1. Introduction
We live in an age of advanced technology from both a hardware and a software viewpoint, the so called “centaur era” in which man and machine work together alongside reality-augmenting computers to assist humans [
1]. The ubiquity of computing shows that technology is not expressed only as laptops, computers, or tablets but is also found in almost everything that surrounds us, such as in communications, banking, and transport; the food industry is no exception.
If the physical and chemical conditions (temperature, pH, aeration, etc.) are favourable, a biotechnological process can induce the growth of a microorganism population, called a biomass, in a vessel through the consumption of some nutrients (carbon, nitrogen, oxygen, vitamins, etc.) that represent the substrate [
2]. In the vessel (bioreactor), many biochemical and biological reactions take place simultaneously. Usually, each elementary reaction is catalysed by a protein (enzyme) and can form a specific product or metabolite. The aim of such a process can be the production of bacteria, yeasts, etc.; the development of particular components (amino acids, medicines, marsh gas, etc.); or biological decontamination (the biological consumption of a polluted substrate by the biomass).
The alcoholic fermentation process is a biotechnological process and is undoubtedly one of the most important steps in winemaking [
3,
4]. The alcoholic fermentation in the winemaking industry is a complex process that must account for particular characteristics, including the following: batch fermentation on natural complex media, anaerobic conditions due to CO
2 production, the composition of the raw material, the low media pH, levels of sulphur dioxide, inoculation with selected yeasts, and interactions with other microorganisms.
Controlling the alcoholic fermentation process is a delicate task in winemaking for several reasons: the process’s complexity, nonlinearity, and non-stationarity, which make modeling and parameter estimation particularly difficult, and the scarcity of on-line measurements of the component concentrations (essential substrates, biomass, and products of interest) [
5,
6]. One of the core issues in industrial winemaking involves developing soft sensors with outstanding performance and robustness to replace the hardware/physical sensors in bioreactors. This would mitigate the disadvantages of real-time measurements, nonlinearity constraints, and other complex mechanisms in the fermentation process [
7].
An alternative to overcome the difficulties mentioned above is to use neural networks (NNs), one of the fastest growing areas of artificial intelligence. With their massive learning capabilities, NNs are able to approximate any continuous functions [
8,
9] and can be applied to nonlinear process modeling [
10,
11]. If properly trained and validated, these models can be used to accurately predict steady-state and dynamic process behaviour and thus improve process control performance [
12,
13].
A NN model can offer information regarding the values of the state variables (as inputs: biomass and temperature from the bioreactor; as outputs: alcohol and the substrate) useful for a control system in the fermentation process. This is is due to the ability of a NN to “learn” the shape of a relationship between variables from the data observed in the training regime and generalize that relationship to the data zone requested in the test regime. Such information is important especially in the exponential phase of biomass production [
14].
Most of the scientific literature indicates that because of the complexity of biotechnological systems regarding alcoholic fermentation, traditional optimization methods utilizing mathematical models and statistically designed experiments are less effective, especially on a production scale. Furthermore, Machine Learning (ML) offers an effective tool to predict biotechnological system behavior and empower the Learn phase in the Design-Build-Test-Learn cycle used in biological engineering [
15]. NNs provide a range of powerful techniques for solving problems in sensor data analysis, fault detection, process identification, and control and have been used in a diverse range of chemical engineering applications [
16]. Moreover, according to [
17], even though both NN and RSM (Response Surface Methodology) can efficiently model the effects of the interactions between the input and the output parameters, the NN model is more robust for predictions in non-linear systems. RSM disregards the “less important” variables based on a limited understanding of their possible interactive effects on the bioprocess output. Since the number of inputs in our experiment is not very large, we did not consider it appropriate to use RSM, which prunes the design space, negatively affecting the results.
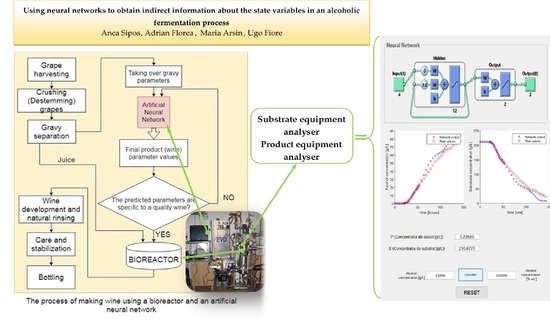
The main aim of this paper was to develop an application that can predict the characteristic variable evolution of a system in the food industry to obtain indirect information about the process regarding the state variables usable in an advanced control system for the alcoholic fermentation batch process of white wine as a knowledge-based system. To achieve this goal, we developed this study in the MATLAB environment and trained a NN. We used the experimental data for an alcoholic fermentation process for white winemaking and then, based on this NN, predicted the desirable variables for this process.
