Development of a Rice Plant Disease Classification Model in Big Data Environment

Abstract
:1. Introduction
1.1. Rice Diseases and Their Symptoms
- Rice leaf blast: elliptical to oval spots generally light colored in centers and edges are dark reddish-brown.
- Brown spot: Fungal infection causes round to oval dark brown color spot.
- Sheath blight: Irregular or oval with greenish grey spots. When the spots become enlarged, the center becomes greyish white and the margin turns a blackish-brown color.
- Bacterial leaf blight: yellowish lesion with uneven edges. Leaves become yellow and gradually die.
- Sheath rot: Spots are irregular with greyish white in the center and a brown margin. There is discoloration of the seed.
- (i)
- Image acquisition: In this step, the images are captured from the field directly through different devices such as camera, mobile phone, etc.
- (ii)
- Image preprocessing: In this stage, preprocessing is performed on the infected images to eliminate the unwanted noises, such as water droplets, and image enhancement is also applied by some standard techniques.
- (iii)
- (iv)
- Feature extraction and selection: In this step [5], at first, important features are generated from the diseased object and then important features are selected from the feature pool. Different feature extraction techniques are used to extract the features related to statistical, color, shape, texture, wavelets, size, area, proximity, and centroids, morphology features, correlation-based feature, textural descriptors using GLCM [2] and color moments, etc. Different soft computing-based feature selection techniques such as rough set theory [6,7], Genetic Algorithm [8], etc. are used to select the important features as well.
- (v)
- Classification: The final step decides the class label of the disease through different classification techniques. Various state-of-the-art classification tools and techniques exist, such as SVM [9], artificial neural network [10], decision tree [11], k-NN [11], and rule-based techniques, etc., to perform the classification task.
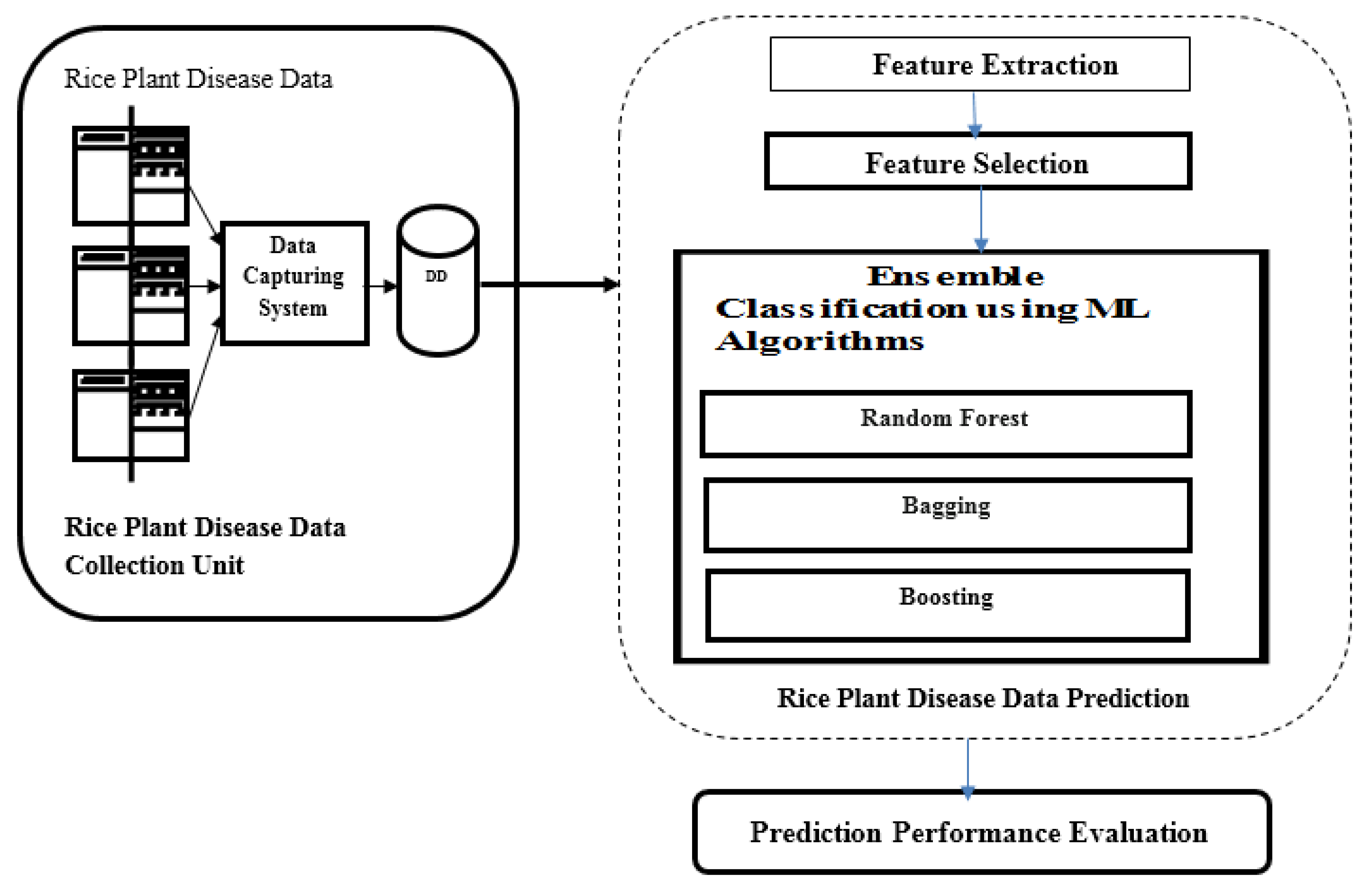
- Analyzing rice plant disease data using a machine learning algorithm in the MapReduce framework of a big data platform;
- Selecting multiple disease feature subsets using a rough set theory-based feature selection algorithm;
- Developing integrated feature extraction, feature selection, and ensemble classification techniques in a map reduce framework for better disease prediction results.
