2.1. One-Class Classification
The assumption underlying the one-class classification problem [
3] is that during the training process, only one class is available, referred to as the target class, while the remaining classes are considered non-target classes. One-class classifiers leverage the distinctive characteristics of the target class to identify a boundary encompassing all target class data or the majority of it. In practical applications, such as wearable devices for individual electrocardiogram monitoring in precision healthcare (predicting conditions like high blood sugar or potassium levels), initially, data may be collected only from healthy patients. It is impractical to wait until a sufficient amount of data are gathered before initiating predictions, presenting a typical scenario for a one-class classification problem.
An alternative solution involves using public data to predict individual health conditions, but this approach has proven ineffective due to the inconsistent physiological characteristics among individuals (e.g., variations in electrocardiogram wavelength, peak positions, and heights). To overcome the limitations of traditional classification algorithms in such situations, one-class classification algorithms play a crucial role.
A suitable one-class classifier must exhibit strong generalization capabilities, maintaining a high recognition rate for non-target classes while avoiding overutilization of target class information to prevent overfitting. Proper handling of target class and outlier [
4,
5] values is essential to derive effective decision boundaries. The one-class classification problem can be mathematically expressed as follows:
Here, is an unknown measurement of data z with respect to the target class group (e.g., distance, density), is the threshold for , and is a function determining whether z is accepted as the target class.
One-Class Support Vector Machine (OC-SVM)
The OC-SVM [
6] is a type of unsupervised algorithm based on the SVM [
7,
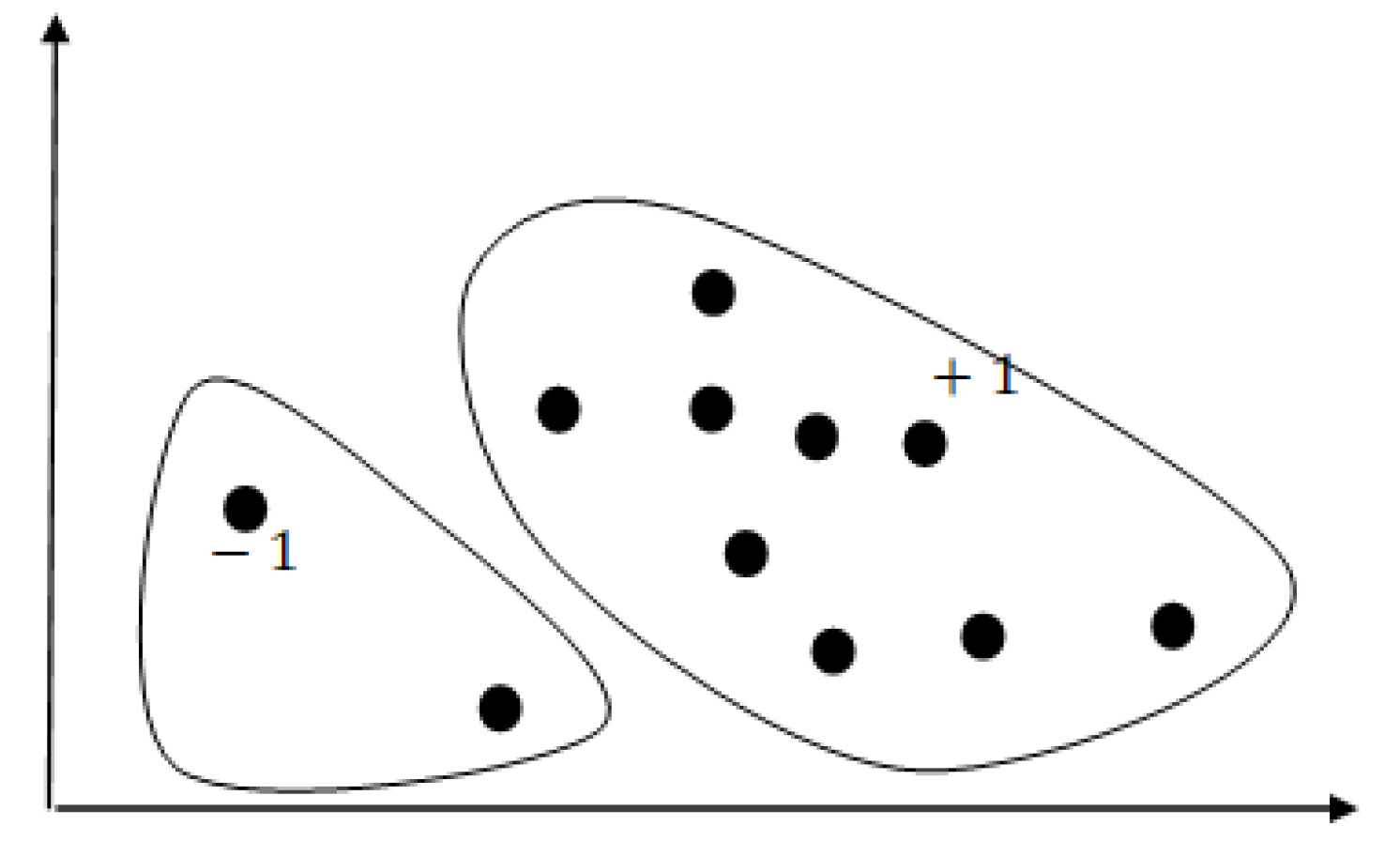
8], which can be used for novelty detection and anomaly detection. The objective of the OC-SVM is to find a decision function or hyperplane, attempting to separate the target class data from the non-target-class data. As illustrated below in
