An Optimum Tea Fermentation Detection Model Based on Deep Convolutional Neural Networks

 , , , and
, , , and
Abstract
:1. Introduction
2. Related Work
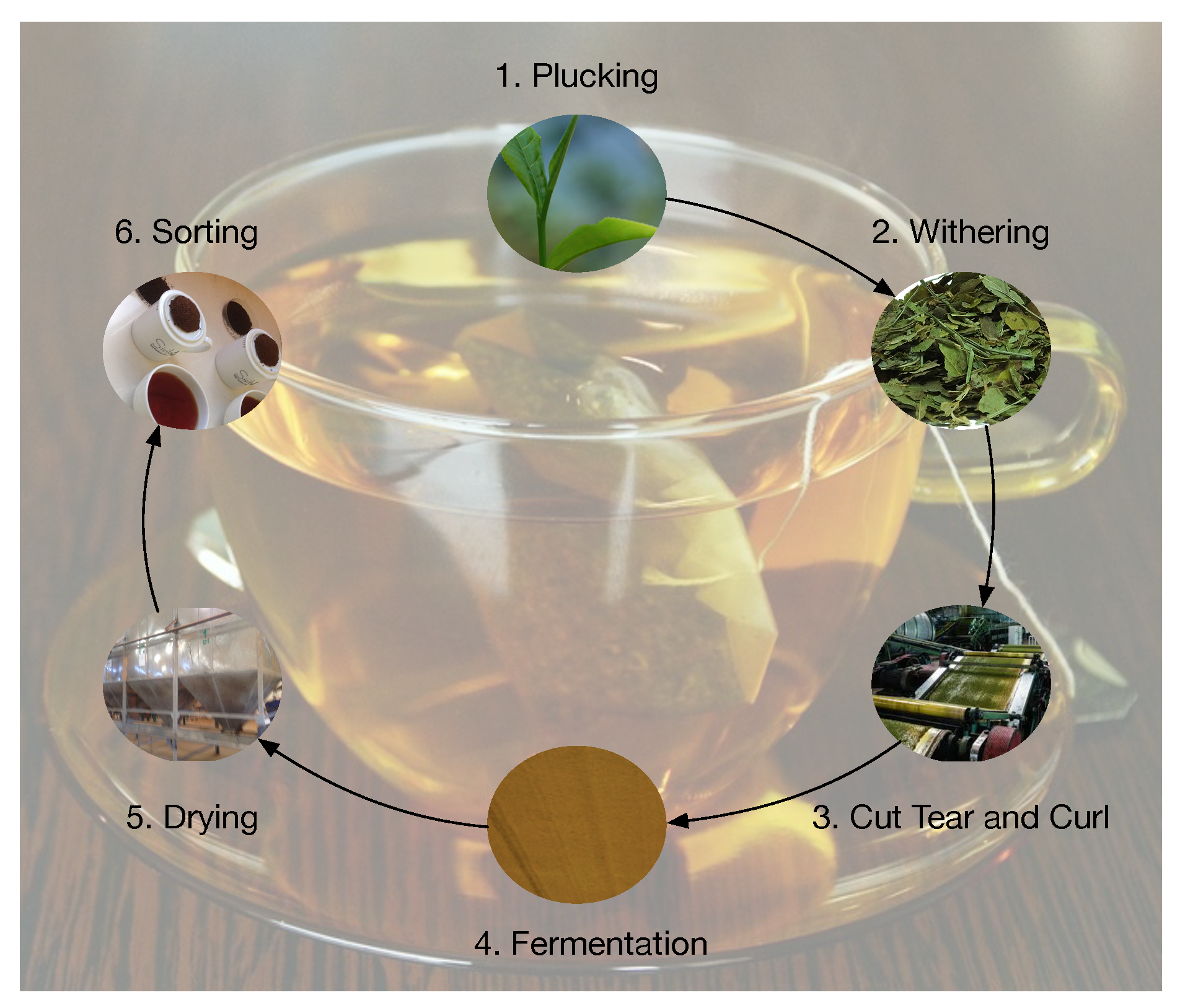
3. Materials and Methods
3.1. Datasets
3.1.1. Tea Fermentation Dataset
3.1.2. LabelMe Dataset
3.2. Data Preprocessing and Augmentation
3.3. Feature Extraction
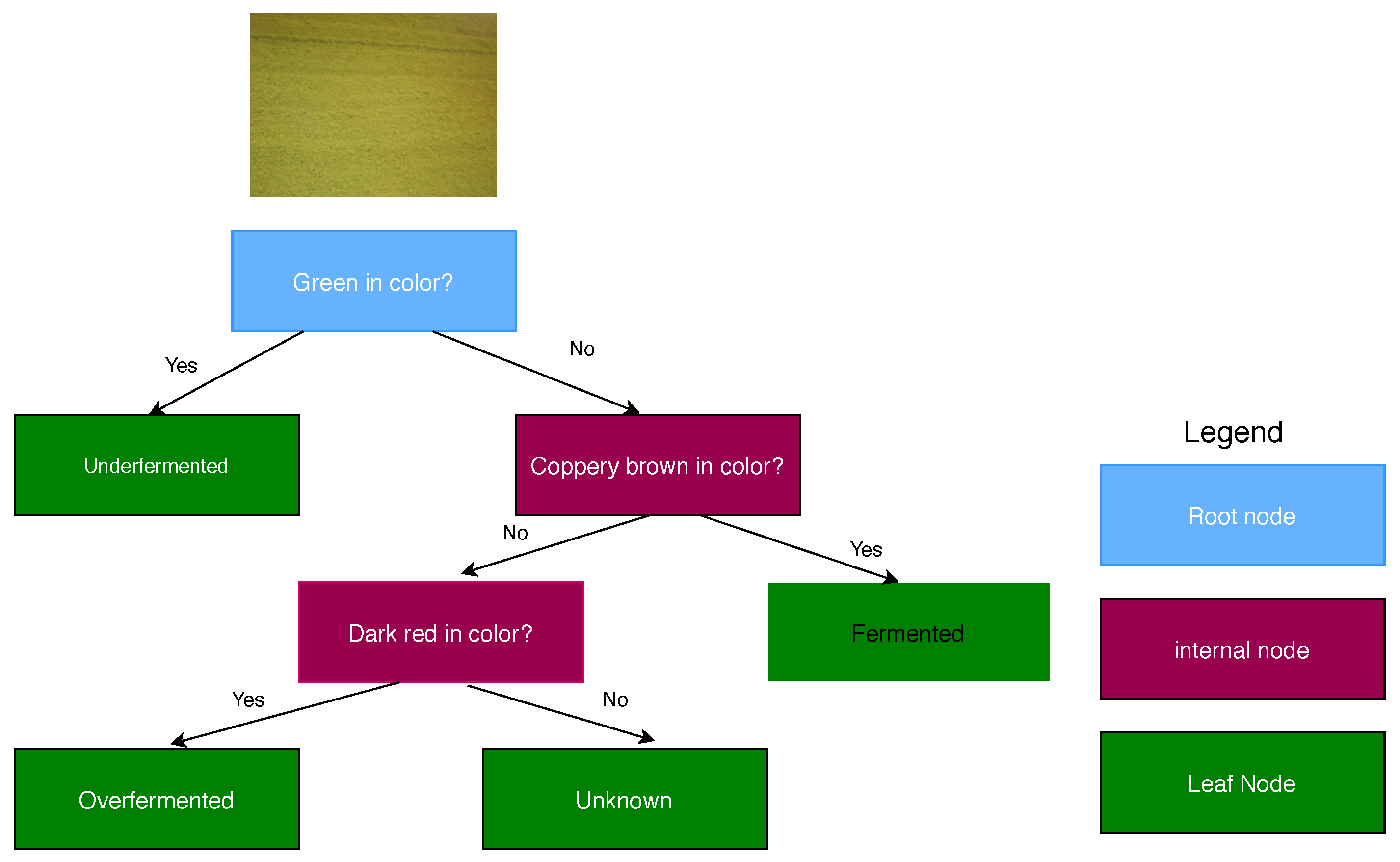
3.3.1. Color Feature Extraction
3.3.2. Texture Feature Extraction
- Finally, the texture image obtained was converted into gray- scale histogram as shown in Figure 7d.
