1. Introduction
Bioprocessing, as with many other manufacturing industries, is at the cusp of an industry-wide shift toward the integration of data-driven approaches for the development of new techniques and the optimization of state-of-the-art approaches. These changes are commonly referred to as Industry 4.0. Industry 4.0 is defined as “the integration of intelligent digital technologies into manufacturing and industrial processes”. This includes the integration of cloud computing, the Internet of Things (IoT), data analytics, machine learning, and deep learning technologies with production facilities to optimize manufacturing processes. This paper focuses on how data-driven approaches, including machine learning (ML) and deep learning (DL), are integrated within the biopharmaceutical industry and how different approaches are used to create safe, effective, and efficient biopharmaceutical products. Specifically, this paper focuses on the use and potential use of ML and DL strategies for the bioprocess optimization of Chinese hamster ovary (CHO) cell cultures. This review provides a novel synopsis of the state-of-the-art concerning data-driven approaches and ML/DL for CHO cell bioprocesses, whereas other reviews have documented a more general overview, focusing on multiple cell types and bioprocess applications or more narrowly focusing on specific types of ML/DL [
1]. Currently, CHO cell cultures are used for recombinant protein expression, which is one of the main components of drug manufacturing [
2]. CHO cells are the industry gold standard due to their capability for post-translational modifications, as well as established standards of good manufacturing practices, compared with other mammalian cells. However, relatively low cell densities, slow growth rate, and low productivity create obstacles for manufacturers due to high demand. These issues affect the entire supply chain and contribute to high manufacturing costs and pricing for these drugs. ML approaches can improve these issues through the implementation of predictive models, data-driven control, and generative artificial intelligence approaches [
3].
Within manufacturing processes utilizing CHO cells, fed-batch bioprocesses are the most widely accepted method for feeding and process control due to industrial familiarity and the advantage of incrementally adding in nutrients, buffers, amino acids, and vitamins [
4]. These processes have enabled the scalable production of recombinant proteins, monoclonal antibodies, vaccines, and cell-based therapies for various biomedical applications, especially recombinant protein-based pharmaceutical processes of which CHO cell-based products comprise 70% of revenue-generating products [
5,
6]. The advancement of ML and DL techniques in CHO cell biomanufacturing processes is poised to provide immediate impact within the biopharmaceutical industry, including the improvement of productivity and efficiency and enabling promising new techniques such as continuous biomanufacturing through perfusion cultures.
2. Summary of Common Machine Learning and Deep Learning Approaches
While often used in similar contexts, there exists a difference between machine learning and deep learning. Machine learning (ML) is the capability of a trained machine or model to imitate human behavior and intelligence. Within ML exists the concept of artificial neural networks (ANNs). Data flow through network nodes from the input layer, where the data are fed into the output layer. Deep learning (DL) is a more specific subset of machine learning that involves the use of neural networks with multiple (two or more) hidden layers that derive often unclear connections between inputs and outputs, whereas architectures that consist of a single hidden layer are defined as shallow multi-layer neural networks. These are inspired by the human brain’s neural structure. These neural structures comprise multiple layers, which can allow for learning and training based on specific tasks, such as image or speech recognition [
2]. DL models are often referred to as “black-box” models because relationships between inputs and outputs made within the hidden layers are either unknown or unintelligible to end users. However, there is significant research focused on implementing explainable AI (XAI) in which ante-hoc or post hoc algorithmic additions are made for black-box models to provide intuitive connections between inputs, model decisions, and outputs [
7].
The application of ML and DL within bioprocesses serves as an augmentation to the traditional design of experiments (DoEs) approaches. These approaches have been crucial for optimizing various parameters and improving protein yields. While traditional DoE methods involve systematically changing variables and observing outcomes, ML and DL can complement this by analyzing large amounts of data more comprehensively and identifying patterns or relationships that might not be immediately apparent. Rodriguez-Granrose et al. and colleagues have discussed the integration of DoE with artificial neural network architecture [
8].
A DoE approach was used with an artificial neural network for optimizing a bioprocess for cell growth. The system used the design of an experimental approach to find optimal bioprocess set points or, in this case, variables and ANNs were used to model and improve the accuracy of the bioprocess model beyond the capabilities of traditional regression models. The process involved the identification of key variables (cell line, seeding density, media supplement percentage, and media exchange percentage) that have a significant impact on the bioprocess (cell growth). These variables are systematically explored using DoE to determine the most optimal condition for the cell growth process. Since ANNs are trained on experimental data to create a predictive model that has the ability to identify the process more accurately, they are preferred over regression models. This hybrid model outperformed both a standard linear regression model as well as an unoptimized neural network.
