

Improved Network and Training Scheme for Cross-Trial Surface Electromyography (sEMG)-Based Gesture Recognition

Abstract
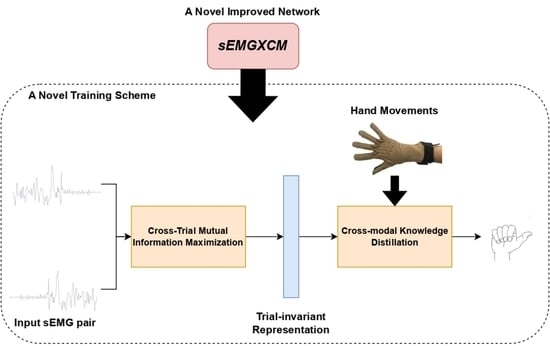
:
1. Introduction
- We design a new end-to-end convolutional neural network for cross-trial sEMG-based gesture recognition, namely sEMGXCM, that captures the spatial and temporal features of sEMG signals as well as the association across different electrodes. The parameter number of the self-attention layer increases as the number of electrodes increases, so sEMGXCM is utilized for sparse multichannel sEMG signals.
- We present a novel two-stage training scheme called sEMGPoseMIM for cross-trial sEMG-based gesture recognition. Specifically, the first stage is designed to maximize the mutual information between the pairs of cross-trial features at the same time step to produce trial-invariant representations. And the second stage models the cross-modal association between sEMG signals and hand movements via cross-modal knowledge distillation to enhance the performance of the trained network.
- A comprehensive evaluation of the proposed network sEMGXCM on the benchmark NinaPro databases is conducted, and the results show the superiority of sEMGXCM for cross-trial gesture recognition. Specifically, compared with the state-of-the-art network, sEMGXCM achieves improvements of +0.7%, +1.3%, +0.5%, +0.3%, +0.3%, +0.6%, and +1.0% on NinaPro DB1-DB7 [20,21,22,23]. We also performed an evaluation of our training scheme sEMGPoseMIM on NinaPro DB1-DB7. The experimental results show the superiority of sEMGPoseMIM for enhancing the cross-trial gesture recognition performance of networks. And the recognition accuracy of sEMGXCM from training it using sEMGPoseMIM is significantly higher than the state-of-the-art method by +1.3%, +1.5%, +0.8%, +2.6%, +1.7%, +0.8% and +0.6% on NinaPro DB1-DB7.
2. Related Work
2.1. sEMG-Based Gesture Recognition
2.2. Mutual Information and Cross-Modal Learning
3. Materials and Methods
3.1. sEMGXCM
3.2. sEMGPoseMIM
3.2.1. Stage 1: Cross-Trial Mutual Information Maximization
3.2.2. Stage 2: Cross-Modal Knowledge Distillation
4. Results
4.1. Datasets and Evaluation Metrics
4.1.1. Datasets and Data Preprocessing
4.1.2. Evaluation Metrics
4.2. Implementation Details
4.3. Comparison of Networks on Cross-Trial sEMG-Based Gesture Recognition
4.4. Effectiveness of sEMGPoseMIM
4.5. Variation on Each Stage
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, J.; Jafari, R. Orientation independent activity/gesture recognition using wearable motion sensors. IEEE Internet Things J. 2018, 6, 1427–1437. [Google Scholar] [CrossRef]
- Oudah, M.; Al-Naji, A.; Chahl, J. Hand gesture recognition based on computer vision: A review of techniques. J. Imaging 2020, 6, 73. [Google Scholar] [CrossRef] [PubMed]
- Abdelnasser, H.; Youssef, M.; Harras, K.A. WiGest: A ubiquitous WiFi-based gesture recognition system. In Proceedings of the IEEE Conference on Computer Communications, Hong Kong, China, 26 April–1 May 2015; pp. 1472–1480. [Google Scholar]
- Ahmed, S.; Kallu, K.D.; Ahmed, S.; Cho, S.H. Hand gestures recognition using radar sensors for human-computer-interaction: A review. Remote Sens. 2021, 13, 527. [Google Scholar] [CrossRef]
- Geng, W.; Du, Y.; Jin, W.; Wei, W.; Hu, Y.; Li, J. Gesture recognition by instantaneous surface EMG images. Sci. Rep. 2016, 6, 36571. [Google Scholar] [CrossRef]
