Guidelines for a Standardized Filesystem Layout for Scientific Data

 , , , , and
, , , , and
Abstract
:1. Introduction
1.1. Motivation
- Finding specific folders in deep folder structures can become a time-consuming task, especially when dealing with large file sizes and a huge number of individual files.
- The tree-like nature of folder hierarchies can highly impede findability. The hierarchy of folders itself is in many cases arbitrary and therefore difficult to define in a general way.
- The lack of standards often leads to diverging and unnecessarily expanded folder structures that are impossible to understand by collaborators or new lab members.
- The new layout should be compatible with existing structures and at least allow for a smooth integration of existing file structures.
- The filesystem layout should allow access through very different scientific workflows. Usage by databases should be similarly possible as an intuitive access of the raw file structure. It should be accessible via graphical user interfaces as well as command line interfaces and thus allow for automation, e.g. via shell scripts.
- Simplicity of the layout definition itself in order to lower the threshold for adopting a standardized way of storing data and metadata in the first place.
1.2. Comparison to Other Approaches
1.3. Aims
- Allow for a mapping of the complete chain of scientific data management:
- Data acquisition (Experiment / Simulation)
- Data analysis
- Publication
Links between the different stages must be possible. - Encourage transparency: The data structure should be understandable and searchable. Folders and files should have meaningful names. The folder hierarchy should be readily apparent to persons unfamiliar with it.
- Support of reproducibility: Ideally the structure should enable reproducibility of data analysis and publications from raw experimental and simulation data.
- All data must remain accessible, understandable, and reusable even when original creators are not present anymore.
- The structure must provide a possibility for saving metadata.
- Integration of existing structures must be feasible rather than having to adapt to our structure.
2. Results
2.1. Implementation
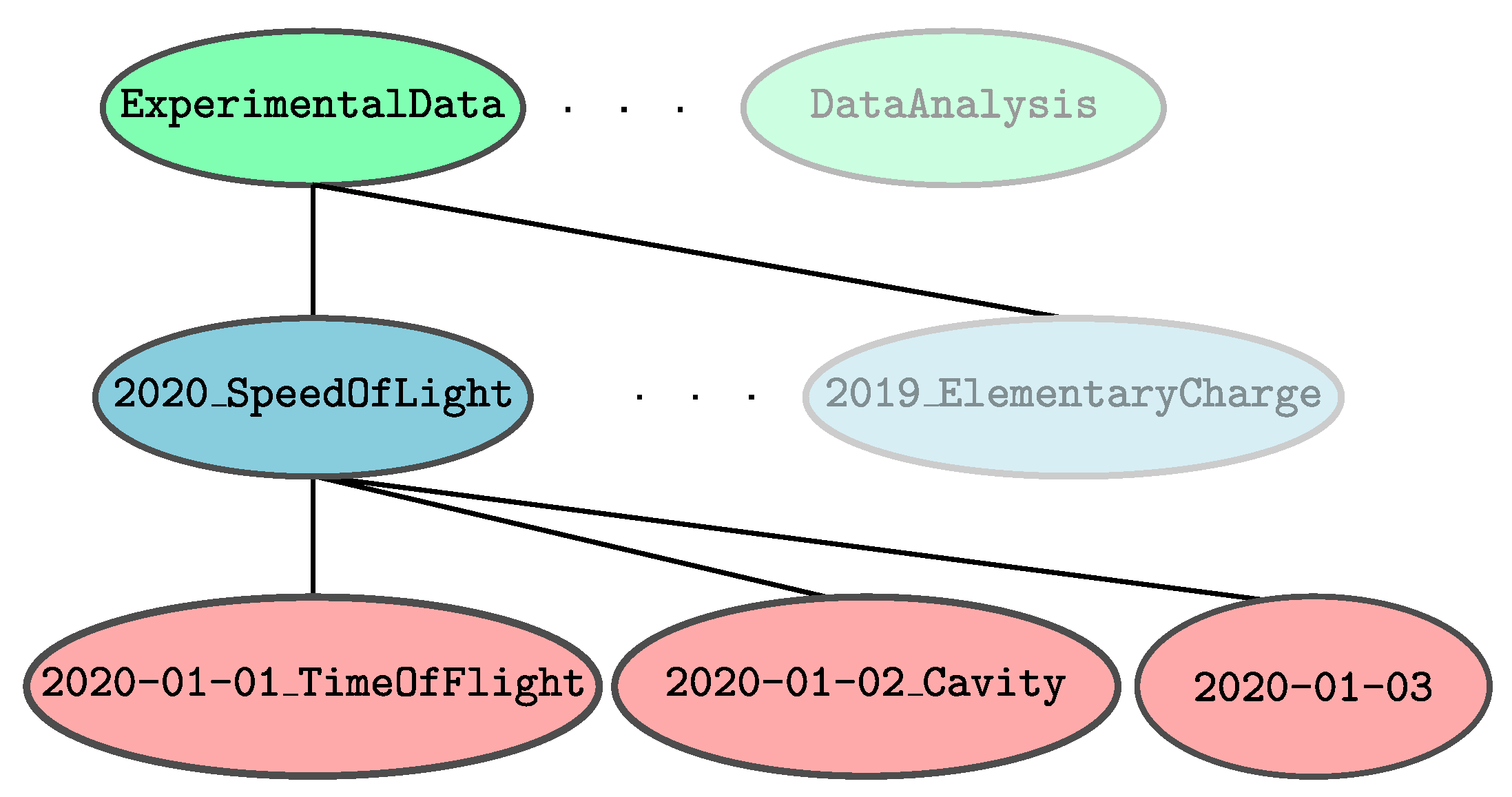
2.1.1. Data Structure
2.1.2. Dates and Years
2.1.3. Categories
2.1.4. Metadata

