
Modelling for Digital Twins—Potential Role of Surrogate Models





Abstract
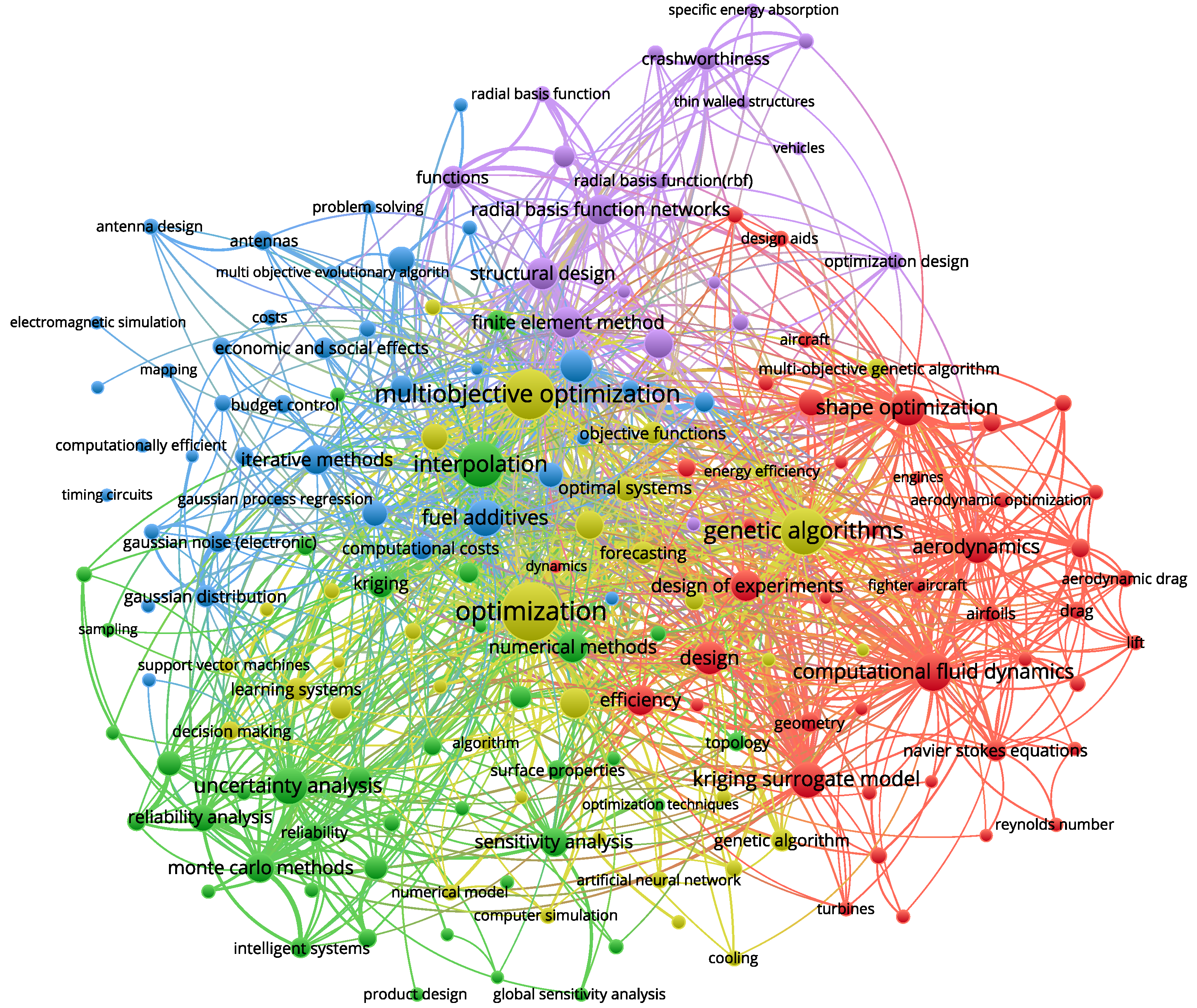
:1. Introduction
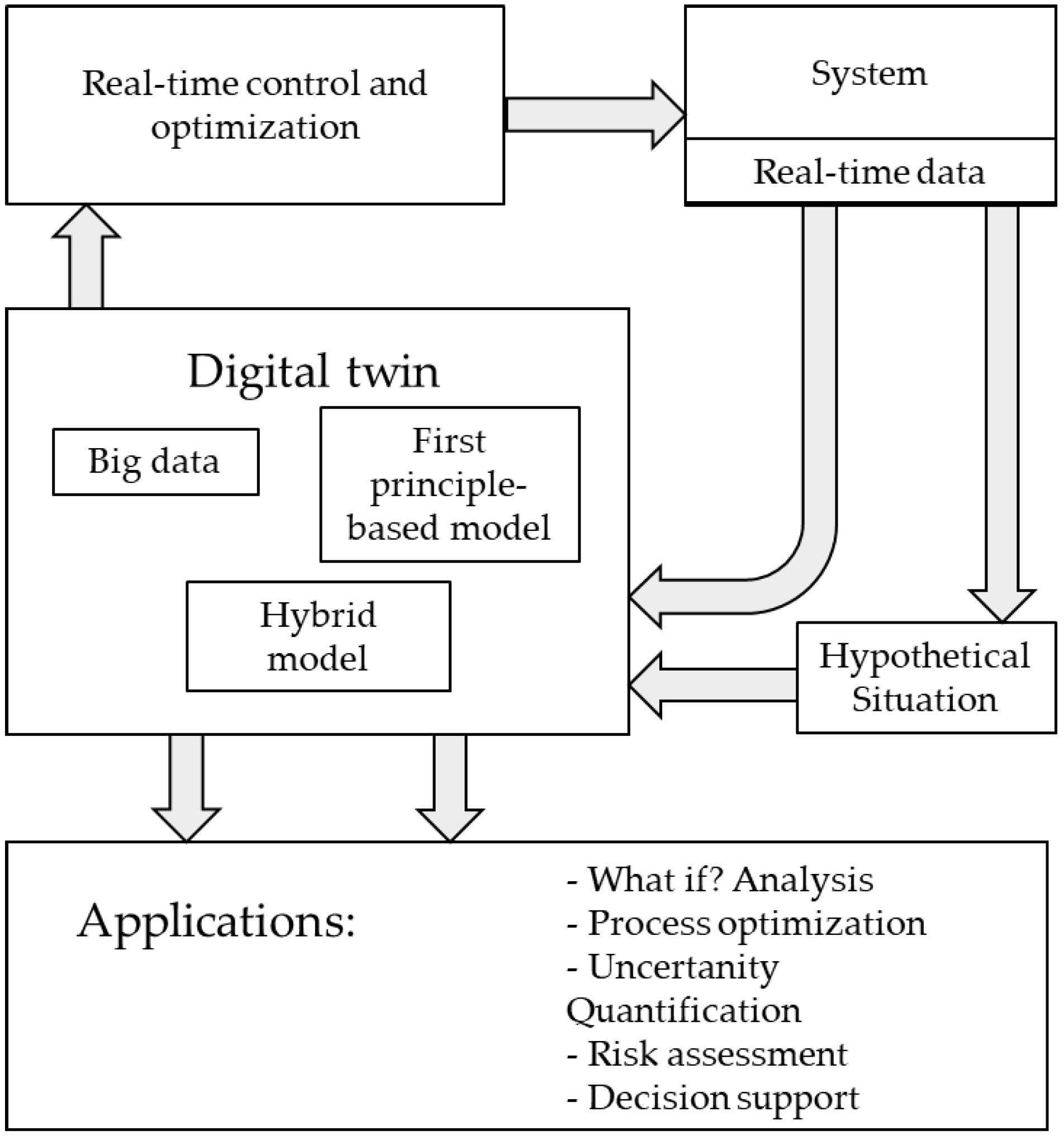
- Real-time monitoring and control could be extended in depth to large systems.
- Greater levels of efficiency and safety could be reached.
- Predictive maintenance scheduling supported by early fault detection.
- Scenarios and risk assessment as well as efficient and well-informed decision-making offer further benefits.
- can be easily extracted from the complex simulators of digital twins,
- handle the uncertainty and complex behaviour of the systems,
- can be easily utilised in optimisation and control algorithms.
- In Section 2 we provide a detailed analysis of the modelling approaches that can be used to build models used in digital twins.
