
On the Choice of Metric to Calibrate Time-Invariant Ensemble Kalman Filter Hyper-Parameters for Discharge Data Assimilation and Its Impact on Discharge Forecast Modelling


Abstract
:1. Introduction
2. Materials and Methods
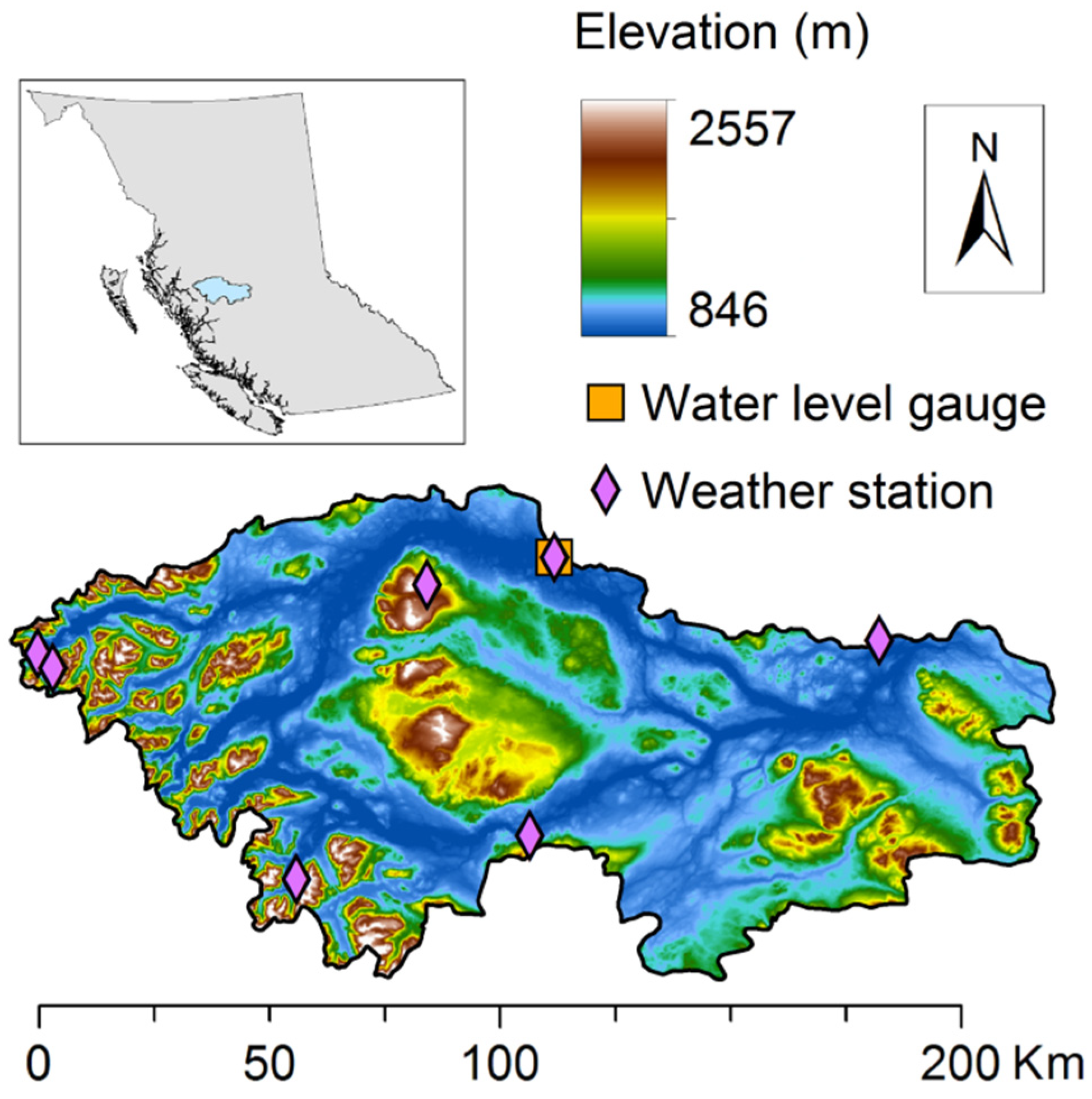
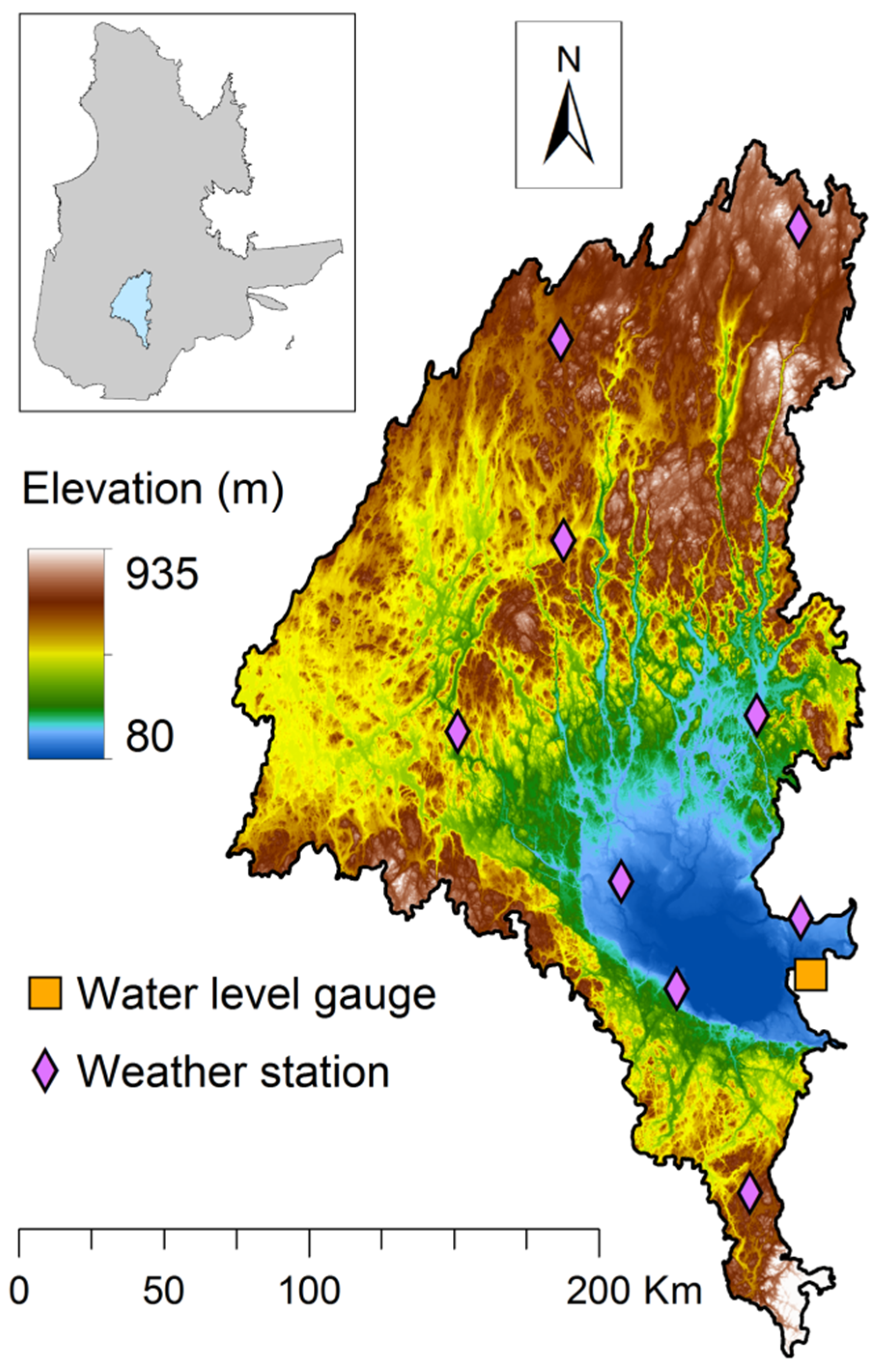
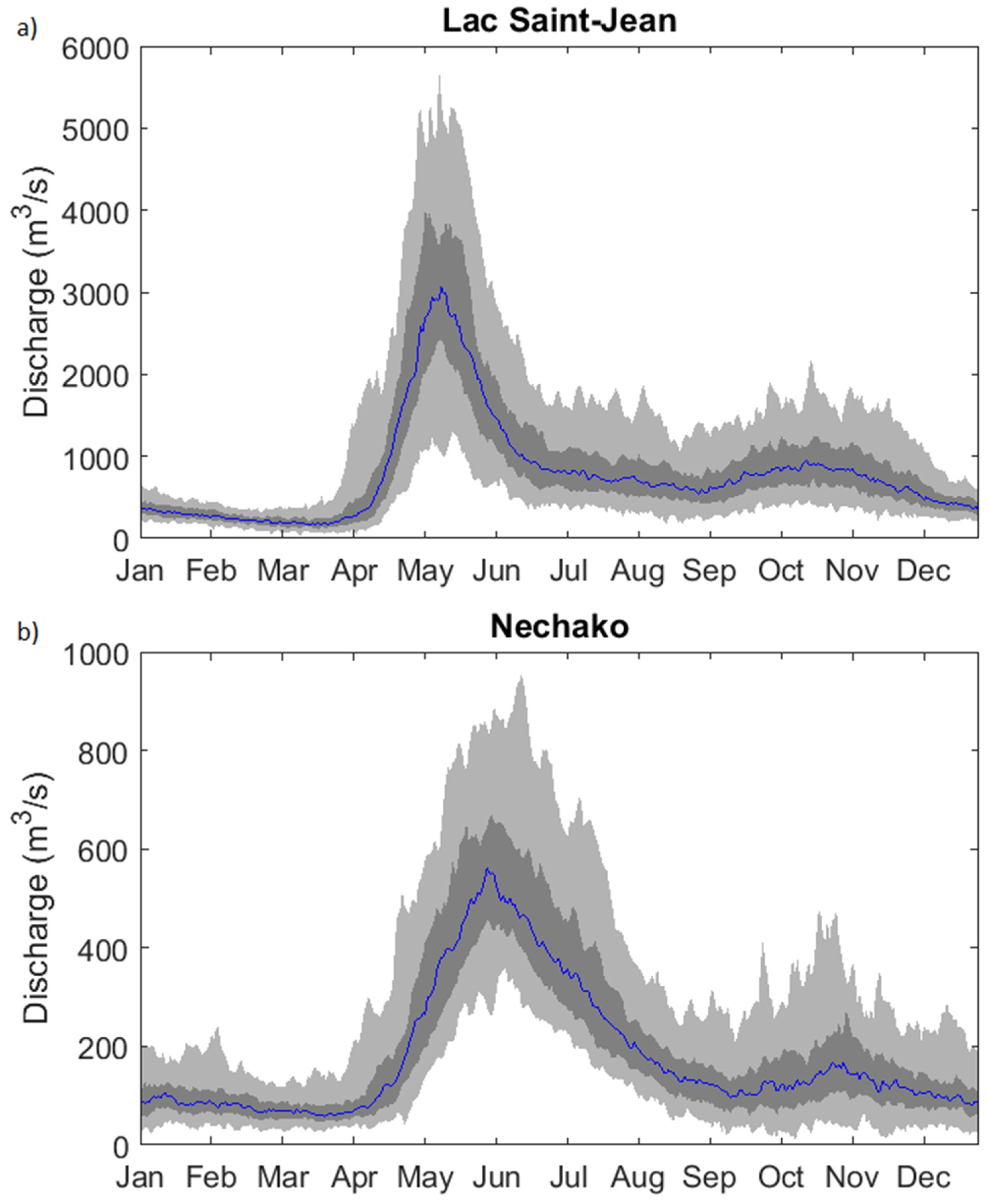
2.1. Study Catchments
2.2. Hydrologic Models
2.3. Ensemble Kalman Filter and Ensemble Square Root Kalman Filter
2.4. Data Assimilation Experiment
2.4.1. Precipitation Ensemble Generation
2.4.2. State Vector Configuration
2.5. Ensemble Forecasting
2.6. Metrics
3. Results and Discussion
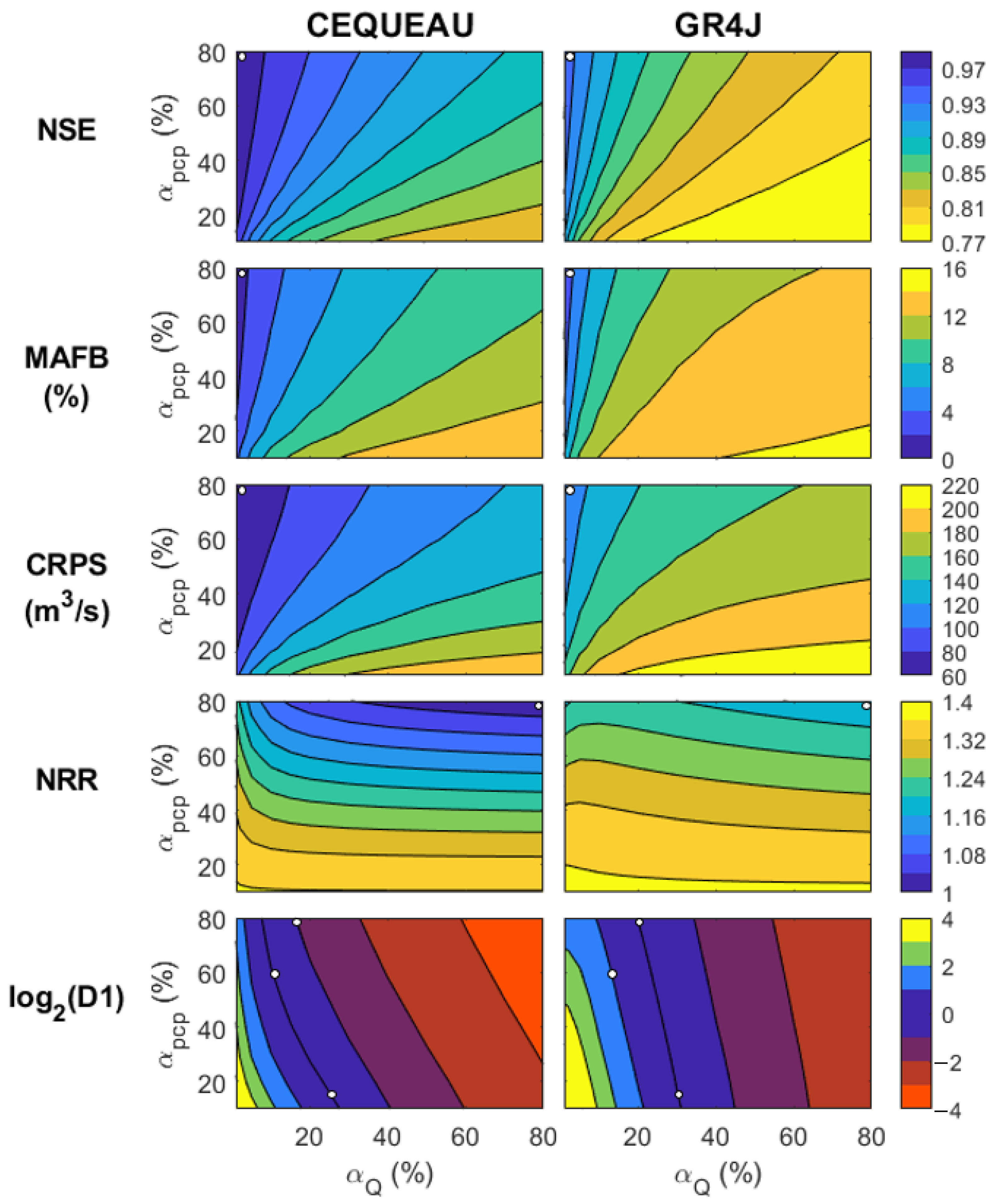
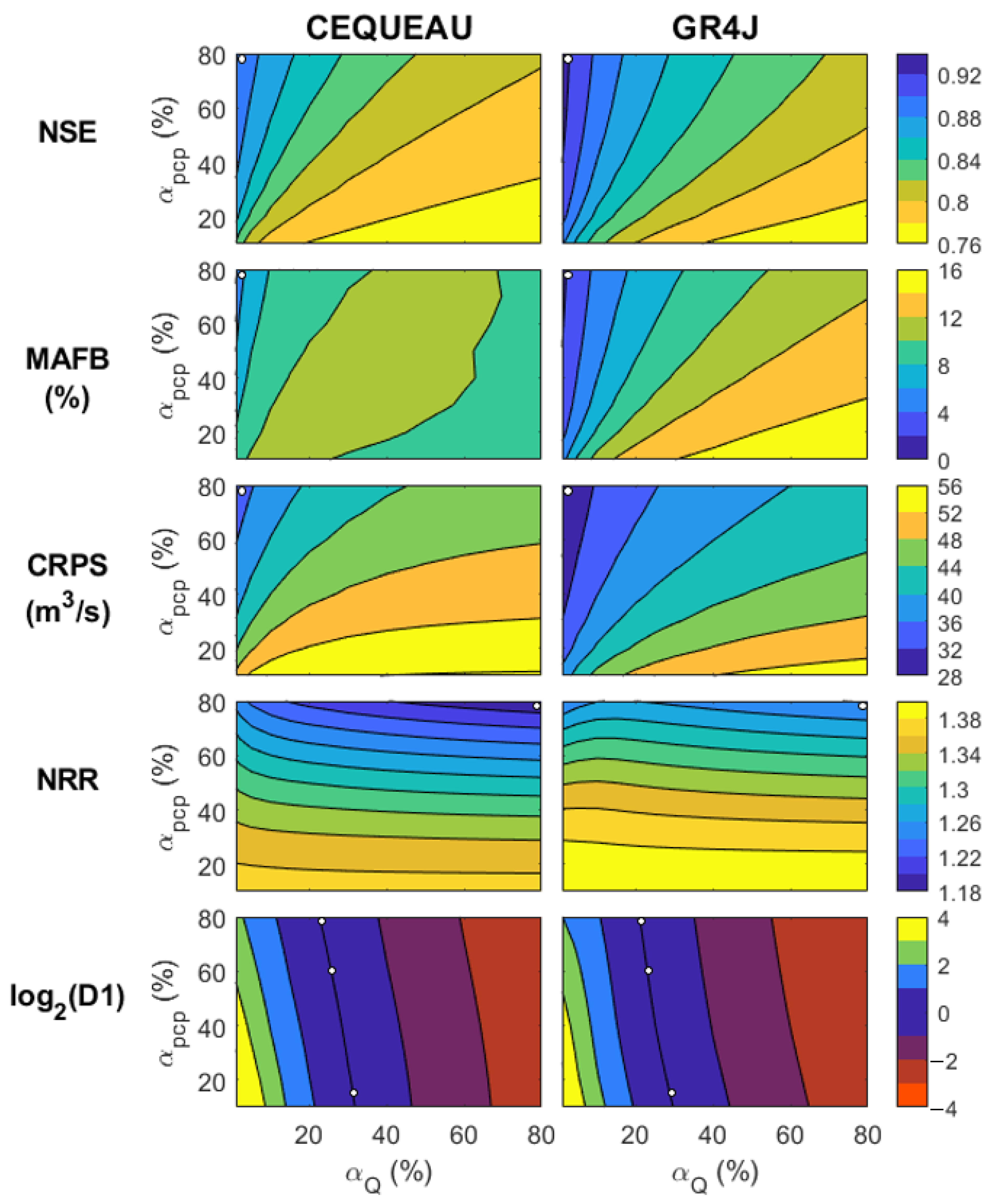
3.1. Calibration of EnSRF Hyper-Parameters
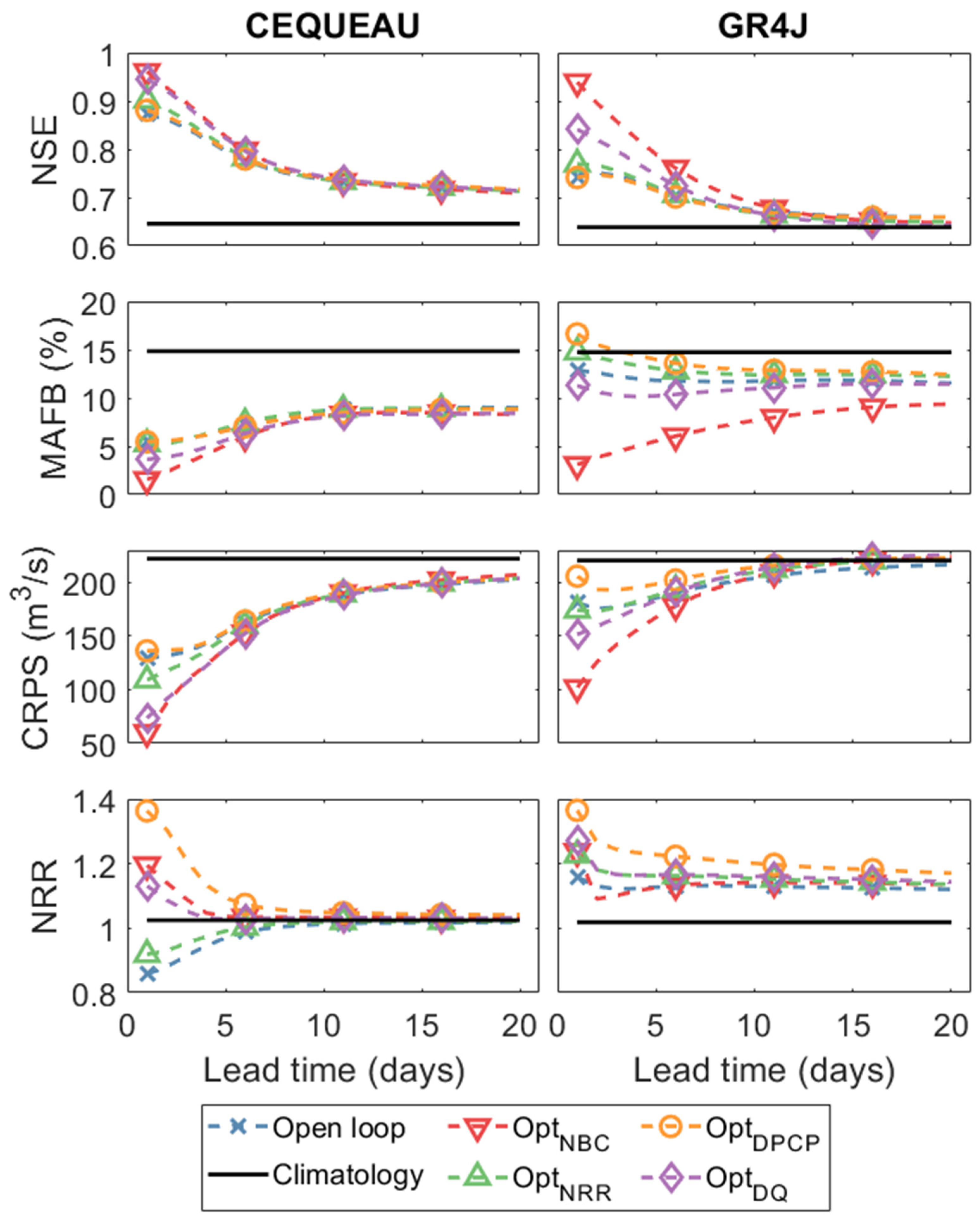
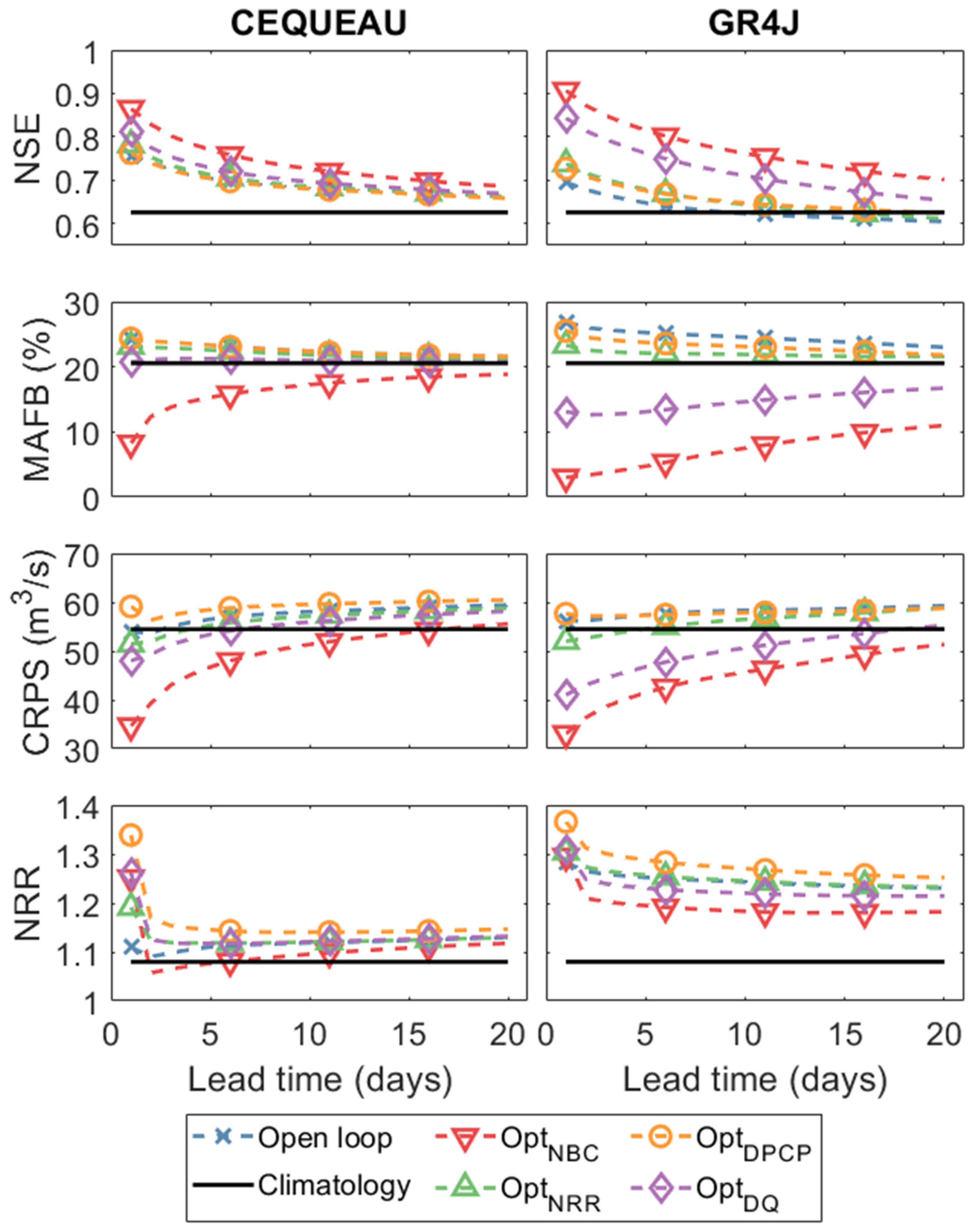
3.2. Discharge Forecasting
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Smith, J.A.; Day, G.N.; Kane, M.D. Nonparametric Framework for Long-range Streamflow Forecasting. J. Water Resour. Plan. Manag. 1992, 118, 82–92. [Google Scholar] [CrossRef]