2. Big Data in Plant Disease Prediction
2.1. Ensemble Classification Techniques
2.2. Previous Works on Rice Plant Disease Prediction
3. Development of Expert Rice Plant Disease Prediction Model
3.1. Feature Selection
- I.
- Partitioning the Objects of the decision system
- (a).
- Partitioning of objects based on decision attribute using indiscernibility relation
- (b).
- Partitioning of objects by applying clustering algorithm on the projections of the dataset.
- II.
- Computation of attribute connecting strength
- III.
- Construction of attribute connecting graph
- For each element :
- (i)
- Ai and Aj are considered as vertices of the graph G, i.e., where V = {} initially;
- (ii)
- An edge (Ai, Aj) is drawn with weight , i.e., where E = {} initially. Thus, E is a proper subset of V × V.
- IV.
- Generation of Reduct
- V.
- Illustration of the feature subset selection method:
- (i)
- At first, DS is partitioned based on D using indiscernibility relation and allowing the following equivalence classes to be obtained:
- (ii)
- Projection on dataset DS for two features C1 and C2 is taken and k-means clustering algorithm is applied on it with k = 2 that produces following two clusters:
- (iii)
- The connecting factor δf1,2 for two attributes C1 and C2 is calculated
- (iv)
- In this way, after applying the clustering algorithm on each pairwise feature in {C1, C2, C3, C4}, a feature connecting set (FCS) representing the connection of every pair of conditional features to the decision feature is constructed.
- (v)
- The elements of FCS with a connecting factor less than the average value are removed, and a modified FCS is formed.
- (vi)
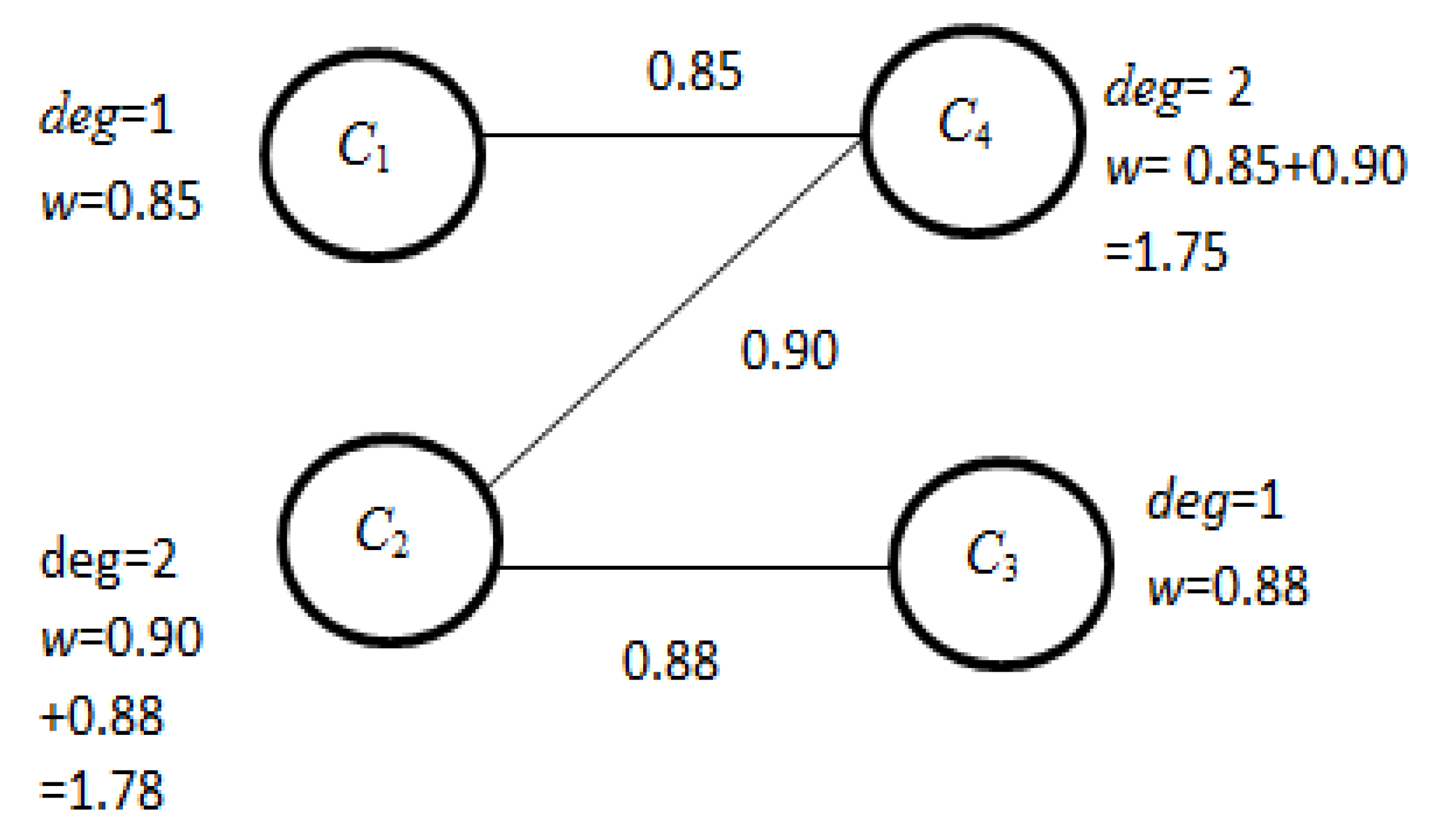
- Now, a feature connecting graph (FCG) is formed from modified FCS. Figure 3 represents the attribute connecting graph for the example data.