Figure 1 represents the optimal ANN that is comprised of 91 functions in a single layer for cell growth modeling. Equal weightage to all four model output functions was provided. As a result, the maximum desirable ANN was determined to be a 1-layer Gaussian ANN. This was also tested in vitro, and the ANN-derived optimal process conditions resulted in 11.2% higher cell doublings as opposed to the linear regression model and 42.2% higher cell doublings compared to the original “one-factor-at-a-time” experimental condition. This hybrid method of ANN-DOE efficiently leverages the artificial neural network to improve bioprocess outcomes that were previously not possible with linear regression itself [
8]. Although this demonstration was not specifically performed on CHO cells, primary cells from the nucleus pulposus tissue of human cadavers, implications for the way that ANN can be leveraged to advance mammalian cell culture productivity are still relevant for CHO-derived recombinant protein bioprocesses. For example, the work of Pinto and coworkers evaluated shallow versus deep neural networks, varying the number of layers between 3 and 5 in a feed-forward neural network (FFNN) using the CHO K-1 cell line [
9]. Overall, this work showed that errors were reduced by 14% and 23.6%, respectively, as the number of hidden layers increased, revealing an overall improvement in model accuracy in deep models versus shallow models. However, computational time increased by more than 30%, indicating an important consideration for leveraging ANNs in real-world industrial processes.
2.1. Machine Learning in Biopharmaceutical Manufacturing
Within ML, two major paradigms exist for model-based approaches and supervised and unsupervised learning. Supervised learning (SL) is a class wherein the models are trained on labeled datasets, where the algorithm learns to map input features to known output labels [
10]. In the context of Chinese hamster ovary cells, various models relating to neural networks have been deployed for predictive modeling. For instance, Hisada et al. utilized the LASSO (Least Absolute Shrinkage and Shrinkage Operator) model, which specialized in predictive score metrics and anomaly detection to predict monoclonal antibody (mAb) productivity changes in CHO cells based on morphological profiles [
11]. They constructed the LASSO model using 368 morphological parameters as explanatory variables to achieve high accuracy in predicting mAb productivity simply from morphological profiles [
11]. This work developed a methodology to predict changes in antibody production in CHO cells using morphological profiling techniques. The researchers optimized an image acquisition pipeline to capture stable morphological profiles of suspension cells and utilized specific morphological parameters for anomaly prediction calculations. By combining morphological profiling with machine learning, the researchers successfully predicted mAb productivity changes solely from early morphological profiles, demonstrating the potential for the non-invasive and quantitative evaluation of subtle quality changes in host cells [
11].
In the context of bioprocess engineering relating to specific cell culture types, various forms of machine learning have been used for predicting outcomes based on historical data, such as optimizing nutrient concentrations for maximum cell growth, cell density, and protein yield [
12]. Unsupervised learning (UL) involves exploring various data patterns without labeled information. These techniques are often applied to clustering similar batches or samples for the identification of process variable anomalies or the self-organization of data, thus assisting qualitative control mechanisms [
12].
From a more fundamental standpoint, most ML algorithms can be broken down into two categories: deterministic or probabilistic. Deterministic models are usually well-defined, rule-based algorithms that provide the same model output each time for a particular set of inputs. One example of a Boolean-based deterministic model is the decision tree [
13,
14,
15], which has been successfully applied in the optimization of the fermentation process and the identification of fermentation parameters. However, the downside of deterministic models is that they do not account for the inherent variability that may be in a system. In Kumar et al.’s work, regression models have been employed to analyze and optimize bioprocessing unit operations [
16].
2.2. Deep Neural Networks in Biopharmaceutical Manufacturing
Neural networks consist of interconnected nodes which process information in different layers. Neural networks are inspired by the human brain, which consists of more than several billion neurons that segregate into three parts: dendrites, soma, and axons [
17]. The primary function of these three components is to receive, transmit, and connect information from one neuron to another.
