

Efficient Multi-Objective Optimization on Dynamic Flexible Job Shop Scheduling Using Deep Reinforcement Learning Approach


Abstract
:1. Introduction
1.1. Related Works
1.2. Contributions
- (1)
- A framework of two layers of DDQN is proposed to optimize the DFJSP of multiple objectives, corresponding to two connected agents with respective task divisions. The goal selector that is the higher DDQN intends to output an optimization goal with a five-element state vector as the feature input. The output of the higher network is one specific reward form, which is applied as one input state of the lower DDQN, along with the goal selector’s five input states. With six states input, the actuator (the lower DDQN) outputs a specific dispatching rule maximizing reward scores.
- (2)
- This work specifies optimization objectives, i.e., minimization of the job’s delay time sum and the machine’s completion time (makespan). Seven compositive dispatching rules and six continuous states are proposed to outline the DFJSP environment. The six states are represented as formulas, and their correlations are erased. The reward function is realized by the goal space with six reward forms, covering the higher DDQN’s goal output.
- (3)
- The simulation experiments are carried out to appear the production environment and realize the dynamic scheduling of flexible workshops based on the proposed mathematical model in Section 2 and DRL architecture in Section 3. A large number of datasets of different production configurations considerably generalize the trained DLDDQN model, enabling it to fit raw test examples and achieve expected objective optimizations.
2. Problem Formulation
- (1)
- Only an operation of one job can be processed at the arranged machine at a time.
- (2)
- The machine’s operation cannot be stopped without completing the running operation, following the atomicity principle.
- (3)
- Jobs are processed following the operation sequence without being skipped or randomly chosen.
- (4)
- The travel time between two consecutive operations and the machine startup time are both negligible.
- (5)
- A job’s unprocessed operations cannot be canceled, and the job processing quality caters to standard requirements.
- (6)
- The buffer size is assumed infinite.
Mathematical Representation
3. Construction of DRL Components
3.1. DRL Preliminaries
3.2. Model Architecture
- (1)
- A five-element state vector for the input of the higher DDQN is observed from the environment (zero vector when the training is initial) as
- (2)
- The higher DDQN applies the goal selection policy to obtain the goal , as shown in Figure 1.
- (3)
- Together with , is included as the input of the lower DDQN to form .
- (4)
- The lower DDQN applies the action selection policy to obtain the action , as shown in Figure 2.
- (5)
- The environment executes the selected compositive dispatching rule that corresponds to the action as shown in “➀ Execute” in Figure 1.
- (6)
- The environment arranges the scheduled operation to its dispatched machine’s queue and then updates the job shop situation, as shown in “➁ Schedule” and “➂ Update” in Figure 1, respectively.
- (7)
- The environment feedbacks to the higher DDQN. Together with (, ) to form an experience item (, the higher DDQN stores the item to the Replay Memory D1. Then, repeat procedures (1)–(3) with the input of the higher DDQN as to obtain and form .
- (8)
- Together with ( to form an experience item (), the lower DDQN stores the item to the Replay Memory D2.
- (9)
- , repeat procedures (4)–(9) until operations of all jobs are completely allocated.
- (10)
- Repeat procedures (1)–(9) until the training epochs end and the trained model converges.
3.3. State Feature Extraction
- All states should directly or indirectly relate to optimization objectives and the reward function. Other redundant features can be excluded.
- Refined states should be quantitatively and qualitatively advantageous to the DDQN training and the most considerable probable reflection of the global and local scheduling environment.
- State features are numerical representations of the state vector on all dimensions and should be easy to calculate when running on a high-performance CPU or GPU. If necessary, state features are intended to be uniformly normalized to maintain training stability and avoid other issues.