- We provide an overview of the major steps of the identification of surrogate models in Section 3.
- In Section 4, the existing applications of surrogate models in digital twins are overviewed.
- The applicability of surrogate models is demonstrated by an industrial case study in Section 5.
- In Section 6, the proposed guideline for the incorporation of surrogate models in digital twins is discussed.
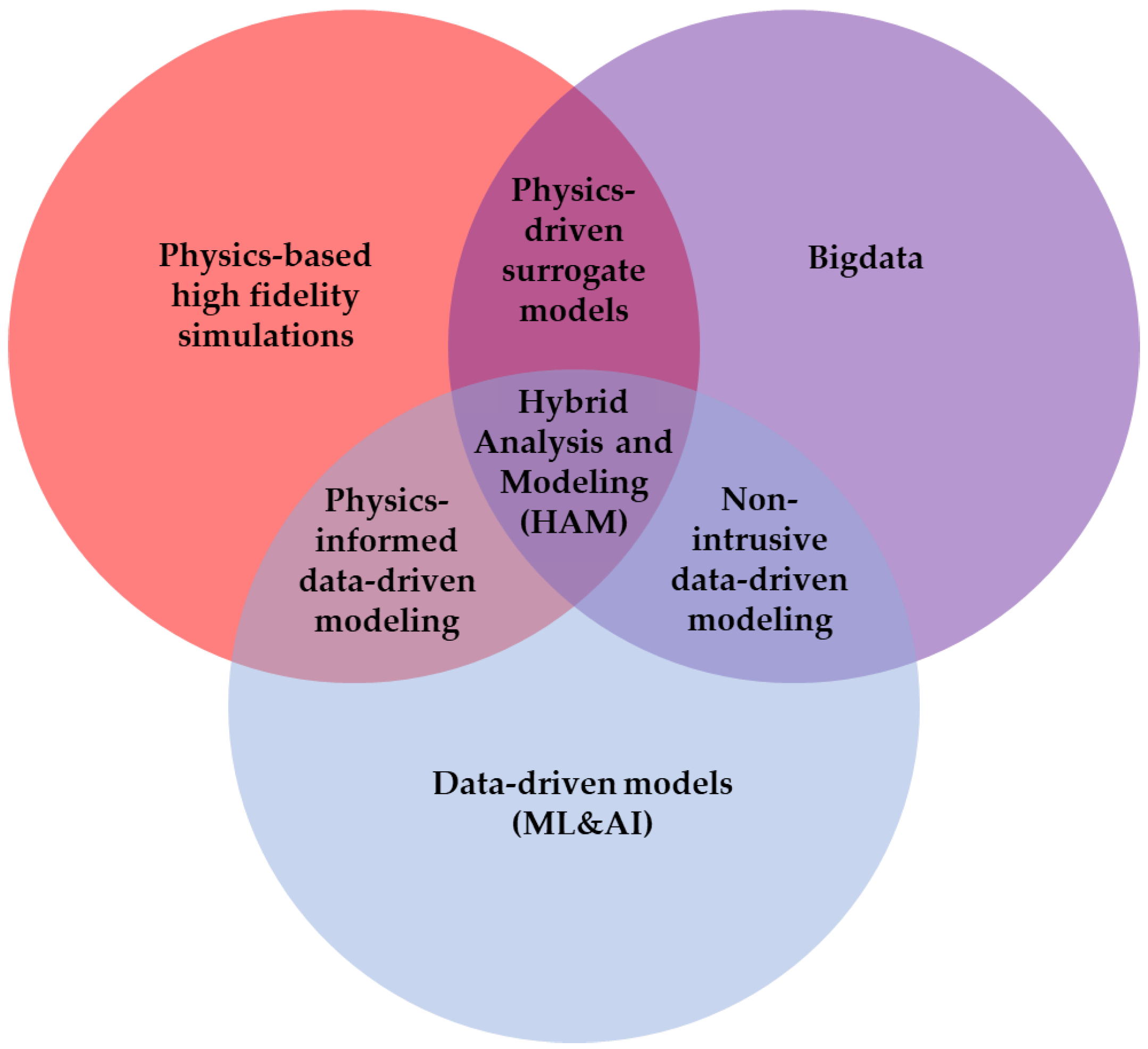
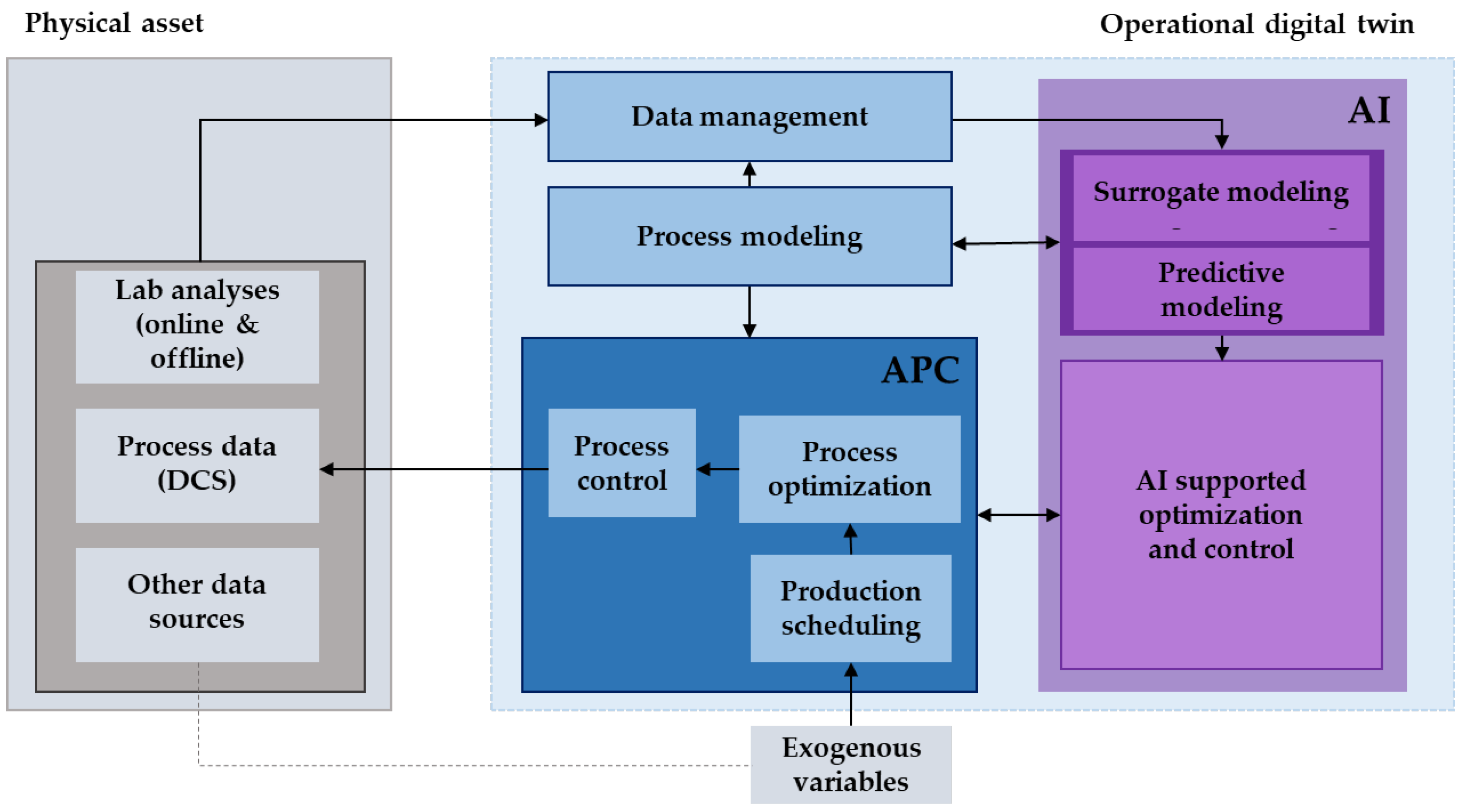
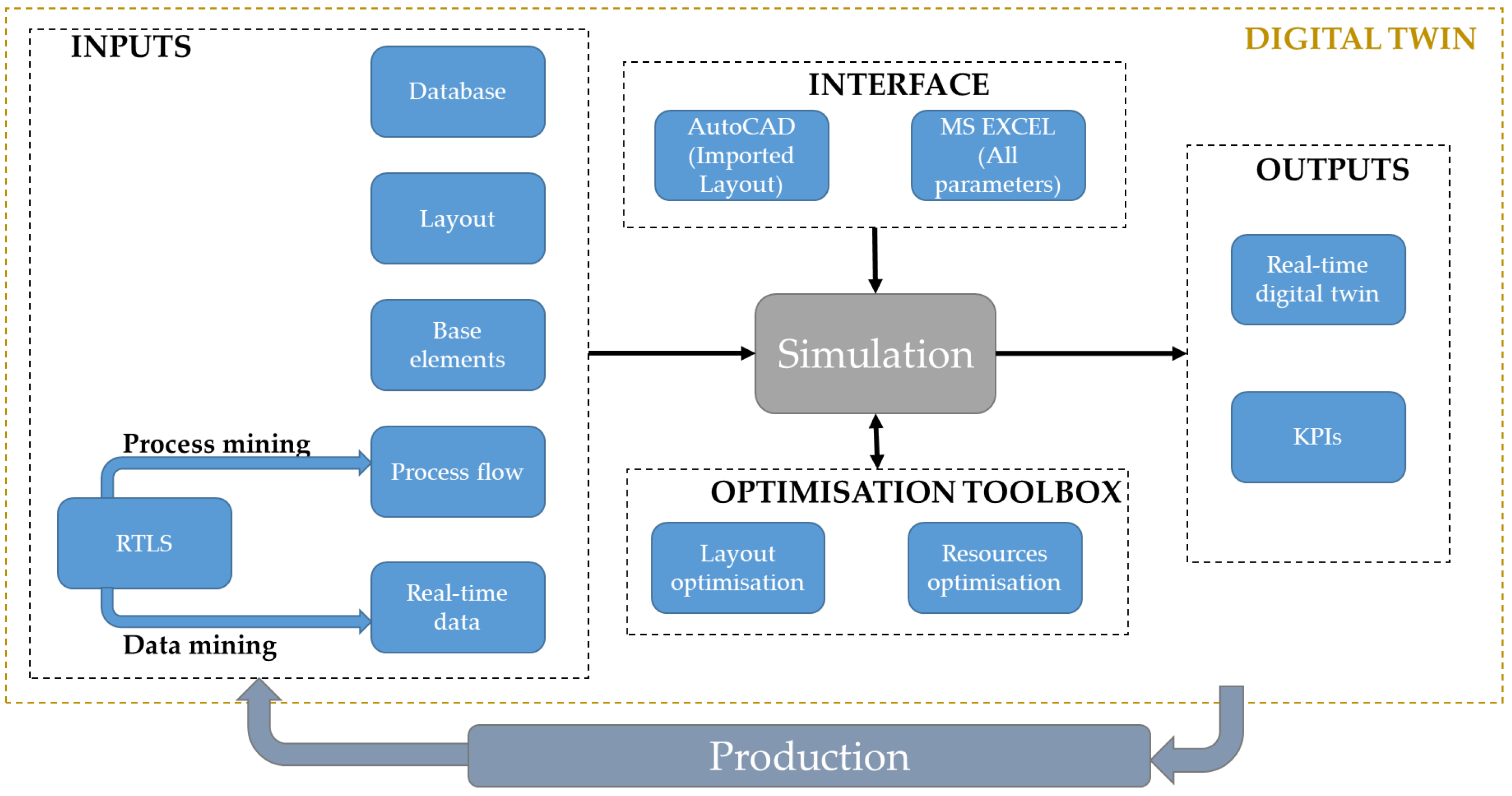
2. Model Building for Digital Twins
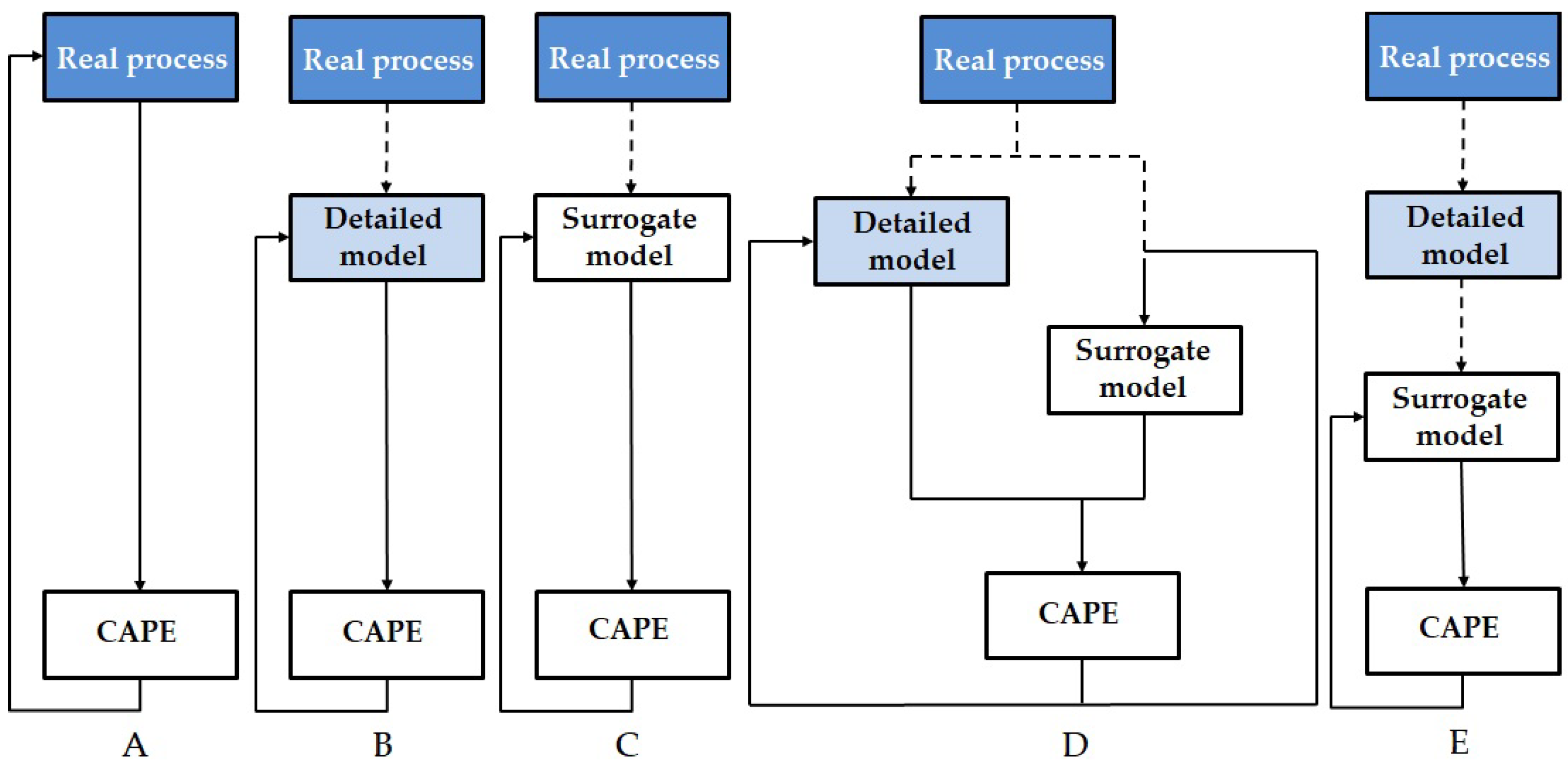
3. Methodology of Surrogate Modelling
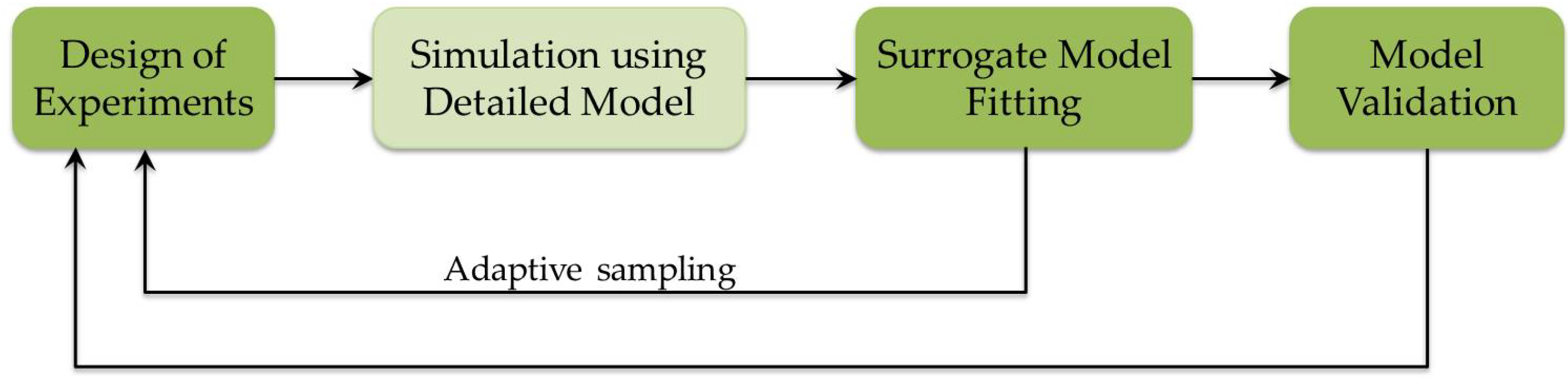
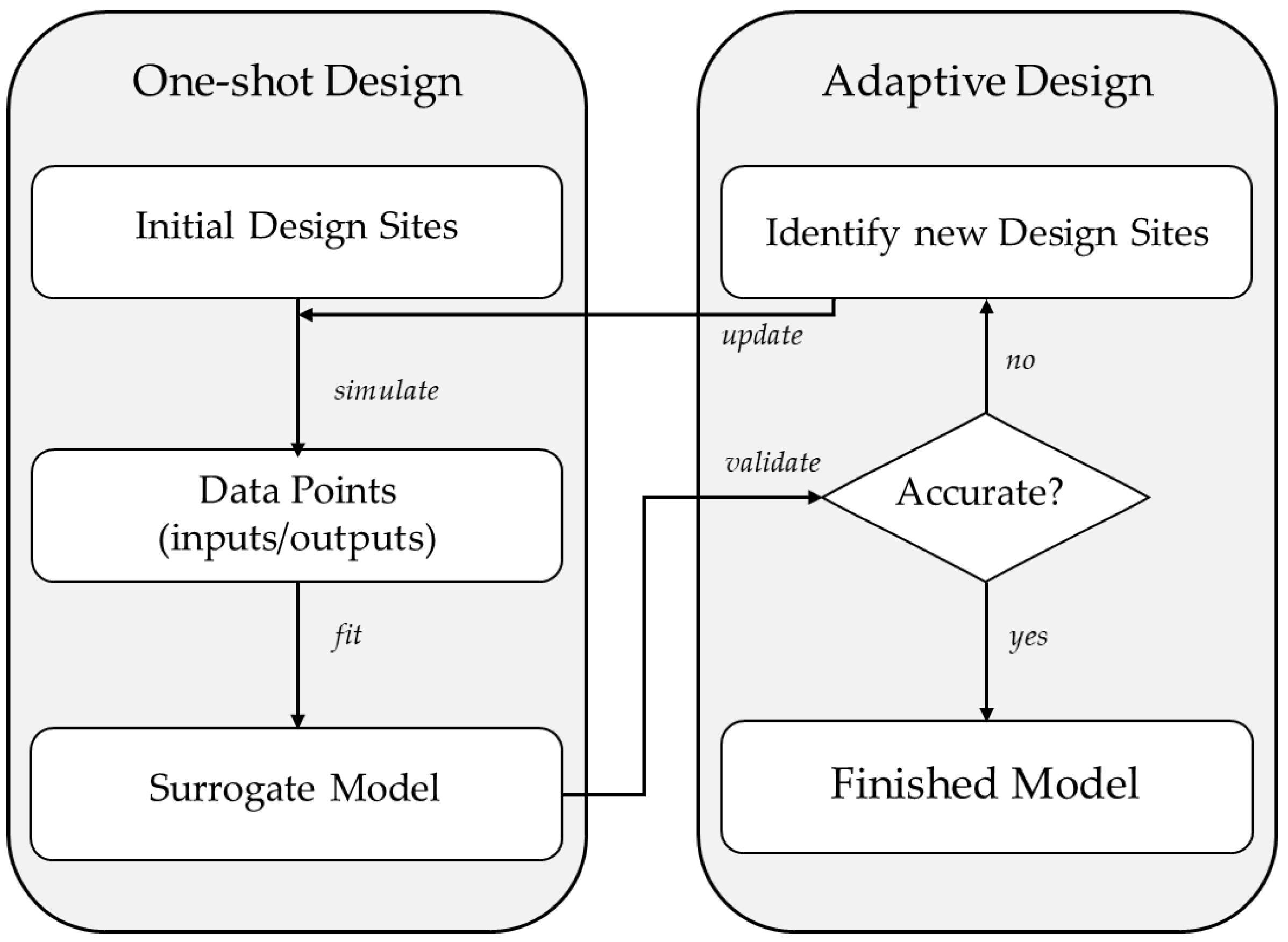
- Design of experiments and sampling for surrogate modelling (Section 3.1).
