Windows PE Malware Detection Using Ensemble Learning

 , ,
, ,
Abstract
:1. Introduction
- (1).
- A hybrid ensemble learning framework consisting of fully connected and convolutional neural networks (CNNs) with the ExtraTrees classifier as a meta-learner for malware recognition.
- (2).
- A comprehensive study of the performance of classifiers for selecting the components of the framework.
2. Related Works
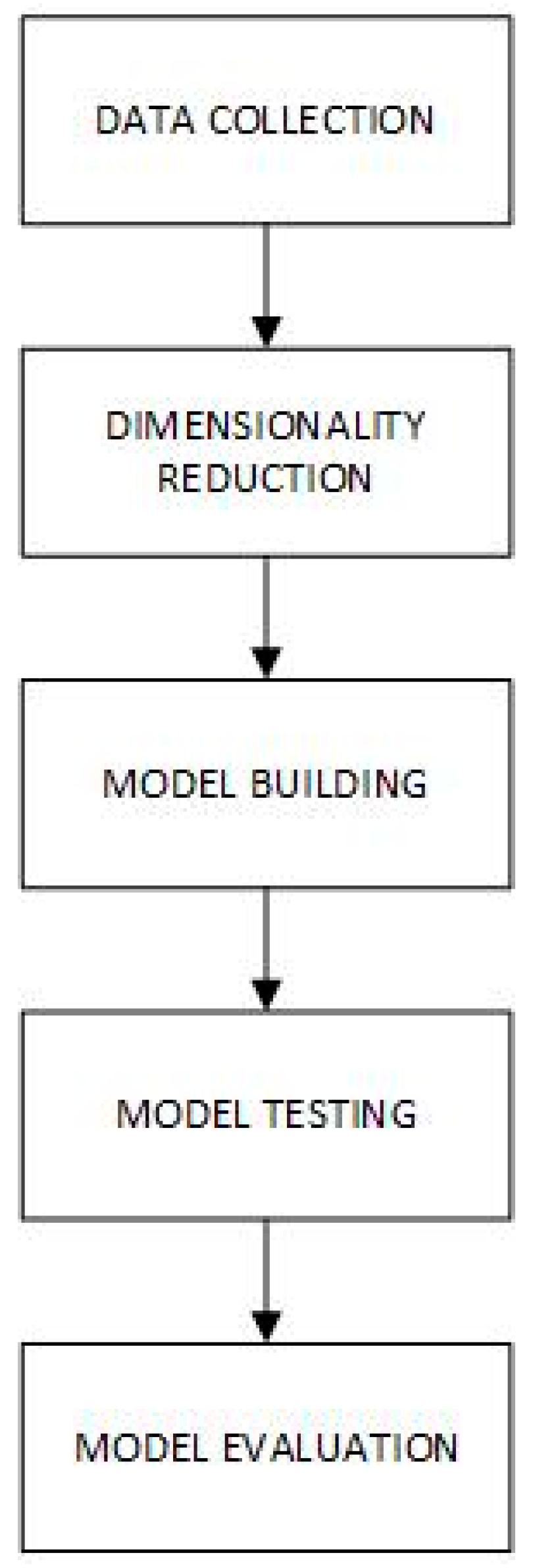
3. Materials and Methods
3.1. Dataset
- NumberOfSections: this refers to the size of the section table, which directly succeeds the headers. This feature is different in both malware and non-malware files.
- MajorLinkerVersion: this is a field in the optional header, and it is the linker major version number.
- AddressOfEntryPoint: this is also a field in the optional header. It is the entry point address. This address is related to the image base obtained as the Portable Executable (PE) file is loaded into memory. It is the starting address for program images, and it is the initialization function address for device drivers. For dynamic-link library (DLL), an entry point is not required. The field is null when there is no entry point.
- ImageBase: this represents the address of the first byte of the image when it loaded into memory. This is usually a multiple of 64K.
- MajorOperatingSystemVersion: a number used to identify the version of the operating system.
- MajorImageVersion: a number used to identify the version of the image. Many benign files have more versions and most malicious files have this feature with a value of zero.
