We apply the state-of the-art deep reinforcement learning algorithm, namely PPO, for loading and unloading rolling cargo from ships.
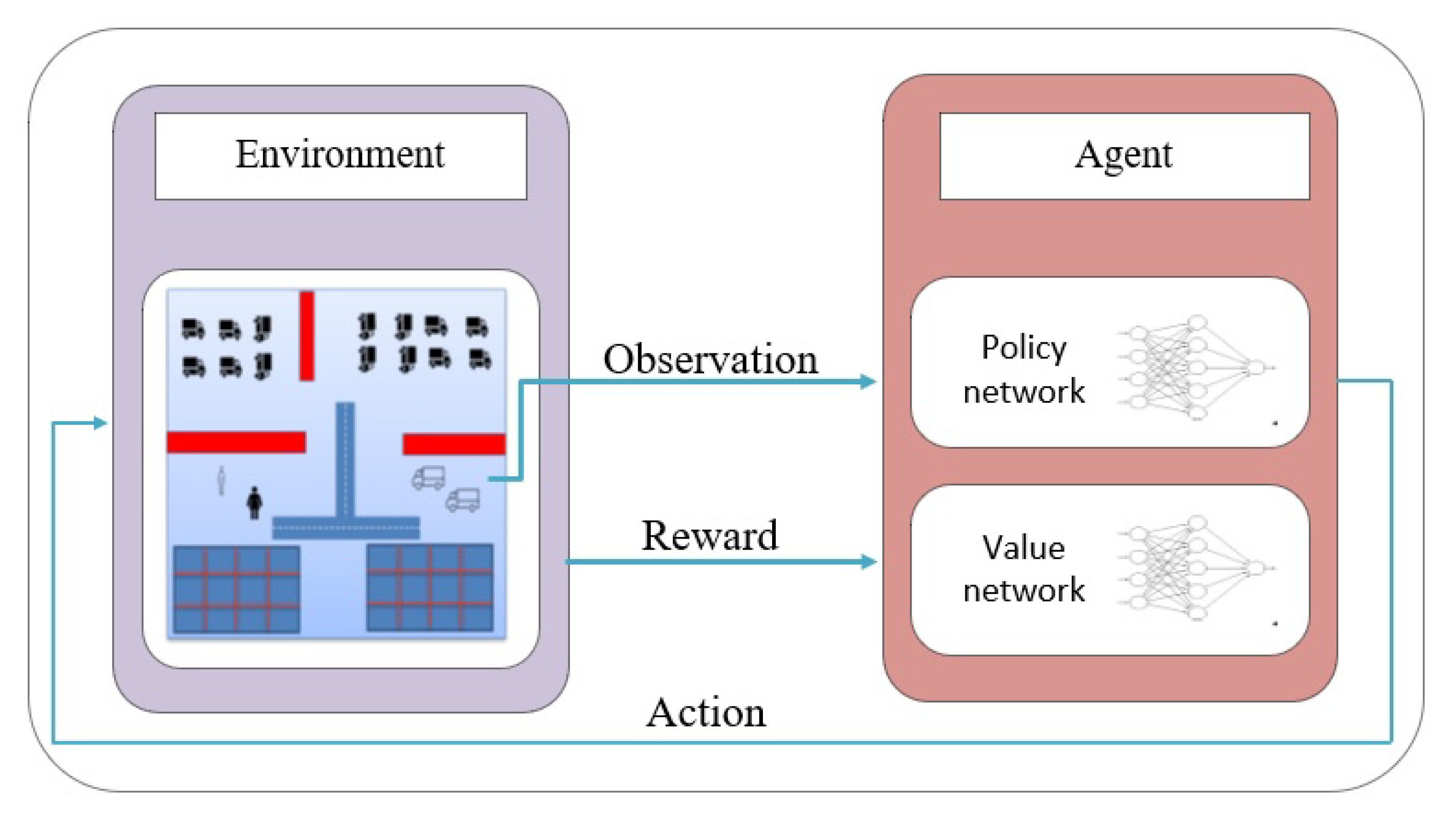
DRL algorithms require a large number of experiences to be able to learn complex tasks, and therefore, it is infeasible to train them in the real world. Moreover, the agents start by exploring the environment and taking random actions, which can be unsafe and damaging to the agent and the surrounding objects. Thus, it is necessary to develop a simulation environment with characteristics similar to reality in order to train the agents, speed up their learning, and avoid material costs. Our study used a simulation based approach performed with Unity3D. The environment in which we expect the agent to operate is the harbor quay and the ship filled with obstacles. The agent is the tug master itself even if it is more accurate to think of the agent as the guiding component, which controls the tug master, since its function is limited to generating the control signals that steer the tug master’s actuators. It is equipped with sensors for obstacle detection and trained and evaluated in a challenging environment making use of the Unity3D learning framework (ML-Agents). The next subsections first describe the algorithm used, then the entire system and the interactions between its components.
