
Predictive Classifier for Cardiovascular Disease Based on Stacking Model Fusion


Abstract
:1. Introduction
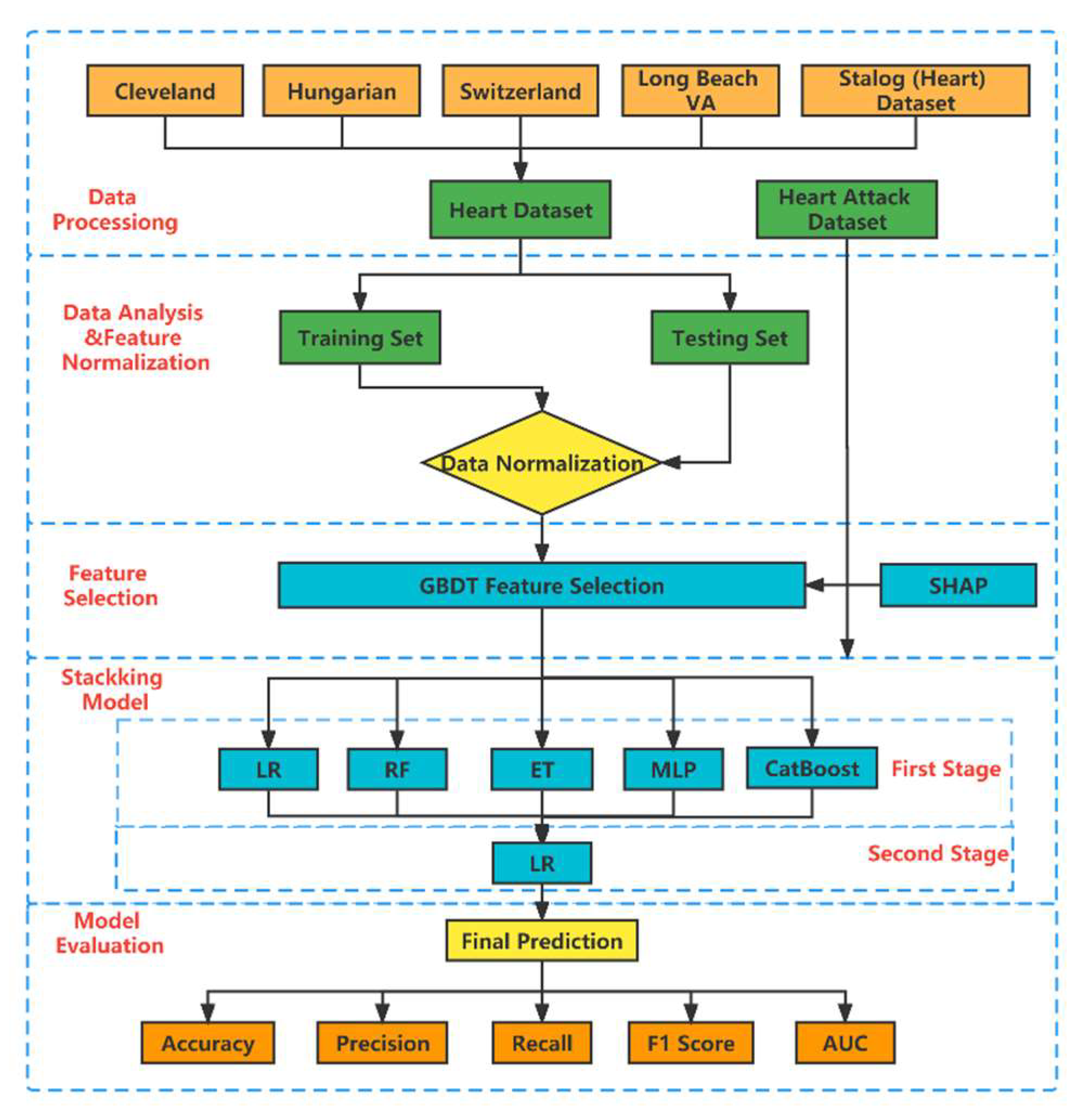
2. Materials and Methods
2.1. Dataset
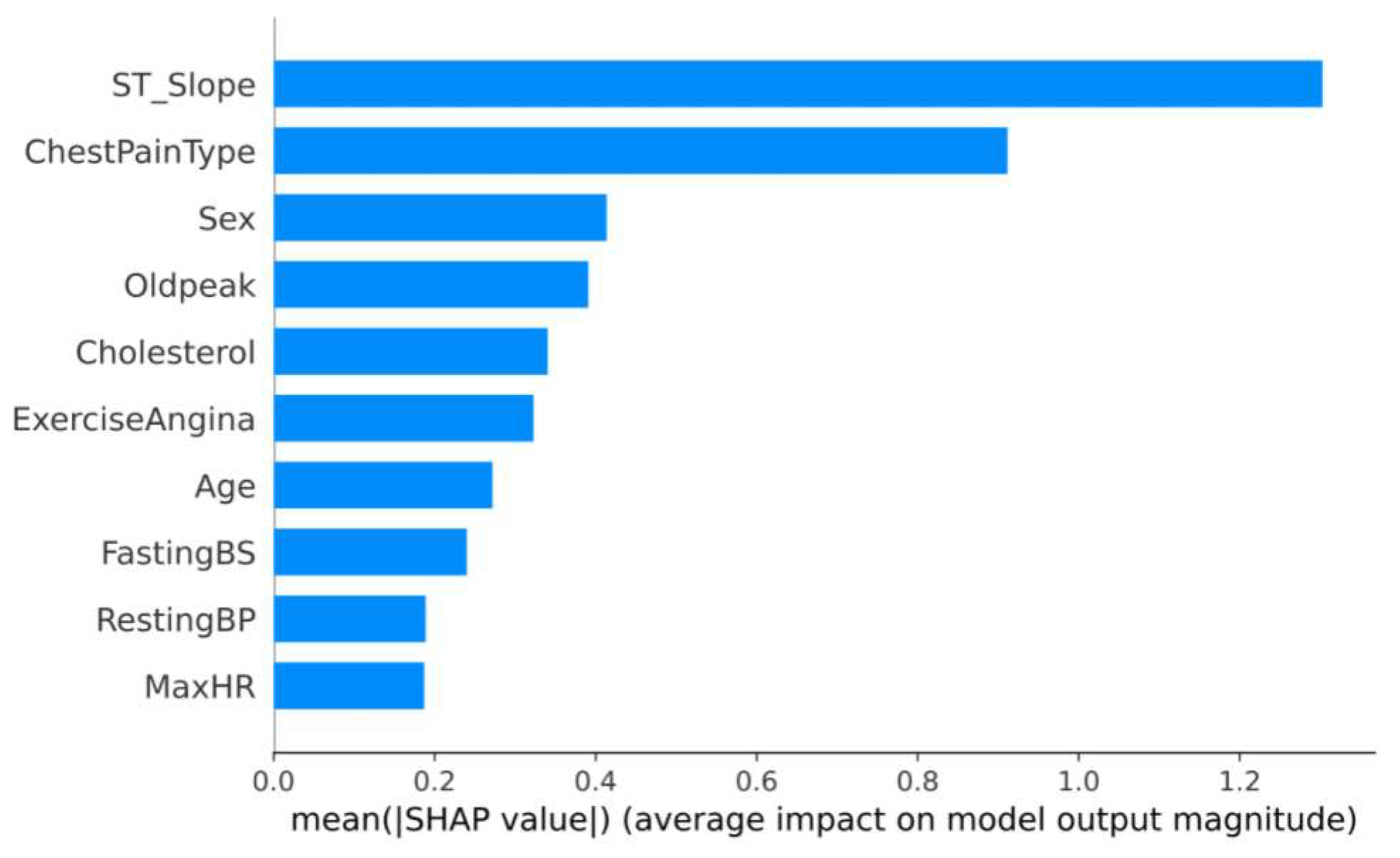
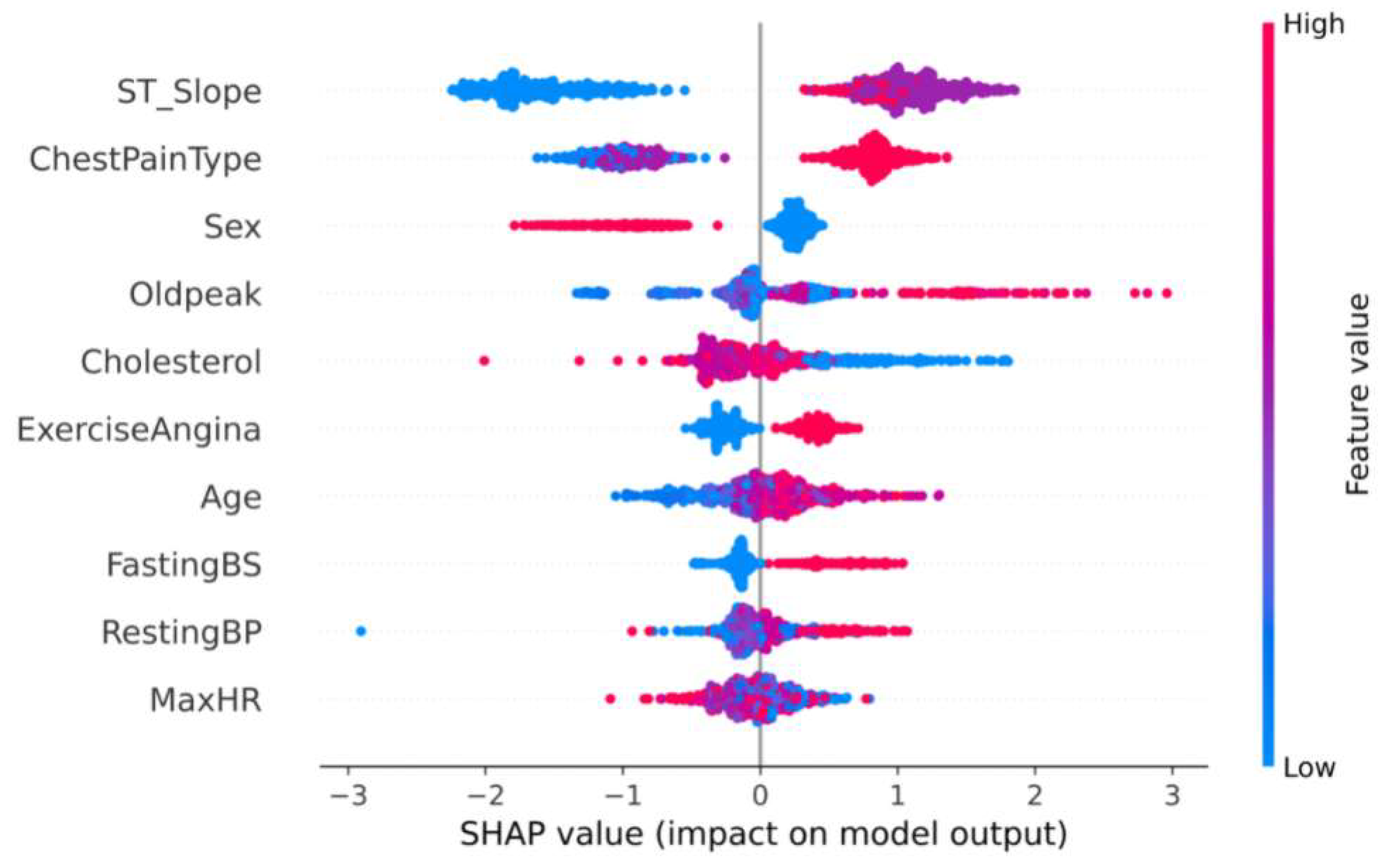
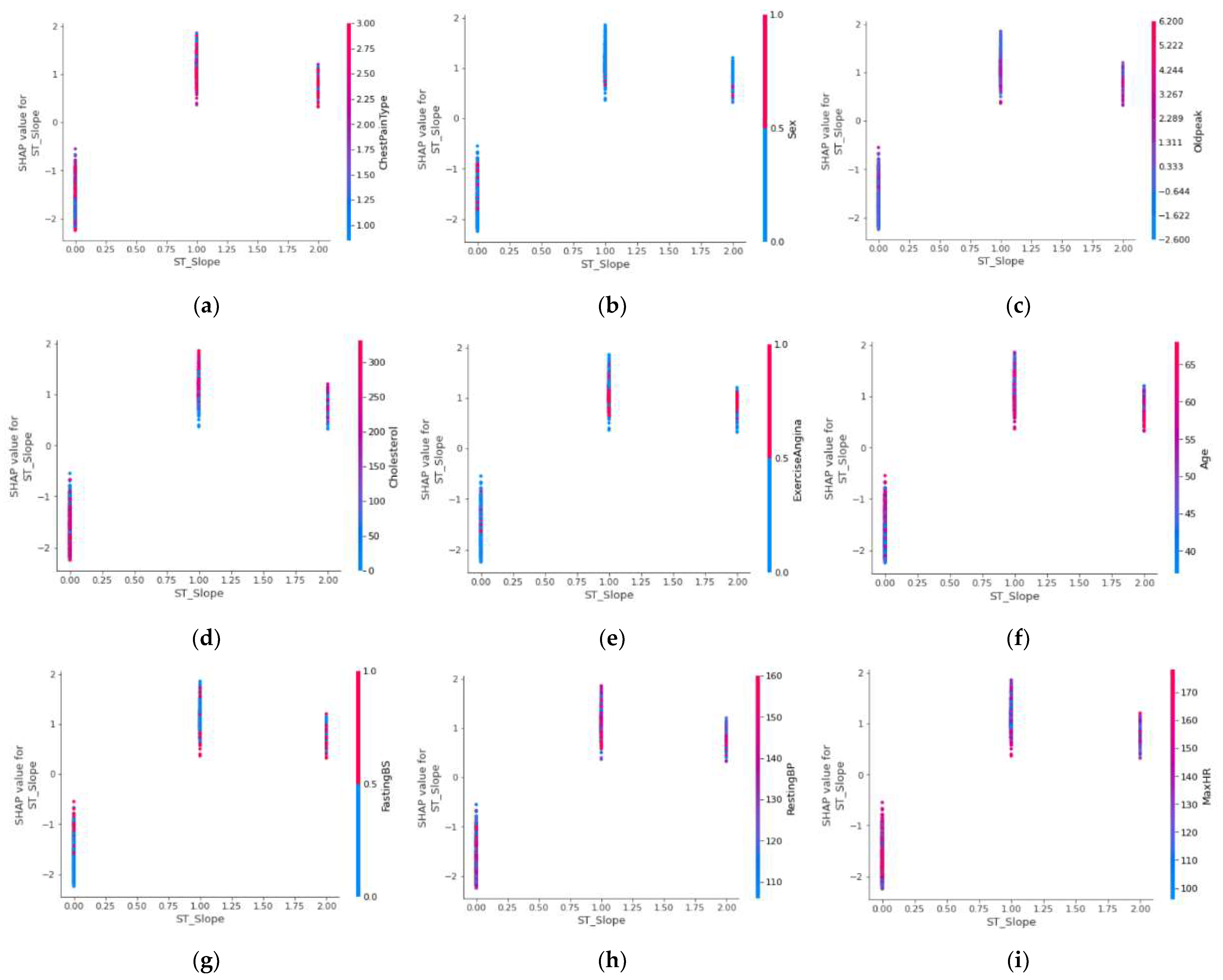
2.2. Feature Select and Analysis
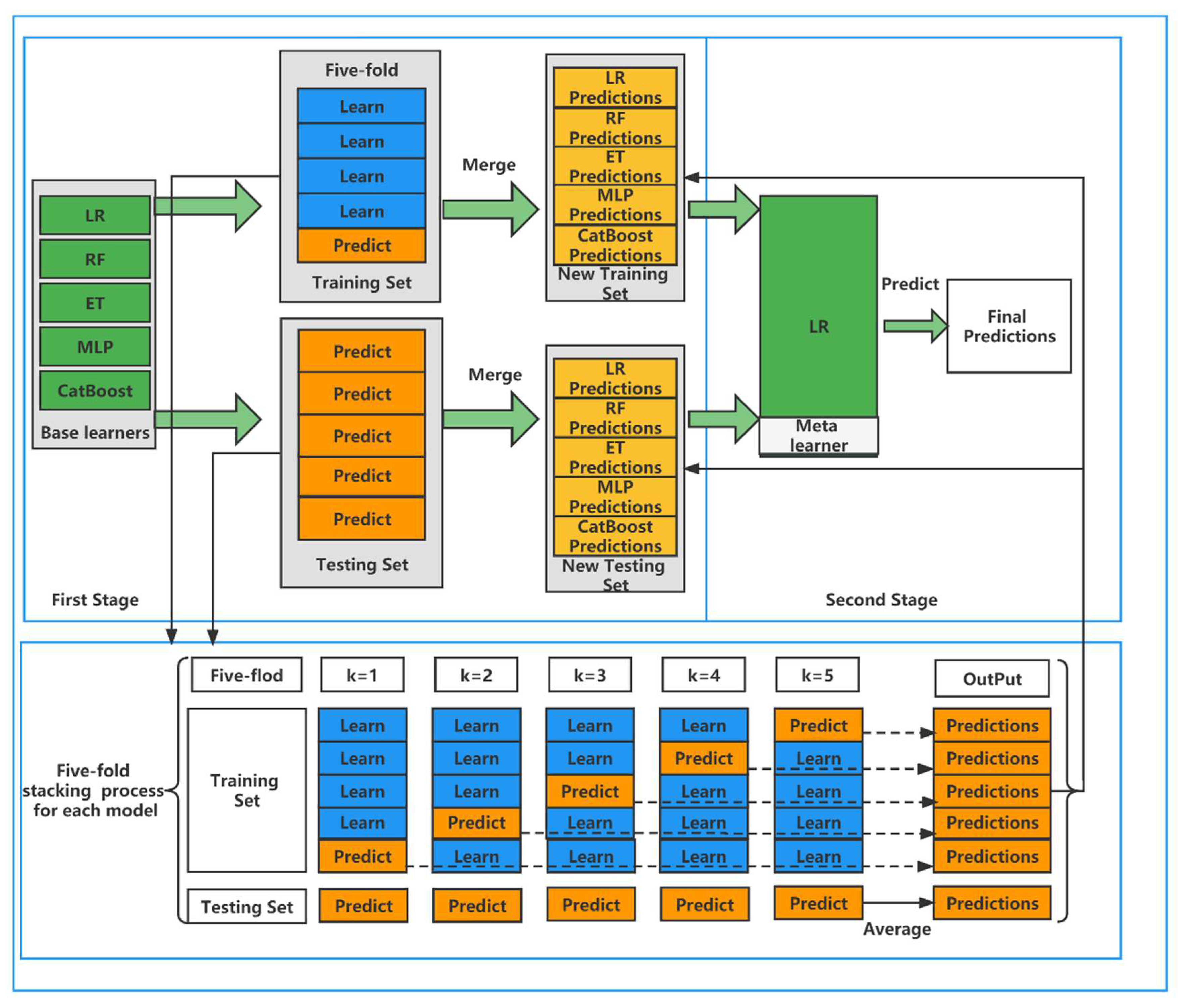
2.3. Model Building
| Algorithm 1: Stacking Model |
| DEFINE: A training set and a testing set . is the training set in five-fold CV process. is the testing set in five-fold CV process. . are base learners, is meta learner. The training set of , the testing set of . |
|
2.4. Evaluation Metrics
3. Results and Discussion
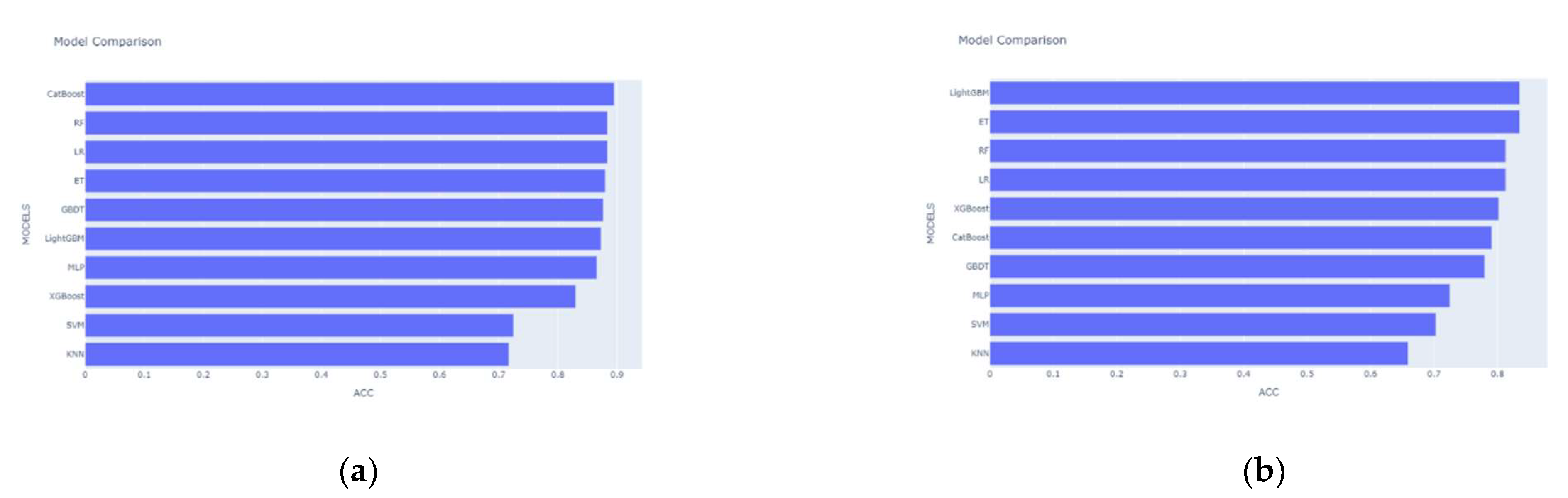
3.1. Results of Feature Selection and Analysis
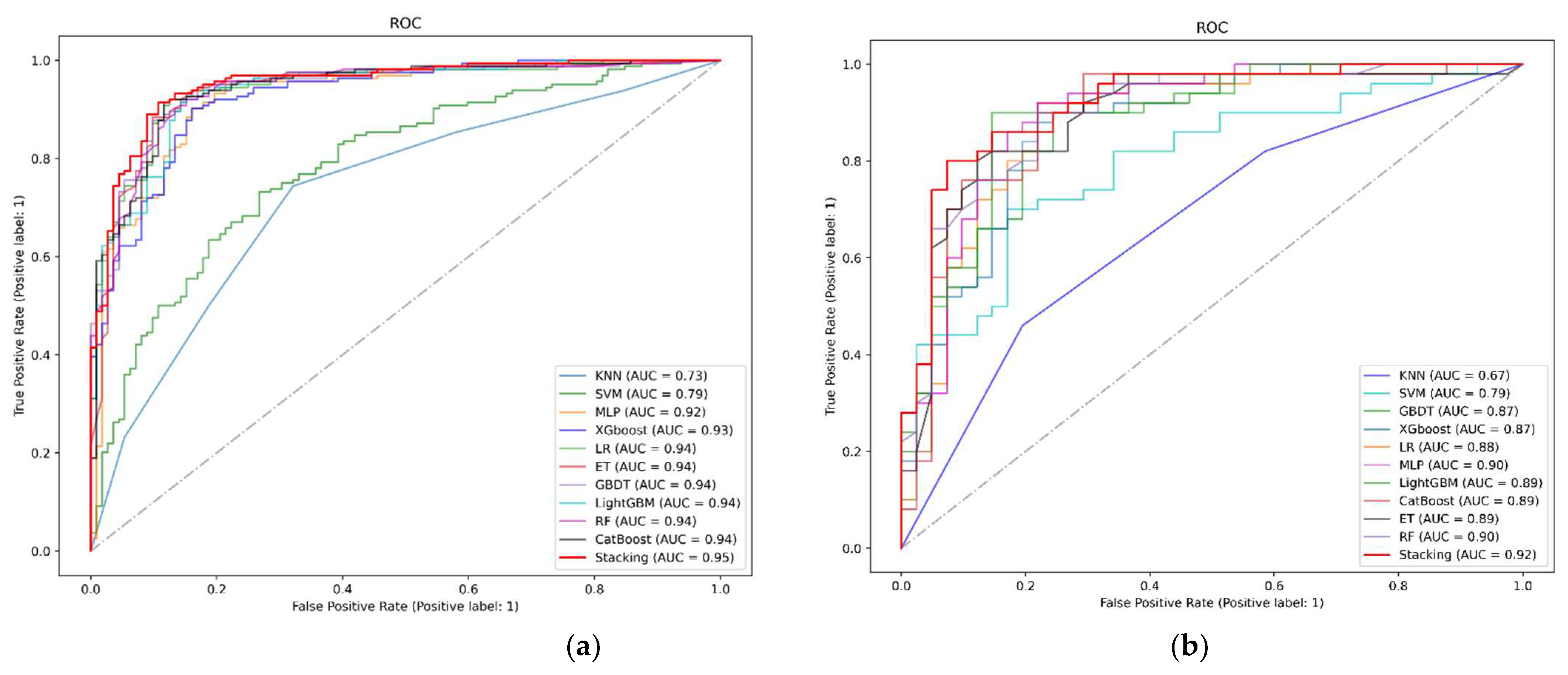
3.2. Results of the Proposed Stacking Model and Other Models
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krittanawong, C.; Virk, H.; Bangalore, S.; Wang, Z.; Johnson, K.W.; Pinotti, R.; Zhang, H.; Kaplin, S.; Narasimhan, B.; Kitai, T.; et al. Machine Learning Prediction in Cardiovascular Diseases: A Meta-Analysis. Sci. Rep. 2020, 10, 16057. [Google Scholar] [CrossRef] [PubMed]
- Kavitha, M.; Gnaneswar, G.; Dinesh, R.; Sai, Y.R.; Suraj, R.S. Heart Disease Prediction Using Hybrid Machine Learning Model. In Proceedings of the 2021 6th International Conference on Inventive Computation Technologies, Tamilnadu, India, 20–22 January 2021. [Google Scholar]
- Jabbar, M.A.; Deekshatulu, B.L.; Chandra, P. Intelligent Heart Disease Prediction System Using Random Forest and Evolutionary Approach. J. Netw. Innov. Comput. 2016, 4, 175–184. [Google Scholar]
- Alkeshuosh, A.H.; Moghadam, M.Z.; Mansoori, I.A.; Abdar, M. Using PSO Algorithm for Producing Best Rules in Diagnosis of Heart Disease. In Proceedings of the 2017 international conference on computer and applications, Doha, United Arab Emirates, 6–7 September 2017. [Google Scholar]