- (1)
- The maximum completion time on the last operations of all assigned machines at rescheduling point , as defined in Equation (11):
- (2)
- The maximum completion time on the last operations of all assigned jobs at rescheduling point , as defined in Equation (12):
- (3)
- The average utilization rate of all machines in the system, , can be formulized in Equation (13):
- (4)
- The predicted average delay rate over unfinished jobs in the system.
| Algorithm 1: Procedure to calculate the predicted average delay rate |
| input: output: 1:←0 2:←0 3:for do 4: if then 5: ←0 6: ←0 7: if 8: ←1 9: end if 10: for do 11: ← 12: if 13: ← 14: if = 1 15: ← 16: ←0 17: else 18: ← 19: end if 20: end if 21: end for 22: end if 23: end for 24: ← 25: return |
- (5)
- The real average delay rate over unfinished jobs in the system.
| Algorithm 2: Procedure to calculate the real average delay rate |
| Input: Output: 1:←0 2:←0 4:for do 5: if then 6: if then 7: ← 8: ← 9: for do 10: 11: ← 12: end for 13: end if 14: end if 15:end for 16: ← 17: return |
3.4. Action Space
3.4.1. Compositive Dispatching Rule 1
| Algorithm 3: Pseudo code of compositive dispatching rule 1 |
| 1: ← 2: ← 3: if Count() = 0 then 4: ← 5: else 6: ← 7: end if 8: ← + 1 9: ← 10: ← 11: arrange of job on to execute a task |
3.4.2. Compositive Dispatching Rule 2
| Algorithm 4: Pseudo code of compositive dispatching rule 2 |
| 1: ← 2: ← 3: if Count() = 0 then 4: ← 5: else 6: ← 7: end if 8: ← 9: ← |
| 10: ← 11: arrange of job on to execute a task |
3.4.3. Compositive Dispatching Rule 3
| Algorithm 5: Pseudo code of compositive dispatching rule 3 |
| 1: ← 2: ← 3: if Count() = 0 then 4: ← 5: else 6: ← 7: end if 8: ← 9: = 10: ← 11: arrange of job on to execute a task |
3.4.4. Compositive Dispatching Rule 4
| Algorithm 6: Pseudo code of compositive dispatching rule 4 |
| 1: ← 2: ← 3: ← 4: ← 5: ← 6: arrange of job on to execute a task |
3.4.5. Compositive Dispatching Rule 5
| Algorithm 7: Pseudo code of compositive dispatching rule 5 |
| 1: ← 2: ← |
| 3: if Count() = 0 then 4: ← 5: else 6: ← 7: end if 8: ← 9: ← 10: ← 11: arrange of job on to execute a task |
3.4.6. Compositive Dispatching Rule 6
| Algorithm 8: Pseudo code of compositive dispatching rule 6 |
| 1: ← 2: ← 3: ← 4: ← 5: ← 6: arrange of job on to execute a task |
3.4.7. Compositive Dispatching Rule 7
| Algorithm 9: Pseudo code of compositive dispatching rule 7 |
| 1: ← 2: ← 3: if Count() = 0 then 4: ← 5: else 6: ← 7: end if 8: ← 9: ← 10: ← 11: arrange of on to execute a task |
3.5. Goal Formations and Reward Functions
| Algorithm 10: Procedure to calculate the predicted total delay time |
