
Real-Time Industrial Process Fault Diagnosis Based on Time Delayed Mutual Information Analysis




Abstract
:1. Introduction
2. Preliminaries
2.1. Information Entropy
2.2. Mutual Information
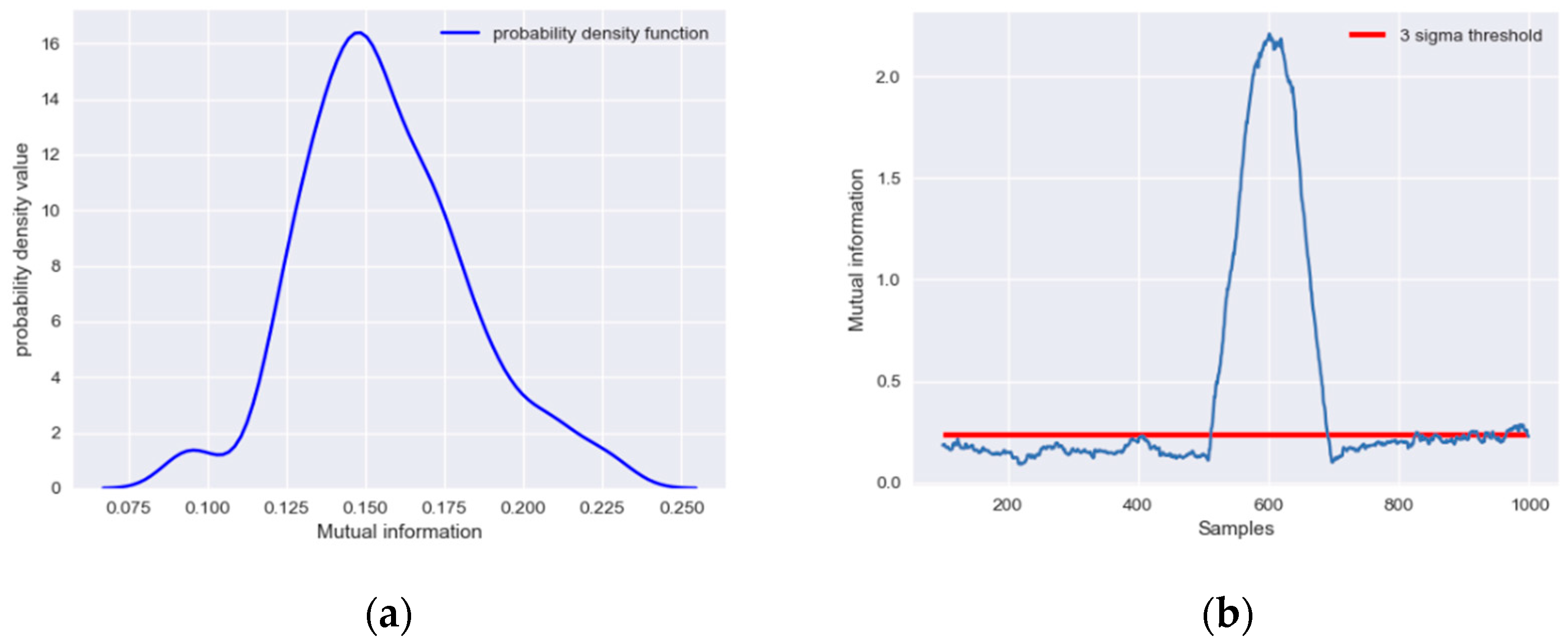
2.3. Kernel Density Estimation Method
2.4. Digraph Model
3. Fault Diagnosis Method with Information Solely Extracted from Process Data
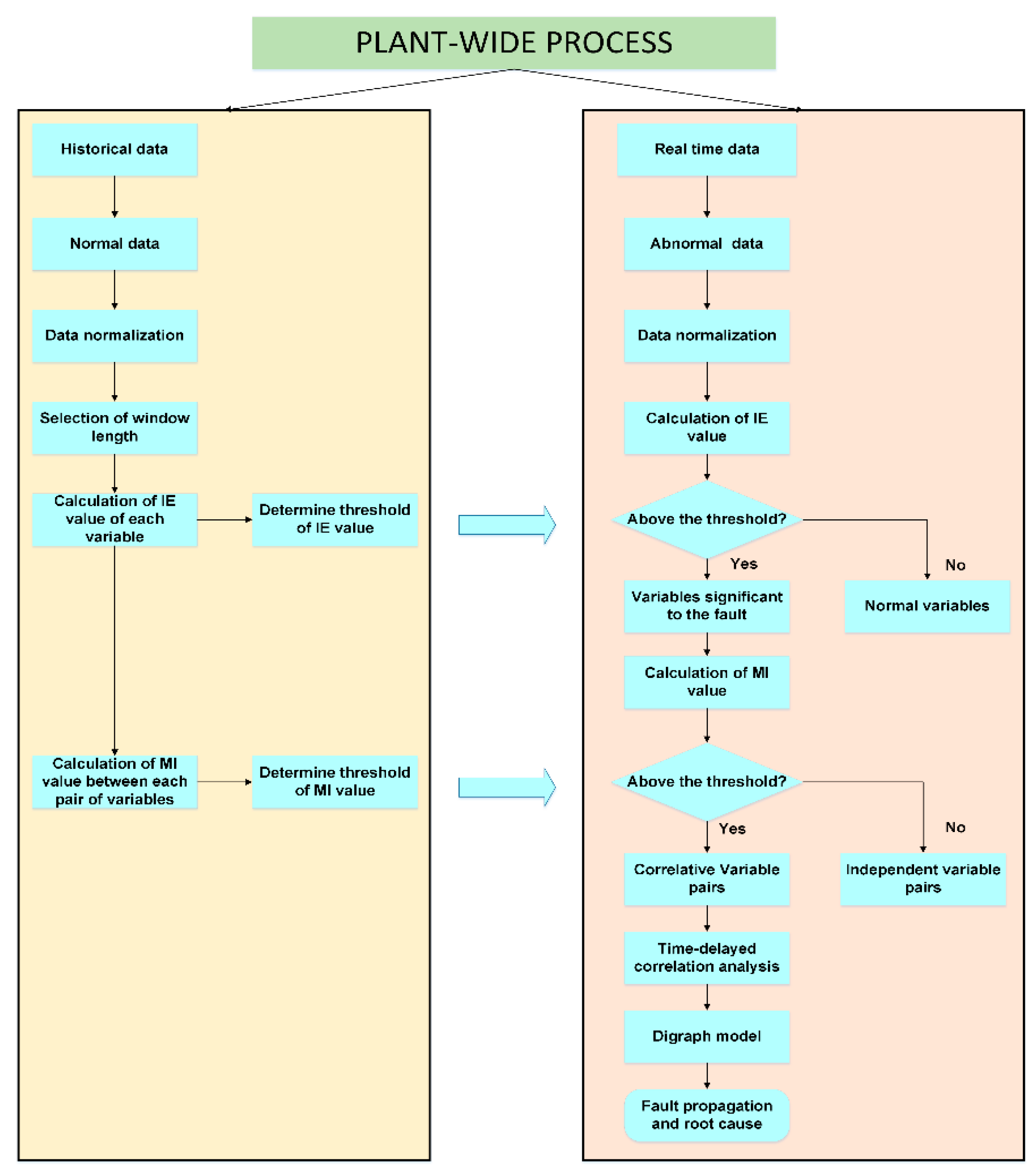
3.1. Procedures for Process Fault Diagnosis
3.2. The Implementation of the Proposed Fault Diagnosis Framework
- (1)
- Select data under normal operation conditions from historical data.
- (2)
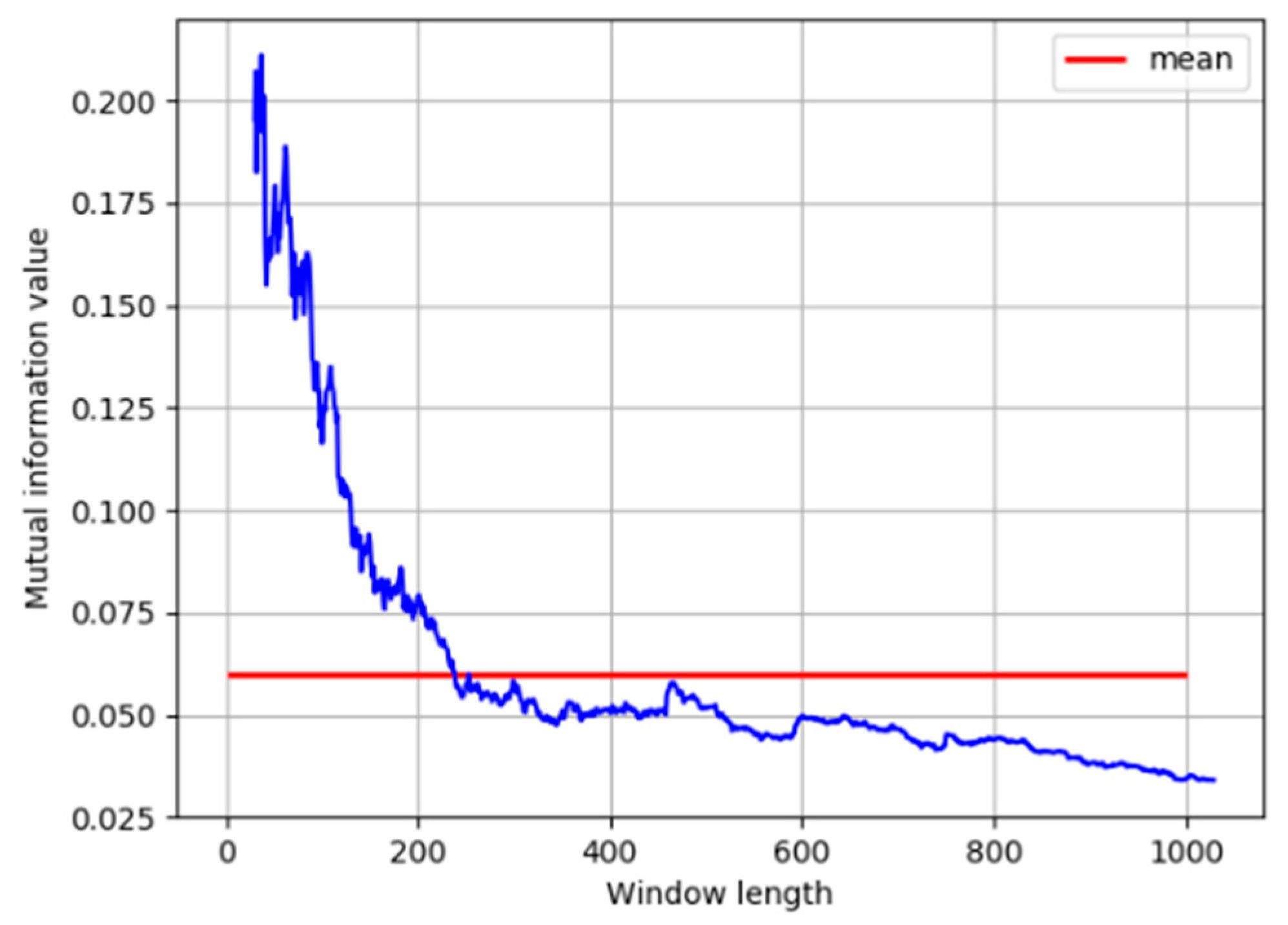
- Normalize the data and choose a suitable window length for the calculation of IE and MI.