- Model selection and fitting the model parameters based on simulation results using a detailed model (Section 3.2).
- Surrogate model validation (Section 3.3).
3.1. Design of Experiments and Sampling for Surrogate Modelling
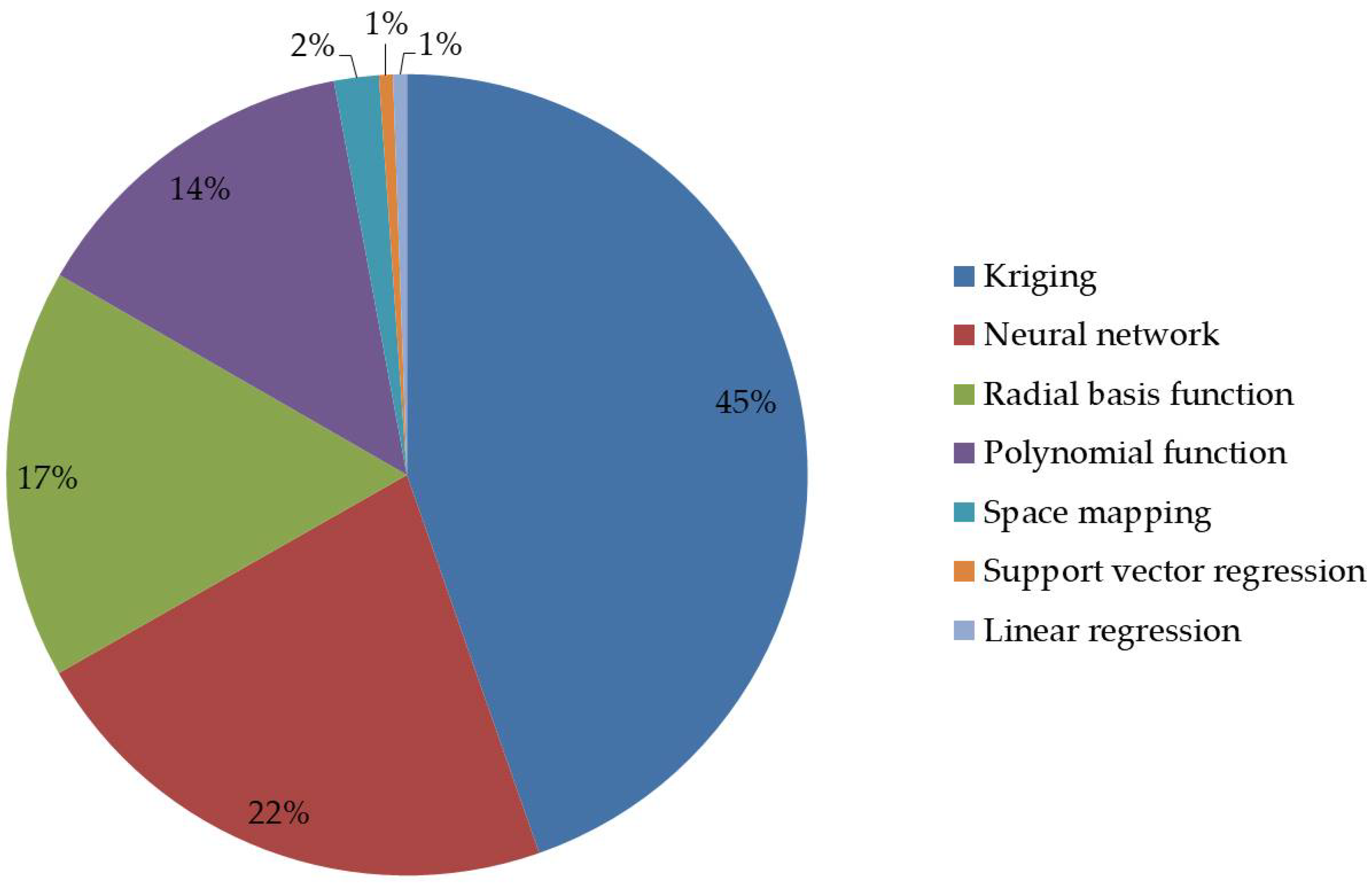
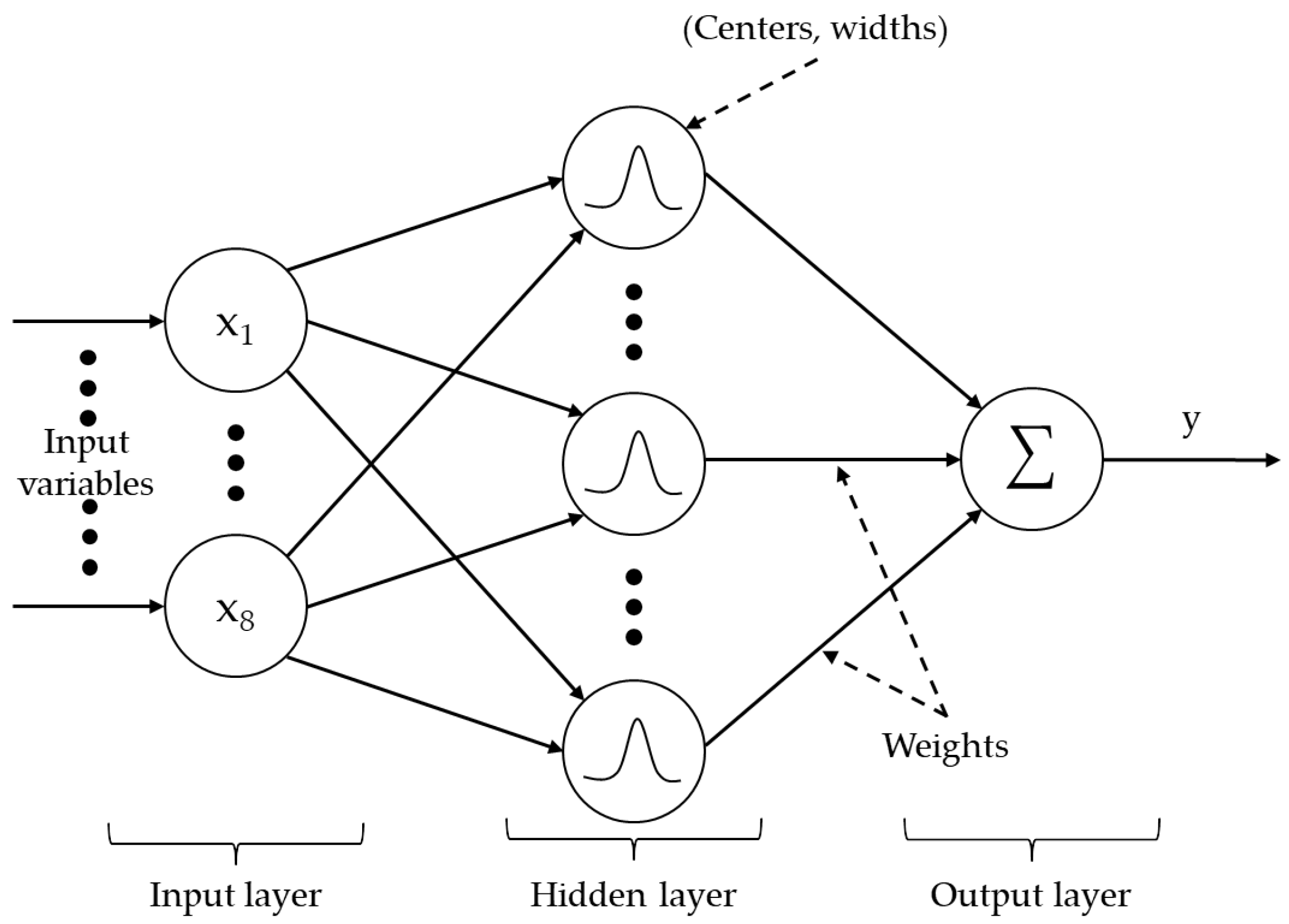
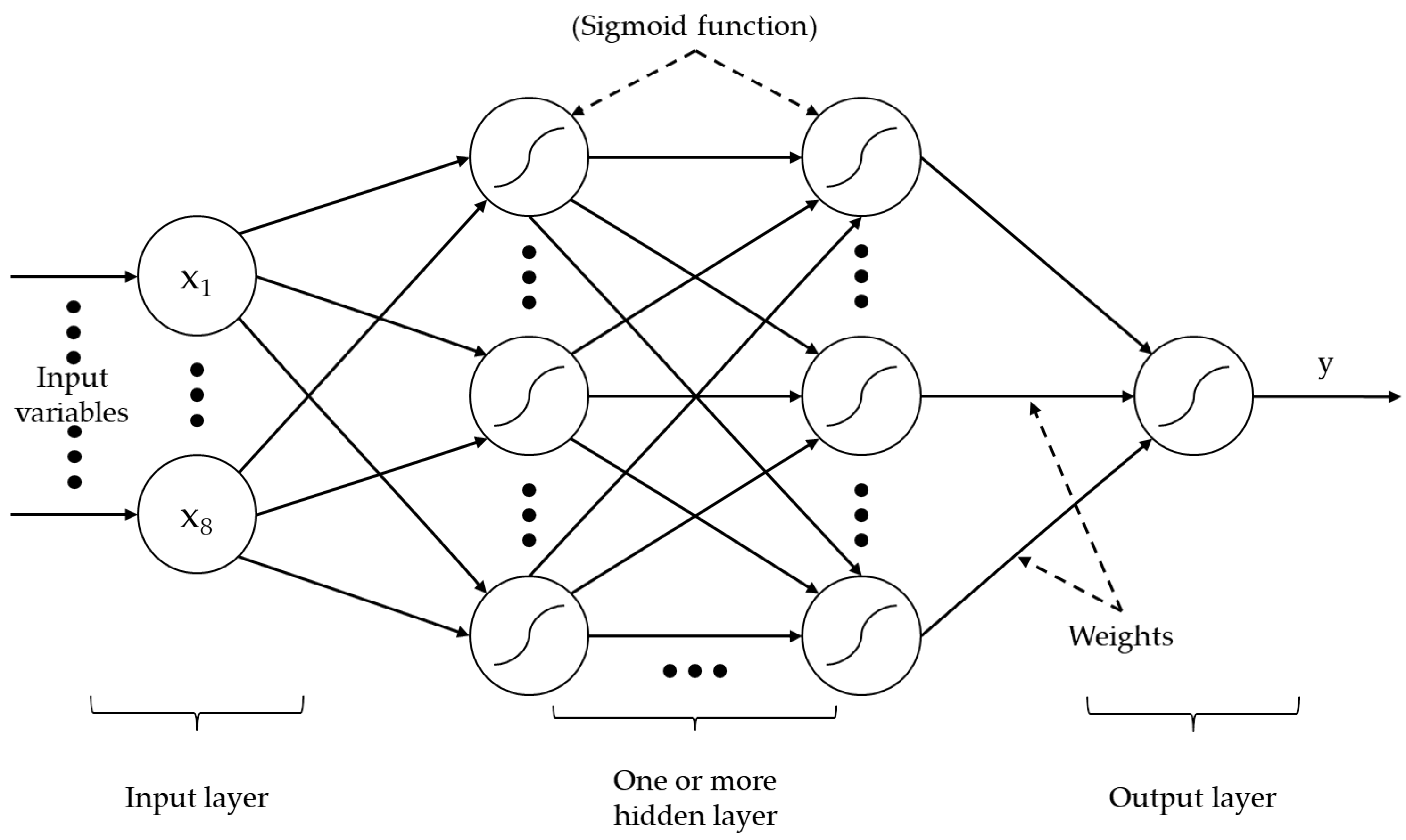
3.2. Model Selection and Surrogate Model Structures
3.3. Surrogate Model Validation and Maintenance

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Problem Type | Surrogate Model Type | Calculated Error Type | Ref. |
|---|---|---|---|
| 1D, 2D and 10D mathematical test functions; engineering problem: Prediction of the thrust on the whole rotor of a small unmanned aerial vehicle (UAV) | Polynomial Function; Radial Basis Function; Kriging | [79] | |
