1. Introduction
In the petroleum industry, the basis for trade settlement between trading parties is the flow of oil, which puts forward high requirements for the measurement technology for oil. Ultrasonic flow meters have gradually replaced traditional flow meters due to their advantages of high accuracy, high sensitivity, no pressure loss, and good repeatability. They are the preferred instrument for measuring the flow rate of liquids with strong corrosion, poor conductivity, and high viscosity. Whether in industrial production, transportation, or long-term use, ultrasonic flow meters may experience various malfunctions, such as sensor failures, gas injection, waxing, etc. In addition, the installation effect of ultrasonic flow meters can also have a certain impact on the measurement of flow. These faults can lead to a decrease in the performance of ultrasonic flow meters, resulting in incorrect readings and the inability to provide guarantees for fair trade. Therefore, designing a fault diagnosis method to timely and accurately diagnose the types of faults present in ultrasonic flow meters is of great significance for the practical use of ultrasonic flow meters.
The traditional diagnostic methods for equipment faults generally start from the principles of the equipment itself and then combine these principles with the experience of experts to achieve the judgment and maintenance of equipment faults. The method of diagnosing abnormal equipment states based on the temperature changes of components is widely used in the fault diagnosis of wind turbines [
1]. Vibration signals, lubricating oil analysis, and acoustic emission are used to detect faults in rolling bearings, large pumping station units, and motors [
2,
3,
4,
5]. However, with the rise of equipment manufacturing processes and the increase in their complexity, such methods based on the principles of the equipment itself not only need to comprehensively consider the influence of multiple relevant factors, but they also put forward high requirements for experts and their experience and analytical ability in fault diagnosis. Therefore, the efficiency and accuracy of fault diagnosis cannot be guaranteed.
In recent years, some scholars have used Bayesian methods to diagnose whether an equipment has faults. Jaramillo et al. [
6] utilized a Bayesian method based on particle filters to achieve the fault diagnosis of wind turbine blades, and experiments showed that this method has a 95% confidence interval. Gyamfi et al. [
7] used a new linear dimensionality reduction method, and the linear classifier constructed by this method can minimize Bayesian errors, resulting in a great improvement in classification ability compared with general linear classifiers. Tan et al. [
8] introduced a novel fault diagnosis approach for gas-leakage monitoring sensors, leveraging naive Bayes classifiers. The method can attain an accuracy of 85% in recognizing abnormal data and of 95% in diagnosing sensor faults. Silva et al. [
9] introduced a method tailored for diagnosing multiple faults in transmission lines. They devised a naive Bayesian classifier to pinpoint the most significant faults in multi-fault scenarios using LC data. This method can achieve an accuracy of 95%. Zhu et al. [
10] proposed a method for detecting equipment faults, employing principal component analysis and a multidimensional Gaussian Bayesian model. The preferred correct recognition rate of the fault state of this method is significantly improved compared with the KNN algorithm. The methods based on Bayesian classifiers are all based on the assumption that the data features are independent; however, there is coupling between the actual collected data of ultrasonic flow meters, and the features may not necessarily be independent of each other. This method relies more on the independence of features, so it is difficult to implement in practical applications.
Some scholars use neural network (NN)-based methods for fault detection. Li et al. [
11] introduced a fault diagnosis technique for rolling bearings using STFT combined with CNN and constructed a CNN model tailored for bearing fault detection. The model presented demonstrated a high level of accuracy. Al-Wahaibi et al. [
12] devised an innovative local–global scale CNN architecture, which integrates local correlation with conventional square kernels and employs distributed one-dimensional filters in distinct permutations to capture the global correlation. Abdelmaksoud et al. [
13] proposed a CNN model for diagnosing faults during asynchronous motor starting, which can detect various faults at three load levels. Due to its dependence on image data from multiple motor signals, this method has high reliability. Experiments based on motion data have shown that the performance of this model is superior to other methods. However, the method based on neural networks requires a large amount of features and data, which is not in line with the actual features that can be collected by ultrasonic flow meters; if data augmentation is employed, it may introduce noise, leading to a reduction in the model’s generalization capability, and exacerbate overfitting, thereby resulting in inferior performance on the test set.
In the 1990s, Vapnik [
14] proposed a classifier based on structural risk minimization criteria, the support vector machine (SVM). SVM is a learning technique renowned for its simplicity, robustness, and formidable generalization prowess. When solving classification problems with high feature dimensions and small sample sizes, support vector machines perform better than other classification methods. Chatterjee et al. [
15] presented an innovative technique for fault diagnosis in lithium-ion batteries utilizing SVM, and simulation studies have shown that this method can detect faults fast with a high coverage range. Huang et al. [
16] introduced an adaptive filter-bank approach for extracting spectral features and employed a retrained SVM to detect faults in automotive electric seats. The accuracy and promptness confirm the effectiveness of this method. Sarita et al. [
17] studied rapid fault detection algorithms by utilizing two sample techniques and fault localization algorithms characterized by wavelet-packet entropy. An algorithm for fault classification, utilizing support vector machines and EWP features, is employed to classify and locate OC faults. This technology can efficiently detect faults in both single IGBTs and multiple IGBTs within a short timeframe, boasting high accuracy. Zhang et al. [
18] proposed a hybrid-kernel SVM classification and diagnosis algorithm based on human-learning optimization (HLO) to diagnose faults in ultrasonic flow meters. Experiments have shown that this algorithm has more significant improvements than diagnostic algorithms based on single-kernel functions. However, this fault diagnosis method for ultrasonic flow meters still has certain shortcomings, as support vector machines are sensitive to parameter selection. The selection of support vector machine parameters mostly relies on experience, which has a certain degree of randomness and cannot guarantee performance.
At present, there are few studies on the fault diagnosis of ultrasonic flow meters, and there is a problem of low diagnostic accuracy in the few studies that use data-driven methods for the fault diagnosis of ultrasonic flow meters. In response to the above issues, this article mainly diagnoses three types of faults in ultrasonic flow meters, namely gas intrusion, waxing, and installation effects. To address the issues of low fault-diagnosis accuracy and high feature dimensions caused by excessive interference information, we introduce a fault diagnosis algorithm utilizing KPCA-CLSSA-SVM. The structure of this paper is outlined as follows:
Section 2 provides the theoretical framework, including an overview of the SVM model, an explanation of the basic principles of the sparrow search algorithm and its improved version, and a detailed elucidation of the proposed fault diagnosis algorithm’s basic workflow.
