1. Introduction
Microbial communities and their interactions play a central role in the understanding of microbial ecosystems [
1], and a current challenge is integrating genetic sequencing data in a deterministic modelling framework [
2,
3]. Using the terminology from the thorough review in current methodologies on the deterministic modelling approaches of microbial community dynamics presented by Song et al. [
4], this articles deals with population-based approaches where species are taken as the interacting units.
The classical ecological concept of species and niche in the microbial world is an elusive one: in the macro world one can clearly differentiate one species from another for reproductive reasons and their ability to give birth to offspring. In the case of bacteria and archea, reproduction goes simply by binary fission and exchange of some functional genes (e.g., the ability to synthesize or metabolize substances) can be acquired in evolutionary scale through lateral gene transfer [
5]. Therefore as an ecological problem is hard to define precisely the ‘niche’ of ‘microbial species’. These obstacles can be circumvented by considering the microbiologist concept of operational taxonomic unit (OTU) based on the clustering of organisms sharing similar sequences of the 16S rDNA marker gene. In the past years considerable efforts have been made to measure the bacterial community composition. Tests such as fluorescence in situ hybridization (FISH), polymerase chain reaction (PCR) dependent techniques, and PCR independent techniques for the analysis of DNA have become a standard tool for studying microbial diversity [
6]. The contribution of this article is a new method to integrate the microbial community measurements in chemostat models, based on any sequencing or fingerprinting technique that can quantify the species abundances over time. In other words, while most models used in bioengineering are functional—in the sense they consider only one species per biological reaction considered—this work is an attempt to merge classical population-based models used in ecology and those used by engineers in biotechnology.
Interactions lie at the heart of ecology. Lotka [
7] and Volterra [
8], independently, presented a 2 dimensional dynamical system to model prey-predator relationships, now known as the Lotka–Volterra (LV) equations. The model is very rich from a mathematical standpoint, and is also a classic equation to study in Mathematical Ecology [
9]. Extensions of the Lotka–Volterra model have derived what is now known as generalized Lotka–Volterra (gLV) models [
10] shown in Equation (1):
where
represents the species abundance,
the intrinsic growth rate of the species, and the terms
reflect the effect of OTU
j on the growth of OTU
i. The equation states that the growth rate of
is proportional to
, but this proportionality constant depends on its intrinsic growth rate multiplied by the sum of all interactions affecting it. Note that if there are no type of interactions (
), one recovers
n uncoupled linear differential equations, and thus the solution becomes
, that is exponential growth on time.
The diagonal terms
are known as intraspecies interaction, while the off diagonal terms are known as the pairwise interspecies interactions. Noting the signs of pairs
, the classical ecological relationships of mutualism or cooperation
, commensalism
, predation or parasitism
, competition
, and ammensalism
can be recovered [
11]. Model (1) has been thoroughly analysed, even when the coefficients
and
are time dependent and exhibit periodicity (which models seasonal traits) [
12,
13]. The gLV model has been used in microbial ecology to some degree of success to study the gut microbiome of mice infected with
C. difficile [
14]. However, the quadratically growing number of parameters to describe interactions naturally entails problems of identifiability if the data set is not large enough, or the system has not been sufficiently perturbed. On a more conceptual ground, the interaction coefficients of a gLV model do not represent mechanistically anything, so even if a model correctly predicts the microbial community dynamics, it might not add to the understanding of what could be physically or biologically taking place. These observations led us to develop what can be considered the core contribution of this article, which is to study the growth rate of each species in a mixed culture: we reconstruct the shape of their growth rate, instead of trying to fit a particular function (such as the gLV equations). As Monod himself commented when developing the growth law that bears their name is that any function with the same shape (monotone, concave, and bounded on the substrate) would have served [
15], in this spirit we formulate the question: what is the shape of the growth functions of multiple species developing together?
As a departing point, the work of Dumont et al. [
16] is presented in
Section 2. They modelled a chemostat experiment where nitrification takes place by considering a glV model coupled with a substrate limited growth expression (
is no longer a constant, but the classic Monod expression) and fitted their model using absolute abundances of the major OTU identified by molecular fingerprints obtained by single-strand conformation polymorphism (SSCP).
Section 3 inspects the model through a mathematical analysis. Some interesting outputs of this analysis are that the number of possible equilibrium points grows exponentially with the number of species, coexistence can be achieved within the same functional group, and bi-stability may arise. In
Section 4, the concept of interaction function is developed such that it generalizes the gLV model. For approximating the interaction function a method of optimal control theory was adapted: The growth rate of each species is modulated by a constrained regular control of the system, thus the growth rate of each OTU is corrected in order to fit the experimental data. The regular control is composed of a feedback part on the species state variable, and a feed forward part, or tracking, on the measurement of abundances of each species; the method involves solving state-dependent Ricatti equations [
17]. In
Section 5, the methodology from
Section 4 is applied to the data from the experiments performed by Dumont et al. [
18] and not just to the most abundant species as it was the case of the model analysed in
Section 3 [
16]. This approach explicitly assumes that dynamics of complex ecosystems are driven by interactions, that are the results of feedback loops of each species on the growth rate of others. The method shows that by following the community dynamics one can propose a growth rate that reconstructs the substrates dynamics, however this cannot be considered a predictive model, but rather a explicatory model. The article ends with a discussion on the scope of applicability and perspectives of the method.
3. Mathematical Analysis
The system of Equation (3) is defined in the region
First, sufficient conditions on the interaction matrix for the system to be well posed are established: meaning that solutions remain bounded and non-negative in time, this ultimately implies that the solution exists for every
[
20].
Second, the equilibria of the system are derived. Possible equilibrium points for this system grow exponentially with the number of OTU considered (n). Stability is not analytically addressed, a numerical scheme calculating every equilibrium point and the system’s Jacobian eigenvalues at the equilibrium point was implemented for studying the system.
3.1. Properties of the System
A bound on the norm of the interaction matrix that depends on the initial conditions and parameters one establishes that solutions will remain positive and bounded.
Lemma 1. For initial conditions , there exists positive scalars , , and such that solutions to (3) satisfy the following inequalities: The proof can be seen in
Appendix A. A bound on the norm of
A is found such that every matrix
A respecting the bound, guaranties that
is a positively invariant set.
Lemma 2. For initial conditions , there exists a constant such that for every matrix A satisfying , the solutions of system (3) with growth rates given by (6), remain in Ω and are bounded.
The importance of Lemma 2 is that by restricting the norm of matrix A the system is well-posed, meaning that the solutions can have biological and physical sense (there is no such thing as negative concentrations). Particularly, one has that , which in this context implies that a bound on the sum of the absolute value of the interaction terms that affects each species allows the system to be well-posed. Note, however, this is a sufficient condition, thus the range of values matrix A can sustain for the system to remain well-posed may be considerably larger.
3.2. Equilibrium Points
In this section, analytical expressions for equilibrium points are shown. However, no analytic expression concerning the stability of such points is presented. In the following pages the reader will appreciate that the expressions of the equilibrium points are not simple, consequently replacing them in a
block matrix and calculating eigenvalues resisted an algebraic treatment. To answer the question of stability a numeric scheme is used by evaluating the Jacobian at the equilibrium point. At the end of the section an algorithm is provided for exploring all the possible equilibria. All the computations for deriving the equations of this section can be found in
Appendix B.
Let
be such that,
Then
Thus, system (3) is rewritten as follows.
Definition 1. An equilibrium point (or steady state) is a point so that the right hand side of Equations (11)–(14) equals zero.
Observe that equilibrium points are by definition non-negative so the state variables can have physical meaning. For studying the cases where contains zero valued entries, the set of non-active coordinates is defined as follows:
Definition 2. Given an equilibrium point of system (3), then the set of non-active coordinates is defined as: . and denote the number of positive entries of of functional groups and , respectively. denotes the total number of positive entries of . The active point is defined by the positive entries of . Analogously, the functions and are defined by the positive entries of . The active interactions is defined as the matrix A without the rows and columns. The active stoichiometry matrix is the matrix Y without the columns.
In order to derive the equilibrium points, it is desirable an invertible matrix. Therefore in what follows of the work it is assumed that matrix A and some of its submatrices have an inverse, this is stated properly in Hypothesis 2.
Hypothesis 2 (H2). Let A be the interaction matrix of size and S be a proper subset of with . Then the matrix defined by taking out the S rows and columns of matrix A is invertible.
Assuming Hypothesis 2 a formula for the active points is derived from Equation (11):
Note as well that at the equilibrium,
can be defined in terms of
,
and
. This is done by adding Equations (12)–(14) which gives:
3.2.1. Both Functional Groups Are Present
The case where in each functional group remains at least one OTU is represented by Hypothesis 3.
Hypothesis 3 (H3). The set satisfies .
By replacing Equation (15) in Equation (12)
can be written as a function of
:
Then by replacing (17) in Equation (13), one gets a fourth degree polynomial for
.
Formulae for coefficients
can be found in
Appendix B.
The equilibrium point can be calculated from the solutions of the system of Equations (15)–(18) with non negative coordinates. If the system only provides solutions with at least one negative entry then the set cannot define an equilibrium point.
3.2.2. Washout of
The washout of is equivalent to Hypothesis 4.
Hypothesis 4 (H4). and .
Under this case note that
depends only on
. Therefore when Equation (15) is replaced in (12), one obtains a quadratic equation for
:
where
can be found in
Appendix B.
Since
then from Equation (14).
In this case the equilibrium point can be calculated from the solutions of the system of Equations (15), (16), (A44) and (21) with non-negative coordinates. If the system only provides solutions with at least one negative entry then the set cannot define an equilibrium point.
3.2.3. Washout of
The washout equilibria means for every . This is equivalent to Hypothesis 5. Note that the structure of a cascade reaction implies that if gets washed out, then so is .
Hypothesis 5 (H5). .
From Equation (12), one gets
then (16) implies
The equilibrium is then given by .
All the former discussion leads to a potential number of
different equilibria. Indeed:
3.3. Stability: Operating and Ecological Diagrams
In this subsection the stability of the equilibrium points is addressed. Operating and ecological diagrams are created from this stability analysis. Both are an illustrative way of representing the long term behaviour of a reactor depending on operating parameters, namely
D and
: In a
plane different zones representing the stability properties of system (3) are identified [
21].
For checking local asymptotic stability of the equilibrium points, the Jacobian of the system is provided and evaluated at each of these points. The resulting matrix’s eigenvalues must have negative real part. A general formula for this Jacobian is presented in
Appendix B (see (A70)).
