1. Introduction and Motivation
Some countries responded pretty quickly to the onset of COVID-19, imposing strict barriers on human movement in order to “flatten the curve” and avoid as much transmission of the virus as possible. Regrettably, others did not take advantage from the lessons learned initially in the Far East, with significant delays in implementing social distancing with concomitant rises in infection and death, particularly among the elderly.
Being an airborne disease, different countries were exposed to the virus at different times; some countries are starting to relax social distancing constraints and are allowing certain sections of the population back to work and school. Nonetheless, the virus remains rampant in many countries, yet there is still time to absorb the lessons learned in other regions to try to keep infection and associated deaths at the lower end of projections.
However, much salient information online appears in a range of languages, so that access to information is restricted by people’s language competencies. It has long been our view that in the 21st century, language cannot be a barrier to access of information. Accordingly, we decided to build a range of MT systems to facilitate access to multilingual content related to COVID-19. Given that Spain, France and Italy suffered particularly badly in Europe, it was important to include Spanish, French and Italian in our plans, so that lessons learned in those countries could be rolled out in other jurisdictions. The UK and the US have also suffered particularly badly, so English obviously had to be included. In contrast, Germany appears to have coped particularly well, so we wanted information written in German to be more widely available.
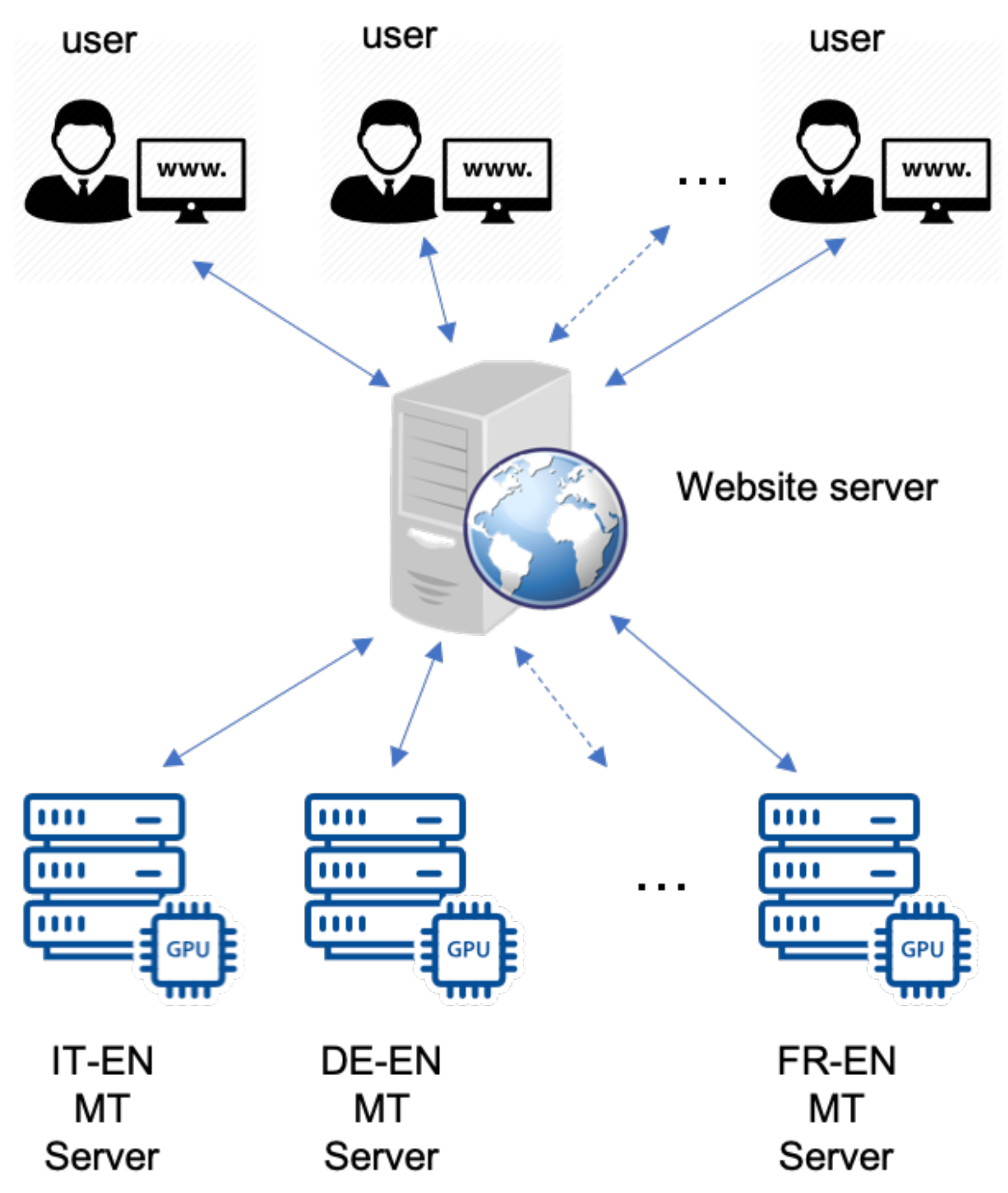
Accordingly, this document describes our efforts to build 8 MT systems—FIGS (French, Italian, German, Spanish. FIGS is a well-known term encompassing these languages in the localisation field) to/from English—using cutting-edge techniques aimed specifically at making available health and related information (e.g., promoting good practice for symptom identification, prevention, treatment, recommendations from health authorities, etc.) concerning the COVID-19 virus both to medical experts and the general public. In the current situation, the volume of information to be translated is huge and is relevant (hopefully) only for a relatively short span of time; relying wholly on human professional translation is not an option, both in the interest of timeliness and due to the enormous costs that would be involved. By making the engines publicly available, we are empowering individuals to access multilingual information that otherwise might be denied them; by ensuring that the MT quality is comparable to that of well-known online systems, we are allowing users to avail of high-quality MT with none of the usual privacy concerns associated with using online MT platforms. Furthermore, we note interesting strengths and weaknesses of our engines following a detailed comparison with online systems. Finally, of course, by building our own engines, we retain control over the systems, which facilitates continuous incremental improvement of the models via feedback and by the availability of additional training data, or novel scientific breakthroughs in the field of Neural MT (NMT).