3.2. Algorithm
The agent should perform a set of tasks , where each is moving trucks from different initial positions to the target states under certain constraints such as static obstacles’ distribution, dynamic obstacles, lane-following, and truck size. We consider the task as being a tuple: . The goal of our policy based approach is to optimize a stochastic policy , which is parameterized by . In other words, the objective is to find a strategy that allows the agents to accomplish the tasks from various initial states with limited experiences. Given the state of the environment at time t for task T, the learning model of our agent predicts a distribution of actions according to the policy, from which an action at is sampled. Then, the agent interacts with the environment performing the sampled action and receives an immediate reward according to the reward function. Afterwards, it perceives next state . In an iterative way, the learning model needs to optimize the loss function that maps a trajectory followed by the policy from an initial state to a finite horizon H. The loss of a trajectory is nothing but negative cumulative reward .
The policy learning is shown in Algorithm 1. In each episode, we collect
N trajectories under the policy
. Afterwards, the gradient of the loss function is computed with regard to the parameter
, and the latter is updated accordingly.
| Algorithm 1: Pseudocode for policy learning. |
![Logistics 05 00010 i001]() |
3.3. DRL Implementation Workflow
The first task is to develop a realistic and complex environment with goal-oriented scenarios. The environment includes ship, walls, walking humans, rolling cargo, lanes, and tug masters. The cargo is uniformly distributed in random positions inside an area representing the quay where cargo should be queued. The maximum linear velocity in the x and y axes is 5 m/s, and the maximum angular velocity in the z axis is 2 rad/s. The agents observe the changes in the environment and collect the data, then send them along with reward signals to the behavior component, which will decide the proper actions. Then, they execute those actions within their environment and receive rewards. This cycle is repeated continuously until the convergence of the solution. The behavior component controlling the agents is responsible for learning the optimal policy. The learning process was divided into episodes with a length of time steps where the agent must complete the task. A discrete time step, i.e., a state, is terminal if:
The agents collide with a dynamic obstacle.
The maximal number of steps in the episode is achieved.
The agents place all cargo in the destinations, which means that all tasks are completed.
Data collection: the set of observations that the agent perceives about the environment. Observations can be numeric or visual. Numeric observations measure the attributes of the environment using sensors, and the visual inputs are images generated from the cameras attached to the agent and represent what the agent is seeing at that point in time. In our application, we use the ray perception sensors, which measure the distance to the surrounding objects. The inputs of the value/policy network are collected instantly by the agents and consist of their local state information. The agents navigate according to this local information, which represents the relative position of agents to surrounding obstacles using nine raycast sensors with between them. No global state data are received from the agents, such as absolute position or orientation in a coordinate reference. In addition, we feed to the input of the neural network other data like the attributes of the sensed cargo.
The agents share the same behavior component. This means that they will learn the same policy and share experience data during the training. If one of the agents discovers an area or tries some actions, then the others will learn from that automatically. This helps to speed up the training.
Action space: the set of actions the agent can take. Actions can either be continuous or discrete depending on the complexity of the environment and agent. In the simulation, the agent can move, rotate, pull, and release the cargo and select the destination where to release the dragged cargo.