Section 3 describes the database used in this study and provides a detailed overview of the experimental procedures. In
Section 4, a rigorous evaluation of the model is conducted, including a comparison of feature distributions before and after processing and the fault diagnosis results obtained using different algorithms. Finally,
Section 5 summarizes the research and concludes with key findings.
3. Experiments and Results
The ultrasonic flow meter is an instrument utilized for measuring fluid flow velocity. Its operational principle relies on the propagation of ultrasonic waves within the fluid medium. Typically, it incorporates a minimum of two transducers—one serving as a transmitter and the other as a receiver. These transducers are often positioned on opposing sides of the pipeline through which the fluid flows. The transmitter emits ultrasonic pulses, which propagate through the fluid to the receiver. The fluid flow exerts an influence on the propagation of ultrasonic waves, impacting the velocity, direction, and flow rate. Through the measurement of the ultrasonic wave propagation time and the received signal strength, the fluid flow velocity and flow rate can be derived.
In the petroleum industry, liquid ultrasonic flow meters frequently encounter diverse faults during prolonged usage. The chemical nature of petroleum leads to wax deposition within the flow meter, while gases like methane in the pipeline also impact its functionality. Moreover, installation effects commonly contribute to errors in the practical application of ultrasonic flow meters. Due to the challenging setup of experimental platforms and limited research in related fields, the dataset used in this study is the publicly available UCI Ultrasonic Flow meter Fault Diagnosis Database collected by the University of Warwick, UK, and the National Engineering Laboratory. An 8-channel ultrasonic flow meter configuration, as shown in
Figure 3, was used. The dataset comprises a total of 540 samples involving four types of flow meters [
26].
Table 1 presents basic information about the dataset, in which flow meter A has two types: normal and installation effects; flow meter B includes three types: normal, gas injection, and waxing; while flow meters C and D encompass four types: normal, gas injection, waxing, and installation effects.
3.1. Data Correlation Analysis
Due to the numerous diagnostic parameters of the flow meter, there might be interdependencies among the collected data. Therefore, it is essential to perform a correlation analysis on the collected data. Since the Pearson correlation coefficient lacks sensitivity to nonlinear relationships and may not precisely represent the correlation between features, the Spearman correlation coefficient is employed to capture the correlation between features. The formula for calculating the Spearman correlation coefficient is as follows:
in which
indicates a positive correlation between two features, and
signifies a negative correlation between them. Taking flow meter D as an example, an analysis of the Spearman correlation coefficients for diagnostic parameters is performed. As shown in
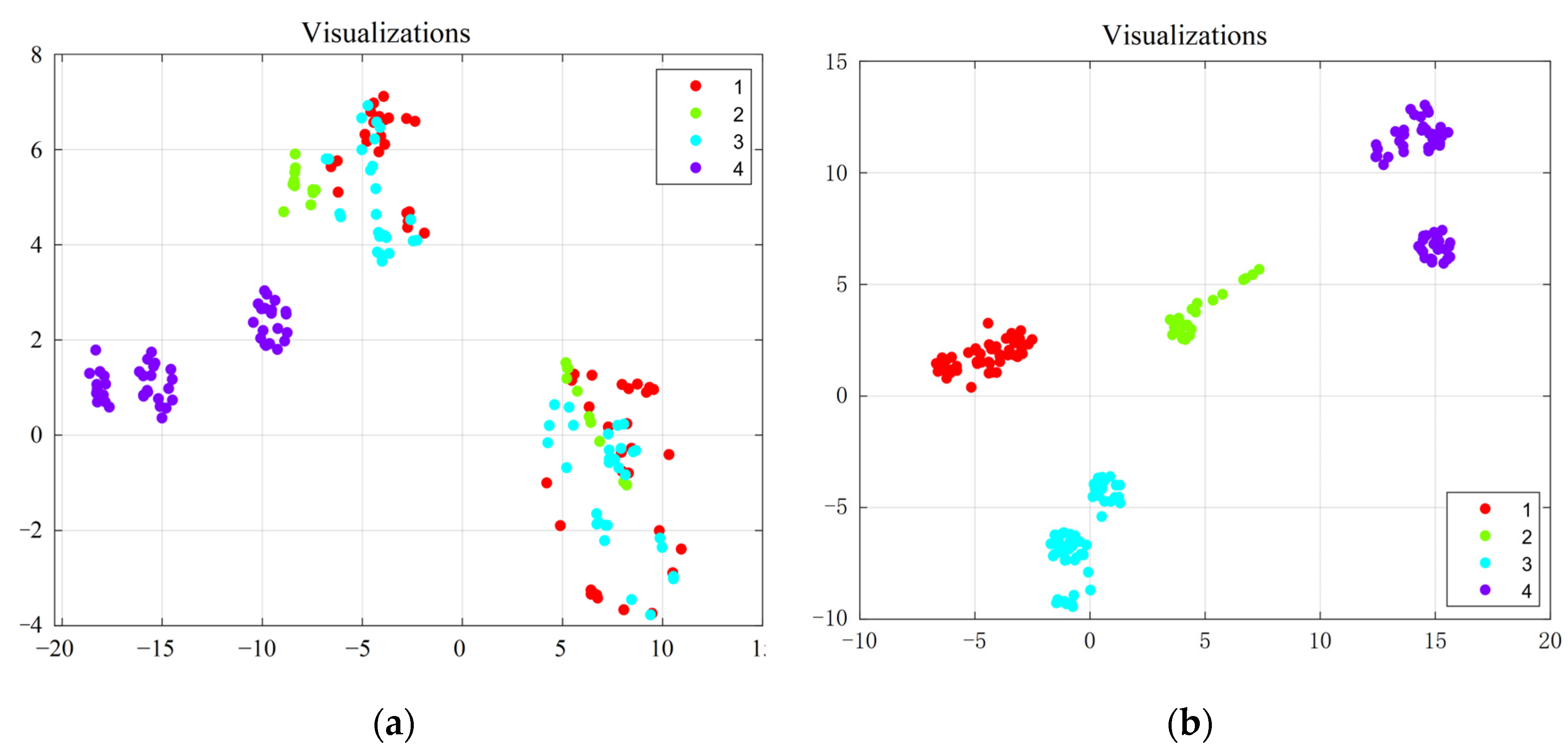
Figure 4, there are notably high correlations between the flow rates of the first, second, and third channels between the sound velocities of the four channels and between the gains at both ends of the channels, as well as between the flight time and the sound velocity. Therefore, it is essential to employ a correlation-based dimensionality reduction algorithm to eliminate highly correlated features to prevent the potential overfitting of the algorithm, and thereby avoiding a reduction in the model accuracy.