- He, J.; Jiang, N. Biometric from surface electromyogram (sEMG): Feasibility of user verification and identification based on gesture recognition. Front. Bioeng. Biotechnol. 2020, 8, 58. [Google Scholar] [CrossRef]
- Phinyomark, A.; Scheme, E. EMG pattern recognition in the era of big data and deep learning. Big Data Cogn. Comput. 2018, 2, 21. [Google Scholar] [CrossRef]
- Wei, W.; Dai, Q.; Wong, Y.; Hu, Y.; Kankanhalli, M.; Geng, W. Surface-electromyography-based gesture recognition by multi-view deep learning. IEEE Trans. Biomed. Eng. 2019, 66, 2964–2973. [Google Scholar] [CrossRef]
- Rahimian, E.; Zabihi, S.; Atashzar, S.F.; Asif, A.; Mohammadi, A. XceptionTime: Independent time-window xceptiontime architecture for hand gesture classification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Virtual, 4–8 May 2020; pp. 1304–1308. [Google Scholar]
- Bittibssi, T.M.; Genedy, M.A.; Maged, S.A. sEMG pattern recognition based on recurrent neural network. Biomed. Signal Process. Control 2021, 70, 103048. [Google Scholar] [CrossRef]
- Hu, Y.; Wong, Y.; Wei, W.; Du, Y.; Kankanhalli, M.; Geng, W. A novel attention-based hybrid CNN–RNN architecture for sEMG-based gesture recognition. PLoS ONE 2018, 13, e0206049. [Google Scholar] [CrossRef]
- Sun, T.; Hu, Q.; Gulati, P.; Atashzar, S.F. Temporal dilation of deep LSTM for agile decoding of sEMG: Application in prediction of Upper-Limb motor intention in NeuroRobotics. IEEE Robot. Autom. Lett. 2021, 6, 6212–6219. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Fauvel, K.; Lin, T.; Masson, V.; Fromont, É.; Termier, A. XCM: An Explainable Convolutional Neural Network for Multivariate Time Series Classification. Mathematics 2021, 9, 3137. [Google Scholar] [CrossRef]
- Castellini, C.; Van Der Smagt, P. Surface EMG in advanced hand prosthetics. Biol. Cybern. 2009, 100, 35–47. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Wong, Y.; Dai, Q.; Kankanhalli, M.; Geng, W.; Li, X. SEMG-based gesture recognition with embedded virtual hand poses and adversarial learning. IEEE Access 2019, 7, 104108–104120. [Google Scholar] [CrossRef]
- Zhao, L.; Wang, Y.; Zhao, J.; Yuan, L.; Sun, J.J.; Schroff, F.; Adam, H.; Peng, X.; Metaxas, D.; Liu, T. Learning View-Disentangled Human Pose Representation by Contrastive Cross-View Mutual Information Maximization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12793–12802. [Google Scholar]
- Belghazi, M.I.; Baratin, A.; Rajeshwar, S.; Ozair, S.; Bengio, Y.; Courville, A.; Hjelm, D. Mutual information neural estimation. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 531–540. [Google Scholar]
- Thoker, F.M.; Gall, J. Cross-modal knowledge distillation for action recognition. In Proceedings of the IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; pp. 6–10. [Google Scholar]
- Atzori, M.; Gijsberts, A.; Castellini, C.; Caputo, B.; Hager, A.G.M.; Elsig, S.; Giatsidis, G.; Bassetto, F.; Müller, H. Electromyography data for non-invasive naturally-controlled robotic hand prostheses. Sci. Data 2014, 1, 140053. [Google Scholar] [CrossRef] [PubMed]
- Pizzolato, S.; Tagliapietra, L.; Cognolato, M.; Reggiani, M.; Müller, H.; Atzori, M. Comparison of six electromyography acquisition setups on hand movement classification tasks. PLoS ONE 2017, 12, e0186132. [Google Scholar] [CrossRef]
- Palermo, F.; Cognolato, M.; Gijsberts, A.; Müller, H.; Caputo, B.; Atzori, M. Repeatability of grasp recognition for robotic hand prosthesis control based on sEMG data. In Proceedings of the International Conference on Rehabilitation Robotics, London, UK, 17–20 July 2017; pp. 1154–1159. [Google Scholar]
