
Discrimination Ability of Assessors in Check-All-That-Apply Tests: Method and Product Development



Abstract
:1. Introduction
- Assess the discrimination ability of the assessors;
- Create consumer clusters based on the level of discrimination of the assessors.
2. Materials and Methods
2.1. Datasets
2.1.1. Cricket Enriched Biscuit Dataset
2.1.2. Gluten Free Brown Rice Biscuits Enriched with Apple Pomace and Flax Seeds Dataset
2.1.3. Strawberry Dataset
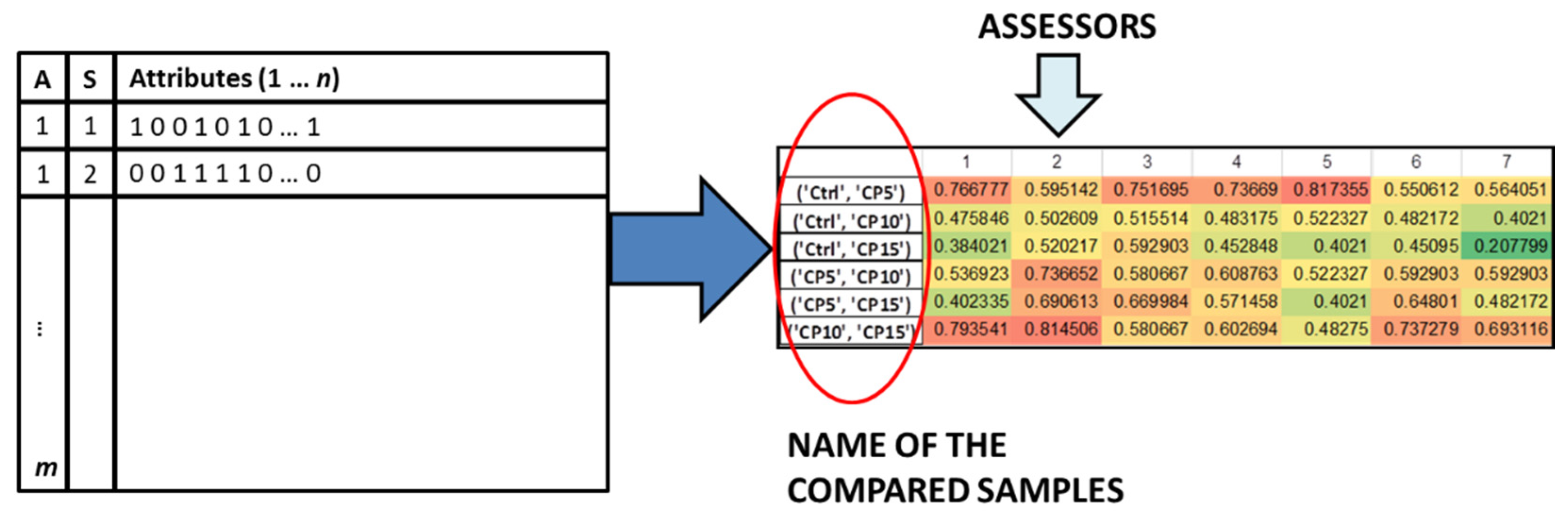
2.2. Data Analysis
2.2.1. Binary Similarity Measures
2.2.2. Check-All-That-Apply Data Evaluation
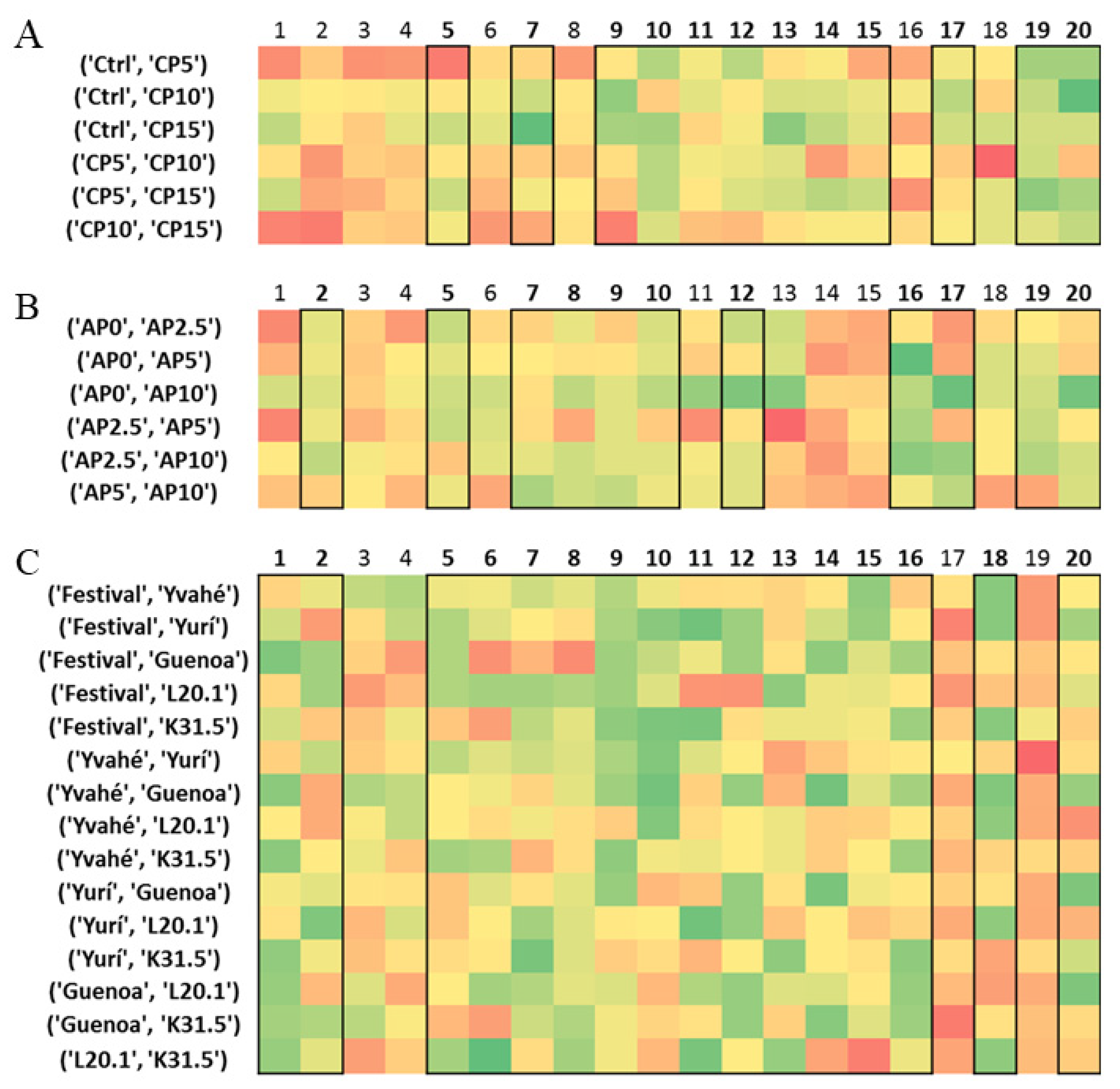
3. Results and Discussion
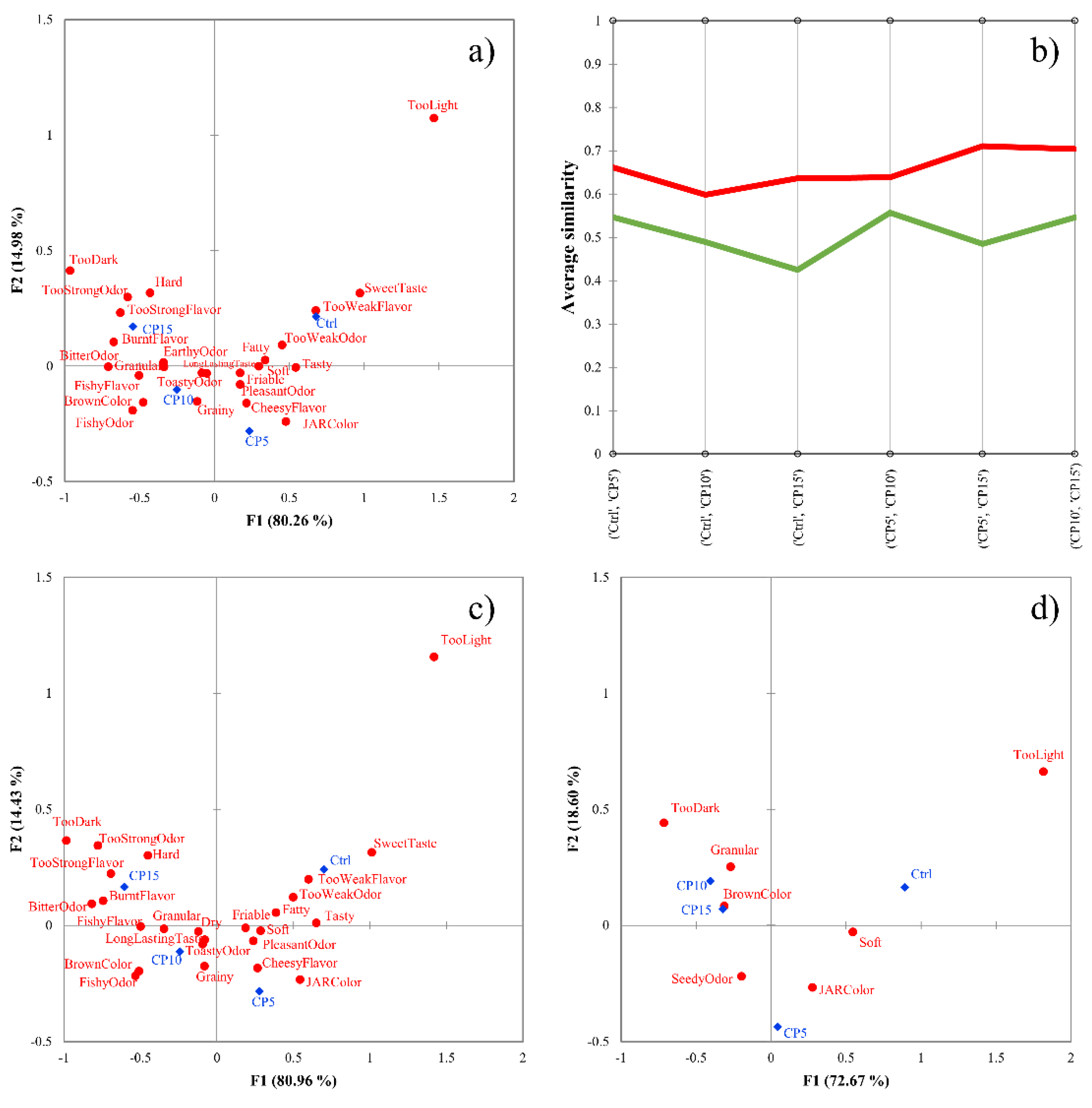
3.1. Cricket Enriched Biscuit Dataset
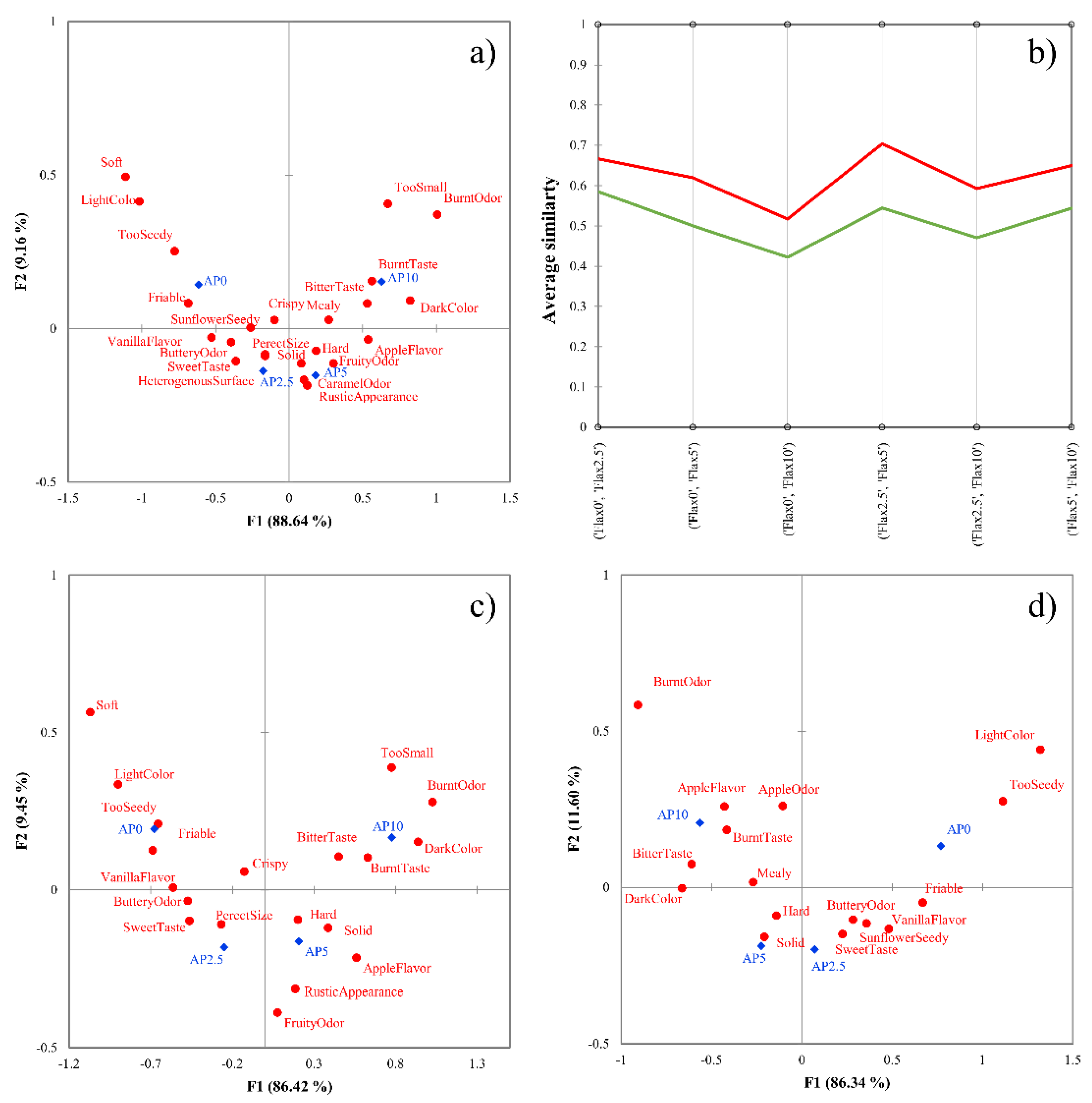