3.2. Data Preprocessing
As per
Section 3.1, although the dataset constructed from the ultrasonic flow meter fault-diagnosis database does not contain any missing data, there are high correlations among many features. Due to the high dimensionality of features, which can lead to computational complexities, it is essential to reduce the dimensionality using kernel principal component analysis (KPCA). The calculation method is as follows [
27]:
The dataset is denoted as
, where
represents a collection of m data points for each feature, and n denotes the number of feature types. Initially,
S will be mapped to a high-dimensional space:
where
is a nonlinear mapping function.
is centralized to obtain
; then, the covariance matrix G is calculated. The eigenvalues of E are computed and arranged in descending order, denoted as
, along with the corresponding eigenvectors
. Defining the eigenvector matrix as
,
is represented as:
Finally, taking the first
k columns of
to form a new matrix
, we obtain the reduced principal-component-dataset matrix
Z:
In the feature space, all sample features have an equal influence on distance, but due to varying value ranges, certain feature values dominate the distances between sample points. To tackle this problem, this paper employs a normalization approach, mapping the data after dimensionality reduction to the range [0, 1].
3.3. Model Determination Experiment of Ultrasonic Flow Meter Fault Diagnosis Based on KPCA-CLSSA-SVM
This paper presents a fault diagnosis algorithm for ultrasonic flow meters by utilizing KPCA-CLSSA-SVM. The algorithm takes parameter features collected from ultrasonic flow meters as input and outputs the type of fault detected in the flow meter.
Using the MATLAB R2019a framework within the libsvm environment, we constructed the fault diagnosis model using KPCA-CLSSA-SVM. To validate the model’s effectiveness, a series of experiments were conducted. The input for the model consists of the aforementioned parameter features, with a size of (Num, Fea). Here, Num represents the sample count for this type of flow meter, while Fea denotes the collected features specific to this flow meter.
The suitability of model parameters determines the excellence of the model’s performance. For the D-type flow meter, experiments were conducted to determine the superiority of the model’s related parameters. Parameters adjusted in the experiments include the kernel-function type for the kernel principal component analysis, the dimensionality of the dataset after dimensionality reduction, the population count of sparrows, the number of iterations for the improved sparrow search algorithm, the kernel-function type, and certain parameters within the kernel function for support vector machines. Ten experiments were conducted for each parameter value, and the average of these ten experimental results was used as the evaluation criterion [
10].
The role of a kernel is to convert the original data into a higher-dimensional space. Different kernel functions perform different transformations on the data, thereby affecting the efficacy of dimensionality reduction. For instance, the commonly used Gaussian kernel function can map data into an infinite-dimensional space, but it typically has a slower computation speed. Conversely, the linear kernel function, often chosen as the primary option, possesses strong interpretability and simplicity in computation but lacks the ability to address nonlinear problems.
To determine the required kernel function for this method, the experimental settings were as follows: the kernel-function types for the kernel principal component analysis were set as polynomial, linear, and Gaussian kernel functions. The dimensionality of the dataset after dimensionality reduction was set to 15. The population count of sparrows was set to 8, the number of iterations for the improved sparrow search algorithm was set to 30, and the type of support vector machine was set as C-SVC, with the kernel-function type set as a linear kernel function. By analyzing the impact of different kernel-function types in the kernel principal component analysis of model performance, the final choice of kernel-function type was determined.
As shown in
Table 2, when the polynomial kernel-function type was selected, the accuracy reached its highest point. Therefore, the polynomial kernel function was chosen for the kernel principal component analysis.
Once the kernel function for the KPCA was determined, further experiments were conducted to select the dimensionality of the dataset after dimensionality reduction. A too-low dimensionality could lead to loss of feature information, making classification more challenging. Conversely, an excessively high dimensionality would increase the computational complexity and potentially lead to overfitting of the model. Using the linear kernel function, the dataset dimensionality after dimensionality reduction was set to 11, 18, 25, and 32. As indicated in
Table 3, when the dimensionality of the dataset after dimensionality reduction was set to 25, the accuracy reached its peak. Therefore, the dataset’s dimensionality after dimensionality reduction was set to 25.
Next, further experiments were conducted on the population count of sparrows. The population count of sparrows was set to 20, 30, 40, and 50. As shown in
Table 4, with an increase in the population count of sparrows, the model’s accuracy improved. The accuracy of the model tended to stabilize when the population count reached 40. However, excessively high population counts could increase algorithmic complexity. Therefore, in this model, the population count of sparrows was set to 30.
Then, experiments were conducted on the number of iterations for the algorithm. The number of iterations for the algorithm was set to 40, 50, 60, and 70. As shown in
Table 5, after reaching 60 iterations, the accuracy of the model tended to stabilize. However, too many iterations could decrease the training speed of the model. Consequently, in this context, the iteration count for the enhanced sparrow search algorithm was established at 50.