Algorithm 1 summarizes this procedure.
| Algorithm 1: Algorithm for Evaluating the Possible Equilibrium Points of System (3). |
![Bioengineering 08 00031 i001]() |
Operating and ecological diagrams are created by running Algorithm 1 for different pairs
. In the case of operating diagrams [
22] (OD) all the pairs
are regrouped such that the points of the set
represent when partial nitrification (PN), complete nitrification (CN), washout (WO), or a combination of them may arise [
23]. PN refers to the state when nitrite (
) accumulates because the OTU of
are washed out and thus no conversion from
to
takes place. On the contrary CN is when nitrate (
) accumulates because of the presence of OTU of
.
In the case of ecological diagrams (ED) the pairs are regrouped such that the points in the set have the same non-active coordinates. In other words, instead of representing areas where either CN, PN or WO take place, ranges of pairs where species coexist are represented. ED provide more information than OD, in the sense that one can deduce the latter from the former.
A first example using operating diagrams is presented to illustrate how adding interactions in a model consisting of 1 OTU in and 1 OTU in may lead to very different outcomes.
The important question of the existence of limit cycles was not resolved in this work. In the numerical analysis of this model at least one stable equilibrium was found for any choice of parameters. This obviously does not exclude the existence of limit cycles, but to what concerns the authors’ intuitions there always seems to be at least one stable equilibrium point.
3.3.1. Case Study 1: 1 AOB and 1 NOB
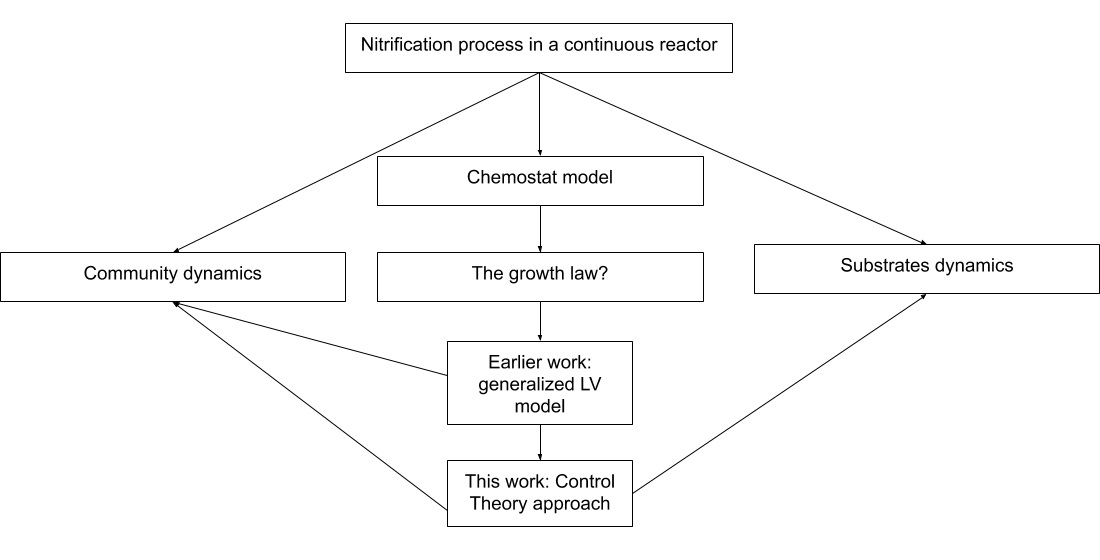
Consider the case where
and
. The operating diagrams when no interactions take place (
) and a non-zero interaction matrix are presented. When
Algorithm 1 is no longer valid (A is not invertible), nevertheless the stability analysis is much simpler and is given in the
Appendix B section. The interaction matrices are shown in
Figure 1a,b, the rational behind the second choice was to force a very strong interaction of
on
and observe its effects. The biological reason behind a negative microbial interaction might be the release of a toxin by
that affects
[
1], or in this case it might represent competition for oxygen; we stress the fact that gLV interactions do not explicitly account for mechanistically anything they just try to represent an ecological relationship taking place. The rest of parameters can be seen in
Table 2.
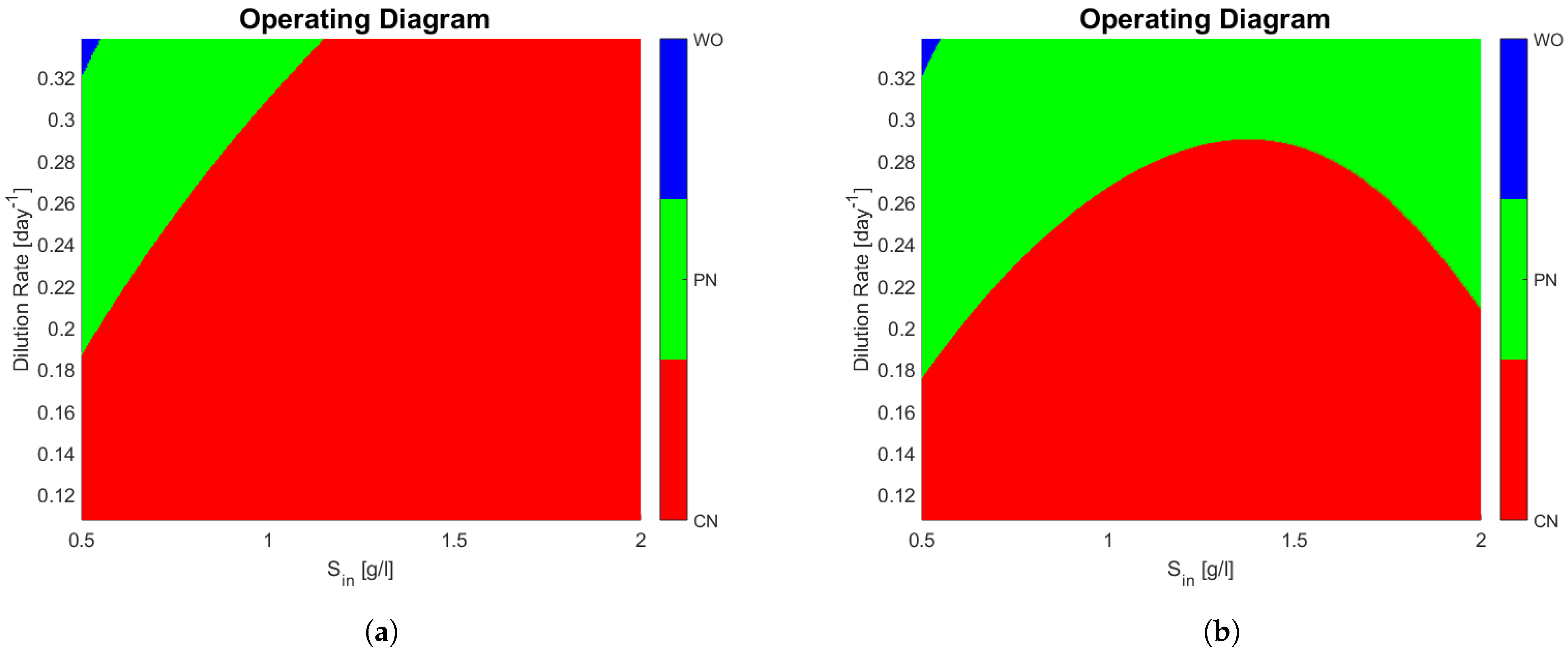
The operating diagrams can be seen in
Figure 2, note how partial nitrification (washout of
) of
Figure 2b is much bigger when compared to
Figure 2a. The shape of the PN region in
Figure 2b is somewhat unintuitive, because at a constant dilution rate (0.24 day
for example) and an increasing
, one passes from a PN zone, to a CN zone, and then back again to a PN zone. The mathematical explanation lies in the fact that
also increases with
, and the affine part
of the growth function of
plays a bigger role than substrate limitation (
).
