Modelling User Preference for Embodied Artificial Intelligence and Appearance in Realistic Humanoid Robots

Abstract
:1. Introduction
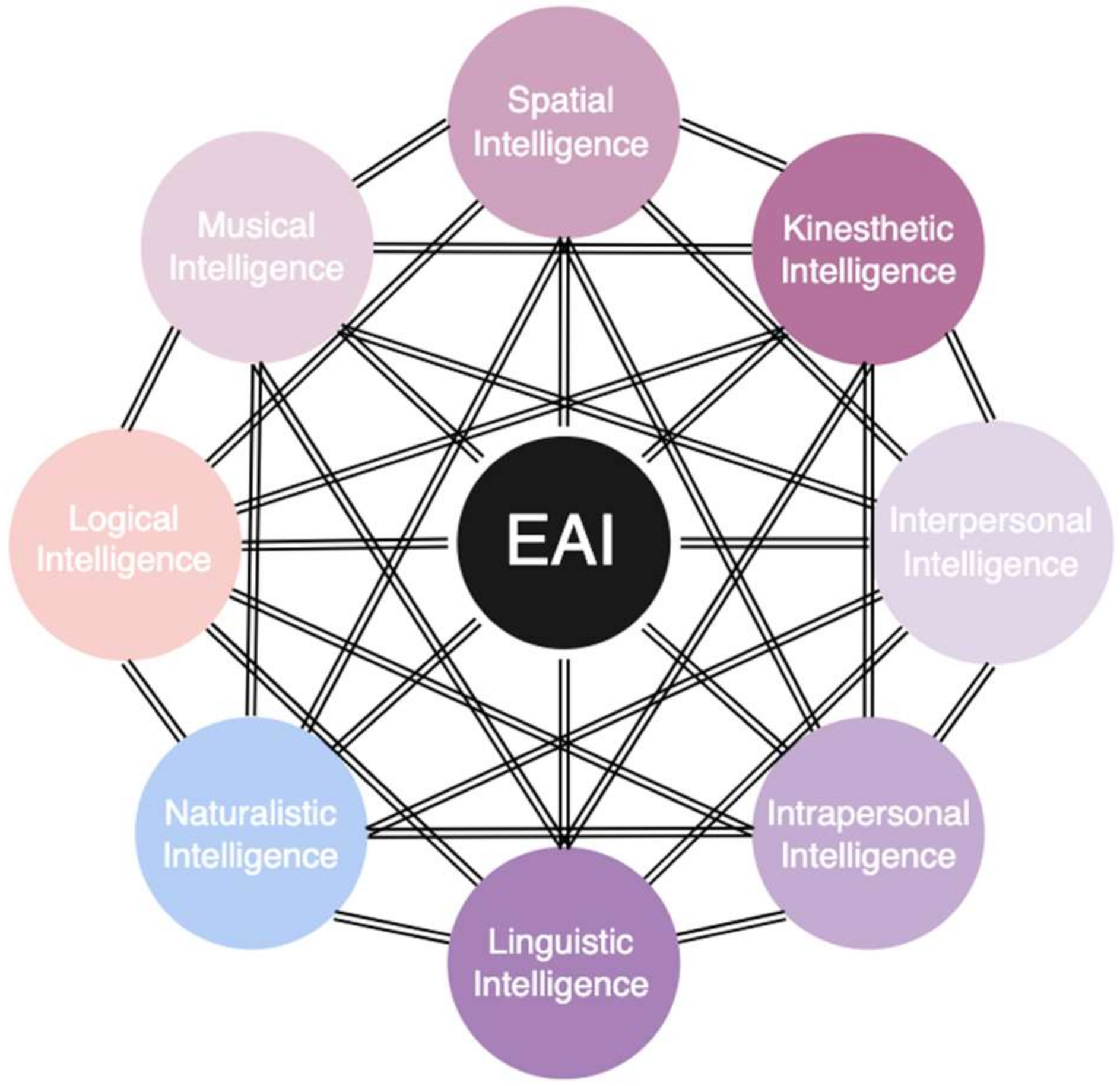
2. Embodied Artificial Intelligence and Emotional Artificial Intelligence
2.1. Practical Applications of Humanoid Robots with EAI
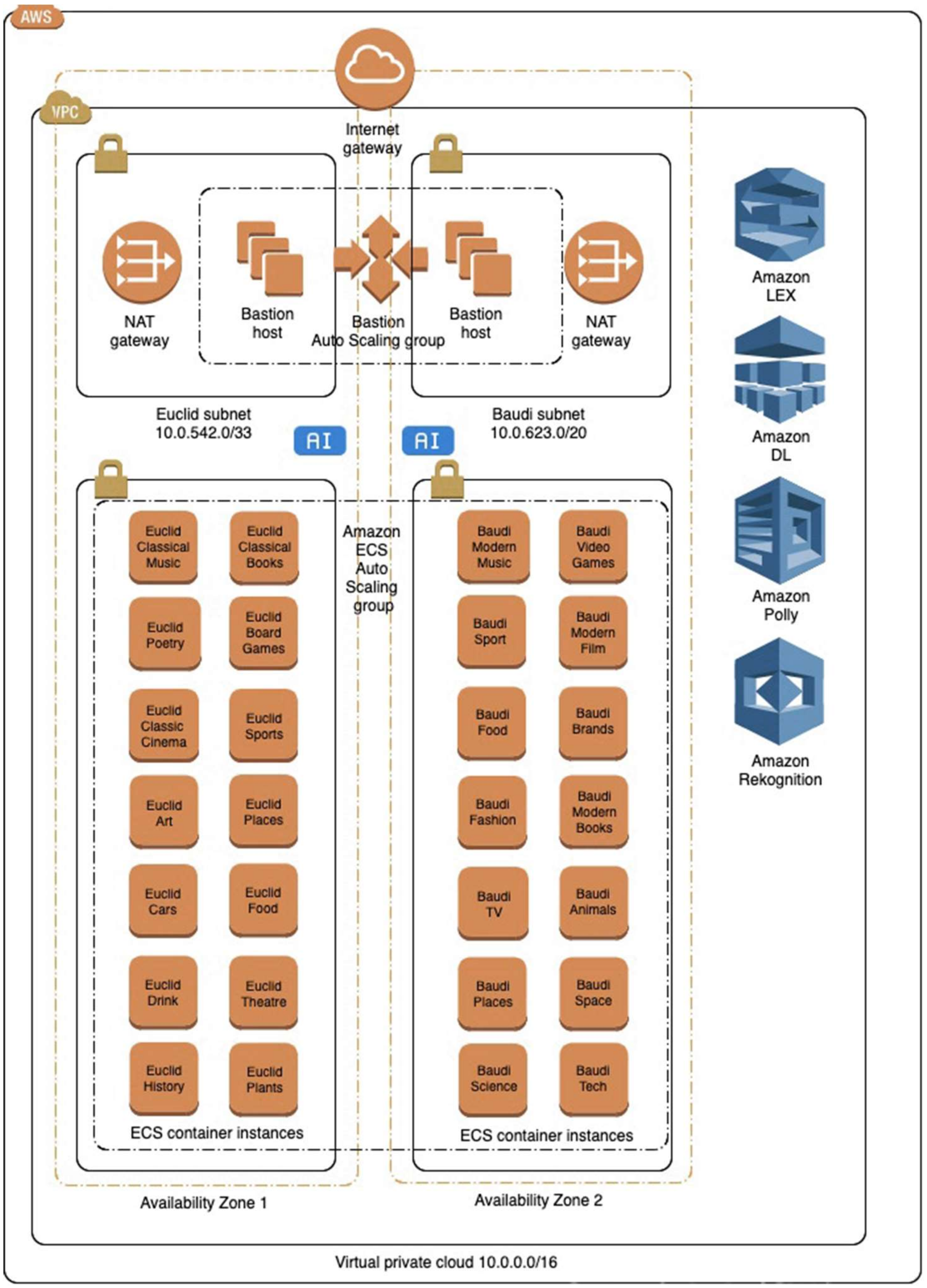
2.2. AI and Natural Language Processing System Design
3. Human–Robot Interaction Experiment
3.1. Population Sample, Recruitment, and Participant Restrictions
3.2. Participants Profiles
4. HRI Questionnaire
4.1. Comparative Analysis of Qualitative and Quantitative Results (All Test Subjects)
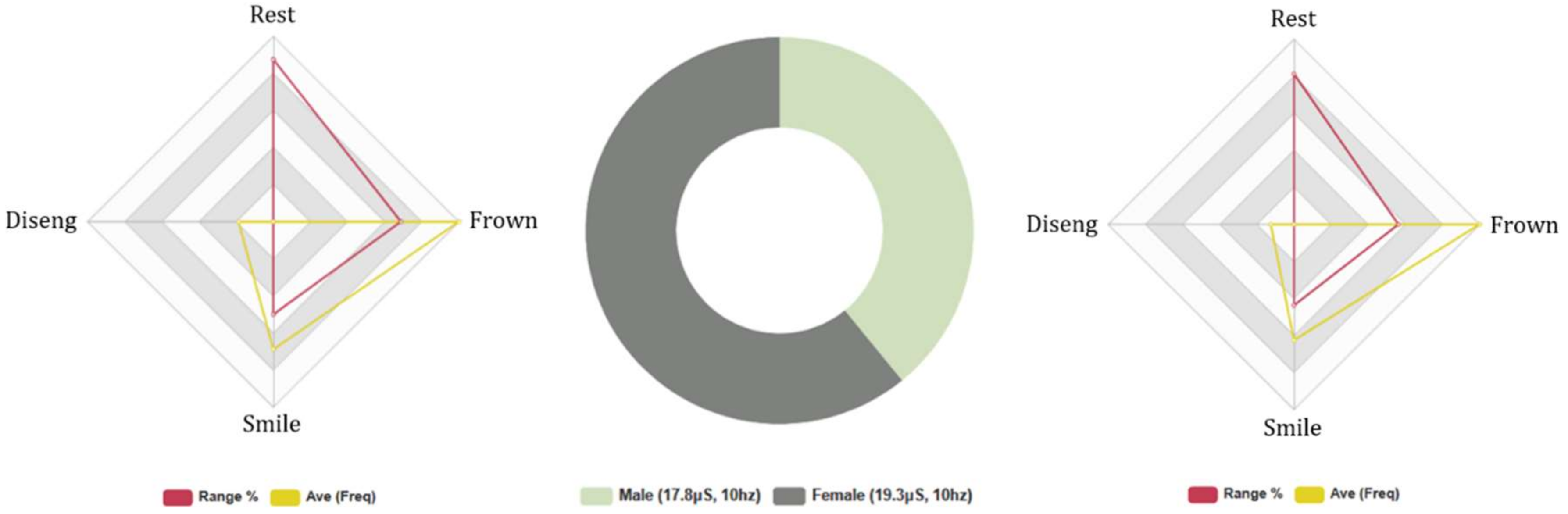
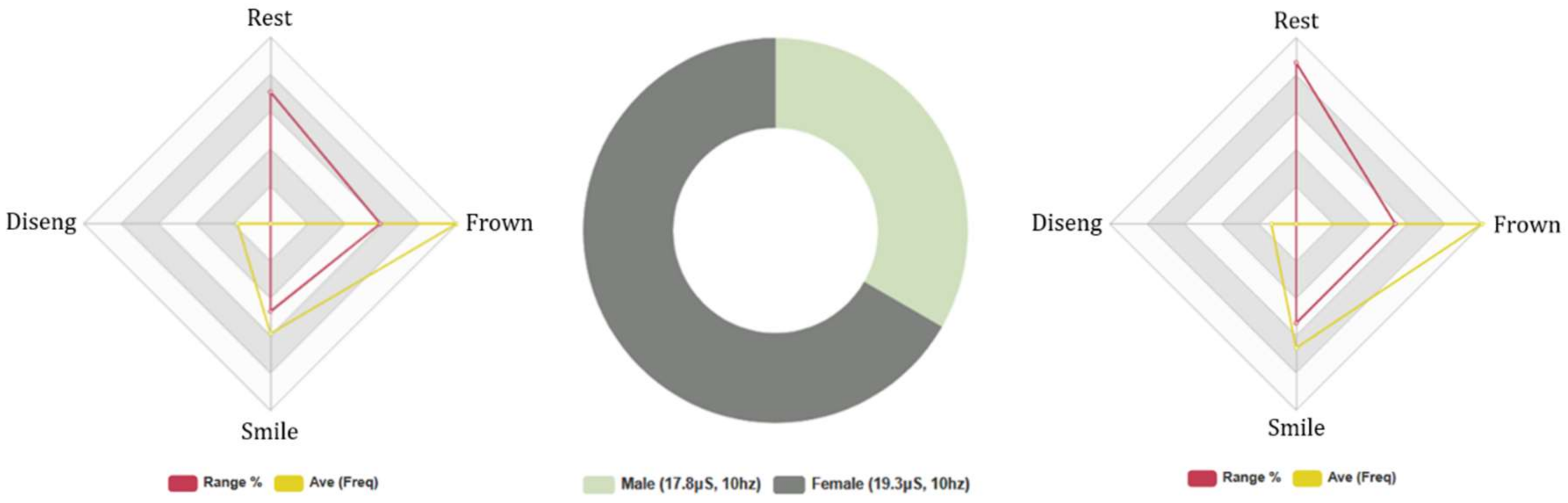
4.2. Comparative Analysis of (Q1–14) and (Q21–35) Results (Male & Female)
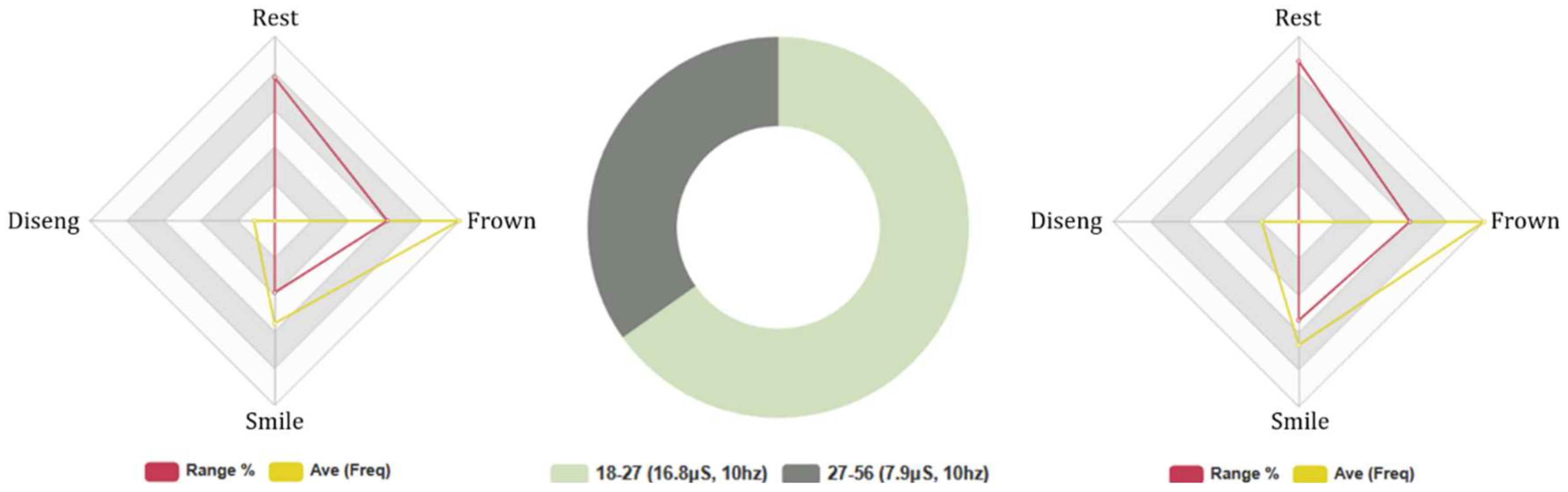
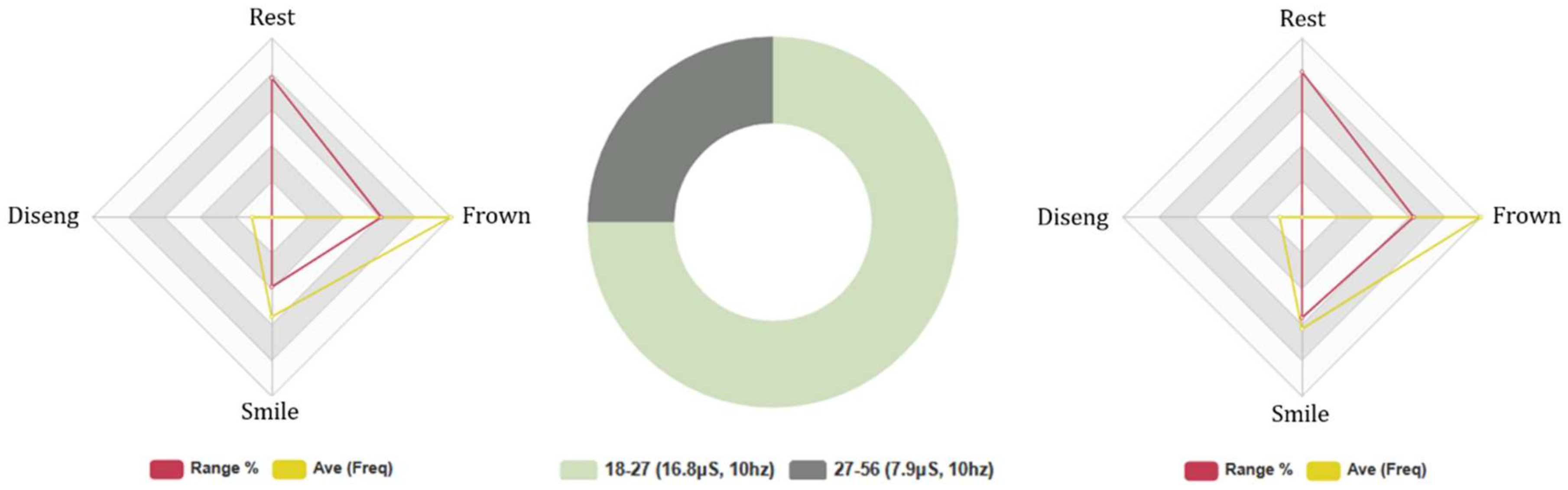
4.3. Comparative Analysis of (Q1–14) and (Q21–35) Results (Age Groups)
4.4. Analysis of FEA and GSR Biometric Data Feeds
- Rest, 0–100%: this configuration is the default position of the FEA system.
- Frown, 0–100%: the frown function measures negative Fes, which examine the position of the lips, cheeks, and eyebrows.
- Smile, 0–100%: similar to the frown function, the FEA system measures the correlation and position of the lips, cheeks, and eyebrows to determine if and to what extent the test subject expresses a positive facial expression.
- Disengage, 0–100%: this mode engages when the system is unable to track the user.