- (3)
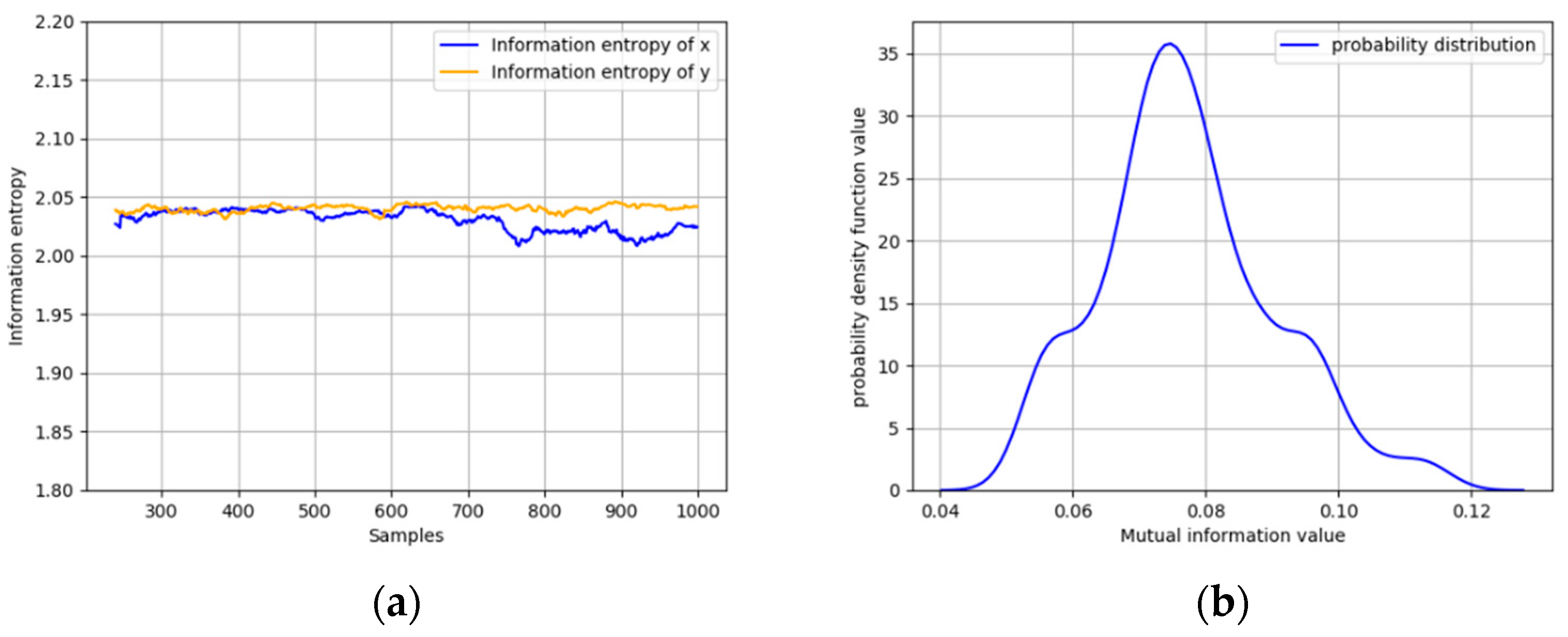
- Calculate IE with a moving window based on kernel density estimation and determine the threshold of each variable.
- (4)
- Calculate the MI of each pair of variables with the moving window and determine the threshold.
- (1)
- Collect real time data, once a fault is detected. These data are usually referred to as abnormal data.
- (2)
- Calculate the IE of each variables using abnormal data and compare it with the thresholds determined previously. Variables that exceed the threshold are selected as the fault nodes in the directed digraph.
- (3)
- Calculate MI of each pair of variables selected in the last step and compare it with the thresholds obtained offline. Variables that exceed the threshold indicate a significant correlation between them, and the nodes are connected with directed arcs in the digraph.
- (4)
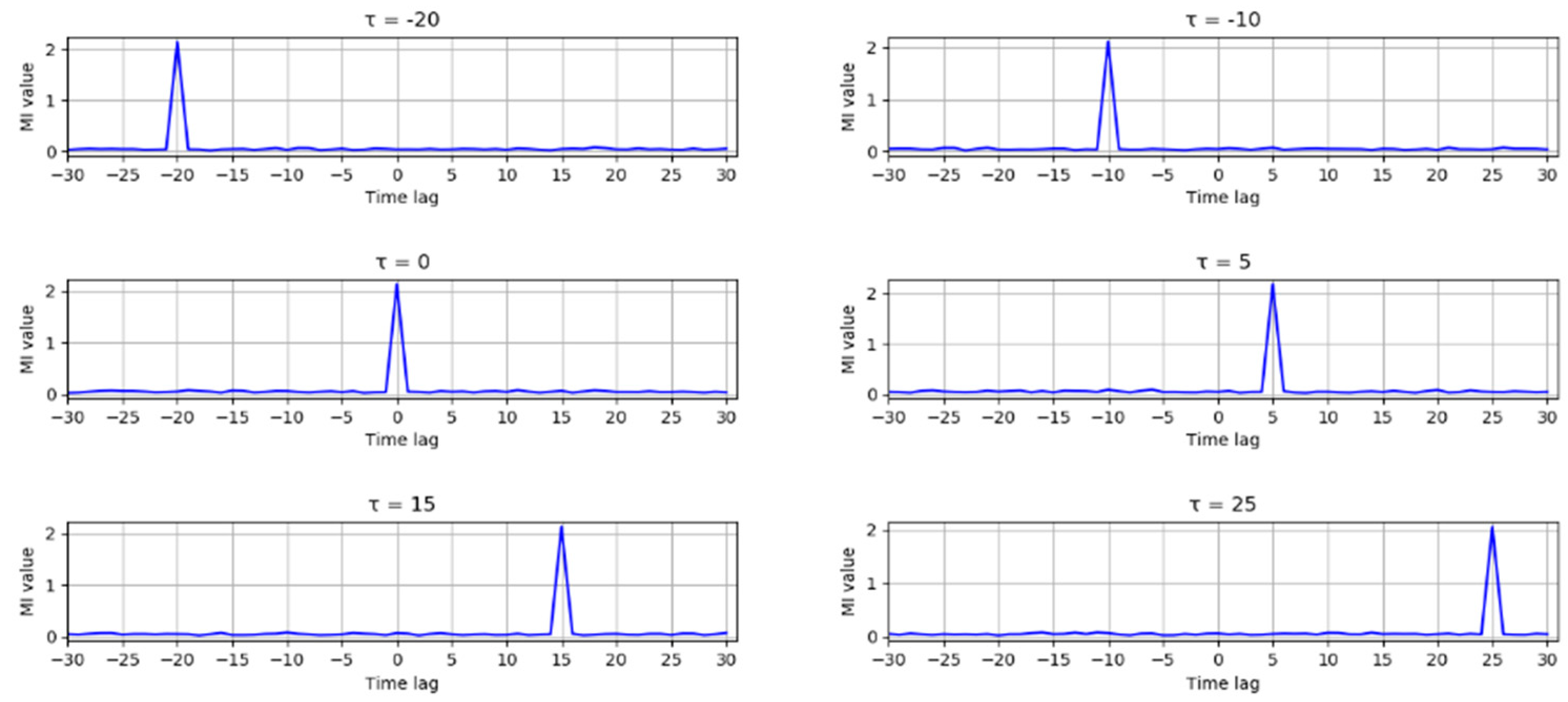
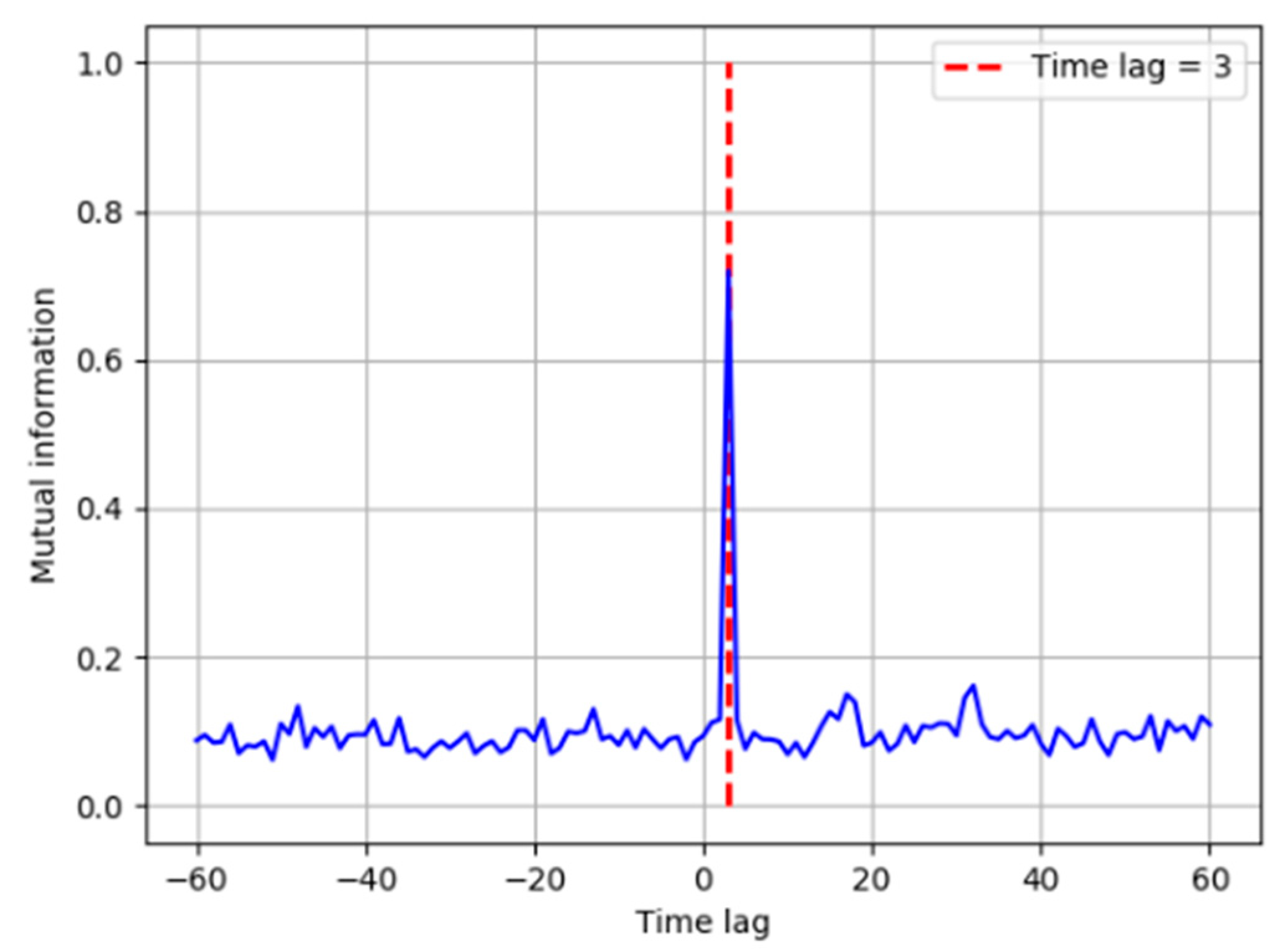
- Calculate the TDMI between correlated variables obtained in the last step to determine the direction of arcs.
