
The Arctan Power Distribution: Properties, Quantile and Modal Regressions with Applications to Biomedical Data




Abstract
:1. Introduction
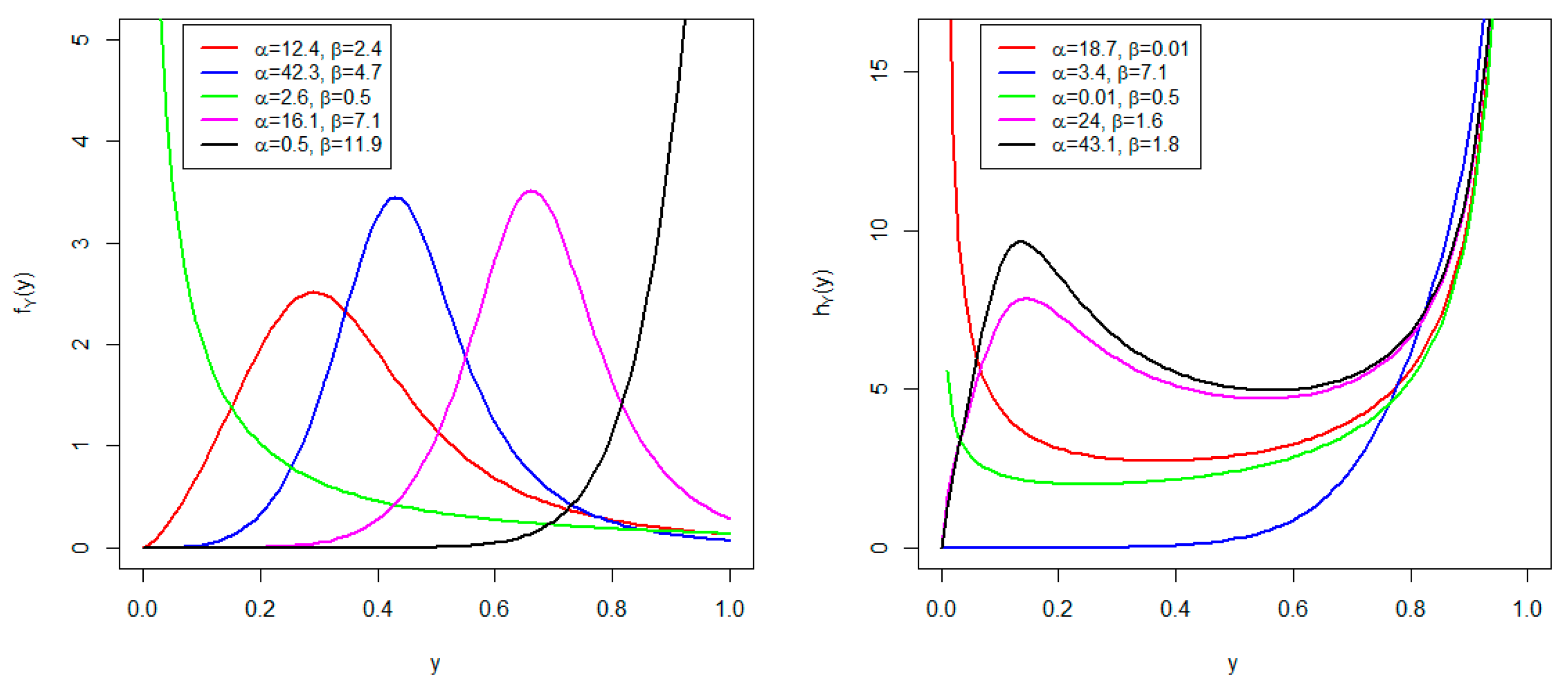
- Develop a flexible unit distribution that is able to model data that are left-skewed, right-skewed, symmetric, J, and reversed-J shapes.
- Develop a unit distribution capable of modeling data with increasing, bathtub, and modified upside-down bathtub hazard rate functions (HRFs).
- Develop quantile regression for modeling response variables that are skewed or contain extreme values.
