1. Introduction
In batch plants, continuous plants, and general manufacturing plants with multiple processing units, multiple products or time-decaying performance, scheduling of production and maintenance is essential to ensure a feasible and economically profitable operation. The aim of scheduling is to define the production sequence, order, allocation, and timing for execution of all production and maintenance tasks. For example, a closed-loop nonlinear model predictive control (NMPC) approach has been developed to simultaneously optimize the cleaning schedule and the flow distribution for refinery preheat trains under fouling [
1]. Production scheduling and maintenance scheduling belong to the same kind of problem (i.e., they follow the same principles, assumptions, and modeling approaches) and, in some instances, have been integrated [
2,
3,
4]. One of the main assumptions used to address these problems is a perfect knowledge of the current and future operating conditions, which includes demand, unit performance, availability, and cost of resources.
However, all processes are by nature dynamic and subject to uncertainty and disturbances. For example, in batch processing, unplanned events such as unit breakdown, new orders, changes in order quantity, performance decay of the unit, and variation in costs and prices affect the performance (technical and economic) and even feasibility of a schedule previously determined [
5]. Therefore, a re-evaluation of the scheduling decision is necessary and advantageous. Traditionally, two alternatives schemes have been defined: (i) rescheduling, where the main objective is to recover feasibility of the operation after a (significantly large) disturbance is observed, and (ii) online scheduling, where the schedule is updated at regular intervals [
6,
7]. Rescheduling can be done via a full re-evaluation of the scheduling problem, via partial modification of the previous scheduling decisions, or by postponing the execution of some actions [
8]. Typically, this is done over the same time horizon as the original schedule and with no new decision variables. Most of the approaches for rescheduling are based on heuristics and aim to do minimal, yet significant, modifications to recover feasibility [
5]. Some others are based on mathematical programming and solve a nonlinear programming (NLP), mixed integer linear programming (MILP) or mixed integer nonlinear programming (MINLP) problem representing a partial scheduling problem (i.e., with a subset of the decisions fixed based on the solution of the initial schedule) [
5,
9]. In the above classification, online scheduling uses all available decision variables, and aims to maximize the performance of the system at every evaluation so that it does not just reject disturbances, but also generates improvements when the system dynamics allow so [
10]. This alternative relies on the solution of optimization problems in a feedback loop using a receding horizon approach (i.e., the time horizon of each schedule evaluation rolls forward and includes new future decisions). The update interval may be fixed and constant, or conditional to the detection of disturbances to the system.
Online scheduling, also referred to as closed-loop scheduling, aims to automate a production and/or maintenance schedule of a plant despite disturbances and variability. However, it has been noted that such a rolling update of the schedule can produce instability in the operation [
10,
11]. Schedule instability, also called schedule nervousness, may be loosely defined as changes in scheduling decisions between consecutive updates which are undesired (the opposite defines schedule stability). Such changes often have important consequences for the operation. For example, some tasks may not be included in the scheduling model (or not included in sufficient detail) and a change in schedule requires revising them as well. Some tasks may require manual intervention and some resources may require a long procurement time. If scheduling decisions change too frequently or too suddenly, there may not be sufficient time to implement those tasks or procure those resources. In addition, from the operator perspective, too many and sudden schedule changes may be perceived as “erroneous” and “nonintuitive”, leading the operator to manually overwrite some decisions. This in turn will most likely generate delays in execution, introduce further disturbances to the operation that have to be corrected later on, and negatively affect performance [
5,
8].
In principle, increasing schedule stability within the closed loop would often facilitate the implementation of scheduling decisions, avoid other disturbances occurring in the long term, and improve the closed-loop performance. This will, however, reduce the ability of the system to react to disturbances. Ensuring a rapid schedule response to changes in conditions and schedule stability are, therefore, both desired objectives.
Refining operations are an example of highly dynamic processes with a high energy demand and environmental impact, which are also subject to many uncertainties and variability. They can benefit from an online optimization of their operation to reduce energy consumption, operating cost, and carbon emissions. A key section of a refinery is the preheat train, a large heat exchanger network that recovers around 70% of the energy in the products of the main distillation column [
12]. An efficient operation of this section ensures satisfying the production targets, while reducing energy consumption. However, it is subject to a wide range of disturbances such as changes in flow rates, operating temperature, and crude blends processed (which occur on the timescale of hours or days), as well as to efficiency losses, among which the most important is fouling. To maintain an efficient operation of the preheat train in the presence of such disturbances and process variability, the flow distribution through the network and the cleaning schedule of the units have to be optimized.
Usually, the cleaning scheduling and the flow distribution problems of preheat trains have been considered independently, ignoring the inherent variability of the process, and solved using heuristics [
13,
14,
15]. This leads to suboptimal operations because key elements of the problem are ignored, or to infeasible operations because operating limits (e.g., the firing limit of the furnace, the limit capacity of the pumps) are reached, causing a need for emergency cleaning actions or a reduction in production rates. It has been shown that, for these type of processes, integrating flow control in the network and scheduling of exchanger cleaning is advantageous because of the strong synergies between them [
16,
17]. Optimizing these two elements in a closed loop is, therefore, important to reject disturbances and improve performance. A closed-loop nonlinear model predictive control (NMPC) approach that does this has been developed [
1]. However, to achieve a successful implementation of an online cleaning scheduling and flow control of preheat trains, issues related to schedule stability have to be addressed first. Schedule stability is of particular importance in this application because (i) the time scale involved spans from weeks to years, which requires the integration of short-term and long-term decisions, and (ii) the nature of the scheduling decisions (i.e., cleaning of units) requires planning ahead of the specialized resources necessary (e.g., crews, cleaning equipment, cranes, usually contracted out with long notices). Refinery operators, therefore, invariably demand some stability in the future scheduling decisions. Schedule stability, disturbance rejection, and performance optimality are all desired objectives for the problem at hand.
Several approaches have been proposed to balance this trade-off between schedule stability and closed-loop schedule performance in various applications related to batch or manufacturing processes. However, to our knowledge, they have not been proposed related to maintenance or cleaning scheduling. Dynamic effects and variability have been considered by using heuristic algorithms to modify the starting time of the task online [
18], by solving an MILP problem that swaps the order or allocation of the task to minimize wait time [
19], and by using constraint programming to repair the schedule [
20]. All of these methods relay an incumbent schedule as a reference and ignore the effects on economic performance. Other rescheduling approaches penalize in an objective function the changes with respect to the incumbent schedule and may include penalties for reallocation of tasks [
21], penalties for changes in the starting time of tasks [
22], or a more detailed discrimination of all rescheduling costs (i.e., starting time deviation cost, unit reallocation cost, resequencing cost) as penalties in the objective function [
8]. As noted, most of these approaches are designed to be used reactively to recover feasibility when large disturbances are observed and not online for closed-loop optimization of a schedule. An early system for online scheduling (SuperBatch) dealt with highly complex processing configurations (plant, recipes, orders, etc.) in batch manufacturing. Schedules were updated every minute, adjusting for external and process variations on a rapid basis, using an unpublished heuristic method evolved from [
18]. The system was successfully applied industrially to scheduling and design of very complex, large-scale food productions [
23,
24] (
Figure 1).
In online or closed-loop scheduling, variability is considered explicitly on a rolling horizon. In this case, the objective function or the constraints of the scheduling problem can be modified to additionally include closed-loop schedule stability requirements. For instance, this may be done by retaining some allocations from previous evaluations and promoting early task allocations as a penalty in the objective function [
25]. Another formulation minimizes the earliness/tardiness in the execution of the tasks and the cost of flexible tasks [
26]. More recently, a state-space representation of the scheduling problem was proposed according to the nonlinear model predictive control (NMPC) paradigm, where the scheduling problem is solved online and automatically includes the effect of disturbances [
10,
11,
27]. The objective is economically driven but does not consider schedule stability.
The previous survey indicated that schedule stability for online scheduling is still an open issue, and there is no single, general approach that optimizes the trade-off between closed-loop performance and schedule stability. First, stability is not well defined and quantified, and there are different metrics for various rescheduling actions. Second, most of the rescheduling formulations have focused on just restoring feasibility while ignoring optimality and opportunities arising from the process dynamics and disturbances. Third, only certain sources of schedule instability have been considered, with no clear definition or guidelines for setting the penalty factors. Fourth, most methods so far do not include the possibility of optimizing continuous control decisions at the same time as discrete scheduling decisions. These methodological limitations result in practical barriers to the online optimization of flow distribution and cleaning scheduling in refinery preheat trains, as well as of other dynamic process systems with analogous features.
The aims of this paper are (i) to present a method for the online optimization of operational schedules and continuous controls under high input and disturbance variability, while considering schedule stability explicitly in the closed loop, and (ii) to demonstrate its application and benefits for the online cleaning scheduling and flow distribution control of refinery preheat trains. The remainder of the paper is structured as follows:
Section 2 briefly presents the modeling framework used to describe the dynamics of preheat trains under fouling and for online integration and optimization of the flow distribution and cleaning scheduling considering disturbances. In
Section 3, some metrics to quantify schedule instability are presented and discussed.
Section 4 introduces three alternative ways to include schedule stability objectives within the closed-loop optimization formulation.
