
Estimating the Precipitation Amount at Regional Scale Using a New Tool, Climate Analyzer




Abstract
:1. Introduction
- Introducing new selection criteria of the precipitation series values that participate in fitting the regional series, with the aim at improving the algorithm’s performances.
- Describing Climate Analyzer software.
- Exemplifying the Climate Analyzer use on the total precipitation series collected in the Dobrogea region (Romania) during 1965–2005. Comparisons of the Climate Analyzer’s output with the results provided by TPM, IDW, KG are provided.
2. Methods and Implementation
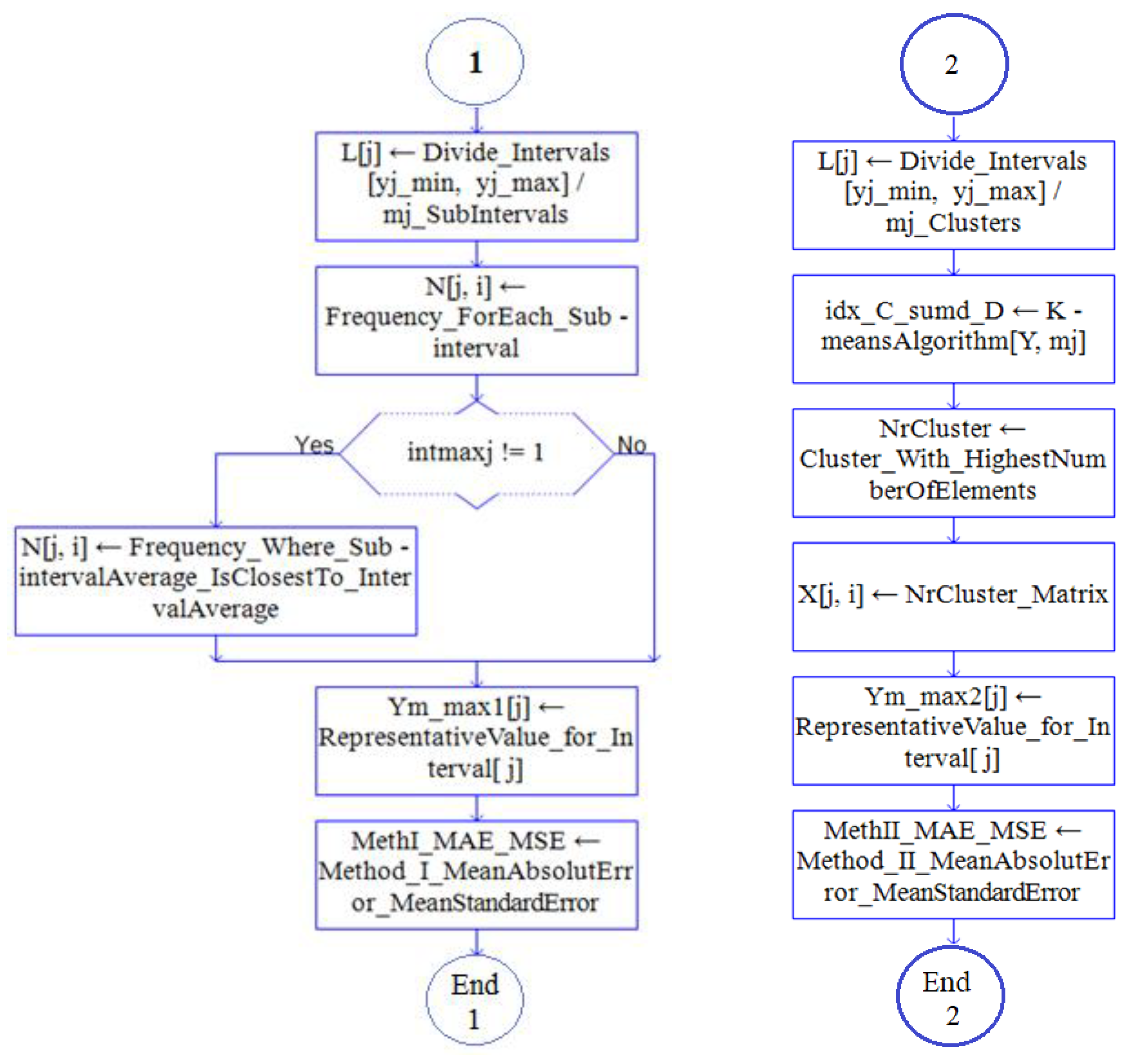
2.1. Method I
- (I1)
- Establish the working intervals: compute the minimum (yj min) and maximum values (yj max), recorded at the jth moment (j = 1, …, n) and their amplitudes (Aj).
- (I2)
- Divide each interval [yj min, yj max] into mj subintervals with the length Lj = Aj/mj, (j = 1, …, n). The number of intervals is selected by the user, based on the user’s experience or different objective criteria.Each sub-interval should contain a sufficient number of values.
- (I3)
- Denote by Yjl, the subinterval l at the moment j and define its frequency, fjl, to be the number of values in Yjl, l = 1, …, mj, j = 1, …, n. Choose the interval whose frequency is maximum, denote it by Ij max and its frequency by fj max.
- (I4)
- Choose the average of the values in Ij max to be the representative value for the period j (j = 1, …, n).
- (I5)
- Compute the Mean Absolute Error (MAE) and Mean Standard Error (MSE) corresponding to all the observation sites.
- (I6)
- Represent graphically the results.