- Ramalingam, V.V.; Dandapath, A.; Karthik Raja, M. Heart Disease Prediction Using Machine Learning Techniques: A Survey Heart Disease Prediction Using Machine Learning Techniques: A Survey. Artic. Int. J. Eng. Technol. 2018, 7, 684–687. [Google Scholar] [CrossRef] [Green Version]
- Katarya, R.; Meena, S.K. Machine Learning Techniques for Heart Disease Prediction: A Comparative Study and Analysis. Health Technol. 2021, 11, 87–97. [Google Scholar] [CrossRef]
- Diwakar, M.; Tripathi, A.; Joshi, K.; Singh, P.; Memoria, M.; Kumar, N. Latest Trends on Heart Disease Prediction Using Machine Learning and Image Fusion. Mater. Today Proc. 2021, 37, 3213–3218. [Google Scholar] [CrossRef]
- Bharti, R.; Khamparia, A.; Shabaz, M.; Dhiman, G.; Pande, S.; Singh, P. Prediction of Heart Disease Using a Combination of Machine Learning and Deep Learning. Comput. Intell. Neurosc. 2021, 2021, 1687–5237. [Google Scholar] [CrossRef]
- Krzowski, B.; Rokicki, J.; Główczyńska, R.; Fajkis-Zajączkowska, N.; Barczewska, K.; Mąsior, M.; Grabowski, M.; Balsam, P. The Use of Machine Learning Algorithms in the Evaluation of the Effectiveness of Resynchronization Therapy. J. Cardiovasc. Dev. Dis. 2022, 9, 17. [Google Scholar] [CrossRef]
- Yan, T.; Zhu, S.; Xie, C.; Zhu, M.; Weng, F.; Wang, C.; Guo, C. Coronary Artery Disease and Atrial Fibrillation: A Bidirectional Mendelian Randomization Study. J. Cardiovasc. Dev. Dis. 2022, 9, 69. [Google Scholar] [CrossRef]
- Sun, W.; Zhang, P.; Wang, Z.; Li, D. Prediction of Cardiovascular Diseases Based on Machine Learning. ASP Trans. Internet Things 2021, 1, 30–35. [Google Scholar] [CrossRef]
- Association, D.; Sun, L.; Zhou, Y.; Zhang, M.; Li, C.; Qu, M.; Cai, Q.; Meng, J.; Fan, H.; Zhao, Y.; et al. Association of Major Chronic Noncommunicable Diseases and Life Expectancy in China, 2019. Healthcare 2022, 10, 296. [Google Scholar] [CrossRef]
- Makino, K.; Lee, S.; Bae, S.; Chiba, I.; Harada, K.; Katayama, O.; Shinkai, Y.; Shimada, H. Absolute Cardiovascular Disease Risk Assessed in Old Age Predicts Disability and Mortality: A Retrospective Cohort Study of Community—Dwelling Older Adults. Am. Hear. Assoc. 2021, 10, 22004. [Google Scholar] [CrossRef] [PubMed]