- Attention, 0–100%: the FEA system measures the frequency of the test subjects eye positions with the camera position to monitor attention rates.
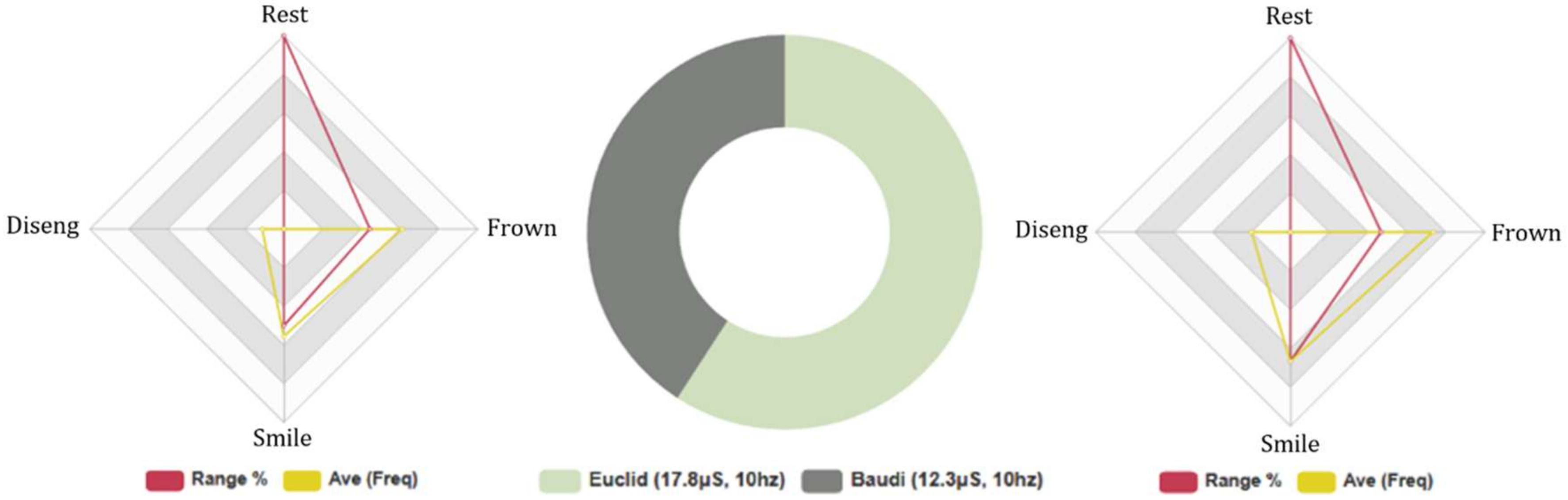
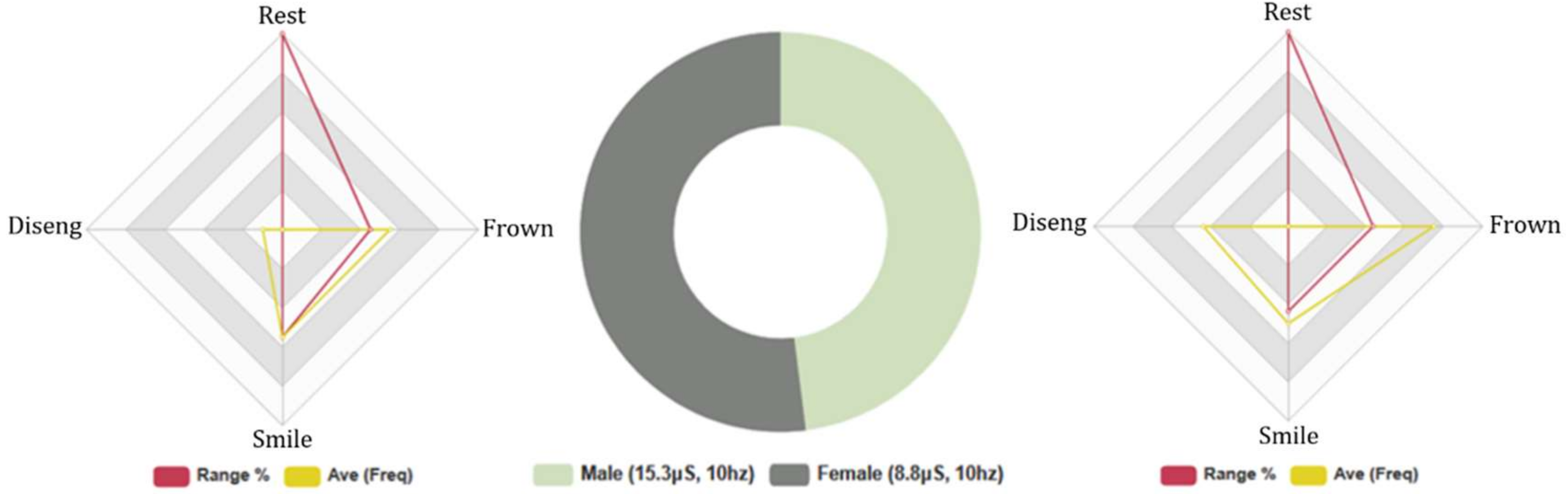
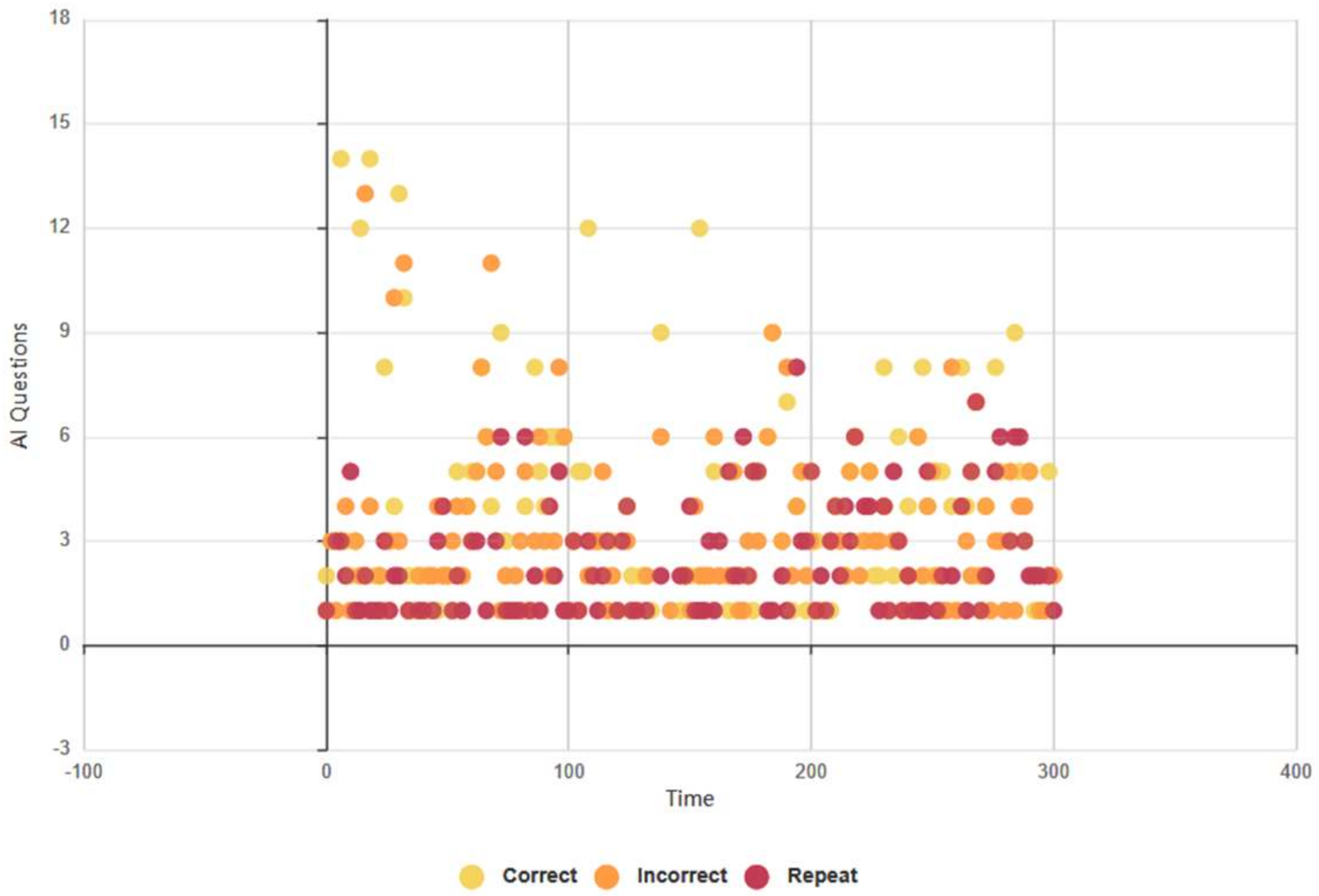
4.4.1. All Test Subjects: 5-Min Conversation. FEA and GSR Data Analysis
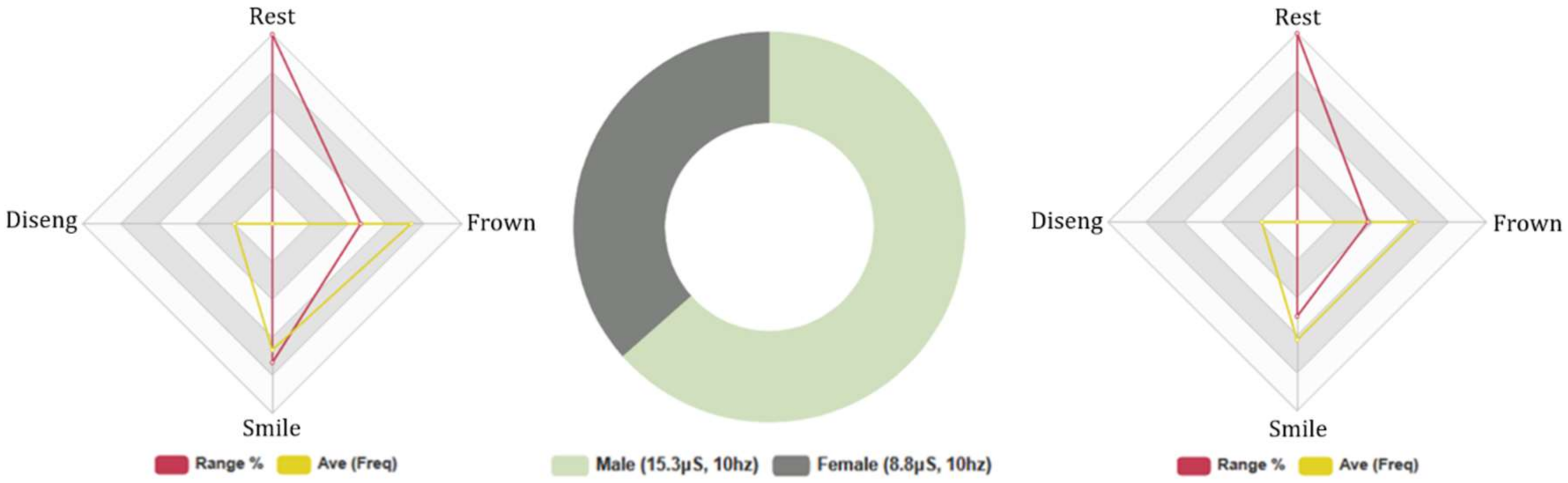
4.4.2. Euclid: Females and Males, 5-Min Conversation. Biometric Data Analysis
4.4.3. All Test Subjects, 5-Min Guessing Game, Biometric Data Analysis
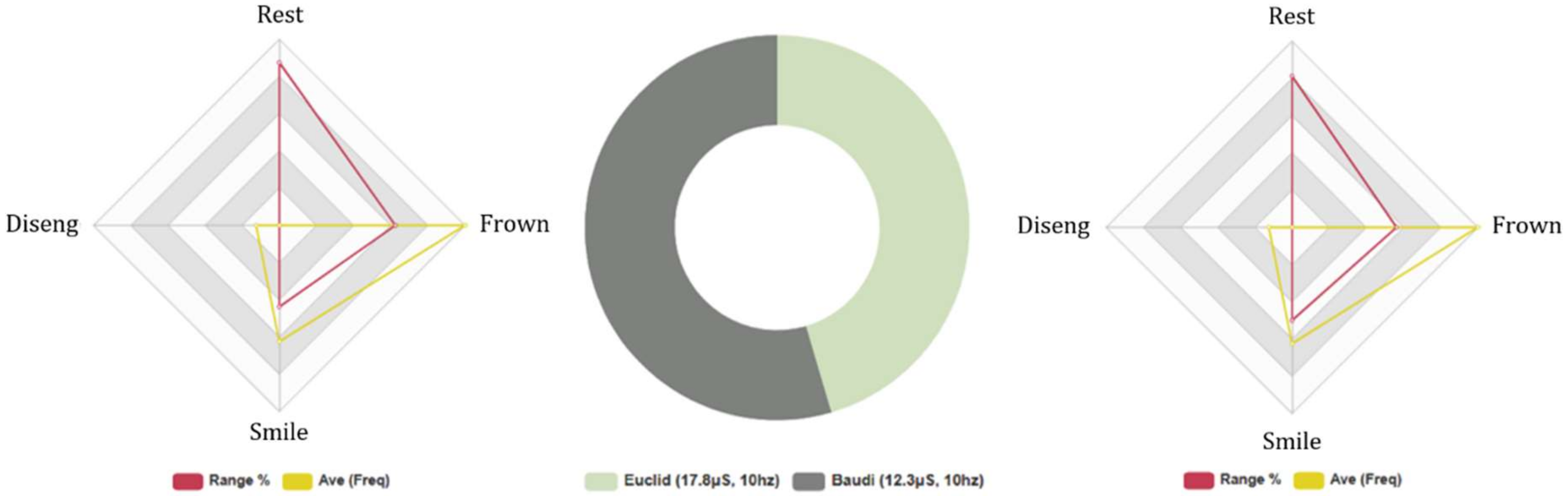
4.4.4. Baudi: Females and Males, 5-Min Conversation. FEA/GSR Data Analysis
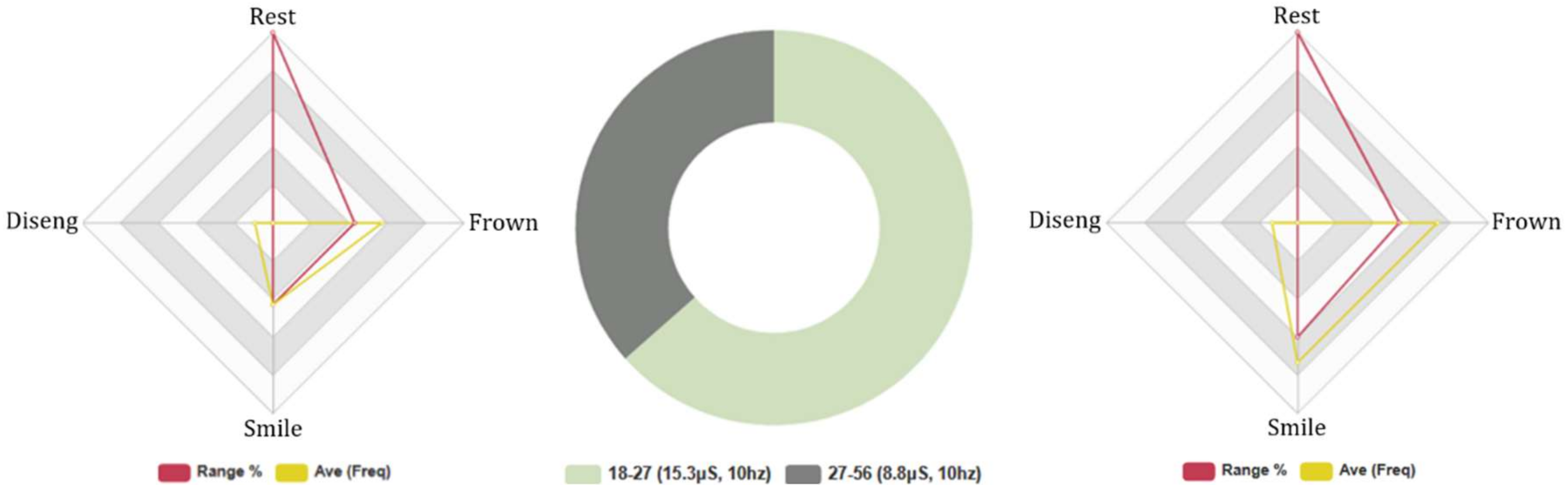
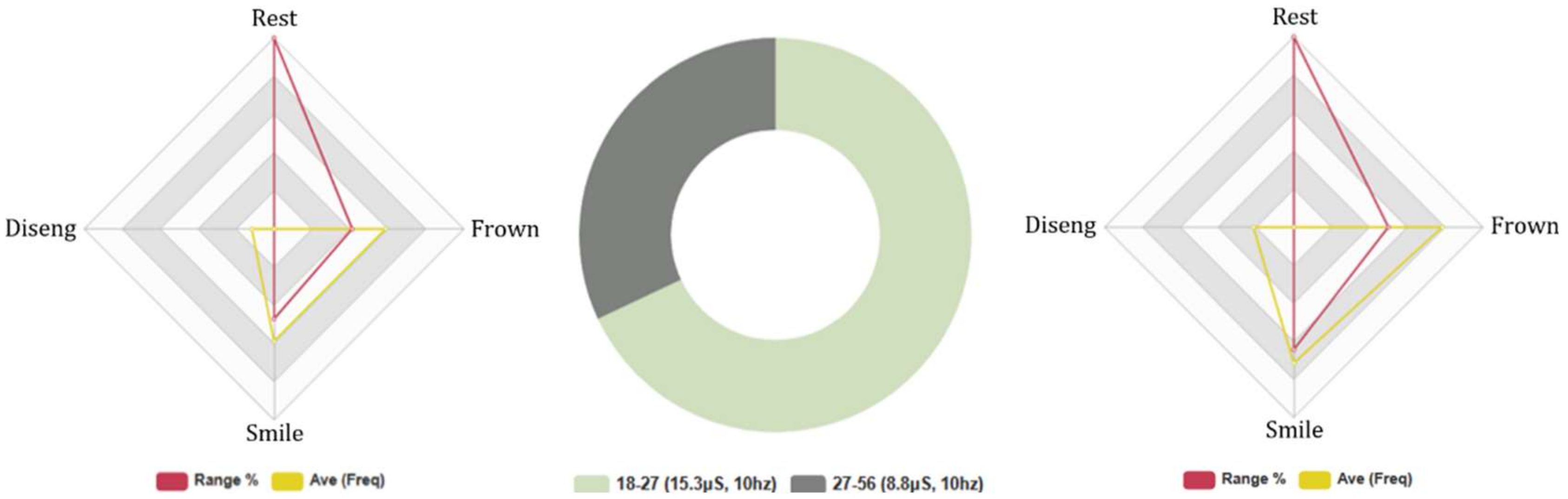
4.4.5. Euclid: Age Groups, 5-Min Conversation. FEA/GSR Data Analysis
4.4.6. Baudi: Age Groups, 5-Min Conversation. FEA/GSR Analysis
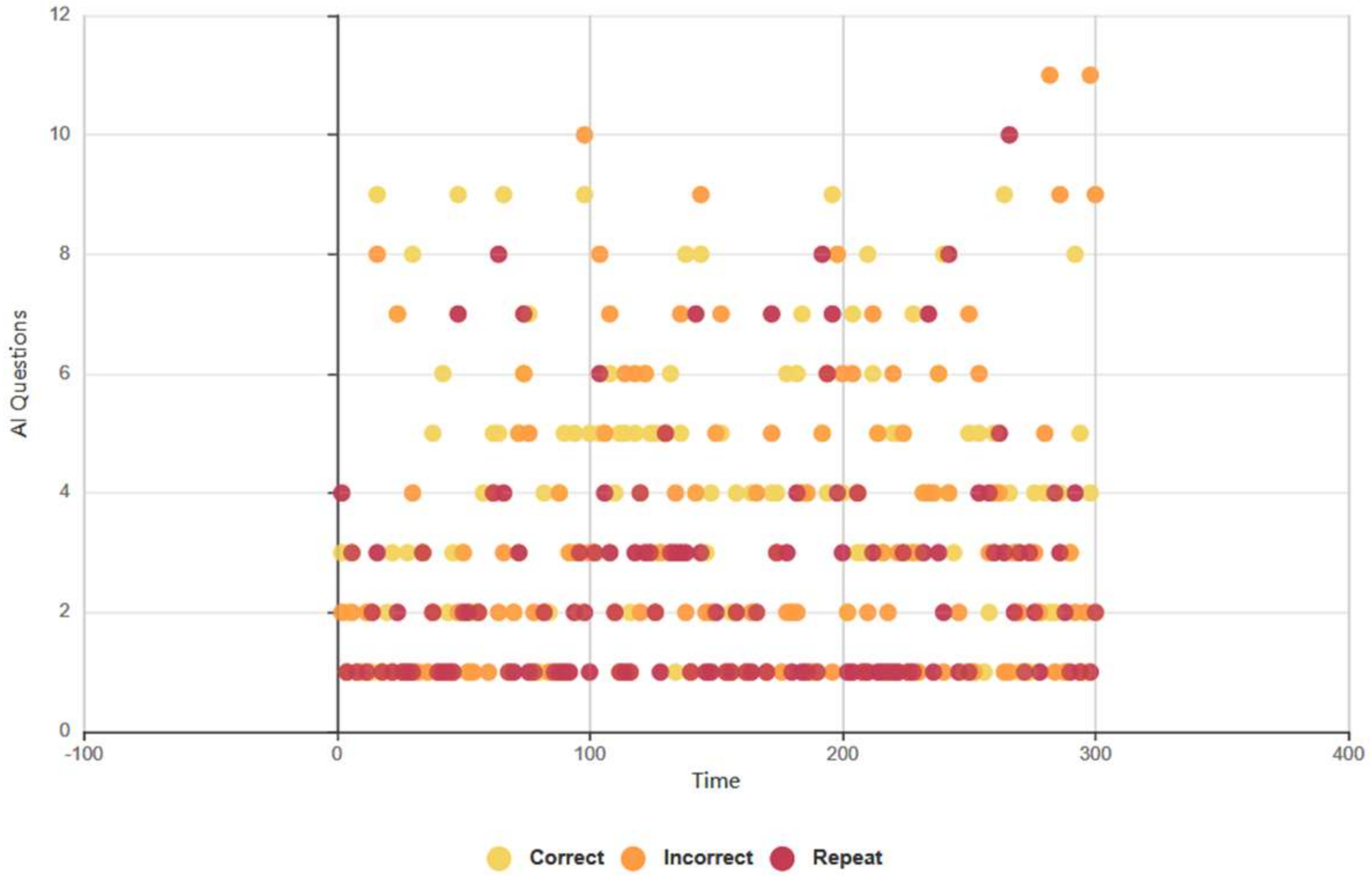
4.5. FEA/GSR Biometric Data Analysis: 5-Min Guessing Game HRI
4.5.1. Euclid: Females and Males 5-Min Guessing Game, FEA/GSR Analysis
4.5.2. Baudi: Females and Males, 5-Min Guessing Game, FEA/GSR Analysis
4.5.3. Euclid: Age Groups: 5-Min Guessing Game, FEA/GSR Analysis
4.5.4. Baudi: Age Groups: 5-Min Guessing Game, FEA/GSR Analysis
4.6. Topical Conversational and Guessing Game AI Data Analysis
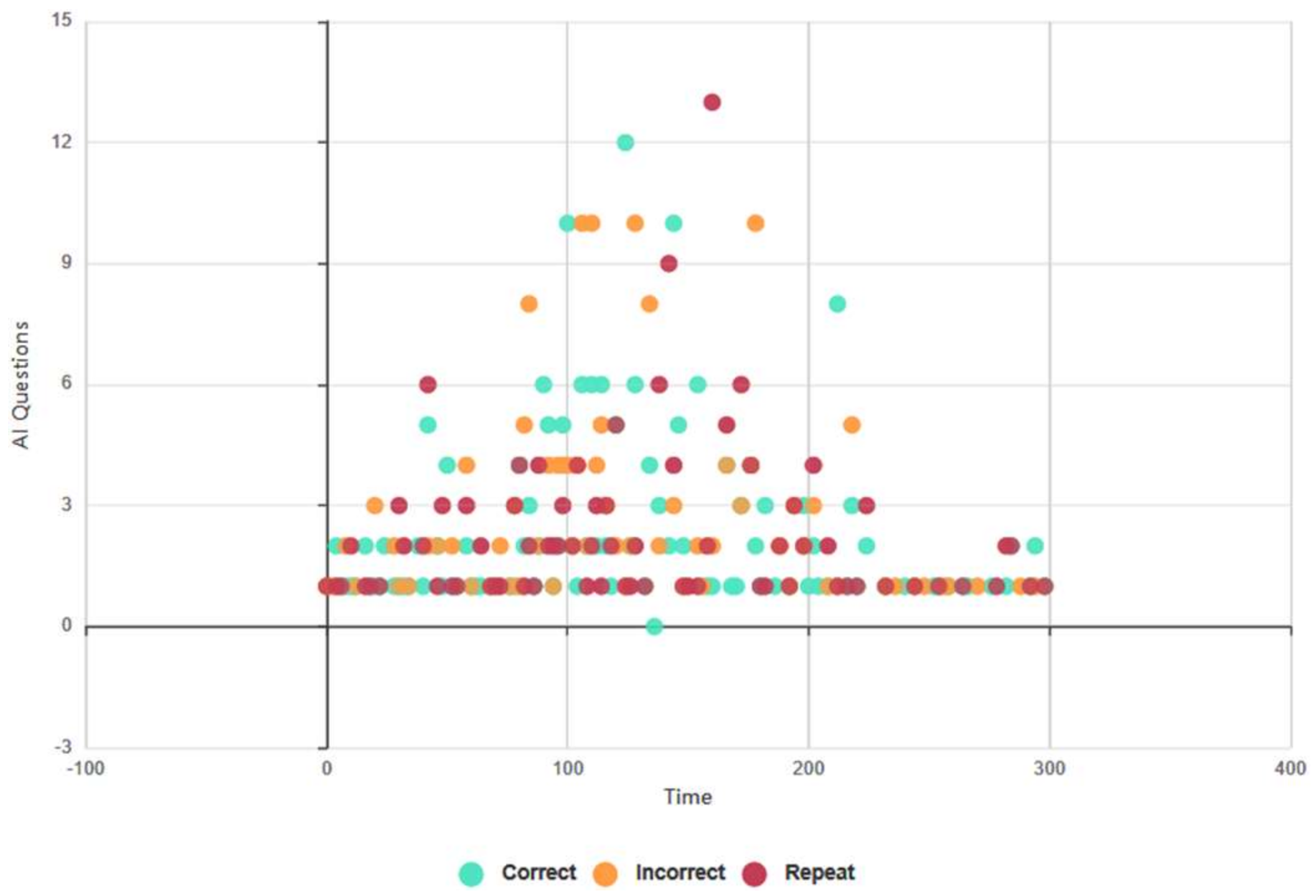
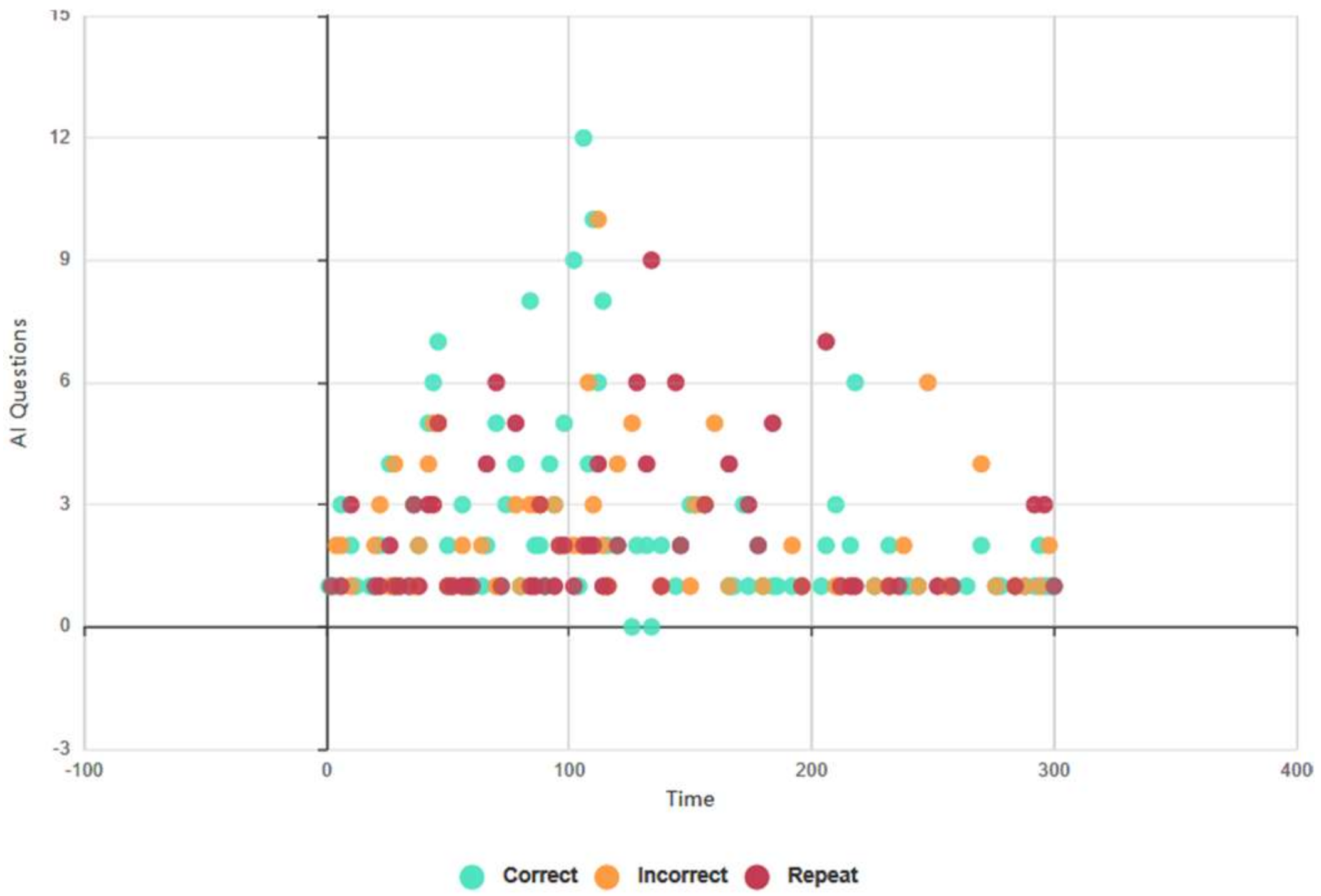
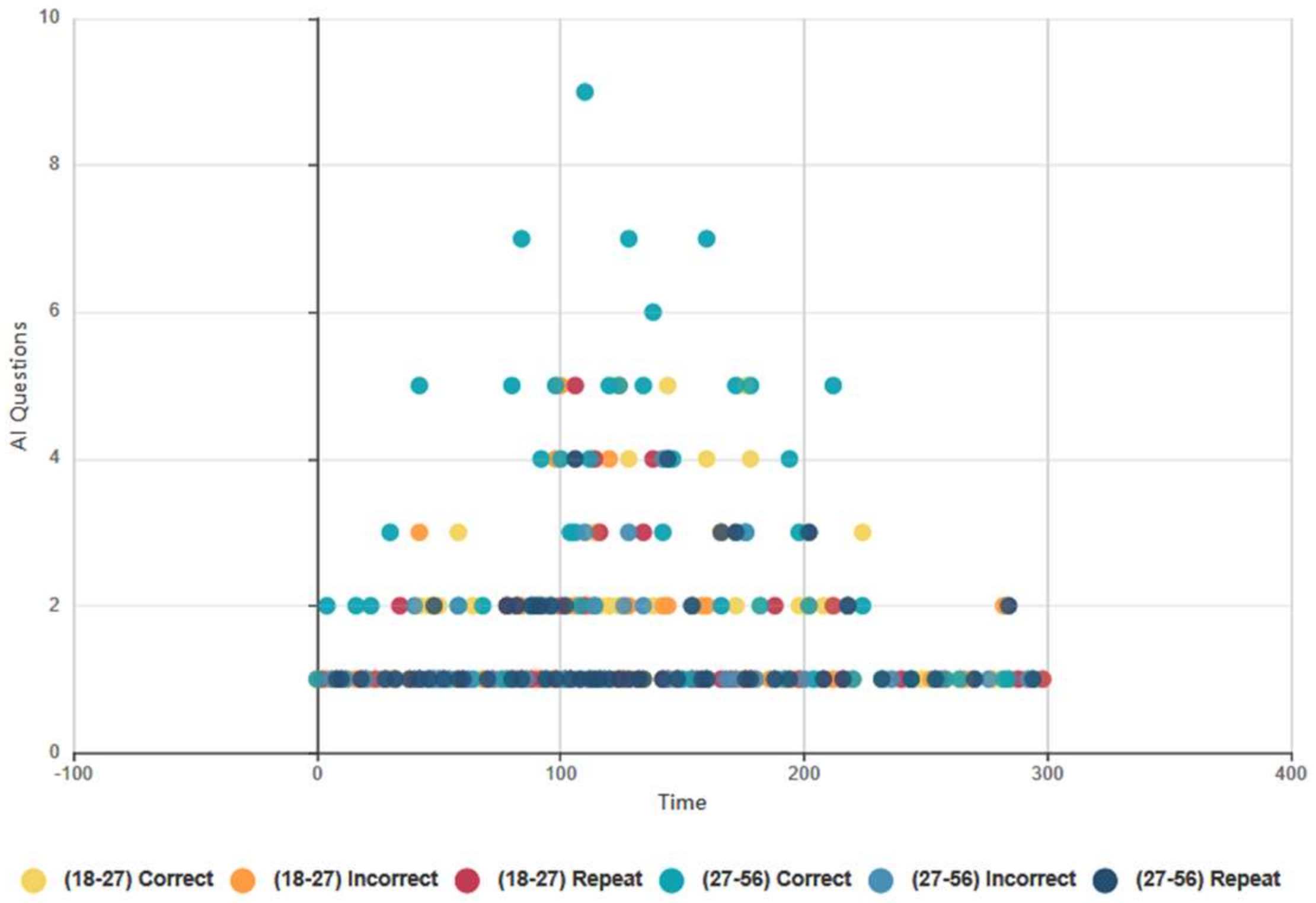
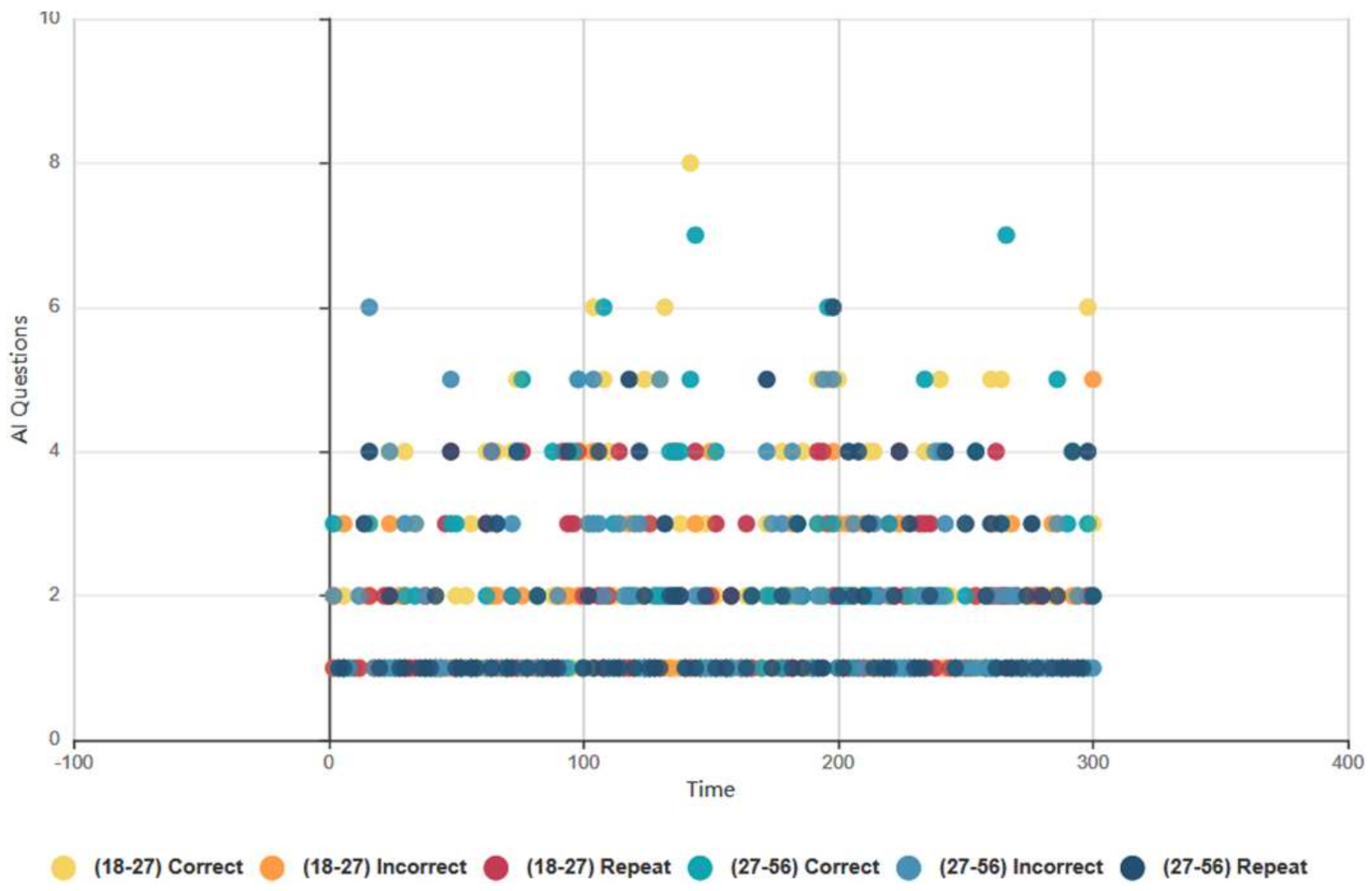
4.6.1. Euclid and Baudi: All Test Subjects, Topical Conversational AI Data
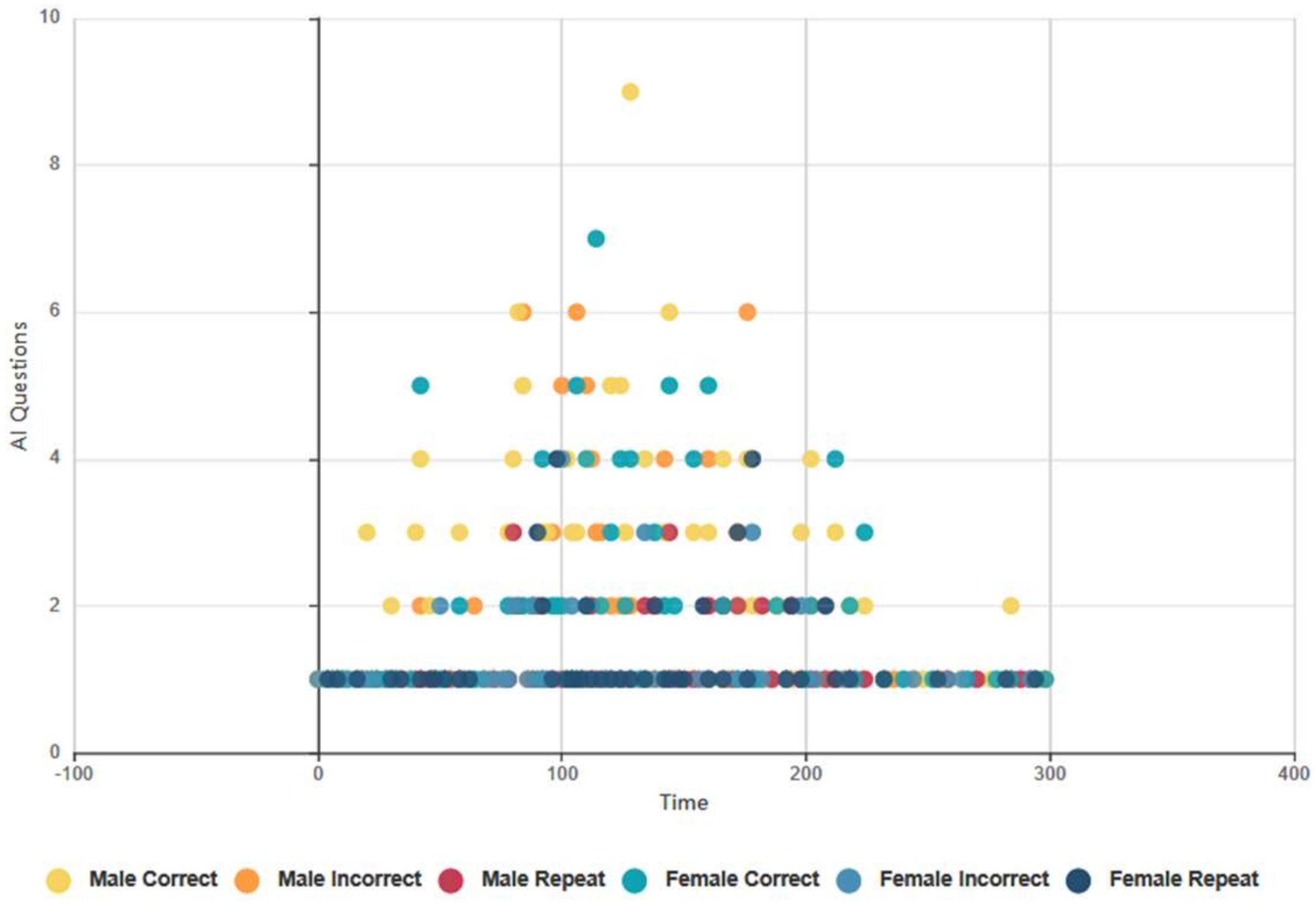
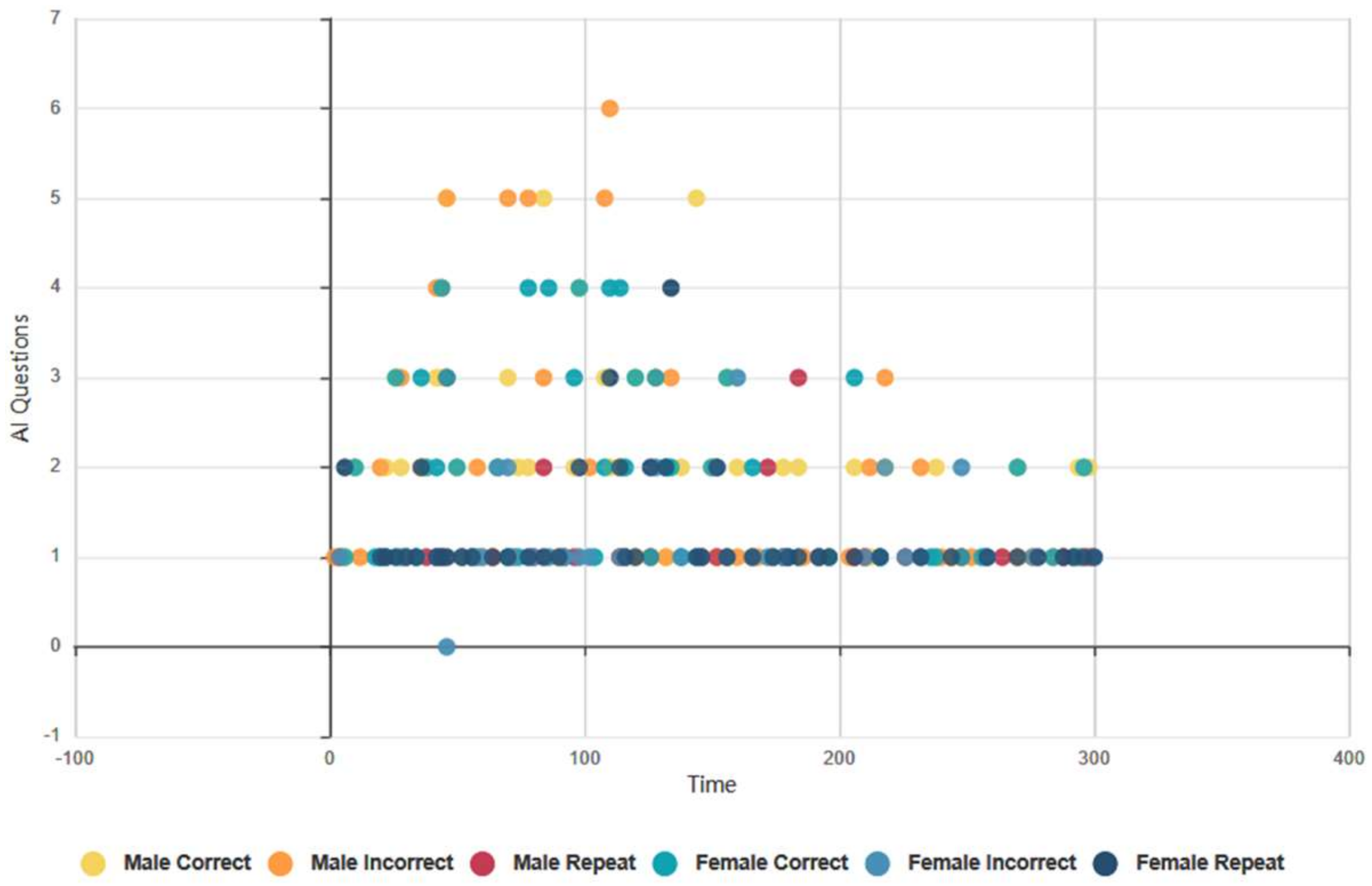