- (vii)
- Now, from FCG, the degrees of connection of each vertex v (here it is C1, C2, C3, and C4) are calculated.
- (viii)
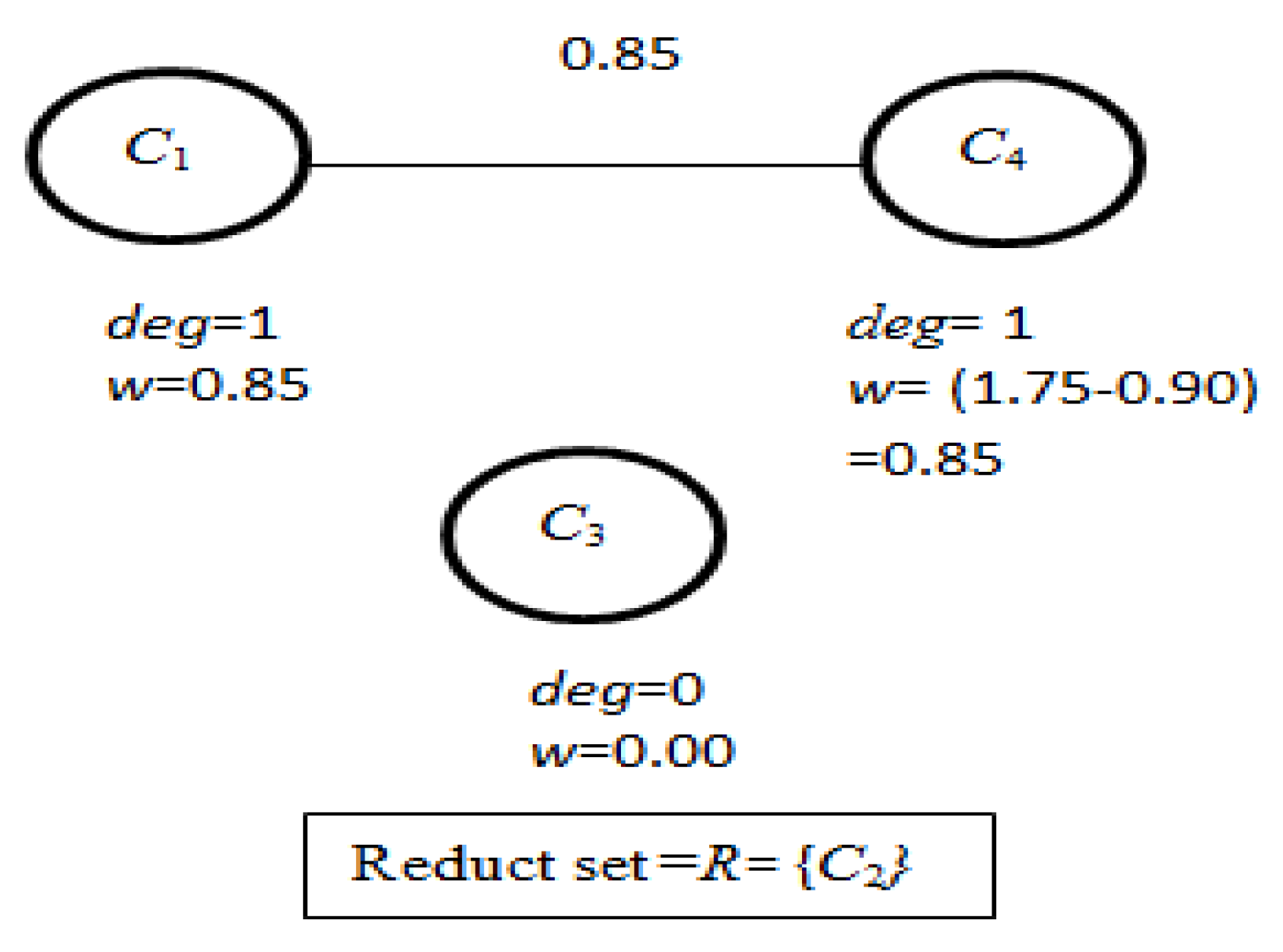
- From FCG, the vertex C2 has the highest degree of connection and according to the ‘Multiple_Reduct_Gen’ algorithm, C2 is considered as the reduct R and removed from ACG with the adjustment of degree of connection of the vertices adjacent to it. Figure 4 represents the modified FCG.
