
SwinGD: A Robust Grape Bunch Detection Model Based on Swin Transformer in Complex Vineyard Environment



Abstract
:1. Introduction
2. Materials and Methods
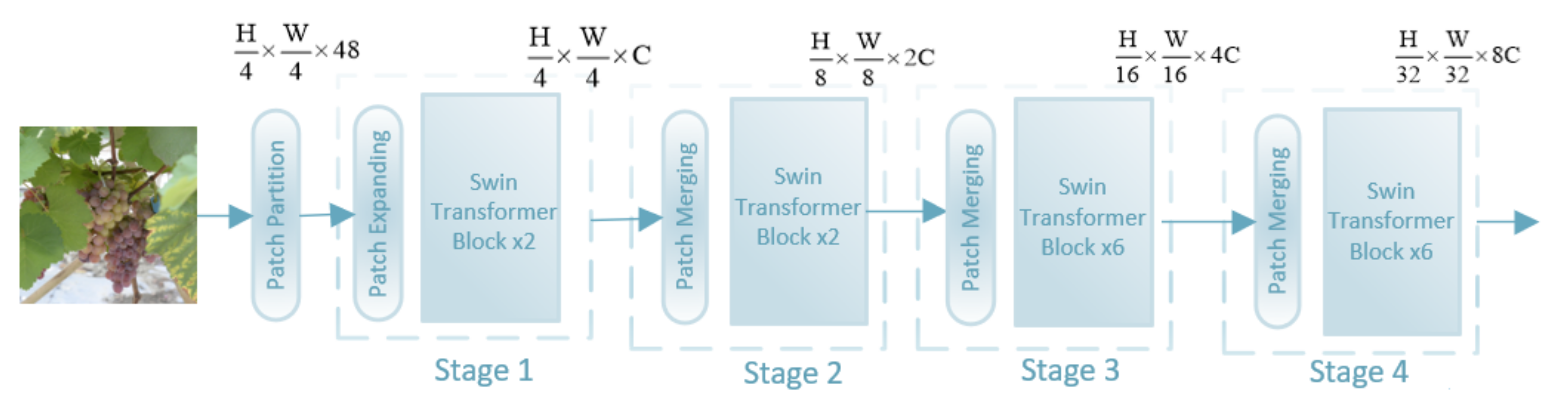
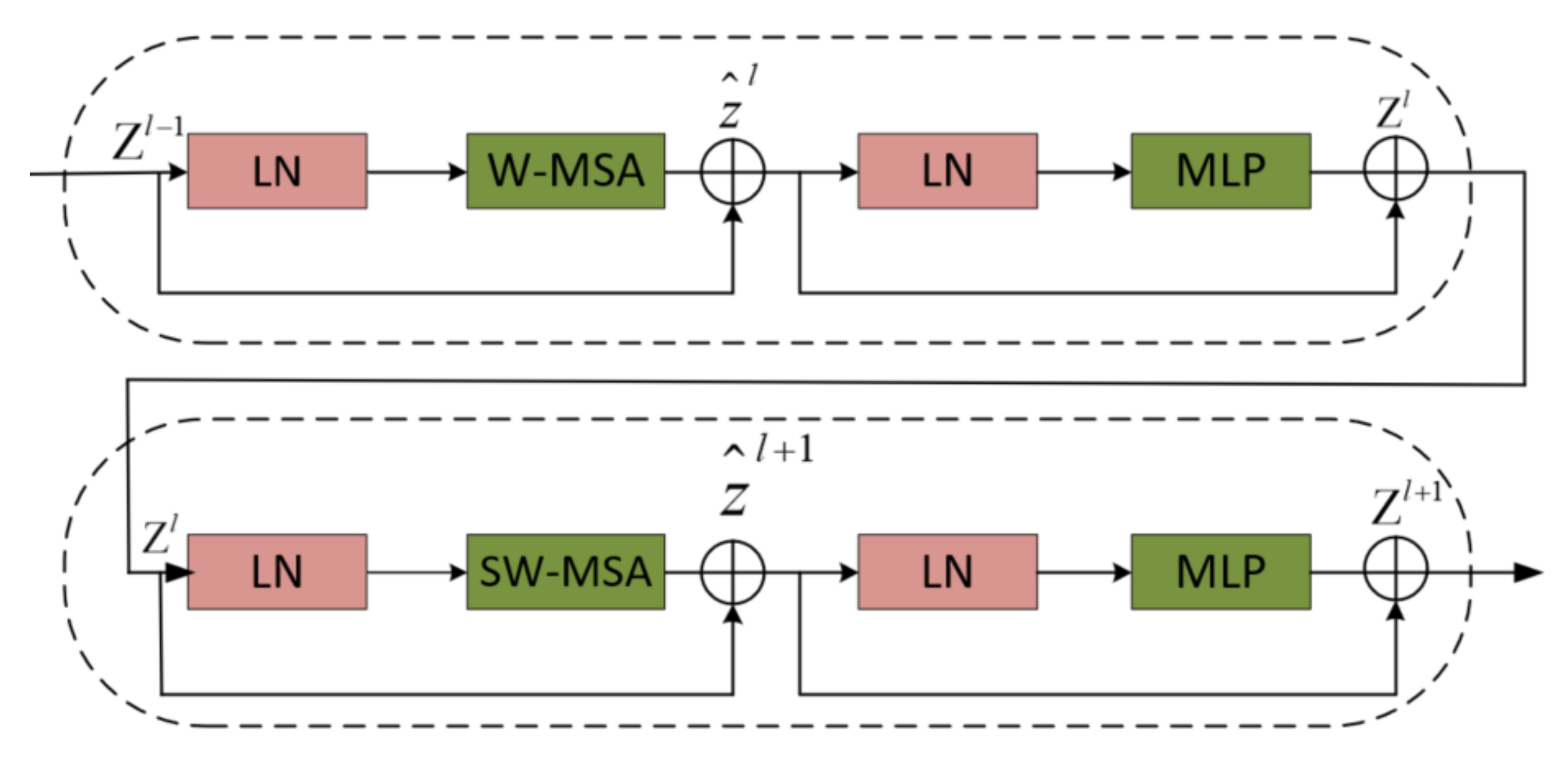
2.1. Architecture Overview
2.2. Training
2.3. Evaluation
- Intersection over union (IoU) is a radio of overlaps between the ground truth and the prediction bounding box in the dataset. The detail is shown in Formula (7):
- True positive (TP) refers to the number of detection boxes that are capable of expression objects. In this paper, the object refers to the red grapes. IoU > 0.5 in the ground truth and prediction bounding box that the bounding box is truly positive.
- False positive (FP) refers to the number of detection boxes in which IoU < 0.5. It shows that the prediction bounding box is not performed well in the object.
- False negative (FN) refers to the number of prediction bounding boxes that are not in the ground truth.