- CheckSum: 90% of the time, when the CheckSum, MajorImageVersion, and DLLCharacteristics of a file are equal to zero, the file is found to be malicious.
- SizeOfImage: this refers to the image size as it is loaded in memory.
3.2. Dimensionality Reduction
3.3. Baseline Machine Learning Models
- Model the data with simple models and examine the data for errors.
- The errors connote data points that are not easy to fit by a simple model.
- For subsequent models, the focus is placed on improving the accuracy of classification on data that are hard to fit.
- Finally, all the predictors are combined by giving each predictor some weights.
3.4. Deep Learning Models
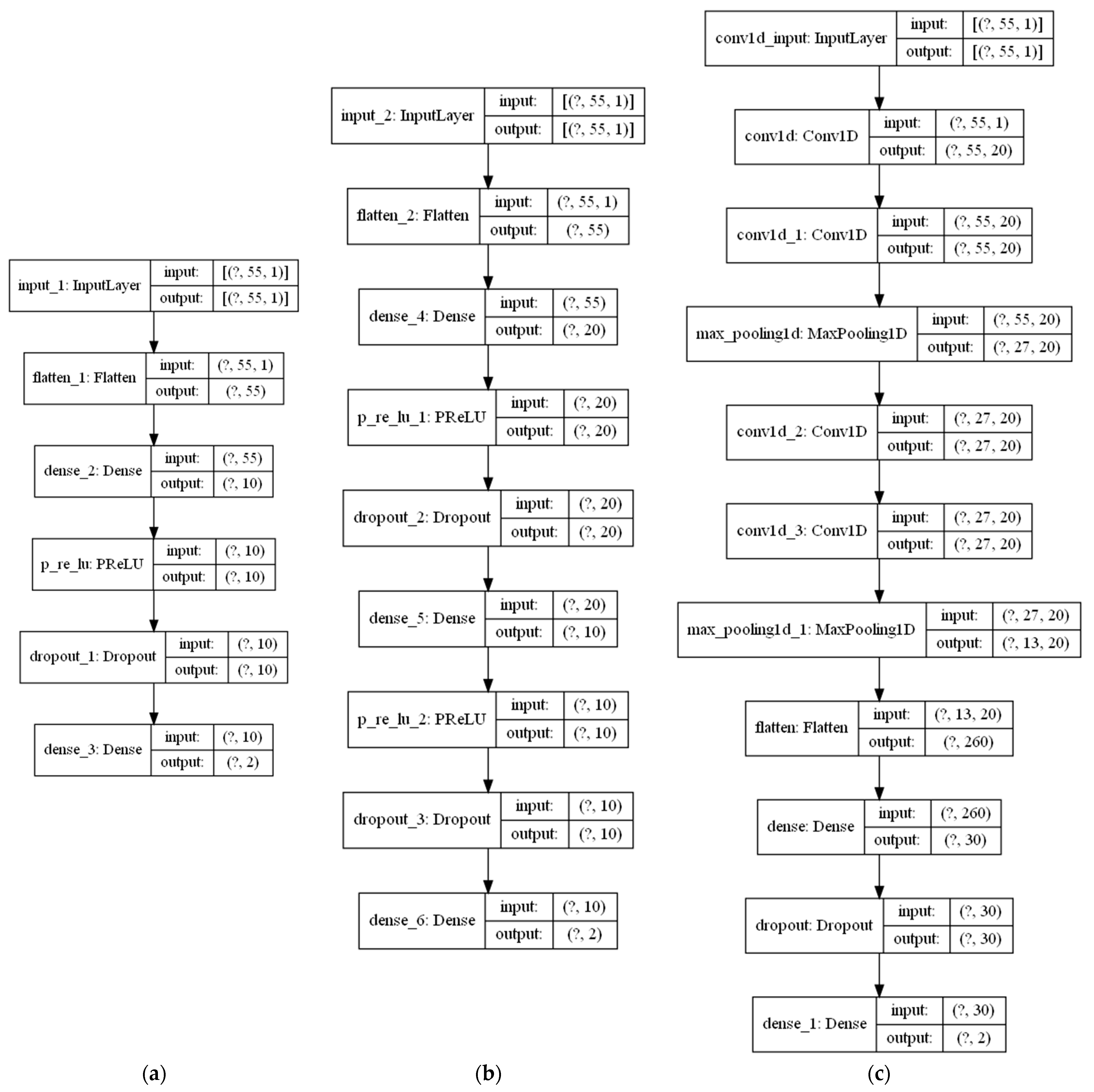
3.4.1. Multilayer Perceptron
3.4.2. One-Dimensional (1D) CNN Model
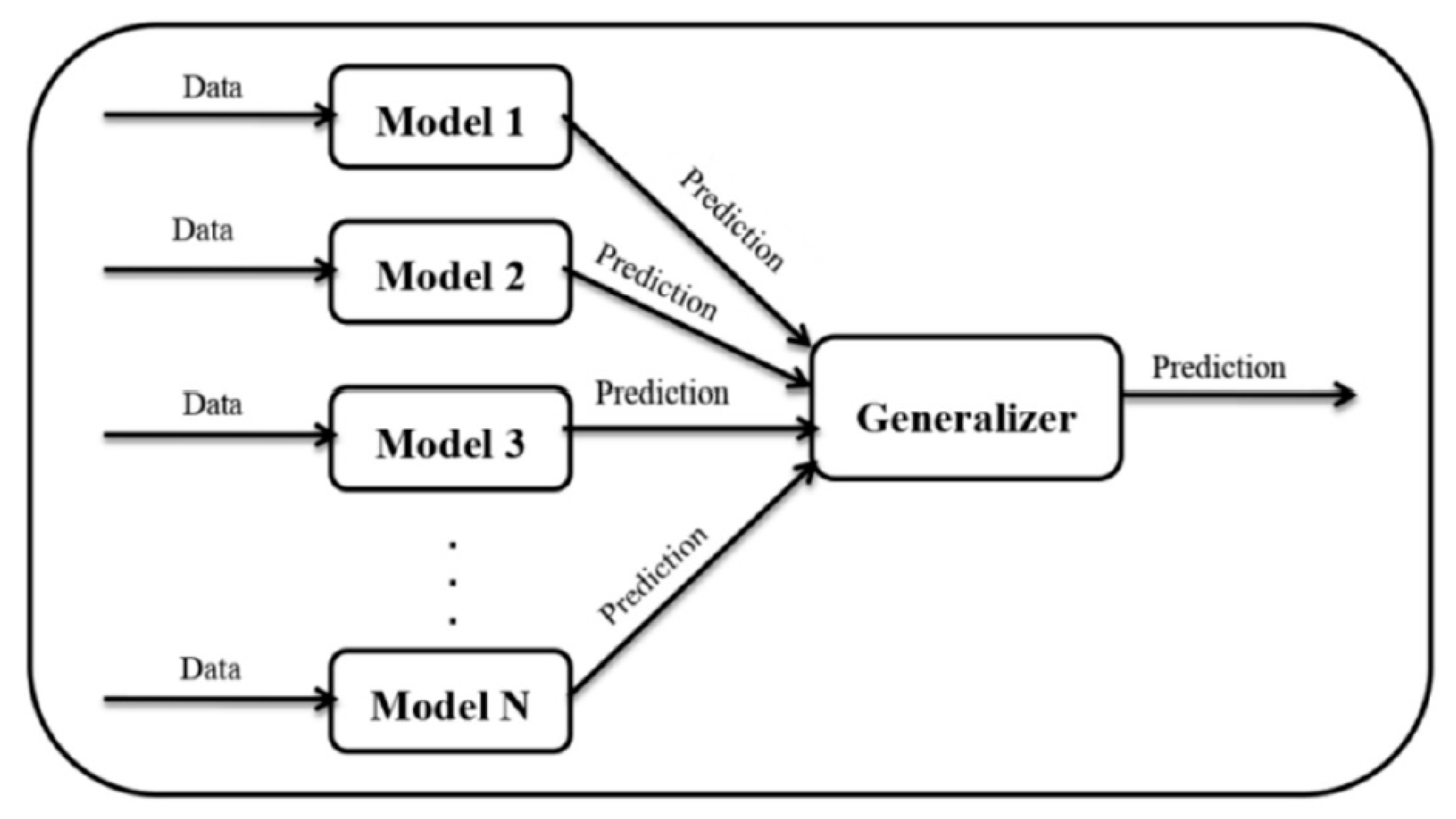
3.5. Ensemble Learning
- Create the ensemble
- Select different base classifiers.
- Select a final-stage classifier.
- Train the ensemble
- Train each of the first-stage classifiers on the training dataset.
- Perform k-fold cross-validation on each of the first-stage classifiers and record their decisions.
- Combine the decisions from the first-stage classifiers to form a feature matrix:
- Train the final-stage classifier on the new (features x predictions) data. Then the ensemble model combines the first-stage learning models and the final-stage model, to get more accurate predictions on unknown data.
- Test on new data.
- Store output predictions from the first-stage classifiers.
- Input first-stage classifier decisions into a final-stage classifier to make a final ensemble prediction.