2.2. Method II
- (II1)
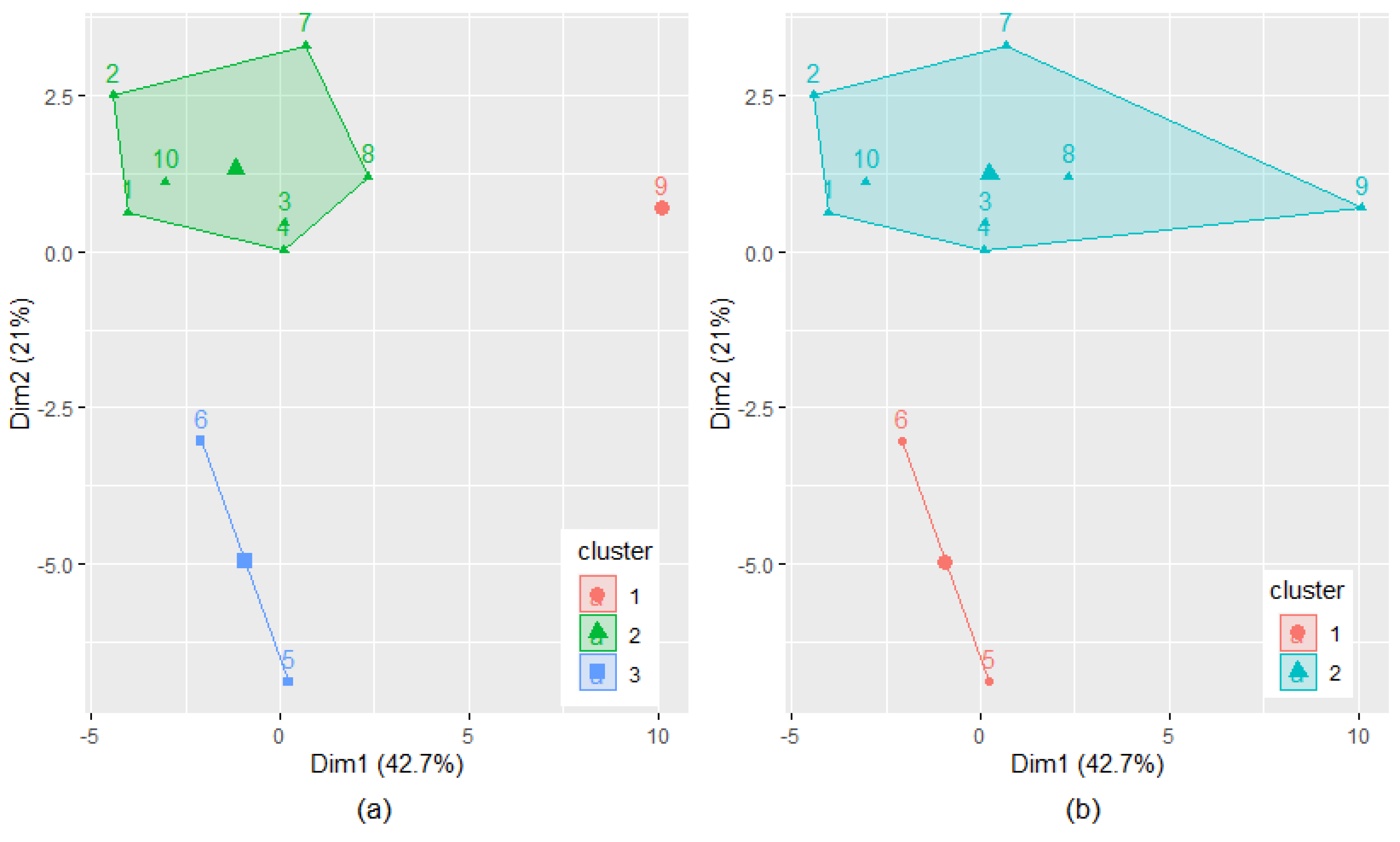
- Choose the number of clusters, k and perform the k-means clustering to group the data series into clusters. This step returns an n-by-1 vector (idx) containing the cluster index for each observation site, the locations of the clusters’ centroids, within-cluster sums of point-to-centroid distances and distances from the points to the centroids.
- (II2)
- Determine the cluster containing the highest number of elements and build a matrix using the data series recorded at the sites from that cluster.
- (II3)