- Precision (P) refers to the ratio of the true prediction bounding boxes in all prediction bounding boxes. The detail is shown in Formula (8):
- Recall (R) refers to the radio of the true bounding boxes in all ground truths. The detail is shown in Formula (9):
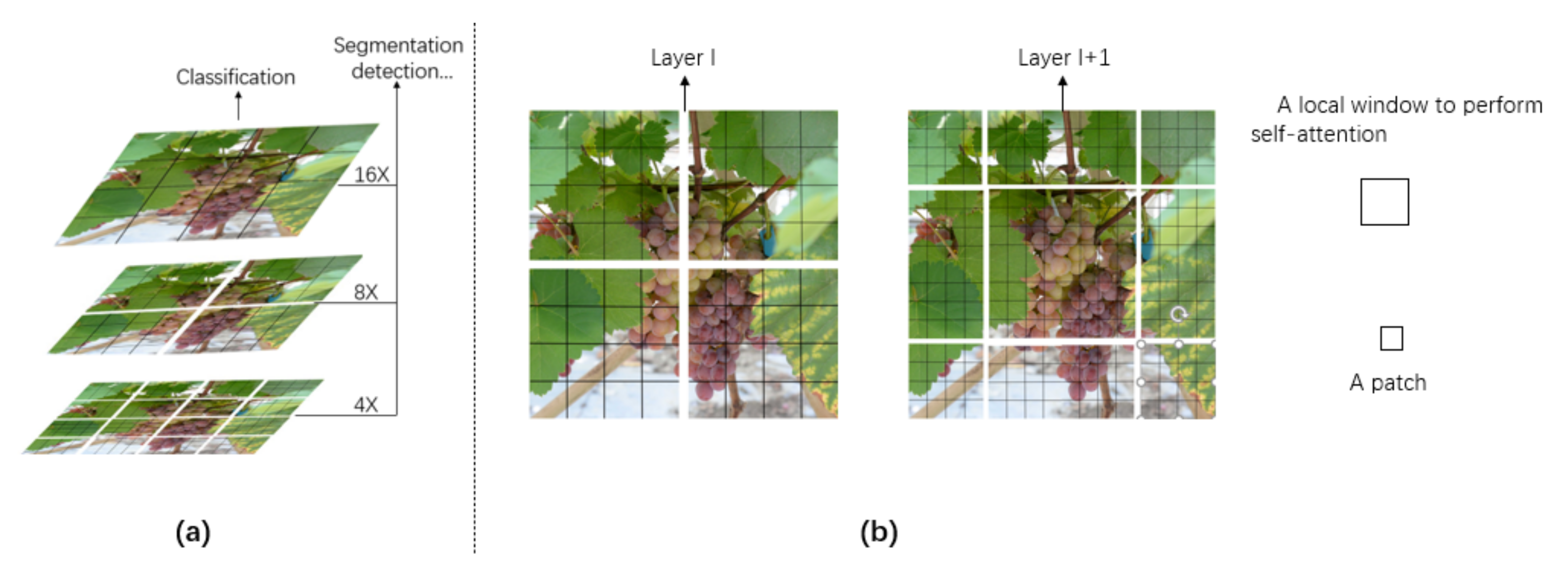
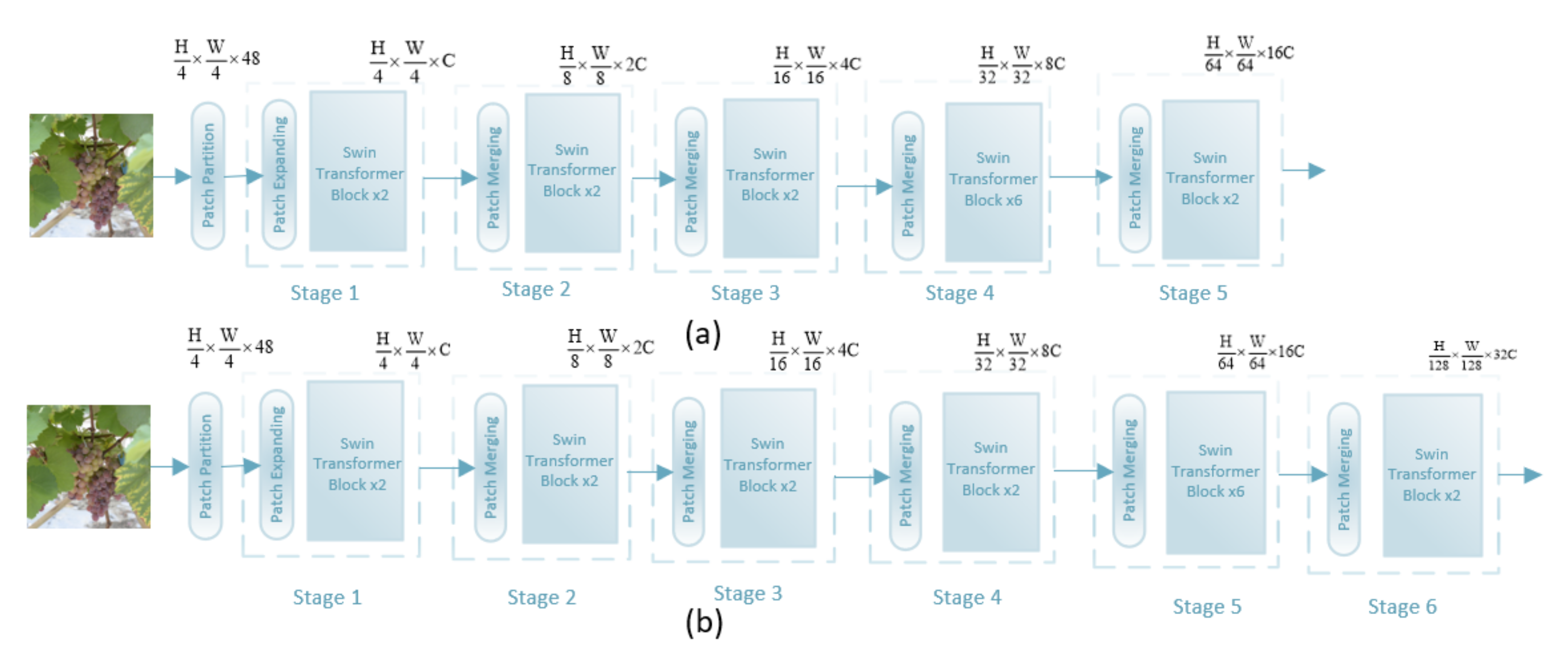
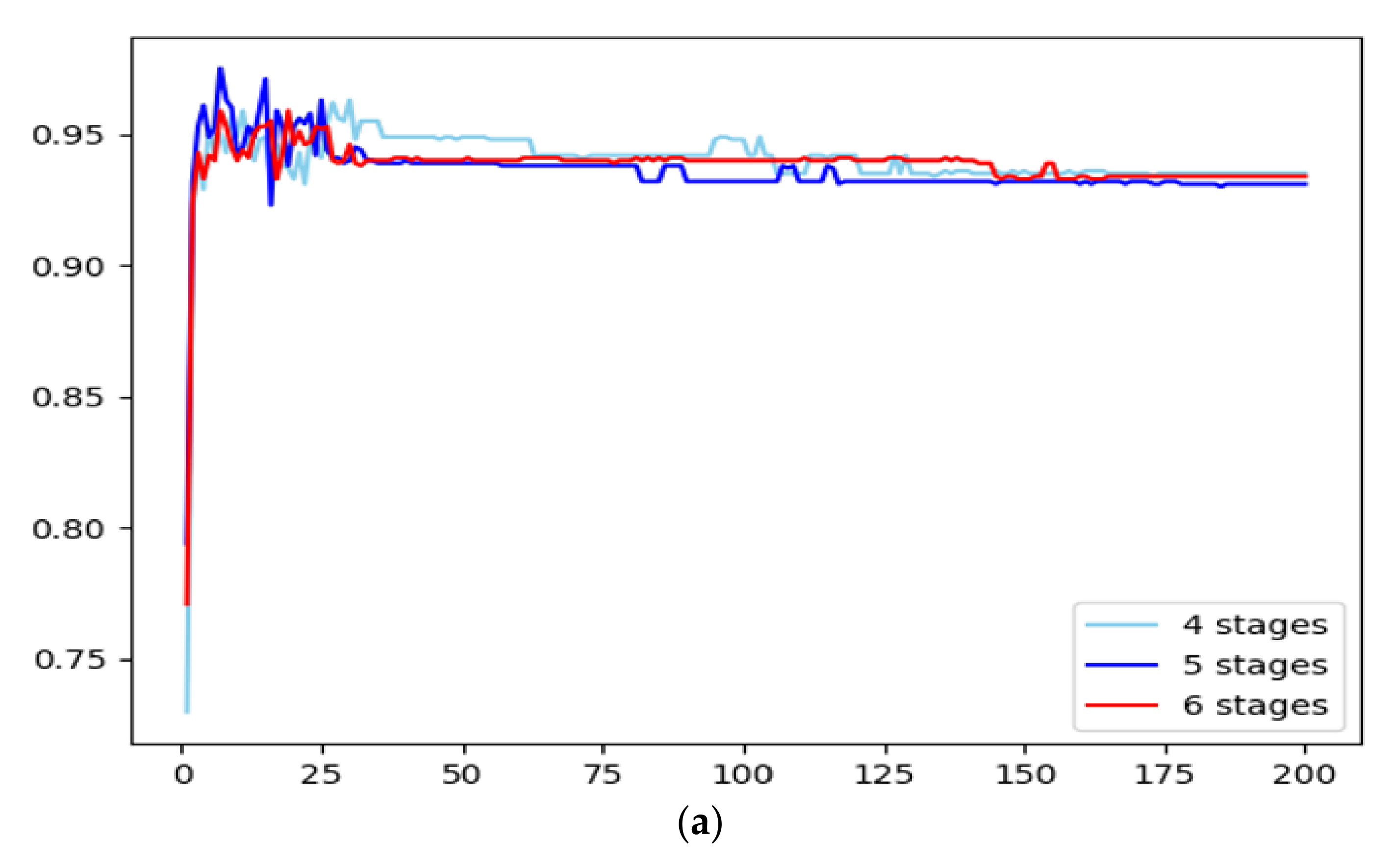
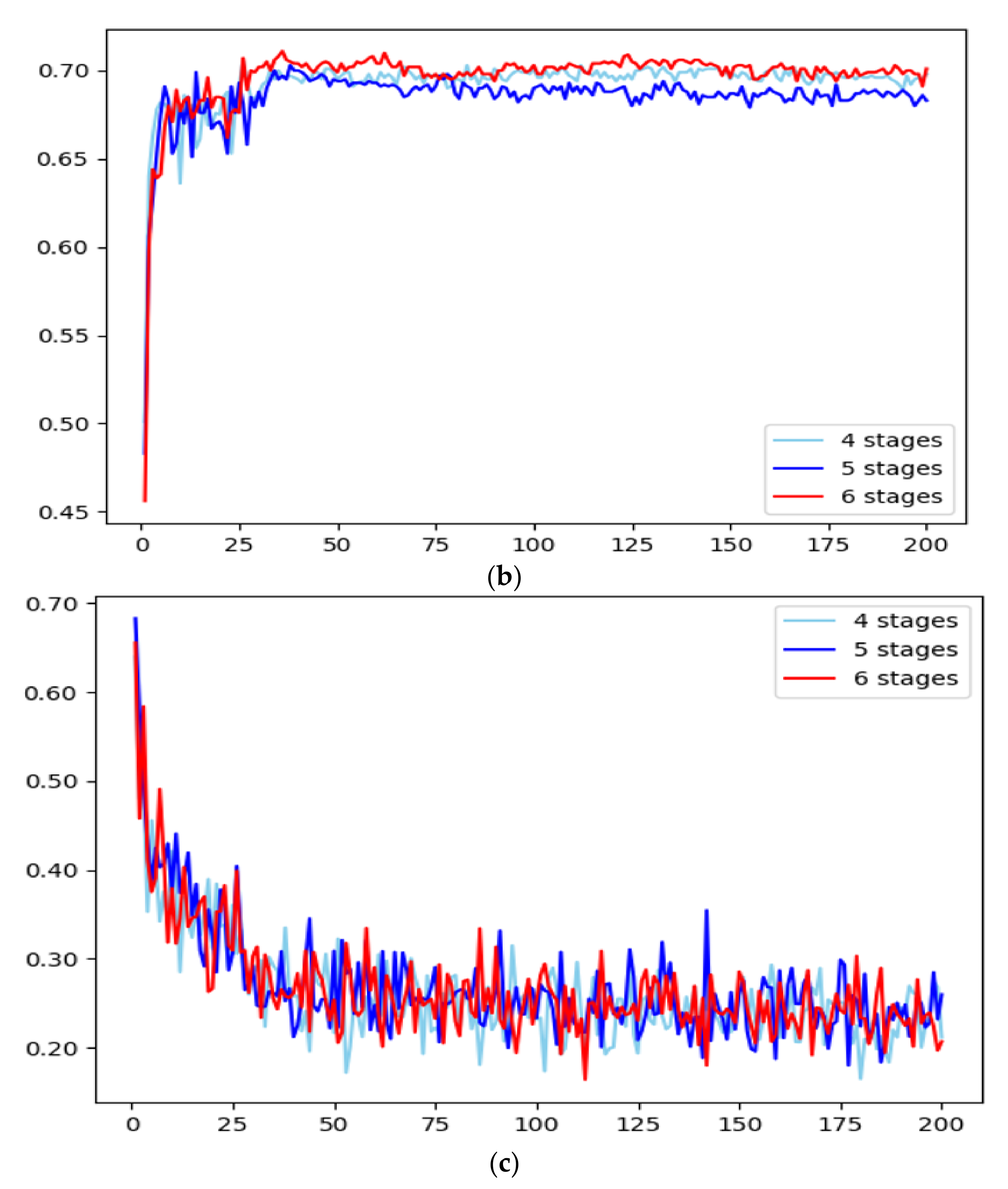
2.4. Swin Transformer Architecture with Different Stages
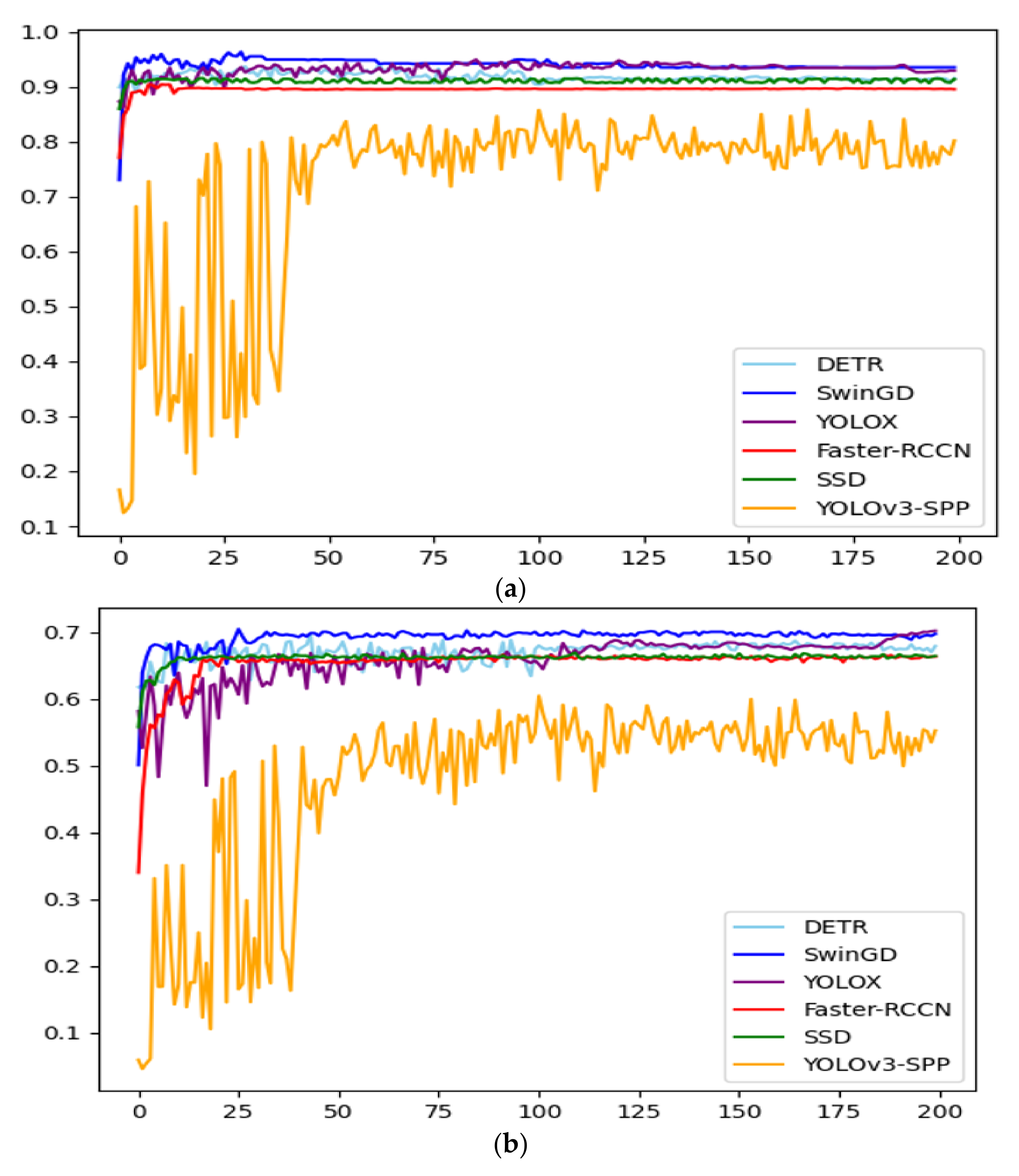
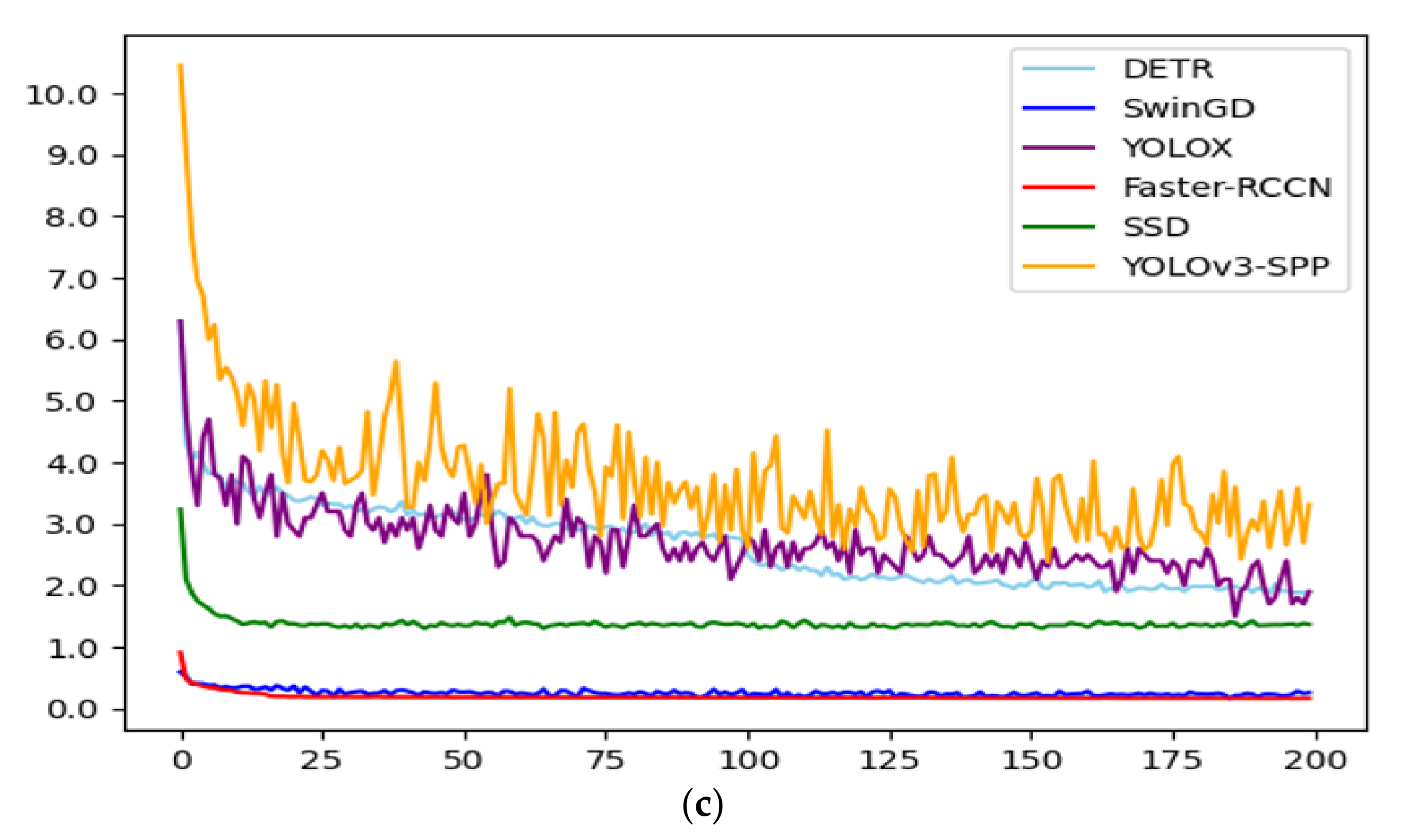
2.5. Comparison of Different Models
3. Results
3.1. Image Dataset
3.2. Image Data Augmentation
3.3. The Effect of SwinGD in Different Cases
3.4. Detection Effect of Dense Grape Bunches and Dark Environment
3.5. The Applicability of SwinGD
3.6. Experiment Result in Different Grape Test Sets
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- C. W. J. Adjustment improvement transformation and upgrading to promote the steady development of China’s grape industry. China Fruit Veg. 2015, 2015, 12–14. [Google Scholar]