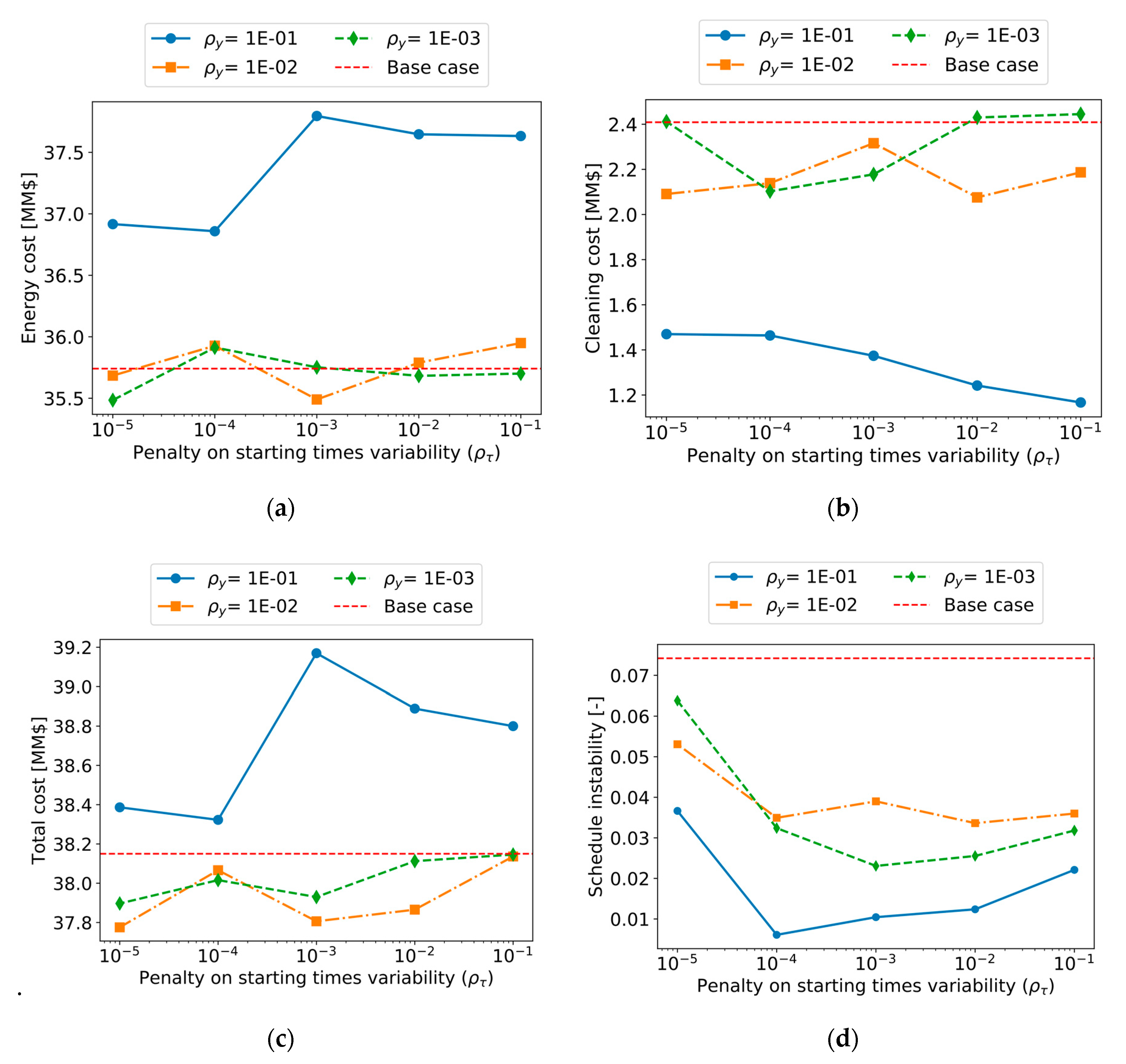
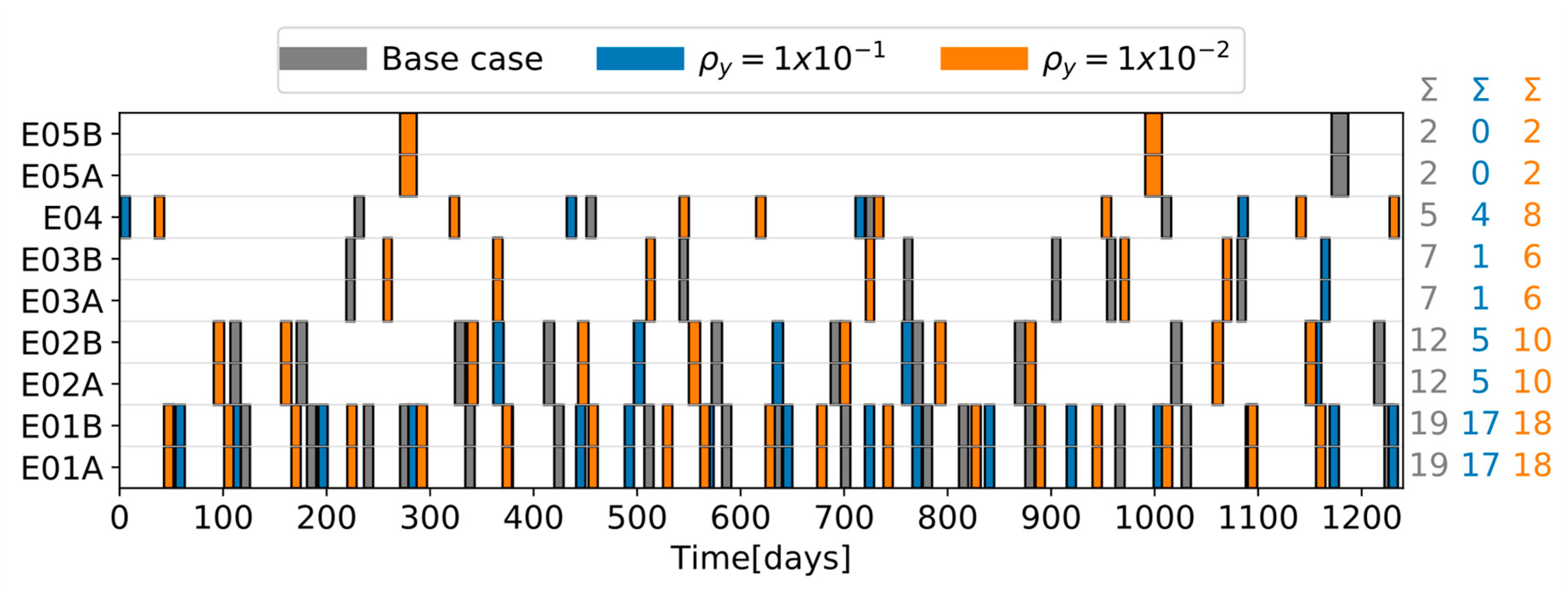
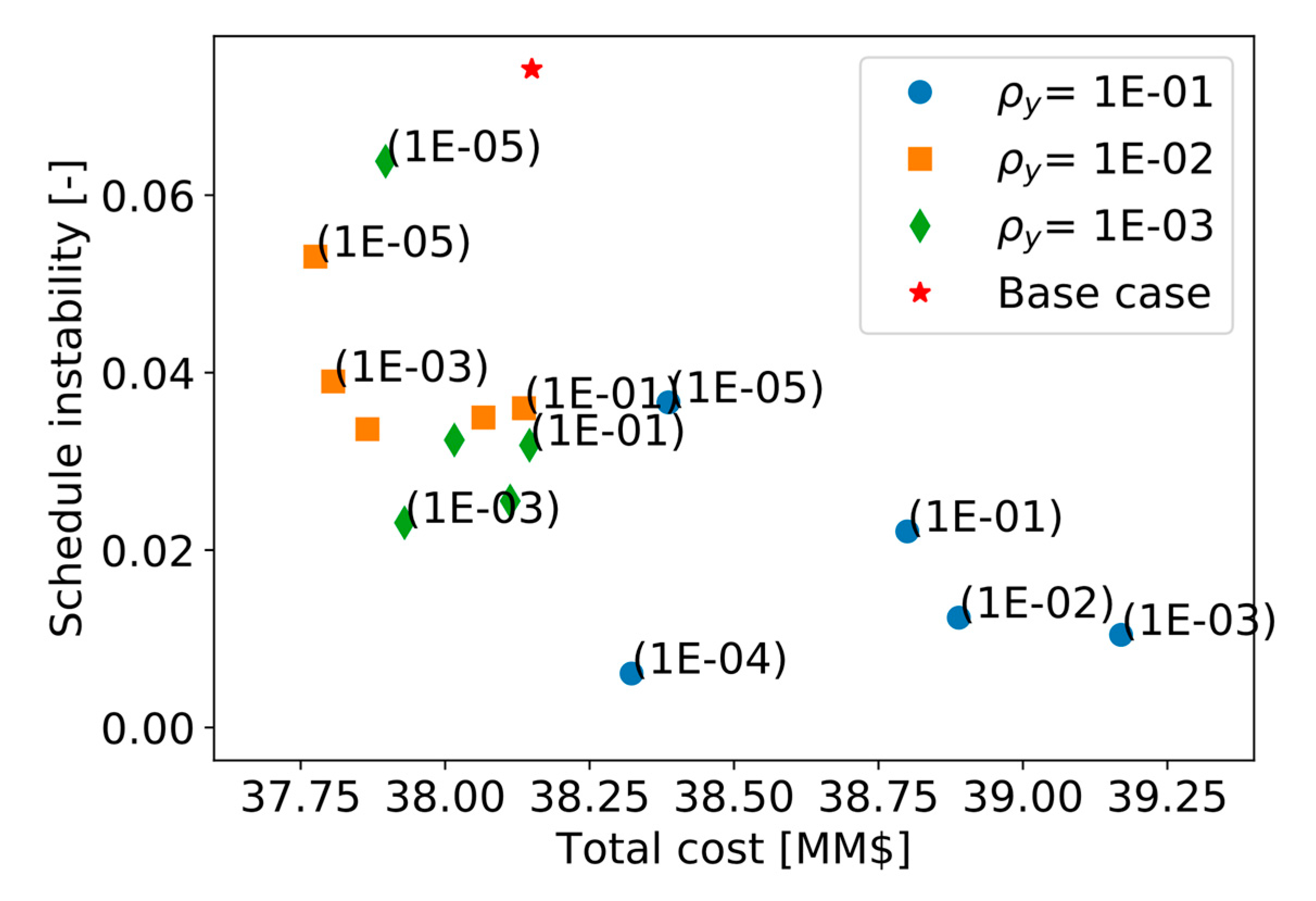
Section 5 introduces a small case study that is used to demonstrate the use of the instability metrics, and it compares the performance (in terms of stability and total cost) of the various formulations aimed at increasing schedule stability.
Section 6 demonstrates the application of the framework to a realistic industrial case study, using historical refinery data and the actual variability observed in the operation of the preheat train. Lastly, the conclusions of the work are drawn in
Section 7.
2. Closed-Loop Optimal Cleaning Scheduling and Control of Preheat Trains
The online optimization approach of the cleaning schedule and dynamic flow distribution of preheat trains under fouling is based on an advanced nonlinear model predictive control (NMPC) strategy, presented in detail in a previous study by the authors [
1]. It defines two feedback control loops, one for the fast dynamics of the process associated with flow distribution (of the order of hours) and another for the slow dynamics associated with fouling and cleaning (of the order of weeks and months).
