Prevalence of Milk Fraud in the Chinese Market and its Relationship with Fraud Vulnerabilities in the Chain

 ,
, 
Abstract
:1. Introduction
2. Materials and Methods
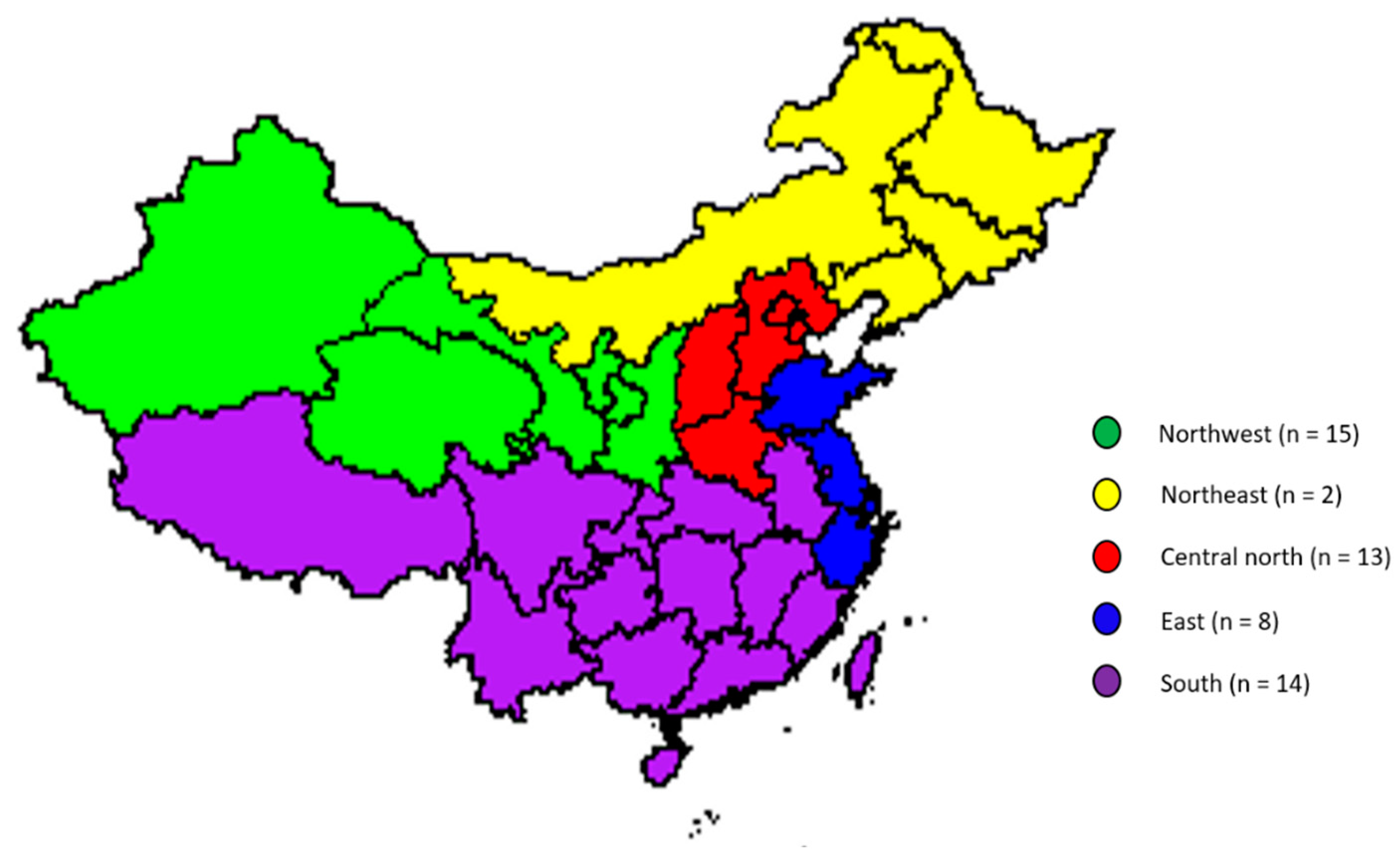
2.1. Sample Collection
2.2. Adulterations and Measurements
2.3. Statistical Analysis
2.3.1. Univariate Analysis: Determination of Boundaries for Each Variable
2.3.2. Multivariate Analysis: Determination of Boundaries for Milk with One-Class Classification Models
2.3.3. Exploratory Analysis and Regression Model
3. Results and Discussion
3.1. Control Samples
3.1.1. Natural Variation of the Control Samples
3.1.2. Control Samples and Univariate Detection Approach
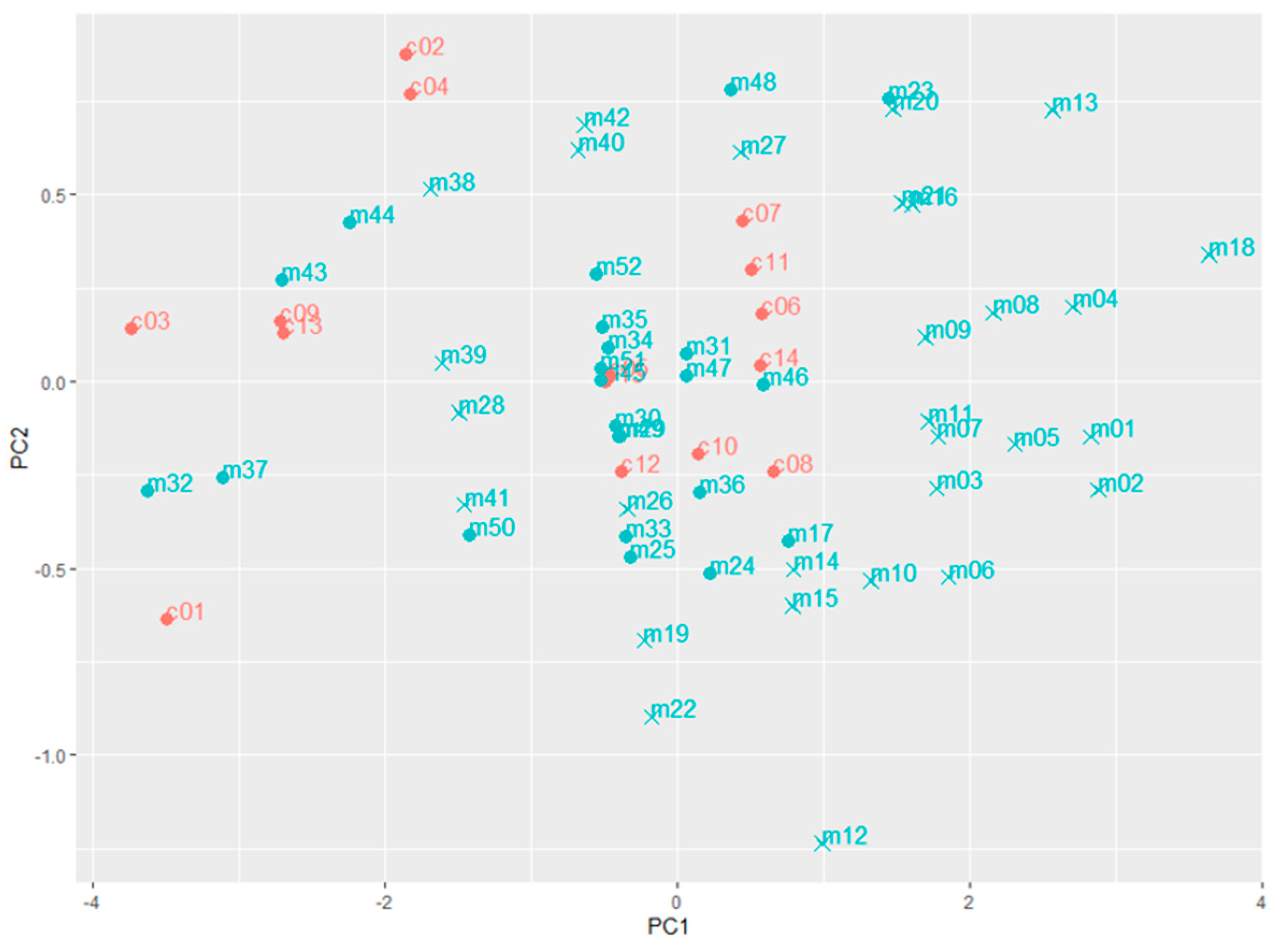
3.1.3. Control Samples and the Multivariate Detection Approach
3.2. Adulterants
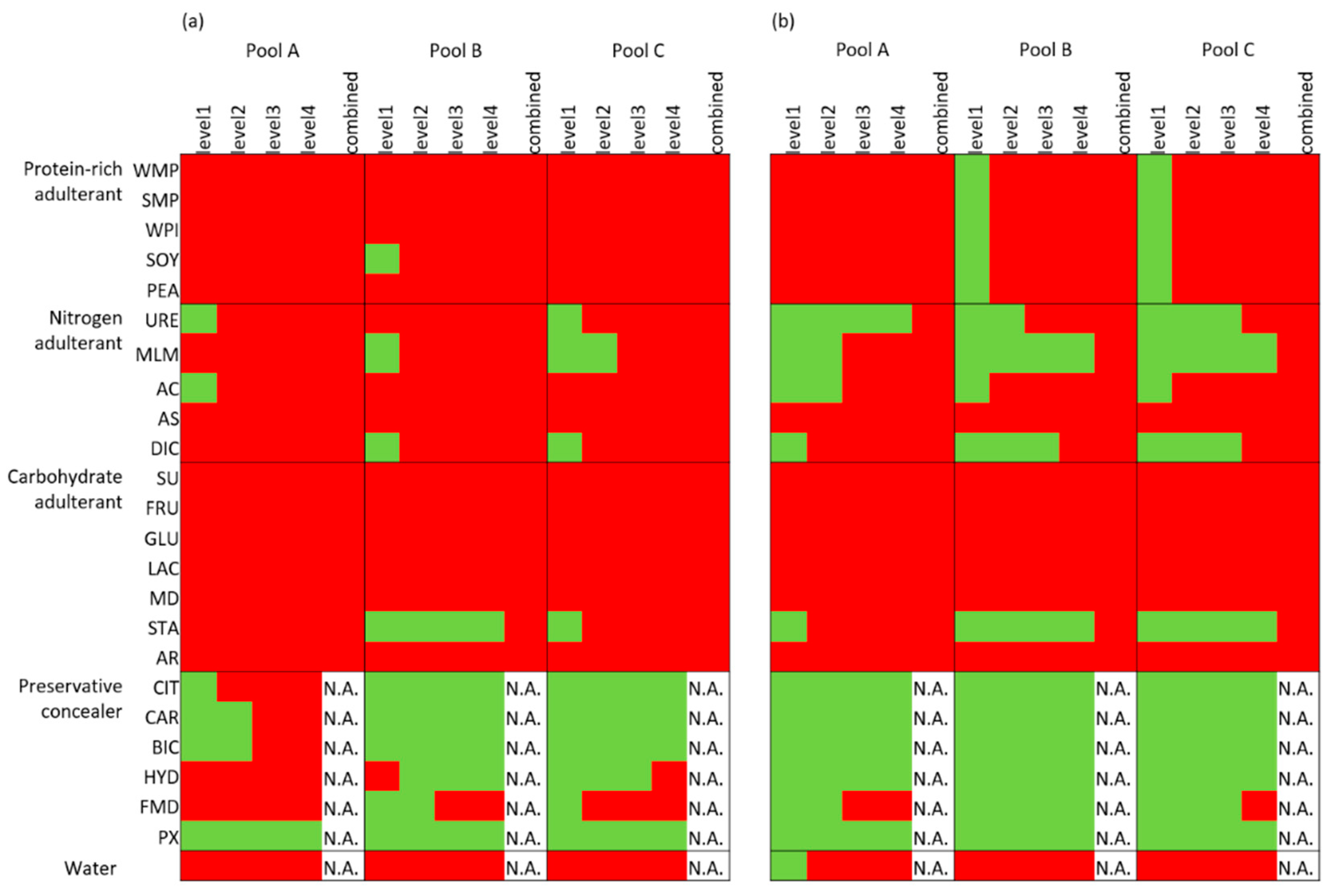
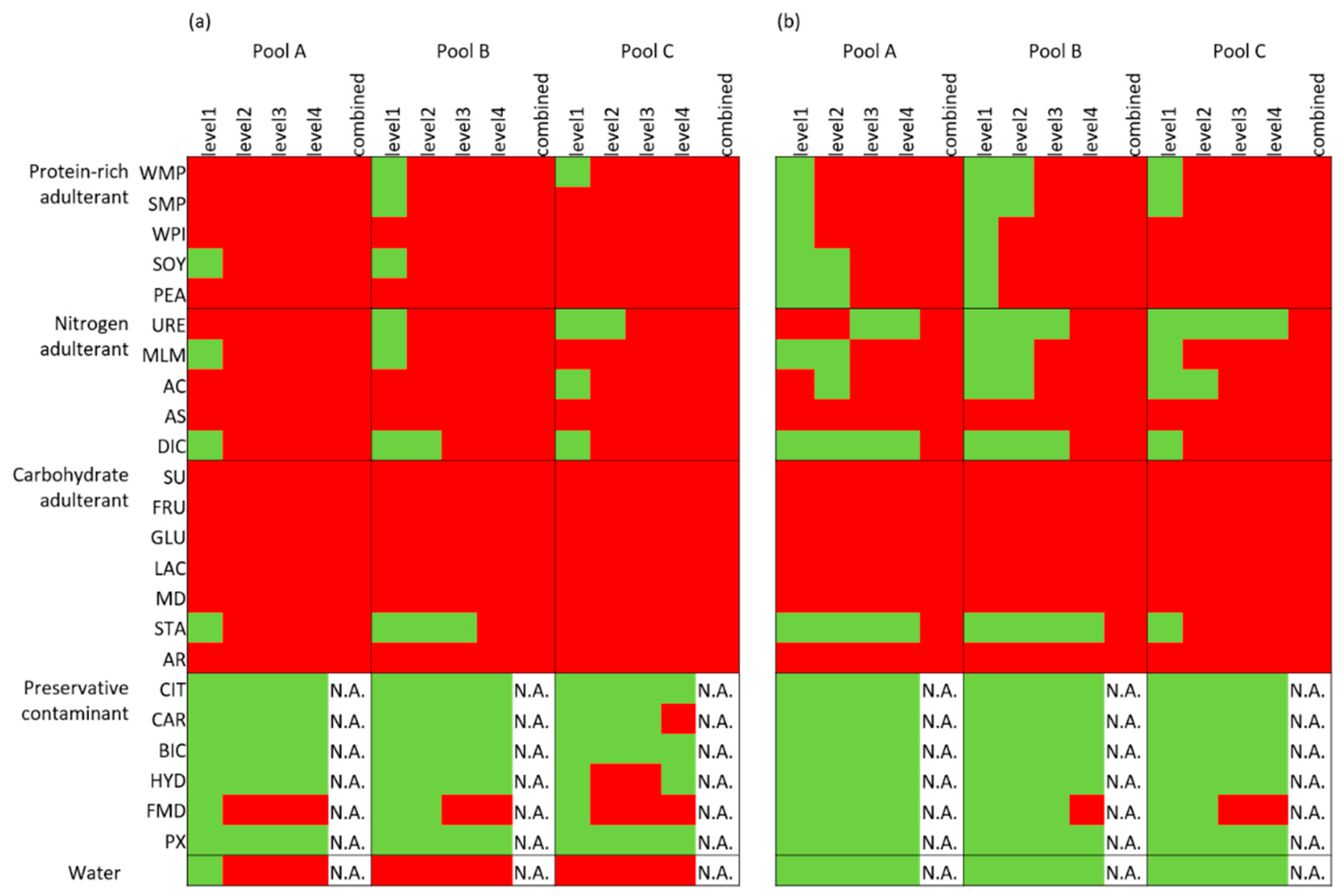
3.2.1. Adulterants and the Univariate Detection Approach
3.2.2. Adulterants and Multivariate Detection Approach
3.2.3. Comparison of Approaches
3.3. Market Survey Samples: What Type of Suspected Milk Samples are Discovered Using the Developed Approaches?
3.3.1. Suspected Samples Flagged by the Univariate Detection Approach
3.3.2. Suspected Samples Flagged by the Multivariate Detection Approach
3.3.3. Overall Suspected Samples of the Market Survey Set
3.4. Relation Between the Origin of the Suspected Milk and the Previously Determined Fraud Vulnerability
3.4.1. Relation Between the Origin of the Suspected Milk and the Fraud Opportunities and Motivations
3.4.2. Relation Between the Origin of the Suspected Milk and the Counteracting Controls
