2.1. Dynamic Flux Balance Models
Dynamic flux balance models (DFBM) are structured genome-based metabolic models developed from flux balance models. The key assumption of DFBM is that the cells act as agents distributing resources through metabolic reaction networks to boost a biological objective, e.g., growth rate [
1]. Accordingly, the DFBM is formulated as an optimization problem. In the literature [
20], both dynamic and static optimization approaches are reported. In the dynamic approach, the nonlinear programming problem is solved over a relatively large time period which is computationally expensive and thus less convenient for uncertainty propagation. In this investigation, static optimization approach is adopted for its simplicity. DFBM is interpreted as a local linear programming problem to maximize a biological objective. In terms of dynamics of intracellular metabolites, there are two type of DFBM models in the literature. One type of DFBM differentiates intracellular and extracellular environments and assumes that the intracellular metabolic reactions are fast enough such as it can be assumed at quasi-steady state [
2,
21]. Accordingly, only the extracellular metabolites and the biomass are described by dynamic state equations. It has been argued that the intracellular metabolite concentrations are not constant and may change over time [
22]. Accordingly, there is a second type of DFBM, used in the current study, which does not differentiate between intracellular and extracellular compartments and the dynamics of all the metabolites are considered [
20,
23]. The governing equations of DFBM are based on discretized mass balances for all metabolites and these are defined by Equations (1a)–(1d).
where
is a vector of
state variables at the time step
k. The state vector
includes concentrations of metabolites and biomass
.
is a vector of
measured variables.
is a constant diagonal matrix with diagonal elements
,
.
is a constant discrete time step size.
is a stoichiometry coefficient matrix, where
is the number of reactions considered in the metabolic network.
is the metabolic flux vector and its calculation is discussed below.
is a constant vector. The initial state
is assumed to be bounded by a finite polyhedron
as Equation (1c). The underlying assumption is that in practice the initial concentrations of the culture medium components are known to be within specific ranges of values
. This assumption is based on the fact that some variation in media formulation occurs due to human factor and variability in raw materials. Hence, this research focuses on the initial uncertainty and we assume all parameters in the state equations to be known accurately. In other words, the method proposed in this research cannot deal with model structure uncertainty like uncertainty in matrix
A. However, the method can be extended to deal indirectly with uncertainty in parameters
defined in the following paragraphs.
are measurement noise vectors of which the elements follow the truncated multivariate normal distribution (TN) [
24,
25]. The probability density function
p for
are defined as per Equation (2).
For
, the mean vector of TN is
; the covariance is
; the corresponding variance vector is
; the lower bound and upper bound are
and
, respectively.
indicates the absolute value of a vector. It is assumed that
and
, which indicate that the absolute values of the lower bound and upper bound, respectively, are within the range of
. For simplicity, the current study assumes the process noise to be zero. Process noise could be included as an additional state but this is beyond the scope of the current work.
Following the assumption that the cell allocates resources optimally, the metabolic flux
vector at each time step is obtained by solving a linear programming (LP) problem, defined by Equations (3a) and (3b).
where
,
,
,
,
.
is the number of linear constraints. The parameter vector
is a nonlinear vector-valued function of states
.
denotes the number of elements in the parameter vector
. Usually, each element
is only function of two states at most and one of these two states is biomass concentration.
denotes the parameter space where the optimal solution of the LP resides. Equation (3a) denotes the objective of the LP that cells are optimizing where the most commonly used objective is the biomass production rate, i.e., growth rate. Thus, cells try to maximize growth rate by allocating limited resources. The LHS (left hand-side) in Equation (3b) describes either the rate of change of metabolite concentrations or the change of metabolite concentrations over a discretization time step
. Matrices
are constant matrices containing the information of the stoichiometry of reactions. RHS in Equation (3b) is a function of
, denoting the metabolic reaction bounds for each step. The matrix
is a matrix of which the elements are the part of the right hand side of the constraints that are functions of states at the previous time interval.