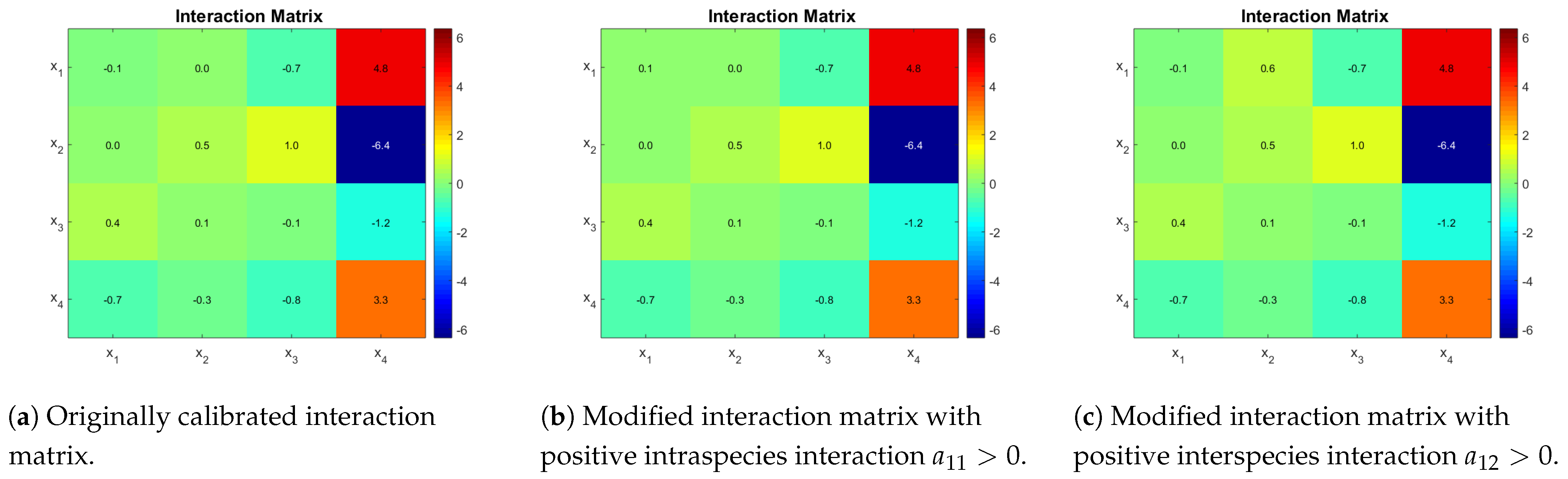
3.3.2. Case Study 2: 2 AOB and 2 NOB
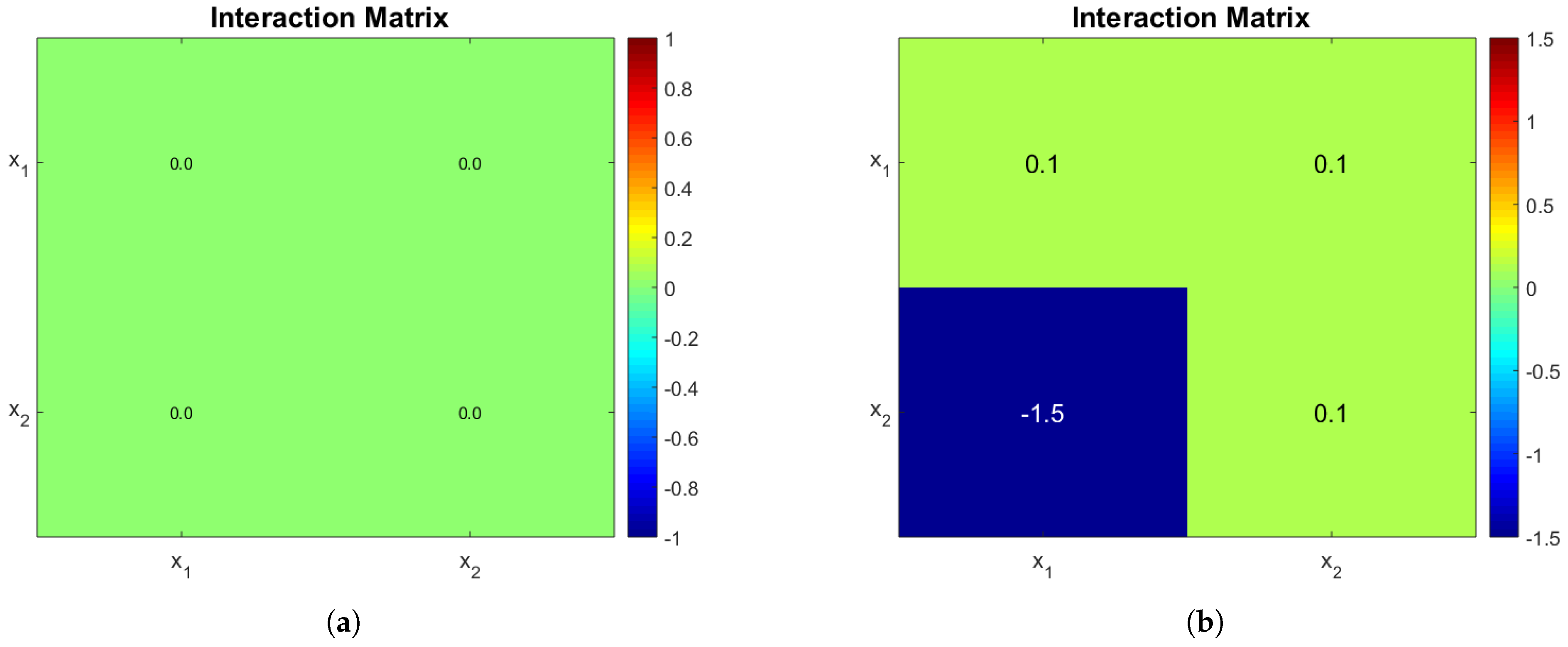
Case study 2 is based on Dumont et al. [
16] model parameters. They proposed a distribution of parameters obtained from a Bayesian estimation method. Their fit describes well the dynamics of the two most abundant OTU in each functional group, but it still fails to capture the measured substrates dynamics. Kinetic parameters of case study 2 can be seen in
Table 3. The estimated interaction matrix is shown in
Figure 3a. A second matrix is presented, which is obtained by the sign change of coefficient
(
Figure 3b), and finally a third one is obtained by using a positive value for
(
Figure 3c). The idea is to show that qualitatively different outcomes can be obtained by changing one interaction at a time.
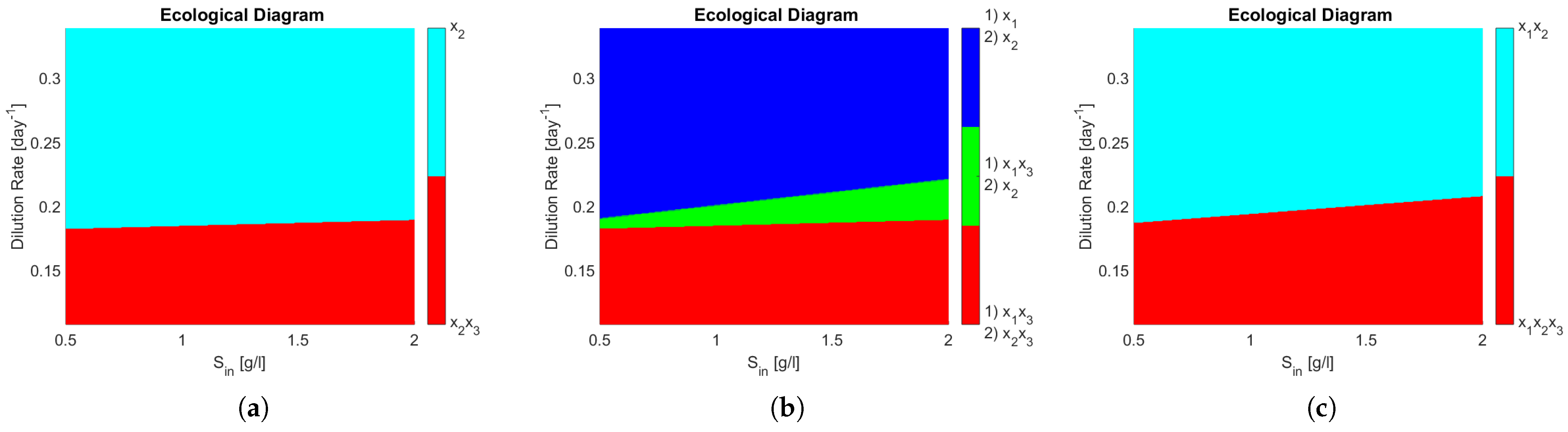
The ecological diagrams are presented in
Figure 4, where the legend indicates the species surviving in the zone of the respective colour. In
Figure 4b, the system exhibits bi-stability (it is represented in numbering as (1) and (2) of the different possible equilibriums). Note how every zone in
Figure 4b has two stable equilibria, meaning that the outcome of the system is determined by its initial conditions, particularly interesting is the green zone where either
coexist or only
remains, because in operational terms this means that either PN or CN may take place. When compared to
Figure 4a, one can see that this change in the interactions of the microbial community can dramatically change the outcome of the reactor in a large operating zone.
One can see that coexistence in the same functional group is never attained in
Figure 4a,b, whereas in
Figure 4c
and
, both AOB, coexist in either partial or complete nitrification. That means that the competitive exclusion principle [
22] (CEP) does not hold. The CEP roughly states that if two species are growing on the same limiting resource, and their growth laws only depend non decreasingly on the resource, then only one of them will survive in the long run. This is interesting in light of reports on wastewater treatment plants where coexistence between species in nitrifying reactors has been shown [
24], thus implying that a more complex growth law (as shown in here) or model structure involving other biological processes is required to include microbial diversity in mathematical models.
4. Generalized Approach for Modelling Interactions
In the following an explanatory model (as opposed to a predictive model) is developed based on the hypothesis that interactions might be driving the nitrification process. In the previous sections interactions were modelled as an affine function of the OTU concentration that multiplies a substrate dependent growth equation. More generally the interaction function represents how the growth rate of species i is affected by the concentration of other species, x:
Given a vector
the interaction function
is denoted as:
Let
be a bounded, positive, and continuous function of
s (e.g., Monod, Haldane). The growth equation of OTU
i becomes:
Note .
Since the growth of a single strain in batch experiments is driven by the substrate concentration, when no interactions are present one should recover expression . Therefore if there are no interactions then . From this hypothesis, note that since if there is minimal presence of OTU, interactions cannot exist. Furthermore for this study it is assumed that is a continuously differentiable function on x. For making explicit all of the former:
Hypothesis 6 (H6). The interaction function previously defined satisfies:
There is an open set such that .
Note the Jacobian matrix of function , then a first order approximation of centred at gives: . When one recovers the growth expression from the previous section (Equation (6)) implying that can be seen as the interaction matrix from model (3).
4.1. Unravelling the Interaction Function
Suppose that the functions , and the yields are well-known. By using experimental measurements of x, represented by , the objective is to reconstruct function . For doing so, the terms are replaced by controls , thus . A control law is obtained by solving a nonlinear optimal tracking problem.
Consider the observable system (25), with
being the output, because we are observing measurements coming from genetic sequencing.
Consider the weighted norms defined by positive definite matrices
Q and
R, represented by
and
, respectively, and
. The optimal tracking problem is defined as:
The control is intended to drive the system to be near a desired output , which in this context are the measurements of the concentrations of OTU. The term , was added for two reasons:
First, because the interest is testing the idea that interactions could be driving the system. Therefore adding a penalization in the objective function for each control to remain near 1 can be seen as an attempt to explain data without any interaction. In other words, if the control terms are found to drift from 1, it means that interactions are necessary to explain the system dynamics.
Second, to force a regularized control. Otherwise note that
u is linear in (25), therefore if the integral cost does not have a non-linear expression of
u the optimal control will be of a bang-bang type with possibly singular arcs [
25]. Since the objective is to find a differentiable expression of
the addition of the regularization term is deemed necessary.
The problem of approximating the solution of the system to a desired reference (
z in this case) is called the optimal tracking problem. For solving such a problem the approach developed by Cimen et al. [
17,
26] was adapted to our problem. The method proposed involves the resolution of Approximating Sequences of Ricatti Equations (ASRE). It consists of iteratively calculating trajectories of System (25) with a certain control law to later feed a non-autonomous Ricatti differential equation with the resulting trajectory. Then, a new control law that uses the solution of the Ricatti equation is proposed and a new trajectory is calculated. The iteration is stopped when a convergence in the output or the control is observed.
The control term should remain positive for the system to be well posed (no negative states), and an upper bound was added to represent the fact that life cannot grow infinitely fast. The tracking problem does not consider a constrained control. Nevertheless, the methods of Cimen et al. [
26] were directly used with an explicit constraint in the synthesis of the control. Even though this is probably suboptimal when the control reaches its bounds, one at least is certain about its optimality when the control never reaches its constraints.
Another departure from their method is that in their formulation an approximation of the dynamics for calculating the trajectories is used. They proved that such a linearisation converges to the original dynamics. In the case here presented the linearisation of the dynamics was not necessary.
The change of variable
is used for technical reasons explained in
Appendix C.
This in turn implies
. The feedback control
, will be of the form
. Where matrix
and vector
solve differential equations. In
Appendix C it is proved that, thanks to the structure of the system, one only needs to calculate
differential equations for the synthesis of the control, instead of
that would imply the direct application of the method, which renders the method—at least theoretically—scalable for a growing number of OTU.