- Develop modal regression for modeling response variables that are asymmetric or heavy-tailed.
2. Development of AP Distribution
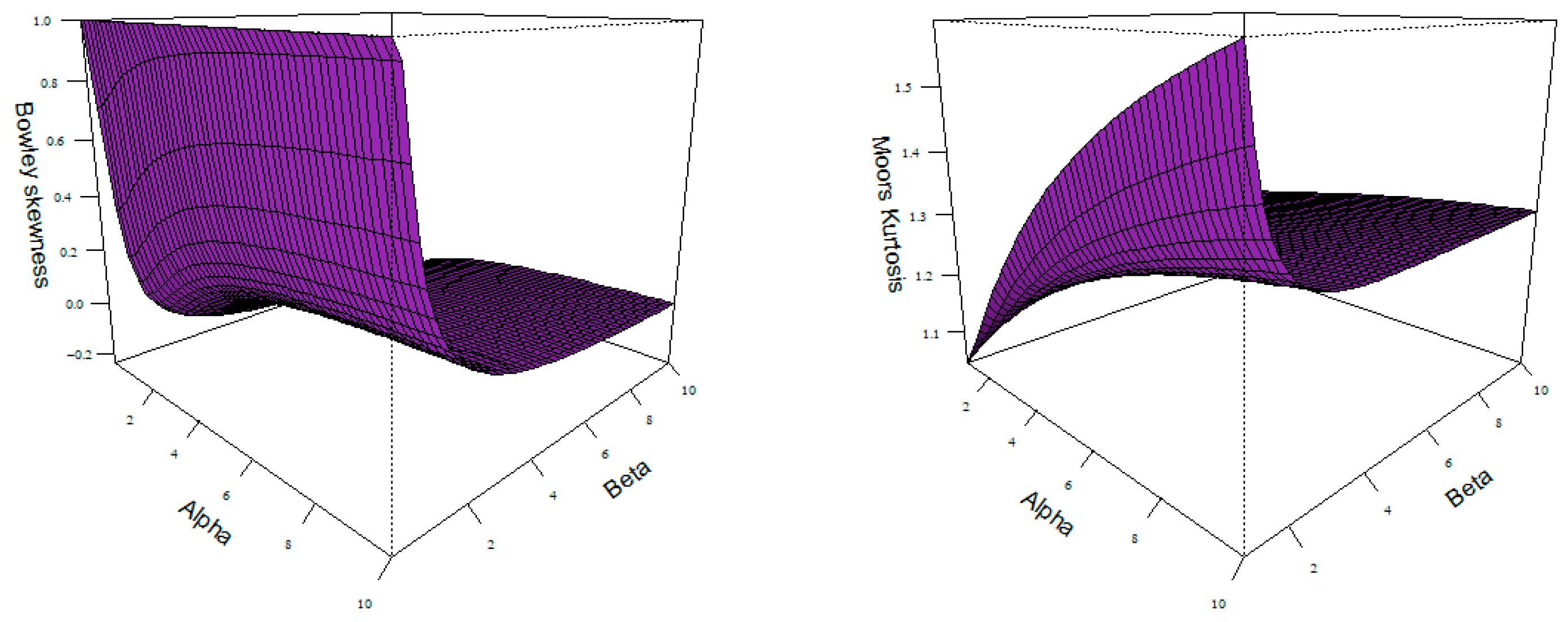
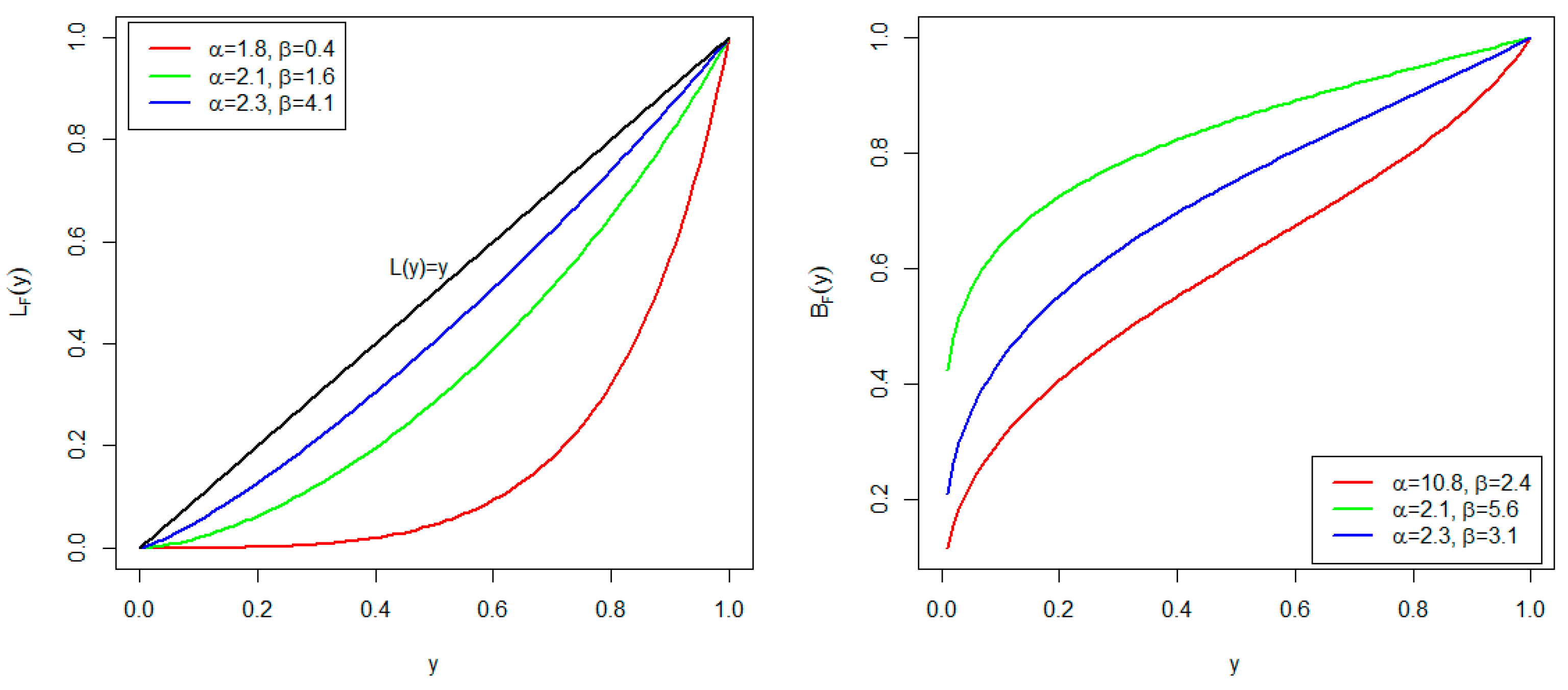
3. Some Statistical Properties
3.1. Mode
3.2. Quantile Function
3.3. Moments and Generating Function
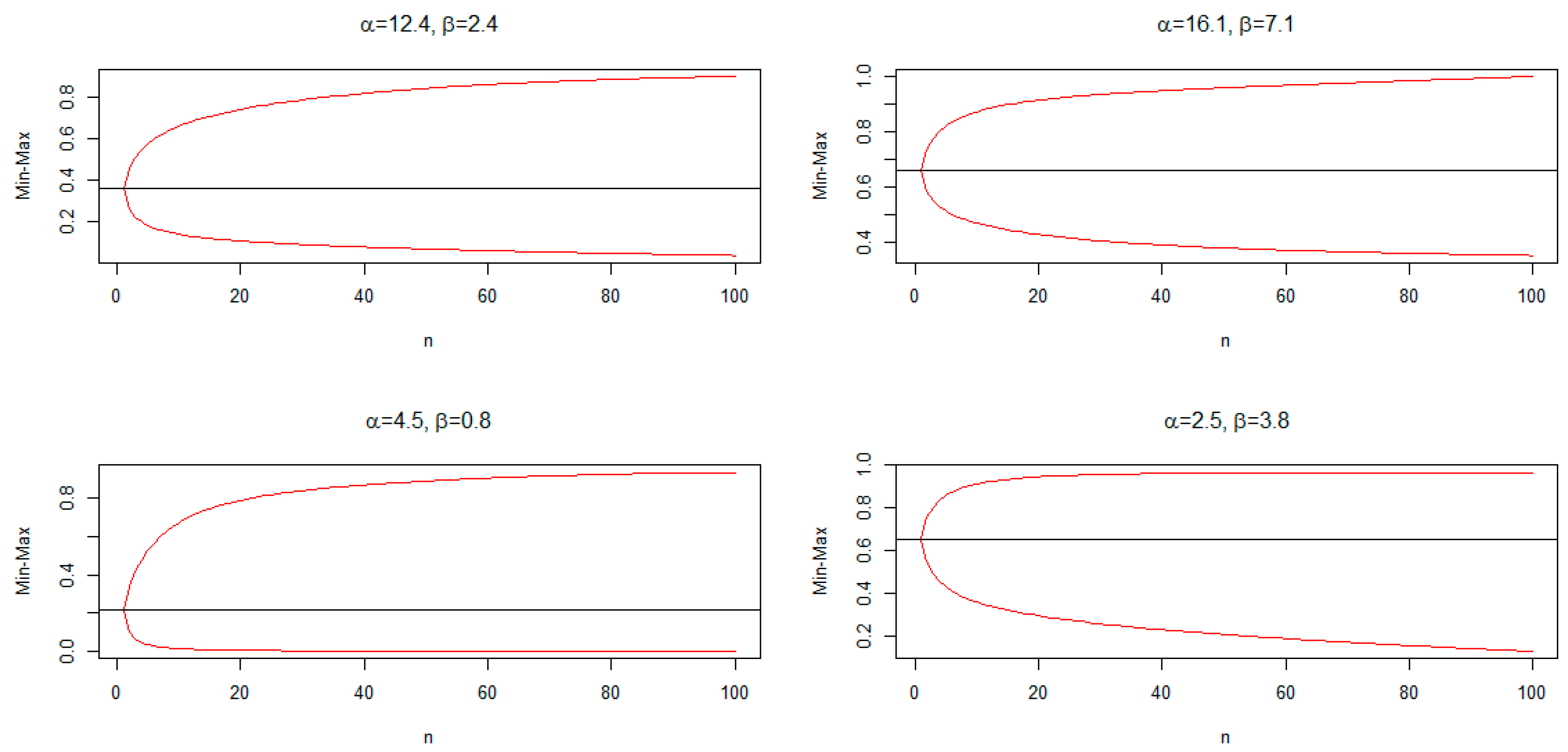
3.4. Order Statistics
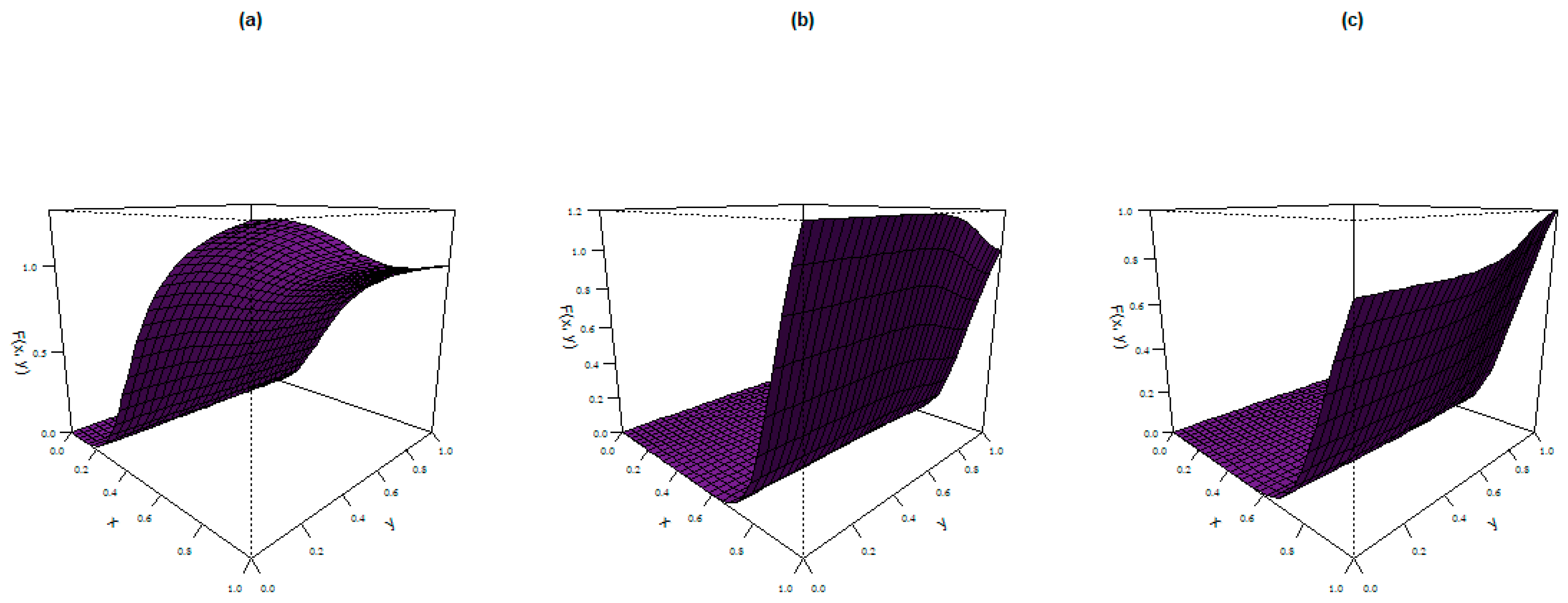
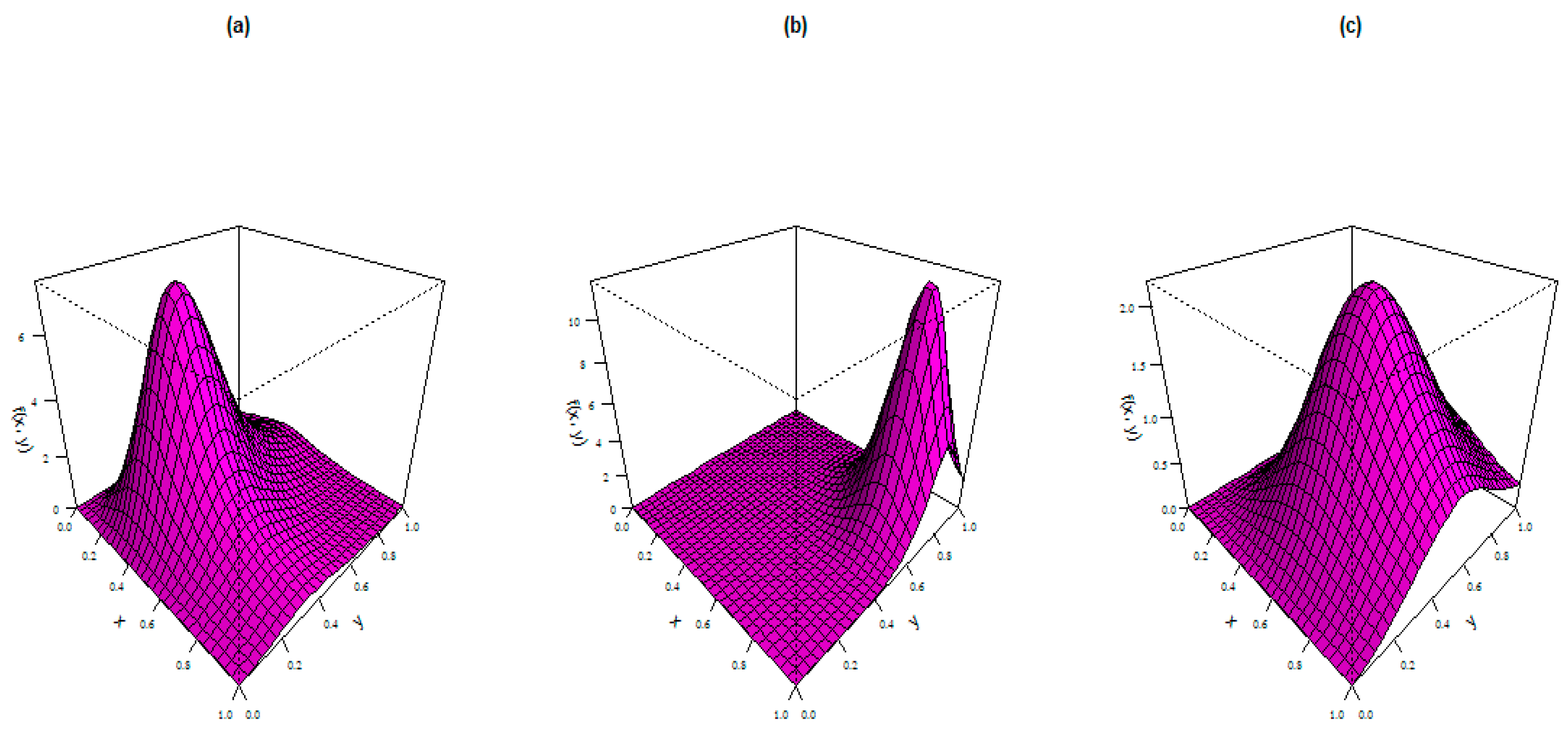
4. Bivariate AP Distribution
- (a)
- ,
- (b)
- and
- (c)
- .