- Luo, L.; Tang, Y.; Zou, X.; Ye, M.; Feng, W.; Li, G. Vision-based extraction of spatial information in grape clusters for harvesting robots. Biosyst. Eng. 2016, 151, 90–104. [Google Scholar] [CrossRef]
- Luo, L.; Tang, Y.; Lu, Q.; Chen, X.; Zhang, P.; Zou, X. A vision methodology for harvesting robot to detect cutting points. Comput. Ind. 2018, 99, 130–139. [Google Scholar] [CrossRef]
- Lu, J.; Sang, N. Detecting citrus fruits and occlusion recovery under natural illumination conditions. Comput. Electron. Agric. 2015, 110, 121–130. [Google Scholar] [CrossRef]
- Zhang, W.; Gong, L.; Chen, S.; Wang, W.; Liu, C. Autonomous Identification and Positioning of Trucks during Collaborative Forage Harvesting. Sensors 2021, 21, 1166. [Google Scholar] [CrossRef] [PubMed]
- Kang, H.; Zhou, H.; Wang, X.; Chen, C. Real-Time Fruit Recognition and Grasping Estimation for Robotic Apple Harvesting. Sensors 2020, 20, 5670. [Google Scholar] [CrossRef]
- Hayashi, S.; Shigematsu, K.; Yamamoto, S.; Kobayashi, K.; Kohno, Y.; Kamata, J.; Kurita, M. Evaluation of a strawberry-harvesting robot in a field test. Biosyst. Eng. 2010, 105, 160–171. [Google Scholar] [CrossRef]
- Van Henten, E.; Van Tuijl, B.V.; Hemming, J.; Kornet, J.; Bontsema, J.; Van Os, E. Field test of an autonomous cucumber picking robot. Biosyst. Eng. 2003, 86, 305–313. [Google Scholar] [CrossRef]
- Si, Y.; Liu, G.; Feng, J. Location of apples in trees using stereoscopic vision. Comput. Electron. Agric. 2015, 112, 68–74. [Google Scholar] [CrossRef]
- Bac, C.W.; Hemming, J.; Van Henten, E.J. Stem localization of sweet-pepper plants using the support wire as a visual cue. Comput. Electron. Agric. 2014, 105, 111–120. [Google Scholar] [CrossRef]
- Mehta, S.; Burks, T. Vision-based control of robotic manipulator for citrus harvesting. Comput. Electron. Agric. 2014, 102, 146–158. [Google Scholar] [CrossRef]
- Zou, X.; Ye, M.; Luo, C.; Xiong, J.; Luo, L.; Wang, H.; Chen, Y. Fault-tolerant design of a limited universal fruit-picking end-effector based on vision-positioning error. Appl. Eng. Agric. 2016, 32, 5–18. [Google Scholar]