After the parameter settings for the data dimensionality reduction algorithm and optimization algorithm were completed, we proceeded to configure some parameters for the support vector machine. Due to the various fault types in ultrasonic flow meters, we selected a multi-classification support vector machine; specifically, C-SVC. The kernel function in SVM significantly influences its classification performance. In this study, experiments were conducted using different kernel functions: linear, polynomial, Gaussian, and sigmoid. The results are presented in
Table 6. When employing the sigmoid kernel function, the SVM exhibits a functionality similar to that of a multi-layer neural network. However, its relatively lower accuracy suggests that neural network algorithms might not be suitable for diagnosing faults in ultrasonic flow meters.
Finally, after deciding on the use of the polynomial kernel function for the support vector machine, we needed to set certain parameters for the polynomial kernel function; specifically, the highest degree of the polynomial. In libsvm, the highest degree of the polynomial is denoted by the parameter “degree”. As shown in
Table 7, when the highest degree is less than 3, the model’s accuracy is positively correlated with the highest degree. This indicates that the linear kernel function and the quadratic polynomial kernel function fail to meet the fitting requirements, and increasing the highest degree of the polynomial kernel function can improve the model’s accuracy. However, when the highest degree is greater than 3, the model’s accuracy is negatively correlated with the highest degree. This is because higher degrees may lead the model to overfit, decreasing its accuracy. When the “degree” is set to 3, indicating a third-degree polynomial kernel function, the model achieves the highest accuracy. Therefore, the highest degree of the polynomial kernel function in this paper was set to 3.
3.4. The Experimental Results