- (ix)
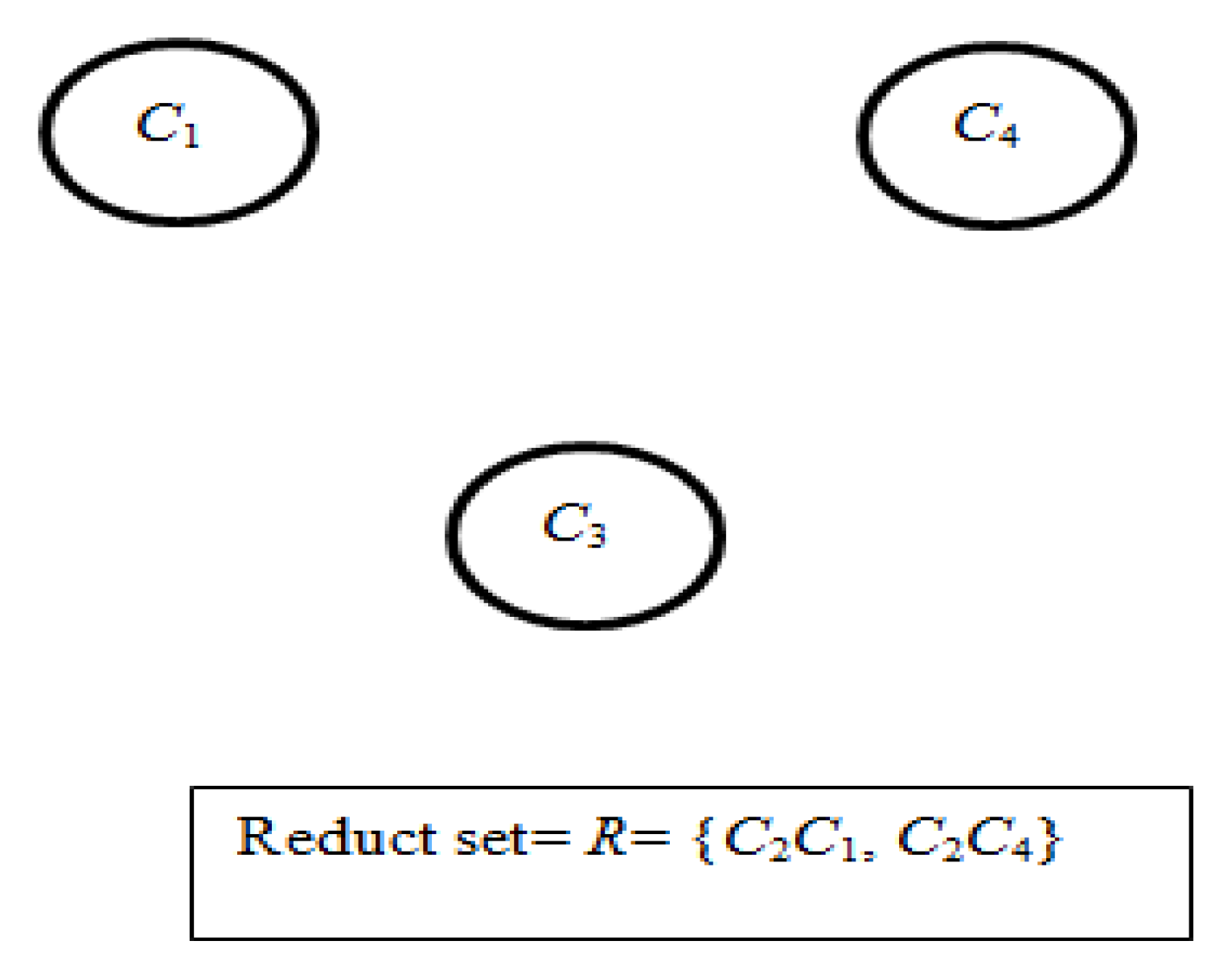
- Now, in the next iteration, two vertices C1 and C4 have the same degree of connection and so, according to the ‘Multiple_Reduct_Gen’ algorithm, for a single reduct in previous iteration and 2-vertices of highest degree of connection in FCG, 2 reducts are obtained. This process provides two reducts at the end of this iteration with R = {C2C1 and C2C4} and FCG becomes empty, as shown in Figure 5, which indicates the termination of the iteration.