The remainder of the paper explains what data we sourced to train these engines, how we trained and tested them to ensure good performance, and our efforts to make them available to the general public. It is our hope that these engines will be helpful in the global fight against this pandemic, so that fewer people are exposed to this disease and its deadly effects.
2. Ethical Considerations in Crisis-Response Situations
There are of course a number of challenges and potential dangers involved in rapid development of MT systems for use by naive and vulnerable users to access potentially sensitive and complex medical information.
There have been alarmingly few attempts to provide automatic translation services for use in crisis scenarios. The best-known example is Microsoft’s rapid response to the 2010 Haiti earthquake [
1], which in turn led to a cookbook for MT in crisis scenarios [
2].
In that paper, Lewis et al. [
2], p. 501 begin by stating that “
MT is an important technology in crisis events, something that can and should be an integral part of a rapid-response infrastructure … If done right, MT can dramatically increase the speed by which relief can be provided”. They go on to say the following:
“We strongly believe that MT is an important technology to facilitate communication in crisis situations, crucially since it can make content in a language spoken or written by a local population accessible to those that do not know the language”
[p. 501]
They also note [pp. 503–504] that “While translation is not [a] widely discussed aspect of crisis response, it is ‘a perennial hidden issue’” [
3]:
“Go and look at any evaluation from the last ten or fifteen years. ‘Recommendation: make effective information available to the government and the population in their own language.’ We didn’t do it …It is a consistent thing across emergencies.”
Brendan McDonald, UN OCHA in [
3].
While it is of course regrettable that natural disasters continue to occur, these days we are somewhat better prepared to respond when humanitarian crises such as COVID-19 occur, thanks to work on translation in crisis situations such as INTERACT. (
https://sites.google.com/view/crisistranslation/home) Indeed, Federici et al. [
4] issue a number of recommendations within that project which we have tried to follow in this work. While they apply mainly to human translation provision in crisis scenarios, they can easily be adapted to the use of MT, as in this paper.
The main relevant recommendation ([Recommendation 1] in their report; we use their numbering in what follows) is that “Emergency management communication policies should include provision for translation” [p. 2], which we take as an endorsement of our approach here. The provision of MT systems has the potential to help:
“improve response, recovery and risk mitigation [by including] mechanisms to provide accurate translation” [Recommendation 1a, p. 8]
“address the needs of those with heightened vulnerabilities [such as] …the elderly” [Recommendation 1b, p. 9]
those “responsible for actioning, revising and training to implement … translation policy within …organization[s]” [Recommendation 2a, p. 9]
Federici et al. [
4] note that “the right to translated information in managing crises must be a part of ‘living policy and planning documents’ that guide public agency actions” [Recommendation 2b, p. 9], and that people have a “right to translated information across all phases of crisis and disaster management” [Recommendation 4a, p. 9]. We do not believe that either of these have been afforded to the public at large during the current crisis, but our provision of MT engines has the potential to facilitate both of these requirements.
[Recommendation 7a, p. 10] notes that “Translating in one direction is insufficient. Two-way translated communication is essential for meeting the needs of crisis and disaster-affected communities.” By allowing translation in both directions (FIGS-to-English as well as English-to-FIGS), we are facilitating two-way communication, which would of course be essential in a patient-carer situation, for example.
By making translation available via MT rather than via human experts, we are helping avoid the need for “training for translators and interpreters …includ[ing] aspects of how to deal with traumatic situations” [Recommendation 8d, p. 11], as well as translators being exposed to traumatic situations altogether.