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Li, S. White Paper on China Dairy 2016. Available online: http://www.sdddc.org/en/download/detail-251.aspx (accessed on 10 April 2020).
- Ministry of Agriculture P.R. China. China Dairy Yearbook. Available online: https://www.yearbookchina.com/navibooklist-n3018062701-1.html (accessed on 10 April 2020).
- Pwc. The Ongoing Modernisation of China’s Dairy Sector. Available online: https://www.pwccn.com/en/food-supply/publications/modernization-of-china-dairy-industry.pdf (accessed on 18 May 2020).
- Xiu, C.; Klein, K.K. Melamine in milk products in China: Examining the factors that led to deliberate use of the contaminant. Food Policy 2010, 35, 463–470. [Google Scholar] [CrossRef]
- Moore, J.C.; Spink, J.; Lipp, M. Development and Application of a Database of Food Ingredient Fraud and Economically Motivated Adulteration from 1980 to 2010. J. Food Sci. 2012, 77, R118–R126. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Xue, J. Economically motivated food fraud and adulteration in China: An analysis based on 1553 media reports. Food Control 2016, 67, 192–198. [Google Scholar] [CrossRef]
- Lam, H.-M.; Remais, J.; Fung, M.-C.; Xu, L.; Sun, S.S.-M. Food supply and food safety issues in China. Lancet 2013, 381, 2044–2053. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Sijtsema, S.J.; Kornelis, M.; Liu, Y.; Li, S. Consumer confidence in the safety of milk and infant milk formula in China. J. Dairy Sci. 2019, 102, 8807–8818. [Google Scholar] [CrossRef]
- Yin, S.; Li, Y.; Xu, Y.; Chen, M.; Wang, Y. Consumer preference and willingness to pay for the traceability information attribute of infant milk formula. Br. Food J. 2017. [Google Scholar] [CrossRef]