3.4. Classification Models
3.4.1. Decision Tree (DT)
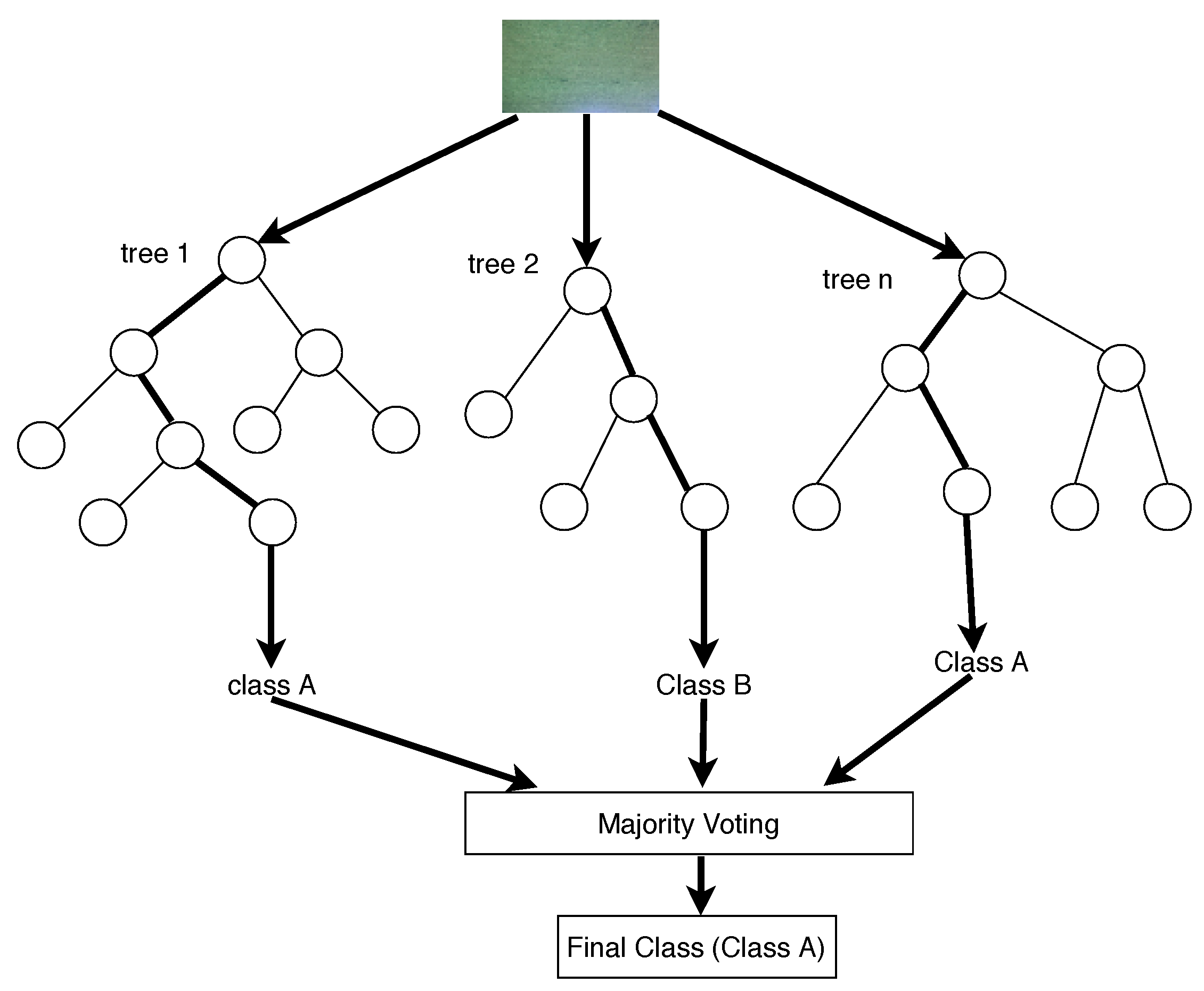
3.4.2. Random Forest (RF)
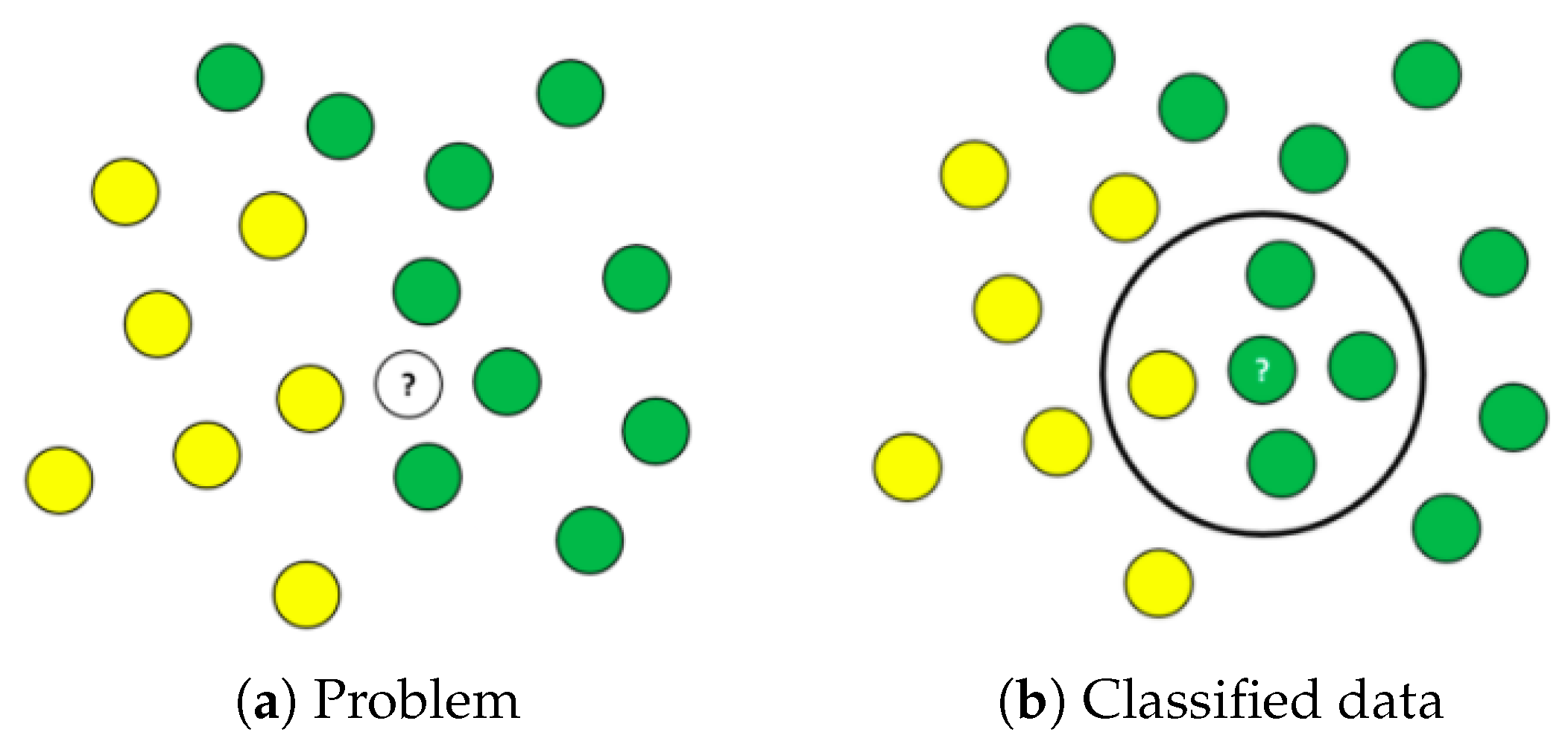
3.4.3. K-Nearest Neigbor (KNN)
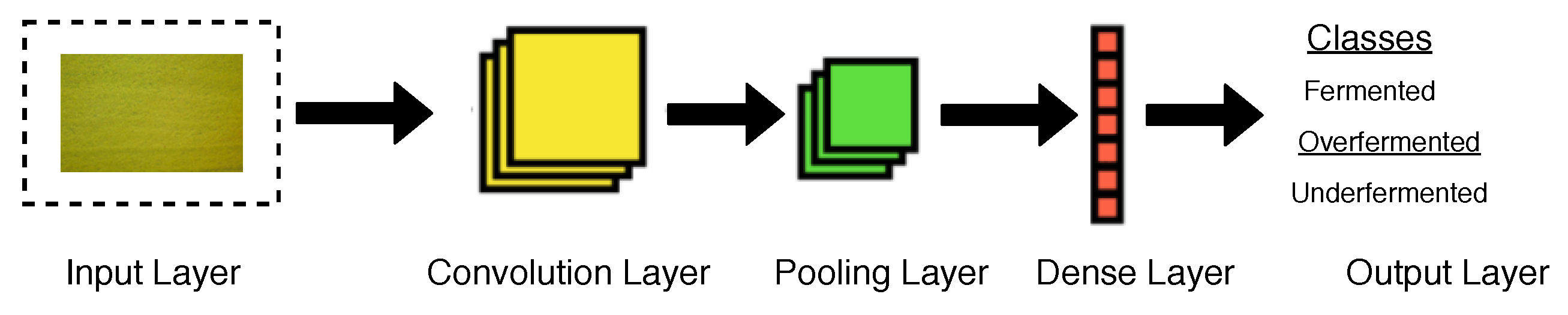
3.4.4. Convolutional Neural Network (CNN)
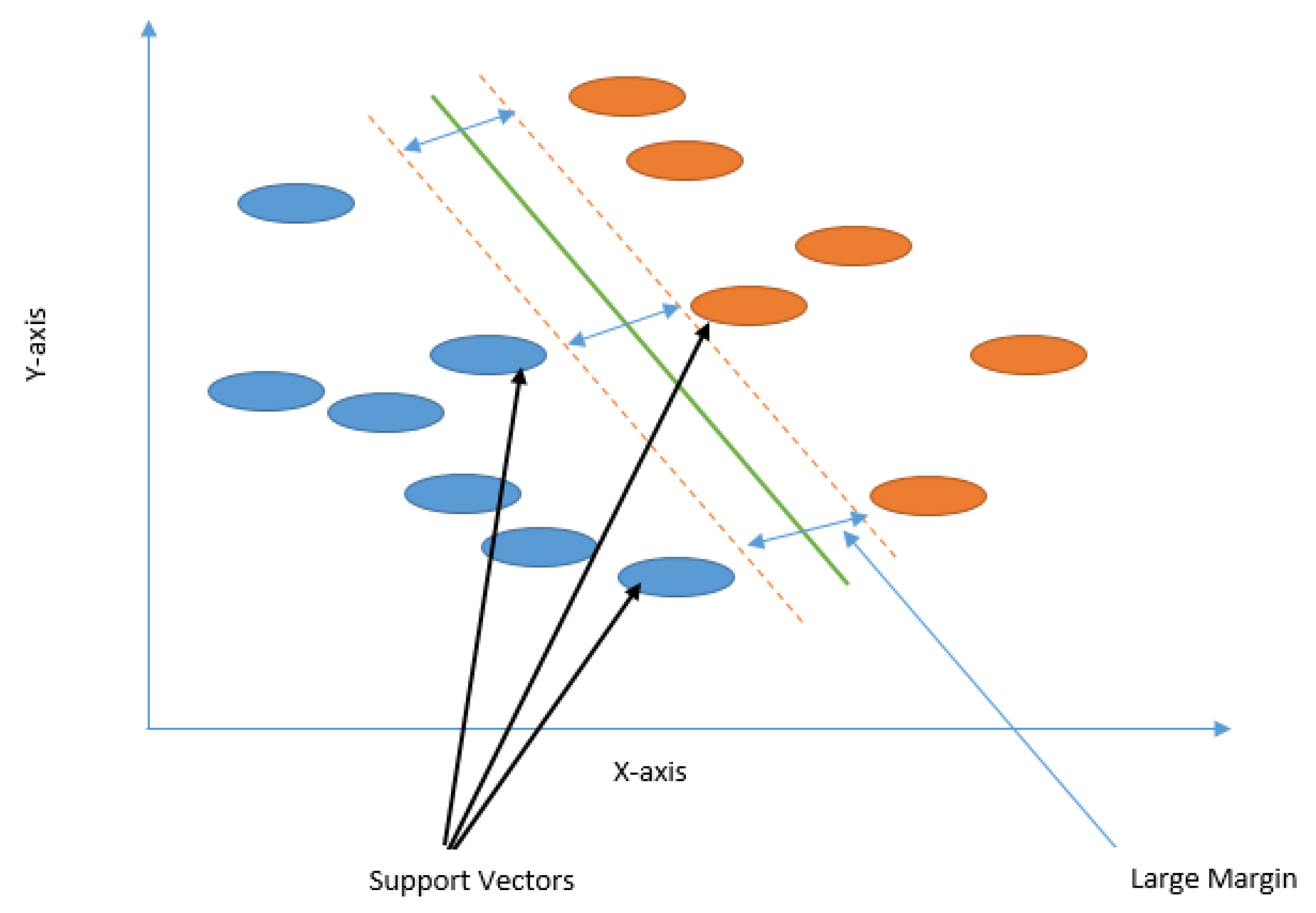
3.4.5. Support Vector Machine (SVM)
3.4.6. Naive Bayes (NB)
3.4.7. Linear Discriminant Analysis (LDA)
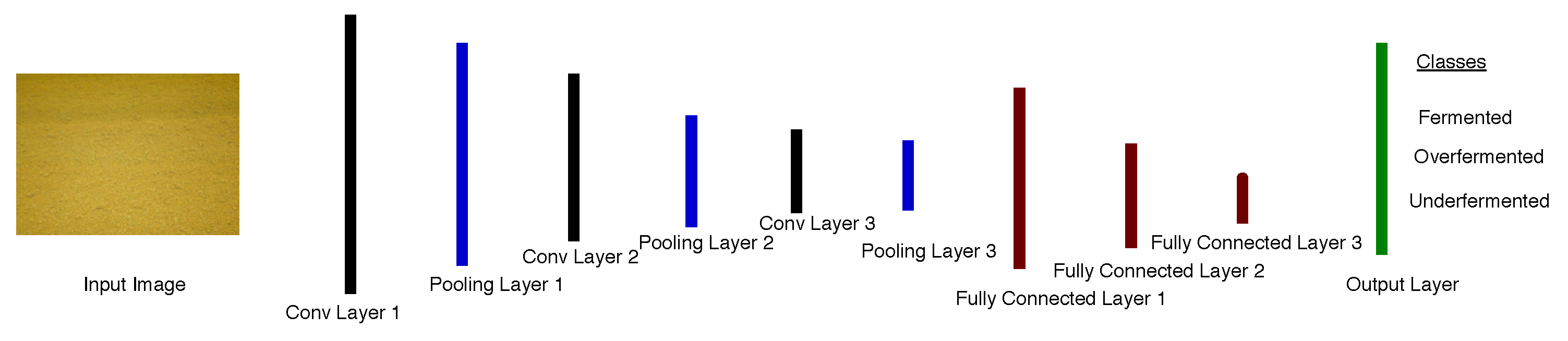
3.5. TeaNet
- The first convolutional layer comprises of 32 filters and a kernel size of 11 × 11 pixels. This layer is followed by a rectified linear unit (ReLU) operation. ReLU is an activation function that provides a solution to vanishing gradients [96]. Its pooling layer has a kernel size of 3 ×3 pixels, with two strides.