Reward shaping: Reward shaping is one of the most important and delicate operations in RL. Since the agent is reward motivated and is going to learn how to act by trial experiences in the environment, simple and goal-oriented functions of rewards need to be defined.
According to this multi-task setting, we implement reward schemes to fulfil each task and achieve the second sub-goal since the task functions are relatively decoupled from each other and, in particular, the relationship between collision avoidance and path planning maneuvers and placement constraints. We train the agent with deep RL to obtain the skill of moving from different positions with various orientations to a target pose while considering the time and collision avoidance, as well as the constraints from both the agent and placement space. Thus, each constraint stated in the specifications should have its appropriate reward and/or penalty function. The reward can be immediate after each action or transition from state-to-state and measured as the cumulative reward at the end of the episode. In addition, the sparse reward function is used instead of continuous rewards since the relationship between the current state and goal is nonlinear.
During the episode:
- −
The task must be completed on time. Therefore, after each action, a negative reward is given to encourage the agent to finish the mission quickly. It equals such that is the maximum number of steps allowed for an episode.
- −
If an object is transported to the right destination, a positive reward is given.
After episode completion: If all tasks are finished, a positive reward is given .
Static collision avoidance: Agents receive a negative reward (−1) if they collide with a static obstacle. Box colliders are used to detect the collisions with objects in Unity3D.
Dynamic collision avoidance: There are two reward schemes: the episode must be terminated if a dynamic obstacle is hit, which means that the tug master fails to accomplish the mission; the second option is to assign a negative reward to the agent and let it finish the episode. A successful avoidance is rewarded as well. To enhance the safety and since dynamic obstacles are usually humans, the second choice is adopted.