is a vector containing constant values such as constant uptake rate limits. Therefore, linear constraints of flux
in Equation (3b) are reaction rate limits or bounds on available resources (nutrients). Numerical examples of these matrices and vectors are shown for the
E. coli model in the results section.
2.3. Extended Kalman Filter (EKF)
Using the minimum required set of measurements,
is defined in Equation (10c),
can be estimated by an observer.
corresponds to the observable subspace of the governing equation (Equations (1a)–(1d)) for each critical region. The state equation of the observable subspace for critical region
is given by Equations (11a)–(11c).
where
and
are the flux-determining state vector and the reaction-rate-determining state vector for critical region
, respectively;
is the stoichiometry submatrix corresponding to
. Similarly
is a sub-vector of
corresponding to
. It should be noticed that, for different critical regions,
involves different states. Accordingly, each critical region requires the use of a different EKF. In addition, it should be noticed that the
matrices are different for each critical region but the measured variables
are the same since the same sensors are used for the entire fermentation.
To estimate
, an standard EKF is used due to its effective and simple structure [
31]. The estimate
and covariance
of
for critical region
are described by Equation (12a) and Equation (12b), respectively.
where
The measurement noise is assumed to be a truncated multivariate normal distribution as Equation (11c). This assumption is needed for estimating finite bounds as explained in the following section. Recall in Equation (2) that
and
, the lower and upper bounds are located within the range of
. The covariance matrix
is always overestimated to ensure boundedness. Although the EKF resulting from this assumption is sub-optimal, it is still sufficient to estimate
.
2.4. Set Propagation and Error Compensation
Since the minimum set of measurements defined by Equations (10a)–(10c) can only ensure the observability of
, the estimation of other states needs different estimation strategies. The idea is to exploit the a priori knowledge of the initial ranges of initial conditions to estimate all states. Instead of predicting specific values of states, set membership estimation (SME) approach is used to predict sets containing all possible states by a series of set operations. These set operations usually include linear mapping, projection, translation, Minkowski addition, intersection, union, and outer approximation. In this research, all sets and multiparametric linear programming operations are performed with the Multi-Parametric Toolbox 3.0 (
https://www.mpt3.org/ accessed on 15 July 2021) [
32] and MATLAB R2018a. The
E. coli example can be found online (
https://github.com/SetMembershipEstimationDFBM/E.coliExample, accessed on 25 September 2021). For DFBM, SME propagates the initial set
by affine mapping as Equation (14). Affine mapping involves two operations: linear mapping of the previous set and translation.
where
represents the set of states at time step
k and
, i.e., the set of initial conditions assumed to be known. In Equation (14), the translation term is approximated by using the estimate
obtained by the EKF. In the application of EKF, the estimate
needs several time steps to converge to the true flux-determining states
. Thus the SME described by Equation (14) may underestimate bounds while the EKF is converging. To mitigate this problem, a correction is implemented to compensate for the estimate error as described below. Since no extra information is available, the compensation of the estimate error is based on the worst case scenario.
The error in the estimate incurred by the observer for critical region
is
. Since
always contains biomass
and
, the corresponding estimate errors are defined as
and
. Let us assume that the function
is first-order differentiable and define Jacobian matrix
.
Substituting the estimate error
,
and Jacobian matrix
into Equation (8), a corrected state equation that accounts for the estimate error is obtained as Equations (16a) and (16b). Equations (16a) and (16b) uses a first order approximation to account for the state deviation
caused by the estimate error
, while the EKF is converging. The error compensation based on linearization provides satisfactory bounds because the error between estimate and measured is small and decreases quickly due to the convergence of EKF.
