

Management Information Systems for Tree Fruit–2: Design of a Mango Harvest Forecast Engine

 ,
,  , ,
, , 
Abstract
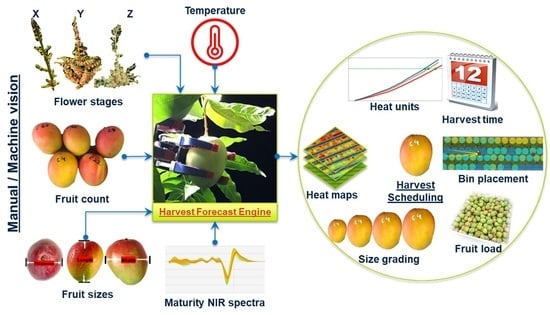
:
1. Introduction
1.1. Need for Harvest Forecast
1.2. Inputs Required for Hearvest Forecast
- (a)
- The cultivar specific heat unit (also known as the thermal time or Growing Degree Days, GDD) maturation requirement from flowering to harvest maturity;
- (b)
- The time at which a harvest-maturity fruit dry matter content (DMC) specification will be achieved, the time and intensity of flowering events, and orchard temperature data.
- (a)
- Fruit count;
- (b)
- Fruit size;
- (c)
- Fruit marketability (proportion of fruit that are marketable).
1.3. Aim and Structure
2. Methodology
2.1. Data Sources
2.2. External Feedback
3. External Feedback
4. Harvest Timing
4.1. GDD
4.2. Temperature Measurement
- S is the matrix of Tm and TM values for use in the calculation of GDD;
- O is a matrix of observed current season daily Tm and TM values;
- N is the matrix of observed current season and historical daily Tm and TM values of the nearest farm sensor;
- B is the matrix of current season daily Tm and TM values from the nearest BoM site;
- H is the matrix of historical (e.g., 10-year average) daily Tm and TM values;
- t1to4 are mutually exclusive periods within the season.
4.3. Peak Flowering Dates
4.4. Accumulation of Storage Reserves
- ∆x is the number of days to harvest maturity date;
- TDMC is the target dry matter content, associated with harvest maturity;
- DMC is the value of dry matter content exceeded in x% of observations of the last measurement date, where x is user defined (typically 90%);
- ∆DMC is the rate of DMC increase (%/day) estimated from average dry matter content at two measurement dates.

4.5. Proposed Workflow on Harvest Timing
5. Harvest Load
5.1. Fruit Number
5.2. Fruit Size
5.3. Fruit Quality
6. Data to Information
6.1. Harvest Schedule
- Yf is the forecast yield (kg) associated with a given flowering event;
- F is the flowering extent (% of terminals) associated with a flowering event;
- Ymax is the maximum fruit yield per hectare (kg/ha), at 100% flowering;
- A is area (ha).
- Yi is the yield, as fruit number, per FEi;
- FEi is the extent of a given flowering event (% of terminals);
- i is the number of the FE;
- FEmax is the maximum flowering in the given season (% of terminals);
- FC is the block fruit count.
6.2. Selective Management
- (i)
- Delineation of areas of early flowering and fruit set as areas for early selective harvest, to match market demands;
- (ii)
- Identification of under and over performing areas within a given block, for investigation of causes;
- (iii)
- Agronomic management (pest, disease, nutrition, and irrigation management).
6.3. Field Bin Allocation
- i is a counter of the data series;
- j is a counter from the ith position of the data series to achieve b;
- n is the size of series;
- Lj is the fruit count series from the left MV camera;
- Rj is the fruit count series from the right MV camera.

7. Criteria for an Electronic Harvest MIS
7.1. Data Acquisition System
7.2. Harvest Forecast Engine as a Component of an Orchard MIS
7.3. MIS System Requirements
8. Conclusions
- Date of flowering;
- Extent of flowering;
- GDD- and DMC-based forecast of harvest timing for each flowering event;
- Fruit count;
- Fruit quality estimation;
- Fruit size distribution.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
- Semistructured Interview Questions:
- How do you currently forecast time of harvest time, and number, size and quality of fruit at harvest?