- Hashino, T.; Bradley, A.A.; Schwartz, S.S. Evaluation of bias-correction methods for ensemble streamflow volume forecasts. Hydrol. Earth Syst. Sci. 2007, 11, 939–950. [Google Scholar] [CrossRef] [Green Version]
- Wood, A.W.; Schaake, J.C. Correcting Errors in Streamflow Forecast Ensemble Mean and Spread. J. Hydrometeorol. 2008, 9, 132–148. [Google Scholar] [CrossRef]
- Schepen, A.; Wang, Q.J. Model averaging methods to merge operational statistical and dynamic seasonal streamflow forecasts in Australia. Water Resour. Res. 2015, 51, 1797–1812. [Google Scholar] [CrossRef]
- Raftery, A.E.; Gneiting, T.; Balabdaoui, F.; Polakowski, M. Using Bayesian Model Averaging to Calibrate Forecast Ensembles. Mon. Weather Rev. 2005, 133, 1155–1174. [Google Scholar] [CrossRef] [Green Version]
- Bourgin, F.; Ramos, M.-H.; Thirel, G.; Andréassian, V. Investigating the interactions between data assimilation and post-processing in hydrological ensemble forecasting. J. Hydrol. 2014, 519, 2775–2784. [Google Scholar] [CrossRef]
- Evensen, G. Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics. J. Geophys. Res. Space Phys. 1994, 99, 10143–10162. [Google Scholar] [CrossRef]
