To evaluate the efficiency of our proposed method, the monthly historical data used in this study include the stock market index, real effective exchange rate (REER) and consumer price index (CPI) of Thailand and Indonesia spanning from January 1997 to May 2021. The stock exchange of Thailand (SET) index data were collected from the Stock Exchange of Thailand website [
24] and the REER and CPI data were acquired from the Bank of Thailand website [
25], whereas the Jakarta stock exchange (JKSE) composite index was obtained from the investing.com database [
26] and its REER and CPI data were taken from the Federal Reserve Economic Data (FRED) statistics [
27]. The dataset is divided into two groups: the data from January 1997 to March 2021 were utilized for the training phase and data from April 2021 to May 2021 were treated as the testing phase. These raw data were transformed into monthly returns by taking the first logarithm difference. A z-score normalization [
28] was subsequently applied to these return time series in order to adjust the range variation to comparable scales. The normalized returns were constructed by extracting the average from attribute values and dividing by the corresponding standard deviation.
3.1. Granger Causality Analysis
This section demonstrates an assessment of the interactions between different pairs of time series using the bivariate Granger causality test [
29]. This analysis helps us to determine whether lagged values of one variable are linearly informative in forecasting another variable. Given two stationary variables
and
at time instant
k, the bivariate Granger causality test follows a pair of regression equations:
where
and
are random disturbances and
J is the maximum lag order. From the equations above, a unidirectional causality from the variable
to variable
is indicated if
in Equation (
14) is significantly different to zero by F-statistics whereas
in the Equation (15) is not significant.
Table 1 presents the results of the Granger causality test for the direction of causality (F-statistics and
p-value in parenthesis) among the normalized returns of the SET index, REER and CPI. The results show that the CPI does Granger-cause the SET index and REER at a 1% level of significance. Although the null hypothesis, which states that REER does not Granger-cause the CPI and SET index, is accepted, the null hypothesis in the opposite direction is rejected with a significance level of 1%. In the case of Indonesia,
Table 2 reveals a two-way directional relationship between the CPI and JKSE index, and also between CPI and REER at a 5% level of significance. In addition, there is a unidirection causality running from the JKSE index to REER. With regard to the causality direction, the sufficient condition for the cointegration between two variables is that the Granger causality must exist in at least one direction [
30]. Since our results indicate unidirectional causality between each pair of variables, it therefore suggests that all factors can be included in the model.
Table 3 presents some descriptive statistics of the monthly normalized return series. All normalized return series for both Thailand and Indonesia are highly leptokurtic and skewed with respect to the normal distribution, as indicated by the kurtosis and skewness measures. These results can be further confirmed by the Jarque–Bera test in which the normality hypothesis is rejected at a 1% significant level for all three variables. Similarly, the ARCH test rejects the null hypothesis of homoscedasticity at a 1% level of significance for all variables except the JKSE index with a 5% level of significance. This suggests the validation of the GARCH model in capturing the volatility interaction among variables, resulting in a plausible assumption of the observational covariance matrix in Equation (
7). Since the VAR approach requires the data input to be stationary prior to the model implementation to avoid spurious regressions, the presence of unit roots was examined by a standard augmented Dickey–Fuller (ADF) test [
31,
32]. The ADF test well rejects the null hypothesis, with a statistical significance of 1% for every variable, which provides strong evidence of stationarity in the normalized return series for both countries.
3.2. Results
A prior requirement for a Kalman-filter-based recursive algorithm is the specification of an initial state vector, as well as its error covariance matrix. At the initial time instant
k = 1, we used the actual initial data during our sample period along with the coefficients estimated from the ordinary least square method to be the elements of the initial state vector,
. The corresponding error covariance matrix
is assumed to be equal to the process noise covariance matrix
Q, which is often assigned to be arbitrarily constant. We estimated the matrix
Q through an average of sample covariances of the state prediction errors. The reference state vector at time instant
k,
, corresponds to a collection of the actual data and parameters evaluated from the VAR(1) model, and this gives
. The noisy state-parameter vector
was sampled from a Gaussian distribution with mean equal to
, and the standard deviation was set to 25% of the reference values. The matrix
Q was thus constructed using the following estimation:
where
m is the number of time instants. There are three sample periods used to approximate the matrix
Q, ranging from the first 12 months up to 60 months: January 1997–December 1997, January 1997–December 1999 and January 1997–December 2001. The resulting matrix
Q applied to the APVAR-KF method was calculated on a statistical basis through the use of Monte Carlo simulations; that is, the matrix
Q was determined by taking an average of over 50 experiments for each time instant. The results presented for the APVAR-KF method were obtained from the best-tuned values of the matrices
and
Q, which relied on the optimal achievable values of MAPE in the training period.
