1. Introduction
The first approach in modeling decision-making process was the rational approach, which considered that decisional choices are available and their effects are known and evaluated in terms of utility. Simon et al. [
1] stated that decisions are taken by actors that are led by the purpose of achieving a maximum benefit by having a satisfactory behavior. The scientific management of Taylor et al. [
2], the administrative theory of Fayol et al. [
3], and M. Weber’s [
4] bureaucracy are good examples of rational-based systems. The biased rational approach considers that the decision-making process concerns many actors that are rational-biased. In this kind of system, obtaining information is important.
Problem-solving led to the emergence of many IT solutions for business management, in more or less advanced forms of integration.
From an informational point of view, decisions are inputs for other decisions. Decisions’ alternatives overlap with inputs for other decisions. Models intertwine and form a graph of concepts in causal and constraint relationships that determine decision-making contexts.
The decision support systems heavily rely upon large volumes of data, information, and knowledge arriving from different sources [
5].
Although it is not considered good practice, many real-world process models contain detailed decision logic, encoded through control data structures. This often results in spaghetti-like and complex process models and reduces maintainability of the models [
6].
Providing information is the goal of any decision support system. Modeling decisions is a concern for formalizing problem solving and involves knowledge formalisms. Most often, computer science proposes breaking the problem into sub-problems. A computer program implements functions. The decision maker uses the functions and formalizes the structured part of the decisional problem. Artificial Intelligence seeks to discover the functions, and, in this way, seeks to give the decision makers the knowledge. The decision maker uses knowledge discovery to create new knowledge and proposes an approach to model the decision by enunciating logical inferences. DROOLS (Decision Rules Object Oriented System) [
7] is a business rules management system that separates the domain level from the decision level, so that decision makers infer rules on data and query results.
Knowledge is expressed by inference rules, and rule execution will infer the result of logical implications in the knowledge base. In literature, the implementation of rules is considered to be feasible with inference engines, considered programs that have control, procedural or operative knowledge, exploiting the knowledge base, and are designed to combine and chain knowledge to infer new knowledge through judgments, plans, demonstrations, decisions, and predictions.
Concepts from business rules are used in the specifications needed to define control. This paper presents a separated decision rules implementation from the domain model with the main purpose of establishing good practices for developing decision support systems.
2. Methods
Our article has a research hypothesis:
Hypothesis 1. Rules help to discover hidden connections between data on fixed assets. We propose a separated decision rules implementation on data about fixed assets. This implementation will enhance search results. In order to pursue this endeavor, we intend to build a rule-based application interface for editing and executing rules on data in an expressive manner.
Inferential Engines have special interaction interfaces with programming languages and run rules to solve a problem [
8]. The rules must be stored separately and defined on the concepts of a common ontology for the members of the organization involved in the same process. The rules provide answers close to the members of the organization who ask questions (queries) on the concepts defined in the common ontology.
As for the decision-making process, we can say that there are two general principles accepted in decision-making:
- (1)
The decision is made in terms of gain-loss;
- (2)
The decision depends on the context; even if the decision-making rules are known, the context of the decision may be different, which means that the meaning of the concepts involved in the decision-making rules changes.
We try to introduce the idea that the specification of rules and constraints of concept use should be part of the level of knowledge modeling rather than the functional level of the developed application. Specifying constraints at the data processing level contextualizes the problem and limits the modeling domain. Specifying constraints at the place and time of manifestation of their knowledge characterizes the context and adapts the decision model.
We chose the fixed asset accounting decisions as the practical example to demonstrate that accountants use accounting techniques and valuation methods to plan and monitor the performance of an organization’s assets. Information on the cost of assets over their life cycle is particularly important if we consider that the life of an asset often exceeds the time period used in the organization’s strategic plans.
Decisions concern the monitoring of the lifecycle of assets and result in acquisition for replacement, upgrading, or repairing. The monitoring follows relationships between values related to the capitalized value (market or utility value), the value of the repairs, the cost of maintenance or disposal, and efficiency indicators in the achievement of the planned production. In principle, this process is the pursuit of the relationship between the demand for assets (expressed in units of value of products and services planned to be achieved) and the supply of assets (production capacity). Accounting decisions monitor the true image of the recognized asset value.
Table 1 presents the information sources for accounting decisions on fixed assets.
An asset is recognized when it is probable that future benefits (income, expenditure cuts, economic, and social benefits) will flow into the enterprise and the asset has a value or cost that can be reliably measured.
Impairment of value refers to the deterioration in the value of an asset, a deterioration that has little chance of disappearing in the future due to moral wear, unfavorable market conditions, etc.