- Handford, C.E.; Campbell, K.; Elliott, C.T. Impacts of Milk Fraud on Food Safety and Nutrition with Special Emphasis on Developing Countries. Compr. Rev. Food Sci. Food Saf. 2016, 15, 130–142. [Google Scholar] [CrossRef] [Green Version]
- Hansen, P.W.; Holroyd, S.E. Development and application of Fourier transform infrared spectroscopy for detection of milk adulteration in practice. Int. J. Dairy Technol. 2019, 72, 321–331. [Google Scholar] [CrossRef]
- Yang, Y.; Huisman, W.; Hettinga, K.A.; Liu, N.; Heck, J.; Schrijver, G.H.; Gaiardoni, L.; van Ruth, S.M. Fraud vulnerability in the Dutch milk supply chain: Assessments of farmers, processors and retailers. Food Control 2019, 95, 308–317. [Google Scholar] [CrossRef]
- Yang, Y.; Huisman, W.; Hettinga, K.A.; Zhang, L.; van Ruth, S.M. The Chinese milk supply chain: A fraud perspective. Food Control 2020. [Google Scholar] [CrossRef]
- Abernethy, G.; Higgs, K. Rapid detection of economic adulterants in fresh milk by liquid chromatography–tandem mass spectrometry. J. Chromatogr. 2013, 1288, 10–20. [Google Scholar] [CrossRef]
- Tittlemier, S.A. Methods for the analysis of melamine and related compounds in foods: A review. Food Addit. Contam.: Part A 2010, 27, 129–145. [Google Scholar] [CrossRef]
- Nurseitova, M.A.; Amutova, F.B.; Zhakupbekova, A.A.; Omarova, A.S.; Kondybayev, A.B.; Bayandy, G.A.; Akhmetsadykov, N.N.; Faye, B.; Konuspayeva, G.S. Comparative study of fatty acid and sterol profiles for the investigation of potential milk fat adulteration. J. Dairy Sci. 2019, 102, 7723–7733. [Google Scholar] [CrossRef] [PubMed]
- Silva, A.F.S.; Rocha, F.R.P. A novel approach to detect milk adulteration based on the determination of protein content by smartphone-based digital image colorimetry. Food Control 2020, 115, 107299. [Google Scholar] [CrossRef]