- Elyamani, R.; Soulaymani, A.; Hami, H. Epidemiology of Cardiovascular Diseases in Morocco: A Systematic Review. Rev. Diabet. Stud. 2021, 17, 57–67. [Google Scholar] [CrossRef] [PubMed]
- Pharr, J.R.; Batra, K.; Santos, A.C. Non-Communicable Disease (NCDs). Healthcare 2021, 9, 696. [Google Scholar] [CrossRef] [PubMed]
- Lbrini, S.; Fadil, A.; Aamir, Z.; Khomali, M.; Jarar Oulidi, H.; Rhinane, H. Big Health Data: Cardiovascular Disease Prevention Using Big Data and Machine Learning. Stud. Comput. Intell. 2021, 971, 311–327. [Google Scholar] [CrossRef]
- Toure, A.I.; Souley, K.; Boncano, A.; Dodo, B.; Haggar, M.; Mahmat, S.; Zakaria, A.; SDjonyabo Akakpo, E.; Gonda, I.; Moustapha, O. Acute Coronary Syndromes in Niger: (West Africa): Epidemiological, Clinical, Para clinical and Therapeutic Aspects. Cardiol. Vasc. Res. 2021, 5, 1–7. [Google Scholar]
- Bihrmann, K.; Gislason, G.; Larsen, M.L.; Ersbøll, A.K. Joint Mapping of Cardiovascular Diseases: Comparing the Geographic Patterns in Incident Acute Myocardial Infarction, Stroke and Atrial Fibrillation, a Danish Register-Based Cohort Study 2014–15. Int. J. Health Geogr. 2021, 20, 41. [Google Scholar] [CrossRef]
- Mir, R.; Elfaki, I.; Khullar, N.; Ahmad Waza, A.; Jha, C.; Muzaffar Mir, M.; Nisa, S.; Mohammad, B.; Ahmad Mir, T.; Maqbool, M.; et al. Role of Selected MiRNAs as Diagnostic and Prognostic Biomarkers in Cardiovascular Diseases, Including Coronary Artery Disease, Myocardial Infarction And Atherosclerosis. J. Cardiovasc. Dev. Dis. 2021, 8, 22. [Google Scholar] [CrossRef]
- Wang, T.J.; Larson, M.G.; Levy, D.; Vasan, R.S.; Leip, E.P.; Wolf, P.A.; D’Agostino, R.B.; Murabito, J.M.; Kannel, W.B.; Benjamin, E.J. Temporal Relations of Atrial Fibrillation and Congestive Heart Failure and Their Joint Influence on Mortality: The Framingham Heart Study. Circulation 2003, 107, 2920–2925. [Google Scholar] [CrossRef] [Green Version]
