
A Puzzle-Based Sequencing System for Logistics Items


Abstract
:1. Introduction
2. Puzzle-Based System
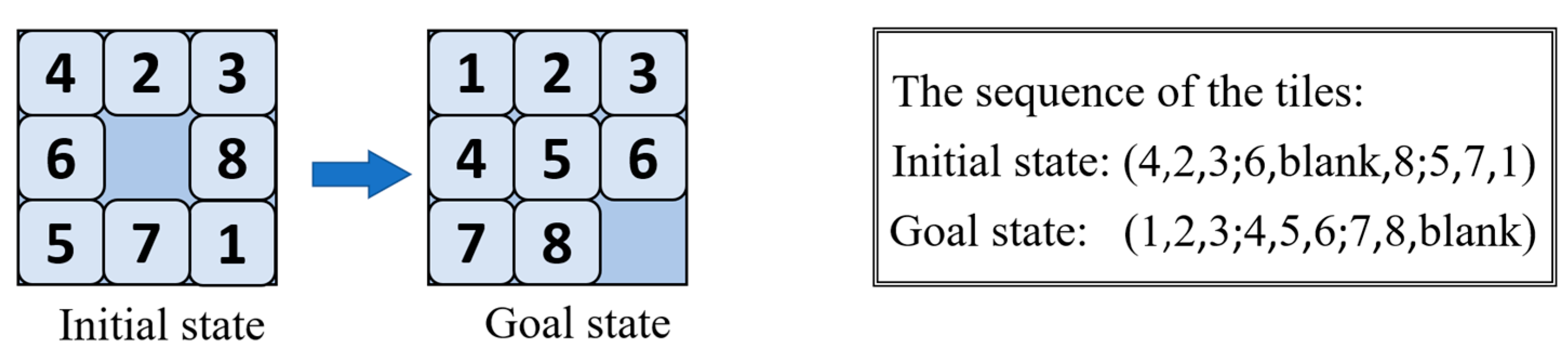
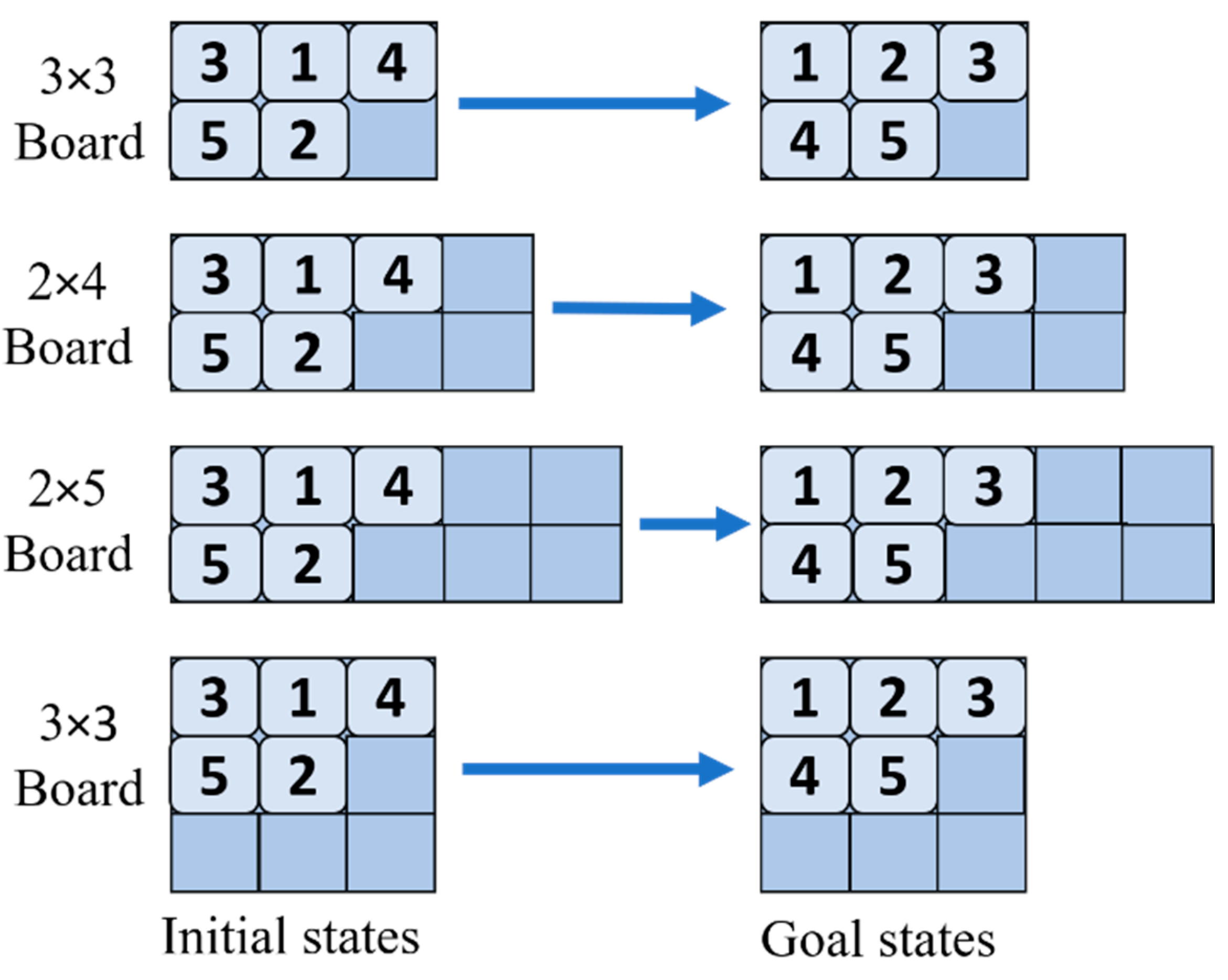
2.1. Sliding Puzzle
2.2. Puzzle Solving Methods
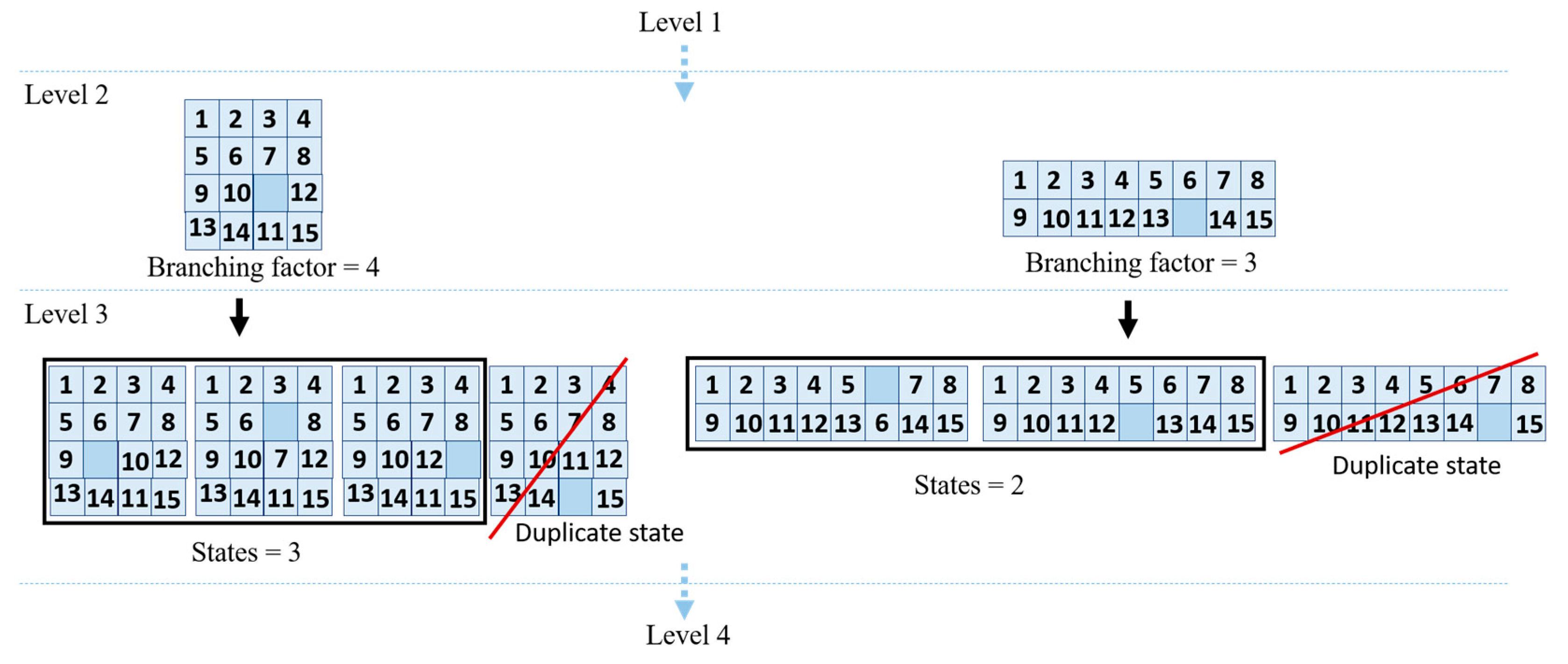
2.2.1. Game Tree
- Start tree creation from the target state;
- Find the input node (the initial configuration) in this tree;
- Track the path which leads to the initial node.