- The second convolutional layer comprises of 64 filters and a kernel size of 3 × 3 pixels and is followed by a ReLU operation; its pooling layer has a kernel size of 2 × 2 pixels.
- Additionally, the third convolutional layer comprises of 128 filters and a kernel size of 3 × 3 pixels, followed by ReLU with a kernel size of 2 × 2 pixels.
- The first full connection layer was made up of 512 neurons, followed by a ReLu and a dropout operation. The dropout operation [120] is proposed to solve overfitting as it trains only a randomly selected nodes. We set the ratio of dropout to 0.5.
- The second full convolutional layer had 128 neurons and was followed by a ReLU and dropout operations.
- The last fully convolutional layer contains three neurons, which represent 3 classes of images in tea fermentation and LabelMe datasets. The output of this layer is transferred to the output layer to determine the class of the input image. A softmax activation function is then implemented to force the sum of the output values to be equal to 1.0. Softmax also limits the individual output values between 0–1.
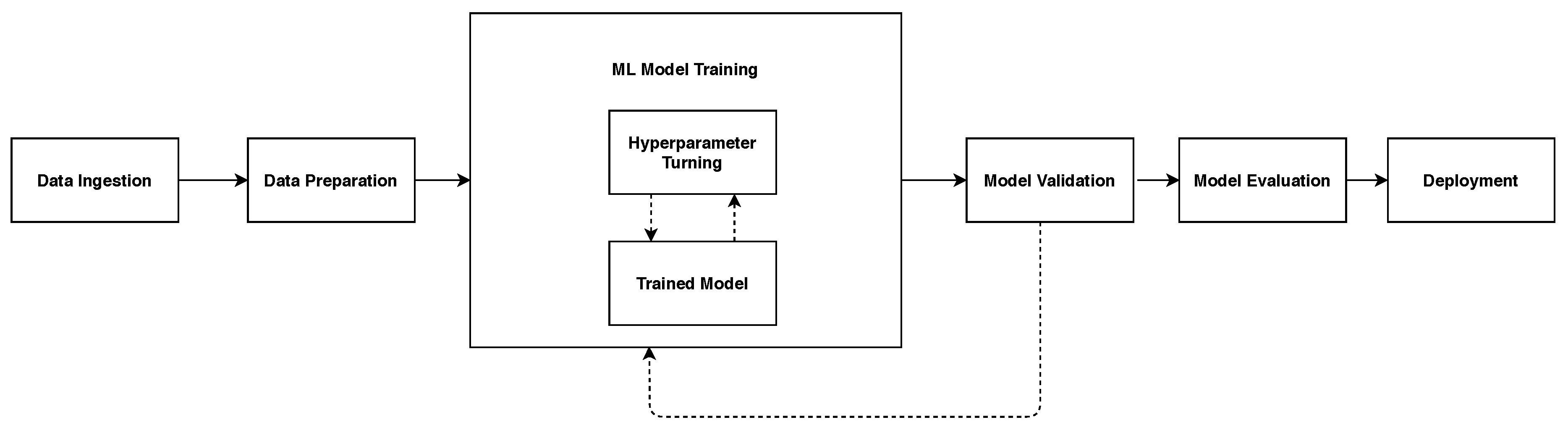
4. Implementation
4.1. Implementation of the Classifiers
4.2. Evaluation Metrics
4.2.1. Precision
4.2.2. Recall
4.2.3. F1-Score
4.2.4. Accuracy
4.2.5. Logarithmic Loss
4.2.6. Confusion Matrix
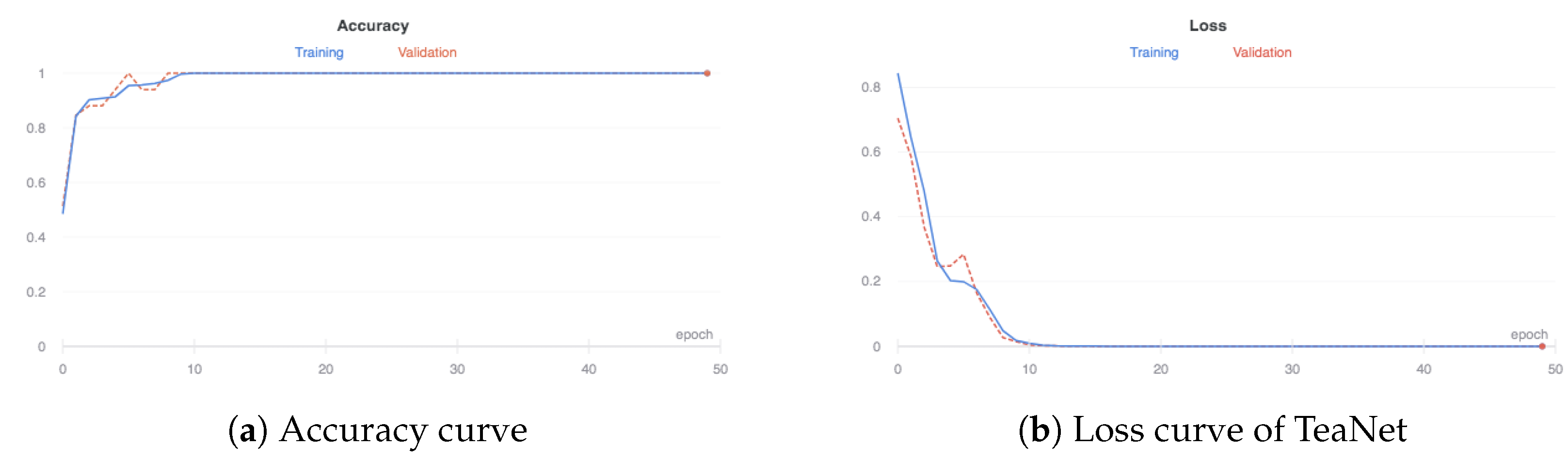
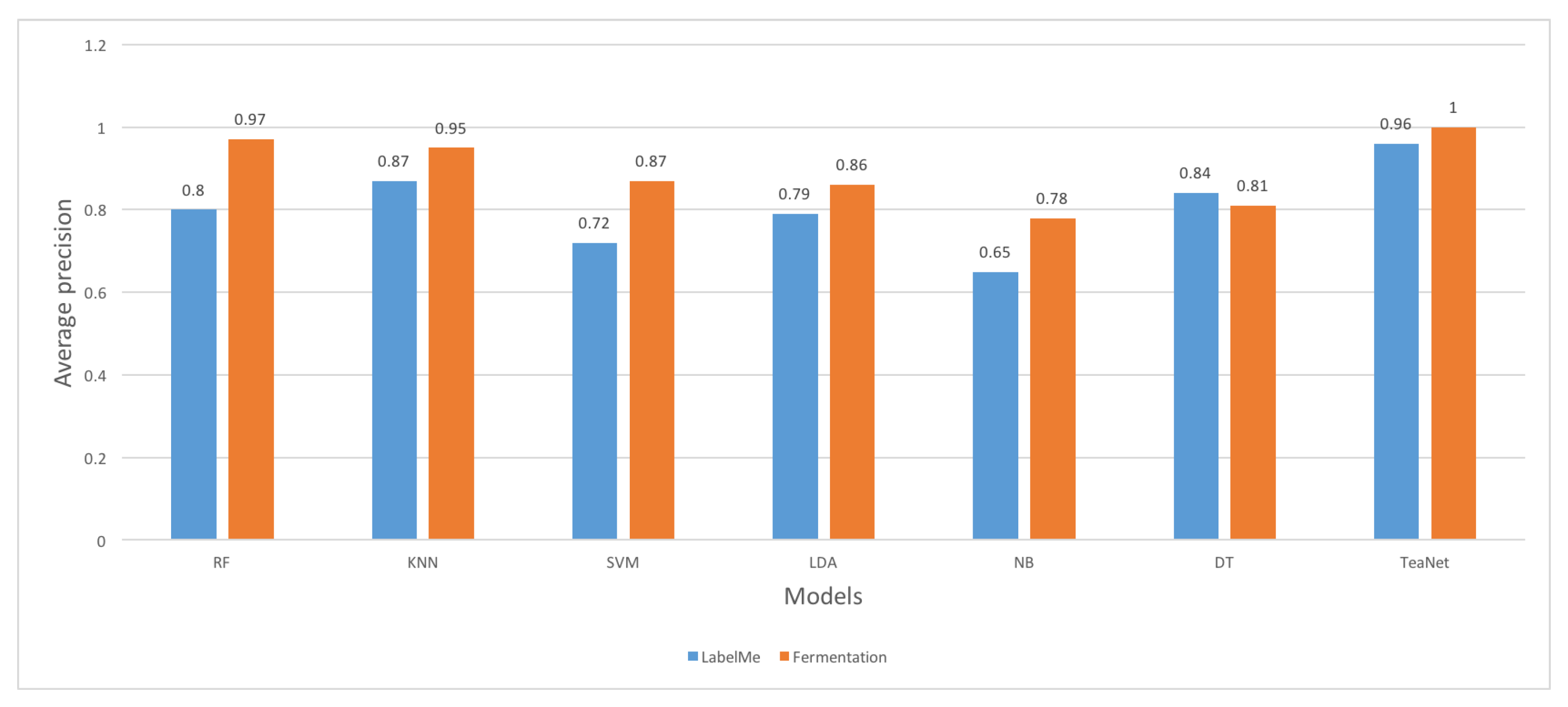
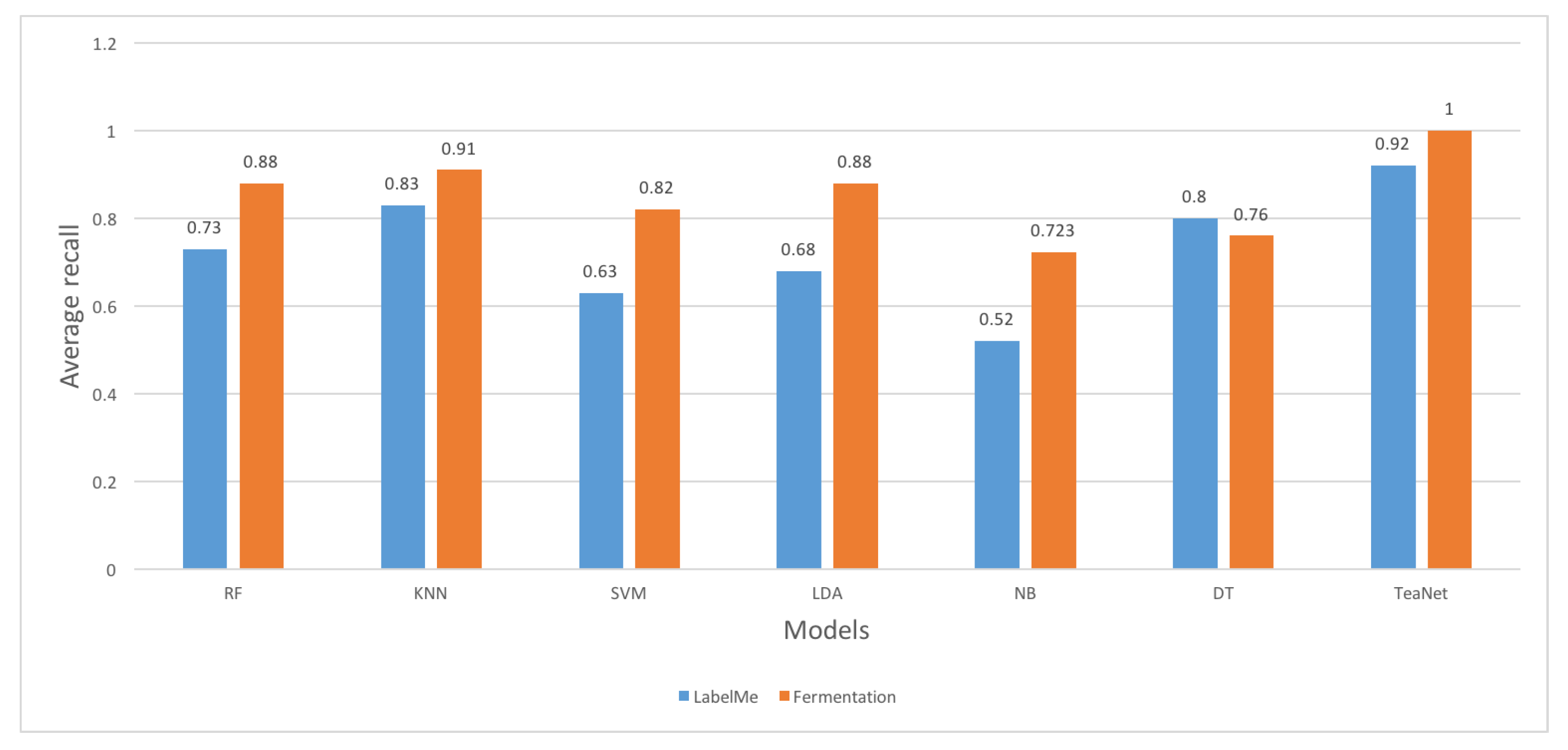
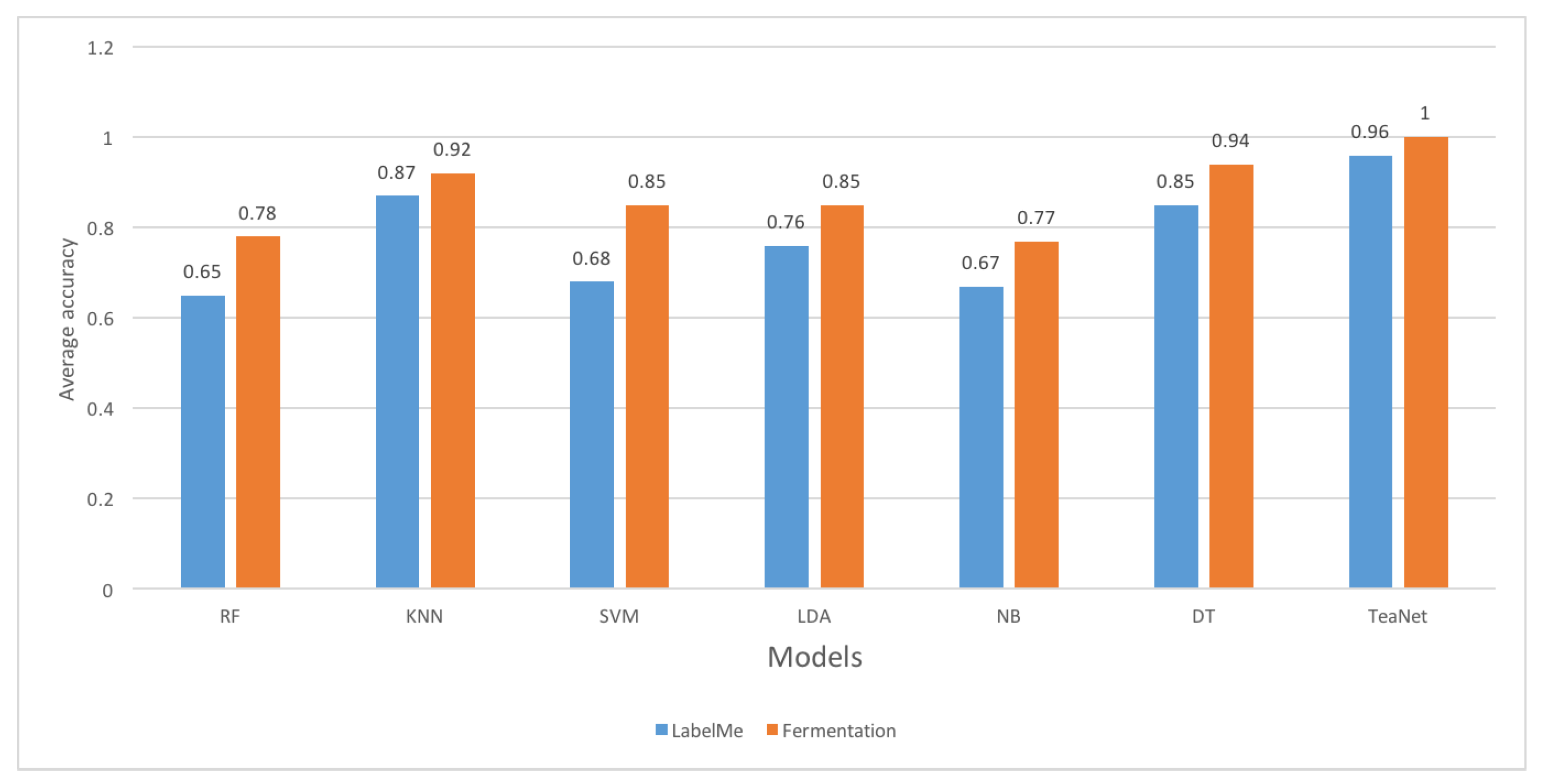
5. Evaluation Results
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| CNN | Convolutional Neural Network |
| SVM | Support Vector Machine |
| DT | Decision Tree |
| RF | Random Forests |
| SVM | Support Vector Machine |
| KNN | K-Nearest Neighbor |
| OpenCV | Open Computer Vision |
| IoT | Internet of Things |
| TF | Theaflavins |
| TR | Thearubins |
| EN | electronic Nose |
| ET | electronic Tongue |
| LDA | Local Discriminant Analysis |
| NB | Naive Bayes |
| KTDA | Kenya Tea Development Agency |
| GDP | Gross Domestic Product |
| MSE | Mean Squarred Error |
| MAE | Mean Absolute Error |
References
- Sigley, G. Tea and China’s rise: Tea, nationalism and culture in the 21st century. Int. Commun. Chin. Cult. 2015, 2, 319–341. [Google Scholar] [CrossRef] [Green Version]
- Yiannakopoulou, E. Green Tea Catechins: Proposed Mechanisms of Action in Breast Cancer Focusing on the Interplay Between Survival and Apoptosis. Anti-Cancer Agents Med. Chem. 2014, 14, 290–295. [Google Scholar] [CrossRef]
- Miura, K.; Hughes, M.C.B.; Arovah, N.I.; Van Der Pols, J.C.; Green, A.C. Black Tea Consumption and Risk of Skin Cancer: An 11-Year Prospective Study. Nutr. Cancer 2015, 67, 1049–1055. [Google Scholar] [CrossRef] [PubMed]
- Hajiaghaalipour, F.; Kanthimathi, M.S.; Sanusi, J.; Rajarajeswaran, J. White tea (Camellia sinensis) inhibits proliferation of the colon cancer cell line, HT-29, activates caspases and protects DNA of normal cells against oxidative damage. Food Chem. 2015, 169, 401–410. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sironi, E.; Colombo, L.; Lompo, A.; Messa, M.; Bonanomi, M.; Regonesi, M.E.; Salmona, M.; Airoldi, C. Natural compounds against neurodegenerative diseases: Molecular characterization of the interaction of catechins from green tea with Aβ1-42, PrP106-126, and ataxin-3 oligomers. Chem. A Eur. J. 2014, 20, 13793–13800. [Google Scholar] [CrossRef] [PubMed]
- Gopalakrishna, R.; Fan, T.; Deng, R.; Rayudu, D.; Chen, Z.W.; Tzeng, W.S.; Gundimeda, U. Extracellular matrix components influence prostate tumor cell sensitivity to cancer-preventive agents selenium and green tea polyphenols. In Proceedings of the AACR Annual Meeting 2014, San Diego, CA, USA, 5–9 April 2014; American Association for Cancer Research (AACR): Philadelphia, PA, USA, 2014; p. 232. [Google Scholar] [CrossRef]
- Lazaro, J.B.; Ballado, A.; Bautista, F.P.F.; So, J.K.B.; Villegas, J.M.J. Chemometric data analysis for black tea fermentation using principal component analysis. In AIP Conference Proceedings; AIP Publishing LLC: Melville, NY, USA, 2018; Volume 2045, p. 020050. [Google Scholar] [CrossRef]
- Saikia, D.; Boruah, P.K.; Sarma, U. A Sensor Network to Monitor Process Parameters of Fermentation and Drying in Black Tea Production. MAPAN 2015, 30, 211–219. [Google Scholar] [CrossRef]
- Mitei, Z. Growing sustainable tea on Kenyan smallholder farms. Int. J. Agric. Sustain. 2011, 9, 59–66. [Google Scholar] [CrossRef] [Green Version]
- Kamunya, S.M.; Wachira, F.N.; Pathak, R.S.; Muoki, R.C.; Sharma, R.K. Tea Improvement in Kenya. In Advanced Topics in Science and Technology in China; Springer: Berlin/Heidelberg, Germany, 2012; pp. 177–226. [Google Scholar] [CrossRef]
- Kagira, E.K.; Kimani, S.W.; Githii, K.S. Sustainable Methods of Addressing Challenges Facing Small Holder Tea Sector in Kenya: A Supply Chain Management Approach. J. Manag. Sustain. 2012, 2. [Google Scholar] [CrossRef] [Green Version]
- Tea Board of Kenya. Kenya Tea Yearly Report; Technical Report; Tea Board of Kenya: Nairobi, Kenya, 2018. [Google Scholar]
- Onduru, D.D.; De Jager, A.; Hiller, S.; Van Den Bosch, R. Sustainability of Smallholder Tea Production in Developing Countries: Learning Experiences from Farmer Field Schools in Kenya; International Journal of Development and Sustainability: Tokyo, Japan, 2012. [Google Scholar]
- Xu, M.; Wang, J.; Gu, S. Rapid identification of tea quality by E-nose and computer vision combining with a synergetic data fusion strategy. J. Food Eng. 2019, 241, 10–17. [Google Scholar] [CrossRef]
- Jayabalan, R.; Malbaša, R.V.; Lončar, E.S.; Vitas, J.S.; Sathishkumar, M. A Review on Kombucha Tea-Microbiology, Composition, Fermentation, Beneficial Effects, Toxicity, and Tea Fungus. Compr. Rev. Food Sci. Food Saf. 2014, 13, 538–550. [Google Scholar] [CrossRef]
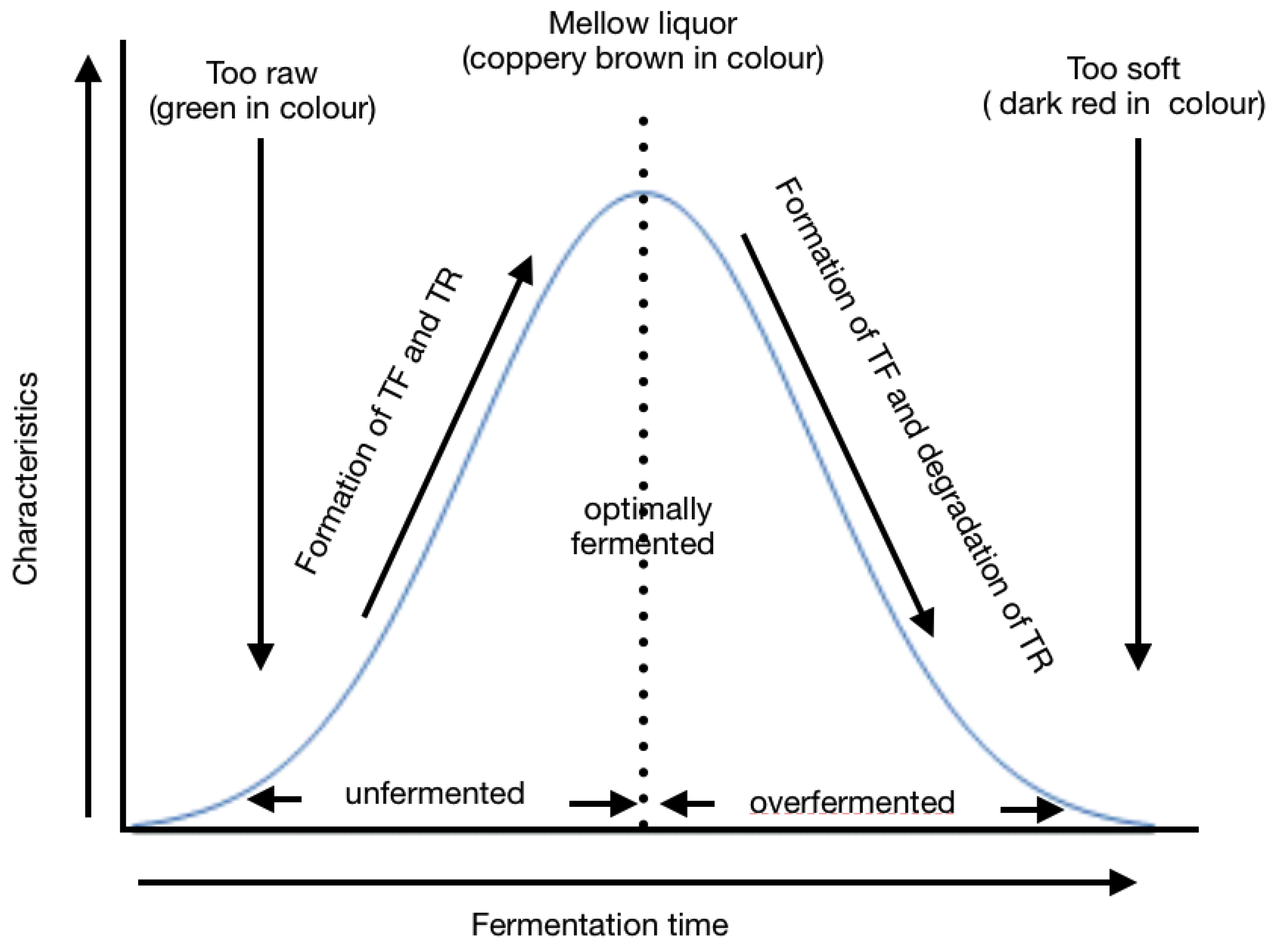
- Jolvis Pou, K. Fermentation: The Key Step in the Processing of Black Tea. J. Biosyst. Eng. 2016, 41, 85–92. [Google Scholar] [CrossRef] [Green Version]
- Asil, M.H.; Rabiei, B.; Ansari, R. Optimal fermentation time and temperature to improve biochemical composition and sensory characteristics of black tea. Aust. J. Crop. Sci. 2012, 6, 550–558. [Google Scholar]
- Memisevic, R. Deep learning: Architectures, algorithms, applications. In Proceedings of the 2015 IEEE Hot Chips 27 Symposium, HCS 2015, Cupertino, CA, USA, 22–25 August 2015. [Google Scholar] [CrossRef]