| input: output: 1: 0 2:for do 3: if then 4: if then 5: 6: end if 7: end if 8:end for 9:return |
| Algorithm 11: Procedure to calculate the reward with the specified goal of higher DDQN in the DLDDQN architecture |
| Input: The chosen goal’s value at rescheduling point and , the total reward sum Output: The total rewards after the action is executed at the current rescheduling point 1:if then 2: if then 3: ← 4: else if then 5: ← |
| 6: else 7: ← 8: end if 9: else if then 10: if then 11: ← 12: else if then 13: ← 14: else 15: ← 16: end if 17:else if then 18: if then 19: ← 20: else if then 21: ← 22:else if then 24: if then 25: ← 26: else if then 27: ← 28: end if 29:else if then 30: if then 31: ← 32: else if then 33: ← 34: end if 35:else if then 36: if then 37: ← 38: else if then 39: ← 40: end if 41:end if 42:return |
4. Numerical Experiments
4.1. Instance Generations
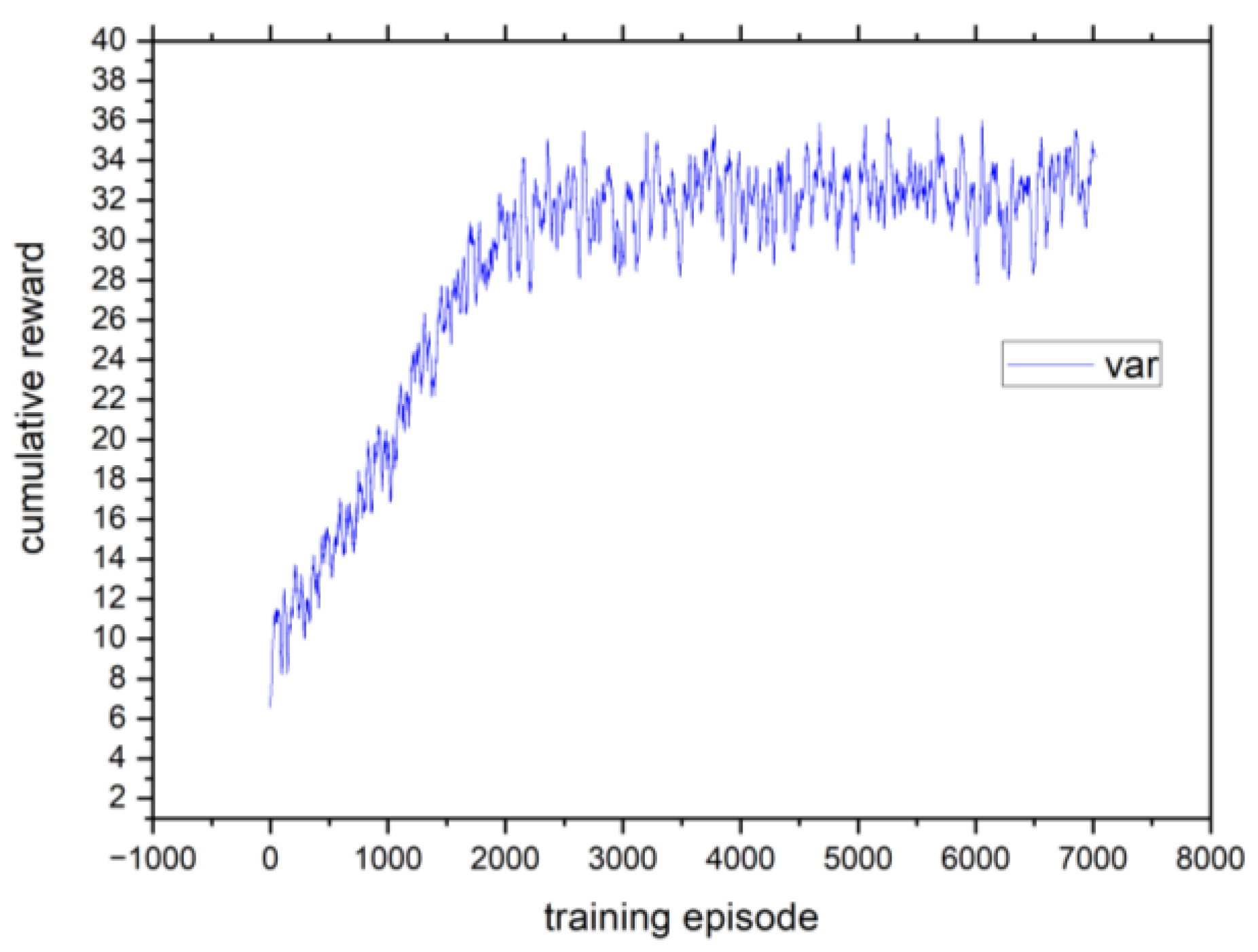
4.2. Sensitivity of Hyperparameters That Influence Performance of the Proposed Framework DLDDQN
4.3. Analysis of a Case Study
4.4. Model Selection and Validation of the Proposed DLDDQN
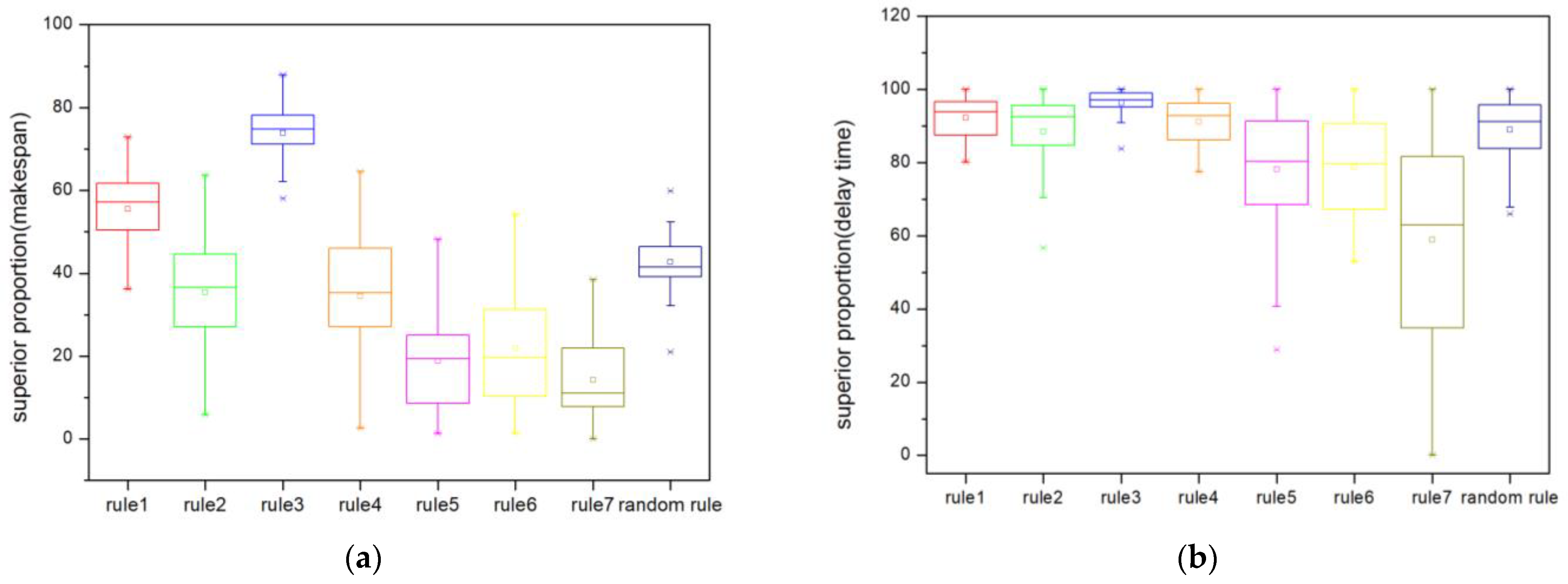
4.5. Comparison with Proposed Compositive Dispatching Rules
4.6. Comparison with Other Methods
5. Conclusions and Future Research Potentials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mohan, J.; Lanka, K.; Rao, A.N. A review of dynamic job shop scheduling techniques. Procedia Manuf. 2019, 30, 34–39. [Google Scholar] [CrossRef]
- Xiong, H.; Shi, S.; Ren, D.; Hu, J. A survey of job shop scheduling problem: The types and models. Comput. Oper. Res. 2022, 142, 105731. [Google Scholar] [CrossRef]
- Zhou, H.; Gu, B.; Jin, C. Reinforcement Learning Approach for Multi-Agent Flexible Scheduling Problems. arXiv 2022, arXiv:2210.03674. [Google Scholar]
- Zeng, Y.; Liao, Z.; Dai, Y.; Wang, R.; Li, X.; Yuan, B. Hybrid intelligence for dynamic job-shop scheduling with deep reinforcement learning and attention mechanism. arXiv 2022, arXiv:2201.00548. [Google Scholar]
- Shahrabi, J.; Adibi, M.A.; Mahootchi, M. A reinforcement learning approach to parameter estimation in dynamic job shop scheduling. Comput. Ind. Eng. 2017, 110, 75–82. [Google Scholar] [CrossRef]
- Monaci, M.; Agasucci, V.; Grani, G. An actor-critic algorithm with deep double recurrent agents to solve the job shop scheduling problem. arXiv 2021, arXiv:2110.09076. [Google Scholar]
- Ferreira, C.; Figueira, G.; Amorim, P. Effective and interpretable dispatching rules for dynamic job shops via guided empirical learning. Omega 2022, 111, 102643. [Google Scholar] [CrossRef]