4.2. Proof of Concept
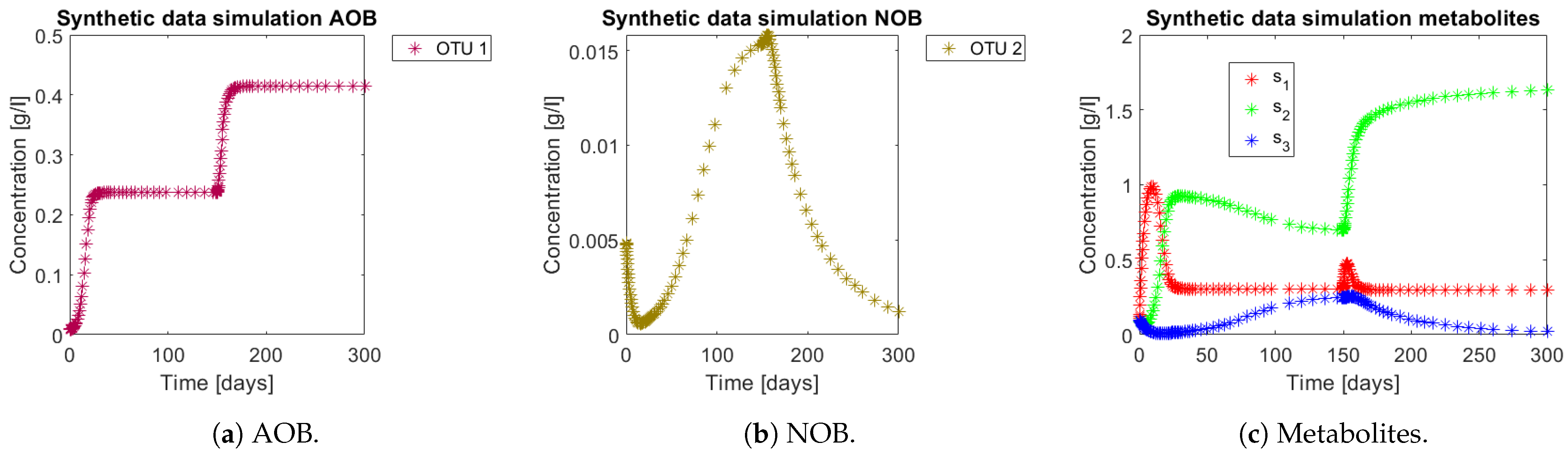
The approach was tested with data generated by simulating model (3) using the parameters of the case study 1 (
Table 2) with interaction matrix given by (
Figure 1b). In the operating diagram of the same case (
Figure 2b) the red zone implies complete nitrification, while the green zone means partial nitrification. For integrating the former phenomena in the simulation, the system was simulated for 300 days, and perturbed at day 150 from the CN zone (
) to a PN zone (
). Simulations can be seen in
Figure 5. Note how from day 150 the NOB population (OTU 2) represented in
Figure 5b decreases, which in turn implies a decrease in
, as seen in
Figure 5c. In the case where no interactions take place, the OD seen in
Figure 2a implies that
would have accumulated all along the trajectory, since the perturbation still remains in the CN zone.
For the tracking procedure the functions
and the yields
were the same as those used for simulating the synthetic data (parameters in
Table 2) and the control is meant to account for the interaction term. The
Q and
R matrices were
and
, respectively, with
and
in order to better track the NOB trajectories, since they are less abundant. The values were obtained by trial and error, by using a single
for both functional groups, beginning with
, in which case one can see how the optimal control becomes
, thus no tracking is performed. Further diminishing the value from
adds too much noise to the control, without significant gains on the quality of the tracking.
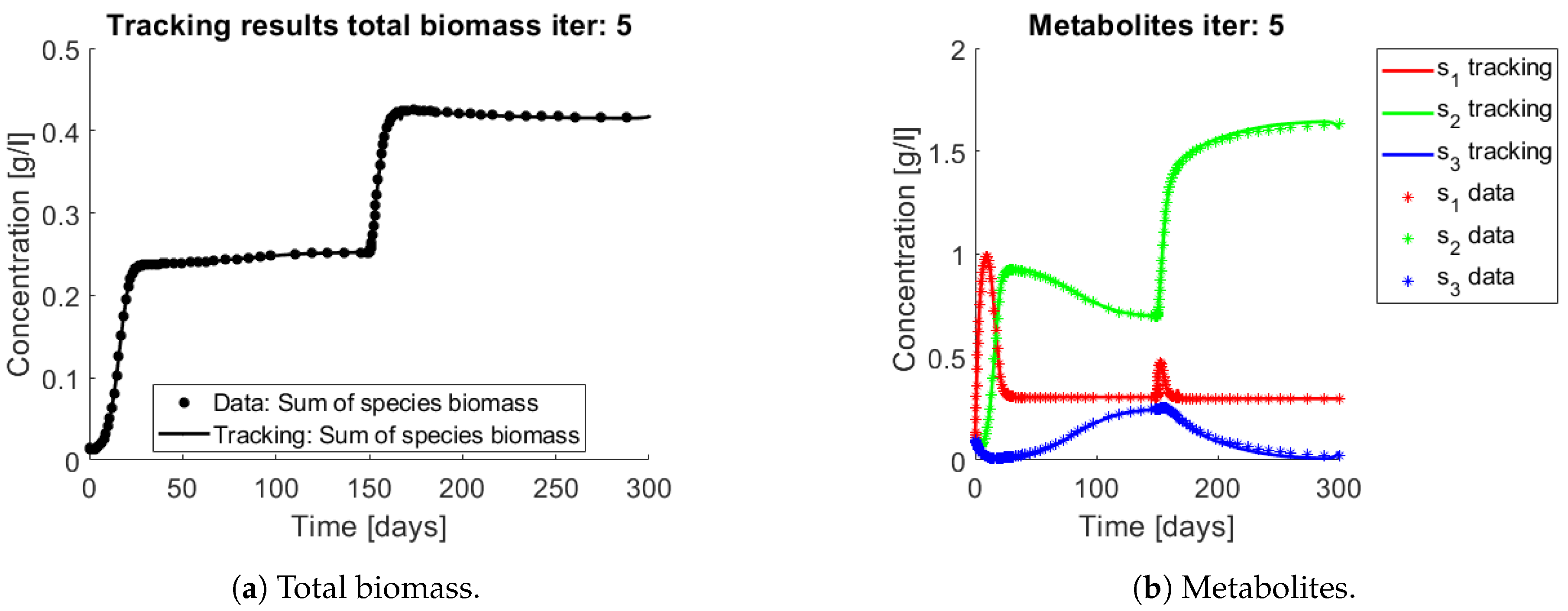
The results of the procedure to identify interactions can be seen in
Figure 6 and
Figure 7.
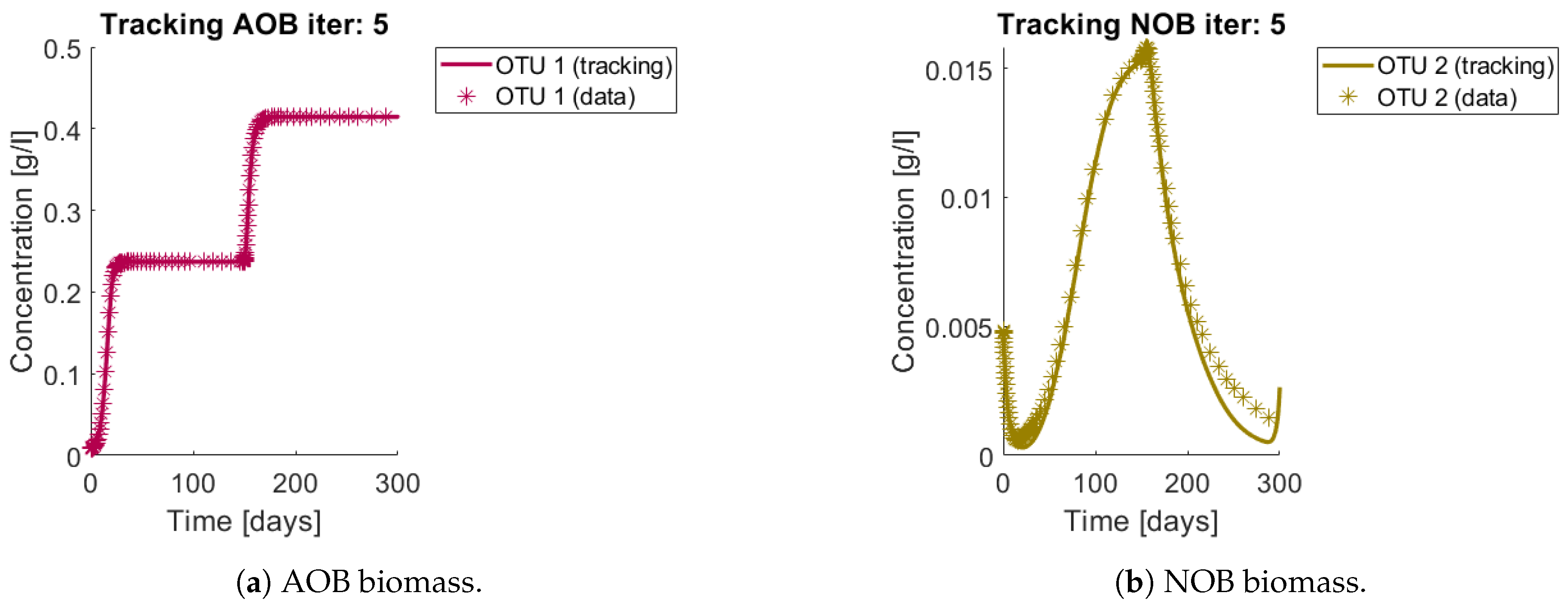
Figure 6a and
Figure 7a,b show the total biomass concentration, and the trajectories for the OTU belonging to
and
, respectively. It can be seen that the method approaches well the trajectories of the OTU, with a better result for the AOB community, which can be explained by the one order of magnitude difference in their concentrations (which in turn is a consequence of the one order of magnitude difference in their yields). The metabolites concentration represented in
Figure 6b are in accordance with the simulated: The method is able to reconstruct the metabolites trajectories from the community measurements.