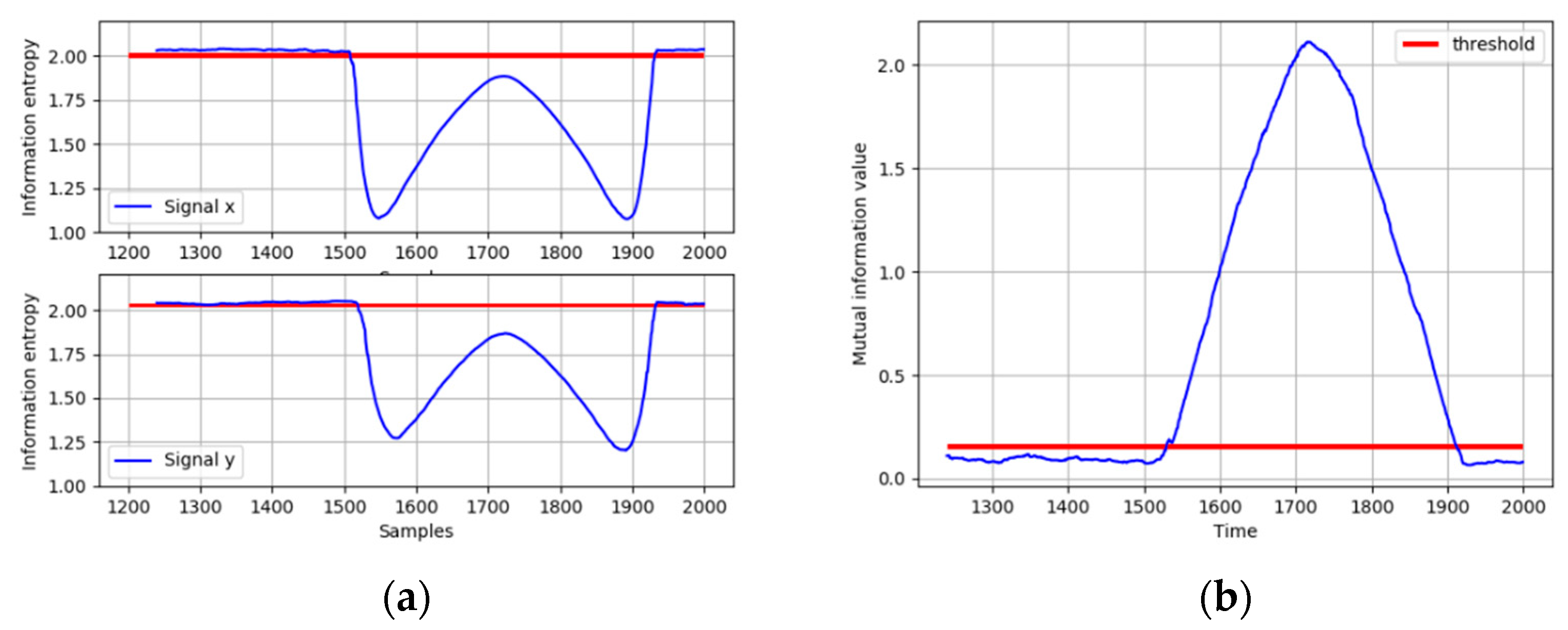
- (5)
- Isolate fault and analyze fault propagation path in the digraph. Root node can be regarded as the source of the fault, and child nodes are regarded as the consequent caused by the fault.
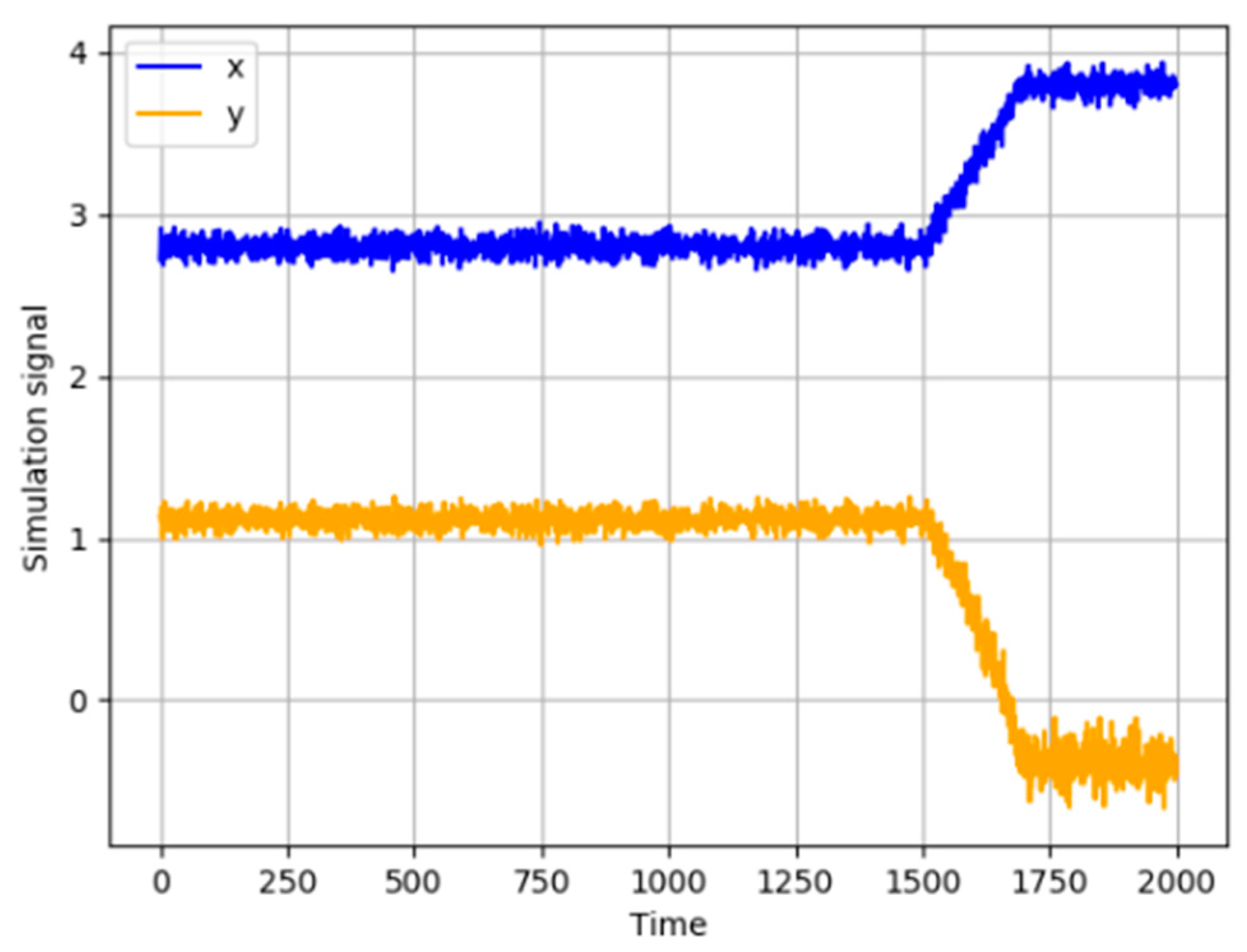
3.3. A Root Cause Identification in a Simulated Example
4. Case Studies
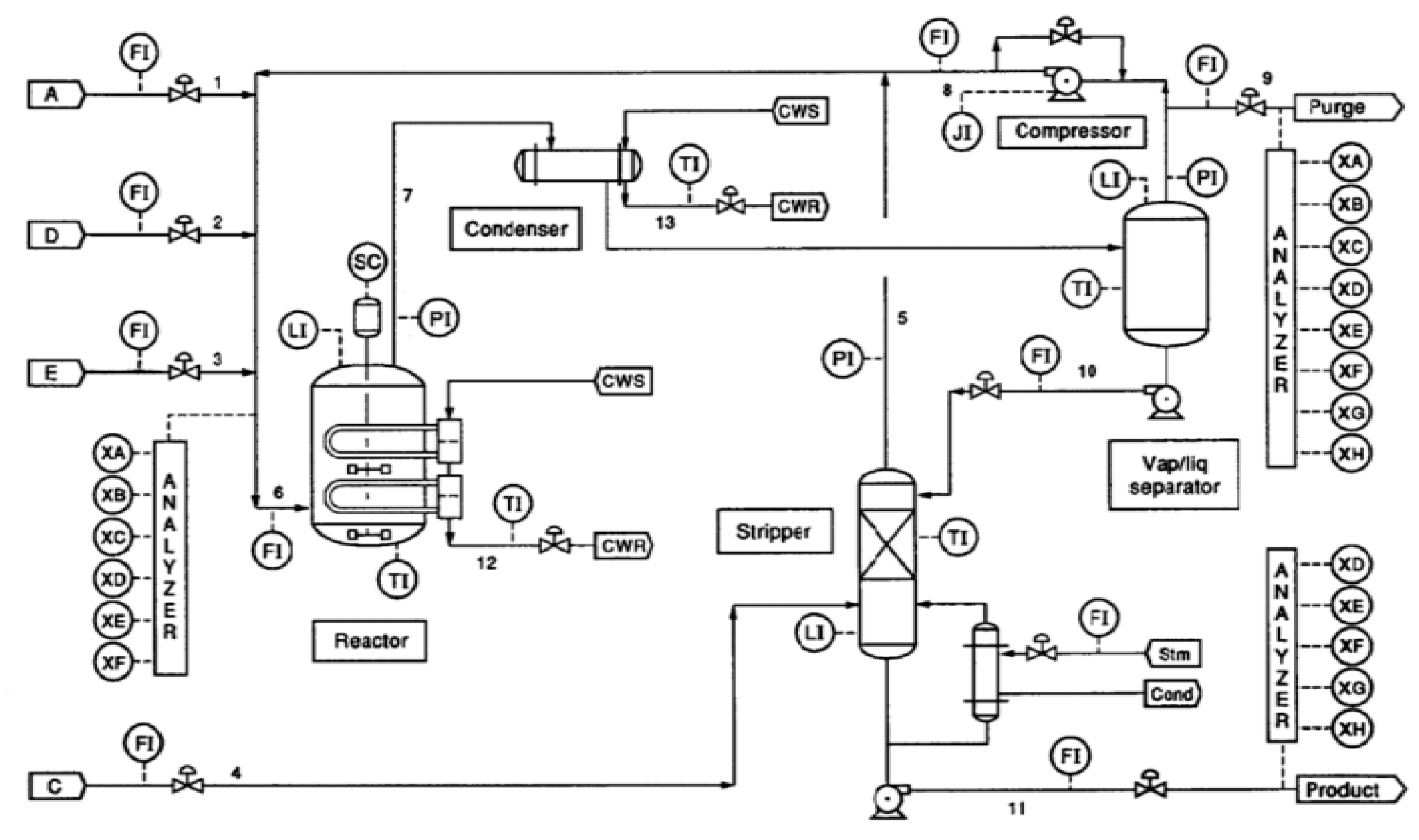
4.1. Tennessee Eastman Process
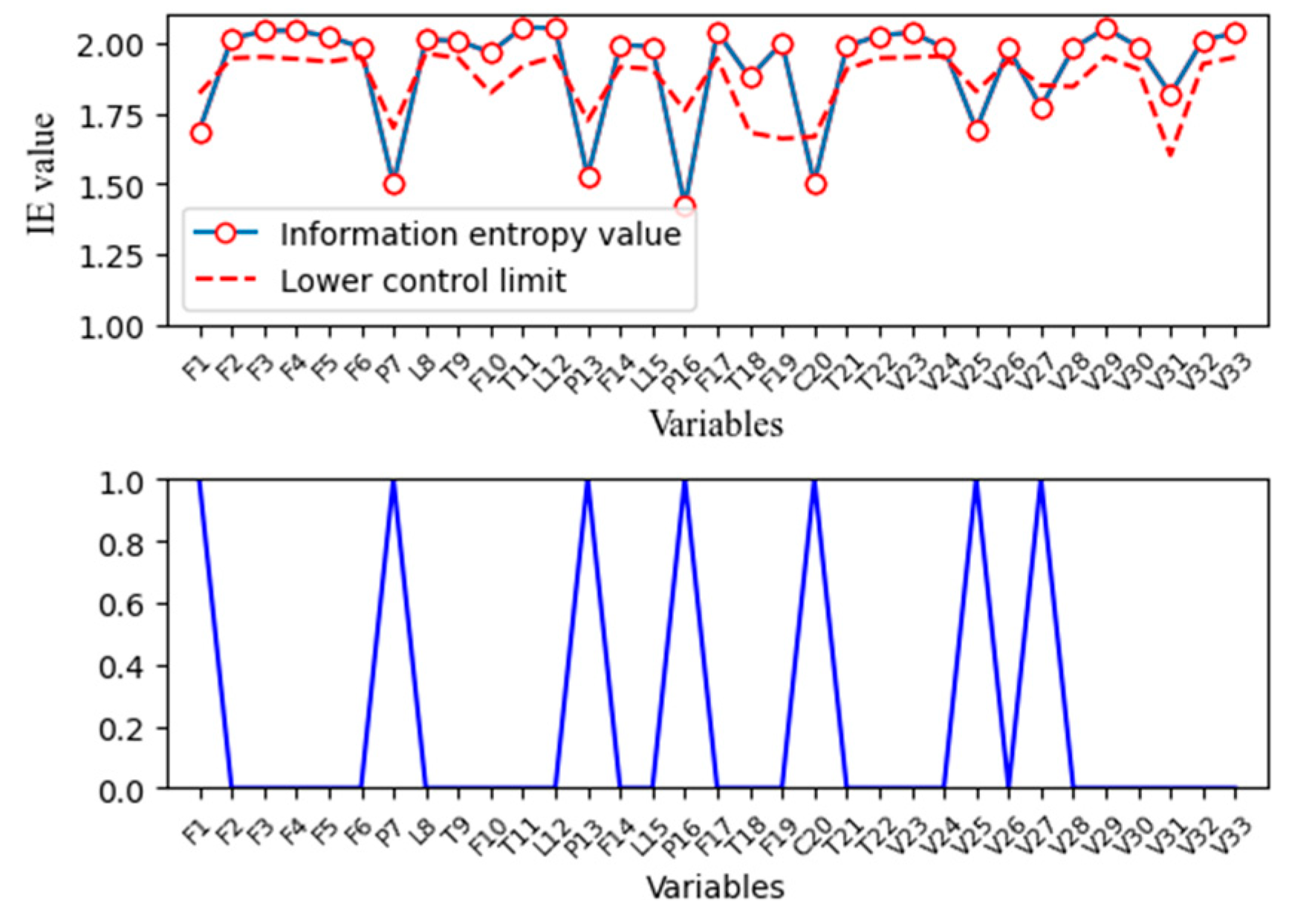
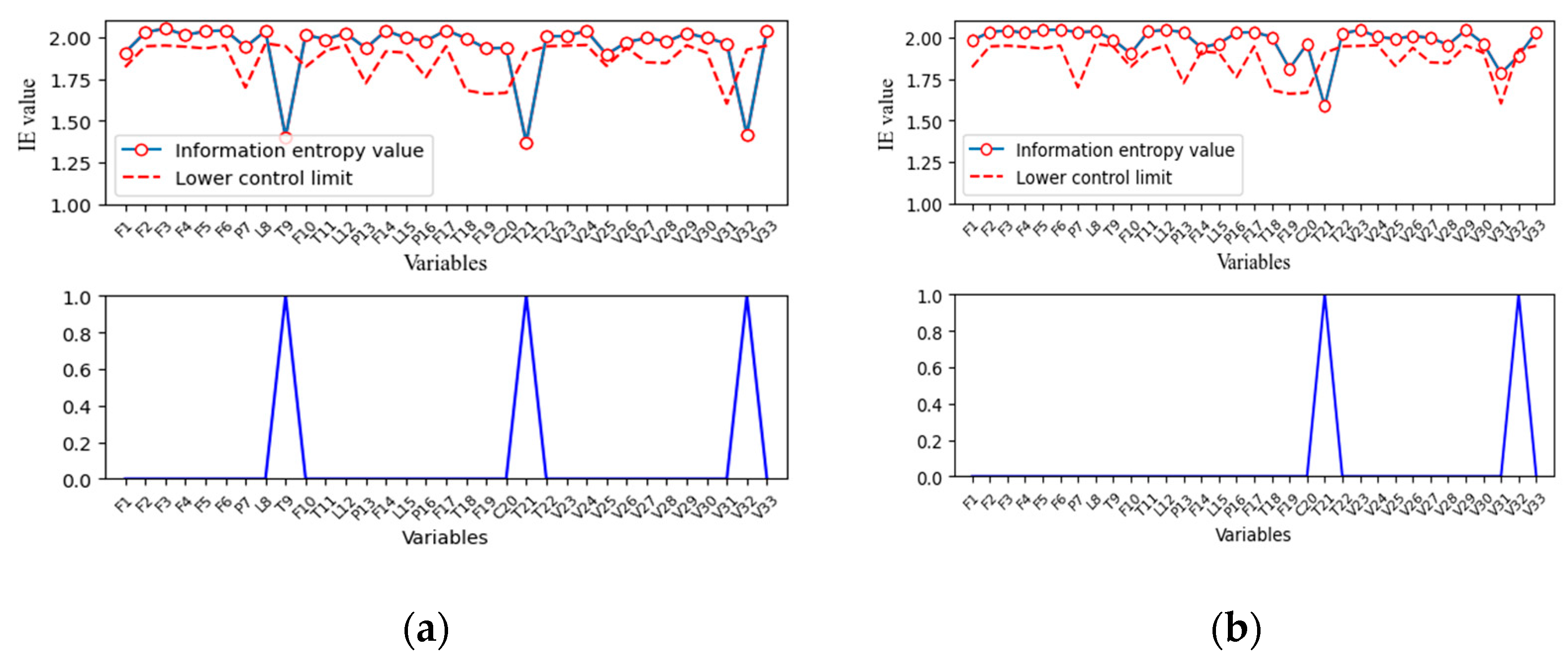
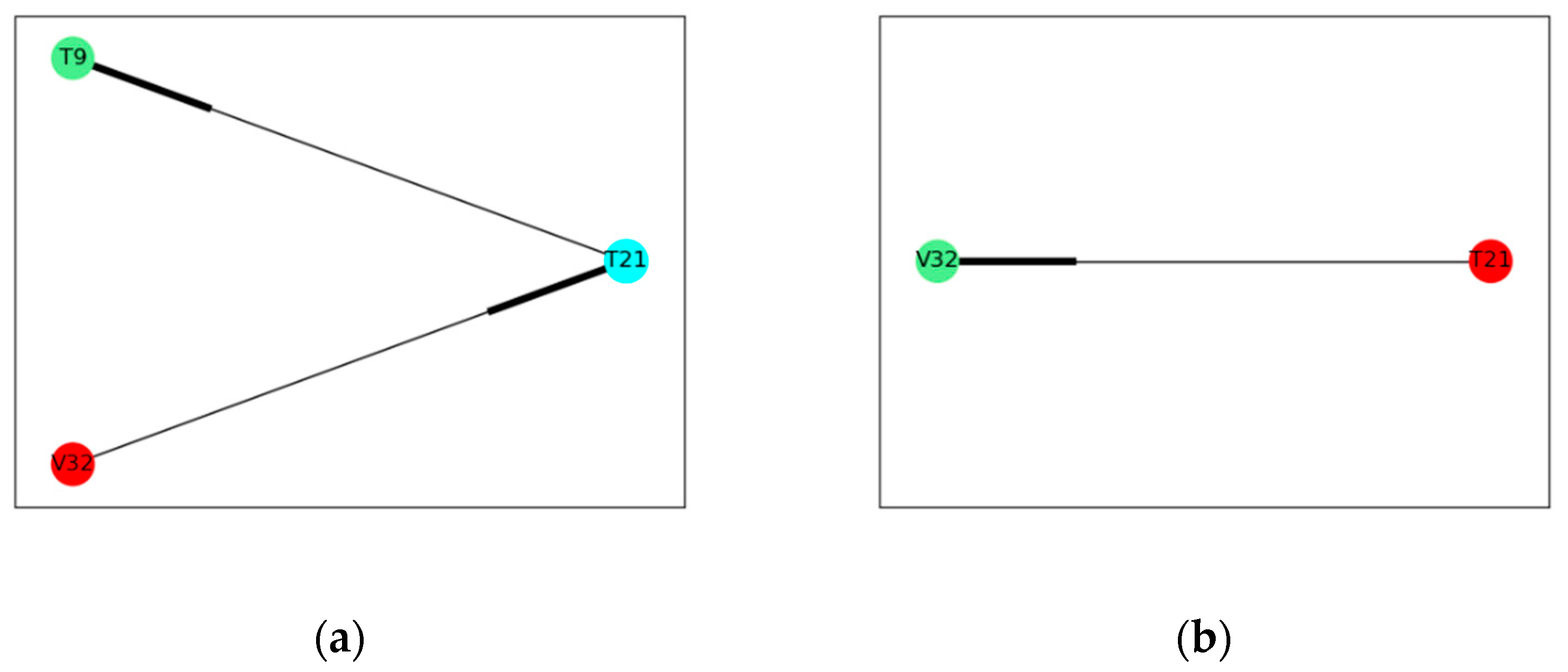
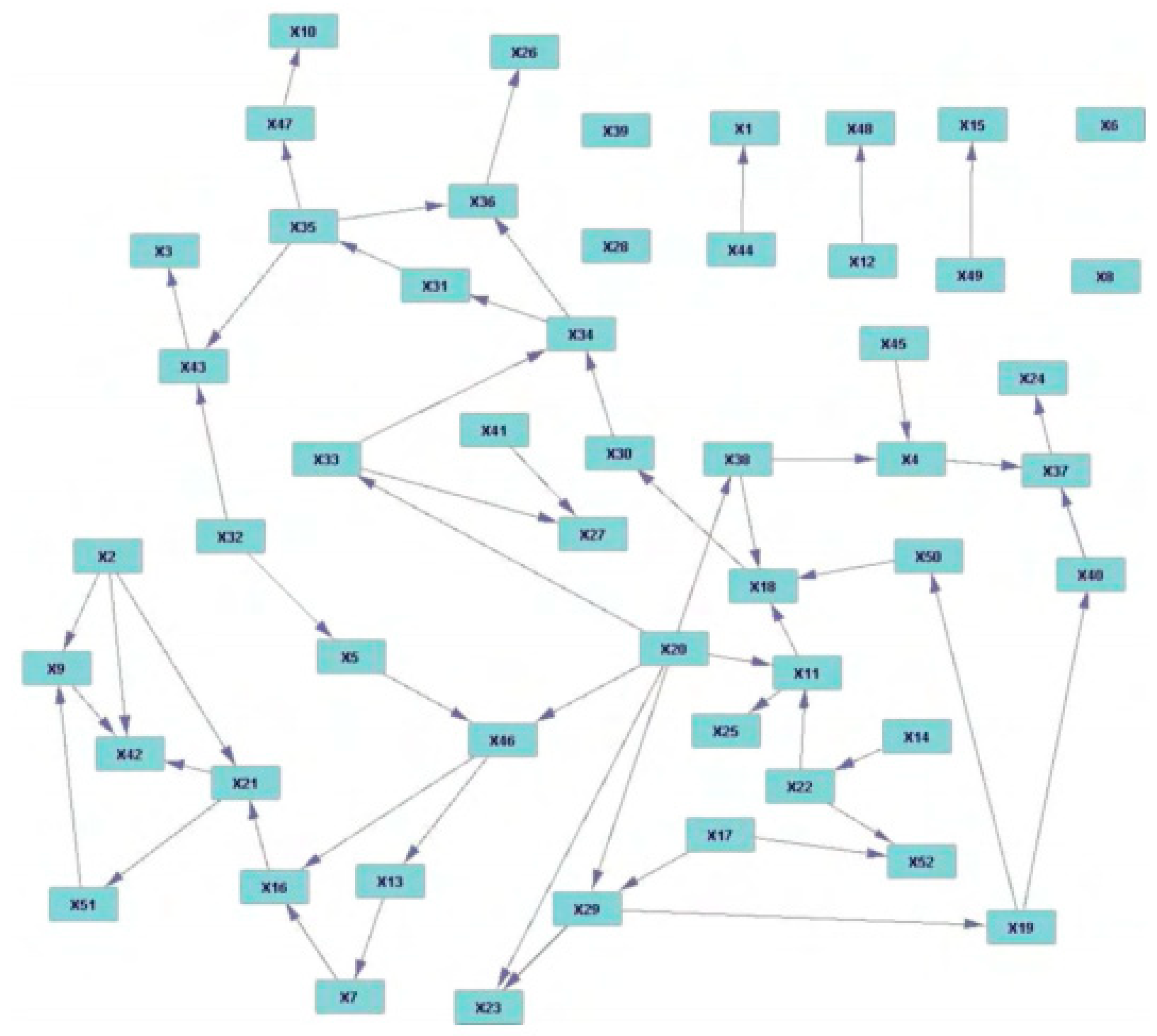
4.1.1. Fault Propagation Analysis in the Tennessee Eastman Process
4.1.2. The Difference between the Correlation of Variables under Normal Operation and Abnormal Operation
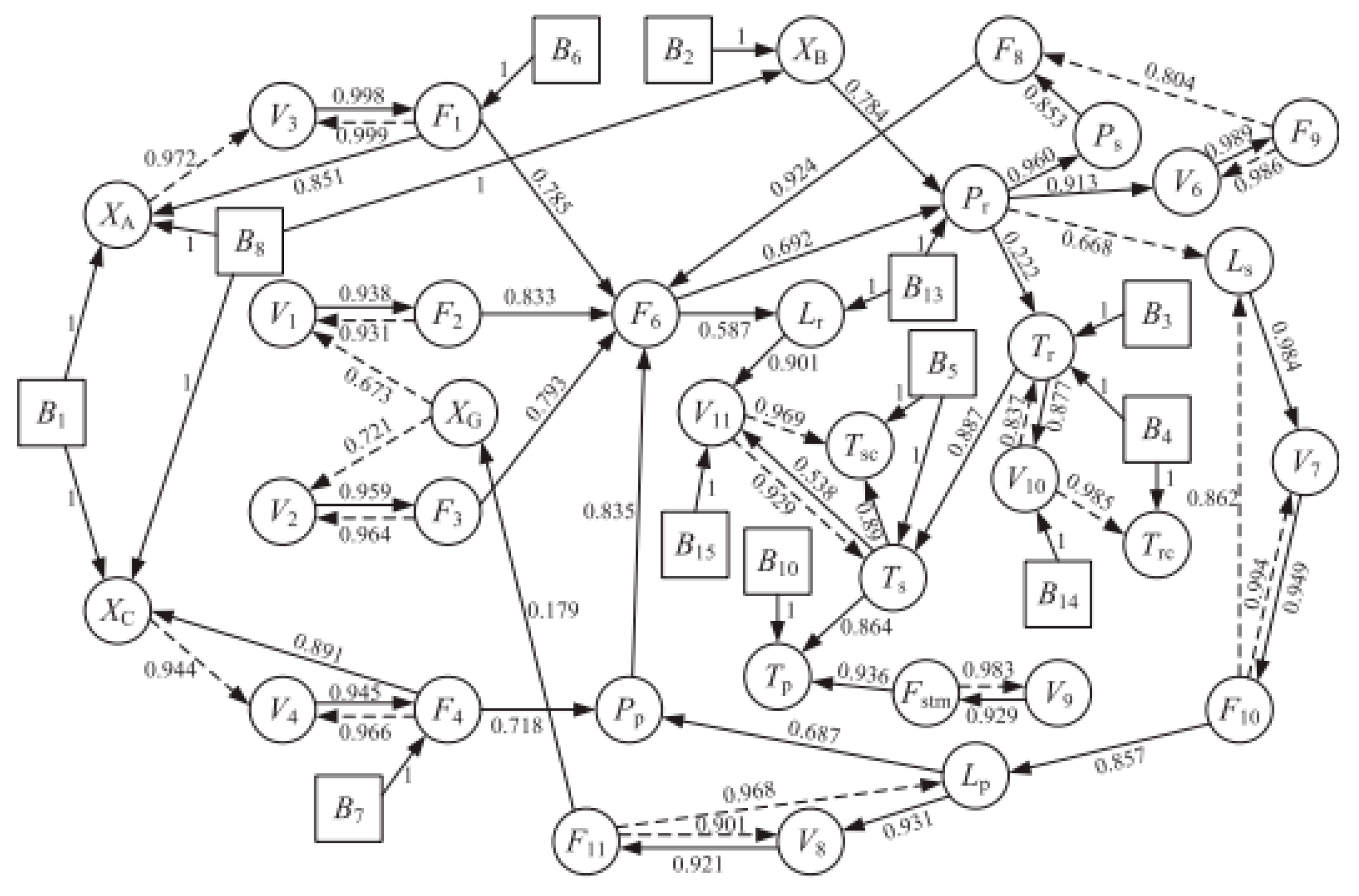
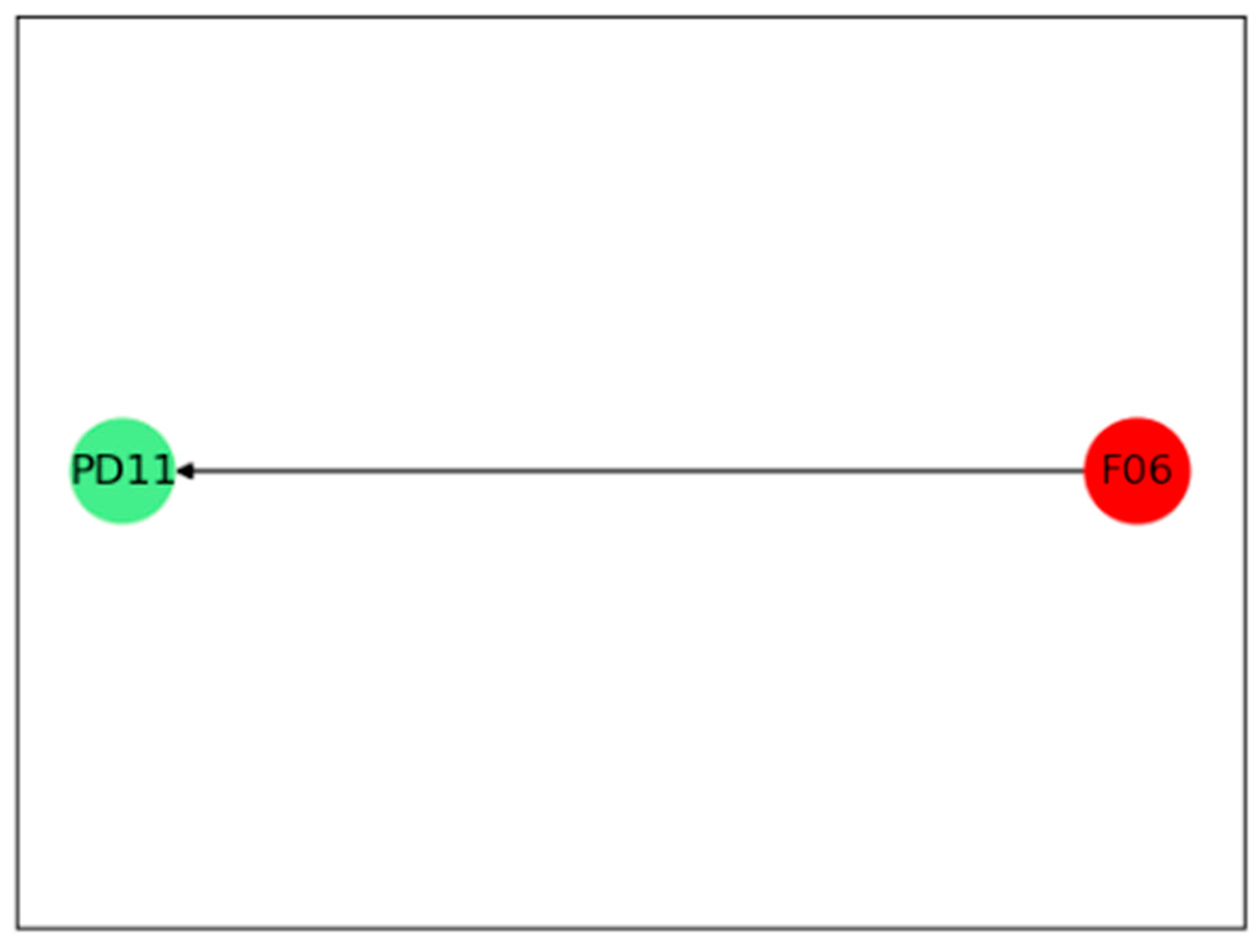
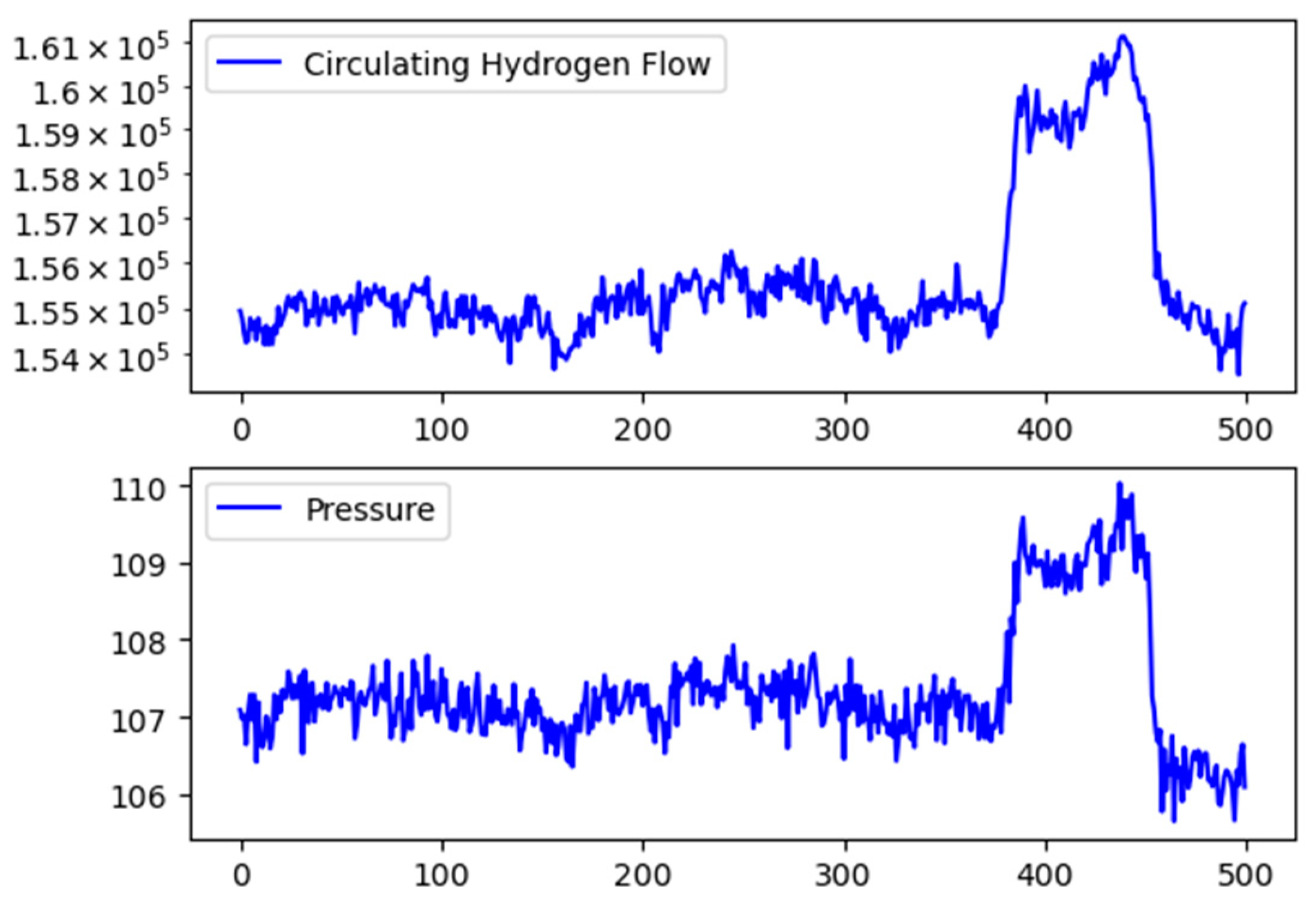
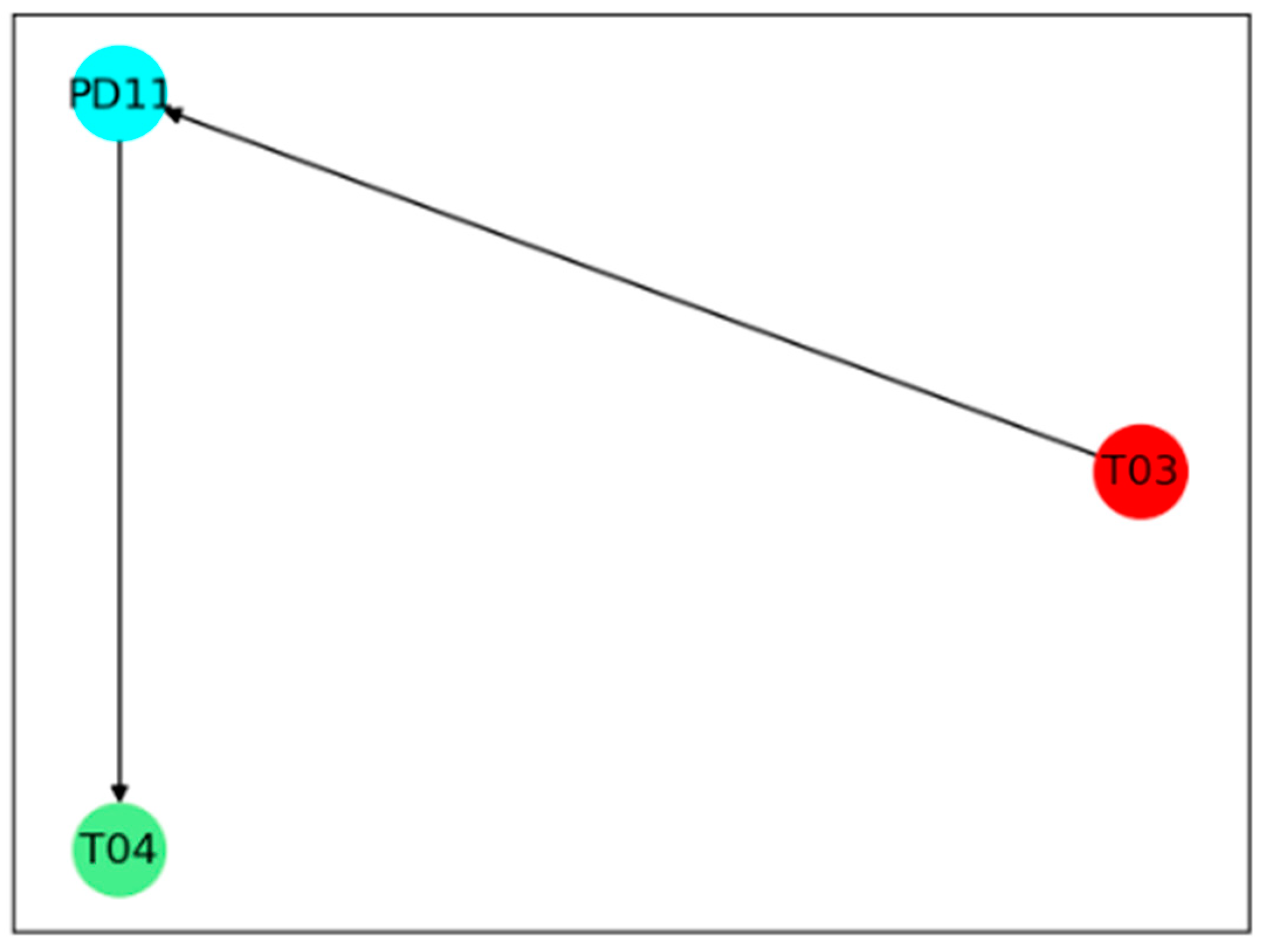
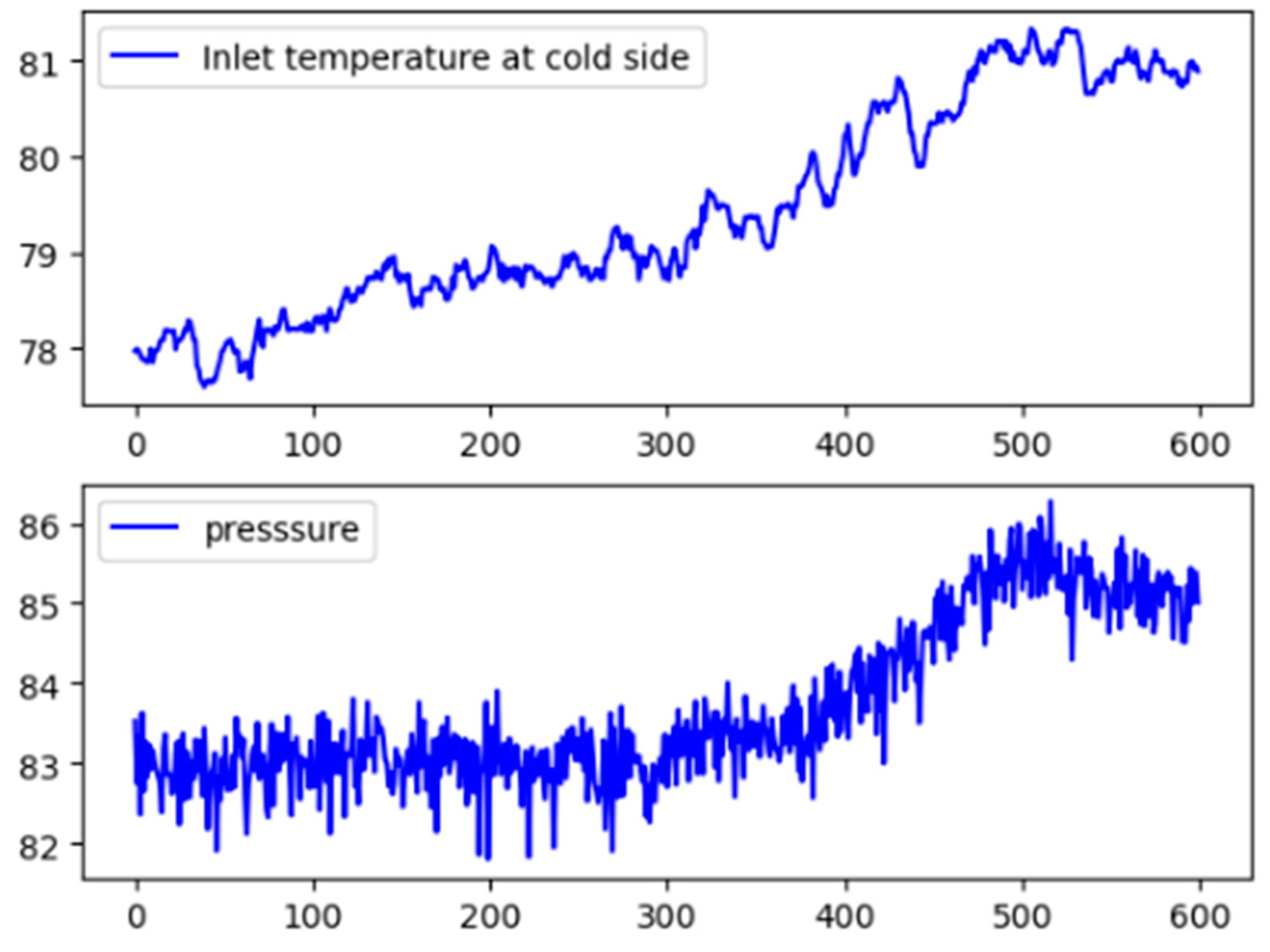
4.2. Fault Propagation Analysis in Continuous Catalytic Reforming Facility