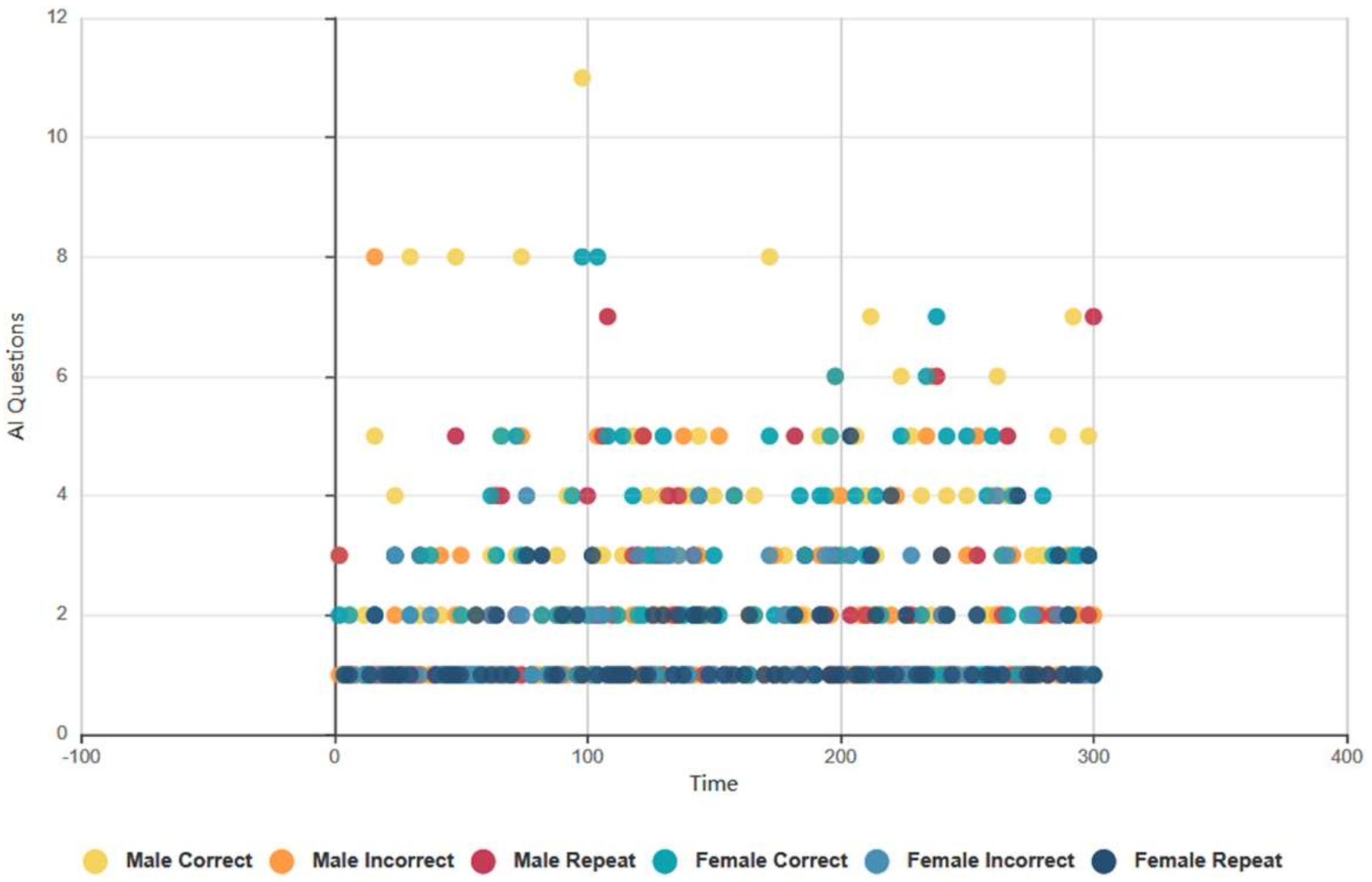
4.6.2. Euclid and Baudi: Males and Females, Topical Conversation AI Data
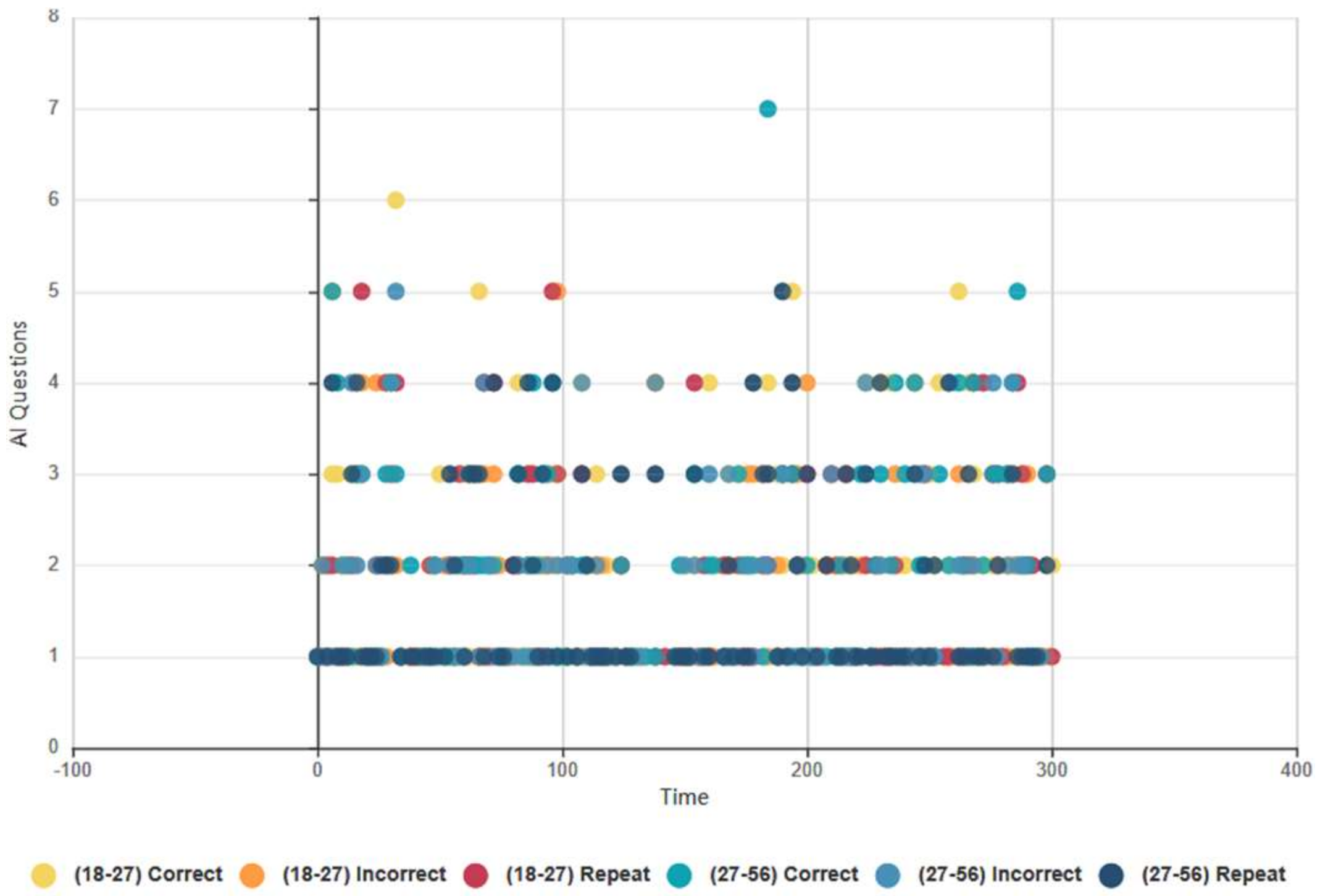
4.6.3. Euclid and Baudi: Age Groups Topical Conversational AI Data
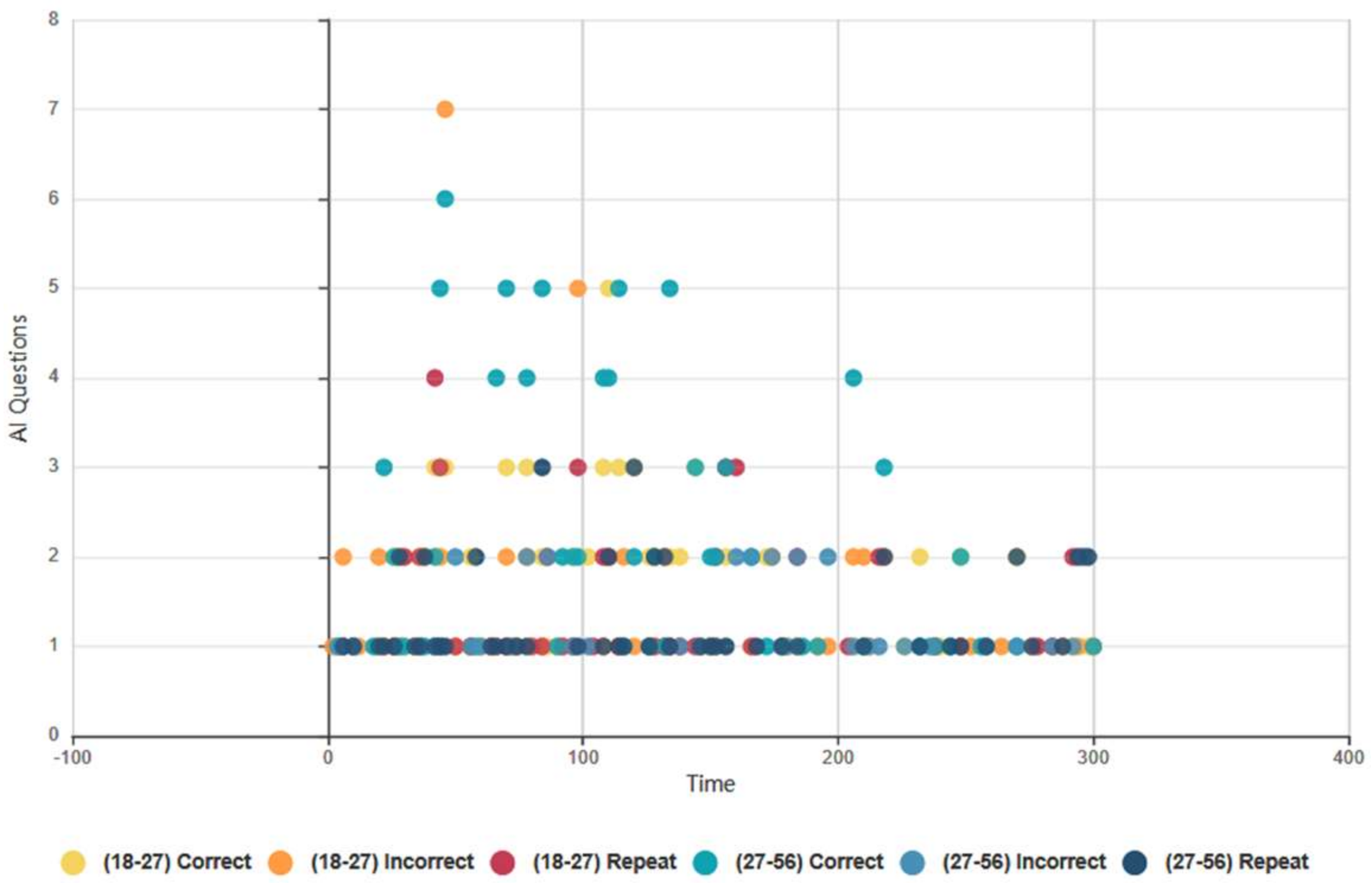
4.6.4. Euclid and Baudi: All Test Subjects, Guessing Game AI Data
4.6.5. Euclid and Baudi: Male and Female Subjects Guessing Game AI Data
4.6.6. Euclid and Baudi: Age Groups Guessing Game AI Data
5. Conclusions
5.1. Employing FEA and GSR to Support Questionnaire Results
5.2. Ethical and Broader Issues in RHR Design and Application in Society
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Hanson, D.; Olney, A.; Prilliman, S.; Mathews, E.; Zielke, M.; Hammons, D.; Fernandez, R.; Stephanou, E. Upending the Uncanny Valley. AAAI 2005, 4, 1728–1729. [Google Scholar]
- Nishio, T.; Yoshikawa, Y.; Ogawa, K.; Ishiguro, H. Development of an Effective Information Media Using Two Android Robots. Appl. Sci. 2019, 9, 3442. [Google Scholar] [CrossRef] [Green Version]
- Ishi, T.; Minato, T.; Ishiguro, H. Motion Analysis in Vocalized Surprise Expressions and Motion Generation in Android Robots. IEEE Robot. Autom. Lett. 2017, 2, 1748–1754. [Google Scholar] [CrossRef]
- Goertzel, B. Why We Need Humanoid Robots Instead of Faceless Kiosks. 2019. Available online: https://www.forbes.com/sites/forbestechcouncil/2019/12/27/why-we-need-humanoid-robot s-instead-of-faceless-kiosks/#4dfc88192e21 (accessed on 15 February 2020).
