
Research and Application of Power Grid Maintenance Scheduling Strategy under the Interactive Mode of New Energy and Electrolytic Aluminum Load

Abstract
:1. Introduction
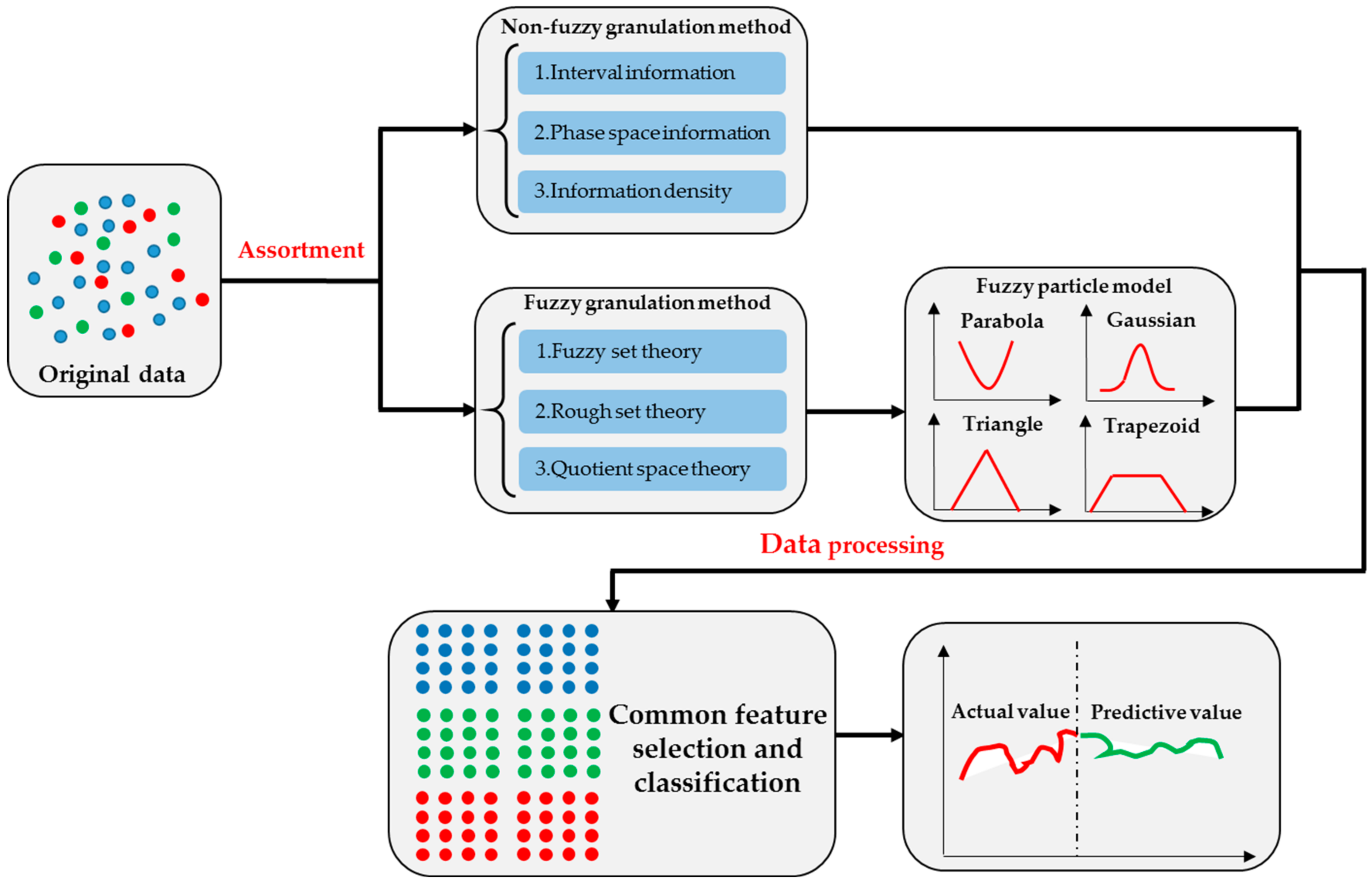
2. Definition and Theory of Information Granulation
3. Support-Vector Machine Regression Prediction Model
3.1. Mathematical Model of SVM
3.2. Progressive Search Algorithm
4. Designation of a Robust Unit Maintenance Scheme
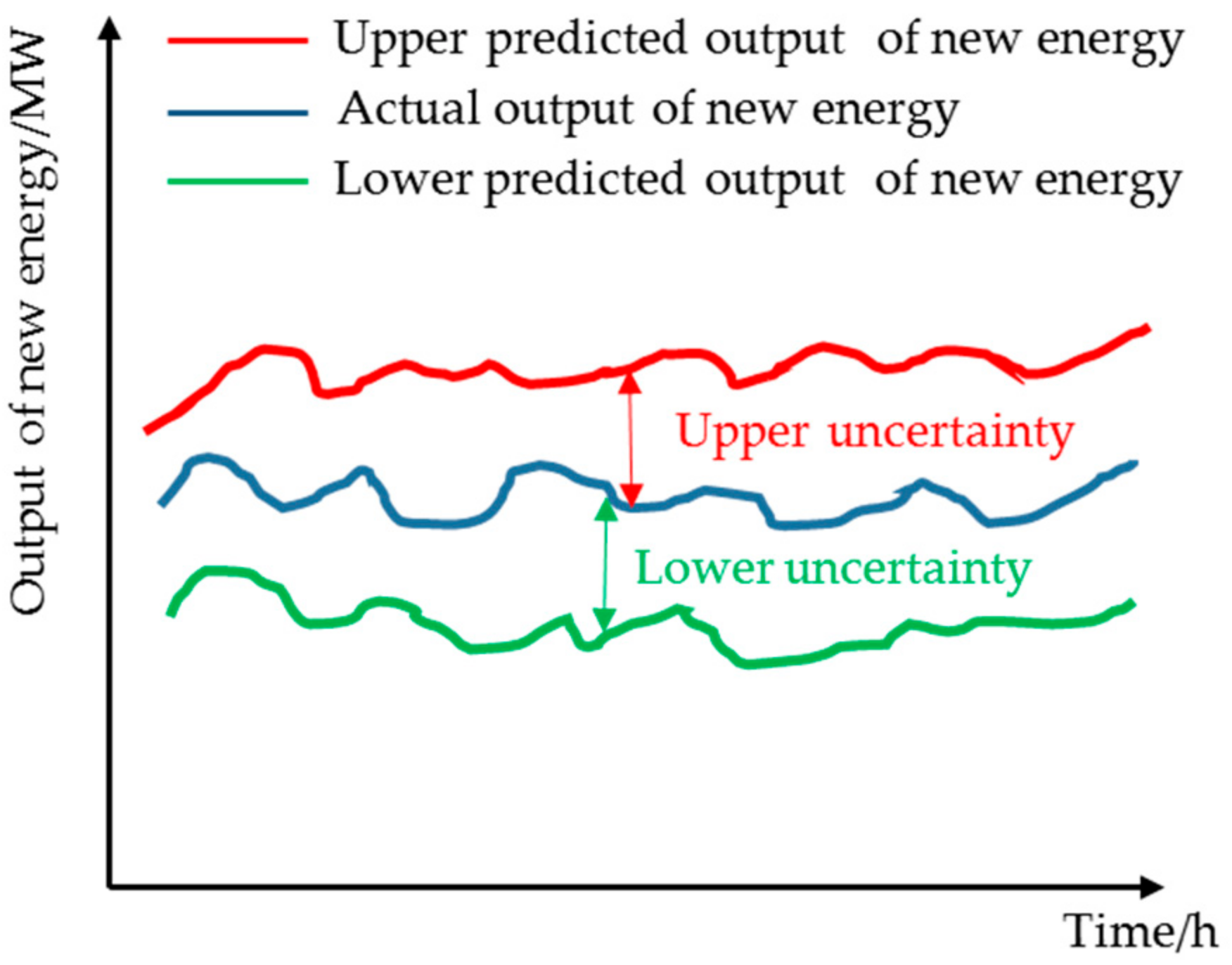
4.1. Analysis of Uncertainty
4.2. Mathematical Model of Robust Unit Maintenance
5. Results Analysis
5.1. Case Study 1: RTS–GMLC Test System
5.1.1. The Result of the IG Method
5.1.2. The Result of the SVM Model
5.1.3. The Result of the Robust Unit Maintenance Model
5.2. Case Study 2: Actual Power Grid in Southwest China
6. Conclusions and Future Work
- 1.
- Study the economic dispatching and unit maintenance methods of power systems under the background of low carbon emissions. Traditional thermal power-generating units will produce a lot of carbon dioxide in the process of power generation, but if power grids rely too much on new energy, such as wind power and light energy, it will increase the risk during system operation. How to strike a balance between low-carbon economic production and reliable operation of power systems remains a challenge;
- 2.