where
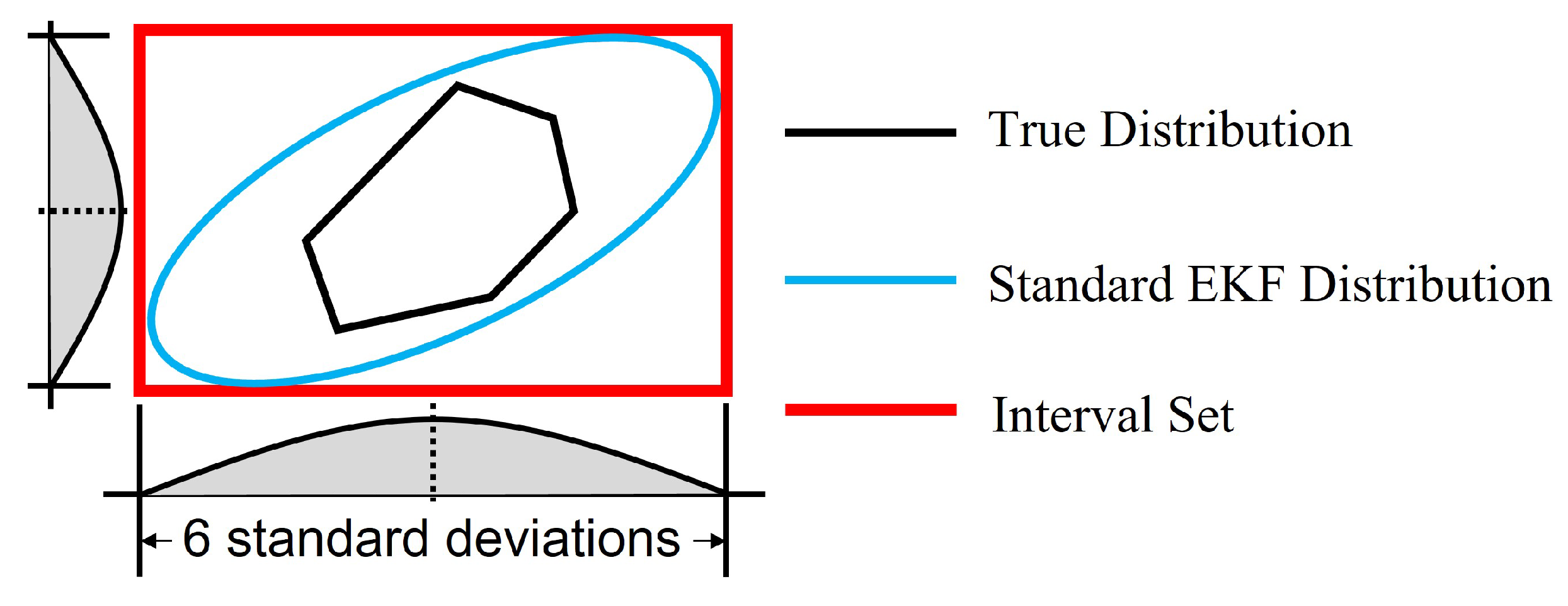
In this work, the noise was assumed to follow a truncated multivariate Gaussian distribution. The corresponding standard multivariate Gaussian distribution of noise contains the truncated one. As illustrated in
Figure 1, when an EKF is used to estimate the states, the distribution of states with a standard Gaussian noise should similarly contain the one with the truncated Gaussian noise, which is the true distribution of states. Moreover, the distribution of states by standard EKF is also a multivariate Gaussian distribution. For Gaussian distribution,
of the samples are within the interval of 6 standard deviations from both sides of the mean for each state. Thus, an interval set based on 6 standard deviations can contain the distribution by standard EKF and eventually contain the true distribution of states as in
Figure 1. Since
is the covariance of a standard EKF, the diagonal elements of matrix
are the variances for each state. Therefore, diagonal elements of
can be used to define the interval set to bound the error
.
To formulate an error compensation operation scheme several set operations are introduced first as follows. The n-dimensional interval set is with lower bound and upper bound as . The outer approximation operation of a bounded set is denoted by , which involves the mapping of the set to a new interval set. If the infimum and supremum are denoted by and , respectively, the outer approximation of the set is . The operator ⊕ is the Minkowski addition of two sets. For example, for two sets and , .