- Piepoli, M.F.; Hoes, A.W.; Agewall, S.; Albus, C.; Brotons, C.; Catapano, A.L.; Cooney, M.-T.; Corrà, U.; Cosyns, B.; Deaton, C.; et al. 2016 European Guidelines on cardiovascular disease prevention in clinical practice: The Sixth Joint Task Force of the European Society of Cardiology and Other Societies on Cardiovascular Disease Prevention in Clinical Practice (constituted by representatives of 10 societies and by invited experts)Developed with the special contribution of the European Association for Cardiovascular Prevention & Rehabilitation (EACPR). Eur. Heart J. 2017, 37, 2315–2381. [Google Scholar]
- Desai, R.J.; Wang, S.V.; Vaduganathan, M.; Evers, T.; Schneeweiss, S. Comparison of Machine Learning Methods With Traditional Models for Use of Administrative Claims With Electronic Medical Records to Predict Heart Failure Outcomes. JAMA Netw. Open 2020, 3, e1918962. [Google Scholar] [CrossRef]
- Alaa, A.M.; Bolton, T.; Angelantonio, E.D.; Rudd, J.H.F.; van der Schaar, M. Cardiovascular Disease Risk Prediction Using Automated Machine Learning: A Prospective Study of 423,604 UK Biobank Participants. PLoS ONE 2019, 14, e0213653. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hussain, W.; Aldahiri, A.; Alrashed, B. Trends in Using IoT with Machine Learning in Health Prediction System. Forecasting 2021, 3, 181–207. [Google Scholar] [CrossRef]
- Kishor, A.; Chakraborty, C. Artificial Intelligence and Internet of Things Based Healthcare 4.0 Monitoring System. Wirel. Pers. Commun. 2021, 2, 1–17. [Google Scholar] [CrossRef]
- Ristevski, B.; Snezana, S. Healthcare and Medical Big Data Analytics; Elsevier: Amsterdam, The Netherlands, 2021. [Google Scholar] [CrossRef]
- Lee, S.S.; Ae, K.K.; Kim, D.; Lim, Y.; Yang, P.; Yi, J.; Kim, M.; Kwon, K.; Pyun, W.B.; Joung, B.; et al. Clinical Implication of an Impaired Fasting Glucose and Prehypertension Related to New Onset Atrial Fibrillation in a Healthy Asian Population without Underlying Disease. Eur. Heart J. 2017, 38, 2599–2607. [Google Scholar] [CrossRef] [PubMed]