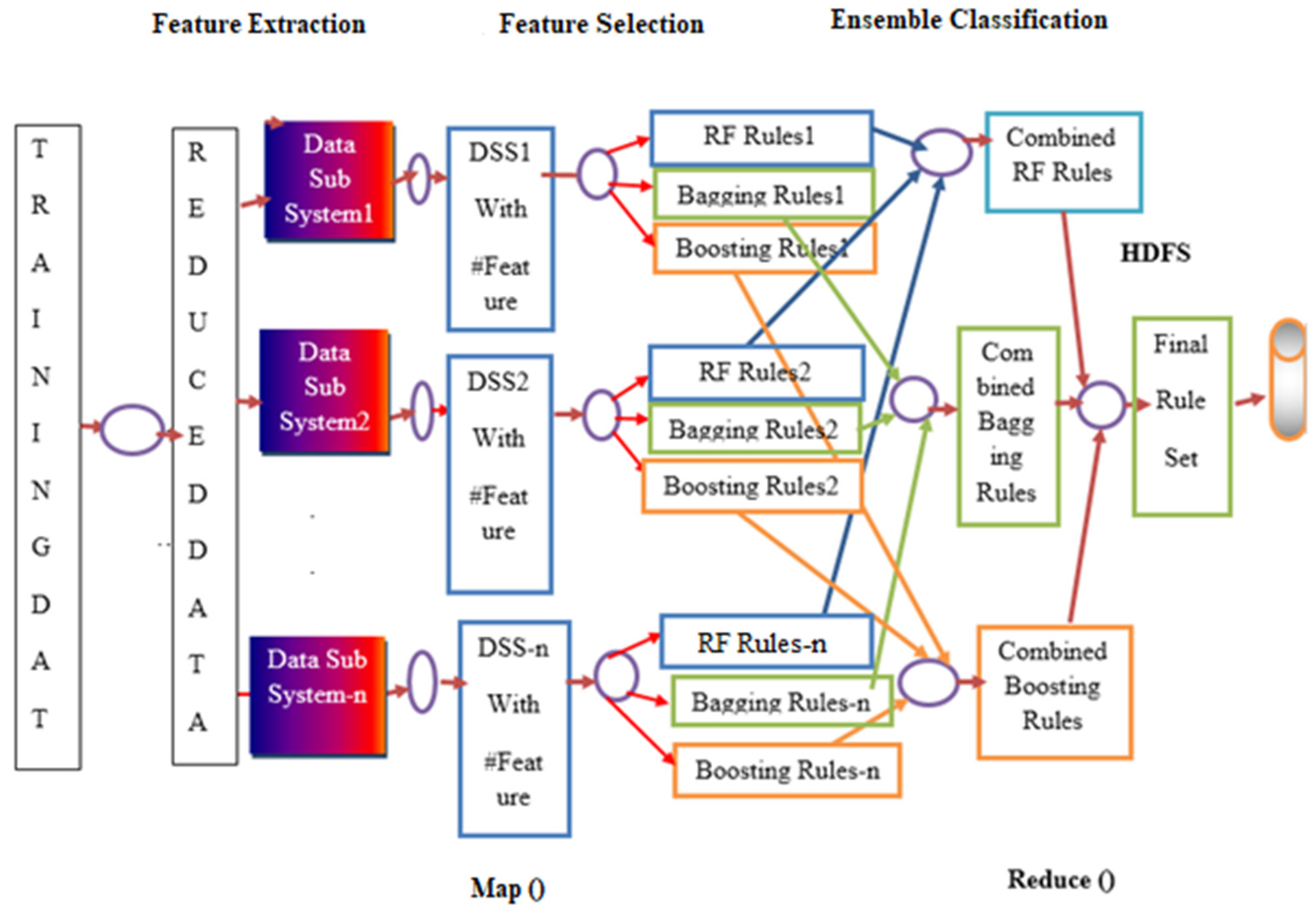
3.2. Multi Classifier-Based Classification Module
| Algorithm 1. Classification Model Generation |
| 1. Initialize a training Dataset d = {(Oi, ci), i = 1, 2, ………, n}, where labels ci is one of 1, 2, 3, ………, k, A set of base classifiers B = {b1, b2, ………, bt} and N = no of nodes |
| 2. Apply feature extraction method on d to obtain the preprocessed reduced dataset DSS |
| 3. Split DSS into DSS1, DSS2, …, DSSN and map into the corresponding node |
| 4. for each node i = 1 to N |
| 5. Apply feature selection method to get the reduced data subsystem RDSi |
| 6. for each base classifier bt in B |
| 7. train bt on RDSi and compute classification rules in Rt |
| 8. end for |
| 9. end for |
| 10. for each node i = 1 to N |
| 11. for each bt |
| 12. Combine all Rt of RDSi and Create rule base CRk for each k |
| 13. end for |
| 14. end for |
| 15. for each test object |
| 16. Apply majority voting rule on CRk to get the label of the test object |
| 17. end for |
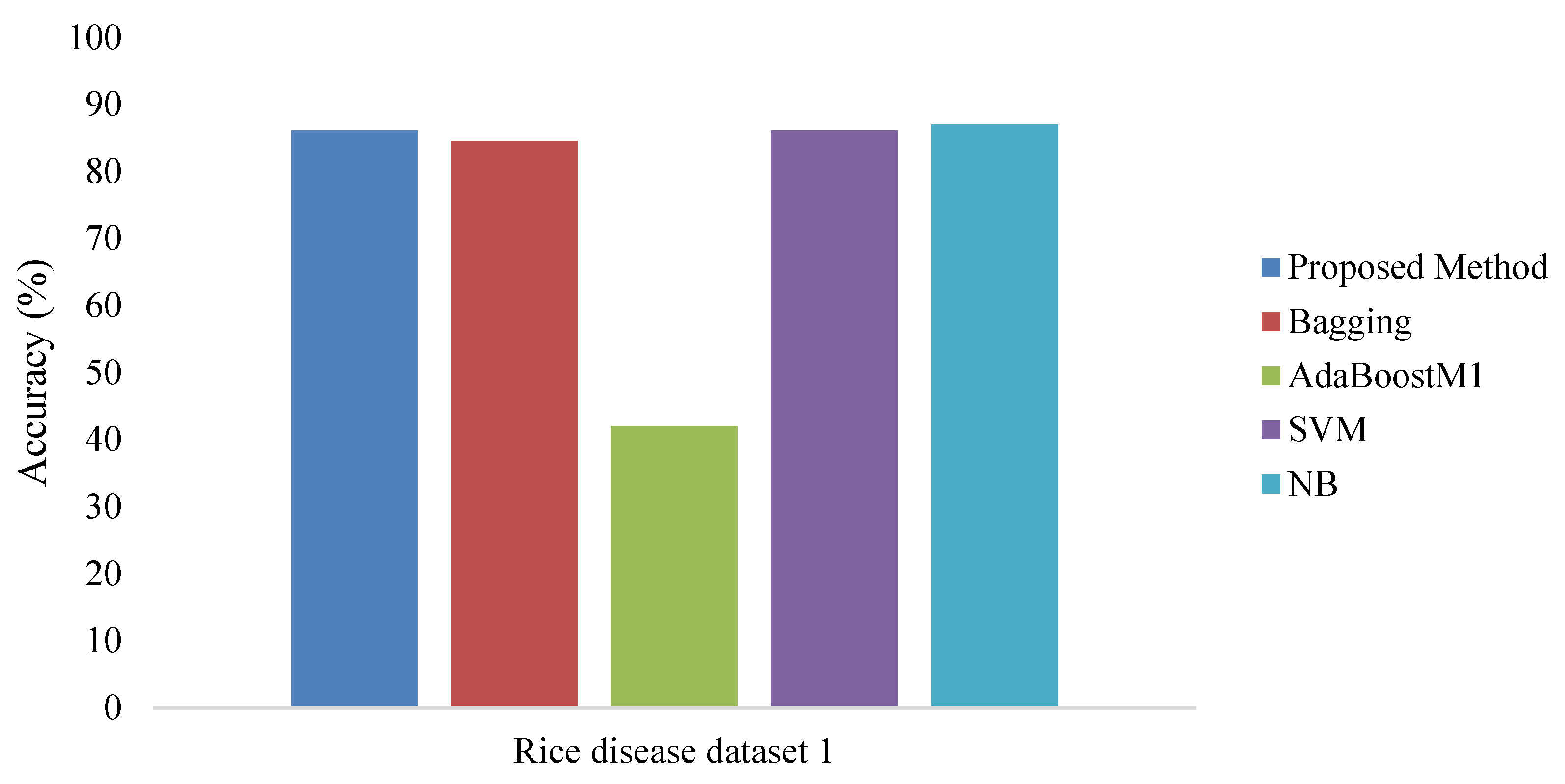
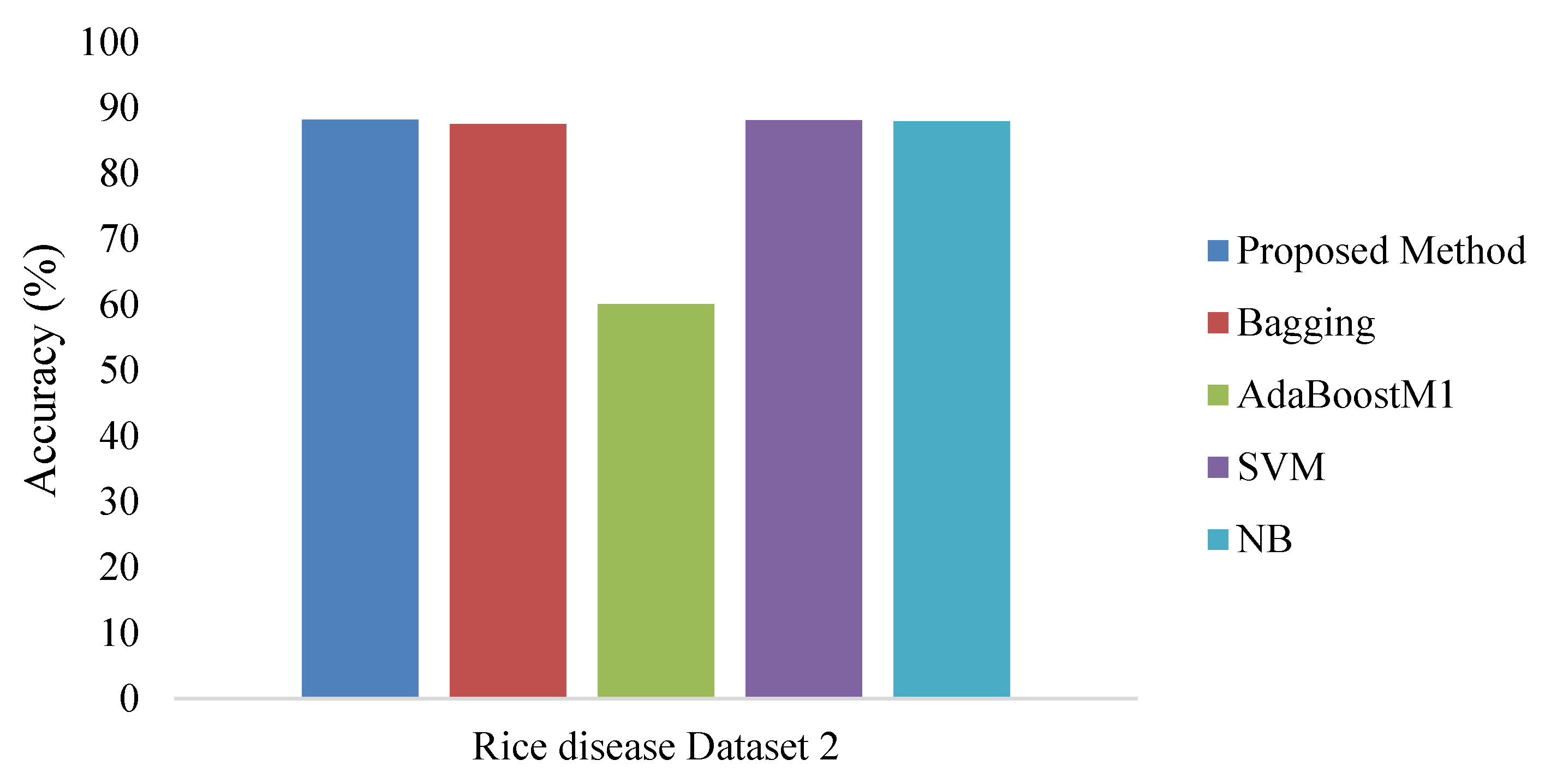
4. Experimental Results
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Verma, P. Rice Productivity and Food Security in India, Centre for Management in Agriculture; Springer: Singapore, 2017. [Google Scholar]
- Phadikar, S.; Sil, J. Rice disease identification using pattern recognition techniques. In Proceedings of the 2008, 11th International Conference on Computer and Information Technology, Khulna, Bangladesh, 24–25 December 2008; pp. 420–423. [Google Scholar]
- Phadikar, S.; Goswami, J. Vegetation indices-based segmentation for automatic classification of brown spot and blast diseases of rice. In Proceedings of the 2016, 3rd International Conference on Recent Advances in Information Technology (RAIT), Dhanbad, India, 3–5 March 2016; pp. 284–289. [Google Scholar]
- Lurstwut, B.; Pornpanomchai, C. Image analysis based on colour, shape and texture for rice seed (Oryza sativa L.) germination evaluation. Agric. Nat. Resour. 2017, 51, 383–389. [Google Scholar]
- Sengupta, S.; Das, A.K. Particle Swarm Optimization based incremental classifier design for rice disease prediction. Comput. Electron. Agric. 2017, 140, 443–451. [Google Scholar] [CrossRef]
- Pawlak, Z. Rough set theory and its applications to data analysis. Cybern. Syst. 1998, 29, 661–688. [Google Scholar] [CrossRef]