- Choose the value representing the period j as the average of the values recorded at j at the stations from the cluster with the highest number of observations.
- (II4)
- Compute the Mean Absolute Error (MAE) and Mean Standard Error (MSE) corresponding to all the observation sites.
- (II5)
- Represent the results graphically.
2.3. Comparison of the Results
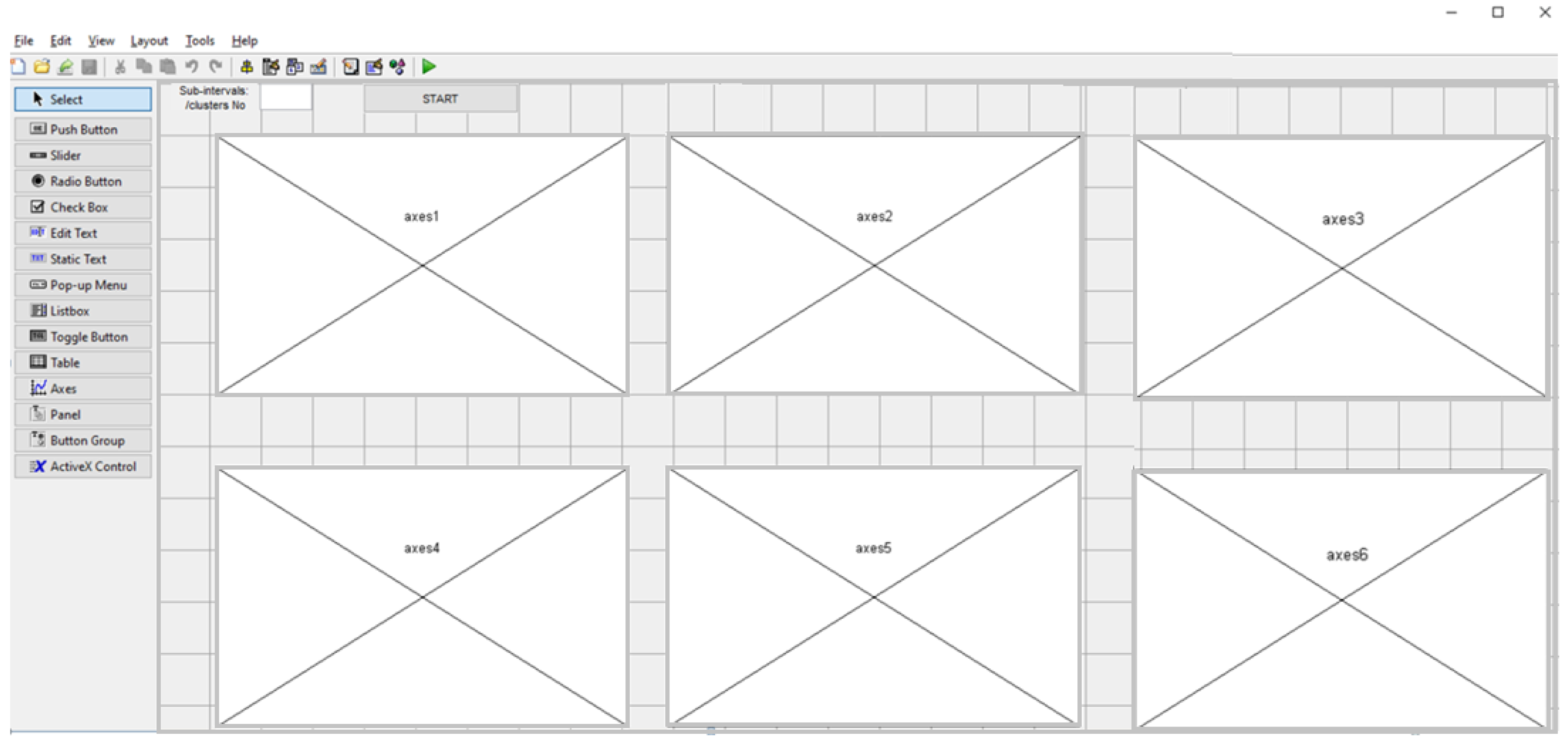
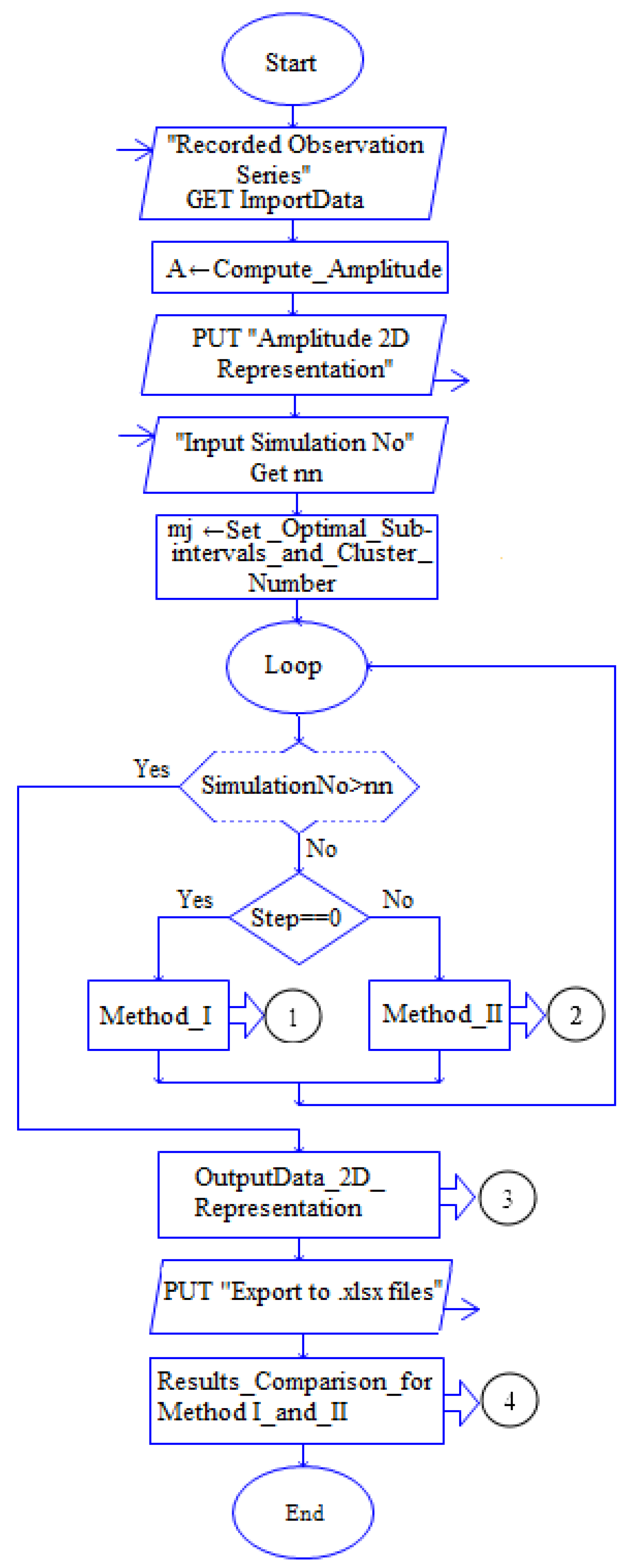
2.4. Implementation
- Compute_Amplitude step involves:
- -
- the calculation of the extreme values (yj min, respectively, yj max) for each j;
- -
