
A Systematic Approach to Diagnostic Laboratory Software Requirements Analysis


Abstract
:1. Introduction
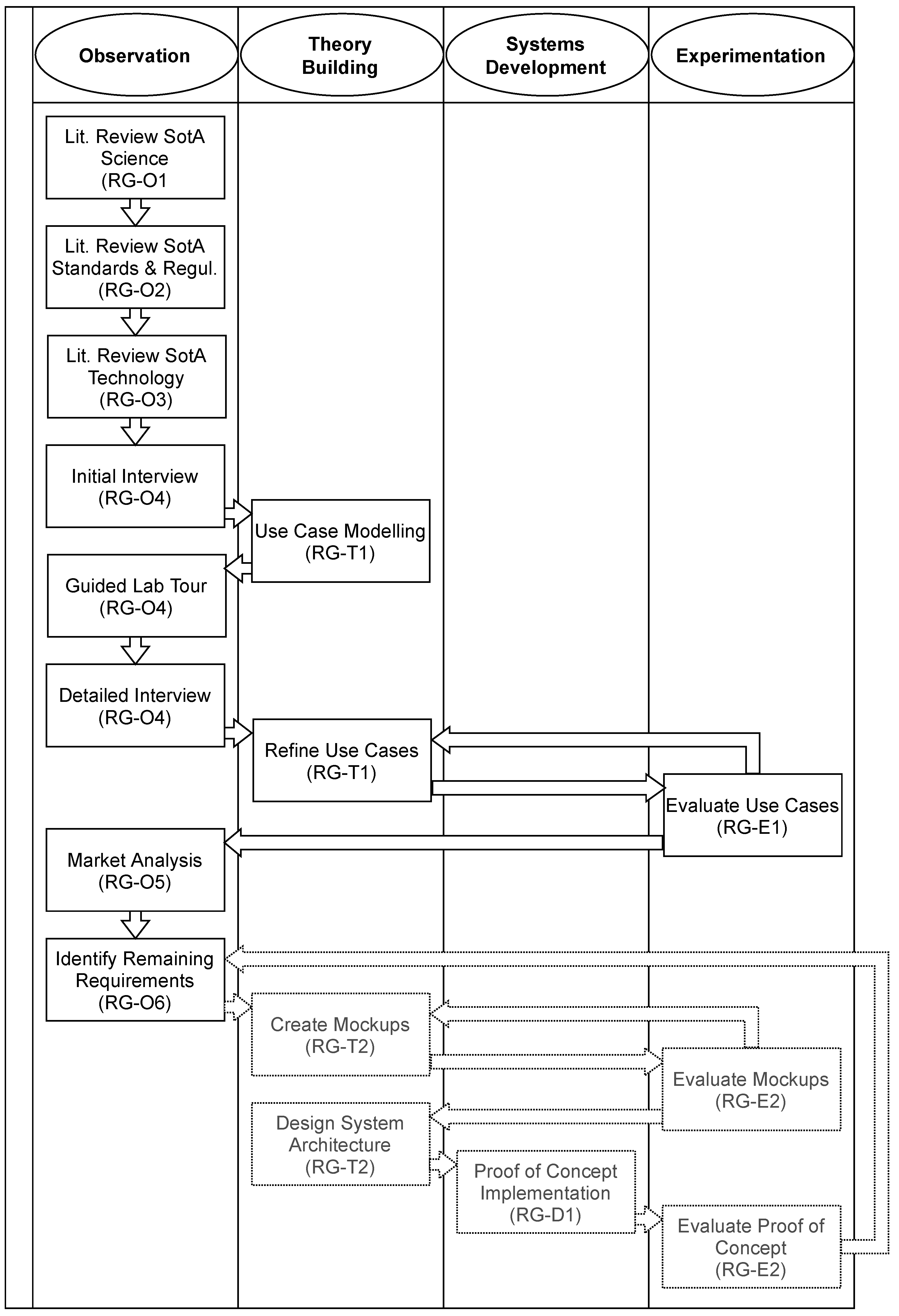
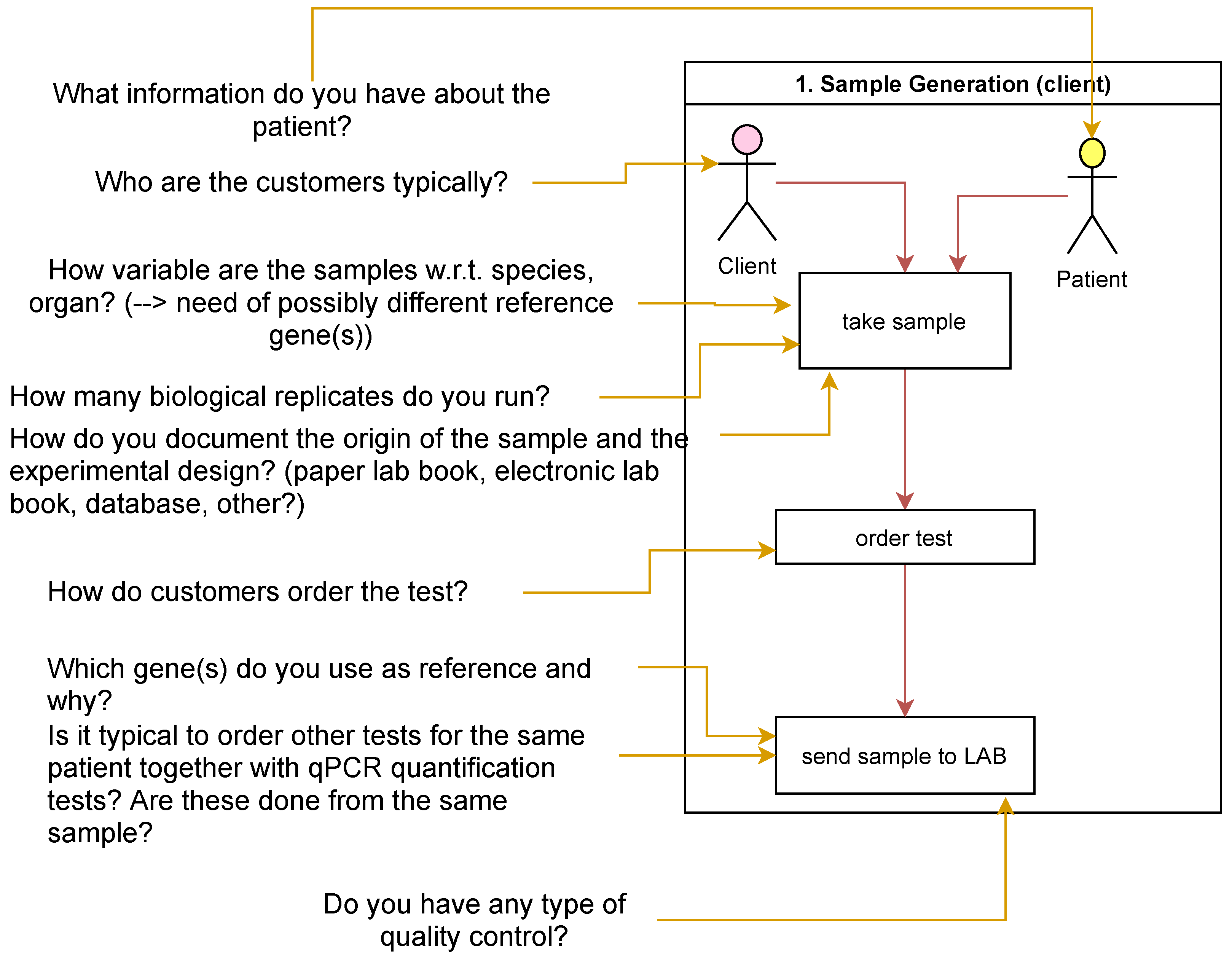
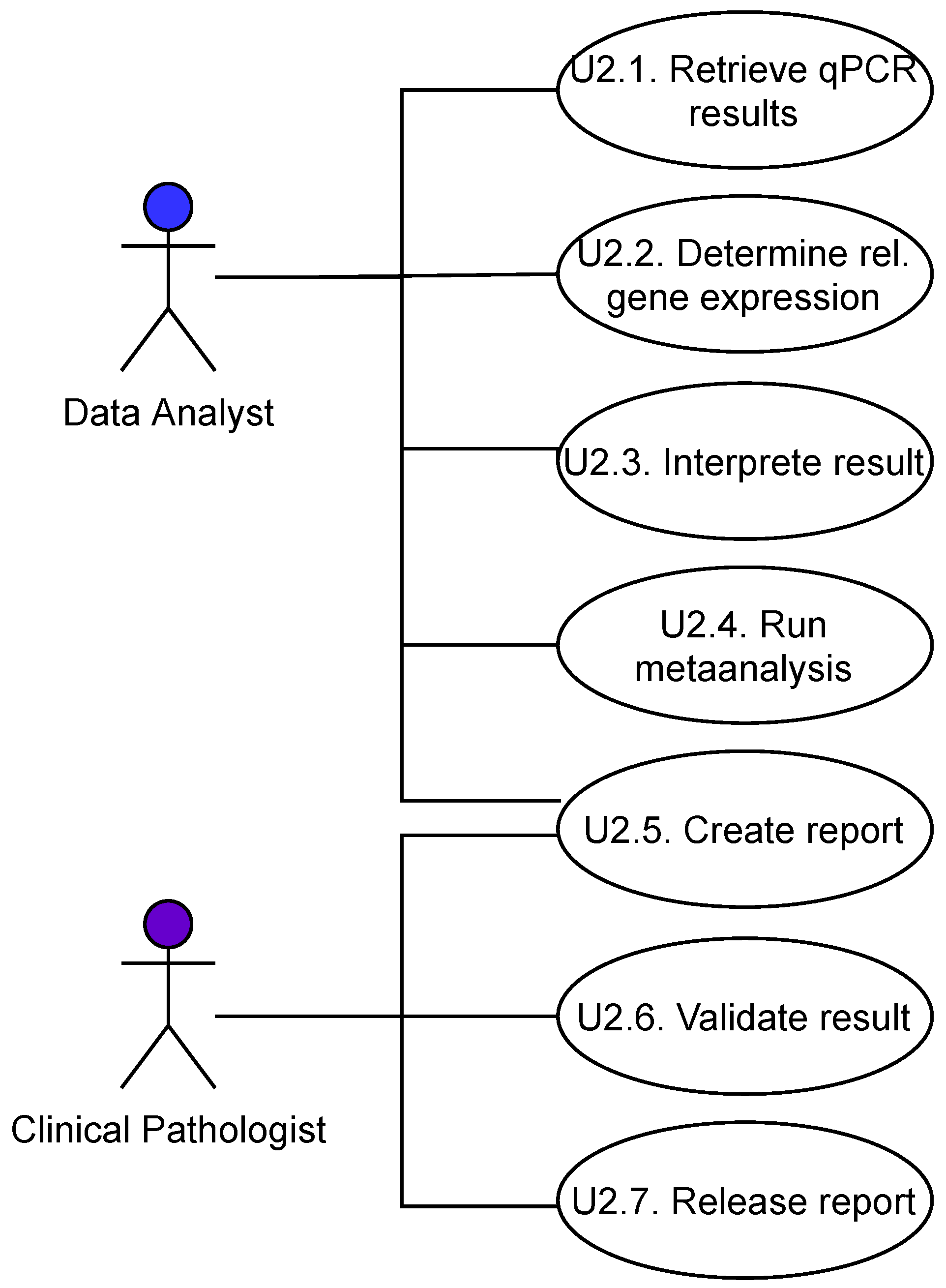
2. Methods
3. Results
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Suwinski, P.; Ong, C.; Ling, M.H.T.; Poh, Y.M.; Khan, A.M.; Ong, H.S. Advancing Personalized Medicine Through the Application of Whole Exome Sequencing and Big Data Analytics. Front. Genet. 2019, 10, 49. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goetz, L.H.; Schork, N.J. Personalized medicine: Motivation, challenges, and progress. Fertil. Steril. 2018, 109, 952–963. [Google Scholar] [CrossRef] [PubMed]
- Behrouzi, A.; Nafari, A.H.; Siadat, S.D. The significance of microbiome in personalized medicine. Clin. Transl. Med. 2019, 8, 16. [Google Scholar] [CrossRef] [PubMed]
- Krause, T.; Wassan, J.T.; Mc Kevitt, P.; Wang, H.; Zheng, H.; Hemmje, M.L. Analyzing Large Microbiome Datasets Using Machine Learning and Big Data. BioMedInformatics 2021, 1, 138–165. [Google Scholar] [CrossRef]
- Krause, T.; Jolkver, E.; Bruchhaus, S.; Kramer, M.; Hemmje, M.L. An RT-qPCR Data Analysis Platform. In Proceedings of the Collaborative European Research Conference (CERC 2021), Cork, Ireland, 9–10 September 2021. [Google Scholar]