- (i)
- The huge number of states
- (ii)
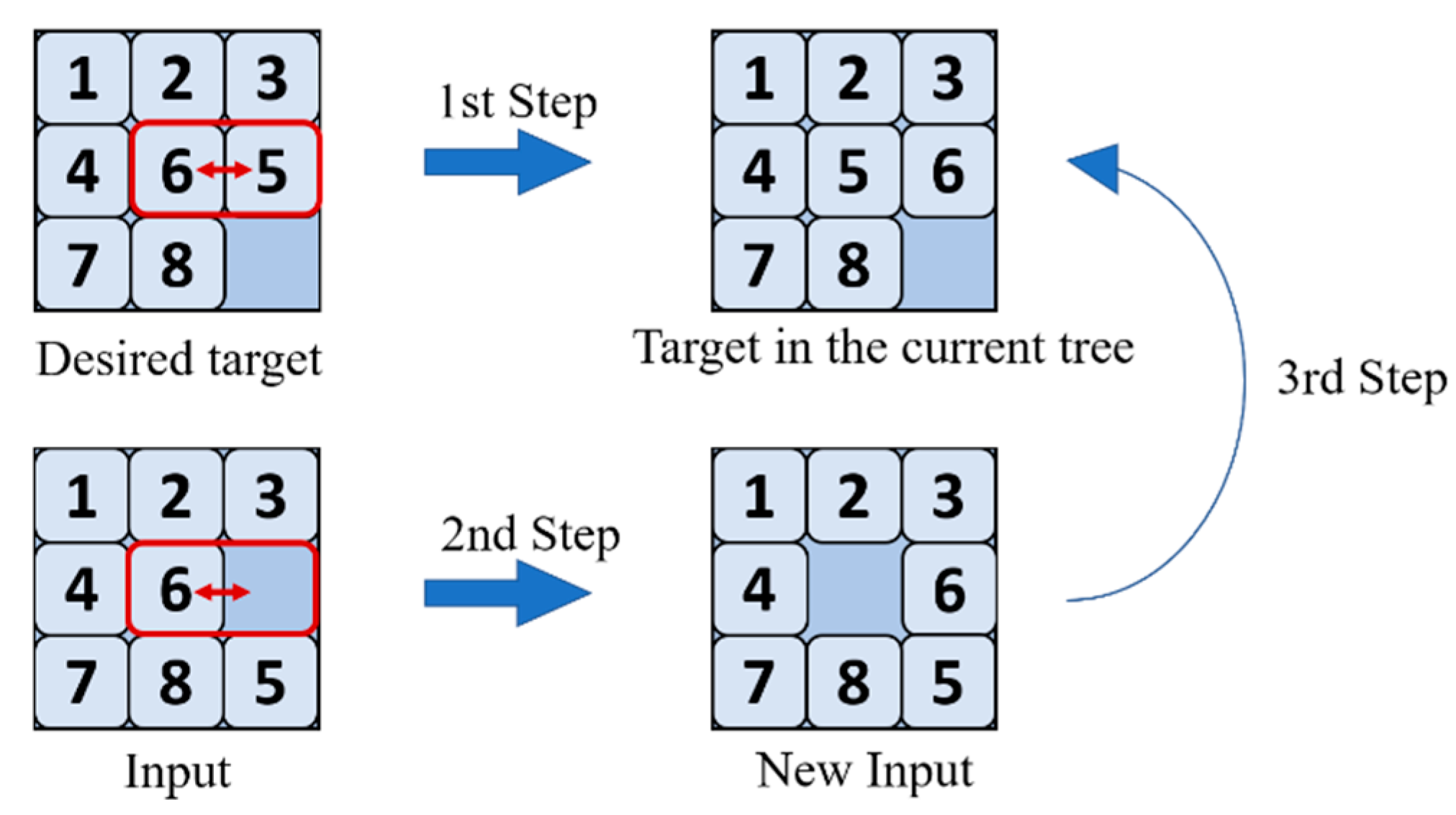
- Searching for different targets
- Change the desired target to the target in the current tree;
- Apply the same changes to the input;
- Find the new input in the current tree.
2.2.2. Pathfinding Algorithms
- (i)
- Uninformed algorithms (blind algorithms)
- (ii)
- Informed algorithms
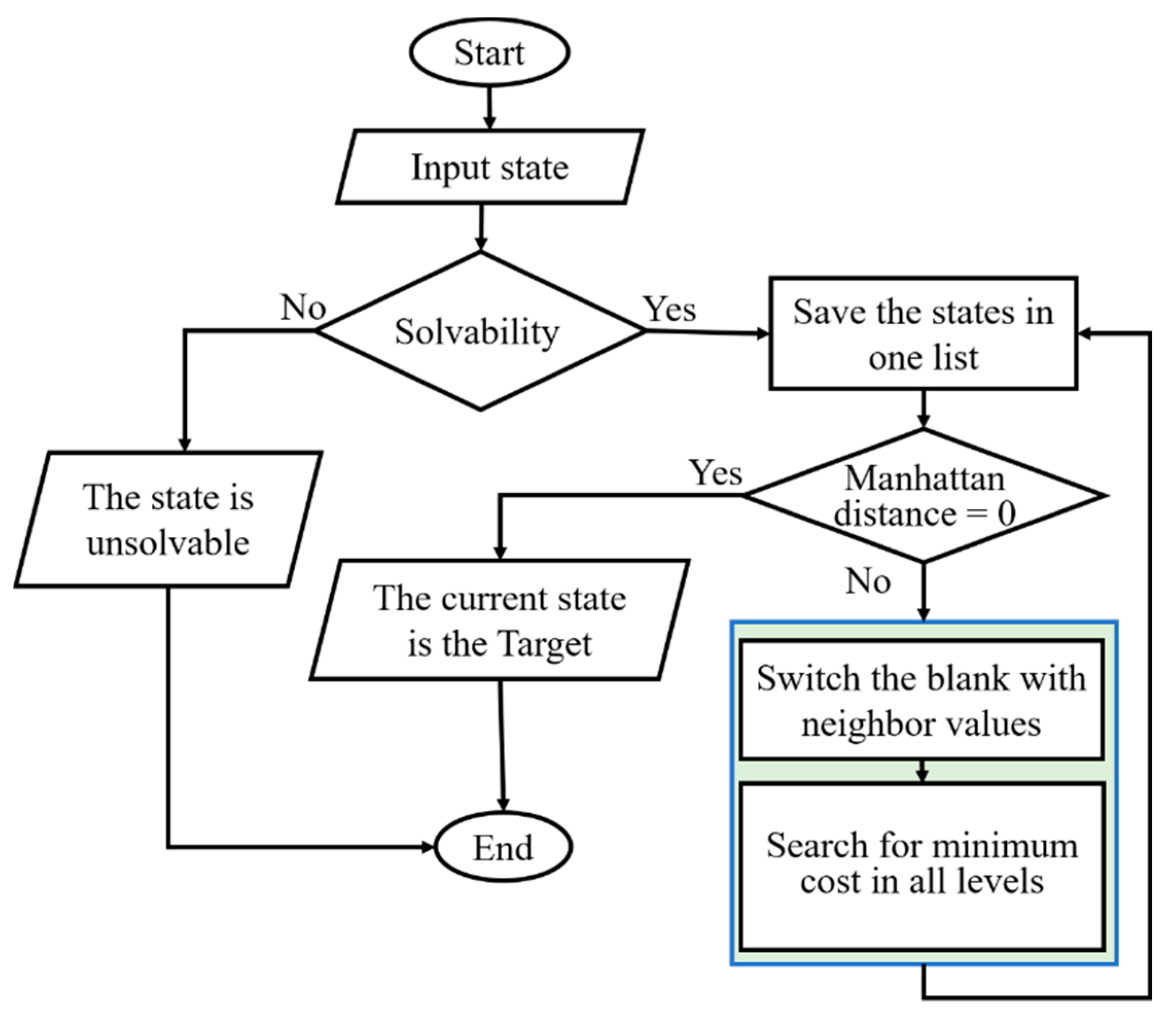
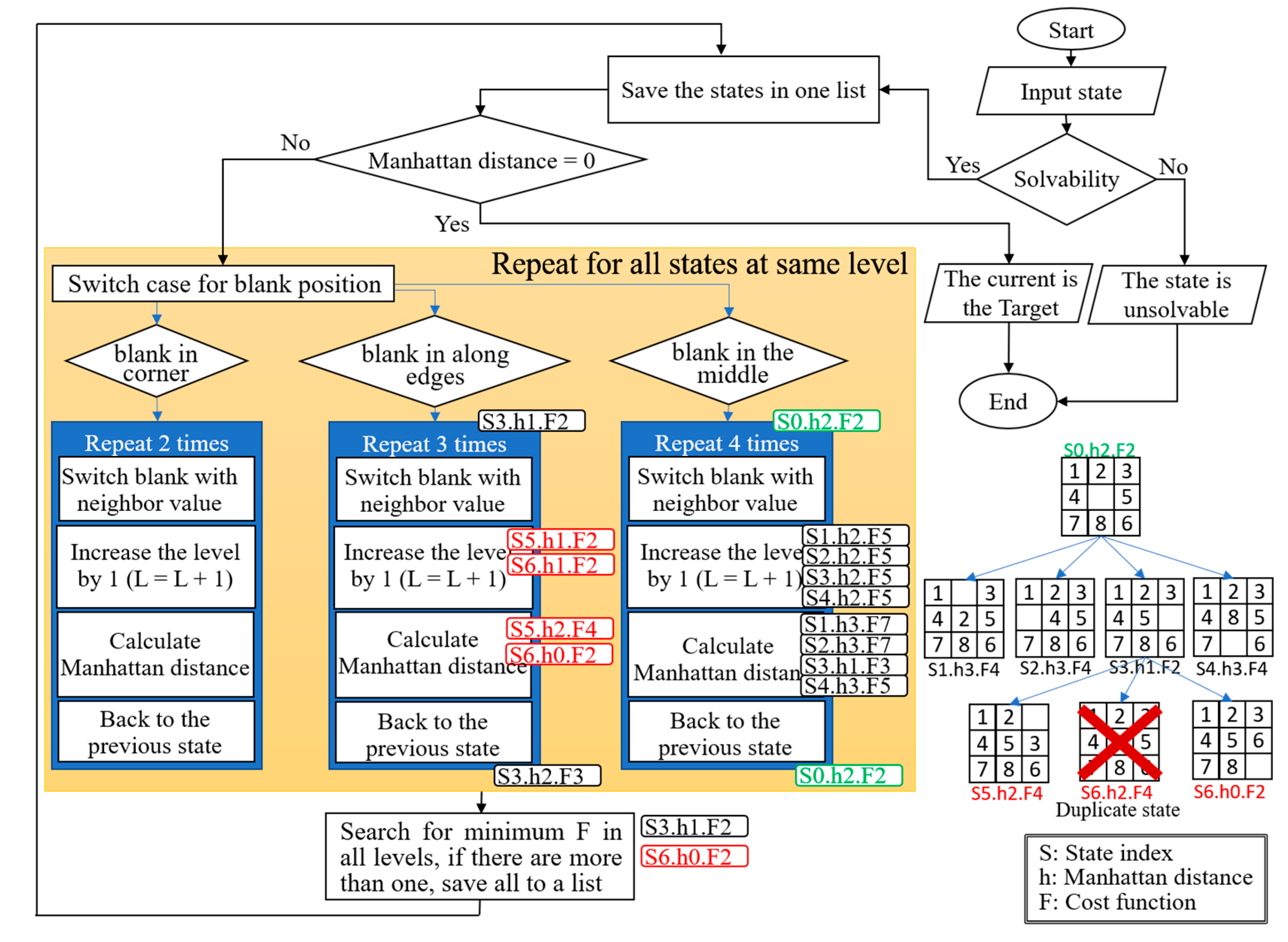
2.3. A-Star Algorithm
| Algorithm 1: A* Implementation for 8-puzzle |
| 1: if solvable then 2: Check Manhattan distance 3: else 4: End Algorithm 5: Repeat until finding the target 6: if Manhattan ≠ 0 then 7: Find a blank 8: Perform Procedure switching blank 9: Search for minimum cost 10: else 11: Input is the target 12: end if 13: end repeat |
| Algorithm 2: Procedure: Switching blank |
| 1: if blank in a corner then 2: Repeat 2 times: switch blank 3: else 4: if blank in along edges then 5: Repeat 3 times: switch blank 6: else 7: if blank in the middle then 8: Repeat 4 times: switch blank 9: end if |
- Switch blank with a neighbor;
- Increase the depth (level in the tree which denotes the solution steps) by 1;
- Recalculate Manhattan distance.
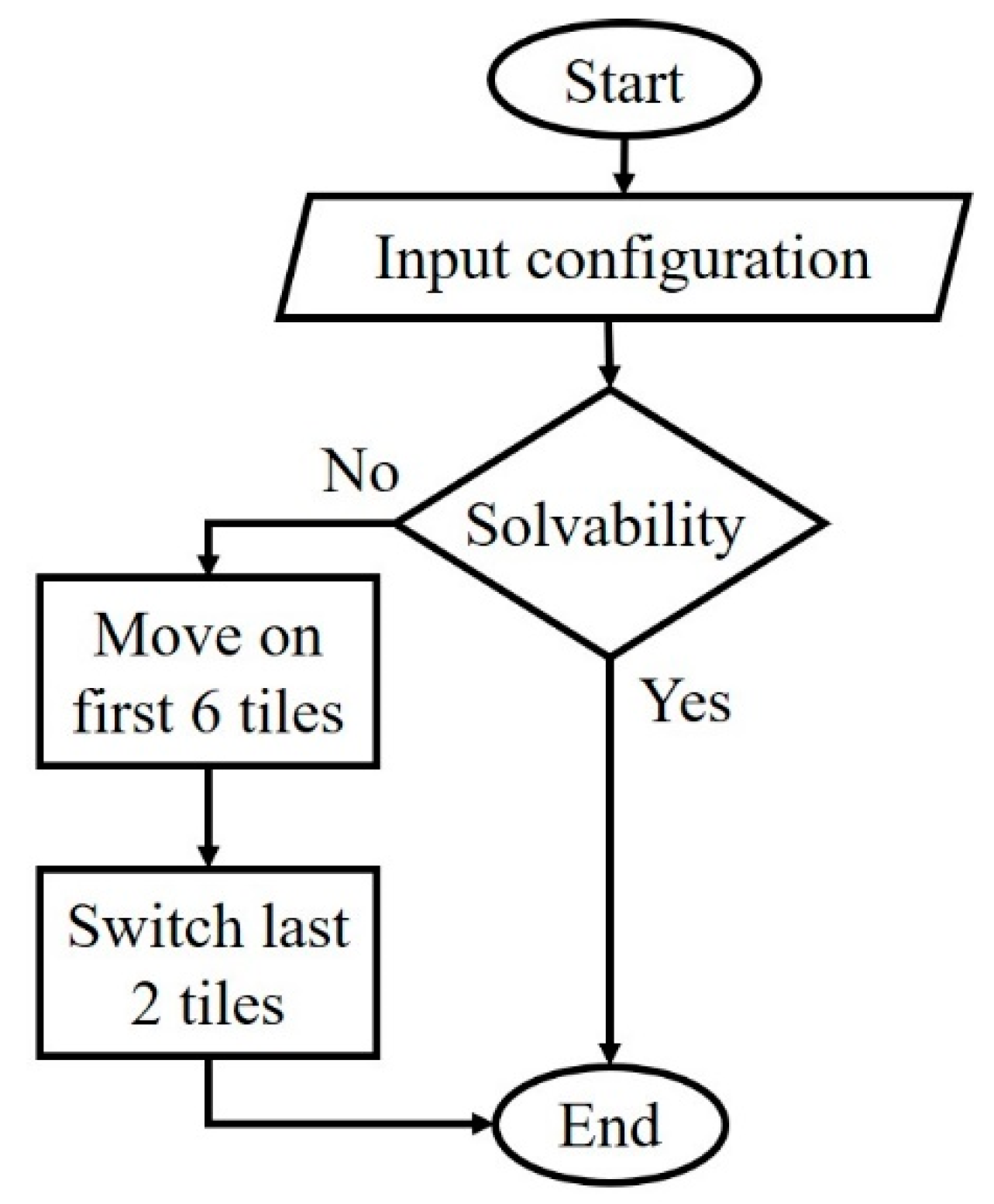
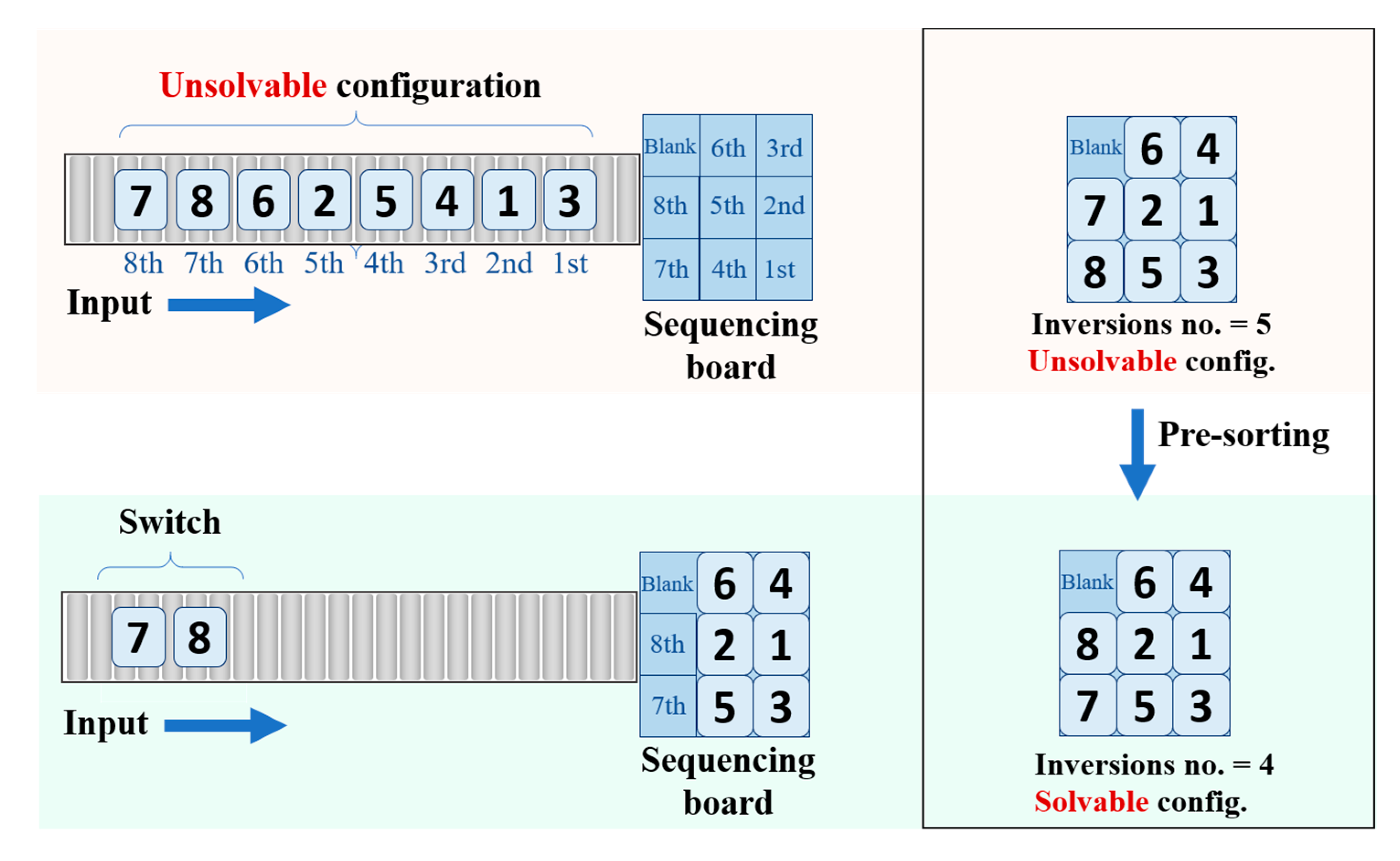
2.4. Solvability Condition
| The Investigated Tile | Tiles Follow the Investigated Tile | Number of Inversions |
| 2 | 1 | 1 |
| 1 | - | 0 |
| 5 | 4 and 3 | 2 |
| 4 | 3 | 1 |
| 3 | - | 0 |
| 8 | 6 and 7 | 2 |
| 6 | - | 0 |
| 7 | - | 0 |
| Total inversions | 6 |
Proposal for the Solvability Problem
- Check the solvability by calculating the inversion number;
- In case of an odd number of inversions, move the first six tiles to their specific positions on the sequencing board;