- Wang, H.; Dong, L.; Zhou, H.; Luo, L.; Tang, Y. YOLOv3-Litchi Detection Method of Densely Distributed Litchi in Large Vision Scenes. Math. Probl. Eng. 2021, 2021, 8883015. [Google Scholar] [CrossRef]
- Huang, P.; Zhu, L.; Zhang, Z.; Yang, C. Row End Detection and Headland Turning Control for an Autonomous Banana-Picking Robot. Machines 2021, 9, 103. [Google Scholar] [CrossRef]
- Wang, Z.; Walsh, K.; Koirala, A. Mango Fruit Load Estimation Using a Video Based MangoYOLO—Kalman Filter—Hungarian Algorithm Method. Sensors 2019, 19, 2742. [Google Scholar] [CrossRef] [Green Version]
- Tang, Y.; Chen, M.; Wang, C.; Luo, L.; Zou, X. Recognition and Localization Methods for Vision-Based Fruit Picking Robots: A Review. Front. Plant Sci. 2020, 11, 510. [Google Scholar] [CrossRef]
- Chen, Y.; Lee, W.S.; Gan, H.; Peres, N.; He, Y. Strawberry Yield Prediction Based on a Deep Neural Network Using High-Resolution Aerial Orthoimages. Remote Sens. 2019, 11, 1584. [Google Scholar] [CrossRef] [Green Version]