- Krasoulis, A.; Kyranou, I.; Erden, M.S.; Nazarpour, K.; Vijayakumar, S. Improved prosthetic hand control with concurrent use of myoelectric and inertial measurements. J. Neuroeng. Rehabil. 2017, 14, 71. [Google Scholar] [CrossRef]
- Dai, Q.; Li, X.; Geng, W.; Jin, W.; Liang, X. CAPG-MYO: A muscle–computer interface Supporting User-defined Gesture Recognition. In Proceedings of the The 2021 9th International Conference on Computer and Communications Management, Singapore, 16–18 July 2021; pp. 52–58. [Google Scholar]
- Mitra, S.; Acharya, T. Gesture recognition: A survey. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2007, 37, 311–324. [Google Scholar] [CrossRef]
- Guo, K.; Orban, M.; Lu, J.; Al-Quraishi, M.S.; Yang, H.; Elsamanty, M. Empowering Hand Rehabilitation with AI-Powered Gesture Recognition: A Study of an sEMG-Based System. Bioengineering 2023, 10, 557. [Google Scholar] [CrossRef]
- Khushaba, R.N.; Al-Timemy, A.H.; Al-Ani, A.; Al-Jumaily, A. A framework of temporal-spatial descriptors-based feature extraction for improved myoelectric pattern recognition. IEEE Trans. Neural Syst. Rehabil. Eng. 2017, 25, 1821–1831. [Google Scholar] [CrossRef]
- Duan, F.; Dai, L.; Chang, W.; Chen, Z.; Zhu, C.; Li, W. sEMG-based identification of hand motion commands using wavelet neural network combined with discrete wavelet transform. IEEE Trans. Ind. Electron. 2015, 63, 1923–1934. [Google Scholar] [CrossRef]
- Kilby, J.; Hosseini, H.G. Extracting effective features of SEMG using continuous wavelet transform. In Proceedings of the 2006 International Conference of the IEEE Engineering in Medicine and Biology Society, New York, NY, USA, 30 August–3 September 2006; pp. 1704–1707. [Google Scholar]
- Doswald, A.; Carrino, F.; Ringeval, F. Advanced processing of sEMG signals for user independent gesture recognition. In Proceedings of the XIII Mediterranean Conference on Medical and Biological Engineering and Computing 2013, Seville, Spain, 25–28 September 2013; Springer: Berlin/Heidelberg, Germany, 2014; pp. 758–761. [Google Scholar]
- Côté-Allard, U.; Fall, C.L.; Campeau-Lecours, A.; Gosselin, C.; Laviolette, F.; Gosselin, B. Transfer learning for sEMG hand gestures recognition using convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Systems, Man, and Cybernetics, Banff, AB, Canada, 5–8 October 2017; pp. 1663–1668. [Google Scholar]
- Gao, Q.; Liu, J.; Ju, Z. Hand gesture recognition using multimodal data fusion and multiscale parallel convolutional neural network for human–robot interaction. Expert Syst. 2021, 38, e12490. [Google Scholar] [CrossRef]
- Xu, L.; Zhang, K.; Yang, G.; Chu, J. Gesture recognition using dual-stream CNN based on fusion of semg energy kernel phase portrait and IMU amplitude image. Biomed. Signal Process. Control 2022, 73, 103364. [Google Scholar] [CrossRef]
- MacKay, D.J. Information Theory, Inference and Learning Algorithms; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Jeon, E.; Ko, W.; Yoon, J.S.; Suk, H.I. Mutual information-driven subject-invariant and class-relevant deep representation learning in BCI. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 739–749. [Google Scholar] [CrossRef]
- Bachman, P.; Hjelm, R.D.; Buchwalter, W. Learning representations by maximizing mutual information across views. Adv. Neural Inf. Process. Syst. 2019, 32, 15535–15545. [Google Scholar]