- (a)
- ,
- (b)
- and
- (c)
- .
5. Estimation Methods and Simulations
5.1. Maximum Likelihood Estimation
5.2. Ordinary and Weighted Least Squares Estimation
5.3. Cramér–Von Mises Estimation
5.4. Anderson–Darling Estimation
5.5. Percentile Estimation
5.6. Product Spacing Estimations
5.7. Monte Carlo Simulation
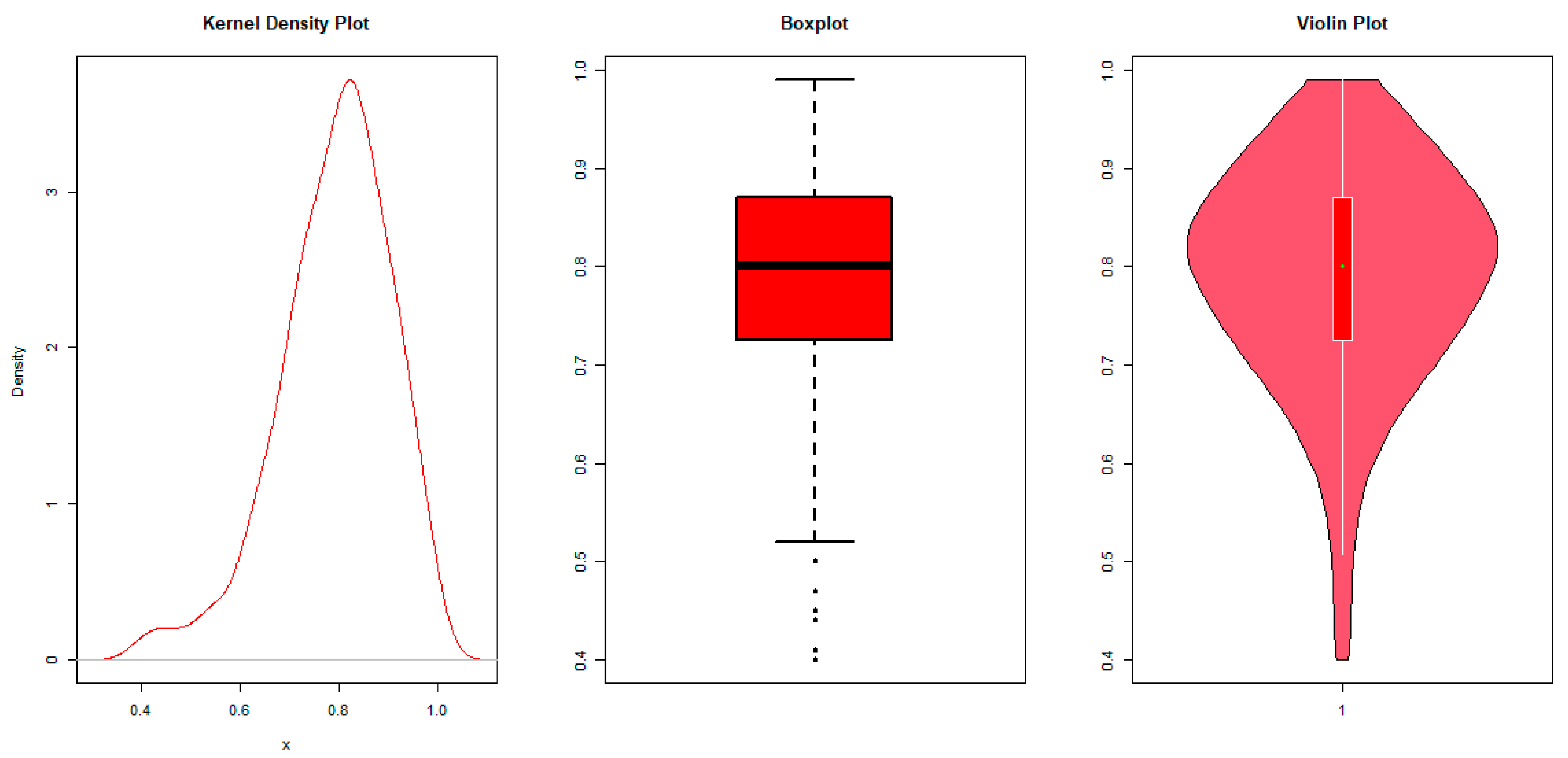
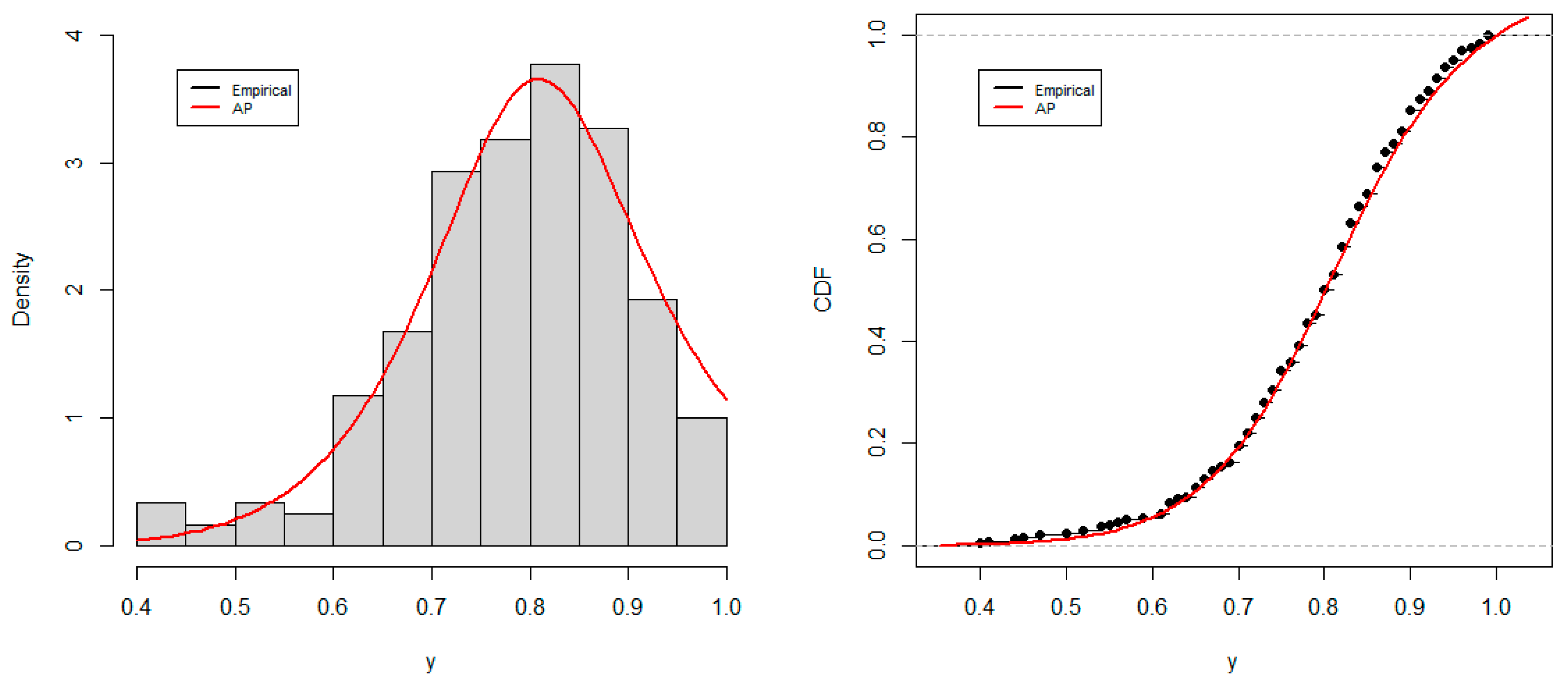
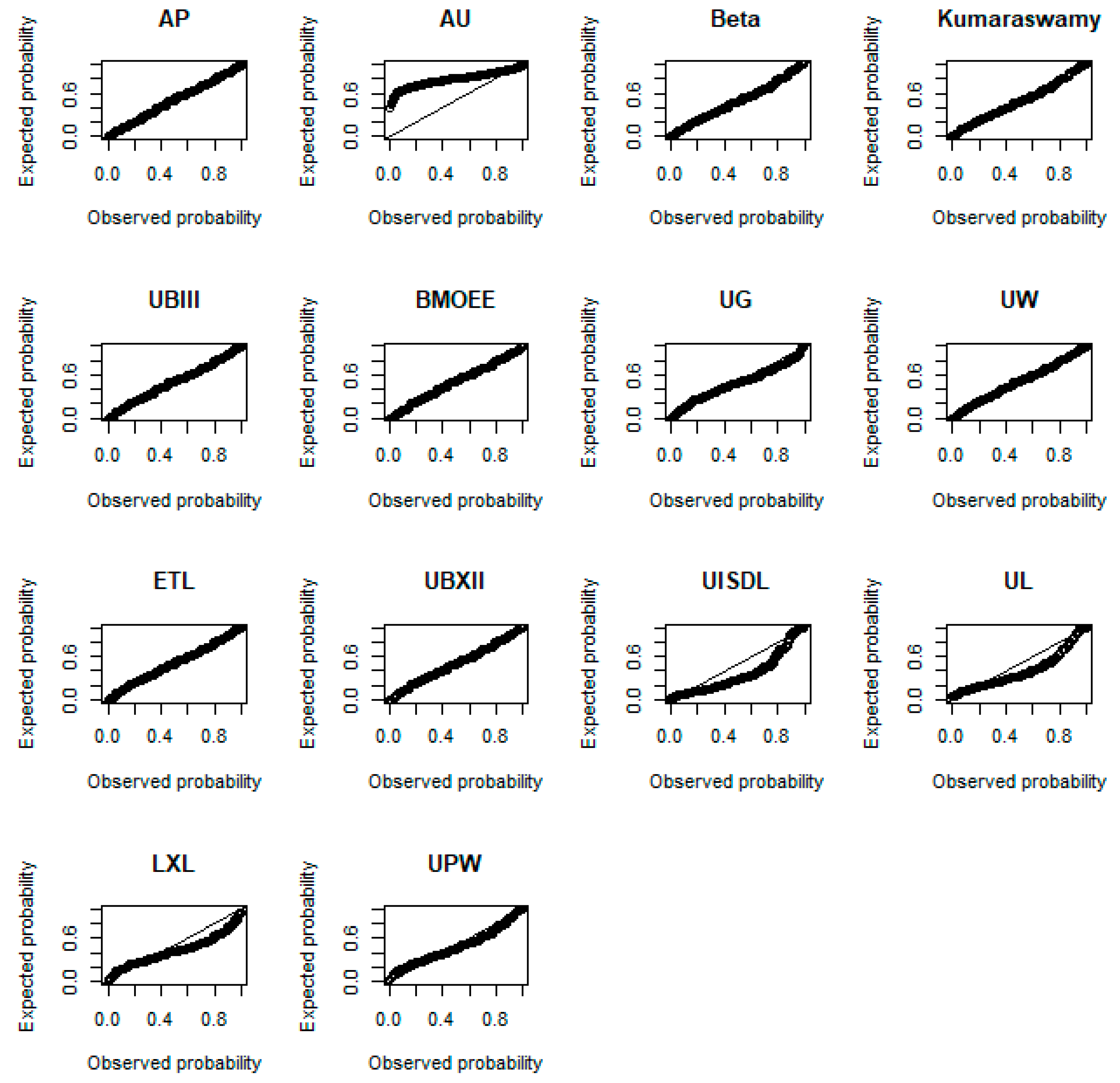
6. Empirical Application
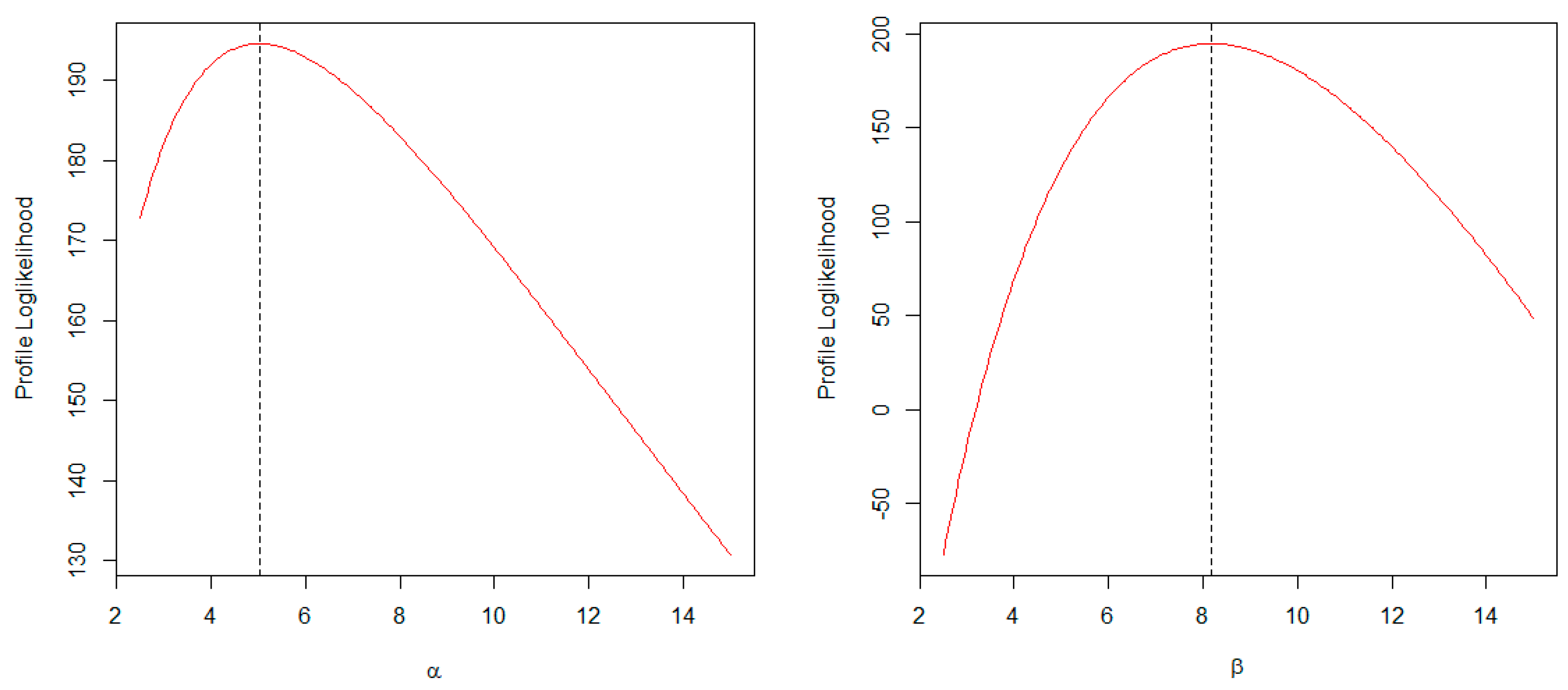
6.1. Frequentist Application
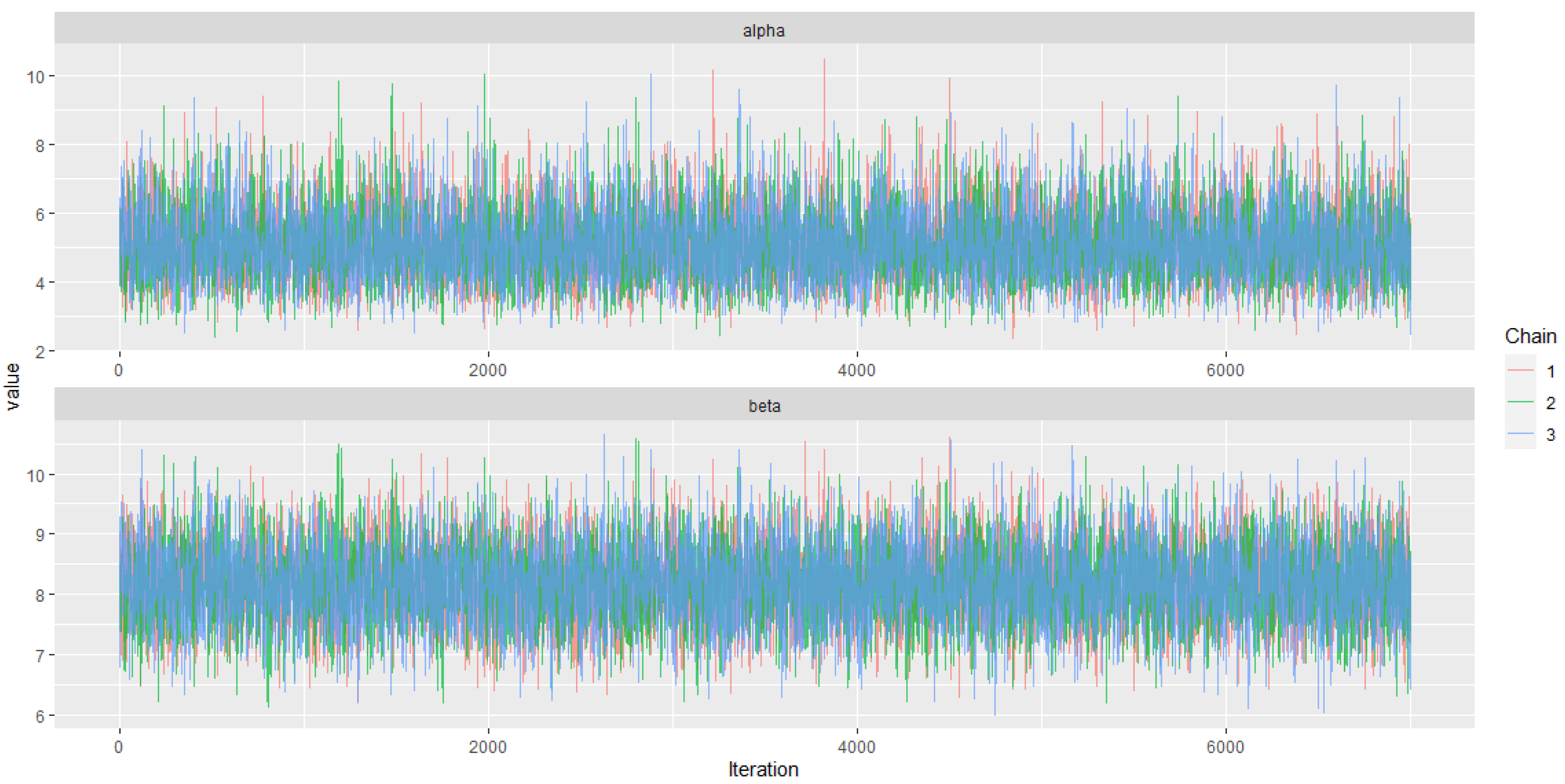
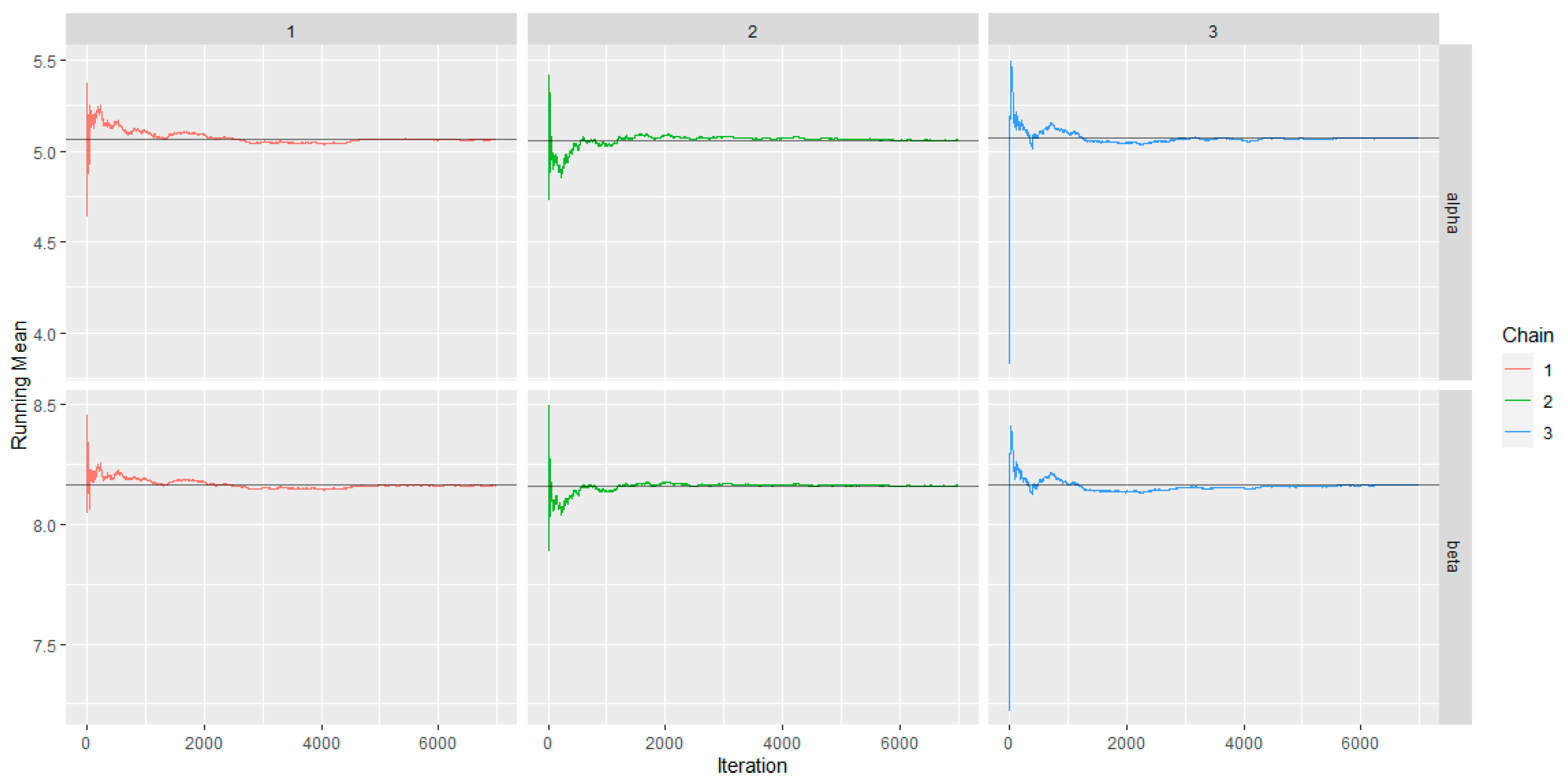
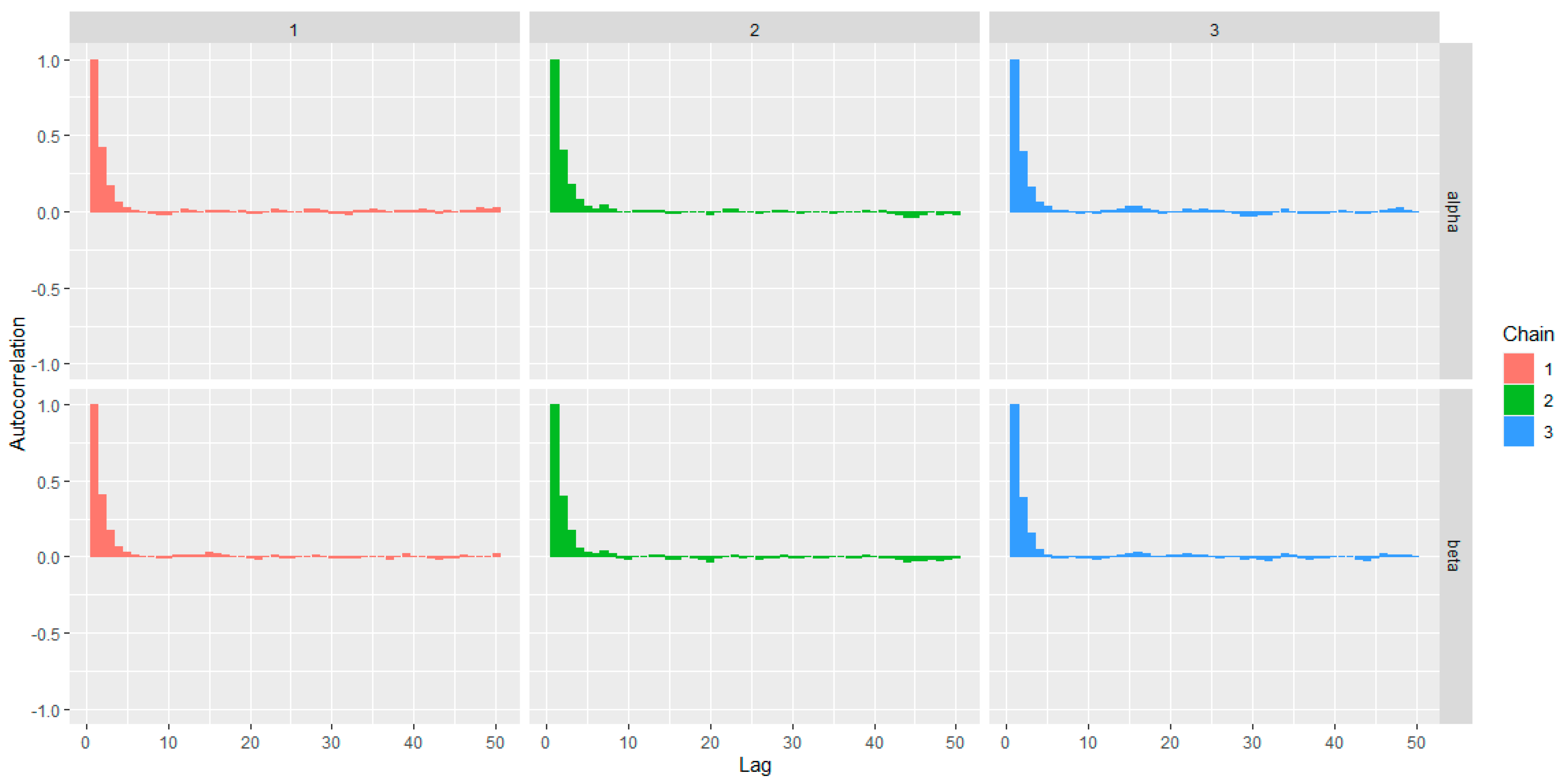
6.2. Bayesian Application
7. Regression Models
7.1. Quantile Regression Model
7.2. Modal Regression
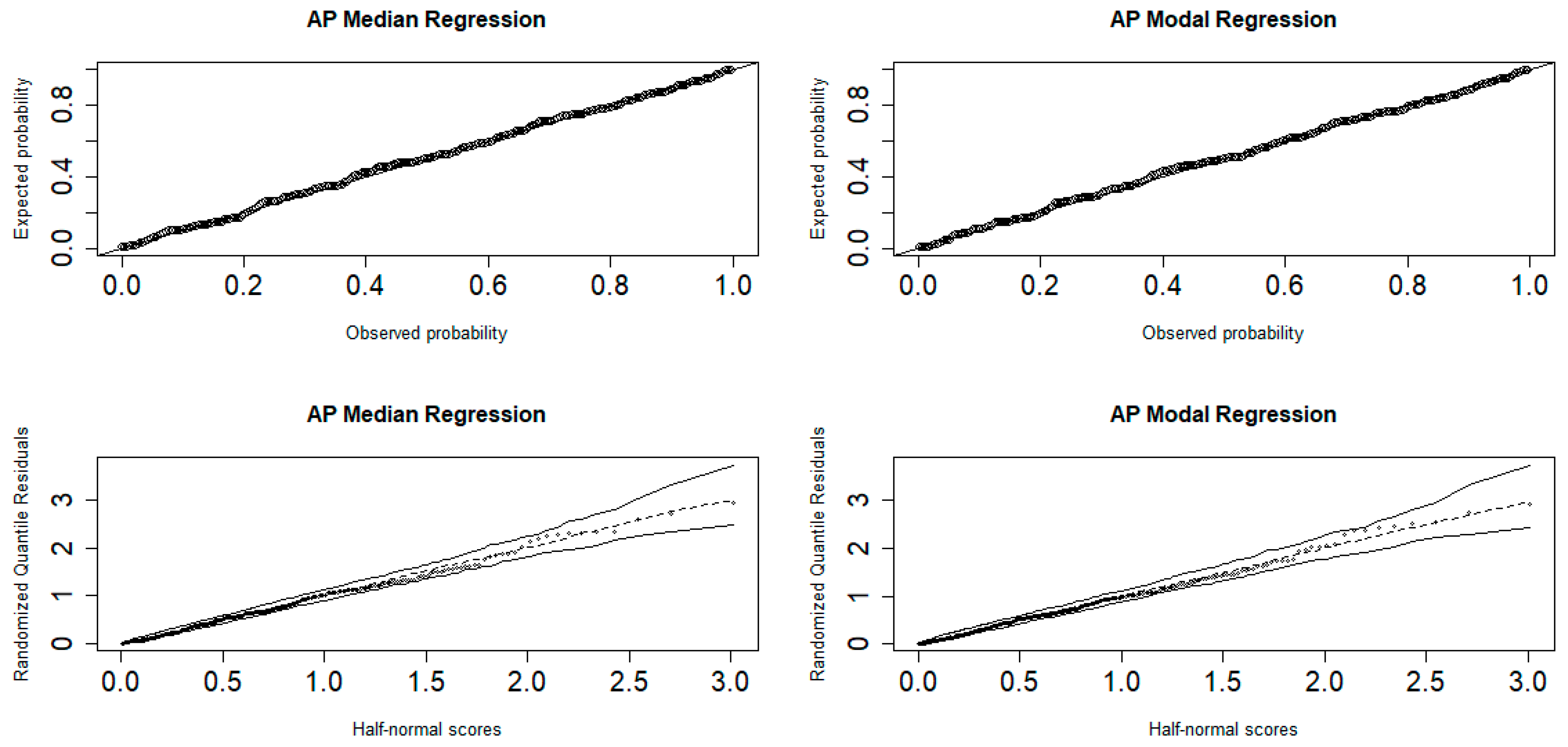
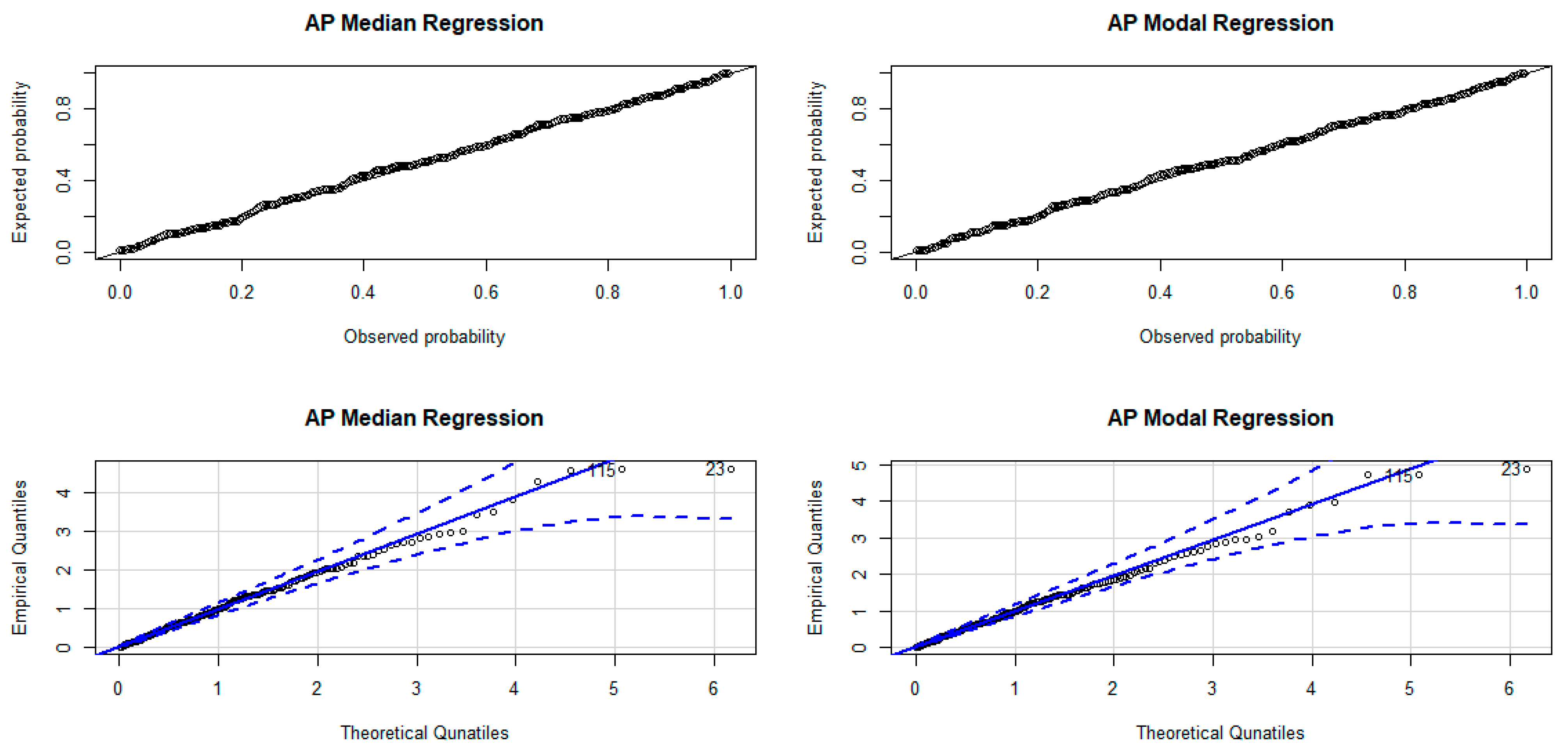
7.3. Residual Analysis
7.4. Monte Carlo Simulation for Regression Models
7.5. Application of Regression Models
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Korkmaz, M.Ç.; Chesneau, C.; Korkmaz, Z.S. The unit folded normal distribution: A new unit probability distribution with the estimation procedures, quantile regression modeling and educational attainment applications. J. Reliab. Stat. Stud. 2022, 15, 261–298. [Google Scholar] [CrossRef]
- Nasiru, S.; Abubakari, A.G.; Chesneau, C. New lifetime distribution for modeling data on the unit interval: Properties, application and quantile regression. Math. Comput. Appl. 2022, 27, 105. [Google Scholar] [CrossRef]