- Alsunaidi, S.J.; Almuhaideb, A.M.; Ibrahim, N.M.; Shaikh, F.S.; Alqudaihi, K.S.; Alhaidari, F.A.; Khan, I.U.; Aslam, N.; Alshahrani, M.S. Applications of Big Data Analytics to Control COVID-19 Pandemic. Sensors 2021, 21, 2282. [Google Scholar] [CrossRef] [PubMed]
- Ali, M.M.; Paul, B.K.; Ahmed, K.; Bui, F.M.; Quinn, J.M.; Moni, M.A. Heart Disease Prediction Using Supervised Machine Learning Algorithms: Performance Analysis and Comparison. Comput. Biol. Med. 2021, 136, 104672. [Google Scholar] [CrossRef]
- Dogan, O.; Tiwari, S.; Jabbar, M.A.; Guggari, S. A Systematic Review on AI/ML Approaches against COVID-19 Outbreak. Complex. Intell. Syst. 2021, 7, 2655–2678. [Google Scholar] [CrossRef]
- Weng, S.F.; Reps, J.; Kai, J.; Garibaldi, J.M.; Qureshi, N. Can Machine-Learning Improve Cardiovascular Risk Prediction Using Routine Clinical Data? PLoS ONE 2017, 12, e0174944. [Google Scholar] [CrossRef] [Green Version]
- Dimopoulos, A.C.; Nikolaidou, M.; Caballero, F.F.; Engchuan, W.; Sanchez-Niubo, A.; Arndt, H.; Ayuso-Mateos, J.L.; Haro, J.M.; Chatterji, S.; Georgousopoulou, E.N.; et al. Machine Learning Methodologies versus Cardiovascular Risk Scores, in Predicting Disease Risk. BMC Med. Res. Methodol. 2018, 18, 179. [Google Scholar] [CrossRef] [PubMed]
- Mohan, S.; Thirumalai, C.; Srivastava, G. Effective Heart Disease Prediction Using Hybrid Machine Learning Techniques. IEEE Access 2019, 7, 81542–81554. [Google Scholar] [CrossRef]
- Akash, I.; Tabassum, S.; Ullah, S.; Nahar, S.; Ittahad, M.; Zaman, U.; Ullah, M.S.; Rahaman, A.; Islam, A.K.M.M. Towards IoT and ML Driven Cardiac Status Prediction System. In Proceedings of the 2019 1st International Conference on Advances in Science, Engineering and Robotics Technology (ICASERT), Dhaka, Bangladesh, 3–5 May 2019. [Google Scholar] [CrossRef]
- Yang, L.; Wu, H.; Jin, X.; Zheng, P.; Hu, S.; Xu, X.; Yu, W.; Yan, J. Study of Cardiovascular Disease Prediction Model Based on Random Forest in Eastern China. Sci. Rep. 2020, 10, 5245. [Google Scholar] [CrossRef] [Green Version]