In the context of biopharmaceutical manufacturing, deep neural networks are used for optimal glycosylation analysis in CHO cells. For instance, Kotidis et al. and colleagues utilized deep neural networks to predict the glycosylation outcomes of monoclonal antibodies produced in CHO cells. By training the ANN model with experimental data on intracellular nucleotide sugar dynamics and extracellular metabolite concentrations, they accurately predicted site-specific glycoform distributions. The ANN model successfully captured the effects of metabolic perturbations, manganese supplementation, and glycosyltransferase knockouts on glycosylation outcomes, showcasing its potential for optimizing glycosylation processes in CHO cell production. Neural networks were crucial in this study for accurately predicting site-specific glycoform distributions of recombinant glycoproteins in CHO cells, offering a data-driven approach that requires minimal biological background knowledge and enables rapid model development for optimizing glycosylation processes, thus enhancing manufacturing efficiency [
18].
Similarly, Antonakoudis et al. developed a hybrid modeling framework that combines mechanistic information in the form of a stoichiometric model with a deep artificial neural network to predict antibody glycosylation patterns in Chinese hamster ovary cells [
19]. By training the neural network with data on bioprocess variables such as metabolite fluxes, cell culture parameters, antibody quality parameters, and glycosylation pathways, the researchers leveraged deep neural network principles to enhance the prediction of product quality (glycan distribution) in bioprocesses involving CHO cells. Within the biopharmaceutical context, these networks can be used for various tasks, such as process optimization based on feed data, quality prediction based on previous attributes, and overall process efficiency due to their predictive and qualitative nature [
20].
2.2.1. Recurrent Neural Networks
Recurrent neural networks (RNNs) are used to model temporal dependencies, such as biomass concentration, pH, and temperature in bioprocess data, which capture sequential patterns such as fermentation dynamics. They have the ability to play a significant role in optimizing biopharmaceutical upstream processes by providing reliable estimates for key process parameters and enabling the study of growth and metabolite-related outcomes over time. RNNs are also used for the prediction of process outcomes and the control of upstream processes. By leveraging historical data and learning patterns from past observations, RNNs can forecast future processing behavior and help make informed decisions for process optimization.
For instance, Smiatek et al. and colleagues harnessed the power of recurrent neural networks (RNNs) to effectively model and predict the behavior of CHO cells in biopharmaceutical upstream processes. Through the development of specific and generic RNN models, they have been able to analyze complex temporal data patterns associated with CHO cell growth, metabolite concentrations, and product titers. By leveraging the capabilities of RNNs, the researchers gained valuable insights into how different process conditions impact CHO cell performance, enabling informed decision-making for process optimization in biopharmaceutical manufacturing. Recurrent neural networks are crucial in this study for their ability to effectively model and predict the dynamic temporal sequences of key process parameters in biopharmaceutical upstream processes involving CHO cells [
21]. The high predictive accuracy and flexibility of RNN models have proven instrumental in capturing the dynamic nature of CHO cell-based bioprocesses and facilitating advancements in biopharmaceutical development. As these variables are classified as temporal dependencies, RNNs are suitable for capturing the sequential nature of these variables and can be trained to predict future anomalies. This is pivotal for the prediction and optimization of time-dependent variables in bioprocessing [
22].
2.2.2. Convolutional Neural Networks
A convolutional neural network (CNN) is a type of neural network that is designed specifically for processing structured grid-like data, such as images or sequences. It has multiple layers, including convolutional layers. Convolutional neural networks excel in extracting spatial features, making them valuable for image-based bioprocess monitoring, and can be applied to analyze the microscopic images of cell cultures, which assists in identifying irregularities and optimizing growth conditions [
23].
For example, Wang et al. utilized the concept of in situ microscopic imaging and deep learning-based image analysis to monitor and analyze the culture process of Chinese hamster ovary (CHO) cells [
24]. They employed a deep learning-based Mask R-CNN algorithm for the segmentation and analysis of online pre-collected images from the suspension culture of CHO cells. The researchers used three different methods of data augmentation and transfer learning technology to improve the performance of the model.
As depicted in
Figure 2, CHO cells have been cultured inside a bioreactor along with a vision probe. The monitor displays the collected images together with the image analysis result. The in situ microscope, equipped with an imaging system and connected to a computer, captures cell images in real-time during the cell culture process. These images are then subjected to deep learning-based image analysis using the Mask R-CNN algorithm, allowing for the accurate segmentation and analysis of the cells. The deep learning method, trained by 183,040 labeled cells of 184 images, effectively-recognized cells within clusters. This approach outperforms traditional methods in terms of common image-based evaluation methods. The researchers analyzed the temporal variations in cell dimensions and shapes, indicating that the majority of cells are approximately spherical, with their average diameter increasing throughout the culture process [
24].
