Automated Configuration of NoSQL Performance and Scalability Tactics for Data-Intensive Applications


Abstract
:1. Introduction
- There is no one-size-fits-all solution to select and configure storage technology for supporting data-intensive applications, because (1) different applications may impose workloads (e.g., in terms of mixing read and write operations, in terms of data aggregation and querying) that are better serviced by a particular type of data storage, (2) the suitability of storage technologies for adaptation may vary, and (3) they come with specific configuration options that are not (and cannot be) represented in standard benchmarks.
- The run-time environment and conditions of a specific data-intensive application may not allow for a statically optimal configuration, for example because of unpredictable deployment settings in a cloud-based deployment, but also because of the dynamics of the application itself, as workloads evolve at run-time. This may jeopardize the effectiveness of performance enhancing tactics (e.g., performance hits of secondary indices for write-heavy workloads).
- Yet dynamic reconfiguration may not pay off: applying a performance tactic at run-time may trigger a temporary overhead and a delay before the tactic becomes effective, and the cost of run-time adaptation may not outweigh the benefit if the window of opportunity is short lived.
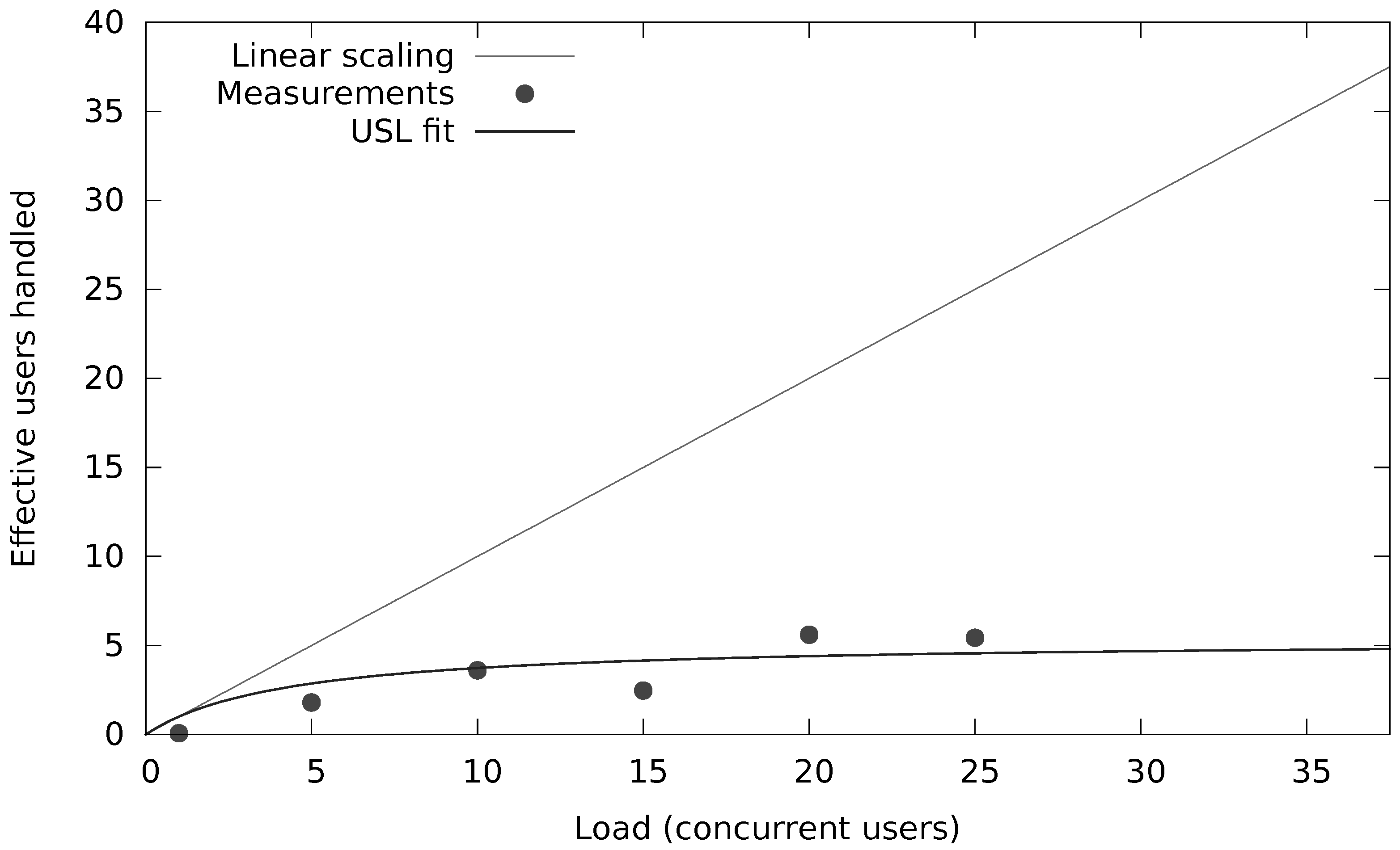
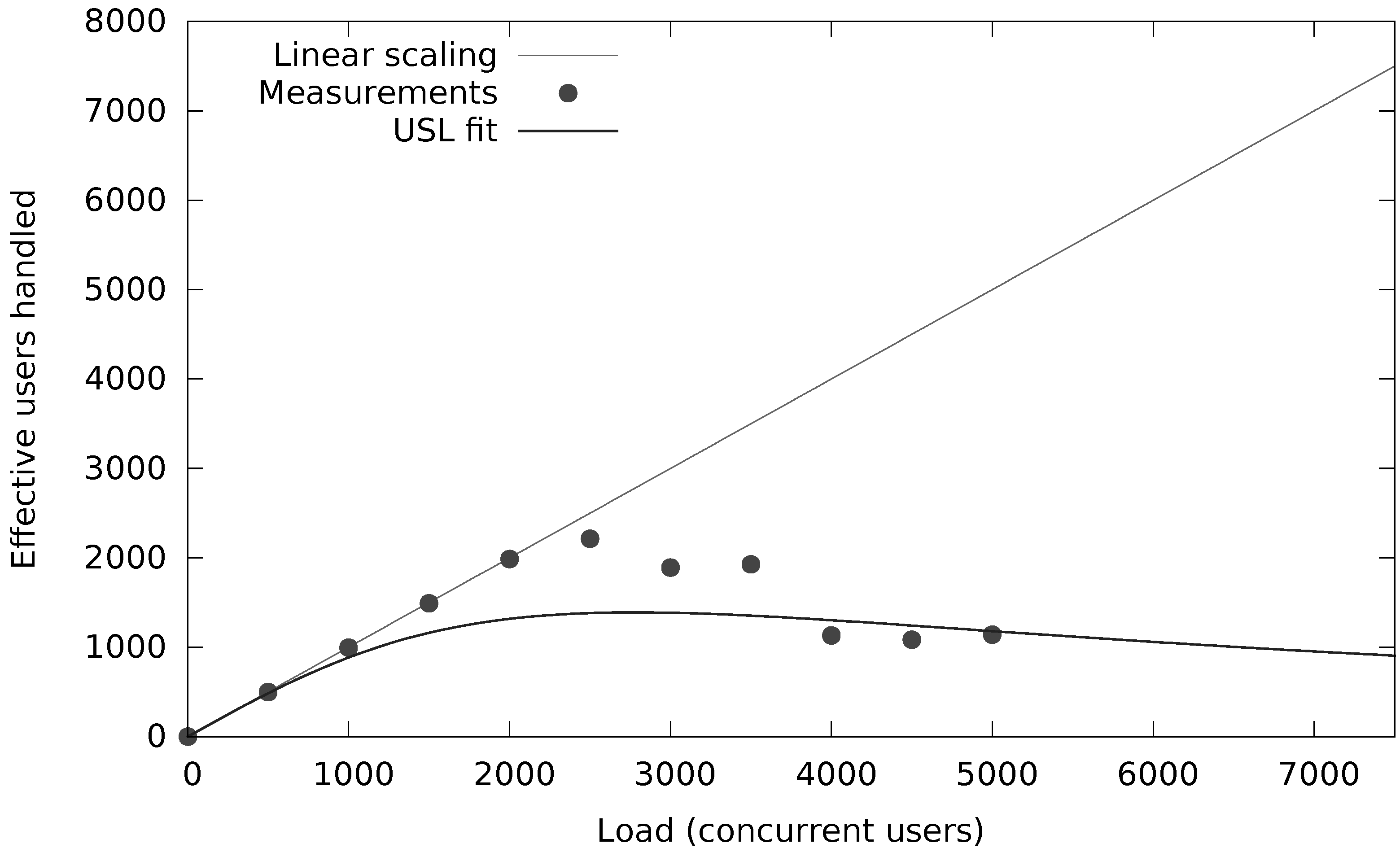
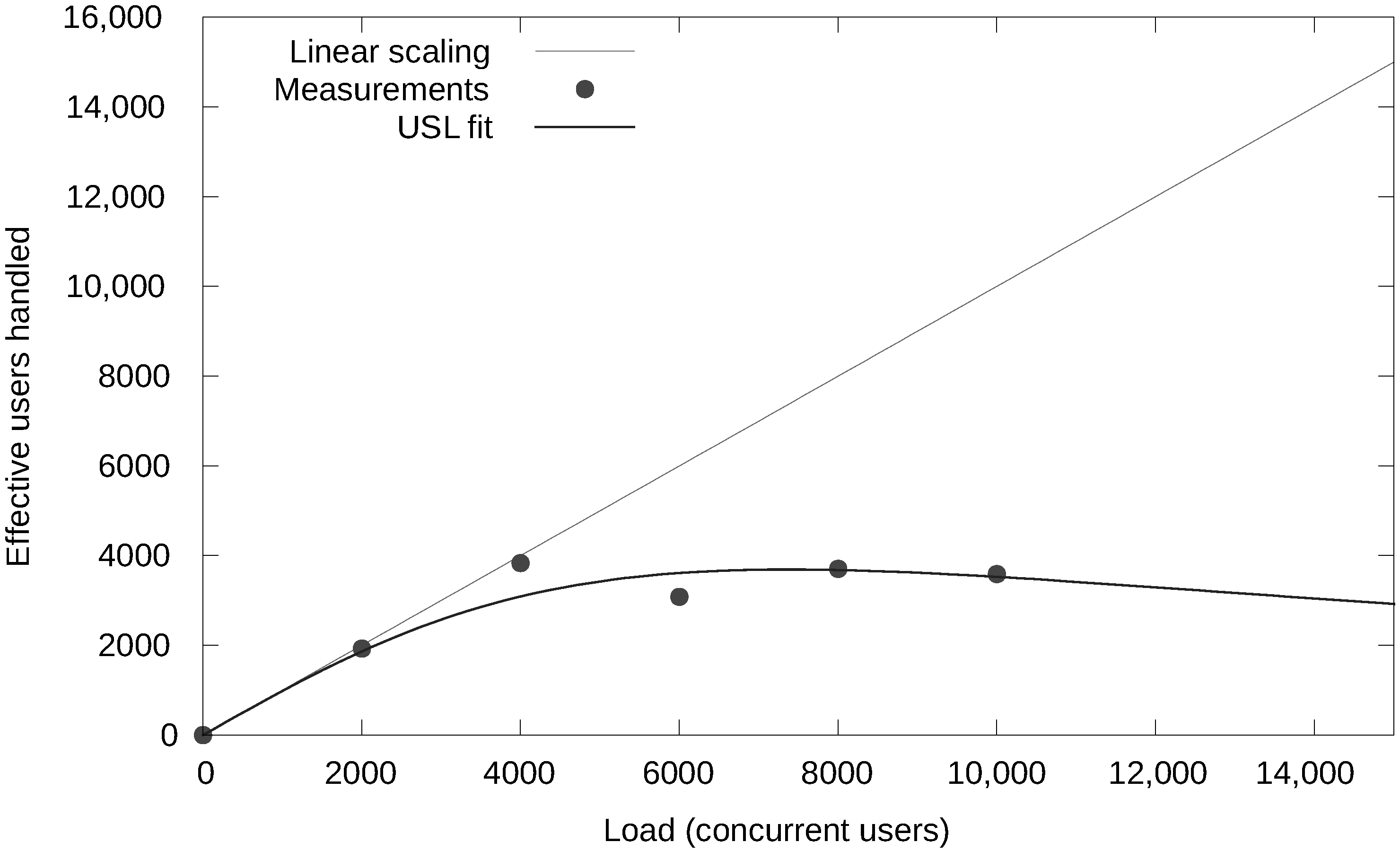
- We have investigated and quantified the impact of different performance and scalability tactics, including vertical and horizontal scaling, sharding, caching, replication, in-memory stores and secondary indices. These benchmarking results and newly collected monitoring information is used to automatically tune at runtime the configuration of NoSQL systems through supervised machine learning on streaming monitoring data with Adaptive Hoeffding Trees.
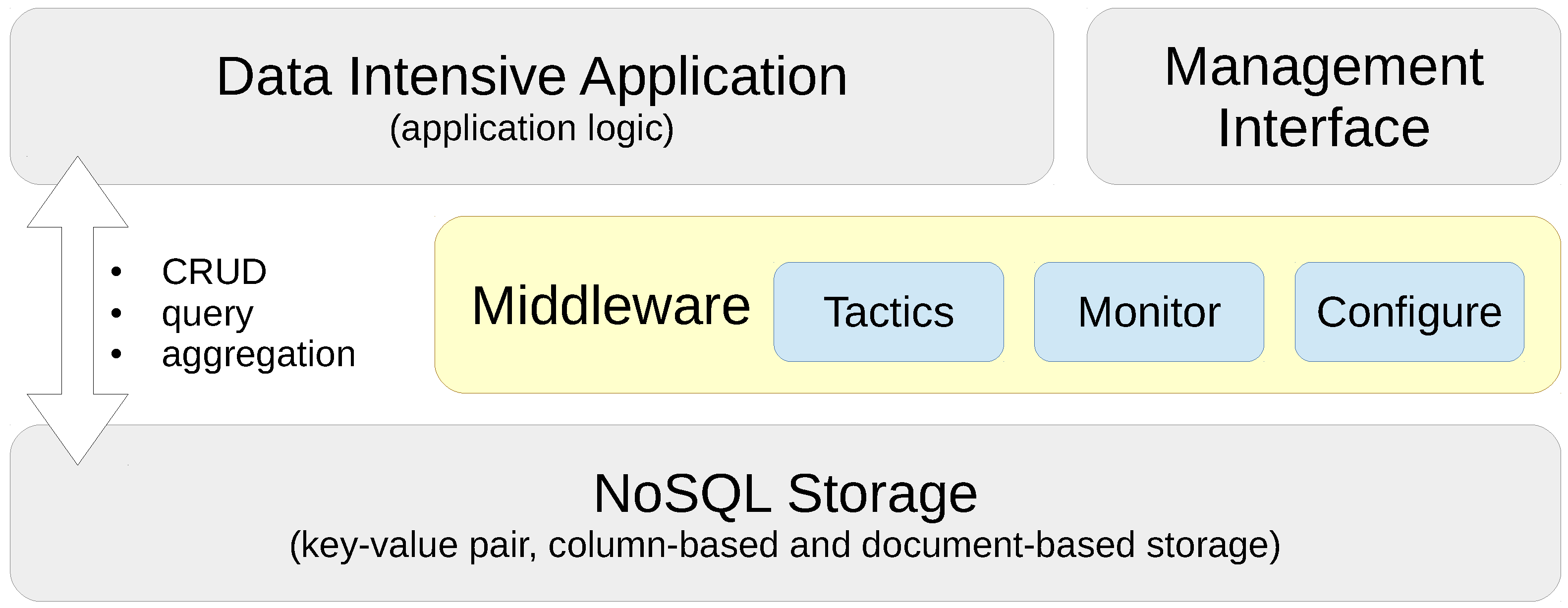
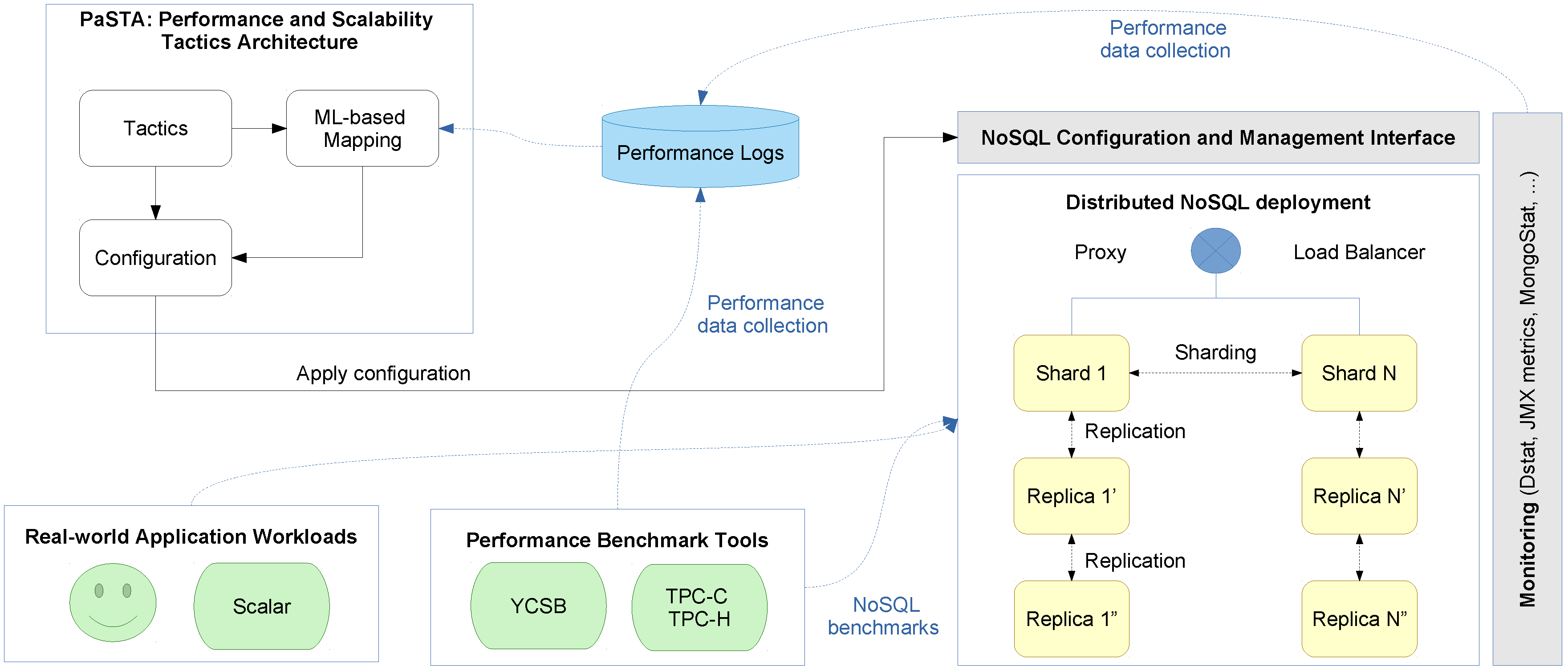
- The impact analysis sketched above is at the basis of a middleware support layer that offers mapping capabilities to associate these high-level tactics, evolving application workloads, and preferences of the architect with the configuration interfaces of a range of underlying NoSQL technologies, with representative platforms for key-value pair, column-based and document-based stores, as depicted in Table 1.