- Barrat, F.J.; Crow, M.K.; Ivashkiv, L.B. Interferon target-gene expression and epigenomic signatures in health and disease. Nat. Immunol. 2019, 20, 1574–1583. [Google Scholar] [CrossRef] [PubMed]
- Hemmje, M.L.; Jordan, B.; Pfenninger, M.; Madsen, A.; Murtagh, F.; Kramer, M.; Bouquet, P.; Hundsdörfer, A.; McIvor, T.; Malvehy, J.; et al. Artificial Intelligence for Hospitals, Healthcare & Humanity (AI4H3): R&D White Paper; Research Institute for Telecommunication and Cooperation (FTK): Dortmund, Germany, 2020. [Google Scholar]
- Walsh, P.; Hemmje, M.L.; Riestra, R.; Kramer, M. Launching the Oncology Assay Development Platform (OncoADEPT): R&D White Paper; Research Institute for Telecommunication and Cooperation (FTK): Dortmund, Germany, 2016. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Abawajy, J. Comprehensive analysis of big data variety landscape. Int. J. Parallel Emergent Distrib. Syst. 2015, 30, 5–14. [Google Scholar] [CrossRef]
- The European Parliament and the Council of the European Union. In Vitro Diagnostic Regulation; IVDR: Publications Office of the European Union: Luxembourg, 2017.