Convolutional neural networks (CNNs) have been specifically used in the context of CHO cells to train the Mask R-CNN algorithm for cell segmentation and analysis. This deep learning-based approach has demonstrated promising performance in accurately identifying and quantifying cell characteristics, providing valuable insights into the culture process of CHO cells. Apart from cell culture image analysis, CNNs can be trained to analyze these microscopic images to assess the viability and metabolic activity of microbial cells during fermentation processes, contamination detection, yield prediction, and image-based scale-up optimization [
25].
2.2.3. Generative Artificial Intelligence
Generative models are a subset of machine learning models that are specifically designed to generate new, synthetic data that resemble a given set of training examples. Unlike discriminative models, which focus on classifying or predicting labels, generative models learn the underlying distribution of the training data and can generate new samples from that distribution [
6]. One such type is the generative adversarial networks (GANs) comprised of a generator and a discriminator neural network. While the discriminator attempts to distinguish between real and generated samples. The generator attempts to create realistic data. With the help of adversarial training, GANs improve over time, thus generating increasingly convincing synthetic data. cGANs, otherwise known as conditional generative adversarial networks, are one step ahead by introducing a conditioning variable [
26]. By associating the conditioning variable with factors like loading or the environment, cGANs are valuable for modeling different structural behaviors. The cGANs learn and replicate the data’s underlying distribution, enabling applications in data augmentation and uncovering complex relationships within structures. In bioprocessing, generative neural networks have been employed for generating synthetic data that can mimic the characteristics of real bioprocess data, which helps in augmenting limited datasets and facilitates model training in diverse situations [
27].
3. Bioprocess Data and ML/DL Targets
Bioprocess data are typically collected within a time series, where the targeted data are collected at predetermined time increments, with the intention of using these collected values to inform process control, predict future values, or detect anomalies within the process. The parameters that are typically monitored during bioprocesses include several online and offline parameters. Online parameters include controlled variables, such as pH, dissolved oxygen (DO), and the media and feed rates in fed-batch and continuous processes. These online variables can be manipulated by cellular processes (waste generation, apoptosis, growth, replication, etc.) but also by control variables such as base addition (controls pH), stir speed (controls DO), and gas flow (which controls/balances off-gas measurements). Offline variables are taken from samples throughout the culture process and include parameters such as viable cell density (VCD), metabolite concentrations, and protein titer. Several commercial instruments are available to measure these parameters, such as the Cedex BioAnalyzer (Roche; Basel, Switzerland), Octet (ForteBio; Fremont, CA, USA), or BioProfile® FLEX2 (NOVA Medical; Waltham, MA, USA).
Within biomanufacturing, there are three approaches that are utilized to produce biopharmaceuticals and other products as follows: batch, fed-batch, and continuous approaches. The mode of the process is chosen based on factors such as the needs of the host organism, efficiency concerns, and product demand. In a batch bioprocess, the process is conducted in a single batch; thus, all the feed and other substances that are necessary for product production are added at the beginning of the batch, and then the product is harvested once the process is complete. These processes are simple in comparison to the other modes; however, they are not as commonly performed due to the extensive time needed to complete a batch, as well as the frequent need to repeat batches to acquire the desired product yield. Fed-batch bioprocessing is a derivation of batch processes in that raw materials and other substances are added to the bioreactor at the beginning of the process, but additional nutrients (including feeds and supplements) are also added during the process. This method is an improvement from batch processes because it allows greater control of cell growth and product yield. The continuous method of biomanufacturing is denoted by the lack of distinct batches within a process. The raw materials and needed supplements are systematically added until the process is manually ended. This method is typically chosen when there is high demand for the product due to its high throughput nature. One of the major benefits of continuous processes that have led many researchers to push for it to become the standard of biomanufacturing is that it can reduce manufacturing costs due to its capability of using more compact laboratories and other facilities [
28,
29]. Another advantage of continuous biomanufacturing is that it provides improved quality control. For example, Bayer has developed continuous bioreactor technology that minimizes the product residence time such that it does not remain in non-ideal conditions (such as temperatures where degrading enzymes are more active) for long periods of time [
30]. Although this methodology shows promise, there are still certain drawbacks that have prevented it from becoming more mainstream in the biopharmaceutical industry. One of the most glaring issues is the need for cell retention devices; these can add operational complexity [
31]. Cell densities are significantly higher within continuous processes; thus, the cells require particular attention to prevent the culture from depleting resources [
31], and there is a risk of CO
2 and other byproduct accumulation [
28]. Without proper attention to process controls, the system can become overwhelmed and lead to failed cultures.