- Moradkhani, H.; Sorooshian, S.; Gupta, H.V.; Houser, P.R. Dual state–parameter estimation of hydrological models using ensemble Kalman filter. Adv. Water Resour. 2005, 28, 135–147. [Google Scholar] [CrossRef] [Green Version]
- Crow, W.T.; Ryu, D. A new data assimilation approach for improving runoff prediction using remotely-sensed soil moisture retrievals. Hydrol. Earth Syst. Sci. 2009, 13, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Chen, F.; Crow, W.T.; Starks, P.J.; Moriasi, D.N. Improving hydrologic predictions of a catchment model via assimilation of surface soil moisture. Adv. Water Resour. 2011, 34, 526–536. [Google Scholar] [CrossRef]
- Trudel, M.; Leconte, R.; Paniconi, C. Analysis of the hydrological response of a distributed physically-based model using post-assimilation (EnKF) diagnostics of streamflow and in situ soil moisture observations. J. Hydrol. 2014, 514, 192–201. [Google Scholar] [CrossRef]
- Abaza, M.; Anctil, F.; Fortin, V.; Turcotte, R. Exploration of sequential streamflow assimilation in snow dominated watersheds. Adv. Water Resour. 2015, 80, 79–89. [Google Scholar] [CrossRef]
- Bergeron, J.M.; Trudel, M.; Leconte, R. Combined assimilation of streamflow and snow water equivalent for mid-term ensemble streamflow forecasts in snow-dominated regions. Hydrol. Earth Syst. Sci. 2016, 20, 4375–4389. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Weerts, A.H.; Clark, M.P.; Franssen, H.-J.H.; Kumar, S.V.; Moradkhani, H.; Seo, D.-J.; Schwanenberg, D.; Smith, P.; Van Dijk, A.I.J.M.; et al. Advancing data assimilation in operational hydrologic forecasting: Progresses, challenges, and emerging opportunities. Hydrol. Earth Syst. Sci. 2012, 16, 3863–3887. [Google Scholar] [CrossRef] [Green Version]
- Clark, M.P.; Rupp, D.E.; Woods, R.A.; Zheng, X.; Ibbitt, R.P.; Slater, A.G.; Schmidt, J.; Uddstrom, M.J. Hydrological data assimilation with the ensemble Kalman filter: Use of streamflow observations to update states in a distributed hydrological model. Adv. Water Resour. 2008, 31, 1309–1324. [Google Scholar] [CrossRef]
- Crow, W.T.; Reichle, R.H. Comparison of adaptive filtering techniques for land surface data assimilation. Water Resour. Res. 2008, 44, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Leisenring, M.; Moradkhani, H. Analyzing the uncertainty of suspended sediment load prediction using sequential data assimilation. J. Hydrol. 2012, 468–469, 268–282. [Google Scholar] [CrossRef]