| Multi-objective reliability-based design optimization of cementless hip prosthesis | Polynomial Function; Kriging | Maximum AE; RME; RMSE | [80] |
| Prediction of the load-bearing capacity of concrete-filled steel square hollow section members | Neural Network | RMSE; Mean AE; | [81] |
| Mathematical and engineering test problems, e.g., Laval nozzle | Radial Basis Function; Kriging; Polynomial Function | RMSE | [82] |
| Evaluate gas-liquid flow in a horizontal pipe | Neural Network | RMSE; | [83] |
| Mathematical test functions | Kriging | RMSE | [84] |
| Optimization of a horizontal axis tidal stream turbine blade | Radial Basis Function; Kriging; Polynomial Function | RMSE | [85] |
| Predict the microstructure of the final rod product | Polynomial Function; Kriging; Radial Basis Function | RMSE | [86] |
| Single-objective global optimization applied within an efficient global optimization framework | Kriging | RMSE | [87] |
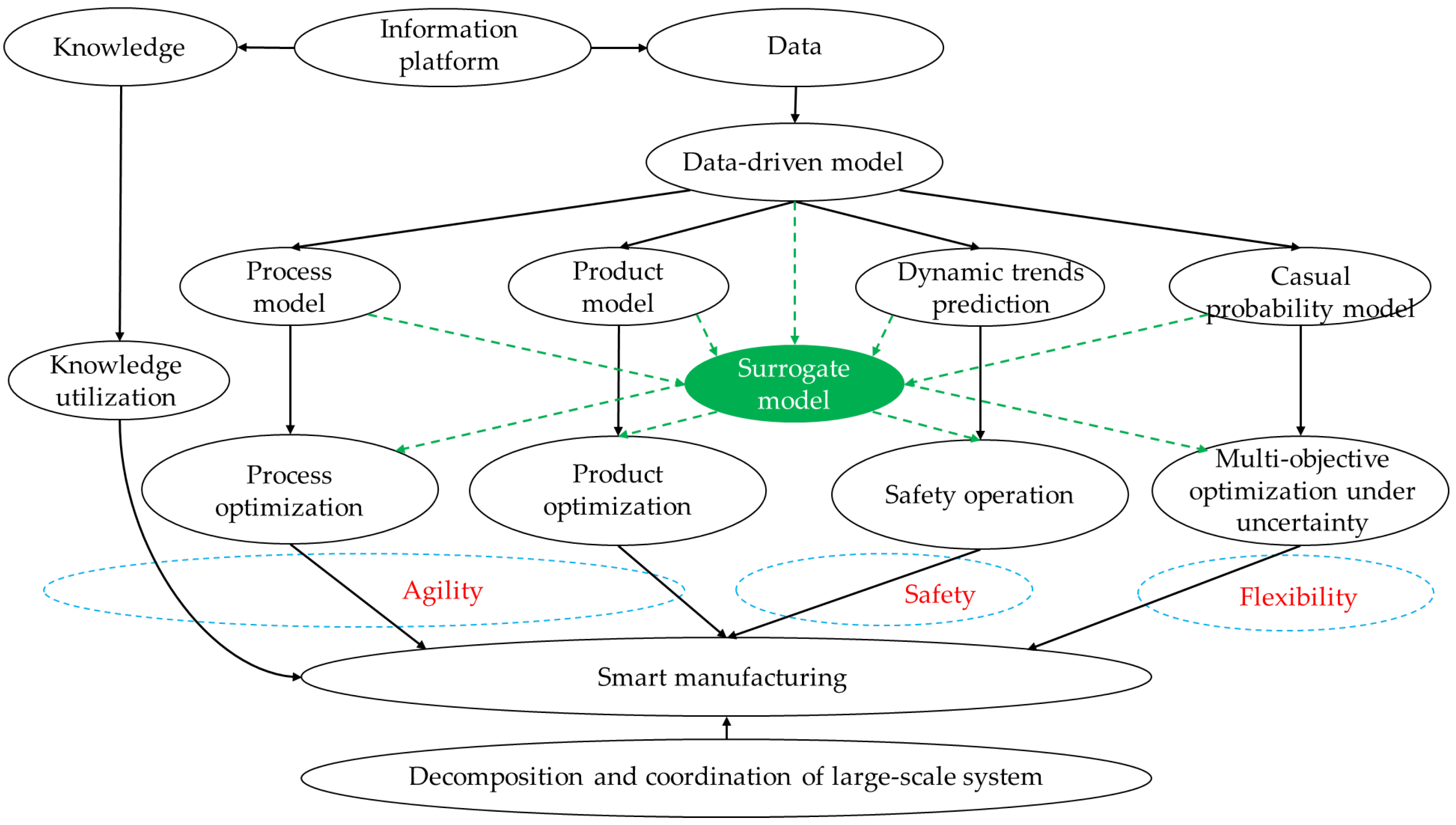
4. Potential Applications of Surrogate Models in Digital Twins
4.1. Potential Applications in Process Industries
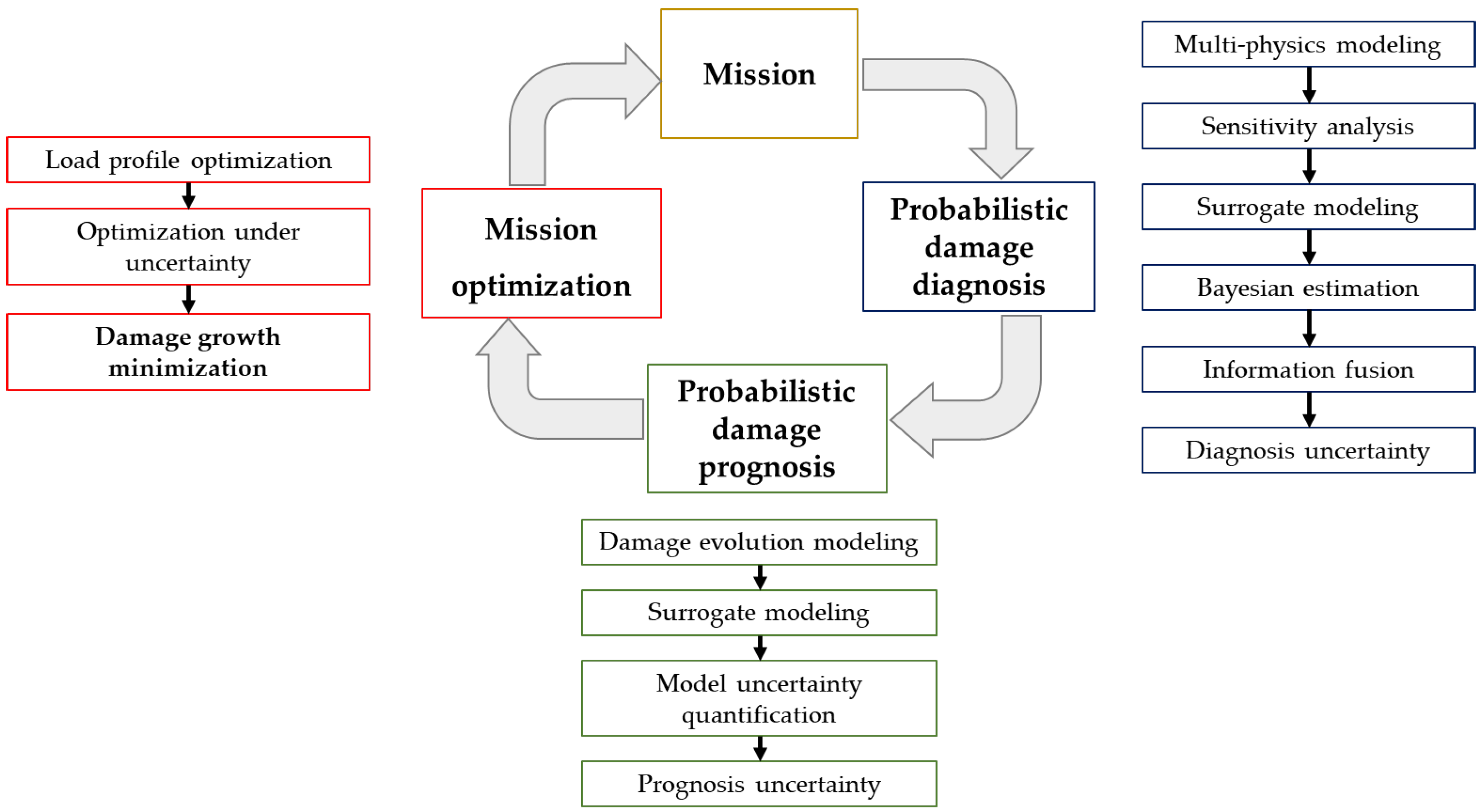
4.2. Potential Applications in Control, Safety and Risk Management
4.3. Potential Applications in Discrete Manufacturing
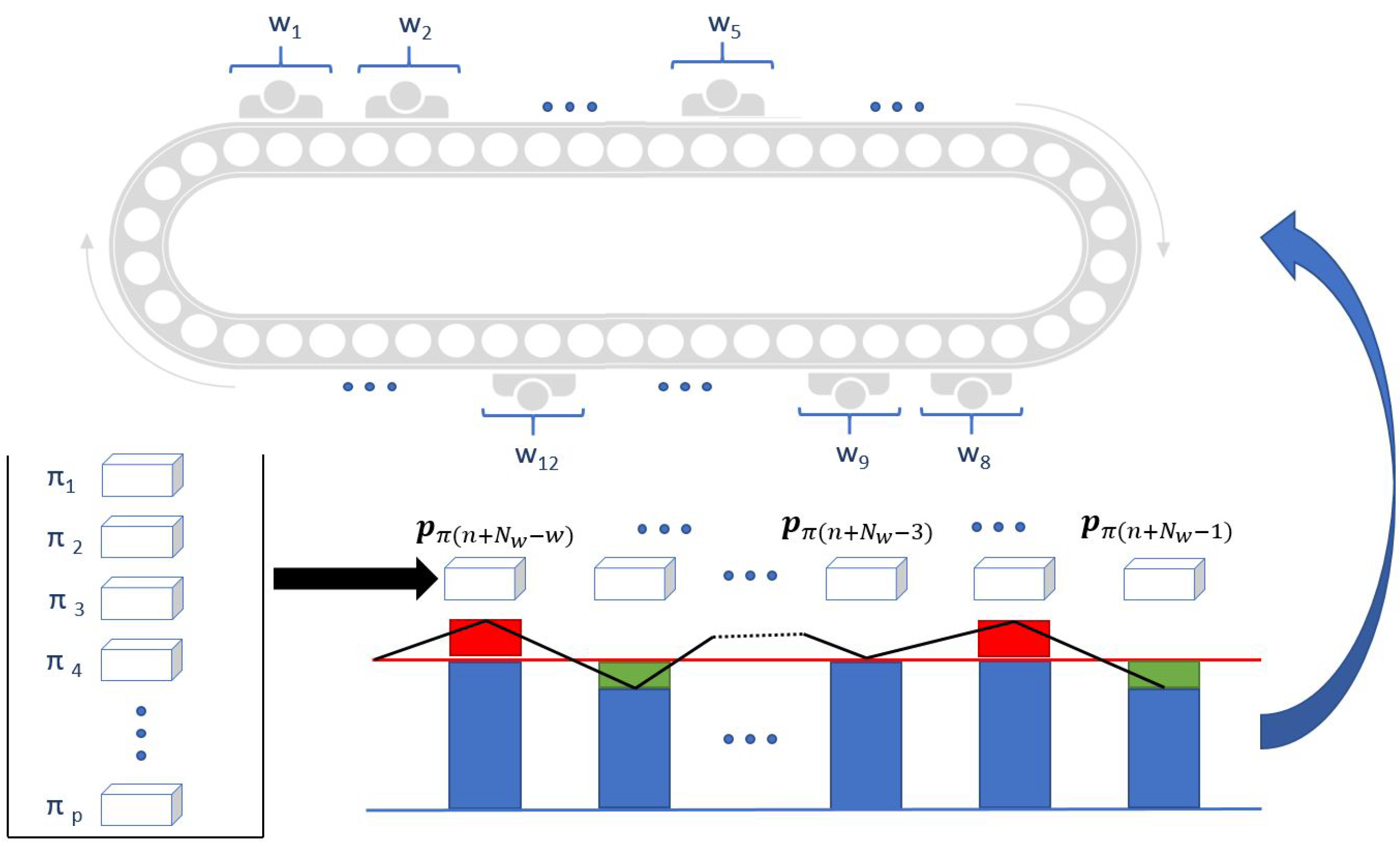
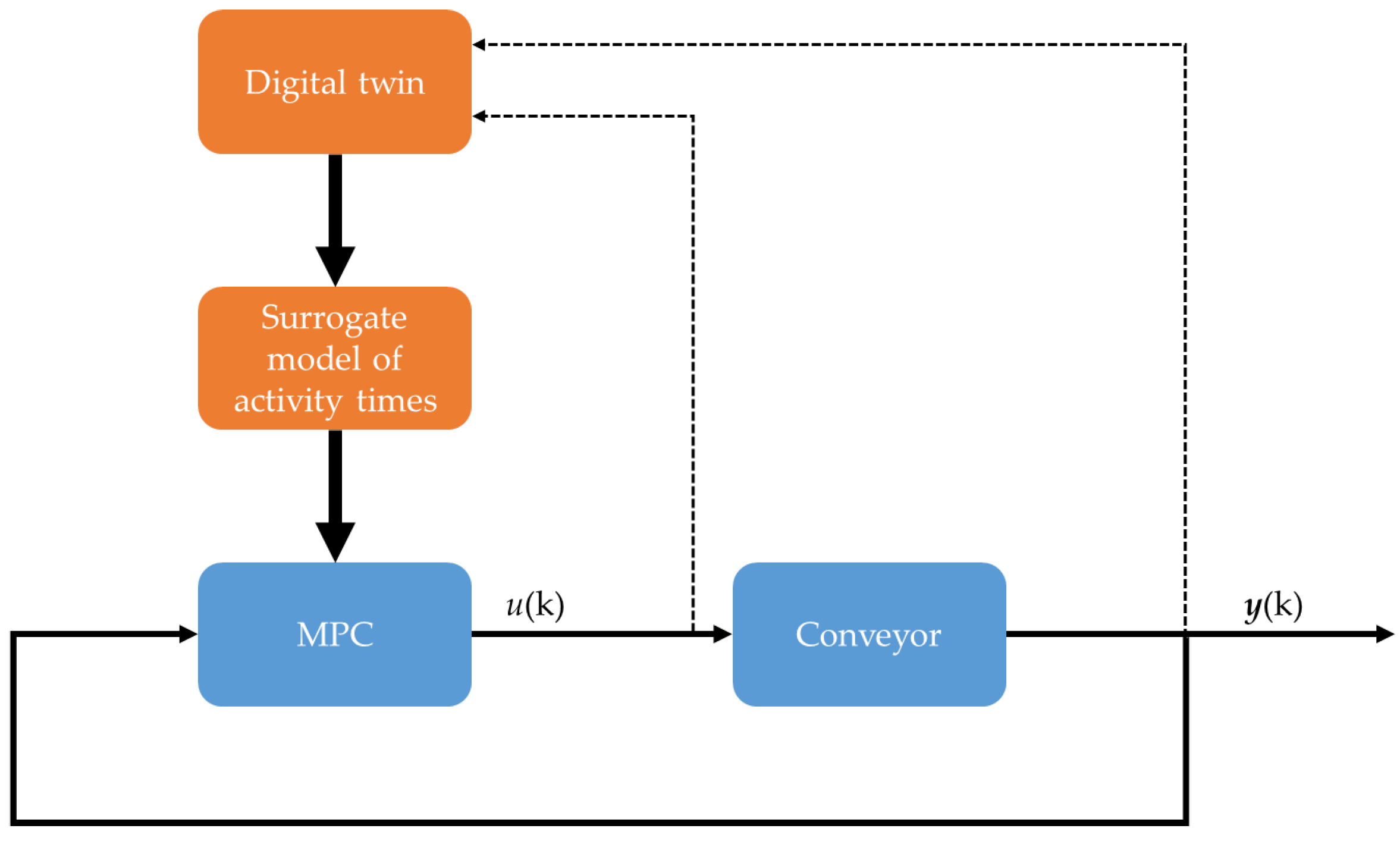
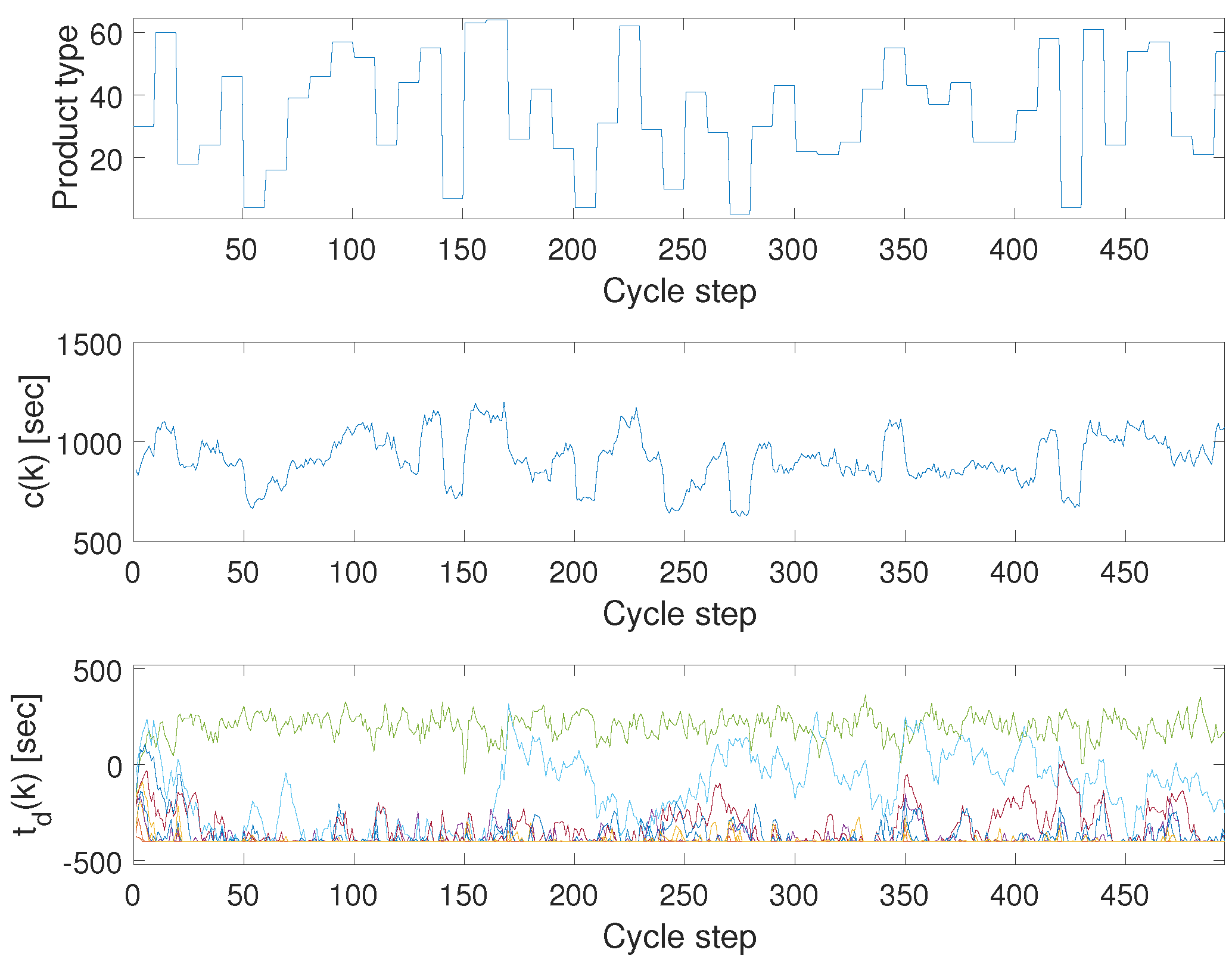
5. Application Example
- Surrogate models should be applied when the discrete event simulator of digital twins cannot be utilised directly in control and optimisation.