- Which of these harvest-forecast functions is most and least important to you? (harvest time forecast, fruit number, size or quality forecast)
- Speaking of the software system used to display harvest forecast information:
- What aspects of this system do you find useful?
- What features do you find irrelevant/difficult to use?
- What features would you like to see added?
- What aspects of the GUI are good and bad?
- What are the barriers to the use of harvest forecast MIS?
References
- Dhonju, H.K.; Walsh, K.B.; Bhattarai, T. Management information systems for tree fruit—1: A review. Horticulturae 2024, 10, 108. [Google Scholar] [CrossRef]
- Queensland Government. Mango Information Kit; Queensland Government: Brisbane, QLD, Australia, 1999. [Google Scholar]
- Anderson, N.T.; Walsh, K.B.; Wulfsohn, D. Technologies for forecasting tree fruit load and harvest timing—From ground, sky and time. Agronomy 2021, 11, 1409. [Google Scholar] [CrossRef]
- Martin, R.D.S.; Dunn, G. How to Forecast Wine Grape Deliveries; Technique Report; Department of Primary Industries: Tatura, VIC, Australia, 2003. [Google Scholar]
- Walsh, B.; Lacey, K. Estimating Your Citrus Crop Load. 2024. Available online: https://www.agric.wa.gov.au/citrus/estimating-your-citrus-crop-load (accessed on 7 February 2024).
- Olsen, J.; Goodwin, J. The methods and results of the Oregon Agricultural Statistics Service: Annual objective yield survey of Oregon hazelnut production. In Proceedings of the VI International Congress on Hazelnut, Tarragona-Reus, Spain, 14 June 2004; Acta Horticulturae. [Google Scholar]
- Islam, M.S.; Scalisi, A.; O’Connell, M.G.; Morton, P.; Scheding, S.; Underwood, J.; Goodwin, I. A ground-based platform for reliable estimates of fruit number, size, and color in stone fruit orchards. HortTechnology 2022, 32, 510–522. [Google Scholar] [CrossRef]
- Sarron, J.; Malézieux, É.; Sané, C.; Faye, É. Mango yield mapping at the orchard scale based on tree structure and land cover assessed by UAV. Remote Sens. 2018, 10, 1900. [Google Scholar] [CrossRef]
- Williams, S.R.; Agrahari Baniya, A.; Islam, M.S.; Murphy, K. A Data Ecosystem for Orchard Research and Early Fruit Traceability. Horticulturae 2023, 9, 1013. [Google Scholar] [CrossRef]
- Anderson, N.T.; Underwood, J.; Rahman, M.; Robson, A.; Walsh, K. Estimation of fruit load in mango orchards: Tree sampling considerations and use of machine vision and satellite imagery. Precis. Agric. 2019, 20, 823–839. [Google Scholar] [CrossRef]
- Ganry, J.; Chillet, M. Methodology to forecast the harvest date of banana bunches. Fruits 2008, 63, 371–373. [Google Scholar] [CrossRef]
- MacKenzie, S.J.; Chandler, C.K. A method to predict weekly strawberry fruit yields from extended season production systems. Agron. J. 2009, 101, 278–287. [Google Scholar] [CrossRef]