- Todo, T. SEER: Simulative emotional expression robot. In ACM SIGGRAPH 2018 Emerging Technologies; AMC Publishers: New York, NY, USA, 2018; pp. 1–2. [Google Scholar]
- Doering, D.; Glas, H.; Ishiguro, H. Modelling Interaction Structure for Robot Imitation Learning of Human Social Behaviour. IEEE Trans. Hum. Mach. Syst. 2019, 49, 219–231. [Google Scholar] [CrossRef]
- Haque, Z.; Nasir, J. Investigating the Uncanny Valley and human desires for interactive robots. In Proceedings of the 2007 IEEE International Conference on Robotics and Biomimetics (ROBIO), Sanya, China, 15–18 December 2007; pp. 2228–2233. [Google Scholar] [CrossRef]
- Yamazaki, R.; Nishio, S.; Ogawa, K.; Matsumura, K.; Minato, T.; Ishiguro, H.; Fujinami, T.; Nishikawa, M. Promoting Socialization of schoolchildren using a teleoperated Android. Int. J. Hum. Robot. 2013, 10. [Google Scholar] [CrossRef]
- Camble, A.; Frances, J. Talking about Disfigurement. 2018. Available online: https://www.sec-ed.co.uk/best-practice/talking-about-disfigurement-1/ (accessed on 18 April 2020).
- Waskul, D.; Vannini, P. Body/Embodiment: Symbolic Interaction and the Sociology of the Body; Routledge: Abingdon, UK, 2012; pp. 1–297. ISBN 13: 9781317173441. [Google Scholar]
- Whitaker, I.; Shokrollahi, K.; Dickson, W. Burns, Oxford Specialist Handbooks in Surgery; Oxford University Press: Oxford, UK, 2019; ISBN 0191503584. 9780191503580. [Google Scholar]
- Harcourt, D.; Rumsey, N. Psychology and Visible Difference. 2008. Available online: https://thepsychologist.bps.org.uk/volume-21/edition-6/psychology-and-visible-difference (accessed on 13 March 2020).