- the amplitude computation for each j;
- Amplitude Representation step: amplitude 2D Graphical Representation.
- Choosing the number of subintervals or clusters.
- 4.
- Collecting the results in the Data Processing from Matlab destination tables.
- 5.
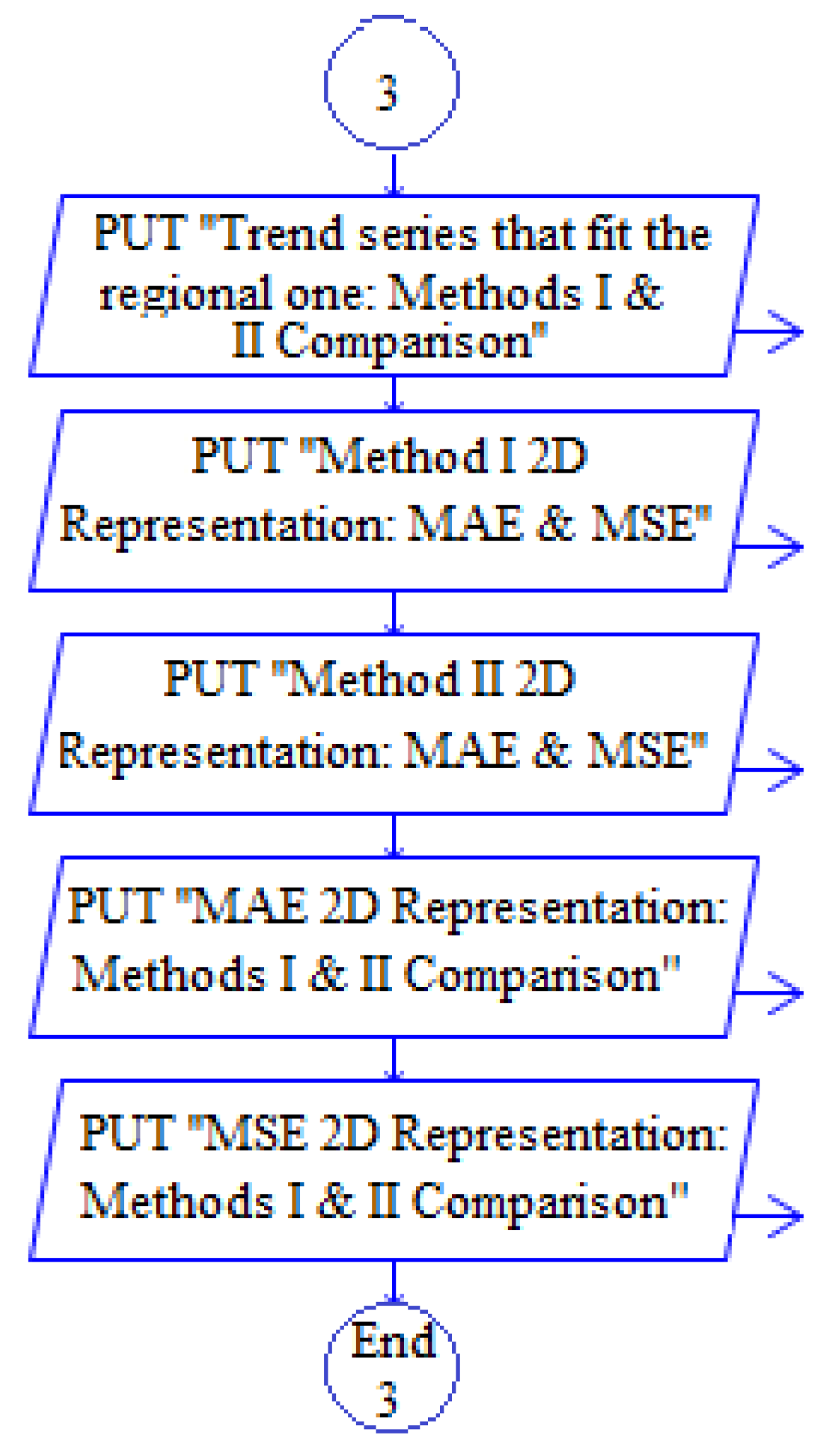
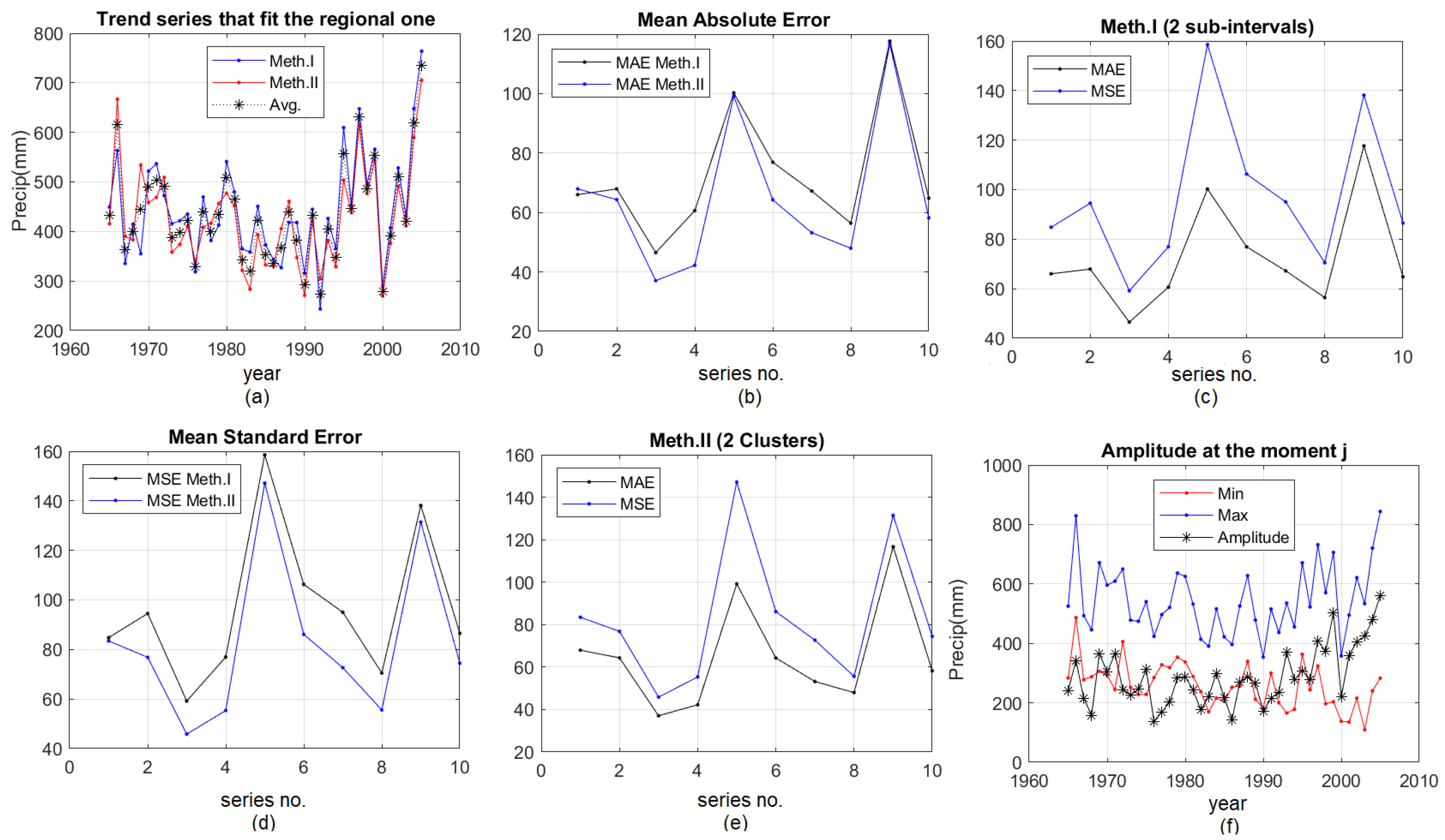
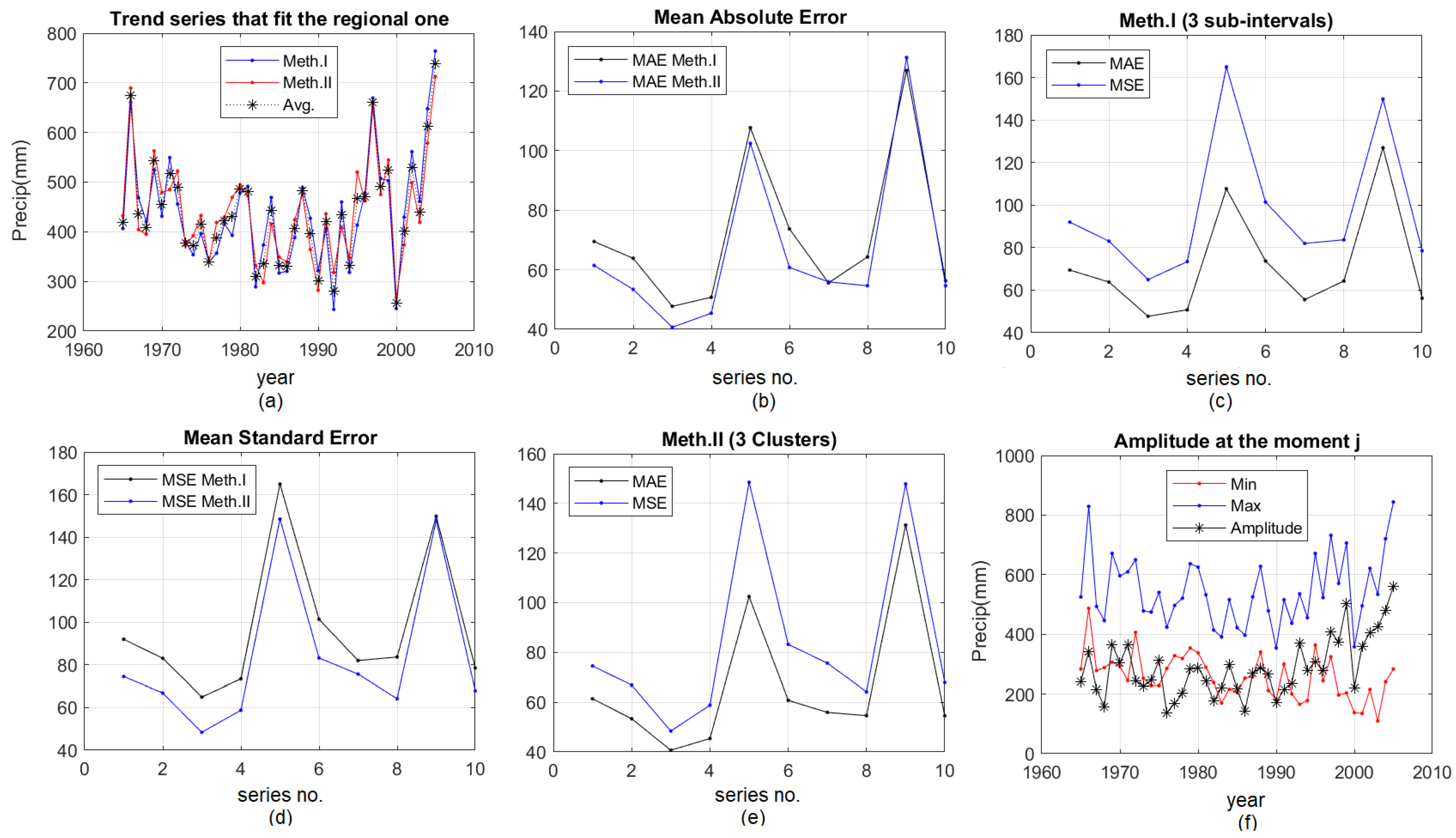
- 2D graphical representations of “Trend series that fit the regional one”, MAE and MSE using both methods (presented in the next section) (Figure 4).
- 6.
- Export to file: the modeling output is exported to the xlsx files.
- 7.