Figure 1, most of the training data are allocated to one region and assigned a value of +1, while data outside this region are assigned a value of −1. The OC-SVM utilizes a kernel function (typically Gaussian) to map the input data to a higher dimensional space and aims to find a minimal hyperplane. Given a set of target class training data
, we can represent the following quadratic programming expression:
Here, N represents the total number of data points, is used to determine the upper limit of outlier values, represents the slack variable for each data point, and is the kernel function.
2.2. One-Class Nearest-Neighbor (OCNN) Algorithm
The OCNN algorithm can be classified into four types based on the number of nearest neighbors [
9,
10] chosen:
Find the nearest neighbor of the test data in the target class, and then find the nearest neighbor of this nearest neighbor (11NN).
Find the nearest neighbor of the test data in the target class, and then find the K-nearest neighbors of this nearest neighbor (1KNN).
Find J-nearest neighbors of the test data in the target class, and then find the nearest neighbor of each of these J-nearest neighbors (J1NN).
Find J-nearest neighbors of the test data in the target class, and then find the K-nearest neighbors of each of these J-nearest neighbors (JKNN).
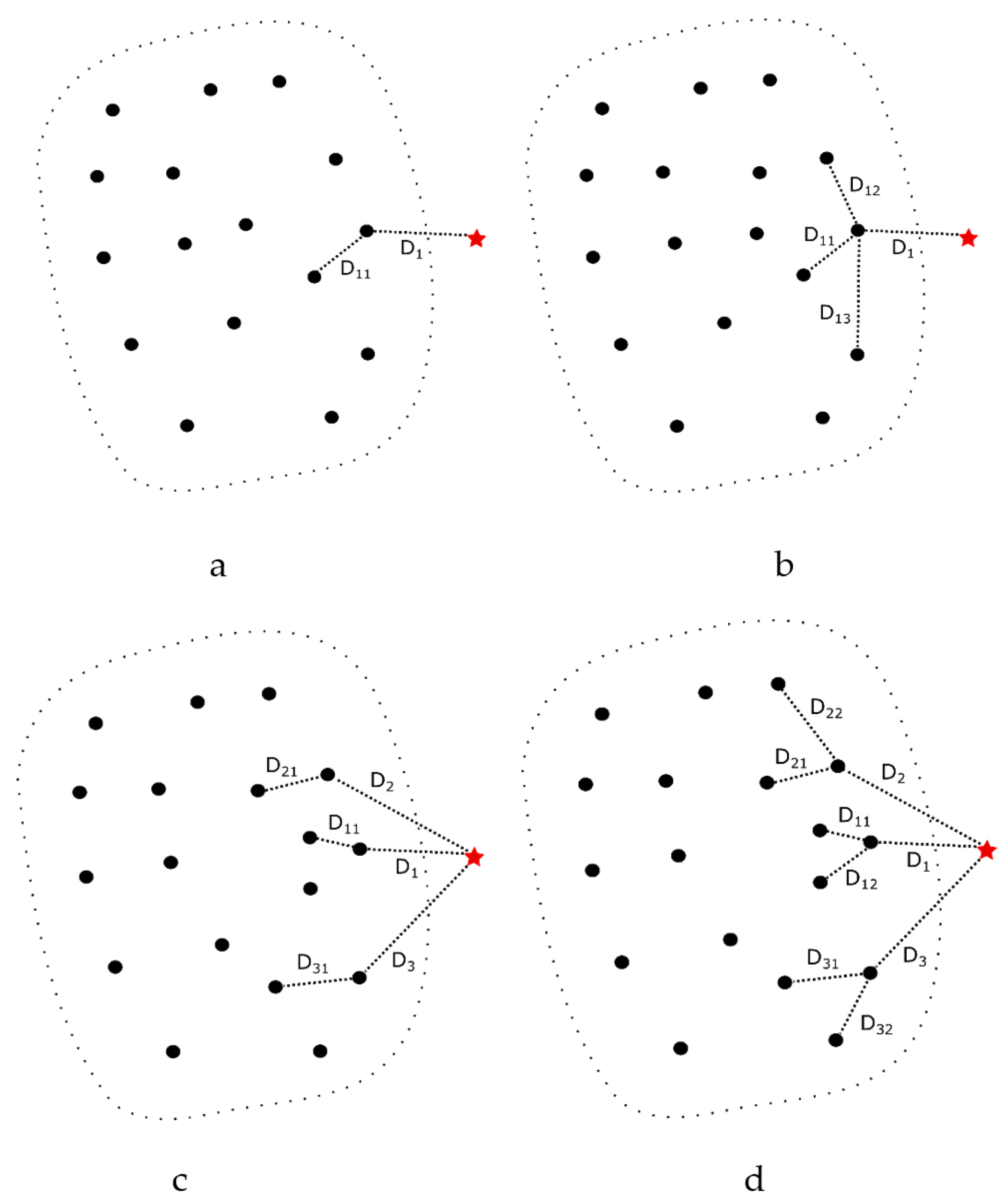
Figure 2 illustrates the four different OCNN methods. The black circles represent the target class data, and the red asterisk represents an unknown data point. To determine whether the unknown data point belongs to the target class, different numbers of nearest neighbors are selected based on the parameters
J and
K. After calculating the average distance of
J-nearest neighbors and the average distance of
K-nearest neighbors, the values are compared with the threshold
. Taking JKNN as an example, the detailed process please referring to Algorithm 1 as follows:
| Algorithm 1 Pseudo-code of JKNN |
- 1:
Input: N target class data points with d dimensions, test data z, nearest neighbor parameters J, K, and threshold . - 2:
Output: Accept or reject the test data z as target class data. - 3:
Calculate the distance from the test data z to the J-nearest neighbors and compute the average. represents the J-nearest neighbors of z, expressed as: - 4:
Calculate the distance from the J-nearest neighbors of the test data z to their respective K-nearest neighbors and compute the average. represents all K-nearest neighbors of the J-nearest neighbors, expressed as: - 5:
If , consider the test data z as the target class; otherwise, consider it as a non-target class.
|
In the OCNN algorithm, the threshold can be fixed at 1 or chosen arbitrarily. Here, we will discuss the relationship between 11NN under different threshold values and other OCNN methods.
In
Figure 2a, when 11NN has a threshold
set to 1, if
, the test data will be classified as a non-target class (outlier), even if
is only slightly larger than
. Intuitively, the distance
from non-target class (or outlier) to its nearest neighbor should be much larger than the distance
from the nearest neighbor to itself. This can be expressed mathematically as:
When , some data that were originally classified as a non-target class due to the rule will be accepted as a target class. This situation aligns more with our intuition about outliers. Finding the optimal will be an important issue, and the optimal will change depending on the dataset and evaluation criteria.
Figure 2b is the 1KNN for non-target class data, and we represent its distance to the nearest neighbor as:
where
is the distance from the test data point to its
i-th nearest neighbor, and we can observe that
should increase as
i increases. Expanding the inequality
we obtain:
Based on the derivations from the inequalities (6) and (7), we obtain:
This demonstrates that the 1KNN method can produce similar effects to 11NN (
). J1NN: In contrast to 1KNN, we consider
J- nearest neighbors for the test data but only consider one nearest neighbor for each of these neighbors. As shown in
Figure 2c, similar to the derivation of 1KNN, we obtain:
This proves that the J1NN method can produce similar effects to 11NN (
). JKNN: We calculate the average distance of
J-nearest neighbors and their respective
K-nearest neighbors. Based on the previous derivations of 1KNN and J1NN, we obtain:
As the parameters J and K vary, we observe that these two parameters will offset each other’s influences. When , JKNN is similar to 11NN (), allowing it to accept more outliers as the target class. When , JKNN is similar to 11NN (), making the criteria more stringent, and more data will be considered as outliers.