3.2. Apple Pomace-Enriched Biscuit Dataset
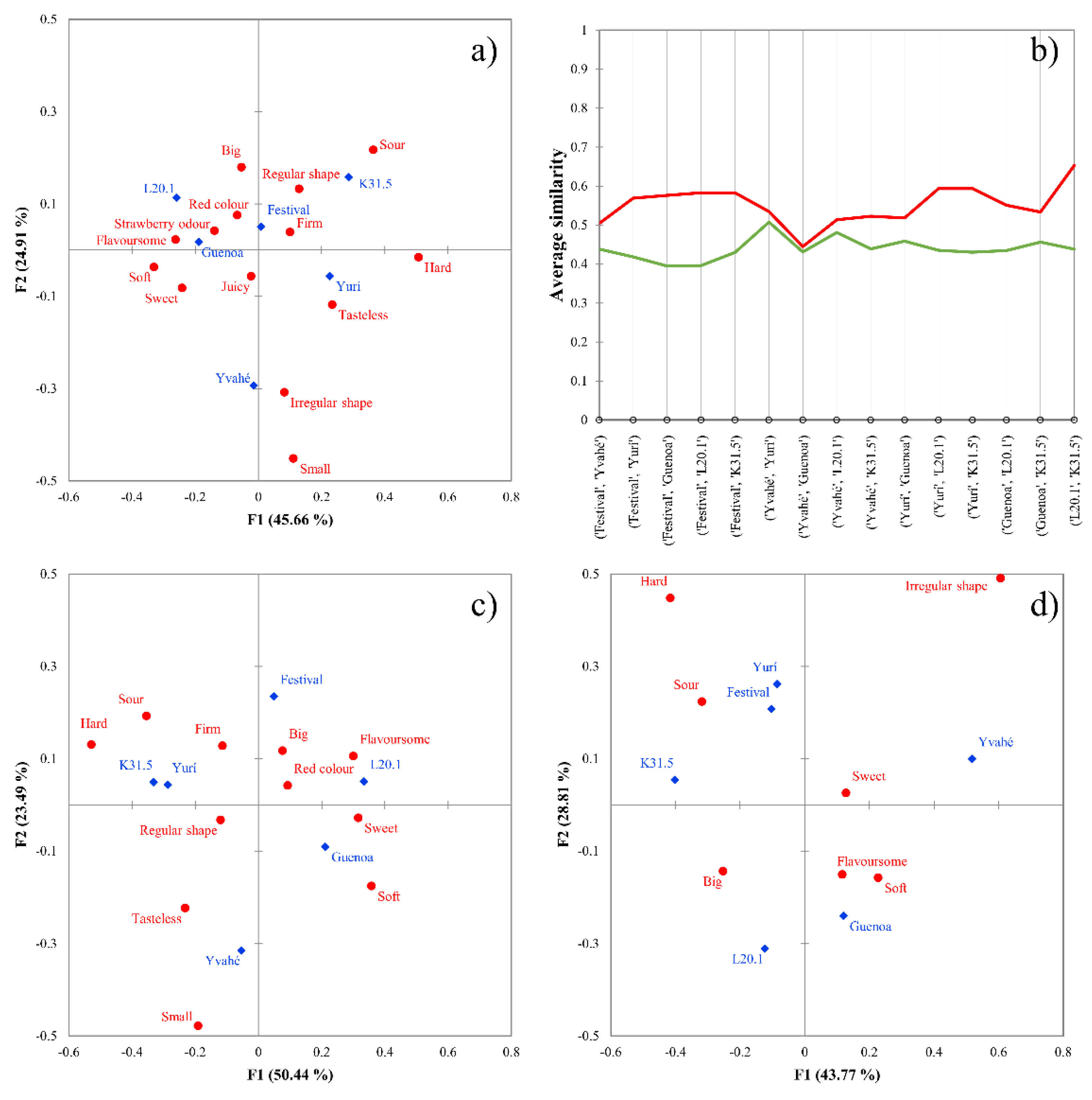
3.3. Strawberry Dataset
3.4. Comparison of Product Liking
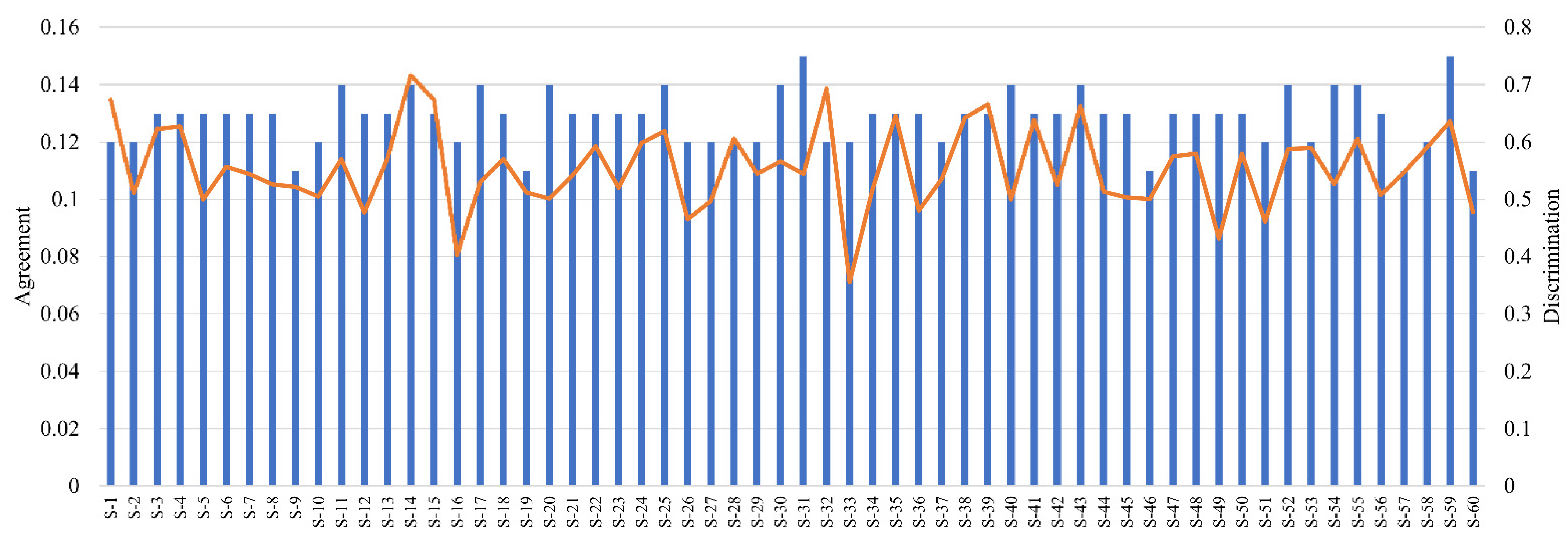
3.5. Comparison with Panelist Agreement
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Meyners, M.; Castura, J.C. Check-All-That-Apply Questions. In Novel Techniques in Sensory Characterization and Consumer Profiling; Varela, P., Ares, G., Eds.; CRC Press: Boca Raton, FL, USA, 2014; pp. 271–307. ISBN 9781466566309. [Google Scholar]
- Alexi, N.; Nanou, E.; Lazo, O.; Guerrero, L.; Grigorakis, K.; Byrne, D.V. Check-All-That-Apply (CATA) with semi-trained assessors: Sensory profiles closer to descriptive analysis or consumer elicited data? Food Qual. Prefer. 2018, 64, 11–20. [Google Scholar] [CrossRef] [Green Version]