- Hu, Z.; Qiu, H.; Su, Z.; Shen, M.; Chen, Z. A Stacking Ensemble Model to Predict Daily Number of Hospital Admissions for Cardiovascular Diseases. IEEE Access 2020, 8, 138719–138729. [Google Scholar] [CrossRef]
- Zheng, H.; Sherazi, S.W.A.; Lee, J.Y. A Stacking Ensemble Prediction Model for the Occurrences of Major Adverse Cardiovascular Events in Patients with Acute Coronary Syndrome on Imbalanced Data. IEEE Access 2021, 9, 113692–113704. [Google Scholar] [CrossRef]
- Ahamed, J.; Mir, R.N.; Chishti, M.A. Industry 4.0 Oriented Predictive Analytics of Cardiovascular Diseases Using Machine Learning, Hyperparameter Tuning and Ensemble Techniques. Ind. Rob. 2022. Ahead-of-print. [Google Scholar] [CrossRef]
- Ting, K.; Witten, I. Stacking Bagged and Dagged Models. In Proceedings of the Fourteenth International Conference on Machine Learning, 8–12 July 1997; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1997. [Google Scholar]
- Lundberg, S.M.; Erion, G.G.; Lee, S.-I. Consistent Individualized Feature Attribution for Tree Ensembles. arXiv 2018, arXiv:1802.03888. [Google Scholar]
- Dash, M.; Liu, H. Feature Selection for Classification. Intell. Data Anal. 1997, 1, 131–156. [Google Scholar] [CrossRef]
- Parthiban, R.; Usharani, S.; Saravanan, D.; Jayakumar, D.; Palani, U.; Stalindavid, D.; Raghuraman, D. Prognosis of Chronic Kidney Disease (CKD) Using Hybrid Filter Wrapper Embedded Feature Selection Method. Eur. J. Mol. Clin. Med. 2020, 7, 2511–2530. [Google Scholar]
- Chen, L.; Xia, M. A Context-Aware Recommendation Approach Based on Feature Selection. Appl. Intell. 2021, 51, 865–875. [Google Scholar] [CrossRef]
- Rao, H.; Shi, X.; Rodrigue, A.K.; Juanjuan, F.; Yingchun, X.; Mohamed, E.; Xiaohui, Y.; Lichuan, G. Feature Selection Based on Artificial Bee Colony and Gradient Boosting Decision Tree. Appl. Soft Comput. 2019, 74, 634–642. [Google Scholar] [CrossRef]