- We have validated and applied our solution in the context of industry-level case studies of data-intensive applications where performance and scalability are key. The acquired insights have been embedded into the design of our PaSTA middleware. The evaluation demonstrates that the machine learning based mapping by our middleware can adapt NoSQL systems to unseen workloads of data-intensive applications.
2. Motivating Use Cases
2.1. Fraud Analytics in Anywhere-Commerce
- Blacklists/whitelists: shipping and billing countries, IP address ranges, credit card PAN numbers, countries derived from IP address and/or card number, and so forth, will affect the risk that is dynamically associated with a particular transaction.
- Velocity rules with sliding windows: In addition, the number of transactions and the cumulative amount spent per customer, the IP address, card/account number and so forth over given period do constitute a second data source for online risk assessment.
- Other thresholds: Additional factors are taken into account, for example the number of credit cards per IP address, and IP addresses per card/account number in absolute values and over a given period.
2.2. Interactive Situational Awareness
3. NoSQL Deployment Environment Overview
3.1. Representative NoSQL Storage Systems
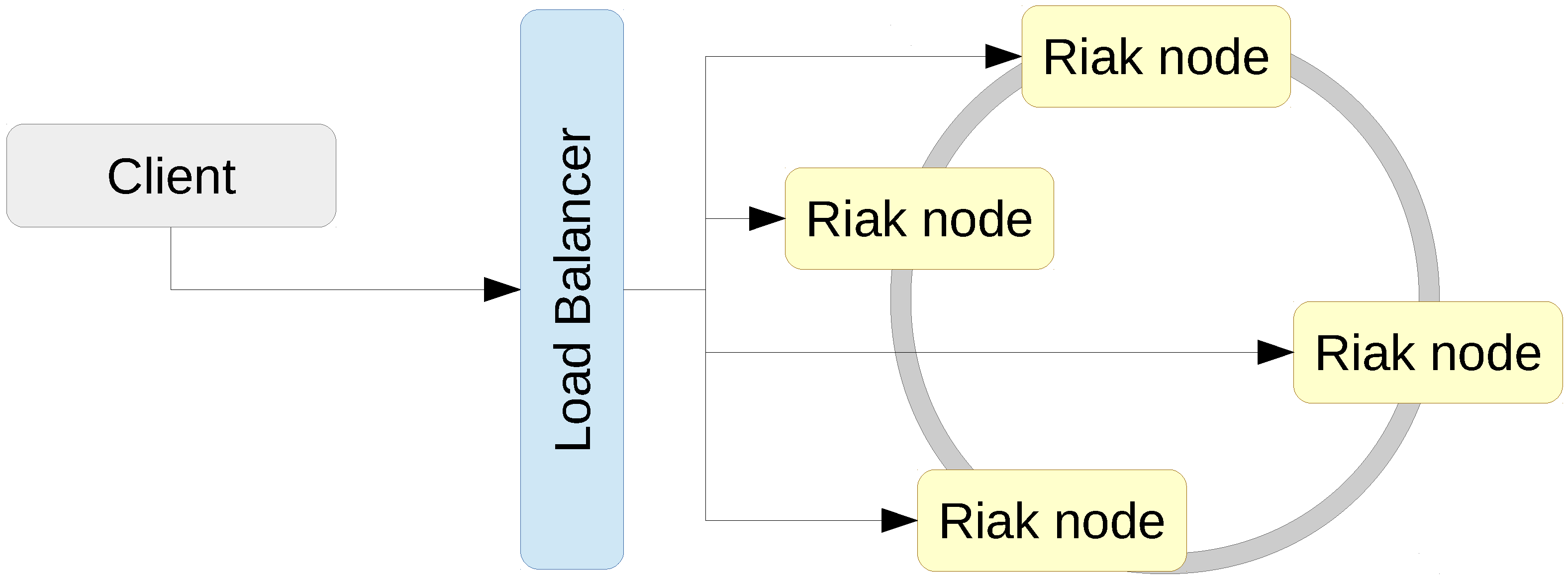
3.1.1. Riak
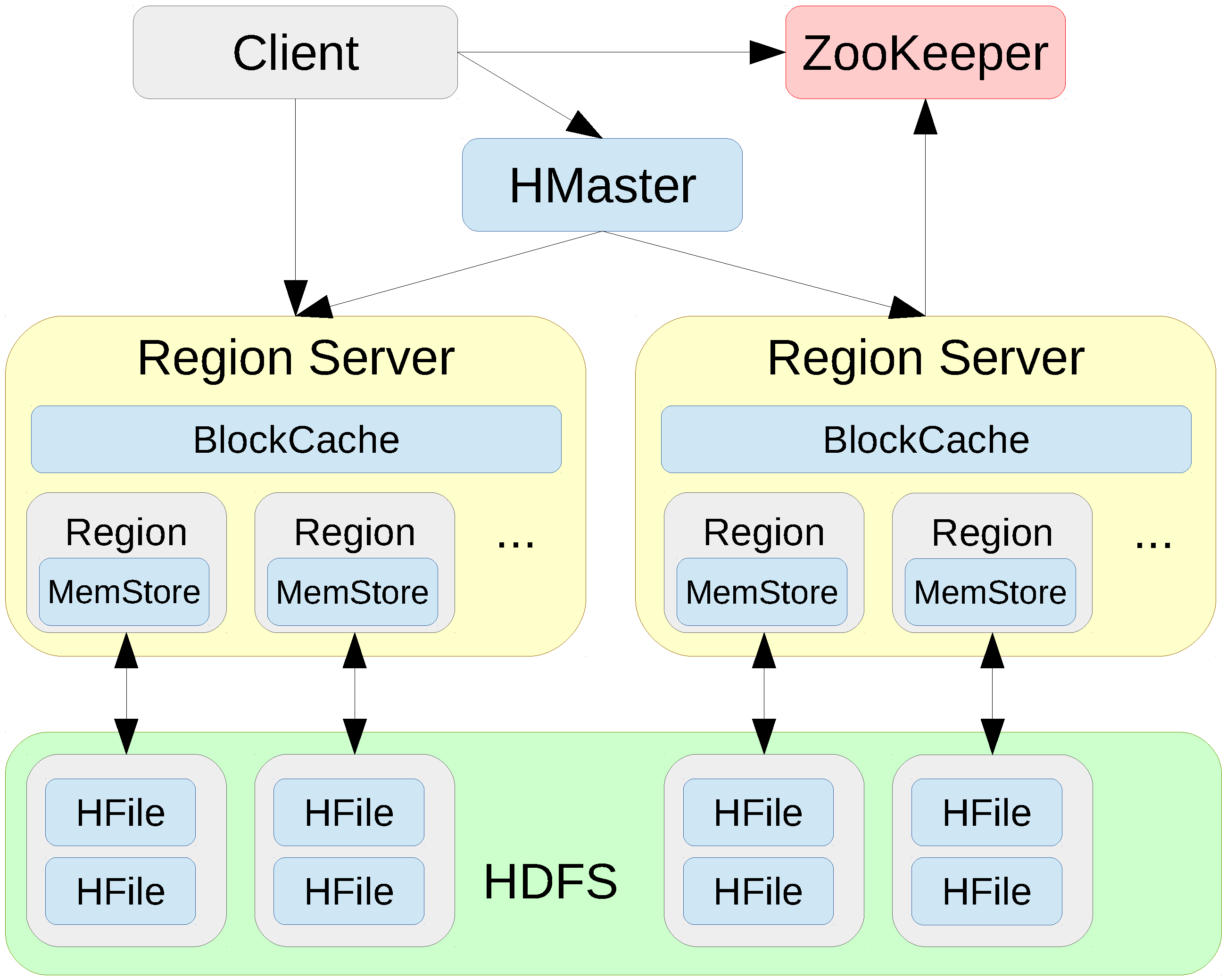
3.1.2. HBase
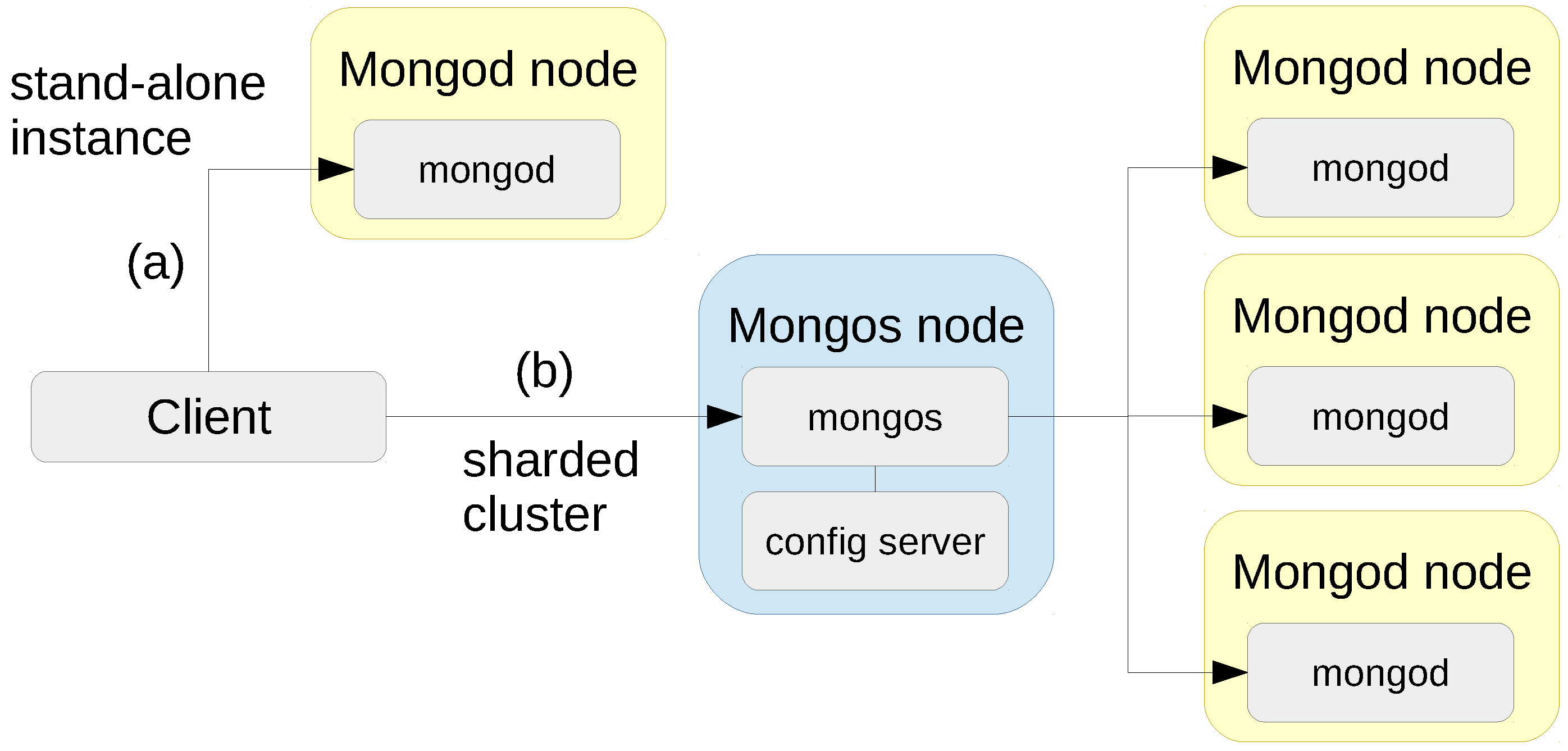
3.1.3. MongoDB
3.2. Distributed Deployment Infrastructures
