methods, it was found that it produced the best such plot for that class of methods. The points were relatively more divergent from the y = 1 line, although giving a higher number of points lying on the y = 1 line (61) as compared to the other two distributional methods (19 and 43).
Our initial intuition drove us to believe that the Word2Vec model would produce the best results. However, from the correlation scores obtained, we were proven otherwise. Overall, the
model provides the best correlation scores with respect to all individual raters, majority score and all rating scores together (overall), which are much higher than the correlation scores yielded by the other similarity metrics. Finally, it could also be pointed out that in comparison to the Word2Vec models, the path-based metrics performed far better with respect to the overall correlation scores (cf.
Table 6), an explanation for which is proffered in
Section 6.3. Clearly, the path-based model has visible advantages in spite of being compared with one of the more robust and state-of-the-art models for semantic similarity, i.e., Word2Vec.

 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}