- Zhong, A.N.; Skowron, A. Rough set-based knowledge discovery process. Int. J. Appl. Math. Comput. Sci. 2001, 11, 603–619. [Google Scholar]
- Freitas, A.A. Data Mining and Knowledge Discovery with Evolutionary Algorithms; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Huang, T.; Yang, R.; Huang, W.; Huang, Y.; Qiao, X. Detecting sugarcane borer diseases using support vector machine. Inf. Process. Agric. 2018, 5, 74–82. [Google Scholar] [CrossRef]
- Zhang, X.; Qiao, Y.; Meng, F.; Fan, C.; Zhang, M. Identification of Maize Leaf Diseases Using Improved Deep Convolutional Neural Networks. IEEE Access 2018, 6, 30370–30377. [Google Scholar] [CrossRef]
- Devijverm, P.A.; Kittlerm, J. Pattern Recognition: A Statistical Approach; Prentice Hall: Englewood Cliffs, NJ, USA, 1982. [Google Scholar]
- Gajanan, D.E.; Shankar, G.G.; Keshav, G.V. Detection of Leaf Disease Using Feature Extraction for Android Based System. Int. Res. J. Eng. Technol. 2018, 5, 95–106. [Google Scholar]
- Phadikar, S.; Sil, J.; Das, A.K. Rice diseases classification using feature selection and rule generation techniques. Comput. Electron. Agric. 2013, 90, 76–85. [Google Scholar] [CrossRef]
- Rishi, N.; Gill, J.S. An Overview on Detection and Classification of Plant Diseases in Image Processing. Int. J. Sci. Eng. Res. IJSER 2015, 3, 110–117. [Google Scholar]
- Nishadi Thanuja, A.S. Healthcare Big Data Analysis using Hadoop MapReduce. Int. J. Sci. Res. Publ. 2019, 9, 60–75. [Google Scholar] [CrossRef]
- Zhou, Z.H. Ensemble Methods: Foundations and Algorithms; Chapman and Hall: London, UK; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Pothen, M.; Eliz, P.; Maya, L. IEEE 2020 Fourth International Conference on Computing Methodologies and Communication (ICCMC). In Proceedings of the Detection of Rice Leaf Diseases Using Image Processing, Erode, India, 11–13 March 2020; pp. 424–430. [Google Scholar]
- Larijani, M.R.; Asli-Ardeh, E.A.; Kozegar, E.; Loni, R. Evaluation of image processing technique in identifying rice blast disease in field conditions based on KNN algorithm improvement by k-means. Food Sci. Nutr. 2019, 7, 3922–3930. [Google Scholar] [CrossRef] [PubMed]