- IEC International Electrotechnical Commission. Medical Device Software—Software Life Cycle Processes; IEC 62304: London, UK, 2006. [Google Scholar]
- ISO 15189; Medical Laboratories—Requirements for Quality and Competence. ISO International Organization for Standardization: Geneva, Switzerland, 2012.
- Berwind, K.; Bornschlegl, M.X.; Kaufmann, M.A.; Hemmje, M.L. Towards a Cross Industry Standard Process to support Big Data Applications in Virtual Research Environments. In Proceedings of the Collaborative European Research Conference (CERC), Cork, Ireland, 23–24 September 2016; Bleimann, U., Humm, B., Loew, R., Stengel, I., Walsh, P., Eds.; 2016. Available online: https://www.cerc-conf.eu/wp-content/uploads/2018/06/CERC-2016-proceedings.pdf (accessed on 6 February 2022).
- Krause, T.; Jolkver, E.; Bruchhaus, S.; Kramer, M.; Hemmje, M.L. GenDAI—AI-Assisted Laboratory Diagnostics for Genomic Applications. In Proceedings of the 2021 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Houston, TX, USA, 9–12 December 2021. [Google Scholar]
- Nunamaker, J.F.; Chen, M.; Purdin, T.D. Systems Development in Information Systems Research. J. Manag. Inf. Syst. 1990, 7, 89–106. [Google Scholar] [CrossRef]