4. Workload Characterization and System Configuration Mapping
4.1. Data Collection and Feature Extraction
4.1.1. Application Agnostic Performance Benchmarks
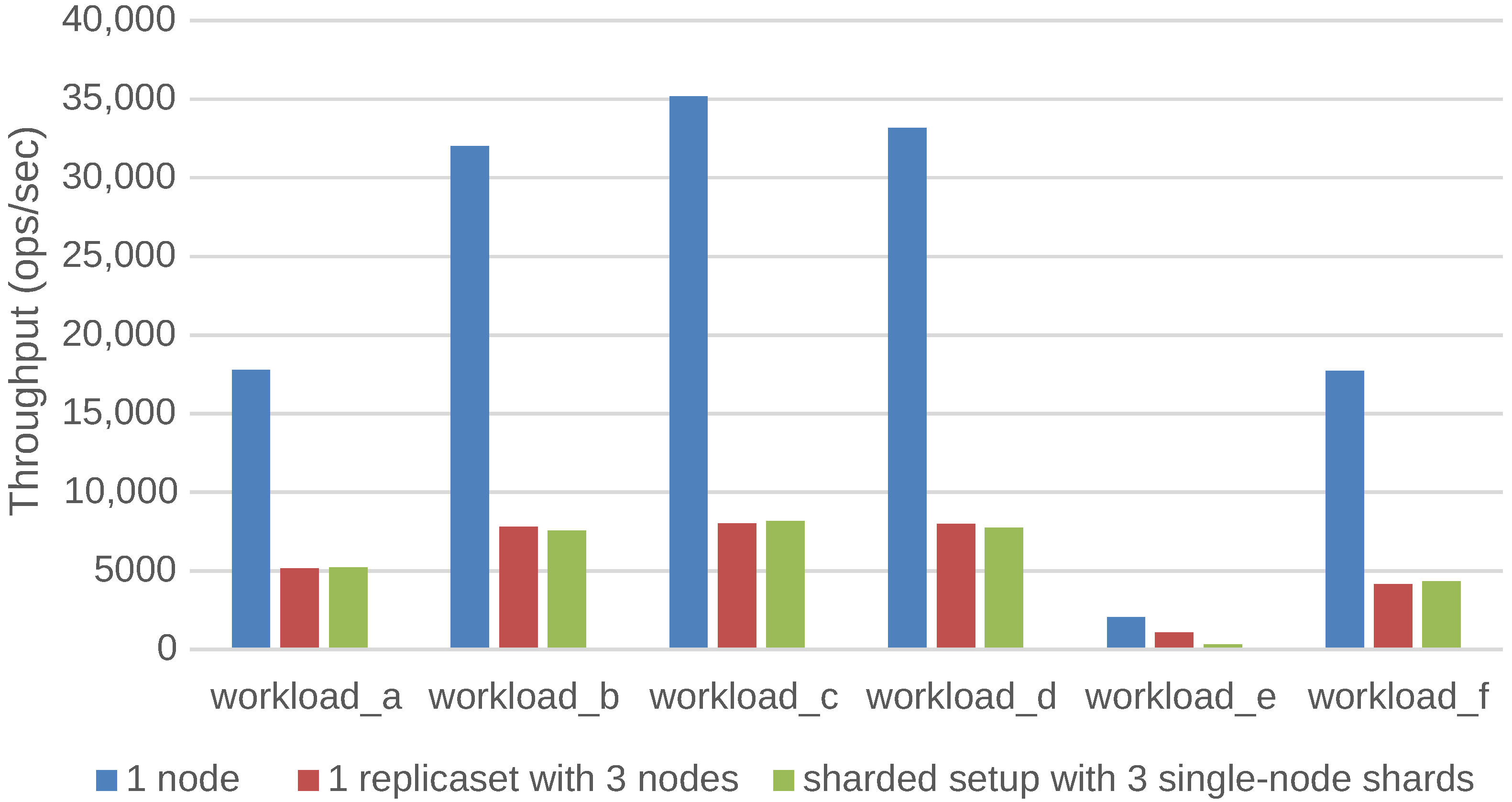
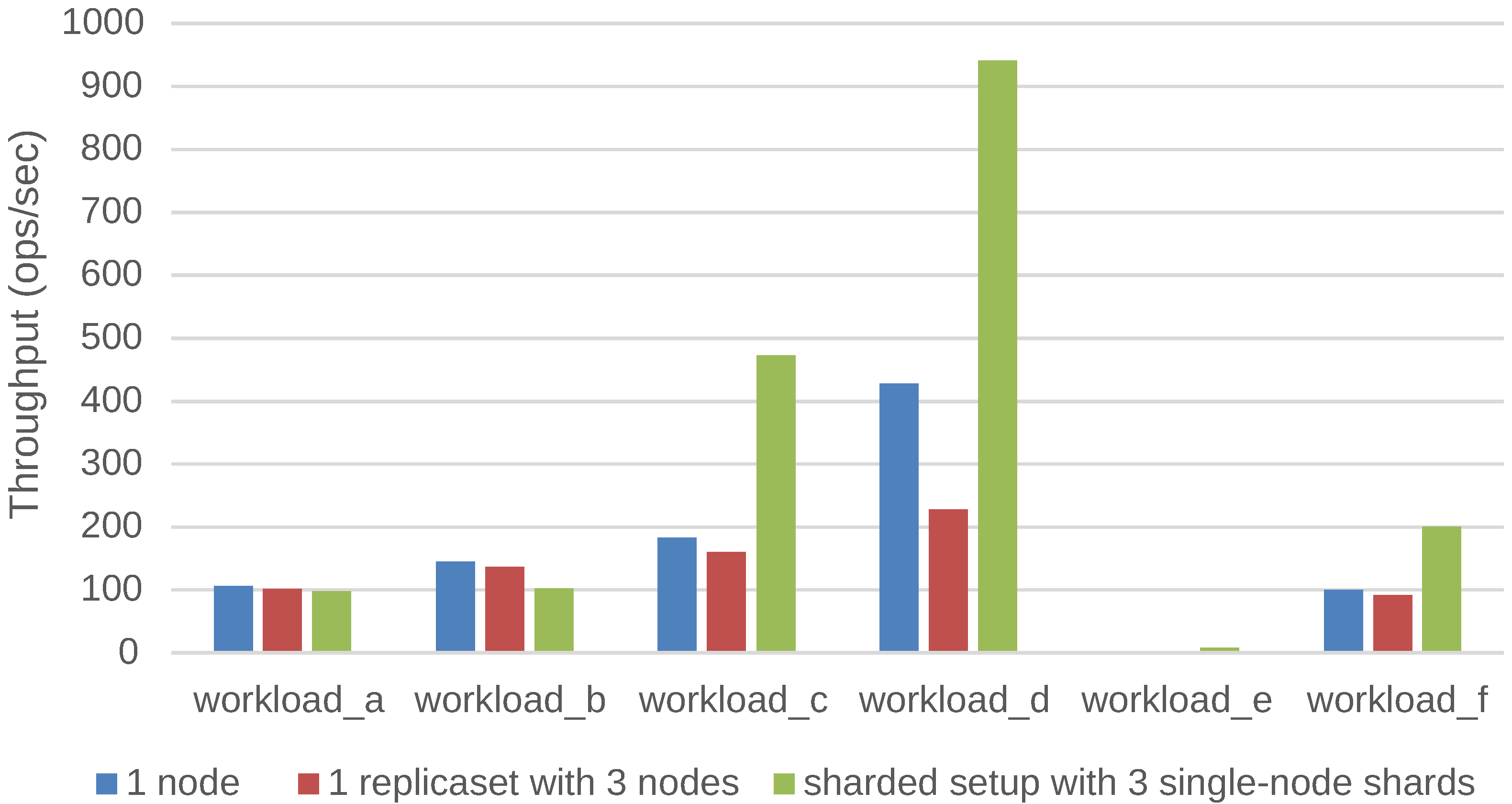
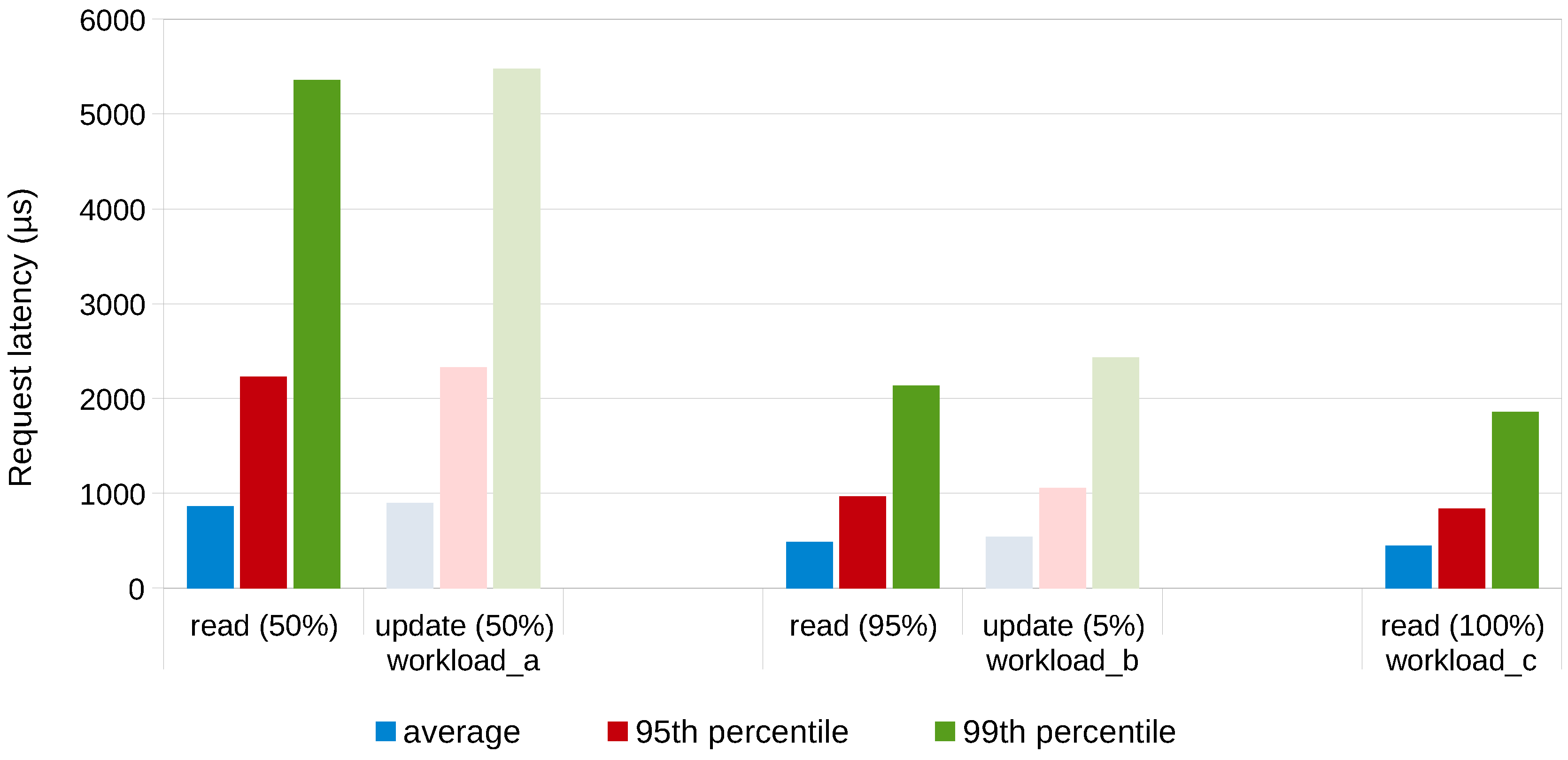
- A:
- 50% read; 50% update; request distribution=zipfian
- B:
- 95% read; 5% update; request distribution=zipfian
- C:
- 100% read; request distribution=zipfian
- D:
- 95% read; 5% insert; request distribution=latest
- E:
- 95% scan (0 to 100 records with uniform probability); 5% insert; request distribution=zipfian
- F:
- 50% read; 50% read-modify-write; request distribution=zipfian
4.1.2. User and Application Specific Workloads
4.1.3. Feature Extraction
- Resource consumption: For each node in the cluster, we collect system metrics about CPU, memory and network usage and this aggregated over different sliding windows (5 s, 30 s and 5 min).
- Data transactions: Amount of read, scan, write, update and query operations, their duration, size of data processed, again aggregated over the same time intervals.
- Storage system configuration and transition: We continuously maintain two sets of attributes (describing the performance and scalability tactics), the first one representing the current configuration, and the second list representing the intended system state. This way we keep track of configuration transitions.
- Key performance indicators: These numeric attributes indicate to what extent the application specific SLAs have been met (or violated).
- Status information: Amount of users and data in the NoSQL system, and whether the current system configuration is stable or changing (including the ongoing duration of the change in seconds).
4.2. Machine Learning Based Configuration Mapping
5. The PaSTA Middleware Implementation
5.1. Bootstrapping the Adaptive Hoeffding Tree Machine Learning Model with Application Agnostic Workloads
- When moving a stand-alone MongoDB server from an OptiPlex desktop machine (throughput = 35,198 ops/s) to a PowerEdge server (throughput = 39,478), the performance does barely increase. The same holds for the average latency.
- For HBase and Riak, on the other hand, performance increases a lot when moving to the PowerEdge server. HBase, for example, achieves 3325 operations per second on an OptiPlex machine, while it achieves a throughput of 19,233 operations per second on a PowerEdge server. This observation indicates that MongoDB is probably reaching a network boundary, which prevents it from further increasing its throughput.
5.2. Dynamic Reconfiguration for Real World Application-Specific Workloads
- Memory and caching are key, that is, a faster machine does not necessarily increase the throughput.
- A less complex data model does not necessarily lead to better performance.
- Sharding is not useful if the data fits in the cache of a stand-alone system.
- A virtualized environment leads to more latency jitter for write operations that require disk access.