Notice that the diagonal elements of
are the variances of each state. Then, if the standard deviation of
is
and of
is
, two interval sets
and
can be defined to bound
and
, respectively, based on the choice of 3 standard deviation ranges, as
and
. In Equation (16b), since
, we have
. Similarly, the other two terms in Equation (16b) can be bounded as
and
, respectively. Therefore, the state deviation
term can be contained within the interval set
according to Equation (18).
where the sets
and
occurring in Equation (18) are combined together. On the other hand,
originates from a different set
and thus Minkowski addition must be used to add the different sets. However, linear mapping of interval sets can lead to irregular convex sets. In computational geometry, traditional algorithms that perform Minkowski addition for two convex irregular high-dimensional polytopes are computationally expensive [
33]. On the other hand, Minkowski addition of two interval sets is computationally efficient because intervals are axis-aligned. Thus, the operator
that converts the irregular set to the axis-aligned set is applied to speed up the computation of the Minkowski addition.
Following the above, the set of states
is bounded by the prior estimate set
according to Equations (19a) and (19b).
where the set of the posterior estimates is
.
denotes the scaling of the set
by the diagonal matrix
. Then the set
is translated by the vector in the big curly brackets. To compensate for the deviation during the convergence of EKF, the interval set
is added by Minkowski addition.
Considering the truncated measurement noise,
is bounded by the lower