| Algorithm 1. Pseudocode of the ensemble learning algorithm. |
 |
3.6. Evaluation
4. Results
4.1. Ssettings of Experiments
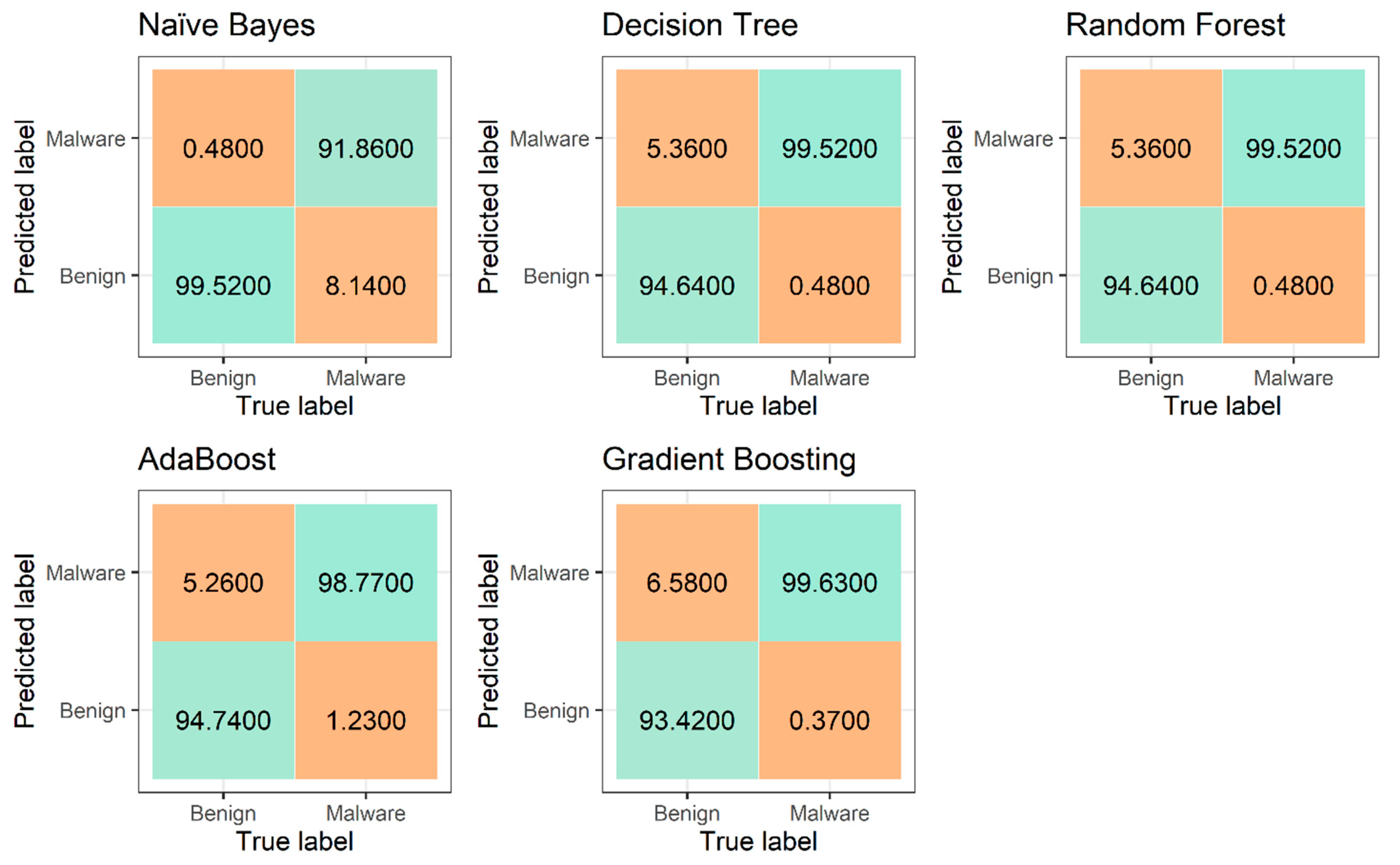
4.2. Results of Machine Learning Methods
4.3. Results of Neural Network Models
4.4. Results of Ensemble Classification
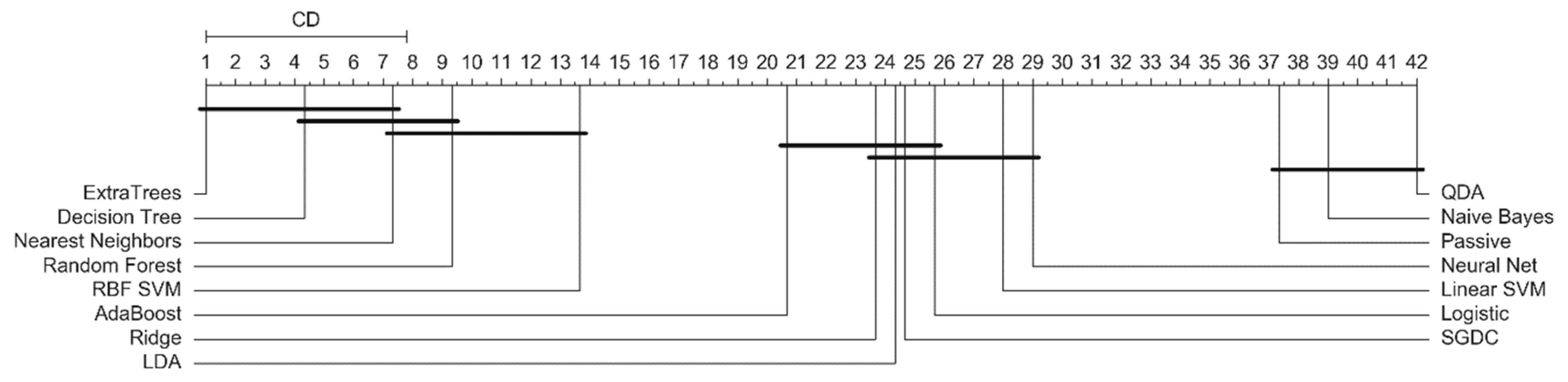
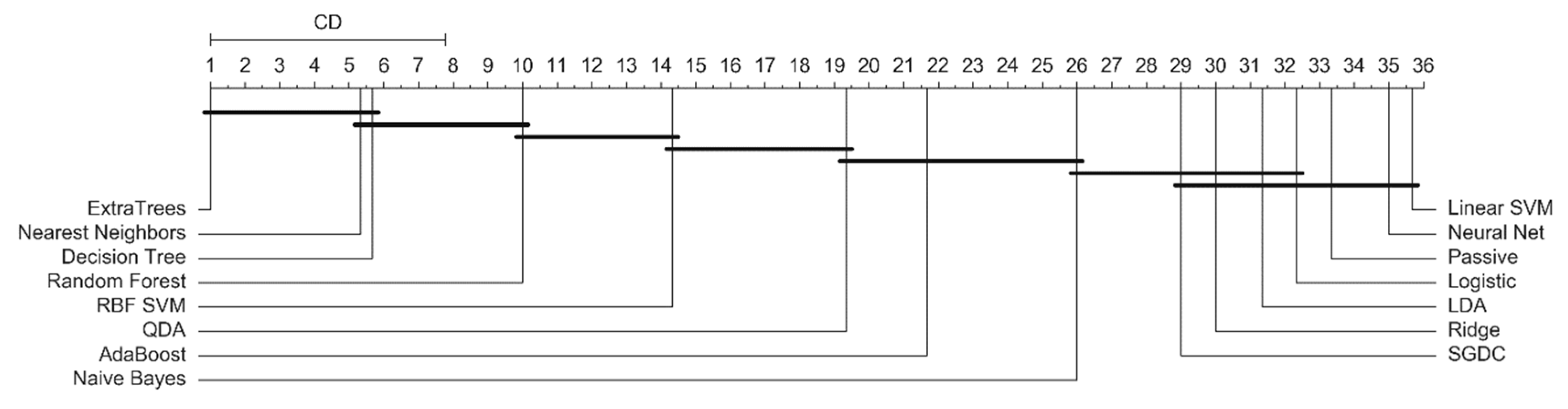
4.5. Statistical Analysis
4.6. Comparison with Previous Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- International Telecommunication Union. Statistics. Available online: https://www.itu.int/en/ITU-D/Statistics/Pages/publications/yb2018.aspx (accessed on 20 November 2019).