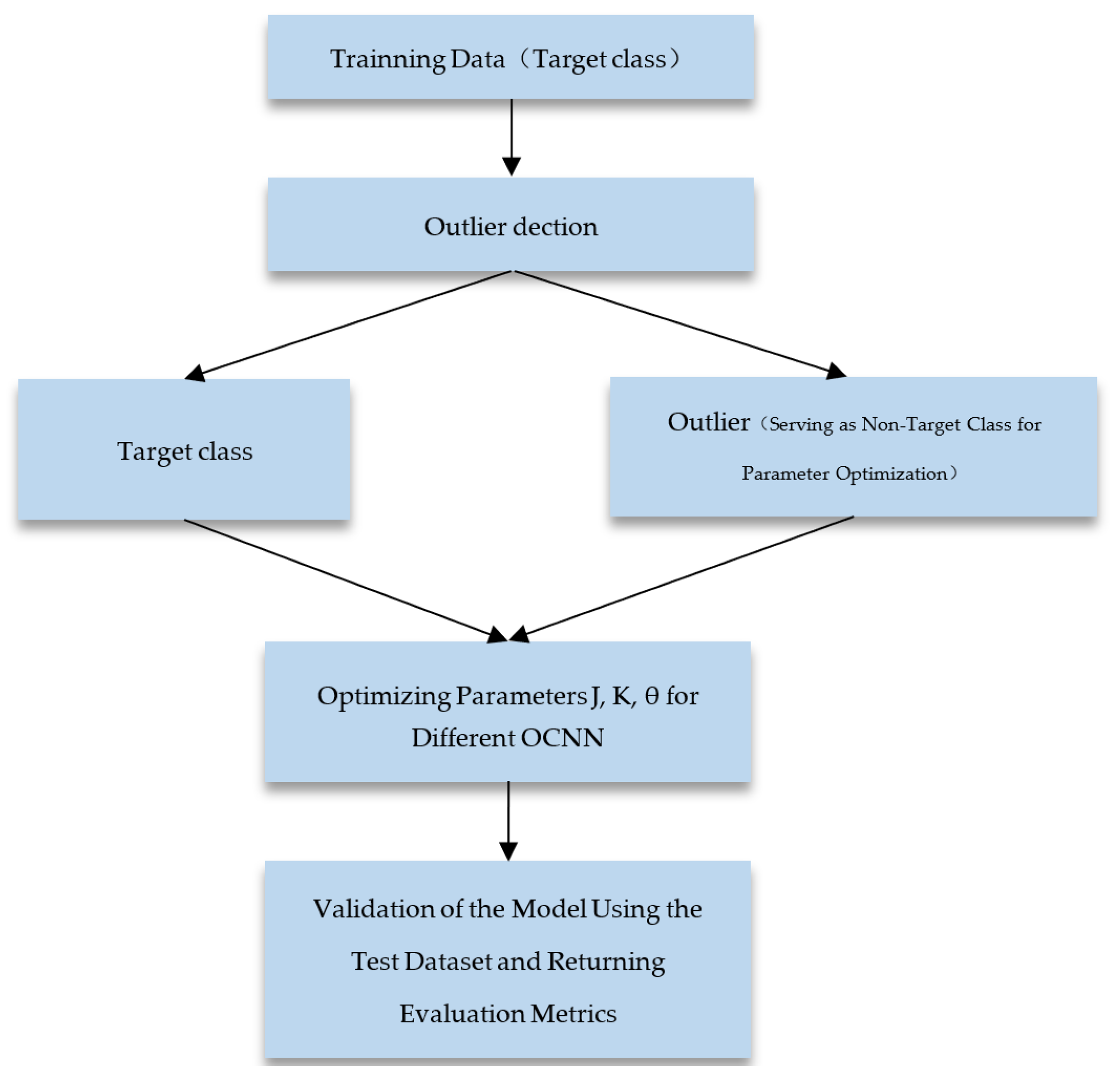
2.3. One-Class Nearest Neighbor (OCNN) Parameter Optimization
Based on the above discussion, we understand the relationships between different types of OCNN classifiers. The settings of parameters , and threshold will be an important topic.