and upper bounds
; let us define a set
. Then, the posterior estimate set
is given by Equations (20a)–(20c). In this study, it is assumed that
and
are much smaller than the volumes of the critical regions.
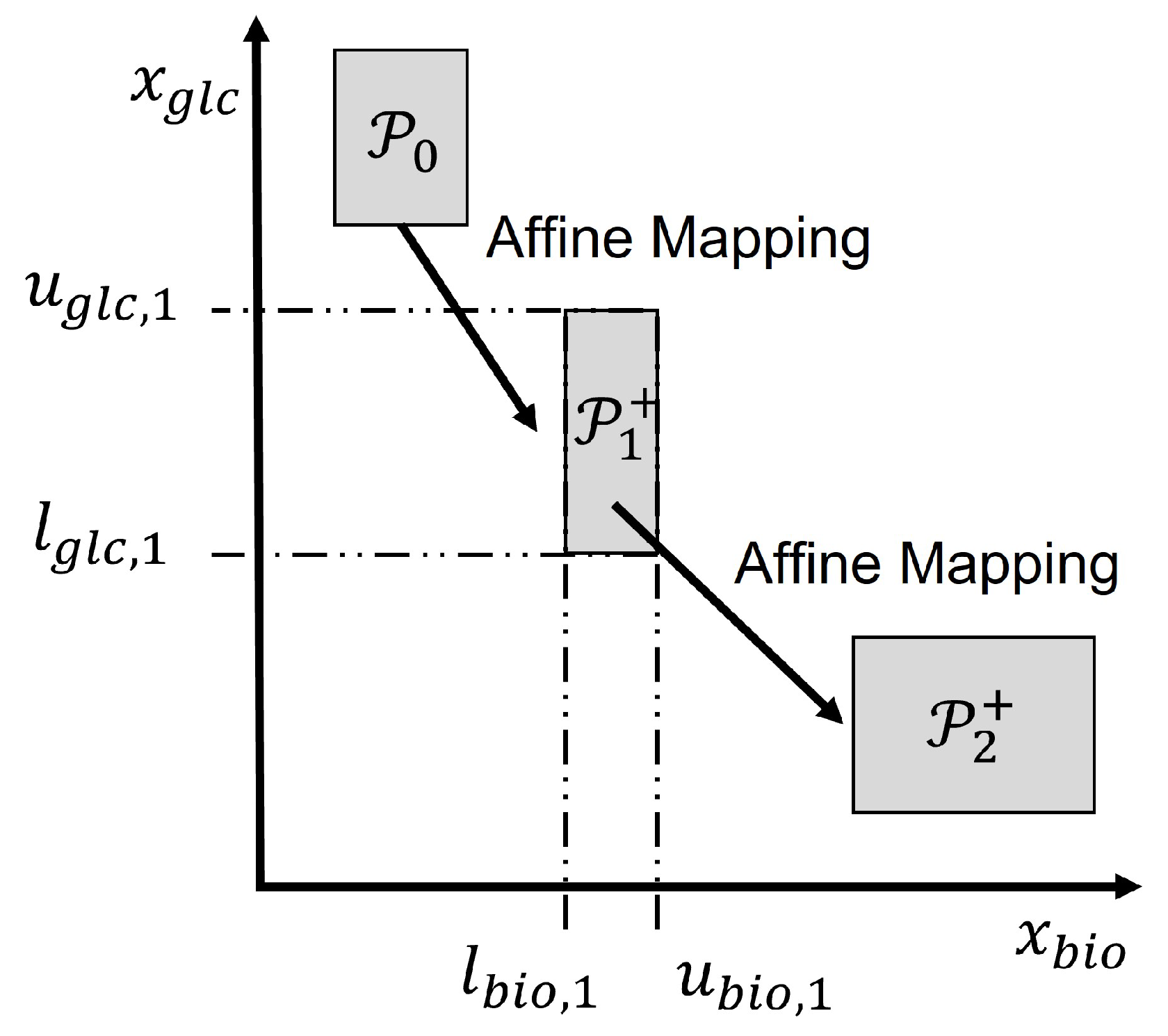
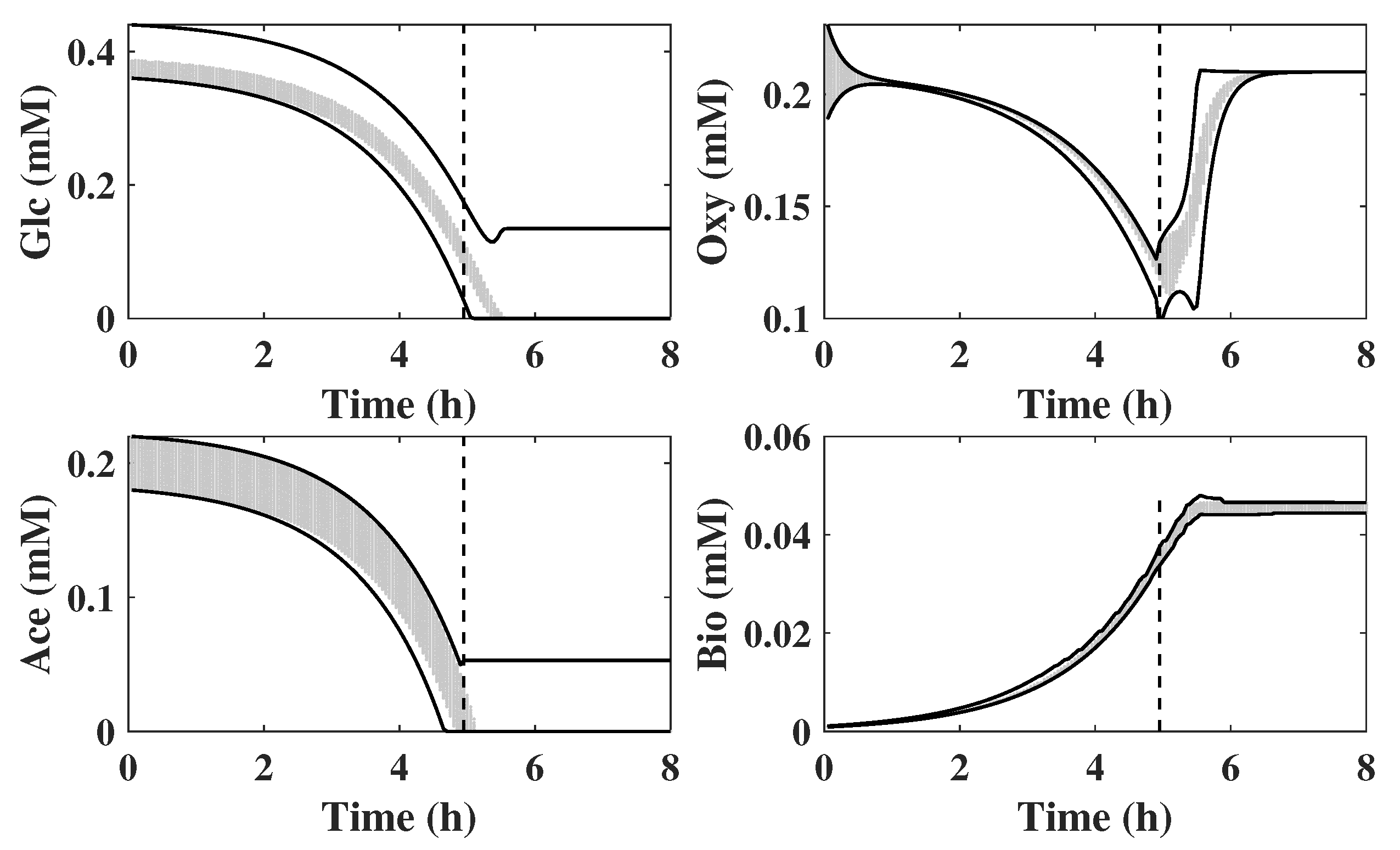
Figure 2 illustrates the set propagation using intervals for an example involving two states, e.g., glucose and biomass concentrations. The initial set
contains all possible initial values of glucose and biomass. Then
is generated through set operations by computational geometry algorithms. Since an interval set is used, it is computationally efficient to project the set
onto the biomass and glucose axes to obtain the corresponding lower bounds
,
and upper bounds
,
as shown in the figure for the set
.
2.5. Detecting the Transition between Critical Regions
The proposed use of multiparametric programming converts the DFBM into a variable structure system composed of subsystems where each critical region corresponds to a subsystem. Along a given time trajectory the states may transit from one critical region to another. When the states estimated by the EKF leave a critical region to enter another critical region , the estimate and the covariance must be reinitialized because for different critical regions may be different, even though the measured states are the same. Moreover, a criterion is required to detect whether the states are entering into a new critical region.