- Namanya, A.P.; Cullen, A.; Awan, I.U.; Disso, J.P. The World of Malware: An Overview. In Proceedings of the IEEE 6th International Conference on Future Internet of Things and Cloud (FiCloud 2018), Barcelona, Spain, 6–8 August 2018; pp. 420–427. [Google Scholar] [CrossRef]
- Gilbert, D.; Mateu, C.; Planes, J. The rise of machine learning for detection and classification of malware: Research developments, trends and challenges. J. Netw. Comput. Appl. 2020, 153, 102526. [Google Scholar] [CrossRef]
- Subairu, S.O.; Alhassan, J.; Misra, S.; Abayomi-Alli, O.; Ahuja, R.; Damasevicius, R.; Maskeliunas, R. An experimental approach to unravel effects of malware on system network interface. In Advances in Data Sciences, Security and Applications; Lecture Notes in Electrical Engineering; Springer: Singapore, 2020; Volume 612, pp. 225–235. [Google Scholar] [CrossRef]
- Azeez, N.A.; Salaudeen, B.B.; Misra, S.; Damasevicius, R.; Maskeliunas, R. Identifying phishing attacks in communication networks using URL consistency features. Int. J. Electron. Secur. Digit. Forensics 2020, 12, 200–213. [Google Scholar] [CrossRef]
- Yong, B.; Wei, W.; Li, K.; Shen, J.; Zhou, Q.; Wozniak, M.; Damaševičius, R. Ensemble machine learning approaches for webshell detection in internet of things environments. Trans. Emerg. Telecommun. Technol. 2020. [Google Scholar] [CrossRef]
- Wei, W.; Woźniak, M.; Damaševičius, R.; Fan, X.; Li, Y. Algorithm research of known-plaintext attack on double random phase mask based on WSNs. J. Internet Technol. 2019, 20, 39–48. [Google Scholar] [CrossRef]
- Boukhtouta, A.; Mokhov, S.A.; Lakhdari, N.-E.; Debbabi, M.; Paquet, J. Network malware classification comparison using dpi and flow packet headers. J. Comput. Virol. Hacking Tech. 2016, 12, 69–100. [Google Scholar] [CrossRef]
- Zatloukal, J.Z. Malware Detection Based on Multiple PE Headers Identification and Optimization for Specific Types of Files. J. Adv. Eng. Comput. 2017, 1, 153–161. [Google Scholar] [CrossRef] [Green Version]
- Odusami, M.; Abayomi-Alli, O.; Misra, S.; Shobayo, O.; Damasevicius, R.; Maskeliunas, R. Android malware detection: A survey. In Applied Informatics. ICAI 2018; Springer: Cham, Switzerland, 2018; Volume 942, pp. 255–266. [Google Scholar] [CrossRef]
- Gardiner, J.; Nagaraja, S. On the security of machine learning in malware detection: A survey. ACM Comput. Surv. 2016, 49, 1–39. [Google Scholar] [CrossRef] [Green Version]
- Ye, Y.; Li, T.; Adjeroh, D.; Iyengar, S.S. A survey on malware detection using data mining techniques. ACM Comput. Surv. 2017, 50, 1–40. [Google Scholar] [CrossRef]
- Souri, A.; Hosseini, R. A state-of-the-art survey of malware detection approaches using data mining techniques. Hum. Centric Comput. Inf. Sci. 2018, 8, 3. [Google Scholar] [CrossRef]
- Ucci, D.; Aniello, L.; Baldoni, R. Survey of machine learning techniques for malware analysis. Comput. Secur. 2019, 81, 123–147. [Google Scholar] [CrossRef] [Green Version]
- Sathyanarayan, V.S.; Kohli, P.; Bruhadeshwar, B. Signature Generation and Detection of Malware Families. In Information Security and Privacy, Proceedings of the Australasian Conference on Information Security and Privacy, ACISP 2008, Wollongong, Australia, 7–9 July 2008; Mu, Y., Susilo, W., Seberry, J., Eds.; Lecture Notes in Computer, Science; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5107, pp. 336–349. [Google Scholar]
- Zhong, W.; Gu, F. A multi-level deep learning system for malware detection. Expert Syst. Appl. 2019, 133, 151–162. [Google Scholar] [CrossRef]
- Vinayakumar, R.; Alazab, M.; Soman, K.P.; Poornachandran, P.; Venkatraman, S. Robust intelligent malware detection using deep learning. IEEE Access 2019, 7, 46717–46738. [Google Scholar] [CrossRef]
- Venkatraman, S.; Alazab, M.; Vinayakumar, R. A hybrid deep learning image-based analysis for effective malware detection. J. Inf. Secur. Appl. 2019, 47, 377–389. [Google Scholar] [CrossRef]
- Lu, T.; Du, Y.; Ouyang, L.; Chen, Q.; Wang, X. Android malware detection based on a hybrid deep learning model. Secur. Commun. Netw. 2020. [Google Scholar] [CrossRef]