- Bai, D.; Chen, S.; Yang, J. Upper arm motion high-density sEMG recognition optimization based on spatial and time-frequency domain features. J. Healthc. Eng. 2019, 2019, 3958029. [Google Scholar] [CrossRef] [PubMed]
- Wen, R.; Wang, Q.; Ma, X.; Li, Z. Human Hand Movement Recognition based on HMM with Hyperparameters Optimized by Maximum Mutual Information. In Proceedings of the 2020 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference, Auckland, New Zealand, 7–10 December 2020; pp. 944–951. [Google Scholar]
- Liu, Y.; Neophytou, A.; Sengupta, S.; Sommerlade, E. Cross-modal spectrum transformation network for acoustic scene classification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Toronto, ON, Canada, 6–11 June 2021; pp. 830–834. [Google Scholar]
- Gu, X.; Guo, Y.; Deligianni, F.; Lo, B.; Yang, G.Z. Cross-subject and cross-modal transfer for generalized abnormal gait pattern recognition. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 546–560. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; Pereira, F., Burges, C., Bottou, L., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25. [Google Scholar]
- Van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Sainath, T.N.; Mohamed, A.R.; Kingsbury, B.; Ramabhadran, B. Deep convolutional neural networks for LVCSR. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 8614–8618. [Google Scholar] [CrossRef]
- Zhang, W.J.; Ouyang, P.R.; Sun, Z.H. A novel hybridization design principle for intelligent mechatronics systems. In The Abstracts of the International Conference on Advanced Mechatronics: Toward Evolutionary Fusion of IT and Mechatronics: ICAM, Tokyo, Japan, 4–6 May 2010; The Japan Society of Mechanical Engineers: Tokyo, Japan, 2010; pp. 67–74. [Google Scholar]
- Mukhopadhyay, A.K.; Samui, S. An experimental study on upper limb position invariant EMG signal classification based on deep neural network. Biomed. Signal Process. Control 2020, 55, 101669. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, Y.; Yu, H.; Yang, X.; Lu, W. Learning Effective Spatial–Temporal Features for sEMG Armband-Based Gesture Recognition. IEEE Internet Things J. 2020, 7, 6979–6992. [Google Scholar] [CrossRef]
- Cheng, P.; Hao, W.; Dai, S.; Liu, J.; Gan, Z.; Carin, L. Club: A contrastive log-ratio upper bound of mutual information. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 1779–1788. [Google Scholar]
- Rubner, Y.; Puzicha, J.; Tomasi, C.; Buhmann, J.M. Empirical evaluation of dissimilarity measures for color and texture. Comput. Vis. Image Underst. 2001, 84, 25–43. [Google Scholar] [CrossRef]
- Hudgins, B.; Parker, P.; Scott, R.N. A new strategy for multifunction myoelectric control. IEEE Trans. Biomed. Eng. 1993, 40, 82–94. [Google Scholar] [CrossRef] [PubMed]
- Recommendation, C. Pulse Code Modulation (PCM) of Voice Frequencies; ITU: Geneva, Switzerland, 1988. [Google Scholar]
- Du, Y.; Wong, Y.; Jin, W.; Wei, W.; Hu, Y.; Kankanhalli, M.S.; Geng, W. Semi-Supervised Learning for Surface EMG-based Gesture Recognition. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017; pp. 1624–1630. [Google Scholar]
- Liu, Y.; Wei, Y.; Yan, H.; Li, G.; Lin, L. Causal Reasoning Meets Visual Representation Learning: A Prospective Study. Mach. Intell. Res. 2022, 19, 485–511. [Google Scholar] [CrossRef]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Han, B.; Liu, C.; Zhang, W. A method to measure the resilience of algorithm for operation management. IFAC-PapersOnLine 2016, 49, 1442–1447. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Labels | Subjects | Trials | Hand Kinematic | Channels | Sampling Rate | Training Trials | Test Trials |