- Crow, W.T.; Yilmaz, M.T. The Auto-Tuned Land Data Assimilation System (ATLAS). Water Resour. Res. 2014, 50, 371–385. [Google Scholar] [CrossRef]
- Thiboult, A.; Anctil, F. On the difficulty to optimally implement the Ensemble Kalman filter: An experiment based on many hydrological models and catchments. J. Hydrol. 2015, 529, 1147–1160. [Google Scholar] [CrossRef] [Green Version]
- Waller, J.A.; Dance, S.L.; Lawless, A.S.; Nichols, N.K. Estimating correlated observation error statistics using an ensemble transform Kalman filter. Tellus A: Dyn. Meteorol. Oceanogr. 2014, 66, 23294. [Google Scholar] [CrossRef] [Green Version]
- Diskin, M.; Simon, E. A procedure for the selection of objective functions for hydrologic simulation models. J. Hydrol. 1977, 34, 129–149. [Google Scholar] [CrossRef]
- Jie, M.-X.; Chen, H.; Xu, C.-Y.; Zeng, Q.; Tao, X.-E. A comparative study of different objective functions to improve the flood forecasting accuracy. Hydrol. Res. 2015, 47, 718–735. [Google Scholar] [CrossRef] [Green Version]
- Fortin, V.; Abaza, M.; Anctil, F.; Turcotte, R. Why Should Ensemble Spread Match the RMSE of the Ensemble Mean? J. Hydrometeorol. 2014, 15, 1708–1713. [Google Scholar] [CrossRef]