In this context, we created and trained different types of neural networks: feed-forward and feedback. After implementation, the application was tested on different configurations of NNs to find the optimal solution from the perspectives of prediction accuracy and simulation time.
The software application predicts the values of the variables that characterise the alcoholic fermentation process of white wine to help food industry specialists more easily control this process in winemaking and reduce production costs. The main benefit of our application is that it can help experts, thereby reducing the need for many time-consuming measurements and increasing the lifecycles of sensors in bioreactors. The novelty of this research lies in the flexibility of its applications, the use of a great number of parameters, and the comparative presentation of the results obtained with different NNs (feedback vs. feed-forward) and different learning algorithms (Backpropagation vs. Levenberg–Marquardt).
The application development stages are as follows:
Characterizing the alcoholic fermentation process and its phases and mapping them to the software
Recording the values of the state variables in alcoholic fermentation in a database that will be used in the prediction application
Setting-up, training, and tuning a NN with the data obtained from the fermentation processes
Using the trained NN to predict, in different situations, the values of some variables that characterise the alcoholic fermentation process.
The rest of the paper is organized into four sections.
Section 2 is split into two parts: The first provides a short background of NNs and their learning algorithms, while the second briefly reviews state-of-the-art papers related to this study.
Section 3 describes the proposed approach—the materials and methods—for modelling the alcoholic fermentation process in making white wines, implementing the NNs and measurement data.
Section 4 analyses the experimental results obtained, providing some interpretations and possible guidelines. Finally,
Section 5 highlights the paper’s conclusions and suggests future research directions.
3. Materials and Methods
The organization of the experiments began with defining the process variables (according to the activity diagram from the scheme presented in
Figure 3). Based on a literature review, we decided that the most appropriate tool to obtain indirect information about the state variables in an alcoholic fermentation process is a NN. The next step was to follow a manual design space exploration to determine the structure, type, and inputs of the multilayer neural networks. The trial and error process was time-consuming and aimed to reduce the prediction errors. We first applied original data and then used normalized data. As inputs for the process, pH and CO
2 were found to be the best options.
Twenty datasets of experimental processes were used for the analysis, which was done in the bioreactor in the research laboratory. The investigation of the experimental data was conducted under four distinct control situations based on the substrate: mash malted, mash malt enriched with vitamin B1 (thiamine), white grape must, and white grape must enriched with vitamin B1 (thiamine). For the experiments,
Saccharomyces oviformis and
Saccharomyces ellipsoideus wine yeasts were seeded on a culture medium [
25]. The bioreactor was equipped with pH, temperature, level, and stir speed controls, as well as dissolved O
2, released CO
2, and O
2 sensors and analysers. The cell concentration was calculated based on three different parameters: optical density, dry substance, and total cell number. The ethanol concentration was determined using HPLC-MS equipment, and the substrate concentration was determined by spectrophotometric techniques. The operating conditions were as follows: working volume—8 L; temperatures of 20, 22, 24, 26, and 28 °C; stirring speed—150 rpm; pH—3.8; and influent glucose concentrations—180 g/L and 210 g/L. The necessary oxygen was dissolved in must without aeration.
A controlling solution for the alcoholic fermentation process was developed using a NN to obtain indirect information about the process.
Figure 4 describes the general framework using both the bioreactor and the software application to predict the process control parameters. The NN used to predict the desired variables of the process was trained with experimental data obtained from the fermentation process taking place in the bioreactor equipped with transductors or by acquiring samples during fermentation and analyzing them in the laboratory. The dataset contains the values of the following variables that characterise the alcoholic fermentation process:
T fermentation temperature [°C]
t time [h]
S0 the initial concentration of the substrate [g/L]
S the substrate concentration [g/L]
X the biomass concentration [g/L]
P the alcohol concentration (product) [g/L]
the mixing speed [rpm];
the optical density of the mass fermentation [AU]
the pO2 [%]
the pH
the released O2 concentration [volume %]
the released CO2 concentration [volume %].
Based on all the training experimental data, we used four input–output configurations for the NN, as presented in
Table 1. These configurations contained the values of the variables necessary to control the process and also some supplementary values to determine a version where the prediction error is minimal.