- Switch the last two tiles on the board.
2.5. Board Shape
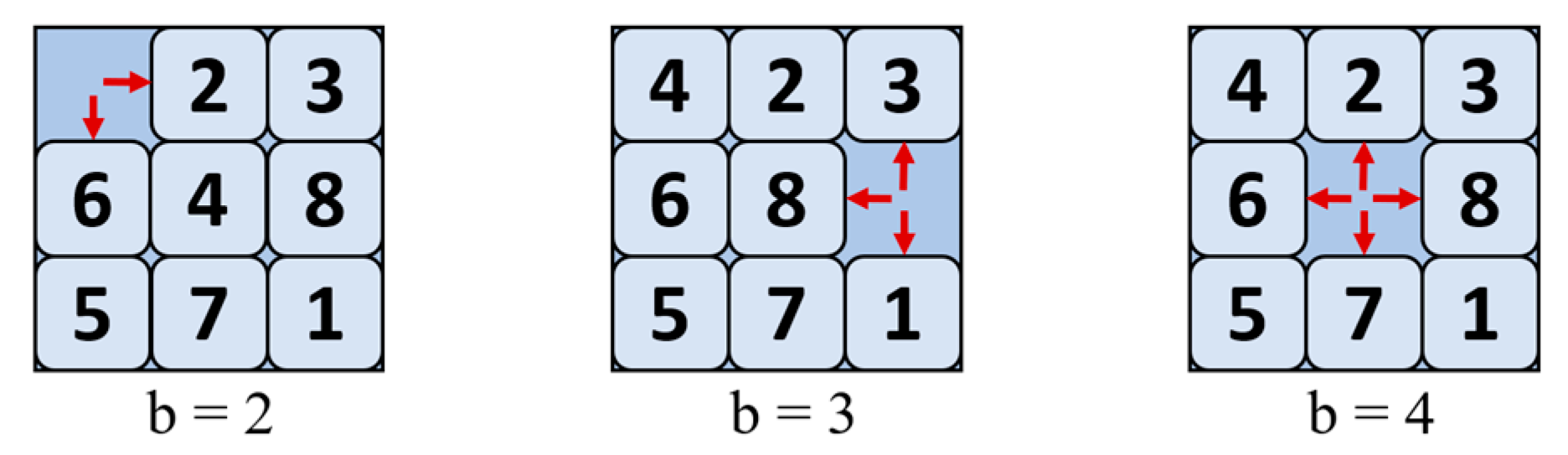
2.5.1. Branching Factor
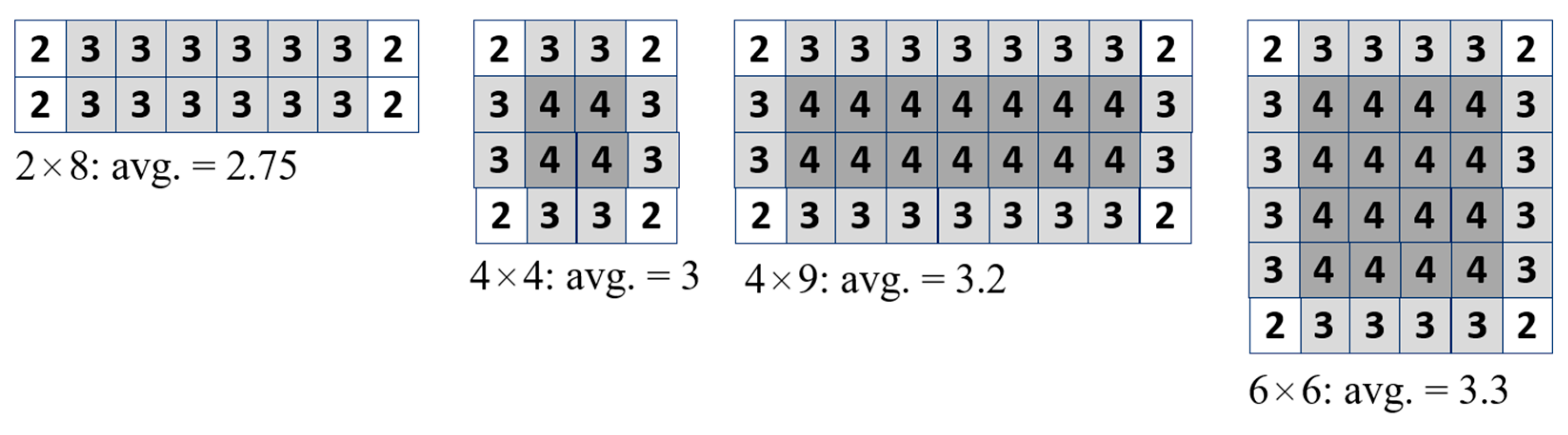
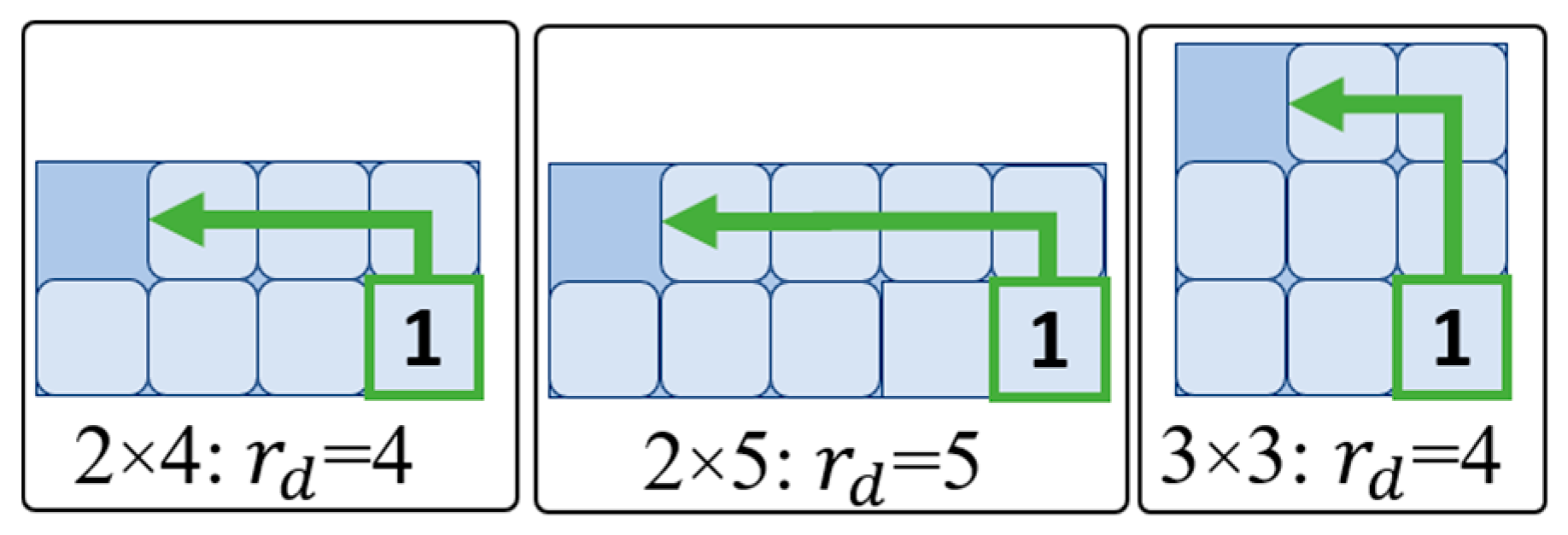
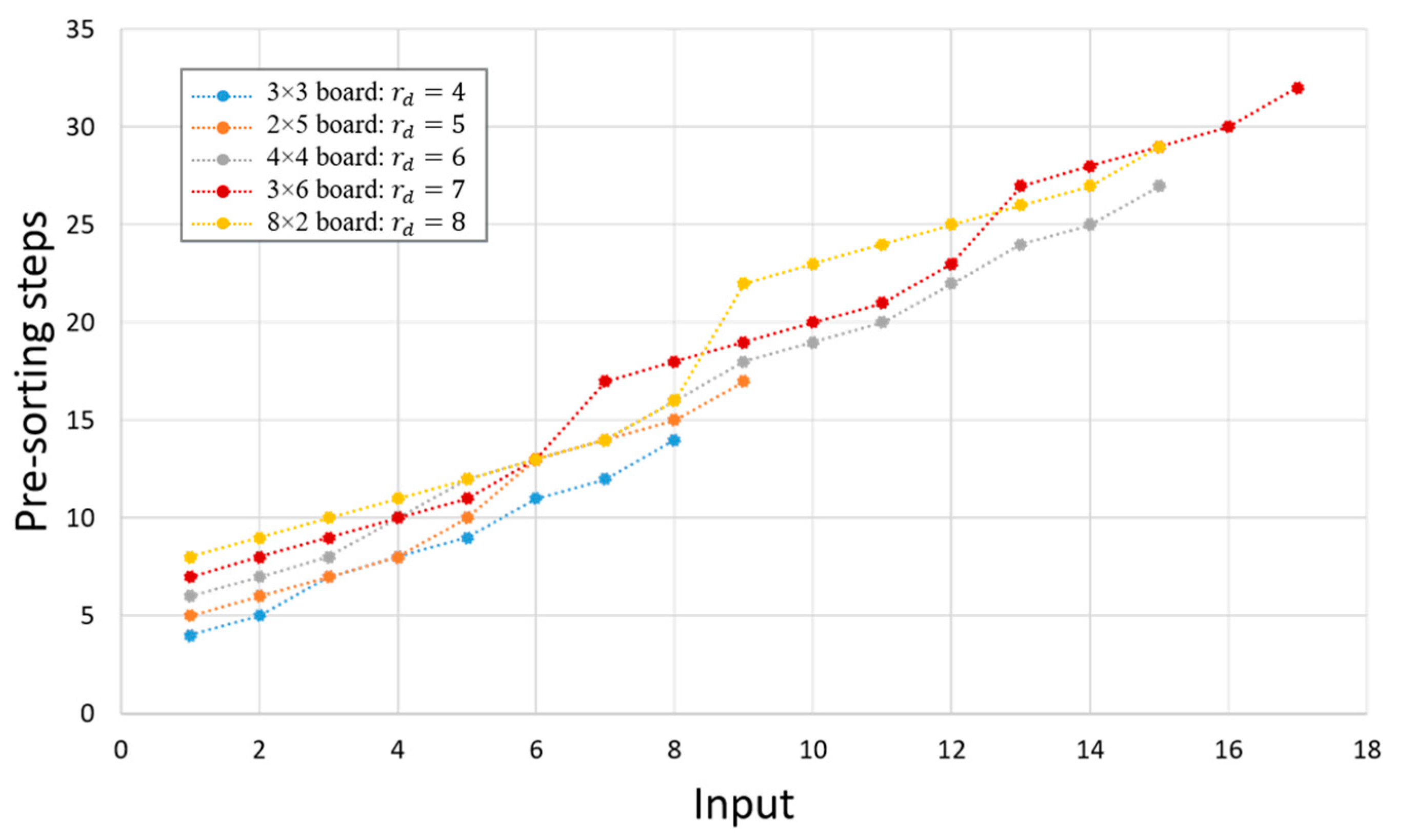
2.5.2. Maximum Rectilinear Distance of One Tile
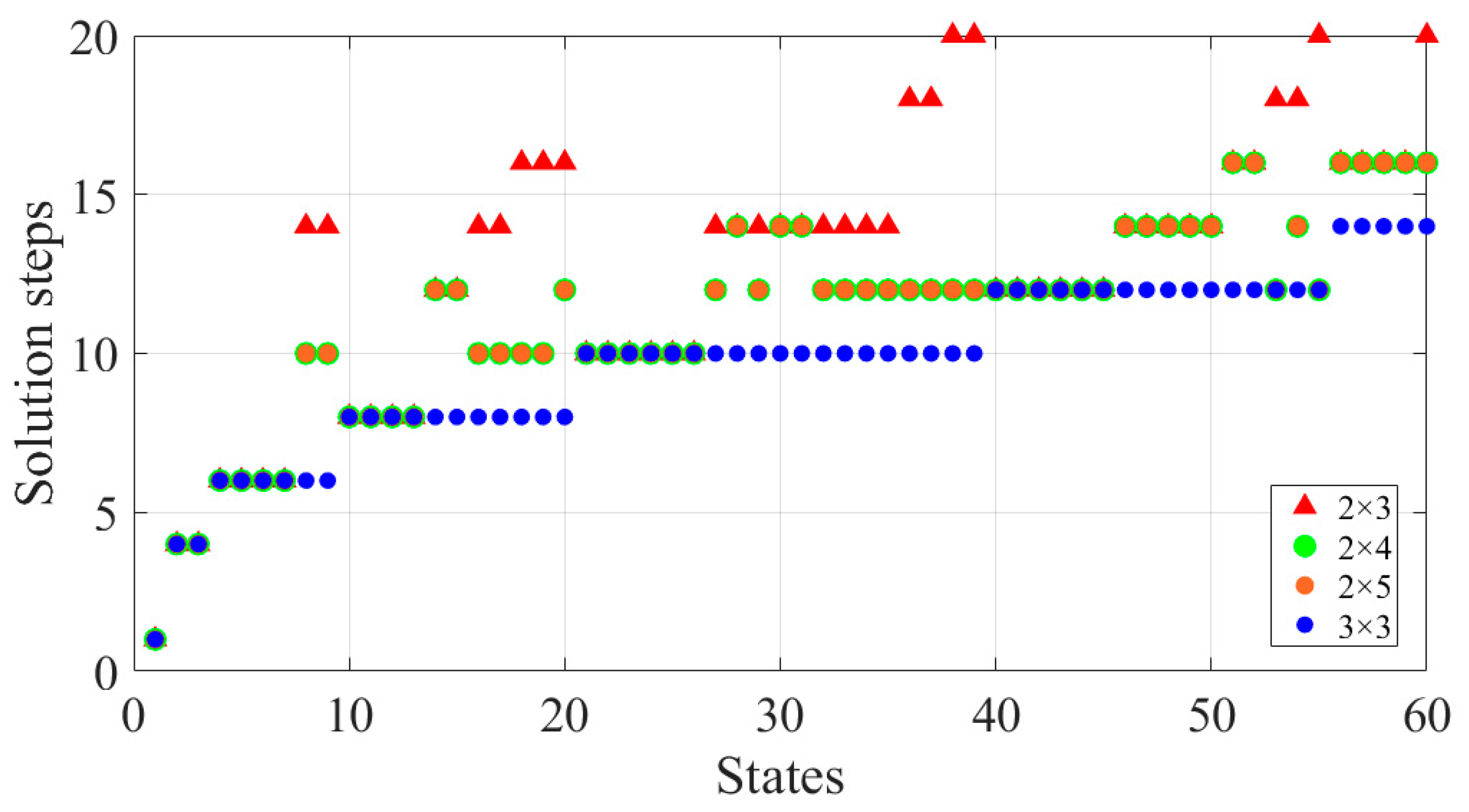
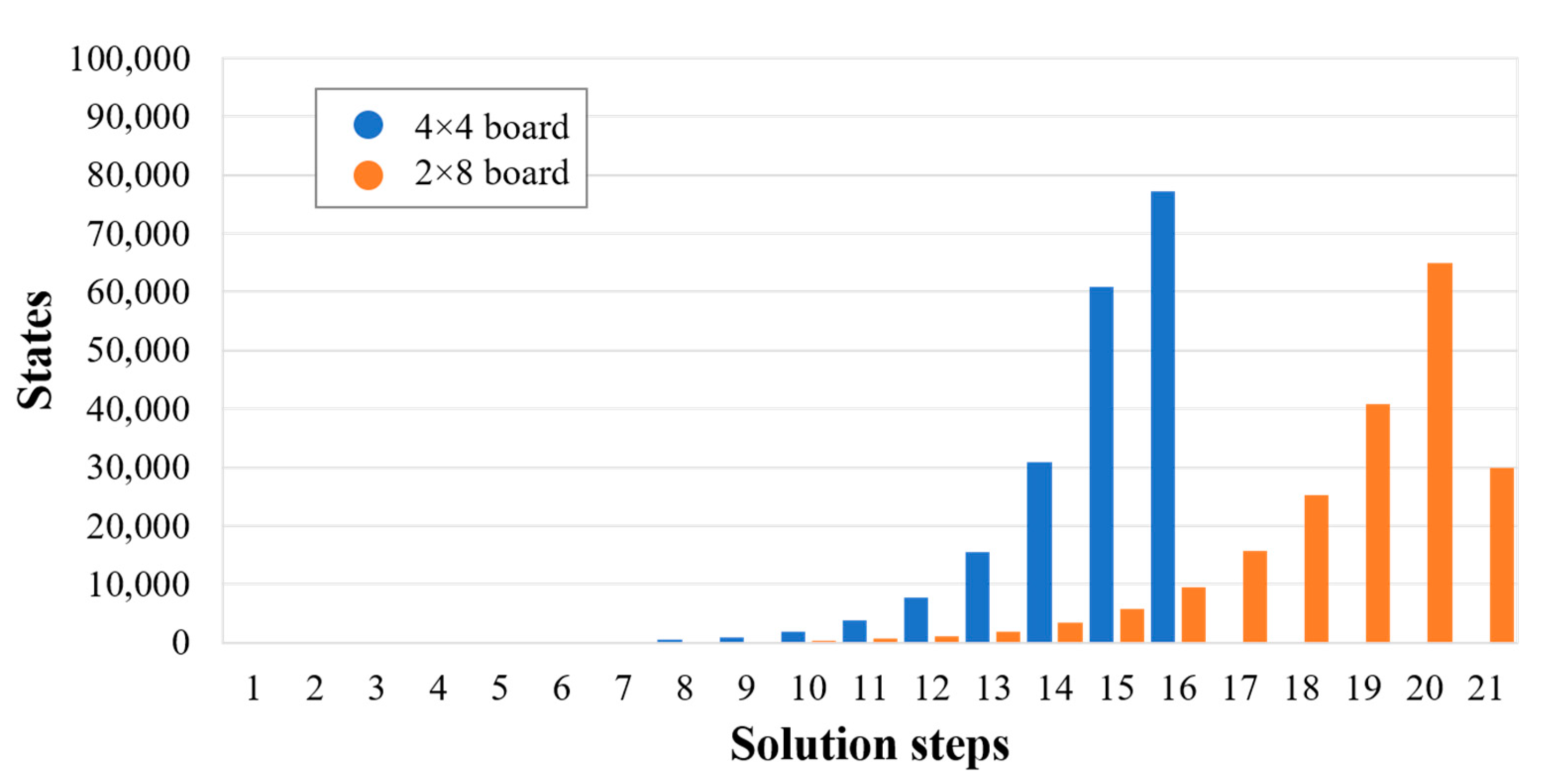
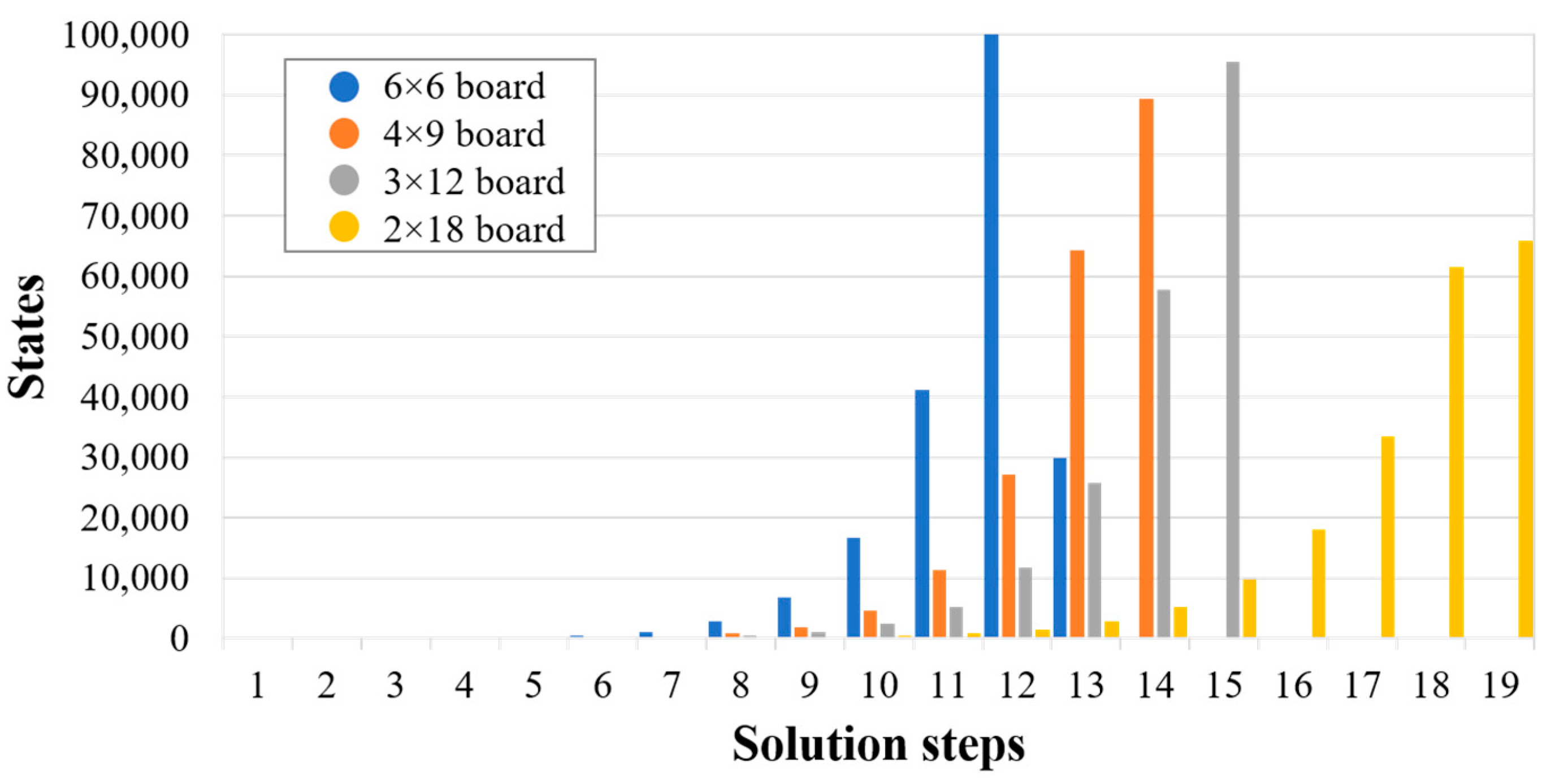
3. Results and Discussion
4. Conclusion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rushton, A.; Croucher, P.; Baker, P. The Handbook of Logistics & Distribution Management; The Chartered Institute of Logistics and Transport: Corby, UK, 2010; p. 636. [Google Scholar]
- Fumi, A.; Scarabotti, L.; Schiraldi, M.M. Minimizing warehouse space with a dedicated storage policy. Int. J. Eng. Bus. Manag. 2013, 5. [Google Scholar] [CrossRef] [Green Version]
- Den Berg, J.P.V.; Zijm, W.H.M. Models for warehouse management: Classification and examples. Int. J. Prod. Econ. 1999, 59, 519–528. [Google Scholar] [CrossRef]
- Daraei, M. Warehouse Redesign Process: A Case Study at Enics Sweden AB. Master’s Thesis, Mälardalen University, Högskoleplan, Västerås, Sweden, 2014; pp. 1–76. [Google Scholar]
- Hsieh, L.F.; Tsai, L. The optimum design of a warehouse system on order picking efficiency. Int. J. Adv. Manuf. Technol. 2006, 28, 626–637. [Google Scholar] [CrossRef]
- Gue, K.R. Very high density storage systems. IIE Trans. 2006, 38, 79–90. [Google Scholar] [CrossRef]
- Gue, K.R.; Kim, B.S. Puzzle-Based Storage Systems. Nav. Res. Logist. 2007, 54, 556–567. [Google Scholar] [CrossRef]
- Shah, B.; Khanzode, V. A comprehensive review and proposed framework to design lean storage and handling systems. Int. J. Adv. Oper. Manag. 2015, 7, 274–299. [Google Scholar] [CrossRef]