- Yoo, S.; Kim, S.; Kim, S.; Kang, B.B. AI-HydRa: Advanced hybrid approach using random forest and deep learning for malware classification. Inf. Sci. 2021, 546, 420–435. [Google Scholar] [CrossRef]
- Nisa, M.; Shah, J.H.; Kanwal, S.; Raza, M.; Khan, M.A.; Damaševičius, R.; Blažauskas, T. Hybrid malware classification method using segmentation-based fractal texture analysis and deep convolution neural network features. Appl. Sci. 2020, 10, 4966. [Google Scholar] [CrossRef]
- Bazrafshan, Z.; Hashemi, H.; Fard, S.M.H.; Hamzeh, A. A survey on heuristic malware detection techniques. In Proceedings of the 5th Conference on Information and Knowledge Technology (IKT), Shiraz, Iran, 28–30 May 2013; pp. 113–120. [Google Scholar]
- Rathore, H.; Agarwal, S.; Sahay, S.; Sewak, M. Malware Detection using Machine Learning and Deep Learning. In Proceedings of the International Conference of Big Data Analytics, Goa, India, 17–20 December 2019; Springer: Cham, Switzerland, 2019; pp. 402–411. [Google Scholar]
- Lee, Y.-S.; Lee, J.-U.; Soh, W.-Y. Trend of Malware Detection Using Deep Learning. In Proceedings of the 2nd International Conference on Education and Multimedia Technology, Okinawa, Japan, 2–4 July 2018; pp. 102–106. [Google Scholar]
- Pluskal, O. Behavioural malware detection using efficient SVM implementation. In Proceedings of the Conference on Research in Adaptive and Convergent Systems—RACS, Prague, Czech Republic, 9–12 October 2015; pp. 296–301. [Google Scholar] [CrossRef]
- Cakir, B.; Dogdu, E. Malware classification using deep learning methods. In Proceedings of the ACMSE 2018 Conference on—ACMSE ’18, Richmond, KY, USA, 29–31 March 2018. [Google Scholar] [CrossRef]
- Ren, Z.; Wu, H.; Ning, Q.; Hussain, I.; Chen, B. End-to-end malware detection for android IoT devices using deep learning. Ad Hoc Netw. 2020, 101, 102098. [Google Scholar] [CrossRef]
- Yuxin, D.; Siyi, Z. Malware detection based on deep learning algorithm. Neural Comput. Appl. 2019, 31, 461–472. [Google Scholar] [CrossRef]
- Pei, X.; Yu, L.; Tian, S. AMalNet: A deep learning framework based on graph convolutional networks for malware detection. Comput. Secur. 2020, 93, 101792. [Google Scholar] [CrossRef]
- Čeponis, D.; Goranin, N. Investigation of dual-flow deep learning models LSTM-FCN and GRU-FCN efficiency against single-flow CNN models for the host-based intrusion and malware detection task on univariate times series data. Appl. Sci. 2020, 10, 2373. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Ma, L.; Yang, W.; Zhong, Y. A method for windows malware detection based on deep learning. J. Signal Process. Syst. 2021, 93, 265–273. [Google Scholar] [CrossRef]
- Abiodun, O.I.; Kiru, M.U.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Umar, A.M.; Linus, O.U.; Arshad, H.; Kazaure, A.A.; Gana, U. Comprehensive Review of Artificial Neural Network Applications to Pattern Recognition. IEEE Access 2019, 7, 158820–158846. [Google Scholar] [CrossRef]
- Dai, Y.; Li, H.; Qian, Y.; Yang, R.; Zheng, M. SMASH: A malware detection method based on multi-feature ensemble learning. IEEE Access 2019, 7, 112588–112597. [Google Scholar] [CrossRef]
- Khasawneh, K.N.; Ozsoy, M.; Donovick, C.; Abu-Ghazaleh, N.; Ponomarev, D. EnsembleHMD: Accurate hardware malware detectors with specialized ensemble classifiers. IEEE Trans. Dependable Secur. Comput. 2018, 17, 620–633. [Google Scholar] [CrossRef] [Green Version]
- Li, D.; Li, Q. Adversarial deep ensemble: Evasion attacks and defenses for malware detection. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3886–3900. [Google Scholar] [CrossRef]
- Xue, D.; Li, J.; Wu, W.; Tian, Q.; Wang, J. Homology analysis of malware based on ensemble learning and multifeatures. PLoS ONE 2019, 14, e0211373. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Gao, C.; Gong, L.; Gu, Z.; Man, D.; Yang, W.; Li, W. Malware detection based on multi-level and dynamic multi-feature using ensemble learning at hypervisor. Mobile Netw. Appl. 2020. [Google Scholar] [CrossRef]
- Galar, M.; Fernandez, A.; Barrenechea, E.; Bustince, H.; Herrera, F. A review on ensembles for the class imbalance problem: Bagging-, boosting-, and hybrid-based approaches. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2012, 42, 463–484. [Google Scholar] [CrossRef]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8. [Google Scholar] [CrossRef]