- Jaeger, S.R.; Beresford, M.K.; Paisley, A.G.; Antúnez, L.; Vidal, L.; Cadena, R.S.; Giménez, A.; Ares, G. Check-all-that-apply (CATA) questions for sensory product characterization by consumers: Investigations into the number of terms used in CATA questions. Food Qual. Prefer. 2015, 42, 154–164. [Google Scholar] [CrossRef]
- Meyners, M.; Castura, J.C.; Carr, B.T. Existing and new approaches for the analysis of CATA data. Food Qual. Prefer. 2013, 30, 309–319. [Google Scholar] [CrossRef]
- Plaehn, D. CATA penalty/reward. Food Qual. Prefer. 2012, 24, 141–152. [Google Scholar] [CrossRef]
- Ares, G.; Dauber, C.; Fernández, E.; Giménez, A.; Varela, P. Penalty analysis based on CATA questions to identify drivers of liking and directions for product reformulation. Food Qual. Prefer. 2014, 32, 65–76. [Google Scholar] [CrossRef]
- Jaeger, S.R.; Chheang, S.L.; Yin, J.; Bava, C.M.; Gimenez, A.; Vidal, L.; Ares, G. Check-all-that-apply (CATA) responses elicited by consumers: Within-assessor reproducibility and stability of sensory product characterizations. Food Qual. Prefer. 2013, 30, 56–67. [Google Scholar] [CrossRef]
- Llobell, F.; Cariou, V.; Vigneau, E.; Labenne, A.; Qannari, E.M. A new approach for the analysis of data and the clustering of subjects in a CATA experiment. Food Qual. Prefer. 2019, 72, 31–39. [Google Scholar] [CrossRef]
- Llobell, F.; Giacalone, D.; Labenne, A.; Qannari, E.M. Assessment of the agreement and cluster analysis of the respondents in a CATA experiment. Food Qual. Prefer. 2019, 77, 184–190. [Google Scholar] [CrossRef]