- Abubakari, A.G.; Luguterah, A.; Nasiru, S. Unit exponentiated Fréchet distribution: Actuarial measures, quantile regression and applications. J. Indian Soc. Probab. Stat. 2022, 23, 387–424. [Google Scholar] [CrossRef]
- Eliwa, M.S.; Ahsan-ul-Haq, M.; Al-Bossly, A.; El-Morshedy, M. Properties and estimation techniques with application to model data from SC16 and P3 algorithms. Math. Probl. Eng. 2022, 2022, 9289721. [Google Scholar] [CrossRef]
- Korkmaz, M.Ç.; Emrah, A.; Chesneau, C.; Yousof, H.M. On the unit-Chen distribution with associated quantile regression and applications. Math. Slovaca 2022, 72, 765–786. [Google Scholar] [CrossRef]
- Korkmaz, M.Ç.; Chesneau, C. On the unit Burr XII distribution with the quantile regression modeling and applications. Comput. Appl. Math. 2021, 40, 29. [Google Scholar] [CrossRef]
- Korkmaz, M.Ç. The unit generalized half normal distribution: A new bounded distribution with inference and application. UPB Sci. Bull. Ser. A 2020, 82, 133–140. [Google Scholar]
- Modi, K.; Gill, V. Unit Burr-III distribution with application. J. Stat. Manag. Syst. 2019, 23, 579–592. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.B.; Chakraborty, S. On the one parameter unit-Lindley distribution and its associated regression model for proportion data. J. Appl. Stat. 2019, 46, 700–714. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.; Dey, S. Unit-Gompertz distribution with applications. Statistica 2019, 79, 25–43. [Google Scholar]