Parameter optimization is a challenging issue in one-class classifiers because, in the training data, only data from the target class can be used, unlike the situation with multi-class data, where traditional classifiers utilize data from different classes to make decision boundaries. Here, we use some methods to identify outliers in the target class data for parameter optimization of the OCNN classifier. Regarding the selection of nearest neighbors and their distance calculations, we can identify the following issues faced by different OCNN classifiers:
Firstly, we assume the target class as negative data and the non-target class as positive data.
False Negatives: In real-world datasets, noise samples may be generated due to human errors (incorrect labeling, operational negligence, etc.). The OCNN classifier described earlier cannot detect this phenomenon. When target class samples exhibit a tight configuration, noise samples far from the cluster will lead to unknown non-target-class data being incorrectly classified as target class data.
False Positives: If we do not find an appropriate decision threshold after removing noise samples from the dataset, the OCNN classifier will identify many test data as non-target-class data. Another situation leading to false positives occurs when the target class in the training data cannot demonstrate sufficient representativeness.
Yin et al. [
11] mentioned that in one-class classification problems, designing an error detection system while simultaneously reducing false negatives and false positives is a difficult task due to the lack of non-target class data. Generally, one-class classifiers are sensitive to parameter settings [
12]. A common approach to optimizing parameters for one-class classifiers is to use generated synthetic samples. Ref. [
13] attempts to assume the distribution of the non-target class using artificially generated samples. However, generating artificial data has some issues, requires in-depth knowledge of the domain, and may lead to overfitting.
In this article, we describe how to optimize the parameters of OCNN classifiers using one-class data using the outliers identified by the above methods, and we consider them as proxies for the non-target class and use cross-validation to optimize parameters , and .
K-Means with Outlier Removal (KMOR) Algorithm
KMOR [
14] is an algorithm based on K-means that can simultaneously detect outliers and perform clustering [
15,
16,
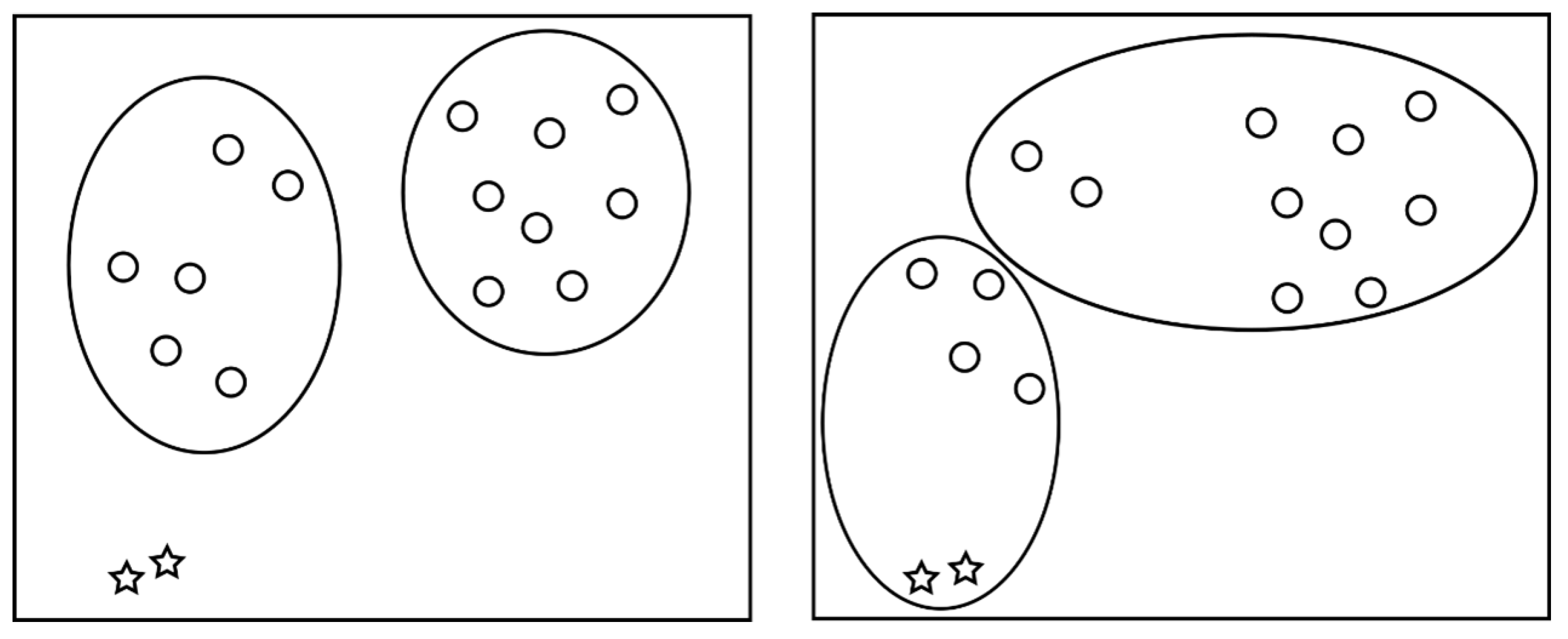
17]. Traditional K-means algorithms can experience drastic changes in clustering results due to the presence of outliers, as illustrated in
Figure 3 below. Circles represent normal data, while asterisks represent outliers. Setting the number of clusters to two, the left portion shows clustering results without considering the presence of outliers, while the right portion demonstrates clustering results that account for outliers, resulting in a more asymmetric clustering outcome.