- Luckow, A.; Kennedy, K.; Ziolkowski, M.; Djerekarov, E.; Cook, M.; Duffy, E.; Schleiss, M.; Vorster, B.; Weill, E.; Kulshrestha, A.; et al. Artificial Intelligence and Deep Learning Applications for Automotive Manufacturing. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data 2018), Seattle, WA, USA, 10–13 December 2018; pp. 3144–3152. [Google Scholar] [CrossRef]
- Shinde, P.P.; Shah, S. A Review of Machine Learning and Deep Learning Applications. In Proceedings of the 2018 4th International Conference on Computing, Communication Control and Automation (ICCUBEA 2018), Pune, India, 16–18 August 2018. [Google Scholar] [CrossRef]
- Zhu, W.; Xie, L.; Han, J.; Guo, X. The Application of Deep Learning in Cancer Prognosis Prediction. Cancers 2020, 12, 603. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khan, S.; Yairi, T. A review on the application of deep learning in system health management. Mech. Syst. Signal Process. 2018. [Google Scholar] [CrossRef]
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.L.; Chen, S.C.; Iyengar, S.S. A survey on deep learning: Algorithms, techniques, and applications. ACM Comput. Surv. (CSUR) 2018. [Google Scholar] [CrossRef]
- Dargan, S.; Kumar, M.; Ayyagari, M.R.; Kumar, G. A Survey of Deep Learning and Its Applications: A New Paradigm to Machine Learning. Arch. Comput. Methods Eng. 2019, 1–22. [Google Scholar] [CrossRef]
- Mahmud, M.; Kaiser, M.S.; Hussain, A.; Vassanelli, S. Applications of Deep Learning and Reinforcement Learning to Biological Data. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2063–2079. [Google Scholar] [CrossRef] [Green Version]
- Gibson, K.; Förster, A. Black Tea Fermentation Dataset; Technical Report; Mendeley Ltd.: London, UK, 2020. [Google Scholar] [CrossRef]
- Barcelo-Ordinas, J.M.; Chanet, J.P.; Hou, K.M.; García-Vidal, J. A Survey of Wireless Sensor Technologies Applied to Precision Agriculture; Wageningen Academic Publishers: Wageningen, The Netherlands, 2013; pp. 801–808. [Google Scholar]
- Ghosh, S.; Tudu, B.; Bhattacharyya, N.; Bandyopadhyay, R. A recurrent Elman network in conjunction with an electronic nose for fast prediction of optimum fermentation time of black tea. Neural Comput. Appl. 2019, 31, 1165–1171. [Google Scholar] [CrossRef]
- Bhattacharyya, N.; Seth, S.; Tudu, B.; Tamuly, P.; Jana, A.; Ghosh, D.; Bandyopadhyay, R.; Bhuyan, M. Monitoring of black tea fermentation process using electronic nose. J. Food Eng. 2007, 80, 1146–1156. [Google Scholar] [CrossRef]
- Mohit Sharma, D.G.; Nabarun Bhattacharya. Electronic Nose—A new way for predicting the optimum point of fermentation of Black Tea. Int. J. Eng. Sci. Invent. 2012, 12, 56–60. [Google Scholar]
- Manigandan, N. Handheld Electronic Nose (HEN) for detection of optimum fermentation time during tea manufacture and assessment of tea quality. Int. J. Adv. Res. 2019, 7, 697–702. [Google Scholar] [CrossRef] [Green Version]
- Das, A.; Ghosh, T.K.; Ghosh, A.; Ray, H. An embedded Electronic Nose for identification of aroma index for different tea aroma chemicals. In Proceedings of the International Conference on Sensing Technology (ICST 2012), Kolkata, India, 18–21 December 2012; pp. 577–582. [Google Scholar] [CrossRef]
- Ai, S.; Wu, R.; Yan, L.; Wu, Y. Evaluation of taste quality in green tea infusion using electronic tongue combined with LS-SVM. In Advanced Materials Research; Trans Tech Publications Ltd.: Stäfa, Switzerland, 2011; Volume 301–303, pp. 1643–1647. [Google Scholar] [CrossRef]
- Zhong, Y.H.; Zhang, S.; He, R.; Zhang, J.; Zhou, Z.; Cheng, X.; Huang, G.; Zhang, J. A Convolutional Neural Network Based Auto Features Extraction Method for Tea Classification with Electronic Tongue. Appl. Sci. 2019, 9, 2518. [Google Scholar] [CrossRef] [Green Version]
- Lvova, L. Electronic Tongue Principles and Applications in the Food Industry. In Electronic Noses and Tongues in Food Science; Elsevier Inc.: Amsterdam, The Netherlands, 2016; pp. 151–160. [Google Scholar] [CrossRef]
- Li, H.; Zhang, B.; Hu, W.; Liu, Y.; Dong, C.; Chen, Q. Monitoring black tea fermentation using a colorimetric sensor array-based artificial olfaction system. J. Food Process. Preserv. 2018, 42, e13348. [Google Scholar] [CrossRef] [Green Version]
- Ghosh, A.; Sharma, P.; Tudu, B.; Sabhapondit, S.; Baruah, B.D.; Tamuly, P.; Bhattacharyya, N.; Bandyopadhyay, R. Detection of Optimum Fermentation Time of Black CTC Tea Using a Voltammetric Electronic Tongue. IEEE Trans. Instrum. Meas. 2015, 64, 2720–2729. [Google Scholar] [CrossRef]
- Zhi, R.; Zhao, L.; Zhang, D. A framework for the multi-level fusion of electronic nose and electronic tongue for tea quality assessment. Sensors 2017, 17, 1007. [Google Scholar] [CrossRef] [Green Version]
- Akuli, A.; Pal, A.; Dey, T.; Bej, G.; Santra, A.; Majumdar, S.; Bhattacharyya, N. Assessment of Black Tea Using Low-Level Image Feature Extraction Technique. In Proceedings of the Global AI Congress 2019; Springer: Singapore, 2020; pp. 453–467. [Google Scholar] [CrossRef]
- Dong, C.; Liang, G.; Hu, B.; Yuan, H.; Jiang, Y.; Zhu, H.; Qi, J. Prediction of Congou Black Tea Fermentation Quality Indices from Color Features Using Non-Linear Regression Methods. Sci. Rep. 2018, 8, 10535. [Google Scholar] [CrossRef] [Green Version]
- Binh, P.T.; Du, D.H.; Nhung, T.C. Control and Optimize Black Tea Fermentation Using Computer Vision and Optimal Control Algorithm. In Lecture Notes in Networks and Systems; Springer: Berlin/Heidelberg, Germany, 2020; Volume 104, pp. 310–319. [Google Scholar] [CrossRef]
- Saranka, S.; Thangathurai, K.; Wanniarachchi, C.; Wanniarachchi, W.K. Monitoring Fermentation of Black Tea with Image Processing Techniques. IPSL 2016, 32, 31–37. [Google Scholar]
- Kumar, A.; Singh, H.; Sharma, S.; Kumar, A. Color Analysis of Black Tea Liquor Using Image Processing Techniques. IJECT 2011, 2, 292–296. [Google Scholar]
- Ghosh, A.; Bag, A.K.; Sharma, P.; Tudu, B.; Sabhapondit, S.; Baruah, B.D.; Tamuly, P.; Bhattacharyya, N.; Bandyopadhyay, R. Monitoring the fermentation process and detection of optimum fermentation time of black tea using an electronic tongue. IEEE Sens. J. 2015, 15, 6255–6262. [Google Scholar] [CrossRef]
- Kim, Y.; Chung, M. An Approach to Hyperparameter Optimization for the Objective Function in Machine Learning. Electronics 2019, 8, 1267. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Wang, J.Z. Automatic linguistic indexing of pictures by a statistical modeling approach. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1075–1088. [Google Scholar] [CrossRef] [Green Version]