- Gómez-Lagos, J.E.; González-Araya, M.C.; Ortega Blu, R.; Acosta Espejo, L.G. A new method based on machine learning to forecast fruit yield using spectrometric data: Analysis in a fruit supply chain context. Precis. Agric. 2023, 24, 326–352. [Google Scholar] [CrossRef]
- Gómez-Lagos, J.E.; González-Araya, M.C.; Soto-Silva, W.E.; Rivera-Moraga, M.M. Optimizing tactical harvest planning for multiple fruit orchards using a metaheuristic modeling approach. Eur. J. Oper. Res. 2021, 290, 297–312. [Google Scholar] [CrossRef]
- Torgbor, B.A.; Rahman, M.M.; Brinkhoff, J.; Sinha, P.; Robson, A. Integrating remote sensing and weather variables for mango yield prediction using a machine learning approach. Remote Sens. 2023, 15, 3075. [Google Scholar] [CrossRef]
- Rahman, M.M.; Robson, A.; Bristow, M. Exploring the potential of high resolution worldview-3 Imagery for estimating yield of mango. Remote Sens. 2018, 10, 1866. [Google Scholar] [CrossRef]
- Amaral, M.H.; McConchie, C.; Dickinson, G.; Walsh, K.B. Growing degree day targets for fruit development of Australian mango cultivars. Horticulturae 2023, 9, 489. [Google Scholar] [CrossRef]
- Walsh, K.; Wang, Z. Monitoring fruit quality and quantity in mangoes. In Achieving Sustainable Cultivation of Mangoes; Burleigh Dodds Science Publishing: Cambridge, UK, 2018; pp. 313–338. [Google Scholar]
- Koirala, A.; Walsh, K.; Wang, Z.; McCarthy, C. Deep learning for real-time fruit detection and orchard fruit load estimation: Benchmarking of ‘MangoYOLO’. Precis. Agric. 2019, 20, 1107–1135. [Google Scholar] [CrossRef]
- Neupane, C.; Pereira, M.; Koirala, A.; Walsh, K.B. Fruit sizing in orchard: A review from caliper to machine vision with deep learning. Sensors 2023, 23, 3868. [Google Scholar] [CrossRef]
- Anderson, N.T.; Walsh, K.B.; Koirala, A.; Wang, Z.; Amaral, M.H.; Dickinson, G.R.; Sinha, P.; Robson, A.J. Estimation of fruit load in Australian mango orchards using machine vision. Agronomy 2021, 11, 1711. [Google Scholar] [CrossRef]
- Ometto, J.C. Bioclimatologia Vegetal; Agronômica Ceres: São Paulo, Brazil, 1981; 425p. [Google Scholar]
- Wang, Z.; Underwood, J.; Walsh, K.B. Machine vision assessment of mango orchard flowering. Comput. Electron. Agric. 2018, 151, 501–511. [Google Scholar] [CrossRef]
- Bermejo, J.; Crisosto, C.; Crisosto, G. Applying non-destructive sensors to improve fresh fruit consumer satisfaction and increase consumption. In Proceedings of the XXIX International Horticultural Congress on Horticulture: Sustaining Lives, Livelihoods and Landscapes (IHC2014), Brisbane, OLD, Australia, 17–22 August 2014; pp. 219–226. [Google Scholar]
- AMIA. Factors That Influence Dry Matter. 2024. Available online: https://www.industry.mangoes.net.au/resources/resources-library/factors-that-influence-dry-matter/ (accessed on 25 January 2024).