- Chen, H.; Yang, D.; Hong, Y.; Gourley, J.J.; Zhang, Y. Hydrological data assimilation with the Ensemble Square-Root-Filter: Use of streamflow observations to update model states for real-time flash flood forecasting. Adv. Water Resour. 2013, 59, 209–220. [Google Scholar] [CrossRef]
- Rasmussen, R.M.; Baker, B.D.; Kochendorfer, J.; Meyers, T.; Landolt, S.; Fischer, A.P.; Black, J.; Thériault, J.M.; Kucera, P.; Gochis, D.J.; et al. How Well Are We Measuring Snow: The NOAA/FAA/NCAR Winter Precipitation Test Bed. Bull. Am. Meteorol. Soc. 2012, 93, 811–829. [Google Scholar] [CrossRef] [Green Version]
- Morin, G.; Paquet, P. Modèle Hydrologique CEQUEAU; INRS-ETE: Rapport de Recherche No R000926; INRS-ÉTÉ: Quebec City, QC, Canada, 2007. [Google Scholar]
- Thornthwaite, C.W. An Approach toward a Rational Classification of Climate. Geogr. Rev. 1948, 38, 55–94. [Google Scholar] [CrossRef]
- U.S. Army Corps of Engineers. Snow Hydrology: Summary Report of the Snow Investigations; Technical Report; U.S. Army Corps of Engineers, North Pacific Division: Portland, OR, USA, 1956.