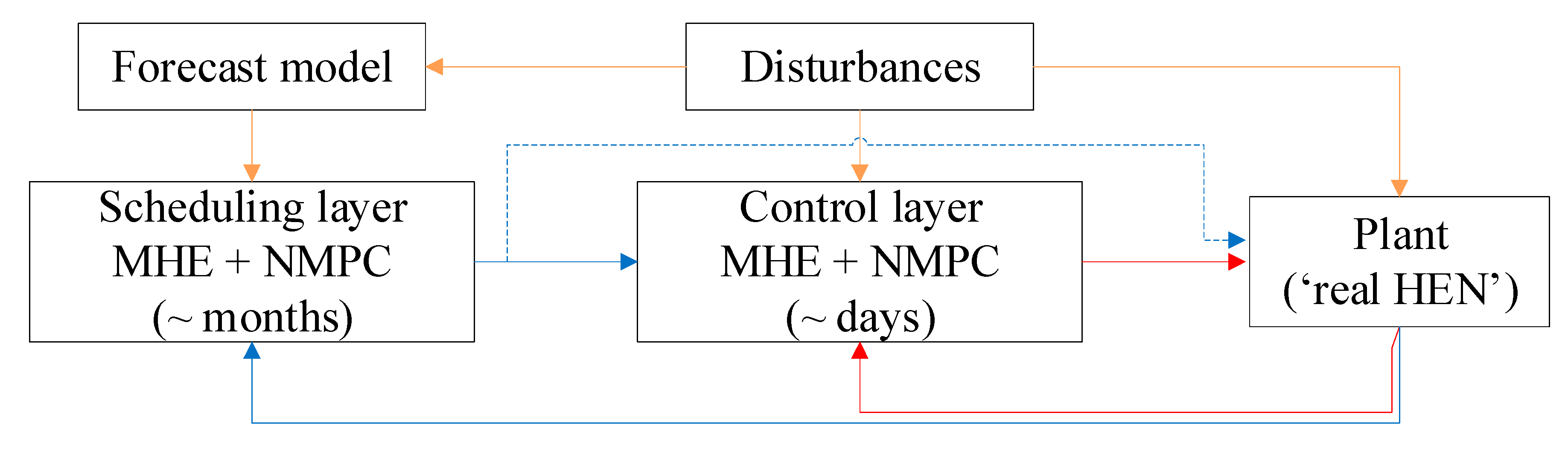
Figure 2 shows a simplified block diagram of the control loops, their components, and interactions. In this figure, the plant block corresponds to the actual system or a representation of it, the control layer refers to the advanced control and state estimator that defines the control elements of the system for rejection of fast disturbances (its inputs are the set schedule, the current state of the system, and disturbances, and the outputs are the control actions), and the scheduling layer refers to the algorithm defining the online scheduling strategy and its corresponding state estimator (its inputs are the current state of the system and a forecast of the disturbances, and the output is the schedule for the current time). Each control loop has two components: a moving horizon estimator (MHE) to update the model parameters and predict the current state of the system on the basis of the latest plant data and a nonlinear model predictive controller (NMPC) to optimize the future operation of the network. These two elements solve optimization problems using a realistically accurate and representative mechanistic, dynamic model of the plant. In particular, the model describes heat transfer, deposition rates, temperature changes, and hydraulic performance of the heat exchangers, as well as their interactions within the network that constitutes the preheat train. A brief, general description of the modeling components is given next, whereas a more detailed presentation of the model formulation and assumptions can be found in [
16].
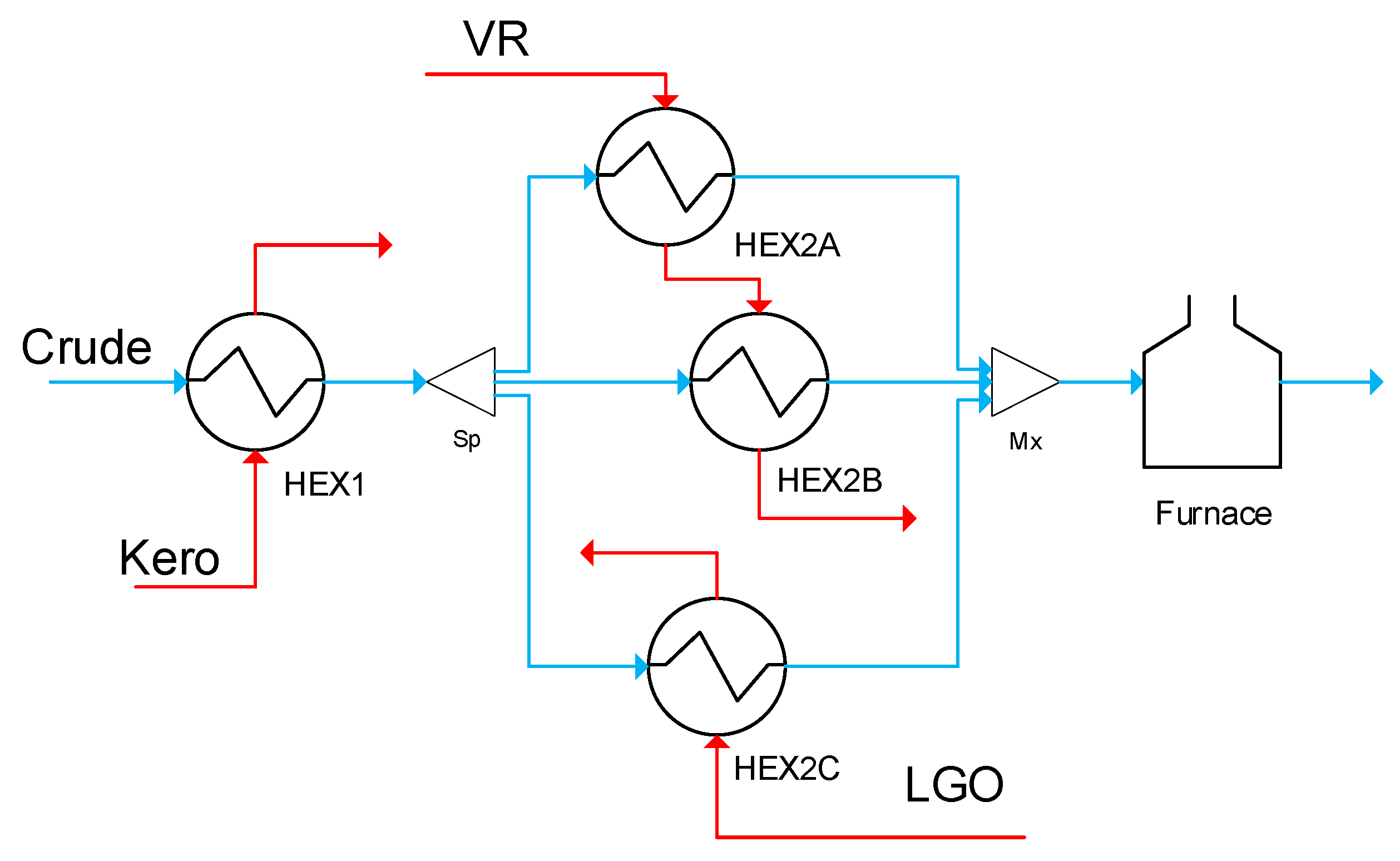
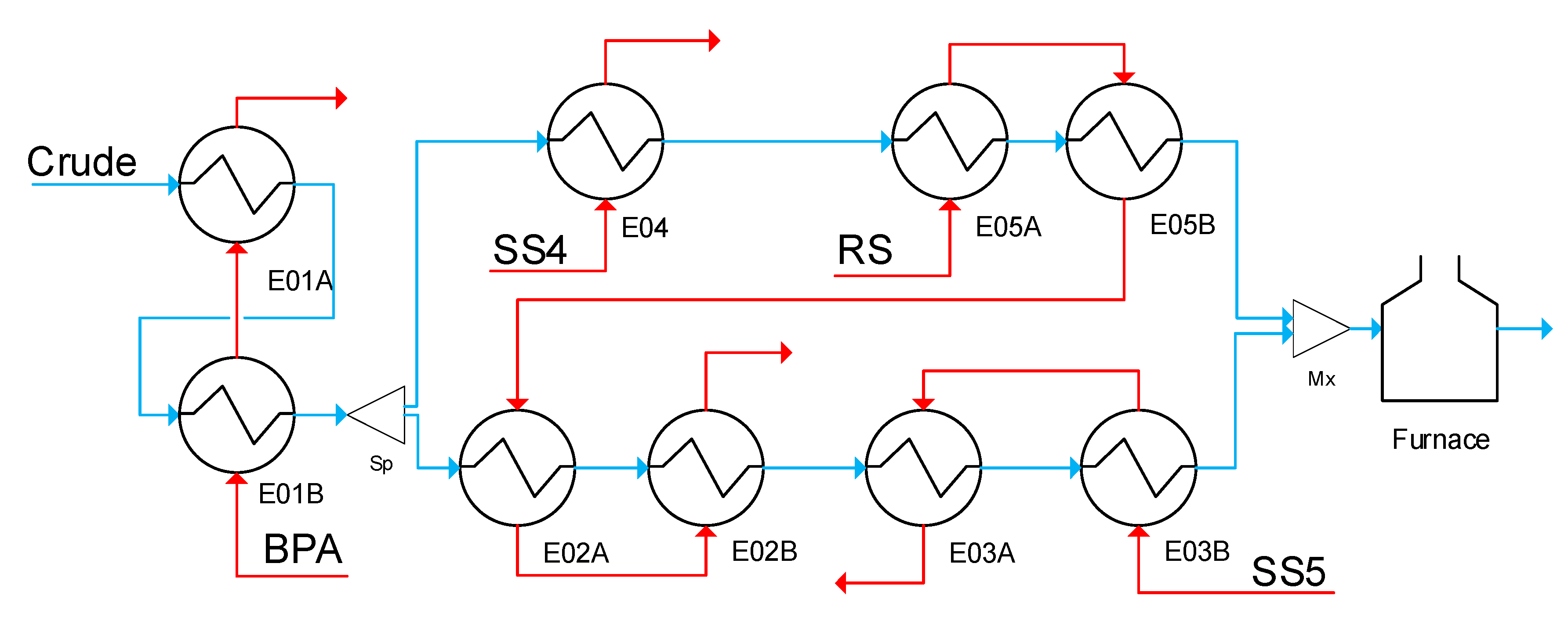
The preheat train model is based on a directed multigraph representation of the heat exchanger network, where each graph corresponds to a stream (e.g., crude oil, naphtha, residue) and the nodes are exchangers, furnace, sources, sinks, mixers, and splitters. At each node, mass and energy balances must be satisfied to ensure network connectivity. The operation of the heat exchangers, all assumed to be of shell and tube type, is represented using an axially lumped, but radially distributed model based on the P-NTU concept [
28,
29], an explicit description of the heat transfer and temperature profiles in the radial direction through different domains (shell, deposit layers, tube wall, tube), as well as hydraulic relations for the tube side pressure drop. The semiempirical reaction fouling model of Ebert–Panchal, Equation (1) [
28], is used to characterize the evolution over time of the thermal resistance of the deposit in a unit. This affects the thermal performance of the unit and is related to the deposit thickness, Equation (2), affecting its hydraulic performance (all variables are defined in the Nomenclature). Experimental or plant data are required to estimate the parameters of the fouling model
). It has been demonstrated that this model adequately captures the main effect of the operating variables of the exchangers (e.g., surface temperature, velocity, shear stress) on the fouling rate [
30]. In addition to these modeling components, operational limits such as the maximum duty of the furnace, the pressure drop limits in the network, bounds of flow split fractions to parallel branches, and pressure drop equalization constraints over parallel branches are included in the form of inequalities in the problem formulation. The resulting large set of nonlinear equality and inequality constraints is a sufficiently accurate [
31] yet compact dynamic model of each exchanger and the network.