- Tylecek, R.; Fisher, R. Consistent Semantic Annotation of Outdoor Datasets via 2D/3D Label Transfer. Sensors 2018, 18, 2249. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fabijańska, A.; Sankowski, D. Image noise removal—The new approach. In Proceedings of the 2007 9th International Conference—The Experience of Designing and Applications of CAD Systems in Microelectronics, Lviv-Polyana, Ukraine, 19–24 February 2007; pp. 457–459. [Google Scholar] [CrossRef]
- Ahmad, K.; Khan, J.; Iqbal, M.S.U.D. A comparative study of different denoising techniques in digital image processing. In Proceedings of the 2019 8th International Conference on Modeling Simulation and Applied Optimization (ICMSAO 2019), Zallaq, Bahrain, 15–17 April 2019. [Google Scholar] [CrossRef]
- Mistry, Y.; Ingole, D.T.; Ingole, M.D. Content based image retrieval using hybrid features and various distance metric. J. Electr. Syst. Inf. Technol. 2017. [Google Scholar] [CrossRef]
- Yang, Y.G.; Zou, L.; Zhou, Y.H.; Shi, W.M. Visually meaningful encryption for color images by using Qi hyper-chaotic system and singular value decomposition in YCbCr color space. Optik 2020, 164422. [Google Scholar] [CrossRef]
- Alamgir, N.; Nguyen, K.; Chandran, V.; Boles, W. Combining multi-channel color space with local binary co-occurrence feature descriptors for accurate smoke detection from surveillance videos. Fire Saf. J. 2018, 102, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.H.; Han, D.; Yang, C.J.; Zhang, T.Y.; Yu, H.Q. Probing operational conditions of mixing and oxygen deficiency using HSV color space. J. Environ. Manag. 2019, 232, 985–992. [Google Scholar] [CrossRef]
- Garcia-Lamont, F.; Cervantes, J.; López, A.; Rodriguez, L. Segmentation of images by color features: A survey. Neurocomputing 2018, 292, 1–27. [Google Scholar] [CrossRef]
- Novak, C.L.; Shafer, S.A. Anatomy of a color histogram. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Champaign, IL, USA, 15–18 June 1992; Volume 1992-June, pp. 599–605. [Google Scholar] [CrossRef] [Green Version]
- Jung, H.; Koo, K.; Yang, H. Measurement-Based Power Optimization Technique for OpenCV on Heterogeneous Multicore Processor. Symmetry 2019, 11, 1488. [Google Scholar] [CrossRef] [Green Version]
- Saroja, G.A.S.; Sulochana, C.H. Texture analysis of non-uniform images using GLCM. In Proceedings of the 2013 IEEE Conference on Information and Communication Technologies (ICT 2013), Thuckalay, India, 11–12 April 2013; pp. 1319–1322. [Google Scholar] [CrossRef]
- Kumar, G.; Bhatia, P.K. A detailed review of feature extraction in image processing systems. In Proceedings of the International Conference on Advanced Computing and Communication Technologies (ACCT), Rohtak, India, 8–9 February 2014; pp. 5–12. [Google Scholar] [CrossRef]
- Preethi, G.; Sornagopal, V. MRI image classification using GLCM texture features. In Proceedings of the IEEE International Conference on Green Computing, Communication and Electrical Engineering (ICGCCEE 2014), Coimbatore, India, 6–8 March 2014. [Google Scholar] [CrossRef]
- Akanbi, O.A.; Amiri, I.S.; Fazeldehkordi, E.; Akanbi, O.A.; Amiri, I.S.; Fazeldehkordi, E. Chapter 4—Feature Extraction. In A Machine-Learning Approach to Phishing Detection and Defense; Syngress: Rockland, MA, USA, 2015; pp. 45–54. [Google Scholar] [CrossRef]
- Xiaofeng, F.; Wei, W. Centralized binary patterns embedded with image euclidean distance for facial expression recognition. In Proceedings of the 4th International Conference on Natural Computation (ICNC 2008), Jinan, China, 18–20 October 2008; Volume 4, pp. 115–119. [Google Scholar] [CrossRef]
- Saravanan, C. Color image to grayscale image conversion. In Proceedings of the 2010 2nd International Conference on Computer Engineering and Applications (ICCEA 2010), Bali Island, Indonesia, 19–21 March 2010; Volume 2, pp. 196–199. [Google Scholar] [CrossRef]
- EMC Education Services. Data Science & Big Data Analytics; John Wiley & Sons, Inc.: Indianapolis, IN, USA, 2015. [Google Scholar] [CrossRef]
- Dahan, H.; Cohen, S.; Rokach, L.; Maimon, O. Proactive Data Mining with Decision Trees; SpringerBriefs in Electrical and Computer Engineering; Springer: New York, NY, USA, 2014. [Google Scholar] [CrossRef]
- Navada, A.; Ansari, A.N.; Patil, S.; Sonkamble, B.A. Overview of use of decision tree algorithms in machine learning. In Proceedings of the 2011 IEEE Control and System Graduate Research Colloquium (ICSGRC 2011), Shah Alam, Malaysia, 27–28 June 2011; pp. 37–42. [Google Scholar] [CrossRef]
- Brunello, A.; Marzano, E.; Montanari, A.; Sciavicco, G. J48SS: A novel decision tree approach for the handling of sequential and time series data. Computers 2019, 8, 21. [Google Scholar] [CrossRef] [Green Version]
- Park, S.; Hamm, S.Y.; Kim, J. Performance Evaluation of the GIS-Based Data-Mining Techniques Decision Tree, Random Forest, and Rotation Forest for Landslide Susceptibility Modeling. Sustainability 2019, 11, 5659. [Google Scholar] [CrossRef] [Green Version]
- Alajali, W.; Zhou, W.; Wen, S.; Wang, Y. Intersection Traffic Prediction Using Decision Tree Models. Symmetry 2018, 10, 386. [Google Scholar] [CrossRef] [Green Version]
- Han, J.; Fang, M.; Ye, S.; Chen, C.; Wan, Q.; Qian, X. Using Decision Tree to Predict Response Rates of Consumer Satisfaction, Attitude, and Loyalty Surveys. Sustainability 2019, 11, 2306. [Google Scholar] [CrossRef] [Green Version]
- Al Hamad, M.; Zeki, A.M. Accuracy vs. cost in decision trees: A survey. In Proceedings of the 2018 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT 2018), Sakhier, Bahrain, 18–20 November 2018. [Google Scholar] [CrossRef]
- Feng, D.; Deng, Z.; Wang, T.; Liu, Y.; Xu, L. Identification of disturbance sources based on random forest model. In Proceedings of the 2018 International Conference on Power System Technology (POWERCON 2018), Guangzhou, China, 6–8 November 2018; pp. 3370–3375. [Google Scholar] [CrossRef]
- Samarakoon, P.N.; Promayon, E.; Fouard, C. Light Random Regression Forests for automatic multi-organ localization in CT images. In Proceedings of the International Symposium on Biomedical Imaging, Melbourne, Australia, 18–21 April 2017; pp. 371–374. [Google Scholar] [CrossRef] [Green Version]
