
Machine Learning and Deep Learning Algorithms for Skin Cancer Classification from Dermoscopic Images


Abstract
:1. Introduction
2. Materials and Methods
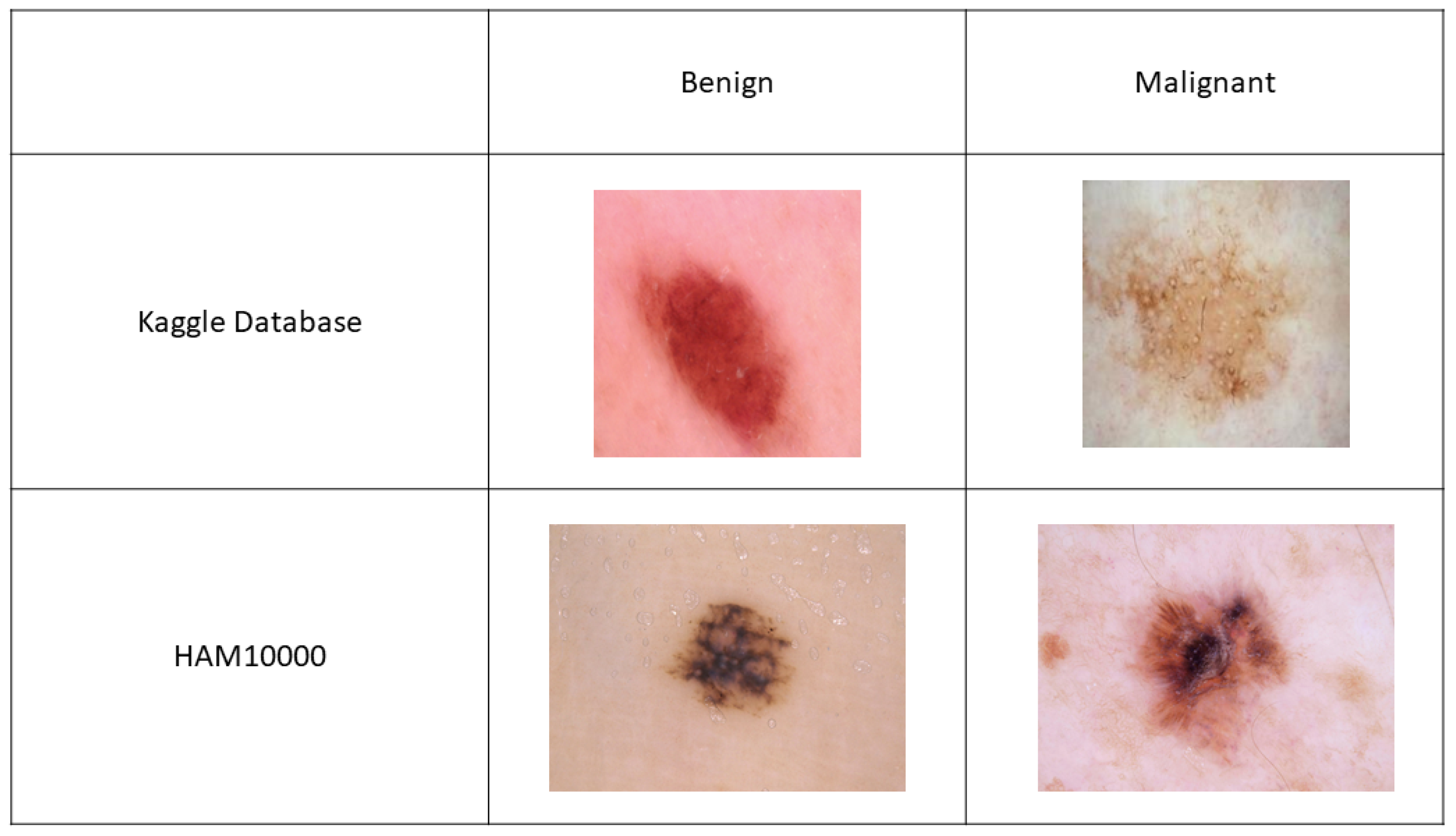
2.1. Data
2.2. Machine Learning Models
2.3. Deep Learning Models
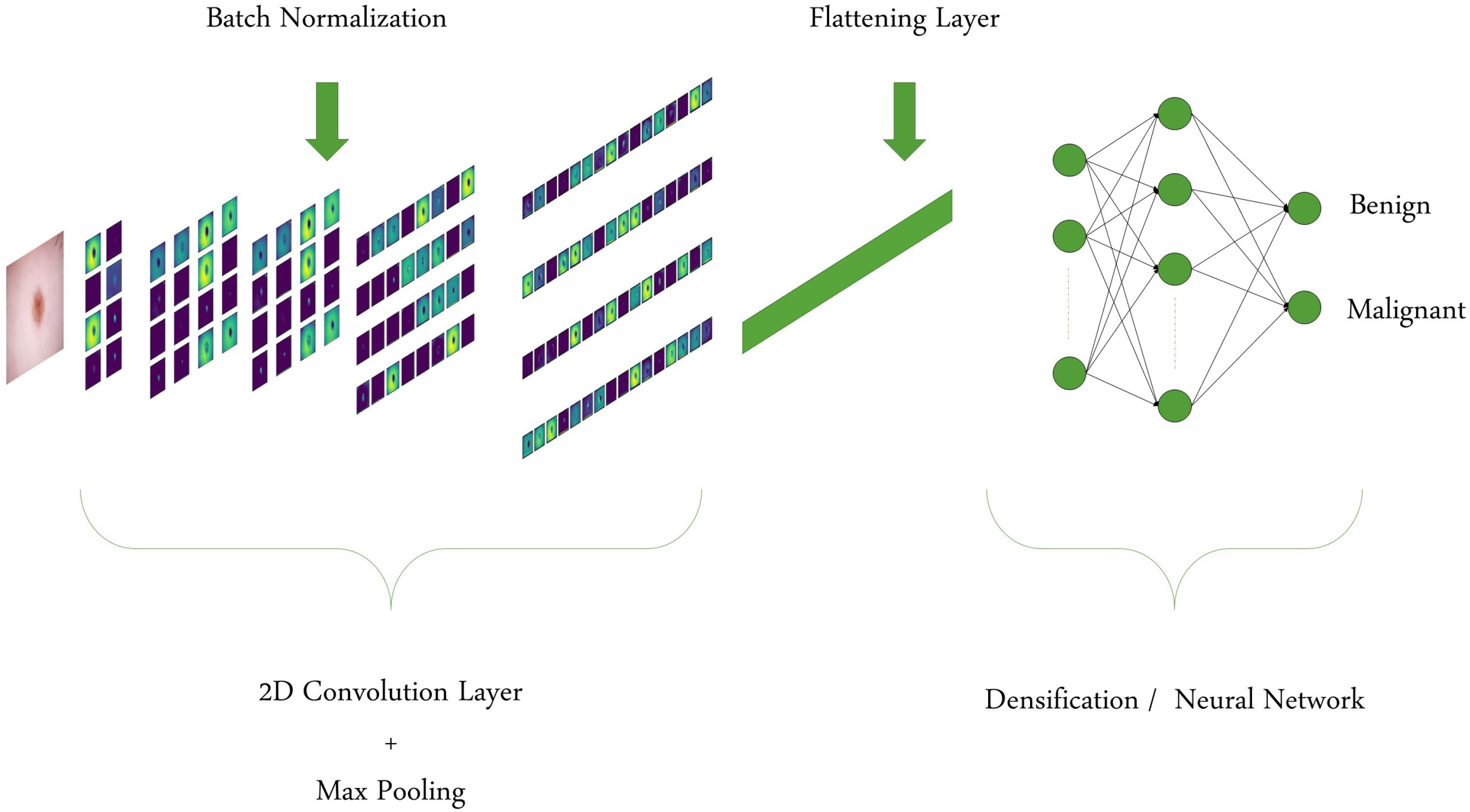
2.3.1. Custom CNN Model
2.3.2. Transfer Learning
2.4. Technical Details and Evaluation Metrics
3. Results and Discussion
3.1. Kaggle Database
3.1.1. ML Models
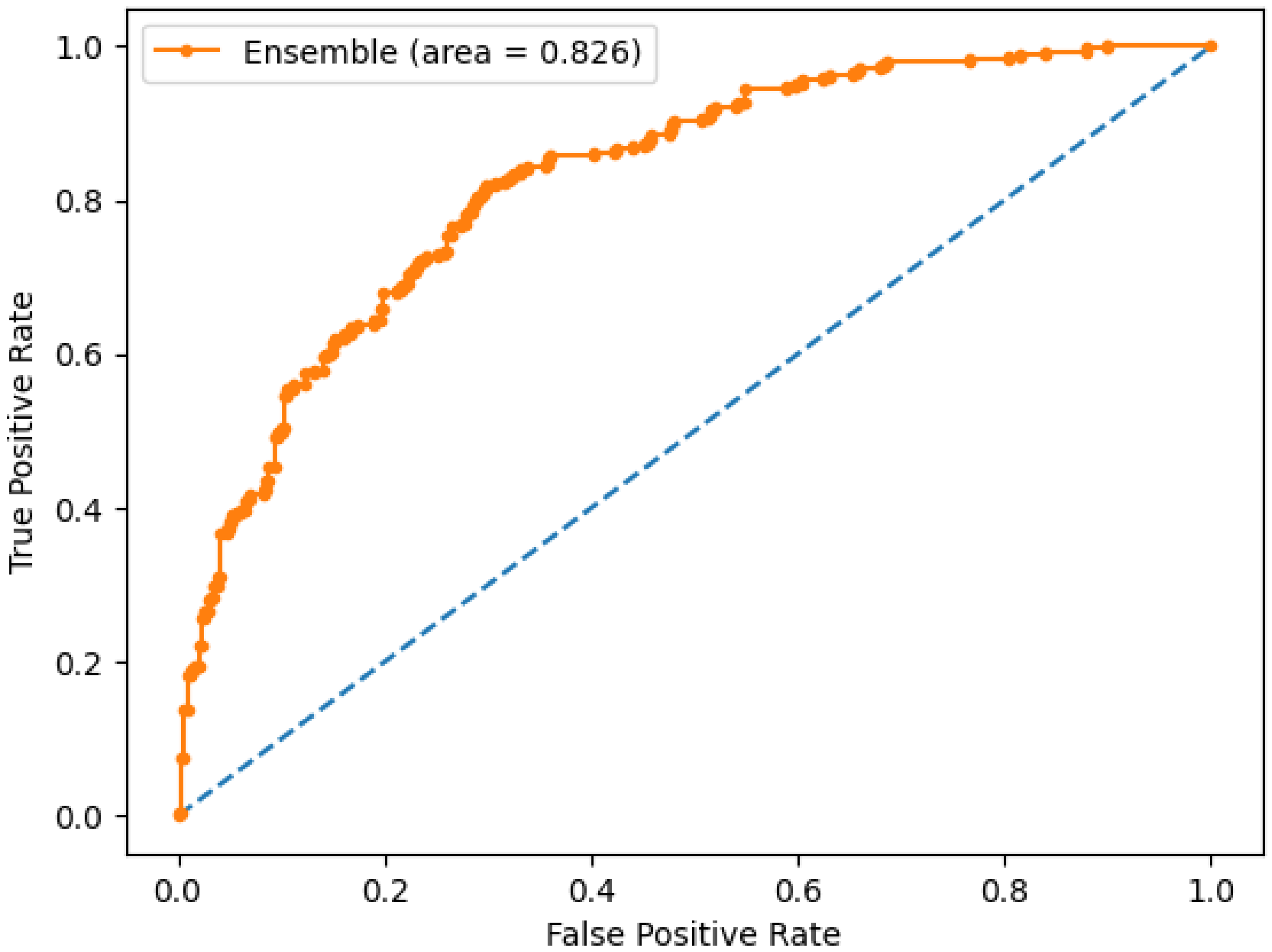
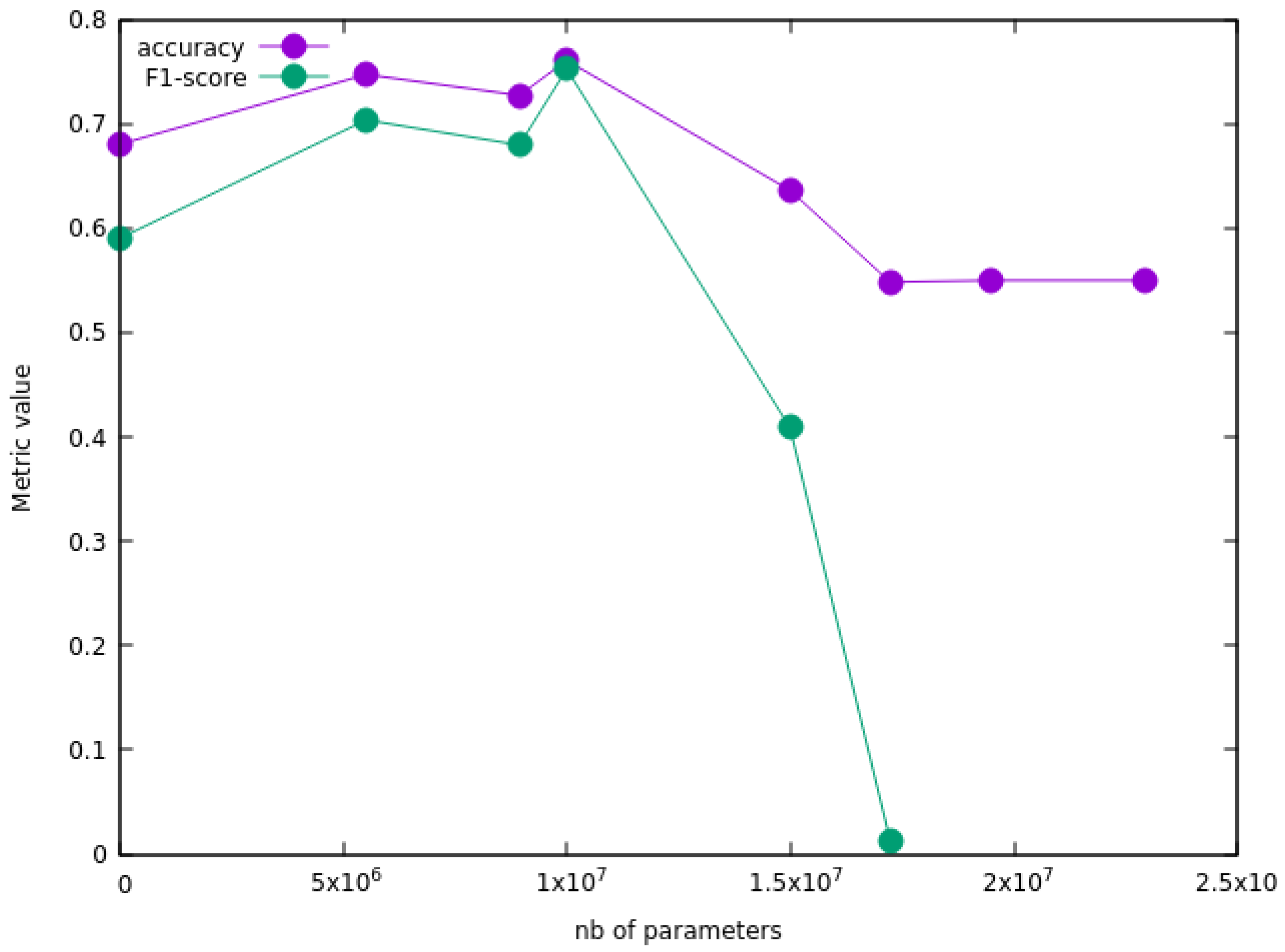
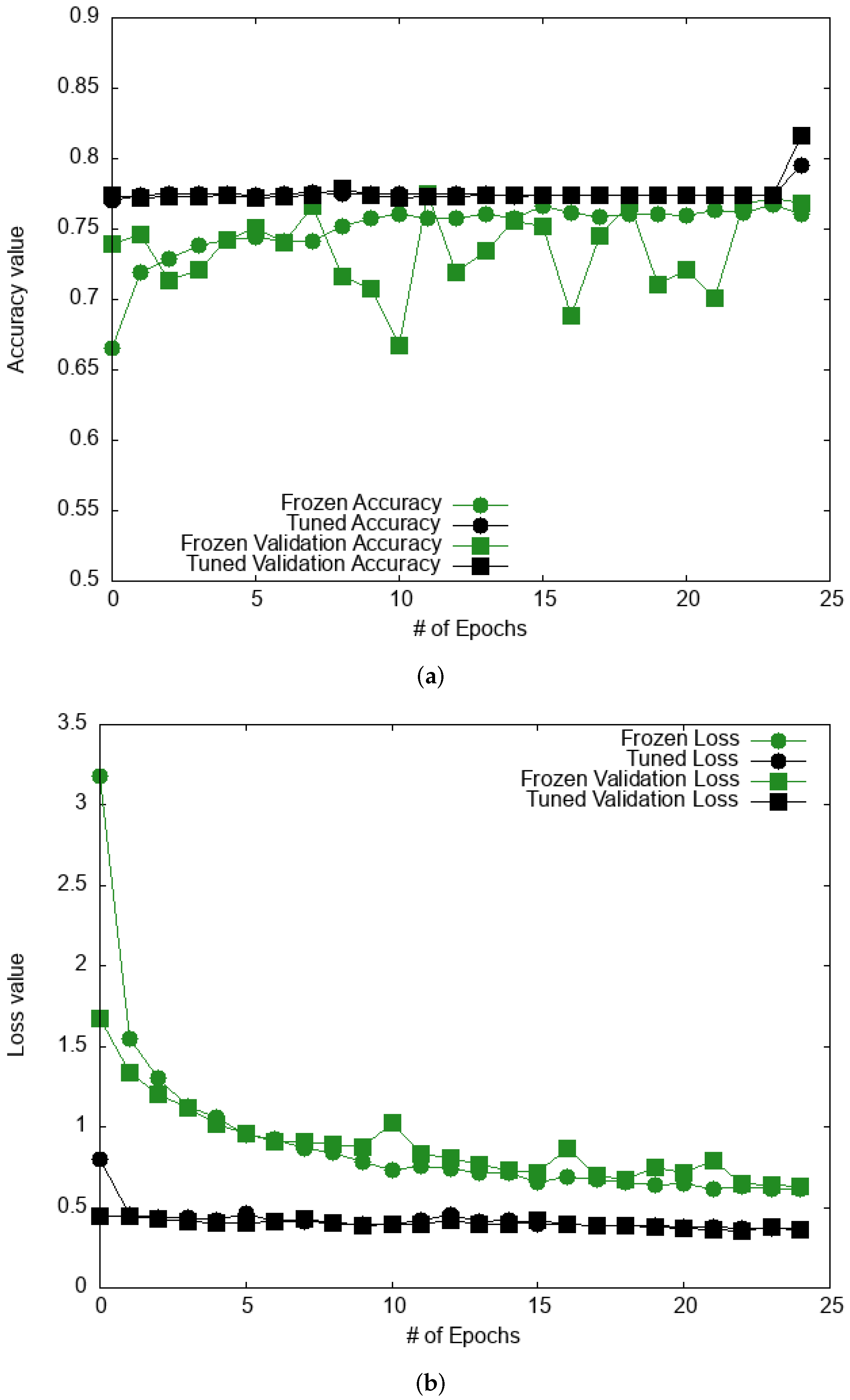
3.1.2. Deep Learning Models
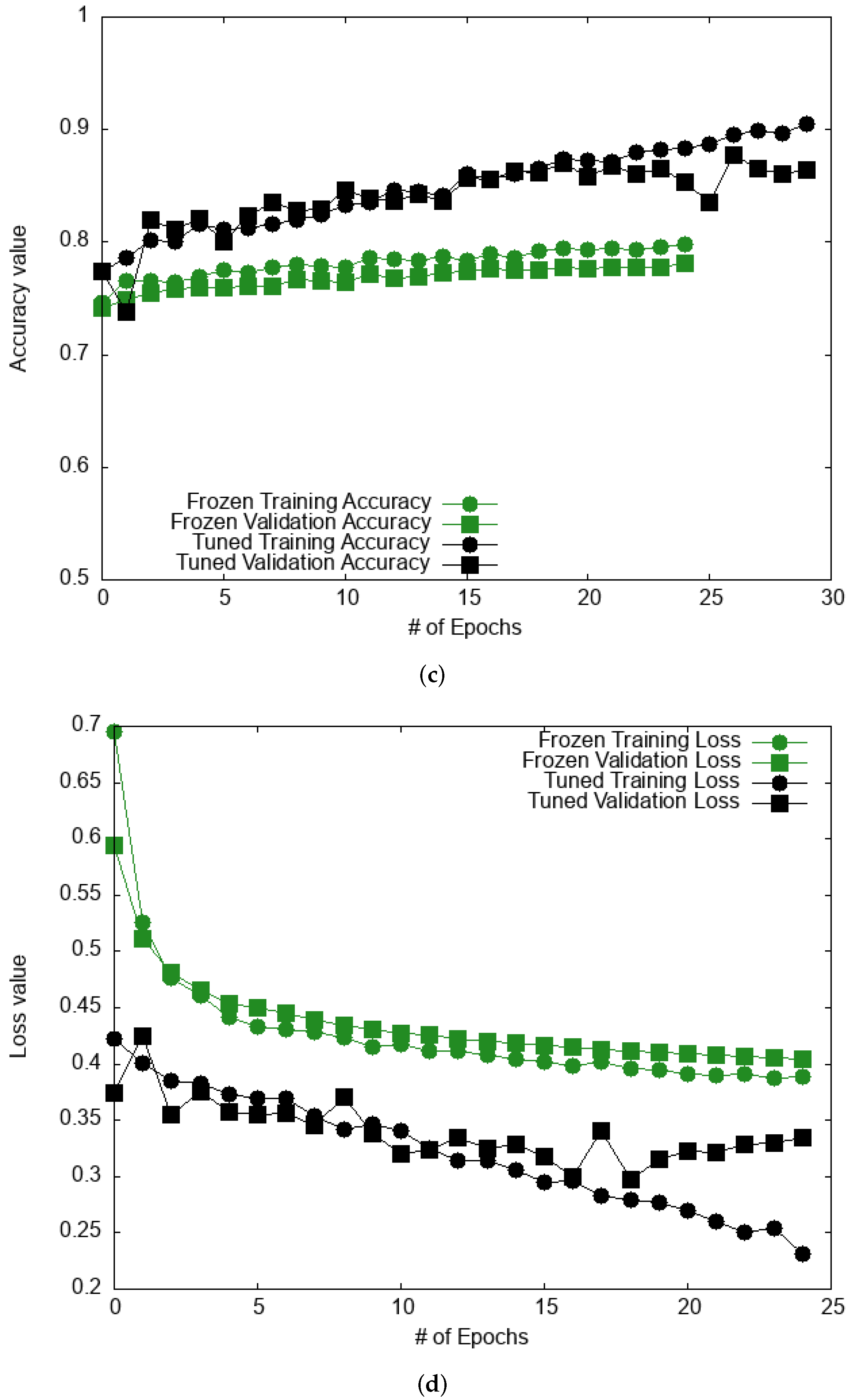
3.2. HAM10000 Database
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rogers, H.W.; Weinstock, M.A.; Feldman, S.R.; Coldiron, B.M. Incidence estimate of nonmelanoma skin cancer (keratinocyte carcinomas) in the us population, 2012. JAMA Dermatol. 2015, 151, 1081–1086. [Google Scholar] [CrossRef] [PubMed]
- Stern, R.S. Prevalence of a history of skin cancer in 2007: Results of an incidence-based model. Arch. Dermatol. 2010, 146, 279–282. [Google Scholar] [CrossRef] [PubMed]
- Koh, H.K. Melanoma screening: Focusing the public health journey. Arch. Dermatol. 2007, 143, 101–103. [Google Scholar] [CrossRef] [PubMed]