- Aleisa, E.E.; Lin, L. For effective facilities planning: Layout optimization then simulation, or vice versa? Proc.-Winter Simul. Conf. 2005, 2005, 1381–1385. [Google Scholar] [CrossRef]
- Inman, R.R. ASRS sizing for recreating automotive assembly sequences. Int. J. Prod. Res. 2003, 41, 847–863. [Google Scholar] [CrossRef]
- Gue, K.R.; Uluda, O.; Furmans, K. A High-Density System for Carton Sequencing. 6th Int. Sci. Symp. Logist. 2012. Available online: https://kevingue.wordpress.com/publications/ (accessed on 16 October 2021).
- Boysen, N.; Stephan, K.; Weidinger, F. Manual order consolidation with put walls: The batched order bin sequencing problem. EURO J. Transp. Logist. 2019, 8, 169–193. [Google Scholar] [CrossRef]
- Boysen, N.; Fedtke, S.; Weidinger, F. Optimizing automated sorting in warehouses: The minimum order spread sequencing problem. Eur. J. Oper. Res. 2018, 270, 386–400. [Google Scholar] [CrossRef]
- Rethmann, J.; Wanke, E. Storage controlled pile-up systems, theoretical foundations. Eur. J. Oper. Res. 1997, 103, 515–530. [Google Scholar] [CrossRef]
- Yalcin, A.; Koberstein, A.; Schocke, K.O. Motion and layout planning in a grid-based early baggage storage system: Heuristic algorithms and a simulation study. OR Spectr. 2019, 41, 683–725. [Google Scholar] [CrossRef]
- Kota, V.R.; Taylor, D.; Gue, K.R. Retrieval time performance in puzzle-based storage systems. J. Manuf. Technol. Manag. 2015, 26, 582–602. [Google Scholar] [CrossRef]
- Gue, K.R.; Furmans, K.; Seibold, Z.; Uludag, O. GridStore: A puzzle-based storage system with decentralized control. IEEE Trans. Autom. Sci. Eng. 2014, 11, 429–438. [Google Scholar] [CrossRef]