Finally, as we describe below, we have taken all possible steps to ensure that the quality of our MT systems is as good as it can be at the time of writing. Using leading online MT systems as baselines, we demonstrate comparable performance—and in some cases improvements over some of the online systems—and document a number of strengths and weaknesses of our models as well as the online engines. We deliberately decided to release our systems as soon as good performance was indicated both by automatic and human measures of translation quality; aiming for fully optimized performance would have defeated the purpose of making the developed MT systems publicly available as soon as possible to try and mitigate the adverse effects of the ongoing international COVID-19 crisis.
3. Assembling Relevant Data Sets
NMT [
5] is acknowledged nowadays as the leading paradigm in MT system-building. However, compared to its predecessor (Statistical MT (SMT): Koehn et al. [
6]), NMT requires even larger amounts of suitable training data in order to ensure good translation quality. For example, Koehn and Knowles [
7] show that using BLEU [
8] as the evaluation metric, English-to-Spanish NMT systems start to outperform SMT with around 15 million words of parallel data, and can beat an SMT system with a huge two billion word in-domain language model when trained on 385 million words of parallel data.
It is well-known in the field that optimal performance is most likely to be achieved by sourcing large amounts of training data which are as closely aligned with the intended domain of application as possible [
9,
10]. Accordingly, we set out to assemble large amounts of good quality data in the language pairs of focus dedicated to COVID-19 and the wider health area.
Table 1 shows how much data was gathered for each of the language-pairs. We found this in a number of places, including: (An additional source of data is the NOW Corpus (
https://www.english-corpora.org/now/), but we did not use this as it is not available for free).
The TAUS Corona data comprises a total of 885,606 parallel segments for EN–FR, 613,318 sentence-pairs for EN–DE, 381,710 for EN–IT, and 879,926 for EN–ES. However, as is good practice in the field, we apply a number of standard cleaning routines to remove ‘noisy’ data, e.g., removing sentence-pairs that are too short, too long or which violate certain sentence-length ratios. This results in 343,854 sentence-pairs for EN–IT (i.e., 37,856 sentence-pairs—amounting to 10% of the original data—are removed), 698,857 for EN–FR (186,719 sentence-pairs, 21% of the original), 791,027 for EN–ES (88,899 sentence-pairs, 10%), and 551327 for EN–DE (61,991 sentence-pairs, 10%).
The EMEA Corpus (a parallel corpus comprised of documents from the European Medicines Agency that focuses on the wider health area) comprises 499,694 segment-pairs for EN–IT, 471,904 segment-pairs for EN–ES, 454,730 segment-pairs for EN–FR, and 1,108,752 segment-pairs for EN–DE.
The Sketch Engine Corpus comprises 4,736,815 English sentences.
The ParaCrawl Corpus (parallel sentences crawled from the Web) comprises 19,675,137 segment-pairs for EN–IT, 34,561,031 segment-pairs for EN–ES, 45,941,170 segment-pairs for EN–FR, and 58,815,994 segment-pairs for EN–DE.
The Wikipedia Corpus (parallel sentences extracted from Wikipedia) comprises 957,004 segment-pairs for EN–IT, 1,811,428 segment-pairs for EN–ES, 818,302 segment-pairs for EN–FR, and 2,459,662 segment-pairs for EN–DE.
Note that we used a part of the ParaCrawl and Wikipedia corpora following the state-of-the-art sentence selection strategy of Axelrod et al. [
11], which is detailed in
Section 4.3.
There have been suggestions (e.g., on Twitter) that the data found in some of the above-mentioned corpora, especially those that were recently released to support rapid development initiatives such as the one reported in this paper, is of variable and inconsistent quality, especially for some language pairs. For example, a quick inspection of samples of the TAUS Corona Crisis Corpus for English–Italian revealed that there are identical sentence pairs repeated several times, and numerous segments that do not seem to be directly or explicitly related to the COVID-19 infection per se, but appear to be about medical or health-related topics in a very broad sense; in addition, occasional irrelevant sentences about computers being infected by software viruses come up, that may point to unsupervised text collection from the Web.
Nonetheless, we are of course extremely grateful for the release of the valuable parallel corpora that we were able to use effectively for the rapid development of the domain-specific MT systems that we make available to the public as part of this work; we note these observations here as they may be relevant to other researchers and developers who may be planning to make use of such resources for other corpus-based applications.