To demonstrate the performance of the APVAR-KF method in estimation and prediction, the classical vector autoregressive model of order one, VAR(1), was taken as a benchmark scheme. Meanwhile, an augmentation between the VAR model and KF with fixed model coefficients in Equation (
2), the VAR-KF method, was additionally computed to illustrate the effects of a two-step procedure with and without time-variant model parameters upon the forecasting accuracy. The mean absolute percentage error (MAPE) and root mean square error (RMSE) were used as the performance evaluation indicators. They are formulated as follows:
and
where
T is the total number of simulations,
represents the actual measured data and
denotes the estimated value.
Table 4 displays the estimation efficiency during the training period through the MAPE and RMSE statistics. According to MAPE and RMSE measures, both hybrid models have a superior estimation performance to the single model with lower MAPE and RMSE values for all variables of both countries. In the case of Thailand, the average MAPE values of VAR(1), VAR-KF and APVAR-KF models are 2.3460%, 2.0556% and 1.4089%, respectively. The VAR-KF approach reduces MAPE and RMSE values by over 10% compared to the benchmark model, whereas those of APVAR-KF by up to 40%. The same estimation pattern can be seen for Indonesia, where the overall improvement when using hybrid models is above 40%. These findings suggest that, by augmenting the Kalman filter in the VAR model, a significant improvement in the estimation accuracy is attained. When comparing among hybrid models, the APVAR-KF model exhibits better MAPE and RMSE values for all variables. The APVAR-KF model improves the quality of the overall estimation by approximately 30% for Thailand and approximately 6% for Indonesia regarding the MAPE values.
To assess the predictability using initial states acquired from three models, the state estimates in March 2021 were treated as the initial state vector for the underlying dynamical Equation (
2) to forecast the state values of April 2021 and May 2021 (the testing phase). There are two different scenarios with respect to the model coefficients. The coefficients remain unchanged from the training phase for the VAR(1) and VAR-KF approaches, whereas those that relied on the APVAR-KF method are based on the parameter estimates in March 2021.
Table 5 demonstrates the forecasting performance in April 2021 of three models in terms of MAPE and RMSE criteria. The hybrid models in comparison with the VAR(1) model for Thailand yield a higher forecasting accuracy for all factors, with the average MAPE being 0.8303% and 0.6213%. These are, respectively, equivalent to a 18.8695% and 39.2900% improvement for the VAR-KF and APVAR-KF models, with the SET index being best improved. Similarly, both VAR-KF and APVAR-KF models achieve a better performance than the benchmark method for Indonesia, with a considerable improvement in the REER variable. Most errors attained from the APVAR-KF model are less than those of the VAR-KF method, except the REER variable of Indonesia, where the errors of using time-variant parameters are slightly greater than using fixed parameters. This indicates that the first time step prediction can predominantly be improved by exploiting the adjustable model parameters.
Table 6 reports the prediction efficiency of May 2021 forecasts. The VAR-KF and APVAR-KF models continue to outperform the traditional VAR(1) method for Thailand, with lower errors for all variables. By comparing among different hybrid algorithms, the APVAR-KF model provides better results for the REER and CPI, with a lower average MAPE of 0.8725%. Nevertheless, a different result arises for Indonesia, where the REER forecasts of the two-step methods are worse than the VAR(1) model despite the fact that the JKSE index and CPI errors achieved by the APVAR-KF technique are lowest among all of the individual algorithms. The predicted values for June 2021 are not shown in this report, considering that the error trends are similar to those in May 2021. The APVAR-KF model remains providing superior predictions for all variables of Thailand and for the main stock market price index of Indonesia.