- Altun, E.; Cordeiro, G.M. The unit-improved second-degree Lindley distribution: Inference and regression modeling. Comput. Stat. 2019, 35, 259–279. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.; Ghitany, M.E. The unit Weibull distribution and associated inference. J. Appl. Probab. Stat. 2018, 13, 1–22. [Google Scholar]
- Pourdarvish, A.; Mirmostafaee, S.M.T.K.; Naderi, K. The exponentiated Topp-Leone distribution: Properties and application. J. Appl. Environ. Biol. Sci. 2015, 5, 251–256. [Google Scholar]
- Kharazmi, O.; Alizadeh, M.; Contreras-Reyes, J.E.; Haghbin, H. Arctan-based family of distributions: Properties, survival regression, Bayesian analysis and applications. Axioms 2022, 11, 399. [Google Scholar] [CrossRef]
- Al-Mofleh, H.; Afify, A.Z.; Ibrahim, N.A. A new extended two-parameter distribution: Properties, estimation methods and, applications in medicine and geology. Mathematics 2020, 8, 1578. [Google Scholar] [CrossRef]
- Iqbal, Z.; Tahir, M.M.; Riaz, N.; Ali, S.A.; Ahmad, M. Generalized inverted Kumaraswamy distribution: Properties and application. Open J. Stat. 2017, 7, 645–662. [Google Scholar] [CrossRef]
- Iqbal, Z.; Hasnain, S.A.; Salman, M.; Ahmad, M.; Hamedani, G.G. Generalized exponentiated moment exponential distribution. Pak. J. Stat. 2014, 30, 537–554. [Google Scholar]
- Gradshteyn, I.S.; Ryzhik, I.M. Tables of Integrals, Series and Products, 7th ed.; Elsevier/Academic Press: Amsterdam, The Netherlands, 2007. [Google Scholar]
- Sklar, A. Random variables, joint distribution functions and copulas. Kybernetika 1973, 9, 449–460. [Google Scholar]
- Elhassanein, A. On statistical properties of a new bivariate modified Lindley distribution with an application to financial data. Complexity 2022, 2022, 2328831. [Google Scholar] [CrossRef]