- Inal, A.F.; Sel, Ç.; Aktepe, A.; Türker, A.K.; Ersöz, S. A Multi-Agent Reinforcement Learning Approach to the Dynamic Job Shop Scheduling Problem. Sustainability 2023, 15, 8262. [Google Scholar] [CrossRef]
- Chang, J.; Yu, D.; Zhou, Z.; He, W.; Zhang, L. Hierarchical Reinforcement Learning for Multi-Objective Real-Time Flexible Scheduling in a Smart Shop Floor. Machines 2022, 10, 1195. [Google Scholar] [CrossRef]
- Ahmadi, E.; Zandieh, M.; Farrokh, M.; Emami, S.M. A multi objective optimization approach for flexible job shop scheduling problem under random machine breakdown by evolutionary algorithms. Comput. Oper. Res. 2016, 73, 56–66. [Google Scholar] [CrossRef]
- Zhu, J.; Wang, H.; Zhang, T. A Deep Reinforcement Learning Approach to the Flexible Flowshop Scheduling Problem with Makespan Minimization. In Proceedings of the 2020 IEEE 9th Data Driven Control and Learning Systems Conference (DDCLS), Liuzhou, China, 19–21 June 2020; pp. 1220–1225. [Google Scholar] [CrossRef]
- Garey, M.R.; Johnson, D.S.; Sethi, R. The complexity of flowshop and jobshop scheduling. Math. Oper. Res. 1976, 1, 117–129. [Google Scholar] [CrossRef]
- Xie, J.; Gao, L.; Peng, K.; Li, X.; Li, H. Review on flexible job shop scheduling. IET Collab. Intell. Manuf. 2019, 1, 67–77. [Google Scholar] [CrossRef]
- Luo, S. Dynamic scheduling for flexible job shop with new job insertions by deep reinforcement learning. Appl. Soft Comput. 2020, 91, 106208. [Google Scholar] [CrossRef]
- Liu, C.-L.; Chang, C.-C.; Tseng, C.-J. Actor-Critic Deep Reinforcement Learning for Solving Job Shop Scheduling Problems. IEEE Access 2020, 8, 71752–71762. [Google Scholar] [CrossRef]
- Panzer, M.; Bender, B. Deep reinforcement learning in production systems: A systematic literature review. Int. J. Prod. Res. 2022, 60, 4316–4341. [Google Scholar] [CrossRef]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy Gradient Methods for Reinforcement Learning with Function Approximation. In Advances in Neural Information Processing Systems 12; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Luo, S.; Zhang, L.; Fan, Y. Dynamic multi-objective scheduling for flexible job shop by deep reinforcement learning. Comput. Ind. Eng. 2021, 159, 107489. [Google Scholar] [CrossRef]
- Hu, H.; Jia, X.; He, Q.; Fu, S.; Liu, K. Deep reinforcement learning based AGVs real-time scheduling with mixed rule for flexible shop floor in industry 4.0. Comput. Ind. Eng. 2020, 149, 106749. [Google Scholar] [CrossRef]
- Lei, K.; Guo, P.; Zhao, W.; Wang, Y.; Qian, L.; Meng, X.; Tang, L. A multi-action deep reinforcement learning framework for flexible Job-shop scheduling problem. Expert Syst. Appl. 2022, 205, 117796. [Google Scholar] [CrossRef]