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Russell, E.L.; Chiang, L.H.; Braatz, R.D. Data-Driven Methods for Fault Detection and Diagnosis in Chemical Processes; Springer Science & Business Media: London, UK, 2000. [Google Scholar]
- Peng, D.; Gu, X.; Xu, Y.; Zhu, Q. Integrating probabilistic signed digraph and reliability analysis for alarm signal optimization in chemical plant. J. Loss Prev. Process Ind. 2015, 33, 279–288. [Google Scholar] [CrossRef]
- Venkatasubramanian, V.; Rengaswamy, R.; Kavuri, S.; Yin, K. A review of process fault and diagnosis. Part III: Process his-tory-based methods. Comput. Chem. Eng. 2003, 27, 327–346. [Google Scholar] [CrossRef]
- Miller, P.; Swanson, R.; Heckler, C. Contribution plots: A missing link in multivariate quality control. Appl. Math. Comput. Sci. 1998, 8, 775–792. [Google Scholar]
- Qin, S.J. Survey on data-driven industrial process monitoring and diagnosis. Annu. Rev. Control 2012, 36, 220–234. [Google Scholar] [CrossRef]
- Zhu, Q.-X.; Meng, Q.-Q.; Wang, P.-J.; He, Y.-L. Novel Causal Network Modeling Method Integrating Process Knowledge with Modified Transfer Entropy: A Case Study of Complex Chemical Processes. Ind. Eng. Chem. Res. 2017, 56, 14282–14289. [Google Scholar] [CrossRef]
- Yuan, T.; Qin, S.J. Root cause diagnosis of plant-wide oscillations using Granger causality. J. Process Control 2014, 24, 450–459. [Google Scholar] [CrossRef]
- Bauer, M.; Cox, J.W.; Caveness, M.H.; Downs, J.J.; Thornhill, N. Finding the Direction of Disturbance Propagation in a Chemical Process Using Transfer Entropy. IEEE Trans. Control Syst. Technol. 2006, 15, 12–21. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Rangarajan, G.; Feng, J.; Ding, M. Analyzing multiple nonlinear time series with extended Granger causality. Phys. Lett. A 2004, 324, 26–35. [Google Scholar] [CrossRef] [Green Version]
- Nagarajan, R.; Meenakshi, U. Granger causality analysis of human cell-cycle gene expression profiles. Stat. Appl. Genet. Mol. Biol. 2010, 9, 1–24. [Google Scholar] [CrossRef]
- Seth, A.; Barrett, A.B.; Barnett, L. Granger Causality Analysis in Neuroscience and Neuroimaging. J. Neurosci. 2015, 35, 3293–3297. [Google Scholar] [CrossRef]