- Codella, N.C.; Nguyen, Q.-B.; Pankanti, S.; Gutman, D.A.; Helba, B.; Halpern, A.C.; Smith, J.R. Deep learning ensembles for melanoma recognition in dermoscopy images. IBM J. Res. Dev. 2017, 61, 5:1–5:15. [Google Scholar] [CrossRef] [Green Version]
- Naik, P.P. Cutaneous malignant melanoma: A review of early diagnosis and management. World J. Oncol. 2021, 12, 7. [Google Scholar] [CrossRef]
- Pereira, P.M.; Fonseca-Pinto, R.; Paiva, R.P.; Assuncao, P.A.; Tavora, L.M.; Thomaz, L.A.; Faria, S.M. Skin lesion classification enhancement using border-line features—The melanoma vs nevus problem. Biomed. Signal Processing 2020, 57, 101765. [Google Scholar] [CrossRef]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef]
- Binder, M.; Kittler, H.; Seeber, A.; Steiner, A.; Pehamberger, H.; Wolff, K. Epiluminescence microscopy-based classification of pigmented skin lesions using computerized image analysis and an artificial neural network. Melanoma Res. 1998, 8, 261–266. [Google Scholar] [CrossRef]
- Kittler, H.; Pehamberger, H.; Wolff, K.; Binder, M. Diagnostic accuracy of dermoscopy. Lancet Oncol. 2002, 3, 159–165. [Google Scholar] [CrossRef]
- Fan, X.; Sun, H.; Yuan, Z.; Li, Z.; Shi, R.; Ghadimi, N. High voltage gain dc/dc converter using coupled inductor and vm techniques. IEEE Access 2020, 8, 131975–131987. [Google Scholar] [CrossRef]