- Uludag, O. GridPick: A High Density Puzzle Based Order Picking System with Decentralized Control. Ph.D. Thesis, Auburn University, Auburn, AL, USA, 2014. [Google Scholar]
- Gue, K.; Hao, G. A High-Density, Puzzle-Based System for Rail-Rail Container Transfers. In Proceedings of the 14th IMHRC Proceedings, Karlsruhe, Germany, 2016; Available online: https://digitalcommons.georgiasouthern.edu/pmhr_2016/14 (accessed on 16 October 2021).
- Hao, G. GridHub: A Grid-Based, High-Density Material Handling System. Ph.D. Thesis, University of Louisville, Louisville, KY, USA, 2020. [Google Scholar]
- Shekari Ashgzari, M.; Gue, K.R. A puzzle-based material handling system for order picking. Int. Trans. Oper. Res. 2021, 28, 1821–1846. [Google Scholar] [CrossRef]
- Yalcin, A.; Koberstein, A.; Schocke, K.O. An optimal and a heuristic algorithm for the single-item retrieval problem in puzzle-based storage systems with multiple escorts. Int. J. Prod. Res. 2019, 57, 143–165. [Google Scholar] [CrossRef]
- Shirazi, E.; Zolghadr, M. An item retrieval algorithm in flexible high-density puzzle storage systems. Appl. Syst. Innov. 2021, 4. [Google Scholar] [CrossRef]
- Tetouani, S.; Chouar, A.; Lmariouh, J.; Soulhi, A.; Elalami, J. A “Push-Pull” rearrangement while routing for a driverless delivery vehicle. Cogent Eng. 2019, 6, 1567662. [Google Scholar] [CrossRef]
- Iordan, A.-E. A Comparative Study of Three Heuristic Functions Used to Solve the 8-Puzzle. Br. J. Math. Comput. Sci. 2016, 16, 1–18. [Google Scholar] [CrossRef]
- Shaban, R.; Natheer Alkallak, I.; Mohamad Sulaiman, M. Genetic Algorithm to Solve Sliding Tile 8-Puzzle Problem. J. Educ. Sci. 2010, 23, 145–157. [Google Scholar] [CrossRef] [Green Version]
- Piltaver, R.; Luštrek, M.; Gams, M. The pathology of heuristic search in the 8-puzzle. J. Exp. Theor. Artif. Intell. 2012, 24, 65–94. [Google Scholar] [CrossRef] [Green Version]