After determining the model parameters, the collected data was fed into the fault diagnosis model. Approximately 80% of the data was used for training, while the other 20% was set aside for testing.
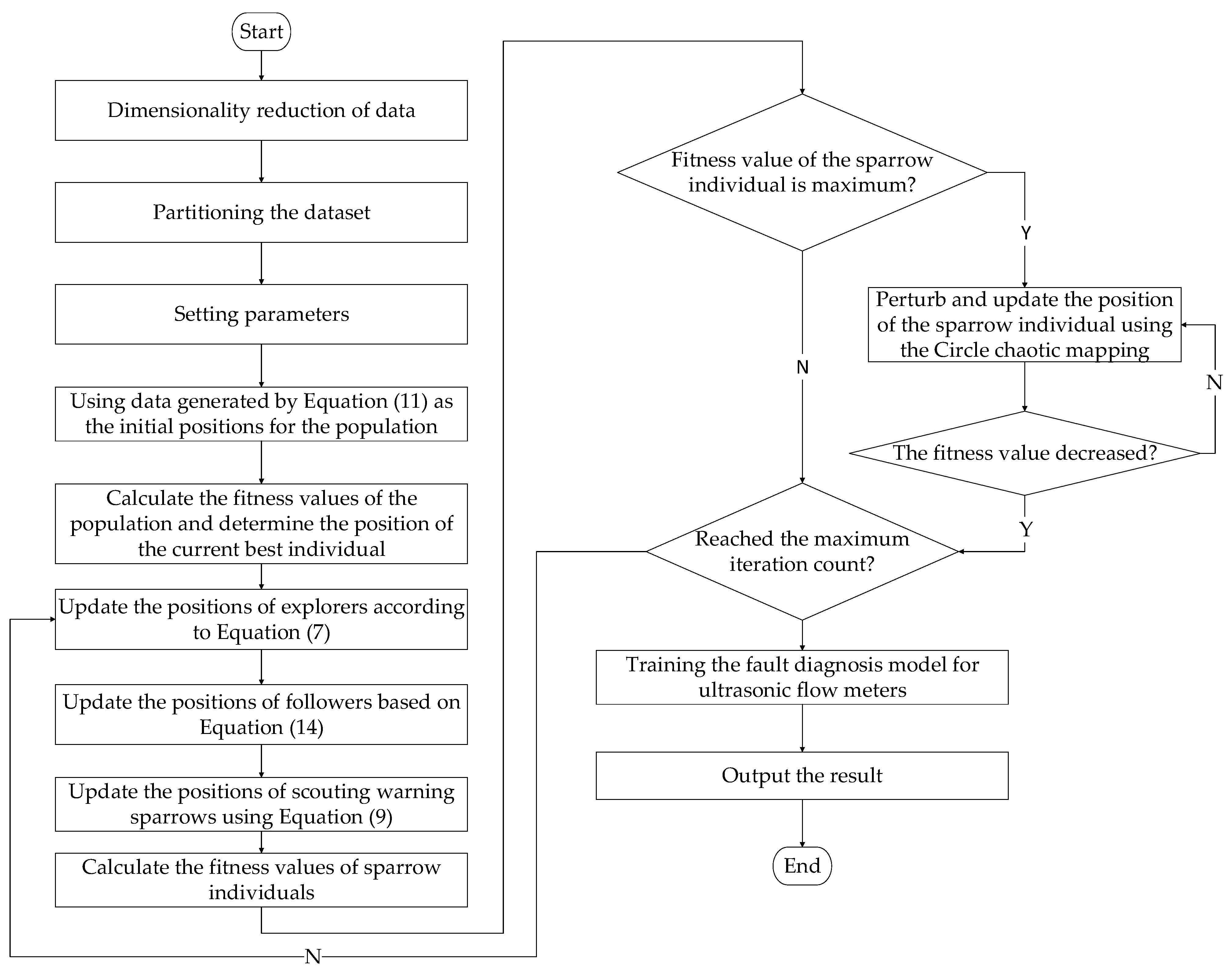
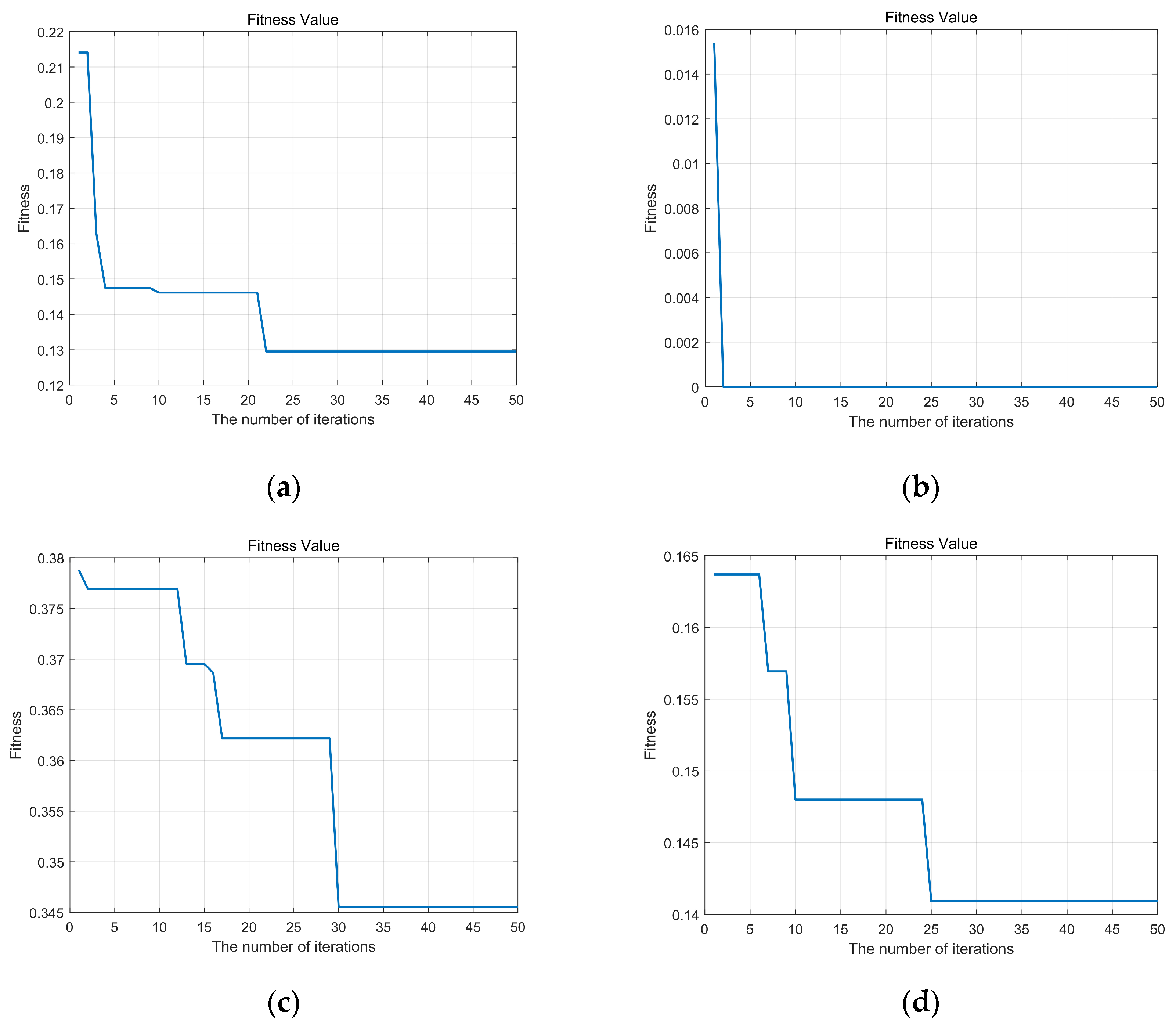
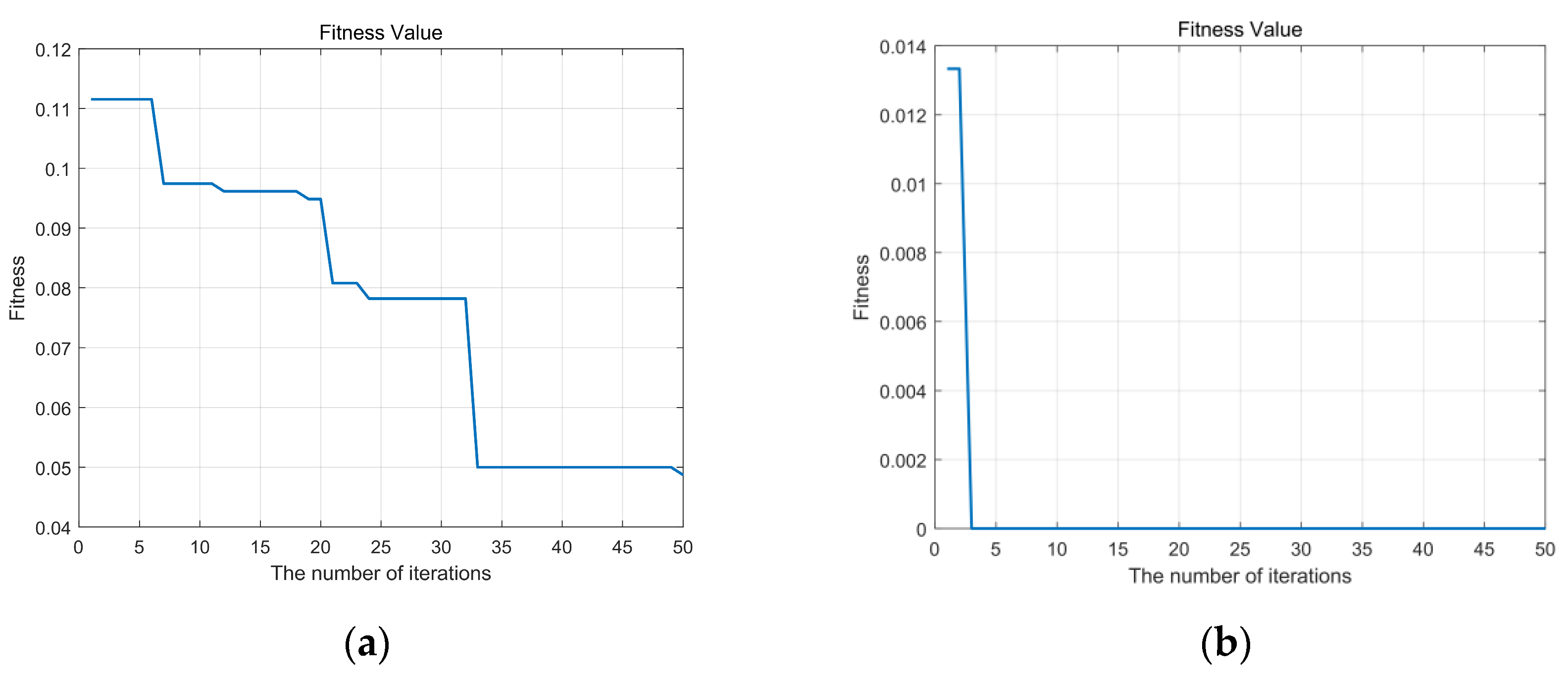
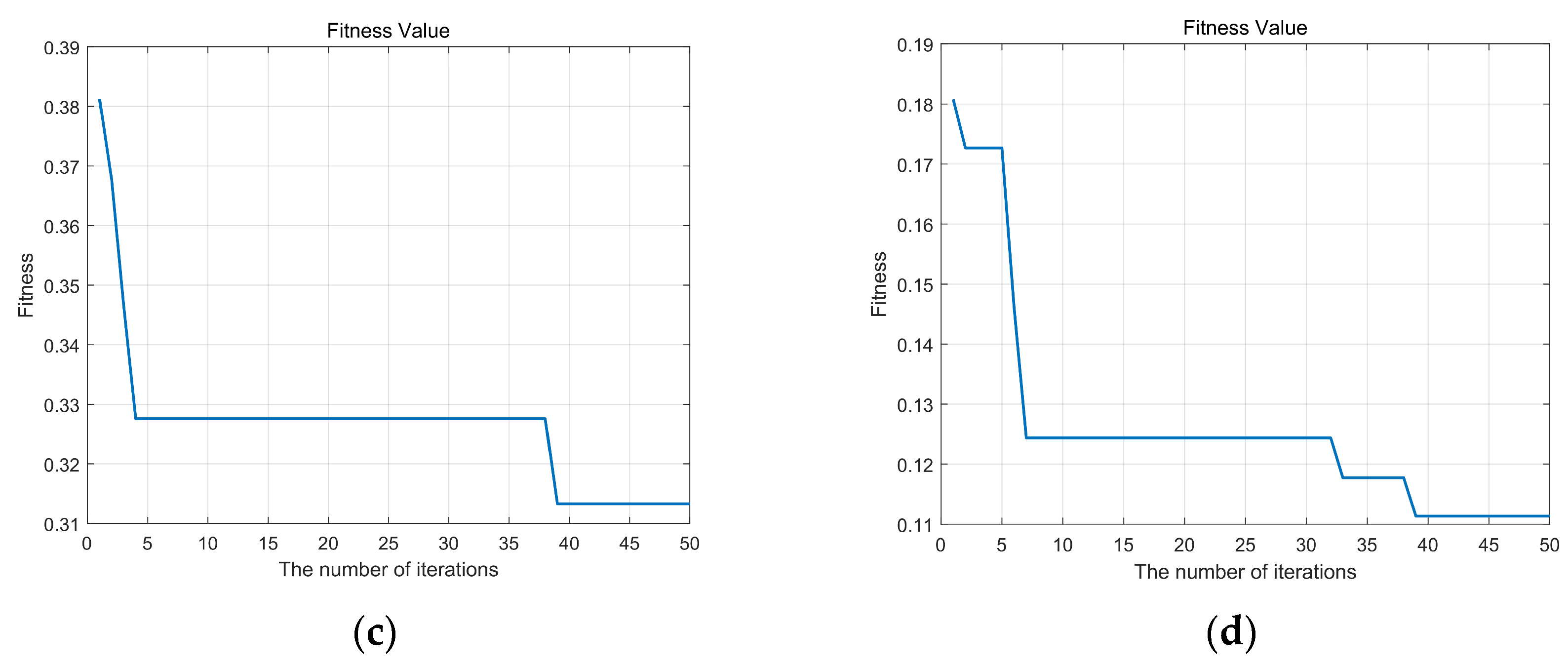
Figure 5 and
Figure 6 display the curves depicting the changes in fitness values with iterations for the sparrow search algorithm, both before and after improvements. Lower fitness values indicate a decreased probability of the algorithm becoming stuck in local optima. Comparing these two sets of graphs, noticeable enhancements are observed in the performance of flow meters A, C, and D, while flow meter B demonstrates relatively minor improvements. This is attributed to the higher dimensionality of the dataset associated with flow meter B, indicating strong separability among its data, thus requiring no algorithmic improvements to achieve optimal parameters with high accuracy.