- Norman, D.A.; Draper, S.W.; Hillsdale, N.J. (Eds.) User Centered System Design: New Perspectives on Human-Computer Interaction; Erlbaum: Mahwah, NJ, USA, 1986. [Google Scholar]
- Pabinger, S.; Rödiger, S.; Kriegner, A.; Vierlinger, K.; Weinhäusel, A. A survey of tools for the analysis of quantitative PCR (qPCR) data. Biomol. Detect. Quantif. 2014, 1, 23–33. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Livak, K.J.; Schmittgen, T.D. Analysis of relative gene expression data using real-time quantitative PCR and the 2(-Delta Delta C(T)) Method. Methods 2001, 25, 402–408. [Google Scholar] [CrossRef] [PubMed]
- Vandesompele, J.; de Preter, K.; Pattyn, F.; Poppe, B.; van Roy, N.; de Paepe, A.; Speleman, F. Accurate normalization of real-time quantitative RT-PCR data by geometric averaging of multiple internal control genes. Genome Biol. 2002, 3, research0034.1. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hellemans, J.; Mortier, G.; de Paepe, A.; Speleman, F.; Vandesompele, J. qBase relative quantification framework and software for management and automated analysis of real-time quantitative PCR data. Genome Biol. 2007, 8, R19. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- What Makes Qbase+ Unique? Available online: https://www.qbaseplus.com/features (accessed on 6 February 2022).