- Lima, L.S.; Rossini, E.L.; Pezza, L.; Pezza, H.R. Bioactive paper platform for detection of hydrogen peroxide in milk. Spectrochim. Acta Part A: Mol. Biomol. Spectrosc 2020, 227, 117774. [Google Scholar] [CrossRef] [PubMed]
- Chung, I.-M.; Park, I.; Yoon, J.-Y.; Yang, Y.-S.; Kim, S.-H. Determination of organic milk authenticity using carbon and nitrogen natural isotopes. Food Chem. 2014, 160, 214–218. [Google Scholar] [CrossRef]
- Liu, N.; Koot, A.; Hettinga, K.; de Jong, J.; van Ruth, S.M. Portraying and tracing the impact of different production systems on the volatile organic compound composition of milk by PTR-(Quad)MS and PTR-(ToF)MS. Food Chem. 2018, 239, 201–207. [Google Scholar] [CrossRef]
- Bergana, M.M.; Adams, K.M.; Harnly, J.; Moore, J.C.; Xie, Z. Non-targeted detection of milk powder adulteration by 1H NMR spectroscopy and conformity index analysis. J. Food Compos. Anal. 2019, 78, 49–58. [Google Scholar] [CrossRef]
- Kamal, M.; Karoui, R. Analytical methods coupled with chemometric tools for determining the authenticity and detecting the adulteration of dairy products: A review. Trends Food Sci. Technol. 2015, 46, 27–48. [Google Scholar] [CrossRef]
- Sánchez, A.; Sierra, D.; Luengo, C.; Corrales, J.C.; de la Fe, C.; Morales, C.T.; Contreras, A.; Gonzalo, C. Evaluation of the MilkoScan FT 6000 Milk Analyzer for Determining the Freezing Point of Goat’s Milk Under Different Analytical Conditions. J. Dairy Sci. 2007, 90, 3153–3161. [Google Scholar] [CrossRef]