This dynamic model for preheat trains under fouling is used in the MHE and NMPC problems in both the scheduling and the control layers (labeled with subscript s and c, respectively) for parameter estimation, as well as to simultaneously optimize the flow distribution in the network and the cleaning schedule. It has been demonstrated, using actual refinery data, that this model has good predictive capabilities over a wide range of operating conditions and long operating times, with an average absolute prediction error in each exchanger of 0.9 °C for the tube-side exit temperature, 1.3 °C for the shell-side exit temperature, and 0.05 bar for the tube-side pressure drop [
1].
Table 1 summarizes the main components, assumptions, and considerations of each feedback loop and their elements. In each layer, the MHE and NMPC formulations use the dynamic model described above to represent the operation of the preheat train and the effects of fouling. In the NMPC formulation of the scheduling layer, which includes binary decision variables, additional inequality constraints are included to represent the changes in operating modes of the exchangers (i.e., “operating” or “being cleaned”) and any conditions optionally imposed on the cleaning sequence (e.g., units to be simultaneously cleaned, periods of no cleanings, exclusive cleanings).
The control layer deals with the fast dynamics, and its main objective is to reject disturbances and minimize operating cost by manipulating flow split profiles, knowing the short-term cleaning schedule to be executed. The objective of the MHE
C is to determine the model parameters that best explain the observations (i.e., temperature and pressure measurements from the plant) over a past estimation horizon, as represented in Equation (3). The adjustable parameters are the deposition and removal constants in the Ebert–Panchal model and the surface roughness, for each of the exchangers in the preheat train. The resulting formulation is an NLP problem. Once the MHE
C problem is solved, the parameters thus obtained are used in the NMPC
C problem (also formulated as an NLP) to determine the optimal flow distribution over a future prediction horizon that minimizes the operating cost, Equation (4). The latter includes the cost of the fuel consumed in the furnace and associated carbon emissions. The prediction time horizon is discretized using a discrete representation. Although the optimal solution covers a long horizon, only the first action is implemented in the plant; the remainder are discarded, and the problem is solved again in the next sampling interval, in the usual MPC scheme. The sampling (update) intervals are much shorter than the control prediction horizon. In this control layer, a forecast is required of the disturbances (changes in input variables) over the future prediction horizon. Here, each input variable (flowrate, temperature, and pressure of input streams) is forecast to remain constant at its last measured value for the entire horizon. As control updates are frequent, this is deemed to be adequate.
The scheduling layer deals with the slow dynamics of the process over long periods of operation. It integrates scheduling and control decisions to minimize the operating cost and to define the future cleaning actions. The MHE
S problem is similar to that of the control layer, and they share the same objective. However, the past estimation horizon of the scheduling layer is longer than in the control layer because more data is necessary to capture the slow dynamics of the system. On the other hand, the NMPC
S problem is significantly different from that of the control layer. First, the future prediction horizon FPH
S is much longer, as it must be able to schedule cleaning actions and quantify their effects and benefits. Second, the objective function includes both operating cost and cleaning cost, Equation (5). Third, the prediction time horizon is here discretized using a continuous rather than a discrete representation, to reduce the number of binary variables of the scheduling problem. Each period of variable length is further discretized using orthogonal collocation on finite elements in order to accurately integrate the differential equations in the model. Fourth, in this scheduling layer, a forecast is also required of the disturbances over the future prediction horizon. Here, each input stream variable (flowrate, temperature, and pressure) is forecast to remain constant for the entire horizon, but fixed at