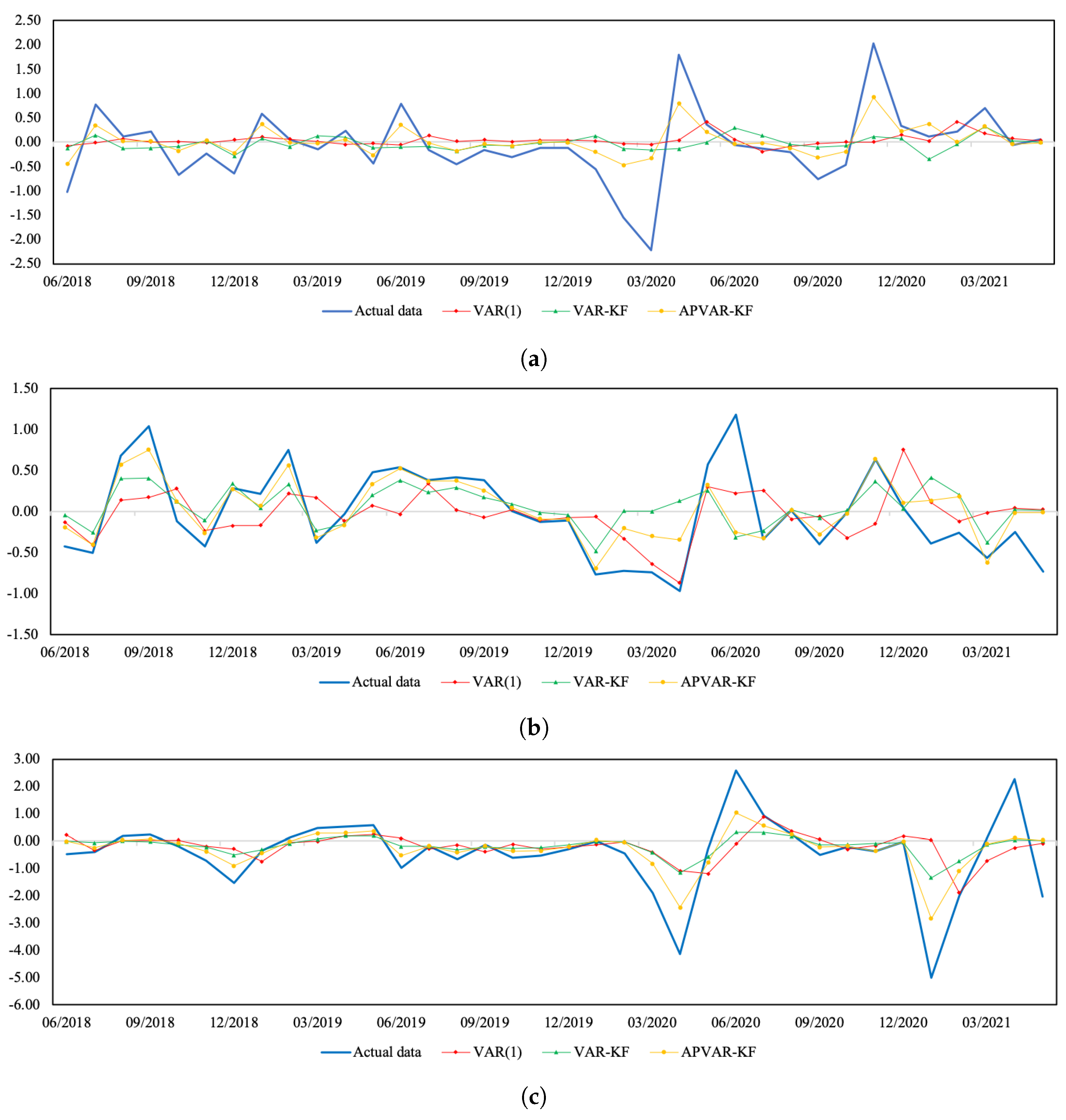
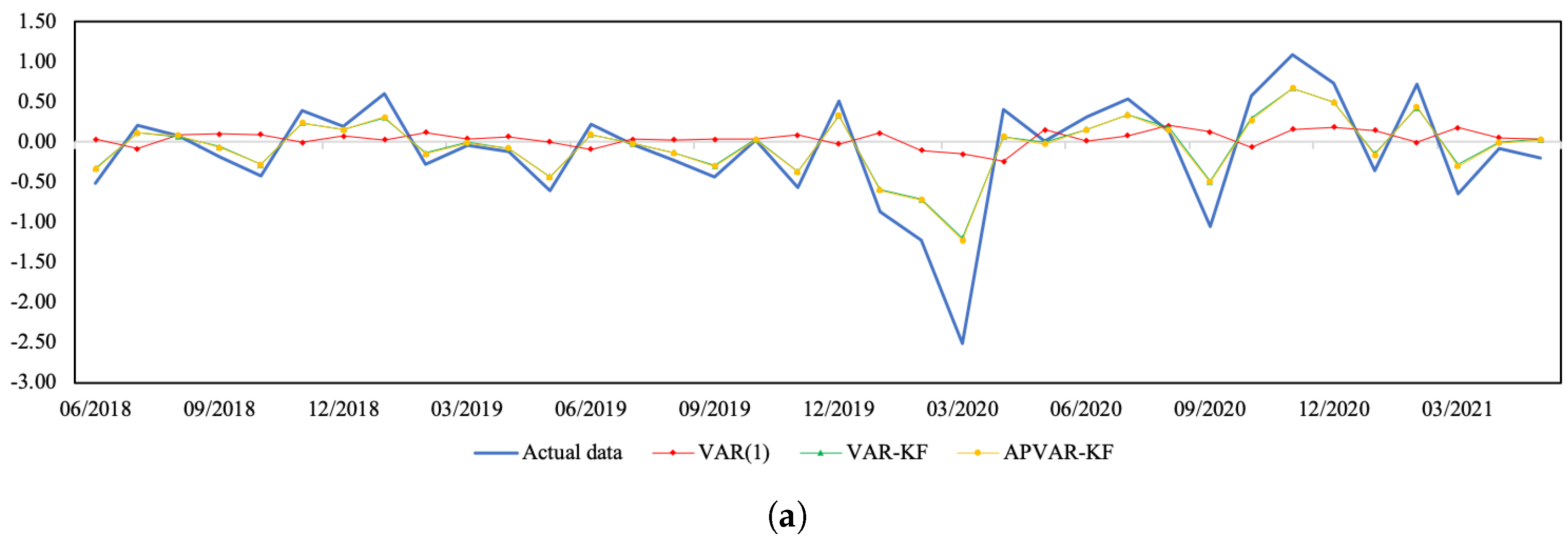
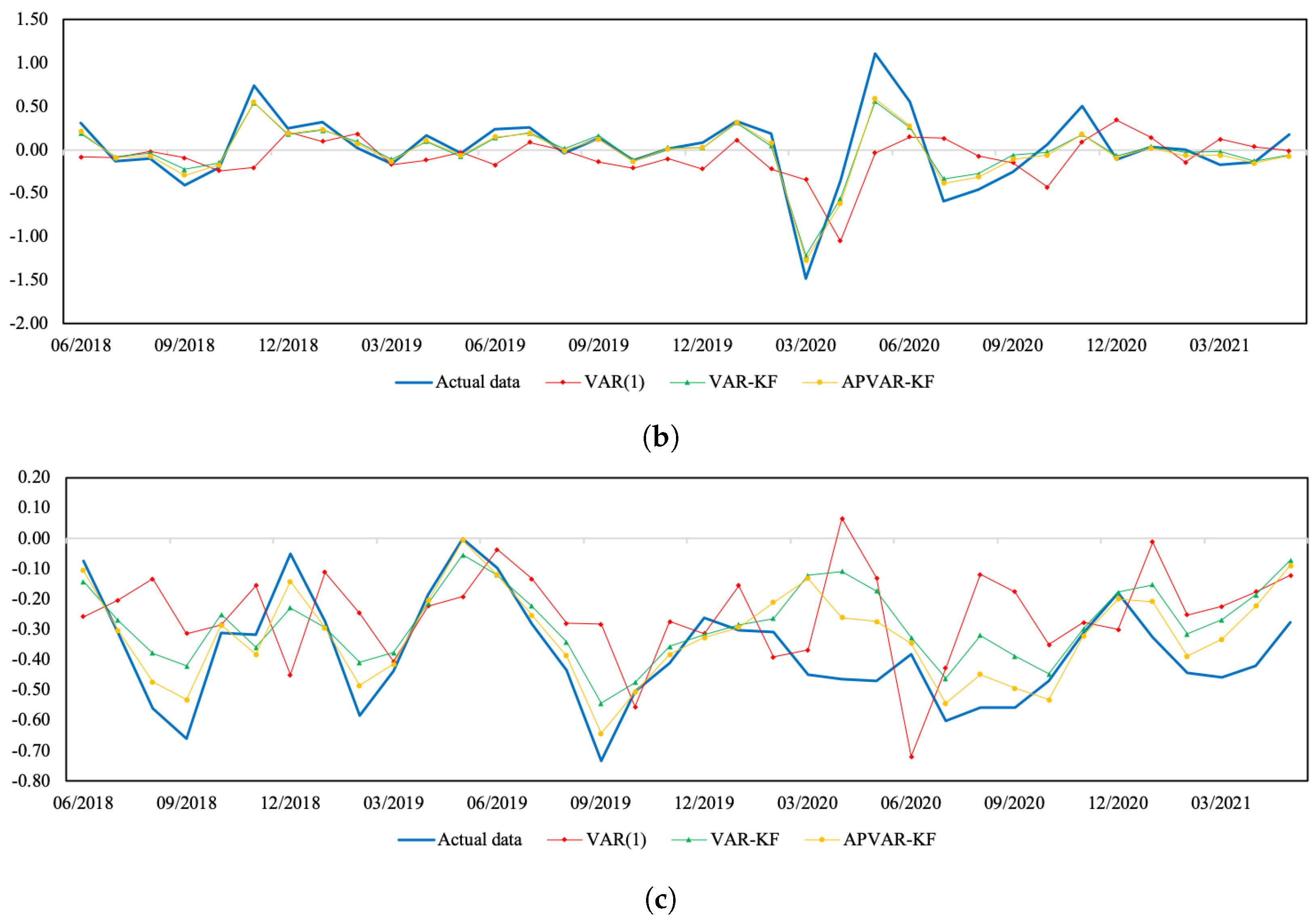
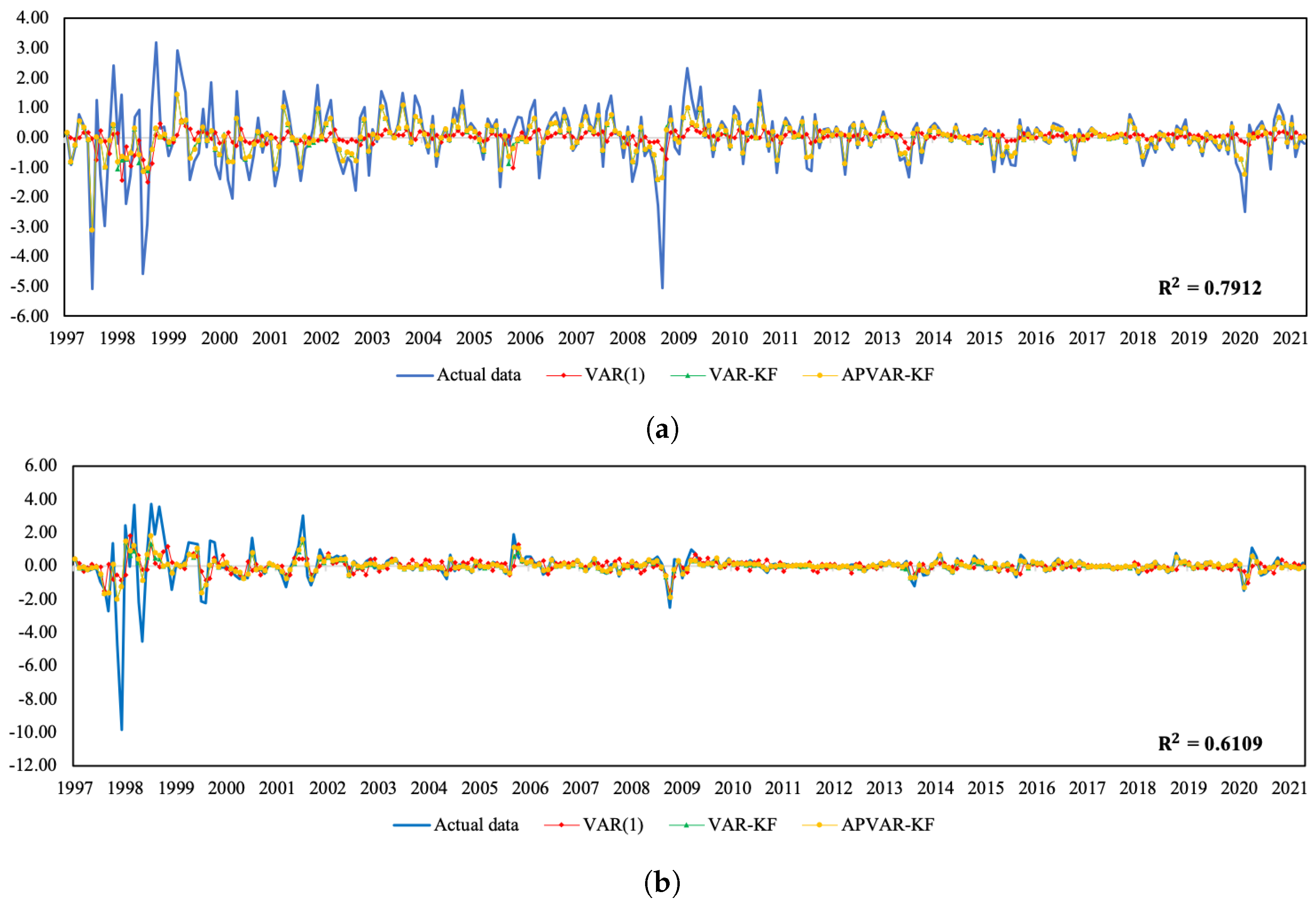
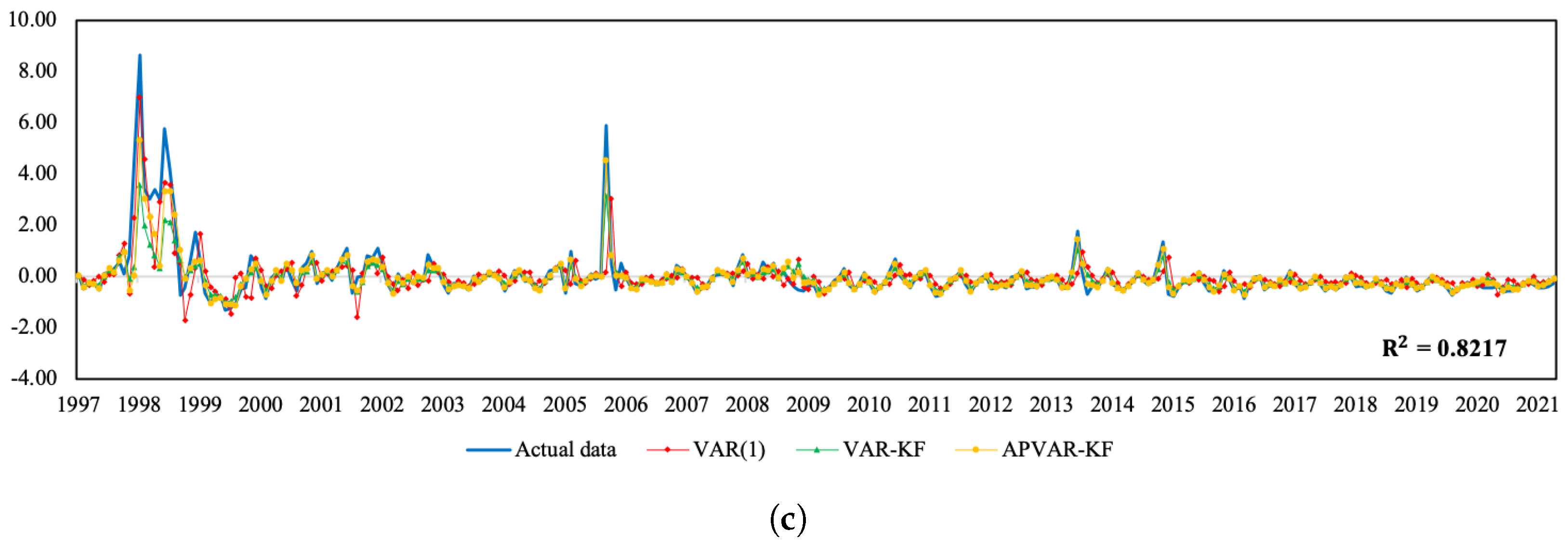
Figure 1 and
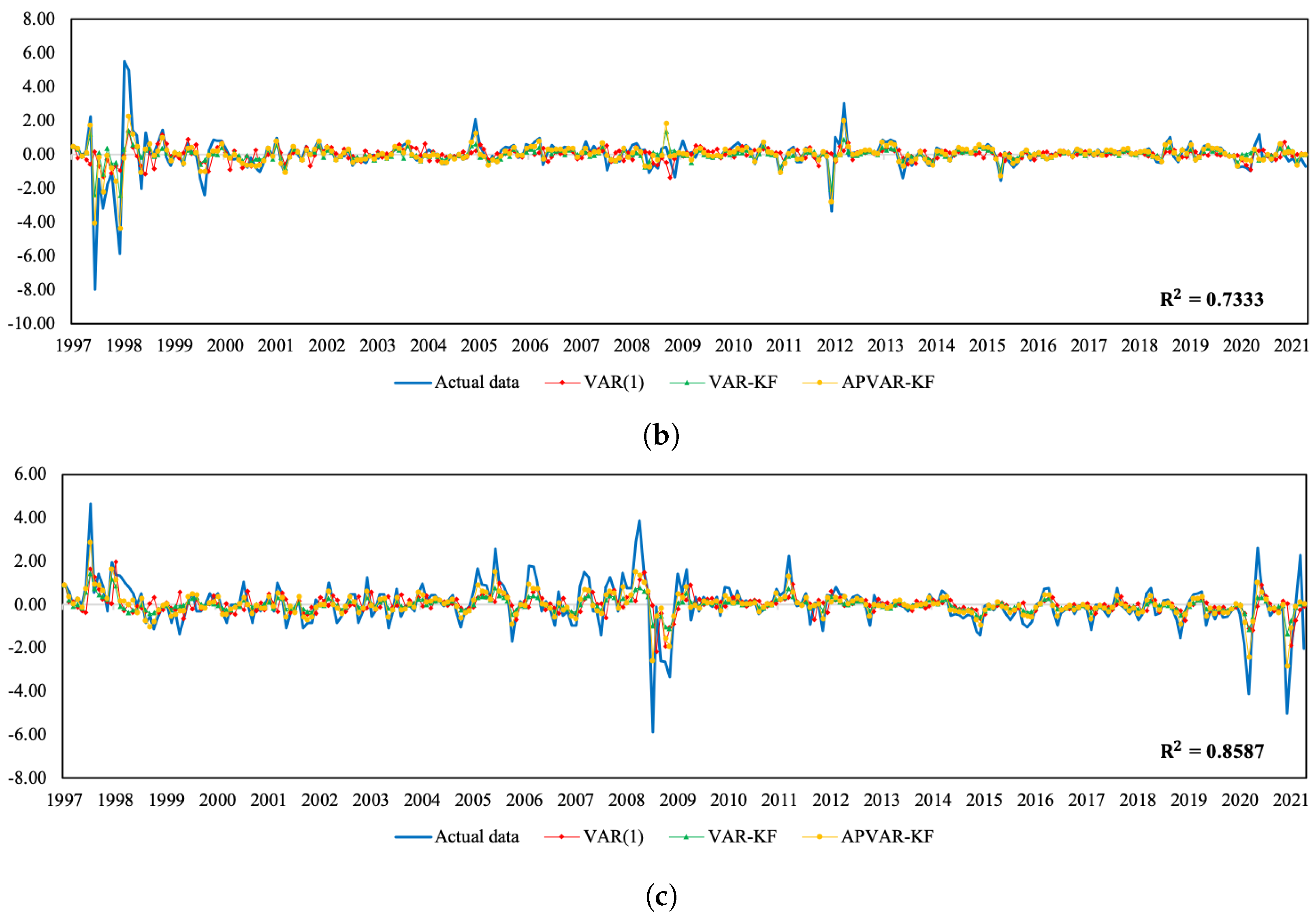
Figure 2 depict a visual comparison between the normalized return estimates and actual data of all three variables of Thailand and Indonesia from July 2018 to May 2021. The plots of actual data and their corresponding estimates over the whole study period can be seen in
Figure A1 and
Figure A2. The discrepancy between the estimated values derived from all approaches and actual data appears to be minor over the tranquil period. In the course of the COVID-19 outbreak, when drastic changes in economic and financial situations took place, the APVAR-KF method performs best in capturing these abrupt changes in all variables, followed by the VAR-KF and VAR(1) models. These results may reflect that a variation in parameters allows the model to better track the actual data, especially during times of high uncertainty. This may be due to that fact that the coefficients of a model system are sequentially updated using recent observations, causing the underlying model to be able to forecast abruptly changing trends. For Indonesia, it appears that the forecasting results derived from the hybrid models exhibit similar increasing trends to the REER actual data, with relatively lower slopes during the testing phase, whereas the opposite trend direction pattern is found in the VAR(1) method. Although the results in
Table 6 indicate a better REER forecasting ability when using the VAR(1) model, a further examination of how the trend direction changes can be of importance.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}