- Ganji, M.; Bevrani, H.; Hami, N. A new method for generating continuous bivariate families. J. Iran. Stat. Soc. 2018, 17, 109–129. [Google Scholar] [CrossRef]
- Zhang, P.; Qiu, Z.; Shi, C. Simplexreg: An R package for regression analysis of proportional data using the simplex distribution. J. Stat. Softw. 2016, 71, 1–21. [Google Scholar] [CrossRef]
- Bantan, R.A.R.; Shafiq, S.; Tahir, M.H.; Elhassanein, A.; Jamal, F.; Almutiry, W.; Elgarhy, M. Statistical analysis of COVID-19 data: Using a new univariate and bivariate statistical model. J. Funct. Spaces 2022, 2022, 2851352. [Google Scholar] [CrossRef]
- Ghosh, I.; Dey, S.; Kumar, D. Bounded M-O extended exponential distribution with applications. Stoch. Qual. Control. 2019, 34, 35–51. [Google Scholar] [CrossRef]
- Kumaraswamy, P. A Generalized probability density function for double-bounded random processes. J. Hydrol. 1980, 46, 79–88. [Google Scholar] [CrossRef]
- Muse, A.H.; Chesneau, C.; Ngesa, O.; Mwalili, S. Flexible parametric accelerated hazard model: Simulation and application to censored lifetime data with crossing survival curves. Math. Comput. Appl. 2022, 27, 104. [Google Scholar] [CrossRef]
- Khan, S.A. Exponentiated Weibull regression for time-to-event data. Lifetime Data Anal. 2018, 24, 328–354. [Google Scholar] [CrossRef]
- Su, Y.S.; Yajima, M. R2jags: A Package for Running Jags from R. 2012. Available online: https://CRAN.R-project.org/package=R2jags (accessed on 21 December 2022).