- Riek, T.; Rabinowitch, B.; Chakrabarti, C.; Robinson, P. How anthropomorphism affects empathy toward robots. In Proceedings of the 2009 4th ACM/IEEE International Conference on Human-Robot Interaction (HRI), La Jolla, CA, USA, 11–14 March 2009; pp. 245–246. [Google Scholar] [CrossRef] [Green Version]
- Kleinman, Z. CES 2018: A Clunky Chat with Sophia, The Robot. 2018. Available online: https://www.bbc.co.uk/news/technology-42616687 (accessed on 19 April 2020).
- Chung, S. Meet Sophia: The Robot Who Laughs, Smiles, and Frowns Just Like Us. 2018. Available online: https://edition.cnn.com/style/article/sophia-robot-artificial-intelligence-smart -creativity/index.html (accessed on 13 March 2020).
- Pessoa, L. Intelligent architectures for robotics: The merging of cognition and emotion. Phys. Life 2019, 31, 157–170. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mori, M. The Uncanny Valley. Energy 1970, 33–35. [Google Scholar] [CrossRef]
- Hanson, D. Expanding the aesthetic possibilities for humanoid robots. In Proceedings of the IEEE-RAS international conference on humanoid robots, Tsukuba, Japan, 5–7 December 2015; Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.472.2518&rep=rep1&type=pdf (accessed on 27 March 2019).
- Hanson, D. Exploring the Aesthetic Range for Humanoid Robots. Corpus ID: 17275411. 2006. Available online: https://www.researchgate.net/publication/228356164_Exploring_the_aesthetic_range_for_humanoid_robots. (accessed on 27 March 2019).