- Linsangan, N.B.; Adtoon, J.J.; Torres, J.L. Geometric analysis of skin lesion for skin cancer using image processing. In Proceedings of the 2018 IEEE 10th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment and Management (HNICEM), Baguio, Philippines, 29 November–2 December 2018; pp. 1–5. [Google Scholar]
- Saba, T. Recent advancement in cancer detection using machine learning: Systematic survey of decades, comparisons and challenges. J. Infect. Public Health 2020, 13, 1274–1289. [Google Scholar] [CrossRef] [PubMed]
- Sharif, M.I.; Li, J.P.; Naz, J.; Rashid, I. A comprehensive review on multi-organs tumor detection based on machine learning. Pattern Recognit. Lett. 2020, 131, 30–37. [Google Scholar] [CrossRef]
- Alquran, H.; Qasmieh, I.A.; Alqudah, A.M.; Alhammouri, S.; Alawneh, E.; Abughazaleh, A.; Hasayen, F. The melanoma skin cancer detection and classification using support vector machine. In Proceedings of the 2017 IEEE Jordan Conference on Applied Electrical Engineering and Computing Technologies (AEECT), Aqaba, Jordan, 11–13 October 2017; pp. 1–5. [Google Scholar]
- Lau, H.T.; Al-Jumaily, A. Automatically early detection of skin cancer: Study based on neural network classification. In Proceedings of the 2009 International Conference of Soft Computing and Pattern Recognition, Malacca, Malaysia, 4–7 December 2009; pp. 375–380. [Google Scholar]