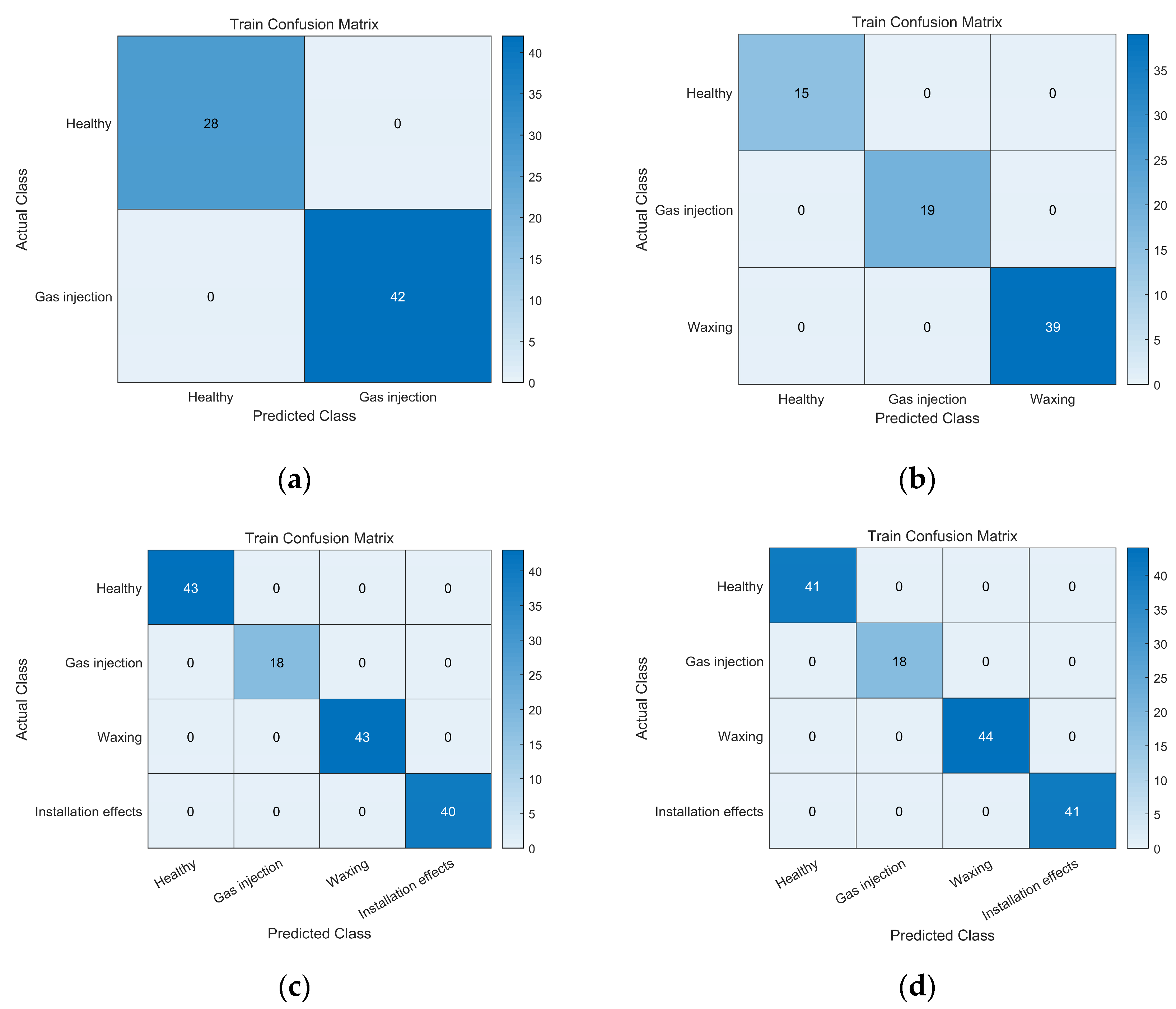
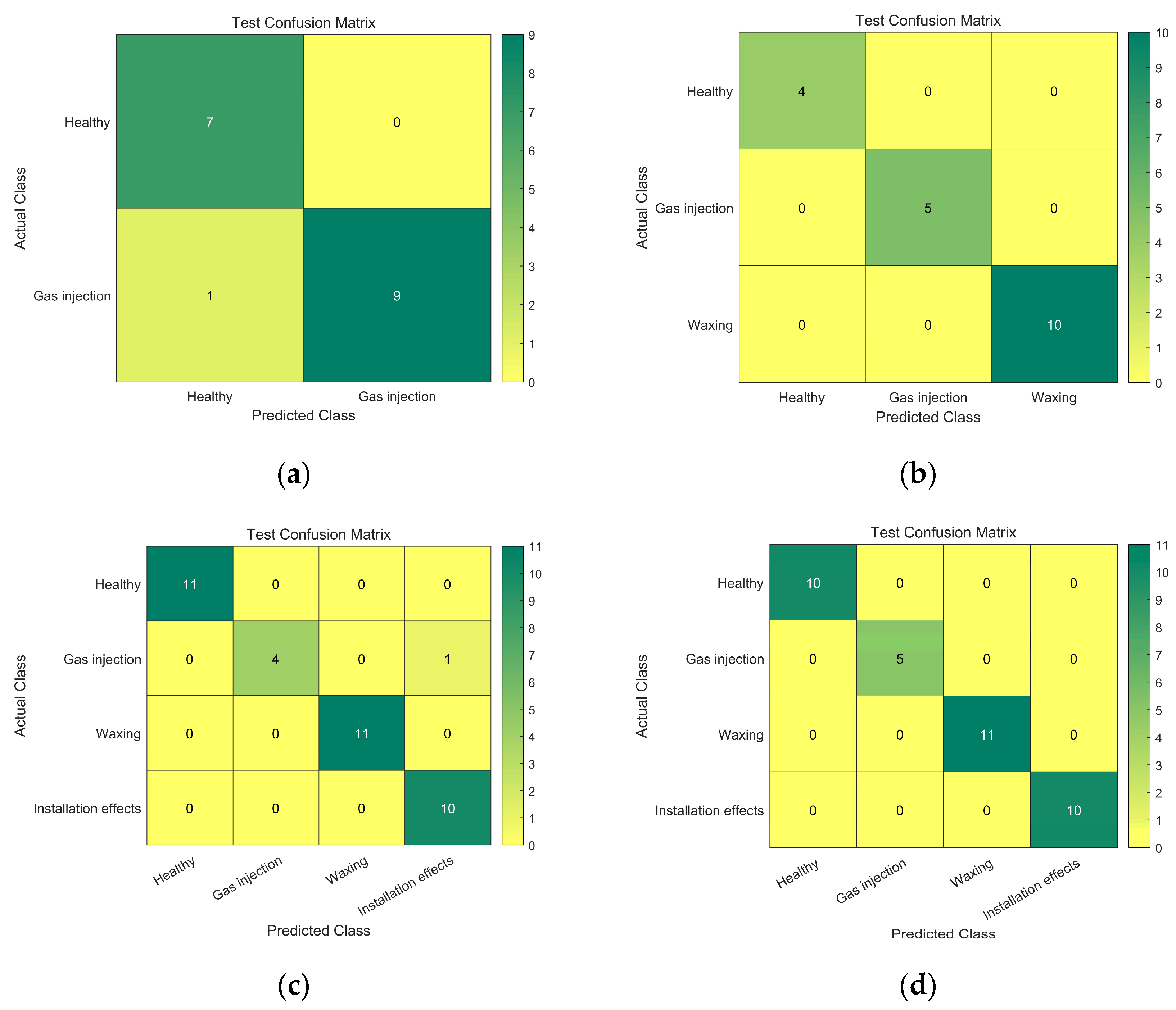
In this part, we will also utilize a confusion matrix as a measure to evaluate the precision of the fault diagnosis model. The confusion matrix measures the model’s classification performance by calculating the number of correct and incorrect classifications.