Online process control parameters are typically set at the beginning of an experiment but can be adjusted throughout the process according to necessities that may arise due to cultural behavior. The typical process setting ranges for CHO cell bioreactors for temperature, DO, and pH at 34–37 °C, 30–50%, and 6.7–7.3, respectively [
32]. These process settings are widely used due to their similarity to human and Chinese hamster body conditions. To control these parameters to the setpoints, bioreactors typically use proportion-integral-derivative (PID) control loops. It has been shown that PID settings can also affect culture outcomes [
33].
Due to the stirring and gas sparging within bioreactors during a process to control DO, antifoam is commonly added to control foaming. Yet, it is important to note that antifoam additions are used sparingly as these chemicals can reduce production and cell growth [
34]. Another critical online parameter for fed-batch and continuous bioprocesses is the feed profile. Feeds are added to cultures to prevent nutrient depletion and increase product titers by extending the culture durations. These feeds are usually more concentrated than the basal media and contain nutrients such as glucose, vitamins, and amino acids to increase the productivity of a culture [
35].
Several offline parameters are commonly measured to gauge the culture’s health. Additionally, product titers are often obtained offline. As the product of CHO cell cultures are normally large biomolecules such as monoclonal antibodies, the glycosylation and charge variant state of the molecules may also be obtained. These properties of the protein are known as critical quality attributes (CQAs). Protein titer refers to the concentration of a particular protein of interest. Monoclonal antibodies (mAbs) are immunoglobulins that are of particular interest as drugs due to the high specificity of these molecules toward receptors in the human body. There are currently 92 mAbs approved by the Food and Drug Administration (FDA) and European Medicine Agency (EMA) for the treatment of autoimmune diseases and cancers in 2022 [
36].
Glycosylation represents a wide range of carbohydrate moieties added to a protein at specific amino acids, also known as post-translational modification. These glycan additions affect the protein function in a human patient [
37] and long-term efficacy [
38]. As of 2018, 62 of the 71 new biopharmaceutical active ingredients that were introduced to the market were recombinant proteins, and 52 of those were derived from mammalian cell lines due to high post-translational modification capability [
39]. Due to the high potential of these mAbs for therapeutics, there have been many advances made in ML to increase mAb protein production.
Another key process parameter is viable cell density (VCD, cells per mL of the culture broth), which has become yet another prime target for optimization in ML and DL applications due to it being a key parameter in determining the success of a culture.
Table 1 summarizes typical online and offline parameters that are monitored during cell culture processes.
The online data obtained from bioreactor cultures can be expansive, with upwards of 15,000 data points for each input parameter/feature. While this may lead one to believe that there is no lack of data available for training ML and DL models, this is one of the current bottlenecks that researchers are working to eliminate. While the quantity of data is expansive, they lack in quality. A very large fraction of the data available from CHO cell cultures is largely homogeneous due to similar media and feed formulations being used, as well as other process controls. This creates an issue of overfitting when training predictive models for optimizing cultures. When the models are trained on data that do not capture the entirety of cell behavior within a culture with varying conditions, this can cause the model to become highly accurate when predicting the values, such as VCD and titer, as long as the input variables are similar to those in the dataset used for training. If the features are outside the scope of these data, then the model’s predictive accuracy greatly decreases. Thus, there is a need to have a diversity of model input data for improved model robustness across all possible culture conditions.