- Reinefeld, A. Complete Solution of the Eight-Puzzle and the Benefit of Node Ordering in IDA*. Int. Jt. Conf. Artif. Intell. 1993, 1, 248–253. [Google Scholar]
- Mishra, A.K.; Siddalingaswamy, P.C. Analysis of tree based search techniques for solving 8-puzzle problem. In Proceedings of the 2017 Innovations in Power and Advanced Computing Technologies, Vellore, India, 21–22 April 2017; pp. 1–5. [Google Scholar]
- Pathak, M.J.; Patel, R.L.; Rami, S.P. Comparative Analysis of Search Algorithms. Int. J. Comput. Appl. 2018, 179, 40–43. [Google Scholar] [CrossRef]
- Nilsson, N.J. Artificial Intelligence: A Modern Approach; Prentice Hall: Hoboken, NJ, USA, 1996; Volume 82, ISBN 0137903952. [Google Scholar]
- Nosrati, M.; Karimi, R.; Hasanvand, H.A. Investigation of the * (Star) Search Algorithms: Characteristics, Methods and Approaches. World Appl. Program. 2012, 2, 251–256. [Google Scholar]
- Zhou, Y.; Cheng, X.; Lou, X.; Fang, Z.; Ren, J. Intelligent Travel Planning System based on A-star Algorithm. In Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference, Chongqing, China, 12–14 June 2020; pp. 426–430. [Google Scholar] [CrossRef]
- Ando, R.; Takefuji, Y. A new perspective of paramodulation complexity by solving massive 8 puzzles. arXiv 2020, arXiv:2012.08231. [Google Scholar]
- Korf, R.E.; Reid, M.; Edelkamp, S. Time complexity of iterative-deepening-A*. Artif. Intell. 2001, 129, 199–218. [Google Scholar] [CrossRef] [Green Version]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | System | Function | Contribution | System Areal-Density for 35 Boxes |
|---|---|---|---|---|
| Gue and Kim [7] | NAVSTORS system | Storing, retrieval | Describe the relationship between storage density and expected retrieval time | 94.4% with two escort |