3.1. User Guide and System Requirements
The software application used to predict the variables of the alcoholic fermentation process was realised in the MATLAB environment. The graphical user interface (GUI) illustrated in
Figure 5 was designed in a user–friendly way, simplifying access to non-specialists in computer science.
The graphical elements of the software application interface include several features. The radio buttons are used to choose which type of NN will be used for training: a feedback or feed-forward network. Through this software application, the user can accomplish the following:
Choose an Excel (*.xlsx) file in which the training data of the network are structured
Choose the type of network to predict the variables
Set up the iteration number that the network will execute in the training process
Set up the neuron number for the hidden layer of the network
Set up the hidden layer number of the network
Comparatively visualize graphics of the desired output of the network and the real output (see
Figure 6)
Predict the desired variable functions of several variables defined as the input network.
From a hardware point of view, the application needs to run properly on systems with quad-core processors, 8 GB RAM, and 4–6 GB of HDD space.
We created an archive with the sources of the applications, which can be accessed at the following web address
http://webspace.ulbsibiu.ro/adrian.florea/html/simulatoare/AlcoholFermentationApplication.zip and downloaded to local computers by any interested parties. Further details about the software’s use are provided by the README.txt file in the archive. The software application was developed using the full MATLAB campus license (MATLAB, Simulink and learning resources) provided for academic use, free of charge by “Lucian Blaga” University of Sibiu with the full support of “Hasso Plattner” Foundation Germany. For this reason, those who use our source must do so only for educational purposes. Besides being free and easy to use, our tool provides the following advantages: flexibility, extensibility, interactivity, and performance.
3.1.1. The Training Phase
The NN training phase presumes the parsing of several experimental data (70% of the data), the generation of several outputs based on the input data, and adjustment of the weight values of the network as a function of the resulting errors among these outputs and the desired outputs from the experimental data set.
At the end of the training phase, the graphical interface will display the errors obtained from training data. These errors are calculated with the following equation:
where
M is the pairs number of the input–output used in training.
3.1.2. The Testing Phase
After NN training phase comes the testing stage. This phase involves the use of several experimental data (the other 30% of the experimental data) and generating several outputs using a NN trained with those data. Then, the outputs are compared with the desired outputs from the experimental data. Based on the differences between these outputs, the errors of the network’s predictions of these values are calculated.
4. Results and Discussion
We simulated several situations with a range of the maximum number of iterations and neurons from the hidden layer/layers to determine the best configuration of the NN. Moreover, we used the first version of the neural network from
Table 1 and then tested the other versions. Each version of the training data has two variants. The first variant contains the original training data without any change from the experimental data, and the second version consists of the training data normalised with the following equation:
where
is the normalised value corresponding to the element with the
i index from the original sequence,
is the value of the element with the
i index from the original sequence, and
is the minimum/maximum value from the original sequence.
In the realised simulations, using the fourth variant of the NN from
Table 1, we varied the following parameters: the number of neurons from the hidden layer, the number of the iterations used for network training, the type of the NN, and the number of hidden layers. For each configuration, the application was run 10 times to obtain the medium value in each case because after the each run, the error values were different (the initial values of the NN weights were randomly generated). The next simulations were performed using a single hidden layer neural network and the Levenberg–Marquardt learning algorithm.
Figure 7 presents the results of the simulations obtained with the file that contained the original training data (not normalised).
As can be observed in the above illustrations, the simulation that used 1500 iterations for the feedback network training with a hidden layer and 12 neurons had the lowest error. Thus, for the following predictions, we used a network trained in this way.
For the simulations with the file that contained the original training data and normalised data by varying number of neurons on hidden layer for 1500 iterations the results are presented in
Figure 8.
Furthermore, we simulated feedback NNs by varying the number of hidden layers and the learning algorithms. Based on these simulations, it was concluded that using one hidden layer in the NN is the best solution because the simulation time increased significantly with greater numbers of hidden layers.
Table 2 presents the simulation results using the Levenberg-Marquardt and Backpropagation algorithms, respectively. The best results with the lowest errors were generated with the Levenberg-Marquardt algorithm.
By analysing the above graphics and tables, it can be concluded that the normalised data generate the lowest Mean Square Error (MSE). However, even though the error is lower with normalized data, this is not significant because from a technological point of view, normalization does not change anything. Thus, the next simulations used the original data (without normalization).
Based on all the simulations presented, the optimal configuration for the NN is as follows:
The network type: feedback
The number of iterations: 1500
The number of hidden layers: 1
The number of neurons from the hidden layer: 12
The learning algorithm: Levenberg-Marquardt.