To address the aforementioned issue, KMOR introduces the concept of the K + 1 cluster, where data identified as outliers are assigned to the K + 1 cluster. Additionally, these outliers are independently treated in the objective function. The objective function of KMOR is defined as follows:
subject to
In the equation, U represents the membership of all data points in the clusters, Z denotes the cluster centers, and if a data point belongs to the jth cluster. restricts the maximum number of data points identified as outliers in the entire dataset.
can be expressed as follows:
The parameter represents the weight of the average distance from all non-outliers to their respective clusters. and control the number of outliers in the dataset. Updating cluster centers and cluster assignments differs slightly from the original K-means. The rules are as follows:
Rule 1: Calculate the distance from each data point to all cluster centers. If the distance from the data point to the cluster center is less than , assign it to the cluster with the shortest distance; otherwise, assign it to cluster .
Rule 2: Update the cluster centers for clusters 1 to K by averaging the data points in each cluster. Data points classified as cluster do not participate in the calculation.
The detailed process please referring to Algorithm 2 as follows:
| Algorithm 2 Algorithm flow for KMOR |
- 1:
Input: X, k, , , , - 2:
Output: Optimal U and Z - 3:
Initialize Z by selecting k points from X randomly - 4:
Foreach 1, …, i do - 5:
Update U by assigning to its nearest center - 6:
end - 7:
s = 0, = 0 - 8:
While True do - 9:
Update U by rule 1 - 10:
Update Z by rule 2 - 11:
s = s +1 - 12:
- 13:
If or then - 14:
Break - 15:
end - 16:
end
|
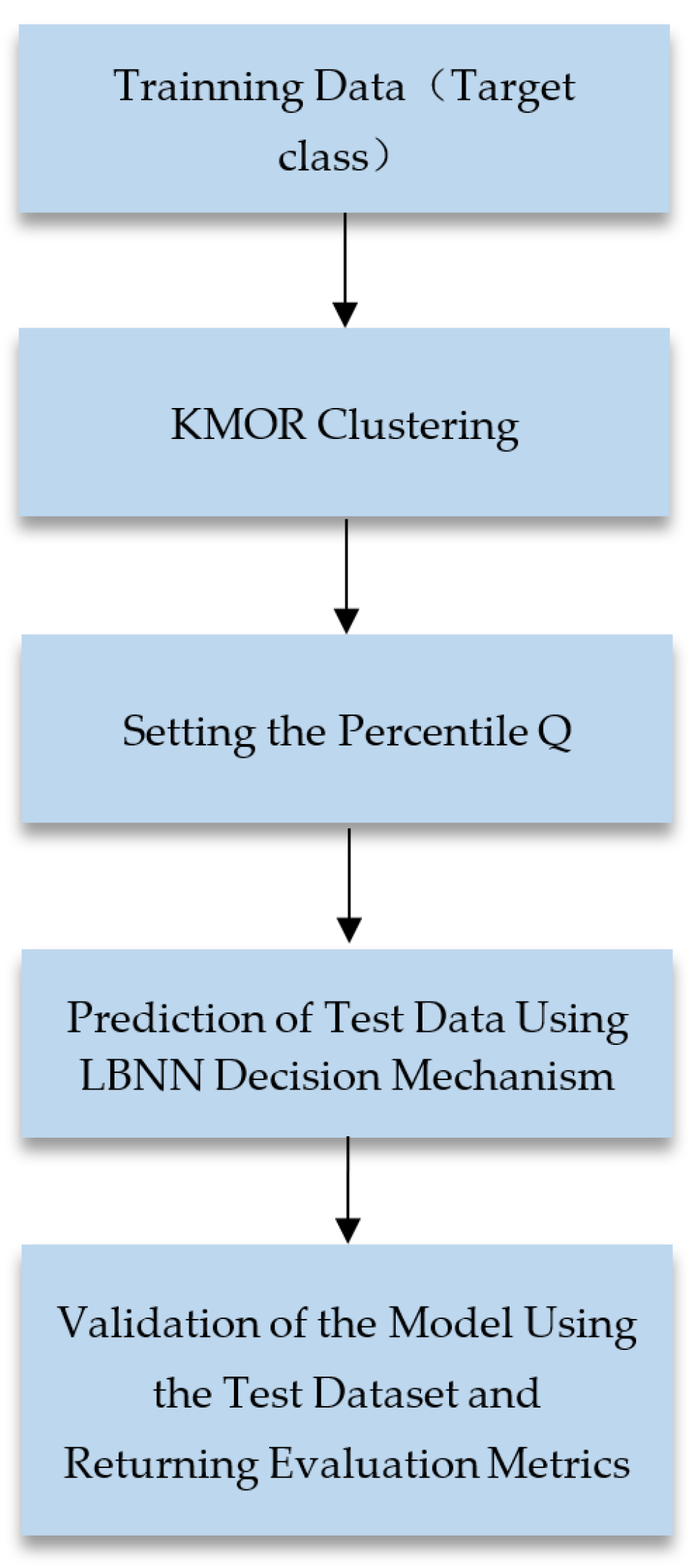
2.6. Location-Based Nearest Neighbor (LBNN) Algorithm
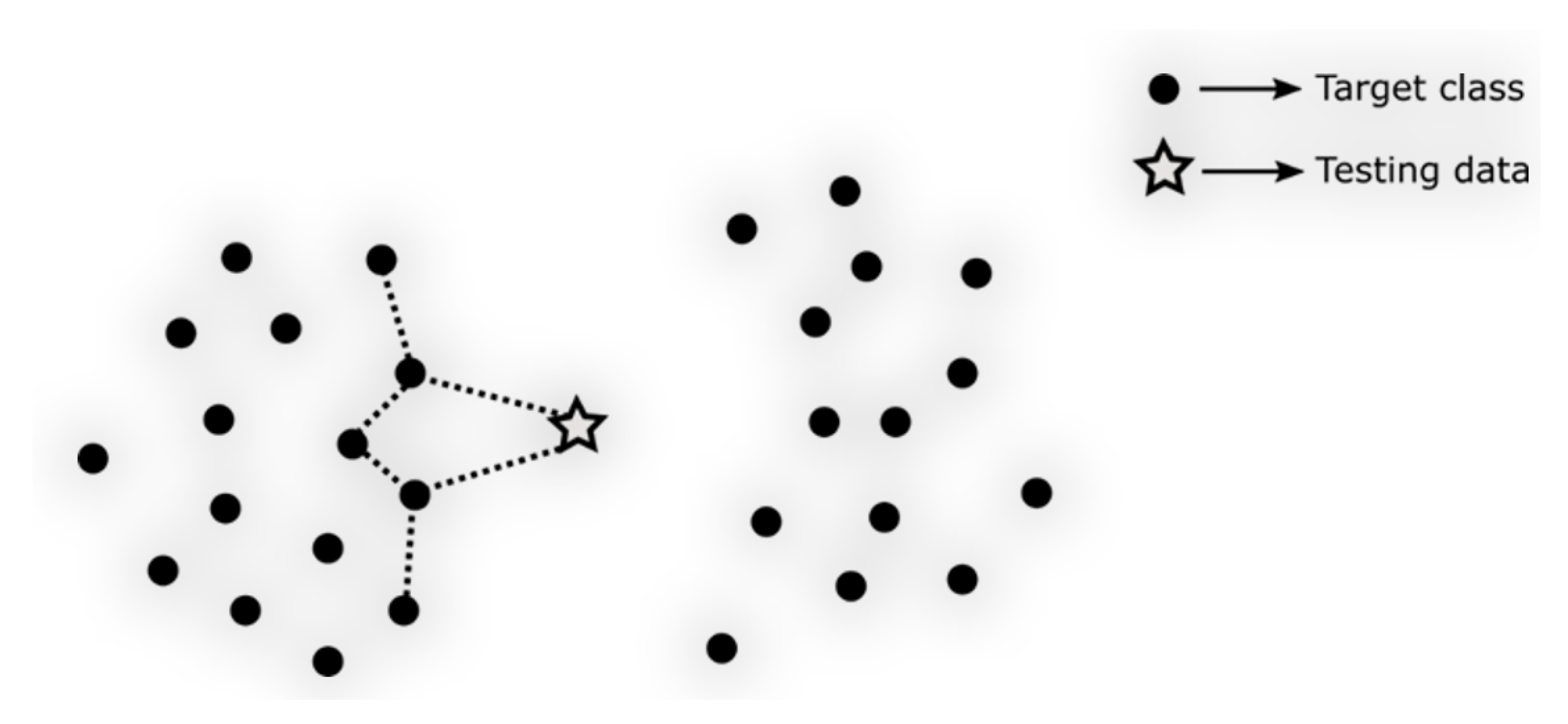
We understand that, whether it’s 11NN or JKNN, when an unknown data point comes in, they both need to perform two rounds of nearest neighbor searches on the entire training dataset. The first-round searches for J-nearest neighbors and the second round searches for J.K-nearest neighbors result in a time complexity of