- Jawaid, S.; Talpur, F.N.; Sherazi, S.T.H.; Nizamani, S.M.; Khaskheli, A.A. Rapid detection of melamine adulteration in dairy milk by SB-ATR–Fourier transform infrared spectroscopy. Food Chem. 2013, 141, 3066–3071. [Google Scholar] [CrossRef] [PubMed]
- Cassoli, L.D.; Sartori, B.; Zampar, A.; Machado, P.F. An assessment of Fourier Transform Infrared spectroscopy to identify adulterated raw milk in Brazil. Int. J. Dairy Technol. 2011, 64, 480–485. [Google Scholar] [CrossRef]
- Coitinho, T.B.; Cassoli, L.D.; Cerqueira, P.H.R.; da Silva, H.K.; Coitinho, J.B.; Machado, P.F. Adulteration identification in raw milk using Fourier transform infrared spectroscopy. J. Food Sci. Technol. 2017, 54, 2394–2402. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Min, L.; Wang, P.; Zhang, Y.; Zheng, N.; Wang, J. Occurrence of aflatoxin M1 in pasteurized and UHT milks in China in 2014–2015. Food Control 2017, 78, 94–99. [Google Scholar] [CrossRef]
- Zheng, N.; Sun, P.; Wang, J.Q.; Zhen, Y.P.; Han, R.W.; Xu, X.M. Occurrence of aflatoxin M1 in UHT milk and pasteurized milk in China market. Food Control 2013, 29, 198–201. [Google Scholar] [CrossRef]
- Du, B.; Wen, F.; Zhang, Y.; Zheng, N.; Li, S.; Li, F.; Wang, J. Presence of tetracyclines, quinolones, lincomycin and streptomycin in milk. Food Control 2019, 100, 171–175. [Google Scholar] [CrossRef]
- Xiong, J.; Peng, L.; Zhou, H.; Lin, B.; Yan, P.; Wu, W.; Liu, Y.; Wu, L.; Qiu, Y. Prevalence of aflatoxin M1 in raw milk and three types of liquid milk products in central-south China. Food Control 2020, 108, 106840. [Google Scholar] [CrossRef]
- Yang, Y.; Hettinga, K.A.; Erasmus, S.W.; Pustjens, A.M.; van Ruth, S.M. Opportunities for fraudsters: When would profitable milk adulterations go unnoticed by common, standardized FTIR measurements? Manuscript submitted.