- Li, S.T.; Xiao, Y.Y.; Zhou, D.; Cai, D. Causal inference in nonlinear systems: Granger causality versus time-delayed MI. Phys. Rev. E 2018, 97, 052216. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schreiber, T.; Schmitz, A. Surrogate time series. Phys. D Nonlinear Phenom. 2000, 142, 346–382. [Google Scholar] [CrossRef] [Green Version]
- Schreiber, T. Measuring Information Transfer. Phys. Rev. Lett. 2000, 85, 461–464. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hajihosseini, P.; Salahshoor, K.; Moshiri, B. Process fault isolation based on transfer entropy algorithm. ISA Trans. 2014, 53, 230–240. [Google Scholar] [CrossRef]
- Reis, M.S.; Gins, G. Industrial Process Monitoring in the Big Data/Industry 4.0 Era: From Detection, to Diagnosis, to Prognosis. Processes 2017, 5, 35. [Google Scholar] [CrossRef] [Green Version]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.; Thomas, M.J.A. Elements of Information Theory; Wiley: New York, NY, USA, 1991; Volume 3, pp. 37–38. [Google Scholar]
- Vastano, J.A.; Swinney, H.L. Information transport in spatiotemporal systems. Phys. Rev. Lett. 1988, 60, 1773–1776. [Google Scholar] [CrossRef] [PubMed]
- Moon, Y.-I.; Rajagopalan, B.; Lall, U. Estimation of mutual information using kernel density estimators. Phys. Rev. E 1995, 52, 2318–2321. [Google Scholar] [CrossRef]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Chapman & Hall: London, UK, 1986. [Google Scholar]
- Chang, C.C.; Yu, C.C. On-line fault diagnosis using the signed directed graph. Ind. Eng. Chem. Res. 1990, 29, 1290–1299. [Google Scholar] [CrossRef]
- Downs, J.; Vogel, E. A plant-wide industrial process control problem. Comput. Chem. Eng. 1993, 17, 245–255. [Google Scholar] [CrossRef]
- Bathelt, A.; Ricker, N.L.; Jelali, M. Revision of the Tennessee Eastman Process Model. IFAC-PapersOnLine 2015, 48, 309–314. [Google Scholar] [CrossRef]
- Braatz, R.; The Braatz Research Group. TE Process Simulator Software. 2002. Available online: http://web.mit.edu/braatzgroup/TE_process.zip (accessed on 3 December 2019).