, where the part of searching for nearest neighbors of nearest neighbors can be anticipated to be mostly within adjacent blocks. In other words, the unknown data point and these nearest neighbors are mainly compared locally (
Figure 4), without considering the overall distribution characteristics of the data. This may affect the final performance of the model. Therefore, we propose a clustering-based nearest neighbor search strategy, LBNN, to compare with 11NN and JKNN.
Our LBNN strategy initially applies KMOR [
18] clustering to the training data, setting a percentile
. For an unknown data point
, we find one nearest neighbor
from each cluster. These nearest neighbors are considered reference points for their respective clusters. Finally, we calculate the distance
between the reference point
and the other data points in the same cluster. If the distance
from the unknown data to any cluster reference point is less than the percentile
Q of its distance
, we classify the unknown data as the target class. Our LBNN strategy has a search time complexity of
, where
k is the number of clusters. The LBNN process is illustrated in Algorithm 3.
| Algorithm 3 Pseudo-code of LBNN |
- 1:
Input: Target training data (D), number of cluster (k) percentile rank (Q), testing data (T) - 2:
Output: an result array R (prediction of T) - 3:
Apply KMOR clustering for Target training data (D), then we get k clusters in D - 4:
number of testing data (T) - 5:
Foreach 1, …, N do - 6:
R[i] = 0 - 7:
end - 8:
Foreach 1, …, N do - 9:
foreach 1, …, k do - 10:
find nearest neighbor P of T[i] in cluster j and - 11:
record this distance d - 12:
compute distance between P and other data in - 13:
cluster j to get length vector L - 14:
If d < O percentile rank of L then - 15:
R[i] = 1 - 16:
Break - 17:
end - 18:
end - 19:
end - 20:
return R
|
2.7. Feature Selection