- Nidhis, A.D.; Pardhu, C.N.V.; Reddy, K.C.; Deepa, K. Cluster Based Paddy Leaf Disease Detection, Classification and Diagnosis in Crop Health Monitoring Unit. In Lecture Notes in Computational Vision and Biomechanics; Springer Nature: Cham, Switzerland, 2019. [Google Scholar]
- Zhou, G.; Zhang, W.; Chen, A.; He, M.; Ma, X. Rapid Detection of Rice Disease Based on FCM-KM and Faster R-CNN Fusion. IEEE Access 2019, 7, 143190–143206. [Google Scholar] [CrossRef]
- Shreekanth, K.N.; Suresha, M.; Naik, H. A Novel Segmentation and Identification of Diseases in Paddy Leaves Using Color Image Fusion Technique. In Proceedings of the IEEE International Conference on Image Information Processing (ICIIP), Shimla, India, 15–17 November 2019. [Google Scholar]
- Kawcher, A.; Shahidi, T.; Syed, M.I.A.; Sifat, M. Rice Leaf Disease Detection Using Machine Learning Techniques. In Proceedings of the IEEE International Conference on Sustainable Technologies for Industry 4.0 (STI), Dhaka, Bangladesh, 24–25 December 2019; pp. 24–25. [Google Scholar]
- Bakar, M.N.A.; Abdullah, A.H.; Rahim, N.A.; Yazid, H.; Misman, S.N.; Masnan, M.J. Rice Leaf Blast Disease Detection Using Multi-Level Colour Image Thresholding. J. Telecommun. Electron. Comput. Eng. JTEC 2018, 10, 1–6. [Google Scholar]
- Ramesh, S.; Vydeki, D. Rice Blast Disease Detection and Classification using Machine Learning Algorithm. In Proceedings of the IEEE International Conference on Micro-Electronics and Telecommunication Engineering, Ghaziabad, India, 20–21 September 2018. [Google Scholar]
- Sengupta, S.; Das, A.K. Dimension Reduction Using Clustering Algorithm and Rough Set Theory. In International Conference on Swarm, Evolutionary, and Memetic Computing; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7677, pp. 705–712. [Google Scholar]
- Das, A.K.; Sengupta, S.; Bhattacharyya, S. A group incremental feature selection for classification using rough set theory based genetic algorithm. Appl. Soft Comput. 2018, 65, 400–411. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, G.Y. RRIA: Rough set and rule tree based incremental knowledge acquisition algorithm. Fundam. Inform. 2004, 59, 299–313. [Google Scholar]
- Bang-Jensen, J.; Gutin, G. Digraphs: Theory, Algorithms and Applications; Springer: Berlin/Heidelberg, Germany, 2008; ISBN 1-85233-268-9. [Google Scholar]
- Alpaydin, E. Introduction to Machine Learning; Prentice-Hall of India PrivateLimited: Delhi, India, 2010. [Google Scholar]