4. Experiments and Results
This section describes how we built a range of NMT systems using the data described in the previous section. We evaluate the quality of the systems using BLEU and chrF [
12]. Both are match-based metrics (so the higher the score, the better the quality of the system) where the MT output is compared against a human reference. The way this is typically done is to ‘hold out’ a small part of the training data as test material, (Including test data in the training material will unduly influence the quality of the MT system, so it is essential that the test set is disjoint from the data used to train the MT engines) where the human-translated target sentence is used as the reference against which the MT hypothesis is compared. BLEU does this by computing
n-gram overlap, i.e., how many words, 2-, 3- and 4-word sequences are contained in both the reference and hypothesis. (Longer
n-grams carry more weight, and a penalty is applied if the MT system outputs translations which are ‘too short’). There is some evidence [
13] that word-based metrics such as BLEU are unable to sufficiently demonstrate the difference in performance between MT systems, (For some of the disadvantages of using string-based metrics, we refer the reader to Way [
14]). So in addition, we use chrF, a character-based metric which is more discriminative. Instead of matching word
n-grams, it matches character
n-grams (up to 6). Since Popović [
15] shows that the best option is to give twice as much weight to recall, we used this variant (chrF2) in this work.
4.1. Building Baseline MT Systems
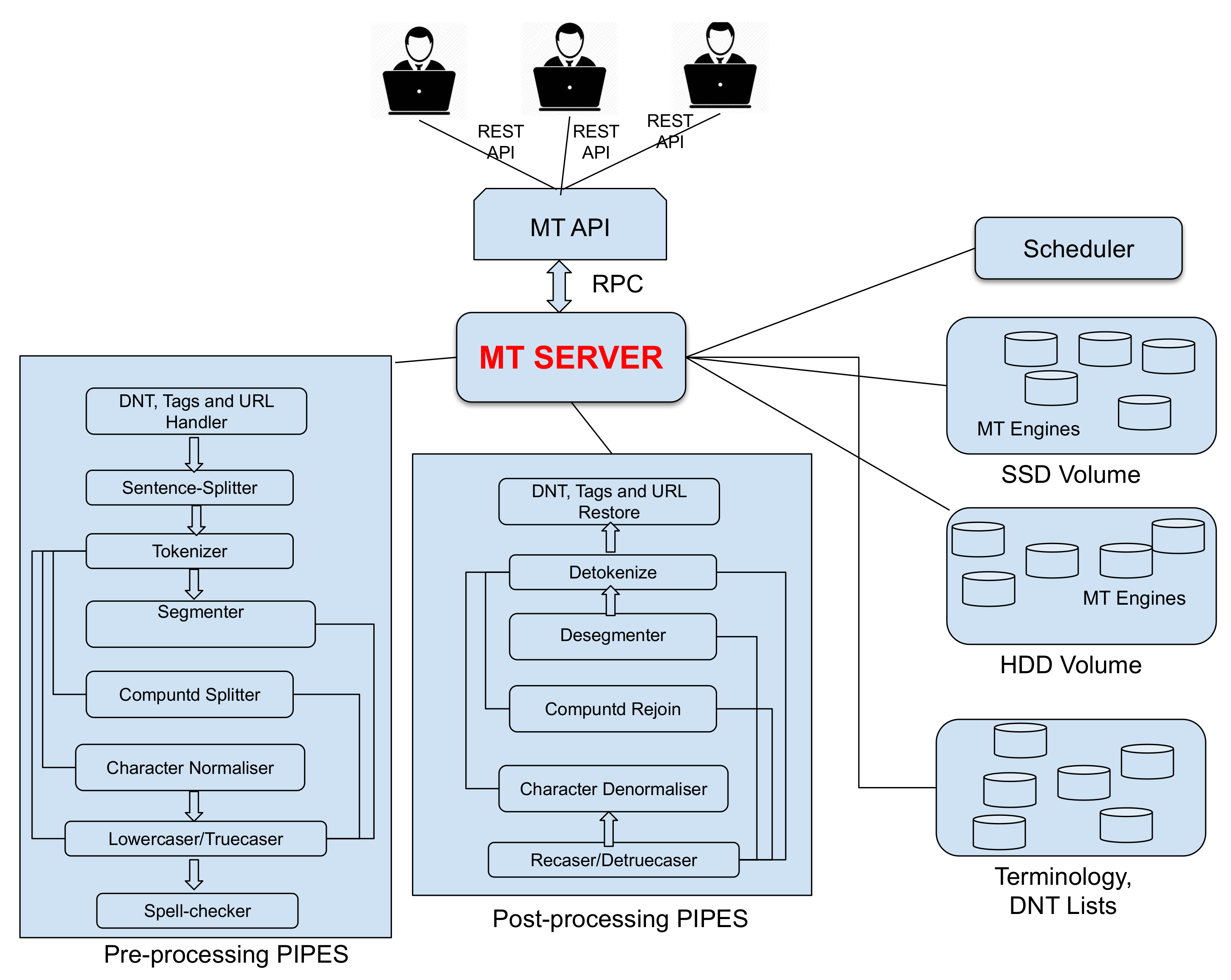
In order to build our NMT systems, we used the MarianNMT [
16] toolkit. The NMT systems are Transformer models [
17]. In our experiments we followed the recommended best set-up from Vaswani et al. [
17]. The tokens of the training, evaluation and validation sets are segmented into sub-word units using the byte-pair encoding technique of Sennrich et al. [
18]. We performed 32,000 join operations.