- Menezes, A.F.B.; Mazucheli, J.; Chakraborty, S. A collection of parametric modal regression models for bounded data. J. Biopharm. Stat. 2021, 31, 490–506. [Google Scholar] [CrossRef]
- Yao, W.; Li, L. A new regression model. Scand. J. Stat. 2014, 41, 656–671. [Google Scholar] [CrossRef]
- Cox, D.R.; Snell, E.J. A general definition of residuals. J. R. Stat. Soc. Ser. B 1968, 30, 248–275. [Google Scholar] [CrossRef]
- Dunn, P.K.; Smyth, G.K. Randomized quantile residuals. J. Comput. Graph. Stat. 1996, 5, 236–244. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | ML | MPS | OLS | WLS | AD | CVM | PE | MADS | MALDS | |
|---|---|---|---|---|---|---|---|---|---|---|
| AE | ||||||||||
| 25 | 0.7609 | 1.1013 | 0.4303 | 0.5079 | 0.5634 | 0.6210 | 0.8969 | 0.1730 | 0.5673 | |
| 50 | 0.8989 | 1.1131 | 0.6865 | 0.7679 | 0.7794 | 0.8387 | 0.9400 | 0.1718 | 0.5865 | |
| 100 | 0.5186 | 0.6330 | 0.5285 | 0.5408 | 0.5316 | 0.6020 | 0.7364 | 0.3013 | 0.4153 | |
| 250 | 0.7563 | 0.8212 | 0.6438 | 0.6947 | 0.6821 | 0.6737 | 0.6598 | 0.4516 | 0.5850 | |
| 350 | 0.8082 | 0.8765 | 0.7720 | 0.8039 | 0.7933 | 0.7969 | 0.6947 | 0.5602 | 0.7547 | |
| 25 | 0.4217 | 0.4674 | 0.3992 | 0.4005 | 0.4065 | 0.4237 | 0.4895 | 0.3323 | 0.4021 | |
| 50 | 0.4294 | 0.4580 | 0.4086 | 0.4158 | 0.4174 | 0.4258 | 0.4584 | 0.2995 | 0.3967 | |
| 100 | 0.3903 | 0.4039 | 0.3947 | 0.3944 | 0.3926 | 0.4016 | 0.4371 | 0.3582 | 0.3858 | |
| 250 | 0.4035 | 0.4115 | 0.3938 | 0.3975 | 0.3966 | 0.3974 | 0.4061 | 0.3673 | 0.3940 | |
| 350 | 0.3949 | 0.4026 | 0.3907 | 0.3944 | 0.3931 | 0.3936 | 0.3904 | 0.3719 | 0.3899 | |
| AB | ||||||||||
| 25 | 0.5584 | 0.6872 | 0.6047 | 0.5382 | 0.5453 | 0.6459 | 0.7676 | 0.6845 | 0.6637 | |
| 50 | 0.5308 | 0.6270 | 0.5159 | 0.5405 | 0.4941 | 0.5491 | 0.9510 | 0.6712 | 0.6083 | |
| 100 | 0.6628 | 0.6447 | 0.7083 | 0.6909 | 0.6867 | 0.6793 | 0.8618 | 0.5800 | 0.6805 | |
| 250 | 0.2803 | 0.2719 | 0.3670 | 0.3164 | 0.3256 | 0.3616 | 0.4728 | 0.5443 | 0.4994 | |
| 350 | 0.2584 | 0.2666 | 0.2306 | 0.2376 | 0.2389 | 0.2336 | 0.4586 | 0.4518 | 0.3332 | |
| 25 | 0.0701 | 0.1000 | 0.0807 | 0.0724 | 0.0686 | 0.0844 | 0.1327 | 0.2182 | 0.1001 | |
| 50 | 0.0442 | 0.0643 | 0.0495 | 0.0435 | 0.0428 | 0.0580 | 0.1059 | 0.1275 | 0.0445 | |
| 100 | 0.0504 | 0.0530 | 0.0493 | 0.0493 | 0.0490 | 0.0500 | 0.0657 | 0.0640 | 0.0480 | |
| 250 | 0.0270 | 0.0286 | 0.0352 | 0.0306 | 0.0314 | 0.0358 | 0.0534 | 0.0557 | 0.0356 | |
| 350 | 0.0226 | 0.0222 | 0.0243 | 0.0176 | 0.0192 | 0.0243 | 0.0520 | 0.0428 | 0.0268 | |
| RMSE | ||||||||||
| 25 | 0.6832 | 0.8824 | 0.6642 | 0.6196 | 0.6373 | 0.7498 | 0.9374 | 0.7249 | 0.7684 | |
| 50 | 0.6291 | 0.7570 | 0.6603 | 0.6831 | 0.5963 | 0.7164 | 1.4860 | 0.7176 | 0.6671 | |
| 100 | 0.7322 | 0.7492 | 0.7848 | 0.7744 | 0.7611 | 0.7921 | 0.9537 | 0.6576 | 0.7420 | |
| 250 | 0.3359 | 0.3366 | 0.4614 | 0.3988 | 0.4108 | 0.4615 | 0.5893 | 0.6260 | 0.5625 | |
| 350 | 0.3129 | 0.3093 | 0.3154 | 0.3086 | 0.3098 | 0.3142 | 0.5602 | 0.5355 | 0.4107 | |
| 25 | 0.0910 | 0.1217 | 0.1029 | 0.0918 | 0.0880 | 0.1174 | 0.1684 | 0.2464 | 0.1214 | |
| 50 | 0.0542 | 0.0782 | 0.0607 | 0.0559 | 0.0493 | 0.0712 | 0.1646 | 0.1592 | 0.0603 | |
| 100 | 0.0612 | 0.0655 | 0.0627 | 0.0618 | 0.0606 | 0.0652 | 0.0875 | 0.0981 | 0.0604 | |
| 250 | 0.0337 | 0.0362 | 0.0402 | 0.0364 | 0.0374 | 0.0411 | 0.0679 | 0.0696 | 0.0446 | |
| 350 | 0.0259 | 0.0259 | 0.0293 | 0.0242 | 0.0249 | 0.0289 | 0.0619 | 0.0560 | 0.0337 | |
| Parameter | ML | MPS | OLS | WLS | AD | CVM | PE | MADS | MALDS | |
|---|---|---|---|---|---|---|---|---|---|---|
| AE | ||||||||||
| 25 | 7.0765 | 10.3643 | 5.9141 | 5.8055 | 6.6186 | 7.5983 | 4.8574 | 1.2794 | 8.3329 | |
| 50 | 5.0499 | 5.9801 | 4.8062 | 4.7651 | 4.7680 | 5.3690 | 4.1797 | 3.3758 | 5.4587 | |
| 100 | 4.3862 | 4.8383 | 4.1504 | 4.2629 | 4.2891 | 4.3589 | 3.9500 | 3.6863 | 4.3552 | |
| 250 | 4.3660 | 4.5560 | 4.2758 | 4.3155 | 4.3307 | 4.3597 | 4.1551 | 3.9716 | 4.4893 | |
| 350 | 4.3334 | 4.4767 | 4.2076 | 4.2748 | 4.2766 | 4.2668 | 4.2163 | 4.1250 | 4.3294 | |
| 25 | 6.4914 | 7.3170 | 5.9496 | 5.9510 | 6.2163 | 6.5382 | 5.5927 | 3.3139 | 5.9368 | |
| 50 | 6.1885 | 6.6336 | 5.9530 | 6.0059 | 6.0516 | 6.2226 | 5.7082 | 4.6987 | 6.1925 | |
| 100 | 6.2534 | 6.5278 | 6.0770 | 6.1657 | 6.1849 | 6.2094 | 5.9914 | 5.5851 | 6.2811 | |
| 250 | 6.1297 | 6.2481 | 6.0714 | 6.1025 | 6.1135 | 6.1240 | 6.0026 | 5.7696 | 6.1201 | |
| 350 | 6.0608 | 6.1514 | 5.9857 | 6.0232 | 6.0258 | 6.0232 | 5.9824 | 5.8618 | 6.0932 | |
| AB | ||||||||||
| 25 | 3.4127 | 5.9293 | 3.3920 | 3.1570 | 3.4268 | 4.2622 | 2.7449 | 3.2862 | 5.8446 | |
| 50 | 1.8288 | 2.1741 | 2.1320 | 1.9167 | 1.7383 | 2.2757 | 1.7767 | 2.4817 | 2.5227 | |
| 100 | 1.0012 | 0.9566 | 1.0738 | 1.0249 | 1.0781 | 1.0474 | 1.0521 | 1.5290 | 1.2026 | |
| 250 | 0.8031 | 0.8054 | 0.8103 | 0.7709 | 0.7570 | 0.7912 | 0.8309 | 1.2029 | 1.0822 | |
| 350 | 0.6395 | 0.6136 | 0.6138 | 0.6133 | 0.6086 | 0.6041 | 0.6972 | 0.8890 | 0.5945 | |
| 25 | 1.2038 | 1.4981 | 1.3240 | 1.2379 | 1.1823 | 1.3926 | 1.2174 | 2.9029 | 1.2698 | |
| 50 | 0.9340 | 0.9660 | 1.0599 | 0.9933 | 0.9327 | 1.0433 | 1.0666 | 2.1079 | 1.2164 | |
| 100 | 0.5449 | 0.5436 | 0.5723 | 0.5544 | 0.5715 | 0.5383 | 0.5769 | 0.9975 | 0.6254 | |
| 250 | 0.4017 | 0.4156 | 0.4049 | 0.4016 | 0.3959 | 0.4026 | 0.4575 | 0.7574 | 0.6456 | |
| 350 | 0.3707 | 0.3538 | 0.3835 | 0.3678 | 0.3652 | 0.3723 | 0.4190 | 0.5258 | 0.3588 | |
| RMSE | ||||||||||
| 25 | 9.0289 | 16.6588 | 7.7515 | 7.0825 | 8.9366 | 10.7903 | 5.1325 | 3.5862 | 19.9363 | |
| 50 | 3.1101 | 4.1306 | 3.7004 | 2.9429 | 2.7048 | 4.3787 | 2.2720 | 3.1047 | 4.0033 | |
| 100 | 1.2746 | 1.4424 | 1.3415 | 1.3020 | 1.3645 | 1.3743 | 1.1958 | 2.0602 | 1.7619 | |
| 250 | 1.0203 | 1.0631 | 1.0172 | 1.0052 | 0.9906 | 1.0217 | 1.0439 | 1.6323 | 1.3097 | |
| 350 | 0.7575 | 0.7559 | 0.7539 | 0.7476 | 0.7376 | 0.7427 | 0.8050 | 1.2130 | 0.7278 | |
| 25 | 1.5369 | 2.0307 | 1.6441 | 1.5388 | 1.5357 | 1.7984 | 1.4325 | 3.3678 | 1.7998 | |
| 50 | 1.2005 | 1.3372 | 1.3614 | 1.2314 | 1.1733 | 1.3964 | 1.2318 | 2.6988 | 1.5320 | |
| 100 | 0.6942 | 0.7728 | 0.7270 | 0.6891 | 0.7131 | 0.7296 | 0.6689 | 1.5722 | 0.8371 | |
| 250 | 0.5388 | 0.5432 | 0.5306 | 0.5343 | 0.5215 | 0.5232 | 0.5916 | 0.9666 | 0.7900 | |
| 350 | 0.4264 | 0.4122 | 0.4673 | 0.4368 | 0.4343 | 0.4534 | 0.4743 | 0.6624 | 0.4570 | |
| Model | Parameter | AIC | DAIC | BIC | AD | CVM | K-S | |
|---|---|---|---|---|---|---|---|---|
| AP | 194.5900 | −385.1756 | 0.0000 | −378.2227 | 0.3670 (0.8806) | 0.0461 (0.8999) | 0.0430 (0.7694) | |
| AU | 0.0000 | 2.0000 | 387.1756 | 5.4765 | 131.0700 (<0.0001) | 28.2090 (<0.0001) | 0.5572 (<0.0001) | |
| Beta | 191.8700 | −379.7345 | 5.4411 | −372.7816 | 0.8732 (0.4310) | 0.1402 (0.4213) | 0.0650 (0.2647) | |