With large amounts of bioprocess data comes the need for pre-processing prior to their use for modeling. This pre-processing includes data curating, feature selection, transformation, and reduction. Curating typically entails imputation for missing values, outlier detection, and treatment or removal, and noise reduction using methods such as signal processing or smoothing. Feature selection entails selecting process variables based on their relevance to the modeling or prediction task, and irrelevant or redundant features are removed from the data [
40]. After the features are selected, they are then transformed to improve ease of implementation. This can include but is not limited to aggregating the data over time intervals, normalizing and standardizing the data using methods such as k-nearest neighbors and support vector machines, and categorizing variables [
41,
42]. The treated data can then be split into training, validation, and testing sets. Once this is complete, steps can be taken to reduce the dimensionality of the data using methods such as principal component analysis (PCA) and t-distributed stochastic neighbor embedding (t-SNE) [
43]. The parameters can then be encoded into numerical representations using methods available through libraries such as Scikit-Learn so that they may be easily fed into ML models [
44].
4. Machine Learning Approaches for Critical Quality Attribute Optimization
The primary goal for using ML in biomanufacturing is to improve product yield (titer) and quality. VCD is a secondary goal, as the product titer is highly correlated with VCD. While statistical models may be used to correlate the relationship between CQAs and critical process variables (CPPs), mechanistic hybrid ML models have increased in prevalence due to their ability to describe the causation in cultural behavior [
45]. One such demonstration of this method in predicting VCD is the development of a hybrid agent-based approach where the CHO cells were treated as individual agents with a flux balance model that predicts changes in metabolite and nutrient concentrations [
46]. The initial cell culture conditions and measured DO and sodium levels were used as the model inputs, and consequently, the model was able to predict VCD, among other CQAs. When the initial VCD was low, the root mean squared error (RMSE) was 2.48; however, when the initial VCD was high, the RMSE was 4.44. Despite this, the hybrid agent-based model was increasingly accurate in predicting glucose and lactate, which is a byproduct that can inhibit cell growth levels [
46]. Another previous work utilizing a hybrid model for VCD prediction combined a multilayer perceptron (MLP) regressor, or feed-forward neural network, random forest (RF), and extreme gradient boosting (XGBoost) algorithm (all developed using Python 3.9.12 default libraries) with mechanistic equations to predict next-day VCD and other CQAs [
47]. Inputs for the ML algorithms were first separated by which specific calculated rate they applied to (specific growth rate, specific productivity, or specific cumulative glucose consumption rate). The correlation analysis and multi-collinearity assessment were then conducted to determine the optimal combination of inputs based on process knowledge and statistical analyses. Hyperparameters for the ML algorithms were determined based on prior knowledge from previous works. Among the selected hyperparameters for the RF regressor were the number of estimators, maximum depth, and minimum split, while the number of estimators, learning rate, maximum depth, and subsample ratio were optimized for the XGBoost regressor. The number of neurons, activation function, and solver were all adjusted to optimize the MLP regressor. Once the VCD was normalized after considering all time points in all the experiments that were conducted, the MLP had the highest RMSE but the lowest mean absolute error (MAE); meanwhile, the XGBoost had the lowest RMSE but the highest MAE. It was also discovered that all three models were capable of accurately predicting VCD for a second CHO cell line. Advances in VCD prediction, such as those previously discussed, have provided a means to enhance therapeutic protein production.
Glycosylation has become a target CQA for process modeling and optimization because of its ability to decrease therapeutic protein immunogenicity through increased protein solubility and stability [
48]. Kinetic models have previously been used due to their means of efficiently demonstrating the cellular mechanisms that comprise glycosylation. However, they are not capable of accurately predicting the specific sites that the glycan moieties take on without large quantities of kinetic variables and an understanding of the enzyme and protein levels within the cells, as well as extensive time for training [
18,
49]. Therefore, machine learning approaches have been developed to address these pitfalls. Kotidis and Kontoravdi developed an ANN to predict the site-specific glycoform distributions of four recombinant proteins that are expressed in three CHO cell lines (GS-CHO, CHO-K1, and CHO-S), two IgG monoclonal antibodies, and two fusion proteins [
18]. They observed that the ANN, both on its own and as part of a hybrid model that paired CHO metabolism kinetics with the data-driven model, outperformed the standalone kinetic model and was successful in modeling and predicting the glycoform distributions with average absolute errors as low as 0.98%. Another approach that has been taken in many previous studies is utilizing data-driven models such as PCA and partial least squares regression (PLSR) to understand the variables that, in turn, affect the glycosylation levels of a culture and how they correlate with one another [
50]. For example, Powers et al. were able to determine how different types of media resulted in different terminal galactosylation rates, how high mannose levels were not correlated with aglycosylation, and how initial glucose concentrations were positively correlated with galactosylation rates using PCA and other multivariate data analysis (MVDA) methods [
51]. The use of PLSR also enables the ease of feature selection. Variable importance in projection (VIP) is a method of feature selection that effectively quantifies the effect that process variables have on CQAs. VIP is also useful in preventing overfitting, as demonstrated when compared to a previously developed genetic method in the context of glycan value predictions using PLSR [
52]. The utilization of the aforementioned methods in the prediction of glycosylation patterns also has the potential to increase understanding of other post-translational modifications that influence potency and immunogenicity.