- Lin, G.; Tang, Y.; Zou, X.; Cheng, J.; Xiong, J. Fruit detection in natural environment using partial shape matching and probabilistic Hough transform. Precis. Agric. 2019, 21, 160–177. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 779–788. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2017, arXiv:2107.08430. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In International Conference on Machine Learning; PMLR: New York, NY, USA, 2021; pp. 10347–10357. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Gao, L.; Liu, H.; Yang, M.; Chen, L.; Xiao, Z. STransFuse: Fusing Swin Transformer and Convolutional Neural Network for Remote Sensing Image Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 1, 10990–11003. [Google Scholar] [CrossRef]
- Lin, A.; Chen, B.; Xu, J.; Zhang, Z.; Lu, G. DS-TransUNet:Dual Swin Transformer U-Net for Medical Image Segmentation. arXiv 2021, arXiv:2106.06716. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W. Hybrid task cascade for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4974–4983. [Google Scholar]
- Han, H.; Gu, J.; Zheng, Z.; Dai, J.; Wei, Y. Relation Networks for Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake, UT, USA, 18–23 June 2018; pp. 3588–3597. [Google Scholar]
- Hu, H.; Zhang, Z.; Xie, Z.; Lin, S. Local Relation Networks for Image Recognition. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 3463–3472. [Google Scholar]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Backbone | Batch Size | Initial Learning Rate | Weights Decay |
|---|---|---|---|---|
| SwinGD | Swin-T | 4 | ||
| DETR | Resnet50 | 4 | ||
| YOLOv3-SPP | Darknet53 | 4 | ||
| Faster- RCNN | VGG16 | 4 | ||
| SSD | SSD300 | 4 | ||
| YOLOX | Modified CSP v5 | 4 |
| Model | The Accuracy of Red Grapes | The Accuracy of Green Grapes |
|---|---|---|
| SwinGD | 91.5% | 79.8% |
| DETR | 82.4% | 76.1% |
| YOLOv3-SPP | 56.0% | 64.4% |
| Faster-RCNN | 73.0% | 70.8% |
| SSD | 54.0% | 59.1% |