- Nahata, H.; Singh, S.P. Deep learning solutions for skin cancer detection and diagnosis. In Machine Learning with Health Care Perspective; Springer: Berlin/Heidelberg, Germany, 2020; pp. 159–182. [Google Scholar]
- Hosny, K.M.; Kassem, M.A.; Foaud, M.M. Skin cancer classification using deep learning and transfer learning. In Proceedings of the 2018 9th Cairo International Biomedical Engineering Conference (CIBEC), Cairo, Egypt, 20–22 December 2018; pp. 90–93. [Google Scholar]
- Wang, D.; Pang, N.; Wang, Y.; Zhao, H. Unlabeled skin lesion classification by self-supervised topology clustering network. Biomed. Signal Processing 2021, 66, 102428. [Google Scholar] [CrossRef]
- Ghassemi, N.; Shoeibi, A.; Rouhani, M. Deep neural network with generative adversarial networks pre-training for brain tumor classification based on mr images. Biomed. Signal Processing 2020, 57, 101678. [Google Scholar] [CrossRef]
- Saba, T.; Khan, M.A.; Rehman, A.; Marie-Sainte, S.L. Region extraction and classification of skin cancer: A heterogeneous framework of deep cnn features fusion and reduction. J. Med. Syst. 2019, 43, 289. [Google Scholar] [CrossRef] [PubMed]