the value of its moving average over the past month, to account for recent variability. Alternative forecasting estimates (e.g., reflecting predicted trends or known planned changes) could be used. Lastly, the optimization problem involves binary decision variables associated with the operating mode of the units at every time point, resulting in an MINLP instead of an NLP formulation. This is a challenging optimization problem because of the large number of binary variables, few constraints on the cleaning sequence, nonlinearities, nonconvexities, and the degeneracy of the objective function (i.e., multiple solutions may have similar values). To solve the MINLP problem that integrates cleaning scheduling and flow control, a reformulation using complementarity constraints is implemented, which allows finding local optimal solutions online in reasonable computational times [
32].
The scheduling layer is not updated as frequently as the control layer because of the different time scales involved. However, the two layers interact strongly so as to ensure that scheduling and control decisions are properly integrated and their synergies exploited. The optimal scheduling actions determined at the scheduling layer until the next schedule update are executed in the plant. They are also sent to the control layer, which determines the best flow distribution according to those cleanings and the disturbances observed. Other schedule decisions in the schedule prediction horizon beyond this first interval are discarded.
For the purpose of this paper, the actual plant is simulated using the same predictive model as used in the NMPC/MEH loops. However, its parameters are modified in order to create a controlled degree of (parametric) model mismatch. The plant parameters are unknown to the feedback loops.
3. Closed-Loop Schedule Stability Metrics
Closed-loop schedule instability must be quantified to determine efficient strategies to reduce it, but no single metric is adequate. In production scheduling, it has been quantified as the difference in the overall quantity of a given product produced at a given time between two consecutive evaluations of the schedule [
33]. Other attempts have quantified the changes in starting time of the same task between two consecutive solutions [
34] or the changes in task allocations among the units [
34,
35]. Reference [
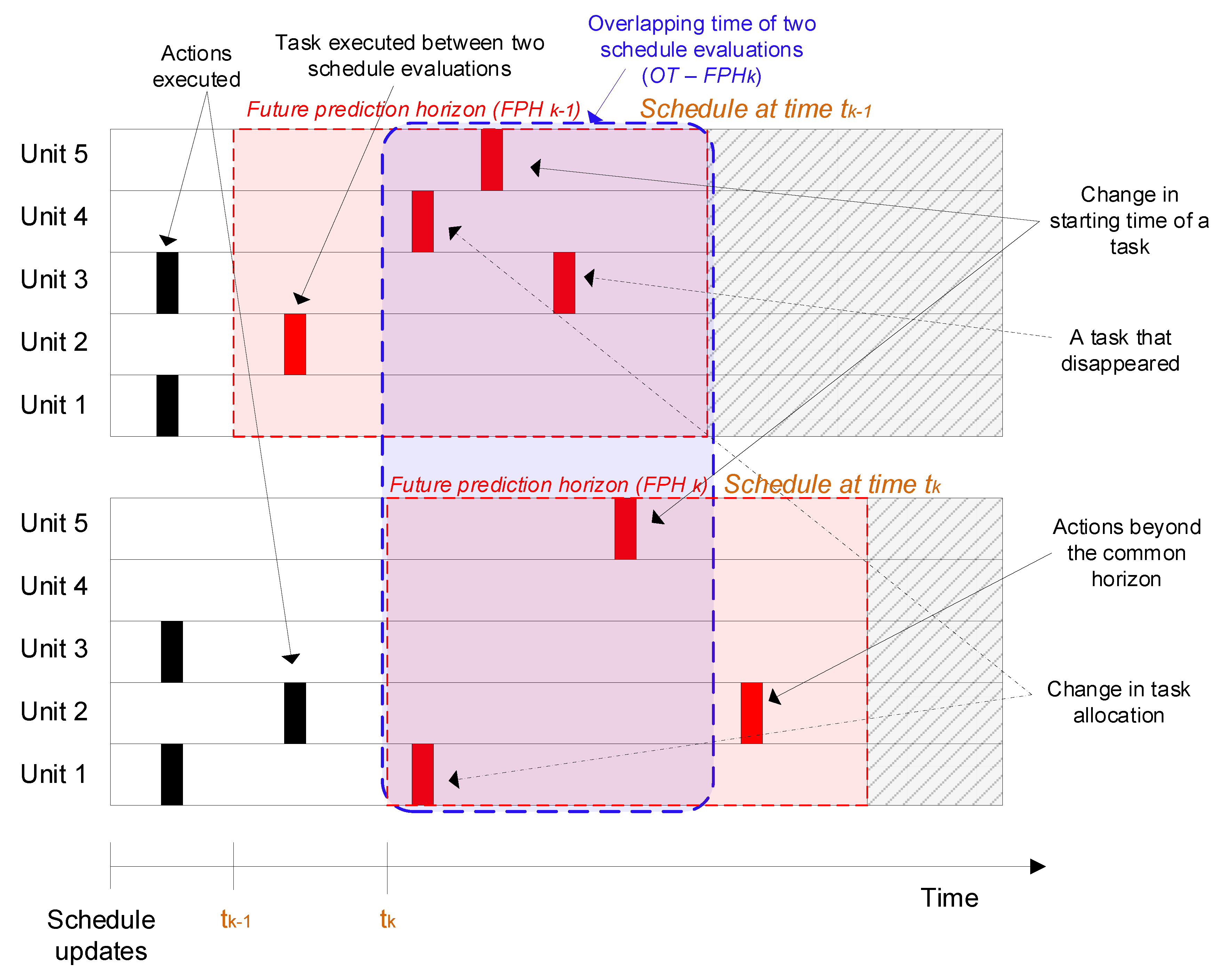
30] considered batch plants; thus, their criterion is not immediately applicable to the problem of interest here, which is a type of maintenance scheduling for a continuous process. An analogous concept will be developed later which is applicable to continuous processes. On the other hand, the differences in the starting time of tasks (the cleanings) and in the task allocations (which exchanger is cleaned and number of cleanings per exchanger) will be used to quantify schedule instability, according to the notation in
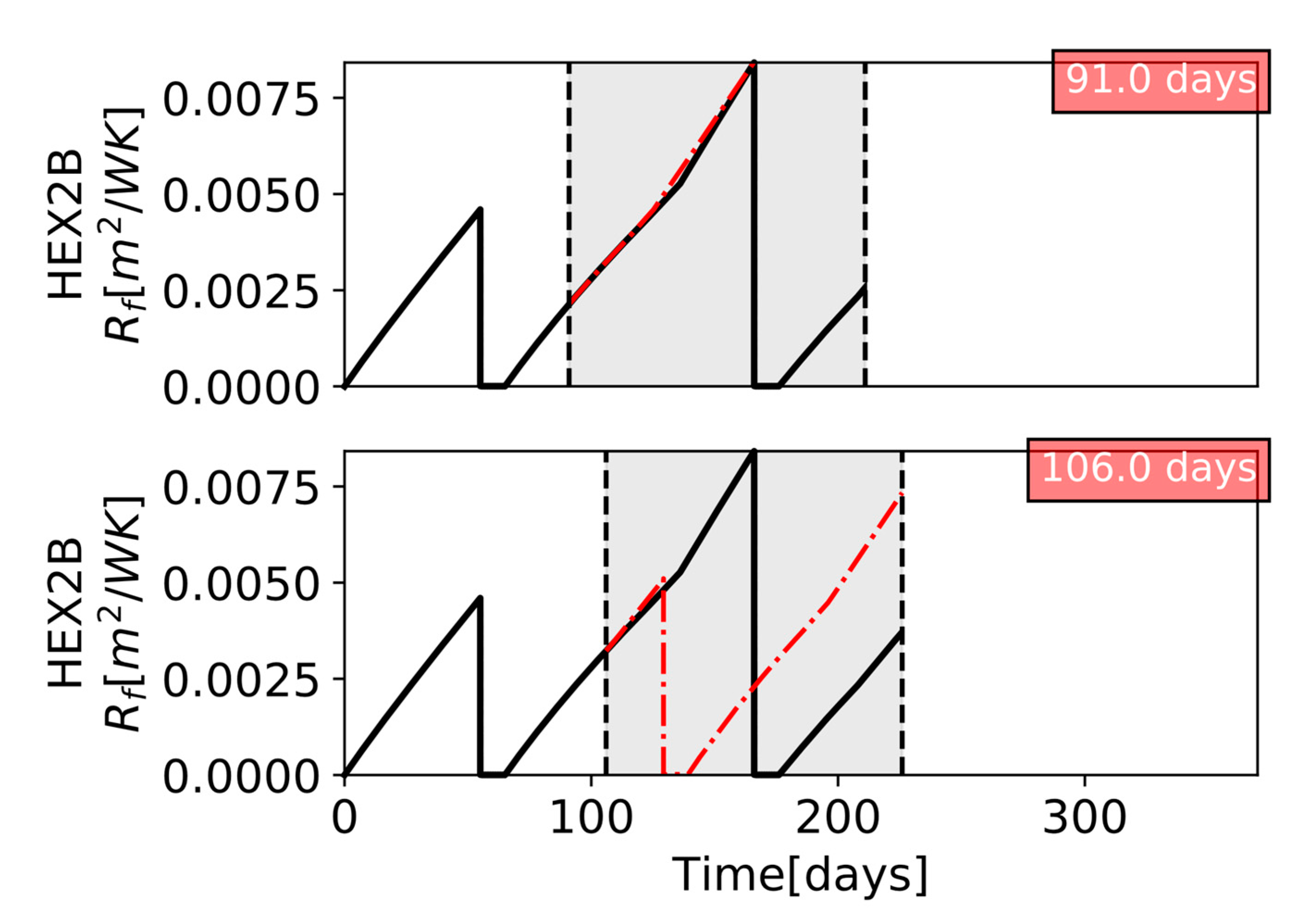
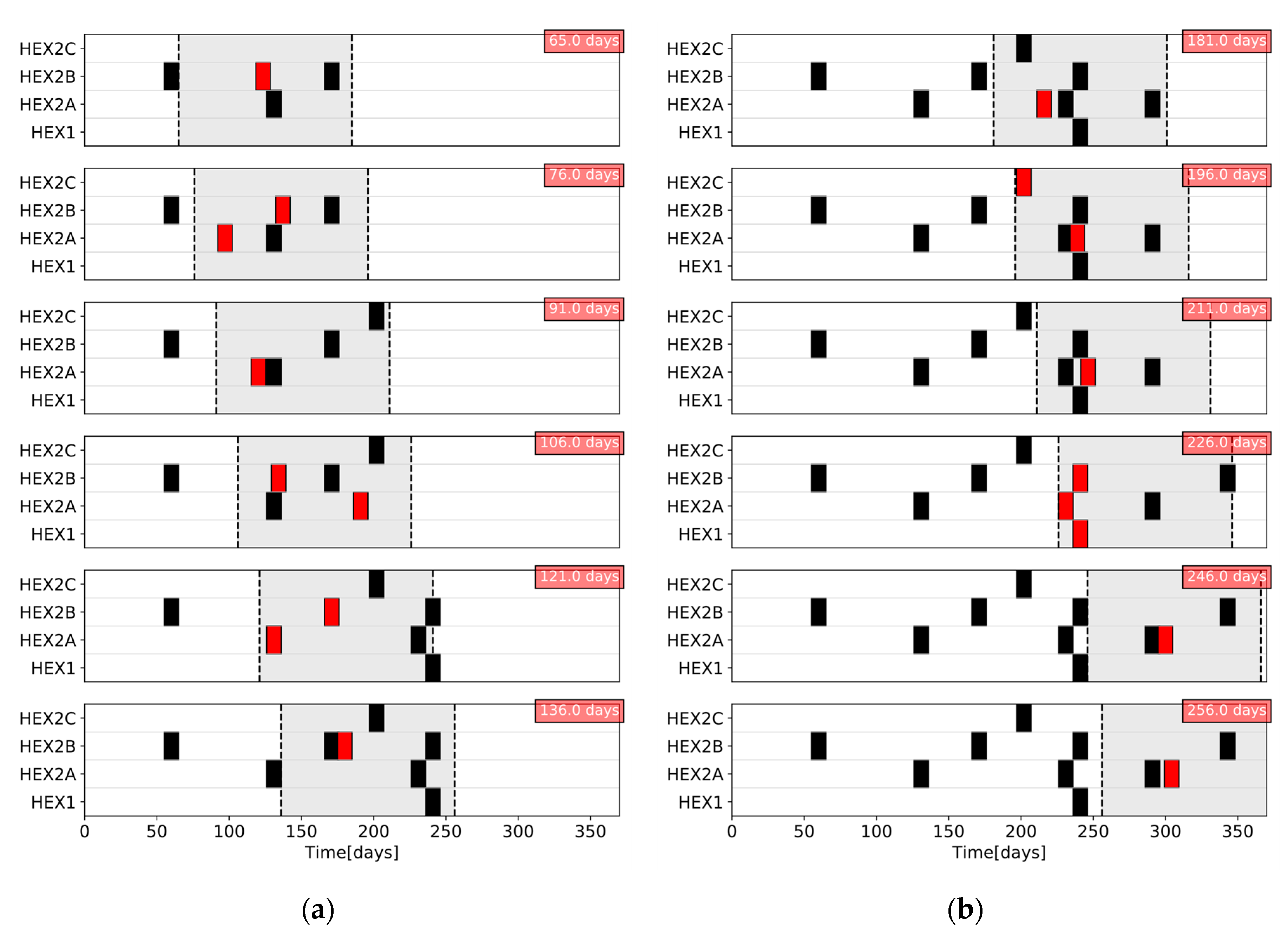
Figure 3.The figure shows the cleaning schedules for a five exchanger network at two consecutive evaluations (at the top, schedule
k − 1 evaluated at time
; at the bottom schedule
k, evaluated at time
) and a representation of the main schedule differences, including changes in task allocations (which units are cleaned) and the starting time of the tasks (when cleanings start). The schedule instability is defined taking into account those actions within the overlapping interval, OI, in the future prediction horizons of the two consecutive schedules. With constant schedule update interval and length of the scheduling prediction horizon,
, the duration of this overlapping interval is also constant and simply equal to their difference,
−
. With variable intervals, the same definitions are indexed according to the schedule evaluation index,
k, i.e., the overlapping interval at evaluation
k,
has duration
−
.
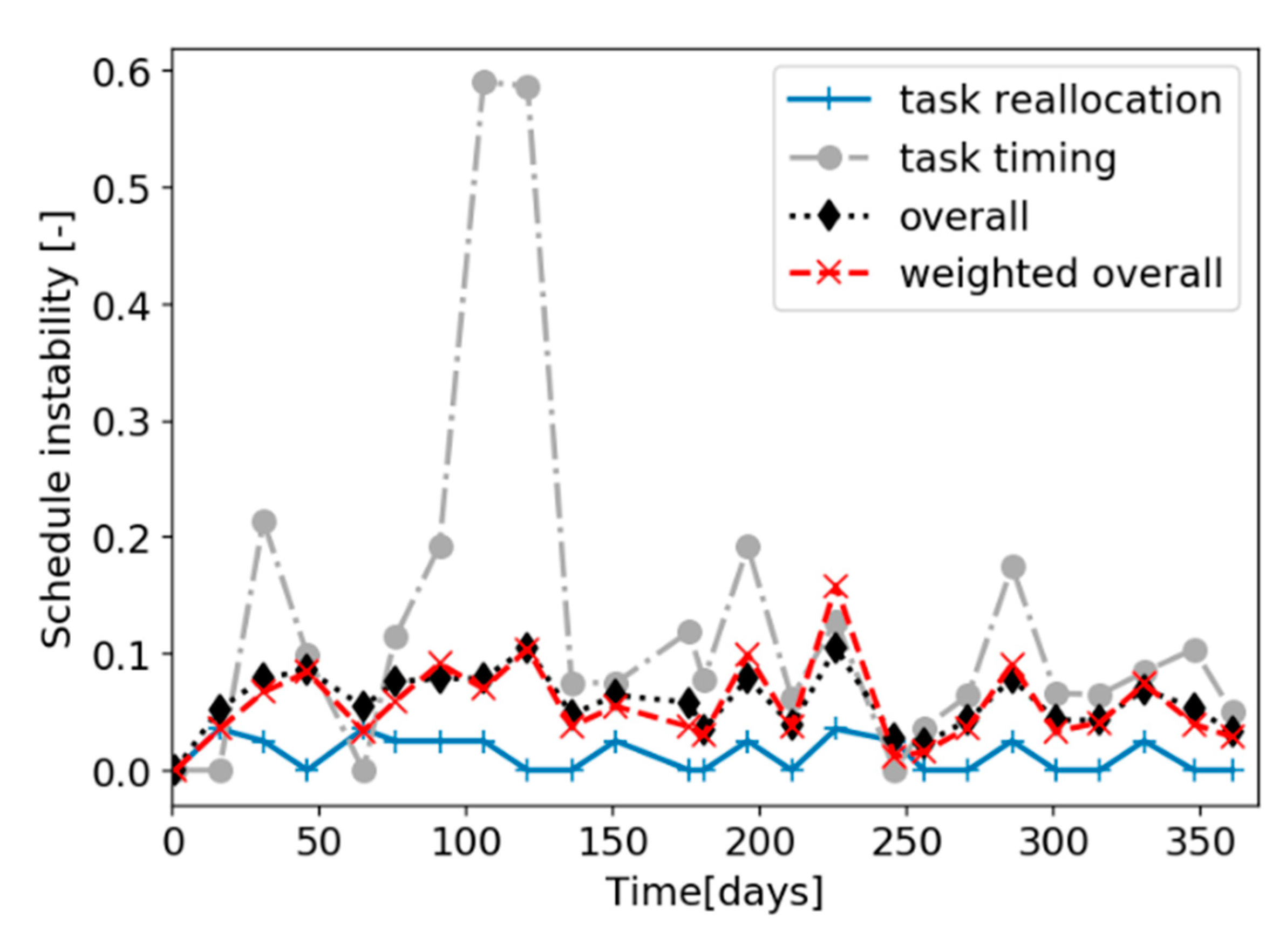
Four metrics of schedule instability are defined next on the basis of these definitions: (1) task time instability, (2) task allocation instability, (3) overall instability, and (4) overall weighted instability. They are defined for consecutive schedule evaluations assuming a continuous time representation, although they also apply with a discrete time representation. Instability metrics are generated every time a schedule is updated, and, in an online application, their time evolution can be tracked on a rolling horizon at each update.