Figure 7 represents the confusion matrices of the prediction results for the training set of the four types of flow meters, and
Figure 8 represents the confusion matrices of the prediction results for the test set of the four types of flow meters. The horizontal axis shows the model’s predictions, while the vertical axis represents the fault categories. It is evident that this algorithm yields favorable classification results for both the test and training sets.
5. Conclusions
During transportation and usage, ultrasonic flow meters often encounter various malfunctions. Failure to promptly detect these issues can disrupt trade fairness and, in severe cases, compromise personnel safety. Traditional malfunction detection methods are relatively slow, involve numerous factors, and demand a higher skill level from the inspectors. This article’s approach is data-driven, and its key innovations are summarized as follows:
The study introduced a comprehensive fault diagnosis approach. The flow data collected inside the pipeline and the features of the flow meter itself can be directly input into the fault diagnosis model. Simultaneously, an attention mechanism has been integrated, allowing the real-time remote acquisition of fault diagnosis results of ultrasonic flow meters under external environmental interference.
This paper improved the classification performance of the SVM using an improved sparrow search algorithm. This improved algorithm was employed to seek parameters that optimize the performance of the SVM. In contrast with traditional methods that rely on empirical parameter selections for the SVM, this approach has the potential to enhance model accuracy.
The study introduced circle chaotic mapping to increase the variation within the sparrow population. Circle chaotic mapping exhibits strong stability and a high chaotic-value coverage rate. Utilizing data generated by the circle chaotic mapping as the initial position information for the population, and perturbing and updating the positions of sparrows whose fitness values have reached their maximum, the variation in the search was effectively increased. Additionally, to avoid the sparrow search algorithm from becoming trapped in local optima, a Levy flight was introduced. Each step direction of a Levy flight is entirely random, with a length following a normal distribution and a variable step size. Improvements in the update expression for the positions of sparrow followers using Levy flights enhance the global search capability and convergence speed while maintaining optimization speed.
Finally, this study conducted experiments on four types of ultrasonic flow meters using features such as the profile coefficient, flow rate, and signal-to-noise ratio, among others, as experimental data. These were utilized for training and testing the model, achieving fault diagnosis for the ultrasonic flow meters. The experimental results indicate that the fault diagnosis predictive models built for the four flow meters using this algorithm had prediction accuracies of over 94%, surpassing the overall diagnostic performance of other algorithms. Hence, the ultrasonic flow meter fault-diagnosis method based on KPCA-CLSSA-SVM has been proved to be a promising solution within the field of ultrasonic flow meter fault diagnosis.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
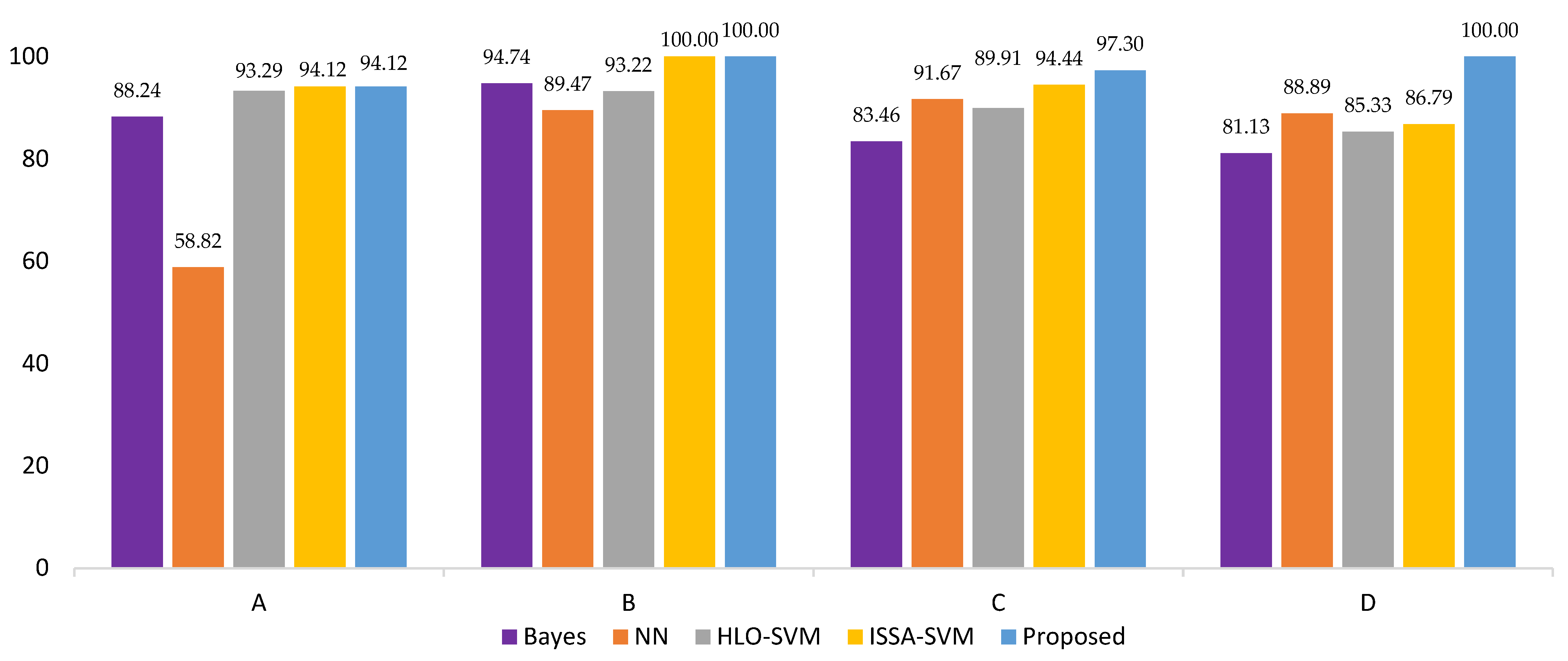{kind=link}