Figure 8 and
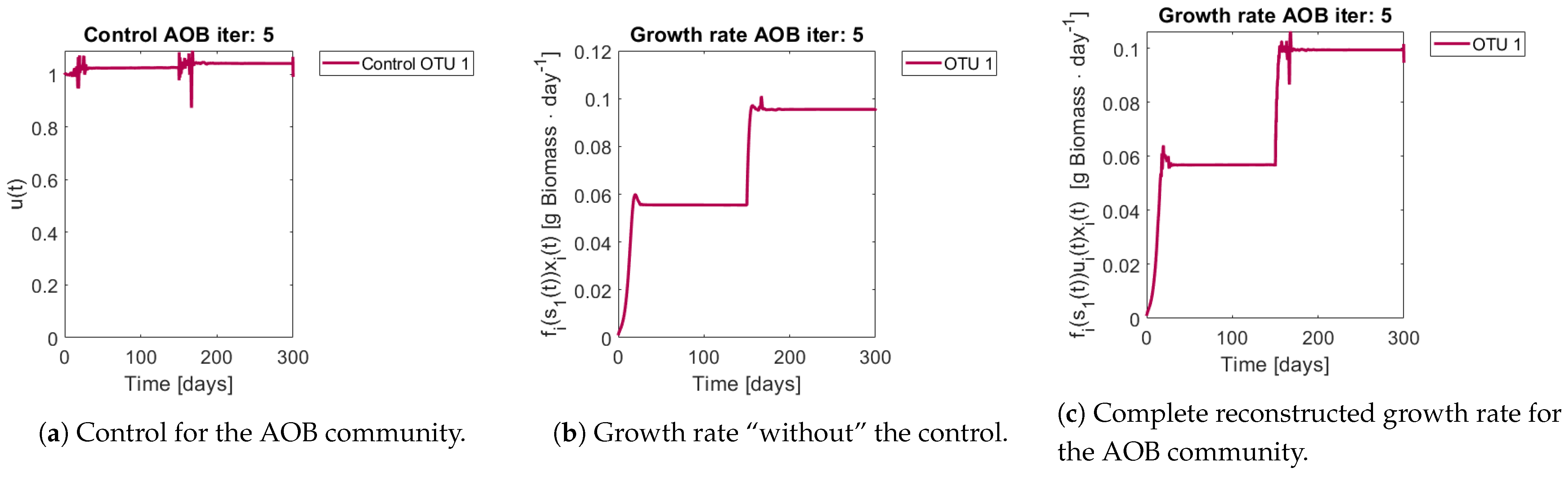
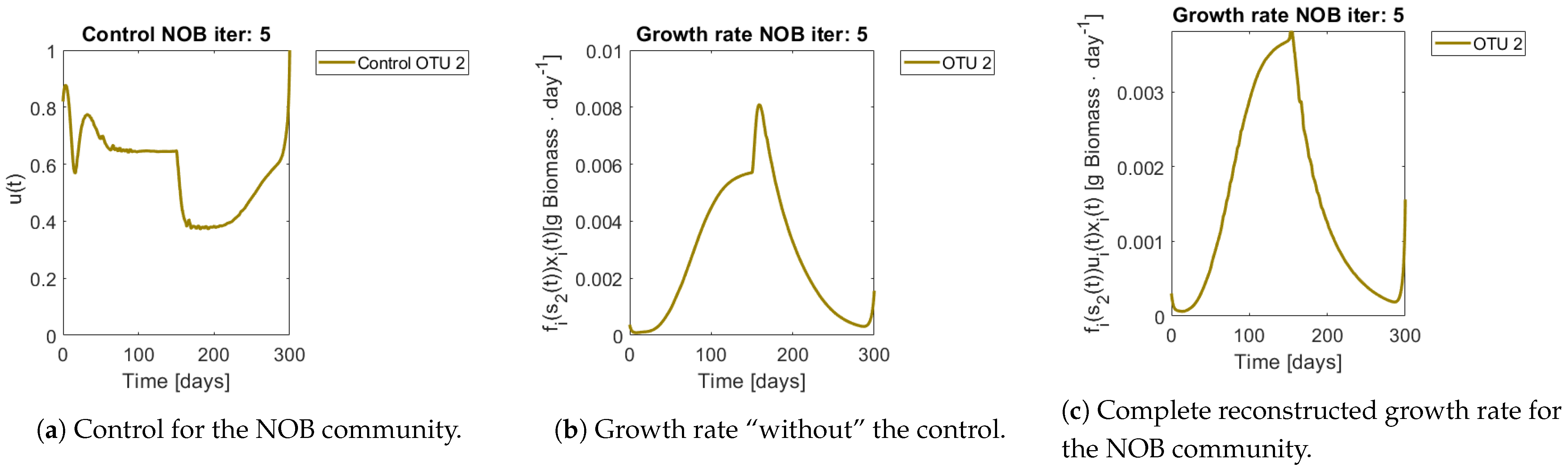
Figure 9 show the controls and the corrected growth rate for each functional group. The control for each functional group can be seen in
Figure 8a and
Figure 9a. Note that from the structure of a quadratic regulator, since there is no cost in the final state, the end value is always 1.
Figure 8b and
Figure 9b show the resulting growth rates for
and
, respectively, without the control
.
Figure 8c and
Figure 9c are the complete expression that determines growth rate, that is
. Note how little the shape changes with respect to
Figure 8b and
Figure 9b, which might mislead the reader to conclude that the control had reduced effects in the dynamics. The way out of this conundrum is to remember that the control’s effects are already included in
and
, and thus in expression
.
A final comment on the identifiability of the interaction terms. Even though one might propose a growth rate with the tracking control that accurately replicates the OTU trajectory , retrieving the original interaction coefficients from the obtained control for this example was not possible. The former was tried by minimizing function with a non linear optimization solver for a 1000 initial random guesses for matrix A. If one also takes into account and as parameters to fit this adds even more degrees of freedom, thus suggesting that the identifiability of growth functions (6) in model (3) might be very low.
5. Application
The tracking problem was applied to data coming from a nitrification process with experimental conditions described in [
27]. For exploring the hypothesis of interactions as drivers of bioreactors performance environmental conditions should be kept as constant as possible. Therefore only data from day 183 onwards was used because a change in the operating temperature happened at that point, which is known to have an effect on kinetics. For choosing which species belong in which functional group, the procedure described of Ugalde-Salas et al. [
28] was used. From day 183 to day 315, 31 OTU were identified in the
group (AOB) and 5 in the
functional group (NOB).
A first example of the procedure is performed when the classified OTU are regrouped in their assigned functional groups by adding their concentrations. A 5 dimensional dynamical system is obtained, thus there are only two interacting functional biomasses: this case is structurally the same as in the proof of concept, but here a real dataset is used. The same procedure is applied where no regrouping occurs and the system state grows to 39.
The knowledge of functions
was based on a study of nitrification’s kinetic parameters [
29]. Particularly given the system’s ammonium and nitrite concentration a Monod function (Equation (27)) was used for
and
with parameters given in
Table 4 calculated from the equation of
Table 2 of the same article. The yields were fitted to match the nitrogen mass balances. The
Q and
R matrices were the same as in the proof of concept section, that is
and
, respectively, with
and
, because data lie in the same order of magnitude than synthetic data.
For the reader to gain understanding of the situation, a simulation of the system using the experiments operating parameters (
D and
) is presented without control (i.e.,
) in
Figure 10 nitrate (
) accumulates all along the trajectory, but when compared to data it is clear that
stops accumulating after a while.
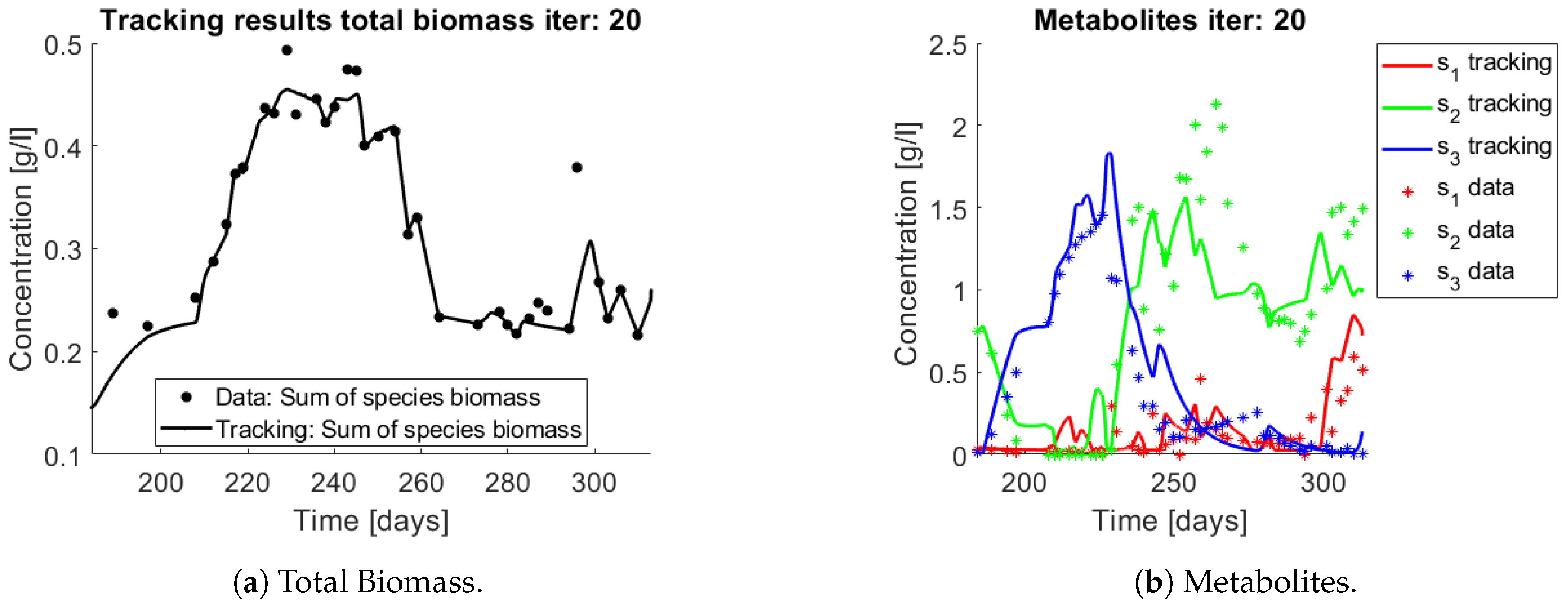
When applying the tracking method one obtains the simulation that can be seen in
Figure 11 and
Figure 12. The method captures the tendencies of the measured substrates as seen in
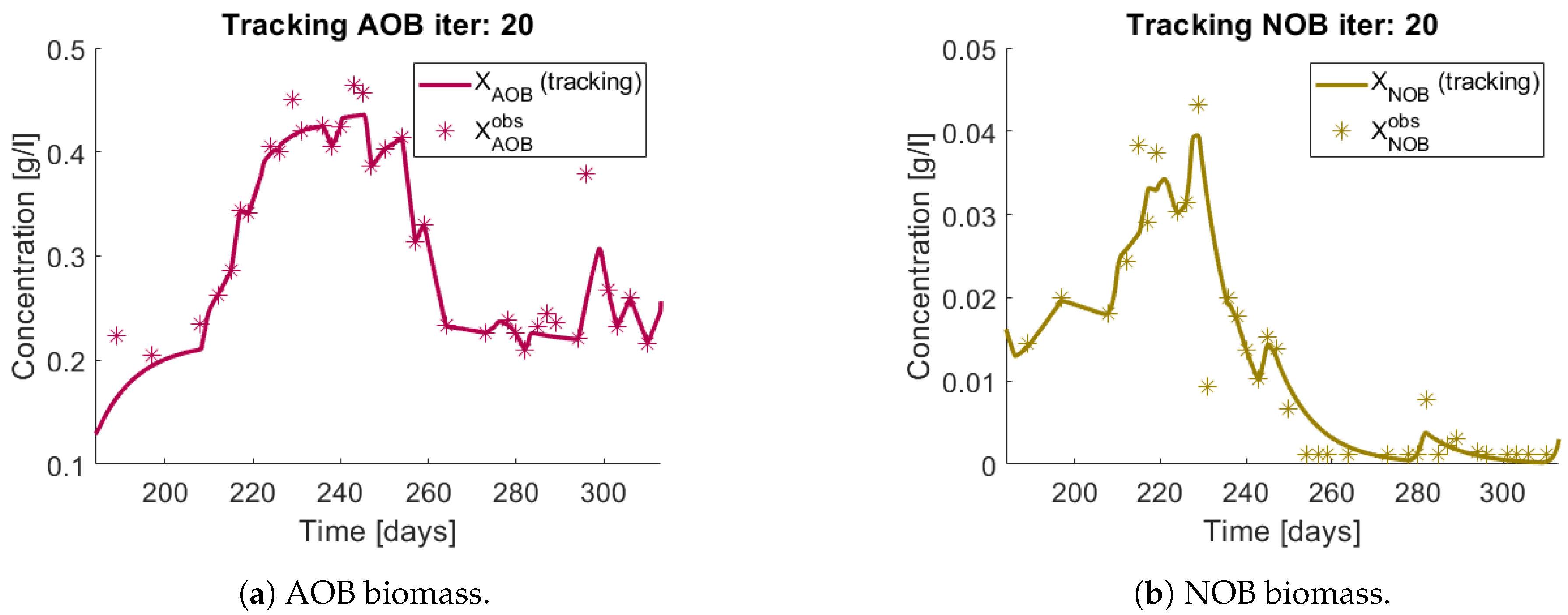
Figure 11b. The tracking of each functional group
(AOB), and
(NOB) can be seen in
Figure 12a,b, respectively.