The metrics defined here can provide useful insights into schedule stability regardless of how the schedule is defined. The only condition for their application is the existence of two consecutive evaluations or predictions of the schedule with a common period. The definition of these metrics is based on the changes occurring within a common period shared by the schedule evaluations. Hence, these metrics can be calculated for two consecutive instances even in cases where their control horizons, scheduling horizons, or update frequencies are different.
The following definitions, sets, and indices are used to define the instability metrics for the online scheduling problem:
. Set of units.
. Set of tasks that can be allocated to the units.
. Set representing time in the .
. Set of schedules evaluated over time.
. Binary variable indicating the allocation of a task to a unit starting at a time in schedule .
. Time when schedule is evaluated.
. Time interval between two consecutive schedule evaluations.
. Set of the starting times of all tasks allocated to unit in schedule and within the time interval .
. Set of the starting times of all tasks allocated to unit in a schedule evaluation and within the operating interval .
. Set assigned to or based on which one has the minimum number of elements.
. Set defined as the complement of .
Although, in this paper, fixed update intervals are used, the formulation is suitable for both fixed and variable update intervals.
For the application at hand, i.e., cleaning scheduling of preheat trains under fouling, it is assumed that only one type of cleaning is available (i.e., mechanical cleaning) so that the set
Tasks has a single element, i.e.,
{1}. Moreover, the set
Units is the set of heat exchanges in the network, and the variable
defined here has the same role as variable
in the problem formulation detailed in [
16], which is associated with the cleaning state of the units over time (i.e., 1 for
being cleaned, 0 for
operating). In this formulation, it is possible to assign multiple mechanical cleanings (i.e., multiple instance of the same type of task) to a unit, at different times.
As the (in)stability of a schedule is a relative concept (i.e., it only applies with reference to a previous one), all metrics apply from the second evaluation only (k ≥ 2) and are undefined (and arbitrarily set to 0) for k = 1.
3.1. Task Timing Instability
A
Task timing instability of schedule
,
, is defined as the difference in the starting times of all tasks
in units
which are common to schedules
and
over the overlapping interval,
. Its mathematical representation is presented in Equation (6). Note that this includes only tasks
j that are defined in both schedules
and
. If multiple executions of task
are included over
in both schedules, the difference in their starting times is only relevant for the minimum number of instances of task
predicted in either one. In addition, if in schedule
, or
, there are no predicted executions of task
in unit
, there is no contribution of this task-unit pair to the overall task timing instability metric.
This instability metric is divided by the future prediction horizon of the scheduling problem at update , , to transform it into a dimensionless quantity. The task timing instability takes a value of zero when there is no difference in the predicted starting time of all the common tasks allocated to all the units in two consecutive schedule evaluations, or when no task of the same type is allocated to the same unit in two consecutive schedules (i.e., all the tasks allocated to a unit disappeared from the schedule or were reallocated to another unit). The task timing instability increases when the difference in the starting times of a task allocated to a unit in two successive schedules is large.
3.2. Task Allocation Instability
A
Task allocation instability of schedule
,
, is defined as the change in the total number of executions of tasks
allocated to unit
in schedule k during the
, with respect to the total number of executions of the same task in the same unit in the previous schedule,
. This is expressed mathematically in Equation (7). This expression assumes that all tasks have the same relative importance for the stability and only considers their total number of executions. In the cleaning scheduling application considered, this refers to the change in the total number of cleanings of each exchanger within
, regardless of their starting time.
This definition of instability is standardized by dividing it by the sum of the maximum number of executions of task that are allowed in unit , .This is a parameter of the scheduling problem, and is specified by the analyst. For example, in the cleaning scheduling problem of preheat trains under fouling, it is the maximum number of cleanings per exchanger that can be executed in the future prediction horizon, which is usually a constraint imposed by the operators.
The task allocation instability becomes zero when there are no changes in the number of tasks of a given type scheduled in each unit regardless of their starting time or when there are no tasks of a given type scheduled in the future prediction horizon. This instability metric increases when one or more instances of a task are added to or deleted from one or multiple units in the current schedule with respect to the previous one.
3.3. Overall Schedule Instability
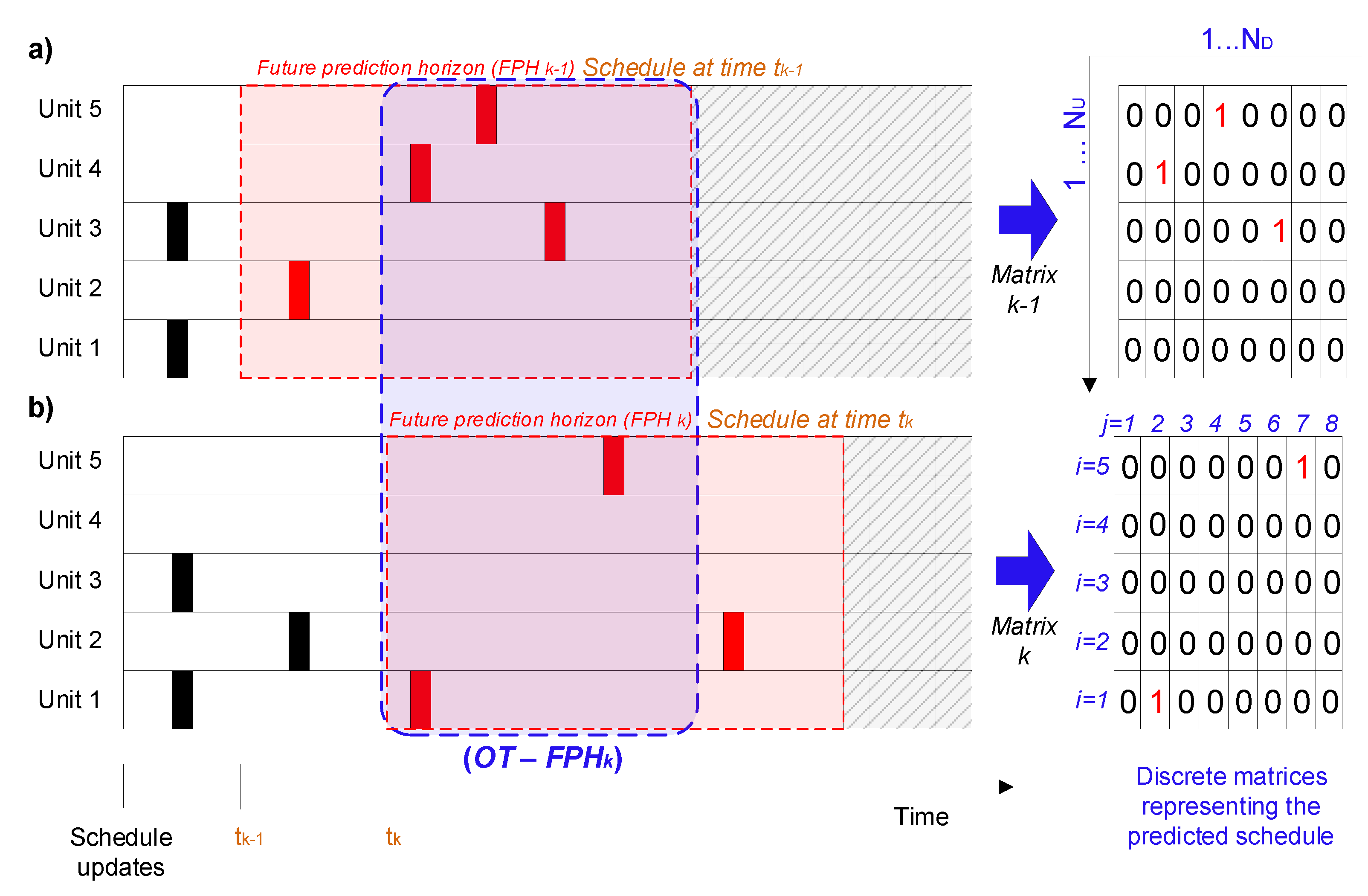
A metric of Overall schedule instability of schedule , should consider all the changes from the previous schedule k − 1, such as changes in the starting time of the tasks, changes in task allocation, addition of new tasks, and disappearance of previous tasks. To compute it, the overlapping interval is discretized using a time step that is lower than or equal to the shortest duration of any of the tasks present in either schedule. In the case of preheat trains, the sampling time of the process is used, which is 1 day, as plant measurements are available as daily averages. With this time discretization, a schedule matrix is defined representing a schedule, with rows, one per each unit, and columns, each representing a snapshot of the tasks scheduled at each time step during the . Each element of the schedule matrix is referred to as x(i,j,k) where i is an index for the units (rows), j is an index for the time instances in the discretized (columns), and k is the schedule index. The entries in the matrix are either 0, representing no task allocated, or 1, representing a task allocation. This definition assumes that there is a single task type to be scheduled, as applicable to the single type of cleaning in the scheduling of preheat trains discussed in this paper. However, it can be easily extended to a more general formulation with multiple tasks, by associating different integer values to each task type or different instability metrics for each task.
Figure 4 illustrates such a schedule matrix encoding for a simple example for schedule
k − 1 evaluated at time
(top schedule in
Figure 4) and schedule
k, evaluated at time
(bottom schedule in
Figure 4). The corresponding schedule matrices (on the right in
Figure 4) have the same dimensions because
, the sampling time, and the number of units do not change between evaluations. With this encoding, it is possible to rapidly calculate the difference between two successive schedules on the basis of the differences in individual elements of the corresponding schedule matrices.
The
Overall schedule instability of schedule
,
, is defined in Equation (8), where the quadratic difference between two consecutive schedule matrices,
and
, is calculated element by element, and all the differences are added up. This instability metric is standardized by dividing it by the size of the schedule matrix (
). All schedule changes are assumed to have the same effect on the overall schedule instability metric. They affect it by the same magnitude and do not differentiate between schedule differences due to changes in the starting time of the tasks, time delays, or changes in task allocations. Because this metric is standardized, it is bound between zero and one and increases with the number of differences between consecutive schedule evaluations.
In the example presented in
Figure 4, there are five changes in the schedule matrices between schedules
and
(see columns 2, 4, 6, and 7 of the matrices in the figure). Then, applying Equation (8), the overall schedule instability of schedule
k is 0.125.