- Grömminger, S. IVDR—In-Vitro-Diagnostic Device Regulation; Johner Institute, 2018; Available online: https://www.johner-institute.com/articles/regulatory-affairs/ivd-regulation-ivdr/ (accessed on 6 February 2022).
- Lefever, S.; Hellemans, J.; Pattyn, F.; Przybylski, D.R.; Taylor, C.; Geurts, R.; Untergasser, A.; Vandesompele, J. RDML: Structured language and reporting guidelines for real-time quantitative PCR data. Nucleic Acids Res. 2009, 37, 2065–2069. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- ThermoFisher Scientific. ExpressionSuite Software. Available online: https://www.thermofisher.com/de/de/home/technical-resources/software-downloads/expressionsuite-software.html (accessed on 6 February 2022).
- Ruijter, J.M.; Ruiz Villalba, A.; Hellemans, J.; Untergasser, A.; van den Hoff, M.J.B. Removal of between-run variation in a multi-plate qPCR experiment. Biomol. Detect. Quantif. 2015, 5, 10–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- MultiD Analyses AB. GenEx. Available online: https://multid.se/genex/ (accessed on 6 February 2022).
- Zanardi, N.; Morini, M.; Tangaro, M.A.; Zambelli, F.; Bosco, M.C.; Varesio, L.; Eva, A.; Cangelosi, D. PIPE-T: A new Galaxy tool for the analysis of RT-qPCR expression data. Sci. Rep. 2019, 9, 17550. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Muller, P.Y.; Janovjak, H.; Miserez, A.R.; Dobbie, Z. Processing of gene expression data generated by quantitative real-time RT-PCR. BioTechniques 2002, 32, 1372–1374, 1376, 1378–1379. [Google Scholar] [PubMed]
- Integromics, S.L.; Applied Biosystems. Real-Time StatMiner: Advanced Data Mining Software for Applied Biosystems RT-PCR Data Analysis. Available online: https://www.gene-quantification.de/qpcr2007/publications/P016-qPCR-2007.pdf (accessed on 6 February 2022).
- Wilhelm, J.; Pingoud, A.; Hahn, M. SoFAR: Software for fully automatic evaluation of real-time PCR data. BioTechniques 2003, 34, 324–332. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tool | Main Purpose | Data Import | Data Format | PCR Efficiency Estimation | Melt Curve Analysis | Selection of Reference Genes | Calculates Cq from Raw | Error Propagation | Normalization | Absolute Quantification | Relative Quantification | Outlier Detection | NA Handling | Statistics | Graphs | MIQE | OS/Framework | Last Update | Costs | Reference | Count “+” |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CAmpER | Quantification | Raw | FLO, ABT, CSV, REX, TXT | + | nd | nd | + | − | − | − | + | nd | − | − | + | − | Web Service | 2009 | discontinued | [18] | 4 |
| Cy0 Method | Quantification | Raw | XLS, TXT, DOC | − | − | − | + | − | − | − | − | − | − | − | − | + | Web Service | 2010 | free | [18] | 2 |
| DART-PCR | Quantification | Raw | XLS | − | − | − | + | − | + | − | + | + | − | − | + | − | Windows, Excel | 2002 | free | [18] | 5 |
| Deconvolution | Quantification | Raw | TXT | − | − | − | − | − | − | + | − | − | − | − | − | + | Perl based | 2010 | free | [18] | 2 |
| ExpressionSuite Software | Quantification | Raw | EDS, SDS | − | + | − | + | − | + | − | + | + | − | + | + | + | Windows | 2019 | free | [25] | 8 |
| Factor-qPCR | Inter-Run Calibration | Raw, Cq | XLS, RDML | − | − | − | − | − | + | − | − | − | − | − | − | + | Windows, Excel | 2020 | free | [26] | 2 |
| GenEx | Quantification | Cq | TXT | + | − | + | − | − | + | + | + | + | + | + | + | + | Windows | 2019 | commercial | [27] | 10 |
| geNorm | Reference Gene Selection | see qbase+ | see qbase+ | − | − | + | − | − | − | − | − | − | − | − | − | − | see qbase+ | 2018 | free | [20] | 1 |
| LinRegPCR | Quantification | Raw | XLS, RDML | + | − | − | + | − | − | + | − | + | − | − | + | + | Windows | 2021 | free | [18] | 6 |
| LRE Analysis | Quantification | Raw | XLS | − | − | − | − | − | − | + | − | − | − | − | − | + | MATLAB based | 2012 | free | [18] | 2 |