As previously stated, the demand for therapeutic proteins is ever-increasing, thus creating the need for high protein yields in cultures. There have been various approaches taken to achieve this, including predictive modeling, pattern recognition, and real-time monitoring. For example, Le et al. utilized support vector regression (SVR) and PLSR to predict final protein titer and lactate concentration [
53]. They observed that the models had similar high accuracies when the bioreactor production data they were trained on utilized either the final titer or final lactate concentration as the objective function. When the data that were collected during the inoculum train were solely used to train the models, the predictive accuracies for the final titer decreased. However, the seed train data proved to be useful in predicting which bioreactor run would be highly or lowly productive. They found that the critical variables in both the inoculum train stage and during production were associated with lactate metabolism and cell growth and determined that low specific glucose consumption was correlated with low lactate production and consumption. From these findings, it was concluded that corrective measures to exploit the CHO cell metabolism to increase productivity while limiting lactate production would need to occur within the first 70 h of the run. An example of employing real-time monitoring to optimize titers is the use of ML to predict the final protein concentrations in bioreactors. Tulsyan et al. developed strategies that comprised switching ML algorithms in real-time for non-linear state estimation [
54] and adaptive state simulation [
55]. Bayrak et al. capitalized on these previous works and developed a methodology in which SVM, PLSR, Gaussian process regression (GPR), regression trees (RT), and ensemble trees (ET) are each evaluated on their performance in learning from real-time data, and the highest performing model is chosen in real-time for titer prediction for the proceeding day [
56]. It was observed that utilizing dynamic feature selection substantially reduced the root mean squared error of cross-validation (RMSEcv) for the PLSR, GPR, and SVM models; thus, it was implemented for the continuation of the study. At the conclusion of the study, it was observed that the PLSR and GP algorithms maintained the lowest error at each time step, thus proving that they are strong candidates for real-time process monitoring [
56].
Table 2 includes a summary of the aforementioned ML and multivariate techniques that have been utilized for CQA optimization.
5. Machine Learning Approaches for Process Control
As previously mentioned, an important aspect of bioreactor process control is PID control. Bioprocesses can be highly variable, non-linear, and complex, thus making it difficult to control various variables to optimize CQAs and product production. Therefore, it has become common practice to utilize PID control, a continuous closed-loop feedback control. This approach uses a sensor that measures and compares various process variables against their setpoint values and then sets the difference as the parameter error. The PID algorithm then adjusts the control output to decrease the parameter error [
57]. There are three variables within the algorithm that determine the controller output: proportional gain (k
p), integral gain (k
i), and derivative gain (k
d). The proportional gain term influences the controller output to be proportional to the system error at each timestep. k
i is dependent on the combined previous errors and how far they deviate from the variable setpoint. Derivative gain is determined by the rate of change in the controller output based on the parameter error it receives over time. The modification of these three variables consists of carefully defining each term based on the nature of the process. It has been demonstrated that utilizing this methodology for PID tuning can have a positive influence on heating the regression rate and setpoint control during prolonged periods of liquid addition within a bioreactor system [
58], thus making it an integral optimization target in biomanufacturing.