- Walsh, K.; McGlone, V.; Han, D. The uses of near infra-red spectroscopy in postharvest decision support: A review. Postharvest Biol. Technol. 2020, 163, 111139. [Google Scholar] [CrossRef]
- Aggelopoulou, A.; Bochtis, D.; Fountas, S.; Swain, K.C.; Gemtos, T.; Nanos, G. Yield prediction in apple orchards based on image processing. Precis. Agric. 2011, 12, 448–456. [Google Scholar] [CrossRef]
- Tombesi, S.; Lampinen, B.D.; Metcalf, S.; DeJong, T.M. Yield in almond is related more to the abundance of flowers than the relative number of flowers that set fruit. Calif. Agric. 2017, 71, 68–74. [Google Scholar] [CrossRef]
- Walsh, K.; McGlone, V.; Wohlers, M. Sampling and Statistics in Assessment of Fresh Produce; Burleigh Dodds Science Publishing: Cambridge, UK, 2022. [Google Scholar]
- Wulfsohn, D.; Gardi, J.E.; Cohen, O.; Garcia-Fiñana, M.; Zamora, I. Pronofrut: Computer-assisted stereology for estimating orchard yields. In Proceedings of the Workshop on Image Analysis and Stereology with applications on Biological and Social Sciences, Santander, Spain, 11–14 September 2018. [Google Scholar]
- Wang, Q.; Nuske, S.; Bergerman, M.; Singh, S. Automated crop yield estimation for apple orchards. Exp. Robot. 2013, 88, 745–758. [Google Scholar] [CrossRef]
- Bargoti, S.; Underwood, J. Deep fruit detection in orchards. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3626–3633. [Google Scholar]
- Wang, Z.; Walsh, K.B.; Verma, B. On-tree mango fruit size estimation using RGB-D images. Sensors 2017, 17, 2738. [Google Scholar] [CrossRef]
- Hectre. Award Winning Orchard Technologies Growers and Packers Love to Use. 2023. Available online: https://hectre.com/ (accessed on 27 January 2023).
- Anderson, N.T.; Subedi, P.P.; Walsh, K.B. Manipulation of mango fruit dry matter content to improve eating quality. Sci. Hortic. 2017, 226, 316–321. [Google Scholar] [CrossRef]
- Amaral, M.H.; Walsh, K.B. In-orchard sizing of mango fruit: 2. Forward estimation of size at harvest. Horticulturae 2023, 9, 54. [Google Scholar] [CrossRef]
- AMIA. Mango Quality Assessment Manual. 2024. Available online: https://www.industry.mangoes.net.au/resources/resources-library/mango-quality-assessment-manual/ (accessed on 7 February 2024).
- Scalisi, A.; McClymont, L.; Peavey, M.; Morton, P.; Scheding, S.; Underwood, J.; Goodwin, I. Detecting, mapping and digitising canopy geometry, fruit number and peel colour in pear trees with different architecture. Sci. Hortic. 2024, 326, 112737. [Google Scholar] [CrossRef]
- Dhonju, H.; Walsh, K.; Bhattarai, T. Harvest bin placement based on machine vision data in mango orchards. In Proceedings of the II International Symposium on Precision Management of Orchards & Vineyards, Tatura, VIC, Australia, 3–8 December 2023. [Google Scholar]
- Dhonju, H.K.; Walsh, K.B.; Bhattarai, T. Web mapping for farm management information systems: A review and Australian orchard case study. Agronomy 2023, 13, 2563. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Information | Input | Data Source |
|---|---|---|
| Harvest timing | flowering | machine vision or manual estimates of the extent of flowering, per week [3] |
| GDD | temperature (daily min and max) [17] | |
| fruit DMC | NIRS measurement [19] | |
| flesh color | destructive visual assessment [18] | |
| Harvest load | fruit count | machine vision or manual estimates [3] |
| fruit size | machine vision or manual estimates [21] | |
| fruit marketability | manual estimates | |
| fruit load | satellite-derived vegetation index imagery and historical time series data [15] |
| Topic | Comments |
|---|---|