- Chatterjee, S.; Dey, D.; Munshi, S.; Gorai, S. Extraction of features from cross correlation in space and frequency domains for classification of skin lesions. Biomed. Signal Processing 2019, 53, 101581. [Google Scholar] [CrossRef]
- Arevalo, J.; Cruz-Roa, A.; Arias, V.; Romero, E.; González, F.A. An unsupervised feature learning framework for basal cell carcinoma image analysis. Artif. Intell. Med. 2015, 64, 131–145. [Google Scholar] [CrossRef]
- Bi, D.; Zhu, D.; Sheykhahmad, F.R.; Qiao, M. Computer-aided skin cancer diagnosis based on a new meta-heuristic algorithm combined with support vector method. Biomed. Signal Processing 2021, 68, 102631. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Rundo, F.; Conoci, S.; Banna, G.L.; Ortis, A.; Stanco, F.; Battiato, S. Evaluation of levenberg–marquardt neural networks and stacked autoencoders clustering for skin lesion analysis, screening and follow-up. IET Comput. Vision 2018, 12, 957–962. [Google Scholar] [CrossRef]
- Younis, H.; Bhatti, M.H.; Azeem, M. Classification of skin cancer dermoscopy images using transfer learning. In Proceedings of the 2019 15th International Conference on Emerging Technologies (ICET), Peshawar, Pakistan, 2–3 December 2019; pp. 1–4. [Google Scholar]