- Workneh, A.D.; Gmira, M. Learning to schedule (L2S): Adaptive job shop scheduling using double deep Q network. Smart Sci. 2023. [Google Scholar] [CrossRef]
- Zhang, M.; Lu, Y.; Hu, Y.; Amaitik, N.; Xu, Y. Dynamic Scheduling Method for Job-Shop Manufacturing Systems by Deep Reinforcement Learning with Proximal Policy Optimization. Sustainability 2022, 14, 5177. [Google Scholar] [CrossRef]
- Liu, R.; Piplani, R.; Toro, C. Deep reinforcement learning for dynamic scheduling of a flexible job shop. Int. J. Prod. Res. 2022, 60, 4049–4069. [Google Scholar] [CrossRef]
- Zhang, C.; Song, W.; Cao, Z.; Zhang, J.; Tan, P.S.; Xu, C. Learning to dispatch for job shop scheduling via deep reinforcement learning. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NIPS’20), Vancouver, BC, Canada, 6–12 December 2020; Curran Associates Inc.: Red Hook, NY, USA, 2020; pp. 1621–1632. [Google Scholar]
- Luo, B.; Wang, S.; Yang, B.; Yi, L. An improved deep reinforcement learning approach for the dynamic job shop scheduling problem with random job arrivals. J. Phys. Conf. Ser. 2021, 1848, 012029. [Google Scholar] [CrossRef]
- Wang, L.; Hu, X.; Wang, Y.; Xu, S.; Ma, S.; Yang, K.; Liu, Z.; Wang, W. Dynamic job-shop scheduling in smart manufacturing using deep reinforcement learning. Comput. Netw. 2021, 190, 107969. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Lapan, M. Deep Reinforcement Learning Hands-On: Apply Modern RL Methods, with Deep Q-Networks, Value Iteration, Policy Gradients, TRPO, AlphaGo Zero and More; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar]
- Dolcetta, I.C.; Ishii, H. Approximate solutions of the Bellman equation of deterministic control theory. Appl. Math. Optim. 1984, 11, 161–181. [Google Scholar] [CrossRef]
- Rafati, J.; Noelle, D.C. Learning representations in model-free Real-Time Flexible Scheduling. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27–28 January 2019; Volume 33, pp. 10009–10010. [Google Scholar]
- Pateria, S.; Subagdja, B.; Tan, A.H.; Quek, C. Hierarchical reinforcement learning: A comprehensive survey. ACM Comput. Surv. CSUR 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Chang, J.; Yu, D.; Hu, Y.; He, W.; Yu, H. Deep Reinforcement Learning for Dynamic Flexible Job Shop Scheduling with Random Job Arrival. Processes 2022, 10, 760. [Google Scholar] [CrossRef]
- Puterman, M.L. Markov decision processes. In Handbooks in Operations Research and Management Science; Elsevier: Amsterdam, The Netherlands, 1990; Volume 2, pp. 331–434. [Google Scholar]
- Fan, J.; Wang, Z.; Xie, Y.; Yang, Z. A theoretical analysis of deep Q-learning. In Proceedings of the 2nd Conference on Learning for Dynamics and Control, Berkeley, CA, USA, 11–12 June 2020. [Google Scholar]