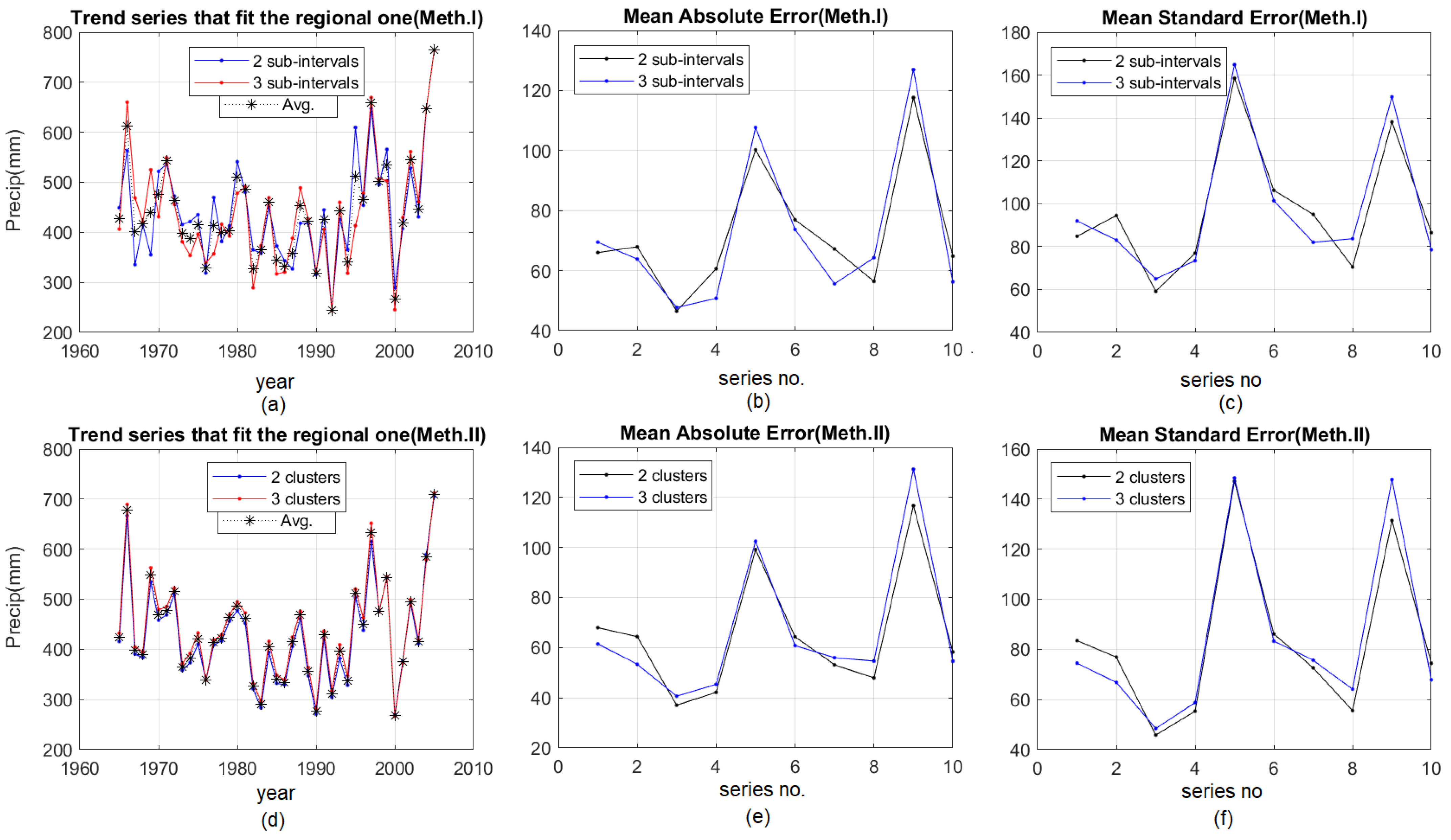
- Performing a comparative study, using both methods for different numbers of subintervals, respectively, different numbers of clusters and the graphical representation of the results for “Trend series that fit the regional one”, MAE and MSE (Figure 5).
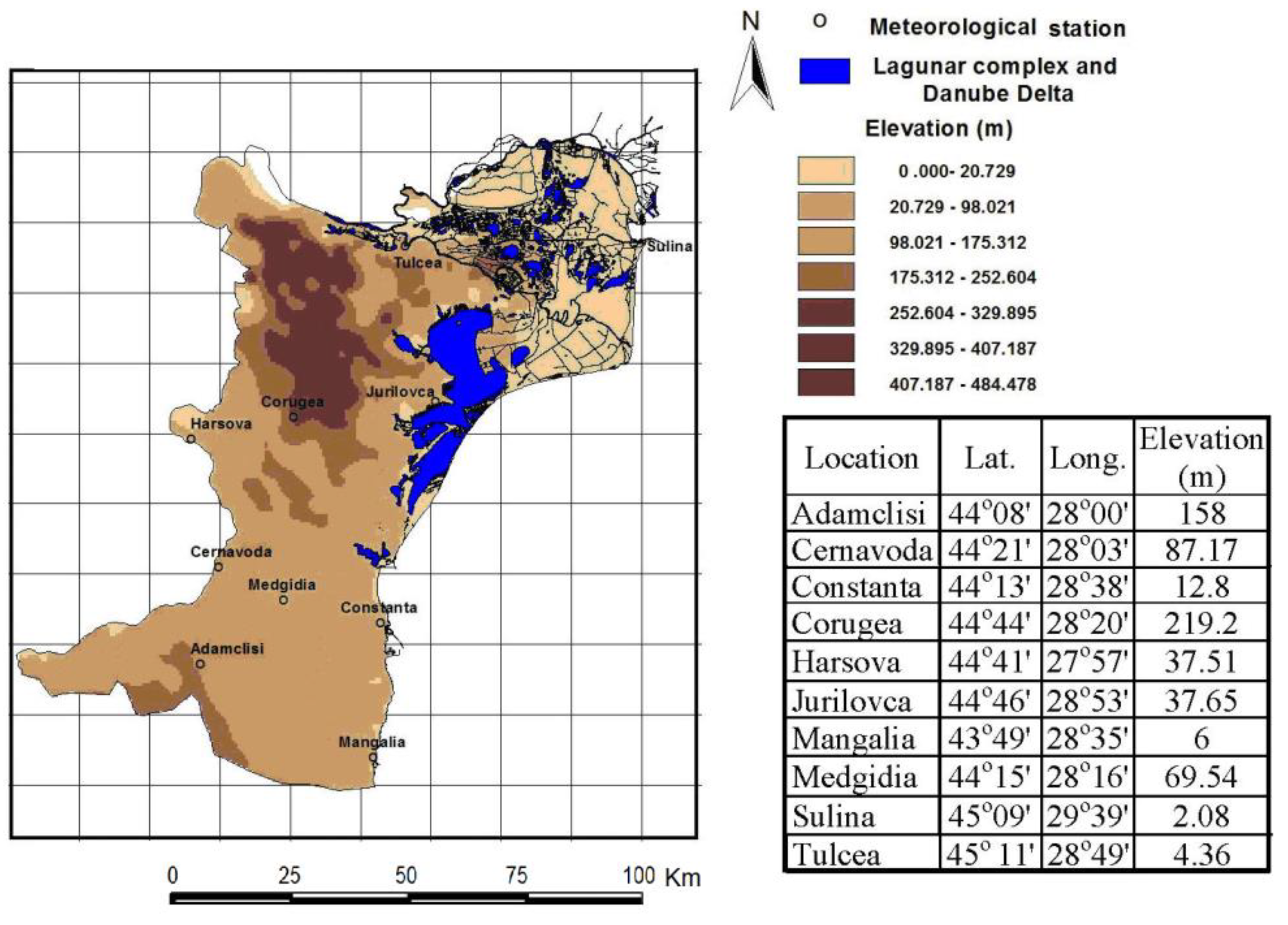
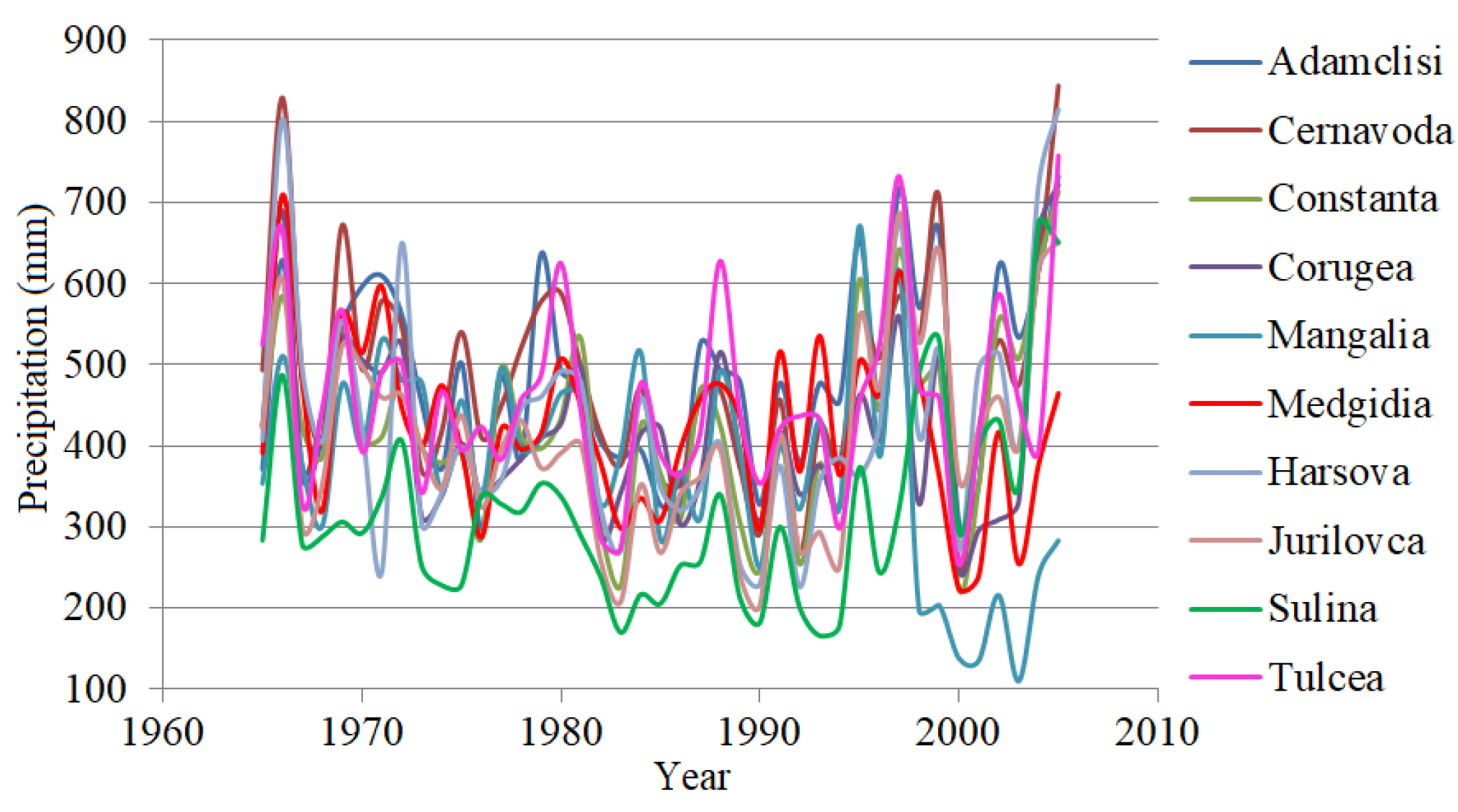
2.5. Data Series
3. Results and Discussion
4. Conclusions
- The optimizing of finding the regional series, in the following two directions:
- The selection (in the k-means algorithm) of the clusters whose elements participate in the construction of the regional series, based on maximizing the ratio BSS/TSS×100. In the previous algorithm version [22,23], when two clusters have the same number of elements (maximum), each could be selected to build the regional series. In this version, choosing the maximum BSS/TSS×100 ensures a higher distance between the clusters and a smaller one inside them. Thus, the homogeneity degree of the series in the clusters is higher, so the estimation of the regional series is better than in the previous version of Method II.
- The choice of the values that participate in building the regional series when at least two subintervals have the same maximum frequency and absolute value of the difference between the subinterval average and the series average.
Let consider that and are such intervals, with the same maximum frequency, , m is the average precipitation in a specific year, and are the averages of and and = . Given that the values in the intervals are in ascending order, this means that ( so . Therefore, selecting would underestimate the regional series (since only the smallest values would participate in the evaluation of the regional series), while selecting would overestimate it; so the best choice is using the values in both intervals for building the regional series. - The second one is implementing the algorithm in user-friendly software, Climate Analyzer, freely available on request. It facilitates the computation of the regional trend. It also provides the graphical visualization of the output of the selected algorithm, offering the facility to compare the results for different segmentations of the series.
- Implementing algorithms for determining the optimal number of clusters, given that the fitting quality depends on the number of groups involved in the regional series computation.
- implementing the IDW and Thiessen Polygons Methods.
- Extending the algorithm for analyzing the occurrence of precipitation events.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Report of the 21st Session on the CLIVAR Scientific Steering Group. In Proceedings of the 21st Session of the CLIVAR Scientific Steering Group, Moscow, Russia, 10–12 November 2014. ICPO Publication Series No. 201 WCRP Informal Report No. 3/2015.