- Haggenmüller, S.; Maron, R.C.; Hekler, A.; Utikal, J.S.; Barata, C.; Barnhill, R.L.; Beltraminelli, H.; Berking, C.; Betz-Stablein, B.; Blum, A.; et al. Skin cancer classification via convolutional neural networks: Systematic review of studies involving human experts. Eur. J. Cancer 2021, 156, 202–216. [Google Scholar] [CrossRef] [PubMed]
- Nematzadeh, S.; Kiani, F.; Torkamanian-Afshar, M.; Aydin, N. Tuning hyperparameters of machine learning algorithms and deep neural networks using metaheuristics: A bioinformatics study on biomedical and biological cases. Comput. Biol. Chem. 2022, 97, 107619. [Google Scholar] [CrossRef] [PubMed]
- Nauta, M.; Walsh, R.; Dubowski, A.; Seifert, C. Uncovering and correcting shortcut learning in machine learning models for skin cancer diagnosis. Diagnostics 2022, 12, 40. [Google Scholar] [CrossRef] [PubMed]
- Thomas, S.M.; Lefevre, J.G.; Baxter, G.; Hamilton, N.A. Interpretable deep learning systems for multi-class segmentation and classification of non-melanoma skin cancer. Med. Image Anal. 2021, 68, 101915. [Google Scholar] [CrossRef]
- Jinnai, S.; Yamazaki, N.; Hirano, Y.; Sugawara, Y.; Ohe, Y.; Hamamoto, R. The development of a skin cancer classification system for pigmented skin lesions using deep learning. Biomolecules 2020, 10, 1123. [Google Scholar] [CrossRef]
- Skin Cancer: Malignant vs. Benign|Kaggle. Available online: https://www.kaggle.com/fanconic/skin-cancer-malignant-vs-benign (accessed on 19 January 2021).