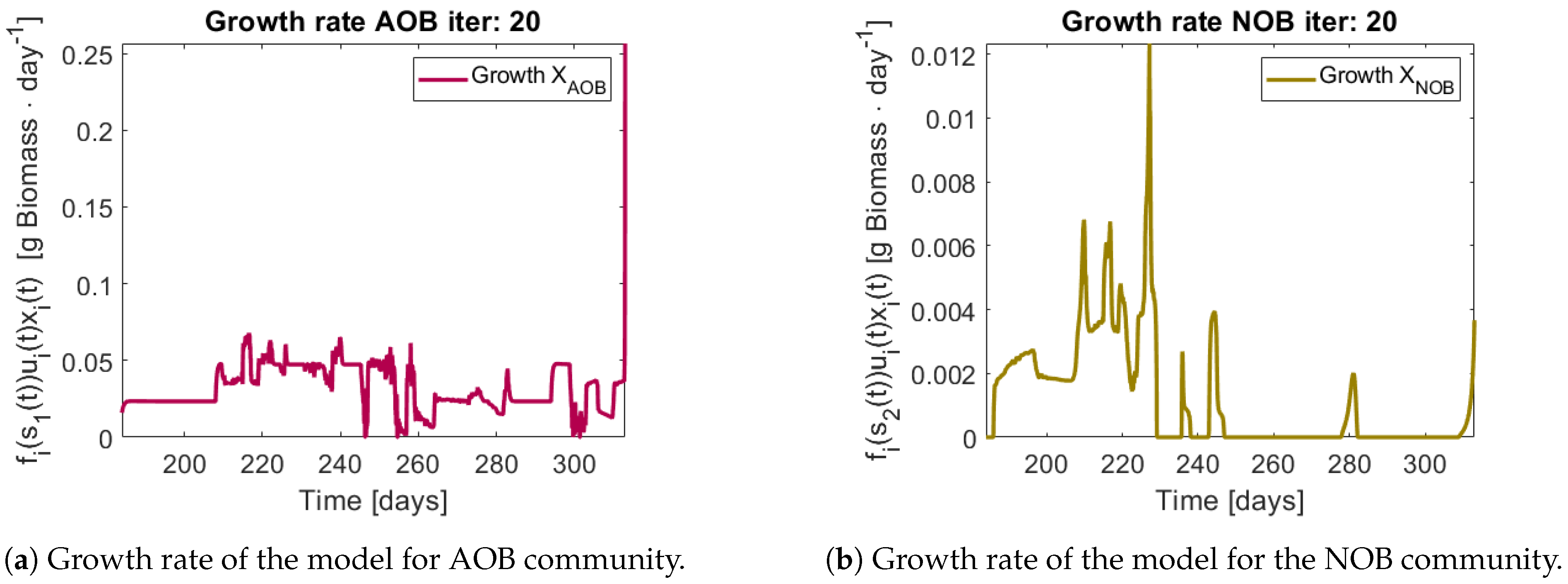
The growth rates of each functional group are shown in
Figure 13. Note in the case of AOB (
Figure 13a) the resulting growth rate shows a noisy curve formed by pulses. The behaviour of the NOB community (
Figure 13b) is qualitatively very similar with somewhat stronger pulses and less noise. The former is to be expected since more OTU were regrouped to compose the AOB biomass, therefore more noise sources were added.
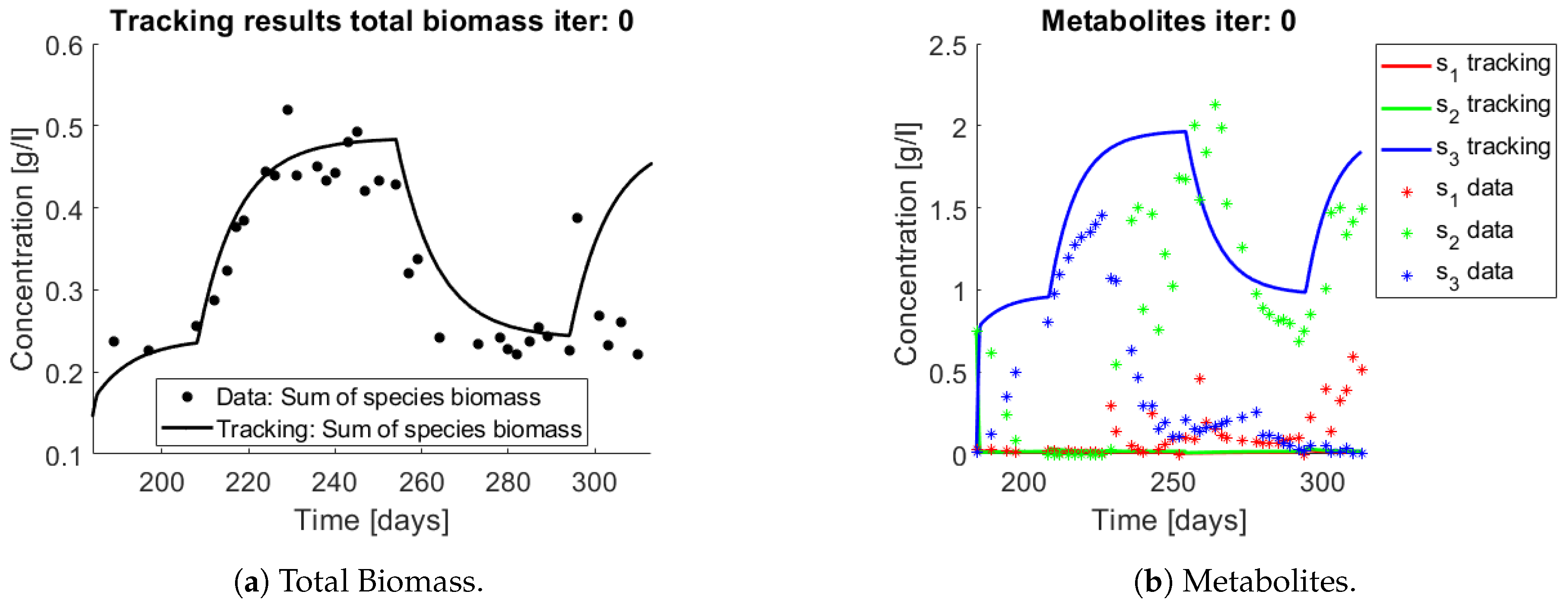
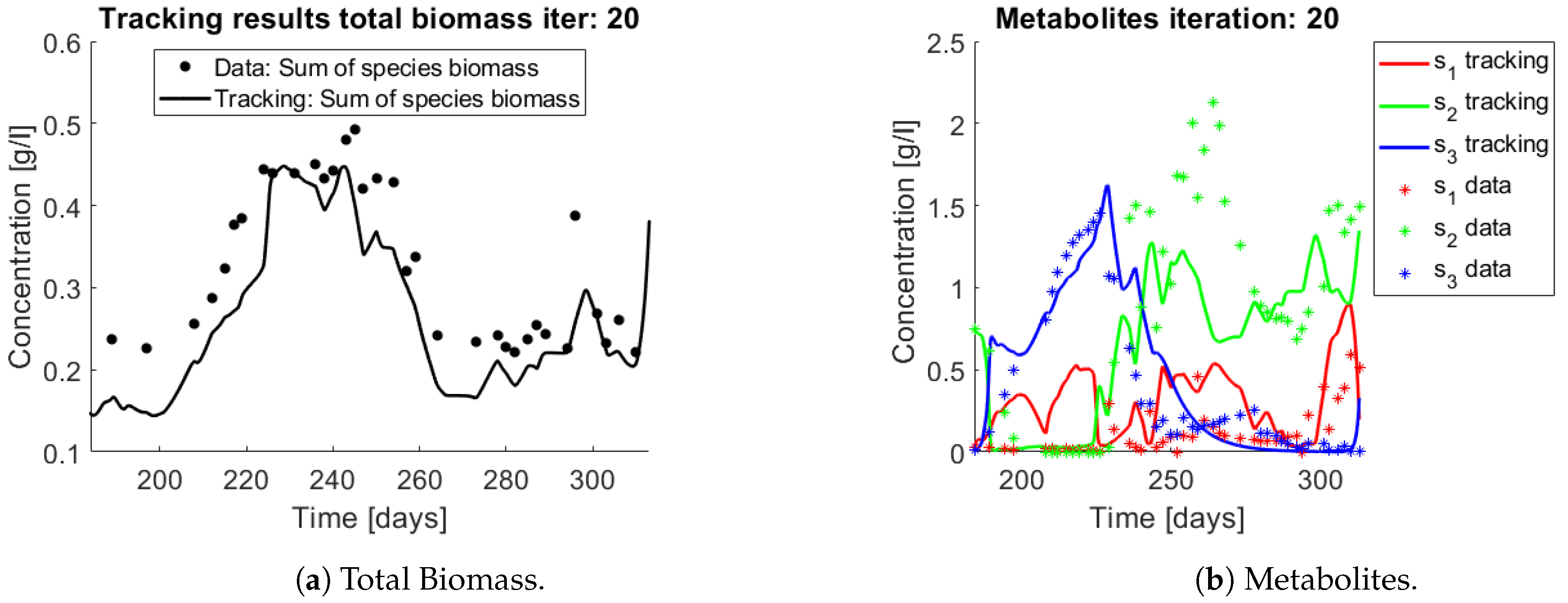
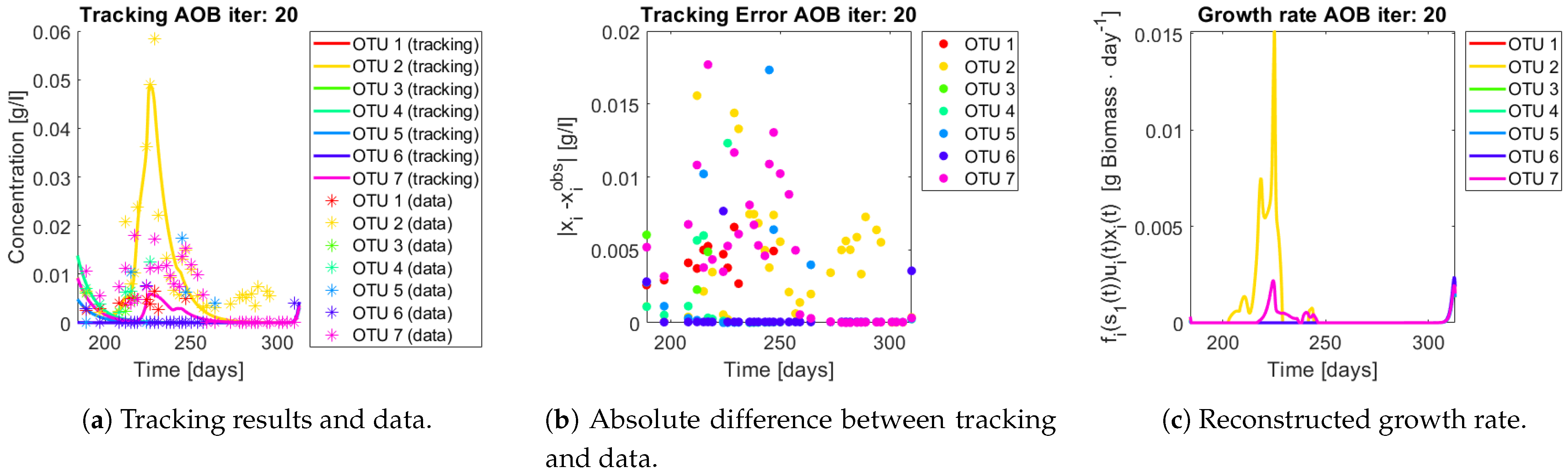
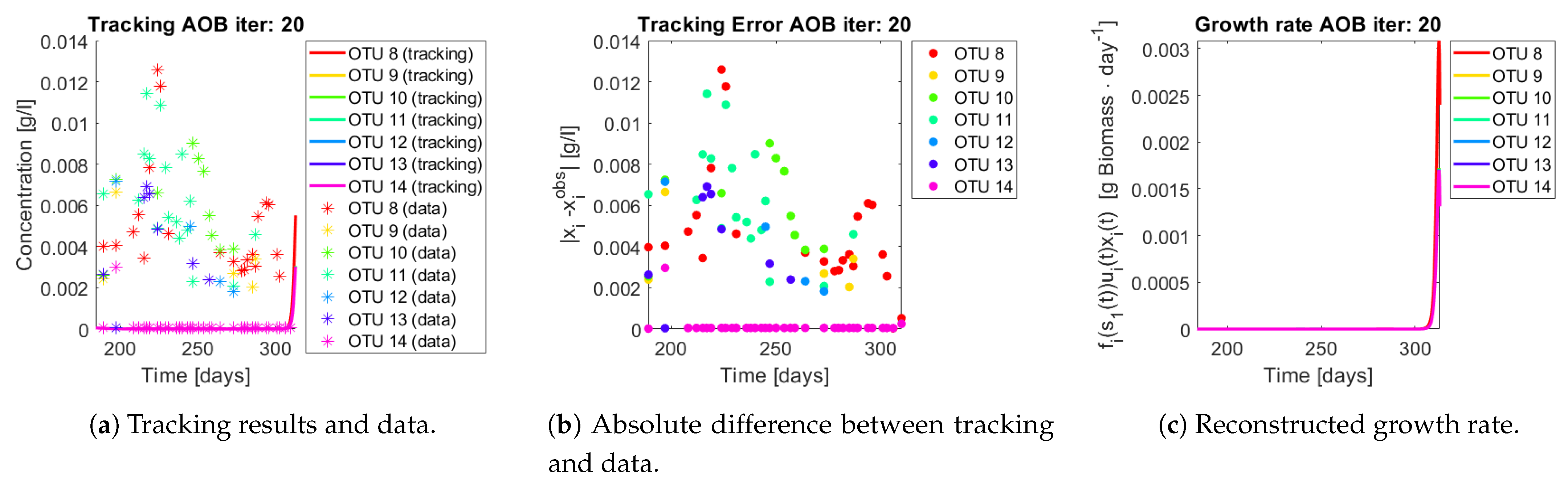
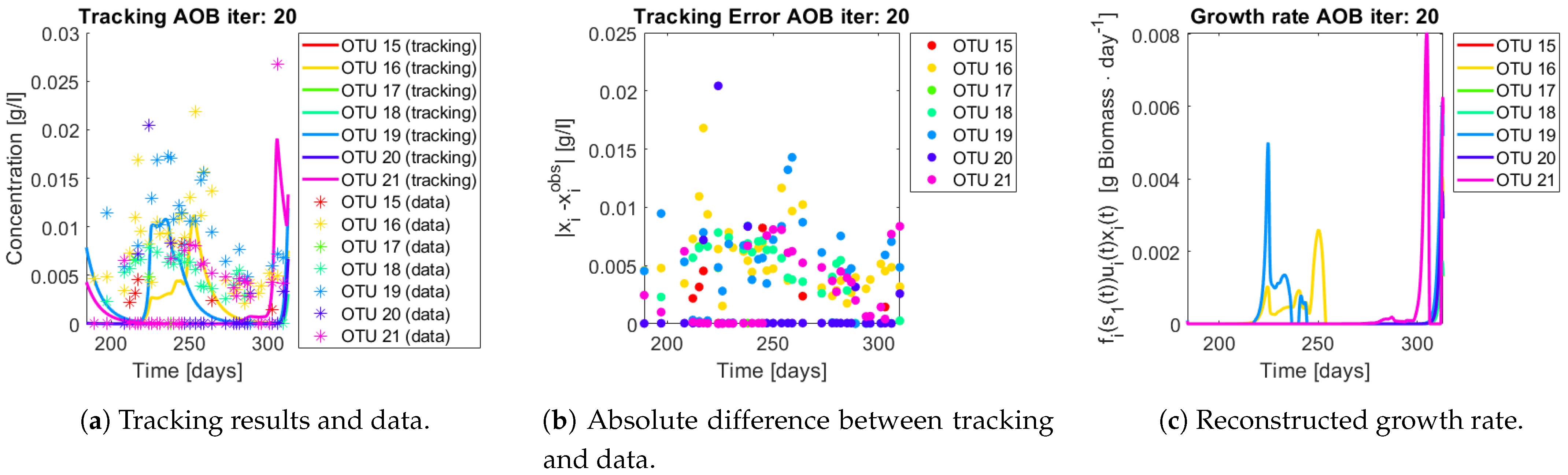
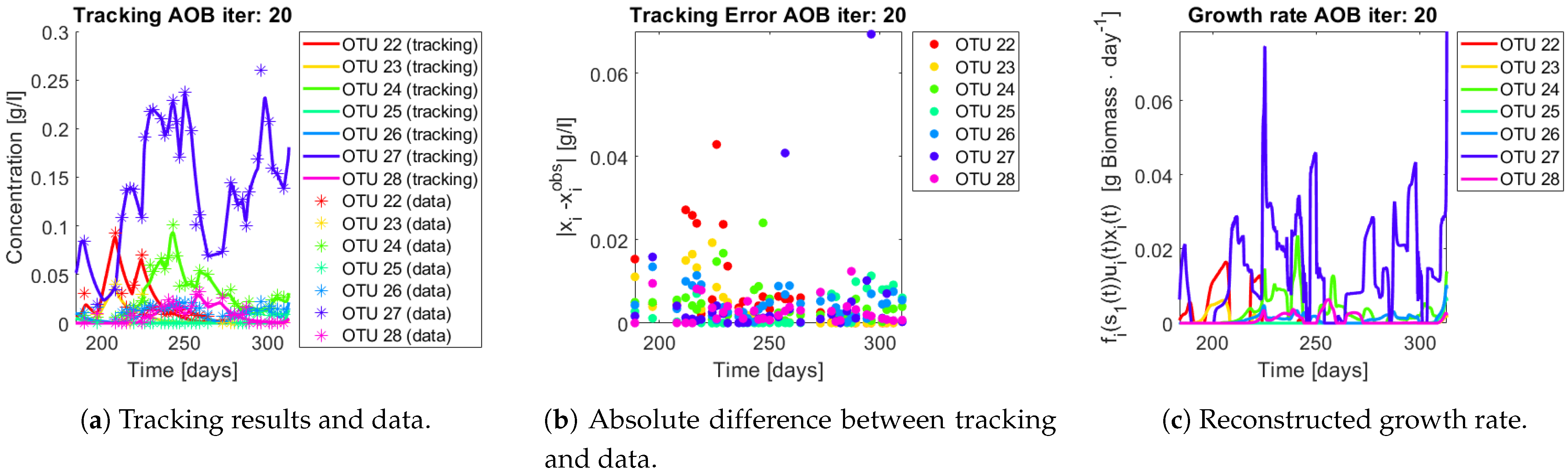
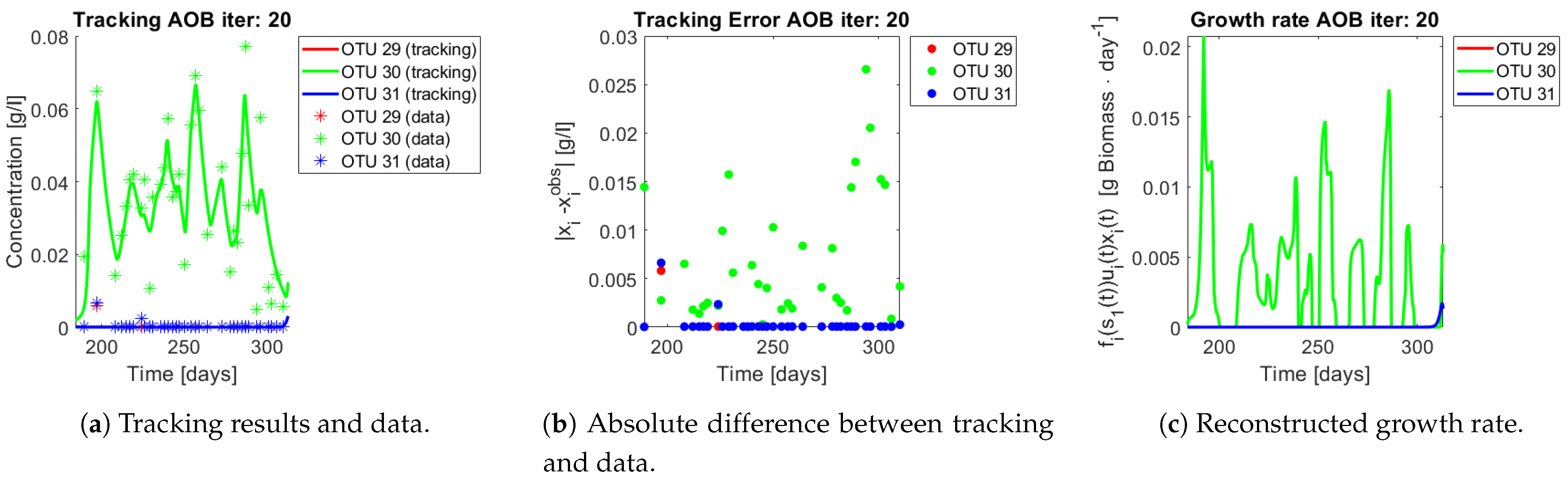
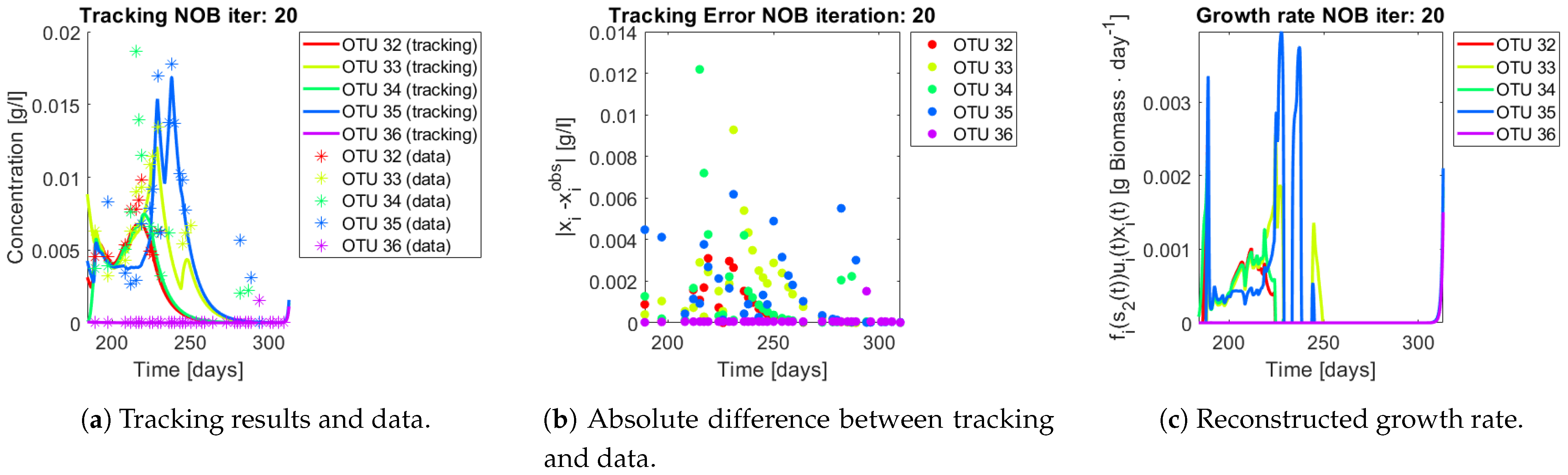
The same procedure is applied without regrouping. The results on total biomass and metabolites are shown in
Figure 14a,b, respectively. Both patterns still fit the data, but to a lesser degree of precision when compared to
Figure 11. This can be explained by inspecting
Figure 15,
Figure 16,
Figure 17,
Figure 18,
Figure 19 and
Figure 20. First note the absolute error of the tracking for each of the OTU in the AOB community (
Figure 15b,
Figure 16b,
Figure 17b,
Figure 18b and
Figure 19b), almost every point lies below
[g/L], implying that the method might not be able to track below that threshold for the members of the AOB community. The former ultimately implies that the most abundant OTU are better tracked, thus the information contained in the least abundant species is not integrated in the model. Notice that the error for the NOB community is lower (
Figure 20b), almost every point lies below
[g/L], this can be explained in the one order of difference in the entry of matrix
Q for the AOB and the NOB community. It may be the case that using appropriate weight matrices that account for the difference between OTU abundances could help in this aspect; in that sense only one rational was tested (inverse of the mean abundance of each OTU in the diagonal entries of matrix
Q) and did not improve the results. When looking at the growth rates (
Figure 15c,
Figure 16c,
Figure 17c,
Figure 18c,
Figure 19c and
Figure 20c) one again observes pulses for each OTU. Finally, note that most OTU were present only for a fraction of the experiment’s duration.