Lane-following: No map or explicit rules are provided to the agent. The agent relies solely on the reward system to navigate, which makes this task different from path following in which a series of waypoints to follow is given to the agent. The agent is rewarded for staying on the lane continuously, i.e., in each step, and since the agent often enters and leaves the lanes during the training, the rewards for lane-following have to be very small so that they do not influence the learning of the objective.
- −
Entering the lane: positive reward .
- −
Staying in the lane: positive reward .
- −
Going out of the lane: negative reward ; should be larger than the entry reward to avoid zigzag behavior.
If we suppose that the lanes are obstacle-free, the accumulated reward is the sum of the obtained rewards during the episode. Otherwise, obstacle avoidance and lane-following are considered as competing objectives. Then, a coefficient
is introduced to make a trade-off between them, as described by Equation (
1), with
and
being the lane-following and obstacle avoidance rewards at time
t, respectively.
Configuration parameters: The most important parameters are explained in the following lines, and the others are summarized in
Table 1.
Batch size: the number of training samples (observations) fed to the network in one iteration; its value is set to 1024.
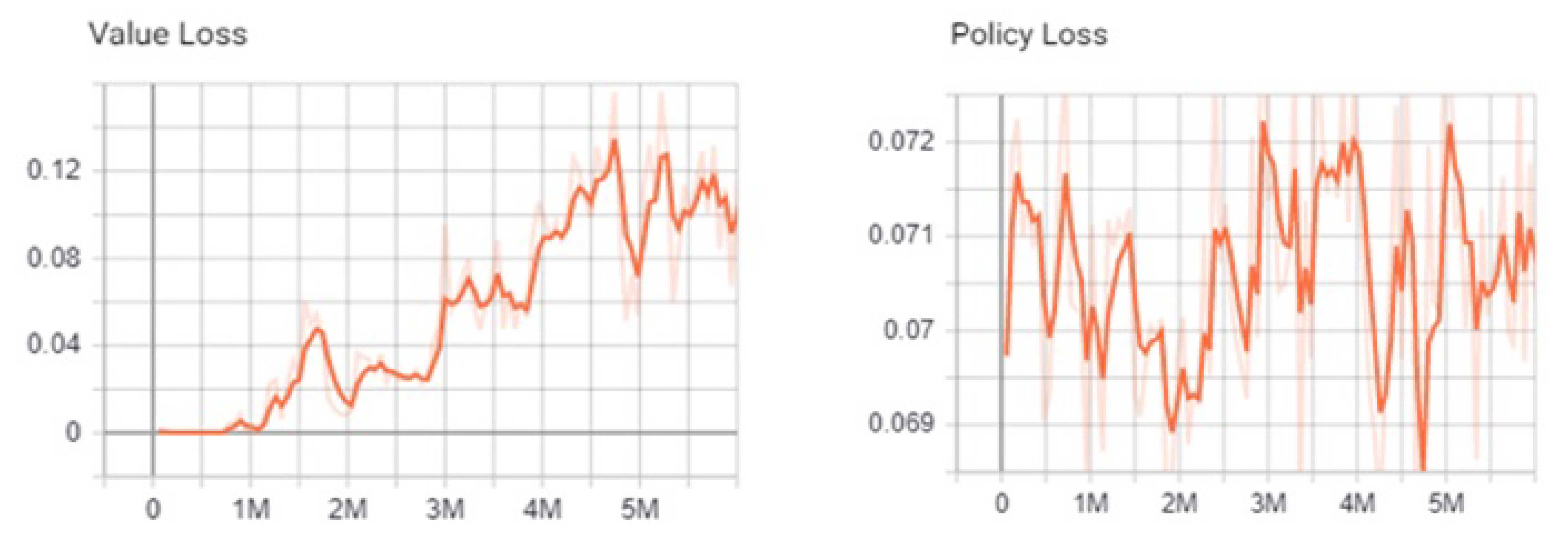
Number of epochs: Each epoch is one complete presentation of the dataset to be learned by a learning machine. After each epoch, the model weights are updated. Each epoch includes many iterations (data size divided by the batch size), and each iteration consists of one feed-forward and back-propagation of only one batch. Three epochs are generally sufficient to digest all the data features.
Learning rate: controls the change amount made by adjusting the weights of the network with respect to the loss gradient, called also the step size. It can simply be defined as how much newly acquired information overrides the old. The learning rate is the most important hyperparameter to tune to achieve good performance in the problem, commonly denoted as beta.
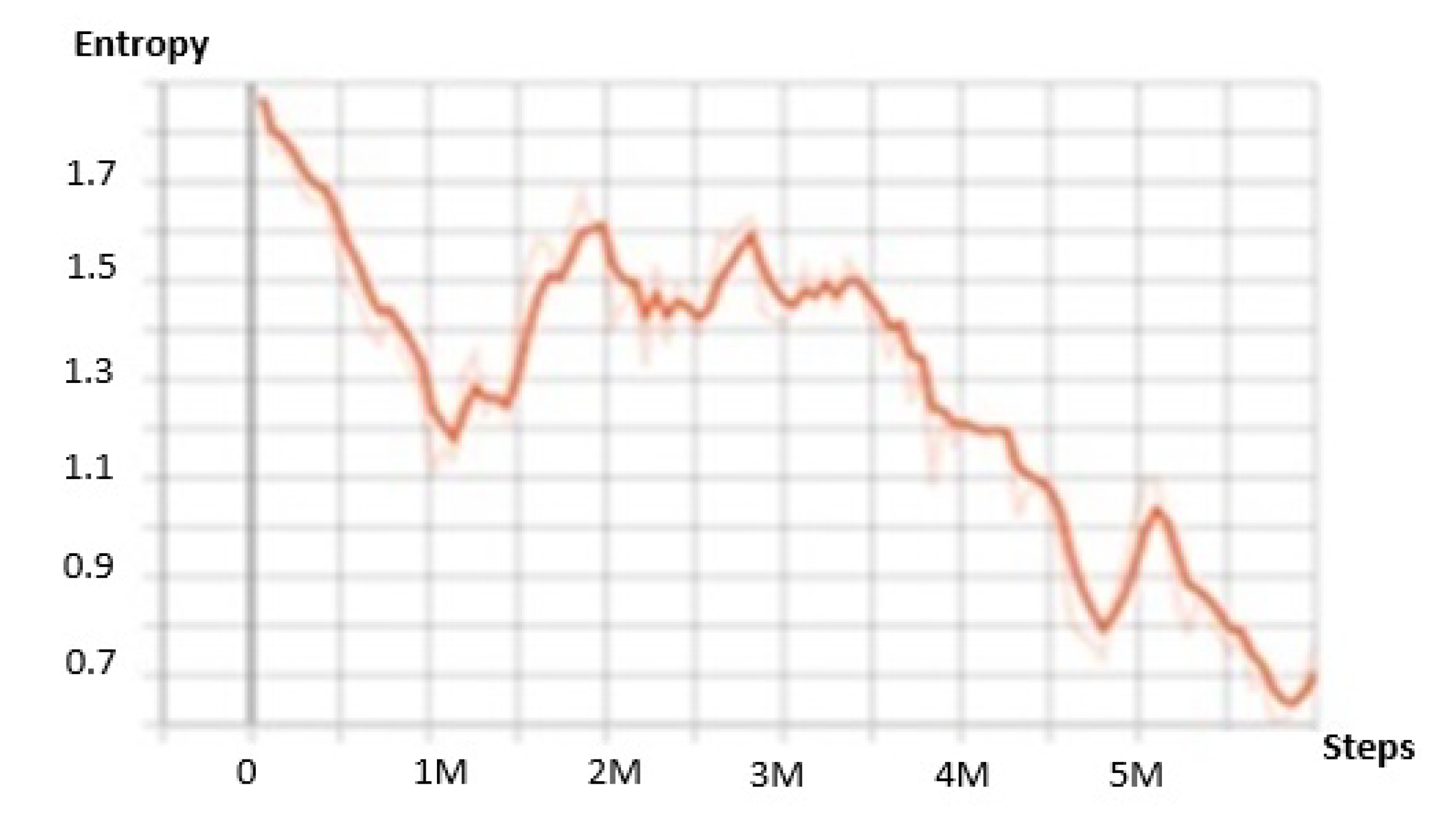
Epsilon decay: controls the decrease in the learning rate so that the exploration and exploitation are balanced throughout the learning. Exploration means that the agent searches over the whole space in the hope to find new states that potentially yield higher rewards in the future. On the other hand, exploitation means the agent’s tendency to exploit the promising states that return the highest reward based on existing knowledge. The value of epsilon decay is generally set around .