With the rapid development of modern technology, the improvement in the performance of hardware and software, and the widespread application of the Internet of Things, data are generated at an unprecedented rate. This includes high-definition videos, images, text, audio, and data obtained from the rise of social relationships and the Internet of Things. Such data often possesses features with multiple dimensions, presenting a challenging task for accurate data analysis and decision making. Feature selection can effectively handle multidimensional data and enhance learning efficiency, a notion that has been proven in both theory and practice.
Feature selection refers to the process of obtaining a subset of features from the original features based on certain criteria. The feature selection criteria gather relevant features of the dataset. It plays a crucial role in reducing the computational cost of data processing by eliminating unnecessary and irrelevant features. Feature selection is considered a preprocessing step for data and learning algorithms, where good feature selection results can improve model accuracy and reduce training time.
In this article, the real-world medical data we used contain a large number of features (64 in total). To enhance the performance of various algorithm models, we employed a stepwise feature selection method called “Stepwise”. The concept is, in each round, to select only one feature at a time, retaining the combination of features with the best performance or continuing until a specified number of features to retain is achieved. Assuming a dataset has ten features, and our evaluation metric is the area under the receiver operating characteristic (ROC) curve, which is the area under the ROC curve (AUC), the detailed process is as follows:
In the first round of feature selection, we select one feature at a time for model training. After testing all features, we retain the feature with the best AUC performance.
Similar to the first step, we choose one feature at a time from the remaining nine features, but this time, we include the feature retained from the first round. In the end, we obtain the two features with the best performance.
We repeat the first and second steps until the specified number of retained features is achieved.



 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}