| Need—on farm | Resourcing: Boxes and tray liners are ordered months before harvest, so we need to anticipate fruit numbers and size. I need months of lead time to arrange harvest labour. I plan on 120 days from flowering to harvest but that can be out a couple of weeks either way. Operation: If I get an order early in the season, I need to know where to find mature fruit. If we know fruit sizes expected from a block, we can set the packline line drops up before sorting starts. The grade of the fruit depends on defect level. Ideally, we would know the proportion (of grade 1/grade 2/reject) fruit before harvest. It’s not just about total weight, it’s when (week) and what (fruit number, size, quality). I have 22 harvest crews working in parallel through a block, each line needing 10 to 17 bins, but my bin runners only hold 6 bins each. I need them to place the bins right the first time. If you know your weekly fruit load you can set a daily volume target depending on the number of days (in the week) you operate. You adjust daily depending on volume picked on previous day. This lets you give the crew notice (whether there will be a weekend break or not). We need to decide whether there’s enough fruit left after a first harvest to justify a second harvest. The amount of fruit discarded in field during harvest or left on tree can vary considerably. Harvest never goes to plan–staff absent, rain or machine issues or other delays, like no transport available. But without a forecast you don’t have a plan. |
| Need—post farm | We spent (AUD)$0.9 M on marketing last year but it’s wasted if fruit isn’t available to deliver to market, or if we supply more than the market is ready to handle. It’s not just about tonnage or number of fruit, fruit size is important. The (fruit) price drops if we supply more than we anticipated to market, and its hard to recover price. We pick with the aim of having the product in the hands of the consumer in 14 days, but with a storage life of 28 days. We need to get the harvest date right. We need forecasts on a weekly basis from all our supplier farms. |
| Forecast issues | Nothing is ‘set and forget’, you need to be able to adjust values as the seasons progresses. For example, nothing may come of a flowering event, it may not set fruit, or the fruit may drop. Things change between years. If the foliage is denser (hiding fruit), I underestimate on fruit count. Hanging time (the time fruit can be left on tree before ripening begins) gives you some flexibility in harvest timing. It varies with cultivar, ranging from 7 to 21 days. You need to factor in our capacity to harvest. Things get busy, any system has to be easy to use, easy to put data in, and easy to see. |
| SN | Cultivar | Flesh Color | GDD |
|---|---|---|---|
| 1 | Honey Gold | 9 | 1560 |
| 2 | Calypso | 7 | 1540 |
| 3 | Keitt | 13 | 1936 |
| 4 | R2E2 | 1600 | |
| 5 | KP | 7 | 1420 |
| Block | Week | ||||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
| |||||||
| A | 0 | 0 | 5 | 5 | 55 | 60 | 60 |
| B | 10 | 50 | 65 | 65 | 85 | 90 | 90 |
| C | 30 | 85 | 90 | 90 | 90 | 90 | 90 |
| D | 10 | 50 | 65 | 65 | 65 | 65 | 65 |
| E | 0 | 20 | 20 | 20 | 60 | 90 | 90 |
| |||||||
| A | 0 | 0 | 8 | 8 | 100 | 100 | 100 |
| B | 20 | 56 | 72 | 72 | 94 | 100 | 100 |
| C | 33 | 94 | 100 | 100 | 100 | 100 | 100 |
| D | 15 | 77 | 100 | 100 | 100 | 100 | 100 |
| E | 0 | 22 | 22 | 22 | 67 | 100 | 100 |
| |||||||
| A | 100 | ||||||
| B | 20 | 52 | 28 | ||||
| C | 33 | 67 | |||||
| D | 77 | 23 | |||||
| E | 22 | 45 | 33 | ||||
| Block | FE1 | FE2 | ||
|---|---|---|---|---|
| GDD | DMC | GDD | DMC | |
| A | 4/10 | 1/10 | 16/10 | 21/10 |
| B | 6/10 | 8/10 | 22/10 | 20/10 |
| C | 6/10 | 9/10 | 24/10 | 27/10 |
| D | 30/9 | 7/10 | 22/10 | 25/10 |
| E | 24/9 | 2/10 | 8/10 | 6/10 |
| (A) | % Flowering | Fruit Count | Avg Weight (kg) | Fruit Weight (kg) | |||||
|---|---|---|---|---|---|---|---|---|---|
| Calendar week | 20 | 21 | 22 | 23 | 24 | 25 | |||
| Orchard A | 60 | 40 | 451,870 | 0.47 | 212,379 | ||||
| Orchard B | 57 | 43 | 457,799 | 0.45 | 206,010 | ||||