Our training set-up is as follows. We consider the size of the encoder and decoder layers to be 6. As in Vaswani et al. [
17], we employ residual connection around layers [
19], followed by layer normalisation [
20]. The weight matrix between embedding layers is shared, similar to Press and Wolf [
21]. Dropout [
22] between layers is set to 0.1. We use mini-batches of size 64 for update. The models are trained with the Adam optimizer [
23], with the learning-rate set to 0.0003 and reshuffling the training corpora for each epoch. As in Vaswani et al. [
17], we also use the learning rate warm-up strategy for Adam. The validation on the development set is performed using three cost functions: cross-entropy, perplexity and BLEU. The early stopping criterion is based on cross-entropy; however, the final NMT system is selected as per the highest BLEU score on the validation set. The beam size for search is set to 12.
The performance of our engines is described in
Table 2. Testing on a set of 1000 held-out sentence pairs, we obtain a BLEU score of 50.28 for IT-to-EN. For the other language pairs, we also see good performance, with all engines bar EN-to-DE—a notoriously difficult language pair—obtaining BLEU scores in the range of 44–50, already indicating that these rapidly-developed MT engines could be deployed ‘as is’ with some benefit to the public in several countries affected by the COVID-19 epidemic.
On these separate ‘Reco’ test sets, MT performance is still reasonable. For IT-to-EN and EN-to-IT, the performance even increases a little according to both BLEU and chrF, but in general translation quality drops off by 10 BLEU points or more. Notwithstanding the fact that these test sets are much shorter than the TAUS sets, we reiterate that the primary motivation behind this work was to build as quickly as we could a range of good-quality MT systems capable of translating information related to the COVID-19 virus. (One may wonder why we eschewed the ‘massively multilingual’ approach of Arivazhagan et al. [
24]. Firstly, note that even with what might be deemed to be ‘moderate’ amounts of data, the hardware requirements are enormous. Secondly, there is evidence [
25,
26] to suggest that multilingual models are not guaranteed to beat individual MT systems for specific language pairs. Nonetheless, it remains an open question as to whether transfer learning techniques could have been used to fine-tune on the different language pairs, as in Neubig and Hu [
27]; we leave this for future work). Accordingly, the systems’ performance on the Reco sets is more indicative of their ability on related but more out-of-domain data; being extracted from the TAUS data set itself, one would expect better performance on truly in-domain data, but this is a less important factor.
Note that as expected, scores for translation into English are consistently higher compared to translation from English. This is because English is relatively morphologically poorer than the other four languages, and it is widely recognised that translating into morphologically-rich languages is a (more) difficult task.
4.2. How Do Our Engines Stack Up against Leading Online MT Systems?
In order to examine the competitiveness of our engines against leading online systems, we also translated the Reco test sets using Google Translate, (
https://translate.google.com/). Bing Translator, (
https://www.bing.com/translator) and Amazon Translate. (
https://aws.amazon.com/translate/. (i) Note that while Google Translate and Bing Translator are free to use, Amazon Translate is free to use for a period of 12 months, as long as you register online; (ii) One of the reviewers suggested that we also look at DeepL:
https://www.deepl.com/en/translator. The free online version available at this URL is almost unusable for even quite small amounts of translation, as here. Nonetheless, its results are extremely impressive. The BLEU scores on the ’Reco’ test sets are as follows: DE-to-EN: 38.3; IT-to-EN: 68.9; FR-to-EN: 42.9; and ES-to-EN: 38.6. For all bar the latter language pair, these results are the best, and in some cases by some distance. Given the turnaround requirements of the journal, we were unable to perform a human evaluation in such a short time, but the actual output clearly deserves to be looked at; (iii) It should also be noted that Systran have in the interim published a series of systems dedicated to COVID-19 material:
https://www.systransoft.com/systran/news-and-events/specialized-corona-crisis-corpus-models/, but again, we have been unable to test their performance in the limited time available). The results for the ‘into-English’ use-cases appear in
Table 4.
As can be seen, for DE-to-EN, in terms of BLEU score, Bing is better than Google, and 1.9 points (5.6% relatively) better than Amazon. In terms of chrF, Amazon is still clearly in 3rd place, but this time Google’s translations are better than those of Bing.
For both IT-to-EN and FR-to-EN, Google outperforms both Bing and Amazon according to both BLEU and chrF, with Bing in 2nd place.
However, for ES-to-EN, Amazon’s system obtains the best performance according to both BLEU and chrF, followed by Google and then Bing.
If we compare the performance of our engines against these online systems, in general, for all four language pairs, our performance is worse; for DE-to-EN, the quality of our MT system in terms of BLEU is better than Amazon’s, but for the other three language pairs we are anything from 0.5 to 10 BLEU points worse.