- Basu, I. Malware detection based on source data using data mining: A survey. Am. J. Adv. Comput. 2016, 3, 18–37. [Google Scholar]
- Zhang, H. The optimality of naive bayes. In Proceedings of the Seventeenth International Florida Artificial Intelligence Research Society Conference, FLAIRS 2004, Miami Beach, FL, USA, 12–14 May 2004; AAAI Press: Menlo Park, CA, USA, 2004; Volume 2, pp. 562–567. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Rätsch, G.; Onoda, T.; Müller, K.R. Regularizing AdaBoost. In Advances in Neural Information Processing Systems; MIT Press: Cambrigde, MA, USA, 1999; pp. 564–570. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Van der Laan, M.J.; Polley, E.C.; Hubbard, A.E. Super Learner. Stat. Appl. Genet. Mol. Biol. 2007, 6. [Google Scholar] [CrossRef] [PubMed]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely Randomized Trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Crammer, K.; Dekel, O.; Keshet, J.; Shalev-Shwartz, S.; Singer, Y. Online Passive-Aggressive Algorithms. J. Mach. Learn. Res. 2006, 7, 551–585. [Google Scholar]
- Azmee, A.B.M.; Protim, P.; Aosaful, M.; Dutta, O.; Iqbal, M. Performance Analysis of Machine Learning Classifiers for Detecting PE Malware. Int. J. Adv. Comput. Sci. Appl. 2020, 11. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Z.; Lu, Y.; Xue, Y. Droiddetector: Android malware characterization and detection using deep learning. Tsinghua Sci. Technol. 2016, 21, 114–123. [Google Scholar] [CrossRef]
- McLaughlin, N.; Martinez del Rincon, J.; Kang, B.; Yerima, S.; Miller, P.; Sezer, S.; Safaei, Y.; Trickel, E.; Zhao, Z.; Doupe, A.; et al. Deep android malware detection. In Proceedings of the Seventh ACM Conference on Data and Application Security and Privacy, CODASPY 2017, Scottsdale, AZ, USA, 22–24 March 2017; pp. 301–308. [Google Scholar]
- Karbab, E.B.; Debbabi, M.; Derhab, A.; Mouheb, D. Android malware detection using deep learning on api method sequences. arXiv 2017, arXiv:1712.08996. [Google Scholar]
- Hou, S.; Saas, A.; Ye, Y.; Chen, L. DroidDelver: An Android Malware Detection System Using Deep Belief Network Based on API Call Blocks. In Web-Age Information Management; Song, S., Tong, Y., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9998. [Google Scholar] [CrossRef]
- Hou, S.; Saas, A.; Chen, L.; Ye, Y.; Bourlai, T. Deep neural networks for automatic android malware detection. In Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Sydney, Australia, 13 July–3 August 2017; pp. 803–810. [Google Scholar]
- Raff, E.; Barker, J.; Sylvester, J.; Brandon, R.; Catanzaro, B.; Nicholas, C.K. Malware detection by eating a whole EXE. In Proceedings of the Workshops of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 268–276. [Google Scholar]
- Krčál, M.; Švec, O.; Bálek, M.; Jašek, O. Deep convolutional malware classifiers can learn from raw executables and labels only. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dense-1 | Dense-2 | 1D-CNN 1 |
|---|---|---|
| A—number of neurons in 1st hidden layer | A—number of neurons in 1st hidden layer B—number of neurons in 2nd hidden layer | F—number of filters in convolutional layers N—number of neurons in the dense layer |
| Input layer of 55 × 1 features | ||
| 1 FC layer (A neurons) | 1 FC layer (A neurons) | 2 Conv1D layers (F 2 × 2 filters) |
| PReLU 2 | PReLU | Max-pooling layer |
| Dropout layer (p = 0.3) | Dropout layer (p = 0.3) | 2 Conv1D layers (F 2 × 2 filters) |
| 1 FC layer (N neurons) | 1 FC layer (A neurons) | Max-pooling layer |
| Softmax output layer | PReLU | 1 FC layer (N neurons) |
| Dropout layer (p = 0.3) | Dropout layer (p = 0.5) | |
| 1 FC layer (B neurons) | 1 FC layer (2 neurons) | |
| Softmax output layer | Softmax output layer | |
| Performance Measure | Calculation |
|---|---|
| False Positive Rate (FPR) (also specificity) | |
| True Positive Rate (TPR) (also sensitivity and recall) | |
| False Negative Rate (FNR) | |
| True Negative Rate (TNR) | |
| Precision | |
| F-score | |
| Accuracy | |