|---|---|---|---|---|---|---|---|---|
| Ninapro DB1 [20] | 52 | 27 | 10 | w | 10 | 100 Hz | 1, 3, 4, 6, 7, 8, 9 | 2,5,10 |
| Ninapro DB2 [20] | 50 | 40 | 6 | w | 12 | 2000 Hz | 1, 3, 4, 6 | 2, 5 |
| Ninapro DB3 [20] | 50 | 11 | 6 | w/o | 12 | 2000 Hz | 1, 3, 4, 6 | 2, 5 |
| Ninapro DB4 [21] | 53 | 10 | 6 | w/o | 12 | 2000 Hz | 1, 3, 4, 6 | 2, 5 |
| Ninapro DB5 [21] | 53 | 10 | 6 | w | 16 | 200 Hz | 1, 3, 4, 6 | 2, 5 |
| Ninapro DB6 [22] | 7 | 10 | 10 | w/o | 16 | 2000 Hz | 1, 3, 5, 7, 9 | 2, 4, 6, 8, 10 |
| Ninapro DB7 [23] | 41 | 22 | 6 | w/o | 12 | 2000 Hz | 1,3,4,6 | 2, 5 |
| Backbone | NinaPro DB1 | NinaPro DB2 | NinaPro DB3 | NinaPro DB4 | NinaPro DB5 | NinaPro DB6 | NinaPro DB7 |
|---|---|---|---|---|---|---|---|
| GengNet [5] | 78.9% (77.8%) | 59.4% (50.2%) | 57.0% (41.0%) | 67.4% (64.8%) | 78.9% (74.0%) | 60.1% (56.4%) | 77.8% (74.6%) |
| XceptionTime [9] | 85.0% (83.6%) | 83.4% (82.1%) | 55.0% (53.0%) | 71.7% (70.2%) | 89.0% (86.7%) | 61.3% (59.5%) | 86.5% (84.1%) |
| XCM [14] | 90.5% (88.3%) | 84.8% (83.7%) | 65.0% (63.7%) | 78.1% (77.4%) | 94.0% (92.0%) | 66.4% (64.9%) | 90.5% (89.1%) |
| sEMGXCM | 91.4% (89.0%) | 86.3% (85.0%) | 66.5% (64.2%) | 78.7% (77.7%) | 94.2% (92.3%) | 66.9% (65.2%) | 91.2% (89.4%) |
| NinaPro DB1 | NinaPro DB2 | NinaPro DB3 | NinaPro DB4 | NinaPro DB5 | NinaPro DB6 | NinaPro DB7 | |
|---|---|---|---|---|---|---|---|
| GengNet [5] | 77.8% | 50.2% | 41.0% | 64.8% | 74.0% | 56.4% | 74.6% |
| DuNet [52] | 79.4% | 52.6% | 41.3% | 64.8% | 77.9% | 56.8% | 74.2% |
| HuNet [11] | 87.0% | 82.2% | 46.7% | 68.6% | 81.8% | 58.0% | 80.7% |
| WeiNet [8] | 88.2% | 83.7% | 64.3% | 51.6% | 90.0% | 64.1% | 88.3% |
| CMAM [16] | 90.1% | 84.8% | 65.7% | 76.1% | 92.5% | 66.1% | 90.6% |
| Our Method | 91.4% | 86.3% | 66.5% | 78.7% | 94.2% | 66.9% | 91.2% |
| NinaPro DB1 | NinaPro DB2 | NinaPro DB3 | NinaPro DB4 | NinaPro DB5 | NinaPro DB6 | NinaPro DB7 | |
|---|---|---|---|---|---|---|---|
| From Scratch | 89.0% | 85.0% | 64.2% | 77.7% | 92.3% | 65.2% | 89.4% |
| Stage 1 Only | 89.7% | 85.2% | 66.3% | 78.4% | 93.1% | 66.0% | 90.1% |
| Stage 2 Only | 89.5% | 85.8% | 65.9% | 76.8% | 92.9% | 65.2% | 89.6% |
| Two Stages | 91.4% | 86.3% | 66.5% | 78.7% | 94.2% | 66.9% | 91.2% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, Q.; Wong, Y.; Kankanhali, M.; Li, X.; Geng, W. Improved Network and Training Scheme for Cross-Trial Surface Electromyography (sEMG)-Based Gesture Recognition. Bioengineering 2023, 10, 1101. https://doi.org/10.3390/bioengineering10091101
Dai Q, Wong Y, Kankanhali M, Li X, Geng W. Improved Network and Training Scheme for Cross-Trial Surface Electromyography (sEMG)-Based Gesture Recognition. Bioengineering. 2023; 10(9):1101. https://doi.org/10.3390/bioengineering10091101
Chicago/Turabian StyleDai, Qingfeng, Yongkang Wong, Mohan Kankanhali, Xiangdong Li, and Weidong Geng. 2023. "Improved Network and Training Scheme for Cross-Trial Surface Electromyography (sEMG)-Based Gesture Recognition" Bioengineering 10, no. 9: 1101. https://doi.org/10.3390/bioengineering10091101
APA StyleDai, Q., Wong, Y., Kankanhali, M., Li, X., & Geng, W. (2023). Improved Network and Training Scheme for Cross-Trial Surface Electromyography (sEMG)-Based Gesture Recognition. Bioengineering, 10(9), 1101. https://doi.org/10.3390/bioengineering10091101