- Georganos, S.; Grippa, T.; Gadiaga, A.; Vanhuysse, S.; Kalogirou, S.; Lennert, M.; Linard, C. An application of geographical random forests for population estimation in Dakar, Senegal using very-high-resolution satellite imagery. In Proceedings of the 2019 Joint Urban Remote Sensing Event (JURSE 2019), Vannes, France, 22–24 May 2019. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, L.; Gao, Y.; Yang, L. An improved random forest algorithm based on attribute compatibility. In Proceedings of the 2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC 2019), Chengdu, China, 15–17 March 2019; pp. 2558–2561. [Google Scholar] [CrossRef]
- Saffari, A.; Leistner, C.; Santner, J.; Godec, M.; Bischof, H. On-line random forests. In Proceedings of the IEEE 12th International Conference on Computer Vision Workshops (ICCV Workshops), Kyoto, Japan, 27 September–4 October 2009; pp. 1393–1400. [Google Scholar] [CrossRef]
- Kouzani, A.Z.; Nahavandi, S.; Khoshmanesh, K. Face classification by a random forest. In Proceedings of the TENCON 2007—2007 IEEE Region 10 Conference, Taipei, Taiwan, 30 October–2 November 2007. [Google Scholar] [CrossRef] [Green Version]
- More, A.S.; Rana, D.P. Review of random forest classification techniques to resolve data imbalance. In Proceedings of the 1st International Conference on Intelligent Systems and Information Management (ICISIM 2017), Aurangabad, India, 5–6 October 2017; Volume 2017-January, pp. 72–78. [Google Scholar] [CrossRef]
- Qunzhu, T.; Rui, Z.; Yufei, Y.; Chengyao, Z.; Zhijun, L. Improvement of random forest cascade regression algorithm and its application in fatigue detection. In Proceedings of the 2019 2nd International Conference on Electronics Technology (ICET 2019), Chengdu, China, 10–13 May 2019; pp. 499–503. [Google Scholar] [CrossRef]
- Patel, S.V.; Jokhakar, V.N. A random forest based machine learning approach for mild steel defect diagnosis. In Proceedings of the 2016 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC 2016), Chennai, India, 15–17 December 2016. [Google Scholar] [CrossRef]
- Xu, B.; Ye, Y.; Nie, L. An improved random forest classifier for image classification. In Proceedings of the IEEE International Conference on Information and Automation (ICIA 2012), Shenyang, China, 6–8 June 2012; pp. 795–800. [Google Scholar] [CrossRef]
- Alam, M.S.; Vuong, S.T. Random forest classification for detecting android malware. In Proceedings of the 2013 IEEE International Conference on Green Computing and Communications and IEEE Internet of Things and IEEE Cyber, Physical and Social Computing, Beijing, China, 20–23 August 2013; pp. 663–669. [Google Scholar] [CrossRef]
- Thanh Noi, P.; Kappas, M. Comparison of Random Forest, k-Nearest Neighbor, and Support Vector Machine Classifiers for Land Cover Classification Using Sentinel-2 Imagery. Sensors 2017, 18, 18. [Google Scholar] [CrossRef] [Green Version]
- Saadatfar, H.; Khosravi, S.; Joloudari, J.H.; Mosavi, A.; Shamshirband, S. A New K-Nearest Neighbors Classifier for Big Data Based on Efficient Data Pruning. Mathematics 2020, 8, 286. [Google Scholar] [CrossRef] [Green Version]
- Florimbi, G.; Fabelo, H.; Torti, E.; Lazcano, R.; Madroñal, D.; Ortega, S.; Salvador, R.; Leporati, F.; Danese, G.; Báez-Quevedo, A.; et al. Accelerating the K-Nearest neighbors filtering algorithm to optimize the real-time classification of human brain tumor in hyperspectral images. Sensors 2018, 18, 2314. [Google Scholar] [CrossRef] [Green Version]
- Fan, G.F.; Guo, Y.H.; Zheng, J.M.; Hong, W.C. Application of the Weighted K-Nearest Neighbor Algorithm for Short-Term Load Forecasting. Energies 2019, 12, 916. [Google Scholar] [CrossRef] [Green Version]
- Aldayel, M.S. K-Nearest Neighbor classification for glass identification problem. In Proceedings of the International Conference on Computer Systems and Industrial Informatics (ICCSII), Sharjah, UAE, 18–20 December 2012. [Google Scholar] [CrossRef]
- Viswanath, P.; Hitendra Sarma, T. An improvement to k-nearest neighbor classifier. In Proceedings of the IEEE Recent Advances in Intelligent Computational Systems (RAICS), Trivandrum, India, 22–24 September 2011; pp. 227–231. [Google Scholar] [CrossRef] [Green Version]
- Sun, S.; Huang, R. An adaptive k-nearest neighbor algorithm. In Proceedings of the 2010 7th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Yantai, China, 10–12 August 2010; Volume 1, pp. 91–94. [Google Scholar] [CrossRef]
- Zhang, S.; Li, X.; Zong, M.; Zhu, X.; Wang, R. Efficient kNN classification with different numbers of nearest neighbors. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 1774–1785. [Google Scholar] [CrossRef]
- Jayaraman, P.P.; Zaslavsky, A.; Delsing, J. Intelligent processing of K-nearest neighbors queries using mobile data collectors in a location aware 3D wireless sensor network. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2010; Volume 6098, pp. 260–270. [Google Scholar] [CrossRef]
- Cord, A.; Chambon, S. Automatic Road Defect Detection by Textural Pattern Recognition Based on AdaBoost. Comput.-Aided Civ. Infrastruct. Eng. 2012, 27, 244–259. [Google Scholar] [CrossRef]
- Roth, H.R.; Farag, A.; Lu, L.; Turkbey, E.B.; Summers, R.M. Deep convolutional networks for pancreas segmentation in CT imaging. Med. Imaging 2015 Image Process. 2015, 9413, 94131G. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Wu, B.; Yang, S.; Wang, Z. Road Damage Detection and Classification with Faster R-CNN. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data 2018), Seattle, WA, USA, 10–13 December 2018; pp. 5220–5223. [Google Scholar] [CrossRef]
- Radopoulou, S.C.; Brilakis, I. Automated Detection of Multiple Pavement Defects. J. Comput. Civ. Eng. 2017, 31. [Google Scholar] [CrossRef] [Green Version]
- Chen, Q.; Fu, Y.; Song, W.; Cheng, K.; Lu, Z.; Zhang, C.; Li, L. An Efficient Streaming Accelerator for Low Bit-Width Convolutional Neural Networks. Electronics 2019, 8, 371. [Google Scholar] [CrossRef] [Green Version]
- Véstias, M.P. A Survey of Convolutional Neural Networks on Edge with Reconfigurable Computing. Algorithms 2019, 12, 154. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Ma, Y.; Ren, G. A Convolutional Neural Network with Fletcher–Reeves Algorithm for Hyperspectral Image Classification. Remote Sens. 2019, 11, 1325. [Google Scholar] [CrossRef] [Green Version]
- Song, J.; Gao, S.; Zhu, Y.; Ma, C. A survey of remote sensing image classification based on CNNs. Big Earth Data 2019, 3, 232–254. [Google Scholar] [CrossRef]