| Matthews Correlation Coefficient (MCC) |
| Performance Measure | Naïve Bayes | Decision Trees | Random Forest | AdaBoost | Gradient Boosting |
|---|---|---|---|---|---|
| Accuracy | 32.53% | 98.29% | 99.24% | 98.06% | 98.06% |
| Error | 67.47% | 1.71% | 0.76% | 1.94% | 1.94% |
| FPR | 99.52 | 5.36% | 2.13% | 5.26% | 6.58% |
| TPR | 8.14% | 99.52% | 99.69% | 98.77% | 99.63% |
| FNR | 91.86% | 0.48% | 0.31% | 1.23% | 0.37% |
| TNR | 0.48% | 94.64% | 97.87% | 94.74% | 93.42% |
| Precision | 0.28 | 0.99 | 0.99 | 0.96 | 0.99 |
| Recall | 0.99 | 0.95 | 0.98 | 0.95 | 0.93 |
| F-measure | 0.44 | 0.97 | 0.98 | 0.96 | 0.96 |
| No. of Neurons in 1st Layer | Acc | Prec | Rec | Spec | FPR | FNR | F1 | AUC | MCC | Kappa |
|---|---|---|---|---|---|---|---|---|---|---|
| 5 | 0.968 | 0.968 | 0.968 | 0.968 | 0.068 | 0.02 | 0.968 | 0.956 | 0.915 | 0.915 |
| 10 | 0.97 | 0.97 | 0.97 | 0.97 | 0.065 | 0.018 | 0.97 | 0.959 | 0.921 | 0.921 |
| 15 | 0.978 | 0.978 | 0.978 | 0.978 | 0.054 | 0.011 | 0.978 | 0.967 | 0.942 | 0.942 |
| 20 | 0.98 | 0.98 | 0.98 | 0.98 | 0.054 | 0.009 | 0.98 | 0.968 | 0.945 | 0.945 |
| 25 | 0.978 | 0.978 | 0.978 | 0.978 | 0.056 | 0.011 | 0.978 | 0.967 | 0.941 | 0.941 |
| 30 | 0.979 | 0.979 | 0.979 | 0.979 | 0.051 | 0.011 | 0.979 | 0.969 | 0.944 | 0.944 |
| 35 | 0.981 | 0.981 | 0.981 | 0.981 | 0.053 | 0.008 | 0.981 | 0.969 | 0.948 | 0.948 |
| 40 | 0.98 | 0.98 | 0.98 | 0.98 | 0.047 | 0.011 | 0.98 | 0.971 | 0.946 | 0.946 |
| 45 | 0.98 | 0.98 | 0.98 | 0.98 | 0.047 | 0.011 | 0.98 | 0.971 | 0.947 | 0.946 |
| 50 | 0.983 | 0.983 | 0.983 | 0.983 | 0.043 | 0.009 | 0.983 | 0.974 | 0.953 | 0.953 |
| No. of Neurons in 1st Layer | No. of Neurons in 2nd Layer | Acc | Prec | Rec | Spec | FPR | FNR | F1 | AUC | MCC | Kappa |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 10 | 0.977 | 0.977 | 0.977 | 0.977 | 0.048 | 0.014 | 0.977 | 0.969 | 0.939 | 0.939 |
| 10 | 20 | 0.979 | 0.979 | 0.979 | 0.979 | 0.052 | 0.011 | 0.979 | 0.968 | 0.943 | 0.943 |
| 10 | 30 | 0.979 | 0.979 | 0.979 | 0.979 | 0.057 | 0.008 | 0.979 | 0.967 | 0.944 | 0.944 |
| 10 | 40 | 0.979 | 0.979 | 0.979 | 0.979 | 0.059 | 0.008 | 0.979 | 0.967 | 0.944 | 0.943 |
| 10 | 50 | 0.982 | 0.982 | 0.982 | 0.982 | 0.048 | 0.008 | 0.982 | 0.972 | 0.952 | 0.952 |
| 20 | 10 | 0.980 | 0.980 | 0.980 | 0.980 | 0.052 | 0.010 | 0.980 | 0.969 | 0.945 | 0.945 |
| 20 | 20 | 0.980 | 0.980 | 0.980 | 0.980 | 0.049 | 0.010 | 0.980 | 0.970 | 0.946 | 0.946 |
| 20 | 30 | 0.984 | 0.984 | 0.984 | 0.984 | 0.041 | 0.007 | 0.984 | 0.976 | 0.957 | 0.957 |
| 20 | 40 | 0.983 | 0.983 | 0.983 | 0.983 | 0.042 | 0.009 | 0.983 | 0.974 | 0.953 | 0.953 |
| 20 | 50 | 0.984 | 0.984 | 0.984 | 0.984 | 0.046 | 0.006 | 0.984 | 0.974 | 0.957 | 0.957 |
| 30 | 10 | 0.981 | 0.981 | 0.981 | 0.981 | 0.043 | 0.011 | 0.981 | 0.973 | 0.950 | 0.950 |
| 30 | 20 | 0.983 | 0.983 | 0.983 | 0.983 | 0.047 | 0.007 | 0.983 | 0.973 | 0.955 | 0.955 |
| 30 | 30 | 0.983 | 0.983 | 0.983 | 0.983 | 0.045 | 0.007 | 0.983 | 0.974 | 0.955 | 0.955 |
| 30 | 40 | 0.982 | 0.982 | 0.982 | 0.982 | 0.051 | 0.006 | 0.982 | 0.971 | 0.953 | 0.952 |
| 30 | 50 | 0.983 | 0.983 | 0.983 | 0.983 | 0.042 | 0.008 | 0.983 | 0.975 | 0.955 | 0.955 |
| 40 | 10 | 0.983 | 0.983 | 0.983 | 0.983 | 0.040 | 0.010 | 0.983 | 0.975 | 0.953 | 0.953 |
| 40 | 20 | 0.984 | 0.984 | 0.984 | 0.984 | 0.038 | 0.008 | 0.984 | 0.977 | 0.958 | 0.958 |
| 40 | 30 | 0.983 | 0.983 | 0.983 | 0.983 | 0.050 | 0.006 | 0.983 | 0.972 | 0.953 | 0.953 |
| 40 | 40 | 0.988 | 0.988 | 0.988 | 0.988 | 0.036 | 0.005 | 0.988 | 0.980 | 0.966 | 0.966 |
| 40 | 50 | 0.987 | 0.987 | 0.987 | 0.987 | 0.040 | 0.004 | 0.987 | 0.978 | 0.964 | 0.964 |
| 50 | 10 | 0.984 | 0.984 | 0.984 | 0.984 | 0.044 | 0.006 | 0.984 | 0.975 | 0.957 | 0.957 |
| 50 | 20 | 0.983 | 0.983 | 0.983 | 0.983 | 0.047 | 0.007 | 0.983 | 0.973 | 0.953 | 0.953 |
| 50 | 30 | 0.985 | 0.985 | 0.985 | 0.985 | 0.042 | 0.005 | 0.985 | 0.976 | 0.961 | 0.961 |
| 50 | 40 | 0.986 | 0.986 | 0.986 | 0.986 | 0.036 | 0.007 | 0.986 | 0.979 | 0.962 | 0.962 |
| 50 | 50 | 0.984 | 0.984 | 0.984 | 0.984 | 0.044 | 0.006 | 0.984 | 0.975 | 0.958 | 0.958 |