- How to formulate a demand response plan during maintenance is also an urgent problem to be solved. During the maintenance period, the output of the unit is reduced sharply. At this time, the power grid can encourage consumers to reduce the demand for load power. On the premise of meeting their basic living requirements, they can achieve a win–win situation for both sides by adjusting the working conditions of air conditioning, lighting, heating equipment, etc.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Nomenclature
| Output of the i-th generator at time t | |
| Maximum and minimum output of the i-th generator at time t | |
| Power consumed by the electrolytic aluminum load at time t | |
| Deep peak regulation cost of thermal power units | |
| Status flag of deep peak regulation at time t | |
| Coal consumption rate of the thermal power unit under normal minimum output state | |
| Coal consumption rate of the thermal power unit under deep peak regulation state | |
| Coal consumption rate of the thermal power unit under normal rated output | |
| Unit coal price | |
| N | The number of generators |
| k | The number of wind farms integrated with the power grid |
| Penalty coefficient of wind abandonment | |
| m | The number of load nodes |
| Maximum output of the i-th wind farm at time t | |
| Actual consumed power of the i-th wind farm at time t | |
| Power in the line at time t | |
| Maximum and minimum power in the line | |
| Unit status flag | |
| Power of the i-th load at the time t | |
| Original power consumed by the electrolytic aluminum load before participating in demand response | |
| Reward coefficient of power regulation in the electrolytic aluminum load | |
| Startup and shutdown time of the i-th unit | |
| The minimum startup and shutdown time of the i-th unit | |
| Uncertainty of wind power output | |
| Upper and lower uncertainty limits of wind power output | |
| Output of the i-th generator at time t-1 | |
| The maximum upper and lower value of unit ramp rate | |
| Unit reserve of the system | |
| Start time and end time of the maintenance plan | |
| Total time of power system dispatching | |
| Duration of unit maintenance |
References
- Hedayati-Mehdiabadi, M.; Zhang, J.; Hedman, K.W. Wind Power Dispatch Margin for Flexible Energy and Reserve Scheduling with Increased Wind Generation. IEEE Trans. Sustain. Energy 2015, 6, 1543–1552. [Google Scholar] [CrossRef]
- Wang, Z.; Shen, C.; Liu, F.; Wu, X.; Liu, C.-C.; Gao, F. Chance-Constrained Economic Dispatch With Non-Gaussian Correlated Wind Power Uncertainty. IEEE Trans. Power Syst. 2017, 32, 4880–4893. [Google Scholar] [CrossRef]
- Li, P.; Yang, M.; Wu, Q. Confidence Interval Based Distributionally Robust Real-Time Economic Dispatch Approach Considering Wind Power Accommodation Risk. IEEE Trans. Sustain. Energy 2021, 12, 58–69. [Google Scholar] [CrossRef]
- Miranda, V.; Hang, P.S. Economic Dispatch Model with Fuzzy Wind Constraints and Attitudes of Dispatchers. IEEE Trans. Power Syst. 2005, 20, 2143–2145. [Google Scholar] [CrossRef] [Green Version]
- Feng, C.; Wang, X. A Competitive Mechanism of Unit Maintenance Scheduling in a Deregulated Environment. IEEE Trans. Power Syst. 2009, 25, 351–359. [Google Scholar] [CrossRef]
- Huang, J.; Chang, Q.; Zou, J.; Arinez, J. A Real-Time Maintenance Policy for Multi-Stage Manufacturing Systems Considering Imperfect Maintenance Effects. IEEE Access 2018, 6, 62174–62183. [Google Scholar] [CrossRef]
- Mirsaeedi, H.; Fereidunian, A.; Mohammadi-Hosseininejad, S.M.; Dehghanian, P.; Lesani, H. Long-Term Maintenance Scheduling and Budgeting in Electricity Distribution Systems Equipped With Automatic Switches. IEEE Trans. Ind. Inform. 2018, 14, 1909–1919. [Google Scholar] [CrossRef]
- Abiri-Jahromi, A.; Fotuhi-Firuzabad, M.; Parvania, M. Optimized Midterm Preventive Maintenance Outage Scheduling of Thermal Generating Units. IEEE Trans. Power Syst. 2012, 27, 1354–1365. [Google Scholar] [CrossRef]
- Fu, C.; Ye, L.; Liu, Y.; Yu, R.; Iung, B.; Cheng, Y.; Zeng, Y. Predictive Maintenance in Intelligent-Control-Maintenance-Management System for Hydroelectric Generating Unit. IEEE Trans. Energy Convers. 2004, 19, 179–186. [Google Scholar] [CrossRef]