3.4. Time-Weighted Overall Schedule Instability
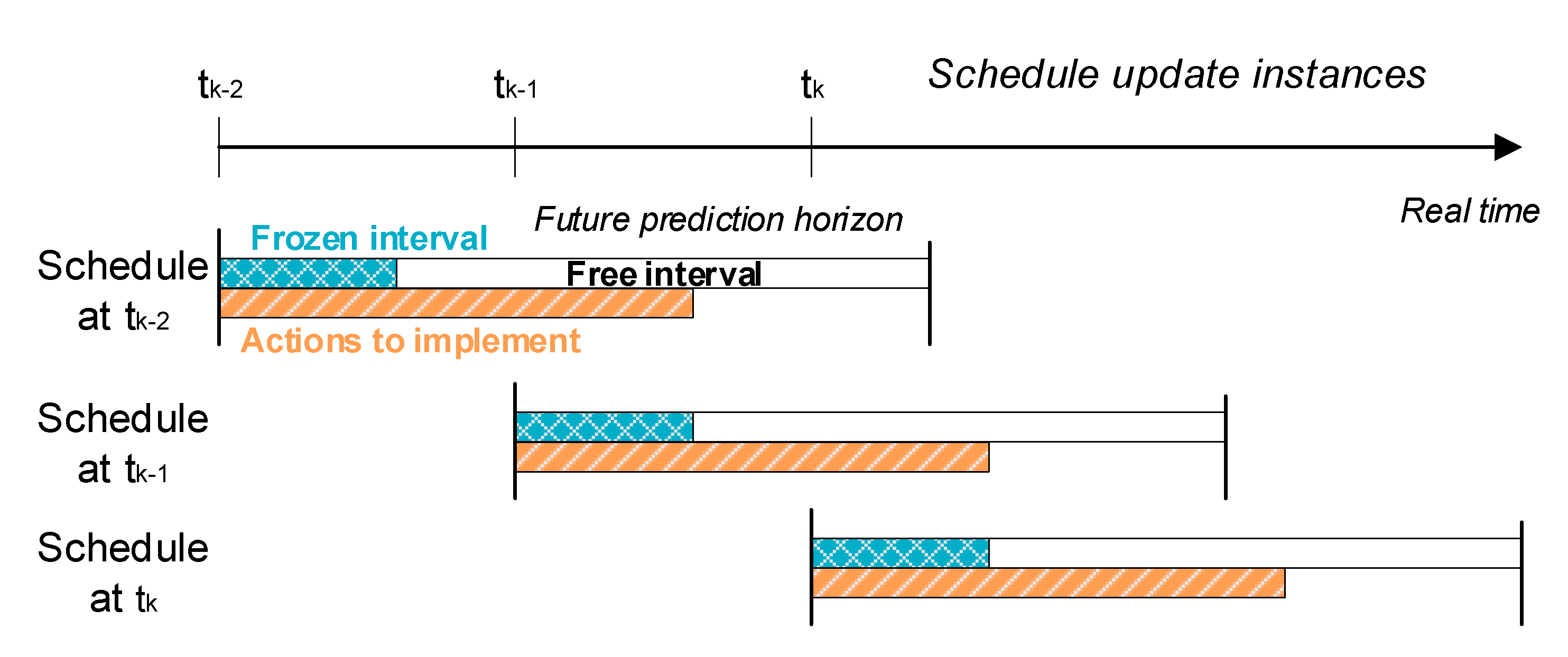
The above Overall schedule instability definition ignores when the difference in the schedules occurs. For example, the values of the overall schedule instability for two different schedules can be the same when changes in the schedule are observed at the beginning of the , which has large implications on the operation because those are the actions to be executed in the current time step, or at the end of the , when they may not be very important and are subject to future changes. The metric described below addresses the case when changes in the schedule closer to the current execution time are undesirable.
A
Time-weighted overall schedule instability metric of schedule
,
, is defined in Equation (9), where weights are used to represent the relative importance of each difference in the schedules with respect to time. This expression uses the same definitions of overall schedule instability, Equation (8), which are based on a matrix representation of the schedule over
. Here, the weights are selected to decrease linearly from one at the beginning of the overlapping interval
, to zero at is end, according to Equation (10). In terms of the
discretizations used in the schedule matrix, we have
for
and
for
. The differences in the schedules closer to the current time are, thus, given a higher relative importance than those that occurring later in the prediction horizon.
Using weights to characterize the relative importance changes in the schedule with respect to time was proposed to calculate schedule instability on the basis of the production quantity of different products [
33,
36], but not for differences in task allocation and timing. Those studies used an exponential decay function to define the weights as a function of time. This could also be used here without adding complexity to the problem. The only difference is that the exponential decay function requires the analysts to set a parameter for the rate of decay, which can be translated as a preference to ignore or not schedule modifications occurring at a future time.
The time-weighted overall schedule instability metric explicitly accounts for the effects of time to indicate that large variability close to the current time is undesirable, whereas that occurring later can be tolerable. However, it does not distinguish whether the source of variability is due to changes in the task allocation or starting time of the task.
Applying the metric defined in Equation (9), the time-weighted overall schedule instability of schedule
k in
Figure 4 is 0.136, which is higher than its overall schedule instability, 0.125. This happens because most of the differences between the two consecutive schedules occurs close to the current time,
, which is reflected in a larger number of differences between the schedule matrices in columns with low indices (columns 2 and 4 of the matrices in
Figure 4). This example shows that the time-weighted metric gives more importance to changes in the schedule that occur closer to the current time and that may require an immediate action.
7. Conclusions and Perspectives