| YOLOX | 85.0% | 78.0% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Zhang, Z.; Luo, L.; Zhu, W.; Chen, J.; Wang, W. SwinGD: A Robust Grape Bunch Detection Model Based on Swin Transformer in Complex Vineyard Environment. Horticulturae 2021, 7, 492. https://doi.org/10.3390/horticulturae7110492
Wang J, Zhang Z, Luo L, Zhu W, Chen J, Wang W. SwinGD: A Robust Grape Bunch Detection Model Based on Swin Transformer in Complex Vineyard Environment. Horticulturae. 2021; 7(11):492. https://doi.org/10.3390/horticulturae7110492
Chicago/Turabian StyleWang, Jinhai, Zongyin Zhang, Lufeng Luo, Wenbo Zhu, Jianwen Chen, and Wei Wang. 2021. "SwinGD: A Robust Grape Bunch Detection Model Based on Swin Transformer in Complex Vineyard Environment" Horticulturae 7, no. 11: 492. https://doi.org/10.3390/horticulturae7110492
APA StyleWang, J., Zhang, Z., Luo, L., Zhu, W., Chen, J., & Wang, W. (2021). SwinGD: A Robust Grape Bunch Detection Model Based on Swin Transformer in Complex Vineyard Environment. Horticulturae, 7(11), 492. https://doi.org/10.3390/horticulturae7110492