- Available online: https://www.kaggle.com/datasets/vbookshelf/rice-leaf-diseases (accessed on 15 June 2022).
- Murphy, P.; Aha, W. UCI Repository of Machine Learning Databases. 1996. Available online: https://www.ics.uci.edu/mlearn/MLRepository.html (accessed on 12 June 2022).
- WEKA. Machine Learning Software. Available online: https://www.cs.waikato.ac.nz/ (accessed on 12 June 2022).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset (Original Attribute) | Bagging (%) | AdaBoost (%) | Proposed Method (%) |
|---|---|---|---|
| Breast Cancer (9) | 94.43 | 95.74 | 96.93 |
| Heart (12) | 82.25 | 82.97 | 84.51 |
| Dermatology (33) | 96.01 | 96.26 | 98.99 |
| Dataset (#Original Attribute) | Classification Methods | Classifiers Parameter Values | ||
|---|---|---|---|---|
| Precision | Recall | F-Measure | ||
| Breast Cancer (9) | Proposed Method | 0.97 | 0.97 | 0.97 |
| Bagging | 0.95 | 0.95 | 0.95 | |
| AdaBoostM1 | 0.96 | 0.96 | 0.96 | |
| Heart (12) | Proposed Method | 0.84 | 0.84 | 0.84 |
| Bagging | 0.82 | 0.82 | 0.82 | |
| AdaBoostM1 | 0.83 | 0.83 | 0.83 | |
| Dermatology (33) | Proposed Method | 0.99 | 0.99 | 0.99 |
| Bagging | 0.96 | 0.96 | 0.96 | |
| AdaBoostM1 | 0.96 | 0.96 | 0.96 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sengupta, S.; Dutta, A.; Abdelmohsen, S.A.M.; Alyousef, H.A.; Rahimi-Gorji, M. Development of a Rice Plant Disease Classification Model in Big Data Environment. Bioengineering 2022, 9, 758. https://doi.org/10.3390/bioengineering9120758
Sengupta S, Dutta A, Abdelmohsen SAM, Alyousef HA, Rahimi-Gorji M. Development of a Rice Plant Disease Classification Model in Big Data Environment. Bioengineering. 2022; 9(12):758. https://doi.org/10.3390/bioengineering9120758
Chicago/Turabian StyleSengupta, Shampa, Abhijit Dutta, Shaimaa A. M. Abdelmohsen, Haifa A. Alyousef, and Mohammad Rahimi-Gorji. 2022. "Development of a Rice Plant Disease Classification Model in Big Data Environment" Bioengineering 9, no. 12: 758. https://doi.org/10.3390/bioengineering9120758
APA StyleSengupta, S., Dutta, A., Abdelmohsen, S. A. M., Alyousef, H. A., & Rahimi-Gorji, M. (2022). Development of a Rice Plant Disease Classification Model in Big Data Environment. Bioengineering, 9(12), 758. https://doi.org/10.3390/bioengineering9120758