The closed-loop schedule stability problem was addressed in this work with an application to the online cleaning scheduling and control of refinery preheat trains under fouling. The various metrics developed to quantify schedule instability for online scheduling account for distinct aspects, such as changes in task allocation, task sequence, starting time of the task, and the earlier or later occurrence of such changes in the future scheduling horizon. The results show that the metrics are useful to characterize the stability of successive schedules, as well as to identify sources of instability and ways to mitigate it. Further stability metric variations could be easily developed (for example, ways of assigning weights to distinct contributions to a schedule change) on the basis of the methods proposed.
It was demonstrated that such stability considerations can be practically and, in a rather general way, introduced in a closed-loop NMPC formulation of the optimal scheduling and control problem, and solved online over a moving horizon, in terms of penalties in an economic objective or via additional constraints. The result is a formulation which enables to specify both schedule stability and performance requirements, explore the balance between schedule reactivity and disturbance rejections, and establish the optimal trade-off between schedule stability and economic benefits.
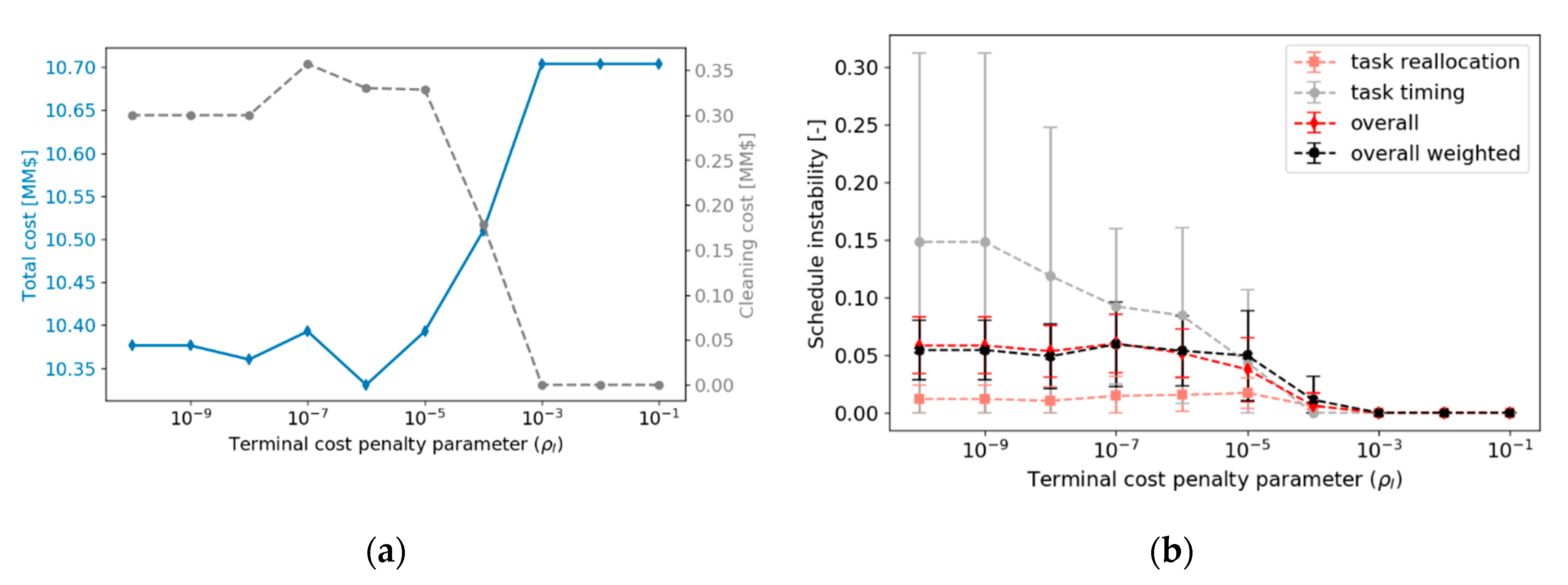
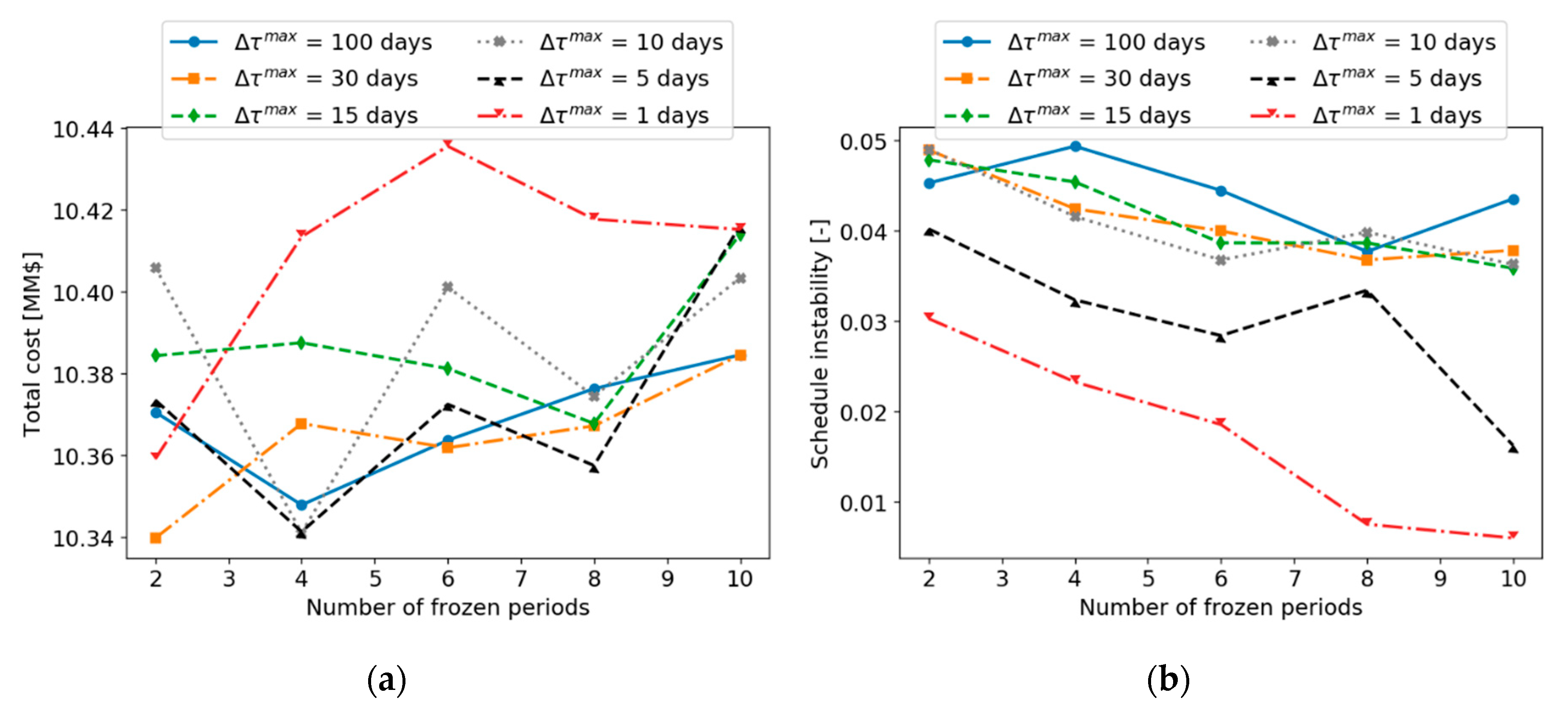
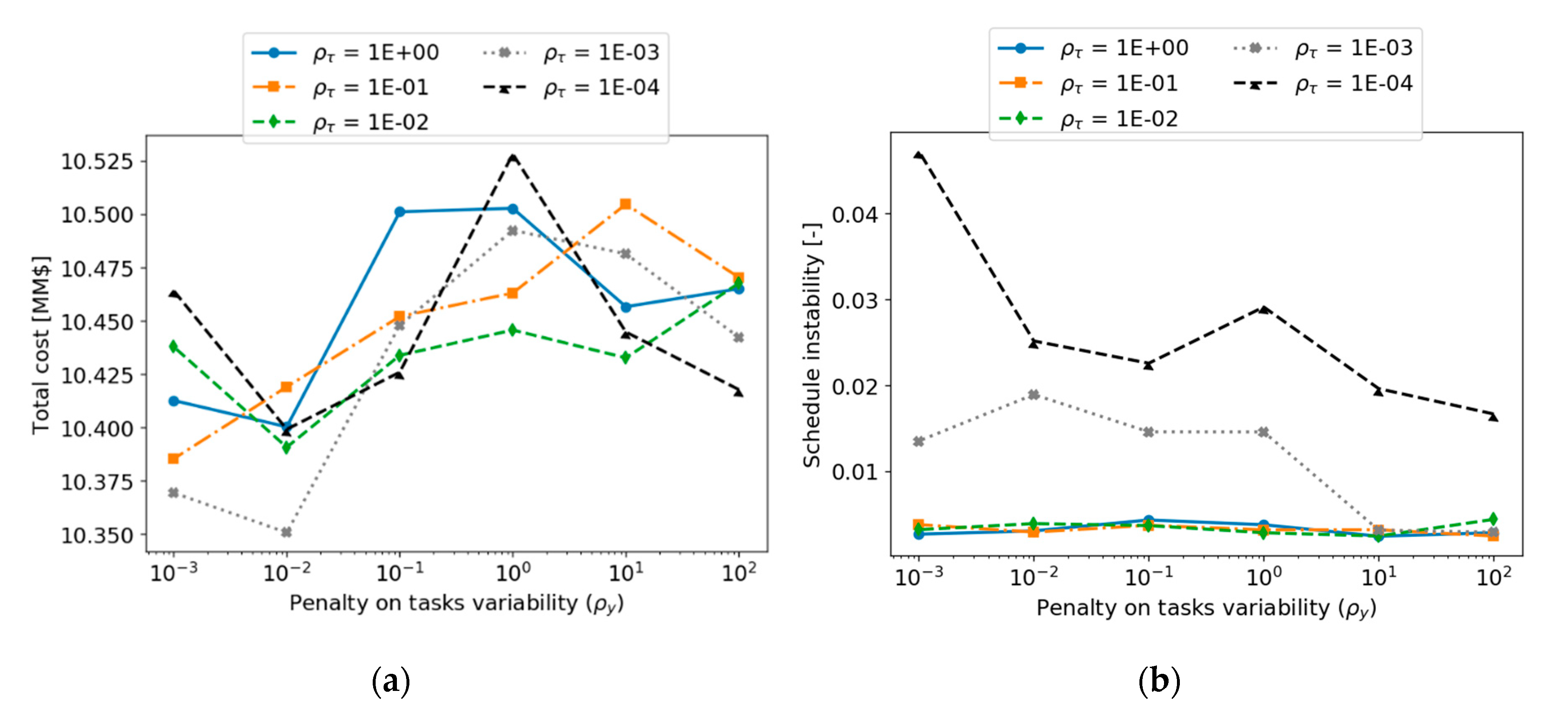
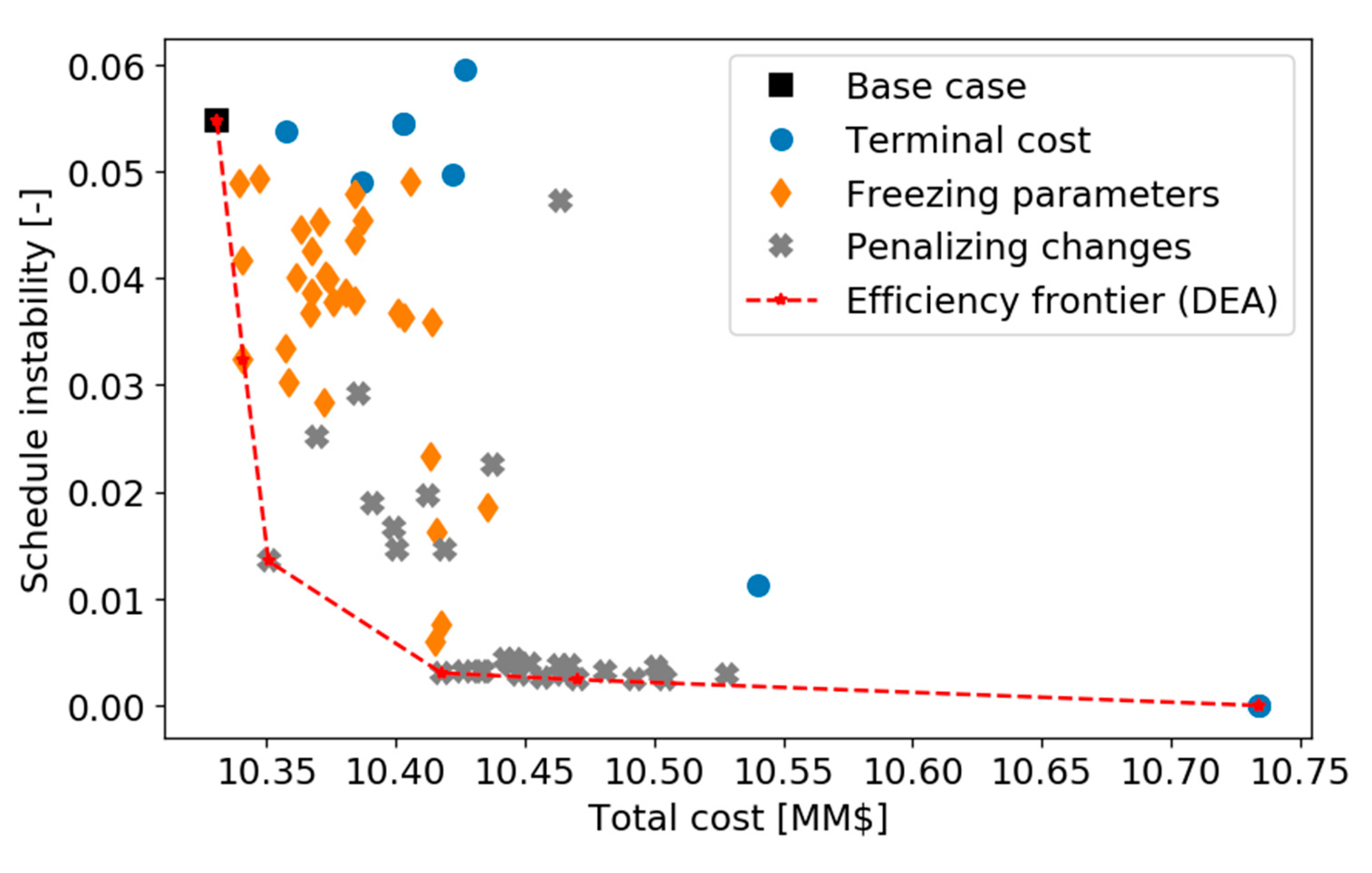
The above methods were demonstrated for the online cleaning scheduling and flow control of refinery preheat trains, a challenging application with significant economic, safety, and environmental impact. An illustrative, small but realistic case study was followed by a demanding industrial case study. Results show that, of the three alternatives evaluated, the terminal cost penalty proved to be inefficient in this case. The other two (fixing some decision in the prediction horizon, and penalizing schedule changes between consecutive evaluations) showed improvements in the closed-loop schedule stability, against various degrees of economic penalties. The results highlight the importance of including stability considerations in an economically oriented online scheduling problem, as a way to obtain feasible solutions for operators over long operating horizons without sacrificing the benefits of a reactive system to reject disturbances or take advantage of them.
Nevertheless, there are still open questions related to the definition of the penalties or bounds in the schedule instability mitigation strategies, as well as the definition of acceptable ranges of schedule stability or instability. Extensions of this work include dealing with multiple task types (as already outlined in the paper) and, for longer-term development, the use of global solution methods and formally incorporating uncertainty in models and solutions.
Application of the metrics developed in this manuscript is not restricted to the specific closed-loop NMPC scheduling implementation detailed here. They are useful to assess schedule stability in general regardless of how schedules are calculated, only relying on the existence of two consecutive evaluations or predictions of the schedule with a common period. The two consecutive instances may have different control horizons, scheduling horizons, or update frequency. Lastly, although this work dealt with a specific application (the optimization of refinery heat exchanger networks subject to fouling), the formulations and solution approach demonstrated here should be applicable with small modifications to other cases where closed-loop scheduling and control of dynamic systems is important, such as batch and semi-continuous processes.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




