- Lv, P.; Wang, X.; Cheng, Y.; Duan, Z. Stochastic double deep Q-network. IEEE Access 2019, 7, 79446–79454. [Google Scholar] [CrossRef]
- Nachum, O.; Gu, S.S.; Lee, H.; Levine, S. Data-efficient hierarchical reinforcement learning. In Advances in Neural Information Processing Systems 31; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 3303–3313. [Google Scholar]
- Han, B.-A.; Yang, J.-J. Research on Adaptive Job Shop Scheduling Problems Based on Dueling Double DQN. IEEE Access 2020, 8, 186474–186495. [Google Scholar] [CrossRef]
- Li, Y.; Gu, W.; Yuan, M.; Tang, Y. Real-time data-driven dynamic scheduling for flexible job shop with insufficient transportation resources using hybrid deep Q network. Robot. Comput. Integr. Manuf. 2022, 74, 102283. [Google Scholar] [CrossRef]
- Katoch, S.; Chauhan, S.S.; Kumar, V. A review on genetic algorithm: Past, present, and future. Multimed. Tools Appl. 2021, 80, 8091–8126. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Problem | State | Objective | DRL | Benchmark | Network | Random Event |
|---|---|---|---|---|---|---|---|
| Liu et al. (2020) [15] | JSP | Discrete | Makespan | Actor-Critic | OR-Library | DNN | Machine breakdown; sudden additional order |
| Luo et al. (2021) [19] | FJSP | Continuous | Tardiness; machine utilization rate | Hierarchy DQN | Generation | DNN | Random job insertion |
| Hu et al. (2020) [20] | FJSP | Continuous | Delay ratio; makespan | DQN | Generation | DNN | None |
| Lei et al. (2022) [21] | FJSP | Discrete | Makespan | Multi-PPO, MPGN | Generation; instances of other papers | GNN | None |
| Abebaw et al. (2023) [22] | JSP | Continuous | Makespan | DDQN | OR-Library | DNN | Machine breakdown; job rework |
| Zhang et al. (2022) [23] | JSP | Continuous | Average machine utilization; order wait time | PPO | Generation | DNN | Machine failure |
| Liu et al. (2022) [24] | FJSP | Continuous | Makespan | DDQN | Generation | DNN | Machine breakdown |
| Zhang et al. (2020) [25] | JSP | Discrete | Makespan | PPO | Generation; instances of other papers | GNN | Job arriving on-the-fly; random machine breakdown |
| Luo et al. (2021) [26] | JSP | Continuous | Makespan | Double Loop DQN | OR-Library | DNN | Random job insertion |
| Wang et al. (2021) [27] | JSP | Discrete | Makespan | PPO | OR-Library; generation | DNN | Machine breakdown; processing time change |
| This paper | FJSP | Continuous | Makespan; delay time sum | Dual Layer DDQN | Generation | DNN | Random job incoming |
| Number | Goal | Objective Property | Way of Cumulative Reward |
|---|---|---|---|