Internal information sources:
The existence of evidence of moral or physical wear.
Information extracted from internal reports that the economic performance of the asset is, or will be, less than estimated, for example, information about the cash flow generated by that asset.
The issues concerning the formalization of accounting decisions about fixed assets are determined by:
various sources of information
the need to make estimates of benefits, depreciation
the difficulty in monitoring the performance of assets
In the following study, we will present solutions for the implementation of the decision models regarding the fixed assets by exemplifying the knowledge necessary for their management activities.
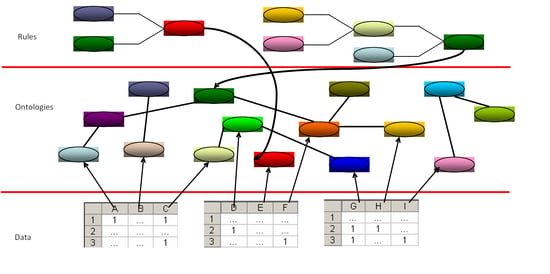
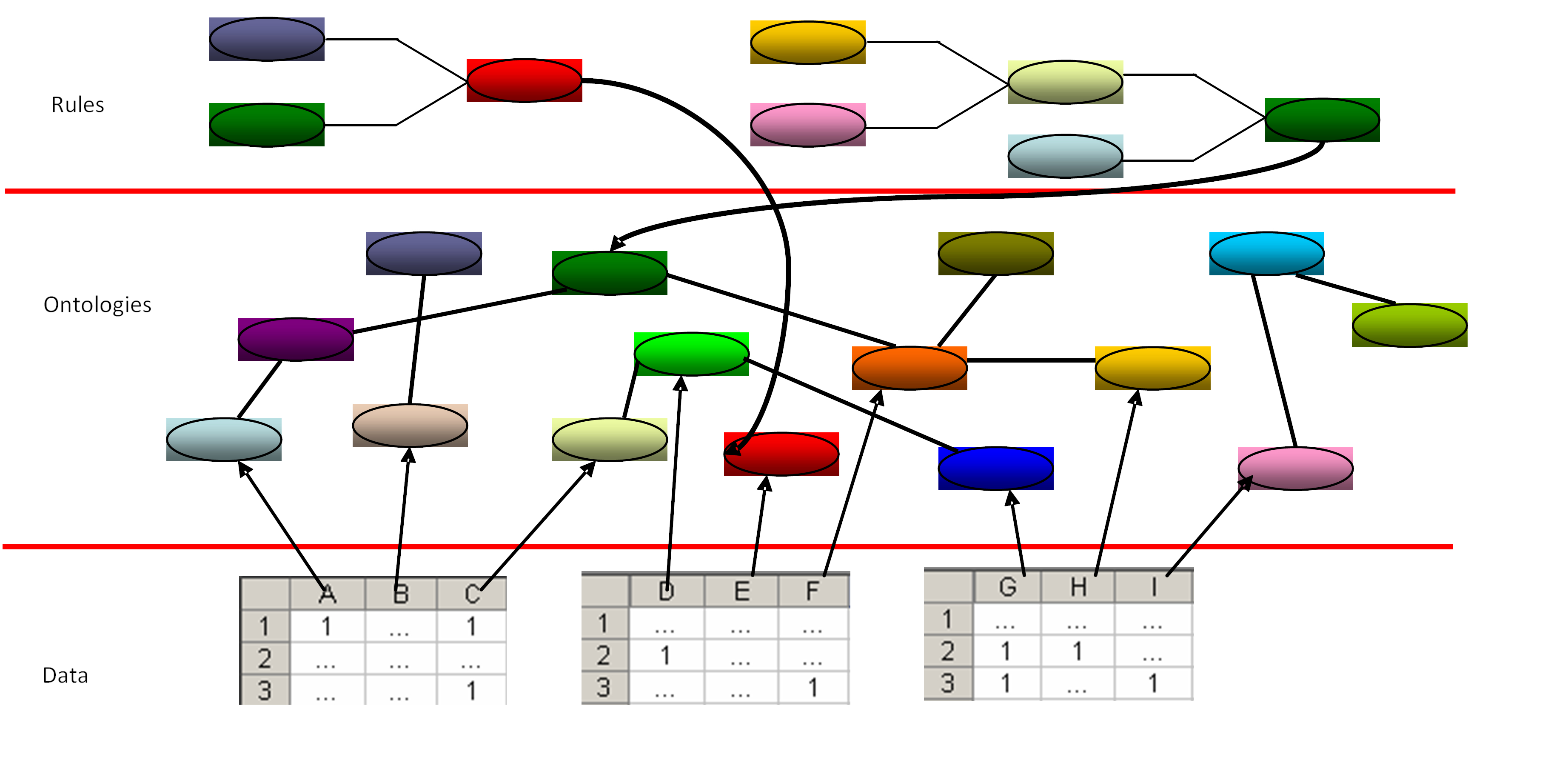
We propose a system IT architecture for substantiating organizational decisions (
Figure 1).