The parameter values exposed herein are the default values recommended for general tasks. For our specific task, optimal hyperparameters are obtained using tuning techniques. In fact, one of the big challenges of DRL is the selection of hyperparameter values. DRL methods include parameters not only for the deep learning model, which learns the policy, but also in the environment and the exploration strategy. The parameters related to the model design make it possible to construct a deep learning model capable of effectively learning latent features of the sampled observations; whereas a proper choice of parameters related to the training process allows the built model to speed up the learning and converge towards the objective.
The hyperparameter optimization problem (HPO) is a challenging task since the hyperparameters interact with each other and do not act independently, which makes the search space very huge. Different types of methods have been used to solve the HPO problem. Basic search methods sample the search space according to a very simple rule and without a guiding strategy, such as the grid search method and the random search method [
37]. More advanced methods are sample based and use a policy to guide the sampling process and update the policy based on evaluating the new sample. The well-known algorithms of this category are Bayesian based optimizers [
38] and population based techniques such as the genetic algorithm, which we opt to use in this paper [
39]. The challenge here is to find a policy that finds the optimal configuration in a few iterations and avoids local optima. The last category includes HPO gradient based methods that perform the optimization by directly computing the partial derivative of the loss function on the validation set [
40].
All the experiments were done using Unity3D Version 2018.4 and ML-Agents v.1.1.0 developed by Unity technologies, San Francisco, US. C# was used to create the environment and scripts controlling the agents, while Python was used to develop the learning techniques and train the agents. The external communicator of Unity allows the agent training using the Python code. The agents use the same brain, which means that their observations are sent to the same model to learn a shared policy. A machine with the microprocessor Intel i7 and a RAM size of 16G was used to run the implemented code.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}