- Oliveri, P. Class-modelling in food analytical chemistry: Development, sampling, optimisation and validation issues—A tutorial. Anal. Chim. Acta 2017, 982, 9–19. [Google Scholar] [CrossRef]
- Beebe, K.R.; Pell, R.J.; Seasholtz, M.B. Chemometrics: A Practical Guide; Wiley-Interscience: New York, NY, USA, 1998; Volume 4. [Google Scholar]
- Gurbanov, R.; Gozen, A.G.; Severcan, F. Rapid classification of heavy metal-exposed freshwater bacteria by infrared spectroscopy coupled with chemometrics using supervised method. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2018, 189, 282–290. [Google Scholar] [CrossRef]
- Gholami, R.; Fakhari, N. Chapter 27—Support Vector Machine: Principles, Parameters, and Applications. In Handbook of Neural Computation; Samui, P., Sekhar, S., Balas, V.E., Eds.; Academic Press: Cambridge, MA, USA, 2017; pp. 515–535. [Google Scholar] [CrossRef]
- Yang, L.; Yang, Q.; Yi, M.; Pang, Z.H.; Xiong, B.H. Effects of seasonal change and parity on raw milk composition and related indices in Chinese Holstein cows in northern China. J. Dairy Sci. 2013, 96, 6863–6869. [Google Scholar] [CrossRef]
- Guo, J.-z.; Liu, X.-l.; Xu, A.j.; Xia, Z. Relationship of Somatic Cell Count with Milk Yield and Composition in Chinese Holstein Population. Agric. Sci. China 2010, 9, 1492–1496. [Google Scholar] [CrossRef]
- Zhao, Z.-h.; Yue, T.-l.; Wang, Y.-n.; Peng, B.-z. Choice of CCP in production process of natural full-cream UHT milk. China Dairy Ind. 2005, 33, 51. [Google Scholar]
- Heck, J.M.L.; van Valenberg, H.J.F.; Dijkstra, J.; van Hooijdonk, A.C.M. Seasonal variation in the Dutch bovine raw milk composition. J. Dairy Sci. 2009, 92, 4745–4755. [Google Scholar] [CrossRef] [PubMed]
- Fox, P.F.; McSweeney, P.L.; Paul, L. Dairy Chemistry and Biochemistry; Springer: Berlin, Germany, 1998. [Google Scholar]
- National Standard of the People’s Republic of China. National Food Safety Standard Sterilized Milk. Available online: http://tradechina.dairyaustralia.com.au/wp-content/uploads/2018/08/GB-25190-2010-National-Food-Safety-Standard-Sterilized-Milk-f1-.pdf (accessed on 10 April 2020).
- De Longhi, R.; Spinardi, N.; Nishimura, M.T.; Miyabe, M.Y.; Aragon-Alegro, L.C.; De Rezende Costa, M.; De Santana, E.H.W. A survey of the physicochemical and microbiological quality of ultra-heat-treated whole milk in Brazil during their shelf life. Int. J. Dairy Technol. 2012, 65, 45–50. [Google Scholar] [CrossRef]
- Schliep, K.; Hechenbichler, K.; Lizee, A. kknn: Weighted k-Nearest Neighbors; R Package Version; R Foundation for statistical Computing: Vienna, Austria, 2016. [Google Scholar]
- Fu, S.; Han, Z.; Huo, B. Relational enablers of information sharing: Evidence from Chinese food supply chains. Ind. Manag. Data Syst. 2017. [Google Scholar] [CrossRef]
- Van Ruth, S.M.; Huisman, W.; Luning, P.A. Food fraud vulnerability and its key factors. Trends Food Sci. Technol. 2017, 67, 70–75. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Compositional Features a | |||||||
|---|---|---|---|---|---|---|---|---|
| Protein (% w/w) | Fat (% w/w) | TS (% w/w) | SNF (% w/w) | Lactose (% w/w) | Density (g/L) | FPD (°C) | ||
| Pools | Pool A (premium, North) | 3.69 | 4.05 | 13.72 | 9.73 | 5.30 | 1034 | 0.567 |
| Pool B (normal, North) | 3.44 | 3.75 | 12.79 | 9.05 | 4.88 | 1031 | 0.524 | |
| Pool C (normal, South) | 3.47 | 3.83 | 13.04 | 9.24 | 5.04 | 1032 | 0.544 | |
| Measured dataset | Mean | 3.54 | 3.95 | 13.24 | 9.33 | 5.06 | 1032 | 0.543 |
| SD | 0.15 | 0.24 | 0.51 | 0.35 | 0.21 | 1 | 0.022 | |
| Measured boundary | Lower boundary | 3.33 | 3.60 | 12.57 | 8.94 | 4.80 | 1031 | 0.516 |
| Upper boundary | 3.73 | 4.42 | 14.03 | 9.85 | 5.39 | 1035 | 0.576 | |
| Variance-adjusted boundary | Lower boundary | 3.13 | 3.26 | 11.90 | 8.55 | 4.54 | 1030 | 0.489 |