- When the model is not linearisable, surrogate models can be extracted from the simulators by Monte Carlo simulation. In this case study, the distributions of the activity times were evaluated and approximated by fuzzy models.
- The resulted models can be further simplified to support problem-specific utilization. In this paper, a simple linear model was extracted from the fuzzy model that represents the activity times in a given confidence.
- The modeller should validate not only the accuracy of the extracted model on a training and validation dataset, but also the performance of the application should be carefully analysed as most of the control and optimisation algorithms need extrapolation from the models.
- The surrogate models should not be oversimplified. Finding the optimal model complexity needs details analysis of the system and the application tasks. In this situation, the principle of Occam’s Razors should be adapted; one should select the solution with the least complexity that makes predictions suitable for the given task.
6. Conclusions
- Data requirement: As shown in Section 3, collecting data of adequate quantity and quality is the key component of suitable surrogate model building. These data may come directly from physical reality (measurements) or even from an adequate simulation of the system (process simulator, CFD-based simulator, etc.).
- Maintenance requirements: Since the generalisation capability of surrogate models can be limited, moreover, processes cannot really operate exactly in a true steady state, the continuous maintenance of surrogate models is considered a decisive task. Application-oriented validation should fit into the whole life cycle of the model as was discussed in Section 3.3.
- Definition of the physical process (manufacturing system) to be modelled.
- Determination of the application task (optimization, control, scheduling, etc.).
- Selection of the suitable modelling approach (physics-based, data-driven or hybrid) based on the knowledge of and information available on the underlying system.
- Collection of appropriate quantity and quality data (depending on the modelling approach).
- Model building (selection of the model type and determination of the model parameters) and model validation.
- Regular supervision of the application environment and model quality.
- Maintenance of the model (modification of the model parameters or structure if necessary).
- Development of surrogate models for process safety: fusion of measured and simulated data for the modelling of process behaviour far from standard process conditions (e.g., runaway state, malfunction).
- Development of automated testing and validation tools that consider the application-specific preferences of the surrogate models.
- Development of automated tools that identify surrogate models based on process data and simulation models and determine the optimal model complexity.
- Study how semi-mechanistic models can be identified and utilized in the framework of digital twins.
Author Contributions
Funding
Conflicts of Interest
References
- Grieves, M. Digital twin: Manufacturing excellence through virtual factory replication. White Pap. 2014, 1, 1–7. [Google Scholar]
- Almada-Lobo, F. The Industry 4.0 revolution and the future of Manufacturing execution systems (MES). J. Innov. Manag. 2015, 3, 16–21. [Google Scholar] [CrossRef]
- Hicks, B. Industry 4.0 and Digital Twins: Key Lessons from NASA. 2020. Available online: https://www.thefuturefactory.com/blog/24 (accessed on 12 November 2020).
- Jbair, M.; Ahmad, B.; Mus’ ab H, A.; Harrison, R. Industrial cyber physical systems: A survey for control-engineering tools. In Proceedings of the 2018 IEEE Industrial Cyber-Physical Systems (ICPS), Saint Petersburg, Russia, 15–18 May 2018; pp. 270–276. [Google Scholar]
- Wang, Q.; Jiao, W.; Wang, P.; Zhang, Y. Digital twin for human-robot interactive welding and welder behavior analysis. IEEE/CAA J. Autom. Sin. 2020, 8, 334–343. [Google Scholar] [CrossRef]
- Rasheed, A.; San, O.; Kvamsdal, T. Digital twin: Values, challenges and enablers from a modeling perspective. IEEE Access 2020, 8, 21980–22012. [Google Scholar] [CrossRef]
- Nentwich, C.; Varela, C.; Engell, S. Optimization of chemical processes applying surrogate models for phase equilibrium calculations. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Lv, Z.; Wang, L.; Han, Z.; Zhao, J.; Wang, W. Surrogate-assisted particle swarm optimization algorithm with Pareto active learning for expensive multi-objective optimization. IEEE/CAA J. Autom. Sin. 2019, 6, 838–849. [Google Scholar] [CrossRef]
- Burnak, B.; Diangelakis, N.A.; Katz, J.; Pistikopoulos, E.N. Integrated process design, scheduling, and control using multiparametric programming. Comput. Chem. Eng. 2019, 125, 164–184. [Google Scholar] [CrossRef]
- Shirmohammadi, R.; Aslani, A.; Ghasempour, R.; Romeo, L.M. CO2 Utilization via Integration of an Industrial Post-Combustion Capture Process with a Urea Plant: Process Modelling and Sensitivity Analysis. Processes 2020, 8, 1144. [Google Scholar] [CrossRef]
- Tsay, C.; Baldea, M. Integrating production scheduling and process control using latent variable dynamic models. Control Eng. Pract. 2020, 94, 104201. [Google Scholar] [CrossRef]
- Pereira, L.M.; Vega, L.F. A systematic approach for the thermodynamic modelling of CO2-amine absorption process using molecular-based models. Appl. Energy 2018, 232, 273–291. [Google Scholar] [CrossRef]
- Egorov, V.; Novakovskii, A.; Zdrachek, E. Modeling of the effect of diffusion processes on the response of ion-selective electrodes by the finite difference technique: Comparison of theory with experiment and critical evaluation. J. Anal. Chem. 2017, 72, 793–802. [Google Scholar] [CrossRef]
- Peitz, S.; Dellnitz, M. A survey of recent trends in multiobjective optimal control—Surrogate models, feedback control and objective reduction. Math. Comput. Appl. 2018, 23, 30. [Google Scholar] [CrossRef] [Green Version]
- Tabatabaei, M.; Hakanen, J.; Hartikainen, M.; Miettinen, K.; Sindhya, K. A survey on handling computationally expensive multiobjective optimization problems using surrogates: Non-nature inspired methods. Struct. Multidiscip. Optim. 2015, 52, 1–25. [Google Scholar] [CrossRef]
- Melab, N.; Gmys, J.; Korosec, P.; Chakroun, I. Synergy between parallel computing, optimization and simulation. J. Comput. Sci. 2020, 44, 101168. [Google Scholar] [CrossRef]
- Borth, M.; Verriet, J.; Muller, G. Digital Twin Strategies for SoS 4 Challenges and 4 Architecture Setups for Digital Twins of SoS. In Proceedings of the 2019 14th Annual Conference System of Systems Engineering (SoSE), Anchorage, AK, USA, 19–22 May 2019; pp. 164–169. [Google Scholar]
- Moher, D.; Shamseer, L.; Clarke, M.; Ghersi, D.; Liberati, A.; Petticrew, M.; Shekelle, P.; Stewart, L.A.; PRISMA-P Group. Preferred reporting items for systematic review and meta-analysis protocols (PRISMA-P) 2015 statement. Syst. Rev. 2015, 4, 1. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, W.; Chebeir, J.; Romagnoli, J.A. Operation optimization of a cryogenic NGL recovery unit using deep learning based surrogate modeling. Comput. Chem. Eng. 2020, 106815. [Google Scholar] [CrossRef]
- Duchêne, P.; Mencarelli, L.; Pagot, A. Optimization approaches to the integrated system of catalytic reforming and isomerization processes in petroleum refinery. Comput. Chem. Eng. 2020, 141, 107009. [Google Scholar] [CrossRef]
- Rall, D.; Schweidtmann, A.M.; Kruse, M.; Evdochenko, E.; Mitsos, A.; Wessling, M. Multi-scale membrane process optimization with high-fidelity ion transport models through machine learning. J. Membr. Sci. 2020, 118208. [Google Scholar] [CrossRef]
- Kim, S.H.; Boukouvala, F. Surrogate-Based Optimization for Mixed-Integer Nonlinear Problems. Comput. Chem. Eng. 2020, 140, 106847. [Google Scholar] [CrossRef]
- Ali, W.; Khan, M.S.; Qyyum, M.A.; Lee, M. Surrogate-assisted modeling and optimization of a natural-gas liquefaction plant. Comput. Chem. Eng. 2018, 118, 132–142. [Google Scholar] [CrossRef]
- Zhong, W.; Qiao, C.; Peng, X.; Li, Z.; Fan, C.; Qian, F. Operation optimization of hydrocracking process based on Kriging surrogate model. Control Eng. Pract. 2019, 85, 34–40. [Google Scholar] [CrossRef]
- Christelis, V.; Kopsiaftis, G.; Mantoglou, A. Performance comparison of multiple and single surrogate models for pumping optimization of coastal aquifers. Hydrol. Sci. J. 2019, 64, 336–349. [Google Scholar] [CrossRef]
- Candelieri, A.; Archetti, F. Sequential model based optimization with black-box constraints: Feasibility determination via machine learning. In Proceedings of the AIP Conference Proceedings, Leiden, The Netherlands, 18–21 September 2018; AIP Publishing LLC: Leiden, The Netherlands, 2019; Volume 2070, p. 020010. [Google Scholar]
- Keßler, T.; Kunde, C.; McBride, K.; Mertens, N.; Michaels, D.; Sundmacher, K.; Kienle, A. Global optimization of distillation columns using explicit and implicit surrogate models. Chem. Eng. Sci. 2019, 197, 235–245. [Google Scholar] [CrossRef]
- Deng, Y.; Yu, B.; Sun, D. Multi-objective optimization of guide vanes for axial flow cyclone using CFD, SVM, and NSGA II algorithm. Powder Technol. 2020, 373, 637–646. [Google Scholar] [CrossRef]
- Beykal, B.; Boukouvala, F.; Floudas, C.A.; Pistikopoulos, E.N. Optimal design of energy systems using constrained grey-box multi-objective optimization. Comput. Chem. Eng. 2018, 116, 488–502. [Google Scholar] [CrossRef]
- Olofsson, S.; Mehrian, M.; Calandra, R.; Geris, L.; Deisenroth, M.P.; Misener, R. Bayesian multiobjective optimisation with mixed analytical and black-box functions: Application to tissue engineering. IEEE Trans. Biomed. Eng. 2018, 66, 727–739. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Nong, D.; Paustian, K. Surrogate-based multi-objective optimization of management options for agricultural landscapes using artificial neural networks. Ecol. Model. 2019, 400, 1–13. [Google Scholar] [CrossRef]
- Quirante, N.; Caballero, J.A. Optimization of a Sour Water Stripping Plant Using Surrogate Models. In Computer Aided Chemical Engineering; Elsevier: Amsterdam, The Netherlands, 2016; Volume 38, pp. 31–36. [Google Scholar]
- Brevault, L.; Balesdent, M.; Hebbal, A.; Patureau De Mirand, A. Surrogate model-based multi-objective MDO approach for partially Reusable Launch Vehicle design. In Proceedings of the AIAA Scitech 2019 Forum, San Diego, CA, USA, 7–11 January 2019; p. 0704. [Google Scholar]
- Nentwich, C.; Engell, S. Application of surrogate models for the optimization and design of chemical processes. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 1291–1296. [Google Scholar]
- Quirante, N.; Javaloyes-Antón, J.; Caballero, J.A. Hybrid simulation-equation based synthesis of chemical processes. Chem. Eng. Res. Des. 2018, 132, 766–784. [Google Scholar] [CrossRef] [Green Version]
- Yang, H.; Hong, S.H.; ZhG, R.; Wang, Y. Surrogate-based optimization with adaptive sampling for microfluidic concentration gradient generator design. RSC Adv. 2020, 10, 13799–13814. [Google Scholar] [CrossRef]
- Shi, H.; You, F. A novel adaptive surrogate modeling-based algorithm for simultaneous optimization of sequential batch process scheduling and dynamic operations. AIChE J. 2015, 61, 4191–4209. [Google Scholar] [CrossRef]