| Gue et al. [11] | GridSequence | Sequencing | High density, decentralized control algorithm | 72.9% |
| Kota et al. [16] | Puzzle-Based system | Storing, retrieval | Determine the retrieval time performance for multi-escorts randomly located in the grid. | 94.4% with two escorts 1 |
| Gue et al. [17] | GridStore system | Storing, retrieval | Retrieve several items by allowing simultaneous moving | 94.4% 1 |
| Uludag [18] | GridPick | Storing, retrieval | Higher throughput, retrieve items to two sides of the grid | 94.4% 1 |
| Gue and Hao [19] | GridHub | Storing, retrieval | Transfer orders in four directions simultaneously within a grid | 95.45% 294.44 for 36 boxes |
| Hao [20] | NU GridHub | Sorting, sequencing | Delivers requested items in the desired sequence to any location | 56.25% for 36 boxes |
| Ashgzari et al. [21] | GridPick+ | Storing, retrieval | Increasing in throughput by 77% | - |
| Yalcin et al. [15] | Grid-based system | Storing, retrieval | Framework for the efficient storage and retrieval of items based on a multi-agent routing algorithm | Up to 100% |
| Yalcin et al. [22] | PBS system | Items retrieval | Retrieve items with a minimum number of items moves | 94.4% 1 |
| Shirazi et al. [23] | PBS system | Items retrieval | Deadlock prevention algorithm | Up to 97.2% 1 |
| Tetouani et al. [24] | Puzzle-based system | Rearrangement while Routing” strategy | Formalize arranging smart boxes in an autonomous delivery vehicle | 97.2% |
| Proposed method | Puzzle-based sequencing system | Sequencing | High-density sequencing system, address unsolvable puzzle configuration | 97.2% |
| Number of Items (i) | Puzzle-Based System | GridSequence System | ||
|---|---|---|---|---|