- Zhang, J.; Liang, Q.; Jiang, R.; Li, X. A Feature Analysis Based Identifying Scheme Using GBDT for DDoS with Multiple Attack Vectors. Appl. Sci. 2019, 9, 4633. [Google Scholar] [CrossRef] [Green Version]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-Generation Hyperparameter Optimization Framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 2623–2631. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Feature | Detailed Information |
|---|---|---|
| 1 | Age | Age |
| 2 | Sex | Sex (Male: 0 or female: 1) |
| 3 | ChestPainType | Four types of chest pain (TA: typical angina, ATA: atypical angina, NAP: non-angina, ASY: asymptomatic) |
| 4 | RestingBP | Resting blood pressure value (Unit mm hg) |
| 5 | Cholesterol | Serum cholesterol concentration (Unit mm/dL) |
| 6 | FastingBS | Fasting blood glucose value (1: blood glucose > 120 mg/dL, 0: other) |
| 7 | RestingECG | Resting electrocardiogram (Normal: normal, ST: with ST-T wave abnormalities (T-wave inversion or ST elevation or depression > 0.05 mv), LVH: possible or definite left ventricular hypertrophy according to criteria) |
| 8 | MaxHR | The maximum heart rate achieved. (Values between 60 and 202) |
| 9 | ExerciseAngina | Whether you have exercise angina (No: 0, Yes: 1) |
| 10 | Oldpeak | Exercise-induced ST-segment drop (ST value judgment) |
| 11 | ST_Slope | Slope of the ST section at the peak of the movement (up, flat, down) |
| ID | Feature | Detailed Information |
|---|---|---|
| 1 | Age | Age |
| 2 | Sex | Sex of the patient (Male: 0, female: 1) |
| 3 | Exang | Exercise induced angina (1 = yes, 0 = no) |
| 4 | Ca | Number of major vessels (0–3) |
| 5 | Cp | Chest Pain type chest pain typeb (1: typical angina, 2: atypical angina, 3: non-anginal pain, 4: asymptomatic) |
| 6 | Trtbps | Resting blood pressure (Unit mm hg) |
| 7 | Chol | Cholestoral in mg/dL fetched via BMI sensor |
| 8 | Fbs | (Fasting blood sugar > 120 mg/dL) (1 = true, 0 = false) |
| 9 | Rest_ecg | Resting electrocardiographic results (0: normal, 1: having ST-T wave abnormality (T wave inversions and/or ST elevation or depression of >0.05 mV), 2: showing probable or definite left ventricular hypertrophy by Estes’ criteria) |