- Schneider, T.; Teixeira, J.; Bretherton, C.S.; Brient, F.; Pressel, K.G.; Schär, C.; Siebesma, A.P. Climate goals and computing the future of clouds. Nat. Clim. Chang. 2017, 7, 3–5. [Google Scholar] [CrossRef]
- Hiez, G. Homogénéisation des données pluviométriques. Cah. ORSTOM Hydrol. 1997, XIX, 129–172. [Google Scholar]
- El Alaoui El Fels, A.; El Mehdi Saidi, M.; Bouiji, A.; Benrhanem, M. Rainfall regionalization and variability of extreme precipitation using artificial neural networks: A case study from western central Morocco. J. Water Clim. Chang. 2021, 12, 1107–1122. [Google Scholar] [CrossRef] [Green Version]
- Srinivas, V.V. Regionalization of Precipitation in India—A Review. J. Indian Inst. Sci. 2013, 93, 153–162. [Google Scholar]
- Li, J.; Heap, A.D. Spatial interpolation methods applied in the environmental sciences: A review. Environ. Model. Softw. 2014, 53, 173–189. [Google Scholar] [CrossRef]
- Bărbulescu, A.; Șerban, C.; Indrecan, M.-L. Improving spatial interpolation quality. IDW versus a genetic algorithm. Water 2021, 13, 863. [Google Scholar] [CrossRef]
- Bărbulescu, A.; Băutu, A.; Băutu, E. Particle Swarm Optimization for the Inverse Distance Weighting Distance method. Appl. Sci. 2020, 10, 2054. [Google Scholar] [CrossRef] [Green Version]
- Ly, S.; Charles, C.; Degré, C. Different methods for spatial interpolation of rainfall data for operational hydrology and hydrological modeling at watershed scale: A review. Biotechnol. Agron. Soc. Environ. 2013, 17, 392–406. [Google Scholar]
- Wu, K.-Y.; Mossa, J.; Mao, L.; Almulla, M. Comparison of different spatial interpolation methods for historical hydrographic data of the lowermost Mississippi River. Ann. GIS 2019, 2, 133–151. [Google Scholar] [CrossRef]
- Lloyd, C. Assessing the effect of integrating elevation data into the estimation of monthly precipitation in Great Britain. J. Hydrol. 2005, 308, 128–150. [Google Scholar] [CrossRef]
- Kurtzman, D.; Navon, S.S.; Morin, E. Improving interpolation of daily precipitation for hydrologic modelling: Spatial patterns of preferred interpolators. Hydrol. Process. 2009, 23, 3281–3291. [Google Scholar] [CrossRef]
- Zhang, X.; Srinivasan, R. GIS-Based spatial precipitation estimation: A comparison of geostatistical approaches. J. Am. Water Resour. Assoc. 2009, 45, 894–906. [Google Scholar] [CrossRef]
- Liu, H.; Chen, S.; Hou, M.; He, L. Improved inverse distance weighting method application considering spatial autocorrelation in 3D geological modeling. Earth Sci. Inform. 2020, 13, 619–632. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, Z.; Zhou, C.; Ming, W.; Du, Z. An Adaptive Inverse-Distance Weighting Interpolation Method Considering Spatial Differentiation in 3D Geological Modeling. Geosciences 2021, 11, 51. [Google Scholar] [CrossRef]
- Ozelkan, E.; Bagis, S.; Ozelkan, E.C.; Ustundag, B.B.; Yucel, M.; Ormeci, C. Spatial interpolation of climatic variables using land surface temperature and modified inverse distance weighting. Int. J. Remote Sens. 2015, 36, 1000–1025. [Google Scholar] [CrossRef]
- Jiang, W.; Zhang, P.; Jiang, H.; Zhao, X. Reconstructing Satellite-Based Monthly Precipitation over Northeast China Using Machine Learning Algorithms. Remote Sens. 2017, 9, 781. [Google Scholar] [CrossRef] [Green Version]
- Ryu, S.; Song, J.J.; Kim, Y.; Sung-Hwa, J.; Younghae, D.; GyuWon, L. Spatial Interpolation of Gauge Measured Rainfall Using. Asia-Pac. J. Atmos. Sci. 2021, 57, 331–345. [Google Scholar] [CrossRef] [Green Version]
- Dragomir, F.L. Theoretical Bases of the Process Simulation; Sitech: Craiova, Romania, 2017. [Google Scholar]
- Dragomir, F.L. Modeling and Simulating the Systems and Processes; Editura Universității Naționale de Apărare Carol I: București, Romania, 2017. [Google Scholar]
- Dragomir, F.L. Decision Theory—Theoretical Notions; Editura Universității Naționale de Apărare Carol I: București, Romania, 2017. [Google Scholar]
- Bărbulescu, A. A new method for estimation the regional precipitation. Water Resour. Manag. 2016, 30, 33–42. [Google Scholar] [CrossRef]
- Bărbulescu, A.; Nazzal, Y.; Howari, F. Statistical analysis and estimation of the regional trend of aerosol size over the Arabian Gulf Region during 2002–2016. Sci. Rep. 2018, 8, 9571. [Google Scholar] [CrossRef] [Green Version]
- Bărbulescu, A.; Barbes, L.; Nazzal, Y. New model for inorganic pollutants dissipation on the northern part of the Romanian Black Sea coast. Rom. J. Phys. 2018, 63, 806. [Google Scholar]
- Bărbulescu, A. Studies on Time Series. Applications in Environmental Sciences; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Zhang, Q.; Han, J.; Yang, Z. Spatiotemporal characteristics of regional precipitation events in the Jing-Jin-Ji region during 1989–2018. Int. J. Climatol. 2002, 41, 1190–1198. [Google Scholar] [CrossRef]
- Chiles, J.-P.; Delfiner, P. Geostatistics. Modeling Spatial Uncertainty, 2nd ed.; Wiley: Hoboken, NJ, USA, 2002. [Google Scholar]
- Bărbulescu, A.; Deguenon, J. Change point detection and models for precipitation evolution. Case study. Rom. J. Phys. 2014, 59, 590–600. [Google Scholar]
- Deguenon, J.; Bărbulescu, A. Trends of extreme precipitation events in Dobrudja. Ovidius Univ. Ann. Ser. Civil Eng. 2011, 1, 73–80. [Google Scholar]
- Soetewey, A.; Stats, R. Available online: https://statsandr.com/blog/clustering-analysis-k-means-and-hierarchical-clustering-by-hand-and-in-r/ (accessed on 20 May 2021).