This demonstrates clearly how strong the online baseline engines are on this test set. However, in the next section, we run a set of experiments which show improved performance of our systems, in some cases comparable to those of these online engines.
4.3. Using “Pseudo In-Domain” Parallel Sentences
The previous sections demonstrate clearly that with some exceptions, on the whole, our baseline engines significantly underperform compared to the major online systems.
However, in an attempt to improve the quality of our engines, we extracted parallel sentences from large bitexts that are similar to the styles of texts we aim to translate, and use them to fine-tune our baseline MT systems. For this, we followed the state-of-the-art sentence selection approach of Axelrod et al. [
11] that extracts ‘pseudo in-domain’ sentences from large corpora using bilingual cross-entropy difference over each side of the corpus (source and target). The bilingual cross-entropy difference is computed by querying in- and out-of-domain (source and target) language models. Since our objective is to facilitate translation services for recommendations for the general public, non-experts, and medical practitioners in relation to COVID-19, we wanted our in-domain language models to be built on such data. Accordingly, we crawled sentences from a variety of government websites (e.g., HSE, (
https://www2.hse.ie/conditions/coronavirus/coronavirus.html) NHS, (
https://www.nhs.uk/conditions/coronavirus-covid-19/). Italy’s Ministry of Health and National Institute of Health, (
https://www.salute.gov.it/nuovocoronavirus and
https://www.epicentro.iss.it/coronavirus/, respectively). Ministry of Health of Spain, (
https://www.mscbs.gob.es) and the French National Public Health Agency) that offer recommendations and information on COVID-19. In
Table 5, we report the statistics of the crawled corpora used for in-domain language model training.
The so-called ‘pseudo in-domain’ parallel sentences that were extracted from the closely related out-of-domain data (such as the EMEA Corpus) were appended to the training data. Finally, we fine-tuned our MT systems on the augmented training data.
In addition to the EMEA Corpus, we made use of ParaCrawl and Wikipedia data from OPUS (
http://opus.nlpl.eu/) [
28] (cf.
Section 3) which we anticipate containing sentences related to general recommendations similar to the styles of the texts we want to translate. We merged the ParaCrawl and Wikipedia corpora, which from now on we refer to as the “ParaWiki Corpus”. First, we chose the Italian-to-English translation direction to test our data selection strategy on EMEA and ParaWiki corpora. Once the best set-up had been identified, we would use the same approach to prepare improved MT systems for the other translation pairs.
We report the BLEU and chrF scores obtained on a range of different Italian-to-English NMT systems on both the TAUS and Reco test sets in
Table 6.
The second row in
Table 6 represents the Italian-to-English baseline NMT system fine-tuned on the training data from the TAUS Corona Crisis Corpus along with 300 K sentence-pairs from the EMEA Corpus using the aforementioned sentence-selection strategy. We expect that training for some extra iterations on a well-considered sample of in-domain and generic data should both improve performance, and avoid overfitting on the TAUS+EMEA data. While we see that this strategy does lead to some improvements on both test sets over the baseline, the gains are only moderate, and are not statistically significant using bootstrap resampling with a 99% confidence level (
p ) [
29]. It is an open question whether including the full EMEA set would improve performance, but adding in the 300 K most similar sentences barely helps; even if we assume that 700 K sentence-pairs are disregarded by our approach, after cleaning and other filtering operations, the remaining subset would be far smaller than 700 K. Nonetheless, we leave this experiment for future work, in order to check definitively whether the additional data proves to be useful.
Currey et al. [
30] generated synthetic parallel sentences by copying target sentences to the source. This method was found to be useful where scripts are identical across the source and target languages. Note too that they showed back-translation to be less effective in low-resource settings where it is hard to train a good back-translation model, so we propose to use the method of Currey et al. [
30] instead.
In our case, since the Sketch Engine Corpus is prepared from the COVID-19 Open Research Dataset (CORD-19), (A free resource of over 45,000 scholarly articles, including over 33,000 with full text, about COVID-19 and the coronavirus family of viruses, cf.
https://pages.semanticscholar.org/coronavirus-research) it includes keywords and terms related to COVID-19, which are often used verbatim across the languages of study in this paper, so we contend that this strategy can help translate terms correctly. Accordingly, we carried out an experiment by adding sentences of the Sketch Engine Corpus (English monolingual corpus) to the TAUS Corona Crisis Corpus following the method of Currey et al. [
30], and fine-tune the model on this training set. The scores for the resulting NMT system are shown in the third row of
Table 6. While this method also brings about moderate improvements on the Reco test set, it is not statistically significant. Interestingly, this approach also significantly lowers the system’s performance on the TAUS test set, according to both metrics. Nonetheless, given the urgency of the situation in which we found ourselves, where the MT systems needed to be built as quickly as possible, the approach of Currey et al. [
30] can be viewed as a worthwhile alternative to the back-translation strategy of Sennrich et al. [
31] which needs a high-quality back-translation model to be built, and the target corpus to be translated into te source language, both of which are time-demanding tasks. (Note that albeit on a different language pair (English-to-German), Khayrallah and Koehn [
32] observe that untranslated sentences (i.e., copying target sentences to the source) can severely negatively impact NMT systems in mid- to high-resource scenarios. However, they note that “short segments, untranslated source sentences and wrong source language have little impact on either [NMT or SMT]” [p. 78]. In our case, we tested the approach of Currey et al. [
30] only when the source side is the copy of the target, and like them, found it to be effective).