| Orchard C | 52 | 48 | 385,563 | 0.46 | 177,359 | ||||
| Orchard D | 22 | 22 | 56 | 350,141 | 0.48 | 168,068 | |||
| Orchard E | 41 | 59 | 363,475 | 0.49 | 178,103 | ||||
| Orchard F | 53 | 47 | 122,750 | 0.47 | 57,693 | ||||
| (B) | Harvest forecast (fruit weight, kg) | ||||||||
| Calendar week | 40 | 41 | 42 | 43 | 44 | 45 | |||
| Orchard A | 127,427 | 84,952 | |||||||
| Orchard B | 117,425 | 88,584 | |||||||
| Orchard C | 92,227 | 85,132 | |||||||
| Orchard D | 36,975 | 36,975 | 94,118 | ||||||
| Orchard E | 73,022 | 105,081 | |||||||
| Orchard F | 30,577 | 27,115 | |||||||
| FORECAST | 36,975 | 92,227 | 257,999 | 127,427 | 258,668 | 226,314 | |||
| % of total | 4 | 9 | 26 | 13 | 26 | 23 | |||
| ACTUAL | 45,975 | 126,123 | 199,798 | 101,752 | 241,765 | 191,459 | |||
| # | Requirement/Component | Description |
|---|---|---|
| 1 | Orchard structure | Farm location, block name, and boundaries |
| 2 | Temperature sensor association | Association of temperature sensors to blocks |
| 3 | Authentication, data access, and security | Access to and securing data at user and farm level |
| 4 | User management | Hierarchy of users required, e.g., owner, manager, and consultants, and permission across farms |
| 5 | Crop management | To handle multiple cultivars of mango with varying production windows Future expandability to other tree-fruit crops |
| 6 | Data standards | Standard data format for compatibility and interoperability with the subsystems (machine vision imaging, manual data collection, dry matter data collection, and temperature), e.g., geolocation data format and date format |
| 7 | Database management | Management of time-series data within a season with access to past season data Management of historical seasonal data |
| 8 | Data transmission | Capability to handle big spatial data including images in terms of rapid upload/ingestion, fetching data from server to client side, and download. |
| 9 | Data visualization with query able web mapping | Time-aware heat map visualization, e.g., of >50 K data values for a given farm, of machine vision data over online basemaps (e.g., Google/ESRI/Bing/hostable drone imagery) and presentation of data. |
| 10 | Visualization of machine vision images | Display of machine vision images of flower and fruit at tree level |
| 11 | User friendliness | User experience in terms of interface interactiveness and responsiveness in farm locations to be confirmed in terms of interactive and responsive map, table, and charts. |
| 12 | RESTful APIs | To enable query ability, interoperability, and automatability between the systems, and progressive development of the system and subsystems |
| 13 | Communication module | Email service to inform users regarding data updates |
| 14 | Operationability | Maintainability and scalability |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dhonju, H.K.; Bhattarai, T.; Amaral, M.H.; Matzner, M.; Walsh, K.B. Management Information Systems for Tree Fruit–2: Design of a Mango Harvest Forecast Engine. Horticulturae 2024, 10, 301. https://doi.org/10.3390/horticulturae10030301
Dhonju HK, Bhattarai T, Amaral MH, Matzner M, Walsh KB. Management Information Systems for Tree Fruit–2: Design of a Mango Harvest Forecast Engine. Horticulturae. 2024; 10(3):301. https://doi.org/10.3390/horticulturae10030301
Chicago/Turabian StyleDhonju, Hari Krishna, Thakur Bhattarai, Marcelo H. Amaral, Martina Matzner, and Kerry B. Walsh. 2024. "Management Information Systems for Tree Fruit–2: Design of a Mango Harvest Forecast Engine" Horticulturae 10, no. 3: 301. https://doi.org/10.3390/horticulturae10030301
APA StyleDhonju, H. K., Bhattarai, T., Amaral, M. H., Matzner, M., & Walsh, K. B. (2024). Management Information Systems for Tree Fruit–2: Design of a Mango Harvest Forecast Engine. Horticulturae, 10(3), 301. https://doi.org/10.3390/horticulturae10030301