- Al-Taani, A.; Nazzal, Y.; Howari, F.; Iqbal, J.; Bou-Orm, N.; Xavier, C.M.; Bărbulescu, A.; Sharma, M.; Dumitriu, C.Ș. Contamination assessment of heavy metals in soil, Liwa area, UAE. Toxics 2021, 9, 53. [Google Scholar] [CrossRef] [PubMed]
- Nazzal, Y.H.; Bărbulescu, A.; Howari, F.; Al-Taani, A.A.; Iqbal, J.; Xavier, C.M.; Sharma, M.; Dumitriu, C.Ș. Assessment of metals concentrations in soils of Abu Dhabi Emirate using pollution indices and multivariate statistics. Toxics 2021, 9, 95. [Google Scholar] [CrossRef] [PubMed]
- Bărbulescu, A.; Maftei, C.; Bautu, E. Modeling the Hydro-Meteorological Time Series. Applications to Dobrudja Region; Lambert Academic Publishing: Saarbrucken, Germany, 2010. [Google Scholar]
- Bărbulescu, A.; Maftei, C. Statistical approach of the behavior of Hamcearca River (Romania). Rom. Rep. Phys. 2021, 73, 703. [Google Scholar]
- Bărbulescu, A.; Maftei, C.; Dumitriu, C.S. The modeling of the climatic process that participates at the sizing of an irrigation system. Bull. Appl. Comput. Math 2002, CII-2048, 11–20. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Crt. No | Series | Distribution | Parameters | Kolmogorov- Smirnov | Chi- Squared | Reject the Null |
|---|---|---|---|---|---|---|
| 1 | Adamclisi | Wakeby | α = 185.8 β = 4.148 γ = 249.34 δ = −0.55834 ξ = 288.45 | 0.9631 | 0.94298 | No |
| 2 | Cernavoda | Log-logistic (3P) | A = 7.853 β = 530.76 γ = −56.791 | 0.9987 | 0.78226 | No |
| 3 | Constanta | Wakeby | α = 1396.7 β = 8.6357 γ = 131.68 δ = −0.17477 ξ = 169.03 | 0.9793 | 0.98812 | No |
| 4 | Corugea | GEV | k = 0.07952 σ = 80.002 μ = 363.68 | 0.9663 | 0.9776 | No |
| 5 | Mangalia | Johnson SB | γ = −1.5528 δ = 5.7129 λ = 2959.6 ξ = −1305.7 | 0.9972 | 0.9711 | No |
| 6 | Medgidia | Log-logistic (3P) | α = 19.78 β = 1142.3 γ = −723.44 | 0.9987 | 0.9284 | No |
| 7 | Harsova | Pearson 6 (4P) | α 1 = 38.828 α2 = 10.541 β = 93.195 γ = 47.668 | 0.9555 | 0.9835 | No |
| 8 | Jurilovca | Generalized logistic | k = 0.10343 σ = 68.053 μ = 397.14 | 0.9946 | 0.9666 | No |
| 9 | Sulina | Wakeby | α = 395.83 β = 4.3011 γ = 80.116 δ = 0.14853 ξ = 148.9 | 0.9975 | 0.9908 | No |
| 10 | Tulcea | Burr | k = 0.94537 α = 7.5822 β = 436.52 | 0.9820 | 0.9281 | No |
| MAE | MSE | MAPE | |||||
|---|---|---|---|---|---|---|---|
| Crt. No | Station | 2 | 3 | 2 | 3 | 2 | 3 |
| 1 | Adamclisi | 66.01 | 69.46 | 84.80 | 92.00 | 13.03 | 14.10 |
| 2 | Cernavoda | 67.92 | 63.84 | 94.52 | 83.04 | 13.07 | 12.36 |
| 3 | Constanta | 46.50 | 47.72 | 59.16 | 64.98 | 11.75 | 12.20 |
| 4 | Corugea | 60.62 | 50.77 | 76.95 | 73.44 | 15.47 | 13.42 |
| 5 | Mangalia | 100.24 | 107.67 | 158.57 | 164.93 | 43.58 | 45.32 |
| 6 | Medgidia | 76.91 | 73.71 | 106.27 | 101.39 | 19.47 | 19.50 |
| 7 | Harsova | 67.21 | 55.60 | 95.03 | 82.00 | 17.36 | 15.33 |
| 8 | Jurilovca | 56.41 | 64.30 | 70.49 | 83.69 | 15.91 | 18.75 |
| 9 | Sulina | 117.66 | 126.95 | 138.15 | 149.82 | 45.35 | 48.47 |
| 10 | Tulcea | 64.81 | 56.26 | 86.52 | 78.52 | 14.15 | 12.88 |
| Average | 72.43 | 71.63 | 97.04 | 97.38 | 20.91 | 21.23 | |
| Crt. No | MAE | MSE | MAPE | ||||
|---|---|---|---|---|---|---|---|
| Station | 2 | 3 | 2 | 3 | 2 | 3 | |
| 1 | Adamclisi | 67.93 | 61.42 | 83.45 | 74.52 | 13.55 | 12.42 |
| 2 | Cernavoda | 64.34 | 53.38 | 76.82 | 66.85 | 12.58 | 10.26 |
| 3 | Constanta | 37.07 | 40.70 | 45.83 | 48.44 | 9.15 | 10.38 |
| 4 | Corugea | 42.23 | 45.41 | 55.35 | 58.81 | 11.17 | 12.11 |
| 5 | Mangalia | 99.15 | 102.46 | 146.16 | 148.51 | 41.16 | 42.24 |
| 6 | Medgidia | 64.27 | 60.78 | 86.10 | 83.22 | 16.61 | 15.94 |
| 7 | Harsova | 53.18 | 55.93 | 72.65 | 75.63 | 13.40 | 14.75 |
| 8 | Jurilovca | 47.98 | 54.62 | 55.60 | 64.18 | 13.62 | 15.85 |
| 9 | Sulina | 116.69 | 131.28 | 130.43 | 147.86 | 43.62 | 49.07 |
| 10 | Tulcea | 58.21 | 58.21 | 74.47 | 67.90 | 12.70 | 12.25 |
| Average | 65.10 | 66.06 | 82.68 | 83.59 | 18.76 | 19.52 | |
| MPPM (Method II) | IDW | Kriging | |||||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | MSE | MAPE | MAE | MSE | MAPE | MAE | MSE | MAPE | |
| Adamclisi | 67.93 | 83.45 | 13.55 | 60.08 | 70.22 | 12.41 | 82.03 | 68.85 | 12.08 |
| Cernavoda | 64.34 | 76.82 | 12.58 | 53.81 | 71.00 | 10.25 | 65.23 | 81.15 | 14.12 |
| Constanta | 37.07 | 45.83 | 9.15 | 48.17 | 59.90 | 12.78 | 43.22 | 51.35 | 11.39 |
| Corugea | 42.23 | 55.35 | 11.17 | 49.23 | 62.40 | 10.93 | 46.04 | 61.65 | 10.32 |
| Mangalia | 99.15 | 146.16 | 41.16 | 56.91 | 72.64 | 13.67 | 56.34 | 70.75 | 13.54 |
| Medgidia | 64.27 | 86.10 | 16.61 | 47.20 | 57.11 | 11.44 | 50.19 | 61.64 | 14.63 |
| Harsova | 53.18 | 72.65 | 13.40 | 61.71 | 84.26 | 54.81 | 62.21 | 84.26 | 54.75 |
| Jurilovca | 47.98 | 55.60 | 13.62 | 69.90 | 88.14 | 25.83 | 61.24 | 75.83 | 20.42 |
| Sulina | 116.69 | 130.43 | 43.62 | 171.23 | 182.93 | 74.79 | 261.63 | 170.87 | 58.74 |
| Tulcea | 58.21 | 74.47 | 12.70 | 92.90 | 111.51 | 14.75 | 75.92 | 93.65 | 13.21 |
| Average | 65.10 | 82.68 | 18.76 | 71.11 | 84.29 | 24.17 | 84.40 | 82.00 | 22.32 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bărbulescu, A.; Postolache, F.; Dumitriu, C.Ș. Estimating the Precipitation Amount at Regional Scale Using a New Tool, Climate Analyzer. Hydrology 2021, 8, 125. https://doi.org/10.3390/hydrology8030125
Bărbulescu A, Postolache F, Dumitriu CȘ. Estimating the Precipitation Amount at Regional Scale Using a New Tool, Climate Analyzer. Hydrology. 2021; 8(3):125. https://doi.org/10.3390/hydrology8030125
Chicago/Turabian StyleBărbulescu, Alina, Florin Postolache, and Cristian Ștefan Dumitriu. 2021. "Estimating the Precipitation Amount at Regional Scale Using a New Tool, Climate Analyzer" Hydrology 8, no. 3: 125. https://doi.org/10.3390/hydrology8030125
APA StyleBărbulescu, A., Postolache, F., & Dumitriu, C. Ș. (2021). Estimating the Precipitation Amount at Regional Scale Using a New Tool, Climate Analyzer. Hydrology, 8(3), 125. https://doi.org/10.3390/hydrology8030125