In our next experiment, we took five million low-scoring (i.e., similar to the in-domain corpora) sentence-pairs from ParaWiki, added them to the training data, and fine-tuned the baseline model on it. As can be seen from row 4 in
Table 6 (i.e., 2 + ParaWiki), the use of ParaWiki sentences for fine-tuning has a positive impact on the system’s performance, as we obtain a statistically significant 3.95 BLEU point absolute gain (corresponding to a 7.74% relative improvement) on the Reco test set over the baseline. This is corroborated by the chrF score.
We then built a training set from all data sources (EMEA, Sketch Engine, and ParaWiki Corpora), and fine-tuned the baseline model on the combined training data. This brings about a further statistically significant gain on the Reco test set (6.75 BLEU points absolute, corresponding to a 13.2% relative improvement (cf. fifth row of
Table 6, “3 + 4”).
Our next experiment involved adding a further three million sentences from ParaWiki. This time, the model trained on augmented training data performs similarly to the model without the additional data (cf. sixth row of
Table 6, “3 + 4*”), which is disappointing.
Our final model is built with ensembles of all eight models that are sampled from the training run (cf. fifth row of
Table 6, “3 + 4”), and one of them is selected based on the highest BLEU score on the validation set. This brings about a further slight improvement in terms of BLEU on the Reco test set. Altogether, the improvement of our best model (‘Ensemble’ in
Table 6, row 7) over our Baseline model is 7.14 BLEU points absolute, a 14% relative improvement. More importantly, while we cannot beat the online systems in terms of BLEU score, we are now in the same ballpark. More encouragingly still, in terms of chrF, our score is higher than both Amazon and Bing, although still a little way off compared to Google Translate.
Given these encouraging findings, we used the same set-up to build improved engines for the other translation pairs. The results in
Table 7 show improvements over the Baseline engines in
Table 2 for almost all language pairs on the Reco test sets: for DE-to-EN, the score dips a little, but for FR-to-EN, we see an improvement of 1.42 BLEU points (4% relative improvement), and for ES-to-EN by 2.09 BLEU points (6.7% relative improvement). While we still largely underperform compared to the scores for the online MT engines in
Table 4, we are now not too far behind; indeed, for FR-to-EN, our performance is now actually better than Amazon’s, by 0.9 BLEU (2.5% relative improvement) and 1.29 chrF points (2.4% relative improvement). For the reverse direction, EN-to-DE also drops a little, but EN-to-IT improves by 1.79 BLEU points (3.8% relatively better), EN-to-ES by 1.02 BLEU points (3.2% relatively better), and EN-to-FR by 2.22 BLEU points (6.5% relatively better). These findings are corroborated by the chrF scores.
4.4. Human Evaluation
Using automatic evaluation metrics such as BLEU and chrF allows MT system developers to rapidly test the performance of their engines, experimenting with the data sets available and fine-tuning the parameters to achieve the best-performing set-up. However, it is well-known [
14] that where possible, human evaluation ought to be conducted in order to verify that the level of quality globally indicated by the automatic metrics is broadly reliable.
Accordingly, for all four ‘into-English’ language pairs, we performed a human evaluation on 100 sentences from the test set, comparing our system (indicated by “DCU” in the tables) against Google Translate and Bing Translator (cf.
Table 8); we also inspected Amazon’s output, but its quality was generally slightly lower, so in the interest of clarity it was not included in the comparisons discussed here. At the time of writing, the countries where the rate of infection of COVID-19 were the highest were the UK and US, so we concentrated more on translation into English rather than from English. As we initially tried to improve translation performance on Italian to English before rolling out the set-up to the other language directions (cf.
Section 4.3), there is somewhat more analysis for this language pair than for the others.
In what follows, we illustrate the strengths and weaknesses of each system using examples from 100 sentences from each test set, according to a range of translational phenomena (such as lexical choice, fluency, and translation omission).
4.4.4. Italian to English
Overall, based on the manual inspection of 100 sentences from the test set, our Italian-to-English MT system shows generally accurate and mostly fluent output with only a few exceptions, e.g., due to the style that is occasionally a bit dry. The overall meaning of the sentences is typically preserved and clearly understandable in the English output. In general, the output of our system compares favourably with the online systems used for comparison, and does particularly well as far as correct translation of the specialized terminology is concerned, even though the style of the online MT systems tends to be better overall.