| Kumaraswamy | 190.7600 | −377.5820 | 7.5936 | −370.5751 | 1.1438 (0.2899) | 0.1916 (0.2845) | 0.0723 (0.1646) | |
| UBIII | 192.5000 | −381.0031 | 4.1725 | −374.0501 | 0.7758 (0.4987) | 0.1191 (0.4996) | 0.0535 (0.4997) | |
| BMOEE | 192.4200 | −380.8355 | 4.3401 | −373.8825 | 0.6848 (0.5715) | 0.0866 (0.6551) | 0.0489 (0.6182) | |
| UG | 177.0300 | −350.0612 | 35.1144 | −343.1082 | 4.9419 (0.0031) | 0.7829 (0.0080) | 0.1106 (0.0058) | |
| UW | 192.0200 | −380.0314 | 5.1442 | −373.0785 | 0.8636 (0.4373) | 0.1328 (0.4467) | 0.0557 (0.4486) | |
| ETL | 192.6800 | −381.3601 | 3.8155 | −374.4072 | 0.6705 (0.5838) | 0.0996 (0.5873) | 0.0520 (0.5370) | |
| UBXII | 193.5000 | −383.0054 | 2.1702 | −376.0525 | 0.5806 (0.6664) | 0.0887 (0.6437) | 0.0522 (0.5321) | |
| UISDL | 54.2900 | −106.5865 | 278.5891 | −103.1101 | 34.4330 (<0.0001) | 20.1010 (<0.0001) | 0.2851 (<0.0001) | |
| UL | 97.6400 | −193.2741 | 191.9015 | −189.7976 | 20.1010 (<0.0001) | 4.0961 (<0.0001) | 0.2365 (<0.0001) | |
| LXL | 154.6800 | −307.3564 | 77.8192 | −303.8799 | 15.7970 (<0.0001) | 3.0033 (<0.0001) | 0.2010 (<0.0001) | |
| UPW | 168.2600 | −330.5111 | 54.6645 | −320.0817 | 5.3084 (0.0021) | 0.8375 (0.0059) | 0.1152 (0.0035) |
| Parameter | Estimate | SE | SD | 2.50% | 50% | 97.50% | Neff | |
|---|---|---|---|---|---|---|---|---|
| 5.0600 | 0.0107 | 1.0150 | 3.3760 | 4.9540 | 7.3560 | 1.0010 | 5500 | |
| 8.1600 | 0.0066 | 0.6300 | 6.9640 | 8.1490 | 9.4110 | 1.0010 | 6200 |
| Parameter | AP Quantile Regression | Parameter | AP Modal Regression | ||||||
|---|---|---|---|---|---|---|---|---|---|
| AE | AB | RMSE | AE | AB | RMSE | ||||
| 50 | 0.7659 | 0.2028 | 0.2533 | 50 | 0.6495 | 0.5931 | 0.6372 | ||
| 150 | 0.7870 | 0.1286 | 0.1586 | 150 | 0.7551 | 0.5240 | 0.5771 | ||
| 250 | 0.7837 | 0.1041 | 0.1304 | 250 | 0.7015 | 0.4583 | 0.5226 | ||
| 350 | 0.7953 | 0.0896 | 0.1104 | 350 | 0.7526 | 0.4226 | 0.4880 | ||
| 450 | 0.7990 | 0.0868 | 0.1071 | 450 | 0.7674 | 0.3745 | 0.4419 | ||
| 550 | 0.7990 | 0.0681 | 0.0844 | 550 | 0.7668 | 0.3499 | 0.4195 | ||
| 50 | 0.4010 | 0.3256 | 0.3983 | 50 | 0.7202 | 0.6676 | 0.7959 | ||
| 150 | 0.3266 | 0.1974 | 0.2407 | 150 | 0.6208 | 0.5630 | 0.7027 | ||
| 250 | 0.3308 | 0.1737 | 0.2122 | 250 | 0.6470 | 0.5746 | 0.7074 | ||
| 350 | 0.3119 | 0.1443 | 0.1742 | 350 | 0.5695 | 0.5176 | 0.6518 | ||
| 450 | 0.3012 | 0.1403 | 0.1711 | 450 | 0.5439 | 0.4813 | 0.6098 | ||
| 550 | 0.2951 | 0.1044 | 0.1309 | 550 | 0.4965 | 0.4450 | 0.5669 | ||
| 50 | 0.6015 | 0.0893 | 0.1157 | 50 | 0.5921 | 0.3502 | 0.4263 | ||
| 150 | 0.6045 | 0.0480 | 0.0614 | 150 | 0.6143 | 0.2171 | 0.2787 | ||
| 250 | 0.6057 | 0.0381 | 0.0469 | 250 | 0.6090 | 0.1694 | 0.2232 | ||
| 350 | 0.6006 | 0.0325 | 0.0410 | 350 | 0.6183 | 0.1563 | 0.2020 | ||
| 450 | 0.6001 | 0.0291 | 0.0371 | 450 | 0.6174 | 0.1259 | 0.1659 | ||
| 550 | 0.6017 | 0.0272 | 0.0336 | 550 | 0.6187 | 0.1193 | 0.1569 | ||
| 50 | 1.8184 | 0.7279 | 0.8795 | 50 | 1.6644 | 0.2465 | 0.2948 | ||
| 150 | 1.6469 | 0.4111 | 0.5266 | 150 | 1.5793 | 0.1477 | 0.1879 | ||
| 250 | 1.5957 | 0.3058 | 0.3971 | 250 | 1.5376 | 0.1026 | 0.1333 | ||
| 350 | 1.5689 | 0.2526 | 0.3190 | 350 | 1.5289 | 0.0840 | 0.1100 | ||
| 450 | 1.5586 | 0.2227 | 0.2891 | 450 | 1.5216 | 0.0721 | 0.0931 | ||
| 550 | 1.5412 | 0.2047 | 0.2602 | 550 | 1.5085 | 0.0693 | 0.0870 | ||
| Parameter | AP Quantile Regression | Parameter | AP Modal Regression | ||||||
|---|---|---|---|---|---|---|---|---|---|
| AE | AB | RMSE | AE | AB | RMSE | ||||
| 50 | 0.1667 | 0.1496 | 0.1906 | 50 | 0.3746 | 0.3802 | 0.6027 | ||
| 150 | 0.1484 | 0.1207 | 0.1502 | 150 | 0.3336 | 0.3336 | 0.5220 | ||
| 250 | 0.1136 | 0.0907 | 0.1097 | 250 | 0.2376 | 0.2422 | 0.3747 | ||
| 350 | 0.1171 | 0.0845 | 0.1021 | 350 | 0.2302 | 0.2282 | 0.3570 | ||
| 450 | 0.1164 | 0.0842 | 0.1028 | 450 | 0.2165 | 0.2085 | 0.3172 | ||
| 550 | 0.1122 | 0.0714 | 0.0856 | 550 | 0.1841 | 0.1748 | 0.2572 | ||
| 50 | 0.4049 | 0.3025 | 0.3523 | 50 | 0.5759 | 0.5815 | 0.6773 | ||
| 150 | 0.3681 | 0.1882 | 0.2312 | 150 | 0.4728 | 0.4831 | 0.5746 | ||
| 250 | 0.4042 | 0.1654 | 0.2011 | 250 | 0.4892 | 0.4385 | 0.5127 | ||
| 350 | 0.3862 | 0.1498 | 0.1808 | 350 | 0.4187 | 0.3793 | 0.4540 | ||
| 450 | 0.3912 | 0.1453 | 0.1771 | 450 | 0.4457 | 0.3684 | 0.4586 | ||
| 550 | 0.3730 | 0.1047 | 0.1324 | 550 | 0.3974 | 0.3408 | 0.4147 | ||
| 50 | 0.7935 | 0.1038 | 0.1363 | 50 | 0.8970 | 0.3344 | 0.4124 | ||
| 150 | 0.8057 | 0.0546 | 0.0699 | 150 | 0.8773 | 0.2046 | 0.2720 | ||
| 250 | 0.8013 | 0.0426 | 0.0519 | 250 | 0.8651 | 0.1441 | 0.2004 | ||
| 350 | 0.8008 | 0.0364 | 0.0457 | 350 | 0.8471 | 0.1296 | 0.1734 | ||
| 450 | 0.7987 | 0.0327 | 0.0414 | 450 | 0.8440 | 0.1052 | 0.1468 | ||
| 550 | 0.8050 | 0.0326 | 0.0394 | 550 | 0.8339 | 0.1025 | 0.1397 | ||
| 50 | 1.2087 | 0.3183 | 0.4361 | 50 | 1.4403 | 0.2164 | 0.2713 | ||
| 150 | 1.2667 | 0.2281 | 0.2932 | 150 | 1.3604 | 0.1242 | 0.1589 | ||
| 250 | 1.2719 | 0.1967 | 0.2448 | 250 | 1.3258 | 0.0870 | 0.1127 | ||
| 350 | 1.2930 | 0.1702 | 0.2034 | 350 | 1.3211 | 0.0700 | 0.0911 | ||
| 450 | 1.2871 | 0.1632 | 0.1971 | 450 | 1.3153 | 0.0609 | 0.0785 | ||
| 550 | 1.2919 | 0.1546 | 0.1845 | 550 | 1.3063 | 0.0588 | 0.0739 | ||
| AP Quantile Regression | AP Modal Regression | ||||||
|---|---|---|---|---|---|---|---|
| Parameter | Estimate | Standard Error | p-Value | Parameter | Estimate | Standard Error | p-Value |
| 1.0119 | 0.1226 | <0.0001 | 0.8903 | 0.1715 | <0.0001 | ||
| 0.0533 | 0.0912 | 0.5585 | 0.0921 | 0.1235 | 0.4560 | ||
| 0.2392 | 0.0940 | 0.0110 | 0.3153 | 0.1559 | 0.0432 | ||
| 0.0169 | 0.0049 | 0.0006 | 0.0253 | 0.0082 | 0.0020 | ||
| 5.6100 | 1.1128 | <0.0001 | 8.4244 | 0.6471 | <0.0001 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nasiru, S.; Abubakari, A.G.; Chesneau, C. The Arctan Power Distribution: Properties, Quantile and Modal Regressions with Applications to Biomedical Data. Math. Comput. Appl. 2023, 28, 25. https://doi.org/10.3390/mca28010025
Nasiru S, Abubakari AG, Chesneau C. The Arctan Power Distribution: Properties, Quantile and Modal Regressions with Applications to Biomedical Data. Mathematical and Computational Applications. 2023; 28(1):25. https://doi.org/10.3390/mca28010025
Chicago/Turabian StyleNasiru, Suleman, Abdul Ghaniyyu Abubakari, and Christophe Chesneau. 2023. "The Arctan Power Distribution: Properties, Quantile and Modal Regressions with Applications to Biomedical Data" Mathematical and Computational Applications 28, no. 1: 25. https://doi.org/10.3390/mca28010025
APA StyleNasiru, S., Abubakari, A. G., & Chesneau, C. (2023). The Arctan Power Distribution: Properties, Quantile and Modal Regressions with Applications to Biomedical Data. Mathematical and Computational Applications, 28(1), 25. https://doi.org/10.3390/mca28010025