- Han, S.S.; Moon, I.J.; Lim, W.; Suh, I.S.; Lee, S.Y.; Na, J.-I.; Kim, S.H.; Chang, S.E. Keratinocytic skin cancer detection on the face using region-based convolutional neural network. JAMA Dermatol. 2020, 156, 29–37. [Google Scholar] [CrossRef]
- Tschandl, P.; Rosendahl, C.; Kittler, H. The ham10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci. Data 2018, 5, 180161. [Google Scholar] [CrossRef]
- Dreiseitl, S.; Ohno-Machado, L. Logistic regression and artificial neural network classification models: A methodology review. J. Biomed. Inform. 2002, 35, 352–359. [Google Scholar] [CrossRef] [Green Version]
- Li, M.; Yuan, B. 2d-lda: A statistical linear discriminant analysis for image matrix. Pattern Recognit. Lett. 2005, 26, 527–532. [Google Scholar] [CrossRef]
- Li, B.; Friedman, J.; Olshen, R.; Stone, C. Classification and regression trees (cart). Biometrics 1984, 40, 358–361. [Google Scholar]
- Sathyadevi, G. Application of cart algorithm in hepatitis disease diagnosis. In Proceedings of the 2011 International Conference on Recent Trends in Information Technology (ICRTIT), Chennai, India, 3–5 June 2011; pp. 1283–1287. [Google Scholar]
- Jahromi, A.H.; Taheri, M. A non-parametric mixture of gaussian naive bayes classifiers based on local independent features. In Proceedings of the 2017 Artificial Intelligence and Signal Processing Conference (AISP), Shiraz, Iran, 25–27 October 2017; pp. 209–212. [Google Scholar]
- Krogh, A.; Vedelsby, J. Neural network ensembles, cross validation, and active learning. Adv. Neural Inf. Processing Syst. 1995, 7, 231–238. [Google Scholar]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Desgranges, C.; Delhommelle, J. Ensemble learning of partition functions for the prediction of thermodynamic properties of adsorption in metal–organic and covalent organic frameworks. J. Phys. Chem. C 2020, 124, 1907–1917. [Google Scholar] [CrossRef]
- Dong, X.; Yu, Z.; Cao, W.; Shi, Y.; Ma, Q. A survey on ensemble learning. Front. Comput. Sci. 2020, 14, 241–258. [Google Scholar] [CrossRef]
- Raina, R.; Ng, A.Y.; Koller, D. Constructing informative priors using transfer learning. In Proceedings of the ICML ’06: 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 713–720. [Google Scholar] [CrossRef] [Green Version]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Ali, M.S.; Miah, M.S.; Haque, J.; Rahman, M.M.; Islam, M.K. An enhanced technique of skin cancer classification using deep convolutional neural network with transfer learning models. Mach. Learn. Appl. 2021, 5, 100036. [Google Scholar] [CrossRef]
- Rodrigues, D.D.A.; Ivo, R.F.; Satapathy, S.C.; Wang, S.; Hemanth, J.; Reboucas Filho, P.P. A new approach for classification skin lesion based on transfer learning, deep learning, and iot system. Pattern Recognit. Lett. 2020, 136, 8–15. [Google Scholar] [CrossRef]
- Guan, Q.; Wang, Y.; Ping, B.; Li, D.; Du, J.; Qin, Y.; Lu, H.; Wan, X.; Xiang, J. Deep convolutional neural network vgg-16 model for differential diagnosing of papillary thyroid carcinomas in cytological images: A pilot study. J. Cancer 2019, 10, 4876. [Google Scholar] [CrossRef]
- Han, S.S.; Kim, M.S.; Lim, W.; Park, G.H.; Park, I.; Chang, S.E. Classification of the clinical images for benign and malignant cutaneous tumors using a deep learning algorithm. J. Investig. Dermatol. 2018, 138, 1529–1538. [Google Scholar] [CrossRef] [Green Version]
- Chaturvedi, S.S.; Tembhurne, J.V.; Diwan, T. A multi-class skin cancer classification using deep convolutional neural networks, Multimed. Tools Appl. 2020, 79, 28477–28498. [Google Scholar]
- Bhuiyan, M.A.H.; Azad, I.; Uddin, M.K. Image processing for skin cancer features extraction. Int. J. Sci. Eng. Res. 2013, 4, 1–6. [Google Scholar]
- Kaur, C.; Garg, U. Artificial intelligence techniques for cancer detection in medical image processing: A review. Mater. Today Proc. 2021. [Google Scholar] [CrossRef]
- Ramlakhan, K.; Shang, Y. A mobile automated skin lesion classification system. In Proceedings of the 2011 IEEE 23rd International Conference on Tools with Artificial Intelligence, Boca Raton, FL, USA, 7–9 November 2011; pp. 138–141. [Google Scholar]