| 1 | makespan | ||
| 2 | makespan | ||
| 3 | makespan | ||
| 4 | total delay time | ||
| 5 | total delay time | ||
| 6 | total delay time |
| Number | Parameter | Value |
|---|---|---|
| 1 | Total number of machines () | randint [10–30] |
| 2 | Arrival interval of new coming jobs () | randint [50–200] |
| 3 | Number of operations for each job () | randint [1–20] |
| 4 | Variable for available machines of each operation () | randint [1–()] |
| 5 | Processing time of in machine () | randint [1–50] |
| 6 | Due date tightness () | randfloat [0.5–2] |
| 7 | Number of initial jobs () | randint [10–20] |
| 8 | Number of new arrival jobs () | randint [10–200] |
| Number | Parameter | Value |
|---|---|---|
| 1 | Total number of machines () | 10 |
| 2 | Number of initial jobs () | 5 |
| 3 | Number of new arrival jobs () | 10 |
| 4 | Arrival interval of new jobs () | 50 |
| 5 | Due date tightness () | 0.5 |
| 6 | Number of operations for each job () | randint (1–5) |
| 7 | Variable for available machines of each operation () | randint (1–8) |
| 8 | Processing time in selected () available machines | randint (1–50) |
| 9 | Arrival time of new coming jobs () | exponential (50) |
| 10 | Due date of jobs () |
| Job | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| arrival time | 0 | 0 | 0 | 0 | 0 | 22 | 11 | 5 | 58 | 32 | 1 | 38 | 31 | 98 | 178 |
| Job | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| due time | 56 | 68 | 33 | 57 | 65 | 60 | 51 | 44 | 126 | 53 | 12 | 83 | 71 | 103 | 247 |
| DDT | m | E_ave | DLDDQN | DQN | DDQN | FIFO | MRT | GA |
|---|---|---|---|---|---|---|---|---|
| 0.5 | 10 | 50 | 443.7/22,579.45 | 507.85/22,819.38 | 482.29/22,967.39 | 907/34,367 | 842/30,217 | 523.25/29,486.96 |
| 100 | 388.6/17,008.4 | 438.24/18,645.23 | 428.51/18,022.21 | 690/21,203 | 755/23,733 | 459.63/20,330.54 | ||
| 200 | 518.7/15,851.8 | 538.63/17,160.44 | 533.27/16,155.25 | 860/20,374 | 919/26,907 | 555.39/20,330.54 | ||
| 20 | 50 | 240.75/2756.15 | 200.14/3458.58 | 196.88/3431.4 | 299/2937 | 319/8212 | 205.82/7067.16 | |
| 100 | 154.5/1764.5 | 205.52/2423.27 | 204.15/2393.77 | 362/1831 | 362/4995 | 234.74/5278.68 | ||
| 200 | 150.6/133.1 | 183.26/470.16 | 172.3/394.66 | 297/22 | 269/1095 | 194.95/886.46 | ||
| 30 | 50 | 95.18/442 | 112.21/795.8 | 116.83/505.42 | 195/64 | 194/1964 | 113.63/2377.63 | |
| 100 | 120.6/233.2 | 140.56/486.37 | 132.26/334.0 | 249/0 | 269/1581 | 143.94/908.44 | ||
| 200 | 103.24/37.85 | 137.41/102.59 | 138.31/134.42 | 215/0 | 268/1461 | 124.22/129.57 | ||
| 1 | 10 | 50 | 396.4/1527.95 | 497.04/4478.87 | 490.7/3349.26 | 883/20,094 | 893/33,496 | 531.87/30,495.17 |