- Boisvert, J.; El-Jabi, N.; St-Hilaire, A.; El Adlouni, S.-E. Parameter Estimation of a Distributed Hydrological Model Using a Genetic Algorithm. Open J. Mod. Hydrol. 2016, 6, 151–167. [Google Scholar] [CrossRef] [Green Version]
- Perrin, C.; Michel, C.; Andréassian, V. Improvement of a parsimonious model for streamflow simulation. J. Hydrol. 2003, 279, 275–289. [Google Scholar] [CrossRef]
- Oudin, L.; Hervieu, F.; Michel, C.; Perrin, C.; Andréassian, V.; Anctil, F.; Loumagne, C. Which potential evapotranspiration input for a lumped rainfall–runoff model? J. Hydrol. 2005, 303, 290–306. [Google Scholar] [CrossRef]
- Fortin, J.-P.; Turcotte, R.; Massicotte, S.; Moussa, R.; Fitzback, J.; Villeneuve, J.-P. Distributed Watershed Model Compatible with Remote Sensing and GIS Data. I: Description of Model. J. Hydrol. Eng. 2001, 6, 91–99. [Google Scholar] [CrossRef]
- Tolson, B.A.; Shoemaker, C.A. Dynamically dimensioned search algorithm for computationally efficient watershed model calibration. Water Resour. Res. 2007, 43, 1–16. [Google Scholar] [CrossRef]
- Whitaker, J.S.; Hamill, T.M. Ensemble Data Assimilation without Perturbed Observations. Mon. Weather Rev. 2002, 130, 1913–1924. [Google Scholar] [CrossRef]
- Abaza, M.; Anctil, F.; Fortin, V.; Turcotte, R. Sequential streamflow assimilation for short-term hydrological ensemble forecasting. J. Hydrol. 2014, 519, 2692–2706. [Google Scholar] [CrossRef]
- Bergeron, J. L’assimilation de Données Multivariées par Filtre de Kalman D’ensemble pour la Prévision Hydrologique. Ph.D. Thesis, Université de Sherbrooke, Sherbrooke, QC, Canada, 2017. [Google Scholar]
- Day, G.N. Extended Streamflow Forecasting Using NWSRFS. J. Water Resour. Plan. Manag. 1985, 111, 157–170. [Google Scholar] [CrossRef]
- Krause, P.; Boyle, D.P.; Bäse, F. Comparison of different efficiency criteria for hydrological model assessment. Adv. Geosci. 2005, 5, 89–97. [Google Scholar] [CrossRef] [Green Version]
- Bennett, N.D.; Croke, B.F.; Guariso, G.; Guillaume, J.H.; Hamilton, S.H.; Jakeman, A.J.; Marsili-Libelli, S.; Newham, L.T.; Norton, J.P.; Perrin, C.; et al. Characterising performance of environmental models. Environ. Model. Softw. 2013, 40, 1–20. [Google Scholar] [CrossRef]
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting through conceptual models part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Hersbach, H. Decomposition of the Continuous Ranked Probability Score for Ensemble Prediction Systems. Weather Forecast 2000, 15, 559–570. [Google Scholar] [CrossRef]
- Anderson, J.L. An Ensemble Adjustment Kalman Filter for Data Assimilation. Mon. Weather Rev. 2001, 129, 2884–2903. [Google Scholar] [CrossRef] [Green Version]
- Desroziers, G.; Berre, L.; Chapnik, B.; Poli, P. Diagnosis of observation, background and analysis-error statistics in observation space. Q. J. R. Meteorol. Soc. 2005, 131, 3385–3396. [Google Scholar] [CrossRef]
- Crow, W.T.; Van Loon, E. Impact of Incorrect Model Error Assumptions on the Sequential Assimilation of Remotely Sensed Surface Soil Moisture. J. Hydrometeorol. 2006, 7, 421–432. [Google Scholar] [CrossRef]
- Beven, K.J. Rainfall-Runoff Modelling: The Primer, 2nd ed.; John Wiley & Sons, Ltd.: Chichester, UK, 2012. [Google Scholar]
- Van Werkhoven, K.; Wagener, T.; Reed, P.; Tang, Y. Sensitivity-guided reduction of parametric dimensionality for multi-objective calibration of watershed models. Adv. Water Resour. 2009, 32, 1154–1169. [Google Scholar] [CrossRef]
- Komma, J.; Blöschl, G.; Reszler, C. Soil moisture updating by Ensemble Kalman Filtering in real-time flood forecasting. J. Hydrol. 2008, 357, 228–242. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Parameter | Lac Saint-Jean | Nechako | Typical Parameter Range [26,29] |
|---|---|---|---|
| Temperature threshold for solid precipitation (STRNE) | −1.222 | 1.540 | (−5,5) |
| Melt rate in forested areas (TFC) | 1.579 | 3.013 | (1,7) |
| Melt rate in open areas (TFD) | 3.916 | 1.397 | (1,7) |