The examples for Italian-English are shown in
Table 12, which includes the Italian input sentence, the English human reference translation, and then the output in English provided by Google Translate, Bing and our final system.
In example 1, even though the style of our MT system’s English output is somewhat cumbersome (e.g., with the repetition of “cells”, although this is found in the other outputs, too), the clarity of the message is preserved, and the translation of all the technical terminology such as “epithelial cells” and “respiratory and gastrointestinal tracts” is correct; interestingly, the MT output of our system pluralizes the noun “tracts”, which is singular in the other outputs as well as in the reference human translation, but this is barely relevant to accuracy and naturalness of style.
Similarly, the style of the MT output of our system is not particularly natural in example 2, where the Italian source has a marked cleft construction that fronts the main action verb but omits part of its subsequent elements, as is frequent in newspaper articles and press releases; this is why the English MT output of our system wrongly has a seemingly final clause that gives rise to an incomplete sentence, which is a calque of the Italian syntactic structure, even though the technical terminology is translated correctly (i.e., “strain” for “ceppo”), and the global meaning can still be grasped with a small amount of effort. By comparison, the meaning of Bing’s output is very obscure and potentially misleading, and the verb tense used in Google Translate’s output is also problematic and potentially confusing.
In the sample of 100 sentences that were manually inspected for Italian-English, only very minor nuances of meaning were occasionally lost in the output of our system, as shown by example 3. Leaving aside the minor stylistic issue in the English output of the missing definite article before the noun “infection” (which is common with Bing’s output, the rest being identical across the three MT systems), the translation with “severe acute respiratory syndrome” in the MT output (the full form of the infamous acronym SARS) for the Italian “sindrome respiratoria acuta grave” seems preferable, and more relevant, than the underspecified rendition given in the reference with “acute respiratory distress syndrome”, which is in fact a slightly different condition.
In example 3, a seemingly minor nuance of meaning is lost in the MT output “in severe cases”, as the beginning of the Italian input can be literally glossed with “in the more/most serious cases”; the two forms of the comparative and superlative adjective are formally indistinguishable in Italian, so it is unclear on what basis the reference human translation opts for the comparative form, as opposed to the superlative. However, even in such a case the semantic difference seems minor, and the overall message is clearly preserved in the MT output.
As far as example 4 is concerned, the MT outputs are very similar and correspond very closely to the meaning of the input, as well as to the human reference translation. Interestingly, our system’s output misses the plural form of the first noun (“some coronavirus” instead of “Some Coronaviruses” as given by the other two MT systems, which is more precise), which gives rise to a slight inaccuracy, even though the overall meaning is still perfectly clear. Another interesting point is the preposition corresponding to the Italian “tra familiari”, which is omitted by our system, but translated by Google as “between family members”, compared to Bing’s inclusion of “among”. Overall, omitting the preposition does not alter the meaning, and these differences seem irrelevant to the clarity of the message. Finally, the translation of “ambiente sanitario” (a very vague, underspecified phrase, literally “healthcare environment”) is interesting, with both our system and Bing’s giving “environment”, and Google’s choosing “setting”. Note that all three MT outputs seem better than the human reference “healthcare centre”, which appears to be unnecessarily specific.
With regard to example 5, the three outputs are very similar and equally correct. The minor differences concern the equivalent of “contagio”, which alternates between “infection” (our system and Google’s) and the more literal “contagion” (Bing, which seems altogether equally valid, but omits the definite article, so the style suffers a bit). Interestingly, Google presents a more direct translation from the original with “time that passes”, while our system and Bing’s omit the relative clause, which does not add any meaning. All things considered, the three outputs are very similar, and on balance of equivalent quality.
Finally, example 6 shows an instance where the performance of our system is better than the other two systems, which is occasionally the case especially with regard to very specialized terminology concerning the COVID-19 disease. The crucial word for the meaning of the sentence in example 6 is “paucisintomatica” in Italian, which refers to a mother who has recently given birth; this is a highly technical and relatively rare term, which literally translates as “with/showing few symptoms”. Our system translates this correctly with the English equivalent “if the mother is paucisymptomatic”, while Google gives the opposite meaning by missing the negative prefix, which would cause a serious misunderstanding, i.e., “If the mother is symptomatic”, and Bing invents a word with “if the mother is paucysy”, which is clearly incomprehensible. Interestingly, the human reference English translation for example 6 gives an overspecified (and potentially incorrect) rendition with “If the mother is asymptomatic”, which is not quite an accurate translation of the Italian original, which refers to mothers showing few symptoms. The remaining translations in example 6 are broadly interchangeable, e.g., with regard to rendering “neonato” (literally “newborn”) with “infant” (Google Translate) or “newborn” (our system and Bing’s); the target sentences are correct and perfectly clear in all cases.






{kind=link}
{kind=link}
{kind=link}