- Dias, L.S.; Ierapetritou, M.G. Integration of planning, scheduling and control problems using data-driven feasibility analysis and surrogate models. Comput. Chem. Eng. 2020, 134, 106714. [Google Scholar] [CrossRef]
- Omairey, S.L.; Dunning, P.D.; Sriramula, S. Multiscale surrogate-based framework for reliability analysis of unidirectional FRP composites. Compos. Part B Eng. 2019, 173, 106925. [Google Scholar] [CrossRef]
- Rafiei, M.; Ricardez-Sandoval, L.A. Integration of design and control for industrial-scale applications under uncertainty: A trust region approach. Comput. Chem. Eng. 2020, 141, 107006. [Google Scholar] [CrossRef]
- Wang, K.; Chen, J.; Xie, L.; Su, H. Decision making scheme of integration design and control under uncertainty for enhancing the economic performance of chemical processes with multiplicity behaviors. Chem. Eng. Res. Des. 2019, 150, 327–340. [Google Scholar] [CrossRef]
- Rodič, B. Industry 4.0 and the new simulation modelling paradigm. Organizacija 2017, 50, 193–207. [Google Scholar] [CrossRef] [Green Version]
- Kljajic, M.; Bernik, I.; Skraba, A. Simulation approach to decision assessment in enterprises. Simulation 2000, 75, 199–210. [Google Scholar] [CrossRef]
- Rasheed, A.; San, O.; Kvamsdal, T. Digital Twin: Values, Challenges and Enablers. arXiv 2019, arXiv:1910.01719. [Google Scholar]
- Löcklin, A.; Müller, M.; Jung, T.; Jazdi, N.; White, D.; Weyrich, M. Digital Twin for Verification and Validation of Industrial Automation Systems–a Survey. In Proceedings of the 2020 25th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Vienna, Austria, 8–11 September 2020; Volume 1, pp. 851–858. [Google Scholar]
- Aivaliotis, P.; Georgoulias, K.; Arkouli, Z.; Makris, S. Methodology for enabling digital twin using advanced physics-based modelling in predictive maintenance. Procedia CIRP 2019, 81, 417–422. [Google Scholar] [CrossRef]
- Wang, X.; Wang, Y.; Tao, F.; Liu, A. New Paradigm of Data-Driven Smart Customisation through Digital Twin. J. Manuf. Syst. 2020, 58, 170–280. [Google Scholar]
- Mencarelli, L.; Pagot, A.; Duchêne, P. Surrogate-based modeling techniques with application to catalytic reforming and isomerization processes. Comput. Chem. Eng. 2020, 135, 106772. [Google Scholar] [CrossRef]
- Dimitrov, N.; Kelly, M.; Vignaroli, A.; Berg, J. From wind to loads: Wind turbine site-specific load estimation using databases with high-fidelity load simulations. Wind Energ. Sci. Discuss 2018, 375, 767–790. [Google Scholar] [CrossRef] [Green Version]
- Slot, R.M.; Sørensen, J.D.; Sudret, B.; Svenningsen, L.; Thøgersen, M.L. Surrogate model uncertainty in wind turbine reliability assessment. Renew. Energy 2020, 151, 1150–1162. [Google Scholar] [CrossRef] [Green Version]
- Li, M.; Wang, Z. Surrogate model uncertainty quantification for reliability-based design optimization. Reliab. Eng. Syst. Saf. 2019, 192, 106432. [Google Scholar] [CrossRef]
- Bhosekar, A.; Ierapetritou, M. Advances in surrogate based modeling, feasibility analysis, and optimization: A review. Comput. Chem. Eng. 2018, 108, 250–267. [Google Scholar] [CrossRef]
- McBride, K.; Sundmacher, K. Overview of surrogate modeling in chemical process engineering. Chem. Ing. Tech. 2019, 91, 228–239. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.H.; Boukouvala, F. Machine learning-based surrogate modeling for data-driven optimization: A comparison of subset selection for regression techniques. Optim. Lett. 2019, 14, 1–22. [Google Scholar] [CrossRef]
- Asher, M.J.; Croke, B.F.; Jakeman, A.J.; Peeters, L.J. A review of surrogate models and their application to groundwater modeling. Water Resour. Res. 2015, 51, 5957–5973. [Google Scholar] [CrossRef]
- Razavi, S.; Tolson, B.A.; Burn, D.H. Review of surrogate modeling in water resources. Water Resour. Res. 2012, 48, 1–32. [Google Scholar] [CrossRef]
- Chatterjee, T.; Chakraborty, S.; Chowdhury, R. A critical review of surrogate assisted robust design optimization. Arch. Comput. Methods Eng. 2019, 26, 245–274. [Google Scholar] [CrossRef]
- Díaz-Manríquez, A.; Toscano, G.; Barron-Zambrano, J.H.; Tello-Leal, E. A review of surrogate assisted multiobjective evolutionary algorithms. Comput. Intell. Neurosci. 2016, 2016, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Bartz-Beielstein, T.; Zaefferer, M. Model-based methods for continuous and discrete global optimization. Appl. Soft Comput. 2017, 55, 154–167. [Google Scholar] [CrossRef] [Green Version]
- Aversano, G.; Bellemans, A.; Li, Z.; Coussement, A.; Gicquel, O.; Parente, A. Application of reduced-order models based on PCA & Kriging for the development of digital twins of reacting flow applications. Comput. Chem. Eng. 2019, 121, 422–441. [Google Scholar]
- Tabar, R.S.; Wärmefjord, K.; Söderberg, R. A new surrogate model–based method for individualized spot welding sequence optimization with respect to geometrical quality. Int. J. Adv. Manuf. Technol. 2020, 106, 2333–2346. [Google Scholar] [CrossRef] [Green Version]
- Meng, F.; Li, Y.; Yuan, S.; Wang, W.; Zheng, Y.; Osman, M.K. Multiobjective Combination Optimization of an Impeller and Diffuser in a Reversible Axial-Flow Pump Based on a Two-Layer Artificial Neural Network. Processes 2020, 8, 309. [Google Scholar] [CrossRef] [Green Version]
- Deng, T.; Ran, Y.; Yin, Y.; Chen, X.; Liu, P. Multi-objective optimization design of double-layered reverting cooling plate for lithium-ion batteries. Int. J. Heat Mass Transf. 2019, 143, 118580. [Google Scholar] [CrossRef]
- Wang, X.; Xu, H.; Wang, J.; Song, W.; Wang, M. Multi-objective optimization of discrete film hole arrangement on a high pressure turbine end-wall with conjugate heat transfer simulations. Int. J. Heat Fluid Flow 2019, 78, 108428. [Google Scholar] [CrossRef]
- Shi, J.; Chu, L.; Braun, R. A Kriging Surrogate Model for Uncertainty Analysis of Graphene Based on a Finite Element Method. Int. J. Mol. Sci. 2019, 20, 2355. [Google Scholar] [CrossRef] [Green Version]
- Trucchia, A.; Egorova, V.; Pagnini, G.; Rochoux, M.C. On the merits of sparse surrogates for global sensitivity analysis of multi-scale nonlinear problems: Application to turbulence and fire-spotting model in wildland fire simulators. Commun. Nonlinear Sci. Numer. Simul. 2019, 73, 120–145. [Google Scholar] [CrossRef] [Green Version]
- Vessaz, C.; Andolfatto, L.; Avellan, F.; Tournier, C. Toward design optimization of a Pelton turbine runner. Struct. Multidiscip. Optim. 2017, 55, 37–51. [Google Scholar] [CrossRef] [Green Version]
- Ali, W.; Duong, P.L.T.; Khan, M.S.; Getu, M.; Lee, M. Measuring the reliability of a natural gas refrigeration plant: Uncertainty propagation and quantification with polynomial chaos expansion based sensitivity analysis. Reliab. Eng. Syst. Saf. 2018, 172, 103–117. [Google Scholar] [CrossRef]
- Yang, M.; Xiao, Z. POD-based surrogate modeling of transitional flows using an adaptive sampling in Gaussian process. Int. J. Heat Fluid Flow 2020, 84, 108596. [Google Scholar] [CrossRef]
- Nentwich, C.; Engell, S. Surrogate modeling of phase equilibrium calculations using adaptive sampling. Comput. Chem. Eng. 2019, 126, 204–217. [Google Scholar] [CrossRef]
- Dias, L.; Bhosekar, A.; Ierapetritou, M. Adaptive Sampling Approaches for Surrogate-Based Optimization. In Computer Aided Chemical Engineering; Elsevier: Amsterdam, The Netherlands, 2019; Volume 47, pp. 377–384. [Google Scholar]
- Jia, L.; Alizadeh, R.; Hao, J.; Wang, G.; Allen, J.K.; Mistree, F. A rule-based method for automated surrogate model selection. Adv. Eng. Inform. 2020, 45, 101123. [Google Scholar] [CrossRef]
- Salem, M.B.; Tomaso, L. Automatic selection for general surrogate models. Struct. Multidiscip. Optim. 2018, 58, 719–734. [Google Scholar] [CrossRef]
- Bauer, M.; Craig, I.K. Economic assessment of advanced process control—A survey and framework. J. Process. Control 2008, 18, 2–18. [Google Scholar] [CrossRef]
- Mayo, S.M.; Rhinehart, R.R.; Madihally, S.V. Advanced Process Control Capital Decisions Must Include Operations Planning for APC Maintenance; School of Chemical Engineering, Oklahoma State University: Stillwater, OK, USA, 2020. [Google Scholar]
- Lu, B.; Chiang, L. Semi-supervised online soft sensor maintenance experiences in the chemical industry. J. Process. Control 2018, 67, 23–34. [Google Scholar] [CrossRef]
- Chen, K.; Castillo, I.; Chiang, L.H.; Yu, J. Soft sensor model maintenance: A case study in industrial processes. IFAC Pap. 2015, 48, 427–432. [Google Scholar]
- Studer, S.; Bui, T.B.; Drescher, C.; Hanuschkin, A.; Winkler, L.; Peters, S.; Mueller, K.R. Towards CRISP-ML (Q): A Machine Learning Process Model with Quality Assurance Methodology. arXiv 2020, arXiv:2003.05155. [Google Scholar]
- Lv, L.; Song, X.; Sun, W. Modify Leave-One-Out Cross Validation by Moving Validation Samples around Random Normal Distributions: Move-One-Away Cross Validation. Appl. Sci. 2020, 10, 2448. [Google Scholar] [CrossRef] [Green Version]
- Dammak, K.; El Hami, A. Multi-objective reliability based design optimization using Kriging surrogate model for cementless hip prosthesis. Comput. Methods Biomech. Biomed. Eng. 2020, 23, 854–867. [Google Scholar] [CrossRef]
- Le, T.T. Surrogate Neural Network Model for Prediction of Load-Bearing Capacity of CFSS Members Considering Loading Eccentricity. Appl. Sci. 2020, 10, 3452. [Google Scholar] [CrossRef]
- Ye, Y.; Wang, Z.; Zhang, X. An optimal pointwise weighted ensemble of surrogates based on minimization of local mean square error. Struct. Multidiscip. Optim. 2020, 62, 529–542. [Google Scholar] [CrossRef]
- Seong, Y.; Park, C.; Choi, J.; Jang, I. Surrogate Model with a Deep Neural Network to Evaluate Gas–Liquid Flow in a Horizontal Pipe. Energies 2020, 13, 968. [Google Scholar] [CrossRef] [Green Version]
- Kang, K.; Qin, C.; Lee, B.; Lee, I. Modified screening-based Kriging method with cross validation and application to engineering design. Appl. Math. Model. 2019, 70, 626–642. [Google Scholar] [CrossRef]
- Kumar, P.M.; Seo, J.; Seok, W.; Rhee, S.H.; Samad, A. Multi-fidelity optimization of blade thickness parameters for a horizontal axis tidal stream turbine. Renew. Energy 2019, 135, 277–287. [Google Scholar] [CrossRef]
- Alizadeh, R.; Jia, L.; Nellippallil, A.B.; Wang, G.; Hao, J.; Allen, J.K.; Mistree, F. Ensemble of surrogates and cross-validation for rapid and accurate predictions using small data sets. Artif. Intell. Eng. Des. Anal. Manuf. 2019, 33, 484–501. [Google Scholar] [CrossRef]
- Palar, P.S.; Shimoyama, K. On efficient global optimization via universal Kriging surrogate models. Struct. Multidiscip. Optim. 2018, 57, 2377–2397. [Google Scholar] [CrossRef] [Green Version]
- Fuller, A.; Fan, Z.; Day, C.; Barlow, C. Digital Twin: Enabling Technologies, Challenges and Open Research. IEEE Access 2020, 8, 108952–108971. [Google Scholar] [CrossRef]
- Gigi, K.E. Digital twins for greater insights. WaterWorld 2020, 36, 11. [Google Scholar]
- Yuan, Z.; Qin, W.; Zhao, J. Smart Manufacturing for the Oil Refining and Petrochemical Industry. Engineering 2017, 3, 179–182. [Google Scholar] [CrossRef]
- Lee, J.; Cameron, I.; Hassall, M. Improving process safety: What roles for Digitalization and Industry 4.0? Process. Saf. Environ. Prot. 2019, 132, 325–339. [Google Scholar] [CrossRef]
- Müller, J.M. Antecedents to digital platform usage in Industry 4.0 by established manufacturers. Sustainability 2019, 11, 1121. [Google Scholar] [CrossRef] [Green Version]