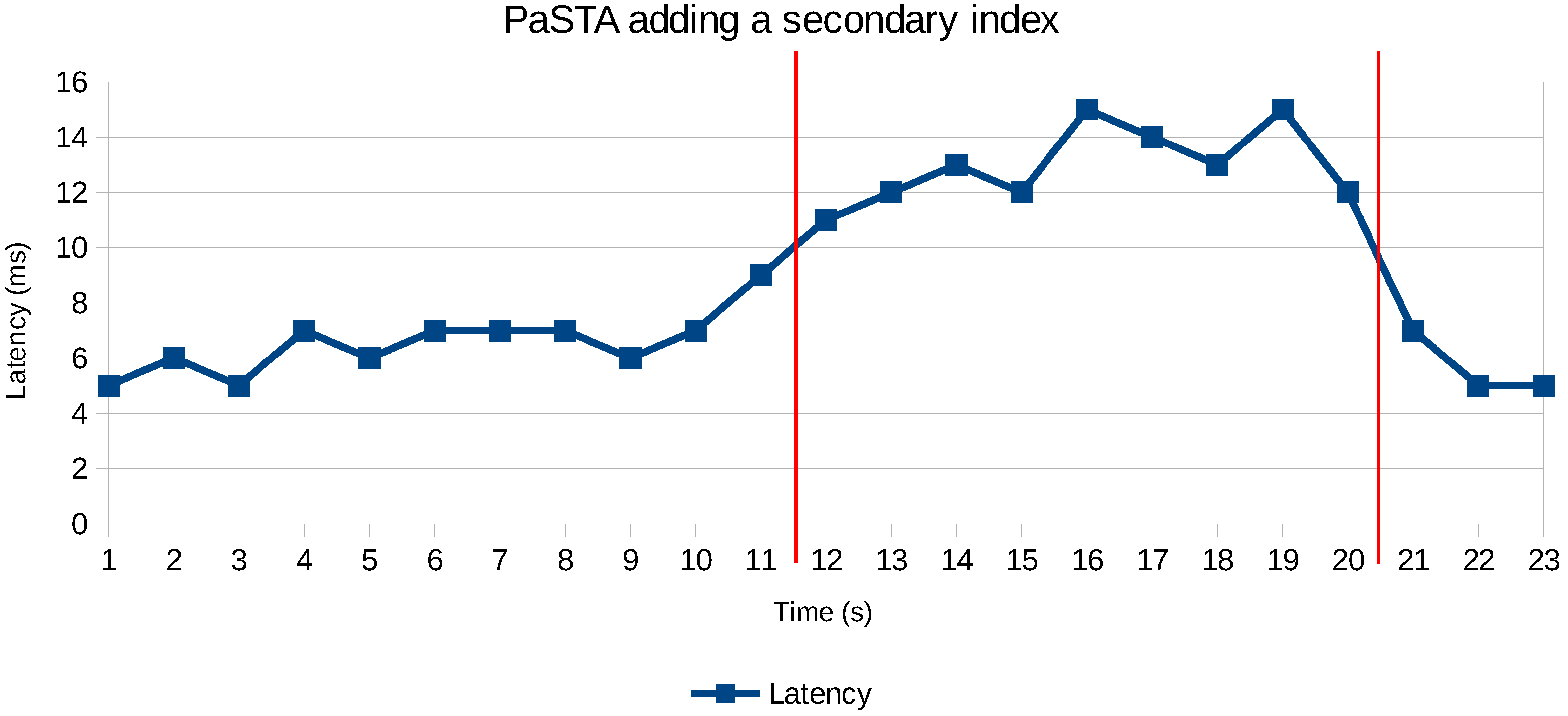
- Secondary index: Add a secondary index for frequently read attributes. The index computation takes time. The index will consume additional memory and will slow down write operations to maintain the secondary index.
- Secondary index: Remove unused secondary indices. The impact is mainly noticeable for write-heavy workloads, but to some extent also for read operations that can benefit from the recovered memory that is now available for caching.
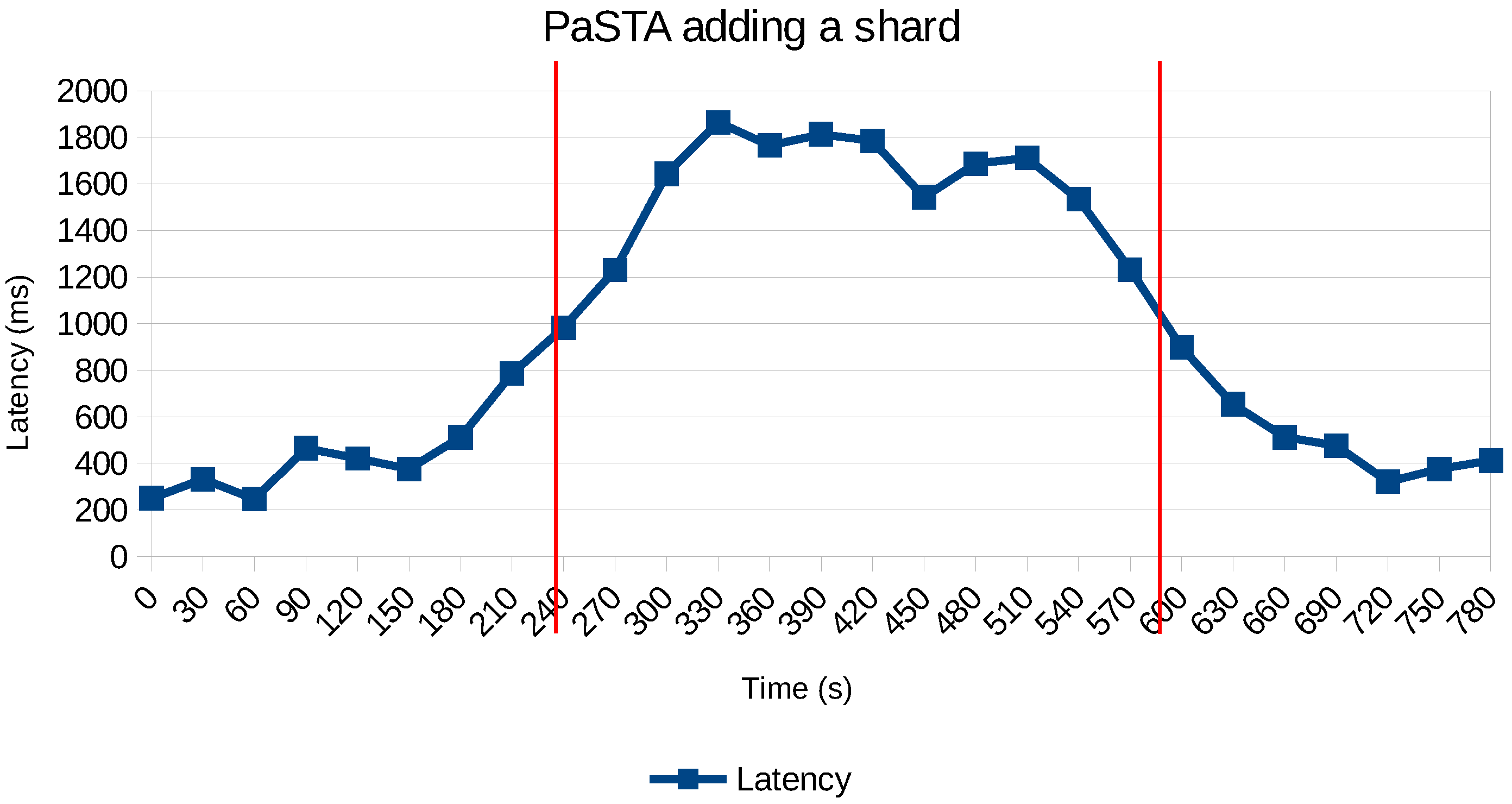
- Sharding: Add a shard to share to keep more data in memory. Spawning a new virtual machine takes 10 s, and reshuffling the data to the new shard has an impact on the internal network of the cluster.
- Replication: Add a node to a replica set to distribute the processing workload over more compute nodes. This tactic is mainly beneficial for read-heavy workloads with little overhead to guarantee data consistency across nodes.
- In-memory storage engine: Increase the request throughput by replicating the data to a node with more processing power or more memory for caching the data and secondary indices. Replicate to an in-memory node to reduce the latency variability.
6. Evaluation with Application-Specific Workloads
6.1. Fraud Analytics
6.2. Situational Awareness
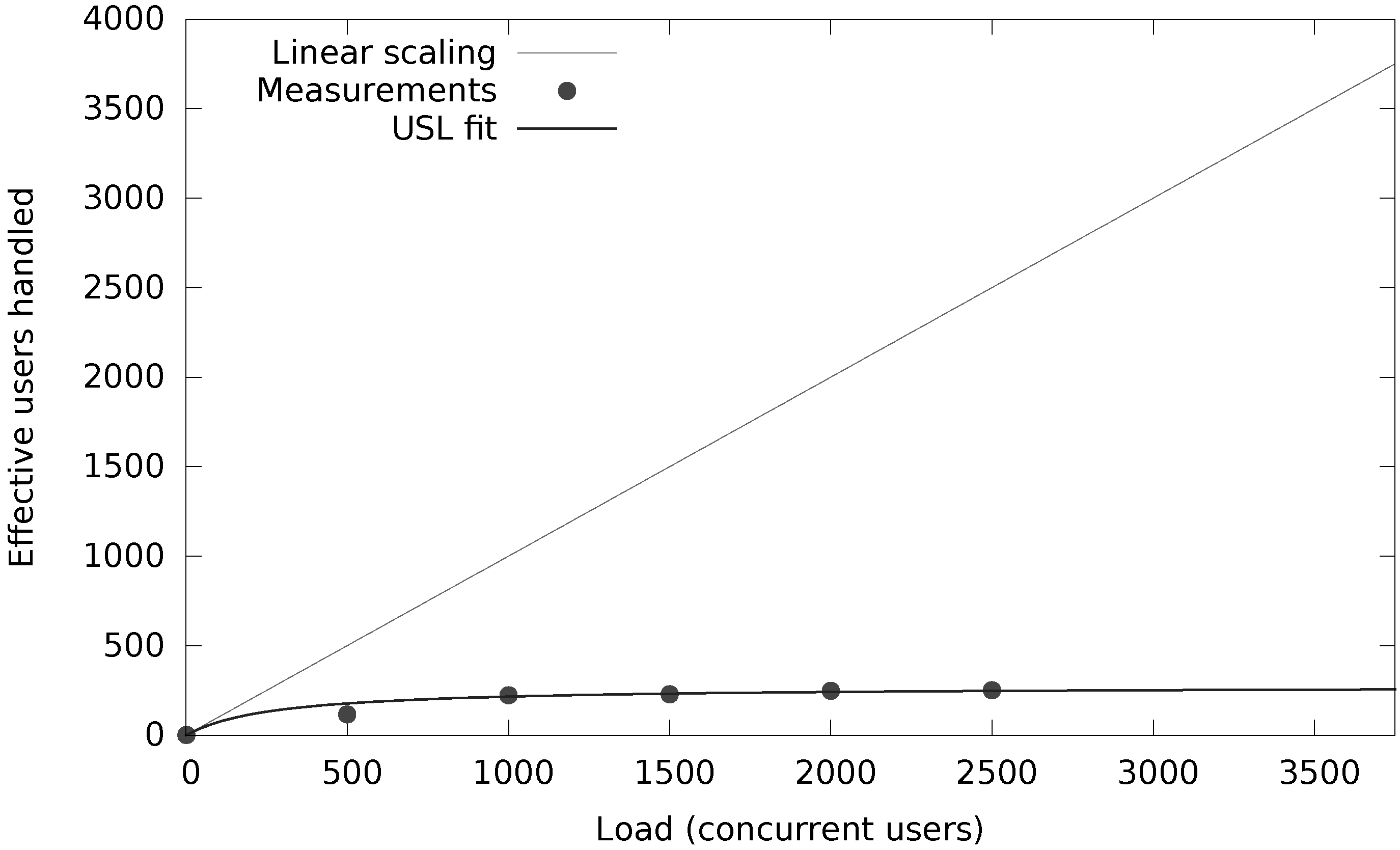
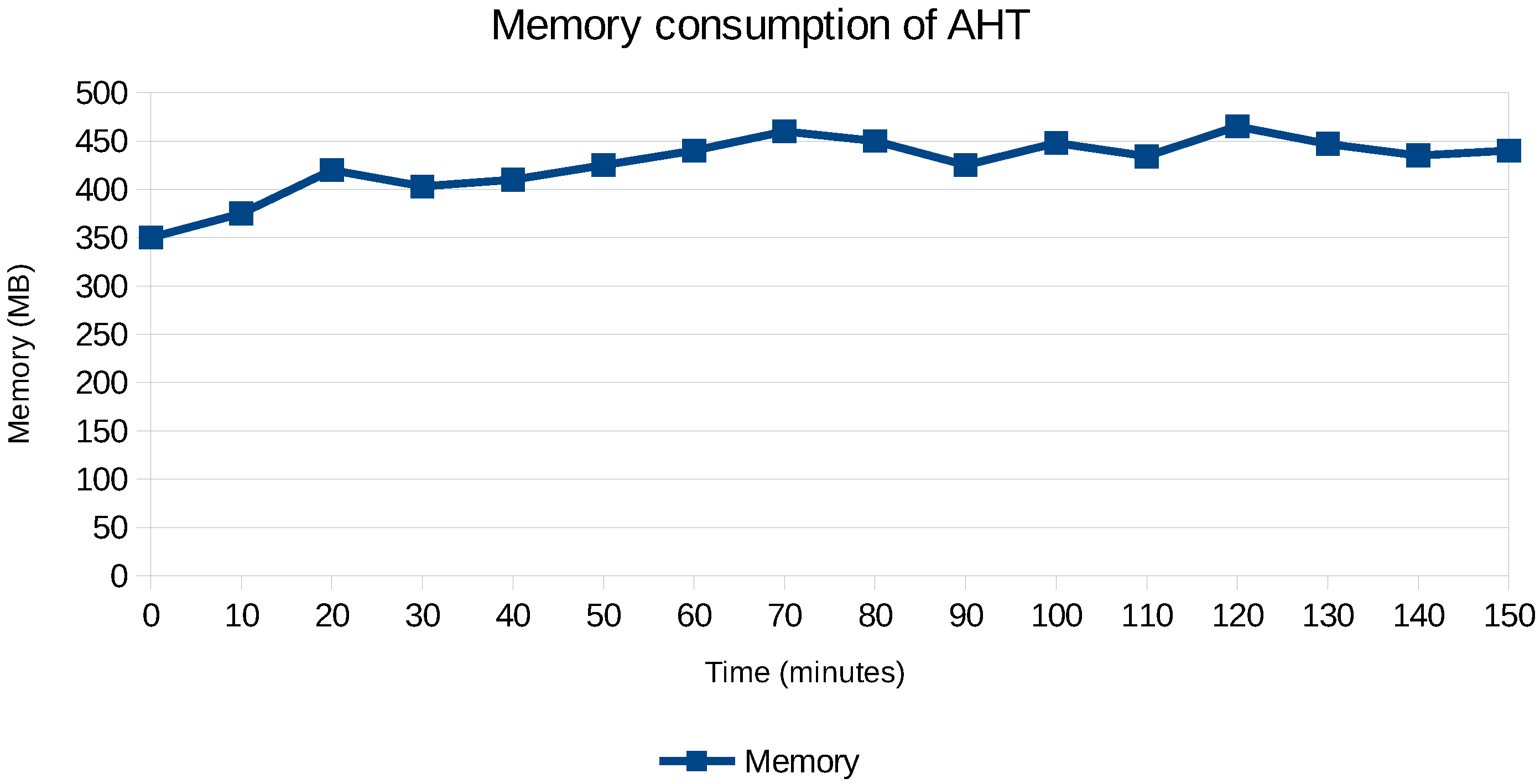
6.3. Performance Impact of Adaptive Hoeffding Trees
6.4. Adaptation to Evolving Workloads
7. Related Work
7.1. Static Workload-Based Optimization
7.2. Autonomic Computing
7.3. Dynamic Workload-Based Optimization
7.3.1. Sharding and Replication
7.3.2. Eventual Consistency
7.3.3. Index Creation
7.4. Threats to Validity
7.5. Summary
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Klein, J.; Gorton, I.; Ernst, N.; Donohoe, P.; Pham, K.; Matser, C. Performance Evaluation of NoSQL Databases: A Case Study. In Proceedings of the 1st Workshop on Performance Analysis of Big Data Systems, Austin, TX, USA, 1 February 2015; pp. 5–10. [Google Scholar] [CrossRef]
- Mozaffari, M.; Nazemi, E.; Eftekhari-Moghadam, A.M. Feedback control loop design for workload change detection in self-tuning NoSQL wide column stores. Expert Syst. Appl. 2020, 142, 112973. [Google Scholar] [CrossRef]
- Hillenbrand, A.; Störl, U.; Levchenko, M.; Nabiyev, S.; Klettke, M. Towards Self-Adapting Data Migration in the Context of Schema Evolution in NoSQL Databases. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering Workshops (ICDEW), Dallas, TX, USA, 20–24 April 2020; pp. 133–138. [Google Scholar]