| 100 | 343.78/9135.8 | 417.44/10,434.38 | 455.07/10,372.92 | 729/13,589 | 787/20,811 | 478.55/23,818.5 | ||
| 200 | 352.4/3386.2 | 448.13/9912.2 | 472.53/8401.61 | 768/4200 | 847/18,567 | 493.84/18,260.04 | ||
| 20 | 50 | 121.5/231.1 | 189.26/970 | 152.98/7291.1 | 354/128 | 358/5934 | 205.58/7144.79 | |
| 100 | 183.76/76.75 | 199.03/870.99 | 192.69/208.49 | 452/87 | 408/4688 | 212.75/4589.49 | ||
| 200 | 194/585.25 | 235.06/992.59 | 222.03/539.58 | 440/0 | 439/2317 | 217.08/1794.76 | ||
| 30 | 50 | 101.22/278.55 | 109.08/364.37 | 104.39/285.82 | 323/2 | 258/3495 | 125.26/2201.4 | |
| 100 | 112.83/449.55 | 125.63/559.36 | 127.53/484.35 | 271/0 | 212/1129 | 129.03/814.17 | ||
| 200 | 157.35/145.9 | 172.72/119.29 | 148.43/155.65 | 370/0 | 318/1118 | 165.5/265.33 | ||
| 2 | 10 | 50 | 325.78/18,573 | 382.14/20,218.93 | 363.33/20,840.85 | 764/33,589 | 699/30,139 | 464.71/25,763.73 |
| 100 | 343.11/12,541.6 | 385.74/14,875.95 | 370.25/13,807.0 | 788/30,588 | 738/28,654 | 490.46/23,826.31 | ||
| 200 | 351.54/9970.55 | 382.82/11884.94 | 419.46/11,155.08 | 663/16,114 | 682/18,230 | 501.84/15,119.49 | ||
| 20 | 50 | 154.4/5052 | 180.09/5569.82 | 178.96/5246.45 | 297/8110 | 321/7309 | 195.67/6984.51 | |
| 100 | 174.98/2595.6 | 194.13/2263.94 | 184.15/2834.0 | 317/4289 | 344/7321 | 216.3/3615.23 | ||
| 200 | 164.8/833.45 | 199.35/797.08 | 188.45/790.41 | 311/1522 | 356/3366 | 205.79/1153.18 | ||
| 30 | 50 | 109.14/727.25 | 139.23/730.05 | 128.46/769.17 | 197/589 | 182/2286 | 143.08/3524.76 | |
| 100 | 102.23/158.5 | 107.19/162.98 | 103.04/163.62 | 171/165 | 158/843 | 128.39/776.18 | ||
| 200 | 100.12/106.3 | 137.47/137.89 | 107.78/132.74 | 193/78 | 201/428 | 126.18/172.81 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Z.; Fan, H.; Sun, Y.; Peng, M. Efficient Multi-Objective Optimization on Dynamic Flexible Job Shop Scheduling Using Deep Reinforcement Learning Approach. Processes 2023, 11, 2018. https://doi.org/10.3390/pr11072018
Wu Z, Fan H, Sun Y, Peng M. Efficient Multi-Objective Optimization on Dynamic Flexible Job Shop Scheduling Using Deep Reinforcement Learning Approach. Processes. 2023; 11(7):2018. https://doi.org/10.3390/pr11072018
Chicago/Turabian StyleWu, Zufa, Hongbo Fan, Yimeng Sun, and Manyu Peng. 2023. "Efficient Multi-Objective Optimization on Dynamic Flexible Job Shop Scheduling Using Deep Reinforcement Learning Approach" Processes 11, no. 7: 2018. https://doi.org/10.3390/pr11072018
APA StyleWu, Z., Fan, H., Sun, Y., & Peng, M. (2023). Efficient Multi-Objective Optimization on Dynamic Flexible Job Shop Scheduling Using Deep Reinforcement Learning Approach. Processes, 11(7), 2018. https://doi.org/10.3390/pr11072018