- Örs, E.; Schmidt, R.; Mighani, M.; Shalaby, M. A Conceptual Framework for AI-based Operational Digital Twin in Chemical Process Engineering. In Proceedings of the 2020 IEEE International Conference on Engineering, Technology and Innovation (ICE/ITMC), Cardiff, UK, 15–17 June 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Xenos, D.P.; Cicciotti, M.; Kopanos, G.M.; Bouaswaig, A.E.; Kahrs, O.; Martinez-Botas, R.; Thornhill, N.F. Optimization of a network of compressors in parallel: Real Time Optimization (RTO) of compressors in chemical plants—An industrial case study. Appl. Energy 2015, 144, 51–63. [Google Scholar] [CrossRef] [Green Version]
- Lie, B. Surrogate and Hybrid Models for Control. In Proceedings of the 60th SIMS Conference, Västerås, Sweden, 12–16 August 2019; Volume 170, pp. 1–8. [Google Scholar]
- Chu, Y.; You, F. Model-based integration of control and operations: Overview challenges advances and opportunities. Comput. Chem. Eng. 2015, 83, 2–20. [Google Scholar] [CrossRef]
- He, R.; Chen, G.; Dong, C.; Sun, S.; Shen, X. Data-driven digital twin technology for optimized control in process systems. ISA Trans. 2019, 95, 221–234. [Google Scholar] [CrossRef] [PubMed]
- Sales-Cruz, M.; Cameron, I.; Gani, R. Tennessee Eastman Plant-wide Industrial Process Challenge Problem. In Product and Process Modelling; Elsevier: Amsterdam, The Netherlands, 2011; pp. 273–303. [Google Scholar]
- Janošovskỳ, J.; Danko, M.; Labovskỳ, J.; Jelemenskỳ, L. Software approach to simulation-based hazard identification of complex industrial processes. Comput. Chem. Eng. 2019, 122, 66–79. [Google Scholar] [CrossRef]
- Kummer, A.; Varga, T. Process simulator assisted framework to support process safety analysis. J. Loss Prev. Process. Ind. 2019, 58, 22–29. [Google Scholar] [CrossRef]
- Wu, J.; Lind, M.; Jørgensen, S.B.; Jensen, N.; Sin, G. Functional Modeling for Process Safety. In Proceedings of the 2nd International Workshop on Functional Modelling for Design and Operation of Engineering Systems and Infrastructures, Okayama, Japan, 30–31 March 2015. [Google Scholar]
- Wu, J.; Lind, M.; Zhang, X.; Jørgensen, S.; Sin, G. Validation of a functional model for integration of safety into process system design. In Computer Aided Chemical Engineering; Elsevier: Amsterdam, The Netherlands, 2015; Volume 37, pp. 293–298. [Google Scholar]
- Bevilacqua, M.; Bottani, E.; Ciarapica, F.E.; Costantino, F.; Di Donato, L.; Ferraro, A.; Mazzuto, G.; Monteriù, A.; Nardini, G.; Ortenzi, M.; et al. Digital twin reference model development to prevent operators’ risk in process plants. Sustainability 2020, 12, 1088. [Google Scholar] [CrossRef] [Green Version]
- Madni, A.M.; Madni, C.C.; Lucero, S.D. Leveraging Digital Twin Technology in Model-Based Systems Engineering. Systems 2019, 7, 7. [Google Scholar] [CrossRef] [Green Version]
- Qi, Q.; Tao, F. Digital twin and big data towards smart manufacturing and industry 4.0: 360 degree comparison. IEEE Access 2018, 6, 3585–3593. [Google Scholar] [CrossRef]
- Karve, P.M.; Guo, Y.; Kapusuzoglu, B.; Mahadevan, S.; Haile, M.A. Digital twin approach for damage-tolerant mission planning under uncertainty. Eng. Fract. Mech. 2020, 225, 106766. [Google Scholar] [CrossRef]
- Thiers, G.; Sprock, T.; McGinnis, L.; Graunke, A.; Christian, M. Automated production system simulations using commercial off-the-shelf simulation tools. In Proceedings of the 2016 Winter Simulation Conference (WSC), Washington, DC, USA, 11–14 December 2016; pp. 1036–1047. [Google Scholar]
- Rodič, B.; Kanduč, T. Leveraging Digital Twin Technology in Model-Based Systems Engineering. Int. J. Math. Model. Methods Appl. Sci. 2015, 9, 1–13. [Google Scholar]
- Jain, S.; Lechevalier, D. Standards based generation of a virtual factory model. In Proceedings of the 2016 Winter Simulation Conference (WSC), Washington, DC, USA, 11–14 December 2016; pp. 2762–2773. [Google Scholar]
- Kirchhof, P. Automatically generating flow shop simulation models from SAP data. In Proceedings of the 2016 Winter Simulation Conference (WSC), Washington, DC, USA, 11–14 December 2016; pp. 3588–3589. [Google Scholar]
- Ruppert, T.; Abonyi, J. Integration of real-time locating systems into digital twins. J. Ind. Inf. Integr. 2020, 20, 1–12. [Google Scholar] [CrossRef]
- Ruppert, T.; Abonyi, J. Software Sensor for Activity-Time Monitoring and Fault Detection in Production Lines. Sensors 2018, 18, 2346. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tamas Ruppert, G.D.; Abonyi, J. Fuzzy activity time-based model predictive control of open-station assembly lines. J. Manuf. Syst. 2020, 54, 12–23. [Google Scholar] [CrossRef]
















| Search Strings/String Pairs | Total Number of Publications |
|---|---|
| “surrogate model” | 5702 |
| “digital twin” | 1577 |
| “surrogate model” AND “optimisation” | 3411 |
| “surrogate model” AND “control” | 754 |
| “digital twin” AND “optimisation” | 241 |
| “digital twin” AND “control” | 461 |
| “surrogate model” AND “digital twin” | 10 |
| Problem Type | Surrogate Model Type | Ref. |
|---|---|---|
| Direct and Global Optimization | ||
| Operation optimisation of a Cryogenics Natural Gas Liquids recovery unit | Neural Network | [19] |
| Optimization of catalytic reforming and light naphtha isomerization | Polynomial Function | [20] |
| Global optimisation of membrane processes | Neural Network | [21] |
| Determine the optimal structure and operating parameters for a process to minimize the sum of operating and capital costs | Kriging and Neural Network | [22] |
| Determine the optimal performance of a process at a natural-gas liquefaction plant based on a single mixed refrigerant | Radial Basis Function | [23] |
| Prediction and optimisation of the reaction and separation performance of a chemical process plant | Support Vector Machines, Kriging and Neural Network | [7] |
| Optimize operating conditions of a hydrocracking process | Kriging | [24] |
| Optimization of pumping rates in a coastal aquifer | Radial Basis Function and Kriging | [25] |
| Feasibility determination via Machine Learning | Support Vector Machine | [26] |
| Global optimisation of distillation columns | Kriging | [27] |
| Multi-objective Optimization | ||
| A multi-objective optimisation of guide vanes | Support Vector Machine | [28] |
| An energy market design problem for a commercial building | Polynomial Function | [29] |
| Maximise the percentage of a scaffold filled with neotissue | Kriging | [30] |
| Multi-objective optimisation of management options for agricultural landscapes | Neural Network | [31] |
| Optimization of a sour water stripping plant | Kriging | [32] |
| Synthesis and Design | ||
| Design of a reusable launch vehicle for multi-mission | Kriging | [33] |
| Optimise the process conditions of hydroformylation process | Neural Network | [34] |
| Optimisation of vinyl chloride monomer production process | Kriging | [35] |
| Design of microfluidic concentration gradient generators | Kriging | [36] |
| Scheduling and Planning | ||
| Integrated optimisation of scheduling and dynamic optimisation problems for a sequential batch process | Piecewise Linear Regression | [37] |
| Integration of planning, scheduling and control; Optimisation of an enterprise of air separation plants | Linear Regression and Neural Network | [38] |
| Reliability analysis of unidirectional fibre-reinforced plastic composites | Polynomial Function | [39] |
| Design and Control | ||
| Simultaneous design and control of the Tennessee Eastman (TE) process | Power Series Expansion | [40] |
| Integration of design and control under uncertainty is developed for multiple steady-state processes | Fuzzy Model | [41] |
| Integration of process design, control and scheduling illustrated by two example problems, a system of two continuous stirred tank reactors and a small residential combined heat and power (CHP) network | State Space Model | [9] |
| Physics-Based Models | Data-Driven Models | Physics-Based Surrogate Models | |
|---|---|---|---|
| Benefits | Solid foundation based on physics and reasoning | Once the model has been trained, it is very stable for making predictionsinferences | Once the model has been trained, it is stable for making predictionsinferences |
| Errorsuncertainties can be bounded and estimated | Takes into account long-term historical data and experiences | Errorsuncertainties can be bounded and estimated | |
| Less susceptible to bias | Less susceptible to bias | ||
| Generalizable to problems with similar physics | Although blackbox-type, it reflects some of the physics | ||
| Drawbacks | Difficult to assimilate very long-term historical data | So far, most of the advanced algorithms function like black boxes | Difficult to assimilate very long-term historical data |
| Sensitive and susceptible to numerical instability | Not possible to bound errors/ uncertainties | Limited generalization of unfore- seen problems | |
| Bias in data is reflected in the model prediction | |||
| Poor generalization of unfore- seen problems |
| Sampling Method | Problem Type | Surrogate Model Type | Ref. |
|---|---|---|---|
| Stationary sampling methods | |||
| Latin Hypercube | Design optimisation of a reversible axial-flow pump based on an ordinary one-way pump | Neural Network | [62] |
| Multi-objective optimisation to obtain the optimal design of a cold plate structure | Polynomial Function | [63] | |
| Multi-objective optimisation and conjugate heat transfer calculation to obtain optimal cooling layouts on a transonic high pressure guide vane | Kriging | [64] | |
| Application of a surrogate model in the vibration analysis of graphene sheets | Kriging | [65] | |
| Halton | Study of surrogate approaches to the nonlinear and multi-scale problem of turbulence and fire-spotting in wildland fire modelling | Radial Basis Function | [66] |
| Design optimisation of a Pelton turbine runner | Radial Basis Function | [67] | |
| Monte Carlo, Halton-based quasi-Monte Carlo | Natural gas pipeline design | Radial Basis Function | [68] |
| Adaptive sampling methods | |||
| Adaptive | Predict the transitional flow past rough flat plates | Radial Basis Function | [69] |
| Process optimisation of hydrofor- mylation of the 1-dodecene process | Support Vector Machine and Kriging | [70] | |
| Mixed-integer nonlinear benchmark problems and a chemical process synthesis case study | Kriging and Neural Network | [22] | |
| Design of microfluidic concentration gradient generators | Kriging | [36] | |
| Feasibility analysis of the continuous manufacturing of pharmaceutical tablets | Kriging and Radial Basis Function | [71] | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bárkányi, Á.; Chován, T.; Németh, S.; Abonyi, J. Modelling for Digital Twins—Potential Role of Surrogate Models. Processes 2021, 9, 476. https://doi.org/10.3390/pr9030476
Bárkányi Á, Chován T, Németh S, Abonyi J. Modelling for Digital Twins—Potential Role of Surrogate Models. Processes. 2021; 9(3):476. https://doi.org/10.3390/pr9030476
Chicago/Turabian StyleBárkányi, Ágnes, Tibor Chován, Sándor Németh, and János Abonyi. 2021. "Modelling for Digital Twins—Potential Role of Surrogate Models" Processes 9, no. 3: 476. https://doi.org/10.3390/pr9030476
APA StyleBárkányi, Á., Chován, T., Németh, S., & Abonyi, J. (2021). Modelling for Digital Twins—Potential Role of Surrogate Models. Processes, 9(3), 476. https://doi.org/10.3390/pr9030476