- Luo, L.; Bao, S.; Mao, J.; Tang, D. Fault Detection and Diagnosis Based on Sparse PCA and Two-Level Contribution Plots. Ind. Eng. Chem. Res. 2016, 56, 225–240. [Google Scholar] [CrossRef]
- Zhu, Q.-X.; Luo, Y.; He, Y.-L. Novel Multiblock Transfer Entropy Based Bayesian Network and Its Application to Root Cause Analysis. Ind. Eng. Chem. Res. 2019, 58, 4936–4945. [Google Scholar] [CrossRef]
- Kim, C.; Lee, H.; Lee, W.B. Process fault diagnosis via the integrated use of graphical lasso and Markov random fields learning & inference. Comput. Chem. Eng. 2019, 125, 460–475. [Google Scholar] [CrossRef]
- Verron, S.; Li, J.; Tiplica, T. Fault detection and isolation of faults in a multivariate process with Bayesian network. J. Process Control 2010, 20, 902–911. [Google Scholar] [CrossRef] [Green Version]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description | Variable | Description |
|---|---|---|---|
| F1 | A feed (stream 1) | T18 | Stripper temperature |
| F2 | D feed (stream 2) | F19 | Stripper steam flow |
| F3 | E feed (stream 3) | C20 | Compressor work |
| F4 | A and C feed (stream 4) | T21 | Reactor cooling water outlet temperature |
| F5 | Recycle flow (stream 8) | T22 | Separator cooling water outlet temperature |
| F6 | Reactor feed rate (stream 6) | V23 | D feed flow (stream 2) |
| P7 | Reactor pressure | V24 | E feed flow (stream 3) |
| L8 | Reactor level | V25 | A feed flow (stream 1) |
| T9 | Reactor temperature | V26 | A and C feed flow (stream 4) |
| F10 | Purge rate (stream 9) | V27 | Compressor recycle valve |
| T11 | Product separator temperature | V28 | Purge valve (stream 9) |
| L12 | Product separator level | V29 | Separator pot liquid flow (stream 10) |
| P13 | Product separator pressure | V30 | Stripper liquid prod flow (stream 11) |
| F14 | Product separator underflow (stream 10) | V31 | Stripper steam valve |
| L15 | Stripper level | V32 | Reactor cooling water flow |
| P16 | Stripper pressure | V33 | Condenser cooling water flow |
| F17 | Stripper underflow (stream 11) |
| No. | Fault Description | Fault Type |
|---|---|---|
| 1 | A/C feed ratio, B composition constant (stream 4) | Step |
| 2 | B composition, A/C ratio constant (stream 4) | Step |
| 3 | D feed temperature (stream 2) | Step |
| 4 | Reactor cooling water inlet temperature | Step |
| 5 | Condenser cooling water inlet temperature | Step |
| 6 | A feed loss (stream 1) | Step |
| 7 | C header pressure loss-reduced availability (stream 4) | Step |
| 8 | A, B, C feed composition (stream 4) | Random variation |
| 9 | D feed temperature (stream 2) | Random variation |
| 10 | C feed temperature (stream 4) | Random variation |
| 11 | Reactor cooling water inlet temperature | Random variation |
| 12 | Condenser cooling water inlet temperature | Random variation |
| 13 | Reaction kinetics | Slow drift |
| 14 | Reactor cooling water valve | Sticking |
| 15 | Condenser cooling water valve | Sticking |
| 16 | Unknown | - |
| 17 | Unknown | - |
| 18 | Unknown | - |
| 19 | Unknown | - |
| 20 | Unknown | - |
| 21 | The valve for stream 4 | Constant position |
| Fault No. | Fault Diagnosis | Fault Analysis |
| 1 | (16,20,27)25(7,13)1 | Pressure disturbance in stripper (from stream 4) |
| 2 | (28,10) | Purge valve varies with the disturbance in B component |
| 4 | (9,32) | Cooling water temperature disturbance in reactor |
| 5 | 22(11,13,16) | Variation of cooling water temperature |
| 6 | 1(7,13,16)25 | Variation of flow in A feed (stream 1) |
| 7 | 4,9,16,2623 | Pressure disturbance in stripper (stream 4) |
| 10 | 18 | Temperature disturbance in stripper (from stream 4) |
| 11 | (9,32) | Cooling water temperature disturbance in reactor |
| 12 | 2211 | Variation of cooling water temperature |
| 14 | 32219 | Reactor cooling water valve failure |
| 17 | 2132 | Reactor cooling water outlet temperature disturbance |
| 18 | 22 | Separator cooling water outlet temperature disturbance |
| 20 | 2718 | Pressure disturbance in stripper |
| 21 | 26 | A and C feed flow (stream 4) valve failure |
| Variable | Description | Variable | Description |
|---|---|---|---|
| T01 | Outlet temperature at cold side | PD15 | Reactor pressure drop 3 |
| T02 | Inlet temperature at hot side | PD16 | Reactor pressure drop 4 |
| T03 | Inlet temperature at cold side | T17 | Furnace outlet temperature 1 |
| T04 | Outlet temperature at hot side | T18 | Reactor outlet temperature 1 |
| F05 | Naphtha feed flow | T19 | Furnace outlet temperature 2 |
| F06 | Circulating hydrogen flow | T20 | Reactor outlet temperature 2 |
| PD07 | Inlet filter pressure drop at cold side | T21 | Furnace outlet temperature 3 |
| PD08 | Inlet pressure at cold side | T22 | Reactor outlet temperature 3 |
| P09 | Circulating hydrogen pressure | T23 | Furnace outlet temperature 4 |
| PD10 | Outlet pressure at cold side | T24 | Furnace temperature drop 1 |
| PD11 | Pressure drop at hot side | T25 | Furnace temperature drop 2 |
| PD12 | Pressure drop at cold side | T26 | Furnace temperature drop 3 |
| PD13 | Reactor pressure drop 1 | T27 | Furnace temperature drop 4 |
| PD14 | Reactor pressure drop 2 | PD28 | Reactor inlet pressure |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, C.; Ma, F.; Wang, J.; Wang, J.; Sun, W. Real-Time Industrial Process Fault Diagnosis Based on Time Delayed Mutual Information Analysis. Processes 2021, 9, 1027. https://doi.org/10.3390/pr9061027
Ji C, Ma F, Wang J, Wang J, Sun W. Real-Time Industrial Process Fault Diagnosis Based on Time Delayed Mutual Information Analysis. Processes. 2021; 9(6):1027. https://doi.org/10.3390/pr9061027
Chicago/Turabian StyleJi, Cheng, Fangyuan Ma, Jianhong Wang, Jingde Wang, and Wei Sun. 2021. "Real-Time Industrial Process Fault Diagnosis Based on Time Delayed Mutual Information Analysis" Processes 9, no. 6: 1027. https://doi.org/10.3390/pr9061027
APA StyleJi, C., Ma, F., Wang, J., Wang, J., & Sun, W. (2021). Real-Time Industrial Process Fault Diagnosis Based on Time Delayed Mutual Information Analysis. Processes, 9(6), 1027. https://doi.org/10.3390/pr9061027