| No. of Filters | No. of Neurons | Acc | Prec | Rec | Spec | FPR | FNR | F1 | AUC | MCC | Kappa |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 20 | 20 | 0.970 | 0.970 | 0.970 | 0.970 | 0.063 | 0.019 | 0.970 | 0.959 | 0.920 | 0.920 |
| 20 | 40 | 0.973 | 0.973 | 0.973 | 0.973 | 0.051 | 0.018 | 0.973 | 0.965 | 0.929 | 0.929 |
| 20 | 60 | 0.977 | 0.977 | 0.977 | 0.977 | 0.054 | 0.012 | 0.977 | 0.967 | 0.939 | 0.939 |
| 40 | 20 | 0.976 | 0.976 | 0.976 | 0.976 | 0.052 | 0.014 | 0.976 | 0.967 | 0.936 | 0.936 |
| 40 | 40 | 0.975 | 0.975 | 0.975 | 0.975 | 0.063 | 0.013 | 0.975 | 0.962 | 0.931 | 0.931 |
| 40 | 60 | 0.976 | 0.976 | 0.976 | 0.976 | 0.047 | 0.016 | 0.976 | 0.968 | 0.936 | 0.936 |
| 60 | 20 | 0.977 | 0.977 | 0.977 | 0.977 | 0.044 | 0.016 | 0.977 | 0.970 | 0.938 | 0.938 |
| 60 | 40 | 0.978 | 0.978 | 0.978 | 0.978 | 0.045 | 0.015 | 0.978 | 0.970 | 0.940 | 0.940 |
| 60 | 60 | 0.977 | 0.977 | 0.977 | 0.977 | 0.047 | 0.015 | 0.977 | 0.969 | 0.939 | 0.939 |
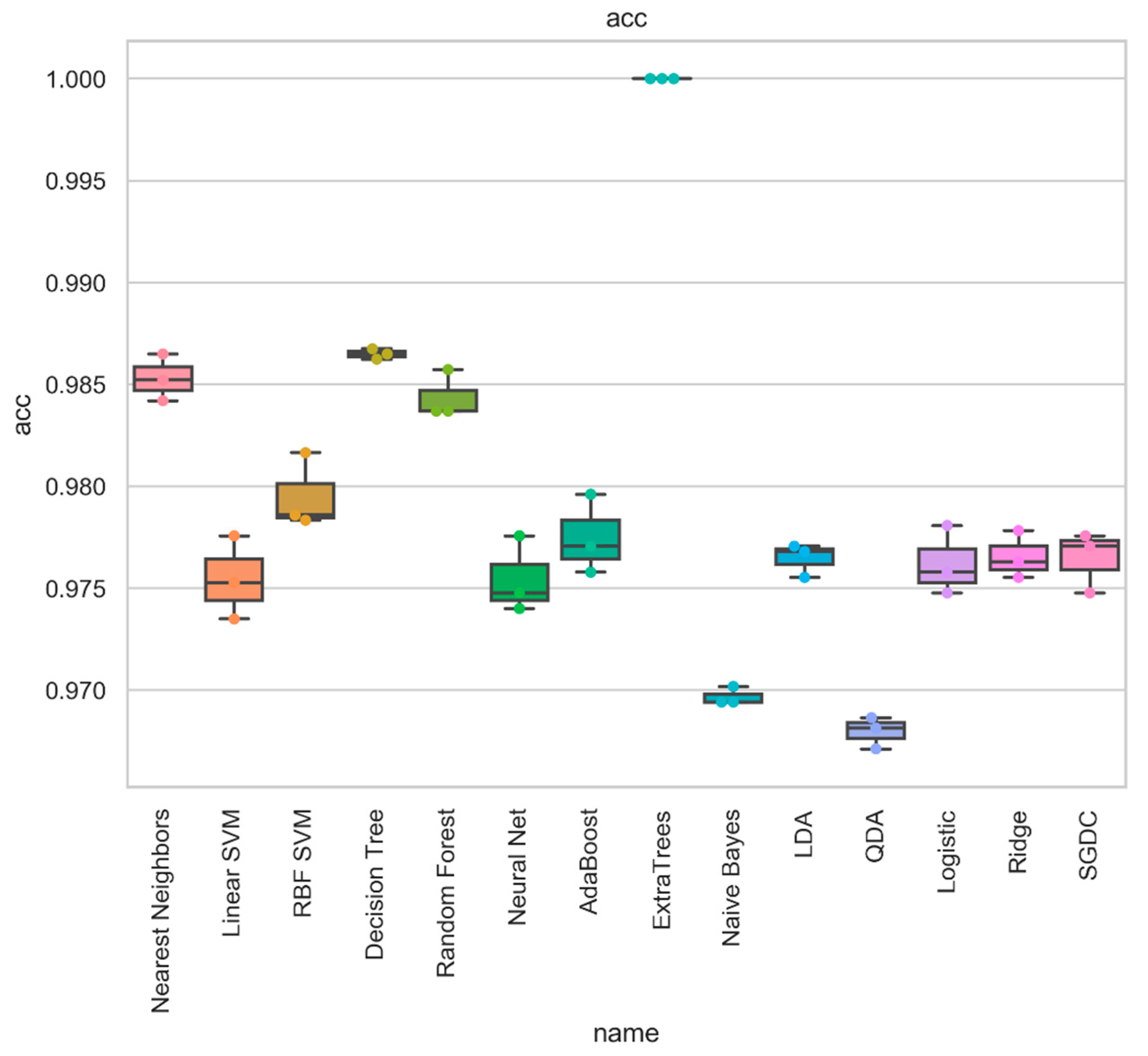
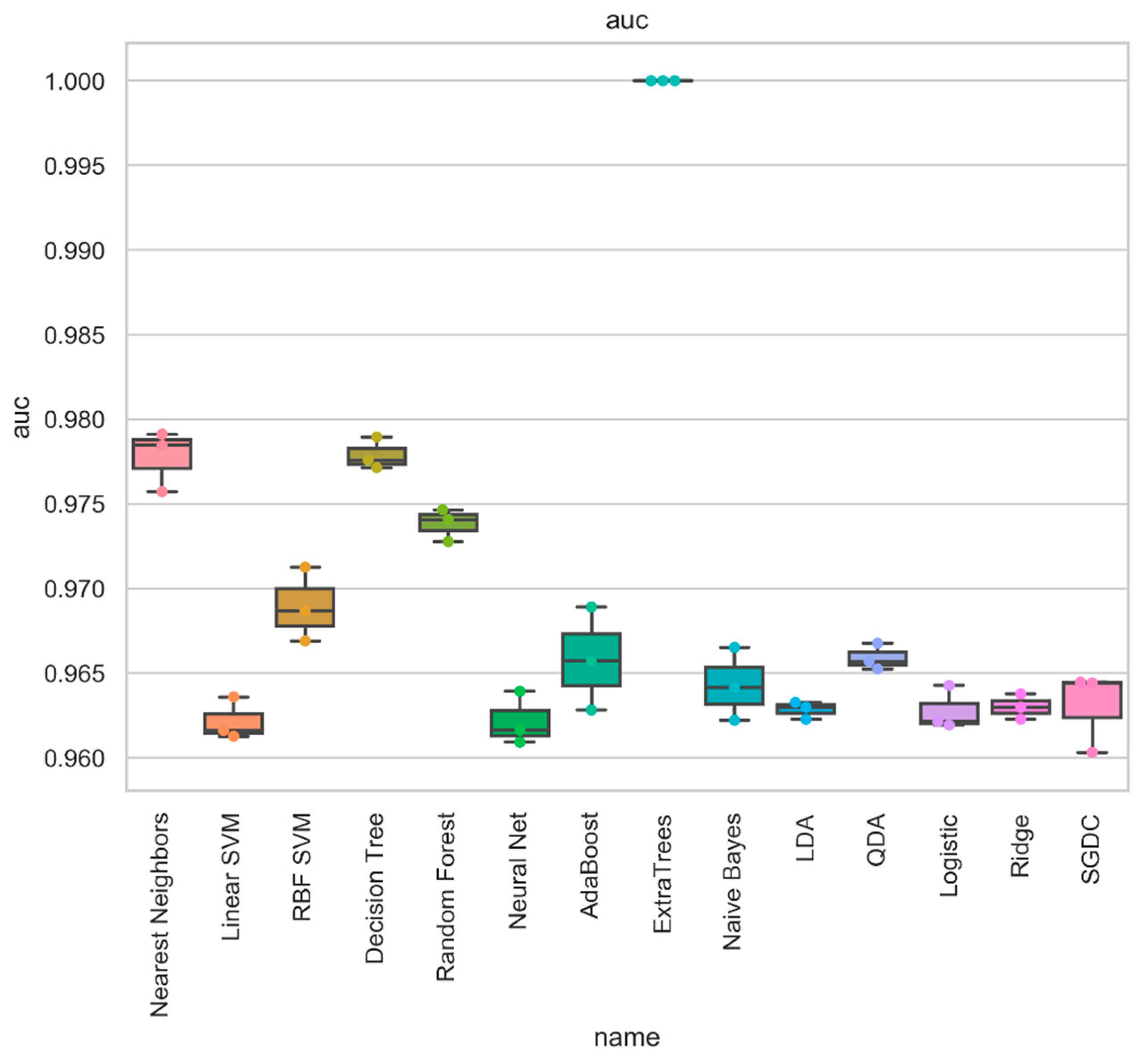
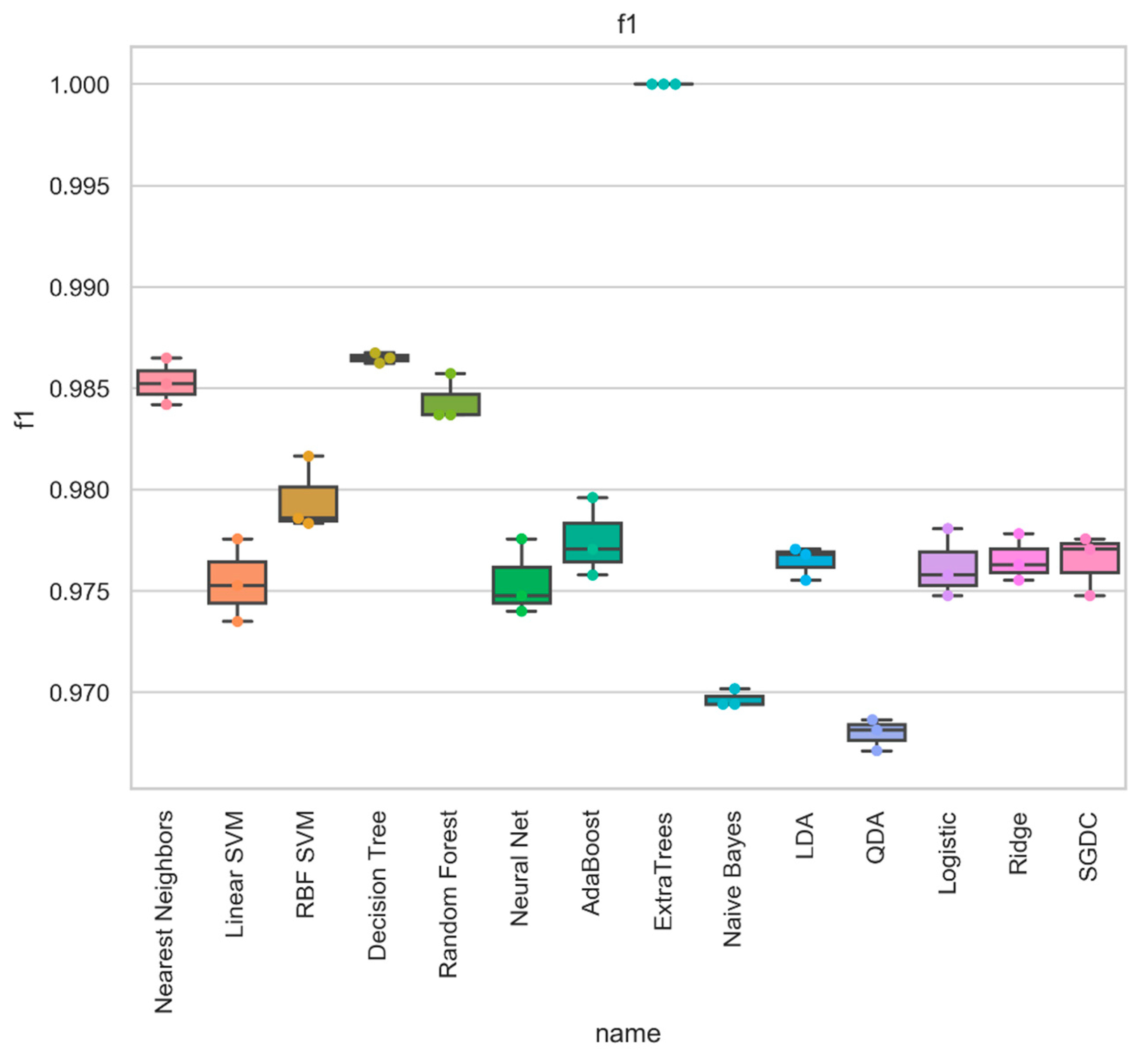
| Metalearner | Acc | Prec | Rec | Spec | FPR | FNR | F1 | AUC | MCC | Kappa |
|---|---|---|---|---|---|---|---|---|---|---|
| Nearest Neighbors | 0.986 | 0.986 | 0.986 | 0.986 | 0.034 | 0.007 | 0.986 | 0.979 | 0.963 | 0.963 |
| Linear SVM | 0.979 | 0.979 | 0.979 | 0.979 | 0.056 | 0.009 | 0.979 | 0.967 | 0.944 | 0.943 |
| RBF SVM | 0.982 | 0.982 | 0.982 | 0.982 | 0.048 | 0.008 | 0.982 | 0.972 | 0.952 | 0.952 |
| Decision Tree | 0.989 | 0.989 | 0.989 | 0.989 | 0.037 | 0.003 | 0.989 | 0.98 | 0.969 | 0.969 |
| Random Forest | 0.984 | 0.984 | 0.984 | 0.984 | 0.044 | 0.007 | 0.984 | 0.975 | 0.957 | 0.957 |
| Neural Net | 0.979 | 0.979 | 0.979 | 0.979 | 0.059 | 0.009 | 0.979 | 0.966 | 0.942 | 0.942 |
| AdaBoost | 0.982 | 0.982 | 0.982 | 0.982 | 0.044 | 0.009 | 0.982 | 0.973 | 0.952 | 0.952 |
| ExtraTrees | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 |
| Naïve Bayes | 0.972 | 0.972 | 0.972 | 0.972 | 0.044 | 0.023 | 0.972 | 0.967 | 0.926 | 0.925 |
| LDA | 0.98 | 0.98 | 0.98 | 0.98 | 0.05 | 0.009 | 0.98 | 0.97 | 0.947 | 0.947 |
| QDA | 0.973 | 0.973 | 0.973 | 0.973 | 0.037 | 0.024 | 0.973 | 0.969 | 0.928 | 0.928 |
| Logistic | 0.981 | 0.981 | 0.981 | 0.981 | 0.05 | 0.009 | 0.981 | 0.97 | 0.948 | 0.948 |
| Passive | 0.978 | 0.978 | 0.978 | 0.978 | 0.07 | 0.006 | 0.978 | 0.962 | 0.941 | 0.94 |
| Ridge | 0.981 | 0.981 | 0.981 | 0.981 | 0.05 | 0.009 | 0.981 | 0.97 | 0.948 | 0.948 |
| SGDC | 0.979 | 0.979 | 0.979 | 0.979 | 0.039 | 0.015 | 0.979 | 0.973 | 0.944 | 0.944 |
| Reference | Benign | Malware | Acc. | Prec. | Recall | F-Score |
|---|---|---|---|---|---|---|
| Yuan et al. (2016) [50] | 880 | 880 | 96.76 | 96.78 | 96.76 | 96.76 |
| McLaughlin et al. (2017) [51] | 863 | 1260 | 98 | 99 | 95 | 97 |
| Karbab et al. (2017) [52] | 37,627 | 20,089 | N/A | 96.29 | 96.29 | 96.29 |
| Hou et al. (2016) [53] | 1500 | 1500 | 93.68 | 93.96 | 93.36 | 93.68 |
| Hou et al. (2017) [54] | 2500 | 2500 | 96.66 | 96.55 | 96.76 | 96.66 |
| Raff et al. (2018) [55] | 1,000,020 | 1,011,766 | 96.41 | n/a | n/a | 89.02 |
| Krčál et al. (2018) [56] | 20 mln. (total) | 97.56 | n/a | n/a | 90.71 | |
| Azmee et al. (2020) [49] | 5012 | 14,599 | 98.6 | 96.3 | 99 | n/a |
| This paper (2020) | 5012 | 14,599 | 100.0 | 100.0 | 100.0 | 100.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Azeez, N.A.; Odufuwa, O.E.; Misra, S.; Oluranti, J.; Damaševičius, R. Windows PE Malware Detection Using Ensemble Learning. Informatics 2021, 8, 10. https://doi.org/10.3390/informatics8010010
Azeez NA, Odufuwa OE, Misra S, Oluranti J, Damaševičius R. Windows PE Malware Detection Using Ensemble Learning. Informatics. 2021; 8(1):10. https://doi.org/10.3390/informatics8010010
Chicago/Turabian StyleAzeez, Nureni Ayofe, Oluwanifise Ebunoluwa Odufuwa, Sanjay Misra, Jonathan Oluranti, and Robertas Damaševičius. 2021. "Windows PE Malware Detection Using Ensemble Learning" Informatics 8, no. 1: 10. https://doi.org/10.3390/informatics8010010
APA StyleAzeez, N. A., Odufuwa, O. E., Misra, S., Oluranti, J., & Damaševičius, R. (2021). Windows PE Malware Detection Using Ensemble Learning. Informatics, 8(1), 10. https://doi.org/10.3390/informatics8010010