- Cire\csan, D.C.; Meier, U.; Masci, J.; Gambardella, L.M.; Schmidhuber, J. Flexible, High Performance Convolutional Neural Networks for Image Classification. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence (IJCAI’11), Barcelona, Catalonia, Spain, 16–22 July 2011; Volume Two, pp. 1237–1242. [Google Scholar]
- Paoletti, M.; Haut, J.; Plaza, J.; Plaza, A. Deep&Dense Convolutional Neural Network for Hyperspectral Image Classification. Remote Sens. 2018, 10, 1454. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.; Mohamed, A.R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Elaidi, H.; Elhaddar, Y.; Benabbou, Z.; Abbar, H. An idea of a clustering algorithm using support vector machines based on binary decision tree. In Proceedings of the 2018 International Conference on Intelligent Systems and Computer Vision (ISCV 2018), Fez, Morocco, 2–4 April 2018; Volume 2018-May, pp. 1–5. [Google Scholar] [CrossRef]
- Chao, C.F.; Horng, M.H. The construction of support vector machine classifier using the firefly algorithm. Comput. Intell. Neurosci. 2015, 2015. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Tong, X. Fuzzy clustering multiple kernel support vector machine. In Proceedings of the International Conference on Wavelet Analysis and Pattern Recognition, Chengdu, China, 15–18 July 2018; Volume 2018-July, pp. 7–12. [Google Scholar] [CrossRef]
- Shahbudin, S.; Zamri, M.; Kassim, M.; Abdullah, S.A.C.; Suliman, S.I. Weed classification using one class support vector machine. In Proceedings of the 2017 International Conference on Electrical, Electronics and System Engineering (ICEESE 2017), Kanazawa, Japan, 9–10 November 2017; Volume 2018-January, pp. 7–10. [Google Scholar] [CrossRef]
- Kranjčić, N.; Medak, D.; Župan, R.; Rezo, M. Support Vector Machine Accuracy Assessment for Extracting Green Urban Areas in Towns. Remote Sens. 2019, 11, 655. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Peng, J.; Yu, Q.; Chen, Y.; Yu, H. Support Vector Machine Algorithm for Automatically Identifying Depositional Microfacies Using Well Logs. Sustainability 2019, 11, 1919. [Google Scholar] [CrossRef] [Green Version]
- Karthika, S.; Sairam, N. A Naïve Bayesian classifier for educational qualification. Indian J. Sci. Technol. 2015, 8. [Google Scholar] [CrossRef] [Green Version]
- Walia, H.; Rana, A.; Kansal, V. A Naïve Bayes Approach for working on Gurmukhi Word Sense Disambiguation. In Proceedings of the 2017 6th International Conference on Reliability, Infocom Technologies and Optimization: Trends and Future Directions (ICRITO 2017), Noida, India, 20–22 September 2017; Volume 2018-January, pp. 432–435. [Google Scholar] [CrossRef]
- Jahromi, A.H.; Taheri, M. A non-parametric mixture of Gaussian naive Bayes classifiers based on local independent features. In Proceedings of the 19th CSI International Symposium on Artificial Intelligence and Signal Processing (AISP 2017), Shiraz, Iran, 25–27 October 2017; Volume 2018-January, pp. 209–212. [Google Scholar] [CrossRef]
- Harahap, F.; Harahap, A.Y.N.; Ekadiansyah, E.; Sari, R.N.; Adawiyah, R.; Harahap, C.B. Implementation of Naïve Bayes Classification Method for Predicting Purchase. In Proceedings of the 2018 6th International Conference on Cyber and IT Service Management (CITSM 2018), Parapat, Indonesia, 7–9 August 2018. [Google Scholar] [CrossRef]
- Dewi, Y.N.; Riana, D.; Mantoro, T. Improving Naïve Bayes performance in single image pap smear using weighted principal component analysis (WPCA). In Proceedings of the 3rd International Conference on Computing, Engineering, and Design (ICCED 2017), Kuala Lumpur, Malaysia, 23–25 November 2017; Volume 2018-March, pp. 1–5. [Google Scholar] [CrossRef]
- Zhao, H.; Wang, Z.; Nie, F. A New Formulation of Linear Discriminant Analysis for Robust Dimensionality Reduction. IEEE Trans. Knowl. Data Eng. 2019, 31, 629–640. [Google Scholar] [CrossRef]
- Singh, A.; Prakash, B.S.; Chandrasekaran, K. A comparison of linear discriminant analysis and ridge classifier on Twitter data. In Proceedings of the IEEE International Conference on Computing, Communication and Automation (ICCCA 2016), Noida, India, 29–30 April 2016; pp. 133–138. [Google Scholar] [CrossRef]
- Jerkovic, V.M.; Kojic, V.; Popovic, M.B. Linear discriminant analysis: Classification of on-surface and in-air handwriting. In Proceedings of the 2015 23rd Telecommunications Forum (TELFOR 2015), Belgrade, Serbia, 24–26 November 2015; pp. 460–463. [Google Scholar] [CrossRef]
- Ghosh, J.; Shuvo, S.B. Improving Classification Model’s Performance Using Linear Discriminant Analysis on Linear Data. In Proceedings of the 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT 2019), Kanpur, India, 6–8 July 2019. [Google Scholar] [CrossRef]
- Shashoa, N.A.A.; Salem, N.A.; Jleta, I.N.; Abusaeeda, O. Classification depend on linear discriminant analysis using desired outputs. In Proceedings of the 2016 17th International Conference on Sciences and Techniques of Automatic Control and Computer Engineering (STA 2016), Sousse, Tunisia, 19–21 December 2016; pp. 328–332. [Google Scholar] [CrossRef]
- Markopoulos, P.P. Linear Discriminant Analysis with few training data. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, New Orleans, LA, USA, 5–9 March 2017; pp. 4626–4630. [Google Scholar] [CrossRef]
- Sun, J.; Cai, X.; Sun, F.; Zhang, J. Scene image classification method based on Alex-Net model. In Proceedings of the 2016 3rd International Conference on Informative and Cybernetics for Computational Social Systems (ICCSS 2016), Jinzhou, China, 26–29 August 2016; pp. 363–367. [Google Scholar] [CrossRef]
- Kim, P. MATLAB Deep Learning: With Machine Learning, Neural Networks and Artificial Intelligence; Apress: New York, NY, USA, 2017; p. 162. [Google Scholar] [CrossRef]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the Importance of Initialization and Momentum in Deep Learning. In Proceedings of the 30th International Conference on International Conference on Machine Learning (ICML’13), Atlanta, GA, USA, 16–21 June 2013; Volume 28, pp. III–1139–III–1147. [Google Scholar]
- Dubosson, F.; Bromuri, S.; Schumacher, M. A python framework for exhaustive machine learning algorithms and features evaluations. In Proceedings of the International Conference on Advanced Information Networking and Applications (AINA), Crans-Montana, Switzerland, 23–25 March 2016; Volume 2016, pp. 987–993. [Google Scholar] [CrossRef]
- Samal, B.R.; Behera, A.K.; Panda, M. Performance analysis of supervised machine learning techniques for sentiment analysis. In Proceedings of the 2017 3rd IEEE International Conference on Sensing, Signal Processing and Security (ICSSS 2017), Chennai, India, 4–5 May 2017; pp. 128–133. [Google Scholar] [CrossRef]