- Tromp, J.; Bullock, A.; Steed, A.; Sadagic, A.; Slater, M.; Frécon, E. Small-group behaviour experiments in the COVEN Project. IEEE Comput. Graph. Appl. 1998, 18, 53–63. [Google Scholar] [CrossRef]
- Garau, M.; Weirich, D. The Impact of Avatar Fidelity on Social Interaction in Virtual Environments. Corpus ID: 141182802. 2003. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.459.8694&rep=rep1&type=pdf (accessed on 27 March 2019).
- Nass, C.; Isbister, K.; Lee, J. Truth is a beauty: Researching conversational agents. In Embodied Conversational Agents; MIT Press: Cambridge, MA, USA, 2000; pp. 374–402. [Google Scholar]
- Bar-Cohen, Y.; Hanson, D.; Marom, A. Introduction. In The Coming Robot Revolution; Springer: New York, NY, USA, 2009. [Google Scholar] [CrossRef]
- Schoenherr, J.R.; Burleigh, T.J. Uncanny sociocultural categories. Front. Psychol. 2015, 5, 1456. [Google Scholar] [CrossRef]
- Browne, W.; Kawamura, K. Uncanny valley revisited. IEEExplore 2005, 151–157. [Google Scholar] [CrossRef]
- Barthelmess, U.; Furbach, U. Do we need Asimov’s Laws? ArXiv 2013, arXiv:1405.0961. [Google Scholar]
- Vallverdu, J. The Eastern Construction of the Artificial Mind. Enrahonar 2011, 47, 233–253. [Google Scholar] [CrossRef]
- Cheetham, M. Editorial: The Uncanny Valley Hypothesis and beyond. Front. Psychol. 2017, 8, 1738. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brink, K.; Wellman, H. Hi, Robot: Adults, Children and The Uncanny Valley. 2017. Available online: https://www.npr.org/sections/13.7/2017/12/16/563075762/hi-robot-adults-children-and-the-uncanny-valley?t=1582650482901 (accessed on 25 February 2020).