{kind=link}




2.1.5. Remarks on Archiving and Purging Data
2.2. Example Data Chains
2.2.1. Finding the Experimental Data for a Publication



2.2.2. From Data Generation to a Conference Talk




3. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| RDMS | Research Data Management System |
| YAML | YAML ain’t markup language |
| md | Markdown |
| FAIR | Findable, Accessible, Interoperable and Reusable |
| PID | Persistent identifier |
Appendix A. Supporting Software
- CaosDB [8] is an Open Source scientific research data management system that uses automated crawling for inserting data. The CaosDB standard crawler is able to insert and update data based on this specification.
- Check SFS is a collection of software tools for creating and checking file structures according to this specification. It is released as Open Source software here: https://gitlab.com/salexan/check-sfs.
References
- Gorgolewski, K.J.; Auer, T.; Calhoun, V.D.; Craddock, R.C.; Das, S.; Duff, E.P.; Flandin, G.; Ghosh, S.S.; Glatard, T.; Halchenko, Y.O.; et al. The brain imaging data structure, a format for organizing and describing outputs of neuroimaging experiments. Sci. Data 2016, 3, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Sansone, S.A.; Rocca-Serra, P.; Field, D.; Maguire, E.; Taylor, C.; Hofmann, O.; Fang, H.; Neumann, S.; Tong, W.; Amaral-Zettler, L.; et al. Toward interoperable bioscience data. Nat. Genet. 2012, 44, 121. [Google Scholar] [CrossRef] [PubMed]
- Ma, X.; Fox, P.; Tilmes, C.; Jacobs, K.; Waple, A. Capturing provenance of global change information. Nat. Clima. Chang. 2014, 4, 409–413. [Google Scholar] [CrossRef]
- Diepenbroek, M.; Grobe, H.; Reinke, M.; Schindler, U.; Schlitzer, R.; Sieger, R.; Wefer, G. PANGAEA—An information system for environmental sciences. Comput. Geosci. 2002, 28, 1201–1210. [Google Scholar] [CrossRef] [Green Version]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dominici, M. An overview of Pandoc. TUGboat 2014, 35, 44–50. [Google Scholar]
- Ben-Kiki, O.; Evans, C.; döt Net, I. YAML Ain’t Markup Language (YAML™) Version 1.2, 3rd ed. 2009. Available online: https://yaml.org/spec/1.2/spec.html (accessed on 23 April 2020).
- Fitschen, T.; Schlemmer, A.; Hornung, D.; tom Wörden, H.; Parlitz, U.; Luther, S. CaosDB—Research Data Management for Complex, Changing, and Automated Research Workflows. Data 2019, 4. [Google Scholar] [CrossRef] [Green Version]
| 1 | See 2.3.9. Data Files in https://isa-specs.readthedocs.io/en/latest/isatab.html. |
| 2 | |
| 3 | As explained in Section 2.1.3, such data are not experimental data in a strict sense but rather observations or measurements. For reasons of simplicity we are using ExperimetalData here. The category could of course be renamed if desired. |

| Category | Experiments | Simulations | Data analysis | Publications |
| ExperimentalData | SimulationData | DataAnalysis | Publications | |
| Project | Descriptive project names (possibly with starting year of the project) but sufficiently general such that individual experiments, analyses, ... belong to one single project. | Publications include articles, conference talks, posters, ... | ||
| (yyyy_)projectname | publicationtype | |||
| Entries | Specific containers with actual results of experiment, simulation, analysis. Have to contain metadata, otherwise no restrictions on substructure. | Individual publications with date and title. | ||
| yyyy-mm-dd(_descriptor) | yyyy(-mm-dd)_title | |||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Spreckelsen, F.; Rüchardt, B.; Lebert, J.; Luther, S.; Parlitz, U.; Schlemmer, A. Guidelines for a Standardized Filesystem Layout for Scientific Data. Data 2020, 5, 43. https://doi.org/10.3390/data5020043
Spreckelsen F, Rüchardt B, Lebert J, Luther S, Parlitz U, Schlemmer A. Guidelines for a Standardized Filesystem Layout for Scientific Data. Data. 2020; 5(2):43. https://doi.org/10.3390/data5020043
Chicago/Turabian StyleSpreckelsen, Florian, Baltasar Rüchardt, Jan Lebert, Stefan Luther, Ulrich Parlitz, and Alexander Schlemmer. 2020. "Guidelines for a Standardized Filesystem Layout for Scientific Data" Data 5, no. 2: 43. https://doi.org/10.3390/data5020043
APA StyleSpreckelsen, F., Rüchardt, B., Lebert, J., Luther, S., Parlitz, U., & Schlemmer, A. (2020). Guidelines for a Standardized Filesystem Layout for Scientific Data. Data, 5(2), 43. https://doi.org/10.3390/data5020043