- Næs, T.; Brockhoff, P.B.; Tomic, O. Statistics for Sensory and Consumer Science, 1st ed.; John Wiley & Sons, Ltd.: Chichester, UK, 2010; ISBN 9780470518212. [Google Scholar]
- Peltier, C.; Brockhoff, P.B.; Visalli, M.; Schlich, P. The MAM-CAP table: A new tool for monitoring panel performances. Food Qual. Prefer. 2014, 32, 24–27. [Google Scholar] [CrossRef]
- Bajusz, D.; Rácz, A.; Héberger, K. Why is Tanimoto index an appropriate choice for fingerprint-based similarity calculations? J. Cheminform. 2015, 7, 20. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rácz, A.; Bajusz, D.; Héberger, K. Life beyond the Tanimoto coefficient: Similarity measures for interaction fingerprints. J. Cheminform. 2018, 10, 48. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rácz, A.; Andrić, F.; Bajusz, D.; Héberger, K. Binary similarity measures for fingerprint analysis of qualitative metabolomic profiles. Metabolomics 2018, 14, 29. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Todeschini, R.; Consonni, V.; Xiang, H.; Holliday, J.; Buscema, M.; Willett, P. Similarity Coefficients for Binary Chemoinformatics Data: Overview and Extended Comparison Using Simulated and Real Data Sets. J. Chem. Inf. Model. 2012, 52, 2884–2901. [Google Scholar] [CrossRef] [PubMed]
- Héberger, K.; Kollár-Hunek, K. Sum of ranking differences for method discrimination and its validation: Comparison of ranks with random numbers. J. Chemom. 2011, 25, 151–158. [Google Scholar] [CrossRef]
- Sziklai, B.R.; Héberger, K. Apportionment and districting by Sum of Ranking Differences. PLoS ONE 2020, 15, e0229209. [Google Scholar] [CrossRef] [PubMed]
- Lagares, L.M.; Minovski, N.; Alfonso, A.Y.C.; Benfenati, E.; Wellens, S.; Culot, M.; Gosselet, F.; Novič, M. Homology modeling of the human p-glycoprotein (Abcb1) and insights into ligand binding through molecular docking studies. Int. J. Mol. Sci. 2020, 21, 4058. [Google Scholar] [CrossRef] [PubMed]
- Hastie, T.; Tibshirani, R.; Friedman, J. Overview of supervised learning. In Elements of Statistical Learning, Data Mining, Inference, Prediction; Springer: New York, NY, USA, 2001; pp. 9–43. [Google Scholar]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Addinsoft XLSTAT Statistical and Data Analysis Solution. New York, USA. 2019. Available online: https://www.xlstat.com (accessed on 18 May 2021).