| LRE Analyzer | Quantification | Raw | XLS | − | − | − | − | − | − | + | − | − | − | − | + | + | Java based | 2014 | free | [18] | 3 |
| MAKERGAUL | Quantification | Raw | CSV | − | − | − | + | − | − | + | − | − | − | − | − | + | Server-Client Arch. | 2013 | free | [18] | 3 |
| PCR-Miner | Quantification | Raw | TXT | + | − | − | + | − | − | − | − | − | − | − | − | + | Web Service | 2011 | free | [18] | 3 |
| PIPE-T | Quantification | Cq | TXT | − | − | − | − | − | + | + | + | + | + | + | + | − | Galaxy | 2019 | free | [28] | 7 |
| pyQPCR | Quantification | Cq | TXT, CSV | + | − | − | − | + | + | − | + | − | + | − | + | + | Python based | 2012 | free | [18] | 7 |
| Q-Gene | Experiment Design and Analysis | Cq | XLS | + | − | − | − | − | + | − | + | − | − | − | + | − | Windows, Excel | 2002 | free | [29] | 4 |
| qBase | Quantification | Cq | XLS, RDML | + | − | + | − | + | + | − | + | + | − | + | + | + | Windows, Excel | 2007 | discontinued | [18] | 9 |
| qbase+ | Quantification | Cq | XLS, RDML | + | − | + | − | + | + | + | + | + | − | + | + | + | Windows, Mac | 2017 | commercial | [22] | 10 |
| qCalculator | Quantification | Cq | XLS | + | − | − | − | − | + | − | + | − | + | − | + | − | Windows, Excel | 2004 | free | [18] | 5 |
| QPCR | Quantification | Raw | CSV, RDML | + | − | − | + | + | + | − | + | − | + | + | + | + | Linux Server | 2013 | free | [18] | 9 |
| qPCR-DAMS | Quantification | Cq | XLS | − | − | − | − | − | + | + | + | − | + | − | − | + | Windows | 2006 | free | [18] | 5 |
| RealTime StatMiner | Quantification | Raw, Cq | TXT | − | − | + | − | + | + | − | + | + | + | + | + | + | Windows | 2014 | commercial | [30] | 9 |
| REST | Quantification | Cq | TXT | − | − | − | − | + | + | − | + | − | − | + | + | + | Windows | 2009 | free | [18] | 6 |
| SARS | Quantification | Cq | XLS, TXT | − | nd | nd | − | − | + | − | + | nd | − | + | − | + | Windows | 2011 | discontinued | [18] | 4 |
| SoFAR | Automated Quantification | Raw | ABT + FLO | + | + | − | + | − | − | − | − | − | − | − | + | − | Windows | 2003 | discontinued | [31] | 4 |
| Process Step | Description | User Stereotype | Commercial Software | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Method Validation | Order Entry | Cycler | Lab Biologist | Data Analyst | Clinical Pathologist | Compliance Manager | GenEx | qbase+ | ||
| Import of Experiment Metadata and Data Storage | Import of sample information | 1 | n.a | n.a | ||||||
| Experiment Design | (Fractional) factorial design when testing for multiple impact factors | 3 | 4 | + | − | |||||
| Power Analysis | Estimate required number of biological replicates to determine statistical difference between groups | 3 | 4 | + | − | |||||
| Data Import | Transfer of data from cycler to analysis workflow | 1 | Cq | Raw, Cq | ||||||
| Data Format | Format of the imported data | 1 | TXT | XLS, RDML | ||||||
| Cycler Compatibility | System accepts data from cycler used by laboratory | 1 | − | + (as RDML) | ||||||
| PCR Efficiency Estimation | For correct estimation of target initial concentration | 1 | 3 | + | + | |||||
| Selection of Reference Genes | Check expression stability of candidate reference genes | 1 | 2 | + | + | |||||
| Sample QC (documentation) | RNA integrity and purity, DNA absence | 1 | n.a | n.a | ||||||
| Cq Calculation | Determine Cq from fluorescence data | 1 | − | − | ||||||
| Error Propagation | Propagating of measurement uncertainty through functions based on the measurement’s value | 3 | − | + | ||||||
| Normalization | Inter-Run Calibration across devices or experiments | 2 | + | + | ||||||
| Relative Quantification | Determine fold change values based on a reference | 1 | + | + | ||||||
| Absolute Quantification | Calculate absolute quantification values | 4 | + | + | ||||||