- Tohid, R.; Wagle, B.; Shirzad, S.; Diehl, P.; Serio, A.; Kheirkhahan, A.; Amini, P.; Williams, K.; Isaacs, K.; Huck, K.; et al. Asynchronous execution of python code on task-based runtime systems. In Proceedings of the ESPM2 2018: 4th International Workshop on Extreme Scale Programming Models and Middleware, Held in conjunction with SC 2018: The International Conference for High Performance Computing, Networking, Storage and Analysis, Dallas, TX, USA, 12 November 2018; pp. 37–45. [Google Scholar] [CrossRef] [Green Version]
- Stancin, I.; Jovic, A. An overview and comparison of free Python libraries for data mining and big data analysis. In Proceedings of the 2019 42nd International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO 2019), Opatija, Croatia, 20–24 May 2019; pp. 977–982. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. arXiv 2016, arXiv:1605.08695. [Google Scholar]
- Fahad, S.K.; Yahya, A.E. Big Data Visualization: Allotting by R and Python with GUI Tools. In Proceedings of the 2018 International Conference on Smart Computing and Electronic Enterprise (ICSCEE 2018), Shah Alam, Malaysia, 11–12 July 2018. [Google Scholar] [CrossRef]
- Baker, B.; Pan, L. Overview of the Model and Observation Evaluation Toolkit (MONET) Version 1.0 for Evaluating Atmospheric Transport Models. Atmosphere 2017, 8, 210. [Google Scholar] [CrossRef] [Green Version]
- Hung, H.C.; Liu, I.F.; Liang, C.T.; Su, Y.S. Applying Educational Data Mining to Explore Students’ Learning Patterns in the Flipped Learning Approach for Coding Education. Symmetry 2020, 12, 213. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Zeng, Z.; Gong, Q.; Zhang, J. CNN model design of gesture recognition based on tensorflow framework. In Proceedings of the 2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC 2019), Chengdu, China, 15–17 March 2019; pp. 1062–1067. [Google Scholar] [CrossRef]
- Li, G.; Liu, Z.; Cai, L.; Yan, J. Standing-Posture Recognition in Human–Robot Collaboration Based on Deep Learning and the Dempster–Shafer Evidence Theory. Sensors 2020, 20, 1158. [Google Scholar] [CrossRef] [Green Version]
- Momm, H.G.; ElKadiri, R.; Porter, W. Crop-Type Classification for Long-Term Modeling: An Integrated Remote Sensing and Machine Learning Approach. Remote Sens. 2020, 12, 449. [Google Scholar] [CrossRef] [Green Version]
- Kosmopoulos, A.; Partalas, I.; Gaussier, E.; Paliouras, G.; Androutsopoulos, I. Evaluation Measures for Hierarchical Classification: A unified view and novel approaches. Data Min. Knowl. Discov. 2013. [Google Scholar] [CrossRef]
- Flach, P. Performance Evaluation in Machine Learning: The Good, the Bad, the Ugly, and the Way Forward. Proc. AAAI Conf. Artif. Intell. 2019, 33, 9808–9814. [Google Scholar] [CrossRef]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2018. [Google Scholar] [CrossRef]
- Hai, M.; Zhang, Y.; Zhang, Y. A Performance Evaluation of Classification Algorithms for Big Data. Procedia Comput. Sci. 2017, 122, 1100–1107. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rank | Country | Percentage |
|---|---|---|
| 1 | China | 20.6% |
| 2 | Sri Lanka | 19.3% |
| 3 | Kenya | 18.2% |
| 4 | India | 7.5% |
| Class | Images Used for Training | Images Used for Validation | Images Used for Testing |
|---|---|---|---|
| Underfermented | 1600 | 40 | 360 |
| Fermented | 1600 | 40 | 360 |
| Overfermented | 1600 | 40 | 360 |
| Total | 4800 | 120 | 1080 |
| Class | Images Used for Training | Images Used for Validation | Images Used for Testing |
|---|---|---|---|
| Coast | 717 | 18 | 161 |
| Forest | 717 | 18 | 161 |
| Highway | 717 | 18 | 161 |
| Total | 2151 | 54 | 483 |
| Layer | Parameter | Activation Function |
|---|---|---|
| input | 150 × 150 × 3 | — |
| Convolution1 (Conv1) | 32 convolution filters (11 × 11), 4 stride | ReLU |
| Pooling1 (Pool1) | Max pooling (3 × 3) 2 stride | — |
| Convolution2 (Conv2) | 64 convolution filters (3 × 3), 1 stride | ReLU |
| Pooling2 (Pool2) | Max pooling (2 × 2) 2 stride | — |
| Convolution3 (Conv3) | 128 convolution filters (3 × 3), 3 stride | ReLU |
| Pooling3 (Pool3) | Max pooling (2 × 2) 2 stride | — |
| Full Connect4 (fc4) | 512 nodes, 1 stride | ReLU |
| Full Connect5 (fc5) | 128 nodes, 1 stride | ReLU |
| Full Connect5 (fc6) | 3 nodes, 1 stride | ReLU |
| Output | 1 node | Softmax |
| Class | Fermented | Overfermented | Underfermented | Sensitivity |
|---|---|---|---|---|
| DT (fermented) | 250 | 32 | 78 | 69.4% |
| DT (overfermented) | 59 | 301 | 0 | 83.6% |
| DT (underfermented) | 271 | 0 | 89 | 75.3% |
| SVM (fermented) | 296 | 22 | 39 | 82.2% |
| SVM (overfermented) | 68 | 291 | 1 | 80.8% |
| SVM (underfermented) | 61 | 0 | 299 | 83.1% |
| KNN (fermented) | 339 | 14 | 7 | 94.2% |
| KNN (overfermented) | 41 | 300 | 19 | 83.3% |
| KNN (underfermented) | 17 | 0 | 343 | 95.3% |
| LDA (fermented) | 331 | 11 | 18 | 92.0 % |
| LDA (overfermented) | 17 | 335 | 8 | 93.3% |
| LDA (underfermented) | 76 | 0 | 284 | 78.9% |
| RF (fermented) | 325 | 14 | 21 | 90.3% |
| RF (overfermented) | 50 | 310 | 0 | 86.1% |
| RF (underfermented) | 45 | 0 | 315 | 87.5% |
| NB (fermented) | 261 | 19 | 80 | 72.5% |
| NB (overfermented) | 89 | 253 | 19 | 70.3% |
| NB (under fermented) | 96 | 0 | 264 | 73.3% |
| TeaNet (fermented) | 360 | 0 | 0 | 100.0% |
| TeaNet (overfermented) | 0 | 360 | 0 | 100.0% |
| TeaNet (underfermented) | 0 | 0 | 360 | 100.0% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kimutai, G.; Ngenzi, A.; Said, R.N.; Kiprop, A.; Förster, A. An Optimum Tea Fermentation Detection Model Based on Deep Convolutional Neural Networks. Data 2020, 5, 44. https://doi.org/10.3390/data5020044
Kimutai G, Ngenzi A, Said RN, Kiprop A, Förster A. An Optimum Tea Fermentation Detection Model Based on Deep Convolutional Neural Networks. Data. 2020; 5(2):44. https://doi.org/10.3390/data5020044
Chicago/Turabian StyleKimutai, Gibson, Alexander Ngenzi, Rutabayiro Ngoga Said, Ambrose Kiprop, and Anna Förster. 2020. "An Optimum Tea Fermentation Detection Model Based on Deep Convolutional Neural Networks" Data 5, no. 2: 44. https://doi.org/10.3390/data5020044
APA StyleKimutai, G., Ngenzi, A., Said, R. N., Kiprop, A., & Förster, A. (2020). An Optimum Tea Fermentation Detection Model Based on Deep Convolutional Neural Networks. Data, 5(2), 44. https://doi.org/10.3390/data5020044