When the system is traversing from one critical region to another, it needs to cross a boundary between the critical regions. Over time the states may cross over several boundaries along their trajectories and these crossings must be detected. Two neighboring critical regions share a boundary where an active constraint will become inactive or vice versa. The activation of a constraint may require the change of constraints related to
. For a given constraint,
is usually only function of two states at most because of commonly used Michaelis-–Menten kinetics [
34] or constraints to prevent the depletion of nutrients [
23] and one of these two states is biomass. So two special cases should be considered as follows when system switches from one critical region to the next:
Case i—
of the old critical region
have one more observable state than the
of the new critical region
. For this case, the switch between critical regions is determined by Equation (21). Equation (21) calculates the norm of the difference between the flux estimates obtained with Equation (7) in the two neighboring regions. Notice that the flux estimate of
is based on estimate
of the old critical region. The value of
is used to detect the occurrence of a switch. If the system is exactly at the boundary of these two critical regions, the flux equation Equation (7) for these two critical regions should result in the same flux value and
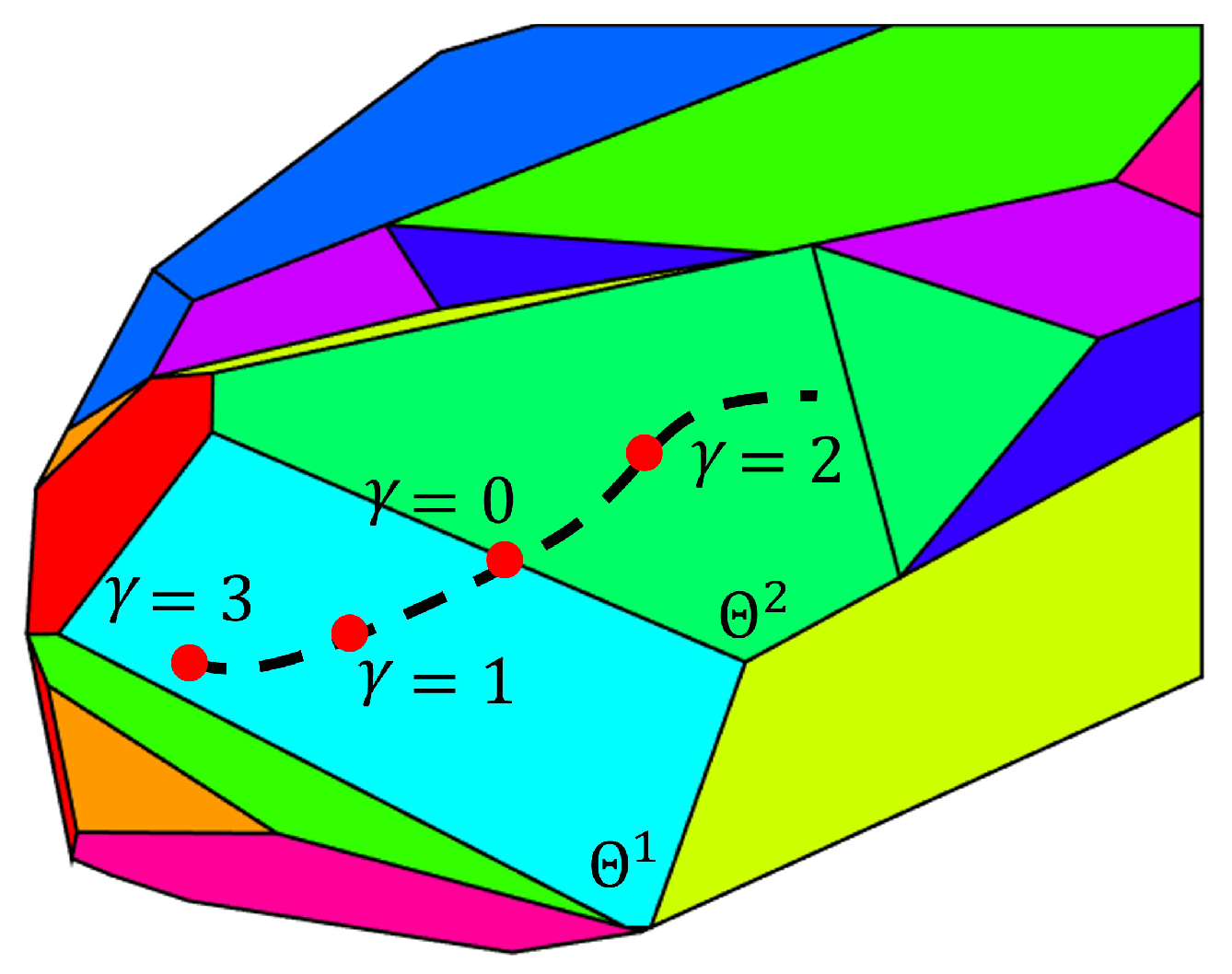
will be zero. A schematic example is shown in
Figure 3. Polygons in different colors represent different critical regions in the parameter space
. As the state evolves with time, the corresponding
changes along the dash line in the parameter space
. As the
approaches the boundary between the critical region
and
,
approaches zero. Correspondingly, a value of
smaller than a user specified tolerance indicates a switch between critical regions, thus requiring reinitialization of the EKF as follows:
is set equal to
and
is set equal to
.
Case ii—
of the new critical region
has one more observable state than the
of the old critical region
. To reinitialize the EKF,
and
can be set to the old values except for the new observable state that is not observable in the old critical region, and thus it needs to be estimated for calculating
. By projecting the set
, the lower
and upper bounds
can be calculated. Since no extra information is available, the mean value of the upper bound and lower bound is used as the nominal value of the unobservable state as per Equation (22).
Equation (23) is used to calculate
. The flux estimate for the new critical region
is based on the nominal values of the unobservable state
combined with
of the old critical region.
To reinitialize the EKF, the estimate and covariance are used together with the estimation of the new state that is added in the new critical region. Assuming the states are close enough to the boundary between the critical regions, then Equation (24) holds.
The initial estimate of new observable state
in the new region can be calculated by solving the Equation (24). Since the new state is between the upper bound and lower bound by SME, the half length between
and
is the worst possible deviation. Then, using a 3 standard deviation range, the initial variance
can be estimated according to Equation (25) and all other covariance terms related to the new state are assumed to be zero.