In both cases, the regrouped and individual tracking, the growth rate varies strongly, raising the question whether the observed pulses are emerging from interactions within the microbial community. When growth rates are compared to the proof of concept section it seems doubtful that a linear pairwise interaction model such as the gLV model could capture the complexity of the particular chemostat analysed. Perhaps these interactions are not constant through time (as opposed to the gLV model) or a different interaction function should be thought of. However the former questions cannot be fully clarified here, because the quality of the genetic sequencing from molecular fingerprints might not be the best when compared to more recent techniques, thus it is unclear if the pulses are due to noise of the measurements.
The interpretation of the correction term as interactions is not the only possible reading. In other contexts the correction term might also be interpreted as a non accounted phenomena ranging from environmental factors (e.g., temperature, pH) to other biological factors (viruses, flock formation, pathogens). Alternative hypotheses for explaining the observed patterns in the microbial community should be considered as well.
6. Conclusions and Perspectives
Over the last decades, advances in genetic sequencing and microbial ecology have opened a gap for modellers in biochemical processes to integrate this valuable information. Considering the success of mass balance models to predict and pilot bioreactors, new models should be built upon them, or at least be compared against them. This article exposed what can be gained from combining population-based models as used in ecology with functional group based approaches as used in bioengineering. The analysis of the gLV model proposed by Dumont et al. [
16] already shows that such a combination can give way to models that include bi-stability, coexistence within a functional group, and unintuitive operational insights such as raising the input ammonium
to achieve partial nitrification. The increased number of parameters of this particular model obviously hinders its potential application, but it surely helps to illustrate what can be gained by joining both types of models. The mathematical analysis focused on the particular case of pairwise interactions, which can be seen as a first order approximation of the introduced concept of interaction function. This opens the question for a broader class of interaction functions that could well represent complex microbial ecosystems, particularly bioreactors.