| 10 | Thalach | Maximum heart rate achieved |
| Dataset | Model | Accuracy (%) | Precision (%) | Recall (%) | F1 Score (%) |
|---|---|---|---|---|---|
| Heart Dataset | KNN | 71.74 | 77.22 | 74.39 | 75.78 |
| SVM | 72.46 | 78.85 | 73.17 | 75.94 | |
| LR | 88.41 | 92.31 | 87.81 | 90 | |
| RF | 87.68 | 90.62 | 88.41 | 89.51 | |
| ET | 88.04 | 92.81 | 86.58 | 89.59 | |
| GBDT | 87.68 | 92.76 | 85.98 | 89.24 | |
| XGBoost | 82.97 | 89.8 | 80.49 | 84.89 | |
| LightGBM | 87.32 | 90.56 | 87.81 | 89.16 | |
| CatBoost | 89.49 | 91.41 | 90.85 | 91.13 | |
| MLP | 87.32 | 90.06 | 88.41 | 89.23 | |
| Stacking | 89.86 | 92.5 | 90.24 | 91.36 | |
| Heart Attack Dataset | KNN | 61.54 | 74.19 | 46 | 56.79 |
| SVM | 70.33 | 67.16 | 72 | 76.92 | |
| LR | 81.32 | 82.35 | 84 | 83.17 | |
| RF | 80.22 | 82 | 82 | 83.17 | |
| ET | 80.22 | 82 | 82 | 82 | |
| GBDT | 78.02 | 82.61 | 76 | 79.17 | |
| XGBoost | 80.22 | 83.33 | 80 | 81.63 | |
| LightGBM | 83.52 | 87.23 | 82 | 84.54 | |
| CatBoost | 79.12 | 81.63 | 80 | 80.81 | |
| MLP | 71.43 | 87.13 | 56 | 68.2 | |
| Stacking | 84.62 | 86 | 86 | 86 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Dong, X.; Zhao, H.; Tian, Y. Predictive Classifier for Cardiovascular Disease Based on Stacking Model Fusion. Processes 2022, 10, 749. https://doi.org/10.3390/pr10040749
Liu J, Dong X, Zhao H, Tian Y. Predictive Classifier for Cardiovascular Disease Based on Stacking Model Fusion. Processes. 2022; 10(4):749. https://doi.org/10.3390/pr10040749
Chicago/Turabian StyleLiu, Jimin, Xueyu Dong, Huiqi Zhao, and Yinhua Tian. 2022. "Predictive Classifier for Cardiovascular Disease Based on Stacking Model Fusion" Processes 10, no. 4: 749. https://doi.org/10.3390/pr10040749
APA StyleLiu, J., Dong, X., Zhao, H., & Tian, Y. (2022). Predictive Classifier for Cardiovascular Disease Based on Stacking Model Fusion. Processes, 10(4), 749. https://doi.org/10.3390/pr10040749