- Brink, K.; Gray, K.; Wellman, H. Creepiness Creeps In: Uncanny Valley Feelings Are Acquired in Childhood. Child. Dev. 2017. [Google Scholar] [CrossRef]
- Feng, S.; Wang, X.; Wang, Q.; Fang, J.; Wu, Y.; Yi, L.; Wei, K. The uncanny valley effect in typically developing children and its absence in children with autism spectrum disorders. PLoS ONE 2018, 13, e0206343. [Google Scholar] [CrossRef]
- Maya, M.; Reichling, D.; Lunardini, F.; Geminiani, A.; Antonietti, A.; Ruijten, P.; Levitan, C.; Nave, G.; Manfredi, D.; Bessette-Symons, B.; et al. Uncanny but not confusing: Multisite study of perceptual category confusion in the Uncanny Valley. Comput. Hum. Behav. 2019, 103. [Google Scholar] [CrossRef]
- Lay, S.; Brace, N.; Pike, G.; Pollick, F. Circling around the Uncanny Valley: Design Principles for Research into the Relation Between Human-likeness and Eeriness. I-Perception 2016. [Google Scholar] [CrossRef]
- Tinwell, A.; Sloan, R.J. Children’s perception of uncanny human-like virtual characters. Comput. Hum. Behav. 2014, 36, 286–296. [Google Scholar] [CrossRef]
- Tung, F. Child Perception of Humanoid Robot Appearance and Behavior. Int. J. Hum. -Comput. Interact. 2016, 32, 493–502. [Google Scholar] [CrossRef]
- Towers-Clark, C. Keep the Robot in The Cage—How Effective (And Safe) Are Co-Bots? 2019. Available online: www.forbes.com/sites/charlestowersclark/2019/09/11/keep-the-robot-in-the-cagehow-effective--safe-are-co-bots/#3279006415cc (accessed on 5 April 2020).
- Patel, V.N. An Emotionally Intelligent AI Could Support Astronauts on a Trip to Mars. 2020. Available online: www.technologyreview.com/s/615044/an-emotionally-intelligent-ai-could-support-astronauts-on-a-trip-to-mars/ (accessed on 15 February 2020).
- McDuff, D.; Kapoor, A. Toward Emotionally Intelligent Artificial Intelligence. 2019. Available online: www.microsoft.com/en-us/research/blog/toward-emotionally-intelligent-artificial-intelligence/ (accessed on 21 February 2020).
- Alasaarela, M. The Rise of Emotionally Intelligent AI. 2017. Available online: https://machinelearnings.co/the-rise-of-emotionally-intelligent-ai-fb9a814a630e (accessed on 22 February 2020).
- Dewan, K. The Rise of AI Makes Emotional Intelligence More Important. 2019. Available online: https://www.entrepreneur.com/article/340637 (accessed on 22 February 2020).
- Jarboe, J. What Is Artificial Emotional Intelligence & How Does Emotion AI Work? 2018. Available online: https://www.searchenginejournal.com/what-is-artificial-emotional-intelligence/255769/ (accessed on 22 February 2020).
- Fatemi, F. Why EQ + AI Is A Recipe for Success. 2018. Available online: https://www.forbes.com/sites/falonfatemi/2018/05/30/why-eq-ai-is-a-recipe-for-success/#61 (accessed on 22 February 2020).
- Nordli, B. Cogito, Whose AI Interprets Human Emotions, Adds $20M. 2019. Available online: https://www.builtinboston.com/2019/09/05/cogito-raises-20m-funding (accessed on 21 February 2020).
- Field, H. Technologists Are Creating Artificial Intelligence to Help Us Tap into Our Humanity. Here is How (and Why). 2019. Available online: https://www.entrepre neur.com/article/340207 (accessed on 13 March 2020).
- Lewis, A.; Guzman, L.; Schmidt, T. Automation, Journalism, and Human-Machine Communication: Rethinking Roles and Relationships of Humans and Machines in News. Digit. J. 2019, 7, 409–427. [Google Scholar] [CrossRef]
- Wiltz, C. What is the state of Emotional Artificial Intelligence? Drive World 2019, 12, 234–255. Available online: www.designnews.com/electronics-test/whats-state-emotional-ai/20315341406148 2 (accessed on 23 March 2020).
- Williams, D. The Rise of Emotional Robots. 2018. Available online: https://www.sapiens.org/technology/emotional-intelligence-robots/ (accessed on 19 March 2020).
- Streeter, B. Seriously Successful Results from HSBC Bank’s Branch Robot Rollout. 2019. Available online: https://thefinancialbrand.com/84245/hsbc-banks-branch-robot-pepper-digital-transformation-phygital/ (accessed on 21 March 2020).
- Pandey, A.K.; Gelin, R. A Mass-Produced Sociable Humanoid Robot: Pepper: The First Machine of Its Kind. IEEE Robot. Autom. Mag. 2018. [Google Scholar] [CrossRef]
- Starr, M. Caring Pepper Robot Hits the Market, Sells Out in a Minute. 2015. Available online: https://www.cnet.com/news/caring-pepper-robot-hits-the-market-sells-out-in-a-minute/ (accessed on 21 February 2020).
- Goodman, J. Robotics Roundtable: Should Robots Look Like Humans, or Like Machines? 2018. Available online: https://internetofbusiness.com/should-robots-look-like-humans-or-like-machines/ (accessed on 21 February 2020).
- Simon, M. The Creepy-Cute Robot that Picks Peppers with its Face. 2018. Available online: www.wired.com/story/the-creepy-cute-robot-that-picks-peppers/ (accessed on 22 February 2020).
- Glaser, A. Pepper, the Emotional Robot, Learns How to Feel Like an American. 2016. Available online: www.wired.com/2016/06/pepper-emotional-robot-learns-feel-like-american/ (accessed on 21 February 2020).
- Hawes, N. Pepper the Emotional Robot May Just Make You Angry. 2014. Available online: https://theconversation.com/pepper-the-emotional-robot-may-just-make-you-angry-27655 (accessed on 21 February 2020).
- Hu, M.S.; Maan, Z.N.; Wu, J.C.; Rennert, R.C.; Hong, W.X.; Lai, T.S. Tissue engineering and regenerative repair in wound healing. Ann. Biomed. Eng. 2014, 42, 1494–1507. [Google Scholar] [CrossRef] [PubMed]
- Guo, J.; Xiang, C.; Conn, R.; Rossiter, J. All-Soft Skin-Like Structures for Robotic Locomotion and Transportation. Soft Robot. 2019. [Google Scholar] [CrossRef] [PubMed]
- Williams, R. Researchers Create a First Autonomous Humanoid Robot with Full-Body Artificial Skin. 2019. Available online: https://inews.co.uk/news/technology/researchers-autonomous-humanoid-robot-artificial-skin-sense-805511 (accessed on 15 February 2020).
- Zilnik, A. Designing a Chatbot’s Personality. 2016. Available online: Chatbotsmagazine.com/designing-a-chatbots-personality-52dcf1f4df7d (accessed on 22 February 2020).
- Pavlus, J. The Next Phase Of UX: Designing Chatbot Personalities. 2016. Available online: https://www.fastcompany.com/3054934/the-next-phase-of-ux-designing-chatbot-personalities. (accessed on 19 March 2020).
- Marr, B. Why AI and Chatbots Need Personality. 2019. Available online: https://www.forbes.com/sites/bernardmarr/2019/08/02/why-ai-and-chatbots-need-personality/#fc7224214f84 (accessed on 23 April 2020).
- Gardner, H. Frames of Mind: The Theory of Multiple Intelligences; Basic Books: New York, NY, USA, 1983; pp. 55–78. ISBN 13: 978-0006862901. [Google Scholar]
- Moltzau, A. AI and Nine Forms of Intelligence. 2019. Available online: https://towardsdatascience.com/ai-and-nine-forms-of-intelligence-5cf587547731 (accessed on 21 February 2020).
- Duffy, B.R. Towards Social Intelligence in Autonomous Robotics: A Review. Int. J. Adv. Robot. Syst. 2001. [Google Scholar] [CrossRef] [Green Version]
- Roberts, J.; Dennison, J. The Photobiology of Lutein and Zeaxanthin in the Eye. J. Ophthalmol. 2015. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Davis, K.; Christodoulou, A.; Seider, S.; Gardner, H. The Theory of Multiple Intelligences. In Cambridge Handbook of Intelligence; Sternberg, R.J., Kaufman, S.B., Eds.; Cambridge University Press: New York, NY, USA, 2011; pp. 485–503. [Google Scholar]
- Tirri, K.; Nokelainen, P.; Komulainen, E. Multiple Intelligences: Can they be measured? Psychological Test and Assessment Modelling. Psychol. Test Assess Modeling 2013, 55, 438–461. [Google Scholar] [CrossRef]
- Núñez-Cárdenas, F.D.; Camacho, J.H.; Tomás-Mariano, V.T.; Redondo, A.M. Application of Data Mining to describe Multiple Intelligences in University Students. IJCOPI 2015, 6, 20–30. [Google Scholar]
- Kretzschmar, K.; Tyroll, H.; Pavarini, G.; Manzini, A.; Singh, I. Can Your Phone Be Your Therapist? Young People’s Ethical Perspectives on the Use of Fully Automated Conversational Agents in Mental Health Support. Biomed. Inform. Insights. 2019. [Google Scholar] [CrossRef] [Green Version]
- Edwards, D. The HeartMath coherence model: Implications and challenges for artificial intelligence and robotics. Ai Soc. 2019, 34, 899–905. [Google Scholar] [CrossRef]
- Maybury, M.T. The mind matters artificial intelligence and its societal implications. IEEE Technol. Soc. Mag. 1990, 9, 7–15. [Google Scholar] [CrossRef]
- Hiren, S. Global Humanoid Robot Market Evolving Industry Trends and Key Insights by 2024. 2019. Available online: http://zmrnewsmagazine.com/18125/global-humanoid-robot-market-evolving-industry-trends-and-key-insights-by-2024/ (accessed on 21 May 2019).
- Zlotowski, J.; Proudfoot, D.; Bartneck, C. More Human Than Human: Does the Uncanny Curve Matter? In Proceedings of the HRI2013, Workshop on Design of Humanlikeness in HRI: From uncanny valley to minimal design, Tokyo, Japan, 3–6 March 2013; pp. 7–13. [Google Scholar]
- Burton, B. Meet Vyommitra, the Legless Female Humanoid Robot India’s Sending to Space. 2020. Available online: https://www.cnet.com/news/meet-vyommitra-the-legless-female-humanoid-robot-indias-sending-to-space/ (accessed on 28 July 2020).
- Ramanathan, M.; Mishra, N.; Thalmann, N.M. Nadine Humanoid Social Robotics Platform. In Lecture Notes in Computer Science; CGI 2019: Advances in Computer Graphics; Gavrilova, M., Chang, J., Thalmann, N., Hitzer, E., Ishikawa, H., Eds.; Springer: Cham, Switzerland, 2019; Volume 11542. [Google Scholar] [CrossRef]
- McCurry, J. Erica, the ‘Most Beautiful and Intelligent’ Android, Leads Japan’s ROBOT Revolution. 2015. Available online: www.theguardian.com/technology/2015/dec/31/erica-the-most-beautiful-and-intelligent-android-ever-leads-japans-robot-revolution (accessed on 28 July 2020).
- Tao, M. Promobot to ‘Mass Produce’ Humanoid Robots. 2019. Available online: https://roboticsandautomationnews.com/2019/11/10/promobot-to-mass-produce-humanoid-robots/26628/ (accessed on 28 July 2020).
- RobotsNu Humanoid Robots for Patient Simulation in Medical Training. 2018. Available online: https://robots.nu/en/newsitem/humanoid-robots-for-patient-simulation (accessed on 28 July 2020).
- Marco, M. This Robot Girl is a Physical Version of Alita. 2019. Available online: https://www.personalrobots.biz/chinas-robot-girl-is-a-physical-version-of-alita/ (accessed on 28 July 2020).
- Malewar, A. A Humanoid Robot Alex Maybe the Futuristic News Anchor. 2019. Available online: https://www.techexplorist.com/humanoid-robot-alex-futuristic-news-anchor/22439/ (accessed on 28 July 2020).
- Muoio, D. Toshiba’s Latest Humanoid Robot Speaks Three Languages and Works in a Mall. 2015. Available online: https://www.businessinsider.com/toshibas-humanoid-robot-junko-chihira-speaks-three-languages-2015-11?r=US&IR=T (accessed on 29 July 2020).
- Greshko, M. Meet Sophia, the Robot That Looks Almost Human. 2018. Available online: https://www.nationalgeographic.com/photography/proof/2018/05/sophia-robot-artificial-intelligence-science/ (accessed on 28 July 2020).
- Block, I. AI robot Ai-Da Presents Her Original Artworks in University of Oxford Exhibition. 2019. Available online: https://www.dezeen.com/2019/06/14/ai-robot-ai-da-artificial-intelligence-art-exhibition/ (accessed on 28 July 2020).
- Harmon, A. Making Friends with a Robot Named Bina48. 2010. Available online: https://www.nytimes.com/2010/07/05/science/05robotside.html (accessed on 28 July 2020).
- Guizzo, E. Telenoid R1: Hiroshi Ishiguro’s Newest and Strangest Android. 2010. Available online: https://spectrum.ieee.org/automaton/robotics/humanoids/telenoid-r1-hiroshi-ishiguro-newest-and-strangest-android (accessed on 28 July 2020).