| Melt temperature in forested areas (TSC) | −0.838 | 1.448 | (−5,5) |
| Melt temperature in open areas (TSD) | 0.167 | 1.173 | (−5,5) |
| Energy exchange coefficient (TTD) | 0.710 | 0.100 | (0,1) |
| Snow ripening temperature (TTS) | −3.630 | −5.639 | (−5,5) |
| Infiltration coefficient for groundwater reservoir (CIN) | 0.153 | 0.076 | (0,1) |
| Discharge coefficient for lake reservoir (CVMAR) | 0.065 | 0.199 | (0,1) |
| Low outlet discharge coefficient for groundwater reservoir (CVNB) | 0.009 | 0.027 | (0,1) |
| High outlet discharge coefficient for groundwater reservoir (CVNH) | 0.400 | 0.300 | (0,1) |
| Low outlet discharge coefficient for surface reservoir (CVSB) | 0.002 | 0.005 | (0,1) |
| Intermediate outlet discharge coefficient for surface reservoir (CVSI) | 0.163 | 0.179 | (0,1) |
| Maximum infiltration coefficient (XINFMA) | 20.000 | 30.000 | (0,100) |
| Percolation threshold from surface to groundwater reservoir (HINF) | 63.171 | 58.608 | (0,1500) |
| Height of intermediate outlet for surface reservoir (HINT) | 65.971 | 99.156 | (0,1500) |
| Height of outlet for lake reservoir (HMAR) | 268.966 | 195.352 | (0,1500) |
| Height of high outlet for groundwater reservoir (HNAP) | 195.884 | 200.619 | (0,1500) |
| Minimum height to use evapotranspiration as potential (HPOT) | 20.000 | 126.719 | (0,100) |
| Surface reservoir capacity (HSOL) | 99.164 | 200.000 | (0,1500) |
| Minimum water for runoff on impermeable surfaces (HRIMP) | 0.000 | 1.245 | (0,50) |
| Fraction of evapotranspiration taken from groundwater reservoir (EVNAP) | 0.895 | 0.365 | (0,1) |
| Thornthwaite formula exponent coefficient (XAA) | 0.885 | 1.228 | (0.5,1.5) |
| Thornthwaite formula thermal index (XIT) | 29.187 | 8.790 | (5,40) |
| Transfer coefficient for routing units (EXXKT) | 0.0198 | 0.0018 | (0,1) |
| Model Parameter | Lac Saint-Jean | Nechako |
|---|---|---|
| Maximum capacity of the surface reservoir (X1) | 27.57 | 27.06 |
| Groundwater exchange coefficient (X2) | 4.69 | −19.76 |
| Maximum capacity of the routing reservoir (X3) | 707.61 | 1045.84 |
| Unit hydrograph time parameter (X4) | 1.12 | 1.014 |
| Rain–snow parameter threshold | 0.0061 | 0.0461 |
| Snow–soil interface melt rate coefficient | 346.91 | 525.33 |
| Maximal snow cover density | 0.000808 | 0.0000293 |
| Compaction coefficient | 0.0032 | 0.0062 |
| Snow–air interface melt rate coefficient | −1.629 | 0.433 |
| Snowmelt temperature threshold | 2.364 | 2.105 |
| Scenario Name | Catchment and Model | ||
|---|---|---|---|
| OptNBC | 80 | 1 | All |
| OptNRR | 80 | 80 | All |
| OptDQ | 10 | 30 | All |
| OptPCP | 60 80 65 80 | 10 20 25 20 | LSJ + CEQUEAU LSJ + GR4J Nechako + CEQUEAU Nechako + GR4J |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bergeron, J.; Leconte, R.; Trudel, M.; Farhoodi, S. On the Choice of Metric to Calibrate Time-Invariant Ensemble Kalman Filter Hyper-Parameters for Discharge Data Assimilation and Its Impact on Discharge Forecast Modelling. Hydrology 2021, 8, 36. https://doi.org/10.3390/hydrology8010036
Bergeron J, Leconte R, Trudel M, Farhoodi S. On the Choice of Metric to Calibrate Time-Invariant Ensemble Kalman Filter Hyper-Parameters for Discharge Data Assimilation and Its Impact on Discharge Forecast Modelling. Hydrology. 2021; 8(1):36. https://doi.org/10.3390/hydrology8010036
Chicago/Turabian StyleBergeron, Jean, Robert Leconte, Mélanie Trudel, and Sepehr Farhoodi. 2021. "On the Choice of Metric to Calibrate Time-Invariant Ensemble Kalman Filter Hyper-Parameters for Discharge Data Assimilation and Its Impact on Discharge Forecast Modelling" Hydrology 8, no. 1: 36. https://doi.org/10.3390/hydrology8010036
APA StyleBergeron, J., Leconte, R., Trudel, M., & Farhoodi, S. (2021). On the Choice of Metric to Calibrate Time-Invariant Ensemble Kalman Filter Hyper-Parameters for Discharge Data Assimilation and Its Impact on Discharge Forecast Modelling. Hydrology, 8(1), 36. https://doi.org/10.3390/hydrology8010036