| Upper boundary | 3.93 | 4.90 | 14.82 | 10.37 | 5.72 | 1038 | 0.608 | |
| Model | Performance for Dataset | Correctly Assigned Samples a (%) | ||
|---|---|---|---|---|
| KNN | SIMCA | SVM | ||
| Model developed from the measured dataset | Training set | 100 | 100 | 100 |
| Cross-validation set | 92 | 88 | 90 | |
| Adulterant test set | 77 | 75 | 79 | |
| Overall performance | 84 | 81 | 84 | |
| Model developed from the variance-adjusted dataset | Training set | 100 | 100 | 100 |
| Cross-validation set | 93 | 91 | 92 | |
| Adulterant test set | 66 | 60 | 63 | |
| Overall performance | 79 | 75 | 77 | |
| ID | Protein (% w/w) | Fat (% w/w) | TS (% w/w) | SNF (% w/w) | Lactose (% w/w) | Density (g/L) | FPD (°C) | Area | Province | Univariate Boundaries | Multivariate Models (KNN) | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Measured Dataset | Variance-Adjusted Dataset | Measured Dataset | Variance-Adjusted Dataset | ||||||||||
| 1 | 3.09 ** | 3.56 * | 12.06 * | 8.42 ** | 4.58 * | 1029 ** | 0.488 ** | N | Tianjin | 7 | 4 | yes | no |
| 2 | 3.07 ** | 3.48 * | 11.94 * | 8.37 ** | 4.55 * | 1029 ** | 0.490 * | NW | Xinjiang | 7 | 3 | yes | no |
| 3 | 3.28 * | 3.49 * | 12.25 * | 8.69 * | 4.65 * | 1030 * | 0.515 * | NW | Xinjiang | 7 | 0 | yes | no |
| 4 | 3.05 ** | 3.79 | 12.35 * | 8.51 ** | 4.71 * | 1029 ** | 0.498 * | N | Henan | 6 | 3 | yes | no |
| 5 | 3.12 ** | 3.61 | 12.18 * | 8.50 ** | 4.62 * | 1030 * | 0.492 * | N | Tianjin | 6 | 2 | yes | no |
| 6 | 2.99 ** | 3.43 * | 12.06 * | 8.58 * | 4.85 | 1030 * | 0.512 * | E | Zhejiang | 6 | 1 | yes | no |
| 7 | 3.14 * | 3.70 | 12.32 * | 8.56 * | 4.67 * | 1030 * | 0.494 * | N | Henan | 6 | 0 | yes | no |
| 8 | 3.28 * | 3.74 | 12.49 * | 8.68 * | 4.64 * | 1030 * | 0.513 * | NW | Xinjiang | 6 | 0 | yes | no |
| 9 | 3.17 * | 3.87 | 12.54 * | 8.62 * | 4.69 * | 1030 * | 0.505 * | NW | Xinjiang | 6 | 0 | yes | no |
| 10 | 3.22 * | 3.40 * | 12.19 * | 8.72 * | 4.74 * | 1031 | 0.497 * | S | Chongqing | 6 | 0 | yes | no |
| 11 | 3.33 | 3.60 * | 12.39 * | 8.73 * | 4.63 * | 1030 * | 0.492 * | S | Yunnan | 6 | 0 | yes | no |
| 12 | 2.95 * * | 3.05 ** | 11.78 ** | 8.69 * | 4.99 | 1031 | 0.510 * | E | Jiangsu | 5 | 3 | yes | no |
| 13 | 3.14 * | 4.16 | 12.75 | 8.55 * | 4.65 * | 1029 ** | 0.496 * | N | Tianjin | 5 | 1 | yes | no |
| 14 | 3.03 ** | 3.57 * | 12.34 * | 8.74 * | 4.96 | 1031 | 0.513 * | S | Yunnan | 5 | 1 | yes | no |
| 15 | 3.17 * | 3.40 * | 12.29 * | 8.85 * | 4.93 | 1031 | 0.510 * | N | Shanxi | 5 | 0 | yes | no |
| 16 | 3.15 * | 4.15 | 12.81 | 8.62 * | 4.70 * | 1030 * | 0.500 * | NW | Xinjiang | 5 | 0 | yes | no |
| 17 | 3.27 * | 3.53 * | 12.41 * | 8.83 * | 4.80 | 1031 | 0.514 * | S | Yunnan | 5 | 0 | no | no |
| 18 | 3.01 ** | 3.63 | 12.26 * | 8.58 * | 4.81 | 1028 ** | 0.538 | S | Hubei | 4 | 1 | yes | no |
| 19 | 3.12 ** | 3.51 * | 12.47 * | 8.95 | 5.07 | 1032 | 0.513 * | S | Yunnan | 4 | 1 | yes | no |
| 20 | 3.25 * | 4.21 | 13.05 | 8.81 * | 4.80 | 1030 * | 0.505 * | N | Hebei | 4 | 0 | yes | no |
| 21 | 3.12 ** | 4.06 | 12.86 | 8.78 * | 4.91 | 1030 * | 0.523 | NW | Shaanxi | 3 | 1 | yes | no |
| 22 | 3.25 * | 3.31 * | 12.32 * | 8.97 | 4.96 | 1032 | 0.520 | N | Beijing | 3 | 0 | yes | no |
| 23 | 3.37 | 4.16 | 13.09 | 8.89 * | 4.75 * | 1030 * | 0.525 | NW | Gansu | 3 | 0 | no | no |
| 24 | 3.30 * | 3.47 * | 12.50 * | 8.99 | 4.94 | 1032 | 0.523 | S | Guangdong | 3 | 0 | no | no |
| 25 | 3.26 * | 3.58 * | 12.67 | 9.07 | 5.06 | 1032 | 0.531 | N | Hebei | 2 | 0 | no | no |
| 26 | 3.09 ** | 3.75 | 12.76 | 9.00 | 5.16 | 1032 | 0.541 | E | Shandong | 1 | 1 | yes | no |
| 27 | 3.26 * | 4.23 | 13.24 | 9.00 | 4.97 | 1031 | 0.570 | NW | Qinghai | 1 | 0 | yes | no |
| 28 | 3.32 * | 3.97 | 13.24 | 9.29 | 5.21 | 1033 | 0.536 | S | Yunnan | 1 | 0 | yes | no |