- Minato, T.; Yoshikawa, Y.; Noda, T.; Ikemoto, S.; Ishiguro, H.; Asada, M. CB2: A child robot with biomimetic body for cognitive developmental robotics. In Proceedings of the 2007 7th IEEE-RAS International Conference on Humanoid Robots, Pittsburgh, PA, USA, 29 November–1 December 2007; IEEE-RAS Humanoids: Pittsburgh, PA, USA, 2007; pp. 557–562. [Google Scholar] [CrossRef]
- Guizzo, E. Robot Baby Diego-San Shows Its Expressive Face on Video. 2013. Available online: https://spectrum.ieee.org/automaton/robotics/humanoids/robot-baby-diego-san (accessed on 20 July 2020).
- Etherington, D. Atlas the Humanoid Robot Shows Off a New and Improved Gymnastics Routine. 2019. Available online: https://techcrunch.com/2019/09/24/atlas-the-humanoid-robot-shows-off-a-new-and-improved-gymnastics-routine/ (accessed on 28 July 2020).
- Sanders, L. Linking Sense of Touch to Facial Movement Inches Robots Toward ‘Feeling’ Pain. 2020. Available online: https://www.sciencenews.org/article/robots-feel-pain-artificial-intelligence (accessed on 28 July 2020).
- Breslin, S. Meet the Terrifying New Robot Cop That’s Patrolling Dubai. 2017. Available online: https://www.forbes.com/sites/susannahbreslin/2017/06/03/robot-cop-dubai/#d6b5c9a6872b (accessed on 28 July 2020).
- Furhat Robotics What’s in a Name? The Story Behind Furhat Robotics. 2019. Available online: https://medium.com/@furhatrobotics/why-the-name-furhat-robotics-af53cd76639c (accessed on 28 July 2020).
- Goodrich, M.; Lee, J.; Kirlik, A. Multitasking and Multi-Robot Management. In The Oxford Handbook of Cognitive Engineering; Oxford University Press: Oxford, UK, 2013; pp. 453–556. [Google Scholar] [CrossRef]
- Hoskins, T. Robot Factories Could Threaten the Jobs of Millions of Garment Workers. 2016. Available online: https://www.theguardian.com/sustainablebusiness/2016/jul/16/robot-factor ies-threaten-jobs-millions-garment-workers-south-east-asia-women (accessed on 19 February 2020).
- Ghose, T. Robots Could Hack Turing Test by Keeping Silent. 2016. Available online: https://www.scientificamerican.com/article/robots-could-hack-turing-test-by-keeping-silent/ (accessed on 25 February 2020).
- Solis, B. Now Hiring: Robots, Please Apply Within. 2019. Available online: www.forbes.com/sites/briansolis/2019/09/17/now-hiring-robots-please-apply-within/ (accessed on 11 February 2020).
- Shell, E.R. AI and Automation Will Replace Most Human Workers Because They Do Not Have to Be Perfect, Just Better Than You. 2018. Available online: www.new sweek.com/2018/11/30/ai-and-automation-will-replace-most-human-workers-because-they-dont-have-be-1225552.html (accessed on 11 February 2020).
- Burkhardt, M. Living in a Robot Society: Perspective of a World-Leading Roboticist. 2019. Available online: //towardsdatascience.com/living-in-a-robot-society-a-perspective-of-a-world-leading-robotocist-51175fb455e3 (accessed on 11 February 2020).
- Yamaguchi, T. Japan’s robotic future. Crit. Asian Stud. 2019, 51, 134–140. [Google Scholar] [CrossRef]
- Chatila, R. Inclusion of Humanoid Robots in Human Society: Ethical Issues. In Humanoid Robotics; Springer: Dordrecht, The Netherlands, 2018. [Google Scholar] [CrossRef]
- Dautenhahn, K. Robots and Us-Useful Roles of Robots in Human Society. In Proceedings of the 2018 ACM/IEEE International Conference on Human-Robot Interaction (HRI ’18); Association for Computing Machinery; New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Mathieson, S.A. Mr Robot: Will Androids Ever be Able to Convince People They Are Human? 2019. Available online: https://www.researchgate.net/publication/341756234_Mr_Robot_Will_androids_ever_be_able_to_convince_people_they_are_human_Guardian_Online (accessed on 19 July 2020).
- The World Economic Forum Can machine’s think? A New Turing Test May Have the Answer. 2019. Available online: www.weforum.org/agenda/2019/08/our-turing-test-for-androids-will-judge-how-lifelike-humanoid-robots-can-be/. (accessed on 14 March 2020).
- Barnfield, N. Face to Face with The Future of AI. Horiz. Mag. Riley Raven. 2020, 8–11. Available online: https://www.staffs.ac.uk/alumni/ horizon-alumni-magazine (accessed on 29 June 2020).
- Yan, J.; Wang, Z.; Yan, Y. Humanoid Robot Head Design Based on Uncanny Valley and FACS. J. Robot. 2014, 2014, 208924. [Google Scholar] [CrossRef] [Green Version]
- Sakamoto, D.; Kanda, T.; Ono, T.; Ishiguro, H.; Hagita, N. Android as a telecommunication medium with a human-like presence. In Proceedings of the 2007 2nd ACM/IEEE International Conference on Human-Robot Interaction (HRI), Arlington, VA, USA, 2–8 March 2007; pp. 193–200. [Google Scholar] [CrossRef]
- Liu, Y.; Shi, L.; Liu, L.; Zhang, Z.; Jinsong, L. Inflated dielectric elastomer actuator for eyeball’s movements: Fabrication, Analysis and Experiments. In Proceedings of the SPIE, San Diego, CA, USA, 10 April 2008; p. 6927. [Google Scholar] [CrossRef]
- Harkness, K.; McKelvie, A. The Measurement of Uncertainty in Caregivers of Patients with Heart Failure. J. Nurs. Meas. 2013, 21, 23. [Google Scholar] [CrossRef] [PubMed]
- Payakpate, J. Knowledge Management Platform for Promoting Sustainable Energy Technologies in Rural Thai Communities. Ph.D. Thesis, Murdoch University, Murdoch, Australia, 2020. [Google Scholar]
- Ishiguro, H. Android science: Toward a new cross-interdisciplinary framework. J. Comput. Sci. 2005, 28, 118–127, Springer, Berlin, Heidelberg; Corpus ID: 6105971. [Google Scholar]
- Harnad, S. The Turing Test Is Not A Trick: Turing Indistinguishability Is A Scientific Criterion. Sigart Bull. 1992, 3, 9–10. [Google Scholar] [CrossRef]
- Harnad, S.; Scherzera, P. First, scale up to the robotic Turing test, then worry about feeling. Artif. Intell. Med. 2008, 44, 83–89. [Google Scholar] [CrossRef] [Green Version]
- Schweizer, P. The Truly Total Turing Test. Minds Mach. 1998, 8, 263–272. [Google Scholar] [CrossRef]
- Gay, L. Educational Research: Competencies for Analysis and Application, 3rd ed.; Merrill Publishing Company: Columbus, OH, USA, 1987; Chapters 2–4; ISBN 13: 978-0675205061. [Google Scholar]
- Palinkas, L.A.; Horwitz, S.M.; Green, C.A.; Wisdom, J.P.; Duan, N.; Hoagwood, K. Purposeful Sampling for Qualitative Data Collection and Analysis in Mixed Method Implementation Research. Adm. Policy Ment. Health Ment. Health Serv. Res. 2015, 42, 533–544. [Google Scholar] [CrossRef] [Green Version]
- Ivaldi, S.; Anzalone, S.; Rousseau, W.; Sigaud, O.; Chetouani, M. Robot initiative in a team learning task increases the rhythm of interaction but not the perceived engagement. Front. Neurorobotics 2014, 8, 5. [Google Scholar] [CrossRef] [Green Version]
- Mavridis, N.; Katsaiti, N.M.; Falasi, A.; Nuaimi, A.; Araifi, H.; Kitbi, A. Opinions and attitudes toward humanoid robots in the Middle East. Ai Soc. 2012, 27, 517–534. [Google Scholar] [CrossRef] [Green Version]
- Ganadas, P.; Henderson, A.; Ji, E. A Research Project in HRI. 2015. Available online: Katrinashaw.com/project/experiment-on-human-robot-deception/ (accessed on 12 March 2019).
- Birmingham, E.; Svärd, J.; Kanan, C.; Fischer, H. Exploring emotional expression recognition in aging adults using the Moving Window Technique. PLoS ONE 2018, 13, e0205341. [Google Scholar] [CrossRef] [PubMed]
- Vaidyam, A.; Torous, J. Chatbots: What Are They and Why Care? 2019. Available online: https://www.psychiatrictimes.com/telepsychiatry/chatbots-what-are-they-and-why-care/page/0/1 (accessed on 11 April 2020).
- Vaidyam, A.N.; Wisniewski, H.; Halamka, J.D.; Kashavan, M.S.; Torous, J.B. Chatbots and Conversational Agents in Mental Health: A Review of the Psychiatric Landscape. J. Psychiatry 2019, 64, 456–464. [Google Scholar] [CrossRef] [PubMed]
- Gardiner, M.; McCue, D.; Negash, L.; Cheng, T.; White, F.; Yinusa-Nyahkoon, S.; Jack, W.; Bickmore, W. Engaging women with an embodied conversational agent to deliver mindfulness and lifestyle recommendations. Patient Educ. Couns. 2017, 100, 1720–1729. [Google Scholar] [CrossRef] [PubMed] [Green Version]


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment | Section 1 | Section 2 | Section 3 | Section 4 |
|---|---|---|---|---|
| Robot | Euclid | Euclid | Baudi | Baudi |
| Task | Timed 5-min spoken conversation with the robot (appearances and hobbies) | The participant plays an animal guessing game (time capped at 5 min) | Timed 5-min spoken conversation with the robot (appearances and hobbies) | The participant plays an animal guessing game (time capped at 5 min) |
| Evaluation | The correct, incorrect, and repeat AI responses are recorded using in Lex | The correct, incorrect, and repeat AI responses are recorded using Lex | The correct, incorrect, and repeat AI responses are recorded in Lex | The correct, incorrect, and repeat AI responses are recorded using Lex |
| Subject Number | Undergrad (UG) Post-Grad (PG) Professional (PRO) | Age, Ethnicity, and Gender | Background | Previous HRI Experience |
|---|---|---|---|---|
| 1 | PG | 22, Male, British | Computational AI | No |
| 2 | UG | 28, Male, British | Robotics and AI | No |
| 3 | UG | 22, Female, British | Computing and Design | No |
| 4 | UG | 20, Male, British | Robotics and AI | No |
| 5 | PRO | 31, Male British | Robotics and AI | Yes |
| 6 | PRO | 45, Male, British | Engineering and Computer Aided Design | No |
| 7 | UG | 29, Female, British | Multimedia | No |
| 8 | PG | 25, Female, British | Game Design & Programming | No |
| 9 | UG | 18, Female, British | Film and Media | No |
| 10 | UG | 20, Male, Asian | Robotics and AI | No |
| 11 | UG | 21, Male, Asian | Robotics and AI | No |
| 12 | PRO | 56, Male, British | Engineering | No |
| 13 | PG | 24, Female, British | Games Programming | No |
| 14 | PRO | 32, Female, British | Film and Media | No |
| 15 | PG | 25, Female British | Game Design & Programming | No |
| 16 | PRO | 55, Male, British | Electronic Engineer | No |
| 17 | PRO | 43, Female, British | Human Factors & Ergonomics | No |
| 18 | PRO | 38, Male, British | Electronics | No |
| 19 | PRO | 32, Female, British | Cognitive Science | No |
| 20 | UG | 25, Male, British | Engineering | No |
| Question 11 | Like | 1 | 2 | 3 | 4 | 5 | Dislike |
| Question 12 | Incompetent | 1 | 2 | 3 | 4 | 5 | Competent |
| Question 13 | Human-like | 1 | 2 | 3 | 4 | 5 | Machine-Like |
| Question 14 | Friendly | 1 | 2 | 3 | 4 | 5 | Unfriendly |
| Question 15 | Fake | 1 | 2 | 3 | 4 | 5 | Natural |
| Question 16 | Responsible | 1 | 2 | 3 | 4 | 5 | Irresponsible |
| Question 17 | Unkind | 1 | 2 | 3 | 4 | 5 | Kind |
| Question 18 | Aware | 1 | 2 | 3 | 4 | 5 | Unaware |
| Question 19 | Moving Naturally | 1 | 2 | 3 | 4 | 5 | Moving Rigidly |
| Question 20 | Pleasant | 1 | 2 | 3 | 4 | 5 | Unpleasant |
| Question 21 | Unintelligent | 1 | 2 | 3 | 4 | 5 | Intelligent |
| Question 22 | Unconscious | 1 | 2 | 3 | 4 | 5 | Conscious |
| Question 23 | Awful | 1 | 2 | 3 | 4 | 5 | Nice |
| Question 24 | Sensible | 1 | 2 | 3 | 4 | 5 | Foolish |
| Question 25 | Artificial | 1 | 2 | 3 | 4 | 5 | Lifelike |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Strathearn, C.; Ma, M. Modelling User Preference for Embodied Artificial Intelligence and Appearance in Realistic Humanoid Robots. Informatics 2020, 7, 28. https://doi.org/10.3390/informatics7030028
Strathearn C, Ma M. Modelling User Preference for Embodied Artificial Intelligence and Appearance in Realistic Humanoid Robots. Informatics. 2020; 7(3):28. https://doi.org/10.3390/informatics7030028
Chicago/Turabian StyleStrathearn, Carl, and Minhua Ma. 2020. "Modelling User Preference for Embodied Artificial Intelligence and Appearance in Realistic Humanoid Robots" Informatics 7, no. 3: 28. https://doi.org/10.3390/informatics7030028
APA StyleStrathearn, C., & Ma, M. (2020). Modelling User Preference for Embodied Artificial Intelligence and Appearance in Realistic Humanoid Robots. Informatics, 7(3), 28. https://doi.org/10.3390/informatics7030028