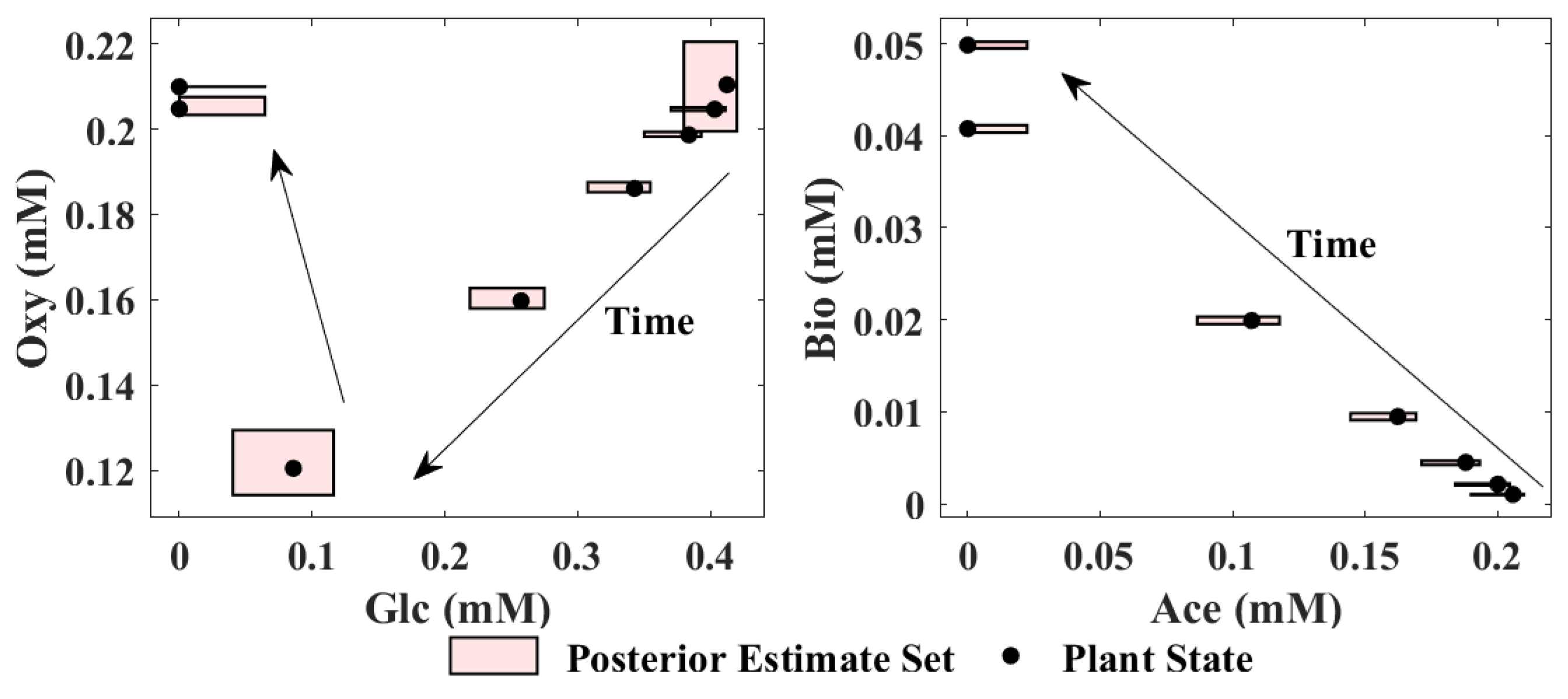
Bounds of states estimated by the SME are rigorously guaranteed in each critical region separately but subject to accurate tuning of the tolerance that is used to switch between the subsystems. The tolerance of
is the only user specified parameter in this research. If the tolerance is too large or small, the EKF may switch the subsystem too early or too late. Accordingly, if the wrong state equations are used in estimation, the bounds on the states may be violated. To avoid such a situation, exhaustive simulations that are initialized with
are conducted to find the tolerance used to switch between critical regions. As an alternative, an overestimated covariance can also be used to reinitialize the EKF when the state enters a new critical region to avoid bound violations.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}