- Cooper, B.F.; Silberstein, A.; Tam, E.; Ramakrishnan, R.; Sears, R. Benchmarking Cloud Serving Systems with YCSB. In Proceedings of the 1st ACM Symposium on Cloud Computing, Indianapolis, IN, USA, 10–11 June 2010; pp. 143–154. [Google Scholar] [CrossRef]
- Haklay, M.M.; Weber, P. OpenStreetMap: User-Generated Street Maps. IEEE Pervasive Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef] [Green Version]
- Fox, A.; Eichelberger, C.; Hughes, J.; Lyon, S. Spatio-temporal indexing in non-relational distributed databases. In Proceedings of the 2013 IEEE International Conference on Big Data, Santa Clara, CA, USA, 6–9 October 2013; pp. 291–299. [Google Scholar] [CrossRef]
- DeCandia, G.; Hastorun, D.; Jampani, M.; Kakulapati, G.; Lakshman, A.; Pilchin, A.; Sivasubramanian, S.; Vosshall, P.; Vogels, W. Dynamo: Amazon’s Highly Available Key-value Store. In Proceedings of the Twenty-first ACM SIGOPS Symposium on Operating Systems Principles, Stevenson, WA, USA, 14–17 October 2007; pp. 205–220. [Google Scholar] [CrossRef]
- Preuveneers, D.; Heyman, T.; Berbers, Y.; Joosen, W. Systematic scalability assessment for feature oriented multi-tenant services. J. Syst. Softw. 2016, 116, 162–176. [Google Scholar] [CrossRef] [Green Version]
- Bifet, A.; Gavaldà, R. Adaptive Learning from Evolving Data Streams. In Proceedings of the 8th International Symposium on Intelligent Data Analysis: Advances in Intelligent Data Analysis VIII, Lyon, France, 31 August–2 September 2009; pp. 249–260. [Google Scholar] [CrossRef]
- Bifet, A.; Holmes, G.; Kirkby, R.; Pfahringer, B. MOA: Massive Online Analysis. J. Mach. Learn. Res. 2010, 11, 1601–1604. [Google Scholar]
- Hulten, G.; Spencer, L.; Domingos, P. Mining time-changing data streams. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001; pp. 97–106. [Google Scholar]
- Marschall, M. Chef Infrastructure Automation Cookbook; Packt Publishing: Birmingham, UK, 2013. [Google Scholar]
- Gunther, N.J. Guerrilla Capacity Planning—A Tactical Approach to Planning for Highly Scalable Applications and Services; Springer: Cham, Switzerland, 2007. [Google Scholar] [CrossRef]
- Khattab, A.; Algergawy, A.; Sarhan, A. MAG: A performance evaluation framework for database systems. Knowl.-Based Syst. 2015, 85, 245–255. [Google Scholar] [CrossRef]
- Gencer, A.E.; Bindel, D.; Sirer, E.G.; van Renesse, R. Configuring Distributed Computations Using Response Surfaces. In Proceedings of the 16th Annual Middleware Conference, Vancouver, BC, Canada, 7–11 December 2015; pp. 235–246. [Google Scholar] [CrossRef] [Green Version]
- Herodotou, H.; Lim, H.; Luo, G.; Borisov, N.; Dong, L.; Cetin, F.B.; Babu, S. Starfish: A Self-tuning System for Big Data Analytics. CIDR. Available online: https://www-db.cs.wisc.edu/cidr/cidr2011/Papers/CIDR11_Paper36.pdf (accessed on 3 August 2020).