| Outlier Detection | Calculate fold change values after relative quantification | 3 | + | + | ||||||
| NA Handling | Remove NA automatically or impute missing values | 3 | + | − | ||||||
| Statistical Tests to assess Differential Gene Expression | Perform appropriate statistical test to determine statistical differences between groups | 4 | + | + | ||||||
| Reporting (Graphs) | Create graphs | 1 | + | + | ||||||
| Reporting (Interpretation) | Interprete results and write coherent report | 1 | 1 | n.a | n.a | |||||
| MIQE | Store MIQE-relevant information | 1 | + | + | ||||||
| Automatization | Automate analysis workflow | 2 | − | − | ||||||
| Feature Area | GenEx | qbase+ |
|---|---|---|
| Experimental Design | Sample number | |
| Experimental design optimization | ||
| Pre-processing of Data | Logged in a file | Inter-run calibration |
| Interplate calibration | ||
| PCR efficiency correction, estimation from standard curve | ||
| Normalize to sample amount (volume processed, amount of RNA used for reverse transcription, or cell count) | ||
| Normalize to reference genes/samples | ||
| Normalize to spike | Normalize to global mean | |
| Missing data handling (detection and interpolation) | Normalize to Global mean on common targets | |
| Convert to log scale | Scaling to mean, max, min, sample, group, positive control | |
| Cq averaging | ||
| Relative quantities and fold changes | ||
| Quality Control | Correct for genomic DNA background | User-defined quality thresholds |
| Average technical replicates | Technical replicates (Replicate variablity) | |
| Primer Dimer Correction | Pos. and neg. controls (Cq boundaries) | |
| Stability of reference targets | ||
| Sample specific characteristics (M value, coefficient of variation) | ||
| Finding optimal reference genes | geNorm | |
| NormFinder | ||
| Geometric averaging | ||
| Absolute Quantification | Standard curves | |
| Reverse Regression | ||
| Limit of detection (LOD) estimation | Copy number analysis | |
| Correlation | Spearman rank correlation coefficient | |
| Pearson correlation coefficient | ||
| Statistics | Descriptive statistics | |
| False Discovery Rate Correction | ||
| Student’s t-test paired, unpaired | ||
| Non-parametric tests (Mann-Whitney, Wilcoxon signed rank) | ||
| One-way ANOVA | ||
| Two-way ANOVA | ||
| Nested ANOVA | ||
| Trilinear decomposition | Survival analysis (Cox prop. hazards) | |
| Cluster Analysis | PCA | |
| P-curve | ||
| Hierarchical clustering/dendogram | ||
| Heatmap analysis | ||
| Sample Classification | Self-organizing map (SOM) | |
| Artificial neural networks (ANN) | ||
| Support vector machine (SVM) | ||
| Concentration Prediction | Partial least square (PLS) | |
| Plots | Correlation Plot/Scatterplot | |
| Bar plots | ||
| Line plots | ||
| Box and whiskers plot | ||
| Heatmap | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krause, T.; Jolkver, E.; Mc Kevitt, P.; Kramer, M.; Hemmje, M. A Systematic Approach to Diagnostic Laboratory Software Requirements Analysis. Bioengineering 2022, 9, 144. https://doi.org/10.3390/bioengineering9040144
Krause T, Jolkver E, Mc Kevitt P, Kramer M, Hemmje M. A Systematic Approach to Diagnostic Laboratory Software Requirements Analysis. Bioengineering. 2022; 9(4):144. https://doi.org/10.3390/bioengineering9040144
Chicago/Turabian StyleKrause, Thomas, Elena Jolkver, Paul Mc Kevitt, Michael Kramer, and Matthias Hemmje. 2022. "A Systematic Approach to Diagnostic Laboratory Software Requirements Analysis" Bioengineering 9, no. 4: 144. https://doi.org/10.3390/bioengineering9040144
APA StyleKrause, T., Jolkver, E., Mc Kevitt, P., Kramer, M., & Hemmje, M. (2022). A Systematic Approach to Diagnostic Laboratory Software Requirements Analysis. Bioengineering, 9(4), 144. https://doi.org/10.3390/bioengineering9040144