Another design approach that has become more prominent within biomanufacturing is iterative modeling. This process typically consists of designing an experiment based on key variables of interest, collecting the experimental data, modeling them via computational and/or physical models, and then making design adjustments based on the results after they have been validated. Park et al. demonstrated this by creating a systematic media design framework that consisted of culture data collection, multivariate statistical analysis, in silico flux analysis with a genome-scale metabolic model, and knowledge-based targeting media components to determine the optimal media and feed combination to increase IgG1 yield and eliminate cellular bottlenecks that impact cell growth and production [
59]. Through this methodology, they were able to determine that one media and feed combination out of the four that were studied outperformed the others. They then analyzed the metabolic fluxes of the CHO cells in the optimal media/feed combination and were able to conclude that an aspartate supplement could enhance growth and productivity within the culture. Another utilization of this method is in the development of data-driven model predictive controls (MPCs) to understand the dynamics between glucose concentration and CQAs such as VCD, osmolality, and byproduct production [
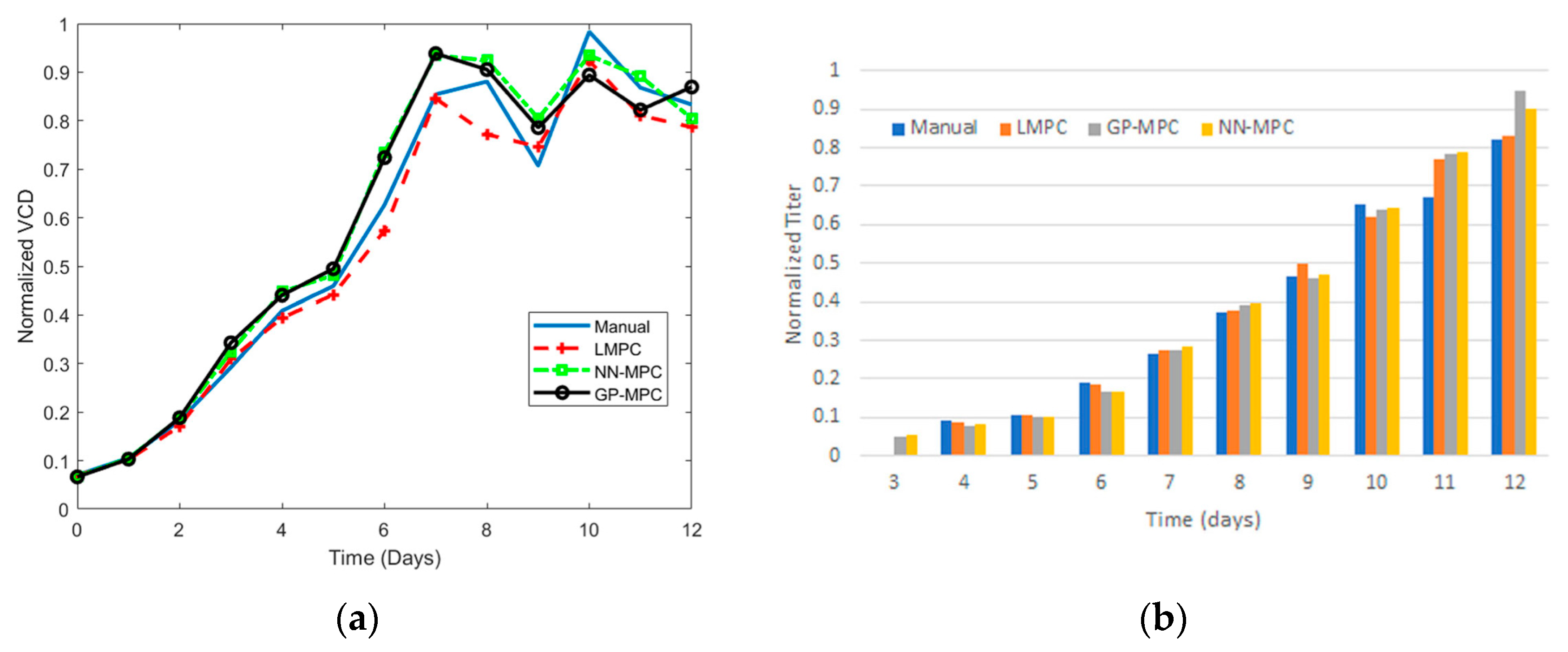
60]. MPCs were derived based on linear regression, Gaussian process regression (GPR), and neural networks and were coupled with a feed–glucose mass balance relationship in order to simulate the fed-batch process. After comparing these MPCs to a rule-based control technique, they found that the GPR-derived MPC outperformed the other models in maximizing VCD (
Figure 3a) and the titer (
Figure 3b), with the neural network-derived MPC following closely after. At the conclusion of the experiment, it was determined that utilizing the non-linear MPCs on volume-based datasets could increase protein production by over 10% [
60]. These demonstrations of iterative design are a testament to the promise that this design approach has for biomanufacturing optimization.


 ,
, 




{kind=link}
{kind=link}
{kind=link}