| 8 | = 9, e = 1 | 88.8% | = 15, e = 7 | 53.3% |
| 15 | = 16, e = 1 | 93.7% | = 24, e = 9 | 62.5% |
| 24 | = 25, e = 1 | 96% | = 35, e = 11 | 68.5% |
| 35 | = 36, e = 1 | 97.2% | = 48, e = 13 | 72.9% |
| 3 × 3 | Better [%] | Same [%] | Worse [%] |
|---|---|---|---|
| vs. 2 × 3 | 61.6 | 38.4 | 0 |
| vs. 2 × 4 | 58.3 | 41.7 | 0 |
| vs. 2 × 5 | 58.3 | 41.7 | 0 |
| Max. Rectilinear Distance of One Tile | Max. Capacity | Board Size |
|---|---|---|
| 4 | 7 | 2 × 4 |
| 8 | 3 × 3 | |
| 5 | 9 | 2 × 5 |
| 11 | 3 × 4 | |
| 6 | 14 | 3 × 5 |
| 15 | 4 × 4 | |
| 7 | 17 | 3 × 6 |
| 19 | 4 × 5 | |
| 8 | 20 | 3 × 7 |
| 23 | 4 × 6 | |
| 24 | 5 × 5 | |
| 9 | 23 | 3 × 8 |
| 10 | 26 | 3 × 9 |
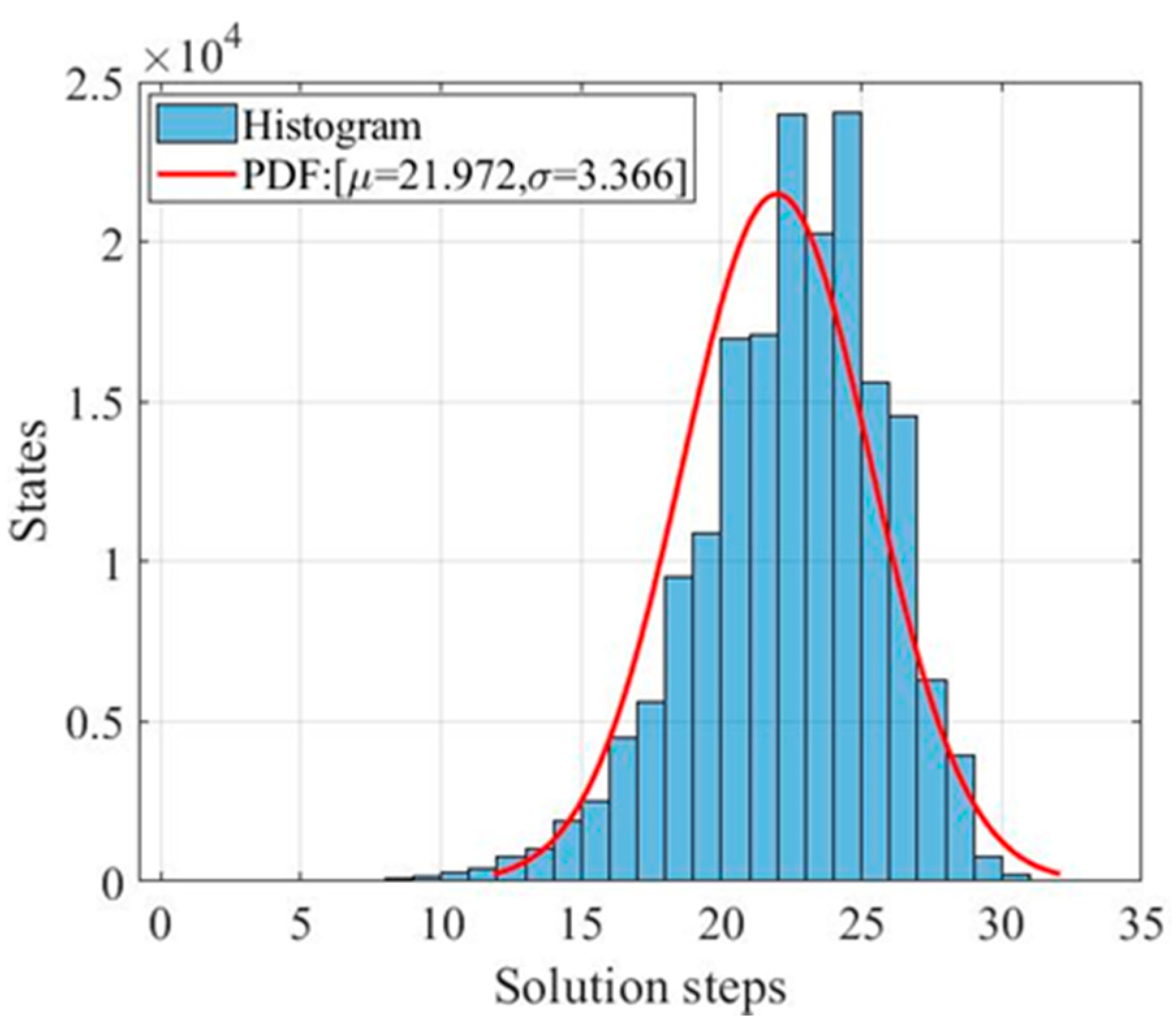
| Comparison Factor | Our Generated Tree | Other Works [25,28,35] |
|---|---|---|
| Maximum number of states | 181,440 | 181,440 |
| Maximum solution steps | 31 | 31 |
| Average solution steps | 21.97 | ≈22 |
| Puzzle Size | Aspect Ratio | Rectilinear Distance |
|---|---|---|
| 4 × 4 | 1 | 6 |
| 2 × 8 | 4 | 8 |
| 6 × 6 | 1 | 10 |
| 4 × 9 | 2.25 | 11 |
| 3 × 12 | 4 | 13 |
| 2 × 18 | 9 | 18 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alahmad, R.; Ishii, K. A Puzzle-Based Sequencing System for Logistics Items. Logistics 2021, 5, 76. https://doi.org/10.3390/logistics5040076
Alahmad R, Ishii K. A Puzzle-Based Sequencing System for Logistics Items. Logistics. 2021; 5(4):76. https://doi.org/10.3390/logistics5040076
Chicago/Turabian StyleAlahmad, Raji, and Kazuo Ishii. 2021. "A Puzzle-Based Sequencing System for Logistics Items" Logistics 5, no. 4: 76. https://doi.org/10.3390/logistics5040076
APA StyleAlahmad, R., & Ishii, K. (2021). A Puzzle-Based Sequencing System for Logistics Items. Logistics, 5(4), 76. https://doi.org/10.3390/logistics5040076