With that line of reasoning, in order to understand what this interaction function should look like, a data-driven approach was presented. It can be simply described as correcting the growth rate expression of each individual species in a mass balance model by explicitly assuming a control loop on the growth rate depending on the species state variables and the measured abundances. The reconstructed growth rates seem to consist of pulses, suggesting that a form of a possible interaction function should reproduce this behaviour. However, the former questions cannot be fully clarified here, because the identification and quantification of OTU from single-strand conformation polymorphism (SSCP) as performed by Dumont et al. [
18] might not be optimal. Indeed, the determination of OTU from SSCP profiles rely on the identification and quantification of peaks and miss many OTU that appear only as background noise [
30]. This type of fingerprinting is thus less accurate than more recent methods such as the sequencing of the 16S ribosomal RNA. In spite of this, one is able to recover the substrates dynamics, implying that the hypothesis of microbial interactions as drivers of a bioprocess, in the form of feedback loops affecting each others growth rates, is not far-fetched.
The use of the tracking technique can be applied in a straightforward manner to already existing models in mixed homogeneous bioreactors, under the condition that the microbial species have already been identified with a particular functionality of the system. Even though the tracking model was proposed for a chemostat setting as a way to correct a substrate limited expression, the method could be used in contexts where less information on the growth function of microbes is known. If one supposes nothing on the growth expression but the fact that is bounded (life cannot grow infinitely fast) the model becomes a linear model and one recovers a classic quadratic regulator for linear systems. This was tested for the data presented in this article and, unfortunately, negative substrate appeared as an output, suggesting that the substrate limitation term is crucial for the model to be well-posed. Nevertheless, even in the former case, the synthesis of the optimal bounded control remains an open theoretical challenge. One might bypass this issue of the current control scheme by, for example, a very thorough use of the Pontryagin maximum principle for the synthesis of the control. In a more general view the reconstruction of the growth function in chemostat systems is already subject to problems of identifiability [
31], integrating genetic sequencing could provide a path for more certainty in model calibration.


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}