This kind of architecture takes into account the following premises:
- (a)
the specific problem-solving knowledge needed in human communication processes is local, context-dependent, and belongs to a human-being. We choose DROOLS, which is a Business Rules Management System (BRMS) solution.
- (b)
ontologies are necessary for sharing common meaning; statistical and mathematical modeling is required in calculations, forecasts, simulations, and data processing under constant risk and uncertainty conditions; modeling allowed by neural networks is required for simulations. We implement the data model in Java.
The class diagram is the one presented in
Figure 2.
The intelligence feature may be provided to a system under the conditions that an internal logic of an application could be used by the internal logic of a second application, and the information manipulated by the system would be organized on the basis of general knowledge in a domain.
We discuss accounting decisions about fixed assets, but for the consistency of the examples presented, we will present several scenarios.
Scenario 1: The accountant must assess fixed asset impairment. He or she knows that in making such assessment, he/she needs to compare the net value with the utility value of the fixed asset but does not know what the utility value of the asset would be. It is highly probable that the net value can be extracted from the company’s database, as it is historical information stored in a database. Unlike the net value, the utility value results from estimates of possible updated benefits. Such information is not stored in a database due to its volatility. Thus, we can say that there is a difference between the database schema and the ontology of the application.
Obtaining the net present value of estimated future benefits from using the asset will most likely be achieved with an actuarial function.
At this point, the decision maker could make the assessment of depreciation by specifying and executing a rule. The rule is presented in
Figure 3.
The rule’s execution results in attributing the impairment characteristic to individuals that comply with the rule.
To visualize depreciable assets, the decision maker will be able to ask a question, and in this way, existing individuals in the ontology will be displayed, and the condition will be displayed (see
Figure 4).
Scenario 2: At the end of the financial year, it is necessary to reassess the fixed assets in order to determine any impairment and to make provisions. The accountant should estimate whether the recoverable amount may be less than the net book value in the future.
Where there are internal sources of qualitative information on declining performance or moral wear, the estimate of impairment will be based on the professional intuition and judgment of the decision-maker.
In the absence of such sources of information, appreciation can be made from historical data about assets that are part of the same asset class and that have once been depreciated. Because it is not a trend set of values, we cannot talk about an estimation based on statistical methods. The best solution is to use a neural classification network. The training set must consist of the input values for asset returns and the output values (0 for underestimated and 1 for depreciation). In
Figure 5 we present the realization of such a neural network.
Scenario 3: The decision maker knows the value of possible repairs, the purchase price of a similar asset, and he/she wants to know what the decision to take for the impaired assets is.
The accountant states two rules:
- (1)
if the net book value added to the repair value does not exceed the purchase price, repair is recommended;
- (2)
if the net book value added to the value of the repair exceeds the purchase price, replacement is recommended.
We tested our rules on a publicly available dataset of Bureau of Economic Analysis—Detailed Data for Fixed Assets and Consumer Durable Goods [
9]. To test a single instance, the lines of codes are those in
Figure 6.
public class Test {
public static void main(String[] args) {
// TODO Auto-generated method stub
KieServices kService=KieServices.Factory.get();
KieContainer kContainer=kService.getKieClasspathContainer();
KieSession kSession=kContainer.newKieSession("ksession-rules");
FixedAsset f1=new FixedAsset(1, 50000.0);
Depreciation d1=new Depreciation(f1);
Utility u1=new Utility(f1, 55000.0);
kSession.insert(f1);
kSession.insert(d1);
kSession.insert(u1);
kSession.fireAllRules();
}
The output is “The value of depreciation is −5000.0”. We notice that the depreciation value was inferred by the Drools rule “The value of depreciation is”. If we decide to define another rule that establishes that the utility value is equal to the market value, we will be able to infer the state of the fixed asset. The main concepts from our domain model are those from the class diagram, namely: FixedAsset, Utility, Repair, and Depreciation. By inferring rules, we were able to set the state of an asset, and after that, we were able to query the knowledge base about the fixed assets list.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}