In the following section, we present graphics with results obtained using all four variants of the neural networks specified in
Table 1. These graphics illustrate a comparison between the NN output used for the tests and the experimental data.
For the first three versions of the training and testing data in
Table 1, all the used values were expressed at the same temperature. For the fourth version, the data set used for training and testing contained values expressed as multiple temperatures. In the next figure (Figure 11), each temperature is graphically represented. For the fourth version from
Table 1, in Figure 11 (a1, b1, c1, and d1), a graphic illustrating the error between the NN output and the experimental data is provided for each temperature.
By comparing the first two variants of NNs specified in
Table 1 from perspective of the alcohol concentration prediction in accordance with the real fermentation process (see
Figure 9), the best NN configuration was found to be the second version because its latent phase is shorter, which is desirable. Furthermore, the alcohol concentration evolution depends on the yeast type, the medium characteristics, the substrate concentration, and the temperature. In variant two, we introduced two additional variables as inputs in the training process: the pH and CO
2 released concentration. The exponential growth phase in the first variant begins after 131 h in comparison with the second variant, which begins after 30 h.
Figure 10 and
Figure 11 also illustrate the prediction of two parameters: the substrate concentration and the alcohol concentration. Based on the substrate consumption, the alcohol is produced. Moreover, in
Figure 11, the NN used the pH values and released CO
2 concentration as additional inputs; in this case, the training and testing data also contain values from multiple fermentation processes (different temperatures).
The illustrations in
Figure 10 are similar to those in
Figure 11. Based on all these combinations (
Figure 11), the best results are obtained at a 20 °C fermentation process temperature, at which the NN output is almost identical with the experimental data (
Figure 11a2), and the errors also have the smallest values (
Figure 11a1).
In all three
Figure 9,
Figure 10,
Figure 11, the results show that the NN variants that used the pH values and released CO
2 concentration from the training data generated better results regardless of the output number.
Since a comparison of our results with other papers would be inadequate due to the lack of an international framework with standardized benchmarks, we chose to compare the data obtained from the simulations with an analytical model developed in a previous work by one of the authors to validate the artificial intelligence algorithms used.
In addition, because our tool is very flexible, we made some comparisons with learning methods (NN with feed forward versus feedback or varying the number of layers and the number of nodes in each layer).
The results also show a good fit with the nonlinear mathematical model of the batch wine alcoholic fermentation process previously developed by Sipos et al. [
25]. The evolution of the concentrations of substrate and alcohol predicted by the model are similar to the observed data (
Figure 12). By graphically comparing the experimental results in
Figure 9,
Figure 10 and
Figure 11 alongside the evolution resulting from the analytical model in
Figure 12, we validated the power of the neural networks, which are entirely data-based and require no previous knowledge of the events that govern the process and are available for learning, analysis, association, and adaptation. For completeness, the equations of the model developed by Sipos et al. considering the latent and exponential growth phases are as follows:
where
represents the maximum specific growth rate [1/h],
is the substrate limitation constant [g/L],
is the alcohol limitation constant [g/L],
is the maximum specific alcohol production rate [g/(g·cells·h)],
is the constant in the substrate term for ethanol production [g/L],
is the constant of fermentation inhibition by ethanol [g/L],
is the ratio of cells produced per the amount of glucose consumed for growth [g/g],
is the ratio of ethanol produced per the amount of glucose consumed for fermentation [g/g],
is the pseudo-constant of CO
2, and
is the kinetic constant [1/h].
Implications for Practice
In the following section, we describe a few advantages of our work. Based on the graphically illustrated results, the proposed solution is useful at least at the educational level when (masters) students are presented with the advantages of software applications/sensors in the fermentation process. The advantages include the following:
faster identification of the moment of transition from the latent to the exponential phase
the use of additional process parameters such as pH and CO2 as inputs to the neural network determining an improvement in the quality of the predictions
the role of temperature in accelerating the fermentation
the need for a rich set of data and test sets that are as standardized as possible
understanding the differences between the learning mechanisms used
the simple extensibility of the application by using genetic algorithms as a training method or for the automatic design of the optimal structure of a neural network.
Moreover, for the companies that produce wine, with the help of this application, the evolution of the quantitative characteristics of the alcoholic fermentation process for white wines can be predicted. The purpose of predicting these process parameters is to obtain information on state variables to automatically drive the process, especially when these parameters cannot be directly measured.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}