- Liong, C.-Y.; Foo, S.-F. Comparison of linear discriminant analysis and logistic regression for data classification. AIP Conf. Proc. 2013, 1522, 1159–1165. [Google Scholar]
- Pham, T.C.; Tran, C.T.; Luu, M.S.K.; Mai, D.A.; Doucet, A.; Luong, C.M. Improving binary skin cancer classification based on best model selection method combined with optimizing full connected layers of deep cnn. In Proceedings of the 2020 International Conference on Multimedia Analysis and Pattern Recognition (MAPR), Ha Noi, Vietnam, 8–9 October 2020; pp. 1–6. [Google Scholar]
- Brinker, T.J.; Hekler, A.; Enk, A.H.; Klode, J.; Hauschild, A.; Berking, C.; Schilling, B.; Haferkamp, S.; Schadendorf, D.; Holland-Letz, T.; et al. Deep learning outperformed 136 of 157 dermatologists in a head-to-head dermoscopic melanoma image classification task. Eur. J. Cancer 2019, 113, 47–54. [Google Scholar] [CrossRef] [Green Version]
- Goyal, M.; Knackstedt, T.; Yan, S.; Hassanpour, S. Artificial intelligence-based image classification for diagnosis of skin cancer: Challenges and opportunities. Comput. Biol. Med. 2020, 127, 104065. [Google Scholar] [CrossRef] [PubMed]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Specificities |
|---|---|
| 2D Convolutional layer | # of filters = 8, size = 3 |
| Max pooling | |
| 2D Convolutional layer | # of filters = 16, size = 3 |
| Max pooling | |
| Batch normalization | |
| 2D convolutional layer | # of filters = 32, size = 3 |
| Max pooling | |
| 2D Convolutional layer | # of filters = 64, size = 3 |
| Max pooling | |
| Flattening layer | |
| Densification | 128 |
| Densification | 2 (number of classes) |
| Model | Accuracy | F-Score | Precision | Recall |
|---|---|---|---|---|
| LR | 0.72 (0.02) | 0.34 | 0.8 | 0.60 |
| LDA | 0.71 (0.03) | 0.33 | 0.75 | 0.59 |
| KNN | 0.66 (0.02) | 0.24 | 0.83 | 0.34 |
| CART | 0.69 (0.02) | 0.35 | 0.73 | 0.68 |
| GNB | 0.64 (0.02) | 0.28 | 0.76 | 0.49 |
| Ensemble | Models | Accuracy | F-Score | Precision | Recall | AUC |
|---|---|---|---|---|---|---|
| E1 | LR, KNN, GNB | 0.71 | 0.62 | 0.49 | 0.83 | 0.81 |
| E2 | LR, LDA, KNN, CART, GNB | 0.73 | 0.66 | 0.55 | 0.83 | 0.83 |
| E3 | LR, LDA, CART | 0.72 | 0.66 | 0.57 | 0.79 | 0.81 |
| Phase | Model | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|---|
| Complete training | Custom CNN | 0.84 | 0.94 | 0.76 | 0.84 |
| Xception | 0.71 | 0.65 | 0.78 | 0.71 | |
| Frozen base | VGG16 | 0.81 | 0.77 | 0.82 | 0.80 |
| ResNet50 | 0.85 | 0.81 | 0.88 | 0.85 | |
| Xception | 0.80 | 0.97 | 0.71 | 0.82 | |
| Fine-tuning | VGG16 | 0.88 | 0.93 | 0.83 | 0.88 |
| ResNet50 | 0.87 | 0.89 | 0.84 | 0.87 |
| Phase | Model | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|---|
| Complete training | Custom CNN | 0.82 | 0.50 | 0.44 | 0.47 |
| Xception | 0.75 | 0.42 | 0.37 | 0.39 | |
| Frozen base | VGG16 | 0.82 | 0.42 | 0.55 | 0.47 |
| ResNet50 | 0.84 | 0.53 | 0.59 | 0.56 | |
| Xception | 0.84 | 0.43 | 0.61 | 0.50 | |
| Fine-tuning | VGG16 | 0.88 | 0.68 | 0.71 | 0.70 |
| ResNet50 | 0.87 | 0.51 | 0.76 | 0.61 | |
| Ensemble | all pre-trained | 0.86 | 0.79 | 0.62 | 0.70 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bechelli, S.; Delhommelle, J. Machine Learning and Deep Learning Algorithms for Skin Cancer Classification from Dermoscopic Images. Bioengineering 2022, 9, 97. https://doi.org/10.3390/bioengineering9030097
Bechelli S, Delhommelle J. Machine Learning and Deep Learning Algorithms for Skin Cancer Classification from Dermoscopic Images. Bioengineering. 2022; 9(3):97. https://doi.org/10.3390/bioengineering9030097
Chicago/Turabian StyleBechelli, Solene, and Jerome Delhommelle. 2022. "Machine Learning and Deep Learning Algorithms for Skin Cancer Classification from Dermoscopic Images" Bioengineering 9, no. 3: 97. https://doi.org/10.3390/bioengineering9030097
APA StyleBechelli, S., & Delhommelle, J. (2022). Machine Learning and Deep Learning Algorithms for Skin Cancer Classification from Dermoscopic Images. Bioengineering, 9(3), 97. https://doi.org/10.3390/bioengineering9030097