| 29 | 3.29 * | 3.84 | 12.91 | 9.05 | 5.00 | 1032 | 0.538 | E | Shandong | 1 | 0 | no | no |
| 30 | 3.29 * | 3.83 | 12.94 | 9.06 | 5.05 | 1032 | 0.532 | N | Beijing | 1 | 0 | no | no |
| 31 | 3.30 * | 3.91 | 12.95 | 9.03 | 4.97 | 1032 | 0.524 | N | Hebei | 1 | 0 | no | no |
| 32 | 3.63 | 3.88 | 13.67 | 9.83 | 5.42 † | 1035 | 0.573 | NE | Heilongjiang | 1 | 0 | no | no |
| 33 | 3.34 | 3.57 * | 12.73 | 9.13 | 5.03 | 1032 | 0.524 | NW | Ningxia | 1 | 0 | no | no |
| 34 | 3.26 * | 3.99 | 13.10 | 9.11 | 5.08 | 1032 | 0.539 | NW | Xinjiang | 1 | 0 | no | no |
| 35 | 3.32 * | 3.97 | 13.17 | 9.19 | 5.11 | 1032 | 0.538 | S | Chongqing | 1 | 0 | no | no |
| 36 | 3.28 * | 3.63 | 12.67 | 9.01 | 4.97 | 1032 | 0.530 | S | Guangdong | 1 | 0 | no | no |
| 37 | 3.58 | 3.85 | 13.57 | 9.74 | 5.40 † | 1035 | 0.566 | S | Guangdong | 1 | 0 | no | no |
| 38 | 3.47 | 4.32 | 13.73 | 9.44 | 5.21 | 1033 | 0.546 | E | Jiangsu | 0 | 0 | yes | yes |
| 39 | 3.60 | 3.86 | 13.40 | 9.55 | 5.18 | 1033 | 0.553 | NE | Heilongjiang | 0 | 0 | yes | yes |
| 40 | 3.55 | 4.20 | 13.55 | 9.35 | 5.02 | 1032 | 0.540 | E | Shandong | 0 | 0 | yes | no |
| 41 | 3.40 | 3.72 | 13.08 | 9.36 | 5.20 | 1033 | 0.548 | NW | Xinjiang | 0 | 0 | yes | no |
| 42 | 3.40 | 4.40 | 13.56 | 9.16 | 4.99 | 1032 | 0.536 | S | Guizhou | 0 | 0 | yes | no |
| 43 | 3.51 | 4.22 | 13.83 | 9.65 | 5.36 | 1034 | 0.560 | N | Hebei | 0 | 0 | no | yes |
| Parameters | East | Central-North | North-West | North-East | Variable Coefficients d | |
|---|---|---|---|---|---|---|
| Percentage (%) of suspected samples in the market survey set (number of suspected/total samples) | 38% (3/8) | 31% (4/13) | 13% (2/15) | 0% (0/2) | - | |
| Fraud factors on opportunities and motivations b | 1. Available technology for milk adulteration | 49 | 46 | 71 | 66 | −0.201 |
| 2. Detectability of adulteration | 51 | 56 | 35 | 58 | −0.056 | |
| 3. Accessibility to production activities | 53 | 49 | 57 | 63 | −0.243 | |
| 4. Relationships within the supply chain | 47 | 61 | 39 | 36 | 0.174 | |
| 5. Valuable components/attributes | 38 | 62 | 39 | 42 | 0.023 | |
| 6. Farmer’s financial pressure imposed by the company | 40 | 61 | 40 | 45 | 0.005 | |
| 7. Level of competition | 73 | 41 | 73 | 53 | 0.096 | |
| 8. Price difference due to regulatory differences | 62 | 47 | 67 | 48 | 0.125 | |
| Fraud factors on Controls c | 9. Application of integrity screening of employees in the company | 51 | 46 | 70 | 63 | −0.172 |
| 10. Strictness of the ethical code of conduct in the company | 45 | 48 | 70 | 61 | −0.188 | |
| 11. Support of a whistle-blowing system in the company | 62 | 47 | 69 | 48 | 0.115 | |
| 12. Specificity of the national food policy | 70 | 48 | 55 | 49 | 0.209 | |
| 13. Availability of a fraud contingency plan | 62 | 45 | 65 | 61 | −0.051 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Zhang, L.; Hettinga, K.A.; Erasmus, S.W.; van Ruth, S.M. Prevalence of Milk Fraud in the Chinese Market and its Relationship with Fraud Vulnerabilities in the Chain. Foods 2020, 9, 709. https://doi.org/10.3390/foods9060709
Yang Y, Zhang L, Hettinga KA, Erasmus SW, van Ruth SM. Prevalence of Milk Fraud in the Chinese Market and its Relationship with Fraud Vulnerabilities in the Chain. Foods. 2020; 9(6):709. https://doi.org/10.3390/foods9060709
Chicago/Turabian StyleYang, Yuzheng, Liebing Zhang, Kasper A. Hettinga, Sara W. Erasmus, and Saskia M. van Ruth. 2020. "Prevalence of Milk Fraud in the Chinese Market and its Relationship with Fraud Vulnerabilities in the Chain" Foods 9, no. 6: 709. https://doi.org/10.3390/foods9060709
APA StyleYang, Y., Zhang, L., Hettinga, K. A., Erasmus, S. W., & van Ruth, S. M. (2020). Prevalence of Milk Fraud in the Chinese Market and its Relationship with Fraud Vulnerabilities in the Chain. Foods, 9(6), 709. https://doi.org/10.3390/foods9060709