- Ares, G.; Jaeger, S.R. Check-all-that-apply questions: Influence of attribute order on sensory product characterization. Food Qual. Prefer. 2013, 28, 141–153. [Google Scholar] [CrossRef]
- Meyners, M.; Castura, J.C.; Worch, T. Statistical evaluation of panel repeatability in Check-All-That-Apply questions. Food Qual. Prefer. 2016, 49, 197–204. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | CATA Terms |
|---|---|
| Cricket enriched biscuit | too dark, too light, nice color, brown color, grainy, too strong odor, too weak odor, cheesy odor, bitter odor, seedy odor, earthy odor, sunflower-seedy odor, toasty odor, pleasant odor, fishy odor, friable, hard, soft, crumbly, fatty, crispy, granular, dry, too strong flavor, too weak flavor, cheesy flavor, seedy flavor, spicy flavor, salty taste, sunflower-seedy flavor, toasty flavor, tasty, sweet taste, sticky, piquant, fishy flavor, burnt flavor, long lasting taste |
| Apple pomace biscuit enriched biscuit | light, dark, homogeneous, heterogenous, seedy, rustic, perfect size, small, fruity odor, citrus odor, apple odor, buttery odor, caramel odor, burnt odor, coconut odor, hard, flexible, chewy, crispy, solid, mealy, sunflower seedy, soft, sticky, friable, tasteless, vanilla flavor, fruity flavor, citrus flavor, apple flavor, caramel flavor, sweet bitter, sour, burnt |
| Strawberry | sweet, sour, strawberry flavor, strawberry odor, flavorsome, tasteless, red color, irregular shape, regular shape, small, big, firm, hard, soft, juicy, dry |
| p = a + b + c + d | Sample 2 | |
|---|---|---|
| Sample 1 | 1 (Attribute present) | 0 (Attribute absent) |
| 1 (Attribute present) | a | b |
| 0 (Attribute absent) | c | d |
| Consensus Limit | Selected Assessors * | Row Minimum | Row Maximum | |
|---|---|---|---|---|
| Dataset 1 (cricket) | 0.53 | 37/67 | 0.21 | 0.89 |
| Dataset 2 (apple pomace enriched biscuit) | 0.55 | 32/60 | 0.10 | 0.96 |
| Dataset 3 (strawberry) | 0.47 | 63/117 | 0.15 | 0.89 |
| Cricket | C1 | C2 | |
| Ctrl | 6.536 b | CP5 | 6.818 a |
| CP5 | 6.339 b | Ctrl | 6.727 a |
| CP10 | 5.357 a | CP10 | 6.182 a |
| CP15 | 4.518 a | CP15 | 6.091 a |
| Apple pomace enriched | C1 | C2 | |
| AP0 | 6.216 c | AP0 | 6.304 c |
| AP2.5 | 5.541 bc | AP2.5 | 5.435 bc |
| AP5 | 5.081 b | AP5 | 4.870 ab |
| AP10 | 3.568 a | AP10 | 3.652 a |
| Strawberry | C1 | C2 | |
| L20.1 | 5.753 b | L20.1 | 6.571 a |
| Festival | 5.247 ab | Guenoa | 6.171 a |
| Guenoa | 5.136 ab | Festival | 6.029 a |
| Yvahé | 4.938 ab | Yvahé | 5.486 a |
| K31.5 | 4.469 a | K31.5 | 5.229 a |
| Yurí | 4.358 a | Yurí | 4.971 a |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gere, A.; Bajusz, D.; Biró, B.; Rácz, A. Discrimination Ability of Assessors in Check-All-That-Apply Tests: Method and Product Development. Foods 2021, 10, 1123. https://doi.org/10.3390/foods10051123
Gere A, Bajusz D, Biró B, Rácz A. Discrimination Ability of Assessors in Check-All-That-Apply Tests: Method and Product Development. Foods. 2021; 10(5):1123. https://doi.org/10.3390/foods10051123
Chicago/Turabian StyleGere, Attila, Dávid Bajusz, Barbara Biró, and Anita Rácz. 2021. "Discrimination Ability of Assessors in Check-All-That-Apply Tests: Method and Product Development" Foods 10, no. 5: 1123. https://doi.org/10.3390/foods10051123
APA StyleGere, A., Bajusz, D., Biró, B., & Rácz, A. (2021). Discrimination Ability of Assessors in Check-All-That-Apply Tests: Method and Product Development. Foods, 10(5), 1123. https://doi.org/10.3390/foods10051123