- Koehler, J.; Koehler, J.; Giblin, C.; Giblin, C.; Gantenbein, D.; Gantenbein, D.; Hauser, R.; Hauser, R. On Autonomic Computing Architectures. In Research Report (Computer Science) RZ 3487(#99302); IBM Research: Zurich, Switzerland, 2003. [Google Scholar]
- Huebscher, M.C.; McCann, J.A. A survey of autonomic computing-degrees, models, and applications. ACM Comput. Surv. 2008, 40, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Tesauro, G.; Kephart, J.O. Utility Functions in Autonomic Systems. In Proceedings of the First International Conference on Autonomic Computing, Washington, DC, USA, 17–18 May 2004; pp. 70–77. [Google Scholar]
- Deb, D.; Fuad, M.M.; Oudshoorn, M.J. Achieving self-managed deployment in a distributed environment. J. Comp. Methods Sci. Eng. 2011, 11, 115–125. [Google Scholar] [CrossRef] [Green Version]
- Hu, Y.; Wong, J.; Iszlai, G.; Litoiu, M. Resource provisioning for cloud computing. In Proceedings of the 2009 Conference of the Center for Advanced Studies on Collaborative Research, Toronto, ON, Canada, 2–5 November 2009; pp. 101–111. [Google Scholar] [CrossRef] [Green Version]
- Koehler, M.; Benkner, S. Design of an Adaptive Framework for Utility-Based Optimization of Scientific Applications in the Cloud. In Proceedings of the 2012 IEEE/ACM Fifth International Conference on Utility and Cloud Computing, Chicago, IL, USA, 5–8 November 2012; pp. 303–308. [Google Scholar] [CrossRef]
- Esteves, S.; Silva, J.a.N.; Carvalho, J.a.P.; Veiga, L. Incremental Dataflow Execution, Resource Efficiency and Probabilistic Guarantees with Fuzzy Boolean Nets. J. Parallel Distrib. Comput. 2015, 79, 52–66. [Google Scholar] [CrossRef]
- Van Aken, D.; Pavlo, A.; Gordon, G.J.; Zhang, B. Automatic Database Management System Tuning Through Large-scale Machine Learning. In Proceedings of the 2017 ACM International Conference on Management of Data, Chicago, IL, USA, 14–19 May 2017; pp. 1009–1024. [Google Scholar] [CrossRef] [Green Version]
- Cruz, F.; Maia, F.; Matos, M.; Oliveira, R.; Paulo, J.; Pereira, J.; Vilaça, R. Met: Workload aware elasticity for nosql. In Proceedings of the 8th ACM European Conference on Computer Systems, Prague, Czech Republic, 15 April 2013; pp. 183–196. [Google Scholar]
- Curino, C.; Jones, E.; Zhang, Y.; Madden, S. Schism: A Workload-driven Approach to Database Replication and Partitioning. Proc. VLDB Endow. 2010, 3, 48–57. [Google Scholar] [CrossRef]
- Couceiro, M.; Chandrasekara, G.; Bravo, M.; Hiltunen, M.; Romano, P.; Rodrigues, L. Q-OPT: Self-tuning Quorum System for Strongly Consistent Software Defined Storage. In Proceedings of the 16th Annual Middleware Conference, Vancouver, BC, Canada, 7–11 December 2015; pp. 88–99. [Google Scholar]
- McKenzie, M.; Fan, H.; Golab, W. Continuous Partial Quorums for Consistency-Latency Tuning in Distributed NoSQL Storage Systems. arXiv 2015, arXiv:1507.03162. [Google Scholar]
- Voigt, H.; Kissinger, T.; Lehner, W. Smix: Self-managing indexes for dynamic workloads. In Proceedings of the 25th International Conference on Scientific and Statistical Database Management, Baltimore, MD, USA, 29–31 July 2013; p. 24. [Google Scholar]
- Kotthoff, L.; Thornton, C.; Hoos, H.H.; Hutter, F.; Leyton-Brown, K. Auto-WEKA: Automatic Model Selection and Hyperparameter Optimization in WEKA. In Automated Machine Learning: Methods, Systems, Challenges; Hutter, F., Kotthoff, L., Vanschoren, J., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 81–95. [Google Scholar]
- Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.T.; Blum, M.; Hutter, F. Auto-sklearn: Efficient and Robust Automated Machine Learning. In Automated Machine Learning: Methods, Systems, Challenges; Hutter, F., Kotthoff, L., Vanschoren, J., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 113–134. [Google Scholar]
- Brewer, E. CAP Twelve Years Later: How the “Rules” Have Changed. Computer 2012, 45, 23–29. [Google Scholar] [CrossRef]
- Jamshidi, P.; Velez, M.; Kästner, C.; Siegmund, N.; Kawthekar, P. Transfer Learning for Improving Model Predictions in Highly Configurable Software. In Proceedings of the 12th International Symposium on Software Engineering for Adaptive and Self-Managing Systems; IEEE Press: Piscataway, NJ, USA, 2017; pp. 31–41. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MongoDB | Cassandra | CouchDB | Elasticsearch | Riak | HBase | Redis | |
|---|---|---|---|---|---|---|---|
| Storage Type | Doc | Col | Doc | Doc | Key-Val | Col | Key-Val |
| Sharding | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Replication | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Secondary index | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ |
| In-memory mode | ✓ | ✓ | ✗ | ✗ | ✓ | ✗ | ✓ |
| Cache tuning | ✓ | ✓ | ✗ | ✓ | ✗ | ✓ | ? |
| Quorums | ✓ | ✓ | ✗ | ✓ | ✓ | ✗ | ✗ |
| Compression | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ? |
| Dell PowerEdge R620 (Server) | Dell OptiPlex 755 (Desktop) | OpenStack (vm) | |
|---|---|---|---|
| Deployment | Native | Native | Virtual machine |
| OS | Ubuntu 16.04 (64-bit) | Ubuntu 16.04 (64-bit) | Ubuntu 16.04 (64-bit) |
| CPU | 2 × Intel Xeon E5-2650 (8 cores) at 2 GHz | Intel Core 2 Duo E6850 (2 cores) at 3 GHz | 2 × vCPU |
| Memory | 64 GB | 4 GB | 4 GB |
| Hard drive | 2 × 900 GB SAS 6 Gbps 10 K RPM | 250 GB Seagate Barracuda 7200.10 ATA | virtual |
| Network | 1 Gigabit | 1 Gigabit | 3 × 1 Gigabit |
| OptiPlex Desktop | |||
|---|---|---|---|
| MongoDB | HBase | Riak | |
| Overall throughput | 35,198 ops/s | 3325 ops/s | 2505 ops/s |
| Average Latency | 445 s | 4747 s | 3174 s |
| Min Latency | 118 s | 211 s | 480 s |
| Max Latency | 103,615 s | 914,431 s | 164,223 s |
| 95th Percentile Latency | 837 s | 8631 s | 4359 s |
| 99th Percentile Latency | 1859 s | 73,407 s | 26,271 s |
| PowerEdge Server | |||
| MongoDB | HBase | Riak | |
| Overall throughput | 39,478 ops/s | 19,233 ops/s | 12,466 ops/s |
| Average Latency | 390 s | 772 s | 1253 s |
| Min Latency | 236 s | 330 s | 783 s |
| Max Latency | 127,679 s | 255,103 s | 173,439 s |
| 95th Percentile Latency | 638 s | 1041 s | 2171 s |
| 99th Percentile Latency | 1032 s | 1699 s | 3039 s |
| Percentile Latency | WiredTiger | InMemory |
|---|---|---|
| 50th Percentile | 547 s | 472 s |
| 90th Percentile | 877 s | 614 s |
| 95th Percentile | 1082 s | 711 s |
| 99th Percentile | 1693 s | 1002 s |
| 99.9th Percentile | 3273 s | 1778 s |
| 99.99th Percentile | 42,071 s | 38,932 s |
| Latency | No Index | Secondary Index |
|---|---|---|
| 50.0th Percentile | 2667 ms | 4.778 ms |
| 99.9th Percentile | 26,539 ms | 13.642 ms |
| Latency | 35 GB Data | 70 GB Data |
|---|---|---|
| 50.0th Percentile | 55.5 ms | 432 ms |
| 90.0th Percentile | 303 ms | 9932 ms |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Preuveneers, D.; Joosen, W. Automated Configuration of NoSQL Performance and Scalability Tactics for Data-Intensive Applications. Informatics 2020, 7, 29. https://doi.org/10.3390/informatics7030029
Preuveneers D, Joosen W. Automated Configuration of NoSQL Performance and Scalability Tactics for Data-Intensive Applications. Informatics. 2020; 7(3):29. https://doi.org/10.3390/informatics7030029
Chicago/Turabian StylePreuveneers, Davy, and Wouter Joosen. 2020. "Automated Configuration of NoSQL Performance and Scalability Tactics for Data-Intensive Applications" Informatics 7, no. 3: 29. https://doi.org/10.3390/informatics7030029
APA StylePreuveneers, D., & Joosen, W. (2020). Automated Configuration of NoSQL Performance and Scalability Tactics for Data-Intensive Applications. Informatics, 7(3), 29. https://doi.org/10.3390/informatics7030029