- Bai, S.; Cheng, Z.; Guo, B. Maintenance Optimization Model with Sequential Inspection Based on Real-Time Reliability Evaluation for Long-Term Storage Systems. Processes 2019, 7, 481. [Google Scholar] [CrossRef] [Green Version]
- Chen, A.; Blue, J. Recipe-Independent Indicator for Tool Health Diagnosis and Predictive Maintenance. IEEE Trans. Semicond. Manuf. 2009, 22, 522–535. [Google Scholar] [CrossRef]
- Nourelfath, M.; Fitouhi, M.-C.; Machani, M. An Integrated Model for Production and Preventive Maintenance Planning in Multi-State Systems. IEEE Trans. Reliab. 2010, 59, 496–506. [Google Scholar] [CrossRef]
- Chen, H.; Lu, N.; Jiang, B.; Xing, Y. Condition-based maintenance optimization for continuously monitored degrading systems under imperfect maintenance actions. J. Syst. Eng. Electron. 2020, 31, 841–851. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, S.; Zhao, Y. Application of support vector machine and least squares vector machine to freight volume forecast. In Proceedings of the 2011 International Conference on Remote Sensing, Environment and Transportation Engineering, Nanjing, China, 24–26 June 2011; pp. 104–107. [Google Scholar]
- Ertekin, Ş.; Bottou, L.; Giles, C.L. Nonconvex Online Support Vector Machines. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 368–381. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mohan, L.; Pant, J.; Suyal, P.; Kumar, A. Support Vector Machine Accuracy Improvement with Classification. In Proceedings of the 2020 12th International Conference on Computational Intelligence and Communication Networks (CICN), Bhimtal, India, 25–26 September 2020; pp. 477–481. [Google Scholar]
- Sun, B.; Song, S.-J.; Wu, C. A new algorithm of support vector machine based on weighted feature. In Proceedings of the 2009 International Conference on Machine Learning and Cybernetics, Baoding, China, 12–15 July 2009; Volume 3, pp. 1616–1620. [Google Scholar]
- Kong, R.; Zhang, B. Autocorrelation Kernel Functions for Support Vector Machines. In Proceedings of the Third International Conference on Natural Computation (ICNC 2007), Haikou, China, 24–27 August 2007; Volume 1, pp. 512–516. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Unit Number | Downtime Period Available for Maintenance | Unit Number | Downtime Period Available for Maintenance |
|---|---|---|---|
| 1 | 4–7 | 11 | 2–5 |
| 2 | 5–6 | 12 | 8–13 |
| 3 | 20–22 | 13 | 9–11 |
| 4 | 31–34 | 14 | 42–46 |
| 5 | 23–28 | 15 | 28–31 |
| 6 | 11–14 | 16 | 12–14 |
| 7 | 21–25 | 17 | 25–26 |
| 8 | 44–46 | 18 | 26–27 |
| 9 | 19–21 | 19 | 11–12 |
| 10 | 17–19 | 20 | 37–39 |
| Model | Average Wind Power Curtailment Rate/% | Total Cost/USD |
|---|---|---|
| Model proposed in this paper | 1.21 | 52,272 |
| Model not considering electrolytic aluminum load | 1.97 | 85,104 |
| Unit Number | Downtime Period Available for Maintenance | Unit Number | Downtime Period Available for Maintenance |
|---|---|---|---|
| 1 | 5–7 | 11 | 20–22 |
| 2 | 8–11 | 12 | 1–3 |
| 3 | 13–15 | 13 | 2–5 |
| 4 | 8–9 | 14 | 14–17 |
| 5 | 5–6 | 15 | 6–8 |
| 6 | 6–8 | 16 | 3–5 |
| 7 | 11–13 | 17 | 12–14 |
| 8 | 17–19 | 18 | 18–20 |
| 9 | 6–7 | 19 | 7–9 |
| 10 | 20–23 | 20 | 19–22 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, B.; Shu, H.; Si, D.; Li, W.; He, J.; Yan, W. Research and Application of Power Grid Maintenance Scheduling Strategy under the Interactive Mode of New Energy and Electrolytic Aluminum Load. Processes 2022, 10, 606. https://doi.org/10.3390/pr10030606
Zhang B, Shu H, Si D, Li W, He J, Yan W. Research and Application of Power Grid Maintenance Scheduling Strategy under the Interactive Mode of New Energy and Electrolytic Aluminum Load. Processes. 2022; 10(3):606. https://doi.org/10.3390/pr10030606
Chicago/Turabian StyleZhang, Bin, Hongchun Shu, Dajun Si, Wenyun Li, Jinding He, and Wenlin Yan. 2022. "Research and Application of Power Grid Maintenance Scheduling Strategy under the Interactive Mode of New Energy and Electrolytic Aluminum Load" Processes 10, no. 3: 606. https://doi.org/10.3390/pr10030606
APA StyleZhang, B., Shu, H., Si, D., Li, W., He, J., & Yan, W. (2022). Research and Application of Power Grid Maintenance Scheduling Strategy under the Interactive Mode of New Energy and Electrolytic Aluminum Load. Processes, 10(3), 606. https://doi.org/10.3390/pr10030606